FastDVDnet: Towards Real-Time Deep Video Denoising Without Flow Estimation
Abstract
In this paper, we propose a state-of-the-art video denoising algorithm based on a convolutional neural network architecture. Until recently, video denoising with neural networks had been a largely under explored domain, and existing methods could not compete with the performance of the best patch-based methods. The approach we introduce in this paper, called FastDVDnet, shows similar or better performance than other state-of-the-art competitors with significantly lower computing times. In contrast to other existing neural network denoisers, our algorithm exhibits several desirable properties such as fast runtimes, and the ability to handle a wide range of noise levels with a single network model. The characteristics of its architecture make it possible to avoid using a costly motion compensation stage while achieving excellent performance. The combination between its denoising performance and lower computational load makes this algorithm attractive for practical denoising applications. We compare our method with different state-of-art algorithms, both visually and with respect to objective quality metrics.
1 Introduction
Despite the immense progress made in recent years in photographic sensors, noise reduction remains an essential step in video processing, especially when shooting conditions are challenging (low light, small sensors, etc.).
Although image denoising has remained a very active research field through the years, too little work has been devoted to the restoration of digital videos. It should be noted, however, that some crucial aspects differentiate these two problems. On the one hand, a video contains much more information than a still image, which could help in the restoration process. On the other hand, video restoration requires good temporal coherency, which makes the restoration process much more demanding. Furthermore, since all recent cameras produce videos in high definition—or even larger—very fast and efficient algorithms are needed.
In this paper we introduce another network for deep video denoising: FastDVDnet. This algorithm builds on DVDnet [45], but at the same time introduces a number of important changes with respect to its predecessor. Most notably, instead of employing an explicit motion estimation stage, the algorithm is able to implicitly handle motion thanks to the traits of its architecture. This results in a state-of-the-art algorithm which outputs high quality denoised videos while featuring very fast running times—even thousands of times faster than other relevant methods.
1.1 Image denoising
Contrary to video denoising, image denoising has enjoyed consistent popularity in past years. A myriad of new image denoising methods based on deep learning techniques have drawn considerable attention due to their outstanding performance. Schmidt and Roth proposed in [38] the cascade of shrinkage fields method. The trainable nonlinear reaction diffusion model proposed by Chen and Pock in [10] builds on the former. In [6], a multi-layer perceptron was successfully applied for image denoising. Methods such as these achieve performances comparable to those of well-known patch-based algorithms such as BM3D [13] or non-local Bayes (NLB [27]). However, their limitations include performance restricted to specific forms of prior, or the fact that a different set of weights must be trained for each noise level.
Another widespread approach involves the use of convolutional neural networks (CNN), e.g. RBDN [37], MWCNN [30], DnCNN [51], and FFDNet [52]. Their performance compares favorably to other state-of-the-art image denoising algorithms, both quantitatively and visually. These methods are composed of a succession of convolutional layers with nonlinear activation functions in between them. A salient feature that these CNN-based methods present is the ability to denoise several levels of noise with only one trained model. Proposed by Zhang et al. in [51], DnCNN is an end-to-end trainable deep CNN for image denoising. One of its main features is that it implements residual learning [22], i.e. it estimates the noise existent in the input image rather than the denoised image. In a following paper [52], Zhang et al. proposed FFDNet, which builds upon the work done for DnCNN. More recently, the approaches proposed in [35, 29] combine neural architectures with non-local techniques.
1.2 Video denoising
Video denoising is much less explored in the literature. The majority of recent video denoising methods are patch-based. We note in particular an extension of the popular BM3D to video denoising, V-BM4D [32], and Video non-local Bayes (VNLB [3]). Neural network methods for video denoising have been even rarer than patch-based approaches. The algorithm in [9] by Chen et al. is one of the first to approach this problem with recurrent neural networks. However, their algorithm only works on grayscale images and it does not achieve satisfactory results, probably due to the difficulties associated with training recurring neural networks [33]. Vogels et al. proposed in [46] an architecture based on kernel-predicting neural networks able to denoise Monte Carlo rendered sequences. The Video Non-Local Network (VNLnet [14]) fuses a CNN with a self-similarity search strategy. For each patch, the network finds the most similar patches via its first non-trainable layer, and this information is later used by the CNN to predict the clean image. In [45], Tassano et al. proposed DVDnet, which splits the denoising of a given frame in two separate denoising stages. Like several other methods, it relies on the estimation of motion of neighboring frames. Other very recent blind denoising approaches include the work by Ehret et al. [16] and ViDeNN [11]. The latter shares with DVDnet the idea of performing denoising in two steps. However, contrary to DVDnet, ViDeNN does not employ motion estimation. Similarly to both DVDnet and ViDeNN, the use of spatio-temporal CNN blocks in restoration tasks has been also featured in [46, 7]. Nowadays, the state-of-the-art is defined by DVDnet, VNLnet and VNLB. VNLB and VNLnet show the best performances for small values of noise, while DVDnet yields better results for larger values of noise. Both DVDnet and VNLnet feature significantly faster inference times than VNLB. As we will see, the performance of the method we introduce in this paper compares to the performance of the state-of-the-art, while featuring even faster runtimes.
