Differentiable Deep Clustering with Cluster Size Constraints
Aude Genevay Gabriel Dulac-Arnold Jean-Philippe Vert
CSAIL, MIT Google Brain Google Brain
Abstract
Clustering is a fundamental unsupervised learning approach. Many clustering algorithms – such as -means – rely on the euclidean distance as a similarity measure, which is often not the most relevant metric for high dimensional data such as images. Learning a lower-dimensional embedding that can better reflect the geometry of the dataset is therefore instrumental for performance. We propose a new approach for this task where the embedding is performed by a differentiable model such as a deep neural network. By rewriting the -means clustering algorithm as an optimal transport task, and adding an entropic regularization, we derive a fully differentiable loss function that can be minimized with respect to both the embedding parameters and the cluster parameters via stochastic gradient descent. We show that this new formulation generalizes a recently proposed state-of-the-art method based on soft--means by adding constraints on the cluster sizes. Empirical evaluations on image classification benchmarks suggest that compared to state-of-the-art methods, our optimal transport-based approach provide better unsupervised accuracy and does not require a pre-training phase.
1 Introduction
Clustering is a fundamental unsupervised learning task, where, given a training set of data and a number of classes , we aim to partition the training data into non-overlapping clusters corresponding to different classes of points. We consider an extension of this problem where we additionally want to classify out-of-sample data not in the training set, i.e., we want to infer a function that maps a given point in the data space to a class. Many clustering techniques exist, such as agglomerative clustering, when is endowed with a metric, or -means, when . However, these methods often fail when applied to complex higher-dimentional data, as the usual metric on the dataspace (e.g. euclidean in ) is not meaningful.
For complex data such as images or strings, recent years have witnessed significant progress in learning representations , where is typically a deep neural network (DNN) with parameters , and is a low dimensional space that intends to capture the underlying structure of the data (Bengio et al., 2013). The representation is usually optimized to either solve a supervised task such as image classification using a training set of labeled images, or, in the absence of labels, can be used to summarize the data, e.g., by using (variational) auto-encoders or GANs (Kingma et al., 2014; Goodfellow et al., 2014).
Any such learned representation can be used in conjunction with any clustering algorithm to cluster the training set mapped to the representation space . However, there is no guarantee that the representation is “good” for this clustering task if it has been optimized for another task. In this work, we propose a new approach to learn a representation well adapted to solve the clustering task, in the absence of labels. This setting has been considered by several authors recently, often under the name of “deep clustering”, and before reviewing existing approaches let us fix some notations.
Setting and notations.
We consider a dataset of points where is the space of input data (e.g., for 3-channel images). Our goal is to cluster the data into clusters, which might correspond to the number of classes in a supervised setting. For a dataset we denote by the embedded dataset , where is a deep neural network with parameters and .
Additionally, we denote by the probability simplex. For any integer , let be the -dimensional vector of ones. Given two vectors , where for , we denote by the vector with entries . For any vector or matrix , we denote by the matrix obtained by applying the operation entrywise, e.g., , and by the transpose of .
A discriminative approach to clustering.
The clustering task can be recast as a classification problem, without relying on a representation of the data, focusing directly on the clustering function . This only makes sense in cases where classes are well separated. In that case, the labels of the training set are known, then one could train a supervised model by minimizing over an empirical risk of the form
Since we are considering an unsupervised setting, is not available. A solution is thus to jointly optimize the above criterion over and to learn both a class assignment and a classifier:
| (1) |
An obvious computational difficulty is that this problem involves the discrete variable . Besides, some kind of regularization is required in this double optimization task to prevent trivial solutions; adding constraints on is crucial to prevent empty or overpopulated clusters. Joulin et al. (2010) propose a convex relaxation of (1) in the case of linear regression with the squared loss for binary problems (). In that case, the objective function is quadratic in and they use the standard semidefinite programming (SDP) relaxation for the matrix to approximate a minimum.
