Predictive Uncertainty Estimation via Prior Networks
Abstract
Estimating how uncertain an AI system is in its predictions is important to improve the safety of such systems. Uncertainty in predictive can result from uncertainty in model parameters, irreducible data uncertainty and uncertainty due to distributional mismatch between the test and training data distributions. Different actions might be taken depending on the source of the uncertainty so it is important to be able to distinguish between them. Recently, baseline tasks and metrics have been defined and several practical methods to estimate uncertainty developed. These methods, however, attempt to model uncertainty due to distributional mismatch either implicitly through model uncertainty or as data uncertainty. This work proposes a new framework for modeling predictive uncertainty called Prior Networks (PNs) which explicitly models distributional uncertainty. PNs do this by parameterizing a prior distribution over predictive distributions. This work focuses on uncertainty for classification and evaluates PNs on the tasks of identifying out-of-distribution (OOD) samples and detecting misclassification on the MNIST and CIFAR-10 datasets, where they are found to outperform previous methods. Experiments on synthetic and MNIST data show that unlike previous non-Bayesian methods PNs are able to distinguish between data and distributional uncertainty.
1 Introduction
Neural Networks (NNs) have become the dominant approach to addressing computer vision (CV) [1, 2, 3], natural language processing (NLP) [4, 5, 6], speech recognition (ASR) [7, 8] and bio-informatics (BI) [9, 10] tasks. Despite impressive, and ever improving, supervised learning performance, NNs tend to make over-confident predictions [11] and until recently have been unable to provide measures of uncertainty in their predictions. Estimating uncertainty in a model’s predictions is important, as it enables, for example, the safety of an AI system [12] to be increased by acting on the model’s prediction in an informed manner. This is crucial to applications where the cost of an error is high, such as in autonomous vehicle control and medical, financial and legal fields.
Recently notable progress has been made on predictive uncertainty for Deep Learning through the definition of baselines, tasks and metrics [13] and the development of practical methods for estimating uncertainty. One class of approaches stems from Bayesian Neural Networks [14, 15, 16, 17]. Traditionally, these approaches have been computationally more demanding and conceptually more complicated than non-Bayesian NNs. Crucially, their performance depends on the form of approximation made due to computational constraints and the nature of the prior distribution over parameters. A recent development has been the technique of Monte-Carlo Dropout [18], which estimates predictive uncertainty using an ensemble of multiple stochastic forward passes and computing the mean and spread of the ensemble. This technique has been successfully applied to tasks in computer vision [19, 20]. A number of non-Bayesian ensemble approaches have also been proposed. One approach based on explicitly training an ensemble of DNNs, called Deep Ensembles [11], yields competitive uncertainty estimates to MC dropout. Another class of approaches, developed for both regression [21] and classification [22], involves explicitly training a model in a multi-task fashion to minimize its Kullback-Leibler (KL) divergence to both a sharp in-domain predictive posterior and a flat out-of-domain predictive posterior, where the out-of-domain inputs are sampled either from a synthetic noise distribution or a different dataset during training. These methods are explicitly trained to detect out-of-distribution inputs and have the advantage of being more computationally efficient at test time.
The primary issue with these approaches is that they conflate different aspects of predictive uncertainty, which results from three separate factors - model uncertainty, data uncertainty and distributional uncertainty. Model uncertainty, or epistemic uncertainty [23], measures the uncertainty in estimating the model parameters given the training data - this measures how well the model is matched to the data. Model uncertainty is reducible111Up to identifiability limits. In the limit of infinite data yields equivalent parameterizations. as the size of training data increases. Data uncertainty, or aleatoric uncertainty [23], is irreducible uncertainty which arises from the natural complexity of the data, such as class overlap, label noise, homoscedastic and heteroscedastic noise. Data uncertainty can be considered a ’known-unknown’ - the model understands (knows) the data and can confidently state whether a given input is difficult to classify (an unknown). Distributional uncertainty arises due to mismatch between the training and test distributions (also called dataset shift [24]) - a situation which often arises for real world problems. Distributional uncertainty is an ’unknown-unknown’ - the model is unfamiliar with the test data and thus cannot confidently make predictions. The approaches discussed above either conflate distributional uncertainty with data uncertainty or implicitly model distributional uncertainty through model uncertainty, as in Bayesian approaches. The ability to separately model the 3 types of predictive uncertainty is important, as different actions can be taken by the model depending on the source of uncertainty. For example, in active learning tasks detection of distributional uncertainty would indicate the need to collect training data from this distribution. This work addresses the explicit prediction of each of the three types of predictive uncertainty by extending the work done in [21, 22] while taking inspiration from Bayesian approaches.
Summary of Contributions. This work describes the limitations of previous methods of obtaining uncertainty estimates and proposes a new framework for modeling predictive uncertainty, called Prior Networks (PNs), which allows distributional uncertainty to be treated as distinct from both data uncertainty and model uncertainty. This work focuses on the application of PNs to classification tasks. Additionally, this work presents a discussion of a range of uncertainty metrics in the context of each source of uncertainty. Experiments on synthetic and real data show that unlike previous non-Bayesian methods PNs are able to distinguish between data uncertainty and distributional uncertainty. Finally, PNs are evaluated on the tasks of identifying out-of-distribution (OOD) samples and detecting misclassification outlined in [13], where they outperform previous methods on the MNIST and CIFAR-10 datasets.
2 Current Approaches to Uncertainty Estimation
This section describes current approaches to predictive uncertainty estimation. Consider a distribution over input features and labels . For image classification corresponds to images and object labels. In a Bayesian framework the predictive uncertainty of a classification model 222Using the standard shorthand for . trained on a finite dataset will result from data (aleatoric) uncertainty and model (epistemic) uncertainty. A model’s estimates of data uncertainty are described by the posterior distribution over class labels given a set of model parameters and model uncertainty is described by the posterior distribution over the parameters given the data (eq. 1).
| (1) |
Here, uncertainty in the model parameters induces a distribution over distributions . The expected distribution is obtained by marginalizing out the parameters . Unfortunately, obtaining the true posterior using Bayes’ rule is intractable, and it is necessary to use either an explicit or implicit variational approximation [25, 26, 27, 28]:
| (2) |
Furthermore, the integral in eq. 1 is also intractable for neural networks and is typically approximated via sampling (eq. 3), using approaches like Monte-Carlo dropout [18], Langevin Dynamics [29] or explicit ensembling [11]. Thus,
| (3) |
Each in an ensemble obtained sampled from is a categorical distribution 333Where is a vector of probabilities: over class labels conditioned on the input , and can be visualized as a point on a simplex. For the same this ensemble is a collection of points on a simplex (fig. 1a), which can be seen as samples of categorical distributions from an implicit conditional distribution over a simplex (fig. 1b) induced via the posterior over model parameters.
