Revisiting Graph Neural Networks:
All We Have is Low-Pass Filters
Abstract
Graph neural networks have become one of the most important techniques to solve machine learning problems on graph-structured data. Recent work on vertex classification proposed deep and distributed learning models to achieve high performance and scalability. However, we find that the feature vectors of benchmark datasets are already quite informative for the classification task, and the graph structure only provides a means to denoise the data. In this paper, we develop a theoretical framework based on graph signal processing for analyzing graph neural networks. Our results indicate that graph neural networks only perform low-pass filtering on feature vectors and do not have the non-linear manifold learning property. We further investigate their resilience to feature noise and propose some insights on GCN-based graph neural network design.
1 Introduction
Graph neural networks (GNN) belong to a class of neural networks which can learn from graph-structured data. Recently, graph neural networks for vertex classification and graph isomorphism test have achieved excellent results on several benchmark datasets and continuously set new state-of-the-art performance Abu-El-Haija et al. (2019); Kipf and Welling (2017); Veličković et al. (2017); Xu et al. (2019). Started with the early success of ChebNet Defferrard et al. (2016) and GCN Kipf and Welling (2017) at vertex classification, many variants of GNN have been proposed to solve problems in social networks Hamilton et al. (2017); Zhang et al. (2018a), biology Veličković et al. (2017, 2019), chemistry Fout et al. (2017); Gilmer et al. (2017), natural language processing Bastings et al. (2017); Zhang et al. (2018b), computer vision Santoro et al. (2017), and weakly-supervised learning Garcia and Bruna (2017).
In semi-supervised vertex classification, we observe that the parameters of a graph convolutional layer in a Graph Convolutional Network (GCN) Kipf and Welling (2017) only contribute to overfitting. Similar observations have been reported in both simple architectures such as SGC Wu et al. (2019) and more complex ones such as DGI Veličković et al. (2019). Based on this phenomenon, Wu et al. (2019) proposed to view graph neural networks simply as feature propagation and propose an extremely efficient model with state-of-the-art performance on many benchmark datasets. Kawamoto et al. (2018) made a related theoretical remark on untrained GCN-like GNNs under graph partitioning settings. From these previous studies, a question naturally arises: Why and when do graph neural networks work well for vertex classification? In other words, is there a condition on the vertex feature vectors for graph neural network models to work well even without training? Consequently, can we find realistic counterexamples in which baseline graph neural networks (e.g. SGC or GCN) fail to perform?
In this study, we provide an answer to the aforementioned questions from the graph signal processing perspective Ortega et al. (2018). Formally, we consider a semi-supervised learning problem on a graph. Given a graph , each vertex has a feature and label , where is a -dimensional Euclidean space and for regression and for classification. The task is to learn a hypothesis to predict the label from the feature . We then characterize the graph neural networks solution to this problem and provide insights to the mechanism underlying the most commonly used baseline model GCN Kipf and Welling (2017), and its simplified variant SGC Wu et al. (2019).
![[Uncaptioned image]](x2.png) Figure 2: A simple realization of gfNN
Figure 2: A simple realization of gfNN
Graph signal processing (GSP) regards data on the vertices as signals and applies signal processing techniques to understand the signal characteristics. By combining signals (feature vectors) and graph structure (adjacency matrix or its transformations), GSP has inspired the development of learning algorithms on graph-structured data Shuman et al. (2012). In a standard signal processing problem, it is common to assume the observations contain some noise and the underlying “true signal” has low-frequency Rabiner and Gold (1975). Here, we pose a similar assumption for our problem.
Assumption 1.
Input features consist of low-frequency true features and noise. The true features have sufficient information for the machine learning task.
Our first contribution is to verify Assumption 1 on commonly used datasets (Section 3). Figure 1 shows the performance of 2-layers perceptrons (MLPs) trained on features with different numbers of frequency components. In all benchmark datasets, we see that only a small number of frequency components contribute to learning. Adding more frequency components to the feature vectors only decreases the performance. In turn, the classification accuracy becomes even worse when we add Gaussian noise to the features.
Many recent GNNs were built upon results from graph signal processing. The most common practice is to multiply the (augmented) normalized adjacency matrix with the feature matrix . The product is understood as features averaging and propagation Hamilton et al. (2017); Kipf and Welling (2017); Wu et al. (2019). In graph signal processing literature, such operation filters signals on the graph without explicitly performing eigendecomposition on the normalized Laplacian matrix, which requires time Vaseghi (2008). Here, we refer to this augmented normalized adjacency matrix and its variants as graph filters and propagation matrices interchangeably.
