打赏本站
微信
 支付宝
支付宝

支付宝
基于 Transformer 的预训练模型在自然语言生成任务中表现出了高性能。然而,新一波的兴趣已经兴起:自动编程语言生成。此任务包括将自然语言指令翻译为编程代码 ...

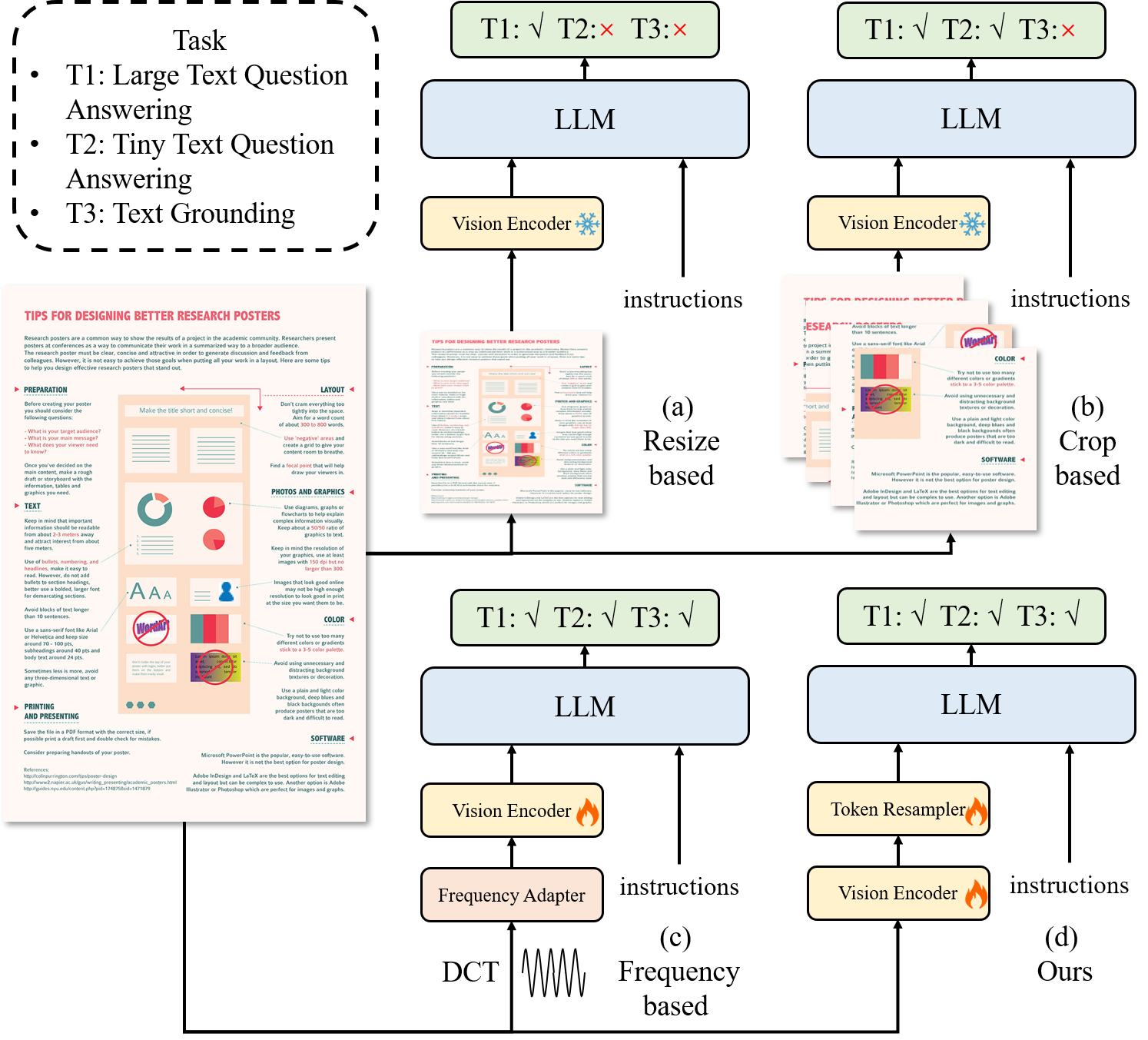
我们推出了 TextMonkey,这是一种专为以文本为中心的任务而定制的大型多模态模型 (LMM),包括文档问答 (DocVQA) 和场景文本分析。我们的方法引入了多个维度的增强:通过采用零初始化的转移窗口注意力,我们在更高的输入分辨率下实现了跨窗口连接并稳定了早期训练;我们假设图像可能包含冗余标记,通过使用相似性过滤掉重要标记,我们不仅可以简化标记长度,还可以提高模型的性能。此外,通过扩展我们的 ...
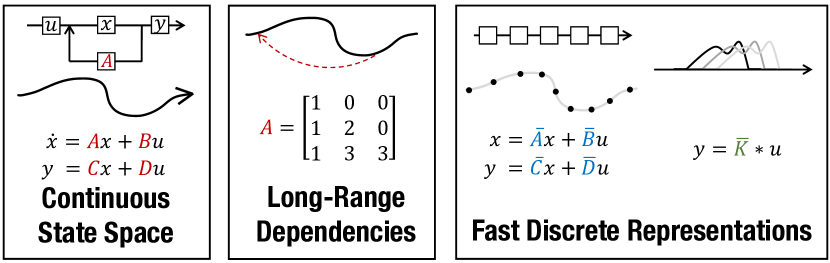
序列建模的中心目标是设计一个单一原则模型,该模型可以跨一系列模式和任务处理序列数据,特别是在长期依赖性方面。尽管包括 RNN、CNN 和 Transformer 在内的传统模型都有专门的变体来捕获长依赖性,但它们仍然难以扩展到 10000 美元或更多步骤的超长序列。最近一种有前途的方法提出了通过模拟基本状态空间模型(SSM)来建模序列\(x'(t)= Ax(t)+ Bu(t),y(t)= Cx(t ...
我们介绍了 VASA,这是一个框架,可以在给定单个静态图像和语音音频剪辑的情况下生成具有吸引人的视觉情感技能 (VAS) 的逼真说话面孔。我们的首屈一指的模型 VASA-1 不仅能够产生与音频完美同步的嘴唇运动,还能捕捉大量面部细微差别和自然头部运动,有助于感知真实性和活力。核心创新包括在面部潜在空间中工作的整体面部动态和头部运动生成模型,以及使用视频开发这种富有表现力和解开的面部潜在空间 ...