A different approach is used by Chang et al. (2017) who recast the clustering problem as a binary classification problem: given two data points, do they belong to the same cluster? The resulting algorithm, Deep Adaptive Clustering (DAC) can be summarized as follows: each data point is mapped to a vector in the unit ball of thanks to , which represents its probability to belong to each class. These probabilities are then compared with the cosine distance, which defines the similarity of the two points. The points are assumed to belong to the same class if the similarity is above a certain threshold. The parameters are then updated in order to increase similarity between similar points.
Learning a ’clustering-friendly’ representation.
However, representations are useful beyond the clustering task, e.g., to extract features or reduce the dimension of a dataset, which is why many methods in the literature rather learn a representation such that becomes easy to cluster. In most cases, the problem consists in minimizing a combined loss made of two terms : (i) a “representation loss” to ensure that the representation space is not degenerate (ii) a “clustering loss” to enforce that the learned representation is relevant for the clustering task. This yields the following optimization problem:
| () |
While the choice of the reconstruction loss of an auto-encoder (with encoder and decoder )
| (2) |
is the standard for the representation loss, these methods vary mostly in their choices of the clustering losses, the auto-encoder model, and the optimization strategies (in particular to prevent trivial solutions).
Song et al. (2013) are one of the earliest to learn a representation for clustering by tweaking the objective function of a standard auto-encoder. They formulate the problem as minimizing the combined loss () with the objective of -means as the clustering loss:
| (3) |
To optimize the objective function over the encoder parameters , the decoder parameters and the cluster centers , they alternate one epoch of stochastic gradient descent over , with one update of the cluster centers and assignments.
While most state-of-the-art methods rely on clustering objectives that are strongly linked to -means, Joint Unsupervised LEarning (JULE) (Yang et al., 2016) uses a clustering loss based on “agglomerative clustering”. Starting from clusters consisting of datapoints, the training alternates between a few steps of agglomerative clustering, i.e., merging similar clusters, and a backward pass during which the network parameters are updated to minimize the clustering loss. Although this method has a more flexible geometry, it requires building an affinity graph of the dataset after each update and is thus computationally heavy.
Xie et al. (2016) propose Deep Embedded Clustering (DEC) which starts with a pre-training phase using only the reconstruction loss and then improves the clustering ability of the representation by optimizing in a self-supervised manner. Their clustering loss is the Kullback-Leibler divergence between the soft-assignments of each point to each cluster and the square of the soft-assignments, which should push the embedding to favor harder assignments. There are several variants of DEC using more sophisticated auto-encoders and training techniques such as Guo et al. (2017). The DEPICT algorithm (Dizaji et al., 2017) similarly minimize the KL divergence to sharpen their assignments but also introduce a classifier , that outputs a probability distribution over the classes (typically, a neural network with softmax activation at the last layer). Thus the clustering loss corresponds to the possibility to discriminate the data in different classes.
The clustering loss in Deep Clustering Network (DCN) (Yang et al., 2017) is the objective of -means in the representation space. However, minimizing the total loss over (cluster centers) and (cluster assignments) jointly is challenging. Thus, Yang et al. (2017) alternate optimization in for fixed , which becomes a variant of AE training, and in for fixed . The Deep -means (DKM) (Fard et al., 2018) algorithm uses the same loss as DCN but relax the assignment problem by replacing the cluster assignments with soft-assignments in the -means objective. This results in a clustering loss can be jointly minimized over and , using stochastic gradient descent (SGD), and leads to state-of-the-art performance in deep clustering (Fard et al., 2018). The latter is the approach which is closest to ours, as we also propose a fully differentiable objective based on -means.
Clustering and optimal transport
There is a link between -means clustering and optimal transport, which was first noticed in Pollard (1982) and studied in more details in Canas and Rosasco (2012). Roughly speaking, optimal transport is equivalent to a constrained formulation of -means in which the cluster sizes are prescribed. This framework makes sense in a setting where the proportion of each class in a dataset is known, but no information is available at the individual level. Cuturi and Doucet (2014) introduced an entropic regularization of that problem which allows for an efficient solver.