Our second contribution shows that multiplying graph signals with propagation matrices corresponds to low-pass filtering (Section 4, esp., Theorem 3). Furthermore, we also show that the matrix product between the observed signal and the low-pass filters is the analytical solution to the true signal optimization problem. In contrast to the recent design principle of graph neural networks Abu-El-Haija et al. (2019); Kipf and Welling (2017); Xu et al. (2019), our results suggest that the graph convolution layer is simply low-pass filtering. Therefore, learning the parameters of a graph convolution layer is unnecessary. Wu et al. (2019, Theorem 1) also addressed a similar claim by analyzing the spectrum-truncating effect of the augmented normalized adjacency matrix. We extend this result to show that all eigenvalues monotonically shrink, which further explains the implications of the spectrum-truncating effect.
Based on our theoretical understanding, we propose a new baseline framework named gfNN (graph filter neural network) to empirically analyze the vertex classification problem. gfNN consists of two steps: 1. Filter features by multiplication with graph filter matrices; 2. Learn the vertex labels by a machine learning model. We demonstrate the effectiveness of our framework using a simple realization model in Figure 2.
Our third contribution is the following Theorem:
Theorem 2 (Informal, see Theorem 7, 8).
Under Assumption 1, the outcomes of SGC, GCN, and gfNN are similar to those of the corresponding NNs using true features.
Theorem 7 implies that, under Assumption 1, both gfNN and GCN Kipf and Welling (2017) have similar high performance. Since gfNN does not require multiplications of the adjacency matrix during the learning phase, it is much faster than GCN. In addition, gfNN is also more noise tolerant.
Finally, we compare our gfNN to the SGC model Wu et al. (2019). While SGC is also computationally fast and accurate on benchmark datasets, our analysis implies it would fail when the feature input is nonlinearly-separable because the graph convolution part does not contribute to non-linear manifold learning. We created an artificial dataset to empirically demonstrate this claim.
2 Graph Signal Processing
In this section, we introduce the basic concepts of graph signal processing. We adopt a recent formulation Girault et al. (2018) of graph Fourier transform on irregular graphs.
Let be a simple undirected graph, where be the set of vertices and be the set of edges.111We only consider unweighted edges but it is easily adopted to positively weighted edges. Let be the adjacency matrix of , be the degree matrix of , where is the degree of vertex . be the combinatorial Laplacian of , be the normalized Laplacian of , where is the identity matrix, and be the random walk Laplacian of . Also, for with , let be the augmented adjacency matrix, which is obtained by adding self loops to , be the corresponding augmented degree matrix, and , , be the corresponding augmented combinatorial, normalized, and random walk Laplacian matrices.
A vector defined on the vertices of the graph is called a graph signal. To introduce a graph Fourier transform, we need to define two operations, variation and inner product, on the space of graph signals. Here, we define the variation and the -inner product by
| (1) |
We denote by the norm induced by . Intuitively, the variation and the inner product specify how to measure the smoothness and importance of the signal, respectively. In particular, our inner product puts more importance on high-degree vertices, where larger closes the importance more uniformly. We then consider the generalized eigenvalue problem (variational form): Find such that for each , is a solution to the following optimization problem:
| (2) |
The solution is called an -th generalized eigenvector and the corresponding objective value is called the -th generalized eigenvalue. The generalized eigenvalues and eigenvectors are also the solutions to the following generalized eigenvalue problem (equation form):
| (3) |
Thus, if is a generalized eigenpair then is an eigenpair of . A generalized eigenvector with a smaller generalized eigenvalue is smoother in terms of the variation . Hence, the generalized eigenvalues are referred to as the frequency of the graph.
The graph Fourier transform is a basis expansion by the generalized eigenvectors. Let be the matrix whose columns are the generalized eigenvectors. Then, the graph Fourier transform is defined by , and the inverse graph Fourier transform is defined by . Note that these are actually the inverse transforms since .
The Parseval identity relates the norms of the data and its Fourier transform:
| (4) |
Let be an analytic function. The graph filter specified by is a mapping defined by the relation in the frequency domain: . In the spatial domain, the above equation is equivalent to . where is defined via the Taylor expansion of ; see Higham (2008) for the detail of matrix functions.
In a machine learning problem on a graph, each vertex has a -dimensional feature . We regard the features as graph signals and define the graph Fourier transform of the features by the graph Fourier transform of each signal. Let be the feature matrix. Then, the graph Fourier transform is represented by and the inverse transform is . We denote as the frequency components of .
