Identity Mappings in Deep Residual Networks
Abstract
Deep residual networks [1] have emerged as a family of extremely deep architectures showing compelling accuracy and nice convergence behaviors. In this paper, we analyze the propagation formulations behind the residual building blocks, which suggest that the forward and backward signals can be directly propagated from one block to any other block, when using identity mappings as the skip connections and after-addition activation. A series of ablation experiments support the importance of these identity mappings. This motivates us to propose a new residual unit, which makes training easier and improves generalization. We report improved results using a 1001-layer ResNet on CIFAR-10 (4.62% error) and CIFAR-100, and a 200-layer ResNet on ImageNet. Code is available at: https://github.com/KaimingHe/resnet-1k-layers.
1 Introduction
Deep residual networks (ResNets) [1] consist of many stacked “Residual Units”. Each unit (Fig. 1 (a)) can be expressed in a general form:
where and are input and output of the -th unit, and is a residual function. In [1], is an identity mapping and is a ReLU [2] function.
ResNets that are over 100-layer deep have shown state-of-the-art accuracy for several challenging recognition tasks on ImageNet [3] and MS COCO [4] competitions. The central idea of ResNets is to learn the additive residual function with respect to , with a key choice of using an identity mapping . This is realized by attaching an identity skip connection (“shortcut”).
In this paper, we analyze deep residual networks by focusing on creating a “direct” path for propagating information — not only within a residual unit, but through the entire network. Our derivations reveal that if both and are identity mappings, the signal could be directly propagated from one unit to any other units, in both forward and backward passes. Our experiments empirically show that training in general becomes easier when the architecture is closer to the above two conditions.
To understand the role of skip connections, we analyze and compare various types of . We find that the identity mapping chosen in [1] achieves the fastest error reduction and lowest training loss among all variants we investigated, whereas skip connections of scaling, gating [5, 6, 7], and 11 convolutions all lead to higher training loss and error. These experiments suggest that keeping a “clean” information path (indicated by the grey arrows in Fig. 1, 2, and 4) is helpful for easing optimization.
To construct an identity mapping , we view the activation functions (ReLU and BN [8]) as “pre-activation” of the weight layers, in contrast to conventional wisdom of “post-activation”. This point of view leads to a new residual unit design, shown in (Fig. 1(b)). Based on this unit, we present competitive results on CIFAR-10/100 with a 1001-layer ResNet, which is much easier to train and generalizes better than the original ResNet in [1]. We further report improved results on ImageNet using a 200-layer ResNet, for which the counterpart of [1] starts to overfit. These results suggest that there is much room to exploit the dimension of network depth, a key to the success of modern deep learning.
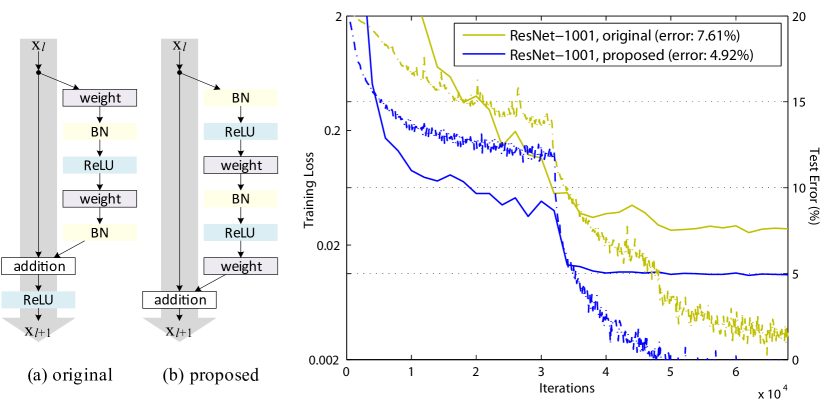
2 Analysis of Deep Residual Networks
The ResNets developed in [1] are modularized architectures that stack building blocks of the same connecting shape. In this paper we call these blocks “Residual Units”. The original Residual Unit in [1] performs the following computation:
| (1) | |||
| (2) |
Here is the input feature to the -th Residual Unit. is a set of weights (and biases) associated with the -th Residual Unit, and is the number of layers in a Residual Unit ( is 2 or 3 in [1]). denotes the residual function, e.g., a stack of two 33 convolutional layers in [1]. The function is the operation after element-wise addition, and in [1] is ReLU. The function is set as an identity mapping: .111It is noteworthy that there are Residual Units for increasing dimensions and reducing feature map sizes [1] in which is not identity. In this case the following derivations do not hold strictly. But as there are only a very few such units (two on CIFAR and three on ImageNet, depending on image sizes [1]), we expect that they do not have the exponential impact as we present in Sec. 3. One may also think of our derivations as applied to all Residual Units within the same feature map size.
