The structure and dynamics of multilayer networks
Abstract
In the past years, network theory has successfully characterized the interaction among the constituents of a variety of complex systems, ranging from biological to technological, and social systems. However, up until recently, attention was almost exclusively given to networks in which all components were treated on equivalent footing, while neglecting all the extra information about the temporal- or context-related properties of the interactions under study. Only in the last years, taking advantage of the enhanced resolution in real data sets, network scientists have directed their interest to the multiplex character of real-world systems, and explicitly considered the time-varying and multilayer nature of networks. We offer here a comprehensive review on both structural and dynamical organization of graphs made of diverse relationships (layers) between its constituents, and cover several relevant issues, from a full redefinition of the basic structural measures, to understanding how the multilayer nature of the network affects processes and dynamics.
keywords:
MSC:
[2010] 00-01, 99-001 Introduction
1.1 The multilayer network approach to nature
If we just turn our eyes to the immense majority of phenomena that occur around us (from those influencing our social relationships, to those transforming the overall environment where we live, to even those affecting our own biological functioning), we realize immediately that they are nothing but the result of the emergent dynamical organization of systems that, on their turn, involve a multitude of basic constituents (or entities) interacting with each other via somehow complicated patterns.
One of the major effort of modern physics is then providing proper and suitable representations of these systems, where constituents are considered as nodes (or units) of a network, and interactions are modeled by links of that same network. Indeed, having such a representation in one hand and the arsenal of mathematical tools for extracting information in the other (as inherited by several gifted centuries of thoughts, concepts and activities in applied mathematics and statistical mechanics) is the only suitable way through which we can even dare to understand the observed phenomena, identify the rules and mechanisms that are lying behind them, and possibly control and manipulate them conveniently.
The last fifteen years have seen the birth of a movement in science, nowadays very well known under the name of complex networks theory. It involved the interdisciplinary effort of some of our best scientists in the aim of exploiting the current availability of big data in order to extract the ultimate and optimal representation of the underlying complex systems and mechanisms. The main goals were i) the extraction of unifying principles that could encompass and describe (under some generic and universal rules) the structural accommodation that is being detected ubiquitously, and ii) the modeling of the resulting emergent dynamics to explain what we actually see and experience from the observation of such systems.
It would look like even pleonastic to report here on each and every original work that was carried out in specific contexts under study (a reader, indeed, will find, along this review, all the relevant literature that was produced so far on this subject, properly addressed and organized in the different sections of the report). At this initial stage, instead, and together with the pioneering articles [1, 2, 3, 4] and classical books [5, 6, 7, 8] on complex networks, we address the interested reader to some other reports [9, 10, 11, 12, 13] that were published recently on this same Journal, which we believe may constitute very good guides to find orientation into the immensely vast literature on the subject. In particular, Ref. [9] is a complete compendium of the ideas and concepts involved in both structural and dynamical properties of complex networks, whereas Refs. [12, 13] have the merit of accompanying and orienting the reader through the relevant literature discussing modular networks [12], and space-embedded networks [13]. Finally, Refs. [10, 11] constitute important accounts on the state of the art for what concerns the study of synchronous organization of networking systems [11], and processes like evolutionary games on networks [10].
The traditional complex network approach to nature has mostly been concentrated to the case in which each system’s constituent (or elementary unit) is charted into a network node, and each unit-unit interaction is represented as being a (in general real) number quantifying the weight of the corresponding graph’s connection (or link). However, it is easy to realize that treating all the network’s links on such an equivalent footing is too big a constraint, and may occasionally result in not fully capturing the details present in some real-life problems, leading even to incorrect descriptions of some phenomena that are taking place on real-world networks.
The following three examples are representative, in our opinion, of the major limitation of that approach.
The first example is borrowed from sociology. Social networks analysis is one of the most used paradigms in behavioral sciences, as well as in economics, marketing, and industrial engineering [14], but some questions related to the real structure of social networks have been not properly understood. A social network can be described as a set of people (or groups of people) with some pattern of contacts or interactions between them [14, 15]. At a first glance, it seems natural to assume that all the connections or social relationships between the members of the network take place at the same level. But the real situation is far different. The actual relationships amongst the members of a social network take place (mostly) inside of different groups (levels or layers), and therefore they cannot be properly modeled if only the natural local-scale point of view used in classic complex network models is taken into account. Let us for a moment think to the problem of spreading of information, or rumors, on top of a social network like Facebook. There, all users can be seen as nodes of a graph, and all the friendships that users create may be considered as the network’s links. However, friendships in Facebook may result from relationships of very different origins: two Facebook’s users may share a friendship because they are colleagues in their daily occupations, or because they are fans of the same football team, or because they occasionally met during their vacation time in some resort, or for any other possible social reason. Now, suppose that a given user gets aware of a given information and wants to spread it to its Facebook’s neighborhood of friends. It is evident that the user will first select that subgroup of friends that he/she believes might be potentially interested to the specific content of the information, and only after will proceed with spreading it to that subgroup. As a consequence, representing Facebook as a unique network of acquaintances (and simulating there a classical diffusion model) would result in drawing incorrect conclusions and predictions of the real dynamics of the system. Rather, the correct way to proceed is instead to chart each social group into a different layer of interactions, and operating the spreading process separately on each layer. As we will see in Section 5, such a multilayer approach leads actually to a series of dramatic and important consequences.
A second paradigmatic example of intrinsically multirelational (or multiplex) systems is the situation that one has to tackle when trying to describe transportation networks, as for instance the Air Transportation Network (ATN) [16] or subway networks [17, 18]. In particular, the traditional study of ATN is by representing it as a single-layer network, where nodes represent airports, while links stand for direct flights between two airports. On the other hand, it is clear that a more accurate mapping is considering that each commercial airline corresponds instead to a different layer, containing all the connections operated by the same company. Indeed, let us suppose for a moment that one wants to make predictions on the propagation of the delays in the flight scheduling through the system, or the effects of such a dynamics on the movement of passengers [19]. In particular, Ref. [16] considered the problem of passenger rescheduling when a fraction of the ATN links, i.e. of flights, is randomly removed. It is well known that each commercial airline incurs in a rather high cost whenever a passenger needs to be rescheduled on a flight of another company, and therefore it tries first to reschedule the passenger by the use of the rest of its own network. As we will see in full details in Section 7, the proper framework where predictions about such dynamical processes can be made suitably is, in fact, considering the ATN as a fully multilayer structure.
Moving on to biology, the third example is the effort of scientists in trying to rank the importance of a specific component in a biological system. For instance, the Caenorhabditis elegans or C. elegans is a small nematode, and it is actually the first ever organism for which the entire genome was sequenced. Recently, biologists were even able to get a full mapping of the C. elegans’ neural network, which actually consists of 281 neurons and around two thousands of connections. On their turn, neurons can be connected either by a chemical link, or by an ionic channel, and the two types of connections have completely different dynamics. As a consequence, the only proper way to describe such a network is a multiplex graph with 281 nodes and two layers, one for the chemical synaptic links and a separate one for the gap junctions’ interactions. The most important consequence is that each neuron can play a very different role in the two layers, and a proper ranking should be then able to distinguish those cases in which a node of high centrality in a layer is just marginally central in the other.
These three examples, along with the many others that the reader will be presented with throughout the rest of this report, well explain why the last years of research in network science have been characterized by more and more attempts to generalize the traditional network theory by developing (and validating) a novel framework for the study of multilayer networks, i.e. graphs where constituents of a system are the nodes, and several different layers of connections have to be taken into account to accurately describe the network’s unit-unit interactions, and/or the overall system’s parallel functioning.
Multilayer networks explicitly incorporate multiple channels of connectivity and constitute the natural environment to describe systems interconnected through different categories of connections: each channel (relationship, activity, category) is represented by a layer and the same node or entity may have different kinds of interactions (different set of neighbors in each layer). For instance, in social networks, one can consider several types of different actors’ relationships: friendship, vicinity, kinship, membership of the same cultural society, partnership or coworker-ship, etc.
Such a change of paradigm, that was termed in disparate ways (multiplex networks, networks of networks, interdependent networks, hypergraphs, and many others), led already to a series of very relevant and unexpected results, and we firmly believe that: i) it actually constitutes the new frontier in many areas of science, and ii) it will rapidly expand and attract more and more attention in the years to come, stimulating a new movement of interdisciplinary research.
Therefore, in our intentions, the present report would like to constitute a survey and a summary of the current state of the art, together with a weighted and meditated outlook to the still open questions to be addressed in the future.
1.2 Outline of the report
Together with this introductory Preamble, the Report is organized along other 8 sections.
In the next section, we start by offering the overall mathematical definitions that will accompany the rest of our discussion. Section 2 contains several parts that are necessarily rather formal, in order to properly introduce the quantities (and their mathematical properties and representation) that characterize the structure of multilayer networks. The reader will find there the attempt of defining an overall mathematical framework encompassing the different situations and systems that will be later extensively treated. If more interested instead in the modeling or physical applications of multilayer networks, the reader is advised, however, to take Section 2 as a vocabulary that will help and guide him/her in the rest of the paper.
Section 3 summarizes the various (growing and not growing) models that have been introduced so far for generating artificial multilayer networks with specific structural features. In particular, we extensively review the available literature for the two classes of models considered so far: that of growing multiplex networks (in which the number of nodes grows in time and fundamental rules are imposed to govern the dynamics of the network structure), and that of multiplex network ensembles (which are ultimately ensembles of networks satisfying a certain set of structural constraints).
Section 4 discusses the concepts, ideas, and available results related to multilayer networks’ robustness and resilience, together with the process of percolation on multilayer networks, which indeed has attracted a huge attention in recent years. In particular, Section 4 will manifest the important differences, as far as these processes are concerned, between the traditional approach of single-layer networks, and the case where the structure of the network has a multilayer nature.
In Section 5, we summarize the state of current understanding of spreading processes taking place on top of a multilayer structure, and discuss explicitly linear diffusion, random walks, routing and congestion phenomena and spreading of information and disease. The section includes also a complete account on evolutionary games taking place on a multilayer network.
Section 6 is devoted to synchronization, and we there describe the cases of both alternating and coexisting layers. In the former, the different layers correspond to different connectivity configurations that alternate to define a time-dependent structure of coupling amongst a given set of dynamical units. In the latter, the different layers are simultaneously responsible for the coupling of the network’s units, with explicit additional layer-layer interactions taken into account.
Section 7 is a large review of applications, especially those that were studied in social sciences, technology, economy, climatology, ecology and biomedicine.
Finally, Section 8 presents our conclusive remarks and perspective ideas.
2 The structure of multilayer networks
Complexity science is the study of systems with many interdependent components, which, in turn, may interact through many different channels. Such systems – and the self-organization and emergent phenomena they manifest – lie at the heart of many challenges of global importance for the future of the Worldwide Knowledge Society. The development of this science is providing radical new ways of understanding many different mechanisms and processes from physical, social, engineering, information and biological sciences. Most complex systems include multiple subsystems and layers of connectivity, and they are often open, value-laden, directed, multilevel, multicomponent, reconfigurable systems of systems, and placed within unstable and changing environments. They evolve, adapt and transform through internal and external dynamic interactions affecting the subsystems and components at both local and global scale. They are the source of very difficult scientific challenges for observing, understanding, reconstructing and predicting their multiscale and multicomponent dynamics. The issues posed by the multiscale modeling of both natural and artificial complex systems call for a generalization of the “traditional” network theory, by developing a solid foundation and the consequent new associated tools to study multilayer and multicomponent systems in a comprehensive fashion. A lot of work has been done during the last years to understand the structure and dynamics of these kind of systems [20, 21, 22, 23, 24]. Related notions, such as networks of networks [25, 26], multidimensional networks [20], multilevel networks, multiplex networks, interacting networks, interdependent networks, and many others have been introduced, and even different mathematical approaches, based on tensor representation [21, 22] or otherwise [23, 24], have been proposed. It is the purpose of this section to survey and discuss a general framework for multilayer networks and review some attempts to extend the notions and models from single layer to multilayer networks. As we will see, this framework includes the great majority of the different approaches addressed so far in the literature.
2.1 Definitions and notations
2.1.1 The formal basic definitions
A multilayer network is a pair where is a family of (directed or undirected, weighted or unweighted) graphs (called layers of ) and
| (1) |
is the set of interconnections between nodes of different layers and with . The elements of are called crossed layers, and the elements of each are called intralayer connections of in contrast with the elements of each () that are called interlayer connections.
In the remainder, we will use Greek subscripts and superscripts to denote the layer index. The set of nodes of the layer will be denoted by and the adjacency matrix of each layer will be denoted by , where
| (2) |
for and . The interlayer adjacency matrix corresponding to is the matrix given by:
| (3) |
The projection network of is the graph where
| (4) |
We will denote the adjacency matrix of by .
This mathematical model is well suited to describe phenomena in social systems, as well as many other complex systems. An example is the dissemination of culture in social networks in the Axelrod Model [27], since each social group can be understood as a layer within a multilayer network. By using this representation we simultaneously take into account:
-
(i)
the links inside the different groups,
-
(ii)
the nature of the links and the relationships between elements that (possibly) belong to different layers,
-
(iii)
the specific nodes belonging to each layer involved.
A multiplex network [28] is a special type of multilayer network in which and the only possible type of interlayer connections are those in which a given node is only connected to its counterpart nodes in the rest of layers, i.e., for every . In other words, multiplex networks consist of a fixed set of nodes connected by different types of links. The paradigm of multiplex networks is social systems, since these systems can be seen as a superposition of a multitude of complex social networks, where nodes represent individuals and links capture a variety of different social relations.
A given multiplex network , can be associated to several (monolayer) networks providing valuable information about it. A specific example is the projection network . Its adjacency matrix has elements
| (5) |
A first approach to the concept of multiplex networks could suggest that these new objects are actually (monolayer) networks with some (modular) structure in the mesoscale. It is clear that if we take a multiplex , we can associate to it a (monolayer) network , where is the disjoint union of all the nodes of , i.e.
| (6) |
and is given by
| (7) |
Note that is a (monolayer) graph with nodes whose adjacency matrix, called supra-adjacency matrix of , can be written as a block matrix
| (8) |
where is the -dimensional identity matrix.
The procedure of assigning a matrix to a multilayer network is often called , or . It is important to remark that the behaviors of and are related but different, since a single node of corresponds to different nodes in . Therefore, the properties and behavior of a multiplex can be understood as a type of non-linear quotient of the properties of the corresponding (monolayer) network .
It is important to remark that the concept of multilayer network extends that of other mathematical objects, such as:
-
1.
Multiplex networks. As we stated before, a multiplex network [28] , with layers is a set of layers , where each layer is a (directed or undirected, weighted or unweighted) graph , with . As all layers have the same nodes, this can be thought of as a multilayer network by taking and for every .
-
2.
Temporal networks [29]. A temporal network can be represented as a multilayer network with a set of layers where , if , while
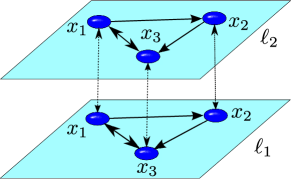
(9) (see the schematic illustration of Fig. 1). Notice that here is an integer, and not a continuous parameter as it will be used later on in Sec. 6.1.1.
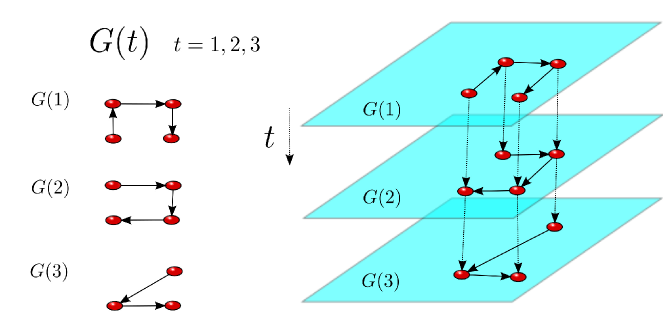
Figure 1: (Color online). Schematic illustration of the mapping of a temporal network into a multilayer network. (Left side) At each time , a different graph characterizes the structure of interactions between the system’s constituents. (Right side) The corresponding multilayer network representation where each time instant is mapped into a different layer. -
3.
Interacting or interconnected networks [24]. If we consider a family of networks that interact, they can be modeled as a multilayer network of layers and whose crossed layers correspond to the interactions between network and (see Fig. 2).
-
4.
Multidimensional networks [20, 30, 31, 32, 33]. Formally, an edge-labeled multigraph (multidimensional network) [30] is a triple where is a set of nodes, is a set of labels representing the dimensions, and is a set of labeled edges, i.e. it is a set of triples .
It is assumed that given a pair of nodes and a label , there may exist only one edge . Moreover, if the model considered is a directed graph, the edges and are distinct. Thus, given , each pair of nodes in can be connected by at most possible edges. When needed, it is possible to consider weights, so that the edges are no longer triplets, but quadruplets , where is a real number representing the weight of the relation between nodes and labeled with . A multidimensional network can be modeled as a multiplex network (and therefore, as a multilayer network) by mapping each label to a layer. Specifically, can be associated to a multilayer network of layers where for every , , ,
(10) and for every .
-
5.
Interdependent (or layered) networks [34, 25, 35]. An interdependent (or layered) network is a collection of different networks, the layers, whose nodes are interdependent to each other. In practice, nodes from one layer of the network depend on control nodes in a different layer. In this kind of representation, the dependencies are additional edges connecting the different layers. This structure, in between the network layers, is often called mesostructure. A preliminary study about interdependent networks was presented in Ref. [34] (there called layered networks). Similarly to the previous case of multidimensional networks, we can consider an interdependent (or layered) network as a multilayer network by identifying each network with a layer.
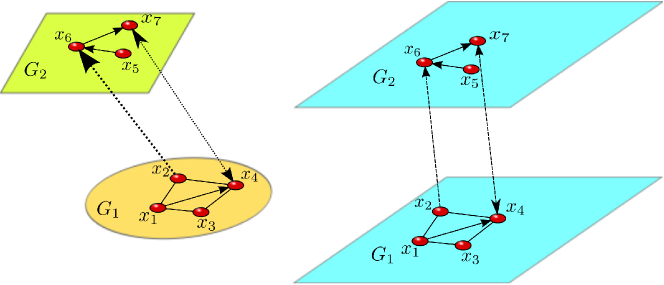
Figure 2: (Color online). Schematic illustration of the rather straightforward mapping of interacting networks into multilayer networks. Each different colored network on the left side corresponds to a different blue layer on the right side. -
6.
Multilevel networks [36]. The formal definition of a multilevel network is the following. Let be a network. A multilevel network is a triple , where is a family of subgraphs of such that
(11) The network is the projection network of and each subgraph is called a slice of the multilevel network . Obviously, every multilevel network can be understood as a multilayer network with layers and crossed layers for every . It is straightforward to check that every multiplex network is a multilevel network, and a multilevel network is a multiplex network if and only if for all .
-
7.
Hypernetworks (or hypergraphs) [37, 38, 17, 39, 40, 41, 42, 43]. A hypergraph is a pair where is a non-empty set of nodes and is a family of non-empty subsets of , each of them called a hyperlink of . Now, if is a graph, a hyperstructure is a triple formed by the vertex set , the edge set , and the hyper-edge set . If is a hypernetwork (or hypergraph), then it can be modeled as a multilayer network, such that for every hyperlink we define a layer which is a complete graph of nodes , and the crossed layers are (see Fig. 3).
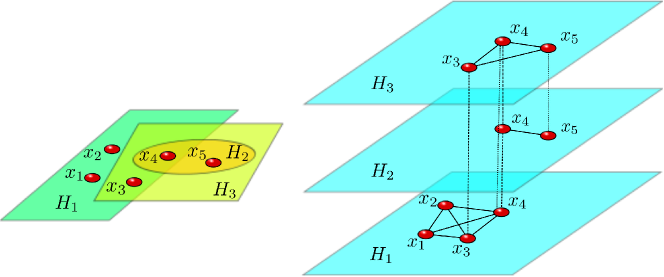
2.1.2 A small (and less formal) handbook
A large amount of studies has shown how representing the elements of a complex system and their interactions with nodes and links can help us to provide insights into the system’s structure, dynamics, and function. However, except for a number of complex systems, the simple abstraction of their organization into a single layer of nodes and links is not sufficient. As we have discussed in the previous section, several extensions of complex networks to multistructure or multirelational networks have been developed in recent years [20, 21, 22, 24, 28, 25, 35, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 16, 58, 59, 60]. In the following, we briefly describe the characteristics of the main ones.
Amongst the mathematical models that consider non-local structures are the hypergraphs (or hypernetworks) [37] and the hyperstructures [17]. However, these models are not able to combine the local scale with the global and the mesoscale structures of the system. For instance, if one wants to model how a rumor spreads within a social network, it is necessary to have in mind not only that different groups are linked through some of their members, but also that two people who know the same person do not necessarily know each other. In fact, these two people may very well belong to entirely different groups or levels. If one tries to model this situation with hypernetworks, then one only takes into account the social groups, and not the actual relationships between their members. In contrast, if one uses the hyperstructure model, then one cannot determine to which social group each contact between two nodes belongs. The key-point that makes hypernetworks and hyperstructures not the best mathematical model for systems with mesoscale structures is that they are both node-based models, while many real systems combine a node-based point of view with a link-based perspective.
Following on with the social network example, when one considers a relationship between two members of a social group, one has to take into account not only the social groups that hold the members, but also the social groups that hold the relationship itself. In other words, if there is a relationship between two people that share two distinct social groups, such as a work and a sporting environment, one has to specify if the relationship arises in the work place, or if it has a sport nature. A similar situation characterizes also public transport systems, where a link between two stations belonging to several transport lines can occur as a part of different lines.
Nevertheless, the use of hypergraph analysis is far from being inadequate. In Ref. [61], the Authors investigate the theory of random tripartite hypergraphs with given degree distributions, providing an extension of the configuration model for traditional complex networks, and a theoretical framework in which analytical properties of these random graphs are investigated. In particular, the conditions that allow the emergence of giant components in tripartite hypergraphs are analyzed, along with classical percolation events in these structures. Moreover, in Ref. [62] a collection of useful metrics on tripartite hypergraphs is provided, making this model very robust for basic analysis.
Another mathematical model capturing multiple different relations that act at the same time is that of multidimensional networks [20, 30, 31, 32, 33, 14, 63, 64, 65, 66, 67]. In a multidimensional network, a pair of entities may be linked by different kinds of links. For example, two people may be linked because they are acquaintances, friends, relatives or because they communicate to each other by phone, email, or other means. Each possible type of relation between two entities is considered as a particular dimension of the network. In the case of a multidimensional network model, a network is a labeled multigraph, that is, a graph where both nodes and edges are labeled and where there can exist two or more edges between two nodes. Obviously, it is possible to consider edge-only labeled multigraphs as particular models of multidimensional networks.
When edge-labeled multigraphs are used to model a multidimensional network, the set of nodes represents the set of entities or actors in the networks, the edges represent the interactions and relations between them, and the edge labels describe the nature of the relations, i.e. the dimensions of the network. Given the strong correlation between labels and dimensions, often the two terms are used interchangeably. In this model, a node belongs to (or appears in) a given dimension if has at least one edge labeled with . So, given a node , is the number of dimensions in which appears, i.e.
| (12) |
Similarly, given a pair of nodes , is the number of dimensions which label the edges between and , i.e. . A multidimensional network can be considered as a multilayer network by making every label equivalent to a layer.
Other alternative models focus on the study of networks with multiple kinds of interactions in the broadest as possible sense. For example, interdependent networks were used to study the interdependence of several real world infrastructure networks in Refs. [25] and [35], where the Authors also explore several properties of these structures such as cascading failures and percolation. Related to this concept, in Ref. [35] the Authors report the presence of a critical threshold in percolation processes, creating an analogy between interdependent networks and ideal gases. The main advantage of interdependent networks is their ability of mapping a node in one relation with many different nodes in another relation. Thus, the mesostructure can connect a single node in a network to several different nodes in a network . This is not possible in other models where there is no explicitly defined mesostructure, and therefore a node is a single, not divisible entity.
Multilevel networks [36] lie in between the multidimensional and the interdependent networks, as they extend both the classic complex network model and the hypergraph model [37]. Multilevel networks are completely equivalent (isomorphic) to multidimensional networks by considering a dimension in conjunction with the equivalent slice . The set corresponding to dimension is the collection of edges labeled with the label , i.e. , while is the collection of nodes and edges of relation , i.e. all the and that are present in at least one edge labeled with . In order to perform more advanced studies such as the shortest path detection, in Ref. [36] Authors introduced also a mesostructure called auxiliary graph. Every vertex of the multilevel network is represented by a vertex in the auxiliary graph and, if a vertex in belongs to two or more slice graphs in , then it is duplicated as many times as the number of slice graphs it belongs to. Every edge of is an edge in the auxiliary graph and there is one more (weighted) edge for each vertex duplication between the duplicated vertex and the original one. This operation breaks the isomorphism with multidimensional networks and brings this representation very close to a layered network [30]. However, these two models are not completely equivalent, since in the multilevel network the one-to-one correspondence of nodes in different slices is strict, while this condition does not hold for layered networks. In Ref. [36], the Authors also define some extensions of classical network measures for multilevel networks, such as the slice clustering coefficient and the efficiency, as well as a collection of network random generators for multilevel structures.
In Ref. [68] the Authors introduce the concept of multiplex networks by extending the popular modularity function for community detection, and by adapting its implicit null model to fit a layered network. The main idea is to represent each layer with a slice. Each slice has an adjacency matrix describing connections between nodes belonging to the previously considered slice. This concept also includes a mesostructure, called interslice couplings which connects a node of a specific slice to its copy in another slice . The mathematical formulation of multiplex networks has been recently developed through many works [23, 28, 45, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 59, 60]. For instance, in Ref. [23] a comprehensive formalism to deal with multiplex systems is proposed, and a number of metrics to characterize multiplex systems with respect to node degree, edge overlap, node participation to different layers, clustering coefficient, reachability and eigenvector centrality is provided.
Other recent extensions include multivariate networks [69], multinetworks [70, 71], multislice networks [68, 72, 73, 74], multitype networks [75, 76, 77], multilayer networks [21, 22, 78, 79], interacting networks [24, 80, 81], and networks of networks [46], most of which can be considered particular cases of the definition of multilayer networks given in Sec. 2.1.1. Finally, it is important to remark that the terminology referring to networks with multiple different relations has not yet reached a consensus. In fact, different scientists from various fields still use similar terminologies to refer to different models, or distinct names for the same model. It is thus clear that the introduction of a sharp mathematical model that fits these new structures is crucial to properly analyze the dynamics that takes place in these complex systems which even nowadays are far from being completely understood.
The notation proposed in Sec. 2.1.1 is just one of the possible ways of dealing with multilayer networks, and indeed there have been other recent attempts to define alternative frameworks. In particular, the tensor formalism proposed in Refs. [21] and [22], which we will extensively review in Sec. 2.3, seems promising, since it allows the synthetic and compact expression of multiplex metrics. Nevertheless, we believe that the notation we propose here is somehow more immediate to understand and easier to use for the study of real-world systems.
In the following, we describe the extension to the context of multilayer networks of the parameters that are traditionally used to characterize the structural properties of a monolayer graph.
2.2 Characterizing the structure of multilayer networks
2.2.1 Centrality and ranking of nodes
The problem of identifying the nodes that play a central structural role is one of the main topics in the traditional analysis of complex networks. In monolayer networks, there are many well-known parameters that measure the structural relevance of each node, including the node degree, the closeness, the betweenness, eigenvector-like centralities and PageRank centrality. In the following, we discuss the extension of these measures to multilayer networks.
One of the main centrality measures is the degree of each node: the more links a node has, the more relevant it is. The degree of a node of a multiplex network is the vector [20, 23]
| (13) |
where is the degree of the node in the layer , i.e. . This vector-type node degree is the natural extension of the established definition of the node degree in a monolayer network.
One of the main goals of any centrality measure is ranking the nodes to produce an ordered list of the vertices according to their relevance in the structure. However, since the node degree in a multiplex network is a vector, there is not a clear ordering in that could produce such a ranking. In fact, one can define many complete orders in , and therefore we should clarify which of these are relevant. Once one has computed the vector-type degree of the nodes, one can aggregate this information and define the overlapping degree [23] of the node , as
| (14) |
i.e. . In fact, many other aggregation measures could be alternatively used to compute the degree centrality, such as a convex combination of , or any norm of .
Other centrality measures, such as closeness and betweenness centrality, are based on the metric structure of the network. These measures can be easily extended to multilayer networks, once the metric and geodesic structure are defined. In Sec. 2.2.3, the reader will find a complete discussion of the metric structures in multilayer networks, which allow straightforward extensions of this kind of centrality measures.
A different approach to measure centrality employs the spectral properties of the adjacency matrix. In particular, the eigenvector centrality considers not only the number of links of each node but also the quality of such connections [82]. There are several different ways to extend this idea to multilayer networks, as discussed in Ref. [28], or in Ref. [83] where eigenvector centrality is used to optimize the outcome of interacting competing networks. In the former reference, several definitions of eigenvector-like centrality measures for multiplex networks are presented, along with studies of their existence and uniqueness.
The simplest way to calculate eigenvector-like centralities in multiplex networks is to consider the eigenvector centrality in each layer separately. With this approach, for every node the eigenvector centrality is another vector
| (15) |
where each coordinate is the centrality in the corresponding layer. Once all the eigenvector centralities have been computed, the independent layer eigenvector-like centrality [28] of is the matrix
| (16) |
Notice that is column stochastic, since all components of are semipositive definite and for every , and the centrality of each node is the row of . As for the degree-type indicators, a numeric centrality measure of each node can be obtained by using an aggregation measure such as the sum, the maximum, or the -norm. The main limitation of this parameter is that it does not fully consider the multilevel interactions between layers and its influence in the centrality of each node.
If one now bears in mind that the centrality of a node must be proportional to the centrality of its neighbors (that are distributed among all the layers), and if one considers that all the layers have the same importance, one has that
| (17) |
so the uniform eigenvector-like centrality is defined [28] as the positive and normalized eigenvector (if it exists) of the matrix given by
| (18) |
where is the transpose of the adjacency matrix of layer . This situation happens, for instance, in social networks, where different people may have different relationships with other people, while one is generically interested to measure the centrality of the network of acquaintances.
A more complex approach is to consider different degrees of importance (or influence) in different layers of the network, and to include this information in the definition of a matrix that defines the mutual influence between the layers. Thus, to calculate the importance of a node within a specific layer, one must take into account also all the other layers, as some of them may be highly relevant for the calculation. Consider, for instance, the case of a boss living in the same block of flats as one of his employees: the relationship between the two fellows within the condominium layer formed by all the neighbors has a totally different nature from that occurring inside the office layer, but the role of the boss (i.e. his centrality) in this case can be even bigger than if he was the only person from the office living in that block of flats. In other words, one needs to consider the situation where the influence amongst layers is heterogeneous.
To this purpose, one can introduce an influence matrix , defined as a non-negative matrix such that measures the influence on the layer given by the layer . Once and have been fixed, the local heterogeneous eigenvector-like centrality of on each layer is defined [28] as a positive and normalized eigenvector (if it exists) of the matrix
| (19) |
So, the local heterogeneous eigenvector-like centrality matrix can be defined as
| (20) |
A similar approach was introduced in Ref. [23], but using a matrix
| (21) |
where and .
Another important issue is that, in general, the centrality of a node within a specific layer may depend not only on the neighbors that are linked to within that layer, but also on all other neighbors of that belong to the other layers. Consider the case of scientific citations in different areas of knowledge. For example, there could be two scientists working in different subject areas (a chemist and a physicist) with one of them awarded the Nobel Prize: the importance of the other scientist will increase even though the Nobel prize laureate had few citations within the area of the other researcher. This argument leads to the introduction of another concept of centrality [28]. Given a multiplex network and an influence matrix , the global heterogeneous eigenvector-like centrality of is defined as a positive and normalized eigenvector (if it exists) of the matrix
| (22) |
Note that is the Khatri-Rao product of the matrices
| (23) |
In analogy with what done before, one can introduce the notation
| (24) |
where . Then, the global heterogeneous eigenvector-like centrality matrix of is defined as the matrix given by
| (25) |
Note that, in general is neither column stochastic nor row stochastic, but the sum of all the entries of is 1.
Other spectral centrality measures include parameters based on the stationary distribution of random walkers with additional random jumps, such as the PageRank centrality [84]. The extension of these measures and the analysis of random walkers in multiplex networks will be discussed in Sec. 5.
2.2.2 Clustering
The graph clustering coefficient introduced by Watts and Strogatz in Ref. [85] can be extended to multilayer networks in many ways. This coefficient quantifies the tendency of nodes to form triangles, following the popular saying “the friend of your friend is my friend”.
Recall that given a network the clustering coefficient of a given node is defined as
| (26) |
If we think of three people , and with mutual relations between and as well as between and , the clustering coefficient of represents the likelihood that and are also related to each other. The global clustering coefficient of is further defined as the average of the clustering coefficients of all nodes. Obviously, the local clustering coefficient is a measure of transitivity [86], and it can be interpreted as the density of the local node’s neighborhood.
Notice that the global clustering coefficient is sometimes defined differently, with an expression that relates it directly to the global features of a network. This alternative definition is not equivalent to the previous one, and it is commonly used in the social sciences [87]. Its expression, sometimes called network transitivity [14], is
| (27) |
In order to extend the concept of clustering to the context of multilayer networks, it is necessary to consider not only the intralayer links, but also the interlayer links. In Ref. [36], the Authors establish some relations between the clustering coefficient of a multilevel network, the clustering coefficient of its layers and the clustering coefficient of its projection network. This generalization is obtained straightforwardly by identifying each slice of a multilevel network with a layer of the corresponding multiplex network . Before giving a definition of the clustering coefficient of a node within a multilevel network , we need to introduce some notation.
For every node let be the set of all neighbors of in the projection network . For every let and be the subgraph of the layer induced by , i.e. , where
| (28) |
Similarly, we will define as the subgraph of the projection network induced by . In addition, the complete graph generated by will be denoted by , and the number of links in by . With this notation we can define the clustering coefficient of a given node in as
| (29) |
Then, the clustering coefficient of can be defined as the average of all .
Once again, the clustering coefficient may be defined in several different ways. For instance, we may consider the average of the clustering coefficients of each layer . However, it is natural to opt for a definition that considers the possibility that a given node has two neighbors and with , with , and with . This is a situation occurring in social networks: one person may know from the aerobic class and from a reading club, while and know each other from the supermarket. Averaging the clustering coefficients of the layers does not help in describing such situations, and an approach based on the projection network seems more relevant, as evidenced by the following example: consider the multiplex network with layers and (Fig. 4); it is easy to check that for all but for all and .
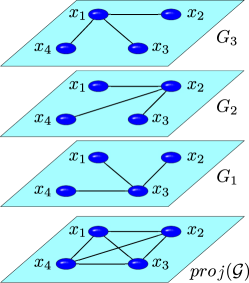
In order to establish a relation between the clustering coefficients of the nodes in the multiplex network, , and the clustering coefficients of the nodes in the projected network, , we can use the same arguments employed in Ref. [36] for multilevel networks. Define as the number of layers in which has less than two neighbors. Then,
| (30) |
Note that Eq. (30) shows that the range of increases with .
While the previous example (Fig. 4) shows the implicit limitations in defining the clustering coefficient of nodes in a multiplex from that of individual layers, still it makes sense to provide an alternative “layers” definition. Similarly to the previous case, let and , where . Note that is the subgraph of the layer induced by . Then, the layer clustering coefficient of node is defined as
| (31) |
Notice that is a subgraph of . Accordingly, and so the largest possible number of links between neighbors of in layer cannot exceed the corresponding largest possible number of links between neighbors of in . Also, we have the relation
| (32) |
where the last sum has terms. We can further assume that the nodes can be rearranged so that for all . Thus, using the method described in Ref. [36], we can obtain a relation between the clustering coefficient in the projected network and the layer clustering coefficient :
| (33) |
Another possible definition of the layer clustering coefficient of a node is the average over the clustering coefficients of the slices
| (34) |
The following relationship between both clustering coefficients holds [36]:
| (35) |
Further generalizations of the notion of clustering coefficient to multilayer networks have been proposed in Refs. [23] and [47]. In Ref. [23], the Authors point out the necessity of extending the notion of triangle to take into account the richness added by the presence of more than one layer. They define a 2-triangle as a triangle formed by an edge belonging to one layer and two edges belonging to a second layer. Similarly, a 3-triangle is a triangle which is composed by three edges all lying in different layers. In order to quantify the added value provided by the multiplex structure in terms of clustering, they consider two parameters of clustering interdependence, and . () is the ratio between the number of triangles in the multiplex which can be obtained only as 2-triangles (3-triangles), and the number of triangles in the aggregated system. Then, is the total fraction of triangles of the aggregated network which cannot be found entirely in one of the layers. They also define a -triad centered at node , for instance , as a triad in which both edge and edge are on the same layer. Similarly, a -triad is a triad whose two links belong to two different layers of the systems. This way, they establish two further definitions of clustering coefficient for multiplex networks. For each node the clustering coefficient is the ratio between the number of -triangles with a vertex in and the number of -triads centered in . A second clustering coefficient is defined as the ratio between the number of -triangles with node as a vertex, and the number of -triads centered in . As the Authors point out, while is a suitable definition for multiplexes with , can only be defined for systems composed of at least three layers, and both coefficients are poorly correlated, so it is necessary to use both clustering coefficients in order to properly quantify the abundance of triangles in multilayer networks. Averaging over all the nodes of the system, they obtain the network clustering coefficients and .
In Ref. [23] the Authors also generalize the definition of transitivity. They propose two measures of transitivity: as the ratio between the number of -triangles and the number of -triads, and as the ratio between the number of -triangles and the number of -triads. As it is stressed by the Authors, clustering interdependencies and , average multiplex clustering coefficients and , and multiplex transitivities and are all global network variables which give a different perspective on the multilayer patterns of clustering and triadic closure with respect to the clustering coefficient and the transitivity computed for each layer of the network.
In Ref. [47], the Authors derive measurements of transitivity for multiplex networks by developing several multiplex generalizations of the clustering coefficient, and provide a comparison between some different formulations of multiplex clustering coefficients. For instance, Authors point out that the balance between intralayer versus interlayer clustering is different in social versus transportation networks, reflecting the fact that transitivity emerges from different mechanisms in these cases. Such differences are rooted in the new degrees of freedom that arise from interlayer connections, and are invisible to calculations of clustering coefficients on single-layer networks obtained via aggregation. Generalizing clustering coefficients for multiplex networks thus makes it possible to explore such phenomena and to gain deeper insights into different types of transitivity in networks. Further multiplex clustering coefficients are defined in Refs. [64, 88, 89].
2.2.3 Metric structures: Shortest paths and distances
The metric structure of a complex network is related to the topological distance between nodes, written in terms of walks and paths in the graph. So, in order to extend the classical metric concepts to the context of multilayer networks, it is necessary to establish first the notions of path, walk and length. In order to introduce all these concepts, we will follow a similar scheme to that used in Ref. [90]. Given a multilayer network , we consider the set
| (36) |
A walk (of length ) in is a non-empty alternating sequence
| (37) |
of nodes and edges with , such that for all there exists an with
| (38) |
If the edges are weighted, the length of the walk can be defined as the sum of the inverse of the corresponding weights. If , the walk is said to be closed.
A path between two nodes and in is a walk through the nodes of in which each node is visited only once. A cycle is a closed path starting and ending at the same node. If it is possible to find a path between any pair of its nodes, a multilayer network is referred to as connected; otherwise it is called disconnected. However, different types of reachability may be considered [20, 23] depending, for example, on whether we are considering only the edges included in some layers.
The length of a path is the number of edges of that path. Of course, in a multilayer network there are at least two types of edges, namely intralayer and interlayer edges. Thus, this definition changes depending on whether we consider interlayer and intralayer edges to be equivalent. Other metric definitions may be easily generalized from monolayer to multilayer networks. So, a geodesic between two nodes and in is one of the shortest path that connects and . The distance between and is the length of any geodesic between and . The maximum distance between any two vertices in is called the diameter of . By we will denote the number of different geodesics that join and . If is a node and is a link, then and will denote the number of geodesics that join the nodes and passing through and respectively.
A multilayer network is a subnetwork of if for every with , there exist with such that , and . A connected component of is a maximal connected subnetwork of . Two paths connecting the same pair of vertices in a multilayer network are said to be vertex-independent if they share no vertices other than the starting and ending ones. A -component is a maximal subset of the vertices such that every vertex in the subset is connected to every other by independent paths. For the special cases , , the -components are called bi-components and three-components of the multilayer network. For any given network, the -components are nested: every three-component is a subset of a bi-component, and so forth.
The characteristic path length is defined as
| (39) |
where , and is also a way of measuring the performance of a graph.
The concept of efficiency, introduced by Latora and Marchiori in Ref. [91] may also be extended to multilayer networks in a similar way to the one used in Ref. [36]. With the same notation, the efficiency of a multilayer network is defined as
| (40) |
It is quite natural to try to establish comparisons between the efficiency of a multilayer network , the efficiency of its projection and the efficiencies of the different layers . In Ref. [36] there are some analytical results that establish some relationships between these parameters.
If we consider interlayer and intralayer edges not to be equivalent, we can give alternative definitions of the metric quantities. Let be a multilayer network, and
| (41) |
be a path in . The length of can be defined as the non-negative value
| (42) |
where
| (43) |
and is an arbitrarily chosen non-negative parameter.
In this case, the distance in between two nodes and is the minimal length among all possible paths in from to .
Notice that for , the previous definition reduces to the natural metric in the projection network , while positive values of correspond to metrics that take into account also the interplay between the different layers.
One can generalize the definition of path length even further by replacing the jumping weight with an non-negative matrix , to account for different distances between layers. Thus, the length of a path becomes
| (44) |
where
| (45) |
The jumping weights can be further extended to include a dependence not only on the two layers involved in the layer jump, but also on the node from which the jump starts.
For a multiplex network, it is also important to quantify the participation of single nodes to the structure of each layer in terms of node reachability [23]. Reachability is an important feature in networked systems. In single-layer networks it depends on the existence and length of shortest paths connecting pairs of nodes. In multilevel systems, shortest paths may significantly differ between different layers, as well as between each layer and the aggregated topological networks. To address this, the so-called node interdependence was introduced in Refs. [57] and [92]. The interdependence of a node is defined as:
| (46) |
where is the total number of shortest paths between node and node on the multiplex network, and is the number of shortest paths between node and node which make use of links in two or more layers. Therefore, the node interdependence is equal to when all shortest paths make use of edges laying on at least two layers, and equal to when all shortest paths use only one layer of the system. Averaging over all nodes, we obtain the network interdependence.
The interdependence is a genuine multiplex measure that provides information in terms of reachability. It is slightly anti-correlated to measures of degree such as the overlapping degree. In fact, a node with high overlapping degree has a higher number of links that can be the first step in a path toward other nodes; as such, it is likely to have a low . Conversely, a node with low overlapping degree is likely to have a high value of , since its shortest paths are constrained to a smaller set of edges and layers as first step. This measure is validated in Ref. [23] on the data set of Indonesian terrorists, where information among 78 individuals are recorded with respect to mutual trust, common operations, exchanged communications and business relationships.
2.2.4 Matrices and spectral properties
It is well known that the spectral properties of the adjacency and Laplacian matrices of a network provide insights into its structure and dynamics [93, 94, 9]. A similar situation is possible for multilayer networks, if proper matrix representations are introduced.
Given a multilayer network , several adjacency matrices can give information about its structure: amongst others, the most used are the adjacency matrix of each layer , the adjacency matrix of the projection network and the supra-adjacency matrix . The spectrum of the supra-adjacency matrix is directly related to several dynamical processes that take place on a multilayer network. Using some results from interlacing of eigenvalues of quotients of matrices [93, 94, 95], in Ref. [79] it was proven that if is the spectrum of the supra-adjacency matrix of an undirected multilayer network and is the spectrum of the adjacency matrix of layer , then for every
| (47) |
A similar situation occurs for the Laplacian matrix of a multiplex network. The Laplacian matrix (also called supra-Laplacian matrix) of a multiplex is defined as the matrix of the form:
| (48) |
In the equation above, I is the identity matrix and is the usual Laplacian matrix of the network layer whose elements are where is the strength of node in layer , . We will see in Sec. 5 that the diffusion dynamics on a multiplex network is strongly related to the spectral properties of . In Ref. [79], the Authors prove that if is the spectrum of the Laplacian matrix of an undirected multilayer network and is the spectrum of the Laplacian matrix of layer , then for every
| (49) |
Similar results can be found using perturbative analysis [59, 96].
In addition to the spectra of the adjacency and Laplacian matrices, other types of spectral properties have been studied for multiplex network, such as the irreducibility [97]. Several problems in network theory involve the analysis not only of the eigenvalues, but also of the eigenvectors of a matrix [9]. This analysis typically includes the study of the existence and uniqueness of a positive and normalized eigenvector (Perron vector), whose existence is guaranteed if the corresponding matrix is irreducible (by using the classic Perron-Frobenius theorem). As for the spectral properties, it is possible to relate the irreducibility of such a matrix with the irreducibility in each layer and on the projection network. In Refs. [28, 97] it was shown that if and the adjacency matrix of the projection network is irreducible, then the matrix defining the global heterogeneous eigenvector-like centrality is irreducible. A similar situation occurs when we consider random walkers in multiplex networks [98]. In this case, the uniqueness of a stationary state of the Markov process is guaranteed by the irreducibility of a matrix of the form
| (50) |
where , , , and is the Hadamard product of matrices and (see Ref. [97]). It can be proven that, under some hypotheses, if the adjacency matrix of the projection network is irreducible, then is irreducible and hence the random walkers proposed in Ref. [98] have a unique stationary state.
2.2.5 Mesoscales: Motifs and modular structures
An essential method of network analysis is the detection of mesoscopic structures known as communities (or cohesive groups). These communities are disjoint groups (sets) of nodes which are more densely connected to each other than they are to the rest of the network [12, 99, 100]. Modularity is a scalar that can be calculated for any partition of a network into disjoint sets of nodes. Effectively, modularity is a quality function that counts intracommunity edges compared to what one would expect at random. Thus, one tries to determine a partition that maximizes modularity to identify communities within a network.
In Ref. [21], there is a definition of modularity for multilayer networks in which the Authors introduce a tensor that encodes the random connections defining the null model. Ref. [68] provides a framework for the study of community structure in a very general setting, covering networks that evolve over time, have multiple types of links (multiplexity), and have multiple scales. The Authors generalize the determination of community structure via quality functions to multislice networks that are defined by coupling multiple adjacency matrices.
As described above, communities are mesoscale structures mainly defined at a global level. One may ask whether more local mesoscales, i.e. those defined slightly above the single node level, can also be extended to multilayer networks. Without doubts, the most important of them are motifs, i.e. small sub-graphs recurring within a network with a frequency higher than expected in random graphs [101]. Their importance resides in the fact that they can be understood as basic building blocks, each associated with specific functions within the global system [102].
Little attention so far has been devoted to understanding the meaning of motifs in multilayer networks. An important exception is presented in Ref. [63] in the framework of the analysis of the Pardus social network, an on-line community that comprises players interacting in a virtual universe. When links are grouped in two layers, corresponding to positively and negatively connoted interactions, some resulting structures, which can be seen as multilayered motifs, appear with a frequency much higher (e.g. triplets of users sharing positive relations) or lower (e.g. two enemy users that both have a positive relation with a third) than expected in random networks.
2.3 Matrices and tensor representation: Spectral properties
There have been some attempts in the literature for modeling multilayer networks properly by using the concept of tensors [21, 22, 47]. Before describing these results, we recall some basic tensor analysis concepts.
There are two main ways to think about tensors:
-
(1)
tensors as multilinear maps;
-
(2)
tensors as elements of a tensor product of two or more vector spaces.
The former is more applied. The latter is more abstract but more powerful. The tensor product of two real vector spaces and , denoted by , consists of finite linear combinations of , where and .
The dual vector space of a real vector space is the vector space of linear functions , indicated by . Denoting by the set of linear functions from to , there is a natural isomorphism between the linear spaces and . Moreover, if is a finite dimensional vector space, then there exists a natural isomorphism (depending on the bases considered) between the linear spaces and . In fact, if is finite-dimensional, the relationship between and reflects in an abstract way the relation between the row-vectors and the column-vectors of a matrix. However, if and are finite-dimensional, then we can identify the linear spaces with . Thus, a tensor can be understood as a linear function , and therefore, once two bases of the corresponding vector spaces have been fixed, a tensor may be identified with a specific matrix.
Now, let us consider a multiplex network made of layers , , with , in order to describe it as a tensor product
| (51) |
where represents the layer .
Linear combinations of a family of vectors are obtained by multiplying a finite number among them by nonzero scalars (usually real numbers) and adding up the results. The span of a family of vectors is the set of all their linear combinations. In the following, we will denote the span of a family of vectors by
| (52) |
Given the sets and , we consider the formal vector spaces on of all their linear combinations as follows:
| (53) |
| (54) |
It is straightforward to check that and are basis of and respectively, and therefore
| (55) |
is a basis of . So, we may give the intuitive meaning of “being in the node and in the layer ”.
| 0 | 1 | 1 | |
| 0 | 0 | 1 | |
| 1 | 0 | 0 |
Now, if we consider a monolayer network of nodes, with , we can identify with the linear transformation such that the matrix associated to with respect to the basis is the adjacency matrix of .
Thus, if the adjacency matrix of is , we can find the set of nodes accessible from any node in one step by multiplying on the left by the canonical basis row-vector. For example, the adjacency matrix of the graph in Fig. 5 is
| (56) |
From node 1, we can access in one step nodes 2 and 3, since
| (57) |
In the same way, a multilayer network of nodes and with layers can be identified with a linear transformation where ,
| (58) |
| (59) |
It is easy to check that is completely determined by the matrix associated to with respect to the basis
| (60) |
As an example, consider the monolayer network , with , whose adjacency matrix is given in Table 1.
| 0 | 1 | 1 | 0 | 1 | 0 | ||
| 1 | 0 | 0 | 1 | 0 | 1 | ||
| 0 | 0 | 0 | 1 | 1 | 0 | ||
| 0 | 0 | 1 | 0 | 0 | 1 | ||
| 1 | 0 | 0 | 0 | 0 | 1 | ||
| 0 | 1 | 0 | 0 | 1 | 0 | ||
Now consider the multiplex network with layers , and nodes , obtained by duplicating the previous monoplex network in both layers, and connecting each node with its counterpart in the other layer (Fig. 6). The adjacency matrix of is given in Table 2.
Of course, the specific matrix representing a tensor depends on the way we order the elements of the basis chosen.
| (61) |
However, if and are two different matrices assigned to the same tensor, there exists a permutation matrix such that , and thus both matrices have the same spectral properties (see Sec. 2.2.4).
If in the previous example we swap the order of layers and nodes, we get a different adjacency matrix, called supra-adjacency matrix of (Table 3), which can be written in the usual form
| (62) |
where is the adjacency matrix of layer . Note that, unlike the case of multiplex networks, the blocks in the supra-adjacency matrix of a general multilayer networks are not necessarily square matrices. It is worth mentioning the dual roles between layers and nodes that may be observed by comparing Table 2 and Table 3.
An example of a generic 2-layer network, can be seen in Fig. 7, where we can pass in one step from node to node , and from node to node . Its adjacency matrix is listed in Table 4. It is important to stress that while the adjacency matrix of a multilayer network with layers and nodes has entries, the adjacency matrix of a multiplex network with the same layers and nodes is completely determined by only elements. In fact, a multiplex network of layers is completely determined by the adjacency matrices corresponding to the layers and its influence matrix , i.e. the non-negative matrix such that is the influence of the layer on the layer .
| 0 | 1 | 1 | 1 | 0 | 0 | ||
| 0 | 0 | 1 | 0 | 1 | 0 | ||
| 1 | 0 | 0 | 0 | 0 | 1 | ||
| 1 | 0 | 0 | 0 | 1 | 1 | ||
| 0 | 1 | 0 | 0 | 0 | 1 | ||
| 0 | 0 | 1 | 1 | 0 | 0 | ||
| 0 | 1 | 1 | 1 | 1 | 0 | ||
| 1 | 0 | 0 | 1 | 0 | 1 | ||
| 0 | 0 | 0 | 1 | 1 | 0 | ||
| 0 | 0 | 1 | 0 | 0 | 1 | ||
| 1 | 1 | 0 | 0 | 0 | 1 | ||
| 0 | 1 | 0 | 0 | 1 | 0 | ||
Multilayer networks, multidimensional networks, hypergraphs, and some other objects can be represented with tensors, which represent a convenient formalism to implement different models [103]. Specifically, tensor-decomposition methods [103, 104] and multiway data analysis [105] have been used to study various types of networks. These kind of methods are based on representing multilayer networks as adjacency higher-order tensors and then applying generalizations of methods such as Singular Value Decomposition (SVD) [106], and the combination of CANDECOMP (canonical decomposition) by Carroll and Chang [107] and PARAFAC (parallel factors) by Harshman [108] leading to CANDECOMP/PARAFAC (CP). These methods have been used to extract communities [104], to rank nodes [109, 110] and to perform data mining [103, 111, 112].