2 FastDVDnet
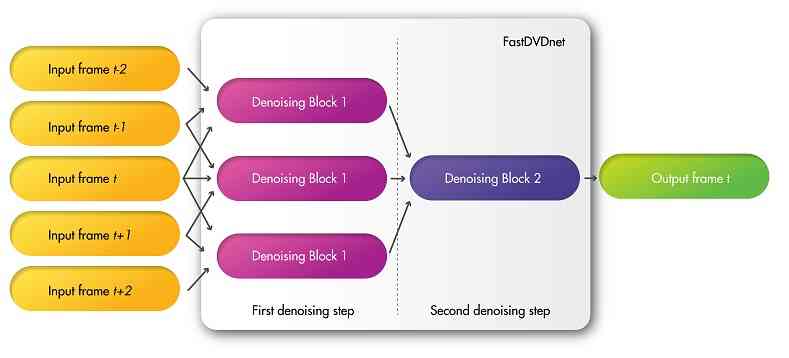
For video denoising algorithms, temporal coherence and flickering removal are crucial aspects in the perceived quality of the results [40, 39]. In order to achieve these, an algorithm must make use of the temporal information existent in neighboring frames when denoising a given frame of an image sequence. In general, most previous approaches based on deep learning have failed to employ this temporal information effectively. Successful state-of-the-art algorithms rely mainly on two factors to enforce temporal coherence in the results, namely the extension of search regions from spatial neighborhoods to volumetric neighborhoods, and the use of motion estimation.
The use of volumetric (i.e. spatio-temporal) neighborhoods implies that when denoising a given pixel (or patch), the algorithm is going to look for similar pixels (patches) not only in the reference frame, but also in adjacent frames of the sequence. The benefits of this are two-fold. First, the temporal neighbors provide additional information which can be used to denoise the reference frame. Second, using temporal neighbors helps to reduce flickering as the residual error in each frame will be correlated.
Videos feature a strong temporal redundancy along motion trajectories. This fact should facilitate denoising videos with respect to denoising images. Yet, this added information in the temporal dimension also creates an extra degree of complexity which could be difficult to tackle. In this context, motion estimation and/or compensation has been employed in a number of video denoising algorithms to help to improve denoising performance and temporal consistency [28, 45, 3, 32, 5].
We thus incorporated these two elements into our architecture. However, our algorithm does not include an explicit motion estimation/compensation stage. The capacity of handling the motion of objects is inherently embedded into the proposed architecture. Indeed, our architecture is composed of a number of modified U-Net [36] blocks (see Section 2.1 for more details about these blocks). Multi-scale, U-Net-like architectures have been shown to have the ability to learn misalignment [50, 15]. Our cascaded architecture increases this capacity of handling movement even further. In contrast to [45], our architecture is trained end-to-end without optical flow alignment, which avoids distortions and artifacts due to erroneous flow. As a result, we are able to eliminate a costly dedicated motion compensation stage without sacrificing performance. This leads to an important reduction of runtimes: our algorithm runs three orders of magnitude faster than VNLB, and an order of magnitude faster than DVDnet and VNLnet.
Figure 1a displays a diagram of the architecture of our method. When denoising a given frame at time , , its neighboring frames are also taken as inputs. That is, the inputs of the algorithm will be . The model is composed of different spatio-temporal denoising blocks, assembled in a cascaded two-step architecture. These denoising blocks are all similar, and consist of a modified U-Net model which takes three frames as inputs. The three blocks in the first denoising step share the same weights, which leads to a reduction of memory requirements of the model and facilitates the training of the network. Similar to [52, 18], a noise map is also included as input, which allows the processing of spatially varying noise [44]. In particular, the noise map is a separate input which provides information to the network about the distribution of the noise at the input. This information is encoded as the expected per-pixel standard deviation of this noise. For instance, when denoising Gaussian noise, the noise map will be constant; when denoising Poisson noise, the noise map will depend on the intensity of the image. Indeed, the noise map can be used as a user-input parameter to control the trade-off between noise removal vs. detail preservation (see for example the online demo in [44]). In other cases, such as JPEG denoising, the noise map can be estimated by means of an additional CNN [20]. The use of a noise map has been shown to improve denoising performance, particularly when treating spatially variant noise [4]. Contrary to other denoising algorithms, our denoiser takes no other parameters as inputs apart from the image sequence and the estimation of the input noise.