If is also an identity mapping: , we can put Eqn.(2) into Eqn.(1) and obtain:
| (3) |
Recursively (, etc.) we will have:
| (4) |
for any deeper unit and any shallower unit . Eqn.(4) exhibits some nice properties. (i) The feature of any deeper unit can be represented as the feature of any shallower unit plus a residual function in a form of , indicating that the model is in a residual fashion between any units and . (ii) The feature , of any deep unit , is the summation of the outputs of all preceding residual functions (plus ). This is in contrast to a “plain network” where a feature is a series of matrix-vector products, say, (ignoring BN and ReLU).
Eqn.(4) also leads to nice backward propagation properties. Denoting the loss function as , from the chain rule of backpropagation [9] we have:
| (5) |
Eqn.(5) indicates that the gradient can be decomposed into two additive terms: a term of that propagates information directly without concerning any weight layers, and another term of that propagates through the weight layers. The additive term of ensures that information is directly propagated back to any shallower unit . Eqn.(5) also suggests that it is unlikely for the gradient to be canceled out for a mini-batch, because in general the term cannot be always -1 for all samples in a mini-batch. This implies that the gradient of a layer does not vanish even when the weights are arbitrarily small.
Discussions
Eqn.(4) and Eqn.(5) suggest that the signal can be directly propagated from any unit to another, both forward and backward. The foundation of Eqn.(4) is two identity mappings: (i) the identity skip connection , and (ii) the condition that is an identity mapping.
These directly propagated information flows are represented by the grey arrows in Fig. 1, 2, and 4. And the above two conditions are true when these grey arrows cover no operations (expect addition) and thus are “clean”. In the following two sections we separately investigate the impacts of the two conditions.
3 On the Importance of Identity Skip Connections
Let’s consider a simple modification, , to break the identity shortcut:
| (6) |
where is a modulating scalar (for simplicity we still assume is identity). Recursively applying this formulation we obtain an equation similar to Eqn. (4): , or simply:
| (7) |
where the notation absorbs the scalars into the residual functions. Similar to Eqn.(5), we have backpropagation of the following form:
| (8) |
Unlike Eqn.(5), in Eqn.(8) the first additive term is modulated by a factor . For an extremely deep network ( is large), if for all , this factor can be exponentially large; if for all , this factor can be exponentially small and vanish, which blocks the backpropagated signal from the shortcut and forces it to flow through the weight layers. This results in optimization difficulties as we show by experiments.
In the above analysis, the original identity skip connection in Eqn.(3) is replaced with a simple scaling . If the skip connection represents more complicated transforms (such as gating and 11 convolutions), in Eqn.(8) the first term becomes where is the derivative of . This product may also impede information propagation and hamper the training procedure as witnessed in the following experiments.
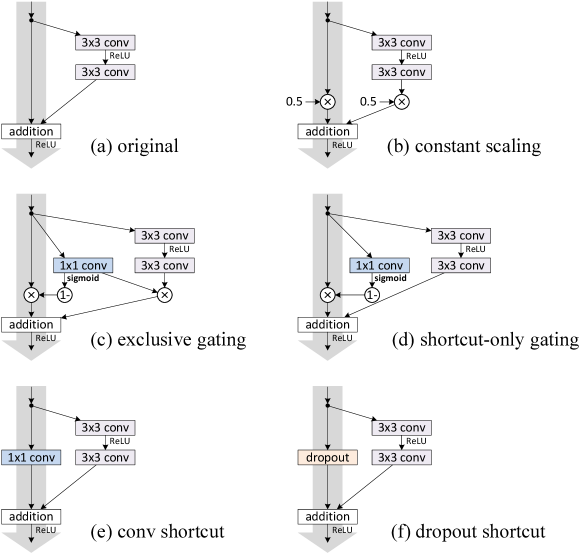
| case | Fig. | on shortcut | on | error (%) | remark |
| original [1] | Fig. 2(a) | 1 | 1 | 6.61 | |
| constant scaling | Fig. 2(b) | 0 | 1 | fail | This is a plain net |
| 0.5 | 1 | fail | |||
| 0.5 | 0.5 | 12.35 | frozen gating | ||
| exclusive gating | Fig. 2(c) | fail | init =0 to | ||
| 8.70 | init =-6 | ||||
| 9.81 | init =-7 | ||||
| shortcut-only gating | Fig. 2(d) | 1 | 12.86 | init =0 | |
| 1 | 6.91 | init =-6 | |||
| 11 conv shortcut | Fig. 2(e) | 11 conv | 1 | 12.22 | |
| dropout shortcut | Fig. 2(f) | dropout 0.5 | 1 | fail |
3.1 Experiments on Skip Connections
We experiment with the 110-layer ResNet as presented in [1] on CIFAR-10 [10]. This extremely deep ResNet-110 has 54 two-layer Residual Units (consisting of 33 convolutional layers) and is challenging for optimization. Our implementation details (see appendix) are the same as [1]. Throughout this paper we report the median accuracy of 5 runs for each architecture on CIFAR, reducing the impacts of random variations.
