Identity Matters in Deep Learning
Abstract
An emerging design principle in deep learning is that each layer of a deep artificial neural network should be able to easily express the identity transformation. This idea not only motivated various normalization techniques, such as batch normalization, but was also key to the immense success of residual networks.
In this work, we put the principle of identity parameterization on a more solid theoretical footing alongside further empirical progress. We first give a strikingly simple proof that arbitrarily deep linear residual networks have no spurious local optima. The same result for linear feed-forward networks in their standard parameterization is substantially more delicate. Second, we show that residual networks with ReLu activations have universal finite-sample expressivity in the sense that the network can represent any function of its sample provided that the model has more parameters than the sample size.
Directly inspired by our theory, we experiment with a radically simple residual architecture consisting of only residual convolutional layers and ReLu activations, but no batch normalization, dropout, or max pool. Our model improves significantly on previous all-convolutional networks on the CIFAR10, CIFAR100, and ImageNet classification benchmarks.
1 Introduction
Traditional convolutional neural networks for image classification, such as AlexNet ([13]), are parameterized in such a way that when all trainable weights are , a convolutional layer represents the -mapping. Moreover, the weights are initialized symmetrically around This standard parameterization makes it non-trivial for a convolutional layer trained with stochastic gradient methods to preserve features that were already good. Put differently, such convolutional layers cannot easily converge to the identity transformation at training time.
This shortcoming was observed and partially addressed by [9] through batch normalization, i.e., layer-wise whitening of the input with a learned mean and covariance. But the idea remained somewhat implicit until residual networks ([6]; [7]) explicitly introduced a reparameterization of the convolutional layers such that when all trainable weights are the layer represents the identity function. Formally, for an input each residual layer has the form rather than This simple reparameterization allows for much deeper architectures largely avoiding the problem of vanishing (or exploding) gradients. Residual networks, and subsequent architectures that use the same parameterization, have since then consistently achieved state-of-the-art results on various computer vision benchmarks such as CIFAR10 and ImageNet.
1.1 Our contributions
In this work, we consider identity parameterizations from a theoretical perspective, while translating some of our theoretical insight back into experiments. Loosely speaking, our first result underlines how identity parameterizations make optimization easier, while our second result shows the same is true for representation.
Linear residual networks.
Since general non-linear neural networks, are beyond the reach of current theoretical methods in optimization, we consider the case of deep linear networks as a simplified model. A linear network represents an arbitrary linear map as a sequence of matrices The objective function is , where for some unknown linear transformation and is drawn from a distribution. Such linear networks have been studied actively in recent years as a stepping stone toward the general non-linear case (see Section 1.2). Even though is just a linear map, the optimization problem over the factored variables is non-convex.
In analogy with residual networks, we will instead parameterize the objective function as
| (1.1) |
To give some intuition, when the depth is large enough, we can hope that the target function has a factored representation in which each matrix has small norm. Any symmetric positive semidefinite matrix can, for example, be written as a product where each is very close to the identity for large so that has small spectral norm. We first prove that an analogous claim is true for all linear transformations with positive determinant111As will be discussed below Theorem 2.1, it is without loss of generality to assume that the determinant of is positive. . Specifically, we prove that for every linear transformation with , there exists a global optimizer of (1.1) such that for large enough depth
| (1.2) |
Here, denotes the spectral norm of The constant factor depends on the conditioning of We give the formal statement in Theorem 2.1. The theorem has the interesting consequence that as the depth increases, smaller norm solutions exist and hence regularization may offset the increase in parameters.
Having established the existence of small norm solutions, our main result on linear residual networks shows that the objective function (1.1) is, in fact, easy to optimize when all matrices have sufficiently small norm. More formally, letting and denote the objective function in (1.1), we can show that the gradients vanish only when provided that See Theorem 2.2. This result implies that linear residual networks have no critical points other than the global optimum. In contrast, for standard linear neural networks we only know, by work of [12] that these networks don’t have local optima except the global optimum, but it doesn’t rule out other critical points. In fact, setting will always lead to a bad critical point in the standard parameterization.
Universal finite sample expressivity.
Going back to non-linear residual networks with ReLU activations, we can ask: How expressive are deep neural networks that are solely based on residual layers with ReLU activations? To answer this question, we give a very simple construction showing that such residual networks have perfect finite sample expressivity. In other words, a residual network with ReLU activations can easily express any functions of a sample of size provided that it has sufficiently more than parameters. Note that this requirement is easily met in practice. On CIFAR 10 (), for example, successful residual networks often have more than parameters. More formally, for a data set of size with classes, our construction requires parameters. Theorem 3.2 gives the formal statement.
