打赏本站
微信
 支付宝
支付宝

支付宝
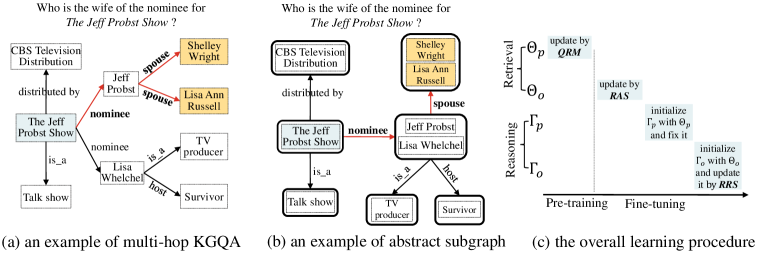
知识图谱多跳问答(KGQA)旨在在大规模知识图谱(KG)上找到距离自然语言问题中提到的主题实体多跳的答案实体。为了应对巨大的搜索空间,现有的工作通常采用两阶段的方法:首先检索与问题相关的相对较小的子图,然后对子图进行推理以准确地找到答案实体。尽管这两个阶段高度相关,但以前的工作采用了截然不同的技术解决方案来开发检索和推理模型,忽略了它们在任务本质上的相关性 ...
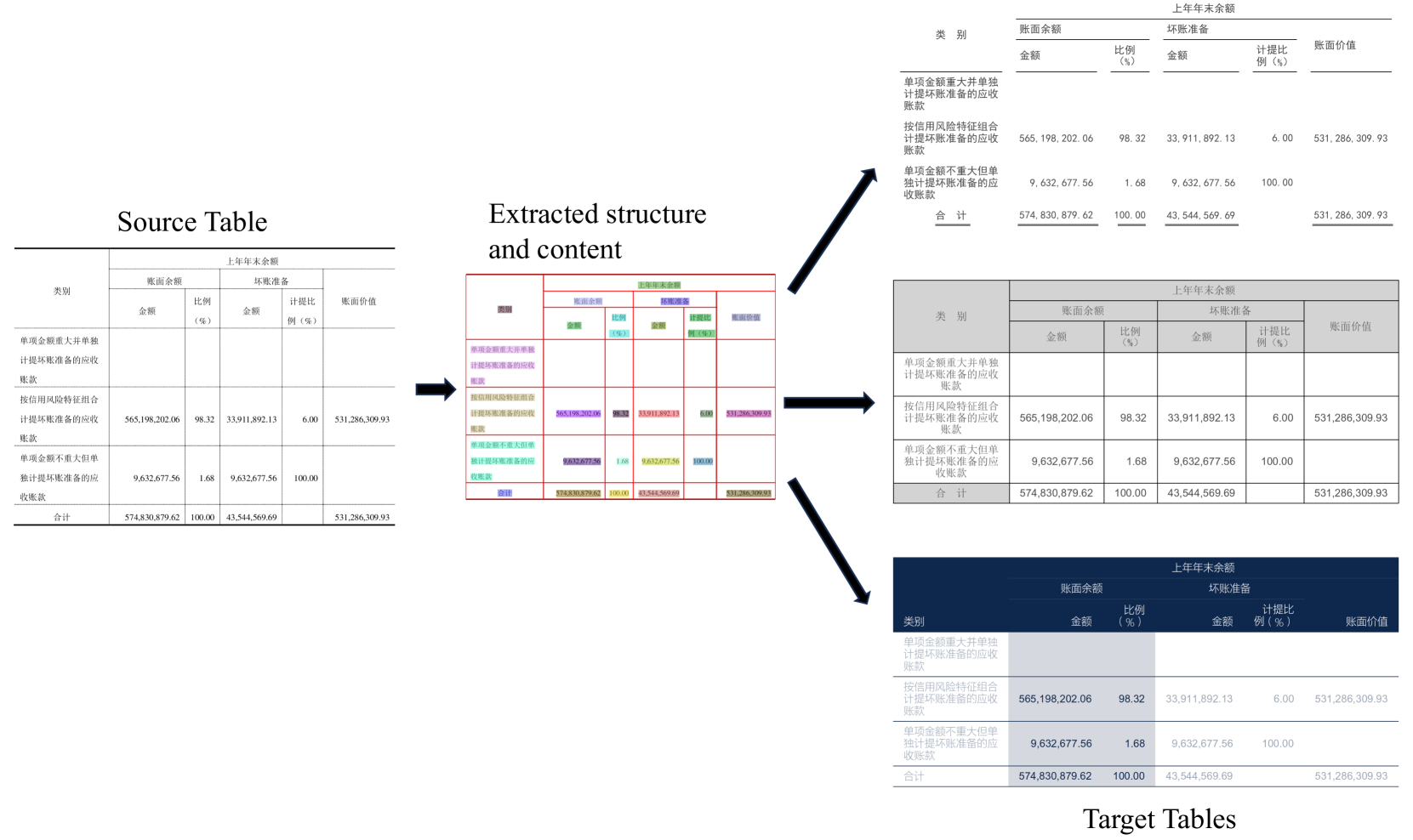
为了克服当前自动表格数据注释方法和随机表格数据合成方法的局限性和挑战,我们提出了一种专门为表格识别设计的合成注释数据的新方法。该方法利用现有复杂表格的结构和内容,有助于高效创建紧密复制目标域中发现的真实样式的表格。通过利用中国财务公告中表格的实际结构和内容,我们开发了该领域第一个广泛的表格注释数据集 ...
