Principled Multilayer Network Embedding
Abstract
Multilayer network analysis has become a vital tool for understanding different relationships and their interactions in a complex system, where each layer in a multilayer network depicts the topological structure of a group of nodes corresponding to a particular relationship. The interactions among different layers imply how the interplay of different relations on the topology of each layer. For a single-layer network, network embedding methods have been proposed to project the nodes in a network into a continuous vector space with a relatively small number of dimensions, where the space embeds the social representations among nodes. These algorithms have been proved to have a better performance on a variety of regular graph analysis tasks, such as link prediction, or multi-label classification.
In this paper, by extending a standard graph mining into multilayer network, we have proposed three methods (“network aggregation,” “results aggregation” and “layer co-analysis”) to project a multilayer network into a continuous vector space. On one hand, without leveraging interactions among layers, “network aggregation” and “results aggregation” apply the standard network embedding method on the merged graph or each layer to find a vector space for multilayer network. On the other hand, in order to consider the influence of interactions among layers, “layer co-analysis” expands any single-layer network embedding method to a multilayer network. By introducing the link transition probability based on information distance, this method not only uses the first and second order random walk to traverse on a layer, but also has the ability to traverse between layers by leveraging interactions. From the evaluation, we have proved that comparing with regular link prediction methods, “layer co-analysis” achieved the best performance on most of the datasets, while “network aggregation” and “results aggregation” also have better performance than regular link prediction methods.
I Introduction
With the rise of the big data phenomenon (and in particular, the rise of social networking), graph mining has become necessary to analyze the diverse relationships between objects and data, and to understand the complex structures of the underlying graph. Analyzing such complex systems is crucial in understanding how a social network forms, or in making predictions about future network behavior.
However, graph mining is sensitive to the topological structures of a network. For example, in social network analysis, graph mining can leverage topology information to identify communities in a network, but does not have the ability to determine if the topology contains noise (or other errors). One way to avoid this is using multilayer network [1]. Multilayer network is a group of networks which depict multiple relationships between nodes, where each layer in the group represents a particular type of relationship [2, 1, 3].
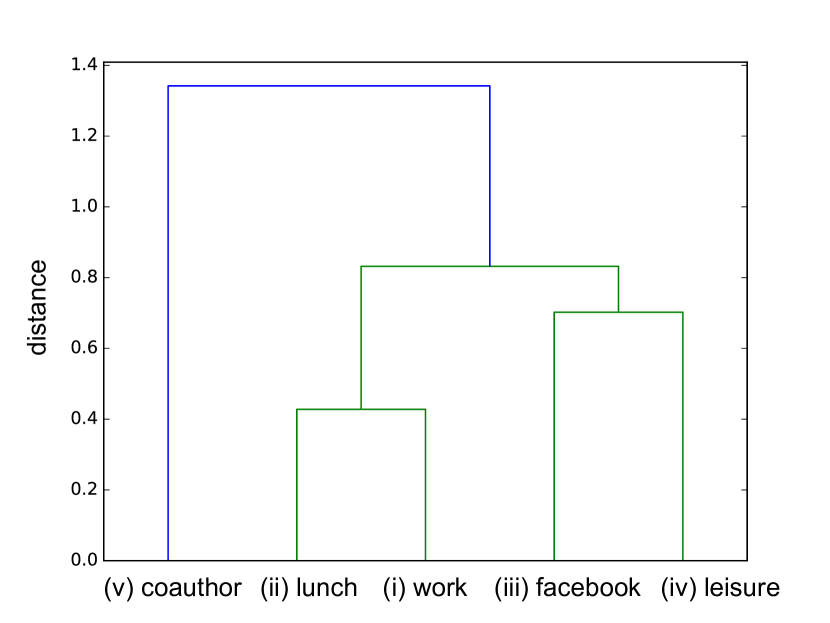
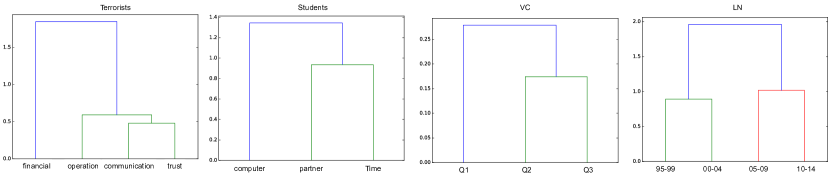
Take the AUCS dataset [4] as an example. The multiple layers represent five different relationship types between 61 employees of a university department: (i) coworking, (ii) having lunch together, (iii) facebook friendship, (iv) spending leisure time together, and (v) coauthorship. Figure 1 shows the distances among these different layers, calculated by [5], where the distance between layers is the distance value of the root node of the smallest subtree containing both layers. From Figure 1, we observe a number of key interactions: for example we observe that being coworkers and having lunch together (representing professional interactions) is strongly related through the low layer distance, and spending lesiure time together is likewise close to being connected on facebook (representing social interactions). In general, by considering multiple relationship types, we argue that multilayer network inherently reflects essential interactions between nodes in a manner that is robust to the noise presents in any individual relationship type.