Each residual layer in our construction is of the form where and are linear transformations. These layers are significantly simpler than standard residual layers, which typically have two ReLU activations as well as two instances of batch normalization.
The power of all-convolutional residual networks.
Directly inspired by the simplicity of our expressivity result, we experiment with a very similar architecture on the CIFAR10, CIFAR100, and ImageNet data sets. Our architecture is merely a chain of convolutional residual layers each with a single ReLU activation, but without batch normalization, dropout, or max pooling as are common in standard architectures. The last layer is a fixed random projection that is not trained. In line with our theory, the convolutional weights are initialized near using Gaussian noise mainly as a symmetry breaker. The only regularizer is standard weight decay (-regularization) and there is no need for dropout. Despite its simplicity, our architecture reaches top- classification error on the CIFAR10 benchmark (with standard data augmentation). This is competitive with the best residual network reported in [6], which achieved . Moreover, it improves upon the performance of the previous best all-convolutional network, , achieved by [15]. Unlike ours, this previous all-convolutional architecture additionally required dropout and a non-standard preprocessing (ZCA) of the entire data set. Our architecture also improves significantly upon [15] on both Cifar100 and ImageNet.
1.2 Related Work
Since the advent of residual networks ([6]; [7]), most state-of-the-art networks for image classification have adopted a residual parameterization of the convolutional layers. Further impressive improvements were reported by [8] with a variant of residual networks, called dense nets. Rather than adding the original input to the output of a convolutional layer, these networks preserve the original features directly by concatenation. In doing so, dense nets are also able to easily encode an identity embedding in a higher-dimensional space. It would be interesting to see if our theoretical results also apply to this variant of residual networks.
There has been recent progress on understanding the optimization landscape of neural networks, though a comprehensive answer remains elusive. Experiments in [5] and [4] suggest that the training objectives have a limited number of bad local minima with large function values. Work by [3] draws an analogy between the optimization landscape of neural nets and that of the spin glass model in physics ([1]). [14] showed that -layer neural networks have no bad differentiable local minima, but they didn’t prove that a good differentiable local minimum does exist. [2] and [12] show that linear neural networks have no bad local minima. In contrast, we show that the optimization landscape of deep linear residual networks has no bad critical point, which is a stronger and more desirable property. Our proof is also notably simpler illustrating the power of re-parametrization for optimization. Our results also indicate that deeper networks may have more desirable optimization landscapes compared with shallower ones.
2 Optimization landscape of linear residual networks
Consider the problem of learning a linear transformation from noisy measurements where is a -dimensional spherical Gaussian vector. Denoting by the distribution of the input data let be its covariance matrix.
There are, of course, many ways to solve this classical problem, but our goal is to gain insights into the optimization landscape of neural nets, and in particular, residual networks. We therefore parameterize our learned model by a sequence of weight matrices ,
| (2.1) |
Here are the hidden layers and are the predictions of the learned model on input More succinctly, we have
It is easy to see that this model can express any linear transformation We will use as a shorthand for all of the weight matrices, that is, the -dimensional tensor that contains as slices. Our objective function is the maximum likelihood estimator,
| (2.2) |
We will analyze the landscape of the population risk, defined as,
Recall that is the spectral norm of . We define the norm for the tensor as the maximum of the spectral norms of its slices,
The first theorem of this section states that the objective function has an optimal solution with small -norm, which is inversely proportional to the number of layers . Thus, when the architecture is deep, we can shoot for fairly small norm solutions. We define . Here denote the least and largest singular values of respectively.
Theorem 2.1.
Suppose and . Then, there exists a global optimum solution of the population risk with norm
We first note that the condition is without loss of generality in the following sense. Given any linear transformation with negative determinant, we can effectively flip the determinant by augmenting the data and the label with an additional dimension: let and , where is an independent random variable (say, from standard normal distribution), and let . Then, we have that and .222When the dimension is odd, there is an easier way to see this – flipping the label corresponds to flipping , and we have .
