Quantum Circuit Learning
Abstract
We propose a classical-quantum hybrid algorithm for machine learning on near-term quantum processors, which we call quantum circuit learning. A quantum circuit driven by our framework learns a given task by tuning parameters implemented on it. The iterative optimization of the parameters allows us to circumvent the high-depth circuit. Theoretical investigation shows that a quantum circuit can approximate nonlinear functions, which is further confirmed by numerical simulations. Hybridizing a low-depth quantum circuit and a classical computer for machine learning, the proposed framework paves the way toward applications of near-term quantum devices for quantum machine learning.
pacs:
Valid PACS appear hereI Introduction
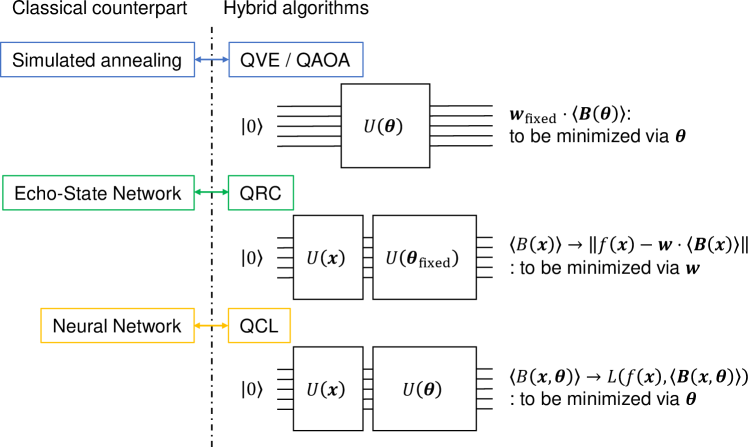
In recent years, machine learning has acquired much attention in a wide range of areas including the field of quantum physics Carleo and Troyer (2017); Rupp et al. (2012); Broecker et al. (2017); Ramakrishnan et al. (2015); August and Ni (2017). Since quantum information processing is expected to bring us exponential speedups on some problems Shor (1997); Nielsen and Chuang (2010), usual machine learning tasks might as well be improved when it is carried on a quantum computer. Also, for the purpose of learning a complex quantum system, it is natural to utilize a quantum system as our computational resource. A variety of machine learning algorithms for quantum computers has been proposed Kerenidis and Prakash ; Wiebe et al. (2012); Rebentrost et al. (2014); Cao et al. , since Harrow-Hassidim-Lloyd (HHL) algorithm Harrow et al. (2009) enabled us to perform basic matrix operations on a quantum computer. These HHL-based algorithms have the quantum phase estimation algorithm Nielsen and Chuang (2010) at its heart, which requires a high-depth quantum circuit. To circumvent a high-depth quantum circuit, which is still a long-term goal on the hardware side, classical-quantum hybrid algorithms consisting of a relatively low-depth quantum circuit such as quantum variational eigensolver Peruzzo et al. (2014); Kandala et al. (2017) (QVE) and quantum approximate optimization algorithm Farhi et al. ; Farhi and Harrow ; Otterbach et al. (2017) (QAOA) have been suggested. In these methods, a problem is encoded into a Hermitian matrix . Its expectation value with respect to an ansatz state is iteratively optimized by tuning the parameter . The central idea of hybrid algorithms is dividing the problem into two parts, each of which can be performed easily on a classical and a quantum computer.
In this paper, we present a new hybrid framework, which we call quantum circuit learning (QCL), for machine learning with a low-depth quantum circuit. In QCL, we provide input data to a quantum circuit, and iteratively tunes the circuit parameters so that it gives the desired output. Gradient-Based systematic optimization of parameters is introduced for the tuning just like backpropagation method Bishop (2006) utilized in feedforward neural networks. We theoretically show that a quantum circuit driven by the QCL framework can approximate any analytical function if the circuit has a sufficient number of qubits. The ability of the QCL framework to learn nonlinear functions and perform a simple classification task is demonstrated by numerical simulations. Also, we show by simulation that a 6-qubit circuit is capable of fitting dynamics of 3 spins out of a 10-spin system with fully connected Ising Hamiltonian. We stress here that the proposed framework is easily realizable on near-term devices.