Nowadays, graph mining methods on multilayer network typically concentrate on different network granularities [6], depending on the task. For example, on node/edge granularity, [7] and [8] focus on developing suitable centrality measures [9] like cross-layer degree centrality for multilayer network [10, 11]. Brodka et.al [12, 13] proposed multilayered local clustering coefficient (MLCC) and cross-layer clustering coefficient (CLCC) to depict cluster coefficient [14] of a node in a multilayer network. In contrast, the cluster level is often used for community detection [1, 15, 3, 16, 17, 18, 19], and the layer level used to analyze the interactions between different layer types [5, 20].
In this paper, we made an attempt to propose three novel graph mining methods for multilayer network by combining analysis at all levels of granularity that is suitable for a range of tasks. We achieve this via embedding the nodes of the multilayer network into a vector space. This vector space can be interpreted as a hidden metric space [21] for the multilayer network that naturally defines concepts of similarity between nodes, and captures many of the aspects of the original multilayer network, facilitating vector-based representation to a variety of machine learning algorithms to solve a range of tasks.
In standard network analysis, many such network embedding methods have been developed [22], such as DeepWalk [23], LINE [24] and node2vec [25]. These methods are all based upon generating samples of random walks over an input graph, with the properties of the random walk varying by method. However, these methods are built on top of a single graph, and to the best of our knowledge, the graph embedding method for multilayer graph has not been rigorously explored. Hence, we propose a generic multilayer graph embedding framework, which applies to any graph embedding method developed for single-layer graphs. In particular, we introduce three principled methods (“Network Aggregation,” “Results Aggregation” and “Network Co-analysis”) for extending graph embedding to multilayer networks:
-
•
Network Aggregation: The assumption for this method is all edges from different layers are equal [1, 3]. Based on this assumption, this method aggregates all networks into a single (weighted) network (where multiple edges between nodes are not allowed) and then applies existing graph embedding algorithms to analysis the merged graph. Note that this merged graph no longer distinguishes between relationship types, as many edges for node pairs that share multiple edges in the multilayer network are not retained.
-
•
Results Aggregation: The assumption for this method is different layers have totally different kinds of edges [26], which implies that even if two nodes have edges in different layers, these edges are totally different and cannot be merged. Based on this assumption, this method applies graph embedding to each layer separately, then merges the vector spaces together to define a vector space of the multilayer network.
-
•
Layer Co-analysis: Unlike the first two methods which only consider inter-layer edges (network aggregation) or intra-layer edges (results aggregation), this method leverages interactions among different layers to allow for traversal between layers, and to retain the structure of each individual layer. Specifically, we introduce a new random walk method that is capable of traversing layers, thereby encoding important interactions between nodes and layers. The methodology of random walk in a multilayer network is a general extension of single-layer embedding methods. For example, node2vec and DeepWalk are both state-of-the-art single-layer graph embedding methods. As node2vec added to DeepWalk the ability to control the homophily and structural equivalence properties of random walk samples, we enable the ability for random walk samples to traverse multiple layers. In particular, we control the degree to which this occurs through the addition of the parameter, which determines the probability that the next step of a random walk will traverse to a different layer in the multilayer network.
In Section II, we gives detailed information on three approaches for performing embedding on multilayer networks. In Section III, we use experimental results to demonstrate that our methods for multilayer network embedding can improve upon the results of node2vec for a link prediction task. In Section IV, we outline related work in single network embedding, and conclude in Section V with discussion and future work.