3 Empirical Evidence of Assumption 1
The results of this paper deeply depend on Assumption 1. Thus, we first verify this assumption in real-world datasets: Cora, Citeseer, and Pubmed Sen et al. (2008). These are citation networks, in which vertices are scientific papers and edges are citations. We consider the following experimental setting: 1. Compute the graph Fourier basis from ; 2. Add Gaussian noise to the input features: for ; 3. Compute the first -frequency component: ; 4. Reconstruct the features: ; 5. Train and report test accuracy of a 2-layers perceptron on the reconstructed features .
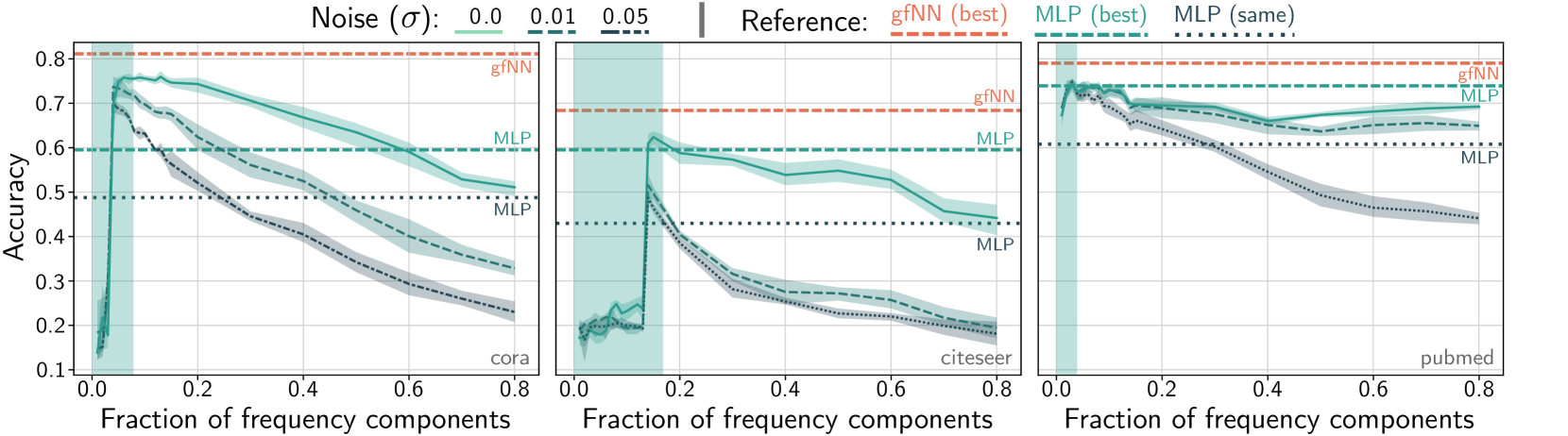
In Figure 3, we incrementally add normalized Laplacian frequency components to reconstruct feature vectors and train a 2-layers MLPs. We see that all three datasets exhibit a low-frequency nature. The classification accuracy of a 2-layers MLP tends to peak within the top 20% of the spectrum (green boxes). By adding artificial Gaussian noise, we observe that the performance at low-frequency regions is relatively robust, which implies a strong denoising effect.
Interestingly, the performance gap between graph neural network and a simple MLP is much larger when high-frequency components do not contain useful information for classification. In the Cora dataset, high-frequency components only decrease classification accuracy. Therefore, our gfNN outperformed a simple MLP. Citeseer and Pubmed have a similar low-frequency nature. However, the performance gaps here are not as large. Since the noise-added performance lines for Citeseer and Pubmed generally behave like the original Cora performance line, we expect the original Citeseer and Pubmed contain much less noise compared with Cora. Therefore, we could expect the graph filter degree would have little effect in Citeseer and Pubmed cases.
4 Multiplying Adjacency Matrix is Low Pass Filtering
Computing the low-frequency components is expensive since it requires time to compute the eigenvalue decomposition of the Laplacian matrix. Thus, a reasonable alternative is to use a low-pass filter. Many papers on graph neural networks iteratively multiply the (augmented) adjacency matrix (or ) to propagate information. In this section, we see that this operation corresponds to a low-pass filter.
Multiplying the normalized adjacency matrix corresponds to applying graph filter . Since the eigenvalues of the normalized Laplacian lie on the interval , this operation resembles a band-stop filter that removes intermediate frequency components. However, since the maximum eigenvalue of the normalized Laplacian is if and only if the graph contains a non-trivial bipartite graph as a connected component (Chung, 1997, Lemma 1.7). Therefore, for other graphs, multiplying the normalized (non-augmented) adjacency matrix acts as a low-pass filter (i.e., high-frequency components must decrease).