Contributions
Following Cuturi and Doucet (2014) we exploit the connection between optimal transport and -means, and rely on entropic regularization to derive a fully-differentiable clustering loss that can be used in () and directly optimized with SGD. We give an insight on the effect of regularization in the cluster assignment problem, and show that the soft -means loss introduced by Fard et al. (2018) can be interpreted as an optimal transport loss with only one marginal constraint. The constraints on cluster sizes that naturally occur with optimal transport allow to enforce a prior on cluster sizes without relying to additional terms in the optimization problem. This leads to better clustering performance on benchmark datasets.
2 Clustering with Optimal Transport
Cluster assignment as an optimal transport problem
Consider sample points embedded in the representation space via , and clusters in that representation space with centers . We want to assign samples to clusters so that:
-
(i)
each sample is assigned to exactly one cluster,
-
(ii)
each cluster contains exactly points,
-
(iii)
the total distance (in the representation space) between cluster centers and their assigned samples is minimal.
The mathematical formulation of the above problem reads as follows:
| () | ||||||
| s.t. | () | |||||
| () | ||||||
where is the vector of cluster proportions.
The above problem is known as optimal transport between the discrete measure and . If we remove the constraint on cluster sizes (), it boils down to the objective function of the -means problem with cluster centers (Pollard, 1982).
Entropic regularization of optimal transport
Solving optimal transport is computationally expensive as it requires solving a large linear program and a common workaround in the literature is to regularize the problem with entropy (Cuturi, 2013). The regularized problem then reads as follows:
| () | ||||||
| s.t. | () | |||||
| () | ||||||
The addition of entropy allows to solve the problem with a much faster iterative algorithm, called Sinkhorn’s algorithm, whose iterations are summarized in Algorithm 1. Although this fast solver is the main reason why regularized optimal transport became routinely used in machine learning tasks, recent papers have exploited the fact that it also leads to a differentiable loss, whose gradients can be easily computed with backpropagation through Sinkhorn iterations (Genevay et al., 2018; Salimans et al., 2018).
It is known that a linear program reaches its maximum on the vertices, which is why the Optimal Transport problem is equivalent to its relaxation to the simplex. The addition of entropy will move the solution away from the optimal vertex, towards the center of the constraint polytope thus yielding smoother assignments (Peyré et al., 2019). This is formalized in the proposition below:
Proposition 1.
Proof.
The proposition is an adaptation of Theorem 1 in (Genevay et al., 2018) to our clustering setting. ∎
The choice of is a crucial question: when epsilon gets smaller – i.e. when we get closer to ’true’ Optimal Transport – Sinkhorn’s algorithm requires more iterations to converge (see e.g. (Peyré et al., 2019)) meaning that a better approximation of optimal transport comes at a heavy computational price. However, it has recently been proved that approximating optimal transport from samples – which is typically the case in machine learning, it is actually beneficial to use not too small to avoid the curse of dimension from which optimal transport suffers (Genevay et al., 2019).
Link with soft-assignments in -means
The optimal transport formulation includes two marginal constraints, one being that each sample is assigned to exactly one cluster and the other being the cluster size. The latter constraint can be omitted to obtain an objective which is that of -means. When regularizing the optimal transport problem with only one marginal constraint, we thus get a differentiable -means objective.
Proposition 2.
Consider the variant of entropy-regularized Optimal Transport with only one marginal constraint (i.e., no prior on cluster sizes):
| s.t. | |||||
then the optimal assignment is given by
| (7) |
Proof.
This is a convex function of with linear constraints. Denoting by the Lagrange multiplier for the constraint, the Lagrangian is :
| (8) | ||||
| (9) | ||||
| (10) |
The first order conditions of the Lagrangian gives (7). ∎
The solution of that problem corresponds exactly to the differentiable -means loss introduced by Fard et al. (2018), which the authors motivated by replacing the in the -means objective (3) with the softmin function. Hence Proposition 2 provides a new interpretation of DKM, and shows that the approach we propose below generalizes DKM by adding constraints on the cluster sizes.

Solving the clustering problem
Several papers in the literature use the -means objective as the clustering loss in (). We propose to replace this by the objective function of regularized optimal transport, which allows to:
-
(i)
enforce a prior on the cluster proportions,
-
(ii)
obtain a loss that is differentiable with respect to both the cluster centers and the embedding parameters .