Though our above analysis is driven by identity , the experiments in this section are all based on ReLU as in [1]; we address identity in the next section. Our baseline ResNet-110 has 6.61% error on the test set. The comparisons of other variants (Fig. 2 and Table 1) are summarized as follows:
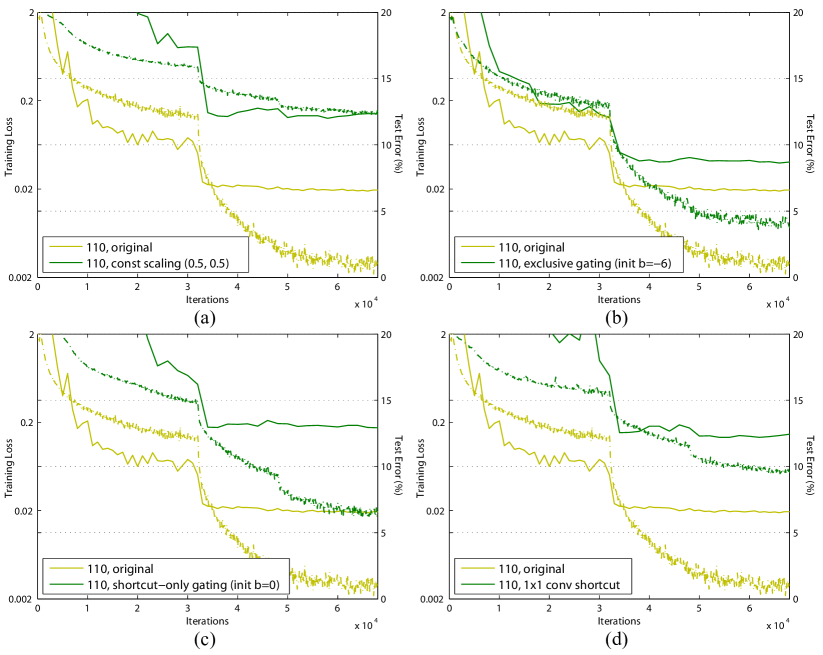
Constant scaling. We set for all shortcuts (Fig. 2(b)). We further study two cases of scaling : (i) is not scaled; or (ii) is scaled by a constant scalar of , which is similar to the highway gating [6, 7] but with frozen gates. The former case does not converge well; the latter is able to converge, but the test error (Table 1, 12.35%) is substantially higher than the original ResNet-110. Fig 3(a) shows that the training error is higher than that of the original ResNet-110, suggesting that the optimization has difficulties when the shortcut signal is scaled down.
Exclusive gating. Following the Highway Networks [6, 7] that adopt a gating mechanism [5], we consider a gating function where a transform is represented by weights and biases followed by the sigmoid function . In a convolutional network is realized by a 11 convolutional layer. The gating function modulates the signal by element-wise multiplication.