Observe that experiments presented in this paper focus on the case of additive white Gaussian noise (AWGN). Nevertheless, this algorithm can be extended to other types of noise, e.g. spatially varying noise (e.g. Poissonian). Let be a noiseless image, while is its noisy version corrupted by a realization of zero-mean white Gaussian noise of standard deviation , then
| (1) |
2.1 Denoising blocks
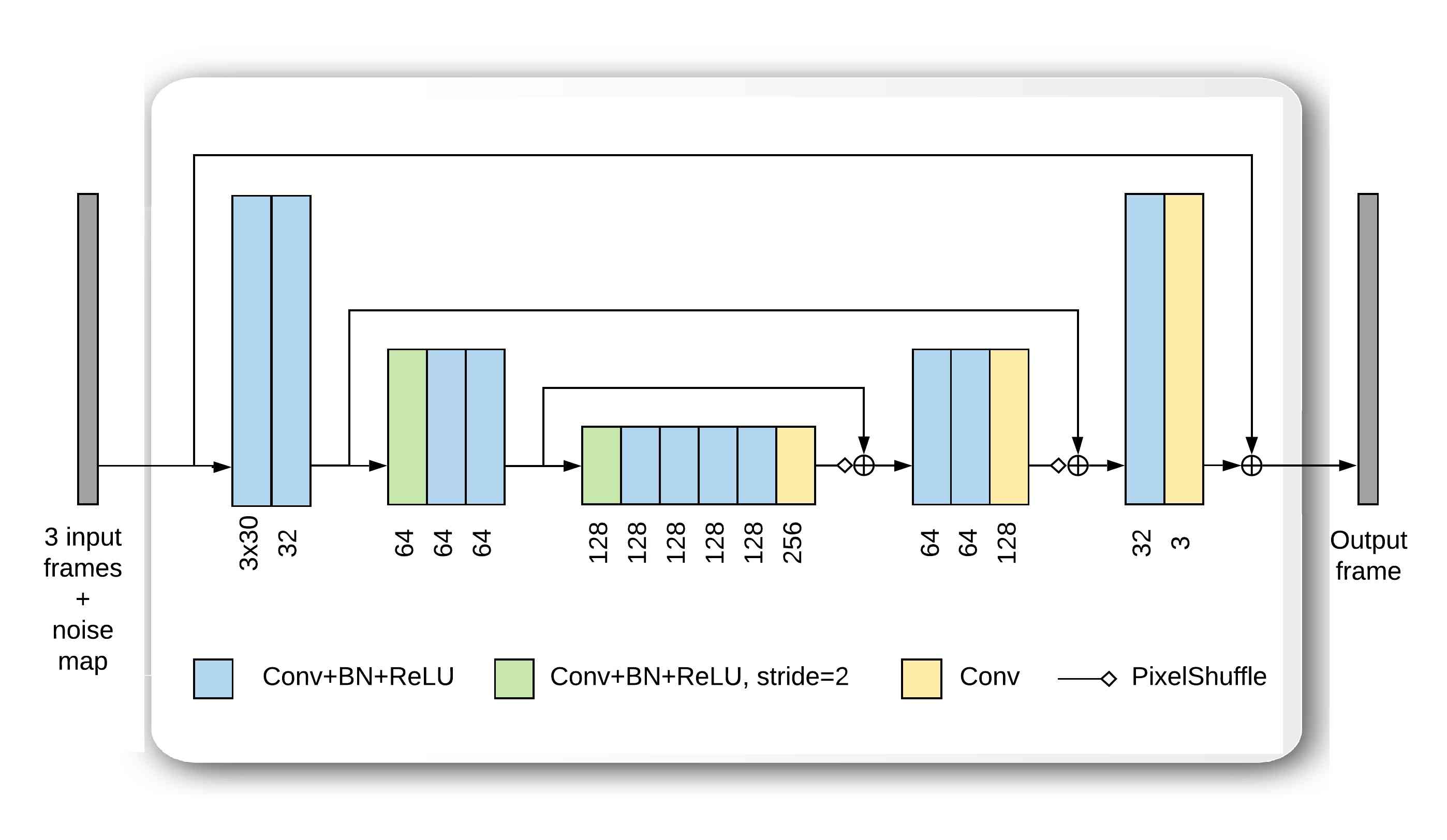
Both denoising blocks displayed in Fig. 1a, Denoising Block 1 and Denoising Block 2, consist of a modified U-Net architecture. All the instances of Denoising Block 1 share the same weights. U-Nets are essentially a multi-scale encoder-decoder architecture, with skip-connections [22] that forward the output of each one of the encoder layers directly to the input of the corresponding decoder layers. A more detailed diagram of these blocks is shown in Fig. 1b. Our denoising blocks present some differences with respect to the standard U-Net:
-
•
The encoder has been adapted to take three frames and a noise map as inputs
-
•
The upsampling in the decoder is performed with a PixelShuffle layer [41], which helps reducing gridding artifacts. Please see the supplementary materials for more information about this layer.
-
•
The merging of the features of the encoder with those of the decoder is done with a pixel-wise addition operation instead of a channel-wise concatenation. This results in a reduction of memory requirements
-
•
Blocks implement residual learning—with a residual connection between the central noisy input frame and the output—, which has been observed to ease the training process [44]
The design characteristics of the denoising blocks make a good compromise between performance and fast running times. These denoising blocks are composed of a total of convolutional layers. In most layers, the outputs of its convolutional layers are followed by point-wise ReLU [26] activation functions , except for the last layer. Batch normalization layers (BN [23]) are placed between the convolutional and ReLU layers.
3 Discussion
Explicit flow estimation is avoided in FastDVDnet. However, in order to maintain performance, we needed to introduce a number of techniques to handle motion and to effectively employ temporal information. These techniques are discussed further in this section. Please see the supplementary materials for more details about ablation studies.
3.1 Two-step denoising
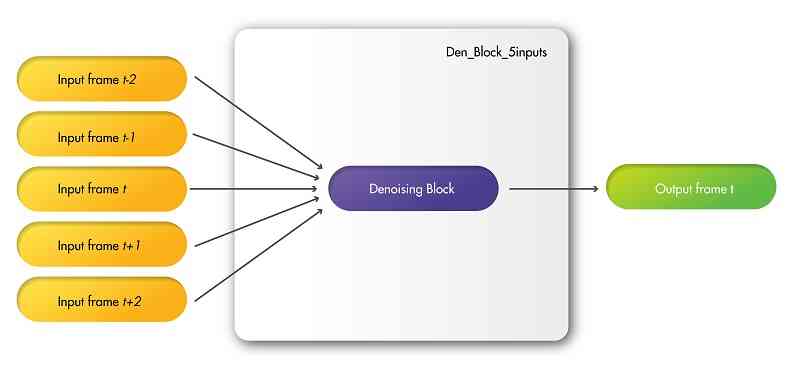
Similarly to DVDnet and ViDeNN, FastDVDnet features a two-step cascaded architecture. The motivation behind this is to effectively employ the information existent in the temporal neighbors, and to enforce the temporal correlation of the remaining noise in output frames. To prove that the two-step denoising is a necessary feature, we conducted the following experiment: we modified a Denoising Block of FastDVDnet (see Fig. 1b) to take five frames as inputs instead of three, which we will refer to as Den_Block_5inputs. In this way, the same amount of temporal neighboring frames are considered and the same information as in FastDVDnet is processed by this new denoiser. A diagram of the architecture of this model is shown in Fig. 2. We then trained this new model and compared the results of denoising of sequences against the results of FastDVDnet (see Section 4 for more details about the training process).
It was observed that the cascaded architecture of FastDVDnet presents a clear advantage on Den_Block_5inputs, with differences in PSNR of up to . Please refer to the supplementary materials for more details. Additionally, results by Den_Block_5inputs present a sharp increase on temporal artifacts—flickering. Despite it being a multi-scale architecture, Den_Block_5inputs cannot handle the motion of objects in the sequences as well as the two-step architecture of FastDVDnet can. Overall, the two-step architecture shows superior performance with respect to the one-step architecture.