The clustering problem () becomes:
| (11) |
where is the reconstruction loss of the auto-encoder defined in (2) and is the result of the regularized optimal transport problem (). This function is differentiable with respect to all its variables, and can be minimized with SGD. We outline the full learning procedure in Algorithm 2.
3 Experiments
We assess the efficiency of our optimal transport-based clustering loss on two classical benchmark datasets for image classification, MNIST and CIFAR10. We compare it against a simple baseline which consists in learning an embedding with an auto-encoder and then running -means on the embedded data, and against the state-of-the-art DKM method of Fard et al. (2018) based on the soft -means loss, which already proved its superiority over existing methods.
Experimental setting
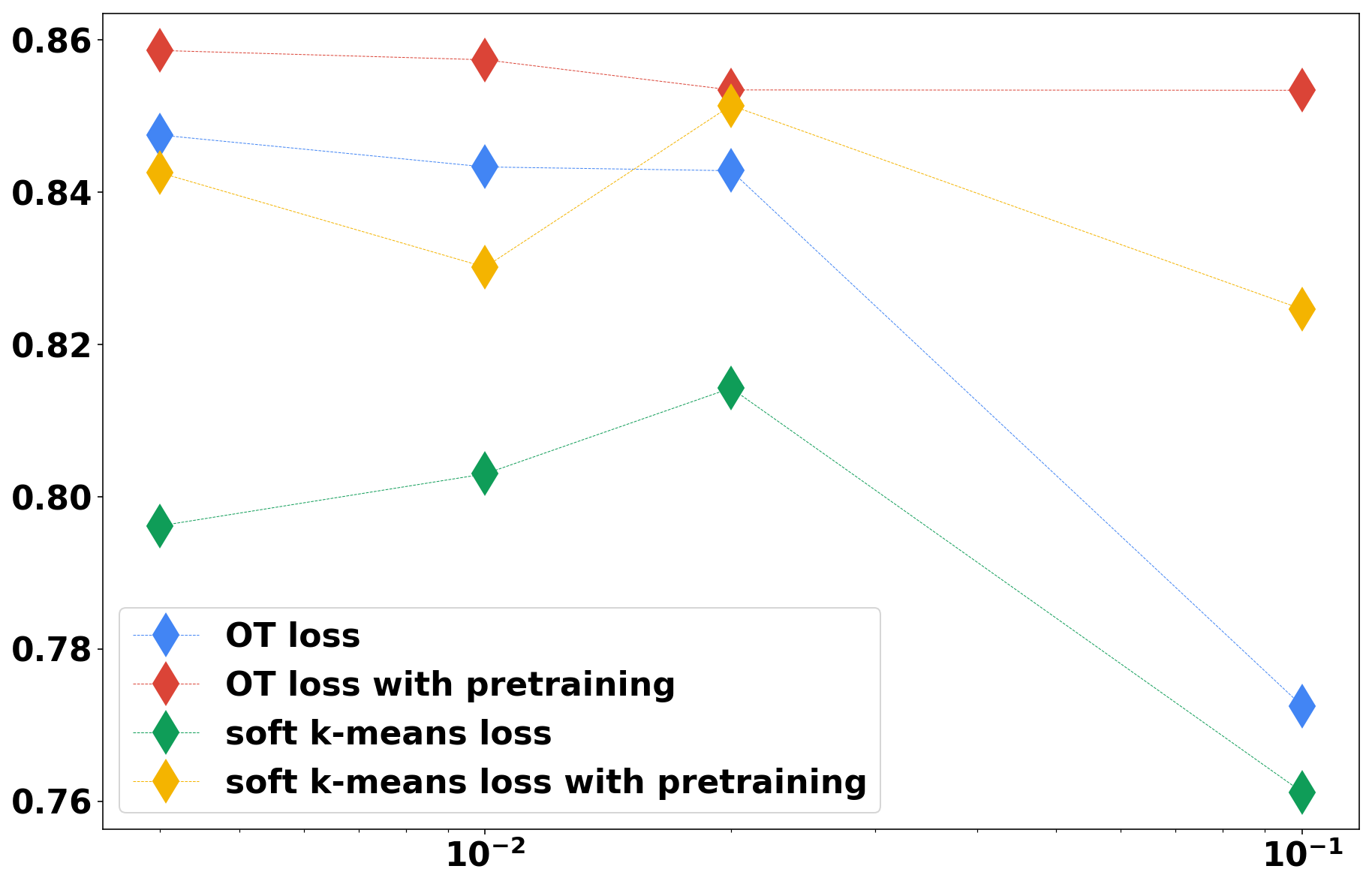
For the MNIST dataset, we follow mutiple examples from the litterature by using a fully connected auto-encoder with 500-250-10-250-500 structure and ReLu activation. For the CIFAR dataset, we use as an encoder a standard convolutional network using ReLu activation, with three convolution layers of respective depths 32, 64, 128, respective kernel sizes 5, 5, 3, and common stride of 2, followed by a fully connected layer to a latent space of dimension 10. In both cases we use batches of size . The gradient updates are made with the Adam algorithm and the standard learning rate from TensorFlow (0.001) with step decay, as there should not be parameter tuning in an unsupervised setting. The algorithm used for training is summarized in Algorithm 2. We also run -means on raw pixels, to give an idea of how much