We investigate the “exclusive” gates as used in [6, 7] — the path is scaled by and the shortcut path is scaled by . See Fig 2(c). We find that the initialization of the biases is critical for training gated models, and following the guidelines222See also: people.idsia.ch/~rupesh/very_deep_learning/ by [6, 7]. in [6, 7], we conduct hyper-parameter search on the initial value of in the range of 0 to -10 with a decrement step of -1 on the training set by cross-validation. The best value ( here) is then used for training on the training set, leading to a test result of 8.70% (Table 1), which still lags far behind the ResNet-110 baseline. Fig 3(b) shows the training curves. Table 1 also reports the results of using other initialized values, noting that the exclusive gating network does not converge to a good solution when is not appropriately initialized.
The impact of the exclusive gating mechanism is two-fold. When approaches 1, the gated shortcut connections are closer to identity which helps information propagation; but in this case approaches 0 and suppresses the function . To isolate the effects of the gating functions on the shortcut path alone, we investigate a non-exclusive gating mechanism in the next.
Shortcut-only gating. In this case the function is not scaled; only the shortcut path is gated by . See Fig 2(d). The initialized value of is still essential in this case. When the initialized is 0 (so initially the expectation of is 0.5), the network converges to a poor result of 12.86% (Table 1). This is also caused by higher training error (Fig 3(c)).
When the initialized is very negatively biased (e.g., ), the value of is closer to 1 and the shortcut connection is nearly an identity mapping. Therefore, the result (6.91%, Table 1) is much closer to the ResNet-110 baseline.
11 convolutional shortcut. Next we experiment with 11 convolutional shortcut connections that replace the identity. This option has been investigated in [1] (known as option C) on a 34-layer ResNet (16 Residual Units) and shows good results, suggesting that 11 shortcut connections could be useful. But we find that this is not the case when there are many Residual Units. The 110-layer ResNet has a poorer result (12.22%, Table 1) when using 11 convolutional shortcuts. Again, the training error becomes higher (Fig 3(d)). When stacking so many Residual Units (54 for ResNet-110), even the shortest path may still impede signal propagation. We witnessed similar phenomena on ImageNet with ResNet-101 when using 11 convolutional shortcuts.
Dropout shortcut. Last we experiment with dropout [11] (at a ratio of 0.5) which we adopt on the output of the identity shortcut (Fig. 2(f)). The network fails to converge to a good solution. Dropout statistically imposes a scale of with an expectation of 0.5 on the shortcut, and similar to constant scaling by 0.5, it impedes signal propagation.
3.2 Discussions
As indicated by the grey arrows in Fig. 2, the shortcut connections are the most direct paths for the information to propagate. Multiplicative manipulations (scaling, gating, 11 convolutions, and dropout) on the shortcuts can hamper information propagation and lead to optimization problems.
It is noteworthy that the gating and 11 convolutional shortcuts introduce more parameters, and should have stronger representational abilities than identity shortcuts. In fact, the shortcut-only gating and 11 convolution cover the solution space of identity shortcuts (i.e., they could be optimized as identity shortcuts). However, their training error is higher than that of identity shortcuts, indicating that the degradation of these models is caused by optimization issues, instead of representational abilities.
4 On the Usage of Activation Functions
| case | Fig. | ResNet-110 | ResNet-164 |
|---|---|---|---|
| original Residual Unit [1] | Fig. 4(a) | 6.61 | 5.93 |
| BN after addition | Fig. 4(b) | 8.17 | 6.50 |
| ReLU before addition | Fig. 4(c) | 7.84 | 6.14 |
| ReLU-only pre-activation | Fig. 4(d) | 6.71 | 5.91 |
| full pre-activation | Fig. 4(e) | 6.37 | 5.46 |
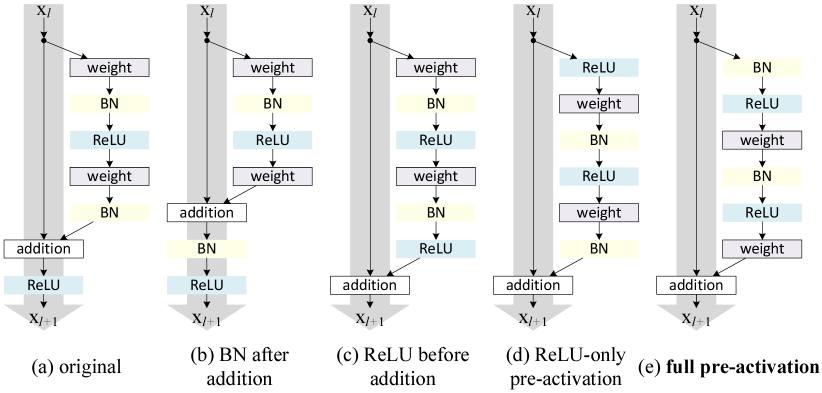
Experiments in the above section support the analysis in Eqn.(5) and Eqn.(8), both being derived under the assumption that the after-addition activation is the identity mapping. But in the above experiments is ReLU as designed in [1], so Eqn.(5) and (8) are approximate in the above experiments. Next we investigate the impact of .