2.4 Correlations in multiplex networks
Multiplex networks encode significantly more information than their single layers taken in isolation, since they include correlations between the role of the nodes in different layers and between statistical properties of the single layers. Discovering the statistically significant correlations in multilayer networks is likely to be one of the major goals of network science for the next years. Here we outline the major types of correlations explored so far. We distinguish between:
-
1.
Interlayer degree correlations
Generally speaking these correlations are able to indicate if the hubs in one layer are also the hubs, or they are typically low degree nodes, in the other layer. -
2.
Overlap and multidegree
The node connectivity patterns can be correlated in two or more layers and these correlations can be captured by the overlap of the links. For example, we usually have a large fraction of friends with which we communicate through multiple means of communications, such as phone, email and instant messaging. This implies that the mobile phone social network has a significant overlap with the one of email communication or the one of instant messaging. The overlap of the links can be quantified by the global or local overlap between two layers, or by the multidegrees of the nodes that determine the specific overlapping pattern. -
3.
Multistrengths and inverse multiparticipation ratio of weighted multiplex
The weights of the links in the different layers can be correlated with other structural properties of the multiplex. For example, we tend to cite collaborators differently from other scientists. These types of correlations between structural properties of the multiplex and the weights distribution are captured by the multistrengths and inverse multiparticipation ratio. -
4.
Node pairwise multiplexity
When the nodes are not all active in all layers two nodes can have correlated activity patterns. For example they can be active on the same, or on different layers. These correlations are captured by the Node Pairwise Multiplexity. -
5.
Layer pairwise multiplexity
When the nodes are not all active in all layers, two layers can have correlated activity patterns. For example they can contain the same active nodes, or different active nodes. These correlations are captured by the Layer Pairwise Multiplexity.
2.4.1 Degree correlations in multiplex networks
Every node of a multiplex has a degree in each layer . The degrees of the same node in different layers can be correlated. For example, a node that is a hub in the scientific collaboration network is likely to be a hub also in the citation network between scientists. Therefore, the degree in the collaboration network is positively correlated with that of the citation network. Negative correlations also exist, when the hubs of one layer are not the hubs of another layer. The methods to evaluate the degree correlations between a layer and a layer are the following:
-
1.
Full characterization of the matrix .
One can construct the matrix(63) where is the number of nodes that have degree in layer and degree in layer . From this matrix, the full pattern of correlations can be determined.
-
2.
Average degree in layer conditioned on the degree of the node in layer
A more coarse-grained measure of correlation is , i.e. the average degree of a node in layer conditioned to the degree of the same node in layer :(64) If this function does not depend on , the degrees in the two layers are uncorrelated. If this function is increasing (decreasing) in , the degrees of the nodes in the two layers are positively (negatively) correlated.
-
3.
Pearson, Spearman and Kendall correlations coefficients
Even more coarse-grained correlation measures are the Pearson, the Spearman and the Kendall’s correlations coefficients.The Pearson correlation coefficient is given by
(65) where . The Pearson correlation coefficient can be dominated by the correlations of the high degree nodes if the degree distributions are broad.
The Spearman correlation coefficient between the degree sequences and in the two layers and is given by
(66) where is the rank of the degree in the sequence and is the rank of the degree in the sequence . Moreover, and . The Spearman coefficient has the problem that the ranks of the degrees in each degree sequence are not uniquely defined because degree sequences must always have some degeneracy. Therefore, the Spearman correlation coefficient is not a uniquely defined number.
The Kendall’s correlation coefficient between the degree sequences and is a measure that takes into account the sequence of ranks and . A pair of nodes and is concordant if their ranks have the same order in the two sequences, i.e. , and discordant otherwise. The Kendall’s is defined in terms of the number of concordant pairs and the number of discordant pairs and is given by
(67) In the equation above, and the terms and account for the degeneracy of the ranks and are given by
(68) where is the number of nodes in the tied group of the degree sequence , and is the number of nodes in the tied group of the degree sequence .
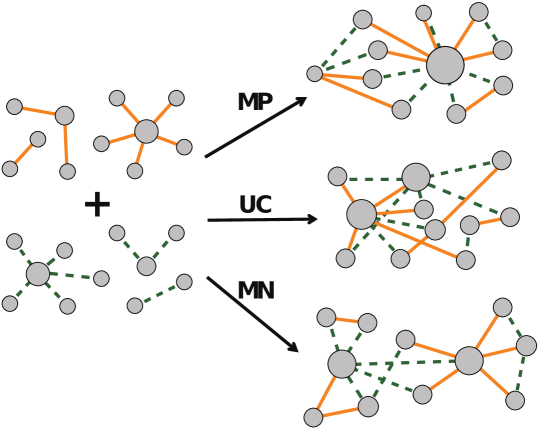
The level of degree correlations in the multiplex networks can be tuned by reassigning new labels to the nodes of the multiplexes [48]. Let us for simplicity consider a duplex where we have two degree sequences and as proposed in Ref. [48]. The label of the nodes in layer 1 and layer 2 can be reassigned in order to generate the desired correlations between the two degree sequences. Assume we have ranked the degree sequences in the two layers. If the labels of the nodes in both sequences are given according to the increasing rank of the degree in each layer, then the sequences are maximally-positive correlated (MP), i.e. the nodes of equal rank in the two sequences are replica nodes of the multiplex. Conversely, if the label of a node in one layer is given according to the increasing rank of the degree in the same layer, and the label of a node in the other layer is given according to the decreasing rank of the degree in the same layer, the two degree sequences are maximally-negative correlated (MN). In Fig. 8, an example is given for the construction of maximally-positive (MP) correlations and maximally-negative (MN) correlations from two given degree sequence in two layers of a multiplex network.
2.4.2 Overlap and multidegree
A large variety of data sets, including the multiplex airport network, on-line social games, collaboration and citation networks [63, 78, 113], display a significant overlap of the links. This means that the number of links present at the same time in two different layers is not negligible with respect to the total number of links in the two layers.
The total overlap between two layers and [49, 63] is defined as the total number of links that are in common between layer and layer :
| (69) |
where .
It is sometimes useful also to define the local overlap between two layers and [49], defined as the total number of neighbors of node that are neighbors in both layer and layer :
| (70) |
The total and local overlap in multilayer networks can be very significant. Take for example the online social game studied in Ref. [63]. In this data set the friendship and the communication layers have a significant overlap, similarly to the communication and trade layers. Even the two “negative” layers of enmity and attack have significant overlap of the links. As a second example of multiplex network with significant overlap, consider the APS data set of citations and collaboration networks [113]. The two layers in this data set display significant overlap because two co-authors are also usually citing each other in their papers.
One way to characterize the link overlap is by introducing the concept of multilinks [49, 113]. A multilink fully determines all the links present between any given two nodes and in the multiplex. Consider for example the multiplex with layers, i.e. the duplex shown in Fig. 9. Nodes 1 and 2 are connected by one link in the first layer and one link in the second. Thus, we say that the nodes are connected by a multilink . Similarly, nodes 2 and 3 are connected by one link in the first layer and no link in layer 2. Therefore, they are connected by a multilink . In general, for a multiplex of layers we can define multilinks, and multidegrees in the following way. Let us consider the vector in which every element can take only two values . We define a multilink as the set of links connecting a given pair of nodes in the different layers of the multiplex: if and only if they are connected in layer . We can therefore introduce the multiadjacency matrices with elements equal to 1 if there is a multilink between node and node , and zero otherwise:
| (71) |
Thus, multiadjacency matrices satisfy the condition
| (72) |
for every fixed pair of nodes . Multiadjacency matrices are a way to describe the same information encoded in the adjacency matrices of each layer, and while they do not encode more information, they can be useful tools to characterize partial overlap and correlations. Finally, we define the multidegree of a node , as the total number of multilinks incident to node , i.e.
| (73) |
For a duplex the non trivial multidegrees, i.e. the multidegrees , have the explicit expression in terms of the adjacency matrix of layer 1 and of layer 2 given by
| (74) |
Considering the example of a social duplex, formed by the same set of agents interacting by mobile phone in layer 1 and by email in layer 2, indicates the number of acquaintances of node that only communicate with it via mobile phone, indicates the number of acquaintances of node that only communicate with it via email, and indicates the number of acquaintances of node that communicate with it via both mobile phone and email.
When the number of layers is very large, it is difficult to keep track of all the different types of multilinks. In this case one can consider the multiplicity of the overlap between node and node indicating the total number of layers in which the two nodes are connected, i.e.
| (75) |
where the nodes and are linked by a multilink .
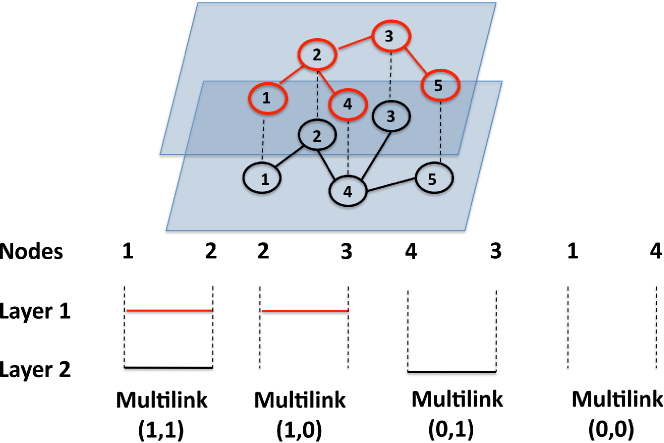
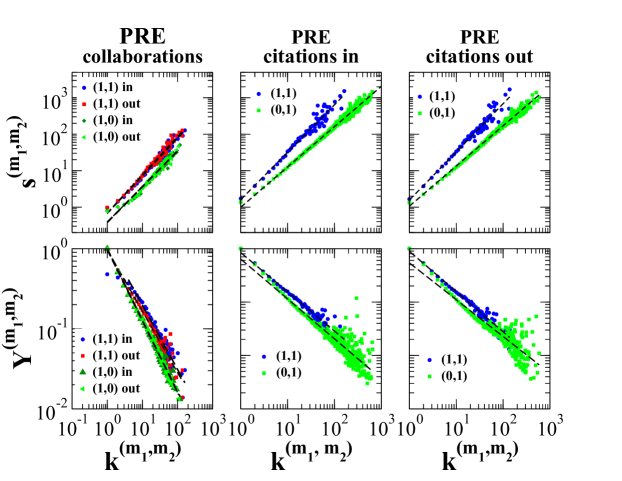
2.4.3 Multistrength and inverse multiparticipation ratio in weighted multiplex networks
In weighted multiplex networks the weights might be correlated with the multiplex network structure in a non trivial way. To study weighted multiplex networks, two new measures, the multistrengths and the inverse multiparticipation ratio have been introduced in Ref. [113]. For layer associated to multilinks , such that , we define the multistrength and the inverse multiparticipation ratio of node , as
| (76) |
| (77) |
respectively. The multistrength measures the total weights of the links incident to node in layer that form a multilink of type . For example, in a social multiplex network where each layer is either mobile phone communication (layer 1) or email communication (layer 2), is the total strength of phone calls of node with people that do not communicate with it by email, is the total strength of email contacts of node with people that do not communicate with it via mobile phone, is the total strength of phone calls of node with people that also communicate with it via email, and is the total strength of email communication of node with people that also communicate with it via mobile phone. The inverse multiparticipation ratio is a measure of the inhomogeneity of the weights of the nodes that are incident to node in layer and at the same time are part of a multilink . Since for every layer and node the non trivial multistrengths must involve multilinks with , the number of non trivial multistrengths is given by . Therefore, for each node, the number of multistrengths that can be defined in a multiplex network of layers is . Similarly to what happens for single layers [114, 115, 116], the average multistrength of nodes with a given multidegree, i.e. , and the average inverse multiparticipation ratio of nodes with a given multidegree, , are expected to scale as
| (78) |
with exponents and . In Ref. [113] the weighted multilink properties of multiplex networks between scientist collaborating (in layer 1) and citing each other (in layer 2) have been analyzed starting from the APS data set. In this case the citation network is also directed, and the Authors find that the exponents and depend on the type of multilink, i.e. they are significantly different for links without overlap and for links with overlap. It is clear from this analysis that many weighted multiplex networks have a distribution of the weights that depends on the non-trivial correlations existing in their structure. In Fig. 10, the multistrength and inverse multiparticipation ratio for the collaboration and citation networks of PRE Authors are shown.
2.4.4 The activities of the nodes and the pairwise multiplexity
From the adjacency matrices of each layer of the network it is possible to construct an activity matrix of elements indicating if node is present in layer . This matrix can be seen as an adjacency matrix between nodes and layers indicating which node is active in each layer of the multiplex. For a undirected multiplex network, node is active in layer if it has a positive degree in layer , i.e. . Therefore we have
| (79) |
where indicates the Kronecker delta. For a directed multiplex network, node is inactive in layer if both its in-degree and its out-degree in layer are zero. Therefore we can define the matrix elements as
| (80) |
The activity of a node has been defined in Ref. [117] and is given by the number of layers in which node is active:
| (81) |
The layer activity has been defined in Ref. [117] and is given by the number of nodes active in layer :
| (82) |
By analyzing a large set of multiplex networks, including a multiplex formed by a very large number of layers, Nicosia and Latora in Ref. [117] have shown that the activity distribution is typically broad and can be fitted by a power-law with . This implies that for some multiplex networks the bipartite network between nodes and layers described by the activity adjacency matrix can be either dense () or sparse () but the typical number of layers in which a node is active is always subject to unbound fluctuations (see Fig. 11). Moreover, in Ref. [117] a broad distribution of layer activities has been reported.
In Ref. [117] the Authors studied the layer pairwise multiplexity measuring the correlation between the layers. The layer pairwise multiplexity is defined as
| (83) |
and quantifies the fraction of nodes that are active in layer as well as in layer . Similarly, one can use the node pairwise multiplexity , measuring the correlation of activities between two nodes. The node pairwise multiplexity, introduced in Ref. [36], is defined as
| (84) |
and quantifies the fraction of layers in which both node and node are active.
In Fig. 12 the network of European airline companies is plotted, where the links between two different companies is weighted with the layer pairwise multiplexity. This method can reveal non trivial correlations between the activities of the nodes in different layers.
3 Generative models
In the last fifteen years large attention has been devoted to unveil the basic mechanisms for the generation of monolayer networks with specific structural properties. The discussion of all generative models for single-layer networks is beyond the scope of this report, and we refer the interested reader to the existing reviews [9, 2, 3, 118, 4] and to more recent works [119, 120] on the subject. Here we mention only that the models introduced so far in the Literature can be cast in two major categories:
-
1.
the growing networks models, including the mechanism of preferential attachment introduced in the Barabási-Albert (BA) model to explain the emergence of power-law distributions, and
-
2.
the static models, describing networks ensembles with given structural properties. Examples of such structural properties are: the degree sequence (the configuration model), the expected degree sequence (the exponential random graph, or the hidden-variable model), the degree sequence and the block structure or the expected degree sequence and the block structure. These network ensembles can be considered as a generalization of the random graphs to more complex network topologies.
Similarly, most of the generative models for multilayer networks can be divided also into two classes:
-
1.
growing multilayer networks models, in which the number of the nodes grows, and there is a generalized preferential attachment rule [55, 57, 121, 122, 123]. These models explain multilayer network evolution starting from simple, and fundamental rules for their dynamics.
-
2.
multilayer network ensembles, which are ensembles of networks with nodes in each layer satisfying a certain set of structural constraints [49, 69, 113, 124]. These ensembles are able to generate multilayer networks with fully controlled set of degree-degree correlations and of overlap.
In the case of multilayer networks the modeling framework is still in its infancy. Yet, different ways to construct multiplex networks with different topological features have been proposed, and summarizing the main results and concepts coming from these works is the object of the present section.
3.1 Multiplex networks models
3.1.1 Growing multiplex networks models
Growing multiplex networks’ models start from the consideration that many real networks are the result of a growing process, such as, for instance, the case of the airport network formed by airline connections of different airline companies [78, 117], or that of the social network between scientists collaborating with each other and citing each other [113]. Similarly to what happens for single-layer networks, the way the links of the new nodes are attached to the existing nodes is not random, therefore it is important to explore the consequences on the resulting topology of assuming different attachment kernels.
In two recent papers [55, 57], a similar growing multiplex model has been proposed. There, the network has a dynamics dictated by growth, and generalized preferential attachment. Starting at time from a duplex network with nodes (with a replica in each of the two layers) connected by links in each layer, the model proceeds as follows:
-
1.
Growth: At each time a node with a replica node in each of the two layers is added to the multiplex. Each newly added replica node is connected to the other nodes of the same layer by links.
-
2.
Generalized preferential attachment: The new link in layers is attached to node with probability proportional to a linear combination of the degree of node in layer 1 and of node in layer 2, i.e.,
(85) where with .
In the case in which the model reduces to two apparently decoupled BA models. Nevertheless, in the multiplex network two replica nodes have the same age, therefore this characteristic of the model is responsible for generating degree-degree correlations in the layers of the duplex. The model for has been solved by the use of the master equation approach [57] giving the joined degree distribution of having a node with degree in layer 1 and degree in layer 2,
| (86) |
The average degree defined in Sec. 2.4.1 in one layer conditioned to the degree in the other layer [57] is given by
| (87) |
Therefore, the two layer have positive degree correlations.
In this case, the degree distribution in each layer is given by the degree distribution of the BA network model. In Ref. [57] it has been shown by mean-field calculations and simulations (see Fig. 13) that also for other values of the parameters the average degree in one layer conditioned to the degree of the other layer remains linear, because older nodes of the multiplex are more connected than younger nodes in both layers. Moreover, in Ref. [55] it has been shown that for and the degree correlations in the two layers become more significant. In fact, the Pearson correlation coefficient defined in Sec. 2.4.1 between the degrees in the two layers has been characterized for the model with and , finding in the limit
| (90) |
where indicates the degree in layer 1 and indicates the degree in layer two. Finally, both Refs. [57] and [55] explore some variations of this model. In Ref. [57] the case of a semilinear attachment kernel (giving rise to networks with different degree distributions) and that of time delay of the arrival of one replica node in one layer have been discussed. In Ref. [55] an initial attractiveness has been added to the generalized preferential attachment, giving rise to two layers formed by scale-free networks with a tunable value of the power-law exponent .
A similar growing multiplex model has been also proposed by Magnani and Rossi in Ref. [122, 123]. In their model, the multiplex layers grow by the addition of new links and new nodes that do not arrive in the different layers at the same time. Also in their case, the way the new links are attached to the rest of the network follows the preferential attachment rule. The model displays layers that have either uncorrelated or positively correlated degree features.
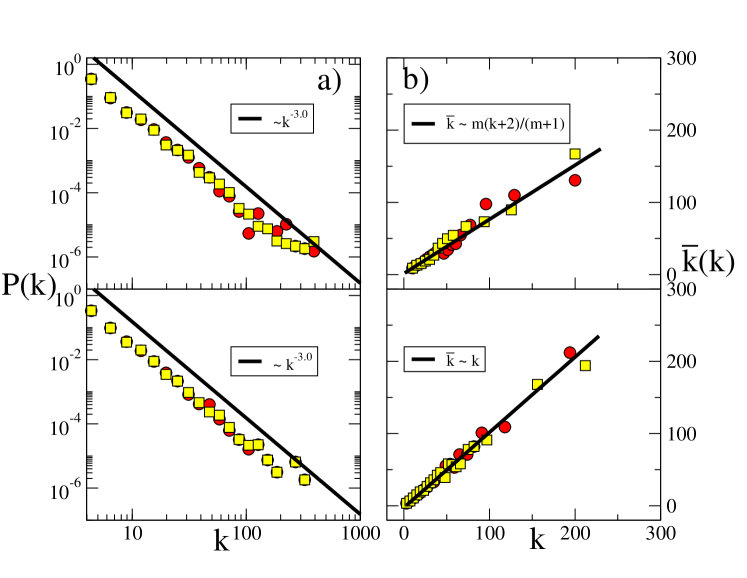
In Ref. [121] it has been shown that growing multiplex networks models can also generate negative degree correlations between the layers. In particular, the attachment kernel used in Ref. [121] is a non-linear kernel. The model includes growth and non-linear preferential attachment depending on the degree of the same node in the different layers. For a duplex, the model is described by the following algorithm. Starting at time from a duplex network with nodes (with a replica in each of the two layers) connected by links in each layer, the model proceed as follows.
-
1.
Growth: At each time , a node with a replica node in each of the two layers is added to the multiplex. Each newly added replica node is connected to the other nodes of the same layer by links.
-
2.
Generalized non-linear preferential attachment: The new links are attached to node with probability in layer and with probability in layer with
(91) where is the degree of node in layer 1, and is the degree of node in layer 2. Notice that here and are two parameters of the model taking real values.
This model displays a very interesting physics, generating multiplex networks with different types of degree distributions, degree-degree correlations, and with a condensation of the links for some parameter values. In Ref. [121], the phase diagram of the model (see Fig. 14) has been completely characterized. The number of distinct degree classes shown in panel of Fig. 14 allows to define a region of parameter space corresponding to homogeneous degree distributions (region ), and another region corresponding to heterogeneous degree distributions (region ). The inverse partition ratio of the degree distribution in a given layer shown in panel (b) of Fig. 14 provides evidence of a condensation occurring for when , or for when , in agreement with the theoretical derivations discussed in Ref. [121]. Finally, the Kendall correlation coefficient between the degrees of corresponding replica nodes shows that the model can display at the same time positive and negative degree-degree correlations in the two layers. Panel (d) of Fig. 14 shows the Kendall correlation coefficient between the degree of corresponding replica nodes, calculated only over the nodes arrived at time . This last panel shows that for every the older nodes have always negatively correlated degrees in the two different layers. Therefore, in the region in which and shown in panel (c) of Fig. 14, only the recently added nodes in the multiplex have positively correlated degrees, due to the stochastic nature in the model.
Other growing multiplex network models have been proposed [36, 117], where the multiplex network grows by the addition of an entire new layer at each time step. In Ref. [36], two nodes and in the new layer are linked with a probability that depends on the quantity there called node multiplexity . In particular, can be either positively correlated with , or negatively correlated to it. In the first case two nodes that are active at the same time in many layers are more likely to be connected in the new layer, in the second case two nodes that are active at the same time in many layers have small probability to be connected in the new layer. In Ref. [117], instead, every node of the new layer will be active with a probability proportional to the activity of the node , i.e.,
| (92) |
where is a parameter of the model. This model enforces a sort of “preferential attachment” of the new layers to nodes of high activity , and a power-law distribution of the activities of the nodes.
3.1.2 Simple static models
The simplest way to obtain a static generative model for multiplex networks is to generalize the existing methods for single-layer ones. Fixing the degree sequence in each layer, one can use a configuration model to obtain a particular realization of the given set of connectivities. Of course, the full structural information in a multiplex includes also the connections between layers. In Refs. [48] and [125], the Authors have made the choice to add interlayer links arbitrarily. A different approach is to keep using a configuration model, but to specify the edges between the layers by means of a joint-degree distribution [56, 126, 127]. Note that, while the terms “joint-degree sequence”, “joint-degree matrix” and “joint-degree distribution” are normally used in literature to indicate quantities related to the degrees of the nodes at the end of the links in a simple network, here they explicitly refer, instead, to multilayer connections [128].
A similar method is to specify the degree sequences together with a probability matrix whose element is the fraction of interlayer links between layers and . The actual link placement is still achieved via uniform random choice [129, 130, 131, 132, 133]. A generalization of this approach has been proposed in Ref. [134]. There, the Authors impose the degree correlations within and between layers by means of a set of matrices that specify the fraction of edges between nodes of given degrees in given layers.
Further models of multilayer networks can be created by defining classes of nodes that share similar structural characteristics. While the definitions of such classes are somewhat arbitrary, these models find application in the detection of higher-level features in real-world networks, mostly related to community structure [135, 136, 137, 138].
The choice of any network model for a particular study results in the imposition of constraints of some sort. Each network model corresponds to a network ensemble, i.e., to the set of networks that satisfy the constraints implicitly imposed by the model. Thus, it is important to study the properties of network ensembles, which we discuss in the following from a statistical physics perspective.
3.1.3 Ensembles of multiplex networks
Network ensembles and their entropy
A given set of constraints can give rise to a microcanonical network ensemble, satisfying the hard constraints, or to a canonical network ensemble in which the constraints are satisfied in average over the ensemble. The canonical network ensembles have been widely studied in the sociological literature under the name of exponential random graphs or models [139, 140, 141, 142], and recently studied by physicists [143, 144, 145, 146, 147]. The most popular examples of microcanonical network ensembles are the ensemble and the configuration model. The distinction between the canonical and microcanonical ensembles allows to draw a well defined parallelism [146] between such network ensembles and the classical ensembles in statistical mechanics where one considers system configurations compatible either with a fixed value of the energy (microcanonical ensembles) or with a fixed average of the energy determined by the thermal bath (canonical ensembles). For example, the random graphs formed by networks of nodes and links is an example of a microcanonical network ensemble, while the ensemble (where each pair of links is connected with probability ) is an example of canonical network ensemble since the number of links can fluctuate but has a fixed average given by . Despite this similarity, an ensemble that enforces an extensive number of hard constraints on its networks (such as the degree sequence) is not equivalent in the thermodynamic limit to the conjugated network ensemble enforcing the same constraints in average (such as the sequence of expected degrees). For instance, the ensemble of regular networks with degrees is clearly not equivalent to the Poisson network in which every node has the same expected degree . The non-equivalence of microcanonical and canonical network ensembles with an extensive number of constraints needs also to be taken into account when characterizing dynamical processes on networks, because it can have relevant effects on their critical behavior.
The entropy of network ensembles is given by the logarithm of the number of typical networks in the ensemble, and it quantifies the complexity of the ensemble. In particular we have that the smaller is the entropy of the ensemble, the smaller is the number of networks satisfying the corresponding constraints, implying that these networks are more optimized. Both the network ensembles and their entropy can be used on several inference problems to extract information from a given network [147, 148].
Multiplex network ensembles
The statistical mechanics of randomized network ensembles (exponential random graphs) has been extended to describe multiplex ensembles [49, 69, 113, 124, 149], and applied to analyze different multiplex data sets [113, 150, 151]. Consider a multiplex formed by labeled nodes and layers. We can represent the multiplex as described for example in Ref. [68]. To this end, we indicate by the set of all the networks at layer forming the multiplex. Each of these networks has an adjacency matrix with matrix elements if there is a link between node and node in layer , and zero otherwise. A multiplex ensemble is specified when the probability for each possible multiplex is given. In a multiplex ensemble, if the probability of a multiplex is given by , the entropy of the multiplex is defined as
| (93) |
and measures the logarithm of the typical number of multiplexes in the ensemble. One can distinguish between microcanonical and canonical multiplex network ensembles, and between uncorrelated and correlated multiplex network ensembles [49].
Uncorrelated multiplex networks ensembles
The uncorrelated multiplex ensembles are ensembles of networks in which the links in different layers are not correlated. Note that the degree in the different layers can nevertheless be eventually correlated, as described below. The probability of an uncorrelated multiplex ensemble is given by
| (94) |
where is the probability of network on layer . In this case, the entropy of the multiplex ensemble is the sum of the entropies of the network in the single layers, i.e.,
| (95) |
In a uncorrelated multiplex network, the links in two different layers and are uncorrelated. In fact, from Eq. (94) it immediately follows that
| (96) |
for every choice of pair of nodes .
Examples of uncorrelated multiplex ensembles are multiplex layers with given degree sequence, or given degree sequence and community structure, directed networks with given in-out degree, weighted networks with given degree and strength of the links, etc.
A pivotal role is played by the ensemble in which we fix either the expected or the exact degree sequence. These degree sequences can be eventually correlated. Let us consider here a simple case of a duplex in which we either fix i) the expected degree sequence (canonical multiplex network ensemble) or ii) the exact degree sequence (microcanonical multiplex network ensemble).
-
1.
i) Fixed expected degree sequence
In the first case, when we fix the expected degree sequence , the probability of the multiplex is given by(97) where is the probability of the link in layer and can be expressed in terms of the Lagrangian multipliers as
(98) The Lagrangian multipliers are fixed by the conditions
(99) where is the expected degree of node in layer . This last expression, in the case in which there is a structural cutoff , has a very simple solution given by
(100) Note that here indicates average over the nodes. This is an example of canonical multiplex networks. The entropy of this multiplex ensemble is called Shannon entropy and is given by
(101) These ensembles can display degree correlations in the different layers, but they are uncorrelated ensembles in the sense that they satisfy Eq. (94) and Eqs. (96).
-
2.
ii) Fixed degree sequence
Here we also consider the microcanonical multiplex network ensembles in which we fix the exact degree sequence in every layer. In this case the probability of a multiplex network is given by(102) where is a normalization constant. We call the entropy of this ensemble Gibbs entropy to distinguish it from the Shannon entropy of the canonical ensembles. We have
(103) where is the Shannon entropy of the conjugated canonical model given by Eq. (101) calculated assuming that the expected degree of each node is given exactly by its degree , and where is given by
(104) where is the Poisson distribution with average calculated at . Therefore, the Gibbs entropy is lower than , and the microcanonical ensemble is not equivalent in the thermodynamic limit to the conjugated canonical ensemble. The multiplex networks in this ensemble can be generated by generating the different networks in the different layers with the configuration model without allowing for multiple edges and tadpoles in the networks.
These types of networks are the most simple examples of multiplex, and many dynamical processes have been first studied on these ensembles, by analyzing also the effect of correlation between the degrees in different layers. In Ref. [49] it has been shown that if a uncorrelated multiplex network ensemble is formed by sparse networks (e.g. Poisson networks, exponential networks with finite average degree, scale-free networks with power-law exponent ), the expected overlap of the links between any two layers of the multiplex is negligible. Therefore, these ensembles cannot be used to describe multiplex networks where the overlap of the links is significant.
Correlated multiplex networks ensembles
The correlated multiplex ensembles are ensembles of networks in which the links in different layers are correlated. In particular, in the correlated multiplex network ensembles, Eq. (94) does not hold, i.e.
| (105) |
In this correlated ensembles, the entropy cannot be expressed as the sum of the entropies , i.e.
| (106) |
Furthermore, one has that it exists at least a pair of layers and and a pair of nodes and for which
| (107) |
Examples of correlated multiplex ensembles are multiplex layers with given multidegree sequence, directed networks with given directed multidegree sequence, weighted networks with given multidegree and multistrength of the links, etc. [49, 113].
In particular, correlated multiplex networks can display a significant overlap of the links. Let us consider here a simple case of a duplex in which we either fix (i) the expected multidegree sequence (canonical multiplex network ensemble) or (ii) the exact multidegree sequence (microcanonical multiplex network ensemble).
-
1.
(i) Fixed expected multidegree sequence
The probability of a multiplex network in which we fix the expected multidegree sequence is given by(108) where is the probability of the multilink between node and node , and is the multiadjacency matrix with elements . For a sparse network, the probabilities of a multilink can be expressed in terms of the Lagrangian multipliers as
(109) while is fixed by the normalization condition . The Lagrangian multipliers are fixed by the conditions
(110) where is the expected multidegree of node . This last expression, in the case in which there is a structural cutoff on the multidegree has a very simple solution given by
(111) for every multilink . This is an example of canonical multiplex networks. The entropy of this multiplex ensemble is called again Shannon entropy and is given by
(112) In order to construct a correlated multiplex ensemble with given multidegree sequence it is sufficient to follow the following scheme.
- (a)
-
(b)
For every pair of node and , draw a multilink with probability and consequently put a link in every layer where , and put no link in every layer where .
-
2.
(ii) Fixed multidegree sequence
The conjugated multiplex network ensemble of the previous example is the ensemble in which we fix the exact multidegree sequence in every layer. In this case the probability of a multiplex network is given by(113) with being a normalization constant. We call again the entropy of this ensemble Gibbs entropy to distinguish it from the Shannon entropy of the canonical ensemble. We have
(114) where is the Shannon entropy of Eq. (101) calculated assuming that the expected multidegrees of a node are given by the exact multidegree of the nodes in the microcanonical ensemble, and where is given by
(115)
Spatial multiplex network ensembles
When the multiplex networks are embedded in a real or in a hidden space (as in the case of the airport multiplex network in Ref. [78]), the overlap of the links can emerge naturally from the correlations induced by the distance in the embedding space. Intuitively, if in every layer links are more likely between nodes that are closer in the embedding space, then one can observe non-negligible overlap of the links because two nodes that are close in the embedding space are more likely to be connected to each other in every layer of the multiplex. We have that, if the probability of a network with nodes on positions is given by
| (116) |
where is the probability of a network in layer , then we can observe a significant overlap of the links [149].
3.2 Ensembles of networks of networks
In this case, there are multiple degrees of freedom that may characterize these complex structures, and therefore several types of networks of networks can be considered:
-
1.
Networks of networks with fixed supernetwork, i.e., networks of networks where if a layer is connected with layer , every node is connected to its replica node in layer [152, 153].
-
2.
Networks of networks with given superdegree distribution, where every node is connected to replica nodes of randomly chosen layers [154].
-
3.
Networks of networks with fixed supernetwork and random permutations of the labels of the nodes, i.e. network of networks where if a layer is connected with layer , any node is connected to a single node , where is taken from a random permutation of the indices [26, 155, 156].
-
4.
Networks of networks with multiple interconnections, where every node has connections with nodes in layer [80].
In order to distinguish the links between nodes of the same layers and the links between nodes of different layers, we will call the latter interlinks.
3.2.1 Case I: Networks of networks with fixed supernetwork and links allowed only between replica nodes
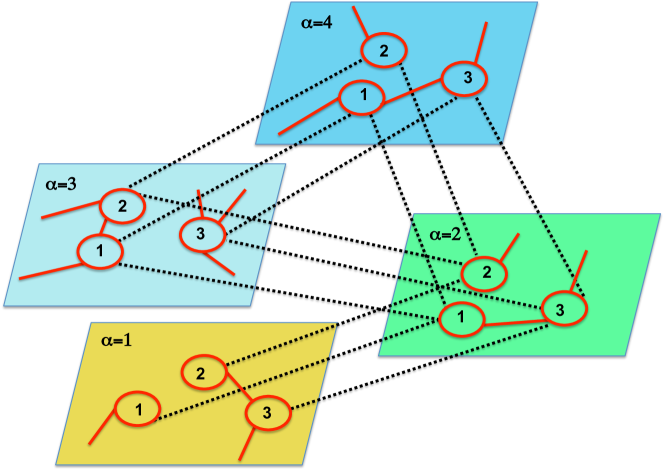
In this subsection we will consider a network of networks in which if network is connected with network , each node of network is connected to the node of network (see Fig. 15). The supra-adjacency matrix of the network of networks has elements if there is a link between node and node , and zero otherwise. In these specific networks, if both and . The network of networks is characterized by an adjacency matrix , such that for every node , . The adjacency matrix is the adjacency matrix of the supernetwork, , of the network of networks. We can consider ensemble of networks where the interlinks between different layers are fixed by the adjacency matrix , but the network in a given layer is random. In particular, we can choose a canonical ensemble of networks of networks in which each layer is a uncorrelated network and each node has a given expected degree in each layer . In this case, the probability of the supra-adjacency matrix is given by
| (117) | ||||
| (118) |
An alternative is to consider an ensemble of networks of networks in which the network in each layer is built using the configuration model, i.e. each node has given degree in layer . In this case, the probability of the supra-adjacency matrix is
| (119) |
3.2.2 Case II: Networks of networks with given superdegree distribution
In this case, each node can be linked only to its replica nodes , but there is no fixed supernetwork between the layers. Nevertheless, we assume that each layer has a given superdegree , i.e. in these networks of networks every node is linked to replica nodes of randomly chosen layers [154] (see Fig. 16).
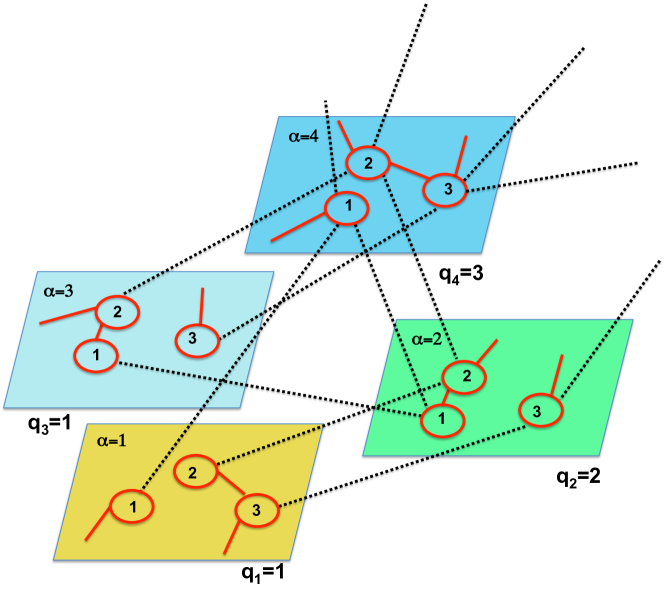
Moreover, each network (layer) is generated randomly according to a canonical or a microcanonical network ensemble. If fact, we can consider a microcanonical version of this model in which the degree sequence in each layer is fixed, or a canonical version of this model in which the expected degree sequence is fixed. Therefore, for the canonical network of networks ensemble, every network of networks with a supra-adjacency matrix has a probability given by
| (120) |
Alternatively, one can consider the microcanonical network of networks ensemble in which every network of networks with a supra-adjacency matrix has a probability given by
| (121) |
3.2.3 Case III: Networks of networks with fixed supernetwork and random permutations of the labels of the nodes
We here consider networks of networks in which if network is connected with
network , each node of network is
connected to a single node of network randomly chosen between the nodes of layer (see Fig. 17). The one to one mapping between the nodes is performed by defining a permutation of the indices such that if and only if node is linked to node . In order to define a undirected network of networks, we need to impose that the permutation is the inverse permutation of , enforcing that if then . The network of networks supra-adjacency matrix has elements
if there is a link between node and node ,
i.e. if and only if , and zero otherwise. In
these specific networks, for ,
if .
The network of networks is characterized by an adjacency
matrix , such that for every node ,
is the adjacency matrix of the supernetwork.
The present case differs substantially from case I. For instance, consider the case of a supernetwork forming a
loop of size between the different layers.
In case I, starting from each node and following only
interlinks between different layers, we can reach only other
nodes, while in case III (as each permutation
is random) the number of different nodes that
can be reached following interlinks
can be significantly higher than (see Fig. 17).
If the supernetwork is a fully connected network of nodes, case I
describes a multiplex with all the replica
nodes in the different layers connected to each other,
while case III does not reduce to the multiplex case.
One can consider an ensemble of networks where the interlinks between different layers are fixed by the adjacency matrix and the permutations , but the network in a given layer is random. In particular, we can choose a canonical ensemble of networks of networks in which each layer is a uncorrelated network, and each node has a given expected degree in each layer . In this case, the probability of the supra-adjacency matrix is given by
| (122) | ||||
| (123) |
An alternative is to consider an ensemble of networks of networks in which the network in each layer is built using the configuration model, i.e. each node has given degree in layer . In this case, the probability of the supra-adjacency matrix is
| (124) |
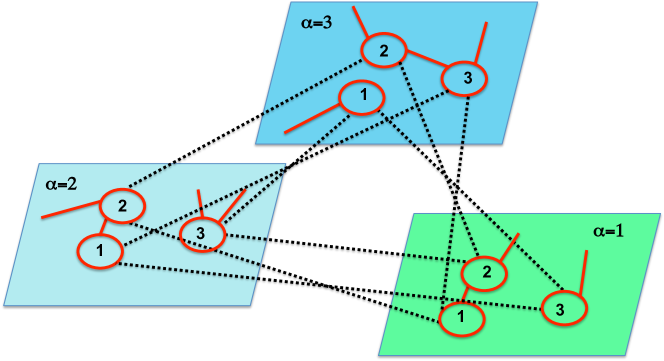
3.2.4 Case IV: Networks of networks with multiple interconnections
The last example assumes that the nodes of a layer can be linked to any other node in other layers, and that also multiple interlinks between one node and the node of other layers are allowed. This model has been used, for instance, in Ref. [80]. The model considers every node as having connections with nodes in layer , and therefore it requires a number of parameters (the degrees ) which is much larger than the number of parameters needed for the other models proposed before, as long as . The typical structure of a network of networks in this ensemble is shown in Fig. 18. Once again, one can have a microcanonical version of this model (in which the degree sequences are fixed), or a canonical version (in which the expected degree sequences are fixed). For the canonical ensemble the supra-adjacency matrix has a probability given by
| (125) |
while for the microcanonical ensemble the probability is
| (126) |
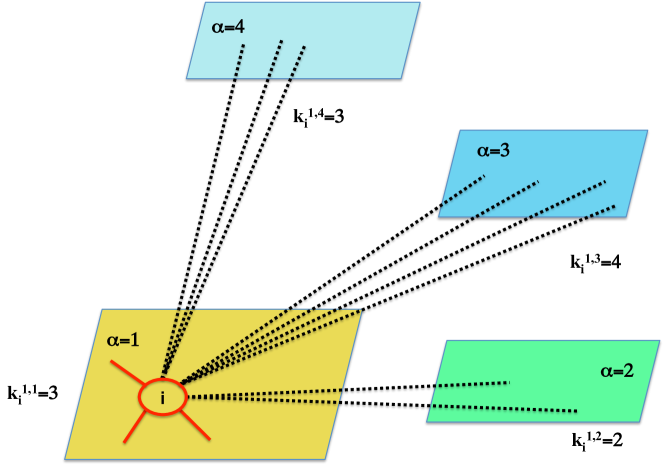
4 Resilience and percolation
The present section is devoted to review the rather huge literature regarding two very relevant, and somehow correlated, processes: resilience of the multilayer networks’ structure under random failures (and/or cascades of failures), and percolation.
Resilience is the ability of a network to maintain its main topological structure under the action of some kind of damages. It is well known that single-layer heterogeneous networks, such as scale-free (SF) networks, are particularly resilient to random damages, whereas they generally are extremely fragile to attacks targeting the nodes with higher degrees. This is, actually, one important motivation that the scientific community has given to the observed SF degree distribution: both technological (e.g. the Internet) and biological networks (e.g. the protein-protein interaction and other biological networks in the cell) display a SF nature because they must be robust against random failures [157, 158, 159, 160, 161, 162, 163]. In a multilayer scenario, nevertheless, conclusions and predictions are far different, and indeed the available literature allows one to conclude that, if a network is interdependent with other networks, its robustness properties can be strongly affected.
On the other side, percolation (from the Latin percolare, whose meaning is “to filter” or “to trickle through”) refers, in classical physics, to the movement and filtering of fluids through porous materials. Within the last fifteen years, the main formalism and predictions of percolation theory have been applied also to complex networks, for the study of the emergence (and robustness) of a giant connected component in the graph having a size of the order of the size of the entire network. In this framework, statistical physics concepts (such as scaling theory and phase transitions) have been used to characterize network percolation properties, and study percolation thresholds. Along this section we will extensively discuss how the traditional percolation theory has been recently generalized to the context of multilayer networks.
4.1 The fragility of multilayer interdependent networks
It is a matter of fact that in many multilayer networks some nodes of a layer are interdependent on nodes in other layers. A node is interdependent on another node in another layer if it needs the other node to function in order to function itself properly. Examples of interdependent networks are found in complex infrastructures, which are increasingly interconnected, in economy where networks of banks, insurance companies, and firms interact with each other, in transportation networks, where railway networks, airline networks and other transportation networks are interdependent, or in biology where the cell is alive only if all its biological networks are functioning at the same time.
When two or more networks are interdependent, a fraction of node failures in one layer can trigger a cascade of failures that propagate in the multilayer network (as it was the case, for instance of the 2003 blackout in Italy [25]), and this is indicative of an increasing fragility of these structures with respect to the single-layer cases [25, 164]. Therefore, new aspects of the robustness of networks emerge when interdependencies are taken into account. Moreover, the impact of the topology of the interdependent networks on their robustness properties is also unexpected: in fact, in absence of correlations, interdependent SF networks are more fragile than Poisson networks when a constant average degree is kept [25]. When we consider multiplex networks or networks of networks with given supernetwork and links allowed only between replica nodes as described in Sec. 3.2.1, the system responds globally to the damage inflicted in a single layer. At any given time, either all the layers have a percolating cluster, or none of them has one [152]. When instead one considers a network of networks with given superdegree sequence as described in Sec. 3.2.2 , layers with different number of interdependencies respond differently to the inflicted damage. In this latter case, the layers with higher number of interdependencies, i.e. with higher superdegree , are more fragile than those with smaller superdegree [154]. Indeed, in these layers the percolation cluster disappears for a fraction of initial damaged nodes smaller than the one that is necessary to disrupt layers with smaller number of interdependencies. Finally, if we consider a network of networks with fixed supernetwork and random permutations of the label of the nodes, as described in Sec. 3.2.3 one has to distinguish between the case in which the supernetwork is a tree, and that in which the supernetwork contains loops [26, 156]. If the supernetwork is a tree, all the layers start to percolate when the fraction of initially damaged nodes is less than , i.e. either all the layers percolate or none of them does [153]. In the case in which the supernetwork contains loops and the supernetwork is a random network with given superdegree distribution, the layers with higher superdegree are more fragile than those with smaller superdegree. In this case the mutually connected component is described by the same equations derived for the network of networks described in Sec. 3.2.2 [154].
The increased fragility of interdependent networks opens new important scientific questions. A major one is the design of optimal strategies to mitigate the dramatic effect of interdependencies and allow for correlated topologies with increased resilience under random damage. This might have consequence for the infrastructure design of the new generation, for reducing risk in financial networks, and for assessing the robustness of the biological networks in the cell. Notice that, while for random interdependent networks percolation is clearly sharpened by the presence of interdependencies, the question weather interdependencies always sharpen the percolation transition has been matter of debate [165, 166, 167].
4.2 Percolation in interdependent networks
After the pioneering and seminal work of Ref. [25], it became clear that, in presence of interdependencies, the robustness of multilayer networks can be evaluated by calculating the size of their mutually connected giant component (MCGC) when a random damage affects a fraction of the nodes in the system. The MCGC of a multilayer network is the largest component that remains after the random damage propagates back and forth in the different layers.
In Fig. 19, it is shown how to construct the MCGC for the case of a multiplex formed by two layers (layer A and layer B) where the replica nodes are interdependent. Assume that a group of nodes in layer A is damaged, all the nodes in the giant component of layer A are active while the nodes that are not in the giant component are not active. Then consider the layer B. All the nodes of layer B that are interdependent with nodes that are not active in layer A, are damaged. Next, set as active all the nodes that remain in the giant component of layer B, and set as not active all the nodes that are not in the giant component. By repeating the algorithm alternating the analysis of layer A and layer B, it is possible to characterize an avalanche of failure events that propagates from one layer to the other one, until the avalanche does not propagate any more. The set of active nodes that remains at the end of the iteration is the MCGC. Between any two nodes in this mutually connected component there are at least two paths, one in one layer A and one in layer B, that connect the two nodes and that pass only through nodes that belong to the mutually connected component. In this case, the MCGC is also called the viable cluster of the network[168].
The size of the MCGC of a multilayer network emerges discontinuously at a critical value , at least in the case of random networks in which there is no overlap of the links in the different layers and every node is interdependent at least on another node in another layer. This is in contrast with the theory of percolation in single-layer networks, where the giant component emerges continuously at a second order phase transition. Moreover, if one approaches the value , the interdependent networks are affected by cascading failures that propagate throughout the structure. Other works have extended the original formalism to network of networks [153, 156, 26], network with partial interdependencies [35] with multiple dependencies links [169] and exploring the effect of targeted attack [170]. Subsequent studies on the subject have been carried out by Son et al. [171]. The Authors call this algorithm an “ epidemic spreading” process, but the algorithm can be more suitably termed as the “message passing algorithm” for this generalized percolation problem [172, 173, 174]. Here we will try to present all this material in a pedagogical way, starting from a generalization of the algorithm of Ref. [171] that can be used both for multiplex and for networks of networks.
4.2.1 The mutually connected giant component of a multilayer network
In this subsection, we will consider a special type of a multilayer network formed by layers , each one formed by interactions between nodes . Every node will be indicated by the pair , which denotes the label of the nodes in the specific layer . We furthermore call all the nodes characterized by the same label but belonging to different layers the “replica nodes”. Every node can be connected to nodes within the same layer with “connectivity links”, or with its “replica nodes” in other layers with “interdependency links”. In Ref. [169], it is further allowed to one node in layer to be interdependent to more than one node in a given layer , but here (if not explicitly otherwise stated) we make the simplifying assumption that every node in layer can be interdependent at most to a node in layer , i.e. on its “replica node”. This framework allows to treat at the same time, multiplex networks and networks of networks as described in Sec. 3.2.1 and Sec. 3.2.2. We define the network of networks with a supra-adjacency matrix of elements if there is a link between node and node and zero otherwise. Therefore, here we will treat multilayer networks in which if both and .
The MCGC is defined in Ref. [171] as the set of nodes that satisfy the following recursive set of equations:
-
1.
at least one neighbor of node in layer is in the MCGC;
-
2.
all the interdependent nodes of node are in the mutually connected giant component.
For a given multilayer network which is locally tree-like, it is easy to construct a “message passing” algorithm [173, 172, 174] that allows us to determine if node is in the mutually connected component. This approach has been proposed in Ref. [171] and further investigated in Ref. [175]. We denote by the message within a layer, from node to node , indicating that node is in the mutually connected component when we consider the cavity graph constructed by removing the link in layer . Furthermore, let us denote by the message between the “replicas” and of node in layers and . indicates that the node is in the mutually connected component when we consider the cavity graph by removing the link between node and node . In addition, we indicate with a node that is removed as an effect of the damage inflicted to the network, otherwise .
If the node is not damaged, i.e. , the message will be equal to one if all the messages coming to node from the interdependent nodes are equal to one, and if at least one message coming from a node neighbor of node in layer and different from node , is equal to one. If the node is instead damaged, the message will be equal to zero.
If the node is not damaged, i.e. , the message will be equal to one if all the messages coming to node from the interdependent nodes different from are equal to one, and if at least one message coming from a node neighbor of node in layer , is equal to one. If the node is instead damaged, the message will be equal to zero.
Therefore, the message passing equations are of the following form:
| (127) |
where indicates the set of nodes which are neighbors of node in layer , and indicates the layers of the nodes interdependent on the node .
Finally, () indicates that the node is (is not) in the mutually connected component, namely
| (128) |
In other words, a node is in the mutually connected component if it is not damaged (i.e. ), if all the messages coming from the interdependent nodes are equal to one, and if at least one message coming from a neighbor node in layer is equal to one. In Ref. [152], it has been shown that these message passing equations can be solved explicitly for every network of networks of this type including both cases described in Sec. 3.2.1 and Sec. 3.2.2 giving, for the messages within each layer
| (129) |
where is the set of layers such that the “replica nodes” are connected to the the node by paths going through the interdependency links. Finally, the Eqs. (128) for can be written exclusively as functions of the messages as
| (130) |
For the network of networks described in Sec. 3.2.3 or Sec. 3.2.4 a similar calculation can be carried out showing that in networks of networks of any type, the mutually connected component can be defined as the following: A node is in the mutually connected giant component if and only if:
-
1.
it has at least one neighbor node in layer that belongs to the mutually connected component;
-
2.
all the nodes that can be reached from node by interdependent links have at least one neighbor node that belongs to the mutually connected component.
4.3 Interdependent multiplex networks
A multiplex network can be considered as a network of networks of the type described in Sec. 3.2.1, in which each layer is connected with all the other layers (the supernetwork formed by the layer is a fully connected network) and each node is connected only to its replica nodes in the other layers. Let us consider a multiplex network in which every layer has a degree distribution and in which every node is interdependent on every one of its replica nodes. In order to evaluate the expected size of the mutually connected component, we average the messages over this ensemble of the network of networks. We indicate with the average message within a layer .