structure is induced in the data by the embedding . Following usual guidelines regarding regularization for optimal transport, we set which gives a good enough approximation of optimal transport without requiring too many Sinkhorn iterations. We show in Fig. 2 that the final performance is robust to the choice of as long as it is not too large.
| -means | AE + -means | soft -means | soft -means (p) | OT | OT (p) | |
|---|---|---|---|---|---|---|
| MNIST | 0.513 | |||||
| CIFAR10 | 0.206 | |||||
Evaluation
After each epoch, we evaluate the different methods by computing the accuracy given by matching clusters to classes through the following formula:
where and are respectively the class label and the cluster index associated to and is the set of permutations of . For the ‘AE + -means’ method, the cluster assignment is made by running -means on the embedded data, while for both ‘soft -means’ and ‘OT’, since these methods also learn the cluster centers we assign the point to cluster such that . The optimal matching between clusters and classes is done via the Hungarian algorithm, as in the literature.
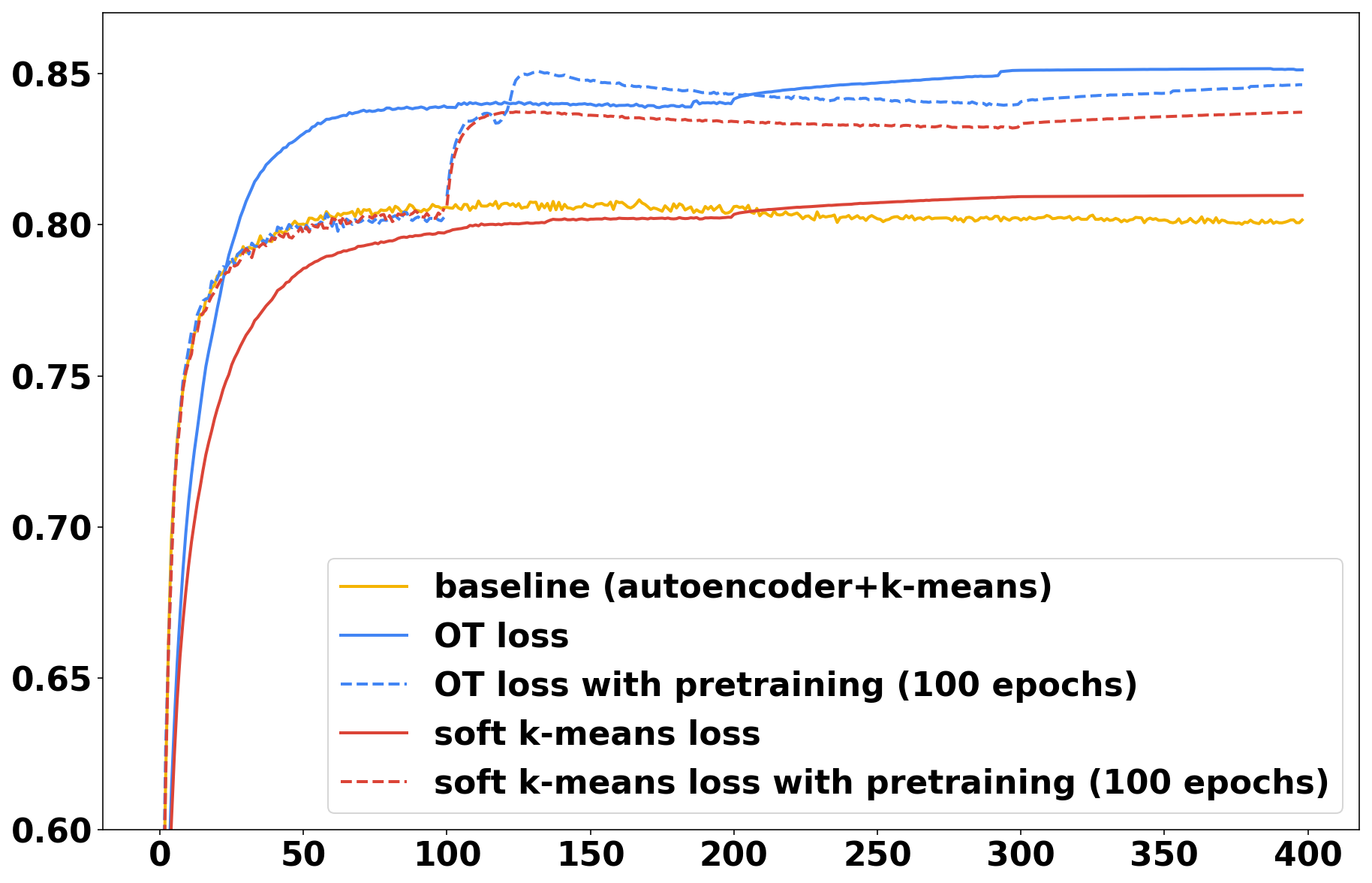
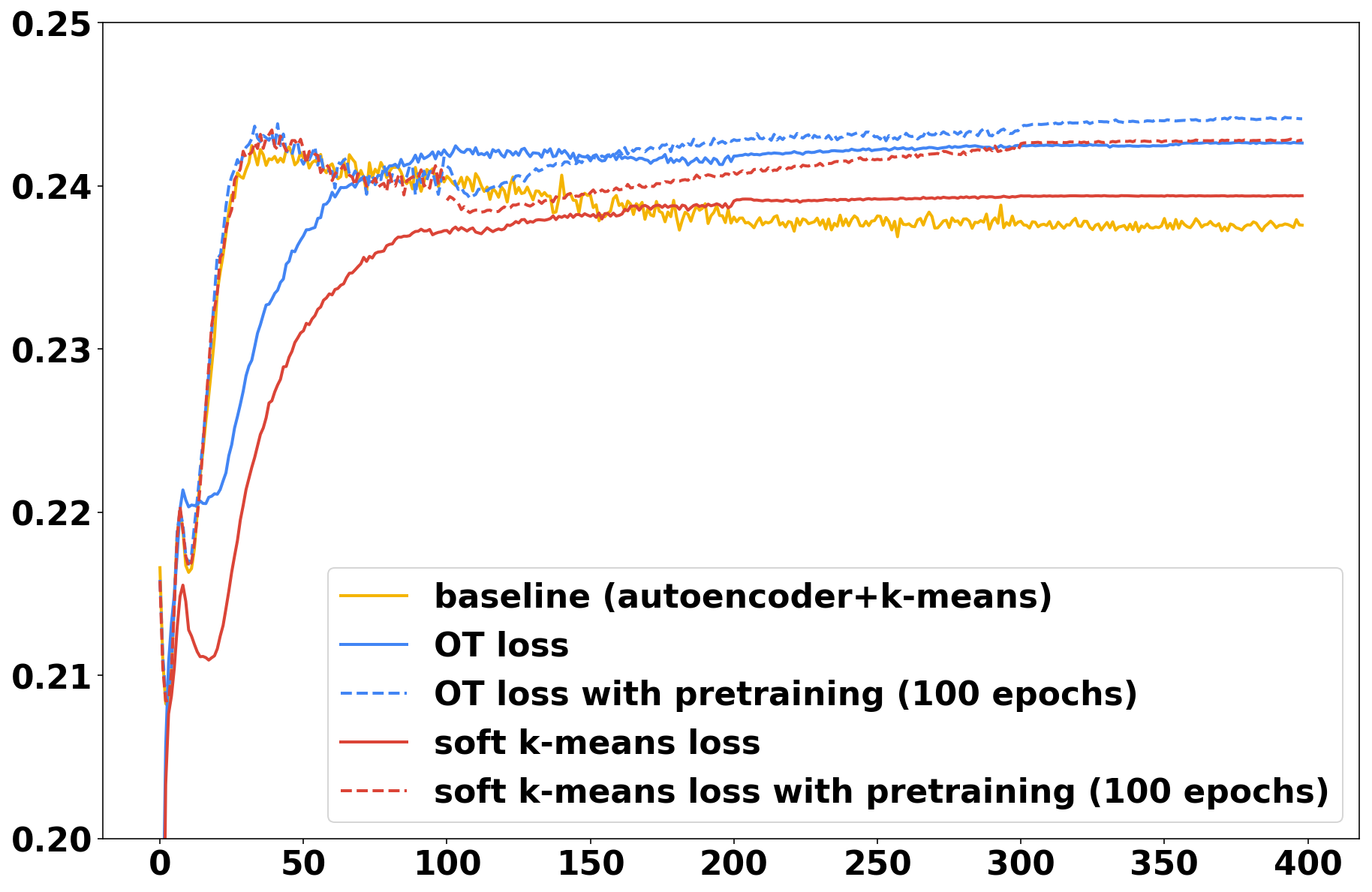
The evolution of accuracy during training for all three methods (auto-encoder + kmeans, soft -means, optimal transport) is plotted in Fig. 1. The curves are averaged over 50 runs. The final accuracies are reported in Table 1 along with the standard deviations. We can seen that the optimal transport loss achieves superior accuracy, but mostly doesn’t need to rely on pre-training to get good performance, contrarily to soft -means, whose performance is only slightly above the