We can increase the low-pass filtering effect by adding self-loops (i.e., considering the augmented adjacency matrix) since it shrinks the eigenvalues toward zero as follows.222The shrinking of the maximum eigenvalue has already been proved in (Wu et al., 2019, Theorem 1). Our theorem is stronger than theirs since we show the “monotone shrinking” of “all” the eigenvalues. In addition, our proof is simpler and shorter.
Theorem 3.
Let be the -th smallest generalized eigenvalue of . Then, is a non-negative number, and monotonically non-increasing in . Moreover, is strictly monotonically decreasing if .
Note that cannot be too large. Otherwise, all the eigenvalues would be concentrated around zero, i.e., all the data would be regarded as “low-frequency”; hence, we cannot extract useful information from the low-frequency components.
The graph filter can also be derived from a first-order approximation of a Laplacian regularized least squares Belkin and Niyogi (2004). Let us consider the problem of estimating a low-frequency true feature from the observation . Then, a natural optimization problem is given by
| (5) |
where . Note that, since , it is a maximum a posteriori estimation with the prior distribution of . The optimal solution to this problem is given by . The corresponding filter is , and hence is its first-order Taylor approximation.
5 Bias-Variance Trade-off for Low Pass Filters
In the rest of this paper, we establish theoretical results under Assumption 1. To be concrete, we pose a more precise assumption as follows.
Assumption 4 (Precise Version of the First Part of Assumption 1).
Observed features consists of true features and noise . The true features have frequency at most and the noise follows a white Gaussian noise, i.e., each entry of the graph Fourier transform of independently identically follows a normal distribution .
Using this assumption, we can evaluate the effect of the low-pass filter as follows.
Lemma 5.
Suppose Assumption 4. For any , with probability at least , we have
| (6) |
where is a probability that a random walk with a random initial vertex returns to the initial vertex after steps.
The first and second terms of the right-hand side of (6) are the bias term incurred by applying the filter and the variance term incurred from the filtered noise, respectively. Under the assumption, the bias increases a little, say, . The variance term decreases in where is a typical degree of the graph since typically behaves like for small .333This exactly holds for a class of locally tree-like graphs Dembo et al. (2013), which includes Erdos–Renyi random graphs and the configuration models. Therefore, we can obtain a more accurate estimation of the true data from the noisy observation by multiplying the adjacency matrix if the maximum frequency of is much smaller than the noise-to-signal ratio .
This theorem also suggest a choice of . By minimizing the right-hand side by , we obtain:
Corollary 6.
Suppose that for some . Let be defined by , and suppose that there exist constants and such that for . Then, by choosing , the right-hand side of (6) is .444 suppresses logarithmic dependencies. ∎
This concludes that we can obtain an estimation of the true features with accuracy by multiplying several times.
6 Graph Filter Neural Network
In the previous section, we see that low-pass filtered features are accurate estimations of the true features with high probability. In this section, we analyze the performance of this operation.
Let the multi-layer (two-layer) perceptron be
| (7) |
where is the entry-wise ReLU function, and is the softmax function. Note that both and are contraction maps, i.e., .
Under the second part of Assumption 1, our goal is to obtain a result similar to . The simplest approach is to train a multi-layer perceptron with the observed feature. The performance of this approach is evaluated by
| (8) |
where is the maximum singular value of .
Now, we consider applying graph a filter to the features, then learning with a multi-layer perceptron, i.e., . Using Lemma 5, we obtain the following result.
Theorem 7.
This means that if the maximum frequency of the true data is small, we obtain a solution similar to the optimal one.
Comparison with GCN
Under the same assumption, we can analyze the performance of a two-layers GCN. The GCN is given by
| (10) |
Theorem 8.
Under the same assumption to Theorem 7, we have
| (11) |
This theorem means that GCN also has a performance similar to MLP for true features. Hence, in the limit of and , all MLP, GCN, and the gfNN have the same performance.
In practice, gfNN has two advantages over GCN. First, gfNN is faster than GCN since it does not use the graph during the training. Second, GCN has a risk of overfitting to the noise. When the noise is so large that it cannot be reduced by the first-order low-pass filter, , the inner weight is trained using noisy features, which would overfit to the noise. We verify this in Section 7.2.
Comparison with SGC
Recall that a degree-2 SGC is given by
| (12) |
i.e., it is a gfNN with a one-layer perceptron. Thus, by the same discussion, SGC has a performance similar to the perceptron (instead of the MLP) applied to the true feature. This clarifies an issue of SGC: if the true features are non-separable, SGC cannot solve the problem. We verify this issue in experiment E2 (Section 7.3).