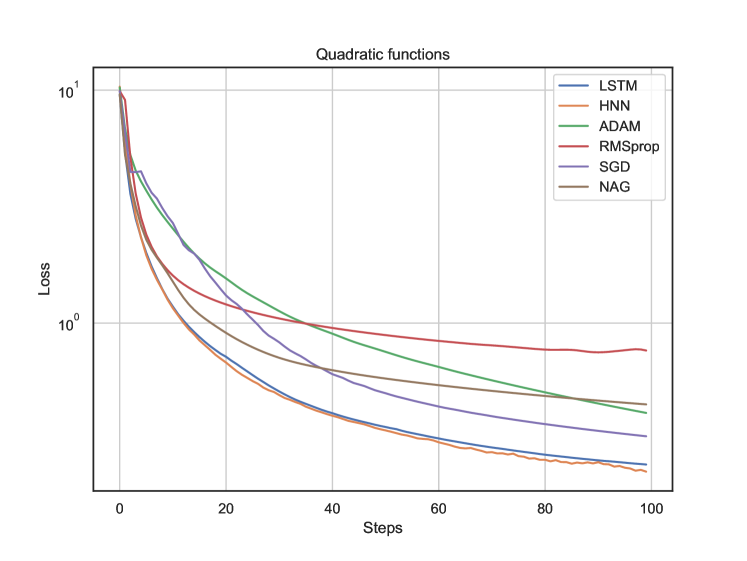
在这项工作中,我们提出了一种基于 ODE 神经网络的元学习器来学习梯度。这种方法使优化器更加灵活,从而对给定任务产生自动归纳偏差。使用最简单的哈密顿神经网络,我们证明了我们的方法优于基于 LSTM 的元学习器(用于人工任务)和优化器中具有 ReLU 激活的 MNIST 数据集 ...
我们用一堆神经网络层推广哈密顿蒙特卡罗算法,并评估其从二维晶格规范理论中的不同拓扑进行采样的能力。我们证明我们的模型能够成功地混合不同拓扑的模式,从而显着降低生成独立规范场配置所需的计算成本。我们的实现可以在 https URL 上找到 ...
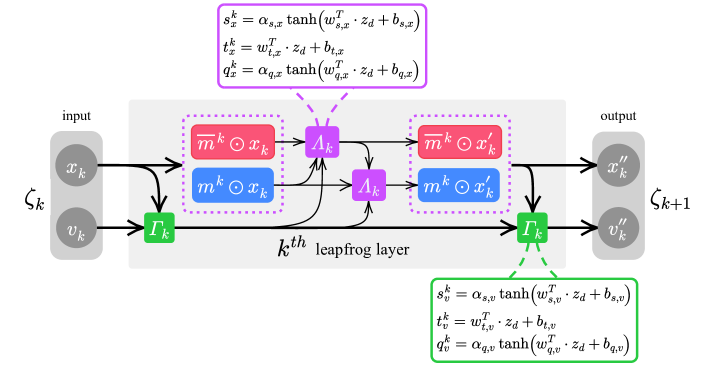
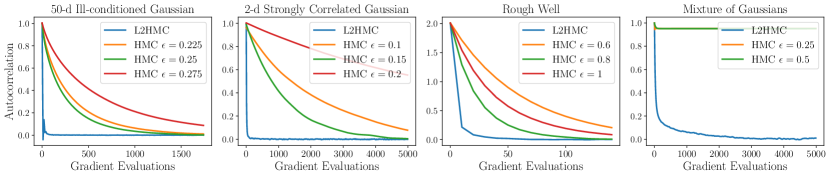
我们提出了一种通用方法来训练马尔可夫链蒙特卡罗内核,由深度神经网络参数化,快速收敛并混合到目标分布。我们的方法概括了哈密顿蒙特卡罗,并经过训练以最大化预期平方跳跃距离(混合速度的代表)。我们在一系列简单但具有挑战性的分布上展示了巨大的经验收益,例如在一个案例中有效样本量提高了 106 倍,并且当标准 HMC 在一秒钟内没有取得可测量的进展时进行混合 ...