3.2 Multi-scale architecture and end-to-end training
In order to investigate the importance of using multi-scale denoising blocks in our architecture, we conducted the following experiment: we modified the FastDVDnet architecture by replacing its Denoising Blocks by the denoising blocks of DVDnet. This results in a two-step cascaded architecture, with single-scale denoising blocks, trained end-to-end, and with no compensation of motion in the scene. In our tests, it was observed that the usage of multi-scale denoising blocks improves denoising results considerably. Please refer to the supplementary materials for more details.
We also experimented with training the multi-scale denoising blocks in each step of FastDVDnet separately—as done in DVDnet. Although the results in this case certainly improved with respect to the case of the single-scale denoising blocks described above, a noticeable flickering remained in the outputs. Switching from this separate training to an end-to-end training helped to reduce temporal artifacts considerably.
3.3 Handling of motion
Apart from the reduction of runtimes, avoiding the use of motion compensation by means of optical flow has an additional benefit. Video denoising algorithms that depend explicitly on motion estimation techniques often present artifacts due to erroneous flow in challenging cases, such as occlusions or strong noise. The different techniques discussed in this section—namely a multi-scale of the denoising blocks, the cascaded two-step denoising architecture, and end-to-end training—not only provide FastDVDnet the ability to handle motion, but also help avoid artifacts related to erroneous flow estimation. Also, and similarly to [51, 45, 44], the denoising blocks of FastDVDnet implement residual learning, which helps to improve the quality of results a step further. Figure 3 shows an example on artifacts due to erroneous flow on three consecutive frames and of how the multi-scale architecture of FastDVDnet is able to avoid them.












4 Training details
The training dataset consists of input-output pairs
where is a collection of spatial patches cropped at the same location in contiguous frames, and is the clean central patch of the sequence. These are generated by adding AWGN of to clean patches of a given sequence, and the corresponding noise map is built in this case constant with all its elements equal to . Spatio-temporal patches are randomly cropped from randomly sampled sequences of the training dataset.
A total of training samples are extracted from the training set of the DAVIS database [24]. The spatial size of the patches is , while the temporal size is . The spatial size of the patches was chosen such that the resulting patch size in the coarser scale of the Denoising Blocks is . The loss function is
| (2) |
where is the output of the network, and is the set of all learnable parameters.
The architecture has been implemented in PyTorch [34], a popular machine learning library. The ADAM algorithm [25] is applied to minimize the loss function, with all its hyper-parameters set to their default values. The number of epochs is set to , and the mini-batch size is . The scheduling of the learning rate is also common to both cases. It starts at for the first epochs, then changes to for the following epochs, and finally switches to for the remaining of the training. In other words, a learning rate step decay is used in conjunction with ADAM. The mix of learning rate decay and adaptive rate methods has also been applied to other deep learning projects [43, 49], usually with positive results. Data is augmented by introducing rescaling by different scale factors and random flips. During the first epochs, the orthogonalization of the convolutional kernels is applied as a means of regularization. It has been observed that initializing the training with orthogonalization may be beneficial to performance [52, 44].
5 Results
















Two different testsets were used for benchmarking our method: the DAVIS-test testset, and Set8, which is composed of color sequences from the Derf’s Test Media collection111https://media.xiph.org/video/derf and color sequences captured with a GoPro camera. The DAVIS set contains color sequences of resolution . The sequences of Set8 have been downscaled to a resolution of . In all cases, sequences were limited to a maximum of frames. We used the DeepFlow algorithm [48] to compute flow maps for DVDnet and VNLB. VNLnet requires models trained for specific noise levels. As no model is provided for , no results are shown for this noise level in either of the tables. We also compare our method to a commercial blind denoising software, Neat Video (NV [1]). For NV, its automatic noise profiling settings were used to manually denoise the sequences of Set8. Note that values shown are the average for all sequences in the testset, the PNSR of a sequence is computed as the average of the PSNRs of each frame.
In general, both DVDnet and FastDVDnet output sequences which feature remarkable temporal coherence. Flickering rendered by our methods is notably small, especially in flat areas, where patch-based algorithms often leave behind low-frequency residual noise. An example can be observed in Fig. 4 (which is best viewed in digital format). Temporally decorrelated low-frequency noise in flat areas appears as particularly bothersome for the viewer. More video examples can be found in the supplementary materials and on the website of the algorithm. The reader is encouraged to watch these examples to compare the visual quality of the results of our methods.
Patch-based methods are prone to surpassing DVDnet and FastDVDnet in sequences with a large portion of repetitive structures as these methods exploit the non-local similarity prior. On the other hand, our algorithms handle non-repetitive textures very well, see e.g. the clarity of the denoised text and vegetation in Fig. 5.
Table 1 shows a comparison of PSNR and ST-RRED on the Set8 and DAVIS dataset, respectively. The Spatio-Temporal Reduced Reference Entropic Differences (ST-RRED) is a high performing reduced-reference video quality assessment metric [42]. This metric not only takes into account image quality, but also temporal distortions in the video. We computed the ST-RRED scores with the implementation provided by the scikit-video library222http://www.scikit-video.org.