7 Experiments
To verify our claims in previous sections, we design two experiments. In experiment E1, we add different levels of white noise to the feature vectors of real-world datasets and report the classification accuracy among baseline models. Experiment E2 studies an artificial dataset which has a complex feature space to demonstrate when simple models like SGC fail to classify.
There are two types of datasets: Real-worlds data (citation networks, social networks, and biological networks) commonly used for graph neural network benchmarking Sen et al. (2008); Yang et al. (2016); Zitnik and Leskovec (2017) and artificially synthesized random graphs from the two circles dataset. We created the graph structure for the two circles dataset by making each data point into a vertex and connect the 5 closest vertices in Euclidean distance. Table 1 gives an overview of each dataset.
| Dataset | Nodes | Edges | Features | Classes | Train/Val/Test Nodes |
|---|---|---|---|---|---|
| Cora | 2,708 | 5,278 | 1,433 | 7 | 140/500/1,000 |
| Citeseer | 3,327 | 4,732 | 3,703 | 6 | 120/500/1,000 |
| Pubmed | 19,717 | 44,338 | 500 | 3 | 60/500/1,000 |
| 231,443 | 11,606,919 | 602 | 41 | 151,708/23,699/55,334 | |
| PPI | 56,944 | 818,716 | 50 | 121 | 44,906/6,514/5,524 |
| Two Circles | 4,000 | 10,000 | 2 | 2 | 80/80/3,840 |
7.1 Neural Networks
We compare our results with a few state-of-the-art graph neural networks on benchmark datasets. We train each model using Adam optimizer Kingma and Ba (2015) (lr=0.2, epochs=50). We use 32 hidden units for the hidden layer of GCN, MLP, and gfNN. Other hyperparameters are set similar to SGC Wu et al. (2019).
gfNN We have three graph filters for our simple model: Left Norm (), Augumented Normalized Adjacency (), and Bilateral ().
SGC Wu et al. (2019) Simple Graph Convolution () simplifies the Graph Convolutional Neural Network model by removing nonlinearity in the neural network and only averaging features.
GCN Kipf and Welling (2017) Graph Convolutional Neural Network (✖) is the most commonly used baseline.
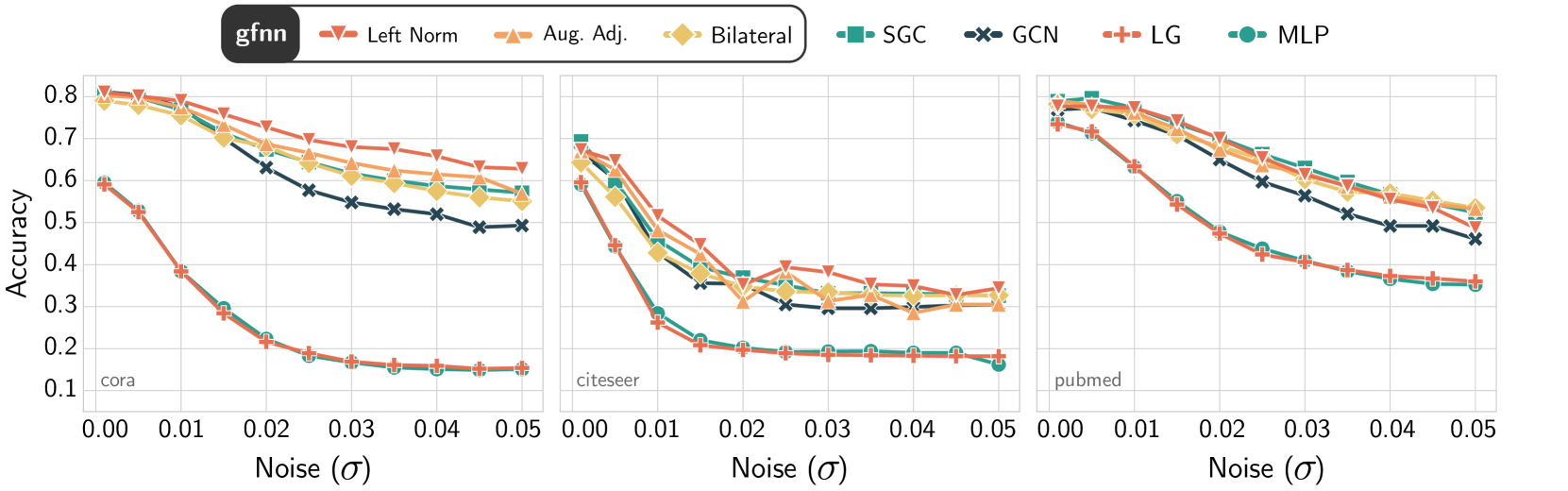
7.2 Denoising Effect of Graph Filters
For each dataset in Table 1, we introduce a white noise into the feature vectors with in range . According to the implications of Theorem 8 and Theorem 7, GCN should exhibit a low tolerance to feature noise due to its first-order denoising nature. As the noise level increases, we see in Figure 4 that GCN, Logistic Regression (LR), and MLP tend to overfit more to noise. On the other hand, gfNN and SGC remain comparably noise tolerant.