II Methods
Given a multilayer network with vertex set , layer set , and multilayer edge set (where and we denote the existence of an edge between and in layer by ), our task in vertex embedding is to learn a mapping function where is the chosen dimension of the vector space. We are effectively looking to find a function that represents the features of a vertex from the multilayer network. Figure 2 shows the three proposed architectures for projecting a multilayer network into a vector space. The following subsections provide details on the implementation and structure of each architecture, as well as the corresponding strategy for constructing the function .

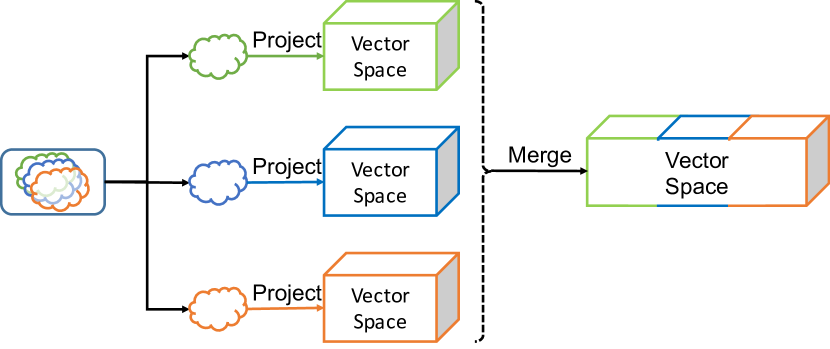

II-A Network Aggregation
Network aggregation is the baseline of the proposed methods for multilayer network embedding, where the layers of the multilayer network are merged to obtain a single network, and the regular node2vec method is applied to the merged graph. Algorithm 1 represents the network aggregation process.
In this method, we have a network aggregation function , i.e. a function that takes a multilayer MN and outputs a merged network that shares the vertex set with the multilayer network, but has an edge set that disallows multi-edges. The mapping function is defined by training on the merged network using node2vec.
Note that by combining all layers together in this method, we have lost the details of each layer and also have no way to leverage the interactions between layers when the function is learned.
II-B Results Aggregation
Here we project each network layer of the multilayer network into a separate vector space, and concatenate the resulting vector spaces. We define each layer graph as where for and learn functions that are combined to form the map as , where denotes the concatenation operator s.t. .
Unlike the network aggregation method, the dimension of the resulting vector space scales with the number of layers in the layer set . Though this method can in theory preserves the structure of each layer, it is also unable to leverage interactions between layers when learning the mapping function. Algorithm 2 outlines the result aggregation process.
II-C Layer Co-analysis
To overcome the fact that neither network aggregation nor results aggregation can leverage interactions between layers, we adopt layer co-analysis for the construction of a vector space that is cognizant of interactions between layers as well as preserving the structure of each layer.
Consider random walks over the multilayer networks depicted in Figure 3, where dotted black lines represent correspondence between the nodes of each layer, and bold lines represent edges in the network. If we use result aggregation in Figure 3(a), there is no path from node to node , as it is not possible to traverse between layers. Therefore the vector space cannot learn to associate these nodes. In contrast, if we run network aggregation on Figure 3(b), we ignore the multi-edge between nodes and (represented by the bold red lines). These issues motivate the need for a method that can traverse the path (represented by the dotted red lines) between layers from to , and that can retain the information implied by the multi-edge.