II Quantum circuit learning
II.1 Algorithm
Our QCL framework aims to perform supervised or unsupervised learning tasks Bishop (2006). In supervised learning, an algorithm is provided with a set of input and corresponding teacher data . The algorithm learns to output that is close to the teacher , by tuning . The output and the teacher can be vector-valued. QCL assigns the calculation of the output to a quantum circuit and the update of the parameter to a classical computer. The objective of learning is to minimize a cost function, which is a measure of how close the teacher and the output is, by tuning . As an example, the quadratic cost is often used in regression problems. On the other hand, in unsupervised learning (e.g. clustering), only input data are provided, and some objective cost function that does not involve teacher is minimized.
Here we summarize the QCL algorithm on qubit circuit:
-
1.
Encode input data into some quantum state by applying a unitary input gate to initialized qubits
-
2.
Apply a -parameterized unitary to the input state and generate an output state .
-
3.
Measure the expectation values of some chosen observables. Specifically, we use a subset of Pauli operators . Using some output function , output is defined to be
-
4.
Minimize the cost function of the teacher and the output , by tuning the circuit parameters iteratively.
-
5.
Evaluate the performance by checking the cost function with respect to a data set that is taken independently from the training one.
II.2 Relation with existing algortihms
Minimization of the quadratic cost can be performed using a high-depth quantum circuit with HHL-based algorithms. For example, Ref. Schuld et al. (2016) shows a detailed procedure. This matrix inversion approach is similar to the quantum support vector machine Rebentrost et al. (2014). As opposed to this, QCL applied to a regression problem minimizes the cost by iterative optimization, successfully circumventing a high-depth circuit.
Quantum reservoir computing (QRC) Fujii and Nakajima (2017) shares a similar idea, in a sense that it passes the central optimization procedure to a classical computer. There, output is defined to be where is a set of observables taken from quantum many-body dynamics driven with a fixed Hamiltonian, and is the weight vector, which is tuned on a classical device to minimize a cost function. The idea stems from a so-called echo-state network approach Jaeger and Haas (2004). If one views QRC as a quantum version of the echo-state network, QCL, which tunes the whole network, can be regarded as a quantum counterpart of a basic neural network. In QVE/QAOA, the famous hybrid quantum algorithms, weighted sum of measured expectation values is minimized by tuning the parameter . There, an input of a problem, such as geometry of a molecule or topology of a graph, is encoded to the weight vector as . This procedure corresponds to a special case of QCL where we do not use the input unitary , and a cost function is utilized. Fig. 1 summarizes and shows the comparison of QVE/QAOA, QRC, and presented QCL framework.
II.3 Ability to approximate a function
First, we consider the case where input data are one dimension for simplicity. It is straightforward to generalize the following argument for higher dimensional inputs.
Let and be an input data and a corresponding density operator of input state. can be expanded by a set of Pauli operators with as coefficients, . A parameterized unitary transformation acting on creates the output state, which can also be expanded by with . Now let be such that . is an expectation value of a Pauli observable itself, therefore, the output is linear combination of input coefficient functions under unitarity constraints imposed on .
When the teacher is an analytical function, we can show, at least in principle, QCL is able to approximate it by considering a simple case with an input state created by single-qubit rotations. The tensor product structure of quantum system plays an important role in this analysis. Let us consider a state of qubits:
| (1) |
This state can be generated for any with single-qubit rotations, namely, where is the rotation of th qubit around axis with angle . The state given by Eq. (1) has higher order terms up to the th with respect to . Thus an arbitrary unitary transformation on this state can provide us with an arbitrary th order polynomial as expectation values of an observable. Terms like in Eq. (1) can enhance its ability to approximate a function.
Important notice in the example given above is that the highest order term is hidden in an observable . To extract from Eq. (1), one needs to transfer the nonlocal observable to a single-qubit observable using entangling gate such as the controlled-NOT gate. Entangling nonlocal operations are the key ingredients of the nonlinearity of an output.
The above argument can readily be generalized to multi-dimensional inputs. Assume that we are given with -dimensional data and want higher terms up to the th for each data, then encode this data into a -qubit quantum state as These input states automatically has an exponentially large number of independent functions as coefficient set to the number of qubits. The tensor product structure of quantum system readily “calculates” the product such as .