It can be observed that for smaller values of noise, VNLB performs better on Set8. Indeed, DVDnet tends to over denoise in some of these cases. FastDVDnet and VNLnet are the best performing algorithms on DAVIS for small sigmas in terms of PSNR and ST-RRED, respectively. However, for larger values of noise DVDnet surpasses VNLB. FastDVDnet performs consistently well in all cases, which is a remarkable feat considering that it runs times faster than DVDnet, times faster than VNLnet, and more than times faster than VNLB (see Section 6). Contrary to other denoisers based on CNNs—e.g. VNLnet—, our algorithms are able to denoise different noise levels with only one trained model. On top of this, the use of methods involve no hand-tuned parameters, since they only take the image sequence and the estimation of the input noise as inputs. Table 2 displays a comparison with ViDeNN. This algorithm has not actually been trained for AWGN, but for clipped AWGN. Then, a FastDVDnet model to denoise clipped AWGN was trained for this case, which we call FastDVDnet_clipped. It can be observed that the performance of FastDVDnet_clipped is superior to the performance of ViDeNN by a wide margin.
| Set8 | VNLB | V-BM4D | NV | VNLnet | DVDnet | FastDVDnet |
|---|---|---|---|---|---|---|
| / 2.86 | / | / | / | / | / | |
| / 6.28 | / | / | / | / | / | |
| / 11.53 | / | / | - | / | / | |
| / | / | / | / | / | / 18.45 | |
| / | / | / | / | / | / 26.75 |
| DAVIS | VNLB | V-BM4D | VNLnet | DVDnet | FastDVDnet |
|---|---|---|---|---|---|
| / | / | / 2.81 | / | / | |
| / | / | / 6.11 | / | / | |
| / | / | - | / | / | |
| / | / | / | / 18.16 | / | |
| / | / | / | / 25.63 | / |
| DAVIS | ViDeNN | FastDVDnet_clipped |
|---|---|---|
| 38.45 | ||
| 33.52 | ||
| 31.23 |
6 Running times
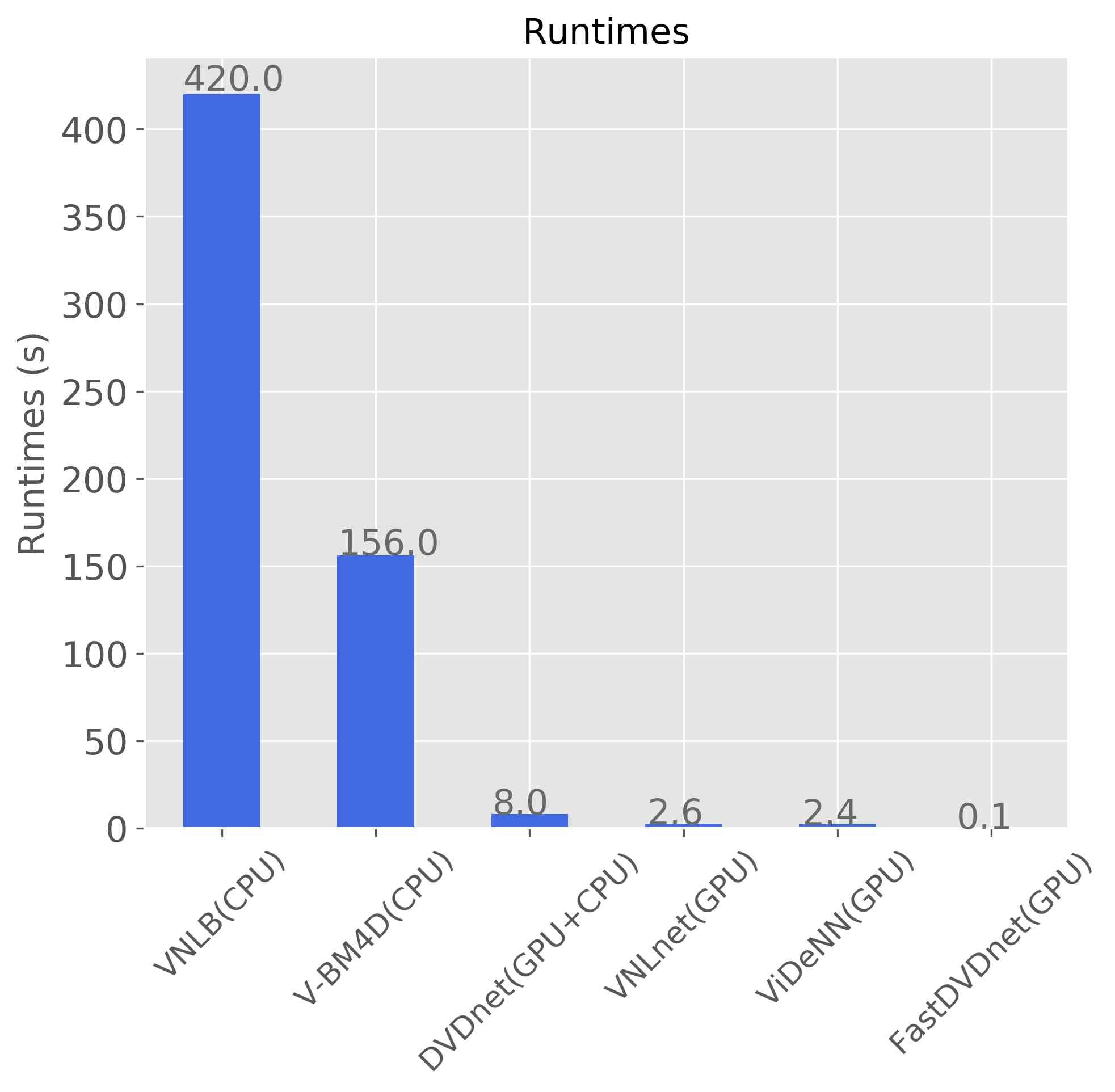
Our method achieves fast inference times, thanks to its design characteristics and simple architecture. Our algorithm takes only to denoise a color frame, which is more than orders of magnitude faster than V-BM4D and VNLB, and more than an order of magnitude faster than other CNN algorithms which run on GPU, DVDnet and VNLnet. The algorithms were tested on a server with a Titan Xp NVIDIA GPU card. Figure 6 compares the running times of different state-of-the-art algorithms.