The equations for the average messages are given in terms of the parameter and the generating functions and defined as
| (131) |
where indicates the average degree in layer , i.e. . We assume here that the damage of the nodes in the different layers is correlated, and that therefore a node is damaged with probability together with all its replica nodes. We have
| (132) |
where indicates the Kronecker delta. This assumption is needed if we interpret the set of different replica nodes in a multiplex like a single node having different types of interactions. Therefore, using Eq. (129), in Ref. [171] it was found that
| (133) |
Moreover, using Eq. (130), the probability for that a randomly chosen node belongs to the mutually connected component is
| (134) |
Equivalent equations have been previously found in Refs. [25, 153] using an alternative derivation. In particular, if all layers have the same topology, then the average messages within different layers are all equal , and are given by
| (135) |
Furthermore, the probability that a node in a given layer is in the mutually connected component is given by
| (136) |
In Ref. [170] the case of targeted attack toward high or low degree nodes have been considered. It has been found in this context that in contrast with the single-layer network scenario, SF interdependent networks are difficult to defend using the strategy of protecting high degree nodes.
4.3.1 Case of a multiplex formed by Poisson networks with the same average degree
In the case of a multiplex formed by Poisson networks with the same average degree , we have that the equation for the order parameter becomes
| (137) |
For every finite it is possible to show that the MCGC emerges discontinuously at . The equation for the order parameter can be written as
| (138) |
The equation has always a solution , but at another solution appears discontinuously when the function is tangential to the axis at the point . Therefore, in order to find the critical values and , we can impose the set of equations
| (139) |
In Fig. 20 we plot the function for , showing that at the equation develops a non trivial solution at .
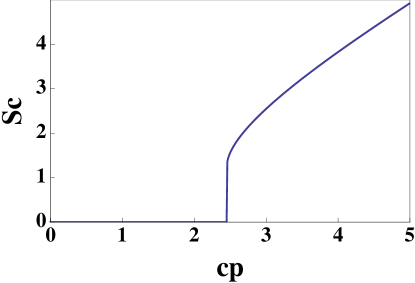
In Fig. 21 we plot the order parameter as a function of , for the case of a duplex, i.e. . It is clear that the order parameter has a discontinuity at . Moreover, it can be shown that the order parameter has a singularity for . In fact, it has been shown [168, 35] that the transition is a discontinuous hybrid transition characterized by a square-root singularity at the phase transition, in other words the order parameter, close to the transition, scales as
| (140) |
for and .
4.3.2 Case of a duplex network formed by two Poisson networks with different average degree
In Ref. [171], the case of a duplex network formed by two Poisson networks (network A and network B) with different degree distribution (with average degree respectively and ) has been studied. The equations determining the emergence of the MCGC reduce to a single equation for given by
| (141) |
Therefore, the phase diagram only depends on the parameters . Also in this case, the emergence of the mutually connected component is described by a discontinuous hybrid transition, at the points of the phase diagram satisfying simultaneously the following set of equations
| (142) |
The phase diagram of the model is shown in Fig. (22) for .
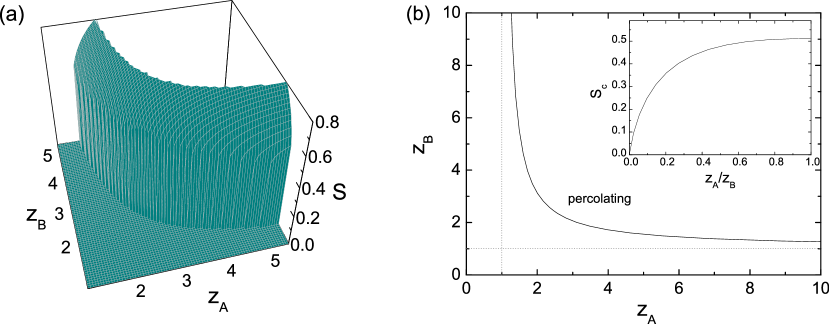
4.3.3 Multiplex networks formed by layers of scale-free networks
In the case of single-layer networks, SF networks (with power-law degree distribution and ) are known to be much more robust to random failures than networks with a finite second moment , e.g. of Poisson networks [157, 158, 159]. Indeed, for SF networks of size , the giant component emerges if the fraction of nodes that are not initially damaged with as . Therefore, these networks continue to have the giant component also if most of the nodes are initially damaged. A finite percolation threshold in these networks is a finite size effect, i.e. the percolation threshold disappears in the limit . The situation is completely different for multiplex networks formed by interdependent SF networks [25]. The percolation threshold for the mutually connected component is finite also for multiplex networks formed by layers of SF networks [25]. In the case in which the layers of the multiplex have the same power-law degree distribution , the mutually connected component emerges discontinuously for as a hybrid phase transition with a square root singularity [25, 168]. In these networks, is not vanishing but remains finite as in the case of a multiplex in which the layers are formed by Poisson networks [25, 168]. In Fig. 23 we show the size of the mutually connected component for two SF networks with the same power-law exponent . As , and keeping the minimal degree constant, the discontinuity of becomes smaller and smaller but is not vanishing as long as . In Ref. [25] it was shown that actually another major difference exists between SF single-layer and multiplex networks. In fact, if we consider a multiplex formed by two SF networks with the same degree distribution, and compare their percolation threshold keeping the average degree constant, changing only the power-law exponent we obtain that the percolation threshold increases as is decreased. This implies that multiplex formed by broader SF are more fragile than multiplex with a steeper degree distribution (see Fig. 24). This surprising result shows that the robustness of multiplex networks has very new and unexpected features.
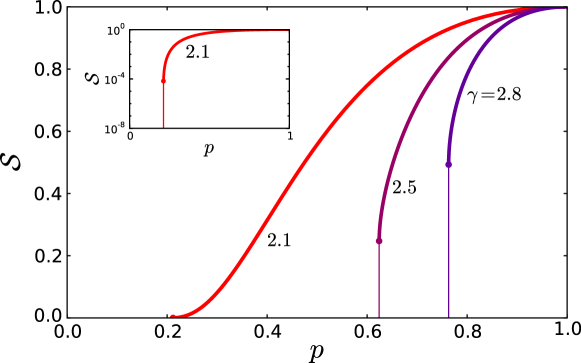
4.3.4 Cascading failures
In the case of a multiplex network, one can follow the propagation of the failures back and forth from one network to the others [25, 155, 176]. In the specific case of a duplex, it is possible to characterize how the failure in one network propagates in the other layer in the following way. We start form the layer A and we consider the equations determining the size of the giant component when the random damage to a fraction of the nodes has been inflicted to the network. In particular, will depend on the average message indicating what is the probability that a node at an end of a link in layer A is in the giant component of the same layer. Then, we consider layer B, where we assume that all the nodes whose replica nodes in layer A are not in the giant component of layer A are damaged. Therefore, we consider all the nodes in layer B that remain in the giant component of layer B after this damage propagating from layer A has been inflicted. The probability that the nodes are not damaged is and, using this probability one can calculate the probability that a random link in layer B reaches a node in the giant component of layer B and the probability that a random node in layer B is in the remaining giant component of layer B. Iterating this process back and forth from one layer to the other, it is possible to describe the propagation of cascading events in the interconnected network. At the end of this iterative procedure, the remaining nodes are the nodes in the mutually connected component. We will call and the probability that, in following a link either in layer A or in layer B, one reaches a node in the giant component of layer A or in the giant component of layer B at the step of this cascading process. Similarly, we will call by and the probability that a node in layer A or in layer B is in the giant component of layer A or of layer B. The propagation of failures from one network to the other can be described by the following equations for the probabilities ,
| (143) |
and by the following equations for the probabilities ,
| (144) |
See Refs. [155, 176] for the general equations describing the cascades of failures in multiplex networks with a generic value of . Eventually, these cascading events stop when the damage does not propagate further in the duplex network. Close to the phase transition , the cascades become systemic events and propagate until the mutually connected component completely disappears. This phenomenon reveals that the interdependent networks can be much more fragile than single-layer networks and are prone to abrupt cascading failures.
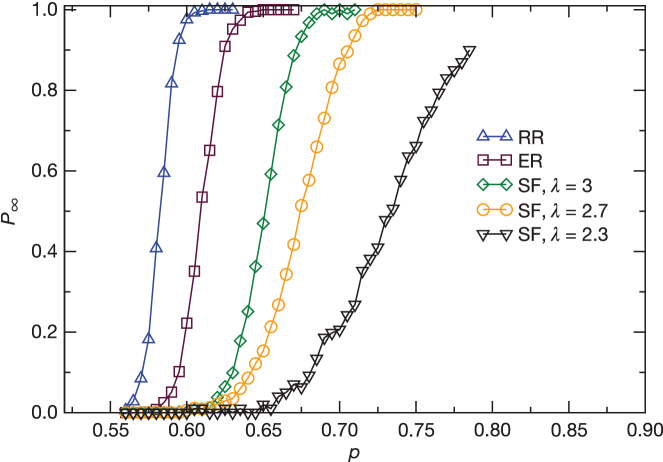
In Ref. [25] the size of the network after steps of propagation of the failures from one network to the other was first studied and characterized. In particular, indicates the fraction of non-damaged nodes in the network after steps. In other words
| (147) |
In Fig. 25 the subsequent values of are plotted for different realizations of a duplex Poisson network with . The solid red line indicates the theoretical predictions valid in the limit . These predictions are very good for small , but for large values of the simulations start to show finite size fluctuations. In particular, the simulations result either in a multiplex network with a non zero mutually connected giant component or in a multiplex network without it, while the deterministic theory predicts that in the the mutually giant component disappears in the network. In Ref. [25] an analysis of the finite size effects was first performed, yielding the following scenario for the average number of steps of a cascade of failures as a function of and :
-
1.
Case The average number of steps of the cascade of failures can be approximated by
(148) -
2.
Case The probability that a critical avalanche of failures has steps scales like
(149) where and are constants, independently on the number of nodes in the multiplex. Therefore, the average number of steps of a critical avalanche of failures is diverging with the multiplex size as
(150) -
3.
Case The average number of steps of the cascade of failures can be approximated by
(151)
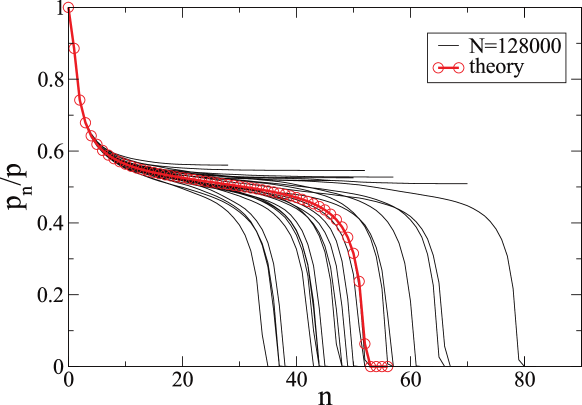
4.3.5 Partial interdependence
If the networks are only partially interdependent, the transition becomes continuous[35, 171]. Different versions of this model have been proposed modulating the degree distribution, and the correlations between the layers [177, 178, 179, 180]. Here we show how a passage between a discontinuous and a continuous transition can occur in the simplest setting of a multiplex, and in particular in a duplex, formed by ER networks. Let us consider a multiplex of layers where each node is interdependent on each of its replica nodes with probability . In this case, the message passing Eqs. still remain valid, where defines all the set of layers for which the node is interdependent on its replica node . We assume that every layer has degree distribution , and that every node is interdependent on every one of its replica nodes. We will describe the emergence of the mutually connected component by averaging the messages over links in each layer. We indicate with the average message within a layer . Similarly to the case of a fully interdependent multiplex, we will assume that the damage of the nodes in the different layers is correlated and that, therefore, we have given by Eq. (132) that we rewrite here for convenience, i.e.
| (152) |
The equations for the average messages within a layer are given in terms of the parameter and the generating functions and defined in Eq. (131). Using Eq. (129) we find
| (153) |
Moreover, using Eq. (130) we can derive the probability for that a randomly chosen node belongs to the mutually connected component
| (154) |
In particular, if all layers have the same topology, then the average messages within different layers are all equal , and are given by
| (155) |
Furthermore, the probability that a node in a given layer is in the mutually connected component is given by
| (156) |
For the nodes of each layer have no interdependencies with the nodes of the other layers, therefore each layer will percolate independently, and the percolation transition will be a second order continuous phase transition. On the contrary, when we have complete interdependency of each node of a given layer on all its replica nodes in the other layers, and the transition will be a discontinuous hybrid transition. Figure 26 reports simulations results of these two limits, in duplex networks of different degree distributions. In particular, there is a tricritical point for which the transition changes its nature, from discontinuous (for ) to continuous (for ).
Let consider a duplex network formed by two Poisson networks with the same average degree . The order parameter is the solution of the equation
| (157) |
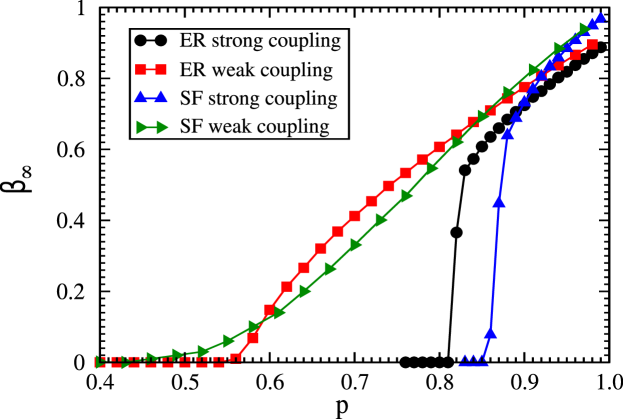
The points of the hybrid phase transition can be found by imposing
and by looking for a non trivial solution . This solution can be found for any characterizing the level of partial interdependence of the tricritical point of the model. For , the emergence of the mutually connected component is dictated by a second order phase transition at a critical value of that can be obtained by imposing the conditions . The tricritical point separates these two regimes, and results [171] from imposing and . This system of equations yields the parameters of the tricritical point:
| (159) |
The avalanches of failures in the partially interdependent networks have been characterized in Refs. [35, 177, 178, 179], where the Authors observe a different scenario depending on the nature of the phase transition in the network. In particular, it has been observed, that if the system is close to the hybrid discontinuous phase transition, the avalanches of failures are very long. In fact, the order parameter decays very slowly with the number of steps of the propagation of the damage back and forth in the two layers, and finally decays to a zero value. On the contrary, the critical avalanches of failures close to the second order phase transition are characterized by an order parameter that decays very rapidly with the number of steps of the propagation of the damage.
4.3.6 Percolation in multiplex networks with multiple support-dependence relations
In Ref. [169], the case of a duplex is considered in which each node can be at the same time connected to several nodes in layer and can have multiple connections within the same layer . It is assumed that a node is in the mutually connected component if the following two conditions are met:
-
1.
there is at least one neighbor of node in layer that is in the mutually connected component;
-
2.
for every layer , there is at least one node connected to node which is in the mutually connected component.
Assuming that the layers are two (layer A and layer B) and that the degrees are drawn from a Poisson degree distribution with , , and , it has been shown in Ref. [169] that the equations determining the probability () that a node in layer A (B) is in the mutually connected component are given by
| (160) |
where () is the initial fraction of damaged node in layer A (B). For these networks, the percolation is hybrid and discontinuous, but in the limit it becomes continuous.
4.4 Interdependent networks of networks
Following Refs. [152, 154, 26, 153, 155, 156], we will consider three major types of networks of networks.
-
1.
Case I:Networks of networks with fixed supernetwork and interdependent links allowed only between replica nodes, where every node of layer is interdependent on its replica node in the same set of layers [152]. This ensemble of network of networks has been described in Sec. 3.2.1.
-
2.
Case II: Networks of networks with fixed supradegree distribution, where every node is interdependent on replica nodes of randomly chosen layers [154]. This ensemble has been described in Sec. 3.2.2.
-
3.
Case III: Networks of networks with fixed supernetwork and random permutation of the labels of the nodes, where every node is interdependent on a node if layer is interdependent on layer , where is a random permutation of the labels of the nodes [26, 153, 155, 156].
4.4.1 Case I: Networks of networks with fixed supernetwork and interdependent links allowed only between replica nodes
In this subsection, we will consider networks of networks in which, if network is interdependent with network , each node of network is interdependent on node of network , and vice versa. This ensemble has been introduced in Sec. 3.2.1, and it has been graphically represented in Fig. 15. The corresponding supra-adjacency matrix has elements if there is a link between node and node , and zero otherwise. In these specific networks, if both and . The graph of interdependencies is characterized by an adjacency matrix such that, for every , . The matrix is the adjacency matrix of the supernetwork .
In Ref. [152] it has been shown that for this type of networks of networks, where each node can be interdependent only on its replica nodes in the other layers, the supernetwork can be a tree or can contain loops, and in both cases, as long as the supernetwork is connected, the size of the mutually connected component is determined by the same equations determining the MCGC in a multiplex network formed by the same layers. This result is strongly dependent on the type of considered networks of networks. For example, for networks of networks of case III the presence of loops in the supernetwork change significantly the mutually connected component [26, 153, 155, 156].
In Ref. [152] it has been shown that the problem of a wide range of networks of networks can be actually reduced to the well studied problem of multiplex networks. The main technical results of Ref. [152] has been to show that the messages within each layer are given by Eq. (129), that we rewrite here for convenience
| (161) |
where is the set of layers such that the “replica nodes” are connected to the node by paths going through the interdependency links, and where indicates that set of label of nodes that are neighbors of node in layer . Ref. [152] considered the case in which the supernetwork is given (fixed by its adjacency matrix ), and where each layer is generated independently from a configuration model with a degree distribution . The supernetwork is, therefore, not random, while the layers are infinite uncorrelated random networks. It is assumed that each layer has a degree sequence , and that the degrees of the replica nodes in the different layers are uncorrelated. Furthermore, it is assumed that the nodes are removed from layers with probability (i.e. they are instigators of cascading failures). Consequently, the probability is given by
| (162) |
In order to evaluate the expected size of the mutually connected component, the messages are averaged over this ensemble. If indicates the average message within a layer , the equations for the average messages within a layer are given in terms of the parameters and the generating functions and are defined as
| (163) |
Without loss of generality, we can consider a connected supernetwork formed by layers. In fact, if the supernetwork is not connected, we can consider each connected component of the supernetwork separately. Using Eq. (161), the expression for is given by
| (164) |
Moreover, using Eq. (130), the probability that a randomly chosen node in layer belongs to the mutually connected component is given by
| (165) |
Thus, as long as the supernetwork is connected, the resulting mutual component is determined by the same equations governing the case of a mutually connected component between the same layers, where the only difference between Eq. (164) and Eq. (133) and between Eq. (165) and Eq. (134) depends on the different choice of the probability for the initial damage inflicted in the network. In the case in which all layers have the same topology and equal probabilities , the average messages within different layers are all equal , and are given by
| (166) |
Furthermore, the probability that a node in a given layer is in the mutually connected component is given by
| (167) |
Therefore, the size of the mutually connected component always depends on the number of layers in the connected supernetwork.
When we include partial interdependence between the nodes, by introducing the probability that a node is interdependent on a linked node in another layer, the Eqs. (164)-(165) become respectively
| (168) |
and
| (169) |
From these results, four main conclusions can be drawn:
-
1.
the transition is hybrid and discontinuous as soon as ,
-
2.
the critical value always depends on the number of layers ,
-
3.
when the mutually connected component emerges at , every layer of the network of networks contains a finite fraction of nodes that is in the mutually connected component, i.e. in each layer the percolation cluster emerges at the same time at ,
-
4.
if we include a partial interdependence of the nodes, the transition changes from discontinuous to continuous at a tricritical point, but also in this case either all layers percolate, or any of them does.
4.4.2 Case II: Networks of networks with given superdegree of the layers
Networks of networks can have a structure more random than the one considered in the above subsection. In Ref. [154], the attention has been addressed to the case in which every node of a network (layer) is connected with randomly chosen replicas in some other networks, and it is interdependent of these nodes with probability . Each network (layer) is generated from a configuration model with the same degree distribution , and each node is connected to other “replica” nodes chosen uniformly at random. We further assume that the degree sequence in each layer is and that the degrees of the replicas of node are uncorrelated. This is the ensemble described in Sec. 3.2.2, and graphically represented in Fig. 16. Every network of networks in this ensemble has a supra-adjacency matrix with probability given by
| (170) |
The initially inflicted random damage is defined by the variables . In particular, if , the node is initially damaged, otherwise . The following probability is considered:
| (171) |
In order to quantify the expected size of the mutually connected component in this ensemble, Ref. [154] considers the average of the messages over this ensemble. The message passage equations for this problem are given by Eqs. (129). Let us first consider the case , where all the links between the different layers indicate an interdependency between the two linked replica nodes. The equations for the average message within a layer are given in terms of the parameter , and the generating functions are given by
| (172) |
In particular, if indicates the average messages within a layer of degree , we obtain
| (173) |
where indicates the probability that a node in layer with is in a connected component of the local supernetwork of cardinality (number of nodes) .
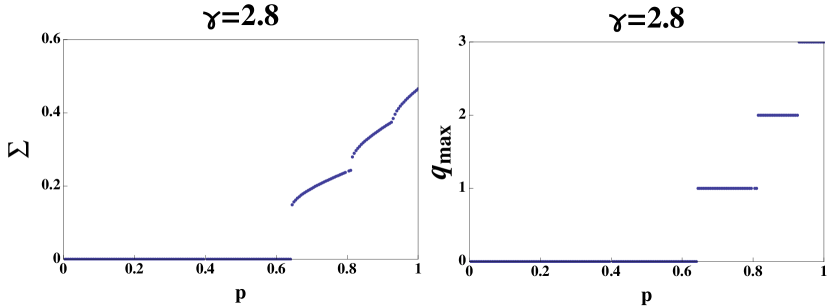
Similarly, the probability that a node in a layer with superdegree is in the mutually connected component is given by
| (174) |
In Ref. [154] it has been shown that Eqs. (173) and Eqs. (174) can be expressed in the following simplified way:
| (175) |
Therefore, in this ensemble the parameter determines both and for any value of the superdegree . For this reason, can be considered the order parameter.
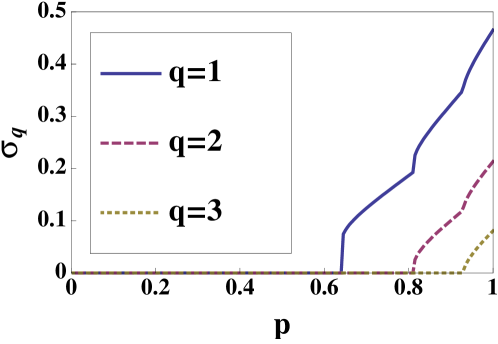
From the study of these equations, the following scenario can be drawn in the limit :
-
1.
if the degrees are heterogeneous, the percolation transitions are multiple, each one corresponding to the emergence of a percolation cluster in each layer with a different value of ;
-
2.
each of these transitions is hybrid and discontinuous, and
-
3.
the layers with higher number of interdependencies are more fragile than those with a smaller number of interdependencies.
The increased fragility of those layers with higher superdegree is in sharp contrast with what happens in the percolation of single layers, in which nodes of high degree are the more robust. In Fig. 27, the order parameter is shown for a power-law distribution , with and a Poisson distribution with average . The multiple discontinuous phase transitions are apparent. Moreover, the degree corresponding to the degree of interdependencies of the percolating layers with maximal value of is shown. Each transition, characterized by a discontinuity of the order parameter , corresponds to the activation of the layers with increasing superdegree . Figure 28 shows that the size of the percolation cluster in the layers with number of interdependencies have multiple discontinuities in correspondence with the discontinuities of the order parameter . Moreover, it is shown that the percolating cluster of layers with higher superdegree is disrupted before the percolating cluster of layers with smaller superdegree.
For , Eqs. (175) are modified as follows:
| (176) |
We note here that, in the case in which the local supernetwork is regular, i.e. , and each layer is formed by a Poisson network with , one finds satisfying the following equation
| (177) |
The emergence of the mutually connected component in the configuration model of a network of networks with can always display multiple percolation transitions corresponding to the activation of layers in increasing value of . Nevertheless, these transitions can be either continuous or discontinuous, depending on the value of .
4.4.3 Case III: Networks of networks with fixed supernetwork and random permutation of the labels of the nodes
Here we consider the robustness of networks of networks described in Sec. 3.2.3 where every node is interdependent on a node if layer is interdependent on layer , and is a random permutation of the labels of the nodes.
In Refs. [26, 153, 155, 156] this structure for the network of networks is implicitly assumed and they demonstrate that the structure of the supernetwork matters. In fact, if the supernetwork is a tree, then the size of its mutual component is determined by the same equations that determine the size of the MCGC in a network of networks of case I. On the other hand, it was found that, for a supernetwork with loops, this is not any more true [26, 155, 156]. In particular, in Refs. [26, 155, 156] the size of the MCGC for a network of networks was explicitly derived for the case of a regular random supernetwork. The size of the mutually connected component when each layer is a Poisson network of average degree and the supernetwork is regular (i.e. the superdegree of each layer has distribution ) is given by
| (178) |
where here partial interdependency of the links is taken into account and indicates the probability that a node is interdependent on a linked node in another layer [26, 156]. We observe here that the Eq. (178) is equivalent to Eq. (177) derived for networks of networks belonging to case II. This result can be generalized. In fact if the supernetwork is a random network with given superdegree distribution the mutually connected component of a network of network of case III follows the same equations determining the MCGC in the network of network of case II. Therefore the following general scenario holds for networks of networks in case III:
-
1.
If the supernetwork is a tree, the MCGC is determined by the same equations determining the MCGC in a network of networks of case I. Therefore, in this case either all the layers are percolating or none does.
-
2.
If the supernetwork is a random network with given superdegree distribution, the MCGC is determined by the same equations determining the MCGC in a network of networks of case II. Therefore, in this case, there are multiple phase transitions and layers with higher superdegree are more fragile than layers with smaller superdegree.
4.5 Effects of correlations and embedding space on percolation properties of multilayer networks
The correlations on multiplex networks have important consequences on their percolation properties. Here we will consider the effects of overlap of the links, degree correlations, and those of the embedding space.
4.5.1 Percolation in networks with overlap of the links
The overlap of the links can change significantly the properties of the percolation transition. In fact, in the limit in which we have a multiplex of totally overlapping layers, the mutually connected giant component of the multiplex is identical to the giant component of a single layer, and the percolation transition is of the second order.
For these reasons, it would be natural to expect that, when the overlap between the layers is over a threshold value, the emergence of the mutually connected component is continuous, while when the overlap is below such a critical value, the emergence of the mutually connected component is described by a hybrid transition.
This problem was tackled by several groups [51, 181, 182, 48], finding different results. In Ref. [51], the Authors have studied the phase diagram corresponding to the message passing algorithm finding a tricritical point for a non vanishing value of the overlap of the links. In [181] the mutually connected component has been studied with different analytical techniques. In this latter case, the Authors do not find any tricritical point, and the percolation transition remains discontinuous for any finite fraction of links without overlap.
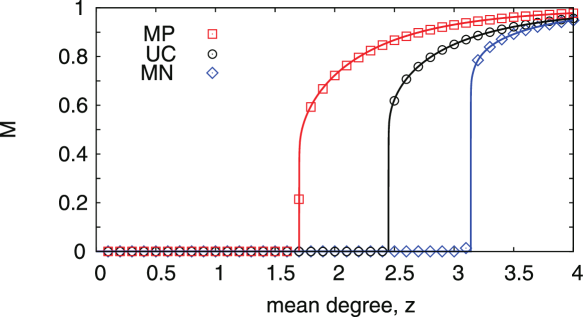
4.5.2 Percolation in networks with degree correlations
The presence of degree correlations in multiplex networks can modify drastically the percolation threshold [183, 184]. The general equations for the percolation transition in correlated multiplex have been first derived in Ref. [168], while Refs. [183, 184, 48] considered the case of single-layer networks with the help of the message passing algorithm of Ref. [175]. Ref. [183] considered multiplex networks in which the replica nodes have the same degree. Refs. [185, 184] studied the robustness of the interdependent world-wide airport network and the world-wide port network with positive degree correlations and clustering. Finally, in Ref. [48] different types of correlation between the degree of the nodes in the different layers have been considered. The Authors investigated the maximal changes induced by the degree correlations for duplex with the same degree sequences, but either uncorrelated by the degree or maximally-positive correlated or maximally-negative correlated. For maximally-positive correlated multiplex networks, the percolation threshold is smaller than that for the maximally-negative correlated case. The networks with uncorrelated degrees in the different layers have a percolation threshold that is in between the previous two. In Fig. 29 the dependence of the fraction of nodes in the MCGC of correlated Poisson networks is shown as a function of the average degree of the nodes. In Ref. [48], the role of targeted attack of multiplex networks is also investigated and discussed.
Other papers have investigated the effect of the degree correlations within a layer on the percolation properties of the network, and in particular assortativity [185], or the effect of clustering [186]. Finally, in Ref. [187], the effect of degree correlations has been studied on a duplex network with partial interdependence.
4.5.3 Percolation in spatial multiplex networks
Many networks are not only interdependent, but also embedded in a physical space. For instance, infrastructures are mostly spatial and therefore it is essential to investigate the role of space in determining their robustness. Ref. [165] has shown that when the multiplex networks are embedded in real space, the interdependencies do not always sharpen the percolation transition. The topic is the subject of debate in the literature [166, 167]. Moreover, the nature of the percolation transition can depend on the typical distance in space of the interdependent nodes. In fact, by modulating the typical distance from two interdependent nodes, the transition can change from discontinuous (for large typical distances), to continuous (for typical distances lower than a threshold value) [188]. This model has been extended in several directions [189, 190, 191]. For example, in Ref. [189] partial interdependence was considered and the Authors found that, in contrast to unembedded networks, for any fraction of dependency links the system collapses in an abrupt transition. Reference [190] tackled the problem of a network that recovers after each cascade. Furthermore, Ref. [191] studied the case of localized attack percolation in spatial networks.
4.6 Other percolation problems
4.6.1 Classical percolation
The percolation of multilayer networks can also be studied in the absence of interdependencies. This is the case in which all the connections, either those between nodes in the same layer and those between nodes in different layers, have the same role and all the links are “dependency links”. In particular, one can consider the giant component as a function of the fraction of damaged nodes in the multilayer structure. In the context of multilayer transportation systems, involving different means of communication such as buses, undergrounds, trains, etc., one station will be in the giant component if by following at least a path using any number of transportation systems, it is possible to reach a finite fraction of other stations. In this case, a node of the structure belongs to the giant component of the multiplex if at least one of its links connects the node to the giant component. This problem has been studied in Ref. [80], considering the model of networks of networks described in Sec. 3.2.4, and graphically shown in Fig. 18. Previously similar problems have been already addressed in the context of networks with different mixing patterns [192], or epidemic spreading [75, 77]. As in the interdependent network case, the percolation threshold depends on the different types of degree correlations between the layers. Ref. [48] investigated and discussed also the role of targeted attacks of multiplex networks. Finally, in Ref. [193] the percolation transition has been characterized for a network in which each layer is a subgraph of some underlying network.
4.6.2 Percolation of antagonistic networks
In Ref. [194], the Authors considered the case in which there is antagonism between the different layers of a multiplex. In particular, they studied the case of a duplex, and they assumed that the function or activity of a node is incompatible with the function or activity of the replica node in the other layer. The nodes in layer are indicated in the following by , while the nodes in layer are indicated by , with . The two nodes and are replica nodes with an antagonistic interaction. In order to determine if a node is in the percolation cluster of the , or if a node is in the percolation cluster of the layer , the following algorithm has been proposed.
A node is part of the percolation cluster in layer if the following recursive set of conditions is satisfied:
-
1.
at least one neighbor of node in layer is in the percolation cluster of layer ;
-
2.
none of the nodes , neighbors of the replica node , are in the percolation cluster of layer .
Similarly, a node is part of the percolation cluster in layer if the following recursive set of conditions is satisfied:
-
1.
at least one neighbor of node in layer is in the percolation cluster of layer ;
-
2.
none of the nodes , neighbors of the replica node , are in the percolation cluster of layer .
For a given multilayer network which is locally tree-like it is possible to construct a “message passing” algorithm that determines if node belongs to the percolation cluster of layer .
We denote by the message within a layer, from node to node . indicates that node is in the percolation cluster of layer when we consider the cavity graph by removing the link in network . In addition, we indicate with a node that is removed from the network as an effect of the damage inflicted to the network, otherwise .
The message passing equations take the following form:
() indicates that the node is (is not) in the percolation cluster of layer . The variables can be expressed in terms of the messages, i.e.
If we consider a duplex formed by two random networks with degree distribution and respectively, we can average the messages in each layer getting the equations for and , that read as
| (181) |
The probabilities , (or ) that a random node in layer A (or layer B) is in the percolation cluster of layer A (or layer B) are given by
| (182) |
This novel percolation problem has surprising features [194]. For example, for a duplex network formed by two Poisson networks with average degree respectively and , the phase diagram is shown in Fig. 30, and displays a bistability of the solutions for some parameter values. In region I, for and none of the two Poisson networks are percolating. In Region II-A only network A contains a percolation cluster. Symmetrically, in region II-B only network B contains a percolation cluster. Nevertheless, in region III, the solution of the model is bistable, and depending on the initial condition of the message passing algorithm, either network A or network B is percolating. Therefore, this percolation problem can display an hysteresis loop, as shown in Ref. [194].
4.6.3 K-core percolation
In Ref. [195], the -core of multiplex networks was defined as the set of nodes between which there are at least paths connecting them in each layer . It has been shown that the -core on a duplex emerges always discontinuously and for every degree distribution as a function of the fraction of removed nodes, following a hybrid transition, with the only exception of the trivial -core. The characterization of the -core composition of a multiplex networks is a significantly richer problem than the characterization of the -core structure of single-layer networks. Moreover, it has been shown that multiplex networks are also less robust than their counterpart single-layer ones, if one considers the destruction of the -cores induced by random removal of the nodes.
4.6.4 Viability in multiplex networks and weak percolation
Different models have been recently proposed that generalize the concept of percolation to interdependent networks. Ref. [196] assumed that each layer has a certain number of resource nodes. Each node of the multiplex will then belong to the viable cluster of the resource network, if it is connected by at least one path to a resource node in each layer. The model displays discontinuity, bistability, and hysteresis in the fraction of viable nodes with respect to the density of networks and the fraction of resource nodes. The model can be used in the context of infrastructures, to show that the recovery from damage can also be extremely slow and difficult, due to hysteresis. In Ref. [197] the weak bootstrap percolation and the weak pruning percolation have been proposed. The weak bootstrap percolation describes the recovery of multiplex networks, while the weak pruning percolation describes the deactivation/damage propagating processes in a multiplex structure. While bootstrap percolation and pruning percolation on single-layers are equivalent, Ref. [197] shows that they do differ in the multiplex case. When layers are formed by Poisson networks, the weak bootstrap percolation includes both continuous and discontinuous transitions, while the weak pruning percolation has only a continuous transition when defined on a duplex, and a discontinuous hybrid transition when defined on a multiplex with 3 or more layers.
4.7 Cascades on multilayer networks
In multilayer networks, cascades can be caused not only by interdependent percolation but also by other processes including cascades of loads [81, 198] described, for instance, by the Bak-Tang-Wiesenfeld sandpile model [199], by the threshold cascade model [50] proposed by Watts in Ref. [200], or by novel cascade processes [201]. In Ref. [81] cascades of loads have been proposed to study the robustness of multilayer infrastructures and power-grids. In that work, it has been shown that moderately increasing the interlayer connectivity can reduce the size of the largest cascade in each layer, and it is therefore advantageous. Nevertheless, it has been shown that too much interconnections can become detrimental for the stability of the multilayer system because it allows single layers to inflict lager cascades to neighbor layers, and furthermore new interconnections increase the capacity and the total possible load, eventually generating larger cascades.
In Ref. [198] the role of multiplexity in the sandpile dynamics was further explored, showing that the avalanche size distribution is not affected by the multiplexity of the network. However, the detailed dynamics is affected by the multiplexity. For example, high-degree nodes in multiplex networks fail more often than in single-layer networks. In Ref. [50] cascades of adoption of a behavior, such as ideas or financial strategies, or movement to join, are studied with the Watts model [200]. It is shown that multiplexity can actually increase the network vulnerability to global cascades. This has relevance for advertising strategies that can become more effective with an increasing multiplexity, or for banks that might become more vulnerable with every new layer in the multiplex. In Ref. [201] a novel cascade model, inspired by the Watts threshold model, has been considered in which some nodes adopt a behavior once enough neighbors in all the layers have also adopted it, and some other nodes adopt the behavior only if enough neighbors in some layers do. This model can either inhibit or facilitate the cascade of events. Moreover, the model in some region of the phase space, allows for abrupt emergence of cascading events, revealing some novel mechanisms for the onset of avalanches that can be useful to characterize civil movements, or product adoption.
5 Spreading processes and games
As in the case of single-layer networks, the characterization of multilayer networks has to be completed with the knowledge about how the structural features of these networks affect their functioning. The ubiquity of multilayer networks in natural, social and technological systems demands to revisit most of the dynamical settings that were previously successfully addressed. This is the goal of this section. The most relevant processes that have been studied include stochastic processes such as random walks, epidemic spreading and evolutionary game dynamics. In addition, each layer can sustain different coevolving processes, that are influencing each other. Thus, the multilayer formalism allows to study the important scenario in which different dynamical processes interplay, such as the competition between different virus strains in a population.
The section is structured as follows. The first part is devoted to diffusion processes starting from the simple cases of linear diffusion and random walks. As a generalization of these processes, we also address the onset of congestion in communication systems. In this latter framework, the diffusion in the network takes into account the limited capacity of the nodes for sending and storing incoming packets. There, the interest lies on uncovering how the multiple routes between network layers affects the onset of jamming in the system.
The second part of the section focuses on spreading processes. In this case, the main goal is to revisit the methods developed for epidemic spreading on complex networks and generalize them to the framework of multilayer. As usual in this context, the main concern is the prediction of the outbreak threshold. However, other measures such as the effect of potential control measures, the coevolution of the disease spreading, and the transmission of information about its impact can be addressed by coupling the dynamical processes in each of the network layers. In addition to disease spreading, another type of contact process, i.e. opinion dynamics, will be reviewed. In this setting, the goal is identifying the conditions for reaching agreement or consensus that, in the context of multilayer networks, can be extended to a problem for the coevolution of different opinions in a system of agents.
Finally, the third part is concerned with the emergence of cooperative traits, and their survival under the framework of natural selection. This topic is quite challenging since defective behaviors are seen to provide more benefits at an individual level, leading to the extinction of cooperation. In the last decade, spatial evolutionary games have been extensively investigated showing that cooperation is promoted thanks to the possibility of forming compact cooperative clusters. This mechanism coined network reciprocity turned out to be enhanced in single heterogeneous networks. One interesting question naturally arises: could network reciprocity be further enhanced? Many different ways of coupling the evolutionary dynamics in each network layer have been proposed, and we will here systematically review the main achievements in this direction.
5.1 Diffusion on multilayer networks
One of the most general issues on networks is the study of transport processes across network topologies [202, 203]. These studies, indeed, are good proxies for many real dynamics involving navigation and flows of many kinds, data in computer networks, resources in technological ones or goods and humans in transportation systems. The variety of such processes ranges from simple diffusive dynamics and random walks [204, 205, 206, 207, 208] to sophisticated protocols aimed at routing information [209, 210, 211, 212]. These efforts allowed to characterize many central features of networks that cannot be captured from intrinsically local properties of nodes, and to design optimal navigation schemes suited to real network architectures.
5.1.1 Linear Diffusion
The study of transport processes in multilayer networks has allowed to add an intrinsic ingredient of real transportation and communication systems, which is the possibility of driving flows by using multiple channels, or modes. The first attempt to address this issue was done by Gómez et al. in Ref. [45], in which simple linear diffusion is generalized to the case of multiplex networks. The time-continuous equations for the linear diffusion in a multiplex composed of networked layers (each of them having one representation of each of the nodes) are:
| (183) |
where ( and ) denotes the state of node in layer . The diffusion coefficients are, in general, different for each of the intralayer diffusive processes ( with ) and for each of the interlayer diffusion dynamics ( with , ). In this way, the first term in the right-hand side of Eq. (183) accounts for the intralayer diffusion, while the second one represents those interlayer processes. Being a multiplex, the latter ones take place between the replicas of a given node in each of the layers.
The above dynamical equations can be casted in the usual form by defining the Laplacian (usually called supra-Laplacian) of the multiplex as an matrix of the form:
| (184) |
where I is the identity matrix and is the usual Laplacian matrix of the network layer whose elements are , and is here the strength of the representation of node in layer , . With this definition of , the diffusion equation (183) can be formulated as .
For the sake of simplicity, one considers that the intralayer diffusion coefficients are set to (without any loss of generality, as each coefficient can be absorbed by the terms of the corresponding Laplacians ) and that the interlayer coefficients are equal to . The simplified Laplacian thus reads:
| (185) |
The above formulation allows to study the role of the interlayer coupling in the diffusion properties of the multiplex, and relating them with those of the set of isolated network layers (). In fact, given the symmetry of the Laplacian (185), the solution of the linear system can be expressed in terms of the eigenvectors and eigenvalues of whose time evolution reads . Thus, the diffusion time-scale, i.e. the time that the multiplex needs to relax to the stationary solution, is given by the inverse of the smallest non-zero eigenvalue of that, for a connected multiplex, is the second eigenvalue (from the smallest , to the largest one), that is .
In Ref. [45] the Authors focused on the case of two layers, , and through perturbation limit they were able to relate the value of for the weak () and strong () interlayer coupling limits. In Ref. [59], Solé et al. extended the perturbative analysis to the full spectrum of , , and for an arbitrary number of layers. The main results of Ref. [59] concerning the smallest non-trivial eigenvalues of are the following:
-
1.
For the set of the smallest non-trivial eigenvalues of increases linearly with .
-
2.
For the set of the smallest non-trivial eigenvalues of are approximately the non-zero eigenvalues of a Laplacian corresponding to a simple network of nodes resulting from taking the average of the layers composing the multiplex, so that the weights of each link in this latter network read as .
The main result of Refs. [45, 59] appears evident when looking at the strong coupling regime, . While for the time scale associated to diffusion goes as , the case shows that the multiplex is always faster than the slowest one of the composing layers. Moreover, although not guaranteed, superdiffusion (i.e. the fact that the multiplex relaxes faster than any of its composing layers) is also possible. In Fig. 31 we show the evolution of for four multiplexes (with and without superdiffusion) composed of two layers.
From the evolution of shown in Fig. 31 it is clear that the diffusive properties (as described by ) of the multiplex do not evolve homogeneously with the interlayer coupling, and there is a value (that depends on the composition of the multiplex) in which the linear increase of changes abruptly. This phenomenon is explained by Radicchi and Arenas in Ref. [96] as a structural transition from a decoupled regime (in which layers behave as independent) to a systemic regime (in which layers are indistinguishable). This change is also explained in terms of the eigenvector associated to the smallest non-zero eigenvalue of the Laplacian of the multiplex, , since it provides useful information about the modular structure of a network, as it is the key ingredient of the spectral partitioning method developed by Fiedler [213, 214, 215]. In Ref. [96], the Authors focused on multiplexes composed of 2 layers A and B and recovered, by solving a minimization problem, the same result as in Ref. [45] for the behavior of for small and large values of . Then, they analyzed the evolution with of the components of the vector focusing on the difference between its first components (those corresponding to the first layer ), , and the remaining (those corresponding to the second layer ), . They observed, as in Ref. [45], that for the components of are of the form (see panel a) of Fig. 32), each one of them having all the entries identical. On the other hand, when , the components of each subvector have the same sign (see panel e) of Fig. 32). Thus, in this limit, the partition of the multiplex into two layers is no longer possible. Furthermore, they found an upper bound for the value as:
| (186) |
where and are the Laplacian matrices of layers and , respectively. The structural phase transition showing the exact value of is apparent in panel c) of Fig. 32 when measuring the evolution of the projection of into as function of .
5.1.2 Random walks
Although linear diffusion provides already a deep understanding of the differences between the behavior of single and multilayer networks, the connection with diffusion phenomena on real systems is not so straightforward due to the discrete nature of flows in real communication and transport systems. In Ref. [98] De Domenico et al. generalized random walks in monolayer graphs to the case of multiplex networks. Figure 33 is an illustration of a path of a random walker (RW) exploring a multiplex network composed of nodes and layers, in which intralayer and interlayer transitions are shown.
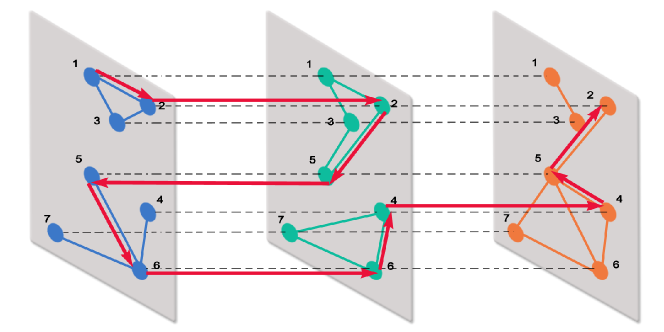
In Ref. [98] a general form for the evolution of the occupation probabilities of a RW in a multiplex of layers and nodes is written as
| (187) |
where is the probability of finding the walker at time in the representation of node in layer . The transition probabilities are encoded in so that is the probability that the walker does not move, is the probability that a walker changes from layer to staying in the same node , is the probability that the walker hops from node to within the same layer , and is the probability that the walker changes from node to node , and also from layer to (this last movement being not actually represented in Fig. 33).
By setting the values of each transition probability, the Authors of Ref. [98] studied different kinds of RWs. As in the case of single-layer networks, the mathematical formulation of RWs makes use of the adjacency matrix, , of the multiplex (also called supra-adjacency matrix) in order to write the expressions for the transition probabilities between nodes and layers. The matrix is of the form
| (188) |
where is the adjacency matrix of layer with elements . Then, the generalization of the classical RW to a multiplex is obtained by setting
| (189) | ||||
| (190) | ||||
| (191) | ||||
| (192) |
In the above expressions is the strength of the interlayer coupling of the representation of node in layer , and is the hopping rate such that accounts for the possibility of the random walker to wait in a given vertex and in a certain layer. In fact, considering the typical assumption in classical RWs, one can set so that (i.e. the walkers never remain in the same position) and, following again the simplification done for linear diffusion, one can further assume that , .
With the help of these assumptions, one can study the diffusion properties of RWs. In Ref. [98], the coverage of the walks (measuring the number of nodes visited at least once in a given time window ) is studied in detail for multiplexes composed of two layers. The main result is that for large enough values of , the time to cover the multiplex is smaller than the whole required to explore each one of the layers separately.
Another important measure (when dealing with RWs) is the concept of communicability [216, 217], that quantifies the number of possible paths communicating two given nodes of a network. In the same framework of classical RWs in multiplex, communicability has also been extended in Ref. [218] to account for the all the walks between any pair of nodes in a multiplex. Indeed, considering the supra-adjacency matrix of Eq. (188), the number of walks of length between the representation of a node in layer and the representation of node in layer is given by different entries of the power of the supra-adjacency matrix, . Considering the definition of communicability in single-layer networks, one is interested in assigning more importance to shorter walks than to long ones. In this way, one defines the communicability matrix as
| (193) |
One can further express the communicability matrix as
| (194) |
where is a matrix containing the communicability between the representations of every pair of nodes within layer of the multiplex. It is important to note that , since takes into account those paths that, while connecting the representations of two nodes within the same layer, can include hops to any other layer different from due to the coupling . Obviously, if , then one has
| (195) |
This means that communicability naturally accounts for the fact that, in a multiplex, information between the representation of two nodes within the same layer flows actually in parallel at the different layers.
5.1.3 Diffusion-based centrality measures
Another relevant aspect of diffusive processes is the evaluation of the importance that the nodes of a network have on its global organization. To this aim, RWs have intensively been used to assess the importance of nodes based on their occupation number, i.e. the probability of finding a walker in each of the nodes in the steady state of the dynamics. In Ref. [98], the Authors study the set of occupation numbers in the steady state of the dynamics, , for the general family of walks described in Eq. (187), including the classical one, by assigning different values for the transition probabilities included in . In Ref. [125], the Authors focused on the generalization of the classical RWs (with ). Since the occupation probabilities in a multiplex refer to each representation of a given node on a given layer , , in order to evaluate the centrality of a given node one must aggregate the occupation numbers for each of its representations in all the layers
| (196) |
so that accounts for the probability of finding the walker in node , regardless of the layer.
One of the most successful applications of RWs to derive centrality measures is the well-known PageRank centrality method [219, 84], which is at the core of the most widely-used search engine of the World-Wide-Web, Google. PageRank is based on a diffusion process that mimics the navigation through webpages as the motion of a random walker following hyperlink pathways. Whereas these link-by-link hops are followed most of the times, there is a small probability that at a given time step the walker performs a long distance hop to an arbitrary node of the system. In this case, the transitions encoded in should be reformulated in the following way with , where is the probability of performing a long distance hop and the elements of are defined as .
In Ref. [54], Halu et al. proposed a different version of the PageRank dynamics that is not as general as the above in the sense that there is a privileged layer that influence the remaining layers of the multiplex. In the case of a -layer multiplex, the nodes in the first one are characterized by means of the usual PageRank on single-layer networks, whereas the transitions between adjacent nodes of the second layer are biased by the centrality of their counterparts in the first layer.
Finally, in Ref. [125] the Authors use the formalism provided by RWs in a multiplex to compute other centrality measures not directly computed from the occupation numbers of the nodes, but with the number of paths that cross them. Examples are betweenness and closeness centralities, which in principle are designed to account for shortest paths, but that can be extended to RW paths.
5.1.4 Routing and congestion phenomena
The processes described in this section are proxies of real diffusion dynamics in transportation and information interconnected networks. In fact, most of the data and human flows in such systems are far from random, and most of the times they follow paths that minimize a distance or certain other cost functions. This is the case of shortest-path diffusion through which the agents (such as data packets or humans) go from an origin node to a destination one following the path that minimizes the number of nodes visited along their trip (in the case of unweighted networks), or the sum of the inverse of the weights associated to each link contained in it (for weighted ones). In this context, the problem of congestion arises when the so-called capacity of nodes is limited, i.e. the number of packets that a node can send to its neighbors per unit time is bounded. However, in a time step, it may occur that a node receives more packets than its capacity. When this event happens for a macroscopic part of the system, congestion shows up.
The usual set up for studying congestion is a situation in which a number of packets, , is injected in the network per unit time, being the origin and destination nodes of these packets randomly assigned, and the probability of an information packet is created. Packets are delivered from the origin to their destination (where they disappear) by hopping between adjacent nodes. As congestion results in the unbalance between the number of packets introduced in the network and that of delivered ones, the following order parameter [220, 221]
| (197) |
is used to monitor the transition to congestion. In the latter equation, is the number of packets that the network is handling at some time , and thus measures the normalized () increase of packets per unit time. Many works in single-layer networks (see for instance Refs. [220, 221, 203, 222, 223, 211]) have studied the transition from the free-flow regime () to the congested one () at some critical load of the network . Many different ways of delivering the packets on top of a variety of network topologies have been introduced in order to delay the onset of congestion.
Recently, several works have addressed the problem of congestion [92, 224, 225, 226] on top of interconnected networks. In Ref. [92], Morris and Barthélemy analyzed an interconnected system formed by two layers which partially resembles a multiplex. In fact, the second layer is composed of a subset of nodes of the first one so that each node in the second layer is directly connected with its representation in the first network. Origin and destinations can be only chosen in the first (large) layer so that, given that the agents travel following the shortest path, when networks are uncoupled the agents do not make use of the second platform. However, coupling enters into play when the diffusion of agents between adjacent nodes is faster in the second of the layers. In this case, agents may find short paths between their origin and destination making use of the second layer. To account for this coupling, the Authors measure the coupling between layers as
| (198) |
where is the fraction of agents traveling from node to node (of the first layer) whereas and are, respectively, the number of shortest paths between the former two nodes and , and those paths that contain edges from both network layers. Obviously , being small (large) in the weakly (strongly) coupled regime. In fact, as increases, the average distance between two nodes in the first layer decreases as an effect of the use of the second layer. However, this effect comes together with the accumulation of the used paths on a very small subset of edges which can lead to a saturation of the system due to congestion. This latter effect is shown by measuring the Gene coefficient that accounts for the distribution of paths across the edges, so that small (large) values of correspond to a spread (concentrated) distribution of the flows across the edges (see Fig. 34). The Authors show that it is possible to obtain an optimal coupling that balances the aforementioned effect, so to obtain an optimal communication multiplex.