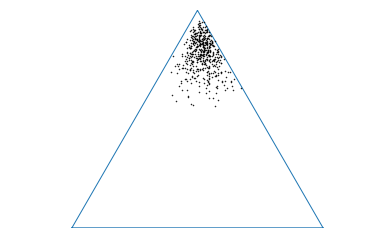

By selecting an appropriate approximate inference scheme and model prior Bayesian approaches aim to craft an approximate model posterior such that the ensemble is consistent in the region of training data, and becomes increasingly diverse when the input is far from the training data. Thus, these approaches aim to craft an implicit conditional distribution over a simplex (fig. 1b) with the attributes that it is sharp at the corners of a simplex for inputs similar to the training data and flat over the simplex for out-of-distribution inputs. Given an ensemble from such a distribution, the entropy of the expected distribution will indicate uncertainty in predictions. It is not possible, however, to determine from the entropy whether this uncertainty is due to a high degree of data uncertainty, or whether the input is far from the region of training data. It is necessary to use measures of spread of the ensemble, such as Mutual Information, to assess uncertainty in predictions due to model uncertainty. This allows sources of uncertainty to be determined.
In practice, however, for deep, distributed black-box models with tens of millions of parameters, such as DNNs, it is difficult to select an appropriate model prior and approximate inference scheme to craft a model posterior which induces an implicit distribution with the desired properties. This makes it hard to guarantee the desired properties of the induced distribution for current state-of-the-art Deep Learning approaches. Furthermore, creating an ensemble can be computationally expensive.
An alternative, non-Bayesian class of approaches derives measures of uncertainty via the predictive posteriors of regression [21] and classification [13, 22, 30] DNNs. Here, DNNs are explicitly trained [22, 21] to yield high entropy posterior distributions for out-of-distribution inputs. These approaches are easy to train and inference is computationally cheap. However, a high entropy posterior over classes could indicate uncertainty in the prediction due to either an in-distribution input in a region of class overlap or an out-of-distribution input far from the training data. Thus, it is not possible to robustly determine the source of uncertainty using these approaches. Further discussion of uncertainty measures can be found in section 4.
3 Prior Networks
Having described existing approaches, an alternative approach to modeling predictive uncertainty, called Prior Networks, is proposed in this section. As previously described, Bayesian approaches aim to construct an implicit conditional distribution over distributions on a simplex (fig 1b) with certain desirable attributes by appropriate selection of model prior and approximate inference method. In practice this is a difficult task and an open research problem.
This work proposes to instead explicitly parameterize a distribution over distributions on a simplex, , using a DNN referred to as a Prior Network and train it to behave like the implicit distribution in the Bayesian approach. Specifically, when it is confident in its prediction a Prior Network should yield a sharp distribution centered on one of the corners of the simplex (fig. 2a). For an input in a region with high degrees of noise or class overlap (data uncertainty) a Prior Network should yield a sharp distribution focused on the center of the simplex, which corresponds to being confident in predicting a flat categorical distribution over class labels (known-unknown) (fig. 2b). Finally, for ’out-of-distribution’ inputs the Prior Network should yield a flat distribution over the simplex, indicating large uncertainty in the mapping (unknown-unknown) (fig. 2c).

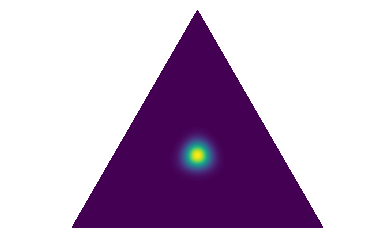
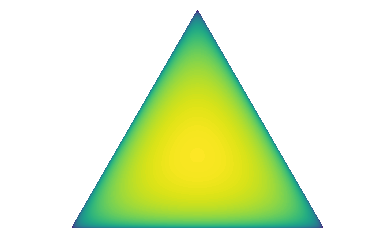
In the Bayesian framework distributional uncertainty, or uncertainty due to mismatch between the distributions of test and training data, is considered a part of model uncertainty. In this work it will be considered to be a source of uncertainty separate from data uncertainty or model uncertainty. Prior Networks will be explicitly constructed to capture data uncertainty and distributional uncertainty. In Prior Networks data uncertainty is described by the point-estimate categorical distribution and distributional uncertainty is described by the distribution over predictive categoricals . The parameters of the Prior Network must encapsulate knowledge both about the in-domain distribution and the decision boundary which separates the in-domain region from everything else. Construction of a Prior Network is discussed in sections 3.1 and 3.2. Before this it is necessary to discuss its theoretical properties.
Consider modifying eq. 1 by introducing the term as follows:
| (4) |
In this expression data, distribution and model uncertainty are now each modeled by a separate term within an interpretable probabilistic framework. The relationship between uncertainties is made explicit - model uncertainty affects estimates of distributional uncertainty, which in turn affects the estimates of data uncertainty. This is expected, as a large degree of model uncertainty will yield a large variation in , and large uncertainty in will lead to a large uncertainty in estimates of data uncertainty. Thus, model uncertainty affects estimates of data and distributional uncertainties, and distributional uncertainty affects estimates of data uncertainty. This forms a hierarchical model - there are now three layers of uncertainty: the posterior over classes, the per-data prior distribution and the global posterior distribution over model parameters. Similar constructions have been previously explored for non-neural Bayesian models, such as Latent Dirichlet Allocation [31]. However, typically additional levels of uncertainty are added in order to increase the flexibility of models, and predictions are obtained by marginalizing or sampling. In this work, however, the additional level of uncertainty is added in order to be able to extract additional measures of uncertainty, depending on how the model is marginalized. For example, consider marginalizing out in eq. 4, thus re-obtaining eq. 1:
| (5) |
Since the distribution over is lost in the marginalization it is unknown how sharp or flat it was around the point estimate. If the expected categorical is "flat" it is now unknown whether this is due to high data or distributional uncertainty. In this situation, it will be necessary to again rely on measures which assess the spread of an MC ensemble, like mutual information (section 4), to establish the source of uncertainty. Thus, Prior Networks are consistent with previous approaches to modeling uncertainty, both Bayesian and non-Bayesian - they can be viewed as an ’extra tool in the uncertainty toolbox’ which is explicitly crafted to capture the effects of distributional mismatch in a probabilistically interpretable way. Alternatively, consider marginalizing out in eq. 4 as follows:
| (6) |
This yields expected estimates of data and distributional uncertainty given model uncertainty. Eq. 6 can be seen as a modification of eq. 1 where the model is redefined as and the distribution over model parameters is now conditional on both the training data and the test input . This explicitly yields the distribution over the simplex which the Bayesian approach implicitly induces. Further discussion of how measures of uncertainty are derived from the marginalizations of equation 4 is presented in section 4.