baseline without pre-training. To assert the statistical significance of the superiority of optimal transport in this framework, we further run a Welch’s t-test over the final accuracies in the 50 runs. Without pre-training, we find out that optimal transport is significantly better than soft -means (p-value of for CIFAR10 and for MNIST). With pre-training, optimal transport is still significantly better than soft -means for MNIST at the 10% level (p-value of 0.10) but it’s not the case for CIFAR10 (p-value of 0.33). Note that for both datasets, pre-training did not yield significantly better performance for optimal transport (p-values ), while it significantly improves soft -means (p-values ).
Fig. 2 displays the accuracy after 200 epochs for each method, as a function of . We see that the competitive advantage of OT over soft -means is robust to the choice of as long as it is not too large. Incidentally, the methods with pre-training are more robust to large values for . Note that these curves are averaged over only 5 runs and thus can not be regarded as statistically significant, they merely serve as a proof of robustness of the method to the chosen parameter.
4 Conclusion and discussion
In this paper we propose a new fully differentiable framework for deep clustering, based on regularized optimal transport, which generalizes the recently proposed approach of Fard et al. (2018) based on soft--means. Its main advantage over competing methods is its ability to naturally enforce a prior on class proportions. This significantly improves performance on datasets with well balanced classes, without relying on pre-training of the embedding.
In our experiments we observed a benefit over soft--means in situations where the classes are balanced. An interesting direction to explore is to extend the application of our method when the prior knowledge on cluster size is not uniform. This may be relevant in cases, for example, when an expert provides a rough estimate of the proportion of different classes, such as the proportion of cancer cells in an histopathological image. While our formulation lends itself naturally to non-uniform cluster proportions, we observed in preliminary experiments that it performs poorly if no care is taken to make sure that the cluster size constraints ( in Algorithm 2) is coherent with the set of cluster centers (vectors in Algorithm 2). We found in particular that this is often poorly achieved by the initialization of the centers via -means (step 4 in Algorithm 2. For instance, consider the case where we have two clusters – say images of ones and images of twos – and we know that we should have 20 % of the former and 80 % of the latter. However, if the -means initialization of the centers puts the first center in the middle of twos and the second center in the middle of ones, the algorithm will try to enforce a 80% proportion on ones and 20% proportion on twos. Generally speaking, to ensure that we are enforcing the cluster proportions properly, some sort of matching has to be done before the learning phase between the indexes of the clusters and the indexes of the classes. This could be done in a supervised way, by using an example from each class to initialize the centers. This extension falls in the framework of one-shot learning, with an additional knowledge on class proportions.