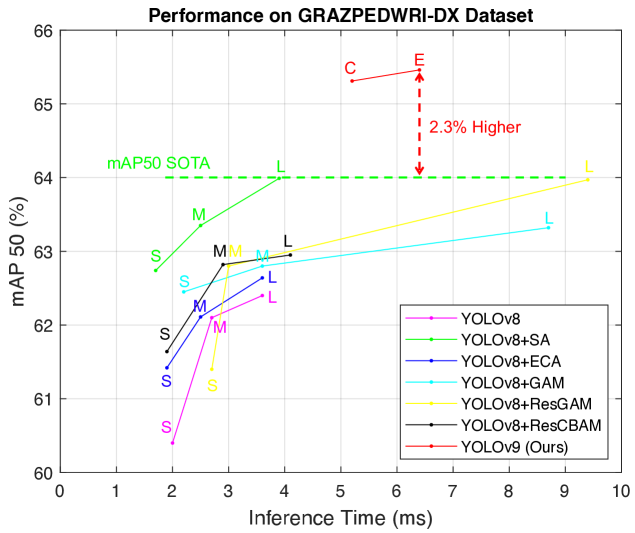
YOLO系列最新版本YOLOv9的推出,使其在各种场景中得到广泛应用。本文首次将YOLOv9算法模型应用到计算机辅助诊断(CAD)的骨折检测任务中,以帮助放射科医生和外科医生解读X射线图像。具体来说,本文在 GRAZPEDWRI-DX 数据集上训练模型,并使用数据增强技术扩展训练集以提高模型性能 ...
Segment Anything Model (SAM) 是一种在大规模数据集上预训练的深度视觉基础模型,打破了一般分割的界限,并激发了各种下游应用。本文介绍了 Hi-SAM,这是一种利用 SAM 进行分层文本分割的统一模型。 Hi-SAM 擅长跨四个层次的文本分割,包括笔画、单词、文本行和段落,同时还实现布局分析 ...

现有的视觉问答方法经常受到跨模式虚假相关性和过于简化的事件级推理过程的影响,无法捕获视频中的事件时间性、因果关系和动态。在这项工作中,为了解决事件级视觉问答的任务,我们提出了一个跨模式因果关系推理的框架。特别是,引入了一组因果干预操作来发现跨视觉和语言模式的潜在因果结构 ...

扩散模型在文本到图像生成领域取得了巨大成功。然而,减轻文本提示和图像之间的错位仍然具有挑战性。未对准背后的根本原因尚未得到广泛调查 ...