Unfortunately, like eq. 1, the marginalization in eq. 6 is generally intractable, though it can be approximated via Bayesian MC methods. For simplicity, this work will assume that a point-estimate (eq. 7) of the parameters will be sufficient given appropriate regularization and training data size.
| (7) |
3.1 Dirichlet Prior Networks
A Prior Network for classification parametrizes a distribution over a simplex, such as a Dirichlet (eq. 8), Mixture of Dirichlet distributions or the Logistic-Normal distribution. In this work the Dirichlet distribution is chosen due to its tractable analytic properties. A Dirichlet distribution is a prior distribution over categorical distribution, which is parameterized by its concentration parameters , where , the sum of all , is called the precision of the Dirichlet distribution. Higher values of lead to sharper distributions.
| (8) |
A Prior Network which parametrizes a Dirichlet will be referred to as a Dirichlet Prior Network (DPN). A DPN will generate the concentration parameters of the Dirichlet distribution.
| (9) |
The posterior over class labels will be given by the mean of the Dirichlet:
| (10) |
If an exponential output function is used for the DPN, where , then the expected posterior probability of a label is given by the output of the softmax (eq. 11).
| (11) |
Thus, standard DNNs for classification with a softmax output function can be viewed as predicting the expected categorical distribution under a Dirichlet prior. The mean, however, is insensitive to arbitrary scaling of . Thus the precision , which controls the sharpness of the Dirichlet, is degenerate under standard cross-entropy training. It is necessary to change the cost function to explicitly train a DPN to yield a sharp or flat prior distribution around the expected categorical depending on the input data.
3.2 Dirichlet Prior Network Training
There are potentially many ways in which a Prior Network can be trained and it is not the focus of this work to investigate them all. This work considers one approach to training a DPN based on the work done in [21, 22] and here. The DPN is explicitly trained in a multi-task fashion to minimize the KL divergence (eq. 12) between the model and a sharp Dirichlet distribution focused on the appropriate class for in-distribution data, and between the model and a flat Dirichlet distribution for out-of-distribution data. A flat Dirichlet is chosen as the uncertain distribution in accordance with the principle of insufficient reason [32], as all possible categorical distributions are equiprobable.
| (12) |
In order to train using this loss function the in-distribution targets and out-of-distribution targets must be defined. It is simple to specify a flat Dirichlet distribution by setting all . However, directly setting the in-distribution target is not convenient. Instead the concentration parameters are re-parametrized into , the target precision, and the means . is a hyper-parameter set during training and the means are simply the 1-hot targets used for classification. A further complication is that learning sparse ’1-hot’ continuous distributions, which are effectively delta functions, is challenging under the defined KL loss, as the error surface becomes poorly suited for optimization. There are two solutions - first, it is possible to smooth the target means (eq. 15), which redistributes a small amount of probability density to the other corners of the Dirichlet. Alternatively, teacher-student training [33] can be used to specify non-sparse target means . The smoothing approach is used in this work. Additionally, cross-entropy can be used as an auxiliary loss for in-distribution data.
| (15) |
The multi-task training objective (eq. 12) requires samples of from the out-of-domain distribution . However, the true out-of-domain distribution is unknown and samples are unavailable. One solution is to synthetically generate points on the boundary of the in-domain region using a generative model [21, 22]. An alternative is to use a different, real dataset as a set of samples from the out-of-domain distribution [22].
4 Uncertainty Measures
The previous section introduced a new framework for modeling uncertainty. This section explores a range of measures for quantifying uncertainty given a trained DNN, DPN or Bayesian MC ensemble. The discussion is broken down into 4 classes of measure, depending on how eq. 4 is marginalized. Details of derivation can be found in Appendix C.
The first class derives measures of uncertainty from the expected predictive categorical , given a full marginalization of eq. 4 which can be approximated either with a point estimate of the parameters or a Bayesian MC ensemble. The first measure is the probability of the predicted class (mode), or max probability (eq. 16), which is a measure of confidence in the prediction used in [13, 22, 30, 23, 11].
| (16) |
The second measure is the entropy (eq. 17) of the predictive distribution [23, 18, 11]. It behaves similar to max probability, but represents the uncertainty encapsulated in the entire distribution.
| (17) |
Max probability and entropy of the expected distribution can be seen as measures of the total uncertainty in predictions.
The second class of measures considers marginalizing out in eq. 4, yielding eq. 1. Mutual Information (MI) [23] between the categorical label and the parameters of the model is a measure of the spread of an ensemble [18] which assess uncertainty in predictions due to model uncertainty. Thus, MI implicitly captures elements of distributional uncertainty. MI can be expressed as the difference of the total uncertainty, captured by the entropy of expected distribution, and the expected data uncertainty, captured by expected entropy of each member of the ensemble (eq. 18). This interpretation was given in [34].
| (18) |
The third class of measures considers marginalizing out in eq. 4, yielding eq. 6. The first measure in this class is the mutual information between and (eq. 19), which behaves in exactly the same way as MI between and , but the spread is now explicitly due to distributional uncertainty, rather than model uncertainty.
| (19) |
Another measure of uncertainty is the differential entropy (eq. 20) of the DPN. This measure is maximized when all categorical distributions are equiprobable, which occurs when the Dirichlet Distribution is flat - in other words when there is the greatest variety of samples from the Dirichlet prior. Differential entropy is well suited to measuring distributional uncertainty, as it can be low even if the expected categorical under the Dirichlet prior has high entropy, and also captures elements of data uncertainty.
| (20) |
The final class of measures uses the full eq. 4 and assesses the spread of due to model uncertainty via the MI between and , which can be computed via Bayesian ensemble approaches.
5 Experiments
The previous sections discussed modeling different aspects of predictive uncertainty and presented several measures of quantifying it. This section compares the proposed and previous methods in two sets of experiments. The first experiment illustrates the advantages of a DPN over other non-Bayesian methods [22, 30] on synthetic data and the second set of experiments evaluate DPNs on MNIST and CIFAR-10 and compares them to DNNs and ensembles generated via Monte-Carlo Dropout (MCDP) on the tasks of misclassification detection and out-of-distribution data detection. The experimental setup is described in Appendix A and additional experiments are described in Appendix B.