We want to make an identity mapping, which is done by re-arranging the activation functions (ReLU and/or BN). The original Residual Unit in [1] has a shape in Fig. 4(a) — BN is used after each weight layer, and ReLU is adopted after BN except that the last ReLU in a Residual Unit is after element-wise addition ( ReLU). Fig. 4(b-e) show the alternatives we investigated, explained as following.
4.1 Experiments on Activation
In this section we experiment with ResNet-110 and a 164-layer Bottleneck [1] architecture (denoted as ResNet-164). A bottleneck Residual Unit consist of a 11 layer for reducing dimension, a 33 layer, and a 11 layer for restoring dimension. As designed in [1], its computational complexity is similar to the two-33 Residual Unit. More details are in the appendix. The baseline ResNet-164 has a competitive result of 5.93% on CIFAR-10 (Table 2).
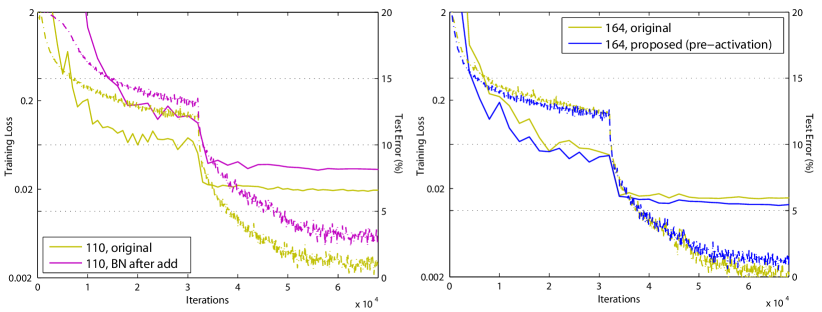
BN after addition. Before turning into an identity mapping, we go the opposite way by adopting BN after addition (Fig. 4(b)). In this case involves BN and ReLU. The results become considerably worse than the baseline (Table 2). Unlike the original design, now the BN layer alters the signal that passes through the shortcut and impedes information propagation, as reflected by the difficulties on reducing training loss at the beginning of training (Fib. 6 left).
ReLU before addition. A naïve choice of making into an identity mapping is to move the ReLU before addition (Fig. 4(c)). However, this leads to a non-negative output from the transform , while intuitively a “residual” function should take values in . As a result, the forward propagated signal is monotonically increasing. This may impact the representational ability, and the result is worse (7.84%, Table 2) than the baseline. We expect to have a residual function taking values in . This condition is satisfied by other Residual Units including the following ones.
Post-activation or pre-activation? In the original design (Eqn.(1) and Eqn.(2)), the activation affects both paths in the next Residual Unit: . Next we develop an asymmetric form where an activation only affects the path: , for any (Fig. 5 (a) to (b)). By renaming the notations, we have the following form:
| (9) |
It is easy to see that Eqn.(9) is similar to Eqn.(4), and can enable a backward formulation similar to Eqn.(5). For this new Residual Unit as in Eqn.(9), the new after-addition activation becomes an identity mapping. This design means that if a new after-addition activation is asymmetrically adopted, it is equivalent to recasting as the pre-activation of the next Residual Unit. This is illustrated in Fig. 5.
The distinction between post-activation/pre-activation is caused by the presence of the element-wise addition. For a plain network that has layers, there are activations (BN/ReLU), and it does not matter whether we think of them as post- or pre-activations. But for branched layers merged by addition, the position of activation matters.