7.3 Expressiveness of Graph Filters
Since graph convolution is simply denoising, we expect it to have little contribution to non-linearity learning. Therefore, we implement a simple 2-D two circles dataset to see whether graph filtering can have the non-linear manifold learning effect. Based on the Euclidean distance between data points, we construct a -nn graph to use as the underlying graph structure. In this particular experiment, we have each data point connected to the 5 closest neighbors. Figure 5 demonstrates how SGC is unable to classify a simple 500-data-points set visually.
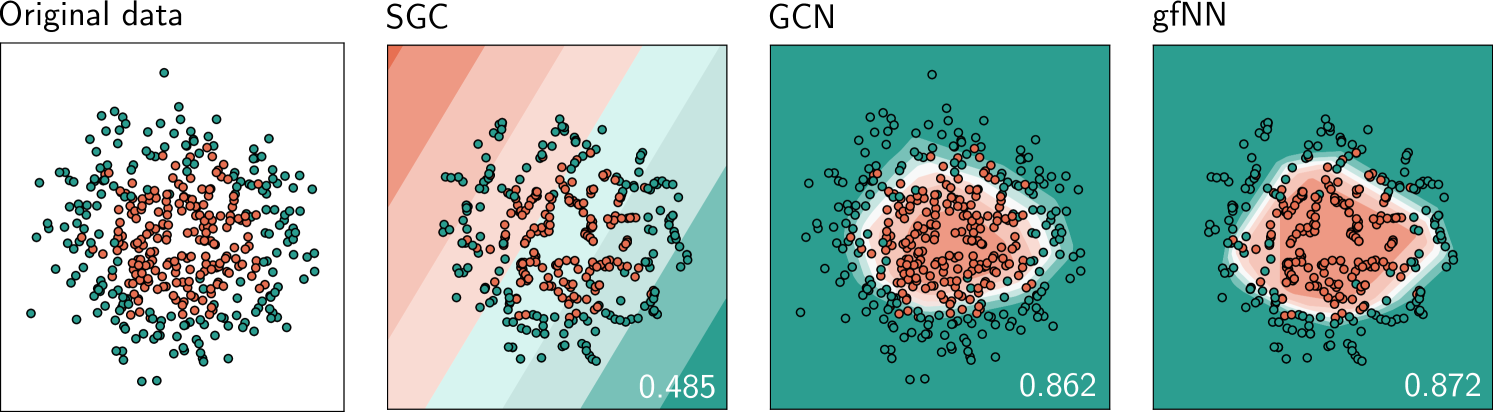
On the other hand, SGC, GCN, and our model gfNN perform comparably on most benchmark graph datasets. Table 2 compares the accuracy (f1-micro for Reddit) of randomized train/test sets. We see that all these graph neural networks have similar performance (some minor improvement might subject to hyperparameters tuning). Therefore, we believe current benchmark datasets for graph neural network have quite “simple” feature spaces.
In practice, both of our analysis and experimental results suggest that the graph convolutional layer should be thought of simply as a denoising filter. In contrast to the recent design trend involving GCN Abu-El-Haija et al. (2019); Valsesia et al. (2019) , our results imply that simply stacking GCN layers might only make the model more prone to feature noise while having the same expressiveness as a simple MLP.
| Denoise | Classifier | Cora | Citeseer | Pubmed | PPI | Two Circles | ||
|---|---|---|---|---|---|---|---|---|
| GCN | 1st order | Non-linear | OOM | OOM | ||||
| SGC | 2nd order | Linear | ||||||
| gfNN | 2nd order | Non-linear |
8 Discussion
There has been little work addressed the limits of the GCN architecture. Kawamoto et al. (2018) took the mean-field approach to analyze a simple GCN model to statistical physics. They concluded that backpropagation improves neither accuracy nor detectability of a GCN-based GNN model. Li et al. (2018) empirically analyzed GCN models with many layers under the limited labeled data setting and stated that GCN would not do well with little labeled data or too many stacked layers. While these results have provided an insightful view for GCN, they have not insufficiently answered the question: When we should we use GNN?.