5.1 Synthetic Experiments
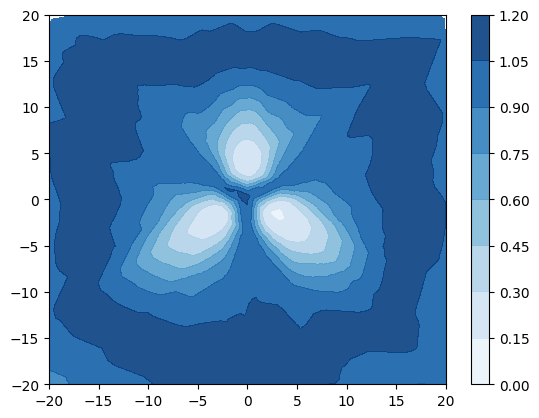
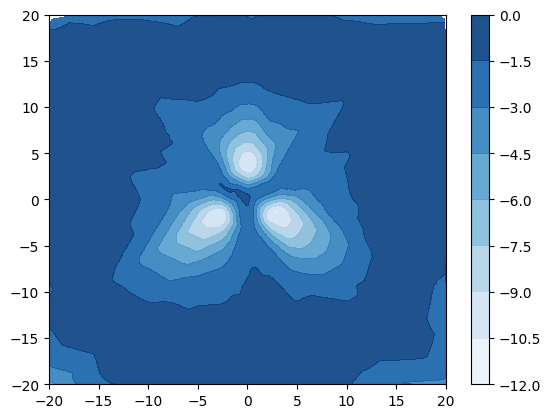
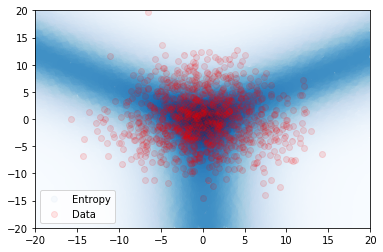
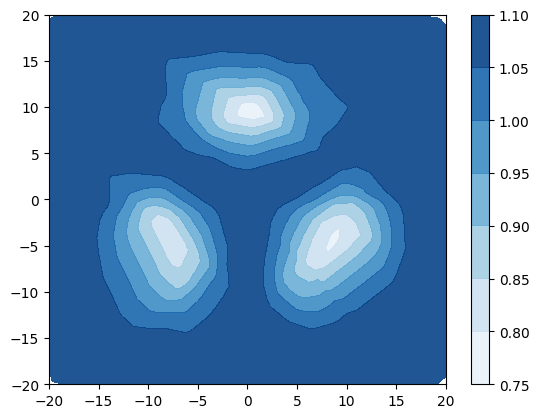
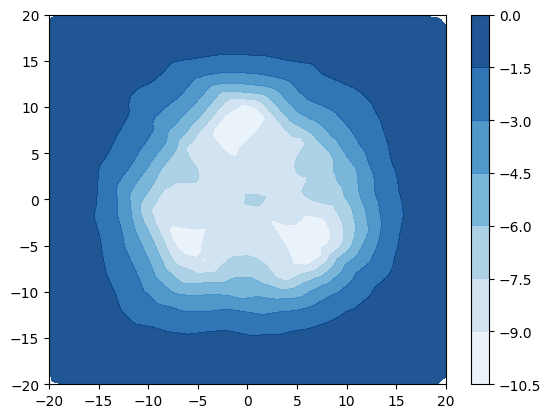
A synthetic experiment was designed to illustrate the limitation of using uncertainty measures derived from [22, 30] to detect out-of-distribution samples. A simple dataset with 3 Gaussian distributed classes with equidistant means and tied isotropic variance is created. The classes are non-overlapping when (fig. 3a) and overlap when (fig. 3d). The entropy of the true posterior over class labels is plotted in blue in figures 3a and 3d, which show that when the classes are distinct the entropy is high only on the decision boundaries, but when the classes overlap the entropy is high also within the data region. A small DPN with 1 hidden layer of 50 neurons is trained on this data. Figures 3b and 3c show that when classes are distinct both the entropy of the DPN’s predictive posterior and the differential entropy of the DPN have identical behaviour - low in the region of data and high elsewhere, allowing in-distribution and out-of-distribution regions to be distinguished. Figures 3e and 3f, however, show that when there is a large degree of class overlap the entropy and differential entropy have different behavior - entropy is high both in region of class overlap and far from training data, making difficult to distinguish out-of-distribution samples and in-distribution samples at a decision boundary. In contrast, the differential entropy is low over the whole region of training data and high outside, allowing the in-distribution region to be clearly distinguished from the out-of-distribution region.

5.2 MNIST and CIFAR-10 Experiments
An in-domain misclassification detection experiment and an out-of-distribution (OOD) input detection experiment were run on the MNIST and CIFAR-10 datasets [35, 36] to assess the DPN’s ability to estimate uncertainty. The misclassification detection experiment involves detecting whether a given prediction is incorrect given an uncertainty measure. Misclassifications are chosen as the positive class. The misclassification detection experiment was run on the MNIST valid+test set and the CIFAR-10 test set. The out-of-distribution detection experiment involves detecting whether an input is out-of-distribution given a measure of uncertainty. Out-of-distribution samples are chosen as the positive class. The OMNIGLOT dataset [37], scaled down to 28x28 pixels, was used as real ’OOD’ data for MNIST. 15000 samples of OMNIGLOT data were randomly selected to form a balanced set of positive (OMNIGLOT) and negative (MNIST valid+test) samples. For CIFAR-10 three OOD datasets were considered - SVHN, LSUN and TinyImagetNet (TIM) [38, 39, 40]. The two considered baseline approaches derive uncertainty measures from either the class posterior of a DNN [13] or an ensemble generated via MC dropout applied to the same DNN [23, 18]. All uncertainty measures described in section 4 are explored for both tasks in order to see which yield best performance. The performance is assessed by area under the ROC (AUROC) and Precision-Recall (AUPR) curves in both experiments as in [13].