The unitarity condition of may have an effect to avoid an overfitting problem, which is crucial for their performance in machine learning or in regression methods. One way to handle it in classical machine learning methods is adding a regularization term to the cost function. For example, ridge regression adds regularization term to the quadratic cost function. Overall is minimized. The weight vector corresponds to the matrix element in QCL. The norm of a row vector , however, is restricted to unity by the unitarity condition, which prevents overfitting, from the unitarity of quantum dynamics. Simple examples of this are given in the Appendix.
II.4 Possible quantum advantages
We have shown by above discussions that approximation of any analytical functions is possible with the use of nonlinearity created by the tensor product. In fact, nonlinear basis functions are crucial for many methods utilized in classical machine learning. They require a large number of basis functions to create a complex model that predicts with high precision. However, the computational cost of learning increases with respect to the increasing number of basis functions. To avoid this problem, the so-called kernel trick method, which circumvents the direct use of a large number of them, is utilized Bishop (2006). In contrast, QCL directly utilizes the exponential number of functions with respect to the number of qubits to model the teacher, which is basically intractable on classical computers. This is a possible quantum advantage of our framework, which was not obvious from the previous approaches like QVE or QAOA.
Moreover, let us now argue about the potential power of QCL representing complex functions. Suppose we want to learn the output of QCL that is allowed to use an unlimited resource in the learning process, via classical neural networks. Then it has to learn the relation between inputs and outputs of a quantum circuit, which, in general, includes universal quantum cellular automata Raussendorf (2005); Janzing and Wocjan (2005). This certainly could not be achieved using a polynomial-size classical computational resource to the size (qubits and gates) of QCL. This implies that QCL has a potential power to represent more complex functions than the classical counterpart. Further investigations are needed including the learning costs and which actual learning problem enjoys such an advantage.
II.5 Optimization procedure
In QVE Peruzzo et al. (2014), it has been suggested to use gradient-free methods like Nelder-Mead. However, gradient-based methods are generally more preferred when the parameter space becomes large. In neural networks, backpropagation method Bishop (2006), which is basically gradient descent, is utilized in the learning procedure.
To calculate a gradient of an expectation value of an observable with respect to a circuit parameter , suppose the unitary consists of a chain of unitary transformations on a state and we measure an observable . For convenience, we use notation . Then is given as We assume is generated by a Pauli product , that is, . The gradient is calculated to be While we cannot evaluate the commutator directly, the following property of commutator for an arbitrary operator enables us to compute the gradient on a quantum circuit:
| (2) |
The gradient can be evaluated by
| (3) |
where . Just by inserting rotation generated by and measuring the respective expectation values , we can evaluate the exact gradient of an observable , via A similar method is used by Li et al. Li et al. (2017) in their research of control pulse optimization with target quantum system.
III Numerical simulations
We demonstrate the performance of QCL framework for several prototypical machine learning tasks by numerically simulating a quantum circuit in the form of Fig. 2 with and . in Fig. 2 is an arbitrary rotation of a single qubit. We use the decomposition . is Hamiltonian of a fully connected transverse Ising model:
| (4) |
The coefficients and are taken randomly from uniform distribution on . Evolution time is fixed to 10. The results shown throughout this section are generated by the Hamiltonian with the same coefficients. Here we note that we have checked a similar result can be achieved with different Hamiltonians. The dynamics under this form of Hamiltonian can generate a highly entangled state and is, in general for a large number of qubits, not efficiently simulatable on a classical computer. Eq. (4) is the basic form of interaction in trapped ions or superconducting qubits, which makes the time evolution easily implementable experimentally. is initialized with random numbers uniformly distributed on . In all numerical simulations, outputs are taken from expectation values. To emulate a sampling, we added small gaussian noise with standard deviation determined by , where and are the number of samples and a calculated expectation value, to . 111 The simulation is carried on using Python library QuTip Johansson et al. (2013). We use BFGS method Nocedal and Wright (2006) provided in SciPy optimization library for optimization of parameters.