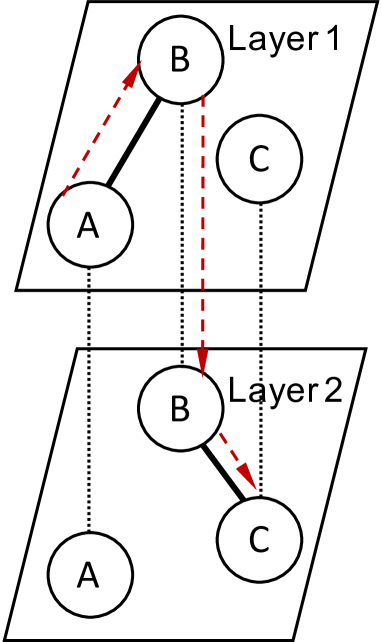
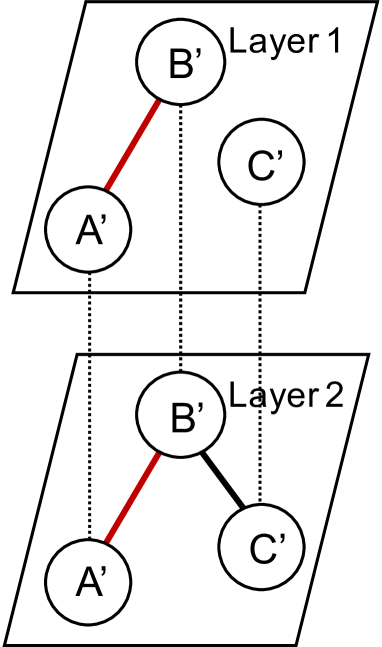
As LINE improved upon the uniform random walks of DeepWalk with weighted 2nd order walks, and node2vec introduced the parameters and to control the local and global biases of the sample random walks, we enable random walks to traverse between layers of a multilayer network, and introduce the parameter to control this tendency. Let represent the number of distinct layers connected to node of the multilayer network . That is, we can represent as in Equation 1.
| (1) |
Where denotes the indicator function. Then we introduce a 2nd order random walk with parameters . If the random walk previously traversed edge and the current node only has edges on layer (i.e. ), then we step according to the node2vec strategy (here, with binary edges), i.e. , where is a multilayer modification to the node2vec , factors as follows:
| (2) |
where is the shortest path between nodes and in layer of the multilayer graph (where nodes may be the same node).
Otherwise, if , the random walk stays on the current layer with probability , and moves along the edge of another layer with probability . That is, the random walk traversal probability for is given by Equation 3.
| (3) |
Pseudocode for this method is given in Algorithm 3, where refers to running stochastic gradient descent on the node2vec loglikelihood [25] with the multilayer random walks taking the place of the standard node2vec walks. In this paper, we only consider binary edges (support for weighted multilayer networks could be incorporated trivially through multiplying the edge traversal probabilities by the normalized edge weights).
Note that in this algorithm, the variable represents how important we view the relationships between layers to be in comparison to the interactions between nodes of the same layer. For , random walks will always traverse to different layers of the multilayer network when possible, whereas will restrict each random walk to stay on the layer in which it was initialized.
III Evaluation
Here we choose five real-world multilayer datasets, comparing the performance of our three multilayer network embedding methods on the link prediction task. In this paper, we set , with 10 random walks of 80 steps initialized from each node (i.e. we have random walks in total for each graph), and compare against two standard methods of link prediction [27]. All experiments in this paper were conducted locally on CPU using a Mac Book Pro with an Intel Core i7 2.5GHz processor and 16GB of 1600MHz RAM. Though this limits the size of our experiments in this preliminary work, our method naturally inherits the runtime scalability of node2vec.
III-A Datasets
Table I shows the size of the five datasets, with layer information as follows:
| Datasets | # Layers | # Nodes | # Edges |
|
||
|---|---|---|---|---|---|---|
| AUCS | 5 | 61 | 353 | none | ||
| Terrorists | 4 | 78 | 623 | none | ||
| Students | 3 | 185 | 311 | none | ||
| VC | 3 | 29 | 250 |
|
||
| LN | 4 | 191 | 511 |
|
-
•
AUCS [4] (AUCS): The multiple layers represent five different relationship types between 61 employees of a university department: (i) coworking, (ii) having lunch together, (iii) Facebook friendship, (iv) onine friendship (having fun together), and (v) coauthorship.
-
•
Terrorist network [28] (Terrorists): Each layer represents known interactions and ties between terrorists in the Noordin Top Terrorist dataset. These ties cover four different relationship types: (i) communication, (ii) financial, (iii) operation, and (iv) trust.
-
•
Student cooperation [29] (Students): Each layer represents a type of cooperation or coordination between 185 students of Ben-Gurion University: (i) Computer Network, which represents students who finished their papers on the same machine. (ii) Partner’s Network, which represents joint work on a submission. (iii) Time Network, which indicates if students submitted papers in the same epoch.
-
•
Vickers Chan 7th grader social dataset [30] (VC): Each layer represents an aspect of interaction between students in a class who were asked the following questions: (i) Who do you get on with in the class? (ii) Who are your best friends in the class? (iii) Who would you prefer to work with?