We experiment with two such designs: (i) ReLU-only pre-activation (Fig. 4(d)), and (ii) full pre-activation (Fig. 4(e)) where BN and ReLU are both adopted before weight layers. Table 2 shows that the ReLU-only pre-activation performs very similar to the baseline on ResNet-110/164. This ReLU layer is not used in conjunction with a BN layer, and may not enjoy the benefits of BN [8].
| dataset | network | baseline unit | pre-activation unit |
|---|---|---|---|
| CIFAR-10 | ResNet-110 (1layer skip) | 9.90 | 8.91 |
| ResNet-110 | 6.61 | 6.37 | |
| ResNet-164 | 5.93 | 5.46 | |
| ResNet-1001 | 7.61 | 4.92 | |
| CIFAR-100 | ResNet-164 | 25.16 | 24.33 |
| ResNet-1001 | 27.82 | 22.71 |
Somehow surprisingly, when BN and ReLU are both used as pre-activation, the results are improved by healthy margins (Table 2 and Table 3). In Table 3 we report results using various architectures: (i) ResNet-110, (ii) ResNet-164, (iii) a 110-layer ResNet architecture in which each shortcut skips only 1 layer (i.e., a Residual Unit has only 1 layer), denoted as “ResNet-110(1layer)”, and (iv) a 1001-layer bottleneck architecture that has 333 Residual Units (111 on each feature map size), denoted as “ResNet-1001”. We also experiment on CIFAR-100. Table 3 shows that our “pre-activation” models are consistently better than the baseline counterparts. We analyze these results in the following.
4.2 Analysis
We find the impact of pre-activation is twofold. First, the optimization is further eased (comparing with the baseline ResNet) because is an identity mapping. Second, using BN as pre-activation improves regularization of the models.
Ease of optimization. This effect is particularly obvious when training the 1001-layer ResNet. Fig. 1 shows the curves. Using the original design in [1], the training error is reduced very slowly at the beginning of training. For ReLU, the signal is impacted if it is negative, and when there are many Residual Units, this effect becomes prominent and Eqn.(3) (so Eqn.(5)) is not a good approximation. On the other hand, when is an identity mapping, the signal can be propagated directly between any two units. Our 1001-layer network reduces the training loss very quickly (Fig. 1). It also achieves the lowest loss among all models we investigated, suggesting the success of optimization.
We also find that the impact of ReLU is not severe when the ResNet has fewer layers (e.g., 164 in Fig. 6(right)). The training curve seems to suffer a little bit at the beginning of training, but goes into a healthy status soon. By monitoring the responses we observe that this is because after some training, the weights are adjusted into a status such that in Eqn.(1) is more frequently above zero and does not truncate it ( is always non-negative due to the previous ReLU, so is below zero only when the magnitude of is very negative). The truncation, however, is more frequent when there are 1000 layers.
Reducing overfitting. Another impact of using the proposed pre-activation unit is on regularization, as shown in Fig. 6 (right). The pre-activation version reaches slightly higher training loss at convergence, but produces lower test error. This phenomenon is observed on ResNet-110, ResNet-110(1-layer), and ResNet-164 on both CIFAR-10 and 100. This is presumably caused by BN’s regularization effect [8]. In the original Residual Unit (Fig. 4(a)), although the BN normalizes the signal, this is soon added to the shortcut and thus the merged signal is not normalized. This unnormalized signal is then used as the input of the next weight layer. On the contrary, in our pre-activation version, the inputs to all weight layers have been normalized.
5 Results
Comparisons on CIFAR-10/100. Table 4 compares the state-of-the-art methods on CIFAR-10/100, where we achieve competitive results. We note that we do not specially tailor the network width or filter sizes, nor use regularization techniques (such as dropout) which are very effective for these small datasets. We obtain these results via a simple but essential concept — going deeper. These results demonstrate the potential of pushing the limits of depth.