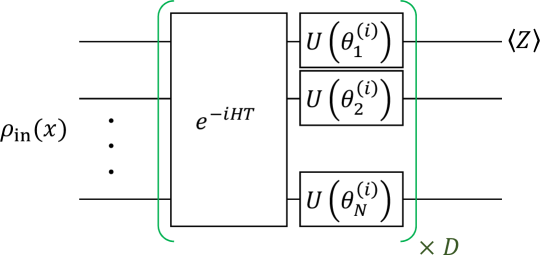
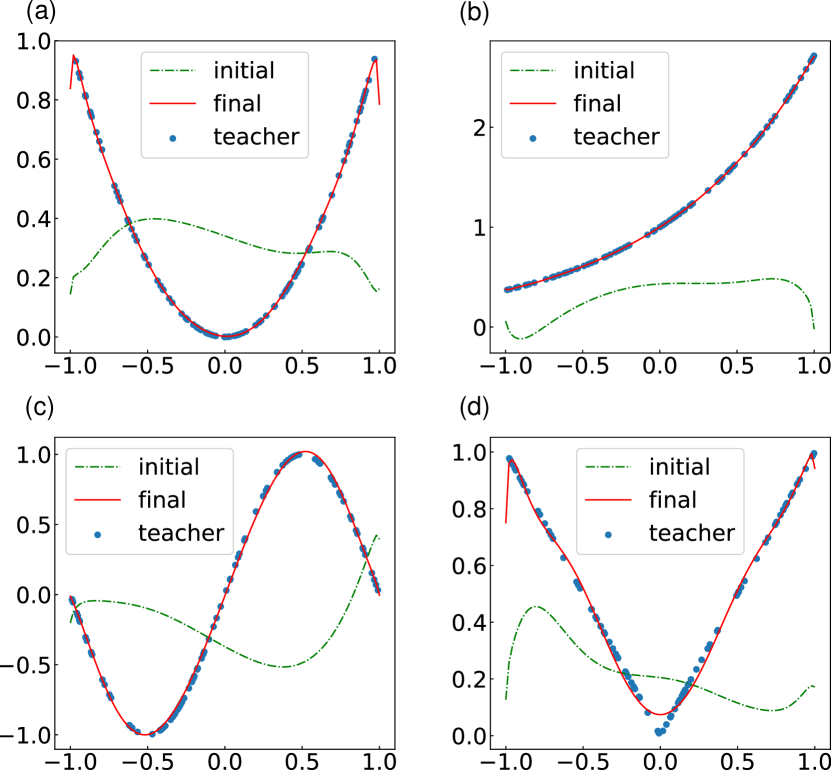
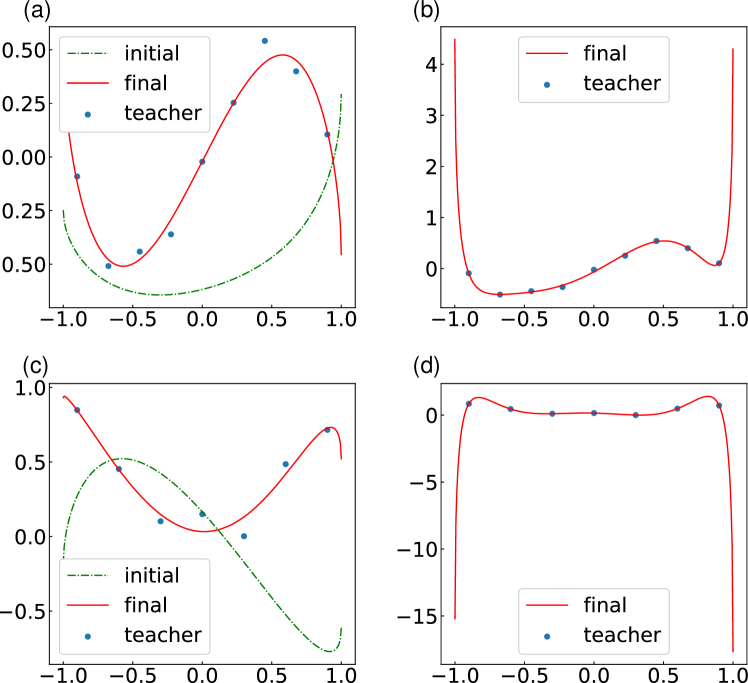
First, we perform fitting of as a demonstration of representability of nonlinear functions Bishop (2006). We use the normal quadratic loss for the cost function. The number of teacher samples is 100. The output is taken from expectation value of the first qubit as shown in Fig. 2. In this simulation, we allow output to be multiplied by a constant which is initialized to unity. This constant and are simultaneously optimized. Input state is prepared by applying to initialized qubits . This unitary creates a state similar to Eq. (1).