The congestion diagram has been studied for usual routing protocols implemented on top of interconnected networks in Refs. [224, 225, 226]. As described above, congestion can be directly connected to the limited capacity of nodes and links for handling the flows. In these latter works, the Authors consider interconnected networks in which some pairs of nodes of different networks are linked, thus providing the communication between the two networks and the mix of their flows. The main conclusion [224, 226] is that the more is the interconnection between networks, the better is the performance of the system in terms of the critical value from which the system gets congested. Moreover, in Ref. [226] the Authors show that when nodes of similar degrees from different networks are linked, the critical value raises considerably, pointing out that the connection of the hubs of the different networks helps to alleviate the saturation of both networks.
5.2 Spreading processes
Among the possible dynamical scenarios of relevance, the analysis of the spreading of diseases and the design of contention policies have capitalized most of the literature in the field of network science [8, 4, 9, 227, 228, 229]. This interest has been rooted in the successful extension of the classical compartmental models used in mathematical epidemiology [230, 231, 232, 233] beyond the mean-field equations, so to incorporate networked architectures that capture realistic interaction patterns. From the physical point of view, the study of epidemic models on top of networks has allowed to extend a paradigm of non-equilibrium phase transitions beyond lattice models [234]. In addition, the study of the spreading of infectious diseases on top of networks gives also insight on other dynamical processes of interest, such as the information and rumor spreading in social networks. Thus, the recent interest on multilayer networks has provided a natural way to extend and improve our understanding of the basics of spreading dynamics in real-world complex systems.
Let us first briefly review two typical compartmental models: the Susceptible-Infected-Susceptible (SIS) and the Susceptible-Infected-Recovered (SIR) models. In both cases susceptible individuals can be infected when they are in contact with an already infected agent. In this case, and considering the time discrete version of SIS and SIR dynamics, there is some probability that the individual takes the infection. Once infected, agents recover with some probability per unit time. The difference between SIS and SIR models is the following: in the SIS model recovered individuals become susceptible of contracting the disease, i.e. there is no acquired immunity after suffering the infection (this setting suits with most of the typical sexually transmitted diseases). At the opposite, in the SIR case, recovered individuals are immune to the disease, and they cannot be infected again. From the dynamical point of view, SIS and SIR models differ in their stationary regime: while for the SIR model the dynamics dies out once there is no infected individual in the population (so that only susceptible and recovered agents coexist), for the SIS model sustained epidemic activity may persist over time as a consequence of the reinfections of recovered agents.
In any case, the key question is whether the spread of the disease causes an epidemic scenario in which a macroscopic part of the population is affected. The typical control parameter in both SIR and SIS models is the ratio between the infection and recovery probabilities, , while the order parameter that quantifies the impact of the disease depends on the type of dynamics used. In the case of the SIR model, the impact of the disease is given by the number of recovered individuals in the final state of the dynamics. For the SIS model, instead, the order parameter is the number of infected agents in the sustained endemic state, that allows to track a non-equilibrium transition between the healthy and the epidemic phases.
5.2.1 Disease spreading on single-layer networks
We start by briefly summarizing the basic equations that capture a disease spreading process on top of a single-layer network. To this aim, we will focus on the SIS model, although other compartmental dynamics such as the SIR model can be casted under the same framework, and we will review the microscopic formalism developed in Ref. [235].
As usual, we consider a network of nodes that, in the most general case, is weighted. We represent the connections between the nodes by the entries of a weighted adjacency matrix . Under the SIS framework, at each time step, an infected node makes a number of trials to transmit the disease to its neighbors with probability per unit time. Since this process has no memory, the probability that node is infected at time follows a Markovian dynamics defined as
| (199) |
where is the probability that node is not being infected by any neighbor at time ,
| (200) |
and are the elements of a matrix representing the probability that node is in contact with node , that is
| (201) |
The first term on the right hand side of Eq. (199) is the probability that node is susceptible () and is infected () by at least one of its neighbors, whereas the second one is the probability that node is infected at time and does not recover. The form of matrix in Eq. (201) allows to capture different kinds of interactions under the same mathematical formulation. For instance, the case (one contact between and per unit time) corresponds to a Contact Process (CP), so that , being the total strength of node . Another general situation is that corresponding to , which yields , leading to a Reactive Process (RP), regardless of whether the network is weighted or not. The latter limit is what is typically adopted for the SIS dynamics.
The phase diagram of the SIS model is then obtained by searching for the stationary solution of Eq. (199), that results in the following equation
| (202) |
and computing the usual order parameter of the SIS model as
| (203) |
Equation (202) has always the trivial solution , (corresponding to ). However, other solutions corresponding to are possible, and they represent the existence of an epidemic state. The relevant question is thus what is the critical value of the control parameter for which is a solution of the SIS dynamics.
The calculation of this critical point is performed by considering that, when the value is close to the critical one the probabilities (). The substitution in Eq. (200) and Eq. (202) yields
| (204) | ||||
| (205) |
where for , and otherwise. The system of Eqs. (205) shows that a non-trivial solution is possible when is an eigenvalue of the matrix . Thus, the problem of finding the epidemic threshold (the minimum value of giving rise to an epidemic) is tantamount to computing the spectra of the contact matrix . In particular, since we are interested in finding the smallest as possible value of , we are interested in the largest eigenvalue, , of the matrix . For a given value of , the critical value for the probability of infection, , that represents the onset of the epidemic phase, is
| (206) |
It is worth analyzing the two limiting cases of CP and RP. In the first case, one obtains the trivial result that the only non-zero solution corresponds to , because the matrix is a transition matrix whose maximum eigenvalue is always . For the RP corresponding to the SIS spreading process, instead, the largest eigenvalue must be calculated [236]. We observe here that the determination of the epidemic threshold for single-layer networks is a subject of active debate [228, 229]. Indeed, there is one potential problem in the derivation of Eq. (206) coming from the fact that the maximal eigenvector of the matrix might be localized on an infinitesimal fraction of nodes in the network. In this case, the order parameter would be non vanishing only on an infinitesimal fraction of the network and, therefore, it is not possible to speak of a true phase transition at determined by Eq. (206). Finally, for annealed networks which rewire their connections on the same time scale of the dynamical process and keep their degree sequence constant, one can approximate as . This matrix has maximal eigenvalue , recovering for these networks [237, 238] the classical result reported in Ref. [239].
The above result was originally obtained by means of the so-called heterogeneous mean-field (HMF) approximation developed in Refs. [239, 240, 241]. The HMF assumes that the contact matrix can be approximated as , and considers that all nodes having the same degree behave equally which, in terms of the microscopic formulation, means that whenever . Under this assumption, valid if the network is dynamically rewiring its connections keeping the degree distribution fixed, one ends up with a system of equations for each degree class present in the network.
By assuming to be the probability that a node of degree is infected and assuming , the HMF equations read
| (207) |
where is the conditional probability that, given a node of degree , this is connected with another one with degree . The stationary solution, , of the above set of equations gives the value of the order parameter . In analogy with the microscopic formulation, one is interested in the non-trivial solutions (yielding ) of
| (208) |
In Refs. [239, 240, 241] it is shown that the above equation has non-trivial solutions when (in agreement with the result obtained via the microscopic formulation). It is important to note that this result points to the fact that for degree-heterogeneous networks (such as SF networks) the epidemic threshold can be extremely small, since the second moment of the degree distribution becomes very large. On its turn, the evidence of an almost absent epidemic threshold in real systems defied the classical results on epidemiology, and demanded for a change in the usual contention policies applied in systems in which an homogeneous structure was assumed.
5.2.2 Disease spreading on interconnected networks
In this context, two main kinds of multilayer networks have capitalized the attention in the recent years: interconnected, and multiplex graphs. As far as disease spreading dynamics is concerned, both substrates have their own relevance, and the generalization of compartmental models such as the SIS and SIR to these substrates has stimulated a great interest. The case of interconnected networks considers the spreading of a disease in several network layers, each node of each network representing a different agent. One example is the case of sexually transmitted diseases. Just think of three networks of sexual contacts: one composed of agents sharing heterosexual relationships, and two other graphs of homosexual (gay and lesbian) contacts. These three networks are connected through edges in which one (or both) of the connected nodes is a bisexual agent. Obviously, the values of the parameters describing the spreading dynamics, such as the infection rates, depend in principle on the nature of the link through which the contagion is produced. In this setting, the key question is to relate the epidemic onset of the whole system with those corresponding to the isolated networks.
Different works have addressed the above issue in both the SIS [242, 243, 244, 53] and SIR [245, 76] frameworks. For the SIS case, different approaches point out to a same central result: An epidemic may appear in the interconnected system even for infection rates for which a disease would be unable to propagate in each isolated network. This result is obtained both via the HMF approximation [242], and via the analysis of the microscopic equations and the spectral properties of the associated connectivity matrix [243, 244, 53].
As pointed above, the SIS dynamics considers different parameters depending on the nature of the contacts and the agents. Focusing on the case of two populations and , () is the infectious rate between individuals belonging to the same network A (B) whereas () is the infectious rate from a node in network A (B) to another one in B (A). The recovery rates are also fixed to () for individuals in population A (B). In this way, one can write the microscopic equations based on the adjacency matrix of the whole interconnected system, which in the case of two coupled networks read as
| (209) |
where submatrices () define the connections between nodes of network A (B), while () define, on their turn, the connections from nodes of network A (B) to those in B (A). In Ref. [53], the exact microscopic equations for generic SIS dynamics are written, extending Eq. (199), which in the case of the usual Reactive scenario (and for two populations) yields
| (210) |
Note that is a vector whose components can take values and depending on the network in which the corresponding agent is placed. In addition, the expression for the probability that a node is not infected by any neighbor (in network A or B), , reads as
| (211) |
where the reaction matrix of the system incorporates the infection rates into the adjacency matrix of the interconnected networks:
| (212) |
As in the case of single-layer networks, the spectral properties of this reaction matrix yield the critical behavior of the system, i.e. the epidemic onset of the interconnected system. As a consequence, one can study different combinations of the transmission parameters to assess the conditions for the emergence of an epidemic as in Ref. [243].
A useful insight about the behavior of the epidemic onset is achieved by treating equally the propagation properties of the disease within each layer ( and ), and by symmetrizing the propagation between them . Consequently, one can derive interesting results based on perturbation theory [53] and spectral graph theory [243, 244]. For instance, the works reported in Refs. [244, 53] show that the epidemic threshold is given by the largest eigenvalue of a matrix defined as , so that
| (213) |
In fact, since the spectral radius of a submatrix is always smaller or equal than that of the whole matrix, one obtains that
| (214) |
i.e. the epidemic threshold of the whole system is always smaller than those of the isolated networks (see Fig. 35). Moreover, in Ref. [244] the Authors analyzed the behavior of the largest eigenvalue as a function of the composing networks, and concluded that whenever two nodes from A and B with large eigenvector components (corresponding to and , respectively) are linked, the epidemic threshold of the entire system reduces dramatically.
The fact that the interconnected system is always more prone to the epidemic than the set of isolated networks can be explained in terms of a perturbative analysis that assumes that . In Ref. [53], the Authors used the former limit to explore the behavior when either (i) there is one dominant layer (e.g. ) and (ii) both layers have roughly the same epidemic onset (). In the first case, they show that the maximum eigenvalue of the whole system is equal to that corresponding to the dominant layer , whereas the nontrivial stationary solution at yields
| (215) |
where is the stationary solution in the dominant network at its epidemic onset. It is clear that the onset of an epidemic in the dominant layer automatically induces the spreading in the other one.
The second limit () reveals the strong synergetic effect of the coupling between layers. If isolated, the networks would have a roughly simultaneous epidemic onset located at their corresponding . However, the interconnection of layers makes a correction of the maximum eigenvalue as
| (216) |
thus pointing out that the critical point of the system is smaller than any of the isolated layers, and that the correction to its value depends on the product of eigenvector centralities between connected nodes belonging to different networks, as pointed out in Ref. [244].
The HMF approximation, although being a coarse-grained picture, also recovers the above result. In this case, one can easily generalize Eq. (207) to the case of interconnected graphs. Once again, in the case of two interconnected graphs A and B, the HMF equations in their time-continuous version read [242],
| (217) |
for the evolution of the fraction of infected individuals in network A having neighbors in network A and neighbors in network B [the evolution for is analogous to Eq. (217)]. Here the degree classes in each network, say A, is characterized by a vector degree ), and the conditional probabilities used in Eq. (217) make use of this vectorial classification of nodes. As in the case of the HMF equations in single-layer networks, in order to derive the epidemic onset, one is interested in the limit where the densities of infected individuals are small, and therefore one works with the linear equation
| (218) |
where , and
| (219) |
Obviously, whenever the maximum eigenvalue of matrix satisfies , any initial fraction of infected individuals decays to the trivial solution . As a result, the critical epidemic point is defined by . The analysis of this condition in uncorrelated networks was carried out in Ref. [242], yielding that , being and the maximum eigenvalues of the isolated networks, and the one corresponding to that of the bipartite network obtained by considering only the links between nodes belonging to different networks. Once again, the HMF approximation allows to conclude that the coupled system can sustain an epidemic even when the isolated networks would be free of disease.
For the SIR model the treatment is quite similar [245, 76]. However, in Ref. [245], based on the analogy between bond percolation and the SIR model, the Authors unveiled one important difference with respect to the case of the SIS dynamics. Whereas for strongly coupled networks the value of the epidemic onset of the whole system is smaller than that of the isolated networks (as in the SIS model), when the coupling is weak (i.e. the internetwork links are much less than those connecting individuals within the same network), the system can sustain an epidemic state in one network while not affecting the remaining ones. These mixed states point out that for the SIR dynamics there is a critical internetwork coupling, below which the network behaves quite similarly to a set of unconnected networks.
5.2.3 Disease spreading on multiplex networks
As pointed out many times already, multiplex networks are, from the structural point of view, just particular cases of multilayer networks in which each node is represented in each of the layers (so that the layers have the same number of nodes). In addition, each layer is connected to another one via connections resulting from the links that each node establishes with its representations in the remaining layers. Given that the results shown for the disease spreading on top of an interconnected network are rooted in the spectral properties of its contact matrix, the case of a single disease spreading on top of a multiplex network can be analyzed in the same way by considering that the () adjacency matrix is of the particular form
| (220) |
However, a multiplex automatically sets the constraint that when a node gets infected by the disease in one layer, and therefore it becomes a spreader of the disease in any of the other layers. This ingredient can only be approached (in the interdependent framework) by setting and , which is a far different case with respect to the weakly coupled regime usually studied in interdependent networks.
In fact, in Ref. [246] the Authors analyzed the SIS model in a multiplex in a similar way to Ref. [53], i.e. by writing the microscopic dynamics. In this case, the expression for the probability that a node is not infected by any neighbor (in network A or B), , reads
| (221) |
where is the adjacency matrix in layer . Note that, at variance with Eq. (211), the vector containing the probability that any node is infected, , has components since now the state of a node must be the same in any of the layers composing the multiplex. One can note that the only difference with an epidemic spreading on the projected network (the network resulting from the sum of the layers) is that the transmission rates are different for each of the layers. The analysis of the microscopic dynamics relates the epidemic onset with the maximum eigenvalue of the matrix, defined as
| (222) |
Again, it is shown that the epidemic onset is always smaller than those of the isolated networks.
The SIR model in multiplex networks has been analyzed in Refs. [247, 248]. In Ref. [247], the Authors made use of a two-layers network in which a SIR disease switches layer at the expense of a cost. They derived the epidemic threshold, obtaining a similar result to that of SIR dynamics in interconnected networks [245] when the coupling between networks is strong: the epidemic threshold cannot be larger than those of the isolated networks. Obviously, multiplexity incorporates naturally the constraint that the network layers are far from the weak coupling regime in which mixed states appeared. In this work, the Authors derived an interesting result concerning the behavior of in a multiplex composed of two ER graphs as a function of the difference, , between the intralayer and interlayer transmission rates and the difference, , between the average degree of both layers. It was shown (see Fig. 36) that the multiplex epidemic threshold grows with (when the intralayer transmission rate increases with respect to the interlayer one), for low values of . However, this trend is reversed when grows enough, so that decreases with .
In Ref. [248], the SIR dynamics is addressed on top of a multiplex containing one physical layer and a second one in which only a subset of the nodes in the first layer takes part. Importantly, the size of this subset is tunable so that they are able to derive the conditions for the spreading of the disease as a function of the size of the second layer.
Competing epidemics
The particular setting of multiplex networks provides the best suited structural backbone for the study of the dynamical interplay between different dynamical processes taking place within the same set of nodes. In this way, multiplexity offers the possibility of incorporating different network layers for each dynamical process at work. This possibility leads to approach a well studied problem in single-layer networks: the competition between the spreading of two different diseases. In Ref. [249], Newman proposed a model in which two consecutive SIR diseases spread within a single-layer network. For the first disease at work, the critical properties and the diffusion of the infections remain the same, as usual. However, the second disease finds it more difficult to spread since those agents recovered from the first of the diseases gain immunity also to the second one. The main result is that, even for SF networks, the epidemic threshold for the coexistence of both diseases is larger than zero. Subsequently, other works extended the framework to the case of simultaneous spreading of diseases [250], or to the SIS model [251].
The further extension of those works to multiplex networks is natural, and adds the possibility of exploring the effects of having two different transmission networks for each one of the diseases, and thus incorporating the fact that different diseases may have different transmission channels. Funk and Jansen were the first to address this issue in Ref. [126] by considering, as in Ref. [249], that the disease spreads in a consecutive way. To this end, they considered a multiplex composed of two networks and a SIR model so that the first spreading takes place in one of the networks leaving a set of recovered nodes. These nodes are also set as recovered in the second layer (as if they were fully immunized) prior to the second spreading that takes place in this second layer. The main result is that a positive correlation between the degrees of the nodes in both layers enhances the immunization of the network to the second spreading (increasing the effective epidemic threshold for the coexistence of two epidemics). This approach has been generalized in Ref. [127] to the scenario of two SIR diseases whose spreading takes place simultaneously in the two layers of the multiplex, allowing to study the influence of delay between two spreading processes and the effect of full and partial immunity.
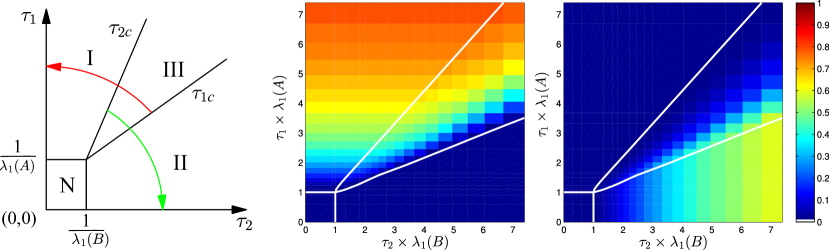
The study of interacting epidemics has been also applied to the SIS model in Refs. [253, 254, 252]. In fact, the extension there to multiplex networks leads to a modification of the standard SIS model into a SI1I2S model with the so-called mutual exclusivity, so that when an agent is affected by one of the diseases, , spreading in layer , this automatically confers immunity to the disease running in the other network layer. Obviously, once this agent becomes susceptible again, it may be infected by any of the two viruses. The analysis can be tackled by writing the microscopic equations of the SI1I2S defined by two adjacency matrices and and considering different disease parameters for each of the two spreading viruses: () for the rate of transmission of disease () and () for the rate of the transition from I1 (I2) to the susceptible state. In Ref. [252], the Authors made use of a coarse-grained microscopic approach shown in Ref. [255] for SIS, and that represents an intermediate step between the accurate microscopic equations [235] and the HMF approximation. The set of equations for the probabilities that agents are infected by the two viruses read as
| (223) | ||||
| (224) |
As usual, this system of equations can be linearized around the trivial solution, ,, and the conditions under which an epidemic in either population , population or both will hold, can be derived. The conditions will depend on both control parameters and . A trivial statement is that whenever and there is no epidemic in any of the network layers. However, a relevant scenario appears when any of the control parameters (or both) is (are) above this threshold, since competition between the spread of the two viruses appears. In Ref. [252], the Authors performed an analytical derivation based on perturbation theory and numerical simulations to derive the phase diagram as a function of and . Analytical and numerical results are shown in Fig. 37, highlighting the existence of four regimes: the free phase (N), epidemic in population and free phase in (I), epidemic in population and free phase in (II), and finally the coexistence of both epidemic states in layers and (III). Interestingly, from the diagrams, it is clear that when the infection rate is large enough in one population, say , it hinders the epidemic onset in , even when . A further relevant result of Ref. [252] is that whenever the two network layers are identical, the coexistence region disappears.
Interaction between social dynamics and epidemic spreading
As mentioned above, the multiplex structure allows to couple different dynamical processes involving the same set of agents being, in principle, different the structural backbone on top of which each process operates. In this way, disease spreading has been recently coupled to social dynamics [256], in order to take into account how the social awareness about the spreading of a disease can influence the impact of the latter. To this aim, the Authors coupled the SIS spreading taking place on a physical network with another compartmental stochastic model in which the state of the agents can be of two kinds: Aware () and Unaware (). The first dynamics is completely characterized by the usual two parameters: the transmission, , and recovery, , rates. The second dynamics takes place on the second layer (a kind of virtual network in which information about the epidemic flows) and the transition between states and is analogous to that in the SIS model: the direct contact of an agent with another one in produces two agents with probability , whereas an aware individual can become unaware with probability . The coupling between the two dynamical models is done by reducing the transmission rates from infected individuals to aware and susceptible ones by a factor ( means that aware individuals become fully immunized). In addition, the state unaware-infected is not admitted and, in a time discrete-version, it becomes aware-infected with probability (if not recovered).
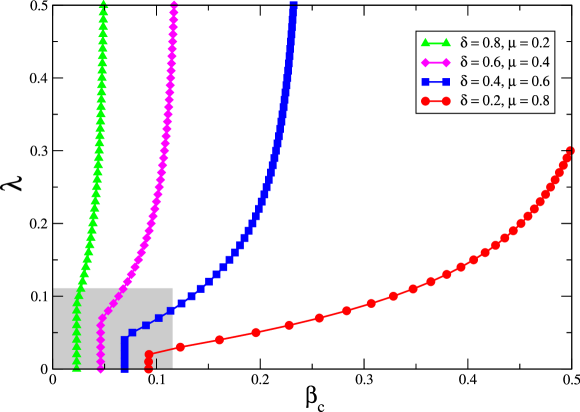
As in Ref. [252], when isolated, the two dynamical processes display a critical point at some values of the respective control parameters, and . In particular: and , where and are the adjacency matrices of the first layer where SIS and Aware-Unaware dynamics take place respectively. Once again, the coexistence of these processes changes the onset of the epidemic state. In particular, when the infection rate of the SIS dynamics is large enough, the infected agents trigger the mechanism of awareness in the virtual layer, thus lowering the incidence of the disease and increasing the epidemic onset. This result is shown in Fig. 38 for several values of and . Interestingly, as the ratio decreases, the value of the epidemic onset is more influenced by the Aware-Unaware dynamics.
Impact of interlayer topological properties
Except for the influence of dynamical processes located in other layers, the network properties between different layers also play a significant role in the diffusion of disease. The first viewpoint comes from the investigation of coupling density, which tries to reproduce the empirical fact that not all the nodes are present on each layer of social networks. In Ref. [257], a fraction of nodes are shared by two layers enabling to form partially overlapped networks. Since there exists the same disease in both layers, the equal transmission probability is assumed, whereas the spreading of infection starts from one random node. The main aim becomes here to explore the effect of the overlapping fraction on the disease propagation with reference to the SIR dynamics model. Based on the theoretical analysis and simulations, the Authors found that the epidemic threshold of multiplex networks depends on both topology and the coupling density. In the limit of , the epidemic threshold is minimum, and both layers have the identical ratio of recovered nodes at any transmission probability. This is because nearly each node belongs to two layers at the same time. However, with decreasing, the epidemic threshold monotonously enhances, so as to reach the maximal value (at ) dominated by the isolated threshold of the layer with larger propagation ability. This point means that, even though there exists negligible differences between the system composed of two isolated networks and the system connected by just a few interlayer connections, these links can make the epidemic threshold of the isolated network with lower spreading ability discontinuously change the threshold of the other layer. This finding is shedding light into the non-medical intervention for the control of the disease propagation.
Of particular interest is distinguishing how the disease spreads if the nodes are coupled by a certain rule from the case of simple overlapping. In a recent investigation [258], a two-route transmitted disease employing SIR model is introduced into the multiplex framework, where two transmission routes take place on each layer, respectively. Moreover, the Authors defined two new measures to evaluate the influence of interlayer links. The first is the degree-degree correlation (DDC) between layers: positive (negative) values indicate that high (low) degree nodes are inclined to have more (less) connections within another layer. The other quantity is the average similarity of neighbors (ASN) from different layers of nodes, which measures how many joint neighbors one node possesses in both layers. The Authors found that, even if both layers are below their respective thresholds, the disease can still propagate across the multiplex system. If the value of DDC is larger, a lower disease threshold and a smaller outbreak size are supported. The epidemic threshold and disease size keep both robust against the change of ASN.
5.2.4 Voluntary prevention measures
Except for the outstanding achievements of the prediction of the outbreak threshold, another task of utmost urgency, during the study of epidemiology, is searching for the effective policy or strategy to control the epidemic spreading, and to warrant public health [259, 260]. This point seems particularly remarkable with worldwide pandemics of severe acute respiratory syndrome (SARS), bird flu and new H1N1 flu [261, 262, 263]. A great number of immunization scenarios, such as targeted immunization [264], ring immunization [265], and acquaintance immunization [266], have been proposed, but the majority of them, based on the premise of compulsory requirements, completely neglects the individuals’ willingness and desires, which instead follow many social factors including religious beliefs, the human rights and social total expenses as well [267, 268, 269, 270]. In this sense, voluntary prevention measures, incorporating both studies of infectious disease and spontaneous human behavior traits, become popular programs [271, 272], namely, the so-called “disease-behavior feedback dynamics study”.
Voluntary vaccination on single-layer networks
Among several existing control measures, vaccination attracts the hugest attention from theoretical and experimental perspectives [273, 274, 275, 276]. During the seasons of disease spreading, the high risk of infection usually stimulates individual vaccination enthusiasm, while high expenses or side effects of a vaccine may lead to the opposite case. Thus, individuals face a dilemma: to vaccinate or not, both of which ways can be managed as two basic strategies with respective cost functions. To resolve this dilemma, game theory has been integrated into individual decision-making processes, where nodes hold the prevention strategy according to risk and expenses in the epidemic campaign [277]. In a recent research [278], where nodes are only allowed to make rational selection (i.e. taking vaccination only if its expense is low), the Authors found that disease outbreak can be more effectively inhibited on SF networks than on random networks. Compared with early theoretical predictions of disease thresholds [239], this interesting outcome indicates that voluntary vaccination can effectively control the spreading of diseases in real-world networks. Similarly, when the imitation dynamics with noise replaces the deterministic rule in the disease-behavior study, multiple effects spontaneously arise: for perfect vaccine, vaccination behavior of SF networks beats that of random networks, while imperfect vaccine enables the promotion of vaccination and eradication of disease to act better on homogeneous connectivity patterns [279]. In Ref. [280] it is found that the spatial population structure shows a “double-edged sword” effect, which fosters vaccine uptake at the low cost of vaccination, but causes vaccination to plummet when the cost goes beyond a certain threshold. More specifically, if a small fraction of individuals consistently holds vaccinating in flu-like diseases, these committed vaccinators can efficiently avoid the clustering of susceptible individuals and stimulate other imitators to take vaccination, thus contributing to the promotion of vaccine uptake [281].
Voluntary prevention behavior on multilayer networks
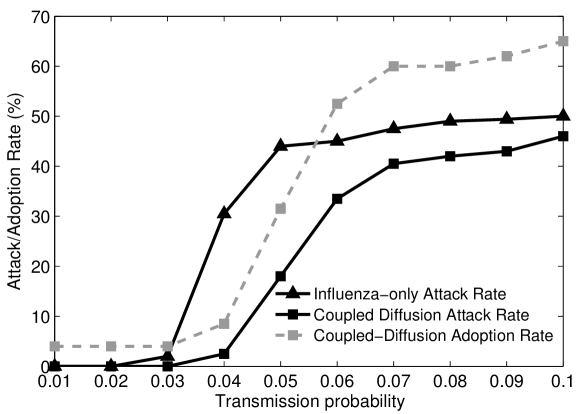
Although both infection diseases and prevention measures diffuse simultaneously through networks and interact with each other, few existing studies have coupled them together. Recently, the research of disease-behavior interactions on top of multilayer structures has also received attention. In the first conceptual work [282], two diffusion processes are implemented in the multiplex viewpoint, where two networks, which are fully or partially coupled via the interlayer links, involve the same individuals yet different intralayer connections. Under such a framework, one network is regarded as the infection network to transmit diseases, and the remaining communication network channels individual influence concerning preventive behavior. Moreover, at variance from the aforementioned case where vaccination is the principal measure on single networks, other prevention behaviors, such as wearing facemasks, washing hands frequently, taking pharmaceutical drugs, and avoiding contact with sick people, are considered as the main strategies, which seem particularly reasonable before attaining effective vaccine [283].
Based on the online surveys, the threshold model is selected, whereas only once the proportion of adopters among intralayer neighbors of communication networks reaches the perceived threshold of adoption pressure (or the proportion of infected individuals exceeds the perceived risk of infection on the infection network), the node can adopt the preventive behavior. Surprisingly, the Authors found that, as compared to the widely used disease-only model, the coupled diffusion model leads to a lower frequency of infection. Figure 39 shows that, as preventive behavior protects a certain people from being infected, the threshold and peak of disease outbreak are effectively suppressed in the new embedded scenario. Furthermore, the sensitivity analysis identifies that the structure of infection network has dramatic influence on both epidemic and adoption percentages, while the variant of communication network produces less effects.
After such a seminal research, the role of multiplex networks in the coupled disease-behavior system has been further investigated. Recently, a triple diffusion process, comprising disease transmission, information flow regarding disease and preventive behaviors against disease, was integrated into multilayer social networks [284]. Among the interaction of the three diffusion dynamics, the negative and positive feedback loops are formed. Here it is worth mentioning that, as compared with Ref.[256] involving the information diffusion as well, the effect of prevention behavior is of particular evidence. Under the help of agent-based method, this new conceptual framework can reasonably replicate the observed trends of influenza infection and online query frequency in the empirical population.
Finally, a similar scenario was proposed in Ref. [285], where the social and biological dynamics processes are embedded into a multiplex viewpoint. Under such a disease-behavior system, biological contagion spreads on one layer, while the main control measure, vaccination, is carried out in the social network. At variance with the case of an isolated network, the Authors suggested that the resulting coupling can bring positive or negative impact on the vaccination coverage during a vaccine scare, i.e. accelerating or decelerating the elimination of disease, which can get support from the empirical examples. Due to the variety of factors on the social layer, the epidemic trajectories and the uptake of control measures can also change to a large extent. Moreover, inspired by these findings, the Authors suggested that the coupled disease-behavior model, which gets empirical validation, can be used as a predictive tool to explore the optimal strategies for public health.
5.2.5 Opinion formation dynamics
Understanding the emergence of a macroscopically ordered state is one of the based questions in natural and social sciences. To elucidate this issue, dozens of experimental and theoretical frameworks have been proposed from viewpoints of statistical physics, economics and sociology [227, 286, 287, 288, 289]. Opinion formation dynamics, as one simple and paradigmatic dynamical process, has attracted particular attention. Up to now, various spin-like setups have been put forward to study the evolution of opinion dynamics, which include the Sznajd model [290], majority rule model [291, 292], bounded confidence model [288, 293], and voter model [294, 295], to name but a few. Among the existing scenarios, the voter model is attracting the most remarkable attention [286, 296], and therefore it is also the main candidate in this subsection.
The basic definition of the voter model is rather simple: each agent (voter) is endowed with a binary variable . At each time step, an agent is chosen along with one of its neighbors and , i.e., the agent adopts the opinion of the neighbor. In this sense, the transition rate of individual opinion is proportional to the fraction of neighboring nodes in the opposite state. The dynamical process is repeated until the states with all sites equal (consensus) are absorbing. In spite of being extremely simple, the voter model produces rich dynamical behaviors [297, 295], especially from the angles of spatial interaction. In one-dimensional lattices, the dynamics is exactly the same as the zero-temperature Glauber dynamics [298]. Turning to two-dimensional lattices, the growth of domains can makes the interfaces quite rough, at odds with usual coarsening systems [299]. Moreover, a series of extended versions, such as the vacillating voter model [300], nonlinear voter model [301], heterogeneous voter model [302], and constrained voter model [303] have also been suggested. In the following we will present more details on the voter model.
Voter model on single-layer networks
As it is well-known, the property of spatial topology usually has a nontrivial influence on the dynamical models. In this sense, the ordering dynamics of voter model should not be exceptional. If employing one complete graph, the mean consensus time can be easily obtained by using the Fokker-Planck equation [304]. The consideration of a heterogeneous connectivity can make the mean consensus time to become closely related with the structural network details. On SF networks with exponent , direct voter model makes to scale as the size of the network for and sublinearly for [296, 305, 306]. Non trivial relationships between and are also found in other versions of the voter model as in Ref. [307]. For small-world networks, the plateau formed by active interfaces hinders the diffusion of opinions, so that the consensus eventually relies on the linear system size [308, 309]. Along this research line, Zschaler et al. recently examined the effect of directed networks on the order-disorder transition [310]. The impact of other spatial mechanisms, such as social influence and heterogeneous beliefs, are also of particular evidence [311, 312].
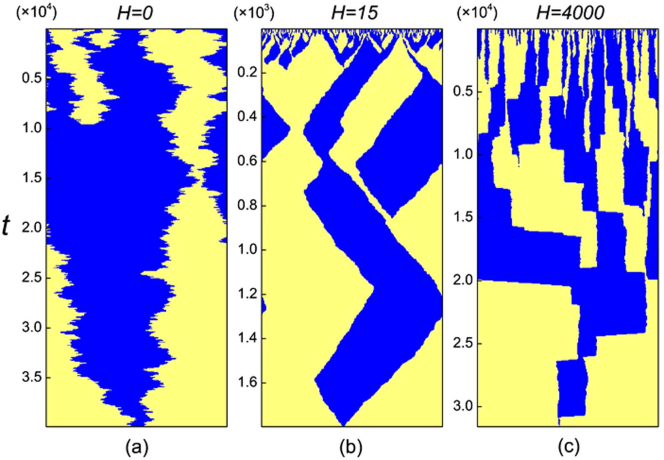
At variance with the aforementioned processes on static networks or in a Markovian memoryless fashion, coevolution voter model has also been duly studied. We first focus on non-Markovian patterns. In recent researches [314, 315], Stark et al. explored the effect of a memory-dependent transition rate, which is determined by the persistence time of individual current opinion. The longer a voter keeps its opinion, the less probable is that it switches the status in the long run. The Authors found that the process towards reaching a macroscopic consensus was accelerated by slowing down the microscopic dynamics. Looking at another recent report [313], where individual ability of opinion switching is weakened during a freezing period , the Authors revealed that an intermediate freezing period can lead to the fastest consensus, i.e. to the smallest . The essence of this accelerated consensus is attributed to the biased random walk of the interface between adjacent opinion clusters (as shown in Fig. 40). Moreover, it is worth checking how the dynamical topology affects the diffusion of opinions. Under such a framework, an agent can adjust its connections with a probability (otherwise it updates its opinion). The state of the system on coevolving networks can be characterized by the interface density quantifying the fraction of edges linking nodes with different states (active links). When the system is in the active phase, while for it keeps the frozen phase. Based on the mean-field approximation approach, Ref. [316] revealed that the competition between opinion imitation and the rewiring links drives a fragmentation transition from the active to the frozen phase.
To mimic some social phenomena and check voting phenomenology, many modifications have also been suggested based on the original voter model. The most renowned extension is the presence of the “zealot”, who never changes its opinion [317]. For low-dimension networks, this type of agent can influence the selection of all the agents, and lead to the general consensus in the form of its own opinion. However, once higher-dimension networks are considered it becomes rather difficult to inspire the consensus in the whole system, but the “zealot” just induces a partial bias in the local neighborhood [318, 302, 319]. In addition, the voter model has also been applied to biological and ecological problems, where people try to protect the diversity of species and fixation in the evolution of competing species [320, 321].
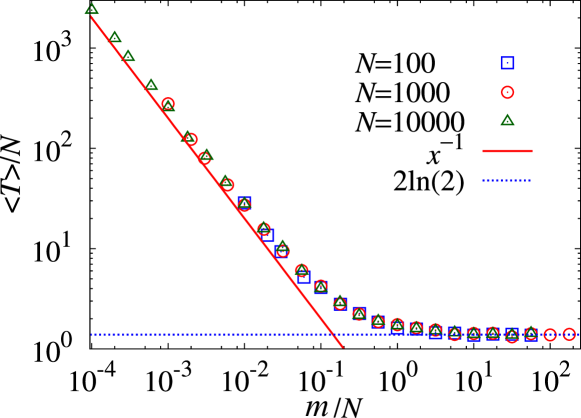
Voter model on multilayer networks
With the fast development of network science, the research of opinion dynamics has also been extended to multilayer networks. One potential approach is to create interlayer links, through which opinions can be exchanged between different networks. In a recent research [322], the Author considered the case of a two-clique graph, which is composed of 2 cliques interconnected by interlayer links. If the size of both cliques is , each node has interlayer links on average. These links are either regularly placed, or distributed at full random. At each time step, one link is randomly selected with equal probability , and then the opinion imitation takes place between two endpoints of this link. In this sense, the impact of the number of interlayer links per node becomes of particular interest. Through strictly mathematical analysis and computational simulations, the Authors unveiled the scaling relationship between the time to consensus and the number of interlayer links per node. If there exist many interlayer links per node, the mean consensus time is , i.e. the system reaches the fast consensus regime, which agrees with the expectation of a complete graph [307]. However, once the number of interlayer links per node is much smaller than unity, the mean consensus time is , i.e. the system attains the slow consensus regime. The crossover between these two regimes takes places at approximately one interlayer link per node, as shown in Fig. 41. Thus, these results suggest that the sparse interlayer connections between two networks extremely decelerate the ordering state for the voter model dynamics.
In Ref. [323], a coevolution voter model is incorporated into a multilayer framework, where a fraction of nodes has the interlayer links across two networks. On each layer (), individual opinion and intralayer link are allowed to evolve in accordance with their own topological temporal scales. Node selects one random neighbor in the same layer. If both have different opinions, node copies the state of with probability , otherwise (with probability ) it severs the connection with and draws a new link to one randomly chosen node in the same layer possessing a state identical to itself. The case preserves the symmetric multilayer setup, namely, the time scales are the same in both layers. At variance, for , an asymmetric multilayer case takes place, namely, different topological time scales characterize the two layers. In the symmetric case, the Authors found that interlayer connectivity plays a critical role in determining the state transition of systems. Once again, the absorbing fragmentation transition appears at a certain threshold value of . Moving to the asymmetric case, the Authors unveiled an anomalous shattered fragmentation transition, where the layer dynamics splits into many isolated components possessing different opinions, namely an explosive growth of the number of disconnected components. Moreover, Ref. [323] also identified the critical degree of interlayer connectivity to stop the fragmentation of one layer by coupling it to another layer that has no fragments.
Finally, it is interesting to consider the application of opinion dynamics in the multiplex perspective. In a recent research [324] a simple model of opinion formation dynamics is proposed to describe the parties competing for votes within a political election. At variance with previous setups of voter model [286, 296], each opinion or party is modeled here as one social network where the contagion dynamics takes place. Every agent, at the election day, can choose either to be active in only one of the two networks (vote for one party) or to be inactive, namely, not to vote on both networks. Based on the simulated annealing algorithm, the Authors showed a rich phase diagram. In a wide region of the phase diagram, the competition between the two parties allows for the emergence of pluralism, namely two antagonistic parties gather a finite share of the total votes. The densely connected network usually wins the election campaign, regardless of the initial distribution. Nevertheless, small perturbations could break the existing equilibrium, and a small minority of committed agents can alter the election outcome, which is consistent with recent claims [325].
5.3 Evolutionary games on multilayer networks
The study of evolutionary games on top of single-layer networks has attracted a lot of interest as a connector between statistical physics, evolutionary dynamics and social sciences [326, 327, 328]. This is a very appealing research topic since the dynamics implemented in the network arises from an evolutionary approach [329]. In addition, the study of evolutionary games on networks has been one of the most studied avenues to understand the emergence of cooperation in different contexts [330]. The emergence of such a collective phenomenon, cooperation, is a key issue that arises when studying seemingly diverse evolutionary puzzles, such as the origin of multicellular organisms [331], the altruistic behavior of humans and primates [332], or the way advanced animal societies, such as ant colonies, work [333, 334], among others.
Previous research on evolutionary games on networks has mainly focused on social dilemmas, in which agents can take one of two strategies: Cooperation (C) and Defection (D). Among these dilemmas, the Prisoner’s Dilemma game (PDG) represents the most addressed paradigm when studying the emergence of cooperation [335, 336]. This game is fully described by the following payoff matrix
| (225) |
showing that when two cooperators meet, each one obtains a “Reward” () whereas the interaction between two defectors causes a “Punishment” () to both. However, cooperation is hampered by the players’ “Temptation” to defect, since defecting against a cooperator yields more payoff than cooperating (), and by the risk arising from cooperating with a defector, as it yields the lowest payoff, usually called “Suckers”, () [337]. These payoffs satisfy the ranking . The social dilemma is thus established, since mutual cooperation yields both an individual and total benefit higher than that of mutual defection.
The pairwise nature of the game is translated to a population scale by making the agents interacting (playing) with each other, and accumulating the payoff obtained from each interaction. After each round of the game, the strategies of the agents are updated so that those agents with less payoff are tempted to copy (replicate) the strategy of those fittest individuals. In unstructured populations, in which players are well-mixed, evolutionary dynamics leads all the individuals to defection [338, 339]. However, the existence of a network of interactions, so that each agent can only play with those directly connected to it, the population can sometimes promote the emergence of cooperation. This mechanism promoting cooperation was coined as network reciprocity [340], and it was observed to be substantially enhanced when the network substrate is SF [341, 342].
Very recently [328] the attention of the community has been extended to the -player () generalization of the PDG, also called Public Goods Game (PGG) [343]. Under this setting, each cooperator contributes a fixed investment to the public good whereas defectors do not contribute. The total contribution of the agents is then multiplied by an enhancement factor and finally the result is equally distributed between all members of the group. The payoff of cooperators and defectors in a group with a fraction of cooperators is, respectively
| (226) | ||||
| (227) |
Thus, defectors obtain the same benefit of cooperators at zero cost, i.e. they free-ride on the effort of cooperators. As in the PDG, the evolutionary outcome of the PGG differs if played on a well-mixed population, in which the dynamics ends up in a full defector population, or on a structured one. In particular, Brandt et al. [344, 345] showed that, when games are restricted to local interactions, cooperation is promoted so that full cooperation is observed for values of the enhancement factor . This result was later generalized to complex networks [346] and bipartite graphs [347, 348].
5.3.1 Pairwise interaction games
Games on interconnected networks
The study about emergence of cooperation in the PDG in networked populations has been also extended to the case of multilayer systems. One of the approaches is to consider that each layer is composed of a different set of agents, so that each of them plays both with those neighbors within the same network layer and with those placed in the other ones [349, 350]. In Ref. [349] the Authors considered the case of 2 interconnected networks in which each agent plays a different game depending on whether the neighbor belongs to its same network, or to the other one. In particular, they considered two possible payoff matrices, one for those interactions between nodes of the same network layer, , that takes the same form of Eq. (225), and the following one for interlayer interactions
| (228) |
Thus, if and are the adjacency matrices of the two networks and is the matrix containing the interlayer connections (so that the total adjacency matrix reads as in Eq. (209)), the payoff of a node belonging to network layer is
| (229) |
where is a two-components vector denoting the strategy of the node in layer at time : reads for Cooperation and for Defection.
Thus, nodes gain payoff according to a PDG when playing with neighbors in the same layer, whereas for interlayer connections the payoff remains the same except for those interactions between two defectors, as the Punishment becomes negative being the smallest possible payoff in this matrix, i.e. the payoff ranking evolves into . This latter change turns the PDG into a Snowdrift game (SDG). In this way, the exploitation that defectors make of cooperators, regardless of the layer where they are located, is hampered by the payoff loss when meeting a defector belonging to the other network layer. The results in Ref. [349] reveal that, both for well-mixed layers and networked ones, it is possible to find polarized states in which cooperation dominates in one of the layers whereas defection does in the other. Figure 42 shows the fraction of cooperators, , as a function of the Temptation . When there are no connections between network layers (), so that the two populations play a PDG, the diagram follows the usual trend in single-layer networks: cooperation resists for small values of and then suddenly decreases so that for . However, polarized states (here revealed by the plateau at ) appear as soon as the two layers are connected, i.e. even for a small number of interlayer links, thus showing the importance that the interconnection between layers has on the evolutionary outcome.
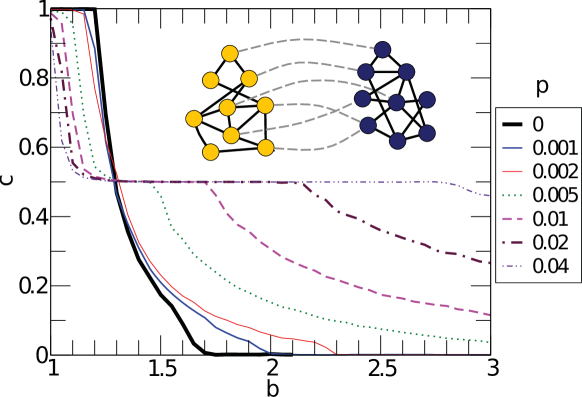
In Ref. [350] the Authors addressed a similar interconnected system of networks, but considering that both intra and interlayer interactions are governed also by the same Eq. (225), i.e. the payoff matrix of the PDG. In this case, the Authors focus on the emergence of cooperation as a function of the density of interlayer links and the topology of each layer at work. In general, for low density of interlayer connections, the overall cooperation of the system is enhanced. In this regime, it was found that those agents connecting the two network layers are more likely to cooperate than those sharing only intralayer links. Furthermore, although in general the interconnection of layers promotes cooperation in the whole system, when looking at the level of single layers, the effect of interconnection can produce a reduction of cooperation in one of the layers that is compensated by the increase in the other one.
Aside from involving payoff via playing games with nodes of other networks, another potential approach is to allow direct information transmission or exchange between layers. In a recent research [351], where PDG and SDG are respectively implemented on different layers, a biased imitation is proposed: a node with probability can mimic the strategy of intralayer neighbor in the same network, otherwise the internetwork neighbor is chosen as the strategy donor. Under such a framework, the Authors try to explore how the cooperation trait varies as a function of a biased probability . The biased probability unveils a multiple effect, which is robust against the change of population structures. A slight decline of the biased probability starting from promotes the cooperation behavior in the PDG layer. On the contrary, this decrease impairs the evolution of cooperation in the SDG subpopulation. Ref. [351] also verifies that qualitatively valid observations can be extended to a much broader parameter space in virtue of the mean-field method.
Games on multiplex networks
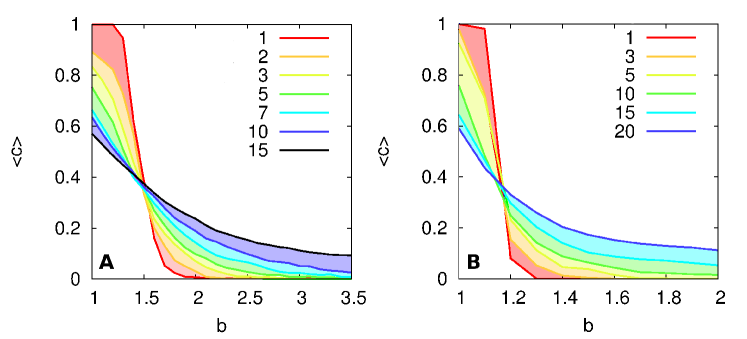
A second stream of works addressed the study of evolutionary dynamics in multilayer networks [352]. In this way, all the layers have the same number of nodes, say , since each node is the representation of a particular agent, and the only links between layers are those connecting the nodes representing the same agent. The assumption of a multiplex imposes dynamical correlations between the states (or strategies) of the replica nodes. In Ref. [352] this correlation is implemented by considering that an agent can, in principle, take different strategies in each of the layers. For instance, in the PDG an agent can be a defector in layers, while it cooperates in the remaining layers. The total payoff of a node in layer at time reads
| (230) |
where the payoff matrix is defined as in Eq. (225). In addition, the total payoff of agent is the sum of all the payoffs accumulated by the different representations across the layers
| (231) |
In Ref. [352] the update of the strategy used by an agent at layer depends on (instead of taking into account only the payoff accumulated at this layer ), thus coupling the evolution of the states of the nodes in a given layer with the dynamical states of the rest of the layers. Figure 43 shows that the correlation between layers influences the cooperation levels of the system in a way that, by increasing the number of layers, the resilience of cooperation is enhanced at the expense of decreasing the level of cooperation observed for small values of the temptation to defect.
Moreover, motivated by the fact that each agent is usually member of different networks in human societies, a completely distinct setup is suggested in Ref. [353]. The system is there composed of 2-layer SF networks. One network, named interaction layer, is used for the accumulation of payoffs, and the other serves as the updating network for strategies or states. The Authors show that, with all the possible combinations of degree mixing, breaking the symmetry through assortative mixing in one layer and/or disassortative mixing in the other as well as preserving the symmetry by means of assortative mixing in both layers, impedes the evolution of cooperation. The essence of this scenario for the cooperation inhibition can be attributed to the collapse of giant cooperation clusters, especially as compared to the case of single-layer SF networks [353].
Games on interdependent networks
The third realm of the evolutionary game in multilayer networks turns to that of interdependent networks. It is worth mentioning that this form possesses evident differences with the aforegoing situations. As compared to the case of interconnected networks, the direct interaction of game and strategy exchanged between network layers are strictly forbidden. On the other hand, the corresponding nodes connected via the internetwork links represent different agents, at variance with the multiplex scenario, thus both the accumulation of payoff and strategy updating are just limited to the same network layer. In this sense, the internetwork links are mainly used to create mutual influence between different networks. Since utility and strategy are prime elements in evolutionary game theory, creating interdependence through both factors becomes a natural choice. The framework of interdependent network games is then the following: agents of each layer do not engage in any game interaction beyond their own layer, but just refer utility or strategy information of other systems during the process of strategy updating with their intranetwork neighbors.
A recent research suggests the case of 2 interdependent networks, network and network , in which each node obtains the payoff by playing the games with its intralayer neighbors [354]. Then the interdependent correlation between networks (the node-to-point interdependence) is realized by defining an utility function as follows:
| (232) |
where , represent the payoffs of a given node in network and that of corresponding partner from network , and is the parameter accounting for the coupling strength between layers. The function is then used for the update of the strategy of agent at layer . Such an expression is a symmetric function, i.e. the payoff of the node in network also accounts for the same part () in its utility. It is worth noting that setting decouples both networks, and the model gets back to the traditional single-layer network case [326]. With the increment of the coupling correlation, the utility of one network depends more and more on the other system. In particular, for , the utility of one node becomes fully determined by the other network, and the updating strategy becomes the process of tossing a coin.

The Authors selected the PDG as the paradigmatic model to explore the effect of the coupling strength. They found that there exists a threshold value () in the system, such that, when the coupling strength is smaller than this threshold, the symmetry of cooperation level in both networks is maintained. However, as the value of exceeds , there is a spontaneous symmetry breaking of the fraction of cooperators between different networks. Figure 44 shows the typical cross sections of phase diagrams for different coupling degree . In the case of , where cooperation level is well promoted, one can observe the existence of three sections: pure cooperators section, mixed strategies section and pure defectors section. If is set as , a novel section emerges: the symmetry breaking section. Moreover, this observation is universally effective on different networks and can be qualitatively predicted by the strategy-couple pair approximation approach, in which an accurate prediction of the phase transition is difficult, due to the fact that long-range interactions are neglected among nodes in the network [326].