Second, we note that here should be thought of as a constant since if is too large (or too small), we can scale the data properly so that . Concretely, if , then we can scaling for the outputs properly so that and . In this case, we have , which will remain a small constant for fairly large condition number . We also point out that we made no attempt to optimize the constant factors here in the analysis. The proof of Theorem 2.1 is rather involved and is deferred to Section A.
Given the observation of Theorem 2.1, we restrict our attention to analyzing the landscape of in the set of with -norm less than ,
Here using Theorem 2.1, the radius should be thought of as on the order of . Our main theorem in this section claims that there is no bad critical point in the domain for any . Recall that a critical point has vanishing gradient.
Theorem 2.2.
For any , we have that any critical point of the objective function inside the domain must also be a global minimum.
Theorem 2.2 suggests that it is sufficient for the optimizer to converge to critical points of the population risk, since all the critical points are also global minima.
Moreover, in addition to Theorem 2.2, we also have that any inside the domain satisfies that
| (2.3) |
Here is the global minimal value of and denotes the euclidean norm333That is, . of the -dimensional tensor . Note that denote the minimum singular value of .
Equation (2.3) says that the gradient has fairly large norm compared to the error, which guarantees convergence of the gradient descent to a global minimum ([11]) if the iterates stay inside the domain which is not guaranteed by Theorem 2.2 by itself.
Towards proving Theorem 2.2, we start off with a simple claim that simplifies the population risk. We use to denote the Frobenius norm of a matrix, and denotes the inner product of and in the standard basis (that is, where denotes the trace of a matrix.)
Claim 2.3.
In the setting of this section, we have,
| (2.4) |
Here is a constant that doesn’t depend on , and denote the square root of , that is, the unique symmetric matrix that satisfies .
Proof of Claim 2.3.
Next we compute the gradients of the objective function from straightforward matrix calculus. We defer the full proof to Section A.
Lemma 2.4.
The gradients of can be written as,
| (2.5) |
where .
Now we are ready to prove Theorem 2.2. The key observation is that each matric has small norm and cannot cancel the identity matrix. Therefore, the gradients in equation (2.5) is a product of non-zero matrices, except for the error matrix . Therefore, if the gradient vanishes, then the only possibility is that the matrix vanishes, which in turns implies is an optimal solution.
Proof of Theorem 2.2.
3 Representational Power of the Residual Networks
In this section we characterize the finite-sample expressivity of residual networks. We consider a residual layers with a single ReLU activation and no batch normalization. The basic residual building block is a function that is parameterized by two weight matrices and a bias vector ,
| (3.1) |
A residual network is composed of a sequence of such residual blocks. In comparison with the full pre-activation architecture in [7], we remove two batch normalization layers and one ReLU layer in each building block.
We assume the data has labels, encoded as standard basis vectors in , denoted by . We have training examples , where denotes the -th data and denotes the -th label. Without loss of generality we assume the data are normalized so that We also make the mild assumption that no two data points are very close to each other.
Assumption 3.1.
We assume that for every , we have for some absolute constant
Images, for example, can always be imperceptibly perturbed in pixel space so as to satisfy this assumption for a small but constant
Under this mild assumption, we prove that residual networks have the power to express any possible labeling of the data as long as the number of parameters is a logarithmic factor larger than .
Theorem 3.2.
Suppose the training examples satisfy Assumption 3.1. Then, there exists a residual network (specified below) with parameters that perfectly expresses the training data, i.e., for all the network maps to
It is common in practice that as is for example the case for the Imagenet data set where and
We construct the following residual net using the building blocks of the form as defined in equation (3.1). The network consists of hidden layers , and the output is denoted by . The first layer of weights matrices maps the -dimensional input to a -dimensional hidden variable . Then we apply layers of building block with weight matrices . Finally, we apply another layer to map the hidden variable to the label in . Mathematically, we have
We note that here and so that the dimension is compatible. We assume the number of labels and the input dimension are both smaller than , which is safely true in practical applications.444In computer vision, typically is less than and is less than while is larger than The hyperparameter will be chosen to be and the number of layers is chosen to be . Thus, the first layer has parameters, and each of the middle building blocks contains parameters and the final building block has parameters. Hence, the total number of parameters is .
Towards constructing the network of the form above that fits the data, we first take a random matrix that maps all the data points to vectors . Here we will use to denote the -th layer of hidden variable of the -th example. By Johnson-Lindenstrauss Theorem ([10], or see [17]), with good probability, the resulting vectors ’s remain to satisfy Assumption 3.1 (with slightly different scaling and larger constant ), that is, any two vectors and are not very correlated.