| CIFAR-10 | error (%) |
|---|---|
| NIN [15] | 8.81 |
| DSN [16] | 8.22 |
| FitNet [17] | 8.39 |
| Highway [7] | 7.72 |
| All-CNN [14] | 7.25 |
| ELU [12] | 6.55 |
| FitResNet, LSUV [18] | 5.84 |
| ResNet-110 [1] (1.7M) | 6.61 |
| ResNet-1202 [1] (19.4M) | 7.93 |
| ResNet-164 [ours] (1.7M) | 5.46 |
| ResNet-1001 [ours] (10.2M) | 4.92 (4.890.14) |
| ResNet-1001 [ours] (10.2M)† | 4.62 (4.690.20) |
| CIFAR-100 | error (%) |
|---|---|
| NIN [15] | 35.68 |
| DSN [16] | 34.57 |
| FitNet [17] | 35.04 |
| Highway [7] | 32.39 |
| All-CNN [14] | 33.71 |
| ELU [12] | 24.28 |
| FitNet, LSUV [18] | 27.66 |
| ResNet-164 [1] (1.7M) | 25.16 |
| ResNet-1001 [1] (10.2M) | 27.82 |
| ResNet-164 [ours] (1.7M) | 24.33 |
| ResNet-1001 [ours] (10.2M) | 22.71 (22.680.22) |
Comparisons on ImageNet. Next we report experimental results on the 1000-class ImageNet dataset [3]. We have done preliminary experiments using the skip connections studied in Fig. 2 & 3 on ImageNet with ResNet-101 [1], and observed similar optimization difficulties. The training error of these non-identity shortcut networks is obviously higher than the original ResNet at the first learning rate (similar to Fig. 3), and we decided to halt training due to limited resources. But we did finish a “BN after addition” version (Fig. 4(b)) of ResNet-101 on ImageNet and observed higher training loss and validation error. This model’s single-crop (224224) validation error is 24.6%/7.5%, vs. the original ResNet-101’s 23.6%/7.1%. This is in line with the results on CIFAR in Fig. 6 (left).
Table 5 shows the results of ResNet-152 [1] and ResNet-200333The ResNet-200 has 16 more 3-layer bottleneck Residual Units than ResNet-152, which are added on the feature map of 2828., all trained from scratch. We notice that the original ResNet paper [1] trained the models using scale jittering with shorter side , and so the test of a 224224 crop on (as did in [1]) is negatively biased. Instead, we test a single 320320 crop from , for all original and our ResNets. Even though the ResNets are trained on smaller crops, they can be easily tested on larger crops because the ResNets are fully convolutional by design. This size is also close to 299299 used by Inception v3 [19], allowing a fairer comparison.
The original ResNet-152 [1] has top-1 error of 21.3% on a 320320 crop, and our pre-activation counterpart has 21.1%. The gain is not big on ResNet-152 because this model has not shown severe generalization difficulties. However, the original ResNet-200 has an error rate of 21.8%, higher than the baseline ResNet-152. But we find that the original ResNet-200 has lower training error than ResNet-152, suggesting that it suffers from overfitting.
Our pre-activation ResNet-200 has an error rate of 20.7%, which is 1.1% lower than the baseline ResNet-200 and also lower than the two versions of ResNet-152. When using the scale and aspect ratio augmentation of [20, 19], our ResNet-200 has a result better than Inception v3 [19] (Table 5). Concurrent with our work, an Inception-ResNet-v2 model [21] achieves a single-crop result of 19.9%/4.9%. We expect our observations and the proposed Residual Unit will help this type and generally other types of ResNets.
| method | augmentation | train crop | test crop | top-1 | top-5 |
|---|---|---|---|---|---|
| ResNet-152, original Residual Unit [1] | scale | 224224 | 224224 | 23.0 | 6.7 |
| ResNet-152, original Residual Unit [1] | scale | 224224 | 320320 | 21.3 | 5.5 |
| ResNet-152, pre-act Residual Unit | scale | 224224 | 320320 | 21.1 | 5.5 |
| ResNet-200, original Residual Unit [1] | scale | 224224 | 320320 | 21.8 | 6.0 |
| ResNet-200, pre-act Residual Unit | scale | 224224 | 320320 | 20.7 | 5.3 |
| ResNet-200, pre-act Residual Unit | scale+asp ratio | 224224 | 320320 | 20.1† | 4.8† |
| Inception v3 [19] | scale+asp ratio | 299299 | 299299 | 21.2 | 5.6 |
Computational Cost. Our models’ computational complexity is linear on depth (so a 1001-layer net is 10 complex of a 100-layer net). On CIFAR, ResNet-1001 takes about 27 hours to train on 2 GPUs; on ImageNet, ResNet-200 takes about 3 weeks to train on 8 GPUs (on par with VGG nets [22]).
6 Conclusions
This paper investigates the propagation formulations behind the connection mechanisms of deep residual networks. Our derivations imply that identity shortcut connections and identity after-addition activation are essential for making information propagation smooth. Ablation experiments demonstrate phenomena that are consistent with our derivations. We also present 1000-layer deep networks that can be easily trained and achieve improved accuracy.