5.3.2 The public goods game
The first work on this game in multilayered networks [355] addressed a simple system composed of two regular lattices that are coupled in the usual coupling way (each node in a layer has a link with its corresponding partner in the other one). The PGG is played according to the usual rules, so that in each of the layers, an individual constitutes a group together with its nearest intralayer neighbors, thus taking part simultaneously in different PGGs. As described for PDG, the coupling between layers comes from an utility function that couples the payoff obtained by the agent in layer , , with that obtained by its partner in the other layer , . In this case, the coupling takes the form
| (233) |
Here the utility function, at variance with Ref. [354], is the same for the two layers, and it incorporates a new ingredient since there is one dominating layer depending on the value of (namely, a biased master-slave interdependence fashion): when () layer () is dominated by layer (). As usual, the utility function is used for updating the strategies of the nodes in each layer. The most interesting result obtained in Ref. [355] is that, when one layer almost dominates the other, cooperation is extraordinarily favored in the slave layer. For and , the corresponding master layer behaves almost equally to an isolated square lattice showing more weakness to defection than the slave one, in which the relation between the strategy and the utility function is almost random. These results are explained in terms of time-scale separation for the spread of strategies that favors the development of cooperator clusters in the slave layer.
Many other kinds of interlayer couplings can be introduced in the utility function. In Ref. [356], using a two-layer topology composed of two identical 2-dimensional lattices, the Authors followed a similar approach to that used in Ref. [354] for the PDG, since each one of the layers has its own utility function, which in its turn depends on what is the state of the other layer. In this case, the utility function for the agent in layer is defined as
| (234) |
where the terms multiplied by and account for the average payoff of the neighbors of in the same layer and that of those neighbors of the corresponding partner in the other layer , respectively. The effect of the coupling parameters and is the promotion of cooperation although this effect is more pronounced for than for the interlayer coupling (see the left panel of Fig. 45). This observation was given the name of interdependent network reciprocity. The essence of this mechanism requires the simultaneous formation of correlated cooperator clusters on both networks, which can get further support from the synchronized evolution of strategy pairs between networks, as shown in the right panel of Fig. 45. If synchronization does not emerge or if the coordination process is disturbed, interdependent network reciprocity fails, resulting in the total collapse of cooperation. Moreover, this promoting effect is proven to take place also in systems involving more than 2 layers, as long as the coordination between the networks is not disturbed.
Another way to model the interlayer coupling via the utility function is the probabilistic interconnection introduced in Ref. [357], in which two lattices are coupled in an interconnected way. However, two nodes of both layers are effectively coupled with probability , so that not all the possible pairs of interlayer links are active. When an interlayer link is active, the utility function of player in layer is influenced, so that apart from the PGG in which it is enrolled within the corresponding layer , it also participates in that centered on its partner in the other layer . In this way, the Authors showed that there is an optimal interlayer connection probability that maximizes the cooperation level.
The information of strategy also plays a crucial role in affecting the trait of other systems. In Ref. [358], the Authors proposed an alternative coupling between two lattices. The coupling is done via the update rule by which the agents decide their strategies (to cooperate or to defect) for the next round of the game instead that via the utility function. The probability that agent in layer adopts the strategy of a neighboring node in the same layer depends here on the difference between their payoff functions and on the fact that the corresponding partner of in layer has the same or a different strategy. If the strategies of both the node and its partner are the same, the probability of changing is decreased with respect to the usual one when the network layers are isolated. This coupling is seen not only to enhance cooperation in both PDG and PGG, but also to sustain the spontaneous emergence of correlated behaviors between the two networks. If the range of information sharing is extended to groups, this promotion effect is even more evident.
5.3.3 Partial overlap and spatial coevolution
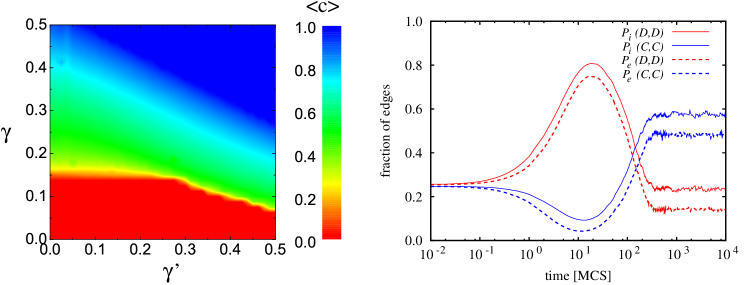
While the effect of interlayer nodes has been extensively identified, the question of what would be the best overlapping level for the resolution of social dilemmas remains unclear. To answer this issue, one scenario of partial overlapping is suggested in Ref. [359], where two networks possessing the same number of nodes compose the interdependent system. Before any interaction, a fraction of the nodes of one layer, nodes, which are chosen uniformly at random, are linked to their corresponding partners in the other one, and the residual nodes have no internetwork partners. Due to the existence of interdependence, the utilities of these overlapping nodes are not simply payoffs obtained from the interactions with the intralayer neighbors in the same network, but they rather involve the performance of their partners in the other network. Here the correlation between the payoffs obtained by a given node and its partner is done by defining the following utility function:
| (235) |
with determining the strength of coupling between layers. In particular, if the node has no external links, its utility simply equals to its own payoff (). The utility function is then used for the update of the strategy of agent at layer . As in the setup of Ref. [354], the utility function has here a symmetric form.
Under such a scenario, cooperation is studied as a function of and . The Authors found that an intermediate density of sufficiently strong coupling between networks (more accurately, and ) warrants an optimal regime for cooperation to survive. This observation is robust to the variations of the strategy updating dynamics, the interaction topology, and the governing social dilemma, thus suggesting a high degree of universality. Similarly to Ref. [350] it is observed that, within a layer, cooperation tends to fixate preferentially in those nodes that are connected with their counterpart in the other layer.
Furthermore, it is instructive to examine how the cooperative behavior survives on the coevolution framework, in which the heterogeneity is usually ubiquitous [360, 361]. In a recent research [362], where no interlayer links exist between two independent structured populations, a utility threshold is designed to manage the emergence of temporary interlayer links. If the current utility of node exceeds this threshold, it is rewarded by one interlayer link to the corresponding partner belonging to the other network in the next time step; otherwise the external link is not formed. As for the evaluation of utility, Eq. (235) is retained. It is easy to estimate that, as long as the utility of all nodes drops below the threshold, the external link is terminated, which returns to decoupled single-layer networks. The Authors showed that an intermediate threshold gives rise to distinguished players that act as strong catalysts of cooperative behavior in both PDG and PGG. However, there also exist critical utility thresholds beyond which distinguished players are no longer able to percolate. The interdependence between the two populations then vanishes, and the survival of cooperation becomes a hard task. Finally, this demonstration of the spontaneous emergence of optimal interdependence by means of a simple coevolutionary rule based on the self-organization of reward and fitness is proven to be universally effective on different interaction networks.
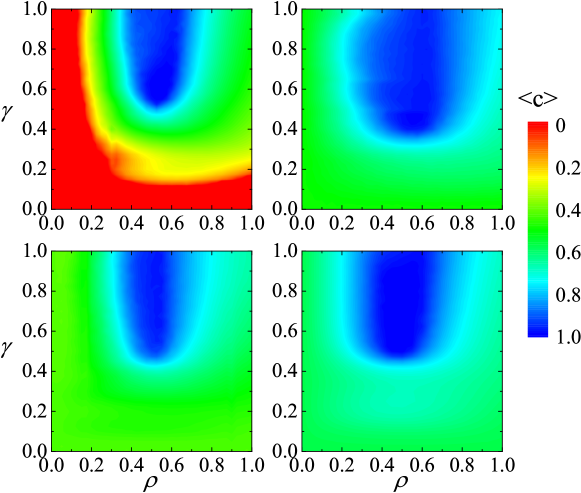
At variance with the scenario of utility threshold, another setup referring to coevolution between strategy and network structures considers the strategy transmission ability [364]. Initially, each node of two independent networks has a low and identical transmission ability . If node succeeds in passing its strategy to one of its intranetwork neighbors, its ability enhances by , ; otherwise becomes . A threshold is selected as the criterion of creating an external link: only when the transmission ability satisfies , player is allowed to have an interlayer link to its corresponding partner in the other network. If drops below the threshold , the external link is terminated. The making and breaking of the interlayer links between the two networks thus serves as individual rewarding and punishment, that reflect the evolutionary success within a network. Here, the utility of a node with (without) interlayer link is in accordance with Ref. [359], yet using the fixed strength of coupling. In this sense, the question becomes what are the optimal conditions for resolving social dilemma.
The Authors showed that, due to coevolutionary rule, the interdependence between networks self-organizes so as to yield optimal conditions for the evolution of cooperation even under extremely adverse conditions. In this case, approximately half of the nodes form an interlayer link, while the other half is denied the participation in the activities beyond their host network. Moreover, due to the spontaneous emergence of a two-class society, with only the upper class being allowed to control and take advantage of the external information, Authors verified that cooperative nodes having the interlayer links are much more competent than defectors in sustaining compact clusters of followers. Such an asymmetric exploitation confers them a strong evolutionary advantage that may resolve even the toughest of social dilemmas.
6 Synchronization
Networked systems, i.e. ensembles of distributed dynamical systems that interact over complex wirings of connections, are prominent candidates to study the emergence of collective organization in many areas of science [2, 9].
In particular, a special interest has been devoted to the analysis of synchronized states (from the Greek ςυγχρονος, meaning “sharing the same time”), as such states play a crucial role in many natural phenomena, like as the emergence of coherent global behaviors in both normal and abnormal brain functions [365], or the food web dynamics in ecological systems [366].
In the past years, the emergence of synchronized states [367] has been extensively reported and studied for the case of mono-layer networks, with the emphasis focusing on how the complexity of the layer topology influences the propensity of the coupled units to synchronize [368, 369, 370, 371]. While the literature on this subject is indeed extremely large, we point the reader to a few monographic reviews and books [9, 11, 372, 373, 374], whose consultation may provide guidance and help in understanding the major accomplishments, results and related concepts.
As soon as the multilayer nature of connections is brought into the game, the subject must be divided into two different scenarios, which have to be individually treated.
In the first case, the different layers correspond to different connectivity configurations that alternate to define a time-dependent structure of coupling amongst a given set of dynamical units. In this scenario, the basic problem is to describe and assess how the existence and stability conditions for the state in which the network’s dynamical units are synchronous are modified with respect to the classic (monolayer) situation, in which the coupling between the networked units is time-independent.
The second case, instead, is the scenario where the different layers are simultaneously responsible for the coupling of the network’s units, with explicit additional layer-layer interactions to be taken into account. It is worth stressing that here an interlayer synchronized state is a different and much more general concept, as it does not necessarily require intralayer synchronization. In other words, the dynamical units within each layer can be out of synchrony, but synchronized with the corresponding units in all other layers.
As a consequence, this section is divided into two main parts, each reporting on one of the two described scenarios, and is intended to summarize for each case the extension of the main analytical treatments and approaches that are traditionally used to deal with synchronization of monolayer networked systems.
6.1 Synchronization in multilayer networks with alternating layers
We start with the case in which the network under consideration is composed of a number of identical dynamical systems, which interact via a time-dependent structure of connections, each of which corresponding, at a given time, to one of the different layers.
Very recent investigations on synchronization of time-varying networks include the treatment of complete synchronization in temporal Boolean networks [375], the analysis of stability of synchronized states in switching networks in the presence of time delays [376], and the investigation of the effects of temporal networking interactions when compared with the corresponding aggregate dynamics where all interactions are present permanently [377].
We focus here on the situation of an ensemble of identical units where the wiring of connections is switching between the different layers following a periodic or aperiodic sequence. It is important to remark that detailed studies of the latter case actually started much before the relatively recent introduction of the concept of multilayer networks. In particular, a widely studied case is the limit of the so-called blinking networks [378, 379], where the switching between different configurations happens rapidly, i.e. with a characteristic time scale much shorter than that of the networked system’s dynamics. Under these conditions, it was found that synchronous motion can be established for sufficiently rapid switching times even in the case where each visited wiring configuration (each network layer) would prevent synchronization under static conditions.
Yet, the limit of blinking networks is not a suitable framework for an adequate description of several natural phenomena. For instance, modeling processes such as mutations in biological systems [380], or adaptations in social systems or financial market dynamics [381] would demand the very opposite limit of time-varying networks whose structure evolution takes place over characteristic time scales that are commensurate with, or even secular with respect to, those of the nodes’ dynamics.
Thus, in the following, we will concentrate on the case in which synchronized states appear in dynamical networks, without making any explicit a priori assumption on the time scale of the variation of the coupling wiring.
6.1.1 The Master Stability Function for time dependent networks
The starting point is the generic equation describing the evolution of an ensemble of identical systems, networking via a time dependent structure of connections:
| (236) |
Here, dots denote temporal derivative, is the -dimensional vector describing the state of the network unit, and and are two vectorial functions describing the local dynamics of the nodes and the output from a node to another, respectively.
Furthermore, are the time varying elements of an symmetric matrix specifying the evolution, in strength and topology, of the network connections. The matrix satisfies the defining properties of a Lagrangian matrix: it has zero row-sums ( and ), strictly positive diagonal terms ( and ) and strictly non-positive off-diagonal terms ( and ).
Our goal is to assess the stability of the synchronized solution , whose existence is indeed warranted by the zero row-sum property of .
To this purpose, we first notice that is symmetric, and therefore it is always diagonalizable and, at all times, admits a set of real eigenvalues and a set of associated orthonormal eigenvectors, such that and .
The zero row-sum condition and the Gershgorin’s circle theorem [382] further ensure that:
-
1.
the spectrum of eigenvalues is such that and ;
-
2.
the smallest eigenvalue , with associated eigenvector , entirely defines the synchronization manifold ();
-
3.
all the other eigenvalues () have associated eigenvectors that form a basis of the space transverse to the manifold of in the -dimensional phase space of Eq. (236).
Notice that all the eigenvalues except the first are strictly positive for connected graphs ( for ).
Consider then , i.e. the deviation of the vector state from the synchronized state, and construct the column vectors and . It is straightforward to show that the linearization of Eq. (236) around the synchronized solution leads, in linear order of , to
| (237) |
where denotes the direct product, and is the Jacobian operator.
The arbitrary state , at each time, can be written as a sum of direct products of the eigenvectors of and a time-dependent set of row-vectors , i.e.
with . Therefore, applying to the left side of each term in Eq. (237), one finally obtains
| (238) |
where and .
The key point here is noticing that the boxed term in Eqs. (238) is what differentiates them from the classical equations used to calculate the Master Stability Function (MSF) [370], as it explicitly accounts for the time variation of the eigenvector basis. In the following, we will first discuss the case where such an extra term vanishes, and later the general case of constructing a quasi-static evolution among different network layers, deriving a proper analytical expression for it.
6.1.2 Commutative layers
Eqs. (238) transform into a set of variational equations of the form
| (239) |
if , i.e. if all eigenvectors are constant in time.
This condition can be satisfied in two different ways, namely either the coupling matrix is constant, as in the case of a monolayer network originally considered in Ref. [370], or the temporal evolution occurs through commutative layers. The latter case means that starting from an initial wiring , the coupling matrix must commute with at all times (). This was explicitly discussed in Ref. [383], where it was shown that:
-
1.
an evolution along commutative graphs (i.e., different commutative layers of a multilayer network) can be constructed by starting from any initial wiring , and
-
2.
such an evolution provides a much better condition for the stability of the synchronous state than that given by a monolayer network.
To show this, the first step is constructing explicitly the set of commutative layers through which the evolution takes place. To this purpose, one can notice that any initial symmetric coupling matrix can be written as , where is an orthogonal matrix whose columns are the eigenvectors of , and is the diagonal matrix formed by the eigenvalues of .
At any other time , a zero row-sum symmetric commuting matrix , defining the layer visited by the structure evolution at that time, can be constructed as
| (240) |
where with . It is easy to show that is positive semidefinite, and since the canonical basis vectors are not collinear with the eigenvector we have . Thus, Eq. (240) provides a way to generate all possible layers that commute with , are positive semidefinite with zero row-sum, and dissipatively couple each network unit. Henceforth, we refer to this set of matrices as the dissipative commuting set (DCS) of . It is important to notice that while not all members of the DCS are true Lagrangian matrices (it is in fact possible for their off-diagonal components to be positive), nevertheless all commuting Lagrangian matrices are contained in the DCS.
In Ref. [383], the Authors proposed a general method to select a set of commutative matrices within the DCS. The method is based on starting from a given layer graph , and producing a large set of different realizations of the same graph. This allows the estimation of the initial distribution of the non-vanishing eigenvalues of the set. Then, one can directly construct to use in Eq. (240) by randomly drawing a set of eigenvalues either according to , or uniformly between and . The former approach can be implemented either by using the spectrum of a different realization of (the so-called eigenvalue surrogate method [383]), or by extracting directly the eigenvalues from the distribution . The latter method, instead, simply corresponds to the random selection of the eigenvalues from a uniform distribution. In either case, the random extractions can be performed in an ordered () or unordered way, and one only needs to extract eigenvalues, since must be always 0.
In addition, Ref. [383] also discusses how the different choices for the construction of commutative layers lead to modifications of the main topological structures. In general, the resulting matrix is a dense matrix that can be associated to a undirected weighted network, whose weight matrix has elements , and for . The main properties that were studied in Ref. [383] are the average value of the strength distribution, the average local clustering coefficient, and the average shortest path length, defined as follows [2, 9, 384, 91].
For weighted networks, the distance between two adjacent nodes and is , and the distance along a path can be expressed as . Then, the distance between two non-adjacent nodes and is the length of one of the shortest paths connecting them:
With these definitions, a network’s average shortest path length is [2, 9, 384, 91]
Similarly, the clustering coefficient of node can be defined as
where is the strength of node . The average local clustering coefficient is then given by , while the strength distribution characterizes the heterogeneity of the network [384, 91].
| Initial condition (scale-free) | |||
| Eigenvalue surrogate method | |||
| Choosing from (ordered) | |||
| Choosing from (unordered) | |||
| Uniform distribution (ordered) | |||
| Uniform distribution (unordered) |
Table 5 summarizes the behavior of these quantities for the different eigenvalue selection strategies described above. The initial layer is the Laplacian matrix of a scale-free (SF) network grown using the preferential attachment algorithm [385], and whose strength distribution follows a power-law . Figure 47 illustrates the strength distributions of the network layers constructed with different methods. It is evident that the eigenvalue surrogate method, as well as the ordered selection of eigenvalues from the initial distribution , do not change the SF character of the strength distribution (thick red and dashed blue lines in panel a). At the same time, they yield values for , and that deviate only slightly from those of the original graph (see Table 5). This indicates that both methods are convenient strategies to construct a commuting set of layers through which the evolution of the graph substantially preserves all the main topological features of the initial condition. Conversely, choosing the eigenvalues from a uniform distribution, either in an ordered or in a unordered way, produces layers that completely destroy the original SF strength distribution (thick red solid line and dashed blue line in panel b). These correspond to structural configurations for which each measured quantity wildly differs from its value in . Finally, the intermediate solution of choosing the eigenvalue spectrum from the initial in a unordered way, while still preserving the power-law tail of the strength distribution (solid black line in panel b), still changes substantially the topological structure of the underlying network.
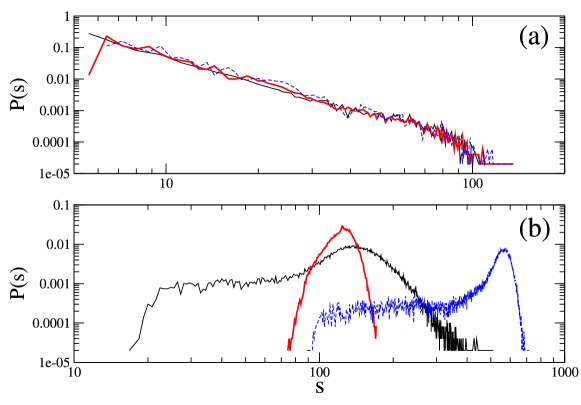
6.1.3 Enhancing synchronization via evolution through commutative layers
Besides the analysis of changes in the structural properties of the layers belonging to the DCS and generated via different methods, one also needs to study the consequences of the evolution through commutative layers on the stability of the synchronization solution.
Replacing by in the kernel , the problem of stability of the synchronization manifold becomes equivalent to studying the -dimensional parametric variational equation
where . This allows to plot the curve vs. , where is the largest of the associated conditional Lyapunov exponents. This curve is classically called the Master Stability Function [370].
For , the synchronized state is transversely stable if all (), multiplied by the same coupling strength , fall in the range where . When evolves inside the DCS, the eigenvectors are fixed in time, and one can make the hypothesis that at time , the modulus of each eigenmode () is bounded by the corresponding maximum conditional Lyapunov exponent
It immediately follows that the transverse stability condition for the synchronization manifold is now that
| (241) |
It is extremely important to notice that condition (241) does not require to be negative at all times.
In fact, one can construct a commutative evolution such that at each time there exists at least one eigenvalue for which , and yet obtain a transversely stable synchronization manifold.
The very relevant conclusion is that a multilayer network where different layers are visited at different times may produce a stable synchronized motion even when the emergence of a synchronous behavior of the units would be prevented by using any of the layers as a constant wiring configuration. Similar conclusions were independently reached in Ref. [386] for fast switching times between commutative layers.
A simple example is a periodic evolution between network layers, with period , during which is given by
| (242) |
where denotes the characteristic function of the interval . Here, the matrices defining the layers are constructed, as before, as . Given , the set of the other matrices is constructed by subsequently shifting the sequence of the eigenvalues of , i.e. , , etc.
If, for instance, , then all the layers will have a direction in the phase space along which the synchronization manifold is transversely unstable. However, if , then condition (241) will be satisfied in all directions transverse to the synchronization manifold, and therefore the synchronized solution will be transversely stable.
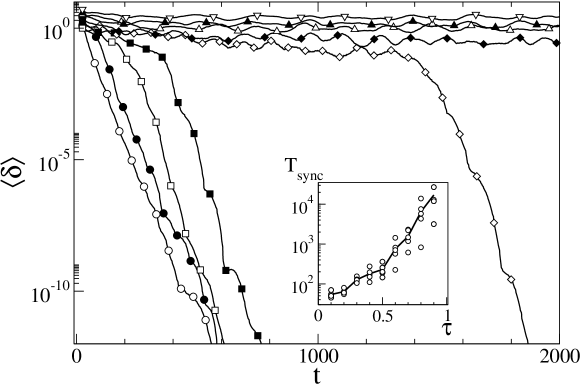
As an example of such an extreme situation, Fig. 48 shows the results of an evolution of a network where the initial layer is a SF graph of Rössler chaotic oscillators, each obeying Eq. (236) with
The evolution of the wiring follows Eq. (242). For one finds that , but is positive for the first 80 eigenvalues, i.e., the synchronization manifold would be unstable in at least 80 different transverse directions in each of the layers, if taken as fixed. However, defining the synchronization error as
and the synchronization transient as the time needed for to become smaller than , we see from the data of Fig. 48 that the multilayer network is always able to synchronize, with a that scales almost exponentially with .
It is important to remark that, while this numerical example is used here just to illustrate the enhancement of synchronization in multilayer commuting graphs under extreme conditions, the validity of condition (241) is general, and by no means limited to periodic evolutions of the connectivity matrices.
A further point that should be stressed is that the multilayer commuting case is substantially different from the fast switching procedure described in Ref. [378]. Indeed, the stability condition does not impose in principle any limitation on the switching time , making it possible to enhance the collective functioning of the network even for wirings evolving over secular (yet finite) time scales.
6.1.4 Non-commutative layers
So far, we considered the case of an evolution through commutative layers, clearly demonstrating the importance of explicitly accounting for a multilayer nature of interactions in networked dynamical systems, and the fact that such multilayer structure can greatly enhance the stability of the synchronization solution. Yet, it is evident that considering commutative layers is too strong an assumption to adequately represent the general case encountered in real world multilayer graphs.
When explicitly dealing with non commutative layers, the boxed term in Eqs. (238) no longer vanishes. Thus, Eqs. (238) do not reduce anymore to a set of variational equations, and one must examine in detail the effects of this extra term on the coupling of the different directions of stability for the synchronous solution. To do so, there are some issues that need to be properly dealt with.
The first is that the boxed term in Eqs. (238) is explicitly proportional to the time derivatives of the eigenvectors of the network Laplacian, and therefore any evolution involving instantaneous jumps from a layer to another of a multilayer structure would result in a divergence. As a consequence, one must consider a quasi-static evolution that depends on two different time scales: first, the network structure is kept constant from time to , period over which it is described by one given layer of the network; then, from to , a smooth switching process takes place, bringing the network from one layer to another.
Second, the switching process should be carefully constructed. Indeed, one needs to find a smooth evolution that, starting from a generic layer whose Laplacian is , leads to another generic layer whose Laplacian is , through a set of intermediate configurations that all maintain the basic conditions for the existence of the synchronized solution. In practice, this means that the switching process should occur through a path of connecting matrices, each displaying the zero-row sum condition, each being diagonalizable, and each sharing the same eigenvector corresponding to the null eigenvalue.
To achieve this, we first consider the matrices and , consisting of the eigenvectors of and , respectively, and describe how to transform one into the other by means of a proper rotation, and in particular a proper rotation around a fixed axis. Then, we use this framework to find a transformation between and .
Eigenvector matrices
Let and be two orthogonal matrices. In our case, we know that the vectors of and correspond to the eigenvectors of two network Laplacians. We also know that at least one vector is common between and . This vector corresponds to the null eigenvalue of the Laplacian, and thus to the synchronization manifold.
We want to find a one-parameter transformation group such that:
-
1.
;
-
2.
contains the vector for all ;
-
3.
.
Existence of a solution
To show that it is always possible to find a solution, first notice that, in general, the transformation from to is a rotation, because the vectors of both matrices form orthonormal bases of the same space. To find , one can simply solve the linear system of equations in variables . As we are free of choosing the set of coordinates, we put ourselves in the basis defined by the matrix . In this basis, , where is the identity.
Now, without loss of generality, assume that the conserved vector is the first vector of , . Then, the transformation matrix will have the form
| (243) |
Notice that, is a unitary matrix, and therefore the absolute value of is equal to 1. In general is an element of the orthogonal group , which means that it is a proper rotation, if its determinant is , or a composition of rotations and reflections, if its determinant is . However, as the form of in Eq. (243) indicates, its determinant equals the determinant of the minor obtained by removing from the first row and the first column. Then, we only need to find a solution to the problem in dimensions. We will henceforth use primes when referring to objects in dimensions.
From these considerations, we have and . But itself is trivially an orthogonal matrix, belonging to . Thus, our problem is equivalent to determining the possibility of finding a path between the identity and .
At this point, we have two cases.
Case 1: . If the determinant of is positive, then belongs to the special orthogonal group . In this case, describing a solution is straightforward. In fact, is the identity component of the orthogonal group. Moreover, as the orthogonal group is a Lie group, is not only connected, but also path-connected. This means that for every orthogonal matrix, there is a continuum of orthogonal matrices of the same dimension connecting it to the identity. Each point along this path corresponds to an orthogonal matrix that can be embedded in by adding a in the top left corner. Since every embedded matrix along the continuum will keep the vector corresponding to the synchronization manifold invariant, a parametrization of the path from the identity to will provide a direct solution to the original problem.
Case 2: . If the determinant of is negative, then belongs to . The same considerations as for Case 1 apply. However, while is also a connected topological space, the identity does not belong to it. This means that there is no path that can connect the identity to , and we cannot solve the problem the same way.
Yet, in our particular case, we do not really care about the labeling of the vectors. In other words, provided that we keep the vector constant, we can very well swap two vectors in the basis given by the matrix . This literally just means creating a new matrix by swapping two rows in . Of course, this imposes a swap of the corresponding columns in the transformation matrix as well. But we also know that swapping two rows (or columns) in a matrix changes the sign of its determinant. This means that the new matrix does not belong to , but rather to . Thus, it is path-connected to the identity, and all the procedure of Case 1 can be applied. The only consequence of the swap is that the implicit order of the eigenvalues will be changed. As this order is irrelevant for our purposes, the problem can always be solved. To illustrate this, consider the following simple example in .
Suppose we want to go from the basis on the left in Fig. 49 (the canonical basis of ) to the one in the middle. Then, the transformation matrix is
The determinant of is , so there is no continuous way to go from the identity to . However, suppose we relabel the and vectors in our original basis, obtaining the basis in the right panel of Fig. 49. Then, the transformation matrix will be
This time, its determinant is 1. Thus , or, equivalently, . This means we can find a path that connects the identity to . This path can be readily turned into a family of transformations:
Note that for every value of the parameter between 0 and 1, the determinant of equals 1. Also, for any value of , the vector remains always constant. However, the main point here is that while leaves unchanged and reflects across the origin, instead rotates the “new ” onto the position previously occupied by , and the “new ” onto the position opposite to that previously occupied by . In other words, the final arrangement of the original transformation is preserved, but this time the transformation is a proper rotation. As we are only interested in getting the final result right, and not in the order of the eigenvectors, we can disregard this difference.
6.1.5 Building a solution for a generic layer switching
Given a specific and , cast in the form discussed above, we build an explicit solution by factoring the transformation into rotations and reflections in mutually orthogonal subspaces. Before describing the actual procedure, we recall two useful results. Proving these results involves constructions we will use in the solution and provides further insight into our original problem. Thus, we present the proofs in the following.
Existence of invariant subspaces
First, any orthogonal operator in a normed space over induces an invariant subspace. This subspace is either 1-dimensional or 2-dimensional. To see this, given , define the operator that acts on as . As is a unitary operator, its spectrum lies on the unit circle. Then, one can find a non-vanishing eigenvector with eigenvalue . In general, , and . Then, we have two cases.
Case 1: is real. In this case, . Then, and . As , at least one between and cannot vanish. Without loss of generality, let the non vanishing component be . Then, all vectors proportional to are mapped by into vectors proportional to . Thus, the 1-dimensional subspace of the vectors proportional to is invariant under .
Case 2: is complex. In this case, and are linearly independent. We prove this by contradiction. First note that is an eigenvector of with eigenvalue , and that .
Now assume that it were . Then one could write
hence
from which it would follow that
| (244) |
Similarly, one could write
hence
from which it would follow that
| (245) |
Having proved that and are linearly independent, apply to :
hence
| (246) |
and
| (247) |
The two equations above imply that
where and . This means that any linear combination of and is mapped by into a linear combination of the same vectors and . As we have proved above that they are linearly independent, this implies that the 2-dimensional subspace determined by the basis is invariant under application of .
Orthogonality of the eigenvector components
We show now that the components and of the eigenvector used in Case 2 of the previous proof are not only linearly independent, but actually orthogonal. To see this, compute the inner product between and , exploiting the fact that the operator preserves the inner product, since it is orthogonal:
| (248) |
Then it is
hence
| (249) |
where we have used .
Similarly, applying the same property of , and using Eq. (246), the squared norm of is
Then, it is
and, using again ,
| (250) |
Now, we know by hypothesis that . Then, if it must be . Alternatively, if , then it is . In this case, from Eq. (248), it follows that
Either way, and are orthogonal.
The solution
Using the two results just shown, we can describe an algorithmic procedure to find the solution to our problem. The initial situation is that we have two orthonormal bases and of . Then, we can build a transformation of into with the following steps:
-
1.
Express the problem in the basis . In this basis, the transformation matrix between and takes the form given by Eq. (243).
-
2.
Consider the operator obtained from by removing the first row and the first column. Let be its dimension.
-
3.
Build the operator that acts on as , where and belong to .
-
4.
Find an eigenvector of , with eigenvalue .
-
5.
Normalize and .
-
6.
If
-
(a)
Pick the non-vanishing component between and . If both are non-zero, choose one of them randomly. Without loss of generality, assume this is .
-
(b)
Create other orthonormal vectors, all orthogonal to , and arrange all these vectors so that is the last of them. This set of vectors is an orthonormal basis of .
-
(c)
Change the basis of the -dimensional sub-problem to . In this basis, all the elements in the last row and in the last column of will be 0, except the last one, which will be .
-
(d)
If , consider a new operator obtained from the old by removing the last row and the last column. Let be its dimension, and restart from step 3. Otherwise stop.
-
(a)
-
7.
If
-
(a)
Create other orthonormal vectors, all orthogonal to and , and arrange all these vectors so that and are the first two of them. This set of vectors is an orthonormal basis of .
-
(b)
Change the basis of the -dimensional sub-problem to . In this basis, all the elements in the first two rows and in the first two columns of will be 0, except the first two.
-
(c)
If , consider a new operator obtained from the old by removing the first two rows and the first two columns. Let be its dimension, and restart from step 3. Otherwise stop.
-
(a)
The steps described above effectively solve the problem of finding the basis transformation by divide-and-conquer. At each repetition, 1 or 2 dimensions are eliminated from the problem. All the subsequent changes of bases do not affect the elements of the transformation matrix determined in the previous steps, because they act on subspaces that are orthogonal to those that have been already eliminated, which include the top left element in and , corresponding to the synchronization manifold. Thus, one can reconstruct the transformation matrix piece by piece. At the end of the procedure, has a block-diagonal form
where the blocks correspond to the action of the orthogonal operator on the invariant subspaces. If the invariant subspace is 1-dimensional, then its block is a single element. Conversely, if the subspace is 2-dimensional, then its block is either a rotation or a reflection. This means that it is either
or
At this point, one can proceed as follows. First, permute the basis vectors from the second onwards so that they correspond, in order, first to all the actual rotation blocks, then to the elements, and finally to the elements. It’s easy to see that this can always be done. In fact, if we call our change-of-basis matrix , we can determine the new form of the transformation matrix, , via the following logical chain:
where is the change-of-basis matrix corresponding to the composition of all changes of bases done in steps 6 or 7 above.
As the matrix that swaps the position of the basis vectors is a permutation matrix, it follows that has exactly the required form
| (251) |
Having obtained the form in Eq. (251), there is still the possibility that the determinant of is . However, as we saw, in this case we can approach the problem by relabeling two vectors of the original basis, which induces a swap of the corresponding columns of . To perform this, first note that, if , then the number of elements in must be odd. Then, there are three possible cases.
Case 1: has at least one element. In this case, permute once more the basis vectors, swapping those corresponding to the first and the first elements in . Then, the first block after the “–” blocks is . Now, relabel the two corresponding vectors, as in the example, swapping the relevant rows in the starting matrix. This makes the block in become
Case 2: has no elements and only one element. In this case, the basis vectors to swap are those corresponding to the first two vectors in the last block of . This will become
Now, change once more the basis of the problem. In particular, leave all the basis vectors unchanged, but map the last three into the eigenvectors of . This is easily accomplished, as the matrix of eigenvectors of is
Then, the new form of is
Case 3: has no elements and at least three elements. Similar to the previous case, swap the basis vectors corresponding to the first two after the “–” blocks. Their block is now
Next, do a change of basis as described in Case 2. The eigenvector matrix of is
so after the basis change the new form of is once more
Whether the determinant of was to start with, or it was and taken care of as one of the cases above, there are now either no elements in , or an even number of them. Then, if there are any, take every two subsequent elements and change their diagonal blocks into
This yields the final general form for the transformation matrix:
| (252) |
Finally, introducing a parameter , we get the required transformation:
| (253) |
Notice that when , , and when , . Also, for every value of , the determinant of is always 1, and the first vector is kept constant, which means that always describes a proper rotation around the axis defined by the eigenvector corresponding to the synchronization manifold. Moreover, note that the first vector has always been left untouched by all the possible basis transformations. Thus, as is varied continuously between 0 and 1, the application of sends into smoothly and continuously, as we need.
Laplacian transformation
To describe how to obtain a transformation between the two Laplacians and , let us first summarize what we have shown.
We started from the matrices and , consisting of the eigenvectors of and . These two matrices are orthonormal bases of . We showed that we can always find a series of basis changes casting the problem in a reference frame where we can explicitly construct a 1-parameter transformation group that transforms into with continuity via a rotation around an axis determined by the eigenvector corresponding to the synchronization manifold.
In formulae, the group is such that and , where is the change-of-basis matrix resulting from the composition of all basis changes done in steps 6 and 7 of the method, the permutation of the vectors to obtain , and the eventual final adjustment in case of negative determinant. To simplify the formalism, in the following we let and .
Then, since and are matrices of eigenvectors, it is
where and are diagonal matrices whose elements are the eigenvalues of and .
However, as is a group of orthogonal transformation, we can write that
where is a basis of . Multiplying the equation above by on the left, we get
| (254) |
where we have used the fact that .
Now, note that all the basis changes done to build are between orthonormal bases. Therefore, their composition is an isometry, as is any , since they are all proper rigid rotations. Thus, any still defines an orthonormal basis of .
Then, we can say that the Laplacian for the parameter is given by the matrix that solves the equation
| (255) |
where is a diagonal matrix whose elements are the eigenvalues of , and consists of the eigenvectors of . However, the equation above has two unknowns, namely and .
To solve this last problem we impose a linear evolution of the eigenvalues of the Laplacians. Thus, for all ,
| (256) |
where and are the eigenvalues of and , respectively. Then, multiplying Eq. (255) on the right by , it is
hence
Multiplying this on the left by , we get
hence
Substituting Eq. (254) into the equation above, we get
| (257) |
In Eq. (257), is known; and have been explicitly built, so they are known as well; is completely determined by Eq. (256). Thus, Eq. (257) defines the Laplacian for any given value of the parameter . The evolution of the eigenvalues follows a simple linear form, imposed by Eq. (256), and the evolution of the eigenvectors is given by Eq. (254).
As a consistency check, it is straightforward to treat the left-hand side of Eq. (257) as an unknown and solve it for either or , recovering and , respectively. Similarly, it is easy to see that for any the determinant of is the product of the eigenvalues defined by Eq. (256).
With this result, we can finally describe the evolution via non-commutative layers. We use the setting introduced in Sec. 6.1.4: at time , the network starts in a layer whose Laplacian is , in which it remains up to time ; then, it switches to a layer whose Laplacian is , completing the switch at time . What is needed is to compute the boxed term in Eqs. (238) for all times .
It is clear that, from to , the term vanishes. To compute its value during the switch, first note that the eigenvector at time is the column of , where . But then, using Eq. (254), it is straightforward to see that the element of the eigenvector is
Notice that in the equation above the only term that depends on time is , since is just a change-of-basis matrix, and is the matrix of eigenvectors of at time . Therefore, it is
This allows us to write a final expression for the extra term that accounts for the time variation of the eigenvectors. In a fully explicit form, this is
| (258) |
However, for all practical purposes, one does not need to use Eq. (258) directly. In fact, considering that most elements of are 0, it is quite simple to compute and store in a symbolic form. Similarly, most of the terms are 0. In fact, they vanish in all the following cases:
-
1.
or (the eigenvector corresponding to the synchronization manifold, and axis of rotation of the basis of eigenvectors);
-
2.
if the element is outside the tridiagonal, i.e. if ;
-
3.
if or , where is the number of “–” blocks in .
Also, for all other cases , is proportional to a sine or a cosine. Thus, we can define to be the matrix whose element is ; also, we can define . Again, can be easily computed and stored in a symbolic form. Then, Eq. (258) becomes
| (259) |
Once more, Eq. (259) can be computed symbolically, and evaluated at any particular time , when needed.
6.2 Synchronization in multilayer networks with coexisting layers
A completely different scenario is that of networking dynamical units with coexisting layers. In this case, indeed, the different layers determine as a whole the overall coupling structure through which the system components interact, and which in general cannot be simply represented in terms of a single time-independent coupling matrix.
The current state of the art on the matter includes only a few direct studies, pointing however to some important considerations and results. In the following, we first summarize the available literature following the categorization given in Section 2, in the hope to point out promising directions to those researchers who, in the near future, will try to approach such a challenging issue. After that, we concentrate on a specific case, involving a two-layer network in a master-slave configuration, in view of the relevance of this situation that extends the very concept of synchronization and provides practical tools to target the dynamics of complex networks toward any desired collective behavior (not necessarily synchronous).
6.2.1 Hypernetworks
In this framework, one considers a set of identical dynamical systems linked through the connections of different layers, that is, all the connections that correspond to the same type of coupling form a layer, and the systems are connected by more than one layer.
Refs. [387, 388] focused on the necessary and sufficient conditions for the stability of the synchronous solution in a hypernetwork. The main conclusion is that, in general, it is not possible to reduce the problem to a simpler monolayer formalism. However, for , such a reduction is indeed possible in three cases of interest: i) if the two associated Laplacians commute; ii) if one of the two layers is unweighted and fully connected; iii) if one of the two networks has an adjacency matrix of the form with . The major result is the definition of a class of networks such that if one of the two coupling layers satisfies condition iii), the reduction can be obtained independently of the structural form of the other network layer. The Authors of Refs. [387, 388] also discuss some generalization of their results to the case of hypernetworks consisting of more than two layers, and present an example of a network of neurons connected by both electrical gap-junctions and chemical synapses.
6.2.2 Interconnected/interdependent networks and networks of networks
Other studies dealt with the problem of seeking connection strategies between interconnected networks (different layers of an overall network) to achieve complete synchronization. In this framework, each of the interconnected layers is a network made of elements of similar or different nature.
Ref. [389] is a combination of experimental, numerical and analytical studies in the case of only two layers. The Authors find that connector nodes (those at the ends of interlayer links), play a crucial role for the setting of the synchronous behavior of the whole system. In particular, the main result is that connecting the hubs of both networks is the best strategy to achieve complete synchronization.
In Ref. [390] the same problem is investigated in the framework of identical layers. A phase transition in the network synchronizability is described when the number of interlinks increases. The exact location of the transition depends exclusively on the algebraic connectivity of the graph models, and it is always observed regardless of the interconnected graphs. Furthermore, by means of computer simulations and analytical methods, Ref. [391] investigates the effects of the degree distribution in determining mutual synchronization of neural networks made of two identical layers. The main claim of Ref. [391] is that a SF topology is more effective in inducing synchronization, or in preventing the system from being synchronized, provided that the interlayer links involve the nodes with larger degrees.
Refs. [392] and [393] studied synchronization in a complex clustered network (or network of clusters) when two clusters interact via random connections, showing that the interplay between interconnections and intraconnections plays a key role in the global synchronizability, as well as in determining different synchronization scenarios. For instance, Ref. [392] demonstrated that the network has the strongest synchronizability only when the number of inter and intraconnections matches perfectly, whereas any mismatch weakens or even destroys the synchronous state. However, Ref. [393] pointed out that in a modular network of phase oscillators there exists an optimal balance condition between the number and weight of inter and intralinks that maximizes at the same time the network’s segregation and integration processes.
Furthermore, in networks of interacting populations of phase oscillators, the onset of coherent collective behavior was studied in Ref. [394]. A typical biological application of the model is the description of interacting populations of fireflies, where each population inhabits a separate tree. The model includes heterogeneity at several levels. Each population consists of a collection of phase oscillators whose natural frequencies are drawn at random from a given distribution. To allow for heterogeneity at the population level, each population has its own frequency distribution. In addition, the system is heterogeneous at the coupling level, as the model explicitly considers the possibility to specify separately the coupling strengths between the members of different populations. The assumption of a global (yet population-weighted) coupling allows for an analytical determination of the critical condition for the onset of a coherent collective behavior.
6.2.3 Multiplex, multiplex with time delay and master-slave configurations
Ref. [395] reports on the synchronization properties of interconnected networks of oscillators with a time delay on the interactions between networks, and analyzes the synchronization scenario as a function of the coupling and communication lag. In particular, the Authors consider the competition between an instantaneous intranetwork and a delayed internetwork coupling. The major result is the discovery of a new breathing synchronization regime, with the emergence of two groups in each network synchronized at different frequencies. Each group has a counterpart in the opposite network, one group being in phase and the other in anti-phase with the counterpart. For strong coupling strengths, however, networks are internally synchronized, in some cases with a phase shift between them.
In Ref. [396] the reader can find an interesting study on the Master Stability Function for class III systems [9]. The motivation is to investigate how the topologies of the layers influence the synchronization criteria and rate for the multiplex network. For that purpose, Ref. [396] considers different topologies, such as random (ER), random regular (RR), small-world (SW) and scale-free (SF), and studies a 2-layered multiplex network formed by interconnecting a layer with ER, SW or SF structure with another layer with an RR structure. This choice of the global topology is motivated by its correspondence to the highest synchronizability. The links between the layers have a constant weight . The inspection of the eigenratio allows to draw non-trivial and interesting conclusions for the synchronization properties. In particular, it is shown that a SW-RR topology enhances the synchronization, even though individually the SF topology has a lower eigenratio and a better synchronizability than the SW topology. In addition, it is shown that the ER-RR configuration displays similar synchronization properties to the SW-RR configuration for small coupling strengths, whereas at large coupling strengths the ER-RR configuration leads to a synchronization scenario similar to that occurring for the SF-RR configuration.
In Ref. [397], using Lyapunov stability theory, the Authors predict theoretically that in a master-slave configuration, complete synchronization between master and slave can be achieved if they have identical connection topologies. This prediction is verified numerically for a two-layer network of Lorenz systems. Ref. [397] also provides some numerical test for the case in which the master and the slave layers have non-identical connection topologies. In this case, the behavior of the system is highly non-trivial, with synchronization and de-synchronization alternately appearing for increasing values of the coupling strength. In this very same context, a fault-tolerant control scheme has been proposed to guarantee synchronization when the coupling connections fail [398].
Other forms of synchronization, such as generalized synchronization, have been explored in networks with unidirectional coupling in a master-slave configuration [399, 400, 401, 402, 403] and with fractional-order dynamics [404].
Finally, in Ref. [405] a relatively simple model is studied, consisting of a pair of bidirectional sub-networks each with an arbitrary number of identical neurons in a ring structure and two-way couplings between the ring sub-networks. Different time delays are introduced in the internal connections within each layer, and in the couplings between the layers. The network exhibits different dynamical phenomena depending on the parity of the number of neurons in the sub-network. Multiple stability switches of the network equilibrium, synchronous and asynchronous periodic oscillations, and the coexistence of the bifurcated periodic oscillations are shown numerically.
6.2.4 Bipartite and multilayer networks
Concurrent synchronization or multisynchronous evolution in networks is a dynamical regime where multiple groups of fully synchronized elements coexist in distinct, possibly chaotic, dynamics, so that elements from different groups are not necessarily synchronized. This kind of behavior has been studied in relation to robotics and neuroscience, where groups of interacting robots or neurons perform synchronous parallel coordinated tasks.
In Refs. [406, 407] the issue of multiple synchronized, possibly chaotic, motions occurring in networks of groups has been independently addressed. In the first study, the Authors tackled the stability of an invariant subspace corresponding to multisynchronicity in unweighted networks. In the second, the stability of the multisynchronous evolution in bipartite networks is evaluated by introducing a MSF that decouples the effects of the network topology from those of the dynamics on the nodes. The MSF approach seems to be inadequate to assess the stability of the synchronous evolution when both intragroup (intralayer) and extra-group (interlayer) connections are allowed in the network. The Authors considered examples of general network topologies, where links are also allowed to fall within each layer, and reported numerical evidence that the presence of diffusive couplings amongst nodes within the same layer can enhance the network synchronizability.
Based on Lyapunov stability theory and linear matrix inequality, the Authors of Ref. [408] studied “inner” (within each network) and “outer” (between two networks) synchronization between two coupled discrete time networks with time delays. They were able to provide sufficient conditions to assess the stability of the synchronous solution within each network, but once again the method used cannot guarantee the stability when both intra-group and extra-group connections are allowed.
In Refs. [409, 410, 411] the synchronization of one-layer [409], two-layer [410], and three-layer center networks [411] of coupled maps has been studied, using linear stability analysis. Multicenter layer networks are characterized by the presence in each layer of nodes with special properties, called center nodes. Each layer is considered adjacent to the layer immediately preceding it and the one immediately following it; the exceptions are the first layer, which is only adjacent to the second, and the last, which is only adjacent to the previous one. All center nodes in a layer are not connected among them (except for the first layer in which they are globally connected) but to all the center nodes in the adjacent layers. In addition, each center node in the last layer has different non-center nodes which are not connected among them. The Authors found conditions for stable synchronization that depend on the number of center nodes and non-center nodes.
A natural framework for synchronization in multilayer networks is that of transmission of information in neural networks. A debate on the role of synchrony in nervous system signaling is addressed in Ref. [412], where a detailed analysis of the relationship between synchronization and rate encoding has been carried out in models of feed-forward multilayer neuronal networks [412, 413, 414]. In Ref. [414], a feed-forward multilayer network of Hodgkin-Huxley neurons was constructed (with no intralayer links), where synchronous firings can develop gradually within the layered network, consistently with experimental findings [412] and with other theoretical work [413].
An analogy between crowd synchrony and multilayer neural network architectures is proposed in Ref. [415]. The Authors showed that a two-layer system of many non-identical oscillators (semiconductor lasers) communicating indirectly via a few mediators (hubs) can synchronize when the number of optically delayed couplings to the hubs, or the strength of the coupling, is large enough. The synchronization transition is discontinuous, but its order depends on the detuning between the hubs. If the detuning is increased, the transition becomes continuous, with a diverging synchronization time near the critical coupling that does not depend on the number of hubs.
6.2.5 Synchronization and the problem of targeting
A very important point to stress is that, as long as the nodes are identical dynamical systems represented by vector states of the kind , with indicating the node, and the layer, the analysis of the synchronization properties may be one of two very different endeavors.
The first involves an extension of the usual synchronization concept that we call intralayer synchronization, and corresponds to analyzing the conditions for which the solution (with and ) is stable.
Notice that the stability conditions of such a solution can be simply found by considering an overall modular-like network of size , and applying to usual MSF formalism [9] to study the spectral properties of the Laplacian matrix, which will have the form of diagonal blocks describing the intralayer connection structures, plus extra blocks describing the interlayer interactions.
The second case is much more general, as it encompasses explicitly the first case as one of its particular instances. It corresponds to assessing the stability conditions of the solution with and ). Such a solution, which we call the interlayer synchronized solution, does not imply necessarily that the dynamical evolution of nodes be synchronized within each layer.
In particular, when restricting the framework to a two-layer network with unidirectional interactions from a master layer to a slave layer, the importance of the interlayer solution was stressed in connection with the problem of targeting the dynamics of a complex network [416], i.e. finding a generic procedure to steer the dynamics of a network toward a given, desired evolution.
In fact, in Ref. [416], the feasibility of targeting any goal dynamics compatible with the natural evolution of the network was proven to be tantamount to demonstrating that two identical layers coupled in a master-slave scheme can identically synchronize [417, 418] when starting from different initial conditions. There, the Authors considered two identical layers, namely a master network (MN) providing the specific and a slave network (SN). Starting from different initial conditions, both layers produce a turbulent regime, i.e. generic dynamics not showing any particular global or local order. The Authors properly engineered a unidirectional pinning action from the MN to the SN with the aim of ultimately synchronizing the dynamics of the two layers.
In the following, we briefly summarize the main results of Ref. [416].
The master network considered is composed of identical, diffusively coupled chaotic units. Calling the vector state of the node , one has:
| (260) |
where and are a local evolution and an vectorial output function, respectively. is a coupling strength, and are the elements of the corresponding zero row-sum Laplacian matrix of the interaction network. Notice that, here and in the following, indicates the master network, and not the number of layers, which is here always 2 (the master and the slave). and are chosen to make the network units of class I, with a monotonically increasing trend of the MSF associated to the intralayer synchronous state [9], which is, therefore, always unstable, regardless of the choice of .
Let now
| (261) |
be the slave network (SN), obtained as a copy of the MN.
As long as both networks remain uncoupled and start from different initial conditions, each one will sustain a different turbulent state, so that , and the SN will never attain the desired goal dynamics.
In Ref. [416], the Authors implemented a pinning strategy to target consisting of sequentially establishing unidirectional links between nodes in the MN and their copies in the SN. The dynamical evolution of the SN is therefore described by:
| (262) |
where is the coupling function between MN and SN, with the condition that , and encodes the pinning procedure, i.e. if there is a link from the node of the MN to the node of the SN, and otherwise. Furthermore, is the parameter ruling the interlayer link strength.
It follows that the equation for the vector describing the difference between the master and the slave layers’ dynamics can be written in terms of its components as
| (263) |
A stable fixed point of Eqs. (263) at is a necessary condition for layers (260) and (262) to display the interlayer synchronized state .
The synchronization error is then defined as .
The linear stability of this solution can be assessed rigorously via the analysis of the linearized system for small , which reads:
| (264) |
where , , and are the Jacobian functions, and is the MN state to be targeted. This equation represents the MSF for the solution corresponding to the identical synchronization between MN and SN. Each of the linear equations (264), solved in parallel to the nonlinear equations for the MN (260), corresponds to a set of conditional Lyapunov exponents at each pinning configuration (PC). Therefore, each particular PC for which the largest of all such exponents is negative makes the interlayer synchronous state stable.