Then we construct middle layers that maps to for every . These vectors will clustered into groups according to the labels, though they are in the instead of in as desired. Concretely, we design this cluster centers by picking random unit vectors in . We view them as the surrogate label vectors in dimension (note that is potentially much smaller than ). In high dimensions (technically, if ) random unit vectors are pair-wise uncorrelated with inner product less than . We associate the -th example with the target surrogate label vector defined as follows,
| (3.2) |
Then we will construct the matrices such that the first layers of the network maps vector to the surrogate label vector . Mathematically, we will construct such that
| (3.3) |
Finally we will construct the last layer so that it maps the vectors to ,
| (3.4) |
Putting these together, we have that by the definition (3.2) and equation (3.3), for every , if the label is is , then will be . Then by equation (3.4), we have that . Hence we obtain that . The key part of this plan is the construction of the middle layers of weight matrices so that . We encapsulate this into the following informal lemma. The formal statement and the full proof is deferred to Section B.
Lemma 3.3 (Informal version of Lemma B.2).
In the setting above, for (almost) arbitrary vectors and , there exists weights matrices , such that,
We briefly sketch the proof of the Lemma to provide intuitions, and defer the full proof to Section B. The operation that each residual block applies to the hidden variable can be abstractly written as,
| (3.5) |
where corresponds to the hidden variable before the block and corresponds to that after. We claim that for an (almost) arbitrary sequence of vectors , there exists such that operation (3.5) transforms vectors of ’s to an arbitrary set of other vectors that we can freely choose, and maintain the value of the rest of vectors. Concretely, for any subset of size , and any desired vector , there exist such that
| (3.6) |
This claim is formalized in Lemma B.1. We can use it repeatedly to construct layers of building blocks, each of which transforms a subset of vectors in to the corresponding vectors in , and maintains the values of the others. Recall that we have layers and therefore after layers, all the vectors ’s are transformed to ’s, which complete the proof sketch. ∎
4 Power of all-convolutional residual networks
Inspired by our theory, we experimented with all-convolutional residual networks on standard image classification benchmarks.
4.1 CIFAR10 and CIFAR100
Our architectures for CIFAR10 and CIFAR100 are identical except for the final dimension corresponding to the number of classes and , respectively. In Table 1, we outline our architecture. Each residual block has the form where are convolutions of the specified dimension (kernel width, kernel height, number of input channels, number of output channels). The second convolution in each block always has stride , while the first may have stride where indicated. In cases where transformation is not dimensionality-preserving, the original input is adjusted using averaging pooling and padding as is standard in residual layers.
We trained our models with the Tensorflow framework, using a momentum optimizer with momentum and batch size is . All convolutional weights are trained with weight decay The initial learning rate is which drops by a factor and and steps. The model reaches peak performance at around steps, which takes about on a single NVIDIA Tesla K40 GPU. Our code can be easily derived from an open source implementation555https://github.com/tensorflow/models/tree/master/resnet by removing batch normalization, adjusting the residual components and model architecture. An important departure from the code is that we initialize a residual convolutional layer of kernel size and output channels using a random normal initializer of standard deviation rather than used for standard convolutional layers. This substantially smaller weight initialization helped training, while not affecting representation.
A notable difference from standard models is that the last layer is not trained, but simply a fixed random projection. On the one hand, this slightly improved test error (perhaps due to a regularizing effect). On the other hand, it means that the only trainable weights in our model are those of the convolutions, making our architecture “all-convolutional”.
| variable dimensions | initial stride | description |
| 1 standard conv | ||
| 9 residual blocks | ||
| 9 residual blocks | ||
| 9 residual blocks | ||
| – | – | global average pool |
| – | random projection (not trained) |
An interesting aspect of our model is that despite its massive size of million trainable parameters, the model does not seem to overfit too quickly even though the data set size is In contrast, we found it difficult to train a model with batch normalization of this size without significant overfitting on CIFAR10.