Our results indicate that we should use the GNN approach to solve a given problem if Assumption 1 holds. From our perspective, GNNs derived from GCN simply perform noise filtering and learn from denoised data. Based on our analysis, we propose two cases where GCN and SGC might fail to perform: noisy features and nonlinear feature spaces. In turn, we propose a simple approach that works well in both cases.
Recently GCN-based GNNs have been applied in many important applications such as point-cloud analysis Valsesia et al. (2019) or weakly-supervised learning Garcia and Bruna (2017). As the input feature space becomes complex, we advocate revisiting the current GCN-based GNNs design. Instead of viewing a GCN layer as the convolutional layer in computer vision, we need to view it simply as a denoising mechanism. Hence, simply stacking GCN layers only introduces overfitting and complexity to the neural network design.
References
- Abu-El-Haija et al. [2019] Sami Abu-El-Haija, Bryan Perozzi, Amol Kapoor, Hrayr Harutyunyan, Nazanin Alipourfard, Kristina Lerman, Greg Ver Steeg, and Aram Galstyan. Mixhop: Higher-order graph convolution architectures via sparsified neighborhood mixing. In Proceedings of the 36th International Conference on International Conference on Machine Learning, volume 97. JMLR, 2019.
- Bastings et al. [2017] Joost Bastings, Ivan Titov, Wilker Aziz, Diego Marcheggiani, and Khalil Sima’an. Graph convolutional encoders for syntax-aware neural machine translation. Empirical Methods in Natural Language Processing, 2017.
- Belkin and Niyogi [2004] Mikhail Belkin and Partha Niyogi. Semi-supervised learning on riemannian manifolds. Machine Learning, 56(1-3):209–239, 2004.
- Bhatia [2013] Rajendra Bhatia. Matrix analysis, volume 169. Springer Science & Business Media, 2013.
- Chung [1997] Fan R.K. Chung. Spectral graph theory. American Mathematical Society, 1997.
- Defferrard et al. [2016] Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. In Advances in neural information processing systems, pages 3844–3852, 2016.
- Dembo et al. [2013] Amir Dembo, Andrea Montanari, and Nike Sun. Factor models on locally tree-like graphs. The Annals of Probability, 41(6):4162–4213, 2013.
- Fout et al. [2017] Alex Fout, Jonathon Byrd, Basir Shariat, and Asa Ben-Hur. Protein interface prediction using graph convolutional networks. In Advances in Neural Information Processing Systems, pages 6530–6539, 2017.
- Garcia and Bruna [2017] Victor Garcia and Joan Bruna. Few-shot learning with graph neural networks. International Conference on Learning Representations, 2017.
- Gilmer et al. [2017] Justin Gilmer, Samuel S. Schoenholz, Patrick F. Riley, Oriol Vinyals, and George E. Dahl. Neural message passing for quantum chemistry. In Proceedings of the 34th International Conference on Machine Learning, volume 70, pages 1263–1272. JMLR, 2017.
- Girault et al. [2018] Benjamin Girault, Antonio Ortega, and Shrikanth S. Narayanan. Irregularity-aware graph fourier transforms. IEEE Transactions on Signal Processing, 66(21):5746–5761, 2018.
- Hamilton et al. [2017] Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems, pages 1024–1034, 2017.
- Higham [2008] Nicholas J. Higham. Functions of matrices: theory and computation, volume 104. SIAM, 2008.
- Kawamoto et al. [2018] Tatsuro Kawamoto, Masashi Tsubaki, and Tomoyuki Obuchi. Mean-field theory of graph neural networks in graph partitioning. In Advances in Neural Information Processing Systems, pages 4361–4371, 2018.
- Kingma and Ba [2015] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. International Conference on Learning Representations, 2015.
- Kipf and Welling [2017] Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations, 2017.
- Laurent and Massart [2000] Beatrice Laurent and Pascal Massart. Adaptive estimation of a quadratic functional by model selection. Annals of Statistics, pages 1302–1338, 2000.
- Li et al. [2018] Qimai Li, Zhichao Han, and Xiao-Ming Wu. Deeper insights into graph convolutional networks for semi-supervised learning. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
- Ortega et al. [2018] Antonio Ortega, Pascal Frossard, Jelena Kovačević, José MF Moura, and Pierre Vandergheynst. Graph signal processing: Overview, challenges, and applications. Proceedings of the IEEE, 106(5):808–828, 2018.