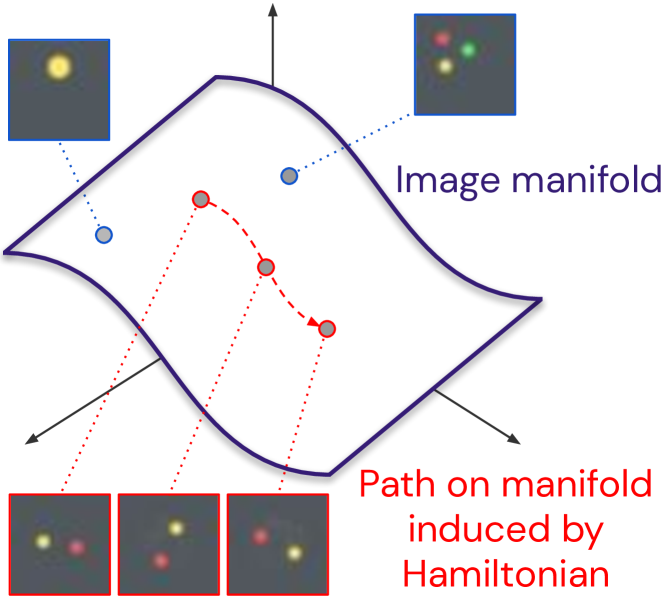
哈密顿形式主义在经典物理学和量子物理学中发挥着核心作用。哈密顿量是对具有守恒量的系统的连续时间演化进行建模的主要工具,并且它们具有许多有用的属性,例如时间可逆性和时间平滑插值。这些属性对于许多机器学习问题(从序列预测到强化学习和密度建模)都很重要,但通常不会由循环神经网络等标准工具提供开箱即用的功能 ...
Transformer 主导了自然语言处理领域,最近还影响了计算机视觉领域。在医学图像分析领域,Transformers也成功应用于全栈临床应用,包括图像合成/重建、配准、分割、检测和诊断。我们的论文旨在提高 Transformers 在医学图像分析领域的认识和应用 ...
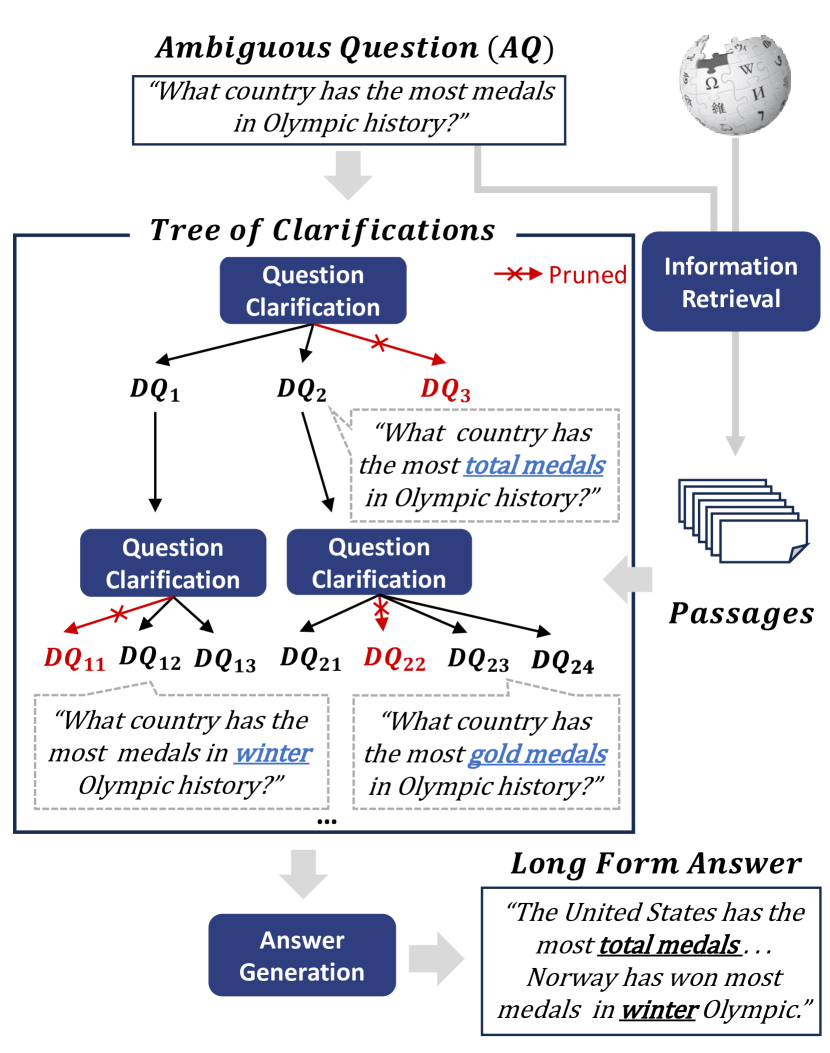
Tree of Clarifications: Answering Ambiguous Questions with Retrieval-Augmented Large Language Models
开放域问答中的问题通常是模棱两可的,允许多种解释。处理这些问题的一种方法是识别歧义问题 (AQ) 的所有可能解释,并生成解决所有这些问题的长式答案,如 Stelmakh 等人 (2022) 所建议的那样 ...