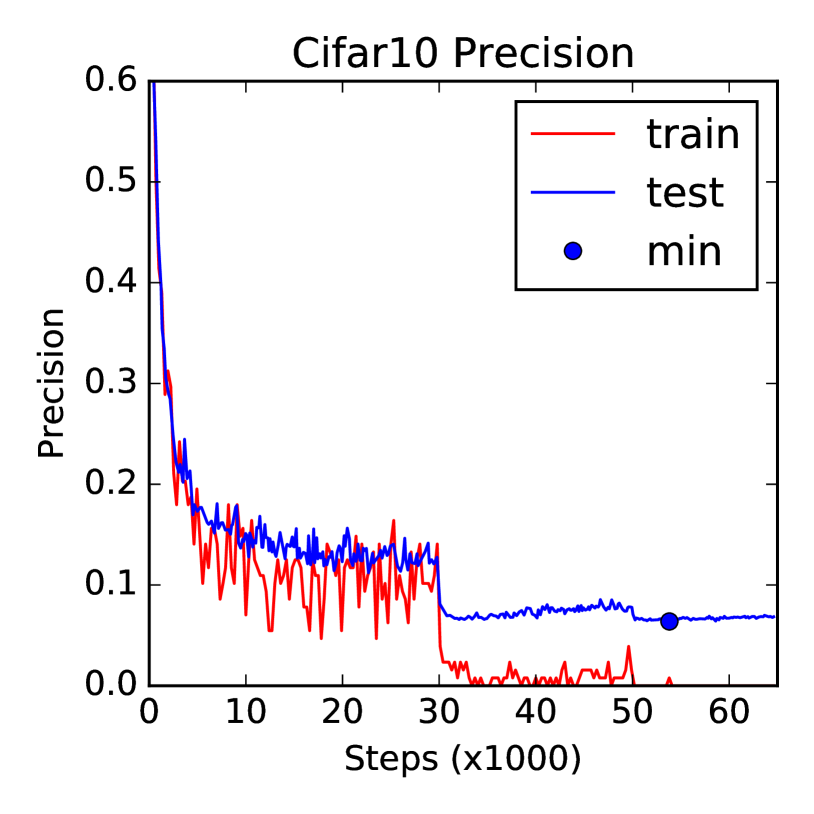
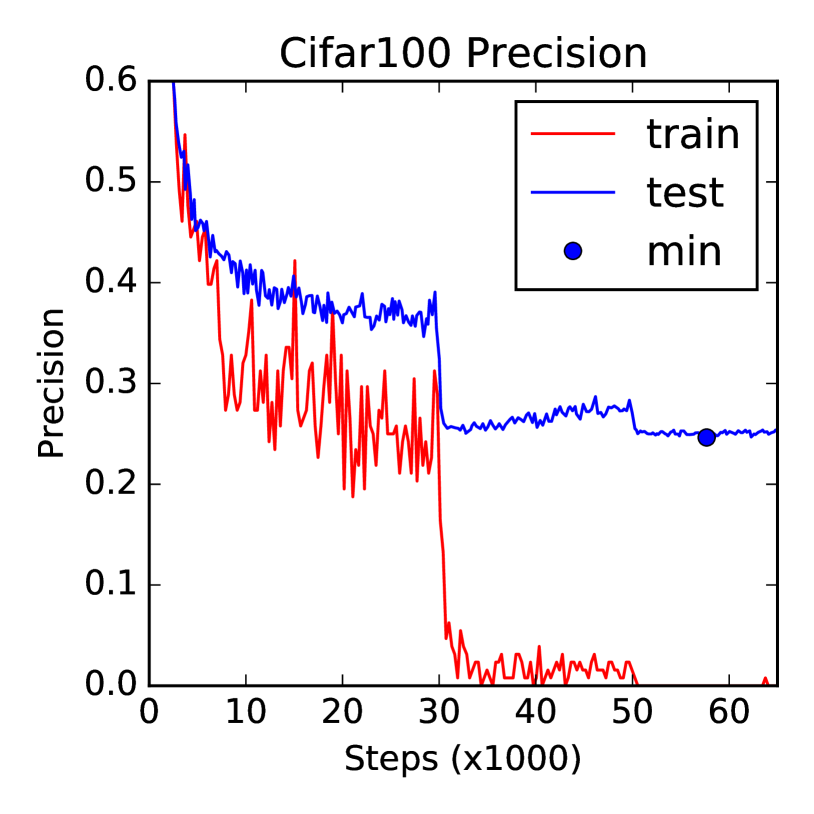
Table 2 summarizes the top- classification error of our models compared with a non-exhaustive list of previous works, restricted to the best previous all-convolutional result by [15], the first residual results [6], and state-of-the-art results on CIFAR by [8]. All results are with standard data augmentation.