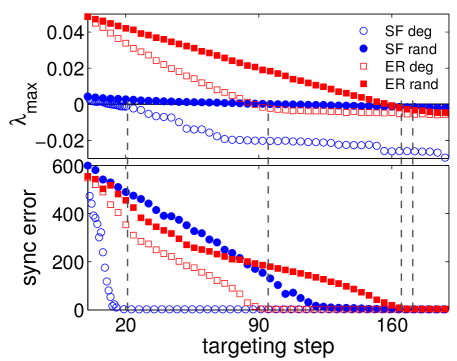
In Ref. [416], the validity of such a targeting procedure was demonstrated for layers of Rössler oscillators, configured with Erdős–Rényi (ER) [419] and Barabási-Albert SF [385] topologies. More precisely, a pair of identical master and slave layers were considered, described by the following set of equations:
where denotes the neighborhood of the node , and the set of pinning nodes for which a unidirectional connection is formed from the master to the slave layers.
By fixing , the Authors of Ref. [416] considered both sequences of pinning nodes following directly the degree ranking, or following a random ranking (in which the order of appearance of each node is fully random), in order to compare between both ends of the whole spectrum of possible targeting strategies.
In Fig. 50, the results are shown for the first 200 targeting steps, sufficient in all cases to attain the desired goal dynamics . It is easy to see that the maximum Lyapunov exponent , obtained from Eq. (264) and reported in the upper panel of the figure, always crosses the zero line exactly in correspondence of a vanishing synchronization error, reported in the lower panel of the figure.
Furthermore, a comparative inspection of Fig. 50 allows to draw two important conclusions: i) for both SF and ER topologies, the degree ranking leads to a much better targeting, as compared to the random scheme, and ii) the relative improvement in SF networks is much more evident than in the ER case, indicating that the dynamics of heterogeneous structures, like the ones encountered in real-world networks, are much easier to be manipulated and targeted.
7 Applications
If the success of a scientific theory can be assessed by its contributions to the understanding of real-world problems, complex networks can possibly be seen as one of the most prosperous developments in the last decades, having found applications in a plethora of different contexts [420]. Nevertheless, it is usually recognized that the traditional network representation is an oversimplification of the corresponding system; for instance, social interactions seldom develop on a single channel, and more than one relationship can bind pairs of people. It is thus not surprising that multilayer networks have raised a great expectation, as they should be able to better represent the topology and dynamics of real-world systems.
In the following, we present a review of works dealing with the analysis of real multilayer networks. Most of them were introduced well before the recent development of the mathematical framework reported here, when Erving Goffman first proposed his frame analysis social theory in 1974. Due to this, the reader should expect a large heterogeneity in concepts and solutions.
This section is organized into three main topics: social, technological and economical networks - a synopsis of the main references is provided in Table 6.
Social networks have captured most of the attention, thanks to the data availability maintained by online communities, and the inherent multilayer structure of social relationships. Yet, relevant problems can also be found in the two latter topics, as for instance the analysis of transportation systems and of trade networks. The end of this section is devoted to other applications, which have hitherto received less attention, but whose relevance, and the relevance of the corresponding multilayer representations, is expected to grow in the near future: this includes biomedicine, e.g. the analysis of the brain dynamics taking into account the layers of neural organization, climate (global networks created by correlation between climatological variables), ecology and psychology.
| Resume of topics and references | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Field | Topic | References | |||||||
| Social | Online communities |
|
|||||||
| Internet | [110, 109, 435] | ||||||||
| Citation networks |
|
||||||||
| Other social networks |
|
||||||||
| Technical | Interdependent systems |
|
|||||||
| Transportation systems |
|
||||||||
| Other technical networks | Warfare: [449] | ||||||||
| Economy | Trade networks |
|
|||||||
| Interbank market | [452] | ||||||||
| Organizational networks | [453, 454, 455] | ||||||||
| Other applications | Biomedicine | [456, 457, 458, 459, 460, 461] | |||||||
| Climate | [24, 462] | ||||||||
| Ecology | [64, 463] | ||||||||
| Psychology | [464] | ||||||||
7.1 Social
7.1.1 Multilayer social networks: an old concept
While the mathematical formulation of multilayer networks is very young, the idea of studying the way social interactions develop on multiple layers dates back to the seventies. The first of such approaches was probably introduced by Erving Goffman in 1974, along with the theory of frame analysis [465]. According to this research method, any communication between individuals (or organizations) is constructed (or framed) in order to maximize the probability of being interpreted in a particular manner by the receiver. Such framing may differ according to the type of relations between the involved individuals, several of them potentially overlapping in a single communication: thus, the output of multiple framings can be interpreted as a multilayer structure.
After this first attempt, White et al. proposed an extension of the classical work by Nadel and Fortes [466] to perform a quantitative analysis of multilayer social networks [467]. A simple three-layer structure is considered, where nodes represent biomedical researchers specialized in the neural control of food and water intake; the three layers respectively represent the existence of a bidirectional personal tie, an unidirectional awareness, and the absence of awareness [468]. Notice that this three-layer structure contains information that, in modern complex network theory, would be synthesized into a single directed network, as the third layer is the complementary of the second. Using this network as a test bed, they proposed a method for detecting blocks that are coherent across the different layers: in other words, they had just introduced the first community detection algorithm. Along this line of research, Greiger and Pattison in Ref. [469] analyzed the multilayer social structure reported in Ref. [470], characterized by business and marriage relationships between important families from Florence in the fifteenth century. Authors showed how a personal hierarchy, comprising information from both layers, can be used to create meaningful partitions of the graph.
Finally, it is worth concluding this short review on the classical social applications by presenting the work proposed in Ref. [471]. Authors argued that an analysis of the health condition in old people, e.g. their resilience to external shocks, can be performed only when multiple networks are simultaneously considered, like living arrangements (i.e. ties created by the residence type), family, or organizations like church or voluntary associations.
7.1.2 Online communities
Information and communications technology (ICT) is behind the boost experienced in the last decade by the online communities. ICT favors users’ interactions through the sharing of multiple contents, from tastes to photos and videos, and at the same time it fulfills one of the most basic social needs: interpersonal communication. On the other hand, all those communication exchanges are stored in a digital support: researchers can thus find plenty of information for analyzing social behaviors, and for representing the wide variety of human interactions under a multilayer framework.
The Pardus social game
One of the most interesting online community data sets has been provided by Pardus, an online game in which more than players live in a virtual, futuristic universe, exploring and interacting with others, pursuing their personal goals by means of different communication channels ranging from instantaneous one-to-one communications, e.g. e-mail and personal messages, while others imply a more stable relationship (friendship, cooperation, attacks, and so forth) [472].
Several papers have used this data set to explore whether particular network topological features were present. For instance, Ref. [63] extracted a six-layers structure, respectively representing friendship or enmity relations between pairs of players, private messages exchange, trading activities, the presence of one-to-one aggressive acts, and placing head money (bounties) on other players. Different characteristics were found for each layer: specifically, negatively connoted (i.e. aggressive) actions are characterized by power-law topologies, while positive ones exhibit a higher clustering coefficient. Furthermore, different layers interact in a non-trivial way: for instance, there is a strong overlap between communication and friendship networks, but also between communication and aggression, and between communication and friendship - see Fig. 51. Ref. [421] expands further those results, by considering the time evolution of such a multilayer network. The network dynamics follows some well-known processes, like triadic closure and network densification. Furthermore, it seems that the Dunbar conjecture is confirmed [473], as out-degrees are limited at around 150 connections. More recently, the effect of the user’s gender was tackled in Ref. [422], demonstrating that the structural properties of the layers are different for men and women, especially when the interaction time scale is considered.
The problem of the triadic closure has more recently been addressed in Ref. [423], through the analysis of a Pardus data set composed of friendship, communication and trading relationships. Specifically, a network growth model is presented, in which links are either added to form a closed triangle with probability , or following a standard preferential attachment mechanism [385] with probability . Such a simple model is yet able to reproduce most of the topological features of the original multilayer network, thus suggesting that both dynamics compete in the real system.
Finally, Ref. [424] tackles the problem of detecting elite structures in the Pardus network, i.e. subgroups of individuals that have the ability of influencing the behavior of others. This is accomplished by means of a modified k-core algorithm. Results indicate that different layer projections can be used to predict how players will perform socially, e.g. their leadership or wealth.
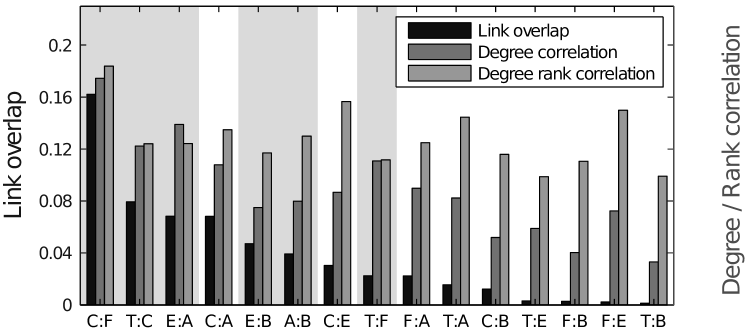
Netflix
Netflix, Inc. is a US-based company specialized in video rental and online streaming. When users navigate in the website, for instance to select the next content they want to watch, an advance recommender system [474] analyzes their tastes and suggests a set of videos expected to be to their liking. In 2006, with the aim of improving this recommendation system and position it above competitor ones, Netflix disclosed a large data set, including millions of movie ratings assigned by users [475].
Two works [425, 426] have examined this data set by considering its structure as a multilayer network. Specifically, the initial bipartite network (users can only be connected to movies) is projected into a movie’s network, i.e. where nodes represent movies, pairwise connected when a single user rated both of them. Furthermore, information about ratings has been used to organize links in three different layers: positive, negative and mixed ratings. The resulting three layers have different characteristics, which are lost when the global projection is considered. For instance, positive and negative networks display a high clustering coefficient, indicating that users tend to like (or dislike) groups of similar movies; on the other hand, mixed ratings create more heterogeneous structures, characterized by larger but sparser communities.
Flickr
Flickr is a worldly recognized online community, specialized in the hosting and sharing of multimedia content like photos and videos. In 2013, the popularity of this web service was such that counted more than 87 million registered users, and 3.5 million new images uploaded daily. Due to the large quantity of information available about interactions between users, it is not a surprise that several studies have leveraged on Flickr to validate network analyzes, both applied (e.g. automatic assignation of tags to photos by means of community detection algorithms [476]) and theoretical (as validating network growing mechanisms against real data [477]).
Recently, three works have focused on the multilayer structure of the Flickr community. While nodes always represent users, these may be linked through different types of relations. Specifically, Authors identify 9 of them, spanning from direct user friendship, to common comments or common tag usage.
First of all, two of them [427, 66] have introduced the concept of multilayer networks in the design of improved recommendation systems, i.e. systems able to recommend new friends or relevant contents to target users. Results indicate that users are more likely to share photos and tags when they are already friends, or in other words, that the social layer drives the semantic one. Also, there is a strong bidirectionality in social relations: if a user comments on the photo of another user, the latter reciprocates by commenting a photo of the former person. It is worth noticing that these results, and especially the relationship between social and semantic connections, could not be inferred if all layers were collapsed into a single-layer network. Furthermore, time is here an essential ingredient: data is then represented as multilayer time-varying graphs.
Finally, Ref. [88] focused on the problem of identifying communities of users across the structure. This is accomplished by firstly generalizing the concept of local clustering coefficient to multilayer networks (see Sec. 2.2.2) averaging the metric as measured in each layer. Secondly, the communities are detected through a growing mechanism, in which nodes are assigned to independent communities when their respective clustering coefficient is higher than a given threshold.
Facebook.com is a social website where people can interact and share tastes and comments about their daily activities. What is uncommon about it, is its popularity: in 2013 it was recognized as the second most visited website in the world, with million registered users, requiring a farm of thousand servers for ensuring its correct operation. As for other online social networks, many works can be found in the Literature which analyze the topology emerging from user interactions, as for instance Refs. [478, 479, 480, 481]; and possibly Facebook has attracted even more scientific attention due to the large business possibilities provided by the system.
The analysis of Facebook as a multilayer network has mainly been possible by the work presented in Ref. [428]. In that reference, Authors have crossed online interaction information with real-world data for a group of students from a private college in the northeast of the United States. The resulting data set comprises five different layers: Facebook friendship, picture friendship (i.e. two users sharing photos), and roommate, dormmate and groupmate relationships. Furthermore, the data set is longitudinal, as it includes information at different time moments between and ; finally, it includes demographic and cultural details of each user.
Taking advantage of the usefulness of such a valuable data set, several works have leveraged on it to perform different types of analyzes, some of them focusing on its multilayer dimension. Among others, they include the study of different types of multilayer structures [68, 429] up to dynamical processes, like peer influence [430].
Youtube
Youtube.com is a website whose purpose is video sharing, i.e. it allows users to upload personal videos and share them with the community. In February 2014, it was recognized as the third website in the world in terms of traffic generated.
While few works have focused on the network dimension of the website, Ref. [431] analyzed in a multilayer context the interactions among Youtube registered users. The resulting network is composed of five layers, each one defining different relations between pairs of users: friendship, co-contacts (i.e. when two users both add a third one as a friend), co-subscription (when they follow the same content), co-subscribed (when two users are followed by the same people), and when they share favorite videos. The tackled problem is the detection of communities of users, sharing the same tastes and interests. The proposed solution is the extraction of structural features from each layer of the network, and their integration via Principal Component Analysis [482].
Other online communities
Beside these popular websites, additional (and usually less well-known) online communities have been studied from the multilayer perspective, representing more specific types of interactions. Here below, some of those analyzes are reported.
In the first one, Ref. [432] analyzes a Swiss online social network connecting musicians through friendship, such that subscribers can be classified either as users (followers and fans) or as artists. Three different layers are considered, respectively created by friendship, communication, and music download. Notably, the three networks share a similar structure, with a clear presence of homophily and reciprocity.
Ref. [89] studies the social network behind the web portal extradom.pl, specialized in gathering people engaged in building their own houses in Poland. Eleven different layers are reconstructed from user interactions, including forum groups and topic creation, or message posting. The interest resides in the analysis of the neighborhood of each user, specifically through a multilayered neighborhood. Results indicate that, while people are exposed to many different types of relationships, they tend to focus themselves in just one or two types.
Finally, Ref. [54] tackles the problem of defining node centrality (see Sec. 2.2.1) by expanding the classical PageRank algorithm [84], and by using as a test bed the social network of the online community at the University of California, Irvine. Such network comprises two layers: the first one representing direct instant messaging, the second the bipartite topology created by users and discussion groups. As it may be expected, taking the multiplex nature of the network into account, i.e. using a multiplex PageRank, helps uncovering the emergence of rankings of nodes that differ from the rankings obtained from the projected topology.
Merging multiple social networks
After realizing the wealth of social networks populating Internet, and how information can straightforwardly be extracted and processed, the reader may wonder about the possibility of merging online networks, where nodes would represent individuals, and links representing friendship (or other relations) between pairs of them sitting at different layers, each layer codifying a different social site. While this is in principle feasible, the main problem resides in the identification of common users across websites, as real names are usually concealed, and the same user can appear under different pseudonyms, or nicknames.
One way of tackling this problem is by using information extracted from Friendfeed, a social media aggregator. Besides performing regular activities like posting messages, it also allows users to register their accounts in other systems, thus allowing the retrieval of the multiple accounts associated to the same user in several social services. Ref. [123] make use of this website to obtain information from Friendfeed, Twitter and YouTube, creating a network of nodes to test different multilayer network generation algorithms. The same data set is also the source in Refs. [122, 433] for node centrality studies.
An alternative approach has been proposed by Ref. [434], where two content-driven websites (Pinterest and Last.fm) are scanned for connections toward a generic social network, Facebook. The work aimed at confirming social bootstrapping as a common technique used by novel websites, that is, the act of recommending new social ties depending on the existence of that link in a different network.
7.1.3 Internet
In the previous part of this section, the World Wide Web has been considered as an instrument to put people in contact, and therefore as an instrument to drive online social networks. Yet, Internet is also the result of social forces: for instance, the structure created by hyperlinks is partly the result of connections between real people. Here we present networks created by hyperlinks between web contents as a social aspect of Internet.
Three papers addressed this problem from a multilayer point of view. Firstly, Refs. [110, 109] consider a data set created by the automatic crawling of unique URLs, connected between them by hyperlinks. Each web page is also associated to one or more anchor text terms, i.e. the visible words of an hyperlink. After an initial data filtering, the final network was composed of pages and terms, each one of them defining a different layer. Upon this network, an algorithm called TOPHITS was developed, aimed at identifying clusters of similar content web pages and at ranking web sites by taking into account the multilayer structure of links.
Ref. [435] describes the creation of a university URL-citations network, a network generated by checking the number of hyperlinks connecting web pages of couples of universities. While this network has a single-layer nature, complementary information has been added, which creates additional graphs supporting (and partly explaining) the initial structure. For instance, two universities can be connected when they share the same primary language, when they are located in the same country, or when they are located within a given physical distance. Results indicate that the topological structure is mainly explained by language, USA and UK universities forming a main cluster, while the geographical distance is not relevant.
7.1.4 Citation networks
Since the beginning of the complex network theory, citation networks captured a lot of attention, especially as far as the topology underlying citations between scientific papers was concerned. In this latter case, analysis is motivated, firstly, by the relative simplicity in obtaining the network structure, and secondly, by the interest in creating new metrics better assessing the importance of manuscripts and journals.
When moving to a multilayer setting, the main source of information comes from the DBLP (formerly known as DataBase systems and Logic Programming, and later as Digital Bibliography & Library Project), a computer science bibliography website hosted by Universität Trier, Germany, nowadays listing more than million references.
Several works have been based on such data set, starting from the seminal paper by Cai et al. about community detection [436]. In this network representation, nodes correspond to Authors, pairwise connected when they have published a paper in the same conference; the more than conferences recognized by DBLP constitute the multilayer structure of the network. Later works have used the same network to study specific characteristics of the system, like for instance node centrality assessment and ranking [437, 438, 33], the discovery of shortest-paths [439], and the identification of coherent subgraphs [440].
On the other hand, the DBLP data set has also been used as a test ground for more general multilayer network analysis. For instance, Ref. [441] proposes the use of higher order tensors algebra to multilayer and time evolving networks, i.e. an offline tensor analysis (OTA) as an extension of the celebrated Principal Component Analysis [483, 484]. Also, Ref. [31] proposes the extension of several well-known metrics, e.g. the degree of a node, as well as new ones, as the case of the dimension relevance of a node in a layer.
7.1.5 Other social interactions
In addition to online human interactions and citations, other types of multilayer social interactions can be found in the Literature. Here, we briefly report them, as an example of the variety of goals and approaches that can be accomplished by means of the multilayer network paradigm.
As a first example, Ref. [442] describes the Scottish Community Alliance, a network composed of local communities of people, deriving from the ancient Highlanders communities. Such a system has the structure of a network of networks, as communities are organized in larger groups at a regional level; but it is also organized in different layers, according to their main topics: “Community Energy Scotland”, “Community Woodlands Association”, the “Federation of City Farms and Community Gardens” and the “Scottish League of Credit Unions”.
Politics is the focus of Ref. [68] and specifically the network created by call voting: nodes thus represent US senators, and pairs of them are connected if they shared similar voting patterns across one year. The analysis of multiple years is thus represented as a multilayer structure. Authors demonstrate the usefulness of such a representation by performing a community analysis, and showing how the community structure can be used to infer information about the global political situation. Specifically, communities are identified, which are associated to important historical situations as the Compromise of year , the beginning of the American Civil War, or the Great Depression.
Another example can be found in Ref. [23] which analyzes the Noordin Top Terrorist Network, composed of known terrorists active in Indonesia [485]. Each network is defined by the interactions between pairs of individuals, i.e. trust, operational, communication and business relations.
The social network built by Saint Paul along its biblical voyage through the Aegean sea is characterized in Ref. [444], which considers the two layers corresponding to strong and weak ties. While the former (including close friends and family) was usually considered to be essential for spreading risky ideas (thus including recruitment to, and spreading of the new religion), results suggest that Saint Paul mainly achieved his mission through a large network of weak social links.
Ref. [445] is concerned about the process of social communication using different technologies as phone calls, or short text messages (SMS). The considered data set has been created from billing information corresponding to a large European metropolitan area, from March 26 to May 31, 2012. It contains more than 63 millions phone-call records, and 20 millions SMS records. The two layers do not perfectly overlap, with a () of users using only phone calls (SMS). Moreover, most of the links, i.e. communications between two people, exclusively occur by means of phone calls, while the share of people exchanging only SMS is as low as .
Finally, Ref. [443] analyzed the networking between representatives from leading groups on national health policy located in Washington DC during year 2003. Three overlapping networks, i.e. layers, are considered: communication, coalition overlap and issue overlap.
7.2 Technical systems
7.2.1 Interdependent systems
One of the most promising fields of application of the multilayer framework is the study of technical interdependent systems, i.e. those sets of systems in which the correct functioning of one of them strongly depends on the status of the others. In other words, the failure of one element does not only provoke the breakdown of similar elements, but also affects the dynamics of other coupled systems. This leads to an iterative process of cascading failures, as summarized before in Sec. 4, that has a devastating effect on the network stability. In a natural way, different types of systems can be represented by layers, connected between them by dependency links [25, 177].
Electrical power grids have been one of the first targets of such analysis, due to their high interconnectedness with both networks of different nature, like communication networks providing synchronization between different stations [25], and of similar kind, like neighboring power grids [81]. The devastating effects of such cascading failure dynamics has been firstly studied in Ref. [25]. Specifically, Authors analyzed the electrical blackout that affected the major part of Italy on 28 September 2003. The shutdown of power stations directly led to the failure of nodes in the Internet communication network, which in turn caused further power station breakdowns.
Two years later, Brummitt et al. in Ref. [81] analyzed the interactions between different power grids, specifically between the three main regions constituting the U.S. network - Western, Eastern, and Texas. Adding some connectivity between the different regions is beneficial, as it suppresses the largest cascade in each system by providing alternative paths. Yet, higher levels of interconnectivity have a negative impact, both because they open pathways for neighboring networks to inflict large cascades, and because new interconnections increase capacity and total possible load, which fuels even larger cascades. In the same spirit, Ref. [446] again considered the interaction between the power grid and the supporting communication network by focusing on the problem of detecting the most central, i.e. the most vulnerable, node. Authors focused on the Maricopa County, the most densely populated county of Arizona, USA. The resulting network comprised power plants, transmission lines, and fiber links.
Beyond power grids, it is worth noticing the completely different problem tackled in Ref. [447]. There, Authors introduced space-based networks, i.e. a technology that allows the sharing of spacecraft on-orbit resources, such as data storage, processing, and downlink [486] - see Fig. 52. Each spacecraft in the network can have different subsystem composition and functionality, and can rely on others to complement (or back-up) its equipment. Thus, in this case, each layer represents a spacecraft, with links connecting different layers representing the possibility of sharing capabilities. Various design insights are derived and discussed, and the capability to perform trade-space analysis with the proposed approach for various network characteristics is indicated.

7.2.2 Transportation systems
Transportation systems are natural candidates for a multilayer network representation. Firstly because connections between different nodes, e.g. direct flights or trains, are explicit, that is, their existence is published, requiring little effort for the network construction. Secondly, because transportation systems are usually interconnected, with a multilayer approach thus being the natural choice for intermodality studies. This latter aspect, i.e. the multimodal nature of transportation, has been tackled in two recent papers. In the first one, a two-layer structure has been created by merging the world wide port and airport networks [184], with the aim of studying the global robustness against random attacks. While previous studies have considered the resilience of coupled systems when such a coupling was of a random nature [25, 35], there Authors focused on the level of similarity between layers, given for instance the fact that well-connected airports are more connected to central ports. Such a similarity is assessed by means of two metrics, namely, the inter degree-degree correlation and the interclustering coefficient. Simulations executed using the topology of such a transportation system reveal that, as the networks become more intersimilar, the system becomes significantly more robust to random failure, as one network is able to back-up the other, when needed.
In the second publication [149], a multilayer structure is used to model the Indian air and train transportation networks, the nodes of the latter being stations, with pairs of them being connected if within one stop distance. Pairs of nodes belonging to different layers, i.e. airport-station pairs, are connected whenever a direct road access between both of them is present. It is worth noticing that both networks have a very different nature. While the airport network is small (with 78 nodes) and presents a scale-free disassortative structure, the rail one is much larger ( stations) and has a topology strongly constrained by the geography, implying a narrow degree distribution and an assortative topology. Yet, such heterogeneity enables a good performance of the global network in terms of navigability.
As for the analysis of individual transportation networks, a few examples can be found in the Literature, in which a multilayer structure is used to model different aspects of the transportation process. For instance, Ref. [448] analyzed the network created by worldwide cargo ship movements; while the of world trade is carried by sea, it is noteworthy that little attention has been devoted to this transportation mode from the field of complex networks. The multilayer structure is given by the three most common classes of cargo ships, i.e. container ships, bulk dry carriers and oil tankers, which usually connect different ports and travel following different patterns. For instance, bulk dry carriers and oil tankers tend to move in a less regular manner between ports than container ships. The understanding of the specific patterns of movement created by each type of ship, instead of analyzing the topological projection of this multilayer network, is motivated by the problem of invasive species spreading: bulk dry carriers and oil tankers often sail empty, thus exchanging large quantities of ballast water and favoring the spreading process.
Finally, the air transport network [19] has also been studied alone, but taking into account the multilayer structure created by different airlines. As demonstrated in Ref. [78], the global network is the result of the interactions between two main types of layers: those created by major airlines on the one side, and those generated by low cost (or low fares) carriers on the other. The former are characterized by a hub-and-spoke topology, with one central hub receiving and dispatching all flights; the latter by a point-to-point configuration, of a more random nature. The topological properties of the global network, as for instance its low diameter or the high clustering coefficient, only appear when several layers of different nature are merged together. While an analysis of the topology of connections may be relevant, at least from a theoretical point of view, the study of the dynamics taking place on top of it is of high interest for the air transport community, as it would allow tackling problems like the propagation of delays through the system, or the effects of such dynamics on the movement of passengers [19]. Ref. [16] tackles the problem of passenger rescheduling when a fraction of the links, i.e. of flights, is randomly removed. A simple dynamical model is executed using two networks: the single-layer projected network, and the whole multilayer structure. In the latter, airlines incur in a cost whenever a passenger needs to change layer, thus effectively reducing the flexibility of the system. Results indicate that the layered structure is associated to a lower resilience of the system against such kind of perturbations. In other words, the use of a projection is a simplification that results in an over-estimation of the resilience of the air transport network, as it does not take into account the cost of moving between layers - see Fig. 53 for more details. At the intersection between the topological and dynamical analysis of the air transport network, Ref. [218] focused on the communicability, i.e. the number of possible routes that two nodes can choose to communicate with each other [216]. By aggregating the communicability corresponding to each departure node, i.e. considering the broadcasting of information to passengers, and by varying the degree of interactions between different layers, it is possible to create airport rankings that takes into account the multilayer structure or, in other words, quantifies the effects of the airline structure on the movement of passengers. The most central node thus varies: while the airport of Paris CdG is the most central in Europe when layers are disconnected (main consequence of the extension of the Air France network), this role is passed to London Stansted and Frankfurt when increasing the coupling.
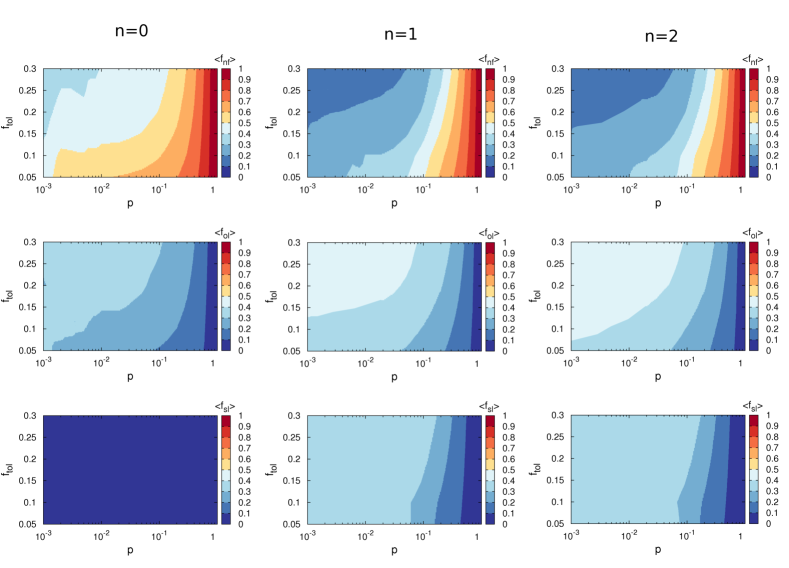
7.2.3 Other technical systems
As a final note on technological systems, it is worth noticing Ref. [449], which analyzes the problem of establishing a reliable communication network between heterogeneous elements, and specifically between different warfighters in an army. Thanks to the technological progress, each soldier and vehicle in the battlefield can be connected to others by means of different communication channels, each one having specific characteristics: being wireless or not, bandwidth, range, etc. When these different systems are considered as heterogeneous layers, the battlefield can be represented by a single multilayer network - see Fig. 54. The challenge is then to ensure a high end-to-end Quality of Service (QoS), i.e. that two units can share information when needed, making use of different communication channels.
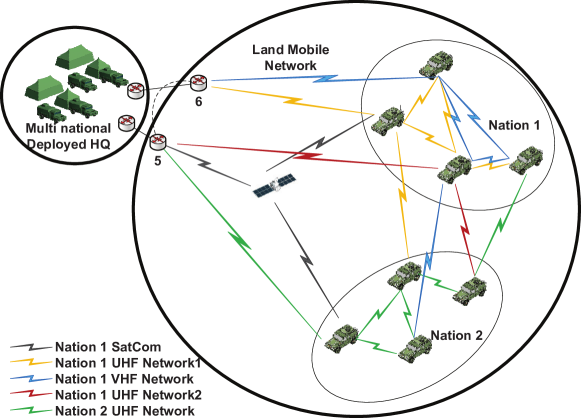
7.3 Economy
7.3.1 Trade networks
The International Trade Network (ITN), also known as the World Trade Web (WTW), is defined as the graph of all import/export relationships between world countries. In recent years, it has been extensively analyzed from the complex network theory point of view, due to its importance: for instance, its topology can be used to assess the likelihood that economic shocks might be transmitted between countries [487].
Traditional network studies have considered the ITN at the aggregate level, in which links represent the presence of a trade relation, irrespectively of the commodity actually traded. Nevertheless, the introduction of the concept of multilayer network has enabled the unfolding of the aggregate ITN such that each layer represents import and export relationships for a given commodity class, according to some standard classification scheme.
This latter approach has been conducted in Refs. [70, 71], by using a network composed of 162 countries (nodes) and 97 layers, evolving yearly from to . In the former work, Authors considered different topological metrics and how they differ across the layers: among others, node centralities (and thus, country rankings) and connected components. On the other hand, the latter work focused on the identification of communities, highlighting the fact that commodity-specific communities have a degree of granularity which is lost in the aggregate analysis. A similar study was performed in Ref. [450], but relying on a different data set: the UNCOMTRADE, collected by the United Nations, which includes information for countries starting from year .
A different approach to trade analysis has been proposed in Ref. [451] regarding the study of maritime flows. Extending the large research body devoted to the study of maritime flows by means of standard complex networks [448, 488, 489], Ref. [451] presents a model where ports (nodes) are connected through five different layers, representing the five main categories of commodities exchanged in maritime business: liquid bulk (i.e. crude oil, oil products, chemicals, etc.), solid bulk (like aggregates, cement, or ores), containers, passengers/vehicles and general cargo. Data have been extracted from the Lloyd’s Voyage Records, covering the months of October and November 2004. An inspection of this disaggregated network suggests that most networks measures, like centrality or clustering, exhibit strong sensitivity to the type of commodity traded in a given set of ports. The most diversified ports are on average, the bigger and more dominant they are in the network, while they also connect over greater physical distances than more specialized ports - see Fig. 55.
7.3.2 Interbank market
The 2008 financial crisis has raised the interest of the scientific community toward the understanding of the complex system emerging from the interaction between financial institutions and markets [490, 491, 492]. Most contributions have focused on the interbank market, where nodes represent financial institutions, and links credit relations between two counterparties. Networks are usually directed and weighted, such that directionality identifies the borrower and the lender, and the weight of the link represents the loan amount.
Ref. [452] is hitherto the only work analyzing this network from a multilayer point of view. Authors utilize a unique database of supervisory reports of Italian banks to the Banca d’Italia, including all bilateral exposures of all Italian banks, broken down by maturity and by the secured and unsecured nature of the contract. Each layer in the network represents a different type of exposure, namely: unsecured overnight, unsecured short-term (less than 12 months), unsecured long-term (more than 12 months), secured short-term and secured long-term. The analysis of these five layers shows a high heterogeneity between them, with the topology of the overall network largely reflecting the one of the unsecured overnight layer. This layer is especially important from the policy-making point of view, as it is the focus of monetary policy operations in several jurisdictions. Notably, such layer is characterized by a high persistence of links over time, such that, if two banks are connected at a given time, they will have a high probability of being connected in the future. This may have important consequences in the stability of the system, in terms of perturbations contagion.
7.3.3 Organizational networks
A third active field of research in economy is the study of organizational networks, i.e. the study of how different organizations interact, by exchanging information, money, or other resources, with the aim of collectively produce a good or a service. While traditionally such interactions had a hierarchical structure, in recent years more complex topologies have emerged, in which the power of the decision making process is spread among many participants [493]. Once again, complex networks stand for as the most suitable instrument for the analysis of the resulting interaction structures [494, 495]. While the importance of the multilayer nature of these networks was recognized almost three decades ago [496, 497], only recently this problem has been mathematically tackled.
One of the first works analyzing organizational networks as multilayer structures is Ref. [453]. There, Authors analyzed more than Research & Development and more than Management & Development alliances involving biotech firms in the United States. The time window considered covers over 30 years, in which data were available quarterly, thus enabling the construction of a 120-layers temporal network. The underlying hypothesis is that the actions of a given firm can be better understood if one takes into account changes in the network structure, like the firm position (centrality). The main result suggests that biotech firms act following a process of preferential attachment, i.e. organizations are more likely to form ties with organizations of similar institutional and structural status.
The multiplex paradigm has also been used to study the interactions between organizations using Information and Communications Technology (ICT) firms for development goals, i.e. the use of ICTs as a tool for empowering less developed countries [454]. Specifically, two nodes can be connected when the corresponding organizations collaborate in implementation or knowledge-sharing projects, thus creating a two-layers network. In Ref. [454], the studied data set comprised 323 projects between years 1997 and 2005, 211 of which were implementation projects and 112 knowledge-sharing projects, for a total of 752 organizations. Results indicate that the existence of a link in one layer is influenced by several factors: the presence of the corresponding link in the other layer, the presence of a common third-party, or the centrality of connected nodes, among others.
Within organizational networks analysis, of special interest has been Corporate Governance, defined as the study of the interrelations between ownership and control of a firm. Stockholders invest their money in a company whose strategic decisions are taken by the top management: as both of them are embedded in a network (for instance, a single investor may hold shares of multiple companies), the resulting structure can be seen as a multilayer network composed of two layers, respectively ownership and control. Thus, a multilayer analysis may give a unique perspective on the relevance of management rather than ownership in the company’s policy. Such an approach has been addressed in Ref. [455], focusing on the shareholding and board structures in the year 2013 for 273 quoted companies on the Italian Stock Market. The main claim is that corporate governance cannot be understood unless ownership and management are taken simultaneously, as the two layers are characterized by a small overlap: while the core of shareholding is composed of banks and financial institutions, the most central nodes in the management layer are large industrial companies.
7.4 Other applications
7.4.1 Biomedicine
The introduction of the complex network methodology in biomedicine caused a kind of a small revolution, as it made possible a real systems medicine: not only studying the elements constituting a living being, but analyzing how they communicate and interact in a systemic way. Two are the main fields where the network approach has been successful. On the one side, the characterization of how the main constituents of the cell are organized: specifically, genes [498, 499], proteins [500, 380] and metabolites [501]. On the other side, and from a higher level perspective, one may find all the works in neuroscience that deals with the complexity of the brain as a network, both anatomically [502] and functionally [503].
Up to now, these networks, e.g. the ones created by interactions between genes, proteins and metabolites, have been considered in an independent fashion. Nevertheless, they are clearly not independent: genes control the production of proteins, which in turn catalyze metabolic reactions. Malfunctions in cells are seldom due to just one element, being instead the result of multiple interactions at different levels. It has been recently suggested that a multilayer approach, i.e. a representation of the cell composed of different layers for each one of these elements, may yield relevant knowledge about the normal dynamics, as well as about the appearance of pathological conditions [456]. The final aim is called personalized medicine, i.e. a medicine focused on the individual and proactive in nature, which would allow a significant improvement in health care by customizing the treatment according to each patient needs [457]. In spite of its importance, such multilayer approach has not yet been achieved.
While a full multilayer representation of the cell has not yet been constructed, there are several situations in which different networks can be combined or analyzed together. For instance, molecule interaction networks can be extracted from different organisms, the objective being the identification of modules that have been preserved across different evolution steps. Following this line of research, in Ref. [458] Authors found common modules by means of a spectral clustering algorithm extending the Perron-Frobenius theorem. Among the resulting shared modules, some examples include the Mini Chromosome Maintenance complex, which plays an important role in eukaryotes DNA replication [504], or the V-ATPase, an ancient and highly preserved enzyme that performs different functions in eukaryotes cells [505]. It has also been proposed the multilayer analysis of the protein-protein interaction network by considering the type of relation connecting pairs of them: physical when they can bind together to form a larger complex, and genetic if one of the two proteins regulates the other, i.e. by triggering the activation (or repression) of the gene responsible for the production of the target protein [459].
Another example of a multilayer approach emerges when a set of data, representing the same molecules, are extracted from different conditions, or are analyzed by different means. These two approaches are explored in Refs. [460, 461]. Specifically, Ref. [460] works with a multilayer structure composed of 130 co-expression networks, in which each layer represents a different experimental condition. The aim was the identification of recurrent heavy subgraphs, i.e. subsets of densely interconnected nodes that consistently appear in the different layers. While this is similar to a community identification task in a single layer, the simultaneous analysis of multiple layers is expected to enhance signal-noise separation. In Ref. [461], an initial data set of gene expressions is used to create two different networks: firstly, a standard co-expression network, where pairs of genes are connected whether a relationship (e.g. statistical correlation) is found between their expression levels; and secondly, an exon co-splicing network, in which nodes represent exons and the edge weights represent correlations between the inclusion rates of two exons across all samples in the data set. These two networks are not independent, but indeed form a two-layers system, as each gene contains several exons. Furthermore, transcription and splicing factors are expected to be consistent among related genes, thus giving rise to coupled modules. This last hypothesis has been confirmed by comparing the obtained modules with data sets of gene functions.
7.4.2 Climate
The last decade has witnessed an increasing interest toward the application of complex network theory to climate science. Networks are usually reconstructed such that nodes correspond to spatial grid points of the Earth, and links are added between pairs of nodes depending on the degree of statistical interdependence between the corresponding pairs of anomaly time series taken from the climate data set. The graph approach then allows a topological and dynamical analysis of the climate system over many scales, i.e. from local properties of a single point and its influence on the whole planet, to global network measures associated to stabilization mechanisms [506, 507, 508].
Ref. [24] constructs a multilayer network, where each layer represents the Earth’s atmospheric condition at a given geopotential height; nodes are associated to pairs of coordinates (i.e. latitude and longitude), and pairs of them are connected with a weight defined by the zero-lag linear correlation between the time series corresponding to the two nodes. In this way, the multilayer network provides a representation of the geostrophic wind field as well as large-scale convection processes in the troposphere and the lower stratosphere. By analyzing its topology, and especially the centrality of nodes (by means of adapted degree, closeness and betweenness centralities), it is possible to extract relevant knowledge about the atmosphere dynamics, without considering fields of temperature, moisture content or other relevant climatological variables that are not straightforward to obtain.
A different approach is proposed in Ref. [462], where a two-layer network is constructed to analyze sea-air interactions. Nodes in the two layers respectively codify positions (pairs of latitudes and longitudes), and links are once more weighted according to a zero-lag linear correlation between time series associated to each node: geopotential heights for points in the air, and surface sea temperature for points in the sea. By analyzing this network, it is possible to recover the coupled Asian monsoon and Walker circulations, known as the Indian and Pacific Ocean (GIP) model.

7.4.3 Ecology
In this subsection, we concentrate on two paperworks that analyzed, from a multilayer point of view, the interactions between animals and the structure of an aquifer system, respectively.
In the first one, the interaction network of a group of 12 female baboons in the De Hoop Nature Reserve, South Africa, is considered [64]. Specifically, three different types of interactions were recorded along 10 years, by means of human observations: agonistic, spatial and grooming interactions. This remarkable data set has then been used to build a multilayer structure, in which each layer represents each one of those social aspects. Beyond the complete, or control, network, two more have been reconstructed, by monitoring the social changes resulting from the death of two subjects, specifically a dominant and a low-ranked female. This allowed Authors to compare the topological properties of the three networks, specifically their clustering coefficients, and analyze how social ties are modified by the two events. The loss of the dominant female resulted in an instability in the dominance hierarchy, which was compensated for by adjustments in the spatial association network. On the other hand, the loss of the low-ranked female had little effect on the social network. This suggests that dominance serves to regulate the interactions of all group members.
A completely different application is proposed in Ref. [463], where the aquifer system of the Orageval catchment in France is studied. In order to correctly describe the structure of this system, a two-layer network representation has been reconstructed, where the two layers respectively map the Oligocene and the Eocene geological layers. After geophysical and drilling investigations, aimed at assessing the general structure of the aquifer system, electrical resistivity tomography was used to reconstruct the connectivity patterns at different spatial resolutions. When combined with temperature and hydraulic head information, this multilayer structure provides the researcher with valuable information about the stream-aquifer interface.
7.4.4 Psychology
While psychology has not traditionally contemplated complex networks as a tool for analyzing human behavior, it is worth noticing the study proposed in Ref. [464]. In this work, the symbolism of dreams and their interpretation, i.e. oneirology [509], is studied by means of networks: nodes represent dream symbols, pairwise connected according to the overlap in their meaning (i.e. the similarity in their corresponding interpretation documents). A different network is created for each considered culture (English, Chinese and Arabic), for then constructing a network of networks by connecting common symbols. Findings suggest that sentiments connected with a given interpretation can be associated with communities in the network, and that communities can be themselves clustered into three main categories of positive, negative, and neutral dream symbols - thus revealing a complex multiscale structure - see Fig. 56.
8 Conclusions and open questions
After having revisited the main theory and applications of multilayer networks, we feel our duty to draw a few concluding remarks, and pinpoint questions that remain still open to future progresses, at the same time addressing the reader to some issues and problems that we consider of key relevance, and that we believe it is more than likely that would attract soon the attention of scientists in the area.
In Section 2 we started with trying to establish a common notation (and some basic definitions) for multilayer networks, this way joining forces that have been spent in the last years to describe the structure of several complex systems. The main inspiration was trying to prove that the different terminologies reported so far could be, in fact, encompassed within a single framework. However, there is still a lot of work ahead in order to set a proper and comprehensive mathematical formalism, and possibly a long way to go. Among the different open problems to be solved, we highlight the following three: i) the need of setting up other metric concepts that could possibly affect relevant parameters of the systems, such as the betweenness, the vulnerability and the efficiency amongst others; ii) the need of gathering a better knowledge and understanding on the mathematical relationships among the values of centrality parameters when measured on each single network’s layer and when, instead, measured on the whole multilayer structure; iii) the need of paying effort for extending other quantifications pertinent to the dynamics of single-layer networks, such as, for instance, those regarding controllability and observability.
In Section 3, we followed up by reviewing the different models that have been proposed for generating multilayer networks endowed with the topological structures observed in real world systems. Possibly, this is the part of state of the art that still lies in its infancy. Definitely, and much more than being confident of, this issue is of the utmost importance. Retrieving the mechanisms at the basis of what is ubiquitously seen in social, technological and biological environments will certainly contribute to uncover the intimate physical processes that ultimately determine the way networked systems shape their interactions. Multilayer and multiplex networks encode indeed, significant more information in their structure with respect to their single-layers taken in isolation. A direct way to extract information from these structures is to look at correlations. For multiplex networks, these can be represented by degree correlations between different layers, or overlap of the links, or correlations in the activities of the nodes. For networks of networks, the degrees of freedom are even more pronounced since the interlinks between the nodes in different layers can be assigned using a large variety of rules. In our Section 3, we have tried to give an overview of generative models using both a growing multilayer network framework, and the framework of an ensemble of networks generating unbiased null models. Growing multiplex network models can be used to generate multiplexes with positive correlation in the degrees of the nodes, when the preferential attachment is linear, or tunable (positive or negative) degree correlation when the preferential attachment is non linear. On the other side, multiplex network ensembles using multilinks can be used to generate multiplex networks with tunable levels of overlap of the links incident to each node, that cannot be generated using the configuration model in each layer of the multiplex.
At variance, in Section 4 we attempted to review what are probably the most studied problems in multilayer networks, i.e. the issues connected to the overall network’s resilience (or fragility) to external perturbations, and to percolation. Such processes, indeed, once defined on multilayer networks, display many relevant and unexpected properties that cannot be simply reported to the case of a single layer. As soon as interdependencies between the nodes in different layers are taken into account, one of the most important questions is to characterize their robustness properties, i.e. their response to random damage. In systems like complex infrastructures, we observe that an increased level of interdependencies can be responsible for an increased fragility of the system that might be affected by cascades of failure events. On the other hand, in a network with interdependencies between the nodes of different layers, the percolation transition can be discontinuous, indicating a discontinuous emergence/disruption of the mutually connected component. At the same time, the response to damage of these networks generates eventually a disrupting avalanche of failures events. The investigation of the effects of multiplexity into the robustness of networks has revealed that when the networks are uncorrelated and each node has at least one interdependency link, the transition is always expected to be discontinuous and characterized by avalanches of failures.
The nature (and structural characteristic) of the interlink might also affect the robustness properties of the network. For instance, in the context of networks of networks, if any node is linked to its replica node and there is a fixed supernetwork, the size of the mutually connected component is independent of the structure of the supernetwork as long as it is connected, while in the case of nodes randomly linked to other nodes in other layers, the structure of the supernetwork matters.Moreover, if the nodes are only connected to their replica ones, either all the layers percolate, or none does. In the case in which the nodes in one layer are linked to random nodes in other layers, one has that layers with higher superdegrees are more fragile than layers with lower superdegrees. Moreover, in the presence of partial interdependence or overlap of the links, the transition can become continuous, and the response to damage less disruptive. This opens the challenging problem of characterizing the general structural conditions that can enhance resilience and robustness of the entire system. While for infrastructure and man made networks it is plausible to assume that the design of the system has not taken into account the role of interdependencies and has therefore resulted in fragile structures, in biological system such as the cell (or the brain) we are more inclined to believe that evolution must have driven the system toward a relatively robust configuration, at least finding a tradeoff between robustness and adaptability of the entire system.
In Sec. 5 we have shown that spreading processes in multilayer networks constitute possibly one of the best suited dynamical frameworks to unveil the effects that the coupling between networks has on their functioning. For instance, linear diffusion being the most simple dynamical setup allows to monitor the transition between two limiting regimes (one in which the networks behave independently and another corresponding to a coordinated functioning) with the transition between these two phases appearing to be abrupt according to the spectrum of the Laplacian. The use of more refined diffusion processes such as random walkers allows to go one step further and device tools for ranking the importance of the nodes, and monitoring it as a function of the coupling between networks. The study of even more realistic diffusion processes, such as those mimicking the transport of information packets, on interconnected networks has been also addressed, although more results on this line are certainly to be expected. In this regard, the transition to congestion in information networks is of key importance.
In addition to the report on diffusion processes, Sec. 5 paid attention to the problem of disease spreading on multilayer networks, where several related disease dynamics propagate on separated network layers, or both social information and infection information simultaneously diffuse and affect each other. Compared with the case of single-layer networks, this new framework can greatly change the threshold of disease outbreak, which is usually shown in the form of a phase transition between the healthy and epidemic phases. More research regarding this important issue is needed since SIR and SIS models seem to behave differently. In particular, SIR dynamics allows system states in which the epidemic regime only occurs in one of the networks (while not affecting the others) whereas for the SIS dynamics the propagation in one network automatically induces the epidemic in all the remaining networks. Besides the prediction of the epidemic threshold, we also emphasized studies that take advantage of the multilayer benchmark to couple the spreading dynamics with the development of voluntary prevention measures to control and eradicate the infection risk. Along this research line, there is still room for many proposals considering interconnected networks. As it is known, social dynamics, including information propagation and opinion formation, plays a non-trivial role in the risk perception under an epidemic threat. Apart from studying the emergence of individual contention measures under disease outbreaks, the same approach seems to be adequate to explore dynamical prevention measures in the Internet, so to control, in a dynamical way, the attack of viruses.
As we have seen in Sec. 5, evolutionary games are another fascinating field of research that can benefit from the multilayer framework. At variance with games in single-layer networks, evolutionary games on different network layers can be coupled via either the utility function or the strategy of the nodes. We summarized the main influence of these kinds of inter-layer coupling on the maintenance of collective cooperation behavior both in pair-wise games (such as the Prisoner’s Dilemma) and -person ones (such as the Public Goods Game). The reviewed studies clearly point out that the different coupling between networks enriches the enhancement of cooperative behaviors provided by spatial reciprocity. In spite of the great achievements, there are still unexplored problems related to evolutionary games that merit further attention. The most obvious issue is extending to multilayer networks other types of games like the Ultimatum game [510, 511], the Rock-Scissor-Paper game [512], the Naming game [513, 514] and the Collective-risk social dilemma [515]. These games usually focus on the emergence of other collective states such as, fairness, species diversity, cyclical dominance, language evolution and prevention of dangerous climate change. Within the novel multilayer framework, one can get a better understanding on the impact that the interaction among different networks plays on the emergence of collective states. For instance, during the campaign of mitigating climate change, the mutual impact of different local systems is crucial. If the total contribution of these systems is less than the expected target, it may cause a cascade of reducing investment leading to the tragedy of the commons [516]. Experimental research is another unexplored field of evolutionary games on multilayer networks. Previous experiments on single-layer networks have unveiled that heterogeneous topology does not promote cooperation [517], which is inconsistent with theoretical predictions [341]. Naturally, if the multilayer interaction is involved, how cooperation trait varies will become of particular importance.
In section 6 we have given a rather complete overview of the current results about synchronization in multilayer networked systems. Starting from the simplest case of only two layers, we have first reported on the enhancement of synchronization when the topological evolution of a network happens through a sequence of commutative layers. We have then demonstrated how one can in fact obtain a fully general treatment, without the need to impose any constraint on the layers and their mutual relations. Other specific cases we considered are coexisting layers, hypergraphs, interconnected networks, multiplex networks and bipartite graphs. Finally, we discussed recent results on the problem of targeting dynamical trajectories of a system. The new approach we described for general network evolution opens several possibilities for research areas in the near future. In particular, it should be noted that by the application of Eq. (256) and Eq. (259) one can effectively specify the evolution of the Laplacian eigenvalues and eigenvectors during the switch from one layer to another. Thus, one can impose any kind of transient behavior in the network. This method can be exploited to achieve finer control on time-evolving complex networks, with potential applications to many areas of social impact.
Further, the role of symmetry on the dynamical properties of multilayer networks is currently completely unexplored. Studies exist describing the importance of topological symmetries for synchronization, but they all deal with single-layer graphs. The addition of new layers could lead to substantially different results, which need to be investigated. Notice that the two cases of temporal layers and spatial layers are likely to involve different mathematics, with potentially different conclusions.
Another very relevant subject of investigation that will certainly attract attention is the study of how a multilayer distribution of links can spontaneously emerge as a consequence of adaptation of the interactions between constituents of a system. In Refs. [518, 519, 520] it was indeed shown that, when considering a single-layer network of phase oscillators and when the interaction weights are themselves dynamical variables evolving by means of differential equations explicitly coupled with the state of the network’s nodes, the asymptotic emergence of a synchronous state is associated with a structural self-organization into a modular and scale-free topology. The extension of this formalism to the case of multilayer interactions between oscillators is in progress, and promises to unveil relevant information on how a multilayer structure of connections emerges spontaneously in connection with the setting of specific collective dynamics.