Results are shown in Fig. 3. All of the functions are well approximated by a quantum circuit driven by presented QCL framework. To approximate highly nonlinear functions such as or a nonanalytical function , QCL has brought out the high order terms which are initially hidden in nonlocal operators. The result of fitting (Fig. 3 (d)) is relatively poor because of its nonanalytical characteristics. A possible solution for this is to employ different functions as an input function, such as Legendre polynomials. Although the choice of input functions affects the performance of QCL, the result shows that QCL with simple input has an ability to output a wide variety of functions.
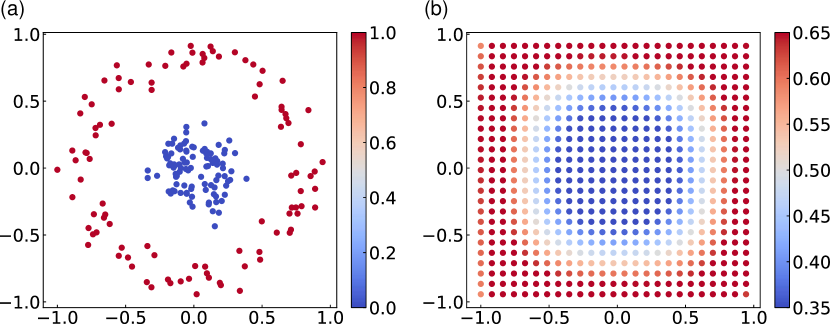
As a second demonstration, the classification problem, which is an important family of tasks in machine learning, is performed. Fig. 4 (a) shows the training data set, blue and red points indicate class 0 and 1 respectively. Here we train the quantum circuit to classify based on each training input data points . We define the teacher for each input to be two dimensional vector for class 0, and for class 1. The number of teacher samples is 200 (100 for class 0, and 100 for class 1). The output is taken from the expectation value of the Pauli operator of the first 2 qubits, and they are transformed by softmax function . For -dimensional vector , softmax function returns -dimensional vector with its th element being . Thus the output is defined by For the cost function, we use the cross-entropy . The input state is prepared by applying to initialized qubits . is the remainder of devided by 2. In this task, the multiplication constant is fixed to unity.
Learned output is shown in Fig. 4 (b). We see that QCL works as well for the nonlinear classification task. The same task can be classically performed using, for example, kernel-trick support vector machine. Kernel-trick approach discards the direct use of a large number of basis functions with respect to the number of qubits, as opposed to QCL approach, which utilizes an exponentially large number of basis functions under certain constraints. In this sense, QCL can benefit from the use of a quantum computer.
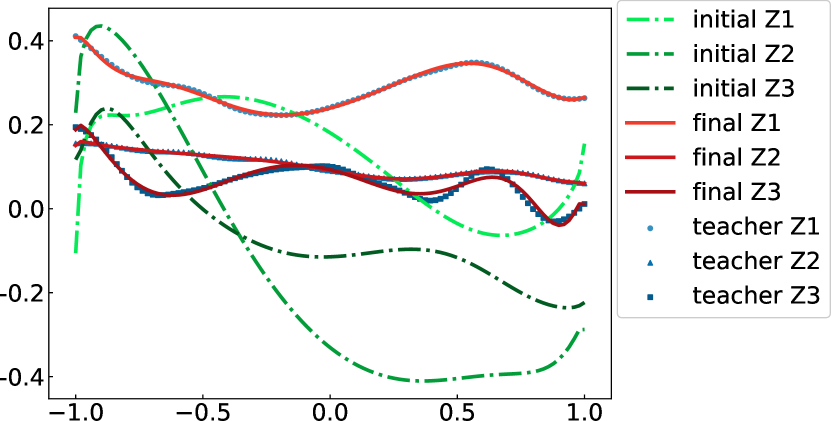
Finally, we demonstrate the ability of QCL to perform a fitting task of quantum many-body dynamics. Simulation of dynamics of the 10-spin system under the fully connected transverse Ising Hamiltonian Eq. (4) is performed in advance to generate teacher data. Coefficients and are taken from a uniform distribution on independently of the coefficients of Hamiltonian in the circuit. The dynamics started from the initialized state . The transient at the beginning of evolution is discarded for duration . For practical use, one can employ dynamics obtained experimentally from a quantum system with unknown Hamiltonian as teacher data. Learned dynamics is of expectation values of 3 spins during . This span of is mapped on uniformly by to be properly introduced to input gate. Output are taken from expectation values of the first, second, and third qubits of the circuit. The quadratic cost function is employed. The number of teacher samples is 100 for each. The multiplication constant is fixed to unity.