| Method | CIFAR10 | CIFAR100 | ImageNet |
remarks |
| All-CNN |
all-convolutional, dropout
|
|||
| Ours |
all-convolutional |
|||
| ResNet | ||||
| DenseNet | N/A |
4.2 ImageNet
The ImageNet ILSVRC 2012 data set has data points with classes. Each image is resized to pixels with channels. We experimented with an all-convolutional variant of the -layer network in [6]. The original model achieved classification error. Our derived model has trainable parameters. We trained the model with a momentum optimizer (with momentum ) and a learning rate schedule that decays by a factor of every two epochs, starting from the initial learning rate Training was distributed across machines updating asynchronously. Each machine was equipped with GPUs (NVIDIA Tesla K40) and used batch size split across the GPUs so that each GPU updated with batches of size
In contrast to the situation with CIFAR10 and CIFAR100, on ImageNet our all-convolutional model performed significantly worse than its original counterpart. Specifically, we experienced a significant amount of underfitting suggesting that a larger model would likely perform better.
Despite this issue, our model still reached top- classification error on the test set ( data points), and top- test error after steps (about one week of training). While no longer state-of-the-art, this performance is significantly better than the reported by [13], as well as the best all-convolutional architecture by [15]. We believe it is quite likely that a better learning rate schedule and hyperparameter settings of our model could substantially improve on the preliminary performance reported here.
5 Conclusion
Our theory underlines the importance of identity parameterizations when training deep artificial neural networks. An outstanding open problem is to extend our optimization result to the non-linear case where each residual has a single ReLU activiation as in our expressivity result. We conjecture that a result analogous to Theorem 2.2 is true for the general non-linear case. Unlike with the standard parameterization, we see no fundamental obstacle for such a result.
We hope our theory and experiments together help simplify the state of deep learning by aiming to explain its success with a few fundamental principles, rather than a multitude of tricks that need to be delicately combined. We believe that much of the advances in image recognition can be achieved with residual convolutional layers and ReLU activations alone. This could lead to extremely simple (albeit deep) architectures that match the state-of-the-art on all image classification benchmarks.
Acknowledgment: We thank Jason D. Lee, Qixing Huang, and Jonathan Shewchuk for helpful discussions and kindly pointing out errors in earlier versions of the paper. We also thank Jonathan Shewchuk for suggesting an improvement of equation (2.3) that is incorporated into the current version. Tengyu Ma would like to thank the support by Dodds Fellowship and Siebel Scholarship.
References
- [1] Antonio Auffinger, Gérard Ben Arous, and Jiří Černỳ. Random matrices and complexity of spin glasses. Communications on Pure and Applied Mathematics, 66(2):165–201, 2013.
- [2] P. Baldi and K. Hornik. Neural networks and principal component analysis: Learning from examples without local minima. Neural Netw., 2(1):53–58, January 1989.
- [3] Anna Choromanska, Mikael Henaff, Michael Mathieu, Gérard Ben Arous, and Yann LeCun. The loss surfaces of multilayer networks. In AISTATS, 2015.
- [4] Yann N Dauphin, Razvan Pascanu, Caglar Gulcehre, Kyunghyun Cho, Surya Ganguli, and Yoshua Bengio. Identifying and attacking the saddle point problem in high-dimensional non-convex optimization. In Advances in neural information processing systems, pages 2933–2941, 2014.
- [5] I. J. Goodfellow, O. Vinyals, and A. M. Saxe. Qualitatively characterizing neural network optimization problems. ArXiv e-prints, December 2014.
- [6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In arXiv prepring arXiv:1506.01497, 2015.
- [7] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. In Computer Vision - ECCV 2016 - 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part IV, pages 630–645, 2016.
- [8] Gao Huang, Zhuang Liu, and Kilian Q. Weinberger. Densely connected convolutional networks. CoRR, abs/1608.06993, 2016.
- [9] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6-11 July 2015, pages 448–456, 2015.
- [10] William B Johnson and Joram Lindenstrauss. Extensions of lipschitz mappings into a hilbert space. Contemporary mathematics, 26(189-206):1, 1984.
- [11] H. Karimi, J. Nutini, and M. Schmidt. Linear Convergence of Gradient and Proximal-Gradient Methods Under the Polyak-Lojasiewicz Condition. ArXiv e-prints, August 2016.