Data Model AUROC AUPR % Err. Max.P Ent. M.I. D.Ent. Max.P Ent. M.I. D.Ent. MNIST DNN 98.0 98.6 - - 26.6 25.0 - - 0.4 MCDP 97.2 97.2 96.9 - 33.0 29.0 27.8 - 0.4 DPN 99.0 98.9 98.6 92.9 43.6 39.7 30.7 25.5 0.6 CIFAR10 DNN 92.4 92.3 - - 48.7 47.1 - - 8.0 MCDP 92.5 92.0 90.4 - 48.4 45.5 37.6 - 8.0 DPN 92.2 92.1 92.1 90.9 52.7 51.0 51.0 45.5 8.5
Table 1 shows that the DPN consistently outperforms both a DNN, and a MC dropout ensemble (MCDP) in misclassification detection performance, although there is a negligible drop in accuracy of the DPN as compared to a DNN or MCDP. Max probability yields the best results, closely followed by the entropy of the predictive distribution. This is expected, as max probability is directly related to the predicted class, while the other measures capture the uncertainty of the entire distribution. The performance difference is more pronounced on AUPR, which is sensitive to misbalanced classes.
Table 2 shows that a DPN consistently outperforms the baselines in OOD sample detection for both MNIST and CIFAR-10 datasets. On MNIST, the DPN is able to perfectly classify all samples using max probability, entropy and differential entropy. On the CIFAR-10 dataset the DPN consistently outperforms the baselines by a large margin. While high performance against SVHN and LSUN is expected, as LSUN, SVHN and CIFAR-10 are quite different, high performance against TinyImageNet, which is also a dataset of real objects and therefore closer to CIFAR-10, is more impressive. Curiously, MC dropout does not always yield better results than a standard DNN, which supports the assertion that it is difficult to achieve the desired behaviour for a Bayesian distribution over distributions.
Data Model AUROC AUPR ID OOD Max.P Ent. M.I. D.Ent. Max.P Ent. M.I. D.Ent. MNIST OMNI DNN 98.7 98.8 - - 98.3 98.5 - - MCDP 99.2 99.2 99.3 - 99.0 99.1 99.3 - DPN 100.0 100.0 99.5 100.0 100.0 100.0 97.5 100.0 CIFAR10 SVHN DNN 90.1 90.8 - - 84.6 85.1 - - MCDP 89.6 90.6 83.7 - 84.1 84.8 73.1 - PN 98.1 98.2 98.2 98.5 97.7 97.8 97.8 98.2 CIFAR10 LSUN DNN 89.8 91.4 - - 87.0 90.0 - - MCDP 89.1 90.9 89.3 - 86.5 89.6 86.4 - DPN 94.4 94.4 94.4 94.6 93.3 93.4 93.4 93.3 CIFAR10 TIM DNN 87.5 88.7 - - 84.7 87.2 - - MCDP 87.6 89.2 86.9 - 85.1 87.9 83.2 - DPN 94.3 94.3 94.3 94.6 94.0 94.0 94.0 94.2
The experiments above suggest that there is little benefit of using measures such as differential entropy and mutual information over standard entropy. However, this is because MNIST and CIFAR-10 are low data uncertainty datasets - all classes are distinct. It is interesting to see whether differential entropy of the Dirichlet prior will be able to distinguish in-domain and out-of-distribution data better than entropy when the classes are less distinct. To this end zero mean isotropic Gaussian noise with a standard deviation noise is added to the inputs of the DNN and DPN during both training and evaluation on the MNIST dataset. Table 3 shows that in the presence of strong noise entropy and MI fail to successfully discriminate between in-domain and out-of-distribution samples, while performance using differential entropy barely falls.
Ent. M.I. D.Ent. 0.0 3.0 0.0 3.0 0.0 3.0 DNN 98.8 58.4 - - - - MCDP 98.8 58.4 99.3 79.1 - - DPN 100.0 51.8 99.5 22.3 100.0 99.8
6 Conclusion
This work describes the limitations of previous work on predictive uncertainty estimations within the context of sources of uncertainty and proposes to treat out-of-distribution (OOD) inputs as a separate source of uncertainty, called Distributional Uncertainty. To this end, this work presents a novel framework, called Prior Networks (PN), which allows data, distributional and model uncertainty to be treated separately within a consistent probabilistically interpretable framework. A particular form of these PNs are applied to classification, Dirichlet Prior Networks (DPNs). DPNs are shown to yield more accurate estimates of distributional uncertainty than MC Dropout and standard DNNs on the task of OOD detection on the MNIST and CIFAR-10 datasets. The DPNs also outperform other methods on the task of misclassification detection. A range of uncertainty measures is presented and analyzed in the context of the types of uncertainty which they assess. It was noted that the max probability of the predictive distribution yielded the best results on misclassification detection. Differential entropy of DPN was best for OOD detection, especially when classes are less distinct. This was illustrated on both a synthetic experiment and on a noise-corrupted MNIST task. Uncertainty measures can be analytically calculated at test time for DPNs, reducing computational cost relative to ensemble approaches. Having investigated PNs for image classification, it is interesting to apply them to other tasks computer vision, NLP, machine translation, speech recognition and reinforcement learning. Finally, it is necessary to explore Prior Networks for regression tasks.
Acknowledgments
This paper reports on research partly supported by Cambridge Assessment, University of Cambridge. This work also partly funded by a DTA EPSRC away and a Google Research award. We would also like to thank members of the CUED Machine Learning group, especially Dr. Richard Turner, for fruitful discussions.
References
- [1] Ross Girshick, “Fast R-CNN,” in Proc. 2015 IEEE International Conference on Computer Vision (ICCV), 2015, pp. 1440–1448.
- [2] Karen Simonyan and Andrew Zisserman, “Very Deep Convolutional Networks for Large-Scale Image Recognition,” in Proc. International Conference on Learning Representations (ICLR), 2015.
- [3] Ruben Villegas, Jimei Yang, Yuliang Zou, Sungryull Sohn, Xunyu Lin, and Honglak Lee, “Learning to Generate Long-term Future via Hierarchical Prediction,” in Proc. International Conference on Machine Learning (ICML), 2017.
- [4] Tomas Mikolov et al., “Linguistic Regularities in Continuous Space Word Representations,” in Proc. NAACL-HLT, 2013.
- [5] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean, “Efficient Estimation of Word Representations in Vector Space,” 2013, arXiv:1301.3781.
- [6] Tomas Mikolov, Martin Karafiát, Lukás Burget, Jan Cernocký, and Sanjeev Khudanpur, “Recurrent Neural Network Based Language Model,” in Proc. INTERSPEECH, 2010.
- [7] Geoffrey Hinton, Li Deng, Dong Yu, George Dahl, Abdel rahman Mohamed, Navdeep Jaitly, Andrew Senior, Vincent Vanhoucke, Patrick Nguyen, Tara Sainath, and Brian Kingsbury, “Deep neural networks for acoustic modeling in speech recognition,” Signal Processing Magazine, 2012.