7 Conclusion
In this paper, we presented FastDVDnet, a state-of-the-art video denoising algorithm. Denoising results of FastDVDnet feature remarkable temporal coherence, very low flickering, and excellent detail preservation. This level of performance is achieved even without a flow estimation step. The algorithm runs between one and three orders of magnitude faster than other state-of-the-art competitors. In this sense, our approach proposes a major step forward towards high quality real-time deep video noise reduction. Although the results presented in this paper hold for Gaussian noise, our method could be extended to denoise other types of noise.
Acknowledgments
Julie Delon would like to thank the support of NVIDIA Corporation for providing us with the Titan Xp GPU used in this research. We thank Anna Murray and José Lezama for their valuable contribution. This work has been partially funded by the French National Research and Technology Agency (ANRT) and GoPro Technology France.
References
- [1] ABSoft. Neat Video. https://www.neatvideo.com, 1999–2019.
- [2] Miika Aittala and Frédo Durand. Burst image deblurring using permutation invariant convolutional neural networks. In European Conference on Computer Vision, pages 748–764. Springer International Publishing, 2018.
- [3] Pablo Arias and Jean-Michel Morel. Video denoising via empirical bayesian estimation of space-time patches. Journal of Mathematical Imaging and Vision, 60(1):70–93, Jan 2018.
- [4] Tim Brooks, Ben Mildenhall, Tianfan Xue, Jiawen Chen, Dillon Sharlet, and Jonathan T. Barron. Unprocessing Images for Learned Raw Denoising. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [5] Antoni Buades, Jose-Luis Lisani, and Marko Miladinovic. Patch-based video denoising with optical flow estimation. IEEE Transactions on Image Processing, 25(6):2573–2586, Jun 2016.
- [6] H.C. Burger, C.J. Schuler, and S. Harmeling. Image denoising: Can plain neural networks compete with BM3D? In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2392–2399, 2012.
- [7] Jose Caballero, Christian Ledig, Andrew Aitken, Alejandro Acosta, Johannes Totz, Zehan Wang, and Wenzhe Shi. Real-time video super-resolution with spatio-temporal networks and motion compensation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4778–4787, 2017.
- [8] C. Chen, Q. Chen, M. Do, and V. Koltun. Seeing motion in the dark. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 3184–3193, 2019.
- [9] Xinyuan Chen, Li Song, and Xiaokang Yang. Deep rnns for video denoising. volume 9971 of SPIE Proceedings, page 99711T. SPIE, Sep 2016.
- [10] Yunjin Chen and Thomas Pock. Trainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6):1256–1272, Jun 2017.
- [11] Michele Claus and Jan van Gemert. Videnn: Deep blind video denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 0–0, 2019.
- [12] Djork-Arné Clevert, Thomas Unterthiner, and Sepp Hochreiter. Fast and accurate deep network learning by exponential linear units (elus). In 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, 2016.
- [13] K Dabov, A Foi, and V Katkovnik. Image denoising by sparse 3D transformation-domain collaborative filtering. IEEE Transactions on Image Processing (TIP), 16(8):1–16, 2007.
- [14] Axel Davy, Thibaud Ehret, Gabriele Facciolo, Jean-Michel Morel, and Pablo Arias. Non-local video denoising by cnn. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- [15] Alexey Dosovitskiy, Philipp Fischer, Eddy Ilg, Philip Hausser, Caner Hazirbas, Vladimir Golkov, Patrick van der Smagt, Daniel Cremers, and Thomas Brox. Flownet: Learning optical flow with convolutional networks. pages 2758–2766. IEEE, Dec 2015.
- [16] Thibaud Ehret, Axel Davy, Jean-Michel Morel, Gabriele Facciolo, and Pablo Arias. Model-blind video denoising via frame-to-frame training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 11369–11378, 2019.
- [17] T. Ehret, J. Morel, and P. Arias. Non-local kalman: A recursive video denoising algorithm. In 2018 25th IEEE International Conference on Image Processing (ICIP), pages 3204–3208, 2018.
- [18] Michaël Gharbi, Gaurav Chaurasia, Sylvain Paris, and Frédo Durand. Deep joint demosaicking and denoising. ACM Transactions on Graphics, 35(6):1–12, Nov 2016.
- [19] Ross Girshick. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, 2015.
- [20] Shi Guo, Zifei Yan, Kai Zhang, Wangmeng Zuo, and Lei Zhang. Toward Convolutional Blind Denoising of Real Photographs. In IEEE Conference on Computer Vision and Pattern Recognition, pages 1712–1722, jul 2019.
- [21] Samuel W. Hasinoff, Dillon Sharlet, Ryan Geiss, Andrew Adams, Jonathan T. Barron, Florian Kainz, Jiawen Chen, and Marc Levoy. Burst photography for high dynamic range and low-light imaging on mobile cameras. ACM Trans. Graph., 35(6), Nov. 2016.
- [22] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016.
- [23] Sergey Ioffe and Christian Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In International Conference on Machine Learning (ICML), pages 448–456. JMLR.org, 2015.
- [24] Anna Khoreva, Anna Rohrbach, and Bernt Schiele. Video object segmentation with language referring expressions. In ACCV, 2018.
- [25] D.P. Kingma and J.L. Ba. ADAM: a Method for Stochastic Optimization. Proc. ICLR, pages 1–15, 2015.
- [26] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. ImageNet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems (NIPS), pages 1–9, 2012.
- [27] M. Lebrun, A. Buades, and J. M. Morel. A nonlocal bayesian image denoising algorithm. SIAM Journal on Imaging Sciences, 6(3):1665–1688, Jan 2013.