Finally, in Sec. 7 we have reviewed the current literature on applications of the multilayer formalism and representation to several cases of relevance in social sciences, technological systems and economy. We firmly believe that in the future biology and biomedicine will greatly take advantage of a multilayer representation, although these two fields of research have until now lag behind. This is mainly due to the difficulty associated with the recording of real data in living organisms, especially with the high resolution needed to discriminate the physical layers. This is, for instance, the case of the human brain: while the human cortex is composed of six layers, each one processing information in a distinctive way, actual recording technologies (e.g. EEG or MEG) can only detect the activity of the top-most layers. When functional representations (i.e. representing the activity of the brain in terms of information processing) will be merged with structural ones (e.g. the connectome, that is, the structure of fibers connecting different parts of the brain), the result will be a complex multilayer network, describing both how and why information moves. Beyond the brain, it is commonly accepted that cells are composed of different networks interacting between them: from the RNA, mRNA, up to proteins and metabolites. While these networks have been deeply studied in separated and isolated fashion, many pathological conditions generate from the wrong interaction of the different networks (layers). Adopting the multilayer paradigm will then provide an elegant mathematical way of representing these cross-interactions, paving the way for a deeper comprehension of the structure and function of cells.
Acknowledgements
We would like to acknowledge gratefully all colleagues with whom we maintained (and are currently maintaining) interactions and discussions on the topic covered in our report.
In particular, we would like to thank J.A. Almendral, A. Amann, R. Amritkar, K. Anand, R.F.S. Andrade, F.T. Arecchi, A. Arenas, S. Assenza, V. Avalos-Gaytán, A. Ayali, N. Azimi-Tafreshi, A. Baronchelli, M. Barthélemy, K.E. Bassler, E. Ben Jacob, P. Bonifazi, J. Bragard, J.M. Buldú, J. Burguete, M. Campillo, A. Cardillo, T. Carroll, D. Cellai, M. Chavez, M. Courbage, A. Díaz-Guilera, L. Dall’Asta, D. De Martino, A.L. Do, S.N. Dorogovtsev, P. Echenique, E. Estrada, L.M. Floría, J. Flores, S. Fortunato, J. Gao, E. García, S. Gómez, A. García del Amo, J.P. Gleeson, C. Gracia-Lazaro, C. Grebogi, P. Grigolini, B. Guerra, R. Gutiérrez, A. Halu, M. Hassler, S. Havlin, H.G.E. Hentschel, A. Hramov, D-U. Hwang, Q. Jin, H. Kim, A. Koronovski, J. Kurths, V. Latora, S. Lepri, I. Leyva, F. Lillo, R. Livi, Y. Liu, E. Lopez, P. Lubkowski, S. Luccioli, H. Mancini, M. Marsili, N. Masuda, D. Maza, S. Meloni, J.F.F Mendes, R. Meucci, B. Min, G. Mindlin, R.J. Mondragon, Y. Moreno, O. Moskalenko, S. Mukherjee, F. Naranjo, A. Navas, M. Newmann, V. Nicosia, J. García-Ojalvo, C.J. Pérez-Vicente, P. Panzarasa, D. Papo, L.M. Pecora, M. Perc, P. Pin, A. Pikovski, A.N. Pisarchick, A. Politi, J. Poncela, F. del Pozo, I. Procaccia, A.A. Rad, I. Reinares, D. Remondini, C. Reyes-Suárez, M. Rosenblum, R. Roy, S. Ruffo, G. Russo, F.D. Sahneh, A. Sánchez, D. de Santos-Sierra, S.E. Schaeffer, C. Scoglio, J.R. Sevilla Escoboza, K. Showalter, L. Solá, S. Solomon, H. E. Stanley, R. Stoop, S. Strogatz, K. Syamal Dana, E. Strano, A. Szolnoki, S. Thurner, A. Torcini, Z. Toroczkai, V. Tsioutsiou, D. Vilone, L. Wang, C-y. Xia, Y. Zhang, K. Zhao, and J. Zhou.
The uncountable number of stimulating and inspired discussions with them (and their sharing with us of unpublished results on the subject) are largely responsible for having spurred and encouraged us to provide the present account on this rapidly growing field of research.
At the same time, we also would like to gratefully acknowledge all the discussions we had (in meetings, Conferences, Workshops, and personal visits) with other colleagues who are not mentioned in the above list (and, for that, we really apologize), which equally inspired our efforts, and opened up our minds in a way that contributed, eventually and substantially, to the realization of the present survey.
This work was partly supported by the Spanish MINECO under projects FIS2011-25167, FIS2012-38949-C03-01, and FIS2012-38266-C02-01; by the European FET project MULTIPLEX “Foundational research on multilevel complex networks and systems” (Reference Number 317532); by the Comunidad de Aragon (FENOL group); the Brazilian CNPq through the PVE project of the Ciencia Sem Fronteiras. C.D.G. acknowledges support by EINS, Network of Excellence in Internet Science, via the European Commission’s FP7 under Communications Networks, Content and Technologies, grant No. 288021; J.G.G is supported by MINECO through the Ramon y Cajal program. Z.W. acknowledges the National Natural Science Foundation of China (Grant No. 11005047).
Note added in proof
After editing the present Report, we learned about the publication of other recent and important contributions which relate to subjects and arguments treated in our Sections. In the following, we provide a list of these additional References that the reader may find useful to consult, together with the number of the Section they refer to.
Section 2:
M. De Domenico, and V. Nicosia, ArXiv e-prints (2014) 1405.0425v1;
I. Laut, C. Räth, L. Wörner, V. Nosenko, S. K. Zhdanov,
J. Schablinski, D. Block, H.M. Thomas, G. E. Morfill, Phys. Rev. E 89
(2014) 023104; R. J. Sánchez-García, E. Cozzo, Y. Moreno,
Phys. Rev. E 89 (2014) 052815; M. De Domenico, M. A. Porter,
A. Arenas, ArXiv e-prints (2014) 1405.0843; C. W. Loe, H. J. Jensen,
ArXiv e-prints (2014) 1406.2205; A. Solé-Ribalta, M. De Domenico,
S. Gómez, A. Arenas, WebSci ’14 Proceedings of the 2014 ACM conference on Web science
(2014) 149-155.
Section 4:
F. Tan, Y. Xia, ArXiv e-prints (2014) 1405.4342; Z. Su, L. Li,
H. Peng, J. Kurths, J. Xiao, Y. Yang, Sci. Rep. 4 (2014) 5413;
L. Daqing, J. Yinan, K. Rui, S. Havlin, Sci. Rep. 4 (2014) 5381;
B. Kotnis, ArXiv e-prints (2014) 1406.2106.
Section 5:
E. Valdano, L. Ferreri, C. Poletto, V. Colizza, ArXiv
e-print (2014) 1406.4815; F. Bagnoli, E. Massaro, ArXiv e-prints
(2014) 1405.5348; W. Wang, M. Tang, H. Yang, Y. Do, Y. C. Lai,
G. W. Lee, Sci. Rep. 4 (2014) 57;
B. Wang, Z. Pei, L. Wang, ArXiv e-prints (2014) 1405.1573;
B. Sun, B. Leonard, P. Ronhovde, Z. Nussinov, ArXiv e-prints (2014)
1406.7282; J. Sanz, Ch.-Y. Xia, S. Meloni, Y. Moreno, ArXiv e-prints
(2014) 1402.4523; M. Salehi, R. Sharma, M. Marzolla, D. Montesi, P. Sivari, M. Magnani, ArXiv
e-prints (2014) 1405.4329; C. Granell, S. Gomez, A. Arenas, ArXiv
e-prints (2014) 1405.4480; A. Chmiel, P. Klimek, S Thurner, ArXiv e-prints (2014) 1405.3801
Section 6:
L. M. Pecora, F. Sorrentino, A. M. Hagerstrom, T. E. Murphy,
R. Roy, Nat. Comm. 5 (2014) 4079;
V. Nicosia, P. S. Skardal, V. Latora, A. Arenas, ArXiv e-prints (2014)
1405.5855v1; M. Asllani, D. M. Busiello, T. Carletti, D. Fanelli,
G. Planchon, ArXiv e-prints (2014) 1406.6401.
Section 7:
D. Hristova, M. Musolesi, C. Mascolo, Proceedings of the 8th AAAI
International Conference on Weblogs and Social Media (ICWSM’14), Ann Arbor, Michigan, USA.
Furthermore, a part of the material quoted in our presentation was taken
from the ArXiv public repository, and we warn the reader that it is very likely
that those Manuscripts could have appeared meanwhile on peer-reviewed Journals.
For instance, we ourselves were made aware of publication of some of those
sources, that we gladly report here below:
Our Ref. [98] was published as
Proc. Nat. Acad. Sci. U.S.A 111 (2014) 8351.
Our Ref. [154] was published as Phys. Rev. E 89 (2014) 062814.
Our Ref. [226] was published as Phys. Rev. E 89 (6) (2014)
062813.
Our Ref. [252] was published as Phys. Rev. E 39 (2014) 062817.
Our Ref. [257] was published as PLoS ONE 9 (3) (2014)
e92200.
Our Ref. [322] was published as Phys. Rev. E 90 (2014) 012802.
Our Ref. [323] was published as Phys. Rev. E 89
(6) (2014) 062818.
References
References
- [1] S. H. Strogatz, Exploring complex networks, Nature 410 (6825) (2001) 268–276. doi:10.1038/35065725.
- [2] R. Albert, A.-L. Barabási, Statistical mechanics of complex networks, Rev. Mod. Phys 74 (1) (2002) 47–97. doi:10.1103/RevModPhys.74.47.
- [3] S. N. Dorogovtsev, J. F. Mendes, Evolution of networks, Adv. Phys. 51 (4) (2002) 1079–1187. doi:10.1080/00018730110112519.
- [4] M. Newman, The structure and function of complex networks, SIAM review 45 (2) (2003) 167–256. doi:10.1137/S003614450342480.
- [5] D. Watts, Small Worlds: The Dynamics of Networks Between Order and Randomness, Princeton University Press, Princeton, NJ, USA, 1999.
- [6] S. Bornholdt, H. G. Schuster (Eds.), Handbook of Graphs and Networks: From the Genome to the Internet, John Wiley & Sons, Inc., New York, NY, USA, 2003.
- [7] S. N. Dorogovtsev, J. F. Mendes, Evolution of networks: From biological nets to the Internet and WWW, Oxford University Press, Oxford, 2003.
- [8] R. Pastor-Satorras, A. Vespignani, Evolution and Structure of the Internet: a statistical physics approach, Cambridge University Press, Cambridge, 2004.
- [9] S. Boccaletti, V. Latora, Y. Moreno, M. Chavez, D.-U. Hwang, Complex networks : Structure and dynamics, Phys. Rep. 424 (4-5) (2006) 175–308. doi:10.1016/j.physrep.2005.10.009.
- [10] G. Szabó, G. Fath, Evolutionary games on graphs, Phys. Rep. 446 (4) (2007) 97–216. doi:10.1016/j.physrep.2007.04.004.
- [11] A. Arenas, A. Díaz-Guilera, J. Kurths, Y. Moreno, C. Zhou, Synchronization in complex networks, Phys. Rep. 469 (3) (2008) 93–153. doi:10.1016/j.physrep.2008.09.002.
- [12] S. Fortunato, Community detection in graphs, Phys. Rep. 486 (2010) 75–174. doi:10.1016/j.physrep.2009.11.002.
- [13] M. Barthélemy, Spatial networks, Phys. Rep. 499 (1-3) (2011) 1–101. doi:10.1016/j.physrep.2010.11.002.
- [14] S. Wasserman, K. Faust, Social Networks Analysis, Cambridge University Press, Cambridge, 1994.
- [15] J. Scott, Social Network Analysis: A Handbook, SAGE Publications, London, 2000.
- [16] A. Cardillo, M. Zanin, J. Gómez-Gardeñes, M. Romance, A. García del Amo, S. Boccaletti, Modeling the multi-layer nature of the european air transport network: Resilience and passengers re-scheduling under random failures, Eur. Phys. J. Special Topics 215 (1) (2013) 23–33. doi:10.1140/epjst/e2013-01712-8.
- [17] R. Criado, M. Romance, M. Vela-Pérez, Hyperstructures, a new approach to complex systems, IJBC 20 (03) (2010) 877–883. doi:10.1142/S0218127410026162.
- [18] R. Criado, B. Hernández-Bermejo, M. Romance, Efficiency, vulnerability and cost: An overview with applications to subway networks worldwide, IJBC 17 (07) (2007) 2289–2301. doi:10.1142/S0218127407018397.
- [19] M. Zanin, F. Lillo, Modelling the air transport with complex networks: A short review, Eur. Phys. J. Special Topics 215 (2013) 5–21. doi:10.1140/epjst/e2013-01711-9.
- [20] M. Berlingerio, M. Coscia, F. Giannotti, A. Monreale, D. Pedreschi, Foundations of multidimensional network analysis, 2011 International Conference on Advances in Social Networks Analysis and Mining (2011) 485–489doi:10.1109/ASONAM.2011.103.
- [21] M. De Domenico, A. Solé-Ribalta, E. Cozzo, M. Kivelä, Y. Moreno, M. A. Porter, S. Gómez, A. Arenas, Mathematical formulation of multilayer networks, Phys. Rev. X 3 (2013) 041022. doi:10.1103/PhysRevX.3.041022.
- [22] M. Kivelä, A. Arenas, M. Barthélemy, J. P. Gleeson, Y. Moreno, M. A. Porter, Multilayer Networks, ArXiv e-printsarXiv:1309.7233.
- [23] F. Battiston, V. Nicosia, V. Latora, Structural measures for multiplex networks, Phys. Rev. E 89 (2014) 032804. doi:10.1103/PhysRevE.89.032804.
- [24] J. Donges, H. Schultz, N. Marwan, Y. Zou, J. Kurths, Investigating the topology of interacting networks, Eur. Phys. J. B 84 (4) (2011) 635–651. doi:10.1140/epjb/e2011-10795-8.
- [25] S. V. Buldyrev, R. Parshani, G. Paul, H. E. Stanley, S. Havlin, Catastrophic cascade of failures in interdependent networks, Nature 464 (7291) (2010) 1025–1028.
- [26] J. Gao, S. V. Buldyrev, H. E. Stanley, S. Havlin, Networks formed from interdependent networks, Nat. Phys. 8 (1) (2012) 40–48.
- [27] R. Axelrod, The dissemination of culture: A model with local convergence and global polarization, J. Confl. Resolut. 41 (2) (1997) 203–226.
- [28] L. Solá, M. Romance, R. Criado, J. Flores, A. García del Amo, S. Boccaletti, Eigenvector centrality of nodes in multiplex networks, Chaos 23 (3) (2013) 033131.
- [29] J. P.Holme, Temporal networks, PR 519 (3) (2012) 97–125.
- [30] M. Coscia, Multidimensional network analysis, Ph.D. thesis, Universitá Degli Studi Di Pisa, Dipartimento di Informatica (2012).
- [31] M. Berlingerio, M. Coscia, F. Giannotti, A. Monreale, D. Pedreschi, Multidimensional networks: foundations of structural analysis., World Wide Web 16 (5-6) (2013) 567–593.
- [32] M. Berlingerio, F. Pinelli, F. Calabrese, Abacus: frequent pattern mining-based community discovery in multidimensional networks., Data Min. Knowl. Discov. 27 (3) (2013) 294–320.
- [33] M. Coscia, G. Rossetti, D. Pennacchioli, D. Ceccarelli, F. Giannotti, "you know because i know": A multidimensional network approach to human resources problem, in: Proc. of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, ASONAM ’13, ACM, New York, NY, USA, 2013, pp. 434–441.
- [34] M. Kurant, P. Thiran, Layered complex networks, Phys. Rev. Lett. 96 (2006) 138701.
- [35] R. Parshani, S. V. Buldyrev, S. Havlin, Interdependent networks: reducing the coupling strength leads to a change from a first to second order percolation transition, Phys. Rev. Lett. 105 (4) (2010) 048701. doi:10.1103/PhysRevLett.105.048701.
- [36] R. Criado, J. Flores, A. García del Amo, J. Gómez-Gardeñes, M. Romance, A mathematical model for networks with structures in the mesoscale, International Journal of Computer Mathematics 89 (3) (2012) 291–309.
- [37] C. Berge, Hypergraphs: Combinatorics of Finite Sets, North-Holland, 1989.
- [38] D. P., Hypergraphs, in: R. Graham, M. Grötschel, L. Lovász (Eds.), Handbook of Combinatorics, North-Holland, 1995, pp. 381–432.
- [39] J. J., Hypernetworks for reconstructing the dynamics of multilevel systems, European Conference on Complex Systems, Saïd Business School, University of Oxford, Oxford, 2006.
- [40] E. Estrada, J. Rodríguez-Velázquez, Subgraph centrality and clustering in complex hyper-networks, Physica A 364 (2006) 581–594.
- [41] E. Konstantinova, V. Skorobogatov, Application of hypergraph theory in chemistry, Discrete Mathematics 235 (2001) 365–383.
- [42] M. Karonski, T. Luczak, Random hypergraphs, in: D. Miklós, V. T.Sós, T. Szõnyi (Eds.), Combinatorics, Paul Erdös is Eighty, Vol. 2, Bolyai Society Mathematical Studies, Budapest, 1996, pp. 283–293.
- [43] J. A. Rodríguez, On the laplacian spectrum and walk-regular hypergraphs, Linear and Multilinear Algebra 51 (2003) 285–297.
- [44] B. Guerra, J. Poncela, J. Gómez-Gardeñes, V. Latora, Y. Moreno, Dynamical organization towards consensus in the Axelrod model on complex networks, Phys. Rev. E 81 (2010) 056105.
- [45] S. Gómez, A. Díaz-Guilera, J. Gómez-Gardeñes, C. J. Pérez-Vicente, Y. Moreno, A. Arenas, Diffusion dynamics on multiplex networks, Phys. Rev. Lett. 110 (2013) 028701.
- [46] G. D’Agostino, A. Scala, Networks of networks: the last frontier of complexity, Understanding Complex Systems, Springer, 2014.
- [47] E. Cozzo, M. Kivelä, M. De Domenico, A. Solé, A. Arenas, S. Gómez, M. A. Porter, Y. Moreno, Clustering Coefficients in Multiplex Networks, ArXiv e-printsarXiv:1307.6780.
- [48] B. Min, S. D. Yi, K.-M. Lee, K.-I. Goh, Network robustness of multiplex networks with interlayer degree correlations, Phys. Rev. E 89 (2014) 042811. doi:10.1103/PhysRevE.89.042811.
- [49] G. Bianconi, Statistical mechanics of multiplex networks: entropy and overlap, Phys. Rev. E 87 (6) (2013) 062806.
- [50] C. D. Brummitt, K. M. Lee, K. I. Goh, Multiplexity-facilitated cascades in networks, Phys. Rev. E 85 (4 Pt 2) (2012) 045102.
- [51] D. Cellai, E. Lopez, J. Zhou, J. P. Gleeson, G. Bianconi, Percolation in multiplex networks with overlap, Phys. Rev. E 88 (5) (2013) 052811.
- [52] E. Cozzo, A. Arenas, Y. Moreno, Stability of Boolean multilevel networks, Phys. Rev. E 86 (3 Pt 2) (2012) 036115.
- [53] E. Cozzo, R. A. Banos, S. Meloni, Y. Moreno, Contact-based social contagion in multiplex networks, Phys. Rev. E 88 (5) (2013) 050801. doi:10.1103/PhysRevE.88.050801.
- [54] A. Halu, R. J. Mondragon, P. Panzarasa, G. Bianconi, Multiplex PageRank, PLoS ONE 8 (10) (2013) e78293.
- [55] J. Y. Kim, K. I. Goh, Coevolution and correlated multiplexity in multiplex networks, Phys. Rev. Lett. 111 (5) (2013) 058702.
- [56] K.-M. Lee, J. Y. Kim, W. kuk Cho, K.-I. Goh, I.-M. Kim, Correlated multiplexity and connectivity of multiplex random networks, New J. Phys. 14 (3) (2012) 033027.
- [57] V. Nicosia, G. Bianconi, V. Latora, M. Barthélemy, Growing multiplex networks, Phys. Rev. Lett. 111 (2013) 058701.
- [58] V.Nicosia, R.Criado, M.Romance, G.Russo, V. Latora, Controlling centrality in complex networks, Sci. Rep. 2 (218).
- [59] A. Solé-Ribalta, M. De Domenico, N. E. Kouvaris, A. Díaz-Guilera, S. Gómez, A. Arenas, Spectral properties of the laplacian of multiplex networks, Phys. Rev. E 88 (2013) 032807.
- [60] O. Yağan, V. Gligor, Analysis of complex contagions in random multiplex networks, Phys. Rev. E 86 (2012) 036103.
- [61] G. Ghoshal, V. Zlatić, G. Caldarelli, M. E. Newman, Random hypergraphs and their applications, Phys. Rev. E 79 (6 Pt 2) (2009) 066118.
- [62] V. Zlatić, G. Ghoshal, G. Caldarelli, Hypergraph topological quantities for tagged social networks, Phys. Rev. E 80 (2009) 036118.
- [63] M. Szell, R. Lambiotte, S. Thurner, Multirelational organization of large-scale social networks in an online world, Proc. Natl. Acad. Sci. U.S.A. 107 (31) (2010) 13636–13641.
- [64] L. Barrett, S. P. Henzi, D. Lusseau, Taking sociality seriously: the structure of multi-dimensional social networks as a source of information for individuals, Proc. Natl. Acad. Sci. U.S.A. 367 (1599) (2012) 2108–2118.
- [65] M. Berlingerio, M. Coscia, F. Giannotti, A. Monreale, D. Pedreschi, The pursuit of hubbiness: Analysis of hubs in large multidimensional networks, J. Comput. Science 2 (3) (2011) 223–237.
- [66] P. Kazienko, K. Musial, T. Kajdanowicz, Multidimensional social network in the social recommender system, Systems, Man and Cybernetics, Part A: Systems and Humans, IEEE Transactions on 41 (4) (2011) 746–759.
- [67] P. Kazienko, K. Musial, E. Kukla, T. Kajdanowicz, P. Bródka, Multidimensional social network: Model and analysis, in: P. Jedrzejowicz, N. T. Nguyen, K. Hoang (Eds.), ICCCI 1, Vol. 6922 of Lecture Notes in Computer Science, Springer, 2011, pp. 378–387.
- [68] P. J. Mucha, T. Richardson, K. Macon, M. A. Porter, J. P. Onnela, Community structure in time-dependent, multiscale, and multiplex networks, Science 328 (5980) (2010) 876–878.
- [69] P. Pattison, S. Wasserman, Logit models and logistic regressions for social networks, ii: Multivariate relationships, Br. J. Math. Stat. Psychol. 52 (1999) 169–193.
- [70] M. Barigozzi, G. Fagiolo, D. Garlaschelli, Multinetwork of international trade: A commodity-specific analysis, Phys. Rev. E 81 (2010) 046104.
- [71] M. Barigozzi, G. Fagiolo, G. Mangioni, Identifying the community structure of the international-trade multi-network, Physica A 390 (11) (2011) 2051 – 2066.
- [72] D. S. Bassett, M. A. Porter, N. F. Wymbs, S. T. Grafton, J. M. Carlson, P. J. Mucha, Robust detection of dynamic community structure in networks, Chaos 23 (1) (2013) –.
- [73] V. Carchiolo, A. Longheu, M. Malgeri, G. Mangioni, Communities unfolding in multislice networks, in: Complex Networks, Springer Berlin Heidelberg, 2011, pp. 187–195.
- [74] P. J. Mucha, M. A. Porter, Communities in multislice voting networks, Chaos 20 (2010) 041108.
- [75] A. Allard, P.-A. Noël, L. J. Dubé, B. Pourbohloul, Heterogeneous bond percolation on multitype networks with an application to epidemic dynamics, Phys. Rev. E 79 (2009) 036113.
- [76] J. Hindes, S. Singh, C. R. Myers, D. J. Schneider, Epidemic fronts in complex networks with metapopulation structure, Phys. Rev. E 88 (2013) 012809.
- [77] A. Vazquez, Spreading dynamics on heterogeneous populations: Multitype network approach, Phys. Rev. E 74 (2006) 066114.
- [78] A. Cardillo, J. Gómez-Gardeñes, M. Zanin, M. Romance, D. Papo, F. del Pozo, S. Boccaletti, Emergence of network features from multiplexity, Sci. Rep. 3 (2013) 1344.
- [79] R. J. Sánchez García, E. Cozzo, Y. Moreno, Dimensionality reduction and spectral properties of multilayer networks, ArXiv e-printsarXiv:1311.1759.
- [80] E. A. Leicht, R. M. D’Souza, Percolation on interacting networks, ArXiv e-printsarXiv:0907.0894.
- [81] C. D. Brummitt, R. M. D’Souza, E. A. Leicht, Suppressing cascades of load in interdependent networks, Proc. Natl. Acad. Sci. U.S.A. 109 (12) (2012) E680–689.
- [82] P. Bonacich, Power and centrality: A family of measures, Amer. J. Sociol. 92 (5) (1987) 1170–1182.
- [83] J. Aguirre, D. Papo, J. M. Buldu, Successful strategies for competing networks, Nat. Phys. 9 (4) (2013) 230–234. doi:10.1038/nphys2556.
- [84] S. Brin, L. Page, The anatomy of a large-scale hypertextual web search engine, in: Computer networks and ISDN systems, Elsevier Science Publishers B. V., 1998, pp. 107–117.
- [85] D. J. Watts, S. H. Strogatz, Collective dynamics of ’small-world’ networks, Nature 393 (6684) (1998) 440–442.
- [86] R. Luce, A. Perry, A method of matrix analysis of group structure, Psychometrika 14 (2) (1949) 95–116.
- [87] V. Latora, M. Marchiori, Economic small-world behavior in weighted networks, Eur. Phys. J. B 52 (2003) 249–263.
- [88] P. Bródka, K. Musial, P. Kazienko, A method for group extraction in complex social networks, in: M. Lytras, P. Ordonez De Pablos, A. Ziderman, A. Roulstone, H. Maurer, J. Imber (Eds.), Knowledge Management, Information Systems, E-Learning, and Sustainability Research, Vol. 111 of Communications in Computer and Information Science, Springer Berlin Heidelberg, 2010, pp. 238–247.
- [89] P. Bródka, P. Kazienko, K. Musiał, K. Skibicki, Analysis of neighbourhoods in multi-layered dynamic social networks, International Journal of Computational Intelligence Systems 5 (3) (2012) 582–596.
- [90] L. da F. Costa, F. Rodrigues, G.Travieso, P. Boas, Characterization of complex networks: A survey of measurements, Advances in Physics 56 (2007) 167–242.
- [91] V. Latora, M. Marchiori, Efficient behavior of small-world networks, Phys. Rev. Lett. 87 (19) (2001) 198701. doi:10.1103/PhysRevLett.87.198701.
- [92] R. G. Morris, M. Barthélemy, Transport on coupled spatial networks, Phys. Rev. Lett. 109 (12) (2012) 128703. doi:10.1103/PhysRevLett.109.128703.
- [93] P. Van Mieghem, Graph Spectra for Complex Networks, Cambridge University Press, Cambridge, 2012.
- [94] A. Brouwer, W. Haemers, Spectra of graphs, Springer, Amsterdam, 2012.
- [95] W. Haemers, Interlacing eigenvalues and graphs, Linear Algebra and its applications 226 (1995) 593–616.
- [96] F. Radicchi, A. Arenas, Abrupt transition in the structural formation of interconnected networks, Nat. Phys. 9 (2013) 717–720.
- [97] R. Criado, J. Flores, E. Garcia, A. G. del Amo, M. Romance, L. Sola, A perron-frobenius theory for block matrices and tensor calculus of multiplex networks, Preprint 1 (2014) 1–20.
- [98] M. De Domenico, A. Solé-Ribalta, S. Gómez, A. Arenas, Random Walks on Multiplex Networks, ArXiv e-printsarXiv:1306.0519.
- [99] M. A. Porter, J.-P. Onnela, P. J. Mucha, Communities in networks, Notices of the American Mathematical Society 56 (2009) 1082–1097.
- [100] M. E. J. Newman, M. Girvan, Finding and evaluating community structure in networks, Phys. Rev. E 69 (2004) 026113.
- [101] R. Milo, S. Shen-Orr, S. Itzkovitz, N. Kashtan, D. Chklovskii, U. Alon, Network motifs: simple building blocks of complex networks, Science 298 (5594) (2002) 824–827.
- [102] S. S. Shen-Orr, R. Milo, S. Mangan, U. Alon, Network motifs in the transcriptional regulation network of escherichia coli, Nature genetics 31 (1) (2002) 64–68.
- [103] T. G. Kolda, B. W. Bader, Tensor decompositions and applications, SIAM REVIEW 51 (3) (2009) 455–500.
- [104] D. M. Dunlavy, T. G. Kolda, , W. P. Kegelmeyer, Multilinear algebra for analyzing data with multiple linkages, in: J. Kepner, J. Gilbert (Eds.), Graph Algorithms in the Language of Linear Algebra, Fundamentals of Algorithms, SIAM, Philadelphia, 2011, pp. 85–114.
- [105] E. Acar, B. Yener, Unsupervised multiway data analysis: A literature survey., IEEE Trans. Knowl. Data Eng. 21 (1) (2009) 6–20.
- [106] C. D. Martin, M. A. Porter, The extraordinary svd, Am. Math. Mon. 119 (10) (2012) 838–851.
- [107] J. Carroll, J.-J. Chang, Analysis of individual differences in multidimensional scaling via an n-way generalization of "Eckart-Young" decomposition, Psychometrika 35 (3) (1970) 283–319.
- [108] R. Harshman, Foundations of the parafac procedure: Models and conditions for an “explanatory” multi-modal factor analysis, UCLA Working Papers in Phonetics 16.
- [109] T. Kolda, B. Bader, The TOPHITS model for higher-order web link analysis, in: Proc. of Link Analysis, Counterterrorism and Security 2006, 2006, pp. 1–12.
- [110] T. G. Kolda, B. W. Bader, J. P. Kenny, Higher-order web link analysis using multilinear algebra, in: ICDM 2005: Proc. of the 5th IEEE International Conference on Data Mining, 2005, pp. 242–249.
- [111] T. G. Kolda, J. Sun, Scalable tensor decompositions for multi-aspect data mining, in: Proc. of the 8th IEEE International Conference on Data Mining (ICDM 2008), 2008, pp. 363–372.
- [112] E. Acar, D. M. Dunlavy, T. G. Kolda, Link prediction on evolving data using matrix and tensor factorizations, in: Proc. of the 2009 IEEE International Conference on Data Mining Workshops, ICDMW ’09, IEEE Computer Society, Washington, DC, USA, 2009, pp. 262–269.
- [113] G. Menichetti, D. Remondini, P. Panzarasa, R. J. Mondragón, G. Bianconi, Weighted Multiplex Networks, ArXiv e-printsarXiv:1312.6720.
- [114] A. Barrat, M. Barthélemy, R. P.-S. A. Vespignani, The architecture of complex weighted networks, PNAS 101 (2004) 3747–3752.
- [115] M. Barthélemy, B. Gondran, E. Guichard, Spatial structure of the internet traffic, Physica A 319 (2003) 633–642.
- [116] E. Almaas, B. Kovacs, T. Vicsek, Z. N. Oltvai, A.-L. Barabási, Global organization of metabolic fluxes in the bacterium escherichia coli., Nature 427 (2004) 839–843.
- [117] V. Nicosia, V. Latora, Measuring and modelling correlations in multiplex networks, ArXiv e-printsarXiv:1403.1546v1.
- [118] S. N. Dorogovtsev, J. F. F. Mendes, Evolution of Networks: From Biological Nets to the Internet and WWW, Oxford University Press, 2003.
- [119] C. I. D. Genio, H. Kim, Z. Toroczkai, K. E. Bassler, Efficient and exact sampling of simple graphs with given arbitrary degree sequence, PLoS ONE 5 (2010) e10012.
- [120] H. Kim, C. I. D. Genio, K. E. Bassler, Z. Toroczkai, Constructing and sampling directed graphs with given degree sequences, New J. Phys. 14 (2) (2012) 023012.
- [121] V. Nicosia, G. Bianconi, V. Latora, M. Barthélemy, Non-linear growth and condensation in multiplex networks, ArXiv e-printsarXiv:1312.3683.
- [122] M. Magnani, L. Rossi, The ml-model for multi-layer social networks, in: ASONAM, IEEE Computer Society, 2011, pp. 5–12.
- [123] M. Magnani, L. Rossi, Formation of multiple networks, in: A. Greenberg, W. Kennedy, N. Bos (Eds.), Social Computing, Behavioral-Cultural Modeling and Prediction, Vol. 7812 of Lecture Notes in Computer Science, Springer Berlin Heidelberg, 2013, pp. 257–264. doi:10.1007/978-3-642-37210-0_28.
- [124] P. Wang, G. Robins, P. Pattison, E. Lazega, Exponential random graph models for multilevel networks, Social Networks 35 (2013) 96–115.
- [125] M. De Domenico, A. Solé-Ribalta, E. Omodei, S. Gómez, A. Arenas, Centrality in Interconnected Multilayer Networks, ArXiv e-printsarXiv:1311.2906.
- [126] S. Funk, V. A. A. Jansen, Interacting epidemics on overlay networks, Phys. Rev. E 81 (2010) 036118.
- [127] V. Marceau, P.-A. Noël, L. Hébert-Dufresne, A. Allard, L. J. Dubé, Modeling the dynamical interaction between epidemics on overlay networks, Phys. Rev. E 84 (2011) 026105.
- [128] A. Patrinos, S. Hakimi, Relations between graphs and integer-pair sequences, Discrete Mathematics 15 (4) (1976) 347 – 358.
- [129] B. Söderberg, General formalism for inhomogeneous random graphs, Phys. Rev. E 66 (2002) 066121.
- [130] B. Söderberg, Random graphs with hidden color, Phys. Rev. E 68 (2003) 015102.
- [131] B. Söderberg, Properties of random graphs with hidden color, Phys. Rev. E 68 (2003) 026107.
- [132] B. Söderberg, Random graph models with hidden color, Acta Phys. Pol. B (2003) 5085.
- [133] A. Barbour, G. Reinert, The shortest distance in random multi-type intersection graphs, Random Structures & Algorithms 39 (2) (2011) 179–209.
- [134] S. Melnik, M. A. Porter, P. J. Mucha, J. P. Gleeson, Dynamics on modular networks with heterogeneous correlations, Chaos 24 (2) (2014) 023106.
- [135] P. W. Holland, K. B. Laskey, S. Leinhardt, Stochastic blockmodels: First steps, Social Networks 5 (2) (1983) 109 – 137.
- [136] S. E. Fienberg, M. M. Meyer, S. S. Wasserman, Statistical analysis of multiple sociometric relations, J. Amer. Statist. Assoc. 80 (389) (1985) 51–67.
- [137] Y. J. Wang, G. Y. Wong, Stochastic blockmodels for directed graphs, Journal of the American Statistical Association 82 (397) (1987) 8–19.
- [138] M. E. J. Newman, E. A. Leicht, Mixture models and exploratory analysis in networks, Proc. Natl. Acad. Sci. U.S.A. 104 (23) (2007) 9564–9569.
- [139] G. Robins, P. Pattison, Y. Kalish, D. Lusher, An introduction to exponential random graph (p)models for social networks, Social Networks 29 (2007) 173–191.
- [140] G. Robins, T. A. B. Snijders, P. Wang, M. Handcock, P. Pattison, Recent developments inexponential random graph (p) models for social networks, Social Networks 29 (2007) 192–215.
- [141] O. Frank, D. Strauss, Markov graphs, J. Am. Stat. Assoc. 81 (395) (1986) 832–842.
- [142] D. Lusher, J. Koskinen, G. Robins, Exponential Random Graph Models for Social Networks, Cambridge University Press,Cambridge, 2013, 2013.
- [143] J. Park, M. E. J. Newman, The statistical mechanics of networks, Phys. Rev. E 70 (2004) 066117.
- [144] G. Bianconi, The entropy of randomized network ensembles, Eurphys. Lett. 81 (2008) 28005.
- [145] T. Squartini, D. Garlaschelli, Analytical maximum-likelihood method to detect patterns in real networks, New J. Phys. 13 (2011) 083001.
- [146] K. Anand, G. Bianconi, Entropy measures for networks: toward an information theory of complex topologies, Phys. Rev. E 80 (2009) 045102.
- [147] M. M. G. Bianconi, P. Pin, Assessing the relevance of node features for network structure, Proc. Natl. Acad. Sci. U.S.A. 106 (28) (2009) 11433–11438.
- [148] M. Rosvall, C. T. Bergstrom, An information-theoretic framework for resolving community structure in complex networks, Proc. Natl. Acad. Sci. U.S.A. 104 (18) (2007) 7327–7331.
- [149] A. Halu, S. Mukherjee, G. Bianconi, Emergence of overlap in ensembles of spatial multiplexes and statistical mechanics of spatial interacting network ensembles, Phys. Rev. E 89 (2014) 012806.
- [150] E. Lazega, P. E. Pattison, Multiplexity, generalized exchange and cooperation in organizations: a case study, Social Networks 21 (1999) 67–90.
- [151] M. T. Heaney, Multiplex networks and interest group influence reputation: An exponential random graph model, Social Networks 36 (2014) 66–81.
- [152] G. Bianconi, S. N. Dorogovtsev, J. F. F. Mendes, Mutually connected component of network of networks, ArXiv e-printsarXiv:1402.0215.
- [153] J. Gao, S. V. Buldyrev, S. Havlin, H. E. Stanley, Robustness of a network of networks, Phys. Rev. Lett. 107 (19) (2011) 195701.
- [154] G. Bianconi, S. N. Dorogovtsev, Multiple percolation transitions in a configuration model of network of networks, ArXiv e-printsarXiv:1402.0218.
- [155] J. Gao, S. V. Buldyrev, S. Havlin, H. E. Stanley, Robustness of a network formed by n interdependent networks with a one-to-one correspondence of dependent nodes, Phys. Rev. E 85 (6 Pt 2) (2012) 066134.
- [156] J. Gao, S. V. Buldyrev, H. E. Stanley, X. Xu, S. Havlin, Percolation of a general network of networks, Phys. Rev. E 88 (2013) 062816.
- [157] D. S. Callaway, M. E. J. Newman, S. H. Strogatz, D. J. Watts, Network robustness and fragility: Percolation on random graphs, Phys. Rev. Lett. 85 (2000) 5468–5471.
- [158] R. Cohen, K. Erez, D. ben Avraham, S. Havlin, Resilience of the internet to random breakdowns, Phys. Rev. Lett. 85 (2000) 4626–4628.
- [159] R. Cohen, K. Erez, D. ben Avraham, S. Havlin, Breakdown of the internet under intentional attack, Phys. Rev. Lett. 86 (2001) 3682–3685.
- [160] R. Cohen, D. ben Avraham, S. Havlin, Percolation critical exponents in scale-free networks, Phys. Rev. E 66 (2002) 036113.
- [161] A. Vázquez, Y. Moreno, Resilience to damage of graphs with degree correlations, Phys. Rev. E 67 (2003) 015101. doi:10.1103/PhysRevE.67.015101.
- [162] P. Crucitti, V. Latora, M. Marchiori, A. Rapisarda, Efficiency of scale-free networks: error and attack tolerance, Physica A 320 (0) (2003) 622 – 642.
- [163] P. Crucitti, V. Latora, M. Marchiori, A. Rapisarda, Error and attack tolerance of complex networks, Physica A 340 (1–3) (2004) 388 – 394.
- [164] A. Vespignani, Complex networks: The fragility of interdependency, Nature 464 (7291) (2010) 984–985.
- [165] S.-W. Son, P. Grassberger, M. Paczuski, Percolation transitions are not always sharpened by making networks interdependent, Phys. Rev. Lett. 107 (2011) 195702.
- [166] Y. Berezin, A. Bashan, S. Havlin, Comment on “percolation transitions are not always sharpened by making networks interdependent”, Phys. Rev. Lett. 111 (2013) 189601.
- [167] S.-W. Son, P. Grassberger, M. Paczuski, Son, grassberger, and paczuski reply:, Phys. Rev. Lett. 111 (2013) 189602.
- [168] G. J. Baxter, S. N. Dorogovtsev, A. V. Goltsev, J. F. F. Mendes, Avalanche collapse of interdependent networks, Phys. Rev. Lett. 109 (2012) 248701. doi:10.1103/PhysRevLett.109.248701.
- [169] J. Shao, S. V. Buldyrev, S. Havlin, H. E. Stanley, Cascade of failures in coupled network systems with multiple support-dependence relations, Phys. Rev. E 83 (2011) 036116.
- [170] X. Huang, J. Gao, S. V. Buldyrev, S. Havlin, H. E. Stanley, Robustness of interdependent networks under targeted attack, Phys. Rev. E 83 (2011) 065101.
- [171] S.-W. Son, G. Bizhani, C. Christensen, P. Grassberger, M. Paczuski, Percolation theory on interdependent networks based on epidemic spreading, Eurphys. Lett. 97 (1) (2012) 16006.
- [172] M. Mezard, A. Montanari, Information, Physics and Computation, Oxford University Press, Oxford, 2009.
- [173] M. Mézard, G. Parisi, The cavity method at zero temperature, J. Stat. Phys. 111 (1-2) (2003) 1–34.
- [174] A. K. Hartmann, M. Weigt, Phase Transitions in Combinatorial Optimization Problems: Basics, Algorithms and Statistical Mechanics, Wiley-VCH, Weinheim, 2005.
- [175] S. Watanabe, Y. Kabashima, Cavity-based robustness analysis of interdependent networks: Influences of intranetwork and internetwork degree-degree correlations, Phys. Rev. E 89 (2014) 012808.
- [176] O. Yağan, V. Gligor, Analysis of complex contagions in random multiplex networks, Phys. Rev. E 86 (2012) 036103.
- [177] R. Parshani, S. V. Buldyrev, S. Havlin, Critical effect of dependency groups on the function of networks, Proc. Natl. Acad. Sci. U.S.A. 108 (3) (2011) 1007–1010.
- [178] A. Bashan, R. Parshani, S. Havlin, Percolation in networks composed of connectivity and dependency links, Phys. Rev. E 83 (2011) 051127.
- [179] Y. Hu, B. Ksherim, R. Cohen, S. Havlin, Percolation in interdependent and interconnected networks: Abrupt change from second- to first-order transitions, Phys. Rev. E 84 (2011) 066116.
- [180] D. Zhou, J. Gao, H. E. Stanley, S. Havlin, Percolation of partially interdependent scale-free networks, Phys. Rev. E 87 (2013) 052812.
- [181] Y. Hu, D. Zhou, R. Zhang, Z. Han, C. Rozenblat, S. Havlin, Percolation of interdependent networks with intersimilarity, Phys. Rev. E 88 (2013) 052805.
- [182] M. Li, R.-R. Liu, C.-X. Jia, B.-H. Wang, Critical effects of overlapping of connectivity and dependence links on percolation of networks, New J. Phys. 15 (9) (2013) 093013.
- [183] S. V. Buldyrev, N. W. Shere, G. A. Cwilich, Interdependent networks with identical degrees of mutually dependent nodes, Phys. Rev. E 83 (2011) 016112.
- [184] R. Parshani, C. Rozenblat, D. Ietri, C. Ducruet, S. Havlin, Inter-similarity between coupled networks, Eurphys. Lett. 92 (6) (2010) 68002.
- [185] D. Zhou, H. E. Stanley, G. D’Agostino, A. Scala, Assortativity decreases the robustness of interdependent networks, Phys. Rev. E 86 (2012) 066103.
- [186] X. Huang, S. Shao, H. Wang, S. V. Buldyrev, H. E. Stanley, S. Havlin, The robustness of interdependent clustered networks, Eurphys. Lett. 101 (1) (2013) 18002.
- [187] L. D. Valdez, P. A. Macri, H. E. Stanley, L. A. Braunstein, Triple point in correlated interdependent networks, Phys. Rev. E 88 (2013) 050803.
- [188] W. Li, A. Bashan, S. V. Buldyrev, H. E. Stanley, S. Havlin, Cascading failures in interdependent lattice networks: The critical role of the length of dependency links, Phys. Rev. Lett. 108 (2012) 228702. doi:10.1103/PhysRevLett.108.228702.
- [189] A. Bashan, Y. Berezin, S. V. Buldyrev, S. Havlin, The extreme vulnerability of interdependent spatially embedded networks, Nat. Phys. 9 (10) (2013) 667–672.
- [190] M. Stippinger, J. Kertész, Enhancing resilience of interdependent networks by healing, ArXiv e-printsarXiv:1312.1993.
- [191] Y. Berezin, A. Bashan, M. M. Danziger, D. Li, S. Havlin, Spatially localized attacks on interdependent networks: the existence of a finite critical attack size, ArXiv e-printsarXiv:1310.0996.
- [192] M. E. J. Newman, Mixing patterns in networks, Phys. Rev. E 67 (2003) 026126.
- [193] S. Guha, D. Towsley, C. Capar, A. Swami, P. Basu, Layered Percolation, ArXiv e-printsarXiv:1402.7057.
- [194] K. Zhao, G. Bianconi, Percolation on interacting, antagonistic networks, Journal of Statistical Mechanics: Theory and Experiment 2013 (05) (2013) P05005.
- [195] N. Azimi-Tafreshi, J. Gómez-Gardeñes, S. N. Dorogovtsev, k-Core percolation on multiplex networks, ArXiv e-printsarXiv:1405.1336.
- [196] B. Min, K.-I. Goh, Multiple resource demands and viability in multiplex networks, Phys. Rev. E 89 (2014) 040802.
- [197] G. J. Baxter, S. N. Dorogovtsev, J. F. F. Mendes, D. Cellai, Weak percolation on multiplex networks, Phys. Rev. E 89 (2014) 042801.
- [198] K.-M. Lee, K.-I. Goh, I.-M. Kim, Sandpiles on multiplex networks, J. Korean Phys. Soc. 60 (4) (2012) 641–647.
- [199] P. Bak, C. Tang, K. Wiesenfeld, Self-organized criticality, Phys. Rev. A 38 (1988) 364–374.
- [200] D. J. Watts, A simple model of global cascades on random networks, Proc. Natl. Acad. Sci. U.S.A. 99 (9) (2002) 5766–5771.
- [201] K.-M. Lee, C. D. Brummitt, K.-I. Goh, Slowed yet explosive global cascades driven by response heterogeneity in multiplex networks, ArXiv e-printsarXiv:1403.3472.
- [202] P. Blanchard, D. Volchenkov, Random Walks and Diffusions on Graphs and Databases, Springer, 2011.
- [203] B. Tadic, G. J. Rodgers, Packet transport on scale-free networks, Advances in Complex Systems (ACS) 05 (04) (2002) 445–456.
- [204] J. D. Noh, H. Rieger, Random walks on complex networks, Phys. Rev. Lett. 92 (11) (2004) 118701.
- [205] S.-J. Yang, Exploring complex networks by walking on them, Phys. Rev. E 71 (2005) 016107.
- [206] L. F. Costa, O. Sporns, L. Antiqueira, M. G. V. Nunes, O. N. Oliveira Jr., Correlations between structure and random walk dynamics in directed complex networks, Appl. Phys. Lett. 91 (5) (2007) 054107.
- [207] S. Condamin, O. Bénichou, V. Tejedor, R. Voituriez, J. Klafter, First-passage times in complex scale-invariant media, Nature 450 (7166) (2007) 77–80.
- [208] J. Gómez-Gardeñes, V. Latora, Entropy rate of diffusion processes on complex networks, Phys. Rev. E 78 (6 Pt 2) (2008) 065102.
- [209] S. Valverde, R. V. Solé, Self-organized critical traffic in parallel computer networks, Physica A 312 (3) (2002) 636–648.
- [210] R. Guimera, A. Díaz-Guilera, F. Vega-Redondo, A. Cabrales, A. Arenas, Optimal network topologies for local search with congestion, Phys. Rev. Lett. 89 (24) (2002) 248701.
- [211] P. Echenique, J. Gómez-Gardeñes, Y. Moreno, Dynamics of jamming transitions in complex networks, Eurphys. Lett. 71 (2) (2005) 325.
- [212] D. De Martino, L. Dall’Asta, G. Bianconi, M. Marsili, Congestion phenomena on complex networks, Phys. Rev. E 79 (1 Pt 2) (2009) 015101.
- [213] M. Fiedler, Algebraic connectivity of graphs, Czechoslovak Mathematical Journal 23 (2) (1973) 298–305.
- [214] M. E. J. Newman, Networks: An Introduction, Oxford University Press, New York, 2010.
- [215] R. Cohen, S. Havlin, Complex Networks: Structure, Robustness and Function, Cambridge University Press, Cambridge, 2010.
- [216] E. Estrada, N. Hatano, Communicability in complex networks, Phys. Rev. E 77 (2008) 036111.
- [217] E. Estrada, N. Hatano, M. Benzi, The physics of communicability in complex networks, Physics reports 514 (3) (2012) 89–119.
- [218] E. Estrada, J. Gómez-Gardeñes, Communicability reveals a transition to coordinated behavior in multiplex networks, ArXiv e-printsarXiv:1312.3234.
- [219] M. Marchiori, The quest for correct information on the web: Hyper search engines, Computer Networks and ISDN Systems 29 (8) (1997) 1225–1235.
- [220] A. Arenas, A. Díaz-Guilera, R. Guimerá, Communication in Networks with Hierarchical Branching, Phys. Rev. Lett. 86 (2001) 3196.
- [221] R. Guimerá, A. Díaz-Guilera, F. Vega-Redondo, A. Cabrales, A. Arenas, Optimal Network Topologies for Local Search with Congestion, Phys. Rev. Lett. 89 (2002) 248701.
- [222] Z. Toroczkai, K. Bassler, Network dynamics: Jamming is limited in scale-free systems, Nature 428 (2004) 716.
- [223] P. Echenique, J. Gómez-Gardeñes, Y. Moreno, Improved routing strategies for internet traffic delivery, Phys. Rev. E 70 (2004) 056105.
- [224] J. Zhou, G. Yan, C.-H. Lai, Efficient routing on multilayered communication networks, Eurphys. Lett. 102 (2) (2013) 28002.
- [225] Y. Zhuo, Y. Peng, C. Liu, Y. Liu, , K. Long, Traffic dynamics on layered complex networks, Phyica A 391 (2011) 2401.
- [226] F. Tan, J. Wu, Y. Xia, C. K. Tse, Traffic congestion in interconnected complex networks, ArXiv e-printsarXiv:1401.0412.
- [227] S. N. Dorogovtsev, A. V. Goltsev, J. F. F. Mendes, Critical phenomena in complex networks, Rev. Mod. Phys 80 (2008) 1275–1335.
- [228] A. V. Goltsev, S. N. Dorogovtsev, J. G. Oliveira, J. F. F. Mendes, Localization and spreading of diseases in complex networks, Phys. Rev. Lett. 109 (2012) 128702. doi:10.1103/PhysRevLett.109.128702.
- [229] M. Boguñá, C. Castellano, R. Pastor-Satorras, Nature of the epidemic threshold for the susceptible-infected-susceptible dynamics in networks, Phys. Rev. Lett. 111 (2013) 068701. doi:10.1103/PhysRevLett.111.068701.
- [230] R. Anderson, R. May, B. Anderson, Infectious diseases of humans: Dynamics and Control, Oxford University Press, Oxford, 1992.
- [231] H. Hethcote, The mathematics of infectious diseases, SIAM Review 42 (2000) 599–653.
- [232] D. Daley, J. Gani, Epidemic Modelling, Cambridge University Press, Cambridge, 1999.
- [233] J. Murray, Mathematical Biology, Springer-Verlag, Berlin, 2002.
- [234] J. Marro, R. Dickman, Nonequilibrium Phase Transition in Lattice Model, Cambridge University Press, Cambridge, 1999.
- [235] S. Gómez, A. Arenas, J. Borge-Holthoefer, S. Meloni, Y. Moreno, Discrete-time markov chain approach to contact-based disease spreading in complex networks, Eurphys. Lett. 89 (3) (2010) 38009.
- [236] F. Chung, L. Lu, V. Vu, Spectra of random graphs with given expected degrees, Proc. Natl. Acad. Sci. U.S.A. 100 (11) (2003) 6313–6318.
- [237] B. Guerra, J. Gómez-Gardeñes, Annealed and mean-field formulations of disease dynamics on static and adaptive networks, Phys. Rev. E 82 (3 Pt 2) (2010) 035101.