- [8] Awni Y. Hannun, Carl Case, Jared Casper, Bryan Catanzaro, Greg Diamos, Erich Elsen, Ryan Prenger, Sanjeev Satheesh, Shubho Sengupta, Adam Coates, and Andrew Y. Ng, “Deep speech: Scaling up end-to-end speech recognition,” 2014, arXiv:1412.5567.
- [9] Rich Caruana, Yin Lou, Johannes Gehrke, Paul Koch, Marc Sturm, and Noemie Elhadad, “Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission,” in Proc. 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 2015, KDD ’15, pp. 1721–1730, ACM.
- [10] Babak Alipanahi, Andrew Delong, Matthew T. Weirauch, and Brendan J. Frey, “Predicting the sequence specificities of DNA- and RNA-binding proteins by deep learning,” Nature Biotechnology, vol. 33, no. 8, pp. 831–838, July 2015.
- [11] B. Lakshminarayanan, A. Pritzel, and C. Blundell, “Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles,” in Proc. Conference on Neural Information Processing Systems (NIPS), 2017.
- [12] Dario Amodei, Chris Olah, Jacob Steinhardt, Paul F. Christiano, John Schulman, and Dan Mané, “Concrete problems in AI safety,” http://arxiv.org/abs/1606.06565, 2016, arXiv: 1606.06565.
- [13] Dan Hendrycks and Kevin Gimpel, “A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks,” http://arxiv.org/abs/1610.02136, 2016, arXiv:1610.02136.
- [14] David JC MacKay, “A practical bayesian framework for backpropagation networks,” Neural computation, vol. 4, no. 3, pp. 448–472, 1992.
- [15] David JC MacKay, Bayesian methods for adaptive models, Ph.D. thesis, California Institute of Technology, 1992.
- [16] Geoffrey E. Hinton and Drew van Camp, “Keeping the neural networks simple by minimizing the description length of the weights,” in Proc. Sixth Annual Conference on Computational Learning Theory, New York, NY, USA, 1993, COLT ’93, pp. 5–13, ACM.
- [17] Radford M. Neal, Bayesian learning for neural networks, Springer Science & Business Media, 1996.
- [18] Yarin Gal and Zoubin Ghahramani, “Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning,” in Proc. 33rd International Conference on Machine Learning (ICML-16), 2016.
- [19] A. Kendall, Y. Gal, and R. Cipolla, “Multi-Task Learning Using Uncertainty to Weight Losses for Scene Geometry and Semantics,” in Proc. Conference on Neural Information Processing Systems (NIPS), 2017.
- [20] A. Kendall and Y. Gal, “What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision,” in Proc. Conference on Neural Information Processing Systems (NIPS), 2017.
- [21] A. Malinin, A. Ragni, M.J.F. Gales, and K.M. Knill, “Incorporating Uncertainty into Deep Learning for Spoken Language Assessment,” in Proc. 55th Annual Meeting of the Association for Computational Linguistics (ACL), 2017.
- [22] Kimin Lee, Honglak Lee, Kibok Lee, and Jinwoo Shin, “Training confidence-calibrated classifiers for detecting out-of-distribution samples,” International Conference on Learning Representations, 2018.
- [23] Yarin Gal, Uncertainty in Deep Learning, Ph.D. thesis, University of Cambridge, 2016.
- [24] Joaquin Quiñonero-Candela, Dataset Shift in Machine Learning, The MIT Press, 2009.
- [25] Charles Blundell, Julien Cornebise, Koray Kavukcuoglu, and Daan Wierstra, “Weight Uncertainty in Neural Networks,” in Proc. International Conference on Machine Learning (ICML), 2015.
- [26] Alex Graves, “Practical variational inference for neural networks,” in Advances in neural information processing systems, 2011, pp. 2348–2356.
- [27] Christos Louizos and Max Welling, “Structured and efficient variational deep learning with matrix gaussian posteriors,” in International Conference on Machine Learning, 2016, pp. 1708–1716.
- [28] Diederik P Kingma, Tim Salimans, and Max Welling, “Variational dropout and the local reparameterization trick,” in Advances in Neural Information Processing Systems, 2015, pp. 2575–2583.
- [29] Max Welling and Yee Whye Teh, “Bayesian Learning via Stochastic Gradient Langevin Dynamics,” in Proc. International Conference on Machine Learning (ICML), 2011.
- [30] Shiyu Liang, Yixuan Li, and R. Srikant, “Enhancing the reliability of out-of-distribution image detection in neural networks,” in Proc. International Conference on Learning Representations, 2018.
- [31] David M. Blei, Andrew Y. Ng, and Michael I. Jordan, “Latent Dirichlet Allocation,” Journal of Machine Learning Research, vol. 3, pp. 993–1022, Mar. 2003.
- [32] Kevin P. Murphy, Machine Learning, The MIT Press, 2012.
- [33] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean, “Distilling the knowledge in a neural network,” 2015, arXiv:1503.02531.
- [34] Stefan Depeweg, José Miguel Hernández-Lobato, Finale Doshi-Velez, and Steffen Udluft, “Decomposition of uncertainty for active learning and reliable reinforcement learning in stochastic systems,” arXiv preprint arXiv:1710.07283, 2017.
- [35] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the ieee, vol. 86, pp. 2278–2324, 1998.
- [36] Alex Krizhevsky, “Learning multiple layers of features from tiny images,” 2009.
- [37] Brenden M. Lake, Ruslan Salakhutdinov, and Joshua B. Tenenbaum, “Human-level concept learning through probabilistic program induction,” Science, vol. 350, no. 6266, pp. 1332–1338, 2015.
- [38] Ian J. Goodfellow, Yaroslav Bulatov, Julian Ibarz, Sacha Arnoud, and Vinay D. Shet, “Multi-digit number recognition from street view imagery using deep convolutional neural networks,” 2013, arXiv:1312.6082.
- [39] Fisher Yu, Yinda Zhang, Shuran Song, Ari Seff, and Jianxiong Xiao, “LSUN: construction of a large-scale image dataset using deep learning with humans in the loop,” 2015, arXiv:1506.03365.
- [40] Stanford CS231N, “Tiny ImageNet,” https://tiny-imagenet.herokuapp.com/, 2017.
- [41] M Buscema, “Metanet: The theory of independent judges,” Substance Use & Misuse, vol. 33, no. 2, pp. 439–461, 1998.
- [42] Martín Abadi et al., “TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems,” 2015, Software available from tensorflow.org.