The result is shown in Fig. 5. It is notable that the 3 observables of a complex 10-spin system can be well fitted, simultaneously, using the 3 observables of a tuned 6-qubit circuit. Although the task performed here is not what is commonly referred to as quantum simulation, we believe that we provide an alternative way to learn a quantum many-body dynamics with a near-term quantum computer. It may also be possible to extract partial information of the system Hamiltonian by taking derivative of the output with respect to , which can readily be performed using the same method of calculating a gradient.
IV Conclusion
We have presented a machine learning framework on near-term realizable quantum computers. Our method fully employs the exponentially large space of the quantum system, in a way that it mixes simply injected nonlinear functions with a low-depth circuit to approximate a complex nonlinear function. Numerical results have shown the ability to represent a function, to classify, and to fit a relatively large quantum system. Also, the theoretical investigation has shown QCL’s ability to provide us a means to deal with high dimensional regression or classification tasks, which has been unpractical on classical computers. We have recently become aware of related works Cincio et al. ; Farhi and Neven ; Benedetti et al. ; Schuld and Killoran (2018); Huggins et al. (2018); Liu and Wang (2018); Schuld et al. (2018); Fanizza et al. (2018); Benedetti et al. (2018).
*
Appendix A Unitarity avoids overfitting
In this appendix, we demonstrate a simple example that supports our claim in the main text that states the unitarity of the transformation has an effect to avoid overfittings. We perform the one-dimensional fitting task with a small number of training data set to see the avoidance of the overfitting. To observe the unitarity effect, we fix the multiplication constant to unity. For simplicity, here we use a 3-qubit circuit in the same form of the main text, with and using as an input gate . In this case, the set of basis function that QCL utilizes is . Therefore for comparison, we run a simple classical linear regression program using the same basis function set.
Fig. 6 (a) and (b) show the result of the task to fit data points of , with Gaussian noise of standard deviation added, using QCL and classical regression, respectively. The result shows that, probably due to the unitarity of the transformation, QCL accepts some errors in the final output, as opposed to the classical one which does not accept any errors in the final output, that is, it overfits. As opposed to constraint on QCL, the classical algorithm in this case output a weight vector with . Fig. 6 (c) and (d) show the result of the task to fit data points of , with Gaussian noise of standard deviation added, using QCL and classical regression, respectively. Again, the same observation can be made. The weight vector obtained by the classical algorithm exhibits in this case.
References
- Carleo and Troyer (2017) G. Carleo and M. Troyer, Science 355, 602 (2017).
- Rupp et al. (2012) M. Rupp, A. Tkatchenko, K.-R. Müller, and O. A. von Lilienfeld, Phys. Rev. Lett. 108, 058301 (2012).
- Broecker et al. (2017) P. Broecker, J. Carrasquilla, R. G. Melko, and S. Trebst, Sci. Rep. 7, 8823 (2017).
- Ramakrishnan et al. (2015) R. Ramakrishnan, P. O. Dral, M. Rupp, and O. A. von Lilienfeld, J. Chem. Theory Comput. 11, 2087 (2015).
- August and Ni (2017) M. August and X. Ni, Phys. Rev. A 95, 012335 (2017).
- Shor (1997) P. W. Shor, SIAM J. Comput. 26, 1484 (1997).
- Nielsen and Chuang (2010) M. A. Nielsen and I. L. Chuang, Quantum Computation and Quantum Information (Cambridge University Press, Cambridge, 2010).
- (8) I. Kerenidis and A. Prakash, arXiv:1704.04992 .
- Wiebe et al. (2012) N. Wiebe, D. Braun, and S. Lloyd, Phys. Rev. Lett. 109, 050505 (2012).