- [238] S. Gómez, J. Gómez-Gardeñes, Y. Moreno, A. Arenas, Nonperturbative heterogeneous mean-field approach to epidemic spreading in complex networks, Phys. Rev. E 84 (3 Pt 2) (2011) 036105.
- [239] R. Pastor-Satorras, A. Vespignani, Epidemic spreading in scale-free networks, Phys. Rev. Lett. 86 (14) (2001) 3200–3203.
- [240] R. Pastor-Satorras, A. Vespignani, Epidemic dynamics and endemic states in complex networks, Phys. Rev. E 63 (6 Pt 2) (2001) 066117.
- [241] M. Boguñá, R. Pastor-Satorras, Epidemic spreading in correlated complex networks, Phys. Rev. E 66 (4 Pt 2) (2002) 047104.
- [242] A. Saumell-Mendiola, M. A. Serrano, M. Boguna, Epidemic spreading on interconnected networks, Phys. Rev. E 86 (2 Pt 2) (2012) 026106.
- [243] F. Sahneh, C. Scoglio, F. Chowdhury, Effect of coupling on the epidemic threshold in interconnected complex networks: A spectral analysis, in: American Control Conference (ACC), 2013, 2013, pp. 2307–2312.
- [244] H. Wang, Q. Li, G. D’Agostino, S. Havlin, H. E. Stanley, P. Van Mieghem, Effect of the interconnected network structure on the epidemic threshold, Phys. Rev. E 88 (2) (2013) 022801.
- [245] M. Dickison, S. Havlin, H. E. Stanley, Epidemics on interconnected networks, Phys. Rev. E 85 (6 Pt 2) (2012) 066109.
- [246] R. Vida, J. Galeano, S. Cuenda, Vulnerability of overlay networks under malware spreading, ArXiv e-printsarXiv:1310.0741.
- [247] B. Min, K.-I. Goh, Layer-crossing overhead and information spreading in multiplex social networks, ArXiv e-printsarXiv:1307.2967.
- [248] O. Yagan, D. Qian, J. Zhang, D. Cochran, Conjoining speeds up information diffusion in overlaying social-physical networks, Selected Areas in Communications, IEEE Journal on 31 (6) (2013) 1038–1048.
- [249] M. E. Newman, Threshold effects for two pathogens spreading on a network, Phys. Rev. Lett. 95 (10) (2005) 108701.
- [250] B. Karrer, M. E. Newman, Competing epidemics on complex networks, Phys. Rev. E 84 (3 Pt 2) (2011) 036106.
- [251] Y. Wang, G. Xiao, J. Liu, Dynamics of competing ideas in complex social systems, New J. Phys. 14 (1) (2012) 013015.
- [252] F. Darabi Sahneh, C. Scoglio, May the Best Meme Win!: New Exploration of Competitive Epidemic Spreading over Arbitrary Multi-Layer Networks, ArXiv e-printsarXiv:1308.4880.
- [253] X. Wei, N. Valler, B. A. Prakash, I. Neamtiu, M. Faloutsos, C. Faloutsos, Competing memes propagation on networks: A case study of composite networks, SIGCOMM Comput. Commun. Rev. 42 (5) (2012) 5–12.
- [254] X. Wei, N. Valler, B. A. Prakash, I. Neamtiu, M. Faloutsos, C. Faloutsos, Competing memes propagation on networks: A network science perspective., IEEE Journal on Selected Areas in Communications 31 (6) (2013) 1049–1060.
- [255] P. V. Mieghem, J. Omic, R. Kooij, Virus spread in networks., IEEE/ACM Trans. Netw. 17 (1) (2009) 1–14.
- [256] C. Granell, S. Gómez, A. Arenas, Dynamical interplay between awareness and epidemic spreading in multiplex networks, Phys. Rev. Lett. 111 (12) (2013) 128701. doi:10.1103/PhysRevLett.111.128701.
- [257] C. Buono, L. G. Alvarez Zuzek, P. A. Macri, L. A. Braunstein, Epidemics in partially overlapped multiplex networks, ArXiv e-printsarXiv:1310.1939.
- [258] D. Zhao, L. Li, H. Peng, Q. Luo, Y. Yang, Multiple routes transmitted epidemics on multiplex networks, Physics Letters A 378 (2014) 770–776. arXiv:1312.6931.
- [259] C. A. Gilligan, An epidemiological framework for disease management, Advances in botanical research 38 (2002) 1–64.
- [260] W. H. Organization, Global tuberculosis control: WHO report 2010, World Health Organization, 2010.
- [261] R. A. Fouchier, T. Kuiken, M. Schutten, G. Van Amerongen, G. J. van Doornum, B. G. van den Hoogen, M. Peiris, W. Lim, K. Stöhr, A. D. Osterhaus, Aetiology: Koch’s postulates fulfilled for sars virus, Nature 423 (6937) (2003) 240.
- [262] M. Small, D. M. Walker, C. K. Tse, Scale-free distribution of avian influenza outbreaks, Phys. Rev. Lett. 99 (18) (2007) 188702.
- [263] C. Fraser, C. A. Donnelly, S. Cauchemez, W. P. Hanage, M. D. Van Kerkhove, T. D. Hollingsworth, J. Griffin, R. F. Baggaley, H. E. Jenkins, E. J. Lyons, et al., Pandemic potential of a strain of influenza a (h1n1): early findings, science 324 (5934) (2009) 1557–1561.
- [264] R. Pastor-Satorras, A. Vespignani, Immunization of complex networks, Phys. Rev. E 65 (3) (2002) 036104.
- [265] J. Müller, B. Schönfisch, M. Kirkilionis, Ring vaccination, Journal of mathematical biology 41 (2) (2000) 143–171.
- [266] R. Cohen, S. Havlin, D. Ben-Avraham, Efficient immunization strategies for computer networks and populations, Phys. Rev. Lett. 91 (24) (2003) 247901.
- [267] V. M. Eguiluz, M. G. Zimmermann, Transmission of information and herd behavior: an application to financial markets, Phys. Rev. Lett. 85 (26) (2000) 5659.
- [268] A. Nowak, J. Szamrej, B. Latané, From private attitude to public opinion: A dynamic theory of social impact., Psychological Review 97 (3) (1990) 362.
- [269] S. Funk, E. Gilad, C. Watkins, V. A. Jansen, The spread of awareness and its impact on epidemic outbreaks, Proc. Natl. Acad. Sci. U.S.A. 106 (16) (2009) 6872–6877.
- [270] P. E. Fine, J. A. Clarkson, Individual versus public priorities in the determination of optimal vaccination policies, American Journal of Epidemiology 124 (6) (1986) 1012–1020.
- [271] C. T. Bauch, Imitation dynamics predict vaccinating behaviour, Proc. R. Soc. B 272 (1573) (2005) 1669–1675.
- [272] C. for Disease Control, Prevention, Preventing seasonal flue., Atlanta: Centers for Disease Control and Prevention, 2008.
- [273] P.-Y. Geoffard, T. Philipson, Disease eradication: private versus public vaccination, American Economic Review 87 (1) (1997) 222–230.
- [274] Y. Ibuka, M. Li, J. Vietri, G. B. Chapman, A. P. Galvani, Free-riding behavior in vaccination decisions: An experimental study, PloS one 9 (1) (2014) e87164.
- [275] P. J. Francis, Dynamic epidemiology and the market for vaccinations, Journal of Public Economics 63 (3) (1997) 383–406.
- [276] C. T. Bauch, A. P. Galvani, D. J. Earn, Group interest versus self-interest in smallpox vaccination policy, Proc. Natl. Acad. Sci. U.S.A. 100 (18) (2003) 10564–10567.
- [277] C. T. Bauch, D. J. Earn, Vaccination and the theory of games, Proc. Natl. Acad. Sci. U.S.A. 101 (36) (2004) 13391–13394.
- [278] H. Zhang, J. Zhang, C. Zhou, M. Small, B. Wang, Hub nodes inhibit the outbreak of epidemic under voluntary vaccination, New Journal of Physics 12 (2) (2010) 023015.
- [279] A. Cardillo, C. Reyes-Suárez, F. Naranjo, J. Gómez-Gardeñes, Evolutionary vaccination dilemma in complex networks, Phys. Rev. E 88 (3) (2013) 032803.
- [280] F. Fu, D. I. Rosenbloom, L. Wang, M. A. Nowak, Imitation dynamics of vaccination behaviour on social networks, Proc. R. Soc. B 278 (1702) (2011) 42–49.
- [281] X.-T. Liu, Z.-X. Wu, L. Zhang, Impact of committed individuals on vaccination behavior, Phys. Rev. E 86 (5) (2012) 051132.
- [282] L. Mao, Y. Yang, Coupling infectious diseases, human preventive behavior, and networks–a conceptual framework for epidemic modeling, Social Science & medicine 74 (2) (2012) 167–175.
- [283] K. Stöhr, M. Esveld, Will vaccines be available for the next influenza pandemic?, Science 306 (5705) (2004) 2195–2196.
- [284] L. Mao, Modeling triple-diffusions of infectious diseases, information, and preventive behaviors through a metropolitan social network—an agent-based simulation, Applied Geography 50 (2014) 31–39.
- [285] C. T. Bauch, A. P. Galvani, Social factors in epidemiology, Science 342 (6154) (2013) 47–49.
- [286] S. Redner, A guide to first-passage processes, Cambridge University Press, 2001.
- [287] C. Castellano, S. Fortunato, V. Loreto, Statistical physics of social dynamics, Reviews of modern physics 81 (2) (2009) 591.
- [288] R. Hegselmann, U. Krause, Opinion dynamics and bounded confidence models, analysis, and simulation, Journal of Artificial Societies and Social Simulation 5 (3).
- [289] J. H. Fowler, C. T. Dawes, Two genes predict voter turnout, The Journal of Politics 70 (03) (2008) 579–594.
- [290] K. Sznajd-Weron, J. Sznajd, Opinion evolution in closed community, International Journal of Modern Physics C 11 (06) (2000) 1157–1165.
- [291] P. Krapivsky, S. Redner, Dynamics of majority rule in two-state interacting spin systems, Phys. Rev. Lett. 90 (23) (2003) 238701.
- [292] Z.-X. Wu, P. Holme, Majority-vote model on hyperbolic lattices, Phys. Rev. E 81 (1) (2010) 011133.
- [293] B. Kozma, A. Barrat, Consensus formation on adaptive networks, Phys. Rev. E 77 (1) (2008) 016102.
- [294] R. A. Holley, T. M. Liggett, Ergodic theorems for weakly interacting infinite systems and the voter model, The annals of probability (1975) 643–663.
- [295] K. Suchecki, V. M. Eguíluz, M. San Miguel, Voter model dynamics in complex networks: Role of dimensionality, disorder, and degree distribution, Phys. Rev. E 72 (3) (2005) 036132.
- [296] V. Sood, S. Redner, Voter model on heterogeneous graphs, Phys. Rev. Lett. 94 (17) (2005) 178701.
- [297] J. Shao, S. Havlin, H. E. Stanley, Dynamic opinion model and invasion percolation, Phys. Rev. Lett. 103 (1) (2009) 018701.
- [298] R. J. Glauber, Time-dependent statistics of the ising model, Journal of mathematical physics 4 (2) (2004) 294–307.
- [299] I. Dornic, H. Chaté, J. Chave, H. Hinrichseh, Critical coarsening without surface tension: The universality class of the voter model, Phys. Rev. Lett. 87 (4) (2001) 045701–045701.
- [300] R. Lambiotte, S. Redner, Dynamics of vacillating voters, Journal of Statistical Mechanics: Theory and Experiment 2007 (10) (2007) L10001.
- [301] J. Molofsky, R. Durrett, J. Dushoff, D. Griffeath, S. Levin, Local frequency dependence and global coexistence, Theoretical Population Biology 55 (3) (1999) 270–282.
- [302] N. Masuda, N. Gibert, S. Redner, Heterogeneous voter models, Phys. Rev. E 82 (1) (2010) 010103.
- [303] F. Vazquez, P. L. Krapivsky, S. Redner, Constrained opinion dynamics: Freezing and slow evolution, Journal of Physics A: Mathematical and General 36 (3) (2003) L61.
- [304] F. Slanina, H. Lavicka, Analytical results for the sznajd model of opinion formation, EPJ B 35 (2) (2003) 279–288.
- [305] C. Castellano, V. Loreto, A. Barrat, F. Cecconi, D. Parisi, Comparison of voter and glauber ordering dynamics on networks, Phys. Rev. E 71 (6) (2005) 066107.
- [306] K. Suchecki, V. M. Eguiluz, M. San Miguel, Conservation laws for the voter model in complex networks, Eurphys. Lett. 69 (2) (2005) 228.
- [307] V. Sood, T. Antal, S. Redner, Voter models on heterogeneous networks, Phys. Rev. E 77 (4) (2008) 041121.
- [308] C. Castellano, D. Vilone, A. Vespignani, Incomplete ordering of the voter model on small-world networks, Eurphys. Lett. 63 (1) (2003) 153.
- [309] D. Vilone, C. Castellano, Solution of voter model dynamics on annealed small-world networks, Phys. Rev. E 69 (1) (2004) 016109.
- [310] G. Zschaler, G. A. Böhme, M. Seißinger, C. Huepe, T. Gross, Early fragmentation in the adaptive voter model on directed networks, Phys. Rev. E 85 (4) (2012) 046107.
- [311] B. Latane, The psychology of social impact., American psychologist 36 (4) (1981) 343.
- [312] S. Galam, Heterogeneous beliefs, segregation, and extremism in the making of public opinions, Phys. Rev. E 71 (4) (2005) 046123.
- [313] Z. Wang, Y. Liu, L. Wang, Y. Zhang, Freezing period strongly impacts the emergence of a global consensus in the voter model, Scientific reports 4 (2014) 3597.
- [314] H.-U. Stark, C. J. Tessone, F. Schweitzer, Decelerating microdynamics can accelerate macrodynamics in the voter model, Phys. Rev. Lett. 101 (1) (2008) 018701.
- [315] H.-U. Stark, C. J. Tessone, F. Schweitzer, Slower is faster: Fostering consensus formation by heterogeneous inertia, Advances in Complex Systems 11 (04) (2008) 551–563.
- [316] F. Vazquez, V. M. Eguíluz, M. San Miguel, Generic absorbing transition in coevolution dynamics, Phys. Rev. Lett. 100 (10) (2008) 108702.
- [317] M. Mobilia, Does a single zealot affect an infinite group of voters?, Phys. Rev. Lett. 91 (2) (2003) 028701.
- [318] M. Mobilia, A. Petersen, S. Redner, On the role of zealotry in the voter model, Journal of Statistical Mechanics: Theory and Experiment 2007 (08) (2007) P08029.
- [319] M. Mobilia, I. T. Georgiev, Voting and catalytic processes with inhomogeneities, Phys. Rev. E 71 (4) (2005) 046102.
- [320] T. Antal, S. Redner, V. Sood, Evolutionary dynamics on degree-heterogeneous graphs, Phys. Rev. Lett. 96 (18) (2006) 188104.
- [321] T. Zillio, I. Volkov, J. R. Banavar, S. P. Hubbell, A. Maritan, Spatial scaling in model plant communities, Phys. Rev. Lett. 95 (2005) 098101. doi:10.1103/PhysRevLett.95.098101.
- [322] N. Masuda, Voter model on the two-clique graph, arXiv preprint arXiv:1403.4763.
- [323] M. Diakonova, M. San Miguel, V. M. Eguiluz, Absorbing and Shattered Fragmentation Transitions in Multilayer Coevolution, ArXiv e-printsarXiv:1403.4534.
- [324] A. Halu, K. Zhao, A. Baronchelli, G. Bianconi, Connect and win: The role of social networks in political elections, Eurphys. Lett. 102 (1) (2013) 16002.
- [325] J. Xie, S. Sreenivasan, G. Korniss, W. Zhang, C. Lim, B. K. Szymanski, Social consensus through the influence of committed minorities, Phys. Rev. E 84 (1) (2011) 011130.
- [326] G. Szabó, G. Fáth, Evolutionary games on graphs, Phys. Rep. 446 (4–6) (2007) 97 – 216.
- [327] C. P. Roca, J. A. Cuesta, A. Sánchez, Evolutionary game theory: Temporal and spatial effects beyond replicator dynamics, Phys. Life Rev. 6 (4) (2009) 208 – 249.
- [328] M. Perc, J. Gómez-Gardeñes, A. Szolnoki, L. M. Floría, Y. Moreno, Evolutionary dynamics of group interactions on structured populations: A review, J. R. Soc. Interface 6 (2013) 20120997.
- [329] M. Nowak, Evolutionary Dynamics: Exploring the equations of life, Belknap Press of Hardvard University Press, Cambridge, Massachusets, 2006.
- [330] M. Nowak, Five rules for the evolution of cooperation, Science 8 (5805) (2006) 1560–1563.
- [331] J. Maynard-Smith, E. Szathmary, The Major Transitions in Evolution, Freeman, Oxford, 1995.
- [332] P. Kappeler, C. van Schaik (eds.), Cooperation in Primates and Humans: Mechanisms and Evolution, Springer-Verlag, Berlin-Heidelberg, 2006.
- [333] E. Wilson, Sociobiology, Belknap Press of Harvard University Press, Cambridge, Massachusets, 2000.
- [334] J. Henrich, R. Boyd, S. Bowles, C. Camere, E. Fehr, H. G. (eds.), Foundations of Human Sociality: Economic Experiments and Ethnographic Evidence from Fifteen Small-Scale Societies, Oxford University Press, Oxford, 2004.
- [335] A. Rapoport, M. Guyer, A taxonomy of 2x2 games, General Systems: Yearbook of the Society for General Systems Research 11 (1996) 203–214.
- [336] R. Axelrod, The Evolution of Cooperation, Basic Books, New York, 1984.
- [337] M. Macy, A. Flache, Learning dynamics in social dilemmas, Proc. Natl. Acad. Sci. U.S.A. 99 (2002) 7229–7236.
- [338] J. Hofbauer, K. Sigmund, Evolutionary Games and Population Dynamics, Cambridge University Press, Cambridge, 1998.
- [339] K. Sigmund, The Calculus of Selfishness, Princeton University Press, Princeton, New Yersey, 2010.
- [340] M. A. Nowak, R. M. May, Evolutionary games and spatial chaos, Nature 359 (6398) (1992) 826–829.
- [341] F. C. Santos, J. M. Pacheco, Scale-free networks provide a unifying framework for the emergence of cooperation, Phys. Rev. Lett. 95 (2005) 098104.
- [342] J. Gómez-Gardeñes, M. Campillo, L. M. Floria, Y. Moreno, Dynamical organization of cooperation in complex topologies, Phys. Rev. Lett. 98 (10) (2007) 108103.
- [343] J. Kagel, A. Roth, The Handbook of Experimental Economics, Princeton University Press, Cambridge, Massachusets, 1995.
- [344] H. Brandt, C. Hauert, K. Sigmund, Punishment and reputation in spatial public goods games, Proc. R. Soc. B 270 (1519) (2003) 1099–1104.
- [345] C. Hauert, G. Szabó, Prisoner’s dilemma and public goods games in different geometries: Compulsory versus voluntary interactions., Complexity 8 (4) (2003) 31–38.
- [346] F. C. Santos, M. D. Santos, J. M. Pacheco, Social diversity promotes the emergence of cooperation in public goods games, Nature 454 (7201) (2008) 213–216.
- [347] J. Gómez-Gardeñes, M. Romance, R. Criado, D. Vilone, A. Sánchez, Evolutionary games defined at the network mesoscale: The public goods game, Chaos 21 (1) (2011) 016113.
- [348] J. Gómez-Gardeñes, D. Vilone, A. Sánchez, Disentangling social and group heterogeneities: Public goods games on complex networks, Eurphys. Lett. 95 (6) (2011) 68003.
- [349] J. Gómez-Gardeñes, C. Gracia-Lazaro, L. M. Floria, Y. Moreno, Evolutionary dynamics on interdependent populations, Phys. Rev. E 86 (5 Pt 2) (2012) 056113.
- [350] L.-L. Jiang, M. Perc, Spreading of cooperative behaviour across interdependent groups, Sci. Rep. 3 (2013) 2483.
- [351] M. Santos, S. Dorogovtsev, J. Mendes, Biased imitation in coupled evolutionary games in interdependent networks, Sci. Rep. 4 (2014) 4436.
- [352] J. Gómez-Gardeñes, I. Reinares, A. Arenas, M. Floria, Evolution of cooperation in multiplex networks, Sci. Rep. 2 (2012) 620.
- [353] Z. Wang, L. Wang, M. Perc, Degree mixing in multilayer networks impedes the evolution of cooperation, Phys. Rev. E 89 (2014) 052813.
- [354] Q. Jin, C.-y. Xia, L. Wang, Z. Wang, Spontaneous symmetry breaking in interdependent networked game, Scientific reports 4 (2014) 4095.
- [355] Z. Wang, A. Szolnoki, M. Perc, Evolution of public cooperation on interdependent networks: The impact of biased utility functions, Eurphys. Lett. 97 (4) (2012) 48001.
- [356] Z. Wang, A. Szolnoki, M. Perc, Interdependent network reciprocity in evolutionary games, Sci. Rep. 3 (2013) 1183.
- [357] B. Wang, X. Chen, L. Wang, Probabilistic interconnection between interdependent networks promotes cooperation in the public goods game, Journal of Statistical Mechanics: Theory and Experiment 2012 (11) (2012) P11017.
- [358] A. Szolnoki, M. Perc, Information sharing promotes prosocial behaviour, New Journal of Physics 15 (5) (2013) 053010.
- [359] Z. Wang, A. Szolnoki, M. Perc, Optimal interdependence between networks for the evolution of cooperation, Sci. Rep. 3 (2013) 2470.
- [360] M. Perc, Z. Wang, Heterogeneous aspirations promote cooperation in the prisoner’s dilemma game, PLoS One 5 (12) (2010) e15117.
- [361] M. Perc, A. Szolnoki, Coevolutionary games—a mini review, BioSystems 99 (2) (2010) 109–125.
- [362] Z. Wang, A. Szolnoki, M. Perc, Rewarding evolutionary fitness with links between populations promotes cooperation, Journal of theoretical biology 349 (2014) 50–56.
- [363] G. Szabó, C. Tőke, Evolutionary prisoner’s dilemma game on a square lattice, Phys. Rev. E 58 (1998) 69–73. doi:10.1103/PhysRevE.58.69.
- [364] Z. Wang, A. Szolnoki, M. Perc, Self-organization towards optimally interdependent networks by means of coevolution, New Journal of Physics 16 (3) (2014) 033041.
- [365] F. Varela, J.-P. Lachaux, E. Rodriguez, J. Martinerie, The brainweb: Phase synchronization and large-scale integration, Nat. Rev. Neurosci. 2 (4) (2001) 229–239.
- [366] E. L. Berlow, Strong effects of weak interactions in ecological communities, Nature 398 (6725) (1999) 330–334.
- [367] S. Boccaletti, J. Kurths, G. Osipov, D. Valladares, C. Zhou, The synchronization of chaotic systems, Phys. Rep. 366 (1–2) (2002) 1 – 101.
- [368] L. F. Lago-Fernández, R. Huerta, F. Corbacho, J. A. Sigüenza, Fast response and temporal coherent oscillations in small-world networks, Phys. Rev. Lett. 84 (2000) 2758–2761.
- [369] T. Nishikawa, A. E. Motter, Y.-C. Lai, F. C. Hoppensteadt, Heterogeneity in oscillator networks: Are smaller worlds easier to synchronize?, Phys. Rev. Lett. 91 (2003) 014101.
- [370] L. M. Pecora, T. L. Carroll, Master stability functions for synchronized coupled systems, Phys. Rev. Lett. 80 (1998) 2109–2112.
- [371] M. Barahona, L. M. Pecora, Synchronization in small-world systems, Phys. Rev. Lett. 89 (2002) 054101.
- [372] A. E. Motter, C. Zhou, J. Kurths, Enhancing complex-network synchronization, Eurphys. Lett. 69 (3) (2005) 334.
- [373] D.-U. Hwang, M. Chavez, A. Amann, S. Boccaletti, Synchronization in complex networks with age ordering, Phys. Rev. Lett. 94 (2005) 138701.
- [374] M. Chavez, D.-U. Hwang, A. Amann, H. G. E. Hentschel, S. Boccaletti, Synchronization is enhanced in weighted complex networks, Phys. Rev. Lett. 94 (2005) 218701.
- [375] F. Li, X. Lu, Complete synchronization of temporal boolean networks, Neural Networks 44 (0) (2013) 72 – 77.
- [376] J. Yao, H. O. Wang, Z.-H. Guan, W. Xu, Passive stability and synchronization of complex spatio-temporal switching networks with time delays, Automatica 45 (7) (2009) 1721 – 1728.
- [377] N. Masuda, K. Klemm, V. M. Eguíluz, Temporal networks: Slowing down diffusion by long lasting interactions, Phys. Rev. Lett. 111 (2013) 188701.
- [378] I. V. Belykh, V. N. Belykh, M. Hasler, Blinking model and synchronization in small-world networks with a time-varying coupling, Physica D: Nonlinear Phenomena 195 (1–2) (2004) 188 – 206.
- [379] D. Stilwell, E. Bollt, D. Roberson, Sufficient conditions for fast switching synchronization in time-varying network topologies, SIAM Journal on Applied Dynamical Systems 5 (1) (2006) 140–156.
- [380] J.-D. J. Han, N. Bertin, T. Hao, D. S. Goldberg, G. F. Berriz, D. Zhang, Lan V.and Dupuy, A. J. M. Walhout, M. E. Cusick, F. P. Roth, M. Vidal, Evidence for dynamically organized modularity in the yeast protein-protein interaction network, Nature 430 (6995) (2004) 88–93.
- [381] P. W. Anderson, K. Arrow, D. Pines, The Economy as an Evolving Complex System, Addison-Wesley Co., Redwood City, CA, 1988.
- [382] S. Geršgorin, Über die abgrenzung der eigenwerte einer matrix, Bulletin de l’Académie des Sciences de l’URSS. Classe des sciences mathématiques et na 6 (1931) 749–754.
- [383] S. Boccaletti, D.-U. Hwang, M. Chavez, A. Amann, J. Kurths, L. M. Pecora, Synchronization in dynamical networks: Evolution along commutative graphs, Phys. Rev. E 74 (2006) 016102.
- [384] J. D. Noh, H. Rieger, Stability of shortest paths in complex networks with random edge weights, Phys. Rev. E 66 (2002) 066127.
- [385] A. L. Barabasi, R. Albert, Emergence of scaling in random networks, Science 286 (5439) (1999) 509–512.
- [386] R. E. Amritkar, C.-K. Hu, Synchronized state of coupled dynamics on time-varying networks, Chaos 16 (1) (2006) 015117.
- [387] D. Irving, F. Sorrentino, Synchronization of dynamical hypernetworks: Dimensionality reduction through simultaneous block-diagonalization of matrices, Phys. Rev. E 86 (2012) 056102.
- [388] F. Sorrentino, Synchronization of hypernetworks of coupled dynamical systems, New J. of Phys. 14 (3) (2012) 033035.
- [389] J. Aguirre, R. Sevilla-Escoboza, R. Gutiérrez, D. Papo, M. Buldú, J. Synchronization of interconnected networks: The role of connector nodes, Phys. Rev. Lett. 112 (2014) 248701. doi:10.1103/PhysRevLett.112.248701.
- [390] J. Martin-Hernandez, H. Wang, P. Van Mieghem, G. D’Agostino, On Synchronization of Interdependent Networks, ArXiv e-printsarXiv:1304.4731.
- [391] S.-J. Wang, X.-J. Xu, Z.-X. Wu, Y.-H. Wang, Effects of degree distribution in mutual synchronization of neural networks, Phys. Rev. E 74 (2006) 041915.
- [392] L. Huang, K. Park, Y.-C. Lai, L. Yang, K. Yang, Abnormal synchronization in complex clustered networks, Phys. Rev. Lett. 97 (2006) 164101.
- [393] A. A. Rad, I. Sendiña Nadal, D. Papo, M. Zanin, J. M. Buldú, F. del Pozo, S. Boccaletti, Topological measure locating the effective crossover between segregation and integration in a modular network, Phys. Rev. Lett. 108 (2012) 228701.
- [394] E. Barreto, B. Hunt, E. Ott, P. So, Synchronization in networks of networks: The onset of coherent collective behavior in systems of interacting populations of heterogeneous oscillators, Phys. Rev. E 77 (2008) 036107.
- [395] V. H. P. Louzada, N. A. M. Araújo, J. S. Andrade Jr., H. J. Herrmann, Breathing synchronization in interconnected networks, Sci. Rep. 3.
- [396] A. Bogojeska, S. Filiposka, I. Mishkovski, L. Kocarev, On opinion formation and synchronization in multiplex networks, in: Telecommunications Forum (TELFOR), 2013 21st, 2013, pp. 172–175.
- [397] C. Li, W. Sun, J. Kurths, Synchronization between two coupled complex networks, Phys. Rev. E 76 (2007) 046204.
- [398] Z. Wang, C. Cai, J. Wang, H. Zhang, Adaptive fault estimation of coupling connections for synchronization of complex interconnected networks, in: C. Guo, Z.-G. Hou, Z. Zeng (Eds.), Advances in Neural Networks-ISNN 2013, Vol. 7952 of Lecture Notes in Computer Science, Springer, 2013, pp. 455–462.
- [399] Y. Shang, M. Chen, J. Kurths, Generalized synchronization of complex networks, Phys. Rev. E 80 (2009) 027201.
- [400] X. Wu, W. X. Zheng, J. Zhou, Generalized outer synchronization between complex dynamical networks, Chaos 19 (1) (2009) –.
- [401] Y. Wu, C. Li, Y. Wu, J. Kurths, Generalized synchronization between two different complex networks, Communications in Nonlinear Science and Numerical Simulation 17 (1) (2012) 349 – 355.
- [402] Q. Xu, S. Zhuang, D. Hu, Y. Zeng, J. Xiao, Generalized mutual synchronization between two controlled interdependent networks, Abstract and Applied Analysis 2014.
- [403] M. M. Asheghan, J. Miguez, Robust global synchronization of two complex dynamical networks, Chaos 23 (2) (2013) 023108.
- [404] M. M. Asheghan, J. Miguez, M. T. Hamidi-Beheshti, M. S. Tavazoei, Robust outer synchronization between two complex networks with fractional order dynamics, Chaos 21 (3) (2011) 033121.
- [405] X. Mao, Stability switches, bifurcation, and multi-stability of coupled networks with time delays, Appl. Math. Comput. 218 (11) (2012) 6263 – 6274.
- [406] Q.-C. Pham, J.-J. Slotine, Stable concurrent synchronization in dynamic system networks, Neural networks 20 (1) (2007) 62–77.
- [407] F. Sorrentino, E. Ott, Network synchronization of groups, Phys. Rev. E 76 (5) (2007) 056114.
- [408] W. Sun, R. Wang, W. Wang, J. Cao, Analyzing inner and outer synchronization between two coupled discrete-time networks with time delays, Cognitive Neurodynamics 4 (3) (2010) 225–231.
- [409] Y.-Q. Gu, C. Shao, X.-C. Fu, Complete synchronization and stability of star-shaped complex networks, Chaos, Solitons & Fractals 28 (2) (2006) 480 – 488.
- [410] M. Liu, Y. Shao, X. Fu, Complete synchronization on multi-layer center dynamical networks, Chaos, Solitons & Fractals 41 (5) (2009) 2584 – 2591.
- [411] Y.-L. Xi, Z.-Y. Wu, X.-C. Fu, Dynamical synchronization and stability of complex networks with multi-layer centers, Chaos, Solitons & Fractals 40 (2) (2009) 635 – 641.
- [412] A. D. Reyes, Synchrony-dependent propagation of firing rate in iteratively constructed networks in vitro, Nat Neurosci 6 (6) (2003) 593–599.
- [413] T. Nowotny, R. Huerta, Explaining synchrony in feed-forward networks: Are mcculloch-pitts neurons good enough?, Biological Cybernetics 89 (4) (2003) 237–241.
- [414] M. Yi, L. Yang, Propagation of firing rate by synchronization and coherence of firing pattern in a feed-forward multilayer neural network, Phys. Rev. E 81 (2010) 061924.
- [415] E. Cohen, M. Rosenbluh, I. Kanter, Phase transition in crowd synchrony of delay-coupled multilayer laser networks, Opt. Express 20 (18) (2012) 19683–19689.
- [416] R. Gutiérrez, I. Sendiña Nadal, M. Zanin, D. Papo, S. Boccaletti, Targeting the dynamics of complex networks, Sci. Rep. 2 (2012) 396.
- [417] L. M. Pecora, T. L. Carroll, Synchronization in chaotic systems, Phys. Rev. Lett. 64 (1990) 821–824.
- [418] L. Kocarev, U. Parlitz, Generalized synchronization, predictability, and equivalence of unidirectionally coupled dynamical systems, Phys. Rev. Lett. 76 (1996) 1816–1819.
- [419] P. Erdős, A. Rènyi, On random graphs, I, Publicationes Mathematicae (Debrecen) 6 (1959) 290–297.
- [420] L. d. F. Costa, O. N. Oliveira Jr, G. Travieso, F. A. Rodrigues, P. R. Villas Boas, L. Antiqueira, M. P. Viana, L. E. Correa Rocha, Analyzing and modeling real-world phenomena with complex networks: a survey of applications, Advances in Physics 60 (3) (2011) 329–412.
- [421] M. Szell, S. Thurner, Measuring social dynamics in a massive multiplayer online game, Social Networks 32 (2010) 313–319.
- [422] M. Szell, S. Thurner, How women organize social networks different from men, Sci. Rep. 3.
- [423] P. Klimek, S. Thurner, Triadic closure dynamics drives scaling laws in social multiplex networks, New J. Phys. 15 (6) (2013) 063008.
- [424] B. Corominas-Murtra, B. Fuchs, S. Thurner, Detection of the elite structure in a virtual multiplex social system by means of a generalized $K$-core, ArXiv e-printsarXiv:1309.6740.
- [425] E.-A. Horvát, K. A. Zweig, One-mode projection of multiplex bipartite graphs., in: ASONAM, IEEE Computer Society, 2012, pp. 599–606.
- [426] E.-A. Horvát, K. Zweig, A fixed degree sequence model for the one-mode projection of multiplex bipartite graphs, Social Network Analysis and Mining 3 (4) (2013) 1209–1224.
- [427] K. Musiał, P. Kazienko, T. Kajdanowicz, Multirelational social networks in multimedia sharing systems, in: Knowledge Processing and Reasoning for Information Society, Academic Publishing House EXIT, Warsaw, 2008, pp. 275–2982.
- [428] K. Lewis, J. Kaufman, M. Gonzalez, A. Wimmer, N. Christakis, Tastes, ties, and time: A new social network dataset using facebook.com., Social Networks 30 (4) (2008) 330–342.
- [429] A. Hashmi, F. Zaidi, A. Sallaberry, T. Mehmood, Are all social networks structurally similar?, in: Advances in Social Networks Analysis and Mining (ASONAM), 2012 IEEE/ACM International Conference on, IEEE, 2012, pp. 310–314.
- [430] K. Lewis, M. Gonzalez, J. Kaufman, Social selection and peer influence in an online social network, Proc. Natl. Acad. Sci. U.S.A.
- [431] L. Tang, X. Wang, H. Liu, Community detection via heterogeneous interaction analysis., Data Min. Knowl. Discov. 25 (1) (2012) 1–33.
- [432] A. Ansari, O. Koenigsberg, F. Stahl, Modeling multiple relationships in social networks, Journal of Marketing Research 48 (4) (2011) 713–728.
- [433] M. Magnani, L. Rossi, Multi-Stratum Networks: toward a unified model of on-line identities, ArXiv e-printsarXiv:1211.0169.
- [434] C. Zhong, M. Salehi, S. Shah, M. Cobzarenco, N. Sastry, M. Cha, Social Bootstrapping: How Pinterest and Last.fm Social Communities Benefit by Borrowing Links from Facebook, ArXiv e-printsarXiv:1402.6500.
- [435] G. A. Barnett, H. W. Park, K. Jiang, C. Tang, I. F. Aguillo, A multi-level network analysis of web-citations among the world’s universities, Scientometrics 99 (1) (2014) 5–26.
- [436] Z. Wu, W. Yin, J. Cao, G. Xu, A. Cuzzocrea, Community detection in multi-relational social networks, in: X. Lin, Y. Manolopoulos, D. Srivastava, G. Huang (Eds.), Web Information Systems Engineering WISE 2013, Vol. 8181 of Lecture Notes in Computer Science, Springer Berlin Heidelberg, 2013, pp. 43–56. doi:10.1007/978-3-642-41154-0_4.
- [437] M. K.-P. Ng, X. Li, Y. Ye, Multirank: Co-ranking for objects and relations in multi-relational data, in: Proc. of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’11, ACM, New York, NY, USA, 2011, pp. 1217–1225.
- [438] X. Li, M. K. Ng, Y. Ye, Har: Hub, authority and relevance scores in multi-relational data for query search., in: SDM, SIAM / Omnipress, 2012, pp. 141–152.
- [439] P. Bródka, P. Stawiak, P. Kazienko, Shortest path discovery in the multi-layered social network., in: ASONAM, IEEE Computer Society, 2011, pp. 497–501.
- [440] B. Boden, S. Günnemann, H. Hoffmann, T. Seidl, Rmics: a robust approach for mining coherent subgraphs in edge-labeled multi-layer graphs., in: A. Szalay, T. Budavari, M. Balazinska, A. Meliou, A. Sacan (Eds.), SSDBM, ACM, 2013, p. 23.
- [441] J. Sun, D. Tao, C. Faloutsos, Beyond streams and graphs: Dynamic tensor analysis, in: Proc. of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’06, ACM, New York, NY, USA, 2006, pp. 374–383.
- [442] A. Walker, The fall and rise of the scottish community, Social Sciences Directory 2 (3).
- [443] M. T. Heaney, Multiplex networks and interest group influence reputation: An exponential random graph model., Social Networks 36 (2014) 66–81.
- [444] D. C. Duling, Paul’s aegean network: The strength of strong ties, Biblical Theology Bulletin: Journal of Bible and Culture 43 (3) (2013) 135–154.
- [445] M. Zignani, C. Quadri, S. Gaitto, G. P. Rossi, Exploiting all phone media? a multidimensional network analysis of phone users’ sociality, arXiv preprint arXiv:1401.3126.
- [446] A. Sen, A. Mazumder, J. Banerjee, A. Das, R. Compton, Identification of most vulnerable nodes in multi-layered network using a new model of interdependency, arXiv preprint arXiv:1401.1783.
- [447] J.-F. Castet, J. H. Saleh, Interdependent multi-layer networks: Modeling and survivability analysis with applications to space-based networks, PLoS ONE 8 (4) (2013) e60402.
- [448] P. Kaluza, A. Kölzsch, M. T. Gastner, B. Blasius, The complex network of global cargo ship movements, Journal of the Royal Society Interface 7 (48) (2010) 1093–1103.
- [449] M. Hauge, L. Landmark, P. Lubkowski, M. Amanowicz, K. Maslanka, Selected issues of qos provision in heterogenous military networks, International Journal of Electronics and Telecommunications 60 (1) (2014) 7–13.
- [450] M. C. Mahutga, The persistence of structural inequality? a network analysis of international trade, 1965–2000, Social Forces 84 (4) (2006) 1863–1889.
- [451] C. Ducruet, Network diversity and maritime flows, Journal of Transport Geography 30 (2013) 77 – 88.
- [452] L. Bargigli, G. Di Iasio, L. Infante, F. Lillo, F. Pierobon, The multiplex structure of interbank networks, arXiv preprint arXiv:1311.4798.
- [453] T. L. Amburgey, A. Al-Laham, D. Tzabbar, B. Aharonson, The structural evolution of multiplex organizational networks: Research and commerce in biotechnology, Advances in Strategic Management 25 (2008) 171–209.
- [454] S. Lee, P. Monge, The coevolution of multiplex communication networks in organizational communities, Journal of Communication 61 (4) (2011) 758–779.
- [455] F. Bonacina, M. D’Errico, E. Moretto, S. Stefani, A. Torriero, A multiple network approach to corporate governance, arXiv preprint arXiv:1401.4387.
- [456] D. Vandamme, W. Fitzmaurice, B. Kholodenko, W. Kolch, Systems medicine: helping us understand the complexity of disease, QJM 106 (10) (2013) 891–895.
- [457] L. Hood, Systems biology and p4 medicine: Past, present, and future, RMMJ 4 (2) (2013) e0012.
- [458] T. Michoel, B. Nachtergaele, Alignment and integration of complex networks by hypergraph-based spectral clustering, Phys. Rev. E 86 (2012) 056111.
- [459] V. Nicosia, V. Latora, Measuring and modelling correlations in multiplex networks, arXiv preprint arXiv:1403.1546.
- [460] W. Li, C.-C. Liu, T. Z. 0001, H. Li, M. S. Waterman, X. J. Zhou, Integrative analysis of many weighted co-expression networks using tensor computation., PLoS Computational Biology 7 (6).
- [461] W. Li, C. Dai, C.-C. Liu, X. J. Zhou, Algorithm to identify frequent coupled modules from two-layered network series: Application to study transcription and splicing coupling., Journal of Computational Biology 19 (6) (2012) 710–730.
- [462] A. Feng, Z. Gong, Q. Wang, G. Feng, Three-dimensional air–sea interactions investigated with bilayer networks, Theoretical and Applied Climatology 109 (3-4) (2012) 635–643.
- [463] A. Mouhri, N. Flipo, F. Rejiba, C. de Fouquet, L. Bodet, G. Tallec, V. Durand, A. Jost, P. Ansart, P. Goblet, Designing a multiscale experimental sampling system for quantifying stream-aquifer water exchanges in a multi-layer aquifer system, Geophysical Research Abstracts 15.
- [464] O. Varol, F. Menczer, Connecting dream networks across cultures, in: Proc. of the Companion Publication of the 23rd International Conference on World Wide Web Companion, WWW Companion ’14, 2014, pp. 1267–1272.
- [465] E. Goffman, Frame analysis: An essay on the organization of experience, Harvard University Press, 1974.
- [466] S. F. Nadel, M. Fortes, The theory of social structure, Cohen & West, 1957.
- [467] H. C. White, S. A. Boorman, R. L. Breiger, Stability of shortest paths in complex networks with random edge weights, Am. J. Sociol. 81 (1976) 730–780.
- [468] B. C. Griffith, V. L. Maier, A. J. Miller, Describing communication networks through the use of matrix-based measures, unpublished paper, Graduate School of Library Science, Drexel University.
- [469] R. L. Breiger, P. E. Pattison, Cumulated social roles: the duality of persons and their algebras, Social Networks 8 (1986) 215–256.
- [470] J. F. Padgett, C. K. Ansell, Robust action and the rise of the medici, Am. J. Sociol. 98 (1993) 1259–1319.
- [471] K. Knipscheer, P. Dykstra, J. de Jong Gierveld, T. van Tilburg, Living arrangements and social networks as interlocking mediating structures, VU University Press, Amsterdam, 1995, Ch. 1, pp. 1–14.
- [472] E. Castronova, Synthetic Worlds: The Business and Culture of Online Games, University of Chicago Press, 2005.
- [473] R. I. Dunbar, Coevolution of neocortical size, group size and language in humans, Behavioral and brain sciences 16 (04) (1993) 681–694.
- [474] L. Lü, M. Medo, C. H. Yeung, Y.-C. Zhang, Z.-K. Zhang, T. Zhou, Recommender systems, Physics Reports 519 (1) (2012) 1 – 49.
- [475] J. Bennett, S. Lanning, The netflix prize, in: Proc. of the KDD Cup Workshop 2007, ACM, New York, 2007, pp. 3–6.
- [476] K. Shen, L. Wu, Folksonomy as a Complex Network, eprint arXiv:cs/0509072arXiv:cs/0509072.
- [477] A. Mislove, H. S. Koppula, K. P. Gummadi, P. Druschel, B. Bhattacharjee, Growth of the flickr social network, in: Proc. of the First Workshop on Online Social Networks, WOSN ’08, ACM, New York, NY, USA, 2008, pp. 25–30.
- [478] A. Nazir, S. Raza, C.-N. Chuah, Unveiling facebook: A measurement study of social network based applications, in: Proc. of the 8th ACM SIGCOMM Conference on Internet Measurement, IMC ’08, ACM, New York, NY, USA, 2008, pp. 43–56.
- [479] B. Viswanath, A. Mislove, M. Cha, K. P. Gummadi, On the evolution of user interaction in facebook, in: Proc. of the 2nd ACM workshop on Online social network, ACM, New York, NY, USA, 2009, pp. 37–42.
- [480] F. Schneider, A. Feldmann, B. Krishnamurthy, W. Willinger, Understanding online social network usage from a network perspective, in: Proc. of the 9th ACM SIGCOMM Conference on Internet Measurement Conference, IMC ’09, ACM, New York, NY, USA, 2009, pp. 35–48.
- [481] N. P. Nguyen, T. N. Dinh, S. Tokala, M. T. Thai, Overlapping communities in dynamic networks: Their detection and mobile applications, in: Proc. of the 17th Annual International Conference on Mobile Computing and Networking, MobiCom ’11, ACM, New York, NY, USA, 2011, pp. 85–96.
- [482] H. Abdi, L. J. Williams, Principal component analysis, Wiley Interdisciplinary Reviews: Computational Statistics 2 (4) (2010) 433–459.
- [483] P. Kroonenberg, J. Leeuw, Principal component analysis of three-mode data by means of alternating least squares algorithms, Psychometrika 45 (1) (1980) 69–97.
- [484] D. Xu, S. Yan, L. Z. 0001, H. Zhang, Z. Liu, H.-Y. Shum, Concurrent subspaces analysis., in: CVPR (2), IEEE Computer Society, 2005, pp. 203–208.
- [485] S. F. Everton, The noordin top terrorist network, in: Disrupting Dark Networks, Cambridge University Press, New York, 2012, pp. 385–397.
- [486] W. D. Ivancic, Architecture and system engineering development study of space-based networks for nasa missions, in: Proc. IEEE Aerospace Conference, ACM, 2003, pp. 1179–1186.
- [487] R. Kali, J. Reyes, The architecture of globalization: a network approach to international economic integration, Journal of International Business Studies 38 (4) (2007) 595–620.
- [488] R. P. Keller, J. M. Drake, M. B. Drew, D. M. Lodge, Linking environmental conditions and ship movements to estimate invasive species transport across the global shipping network, Diversity and Distributions 17 (1) (2011) 93–102.
- [489] C. Ducruet, T. Notteboom, The worldwide maritime network of container shipping: spatial structure and regional dynamics, Global networks 12 (3) (2012) 395–423.
- [490] M. Boss, H. Elsinger, M. Summer, S. Thurner 4, Network topology of the interbank market, Quantitative Finance 4 (6) (2004) 677–684.
- [491] K. Soramäki, M. L. Bech, J. Arnold, R. J. Glass, W. E. Beyeler, The topology of interbank payment flows, Physica A 379 (1) (2007) 317–333.
- [492] P. Gai, S. Kapadia, Contagion in financial networks, Proc. R. Soc. A 466 (2120) (2010) 2401–2423.
- [493] L. M. Camarinha-Matos, H. Afsarmanesh, Collaborative networks: a new scientific discipline, Journal of intelligent manufacturing 16 (4-5) (2005) 439–452.
- [494] L. Dooley, D. O’sullivan, Managing within distributed innovation networks, International Journal of Innovation Management 11 (03) (2007) 397–416.
- [495] C. Durugbo, W. Hutabarat, A. Tiwari, J. R. Alcock, Modelling collaboration using complex networks, Information Sciences 181 (15) (2011) 3143–3161.
- [496] M. Granovetter, Economic action and social structure: the problem of embeddedness, American journal of sociology (1985) 481–510.
- [497] J. Galaskiewicz, W. Bielefeld, Nonprofit organizations in an age of uncertainty: A study of organizational change, Transaction Publishers, 1998.
- [498] A.-L. Barabási, Z. N. Oltvai, Network biology: understanding the cell’s functional organization, Nat. Rev. Genet. 5 (2) (2004) 101–113.
- [499] A.-L. Barabasi, N. Gulbahce, J. Loscalzo, Network medicine: a network-based approach to human disease, Nat. Rev. Genet. 12 (1) (2011) 56–68.
- [500] H. Jeong, S. P. Mason, A. L. Barabási, Z. N. Oltvai, Lethality and centrality in protein networks, Nature 411 (6833) (2001) 41–42.
- [501] R. Guimera, L. A. N. Amaral, Functional cartography of complex metabolic networks, Nature 433 (7028) (2005) 895–900.
- [502] O. Sporns, The human connectome: a complex network, Annals of the New York Academy of Sciences 1224 (1) (2011) 109–125.
- [503] E. Bullmore, O. Sporns, Complex brain networks: graph theoretical analysis of structural and functional systems, Nat. Rev. Neurosci. 10 (3) (2009) 186–198.
- [504] R. J. Fletcher, B. E. Bishop, R. P. Leon, R. A. Sclafani, C. M. Ogata, X. S. Chen, The structure and function of mcm from archaeal m. thermoautotrophicum, Nat Struct Mol Biol 10 (3) (2003) 160–167.
- [505] H. Kibak, L. Taiz, T. Starke, P. Bernasconi, J. Gogarten, Evolution of structure and function of v-atpases, J. Bioenerg. Biomemb. 24 (4) (1992) 415–424.
- [506] K. Yamasaki, A. Gozolchiani, S. Havlin, Climate networks around the globe are significantly affected by el niño, Phys. Rev. Lett. 100 (2008) 228501.
- [507] J. F. Donges, Y. Zou, N. Marwan, J. Kurths, The backbone of the climate network, Eurphys. Lett. 87 (4) (2009) 48007.
- [508] K. Steinhaeuser, A. Ganguly, N. Chawla, Multivariate and multiscale dependence in the global climate system revealed through complex networks, Climate Dynamics 39 (3-4) (2012) 889–895.
- [509] L. H. de Saint-Denys, Dreams and how to guide them, Duckbacks, 1982.
- [510] W. Güth, R. Schmittberger, B. Schwarze, An experimental analysis of ultimatum bargaining, Journal of economic behavior & organization 3 (4) (1982) 367–388.
- [511] G. E. Bolton, R. Zwick, Anonymity versus punishment in ultimatum bargaining, Games and Economic Behavior 10 (1) (1995) 95–121.
- [512] M. Peltomäki, M. Alava, Three-and four-state rock-paper-scissors games with diffusion, Phys. Rev. E 78 (3) (2008) 031906.
- [513] A. Baronchelli, M. Felici, V. Loreto, E. Caglioti, L. Steels, Sharp transition towards shared vocabularies in multi-agent systems, J. Stat. Mech. Theor. Exp. 06 (2006) P06014. doi:10.1088/1742-5468/2006/06/P06014.
- [514] A. Baronchelli, L. Dall’Asta, A. Barrat, V. Loreto, Topology-induced coarsening in language games, Phys. Rev. E 73 (1) (2006) 015102.
- [515] M. Milinski, R. D. Sommerfeld, H.-J. Krambeck, F. A. Reed, J. Marotzke, The collective-risk social dilemma and the prevention of simulated dangerous climate change, Proc. Natl. Acad. Sci. U.S.A. 105 (7) (2008) 2291–2294.
- [516] G. Hardin, The tragedy of the commons, Science 162 (3859) (1968) 1243–1248.
- [517] C. Gracia-Lázaro, A. Ferrer, G. Ruiz, A. Tarancón, J. A. Cuesta, A. Sánchez, Y. Moreno, Heterogeneous networks do not promote cooperation when humans play a prisoner’s dilemma, Proc. Natl. Acad. Sci. U.S.A. 109 (32) (2012) 12922–12926.
- [518] S. Assenza, R. Gutiérrez, J. Gómez-Gardeñes, V. Latora, S. Boccaletti, Emergence of structural patterns out of synchronization in networks with competitive interactions, Sci. Rep. 1. doi:10.1038/srep00099.
- [519] R. Gutiérrez, A. Amann, S. Assenza, J. Gómez-Gardeñes, V. Latora, S. Boccaletti, Emerging meso- and macroscales from synchronization of adaptive networks, Phys. Rev. Lett. 107 (2011) 234103. doi:10.1103/PhysRevLett.107.234103.
- [520] V. Avalos-Gaytán, J. A. Almendral, D. Papo, S. E. Schaeffer, S. Boccaletti, Assortative and modular networks are shaped by adaptive synchronization processes, Phys. Rev. E 86 (2012) 015101. doi:10.1103/PhysRevE.86.015101.