-
•
Leskovec-Ng collaboration dataset [31, 32, 33]111The dataset can be downloaded from https://sites.google.com/site/pinyuchenpage/datasets (LN): The coauthorship networks of Jure Leskovec and Andrew Ng from 1995 to 2014. A four layer multilayer graph is defined by partitioning the coauthorship networks into 5-year intervals. For each layer, there is an edge between two researchers if they coauthored at least one paper in the corresponding 5-year interval. In addition, each researcher is labeled as “Leskovec’s collaborator” or “Ng’s collaborator” depending upon collaboration frequency.
III-B Link Prediction Evaluation
Here we perform the link prediction task with respect to the merged graph as defined in Section II-A. This is because the purpose of our proposed three methods is to leverage multilayer relationships of the datasets to inform the node embedding, this embedding does not inherently associate nodes (or edges between them) with particular layers of the multilayer network.
We split each edge set into a training subset and a test subset , where . In this paper, we randomly chose of the edges from each as .
For a multilayer network trained on , we use our proposed embedding methods to find the corresponding vector spaces. We then calculate the distances of node pairs corresponding to , and reorder these distances into an ascending list. In order to predict links in the sampled multilayer network, we treat the first node pairs in have edges. Comparing these predicted edges with the true edges in , we can evaluate the outcome of our methods. Here, we introduce accuracy rate (see Equation 4) and F1-score (see Equation 5) to do the evaluation. First of all, accuracy rate indicates the number of edges that has been corrected estimated in .
| (4) |
Second, as F1-score is the harmonic mean of the precision and recall values for each layer, Equation 5 evaluates the average F1-score of each layer. Here, , and are the precision and recall values for each layer . Larger F1-score means better prediction performance.
| (5) |
In addition, we introduce two famous local link prediction methods [27] “Common Neighbor Similarity” and “Jaccard Similarity” on merged network as the comparison methods. Where Common Neighbor Similarity is defined in Equation 6, and Jaccard Similarity is defined in Equation 7. Where , stands for the neighborhoods of the node in the merged graph.
| (6) |
| (7) |
Table II shows the accuracy and F1-Score results for different datasets. In addition, we use bold text to indicate the best performance for each datasets. From the table we can tell that except LN datasets, our methods can achieve higher accuracy and F1-score for the rest of the datasets.
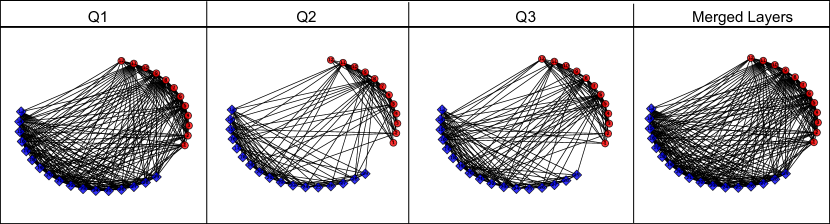
We use Figure 1 and Figure 4 to show the layer distance for each corresponding dataset. In addition, we use Figure 5 to show topology of each layer and the corresponding merged layers of three multilayer networks. As VC and LN have label information, we use different shape and color to demonstrate nodes with different labels. Combine all these evaluations, we give a detailed analysis for each datasets.
-
•
For AUCS, Terrorists and Students datasets: As AUCS dataset represents the interactions activities among employees, Terrorists dataset shows how terrorists work together, and Students dataset indicates the collaboration among students. It is clear that different layers have strong influence with each other. Which means if we want to predict edges information among two nodes, the important interactions of these two nodes among different layers should be considered. What’s more, take the topology of layers of Terrorists dataset in Figure 5(a) as an example, there are strong interactions among four layers, although layer 2 (Financial) has a small number of nodes, but layer co-analysis can recover necessarily information by random walk on different layers. Hence, it is reasonable and important to consider the interactions for different layers.
-
•
For VC dataset: As different questions indicate different problems, these different layers have relatively weak connections. For example, we cannot argue that a person gets on with (Q1) are all of his/her best friends, while the best friends of a person (Q2) are the same group of people that the person wants to work with (Q3). As shown in Figure 5(b), the first question is too general, which causes to create lots of noises (unnecessary edges) and therefore cannot indicate the true relationships among these nodes. If we combine these layers together or put more concentration on interactions among layers, then neither network aggregation nor layer co-analysis can reveal true information instead of just introducing more noises into the analysis.