- [28] Ce Liu and William Freeman. A high-quality video denoising algorithm based on reliable motion estimation. In European Conference on Computer Vision (ECCV), pages 706–719. Springer, 2015.
- [29] Ding Liu, Bihan Wen, Yuchen Fan, Chen Change Loy, and Thomas S Huang. Non-local recurrent network for image restoration. In Advances in Neural Information Processing Systems, pages 1680–1689, 2018.
- [30] Pengju Liu, Hongzhi Zhang, Kai Zhang, Liang Lin, and Wangmeng Zuo. Multi-level wavelet-CNN for image restoration. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, 2018.
- [31] Andrew L Maas, Awni Y Hannun, and Andrew Y Ng. Rectifier nonlinearities improve neural network acoustic models. In in ICML Workshop on Deep Learning for Audio, Speech and Language Processing, 2013.
- [32] Matteo Maggioni, Giacomo Boracchi, Alessandro Foi, and Karen Egiazarian. Video denoising, deblocking, and enhancement through separable 4-d nonlocal spatiotemporal transforms. IEEE Transactions on Image Processing, 21(9):3952–3966, Sep 2012.
- [33] Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. On the difficulty of training recurrent neural networks. In ICML, pages 1310–1318, 2013.
- [34] Adam Paszke, Gregory Chanan, Zeming Lin, Sam Gross, Edward Yang, Luca Antiga, and Zachary Devito. Automatic differentiation in PyTorch. Advances in Neural Information Processing Systems 30, pages 1–4, 2017.
- [35] Tobias Plötz and Stefan Roth. Neural nearest neighbors networks. In Advances in Neural Information Processing Systems (NIPS), pages 1087–1098, 2018.
- [36] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional Networks for Biomedical Image Segmentation, volume 9351 of Lecture Notes in Computer Science, chapter chapter 28, pages 234–241. Springer International Publishing, 2015.
- [37] V. Santhanam, V.I. Morariu, and L.S. Davis. Generalized Deep Image to Image Regression. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [38] U. Schmidt and S. Roth. Shrinkage fields for effective image restoration. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), number 8, pages 2774–2781, 2014.
- [39] K. Seshadrinathan and A.C. Bovik. Motion tuned spatio-temporal quality assessment of natural videos. IEEE Transactions on Image Processing, 19(2):335–350, Feb 2010.
- [40] Tamara Seybold. Noise Characteristics and Noise Perception, pages 235–265. Springer International Publishing, 2018.
- [41] Wenzhe Shi, Jose Caballero, Ferenc Huszar, Johannes Totz, Andrew P. Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1874–1883. IEEE, Jun 2016.
- [42] Rajiv Soundararajan and Alan C. Bovik. Video quality assessment by reduced reference spatio-temporal entropic differencing. IEEE Transactions on Circuits and Systems for Video Technology, 2013.
- [43] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. Rethinking the Inception Architecture for Computer Vision. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2818–2826, dec 2015.
- [44] Matias Tassano, Julie Delon, and Thomas Veit. An analysis and implementation of the ffdnet image denoising method. Image Processing On Line, 9:1–25, Jan 2019.
- [45] Matias Tassano, Julie Delon, and Thomas Veit. DVDnet: A fast network for deep video denoising. In IEEE International Conference on Image Processing, Sep 2019.
- [46] Thijs Vogels, Fabrice Rousselle, Brian Mcwilliams, Gerhard Röthlin, Alex Harvill, David Adler, Mark Meyer, and Jan Novák. Denoising with kernel prediction and asymmetric loss functions. ACM Transactions on Graphics, 37(4):1–15, Jul 2018.
- [47] Wei Wang, Xin Chen, Cheng Yang, Xiang Li, Xuemei Hu, and Tao Yue. Enhancing low light videos by exploring high sensitivity camera noise. pages 4110–4118, 10 2019.
- [48] Philippe Weinzaepfel, Jerome Revaud, Zaid Harchaoui, and Cordelia Schmid. DeepFlow: Large displacement optical flow with deep matching. In IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, Dec. 2013.
- [49] Ashia C Wilson, Rebecca Roelofs, Mitchell Stern, Nati Srebro, and Benjamin Recht. The marginal value of adaptive gradient methods in machine learning. In Advances in Neural Information Processing Systems (NIPS), pages 4148–4158, 2017.
- [50] Shangzhe Wu, Jiarui Xu, Yu-Wing Tai, and Chi-Keung Tang. Deep High Dynamic Range Imaging with Large Foreground Motions. In European Conference on Computer Vision (ECCV), pages 117–132, 2018.
- [51] Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Transactions on Image Processing, 26(7):3142–3155, Jul 2017.
- [52] Kai Zhang, Wangmeng Zuo, and Lei Zhang. Ffdnet: Toward a fast and flexible solution for cnn-based image denoising. IEEE Transactions on Image Processing, 27(9):4608–4622, Sep 2018.
Supplemental Materials
1 Two-step denoising
FastDVDnet features a two-step cascaded architecture. The motivation behind this is to effectively employ the information existent in the temporal neighbors, and to enforce the temporal correlation of the remaining noise in output frames. To prove that the two-step denoising is a necessary feature, we conducted the following experiment: we modified a Denoising Block of FastDVDnet (see the associated paper) to take five frames as inputs instead of three, which we will refer to as Den_Block_5inputs. In this way, the same amount of temporal neighboring frames are considered and the same information as in FastDVDnet is processed by this new denoiser. A diagram of the architecture of this model is shown in Fig. S1. We then trained this new model and compared the results of denoising of sequences against the results of FastDVDnet.