- [43] Timothy Dozat, “Incorporating Nesterov Momentum into Adam,” in Proc. International Conference on Learning Representations (ICLR), 2016.
Appendix A Experimental Setup and Datasets
For both core and additional experiments models were trained on the MNIST [35], SVHN [38] and CIFAR [36] datasets. Dataset sizes can be found in table 4.
Dataset Train Valid Test Classes MNIST 55000 5000 10000 10 SVHN 73257 - 26032 CIFAR-10 50000 - 10000 CIFAR-100 50000 - 10000 100
In addition to the datasets described above, the OMNIGLOT [37], SEMEION [41], LSUN [39] and TinyImagenet [40] datasets were used for out-of-distribution input detection experiments. For these datasets only their test sets were used, described in table 4. TinyImagenet was resized down to 32x32 from 64x64 and OMNIGLOT was resized down to 28x28 using bilinear interpolation.
Dataset Size OMNIGLOT 32460 SEMEION 1593 LSUN 10000 tinyImagenet 10000
For all datasets the input features were re-scaled to the range -1.0 and 1.0 from the range 0 and 255. No additional preprocessing was done models trained on the MNSIT and SVHN datasets. For models trained on CIFAR-10, images were randomly flipped left-right, shifted by 4 pixels and rotated by 15 degrees as a form of data augmentation.
All networks for all experiments were constructed using variants on the VGG [2] architecture for image classification. Models were implemented in Tensorflow [42]. Details of the architectures used for each dataset can be found in table 6. For convolutional layers dropout was used with a higher keep probability than for fully-connected layers.
Dataset Arch. Activation Conv Depth FC Layers FC units MNIST VGG-6 ReLU 4 1 100 SVHN VGG-16 Leaky ReLU 13 2 2048 CIFAR-10 VGG-16 Leaky ReLU 13 2 2048
The training configuration for all models is described in table 7. Interestingly, it was necessary to use less dropout for the DPN, due to the regularization effect of the noise data. All models trained using the NADAM optimizer [43]. For the models trained on MNIST expenentially decaying learning rates were used. Models trained on SVHN and CIFAR-10 used 1-Cycle learning rates, where learning rates are linearly increased from the initial learning rate to 10x the initial learning rate for half a cycle and then linearly decreased back down to the initial learning rate for the remained of the cycle. Learning rates are then linearly decreased until 1e-6 for the remaining training epochs. This approach has been shown to act both as a reguralizer as well as speed up training of models [cycle-lr].
Dataset Model Dropout LR Cycle Len. Epochs CE weight OOD data MNIST DNN 0.50 1e-3 - 30 - - - DPN 0.95 1e-3 - 10 1e3 0.0 MNIST FA SVHN DNN 0.50 1e-3 30 40 - - - DPN 0.50 7.5e-4 30 40 1e3 1.0 CIFAR-10 CIFAR-10 DNN 0.50 1e-3 30 45 - - - DPN 0.70 7.5e-4 70 100 1e2 1.0 CIFAR-100
For the DPN trained on MNIST data the out-of-distribution data was synthesized using a Factor Analysis model with a 50-dimensional latent space. In standard factor analysis the latent vectors have an isotropic standard normal distribution. To push the FA model to produce data at the boundary of the in-domain region the variance on the latent distribution was increased.
Appendix B Additional Experiments
Further experiments have been run in addition to the core experiments described in section 5. In appendix B.1 the MNIST DNN and DPN described in section 5.2 is evaluated against other out-of-distribution datasets. In appendix B.2 and B.3 a DPN is trained on the SVHN [38] and CIFAR-10 [36] datasets, respectively, and evaluated on the tasks of misclassification detection and out-of-distribution input detection.
B.1 Additional MNIST experiments
In Table 8 out-of-distribution input detection is run against the SEMEION, SVHN and CIFAR-10 datasets. SEMEION is a dataset of greyscale handwritten 16x16 digits, whose primary difference from MNIST is that there is no padding between the edge of the image and the digit. SEMEION digits were upscaled to 28x28 for these experiments. For the SVHN and CIFAR-10 experiments, the images were transformed into greyscale and downsampled to 28x28 size.
The purpose here is to investigate how out-of-distribution input detection performance is affected by the similarity of the OOD data to the in-domain data. Here, SEMEION is the most similar dataset to MNIST, as it is also composed of greyscale handwritten digits. SVHN, also a dataset over digits 0-9, is less similar, as the digits are now embedded in street signs. CIFAR-10 is the most different, as it is a dataset of real objects. In all experiments presented in table 8 the DPN outperforms the baselines. Performance of all models is worst on SEMEION and best on CIFAR-10, illustrating how OOD detection is more challenging as the datasets become less distinct. Note, As SEMEION is a very small dataset it was not possible to get a balanced set of MNIST and SEMEION images, so AUPR is a better performance metric than AUROC on this particular experiment.
OOD Data Model AUROC AUPR Max.P Ent. M.I. D.Ent. Max.P Ent. M.I. D.Ent. SEMEION DNN 92.7 92.9 - - 76.4 76.7 - - MCDP 95.2 95.3 95.4 - 84.1 84.2 87.3 - DPN 99.5 99.6 99.1 99.7 96.9 97.5 90.8 98.6 SVHN DNN 98.7 98.9 - - 98.5 98.7 - - MCDP 98.2 98.4 98.1 - 98.0 98.3 97.9 - DPN 99.9 100.0 99.5 100.0 99.9 100.0 98.5 100.0 CIFAR10 DNN 99.4 99.5 - - 99.3 99.4 - - MCDP 99.1 99.3 98.9 - 98.9 99.2 98.6 - DPN 100.0 100.0 99.5 100.0 100.0 100.0 98.2 100.0
B.2 SVHN Experiments
This section describes misclassification and out-of-distribution input detections experiments on the SVHN dataset. A DPN trained on SVHN used the CIFAR-10 dataset as the noise dataset, rather than using a generative model like Factor Analysis, VAE or GAN. Investigation of appropriate methods to synthesize out-of-distribution data for complex datasets is beyond the scope of this work.
Table 9 describes the misclassification detection experiment on SVHN. Note, all models achieve comparable classification error (4.3-5.1%). The DPN outperforms the baselines according to AUPR but achieves lower performance in AUROC on misclassification detection using all measures.