-
•
For LN dataset: this dataset is a temporal dataset across 20 years that people joins or leaves the Leskovec’s group or Andrew Ng’s group. As shown in Figure 5(c), different layers in different time do not show any interactions. For example, in the first layer (LN_1995_1999), there is no blue nodes, and for the second (LN_2000_2004) and third layer (LN_2005_2010), two groups are expanded by themselves. what’s more, as the time span of the multilayer network is too large, this particular feature indicates the fact that the interaction among these layers is not the key reason to form the topology in each corresponding layer. What’s more, as there are a 5 years span between layers, the noises in these layers are the major reason why our methods cannot function well. Instead, the original Jaccard method is the best. Because this method only cares about the average number of shared neighbors for two nodes. So the noise has the least affected for such method.
| Datasets | Accuracy / F1-Score for Different Methods | ||||
| Regular Link Prediction Methods | Our Methods | ||||
| Common Neighbor | Jaccard Similarity | Network Aggregation | Results Aggregation | Networks Co-analysis | |
| AUCS | 0.029 / 0.056 | 0.051 / 0.097 | 0.184 / 0.311 | 0.092 / 0.168 | 0.207 / 0.343 |
| Terrorists | 0.012 / 0.024 | 0.016 / 0.032 | 0.229 / 0.373 | 0.090 / 0.166 | 0.347 / 0.515 |
| Students | 0.015 / 0.030 | 0.138 / 0.243 | 0.139 / 0.225 | 0.063 / 0.119 | 0.127 / 0.2444 |
| VC | 0.049 / 0.093 | 0.098 / 0.178 | 0.400 / 0.571 | 0.650 / 0.788 | 0.550 / 0.710 |
| LN | 0.027 / 0.053 | 0.206 / 0.342 | 0.103 / 0.187 | 0.070 / 0.130 | 0.083 / 0.153 |


IV Related Work on Random Walk based Network Embedding
In this section, we review related work on standard network embedding, that is, embedding methods proposed for single-layer graphs. With the development of unsupervised feature learning techniques [34], deep learning methods proved successful in natural language processing tasks through neural language models. These models have been used to capture the semantic and syntactic structures of human language [35], and even logical analogies [36], by embedding words as vectors. As a graph can be interpreted as a kind of language (by treating random walks as the equivalent of sentences), DeepWalk [23] introduced such methods into network analysis, allowing for the projection of network nodes into a vector space. To solve the scalability problem of this method when applied to real world information networks (which often contain millions of nodes), LINE [24] was developed. LINE extended the uniform random walks of DeepWalk to 1st and 2nd order weighted random walks, and it can project a network with millions of vertices and billions of edges into a vector space in a few hours.
However, both methods have limitations. As DeepWalk uses uniform random walks for searching, it cannot provide control over the explored neighborhoods. In contrast, LINE proposes a breadth-first strategy to sample nodes and optimize the likelihood independently over 1-hop and 2-hop neighbors, but it has no flexibility in exploring nodes at future depths. In order to deal with both of these limitations, node2vec [25] provides a flexible and controllable strategy for exploring network neighborhoods through the parameters and . From a practical standpoint, node2vec is scalable and robust to perturbations. Of course, none of these methods can deal with random walk samples that intelligently consider traversals between layers of multilayer networks. One of our methods (layer co-analysis) is therefore a natural progression of the literature in extending the capabilities of the random walk samples.
V Discussion and Future Work
In this paper, we demonstrate three different methods to project multilayer network into a representative vector space. The first method (Network Aggregation) aggregates all layers together to construct a merged network, and use standard network embedding method to project a multilayer network into a vector space. The second method (Results Aggregation) uses standard network embedding to obtain a vector space for each corresponding layer, and then combines these vector spaces together to construct a new vector space for the multilayer network. At last, as the first two methods do not leverage the important interactions between layers, we introduce a layer co-analysis method which leverage interactions among layers. In layer co-analysis, we use to constrain the behavior of the walk, where the greater the , the greater the chance of the random walk to stay in the same layer. On the contrary, the smaller the , the greater the possibility of random walk to choose different layers. In the evaluation part, we compare the accuracy and F1-score for five datasets, by comparing to regular link prediction methods, we have proved that our method do have the ability to project a multilayer network into the suitable vector space.