Table 1 displays the PSNRs on four color sequences for both denoisers. It can be observed that the cascaded architecture of FastDVDnet presents a clear advantage on Den_Block_5inputs, with an average difference of PSNRs of . Additionally, results by Den_Block_5inputs present a sharp increase on temporal artifacts—flickering. Despite it being a multi-scale architecture, Den_Block_5inputs cannot handle the motion of objects in the sequences as well as the two-step architecture of FastDVDnet can. Overall, the two-step architecture shows superior performance with respect to the one-step architecture.
| FastDVDnet | Den_Block_5inputs | ||
|---|---|---|---|
| hypersmooth | 37.34 | 35.64 | |
| motorbike | 34.86 | 34.00 | |
| rafting | 36.20 | 34.61 | |
| snowboard | 36.50 | 34.27 | |
| hypersmooth | 32.17 | 31.21 | |
| motorbike | 29.16 | 28.77 | |
| rafting | 30.73 | 30.03 | |
| snowboard | 30.59 | 29.67 | |
| hypersmooth | 29.77 | 28.92 | |
| motorbike | 26.51 | 26.19 | |
| rafting | 28.45 | 27.88 | |
| snowboard | 28.08 | 27.37 |
2 Multi-scale architecture and end-to-end training
In order to investigate the importance of using multi-scale denoising blocks in our architecture, we conducted the following experiment: we modified the FastDVDnet architecture by replacing its Denoising Blocks by the denoising blocks of DVDnet. This results in a two-step cascaded architecture, with single-scale denoising blocks, trained end-to-end, and with no compensation of motion in the scene. We will call this new architecture FastDVDnet_Single. Table 2 shows the PSNRs on four color sequences for both FastDVDnet and FastDVDnet_Single. It can be seen that the usage of multi-scale denoising blocks improves denoising results considerably. In particular, there is an average difference of PSNRs of in favor of the multi-scale architecture.
| FastDVDnet | FastDVDnet_Single | ||
|---|---|---|---|
| hypersmooth | 37.34 | 36.61 | |
| motorbike | 34.86 | 34.30 | |
| rafting | 36.20 | 35.54 | |
| snowboard | 36.50 | 35.50 | |
| hypersmooth | 32.17 | 31.54 | |
| motorbike | 29.16 | 28.82 | |
| rafting | 30.73 | 30.36 | |
| snowboard | 30.59 | 30.04 | |
| hypersmooth | 29.77 | 29.14 | |
| motorbike | 26.51 | 26.22 | |
| rafting | 28.45 | 28.11 | |
| snowboard | 28.08 | 27.56 |
3 Ablation studies
A number of modifications with respect to the baseline architecture discussed in the associated paper have been tested, namely:
-
•
the use of Leaky ReLU [31] or ELU [12] instead of ReLU. In neither case significant changes in performance were observed, with average differences in PSNR of less than on all the sequences and standard deviation of noise considered.
-
•
optimizing with respect to the Huber loss [19] instead of the norm. No significant change of performance was observed. The mean difference in PSNR on all the sequences and standard deviation of noise considered was in favor of the norm case.
-
•
removing batch normalization layers. An drop in performance of on average was observed for this case.
-
•
taking more input frames. The baseline model was modified to take 7 and 9 input frames instead of 5. No improvement in performance was observed in neither case. It was also observed an increased difficulty of these models, which have more parameters, to converge during training with respect to the case with 5 input frames.
4 Upscaling layers
In the multi-scale denoising blocks, the upsampling in the decoder is performed with a PixelShuffle layer [41]. This layer repacks its input of dimension into an output of size , where are the number of channels, the height, and the width, respectively. In other words, this layer constructs all the non-overlapping patches of its output with the pixels of different channels of the input, as shown in Fig. S2
5 Gaussian noise model
Recently, a number of algorithms have been proposed for video and burst denoising in low-light conditions, e.g. [8, 47, 21]. What is more, some of these works argue that real noise cannot be accurately modeled with a simple Gaussian model. Yet, the algorithm we propose here has been developed for Gaussian denoising because although Gaussian i.i.d. noise is not utterly realistic, it eases the comparison with other methods on comparable datasets—one of our primary goals. We believe Gaussian denoising is a middle ground where different denoising architectures can be compared fairly. Some networks which are proposed to denoise a specific low-light dataset are designed and overfitted given the image processing pipe of said dataset. In some cases, the comparison against other methods which have not been designed for the given dataset—e.g. the current version of our method—might not be accurate. Nonetheless, low-light denoising is not the main objective of our submission. Rather, it is to show that a simple, yet carefully designed architecture can outperform other more complex methods. We believe that the main challenge to denoising algorithms is the input signal-to-noise ratio. In this regard, the presented results have similar characteristics to low-light videos.
6 Permutation invariance
The algorithm proposed for burst deblurring and denoising in [2] features invariance to the permutation of the ordering of its input frames. One might be tempted to replicate its characteristics in an architecture such as ours to benefit from the advantages of the permutation invariance. However, the application of our algorithm is video denoising—which is not identical to burst denoising. Actually, the order in the input frames is a prior exploited by our algorithm to enforce the temporal coherence in the output sequence. In other words, permutation invariance is not necessarily desirable in our case.
7 Recursive processing
As previously discussed, in practice, the processing of our algorithm is limited to five input frames. Given this limitation, one would wonder if the theoretic performance bound might be lower to that of other solutions based on recursive processing (i.e. using the output frame in time as input to the next frame in time ). Yet, our experience with recursive filtering of videos is that it is difficult for the latter methods to be on par with methods which employ multiple frames as input. Although, in theory, recursive methods are asymptotically more powerful in terms of denoising than multi-frame methods, in practice the performance of recursive methods suffers due to temporal artifacts. Any misalignment or motion compensation artifact which might appear in the output frame at a given time is very likely to appear in all subsequent outputs. An interesting example to illustrate this point is the comparison of the method in [17] versus the video non-local Bayes denoiser (VNLB [3]). The former implements a recursive version of VNLB, which results in a lower complexity algorithm, but with very inferior performance with respect to the latter.