- Rebentrost et al. (2014) P. Rebentrost, M. Mohseni, and S. Lloyd, Phys. Rev. Lett. 113, 130503 (2014).
- (11) Y. Cao, G. G. Guerreschi, and A. Aspuru-Guzik, arXiv:1711.11240 .
- Harrow et al. (2009) A. W. Harrow, A. Hassidim, and S. Lloyd, Phys. Rev. Lett. 103, 150502 (2009).
- Peruzzo et al. (2014) A. Peruzzo, J. McClean, P. Shadbolt, M. Yung, X. Zhou, P. J. Love, A. Aspuru-Guzik, and J. L. O’Brien, Nat. Commun. 5 (2014).
- Kandala et al. (2017) A. Kandala, A. Mezzacapo, K. Temme, M. Takita, M. Brink, J. M. Chow, and J. M. Gambetta, Nature 549, 242 (2017).
- (15) E. Farhi, J. Goldstone, and S. Gutmann, arXiv:1411.4028 .
- (16) E. Farhi and A. W. Harrow, arXiv:1602.07674 .
- Otterbach et al. (2017) J. S. Otterbach, R. Manenti, N. Alidoust, A. Bestwick, M. Block, B. Bloom, S. Caldwell, N. Didier, E. S. Fried, S. Hong, P. Karalekas, C. B. Osborn, A. Papageorge, E. C. Peterson, G. Prawiroatmodjo, N. Rubin, C. A. Ryan, D. Scarabelli, M. Scheer, E. A. Sete, P. Sivarajah, R. S. Smith, A. Staley, N. Tezak, W. J. Zeng, A. Hudson, B. R. Johnson, M. Reagor, M. P. da Silva, and C. Rigetti, (2017), arXiv:1712.05771 .
- Bishop (2006) C. M. Bishop, Pattern Recognition and Machine Learning (Spriger, New York, 2006).
- Schuld et al. (2016) M. Schuld, I. Sinayskiy, and F. Petruccione, Phys. Rev. A 94, 022342 (2016).
- Fujii and Nakajima (2017) K. Fujii and K. Nakajima, Phys. Rev. Appl. 8, 024030 (2017).
- Jaeger and Haas (2004) H. Jaeger and H. Haas, Science 304, 78 (2004).
- Raussendorf (2005) R. Raussendorf, Phys. Rev. A 72, 022301 (2005), 0412048v1 .
- Janzing and Wocjan (2005) D. Janzing and P. Wocjan, Quantum Inf. Process. 4, 129 (2005).
- Li et al. (2017) J. Li, X. Yang, X. Peng, and C. Sun, Phys. Rev. Lett. 118, 150503 (2017).
- Note (1) The simulation is carried on using Python library QuTip Johansson et al. (2013). We use BFGS method Nocedal and Wright (2006) provided in SciPy optimization library for optimization of parameters.
- (26) L. Cincio, Y. Subasi, A. T. Sornborger, and P. J. Coles, arXiv:1803.04114 .
- (27) E. Farhi and H. Neven, arXiv:1802.06002 .
- (28) M. Benedetti, D. Garcia-Pintos, Y. Nam, and A. Perdomo-Ortiz, arXiv:1801.07686 .
- Schuld and Killoran (2018) M. Schuld and N. Killoran, (2018), arXiv:1803.07128 .
- Huggins et al. (2018) W. Huggins, P. Patel, K. B. Whaley, and E. M. Stoudenmire, (2018), arXiv:1803.11537 .
- Liu and Wang (2018) J.-G. Liu and L. Wang, (2018), arXiv:1804.04168 .
- Schuld et al. (2018) M. Schuld, A. Bocharov, K. Svore, and N. Wiebe, (2018), arXiv:1804.00633 .
- Fanizza et al. (2018) M. Fanizza, A. Mari, and V. Giovannetti, (2018), arXiv:1805.03477 .
- Benedetti et al. (2018) M. Benedetti, E. Grant, L. Wossnig, and S. Severini, (2018), arXiv:1806.00463 .
- Johansson et al. (2013) J. Johansson, P. Nation, and F. Nori, Comput. Phys. Commun. 184, 1234 (2013).
- Nocedal and Wright (2006) J. Nocedal and S. Wright, Numerical Optimization (Springer, New York, 2006).