To the best of our knowledge, since this paper is a first-line research for principled graph embedding a multilayer network into a vector space, our experimental results suggest some future work and new challenges along this line: (i) From evaluation aspect, as we only use link prediction as the evaluation in this paper, the performance on multi-label classification is worth exploring. In addition, as our methods can be simply applied to layers with weighted edges and weighted interactions, we will test the performance on weighted multilayer network. (ii) From algorithm perspective, the proposed co-layer analysis method involves an additional layer transition probability for multilayer network embedding. In the future work, we will further discuss how to automatically learn by analyzing layer distance for a multilayer network. (iii) From the data type perspective, as attributed graphs have been widely introduced in big data analysis, we will continue to discuss the possibility to project an attributed multilayer graphs into a proper vector space by taking into the node/edge’s properties.
References
- [1] S. Boccaletti, G. Bianconi, R. Criado, C. I. Del Genio, J. Gómez-Gardenes, M. Romance, I. Sendina-Nadal, Z. Wang, and M. Zanin, “The structure and dynamics of multilayer networks,” Physics Reports, vol. 544, no. 1, pp. 1–122, 2014.
- [2] M. De Domenico, A. Solé-Ribalta, E. Cozzo, M. Kivelä, Y. Moreno, M. A. Porter, S. Gómez, and A. Arenas, “Mathematical formulation of multilayer networks,” Physical Review X, vol. 3, no. 4, p. 041022, 2013.
- [3] C. W. Loe and H. J. Jensen, “Comparison of communities detection algorithms for multiplex,” Physica A: Statistical Mechanics and its Applications, vol. 431, pp. 29–45, 2015.
- [4] J. Kim and J.-G. Lee, “Community detection in multi-layer graphs: A survey,” ACM SIGMOD Record, vol. 44, no. 3, pp. 37–48, 2015.
- [5] M. De Domenico, V. Nicosia, A. Arenas, and V. Latora, “Structural reducibility of multilayer networks,” Nature communications, vol. 6, 2015.
- [6] C. De Bacco, E. A. Power, D. B. Larremore, and C. Moore, “Community detection, link prediction and layer interdependence in multilayer networks,” arXiv preprint arXiv:1701.01369, 2017.
- [7] M. T. Heaney, “Multiplex networks and interest group influence reputation: An exponential random graph model,” Social Networks, vol. 36, pp. 66–81, 2014.
- [8] Y. Hu, S. Havlin, and H. A. Makse, “Conditions for viral influence spreading through multiplex correlated social networks,” Physical Review X, vol. 4, no. 2, p. 021031, 2014.
- [9] E. Costenbader and T. W. Valente, “The stability of centrality measures when networks are sampled,” Social networks, vol. 25, no. 4, pp. 283–307, 2003.
- [10] P. Bródka, K. Skibicki, P. Kazienko, and K. Musiał, “A degree centrality in multi-layered social network,” in Computational Aspects of Social Networks (CASoN), 2011 International Conference on. IEEE, 2011, pp. 237–242.
- [11] P. Bródka, P. Kazienko, K. Musiał, and K. Skibicki, “Analysis of neighbourhoods in multi-layered dynamic social networks,” International Journal of Computational Intelligence Systems, vol. 5, no. 3, pp. 582–596, 2012.
- [12] P. Kazienko, P. Brodka, and K. Musial, “Individual neighbourhood exploration in complex multi-layered social network,” in Web Intelligence and Intelligent Agent Technology (WI-IAT), 2010 IEEE/WIC/ACM International Conference on, vol. 3. IEEE, 2010, pp. 5–8.
- [13] P. Bródka, K. Musial, and P. Kazienko, “A method for group extraction in complex social networks,” Knowledge Management, Information Systems, E-Learning, and Sustainability Research, pp. 238–247, 2010.
- [14] T. Zhou, G. Yan, and B.-H. Wang, “Maximal planar networks with large clustering coefficient and power-law degree distribution,” Physical Review E, vol. 71, no. 4, p. 046141, 2005.
- [15] M. De Domenico, A. Lancichinetti, A. Arenas, and M. Rosvall, “Identifying modular flows on multilayer networks reveals highly overlapping organization in interconnected systems,” Physical Review X, vol. 5, no. 1, p. 011027, 2015.