Appendix: Implementation Details
The implementation details and hyper-parameters are the same as those in [1]. On CIFAR we use only the translation and flipping augmentation in [1] for training. The learning rate starts from 0.1, and is divided by 10 at 32k and 48k iterations. Following [1], for all CIFAR experiments we warm up the training by using a smaller learning rate of 0.01 at the beginning 400 iterations and go back to 0.1 after that, although we remark that this is not necessary for our proposed Residual Unit. The mini-batch size is 128 on 2 GPUs (64 each), the weight decay is 0.0001, the momentum is 0.9, and the weights are initialized as in [23].
On ImageNet, we train the models using the same data augmentation as in [1]. The learning rate starts from 0.1 (no warming up), and is divided by 10 at 30 and 60 epochs. The mini-batch size is 256 on 8 GPUs (32 each). The weight decay, momentum, and weight initialization are the same as above.
When using the pre-activation Residual Units (Fig. 4(d)(e) and Fig. 5), we pay special attention to the first and the last Residual Units of the entire network. For the first Residual Unit (that follows a stand-alone convolutional layer, conv1), we adopt the first activation right after conv1 and before splitting into two paths; for the last Residual Unit (followed by average pooling and a fully-connected classifier), we adopt an extra activation right after its element-wise addition. These two special cases are the natural outcome when we obtain the pre-activation network via the modification procedure as shown in Fig. 5.
The bottleneck Residual Units (for ResNet-164/1001 on CIFAR) are constructed following [1]. For example, a unit in ResNet-110 is replaced with a unit in ResNet-164, both of which have roughly the same number of parameters. For the bottleneck ResNets, when reducing the feature map size we use projection shortcuts [1] for increasing dimensions, and when pre-activation is used, these projection shortcuts are also with pre-activation.
References
- [1] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR. (2016)
- [2] Nair, V., Hinton, G.E.: Rectified linear units improve restricted boltzmann machines. In: ICML. (2010)
- [3] Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A.C., Fei-Fei, L.: ImageNet Large Scale Visual Recognition Challenge. IJCV (2015)
- [4] Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft COCO: Common objects in context. In: ECCV. (2014)
- [5] Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural computation (1997)
- [6] Srivastava, R.K., Greff, K., Schmidhuber, J.: Highway networks. In: ICML workshop. (2015)
- [7] Srivastava, R.K., Greff, K., Schmidhuber, J.: Training very deep networks. In: NIPS. (2015)
- [8] Ioffe, S., Szegedy, C.: Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: ICML. (2015)
- [9] LeCun, Y., Boser, B., Denker, J.S., Henderson, D., Howard, R.E., Hubbard, W., Jackel, L.D.: Backpropagation applied to handwritten zip code recognition. Neural computation (1989)
- [10] Krizhevsky, A.: Learning multiple layers of features from tiny images. Tech Report (2009)
- [11] Hinton, G.E., Srivastava, N., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.R.: Improving neural networks by preventing co-adaptation of feature detectors. arXiv:1207.0580 (2012)
- [12] Clevert, D.A., Unterthiner, T., Hochreiter, S.: Fast and accurate deep network learning by exponential linear units (ELUs). In: ICLR. (2016)
- [13] Graham, B.: Fractional max-pooling. arXiv:1412.6071 (2014)
- [14] Springenberg, J.T., Dosovitskiy, A., Brox, T., Riedmiller, M.: Striving for simplicity: The all convolutional net. arXiv:1412.6806 (2014)
- [15] Lin, M., Chen, Q., Yan, S.: Network in network. In: ICLR. (2014)
- [16] Lee, C.Y., Xie, S., Gallagher, P., Zhang, Z., Tu, Z.: Deeply-supervised nets. In: AISTATS. (2015)
- [17] Romero, A., Ballas, N., Kahou, S.E., Chassang, A., Gatta, C., Bengio, Y.: Fitnets: Hints for thin deep nets. In: ICLR. (2015)
- [18] Mishkin, D., Matas, J.: All you need is a good init. In: ICLR. (2016)
- [19] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z.: Rethinking the inception architecture for computer vision. In: CVPR. (2016)
- [20] Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A.: Going deeper with convolutions. In: CVPR. (2015)
- [21] Szegedy, C., Ioffe, S., Vanhoucke, V.: Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv:1602.07261 (2016)
- [22] Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: ICLR. (2015)
- [23] He, K., Zhang, X., Ren, S., Sun, J.: Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In: ICCV. (2015)