Model AUROC AUPR % Err. Max.P Ent. M.I. D.Ent. Max.P Ent. M.I. D.Ent. DNN 90.1 91.8 - - 47.7 46.8 - - 4.3 MCDP 92.0 92.2 92.0 - 46.4 43.5 40.4 - 4.3 DPN 90.1 90.1 90.1 91.2 55.3 54.8 54.8 46.0 5.1
Table 10 reports the out-of-distribution detection performance of SVHN vs CIFAR-10, CIFAR-100, LSUN and TinyImageNet datasets, respectively. In all experiments the DPN is seen to consistently achieves highest performance. Note, the DPN uses CIFAR-10 as the training out-of-distribution dataset, so it is unsurprising that it achieves near-perfect performance on a held-out set of CIFAR-10 data. Interestingly, there is a larger margin between the DNN and MCDP on SVHN than on networks trained either on MNIST or CIFAR-10.
OOD Data Model AUROC AUPR Max.P Ent. M.I. D.Ent. Max.P Ent. M.I. D.Ent. CIFAR10 DNN 92.5 93.8 - - 91.4 92.1 - - MCDP 95.6 96.0 96.3 - 94.4 95.0 95.8 - DPN 99.9 99.9 99.9 99.9 100.0 100.0 100.0 99.9 CIFAR100 DNN 92.4 93.8 - - 91.4 92.1 - - MCDP 94.2 94.8 95.4 - 94.2 94.8 95.4 - DPN 99.8 99.8 99.8 99.8 99.8 99.8 99.8 99.8 LSUN DNN 91.9 93.4 - - 90.7 91.3 - - MCDP 95.9 96.3 97.0 - 94.9 95.3 96.8 - DPN 100.0 100.0 100.0 100.0 99.9 99.9 99.9 100.0 TIM DNN 93.1 94.2 - - 91.8 92.5 - - MCDP 96.3 96.7 97.1 - 95.3 95.8 96.8 - DPN 100.0 100.0 100.0 100.0 99.9 99.9 99.9 100.0
B.3 CIFAR-10 Experiments
This section presents the results of misclassification and out-of-distribution input detection experiments on the CIFAR-10 dataset. A DPN trained on CIFAR-10 used the CIFAR-100 dataset as the out-of-distribution training dataset. CIFAR-100 is similar to CIFAR-10 but describes different objects than CIFAR-10, so there is no class overlap. This is the most challenging set of experiments, as visually CIFAR-10 is much more similar to CIFAR-100, LSUN and TinyImageNet, so out-of-distribution input detection is likely to more difficult than for simpler tasks like MNIST and SVHN.
Table 11 gives the results of the misclassification detection experiment on CIFAR-10. All models achieve comparable classification error (8-8.5%), with the DPN achieving a slightly higher performance than the baselines in AUPR.
Model AUROC AUPR % Err. Max.P Ent. M.I. D.Ent. Max.P Ent. M.I. D.Ent. DNN 92.4 92.3 - - 48.7 47.1 - - 8.0 MCDP 92.5 92.0 90.4 - 48.4 45.5 37.6 - 8.0 DPN 92.2 92.1 92.1 90.9 52.7 51.0 51.0 45.5 8.5
Table 12 reports the results of the out-of-distribution detection of CIFAR-10 vs CIFAR-100, SVHN, LSUN and TinyImageNet datasets. In all experiments the DPNs achieve the best performance, outperforming the baselines by a larger margin than previously. Note, CIFAR-100 is used as OOD training data for the DPN, so high performance on it is expected. TinyImageNet is the most similar to CIFAR-10 (other than CIFAR-100) and it the most challenging OOD detection task, as the baseline approaches achieve the lowest performance on it. Notably, In each experiment the performance of the baseline approaches is noticeable lower than before, especially using mutual information of MCDP as a measure of uncertainty. This indicates that it is indeed difficult to control the behaviour of Bayesian distributions over distributions for complex tasks. This set of experiments clearly demonstrates that Prior Networks perform well on much more difficult datasets than MNIST and are able to outperform previously proposed Bayesian and non-Bayesian approaches.
OOD Data Model AUROC AUPR Max.P Ent. M.I. D.Ent. Max.P Ent. M.I. D.Ent. CIFAR100 DNN 86.4 87.2 - - 82.6 84.3 - - MCDP 86.4 87.5 85.7 - 83.0 84.9 81.5 - DPN 95.6 95.7 95.7 95.8 95.1 95.1 95.1 95.5 SVHN DNN 90.1 90.8 - - 84.6 85.1 - - MCDP 89.6 90.6 83.7 - 84.1 84.8 73.1 - DPN 98.1 98.2 98.2 98.5 97.7 97.8 97.8 98.2 LSUN DNN 89.8 91.4 - - 87.0 90.0 - - MCDP 89.1 90.9 89.3 - 86.5 89.6 86.4 - DPN 94.4 94.4 94.4 94.6 93.3 93.4 93.4 93.3 TIM DNN 87.5 88.7 - - 84.7 87.2 - - MCDP 87.6 89.2 86.9 - 85.1 87.9 83.2 - DPN 94.3 94.3 94.3 94.6 94.0 94.0 94.0 94.2
Appendix C Derivations for Uncertainty Measures and KL divergence
This appendix provides the derivations and shows how calculate the uncertainty measures discussed in section 4 for a DNN/DPN and a Bayesian Monte-Carlo Ensemble. Additionally, it describes how to calculate the KL divergence between two Dirichlet distributions.
C.1 Entropy of Predictive Distribution for Bayesian MC Ensemble
Entropy of the predictive posterior can be calculated for a Bayesian MC Ensemble using the following derivation, which is taken from Yarin Gal’s PhD thesis [23].
C.2 Differential Entropy of Dirichlet Prior Network
The derivation of differential entropy simply quotes the standard result for Dirichlet distributions. Notably the are a function of and is the digamma function and is the Gamma function.
C.3 Mutual Information for Bayesian MC Ensemble
The Mutual information between class label and parameters can be calculated for a Bayesian MC Ensemble using the following derivation, which is also taken from Yarin Gal’s PhD thesis [23]:
C.4 Mutual Information for Dirichlet Prior Network
The mutual information between the labels y and the categorical for a DPN can be calculated as follows, using the fact that MI is the difference of the entropy of the expected distribution and the expected entropy of the distribution.
The second term in this derivation is a non-standard result. The expected entropy of the distribution can be calculated in the following way:
Here the expectation is calculated by noting that the standard result of the expectation of wrt a Dirichlet distribution can be used if the extra factor is accounted for by adding 1 to the associated concentration parameter and multiplying by in order to have the correct normalizing constant.
C.5 KL Divergence between two Dirichlet Distributions
The KL divergence between two Dirichlet distributions and can be obtained in closed form as follows: