A Simple Parallel and Distributed Sampling Technique:
Local Glauber Dynamics
Abstract
Sampling constitutes an important tool in a variety of areas: from machine learning and combinatorial optimization to computational physics and biology. A central class of sampling algorithms is the Markov Chain Monte Carlo method, based on the construction of a Markov chain with the desired sampling distribution as its stationary distribution. Many of the traditional Markov chains, such as the Glauber dynamics, do not scale well with increasing dimension. To address this shortcoming, we propose a simple local update rule based on the Glauber dynamics that leads to efficient parallel and distributed algorithms for sampling from Gibbs distributions.
Concretely, we present a Markov chain that mixes in rounds when Dobrushin’s condition for the Gibbs distribution is satisfied. This improves over the LubyGlauber algorithm by Feng, Sun, and Yin [PODC’17], which needs rounds, and their LocalMetropolis algorithm, which converges in rounds but requires a considerably stronger mixing condition. Here, denotes the number of nodes in the graphical model inducing the Gibbs distribution, and its maximum degree. In particular, our method can sample a uniform proper coloring with colors in rounds for any , which almost matches the threshold of the sequential Glauber dynamics and improves on the threshold of Feng et al.
1 Introduction
Locally Checkable Labeling (LCL) [NS95] problems have been studied extensively for more than three decades [Lin87]. Sampling from the solution space of such LCLs, however, has not attracted a lot of attention and has been investigated only by a recent work [FSY17], despite its numerous motivations, which we will outline in the following.
Markov Chain Monte Carlo Method
The Markov Chain Monte Carlo (MCMC) method is a central class of algorithms for sampling, that is, for randomly drawing an element from a ground set according to a certain probability distribution. It works by constructing a Markov chain with the targeted sampling distribution as its stationary distribution. Within a number of steps, known as the mixing time, the Markov chain converges; its state then (approximately) follows this distribution. Besides the intrinsic interest of such a general sampling method, in particular for complex distributions where simple sampling techniques fail, the MCMC method gives rise to efficient approximation algorithms in a variety of areas: enumerative combinatorics (due to the fundamental connection between sampling and counting established by Jerrum, Valiant, and Vazirani [JVV86]), simulated annealing [NSS86] in combinatorial optimization, Monte Carlo simulations [MRR+53] in statistical physics, computation of intractable integrals for, among many others, Bayesian inference [ADFDJ03] in machine learning.
Parallel and Distributed Sampling
The employment of MCMC methods is particularly important when confronted with high-dimensional data, where traditional (exact) approaches quickly become intractable. Such data sets are not only increasingly frequent, but also critical for the success of many applications. For instance in machine learning, higher-dimensional models help expressability and hence predictability. It is thus central that MCMC algorithms scale well with increasing dimensions. This is not the case, however, for most sequential methods, as they process and update the variables one by one, that is, a single site per step. To speed up the sampling process, Markov chain updates can be parallelized by spreading the variables across several processors. In other settings, such as distributed machine learning, the (data associated to) variables might already be naturally distributed among several machines, and the overhead of aggregating them into one machine, if they fit there in the first place, would be untenable.
Local Sampling
In either case, to avoid overhead in communication and coordination, local update rules for Markov chains are needed: a machine must be able to change the value of its variables without knowing all the values of the variables on other machines. Yet, the joint distribution, over all variables in the system, must converge to a certain distribution. This local sampling problem was introduced in a recent work by Feng, Sun, and Yin [FSY17], whose title asks “What can be sampled locally?”. We address this question by providing a simple and generic sampling technique—the Local Glauber Dynamics, informally introduced in Section 1.2 and formally described in Section 2—which is applicable for a wide range of distributions, as stated in Section 1.1. This moves us a step closer towards an answer of this question, thus towards the goal of generally understanding what can be sampled locally. Besides its many practical ramifications, especially on the area of distributed machine learning, this gives us a theoretical insight about the locality of problems, whose systematic study has been initiated by the seminal works of Linial [Lin87] and Naor and Stockmeyer [NS95] with the pithy title “What can be computed locally?”.
1.1 Our Result, and Related Work
For the sake of succinctness and comprehensibility of the presentation, we state and prove our main result in terms of the special case that gets most attention for sequential sampling: sampling proper colorings of a graph. We refer to [FV07] for a survey on sequential sampling of proper colorings. Our result applies to a more general set of distributions, however, as explained in the remark at the end of this section. Note that independently and simultaneously, Feng, Hayes, and Yin [FHY18] arrived at the same result.
Theorem 1.1.
A uniform proper -coloring of an -node graph with maximum degree can be sampled within total variation distance in rounds, where for any .
Our parallel and distributed sampling algorithm improves over the LubyGlauber algorithm by Feng, Sun, and Yin [FSY17], which needs rounds, and their LocalMetropolis algorithm, which converges in rounds but requires a considerably stronger mixing condition of . They state that “We also believe that the threshold is of certain significance to this [LocalMetropolis] chain as the Dobrushin’s condition to the Glauber dynamics.”, thus implying that this value is a barrier for their approach. This is also justified by the supposedly easiest special case of a tree that leads to the same threshold for their algorithm. Our result gets rid of the additional while not incurring any loss in the round complexity, with a considerably easier and more natural update rule. Not only our proof is simpler and shorter, also our algorithm is asymptotically best possible, as there is an lower bound [GJL17, FSY17] due to the exponential correlation between variables.
The threshold of corresponds to Dobrushin’s condition, thus almost matches the threshold of the sequential Glauber dynamics [Jer95, SS97] at . In other words, we present a technique that fully parallelizes the Glauber dynamics, speeding up the mixing time from steps to rounds. In terms of number of colors needed, Dobrushin’s condition can be undercut: Vigoda [Vig00] and two very recent works [CM18, DPP18] showed that, when resorting to a different highly non-local Markov chain, is enough. This gives rise to the question whether efficient distributed algorithms intrinsically need to be stuck at Dobrushin’s condition, which would imply that this bound is inherent to the locality of the sampling process, or whether our threshold is an artifact of our possibly suboptimal dynamics.
Remark 1.2.
In fact, our technique directly applies for sampling from the Gibbs distribution induced by a Markov random field111This captures many graph problems—such as independent set, vertex cover, graph homomorphism—and physical models—such as Ising model, Potts model, general spin systems, and hardcore gas model. if Dobrushin’s condition [Dob68] is satisfied. More generally, it can used for sampling from any local (that is, constant-radius) constraint satisfaction problems, which is universal for conditional independent joint distributions, due to Hammersley-Clifford’s fundamental theorem [HC71]. Moreover, our proof presented here captures all the difficulties that arise in these more general cases, thus can be adapted in a straight-forward manner. We defer this generalization to the full version of the paper.
1.2 Our Sampling Technique, and Related Approaches
Over the past few years, several methods to parallelize sequential Markov chains have been proposed. Most of them rely on a heavy coordination machinery, are special purpose, and/or do not provide any theoretical guarantees. In the following, we briefly outline two of the most promising and more generic parallel and distributed sampling techniques, in the context of colorings.
The most natural one follows a standard decentralization approach, also implemented in the LubyGlauber algorithm by [FSY17]: an independent set of nodes (e.g., a color class of a proper coloring) simultaneously updates their color [FSY17], ensuring that no two neighboring nodes change their color at the same time. This approach mainly suffers from the limitation that the number of independent sets needed to cover all nodes might be large, which slows down mixing. In particular, a multiplicative -term in the mixing time seems inevitable [GLGG11, FSY17]. In the worst case of a clique, this approach falls back to sequential sampling, updating one node after the other. Moreover, this method requires an independent set to be computed, which incurs a significant amount of additional communication and coordination.
An orthogonal direction was pursued by [NSWA08, YXQ09, FSY17], where methods are introduced to update the colors of all nodes simultaneously. One example is the LocalMetropolis algorithm by [FSY17]. This extreme parallelism, however, comes at a cost of either introducing a bias in the stationary distribution, resulting in a non-uniform coloring [NSWA08, YXQ09], or having to demand stronger mixing conditions [FSY17].
Our Local Sampling Technique
We aim for the middle ground between these two approaches, motivated by the following observation: we do not need to prevent simultaneous updates of adjacent nodes, only simultaneous conflicting updates of adjacent nodes. Preventing two adjacent nodes in the first place from picking a new color in the same round seems to be way too restrictive, in particular because it is unlikely that both nodes aim for the same new color. On the other hand, if all nodes update their colors simultaneously, a node is expected to have a conflict with at least one of its neighbors, which prevents progress.
We interpolate between the two extreme cases by introducing a marking probability, so that only a small fraction of a node’s neighbors is expected to update the color, and hence also, in worst case, only these can conflict with its update. Concretely, we propose the following generic sampling method, which we call Local Glauber Dynamics: In every step, every variable independently marks itself at random with a certain (low) probability. If it is marked, it samples a proposal at random and checks with its neighbors whether the proposal leads to a conflict with their current state or their new proposals (if any). If there is a conflict, the variable rolls back and stays with its current state, otherwise the state is updated. As opposed to sequential sampling, where only one variable per step updates its value, here the expected number of variables simultaneously updating their value is , resulting in the desired speed-up from , say, to . Of course, the main technical aspect lies in showing that this simple update rule converges to the uniform distribution in rounds, which we prove in Section 2.
1.3 Notation and Preliminaries
Model
We work with the standard distributed message-passing model for the study of locality: the model introduced by Linial [Lin87], defined as follows. Given a graph on nodes with maximum degree , the computation proceeds in rounds. In every round, every node can send a message to each of its neighbors. We do not limit the message sizes, but for the algorithm that we present, -bit messages suffice. In the end of the computation, every node outputs a color. The quantity of main interest is the round complexity, i.e., the number of rounds until the joint output of all nodes satisfies a certain condition. We assume that all nodes have knowledge of and .
Markov Chain
We consider a Markov chain , where is the coloring of the graph in round . We will omit the round index, and use for the coloring at time and for the coloring at time , for a , instead.
Mixing Time
For a Markov chain with stationary distribution , let denote the distribution of the random coloring of the chain at time , conditioned on . The mixing time is defined to be the minimum number of rounds needed so that the Markov chain is -close (in terms of total variation distance) to its stationary distribution , regardless of . The total variation distance between two distributions over is defined as .
Path Coupling
The Path Coupling Lemma by Bubley and Dyer [BD97, Theorem 1] (also see [FSY17, Lemma 4.3]) gives rise to a particularly easy way of designing couplings. In a simplified version, it says that it is enough to define the coupling of a Markov chain only for pairs of colorings that are adjacent, that is, differ at exactly one node. The expected number of differing nodes after one coupling step then can be used to bound the mixing time of the Markov chain.
Lemma 1.3 (Path Coupling [BD97], simplified).
For , let . If there is a coupling of the Markov chain, defined only for with , that satisfies for some , then .
2 Local Glauber Dynamics
Local Glauber Dynamics
We define a transition from to in one round as follows. Every node marks itself independently with probability . If it is marked, it proposes a new color uniformly at random, independently from all the other nodes. If this proposed color does not lead to a conflict with the current and the proposed colors of any neighbor, that is, and for any 222To simplify notation, we assume that in case is not marked., then accepts color , thus sets . Otherwise, keeps its current color, that is, sets . Note that the condition is necessary to guarantee reversibility of the Markov chain.
Stationary Distribution
The local Glauber dynamics is ergodic: it is aperiodic, as there is always a positive probability of not changing any of the colors, and irreducible, since any (proper) coloring can be reached from any coloring. Moreover, the chain might possibly start from an improper coloring, but it will never move from a proper to an improper coloring, that is, it is absorbing to proper colorings. It is easy to verify that this local Glauber dynamics, due to its symmetric update rule, satisfies the detailed balance equation for the uniform distribution, meaning that the transition from to has the same probability as a transition from to for proper colorings. The chain thus is reversible and has the uniform distribution over all proper colorings as unique stationary distribution.
Mixing Time
Informally speaking, the Path Coupling Lemma says that if for all and which differ in one node, we can define a coupling in such a way that the expected number of nodes at which and differ is bounded away from 1 from above, then the chain converges quickly. In Section 2.1, we formally describe such a path coupling, in Section 2.2, we list necessary (but not necessarily sufficient) conditions for a node to have two different colors after one coupling step, which is then used in Section 2.3 to bound the expected number of differing nodes by for some constant , depending on . Application of Lemma 1.3 then concludes the proof of Theorem 1.1.
2.1 Description of Path Coupling
We look at two colorings and that differ at a node only. That is, , for some , which we will naturally refer to as red and blue, respectively, and for all . In the following, we explain how every node comes up with a pair of new proposals, which then will be accepted or rejected based on the local Glauber dynamics rules.
Marking
In both chains, every node is marked independently with probability , using the same randomness in both chains. In the following, we restrict our attention to marked nodes only; non-marked nodes are thought of proposing their current color as new color, i.e., and .
Consistent, Mirrored, and Flipped Proposals
We introduce two possible ways of how proposals for a node can be sampled: consistently and mirroredly. For the consistent proposals, both chains propose the same randomly chosen color, that is, for a u.a.r. . For the mirrored proposals, both chains assign the same random proposal if it is neither red nor blue, and a flipped proposal (i.e., red to one and blue to the other chain) otherwise. More formally, and if and the element in , and if , for a u.a.r. . We say that has flipped proposals if . Note that we say mirrored proposal to refer to the process of sampling mirroredly, and we say flipped if, as a result of sampling mirroredly, a node proposes different colors in the two chains.
Breadth-First Assignment of Proposals
Let be the set of nodes with current color red or blue, as well as its inclusive neighborhood, without , where . We ignore this set for the moment, and focus on the set of marked nodes that are not adjacent to a node with color red or blue (except for possibly ). Informally speaking, we will go through these nodes in a breadth-first manner, with increasing distance to node , and fix their proposals layer by layer, but defer the assignment of nodes not (yet) adjacent to a node with flipped proposals, as follows. We repeatedly add all (still remaining) nodes that have a node in the last layer with flipped proposals to a new layer, and sample their proposals mirroredly, thus perform a breadth-first assignment on nodes with flipped proposals only. All remaining nodes sample their proposals consistently. Note that this in particular guarantees that a node is sampled consistently only if it not adjacent to a node with flipped proposals.
More formally, this can be described as follows. We define , even if is not marked. For node , if marked, the proposals are sampled consistently. For and , the proposals are sampled mirroredly. For the subsequent layer, we restrict the attention to (new) neighbors of nodes in with flipped proposals only, i.e., consider for .
For all remaining (marked) nodes, that is, nodes in and nodes in , proposals are sampled consistently. See Figure 1 for an illustration of this breadth-first-based approach.
Accept Proposals
The proposals and in the chains and are accepted or rejected based on the local Glauber dynamics rules, leading to colorings .

2.2 Properties of the Coupling
The main observation is the following. If we ignore nodes with current colors red and blue for the moment, one can argue that and can only differ at a node different from if its proposals are flipped. Flipped proposals, however, can only arise when the proposals are sampled mirroredly, which happens only if there is a node in the preceding layer with flipped proposals (due to the breadth-first order in which we assign the proposals). A node thus can lead to an inconsistency only if there is path in from to this node consisting of nodes with flipped proposals, called a flip path.
We will next make this intuition with the flip paths more precise, in two parts: for nodes in (that sample their proposals mirroredly if adjacent to a node with flipped proposals) in Lemma 2.1 and for nodes in (that always sample their proposals consistently) in Lemma 2.2. See Figure 2 for an illustration of these two cases.
Lemma 2.1.
If and differ at , there is a flip path of length in , with the additional property that the proposal of is the opposite of the last color (in red and blue) seen on this path, in both chains. More formally, , where and if , and and if .
Proof.
We first argue that ’s proposals must be flipped and accepted in both chains. Trivially, acceptance of a consistent proposal in both chains or rejection in both chains leads to . Moreover, observe that flipped proposals are, by construction, either accepted in both or rejected in both chains, as flipping changes the role of red and blue, but not the overall behavior. Indeed, suppose, without loss of generality, that is rejected by . Thus, in particular, has a neighbor with current color or proposal in . As we are restricting our attention to the set which does not have any adjacent node with current color red or blue, except for , either or proposes . So either must have different current colors (if ) or have mirrored proposals (if , then for some , because at the latest ’s flipped proposal leads to being added to the subsequent layer, by how we assign the proposals in breadth-first manner) and hence flipped proposals. Thus, ’s proposal in will be rejected by , since either has color or proposes .
It thus remains to rule out the case of consistent proposals that are accepted in one and rejected in the other chain. Towards a contradiction, suppose that proposes the same color in both chains, and that it is accepted in one and rejected in the other. Since and , this can happen only if is adjacent either to or to at least one node with flipped proposals, as otherwise all proposals and all current colors in ’s inclusive neighborhood would be the same, leading to the same behavior in both chains. In both cases, for some , which means that its proposals are sampled mirroredly. Hence, , as otherwise the proposals would be flipped. Now, since neither ’s current color nor ’s proposals is red or blue, and neighbors of can differ in their colors or proposals only if red or blue is involved, the proposals are either accepted or rejected in both chains. It follows that indeed only nodes in with flipped proposals that are accepted in both chains can have different colors in and .
By construction of the layers, and since for some , there must exist a sequence of nodes connecting to in : a flip path of length . Moreover, the proposal is accepted in a chain only if the proposed color is the opposite of the color (red or blue) that is seen on the path (either as proposal if , or as current color of if ). ∎
Lemma 2.2.
If and differ at , there is a path of length in , called almost flip path, with the additional property that the proposal of is either red or blue, that is, .
Proof.
Since, by definition of the coupling, samples its proposals consistently, and can only differ at if the proposal is accepted in one and rejected in the other chain. This can happen only if is adjacent to either or to at least one node with flipped proposals. Otherwise, all proposals and all current colors in ’s inclusive neighborhood would be the same, leading to the same behavior. Hence, is adjacent to some for some . By construction of the layers, there must exist a sequence of nodes connecting to in : an almost flip path of length . Note that, in particular, because neighbors of nodes in are by definition sampled consistently (as they are in ), and a node at the end of an almost flip path has a neighbor with flipped proposals, this last node on an almost flip path must be in .
The proposal is accepted in one and rejected in the other chain only if . In that case, the chain with the same color on the end of the path will reject, the other will (possibly) accept. ∎
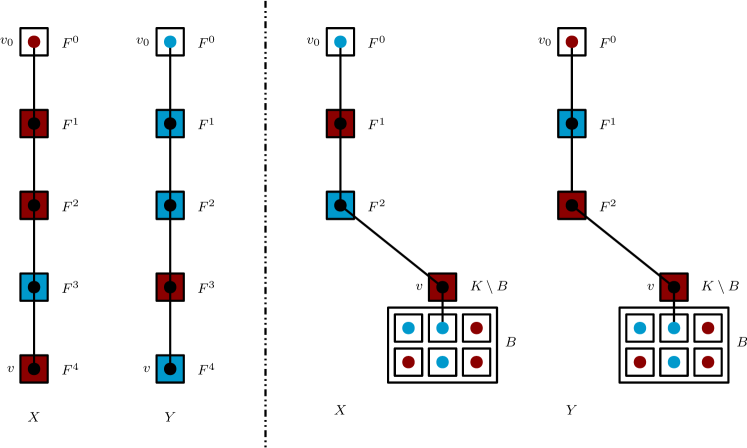
An almost flip path on the right: samples its proposals consistently. In chain , the proposal will be accepted, in chain , it will be rejected, leading to . The disk color corresponds to the node’s current color, where black means any color except red and blue. The color of the box around a node indicates this node’s proposed color, where white means any color ( also red and blue, but consistent).
2.3 Bounding the Expected Number of Differing Nodes
We show that for some , by bounding the expectations and separately. We will see that, as , both terms can be bounded by , leading to an expected number of roughly , which is strictly less than 1 for .
Nodes
Section 2.2, or more precisely, Lemmas 2.1 and 2.2, show that the number of nodes (different from ) that have different colors in and can be bounded by the number of (almost) flip paths with an additional property. We will next see that the expected number of such (almost) flip paths can be expressed as a geometric series summing over the depths of the layers.
There are at most paths of length in . Moreover, each such path has probability of being a flip or almost flip path with the mentioned additional property, since all intermediate nodes need to mark themselves and to propose one arbitrary color in , and needs to mark itself and to propose the one color in as specified in Lemmas 2.1 and 2.2, respectively. Note that a path in can either be a flip path or an almost flip path, but never both. Moreover, observe that node does not need to be marked. We get
| (1) |
Node
Chains and can agree at node only if at least one the proposals is accepted. For that, needs to be marked and its proposal needs to be different from all the at most current colors of its neighbors, that is, , which happens with probability at least . Moreover, the proposals of ’s neighbors (if marked) need to avoid at most three colors in , possibly less, which happens with probability at least . We thus get
| (2) |
Wrap-Up
Overall, combining Equations 1 and 2, we get
For and small enough, this is strictly bounded away from 1 from above, where the hidden constant depends on (but not on or ).
References
- [ADFDJ03] Christophe Andrieu, Nando De Freitas, Arnaud Doucet, and Michael I. Jordan. An Introduction to MCMC for Machine Learning. Machine Learning, 50(1-2):5–43, 2003.
- [BD97] Russ Bubley and Martin Dyer. Path Coupling: A Technique for Proving Rapid Mixing in Markov Chains. In the Proceedings of the Symposium on Foundations of Computer Science (FOCS), pages 223–231, 1997.
- [CM18] Sitan Chen and Ankur Moitra. Linear programming bounds for randomly sampling colorings. arXiv preprint arXiv:1804.03156, 2018.
- [Dob68] Roland L. Dobruschin. The Description of a Random Field by Means of Conditional Probabilities and Conditions of its Regularity. Theory of Probability & Its Applications, 13(2):197–224, 1968.
- [DPP18] Michelle Delcourt, Guillem Perarnau, and Luke Postle. Rapid mixing of glauber dynamics for colorings below vigoda’s threshold. arXiv preprint arXiv:1804.04025, 2018.
- [FHY18] Weiming Feng, Thomas P. Hayes, and Yitong Yin. Distributed symmetry breaking in sampling (optimal distributed randomly coloring with fewer colors). arXiv preprint arXiv:1802.06953, 2018.
- [FSY17] Weiming Feng, Yuxin Sun, and Yitong Yin. What Can Be Sampled Locally? In Proceedings of the International Symposium on Principles of Distributed Computing (PODC), pages 121–130, 2017.
- [FV07] Alan Frieze and Eric Vigoda. A Survey on the Use of Markov Chains to Randomly Sample Colourings. Oxford Lecture Series in Mathematics and its Applications, 34:53, 2007.
- [GJL17] Heng Guo, Mark Jerrum, and Jingcheng Liu. Uniform Sampling Through the Lovász Local Lemma. Proceedings of the Symposium on Theory of Computing (STOC), pages 342–355, 2017.
- [GLGG11] Joseph Gonzalez, Yucheng Low, Arthur Gretton, and Carlos Guestrin. Parallel Gibbs Sampling: From Colored Fields to Thin Junction Trees. In the Proceedings of the International Conference on Artificial Intelligence and Statistics, pages 324–332, 2011.
- [HC71] John M. Hammersley and Peter Clifford. Markov Fields on Finite Graphs and Lattices. 1971.
- [Jer95] Mark Jerrum. A Very Simple Algorithm for Estimating the Number of k-Colorings of a Low-Degree Graph. Random Structures & Algorithms, 7(2):157–165, 1995.
- [JVV86] Mark R. Jerrum, Leslie G. Valiant, and Vijay V. Vazirani. Random Generation of Combinatorial Structures from a Uniform Distribution. Theoretical Computer Science, 43:169–188, 1986.
- [Lin87] Nathan Linial. Distributive Graph Algorithms - Global Solutions From Local Data. In the Proceedings of the Symposium on Foundations of Computer Science (FOCS), pages 331–335. IEEE, 1987.
- [MRR+53] Nicholas Metropolis, Arianna W. Rosenbluth, Marshall N. Rosenbluth, Augusta H. Teller, and Edward Teller. Equation of State Calculations by Fast Computing Machines. The Journal of Chemical Physics, 21(6):1087–1092, 1953.
- [NS95] Moni Naor and Larry Stockmeyer. What Can Be Computed Locally? SIAM Journal on Computing, 24(6):1259–1277, 1995.
- [NSS86] Surendra Nahar, Sartaj Sahni, and Eugene Shragowitz. Simulated Annealing and Combinatorial Optimization. In Proceedings of the Design Automation Conference, pages 293–299. IEEE Press, 1986.
- [NSWA08] David Newman, Padhraic Smyth, Max Welling, and Arthur U. Asuncion. Distributed Inference for Latent Dirichlet Allocation. In Advances in Neural Information Processing Systems, pages 1081–1088, 2008.
- [SS97] Jesús Salas and Alan D. Sokal. Absence of Phase Transition for Antiferromagnetic Potts Models via the Dobrushin Uniqueness Theorem. Journal of Statistical Physics, 86(3-4):551–579, 1997.
- [Vig00] Eric Vigoda. Improved Bounds for Sampling Colorings. Journal of Mathematical Physics, 41(3):1555–1569, 2000.
- [YXQ09] Feng Yan, Ningyi Xu, and Yuan Qi. Parallel Inference for Latent Dirichlet Allocation on Graphics Processing Units. In Advances in Neural Information Processing Systems, pages 2134–2142, 2009.