- Rabiner and Gold [1975] Lawrence R. Rabiner and Bernard Gold. Theory and application of digital signal processing. Englewood Cliffs, NJ, Prentice-Hall, Inc., 1975.
- Santoro et al. [2017] Adam Santoro, David Raposo, David G. Barrett, Mateusz Malinowski, Razvan Pascanu, Peter Battaglia, and Timothy Lillicrap. A simple neural network module for relational reasoning. In Advances in Neural Information Processing Systems, pages 4967–4976, 2017.
- Sen et al. [2008] Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. Collective classification in network data. AI magazine, 29(3):93–93, 2008.
- Shuman et al. [2012] David I. Shuman, Sunil K. Narang, Pascal Frossard, Antonio Ortega, and Pierre Vandergheynst. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains. arXiv preprint arXiv:1211.0053, 2012.
- Valsesia et al. [2019] Diego Valsesia, Giulia Fracastoro, and Enrico Magli. Learning localized generative models for 3d point clouds via graph convolution. International Conference on Learning Representations, 2019.
- Vaseghi [2008] Saeed V. Vaseghi. Advanced digital signal processing and noise reduction. John Wiley & Sons, 2008.
- Veličković et al. [2017] Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks. International Conference on Learning Representations, 2017.
- Veličković et al. [2019] Petar Veličković, William Fedus, William L. Hamilton, Pietro Liò, Yoshua Bengio, and R. Devon Hjelm. Deep graph infomax. International Conference on Learning Representations, 2019.
- Wu et al. [2019] Felix Wu, Tianyi Zhang, Amauri Holanda de Souza Jr., Christopher Fifty, Tao Yu, and Kilian Q. Weinberger. Simplifying graph convolutional networks. In Proceedings of the 36th International Conference on International Conference on Machine Learning, volume 97. JMLR, 2019.
- Xu et al. [2019] Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? International Conference on Learning Representations, 2019.
- Yang et al. [2016] Zhilin Yang, William W Cohen, and Ruslan Salakhutdinov. Revisiting semi-supervised learning with graph embeddings. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, volume 48. JMLR, 2016.
- Zhang et al. [2018a] Jiani Zhang, Xingjian Shi, Junyuan Xie, Hao Ma, Irwin King, and Dit-Yan Yeung. Gaan: Gated attention networks for learning on large and spatiotemporal graphs. In Proceedings of the Thirty Fourth Conference on Uncertainty in Artificial Intelligence (UAI), 2018a.
- Zhang et al. [2018b] Yuhao Zhang, Peng Qi, and Christopher D. Manning. Graph convolution over pruned dependency trees improves relation extraction. Empirical Methods in Natural Language Processing, 2018b.
- Zitnik and Leskovec [2017] Marinka Zitnik and Jure Leskovec. Predicting multicellular function through multi-layer tissue networks. Bioinformatics, 33(14):i190–i198, 2017.
Appendix A Proofs
Proof of Theorem 3.
Since the generalized eigenvalues of are the eigenvalues of a positive semidefinite matrix , these are non-negative real numbers. To obtain the shrinking result, we use the Courant–Fisher–Weyl’s min-max principle [Bhatia, 2013, Corollary III. 1.2]: For any ,
| (13) | ||||
| (14) | ||||
| (15) |
Here, the second inequality follows because for all Hence, the inequality is strict if , i.e., . ∎
Lemma 9.
If has a frequency at most then .
Proof.
By the Parseval identity,
| (16) | ||||
| (17) | ||||
| (18) | ||||
| (19) |
∎
Proof of Lemma 5.
By substituting , we obtain
| (20) |
By Lemma 9, the first term is bounded by . By the Parseval identity (4), the second term is evaluated by
| (21) | ||||
| (22) |
By [Laurent and Massart, 2000, Lemma 1], we have
| (23) |
By substituting with , we obtain
| (24) |
Note that , and
| (25) |
since entry of is the probability that a random walk starting from is on at step, we obtain the lemma. ∎
Proof of Theorem 7.
Lemma 10.
If has a frequency at most then there exists such that has a frequency at most and .
Proof.
We choose by truncating the frequency components greater than . Then,
| (27) | ||||
| (28) | ||||
| (29) | ||||
| (30) | ||||
| (31) | ||||
| (32) | ||||
| (33) |
∎
Proof of Theorem 8.
| (34) | |||
| (35) | |||
| (36) | |||
| (37) |
∎