- [12] K. Kawaguchi. Deep Learning without Poor Local Minima. ArXiv e-prints, May 2016.
- [13] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105, 2012.
- [14] D. Soudry and Y. Carmon. No bad local minima: Data independent training error guarantees for multilayer neural networks. ArXiv e-prints, May 2016.
- [15] J. T. Springenberg, A. Dosovitskiy, T. Brox, and M. Riedmiller. Striving for Simplicity: The All Convolutional Net. ArXiv e-prints, December 2014.
- [16] Eric W. Weisstein. Normal matrix, from mathworld–a wolfram web resource., 2016.
- [17] Wikipedia. Johnson–lindenstrauss lemma — wikipedia, the free encyclopedia, 2016.
Appendix A Missing Proofs in Section 2
In this section, we give the complete proofs for Theorem 2.1 and Lemma 2.4, which are omitted in Section 2.
A.1 Proof of Theorem 2.1
It turns out the proof will be significantly easier if is assumed to be a symmetric positive semidefinite (PSD) matrix, or if we allow the variables to be complex matrices. Here we first give a proof sketch for the first special case. The readers can skip it and jumps to the full proof below. We will also prove stronger results, namely, , for the special case.
When is PSD, it can be diagonalized by orthonormal matrix in the sense that , where is a diagonal matrix with non-negative diagonal entries . Let , then we have
| (since ) | ||||
We see that the network defined by reconstruct the transformation , and therefore it’s a global minimum of the population risk (formally see Claim 2.3 below). Next, we verify that each of the has small spectral norm:
| (since is orthonormal) | ||||
| (A.1) |
Since , we have . It follows that
| (since for all ) |
Then using equation (A.1) and the equation above, we have that , which completes the proof for the special case.
Towards fully proving the Theorem 2.1, we start with the following Claim:
Claim A.1.
Suppose is an orthonormal matrix. Then for any integer , there exists matrix and a diagonal matrix satisfies that (a) and , (b) is an diagonal matrix with on the diagonal, and (c) If is a rotation then .
Proof.
We first consider the case when is a rotation. Each rotation matrix can be written as . Suppose . Then we can take and . We can verify that
Next, we consider the case when is a reflection. Then we have that can be written as , where is the reflection with respect to the -axis. Then we can take and and complete the proof. ∎
Next we give the formal full proof of Theorem 2.1. The main idea is to reduce to the block diagonal situation and to apply the Claim above.
Proof of Theorem 2.1.
Let be the singular value decomposition of , where , are two orthonormal matrices and is a diagonal matrix with nonnegative entries on the diagonal. Since and , we can flip properly so that . Since is a normal matrix (that is, satisfies that ), by Claim C.1, we have that can be block-diagonalized by orthonormal matrix into , where is a real block diagonal matrix with each block being of size at most . Using Claim A.1, we have that for any , there exists such that
| (A.2) |
and . Let and . We can rewrite equation (A.2) as
| (A.3) |
Moreover, we have that is a diagonal matrix with on the diagonal. Since ’s are orthonormal matrix with determinant 1, we have . That is, has an even number of ’s on the diagonal. Then we can group the ’s into blocks. Note that is the rotation matrix . Thus we can write as a concatenation of ’s on the diagonal and block . Then applying Claim A.1 (on each of the block ), we obtain that there are such that
| (A.4) |
where . Thus using equation (A.3) and (2.3), we obtain that
Moreover, we have that for every , , because is an orthonormal matrix. The same can be proved for . Thus let for and , and we can rewrite,
We can deal with similarly by decomposing into matrices that are close to identity matrix,
Last, we deal with the diagonal matrix . Let . We have . Then, we can write where and is an integer to be chosen later. We have that . When , we have that
| (since for ) |
Let and then we have . Finally, we choose and , 666Here for notational convenience, are not chosen to be integers. But rounding them to closest integer will change final bound of the norm by small constant factor. and let . We have that and
Moreover, we have , as desired. ∎
A.2 Proof of Lemma 2.4
We compute the partial gradients by definition. Let be an infinitesimal change to . Using Claim 2.3, consider the Taylor expansion of
By definition, this means that the .∎
Appendix B Missing Proofs in Section 3
In this section, we provide the full proof of Theorem 3.2. We start with the following Lemma that constructs a building block that transform vectors of an arbitrary sequence of vectors to any arbitrary set of vectors, and main the value of the others. For better abstraction we use , to denote the sequence of vectors.
Lemma B.1.
Let be of size . Suppose is a sequences of vectors satisfying a) for every , we have , and b) if and contains at least one of , then . Let be an arbitrary sequence of vectors. Then, there exists such that for every , we have , and moreover, for every we have .
Proof of Lemma B.1.
Without loss of generality, suppose . We construct as follows. Let the -th row of be for , and let where denotes the all 1’s vector. Let the -column of be for . Next we verify that the correctness of the construction. We first consider . We have that is a a vector with -th coordinate equal to . The -th coordinate of is equal to , which can be upperbounded using the assumption of the Lemma by
| (B.1) |
Therefore, this means contains a single positive entry (with value at least ), and all other entries being non-positive. This means that where is the -th natural basis vector. It follows that . Finally, consider . Then similarly to the computation in equation (B.1), is a vector with all coordinates less than . Therefore is a vector with negative entries. Hence we have , which implies . ∎
Now we are ready to state the formal version of Lemma 3.3.
Lemma B.2.
Suppose a sequence of vectors satisfies a relaxed version of Assumption 3.1: a) for every , b) for every , we have . Let be defined above. Then there exists weigh matrices , such that given , we have,
We will use Lemma B.1 repeatedly to construct building blocks , and thus prove Lemma B.2. Each building block takes a subset of vectors among and convert them to ’s, while maintaining all other vectors as fixed. Since they are totally layers, we finally maps all the ’s to the target vectors ’s.
Proof of Lemma B.2.
We use Lemma B.1 repeatedly. Let . Then using Lemma B.1 with and for , we obtain that there exists such that for , it holds that , and for , it holds that . Now we construct the other layers inductively. We will construct the layers such that the hidden variable at layer satisfies for every , and for every . Assume that we have constructed the first layer and next we use Lemma B.1 to construct the layer. Then we argue that the choice of , , and satisfies the assumption of Lemma B.1. Indeed, because ’s are chosen uniformly randomly, we have w.h.p for every and , . Thus, since , we have that also doesn’t correlate with any of the . Then we apply Lemma B.1 and conclude that there exists such that for , for , and for . These imply that
Therefore we constructed the layers that meets the inductive hypothesis for layer . Therefore, by induction we get all the layers, and the last layer satisfies that for every example . ∎
Proof of Theorem 3.2.
We use formalize the intuition discussed below Theorem 3.2. First, take for sufficiently large absolute constant (for example, works), by Johnson-Lindenstrauss Theorem ([10], or see [17]) we have that when is a random matrix with standard normal entires, with high probability, all the pairwise distance between the the set of vectors are preserved up to factor. That is, we have that for every , , and for every , . Let and . Then we have ’s satisfy the condition of Lemam B.2. We pick random vectors in . Let be defined as in equation (3.2). Then by Lemma B.2, we can construct matrices such that
| (B.2) |
Note that , and ’s are random unit vector. Therefore, the choice of , , and satisfies the condition of Lemma B.1, and using Lemma B.1 we conclude that there exists such that
| (B.3) |
By the definition of in equation (3.2) and equation (B.2), we conclude that , which complete the proof. ∎
Appendix C Toolbox
In this section, we state two folklore linear algebra statements. The following Claim should be known, but we can’t find it in the literature. We provide the proof here for completeness.
Claim C.1.
Let be a real normal matrix (that is, it satisfies ). Then, there exists an orthonormal matrix such that
where is a real block diagonal matrix that consists of blocks with size at most .
Proof.
Since is a normal matrix, it is unitarily diagonalizable (see [16] for backgrounds). Therefore, there exists unitary matrix in and diagonal matrix in such that has eigen-decomposition . Since itself is a real matrix, we have that the eigenvalues (the diagonal entries of ) come as conjugate pairs, and so do the eigenvectors (which are the columns of ). That is, we can group the columns of into pairs , and let the corresponding eigenvalues be . Here . Then we get that . Let , then we have that is a real matrix of rank-2. Let be a orthonormal basis of the column span of and then we have that can be written as where is a matrix. Finally, let , and we complete the proof. ∎
The following Claim is used in the proof of Theorem 2.2. We provide a proof here for completeness.
Claim C.2 (folklore).
For any two matrices , we have that
Proof.
Since is the smallest eigenvalue of , we have that
Therefore, it follows that
Taking square root of both sides completes the proof. ∎