- [16] M. Domenico, A. Lancichinetti, A. Arenas, and M. Rosvall, “Identifying modular flows on multilayer networks reveals highly overlapping organization in social systems,” Phys. Rev, vol. 5, p. 011027, 2015.
- [17] P.-Y. Chen and A. O. Hero III, “Multilayer spectral graph clustering via convex layer aggregation,” arXiv preprint arXiv:1609.07200, 2016.
- [18] L. G. Jeub, M. W. Mahoney, P. J. Mucha, and M. A. Porter, “A local perspective on community structure in multilayer networks,” Network Science, pp. 1–20, 2017.
- [19] D. R. DeFord and S. D. Pauls, “Spectral clustering methods for multiplex networks,” arXiv preprint arXiv:1703.05355, 2017.
- [20] A. R. Benson, D. F. Gleich, and J. Leskovec, “Higher-order organization of complex networks,” Science, vol. 353, no. 6295, pp. 163–166, 2016.
- [21] M. Boguna, D. Krioukov, and K. C. Claffy, “Navigability of complex networks,” Nature Physics, vol. 5, no. 1, pp. 74–80, 2009.
- [22] S. Chen, S. Niu, L. Akoglu, J. Kovačević, and C. Faloutsos, “Fast, warped graph embedding: Unifying framework and one-click algorithm,” arXiv preprint arXiv:1702.05764, 2017.
- [23] B. Perozzi, R. Al-Rfou, and S. Skiena, “Deepwalk: Online learning of social representations,” in Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2014, pp. 701–710.
- [24] J. Tang, M. Qu, M. Wang, M. Zhang, J. Yan, and Q. Mei, “Line: Large-scale information network embedding,” in Proceedings of the 24th International Conference on World Wide Web. ACM, 2015, pp. 1067–1077.
- [25] A. Grover and J. Leskovec, “node2vec: Scalable feature learning for networks,” in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2016, pp. 855–864.
- [26] M. Berlingerio, F. Pinelli, and F. Calabrese, “Abacus: frequent pattern mining-based community discovery in multidimensional networks,” Data Mining and Knowledge Discovery, vol. 27, no. 3, pp. 294–320, 2013.
- [27] T. Zhou, L. Lü, and Y.-C. Zhang, “Predicting missing links via local information,” The European Physical Journal B-Condensed Matter and Complex Systems, vol. 71, no. 4, pp. 623–630, 2009.
- [28] N. Roberts, “Roberts and everton terrorist data: Noordin top terrorist network (subset),” Machinereadable data file, 2011.
- [29] M. Fire, G. Katz, Y. Elovici, B. Shapira, and L. Rokach, “Predicting student exam’s scores by analyzing social network data,” in International Conference on Active Media Technology. Springer, 2012, pp. 584–595.
- [30] M. Vickers and S. Chan, “Representing classroom social structure,” Victoria Institute of Secondary Education, Melbourne, 1981.
- [31] P.-Y. Chen and A. O. Hero, “Multilayer spectral graph clustering via convex layer aggregation: Theory and algorithms,” IEEE Transactions on Signal and Information Processing over Networks, 2017.
- [32] B. Zhang, T. K. Saha, and M. Al Hasan, “Name disambiguation from link data in a collaboration graph,” in Advances in Social Networks Analysis and Mining (ASONAM), 2014 IEEE/ACM International Conference on. IEEE, 2014, pp. 81–84.
- [33] T. K. Saha, B. Zhang, and M. Al Hasan, “Name disambiguation from link data in a collaboration graph using temporal and topological features,” Social Network Analysis and Mining, vol. 5, no. 1, p. 11, 2015.
- [34] Y. Bengio, A. Courville, and P. Vincent, “Representation learning: A review and new perspectives,” IEEE transactions on pattern analysis and machine intelligence, vol. 35, no. 8, pp. 1798–1828, 2013.
- [35] R. Collobert and J. Weston, “A unified architecture for natural language processing: Deep neural networks with multitask learning,” in Proceedings of the 25th international conference on Machine learning. ACM, 2008, pp. 160–167.
- [36] T. Mikolov, W.-t. Yih, and G. Zweig, “Linguistic regularities in continuous space word representations.” in Hlt-naacl, vol. 13, 2013, pp. 746–751.