Another extension of our method would be relax the strict constraint of cluster proportions to a soft constraint, using for example unbalanced optimal transport with a relaxed version of the Sinkhorn algorithm which penalizes the marginal constraints instead of enforcing them strongly (Chizat et al., 2018). This may be particularly relevant when small batches are considered, as one would not expect the composition of each batch to perfectly reflect the overall composition.
Finally, we note that our formulation of the clustering problem with optimal transport is closely linked to that of Dulac-Arnold et al. (2019), who propose an algorithm to learn a classifier from label proportions in mini-batches. The main difference is that instead of using to parametrize an embedding, the authors directly use it to predict the probability of belonging to class . The last layer of is a softmax, and thus the term is replaced by . Besides, they loosen the marginal constraint prescribing the clusters proportions by using unbalanced optimal transport. The latter can also be implemented in our proposed method, as it consists in using a variation of Sinkhorn’s algorithm (Chizat et al., 2018). However, the performance that they report for large batch sizes in lower than what we report for the fully unsupervised task in our experiments. This would make our optimal transport approach a good candidate for the learning with proportions problem.
References
- Bengio et al. (2013) Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell., 35(8):1798–1828, August 2013.
- Canas and Rosasco (2012) Guillermo Canas and Lorenzo Rosasco. Learning probability measures with respect to optimal transport metrics. In Advances in Neural Information Processing Systems, pages 2492–2500, 2012.
- Chang et al. (2017) Jianlong Chang, Lingfeng Wang, Gaofeng Meng, Shiming Xiang, and Chunhong Pan. Deep adaptive image clustering. In Proceedings of the IEEE International Conference on Computer Vision, pages 5879–5887, 2017.
- Chizat et al. (2018) Lenaic Chizat, Gabriel Peyré, Bernhard Schmitzer, and François-Xavier Vialard. Scaling algorithms for unbalanced optimal transport problems. Mathematics of Computation, 87(314):2563–2609, 2018.
- Cuturi (2013) Marco Cuturi. Sorn distances: Lightspeed computation of optimal transport. In Advances in neural information processing systems, pages 2292–2300, 2013.
- Cuturi and Doucet (2014) Marco Cuturi and Arnaud Doucet. Fast computation of Wasserstein barycenters. In International Conference on Machine Learning, pages 685–693, 2014.
- Dizaji et al. (2017) K. G. Dizaji, A. Herandi, C. Deng, W. Cai, and H. Huang. Deep clustering via joint convolutional autoencoder embedding and relative entropy minimization. In 2017 IEEE International Conference on Computer Vision (ICCV), pages 5747–5756, Oct 2017. doi: 10.1109/ICCV.2017.612.
- Dulac-Arnold et al. (2019) G. Dulac-Arnold, N. Zeghidour, M. Cuturi, L. Beyer, and J.-P. Vert. Deep multi-class learning from label proportions. Technical Report 1905.12909, arXiv, 2019.
- Fard et al. (2018) Maziar Moradi Fard, Thibaut Thonet, and Eric Gaussier. Deep -means: Jointly clustering with -means and learning representations. arXiv preprint arXiv:1806.10069, 2018.
- Genevay et al. (2018) Aude Genevay, Gabriel Peyré, and Marco Cuturi. Learning generative models with Sinkhorn divergences. In International Conference on Artificial Intelligence and Statistics, 2018.
- Genevay et al. (2019) Aude Genevay, Lénaic Chizat, Francis Bach, Marco Cuturi, and Gabriel Peyré. Sample complexity of Sinkhorn divergences. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics (AISTATS), Naha, Okinawa, Japan, 2019.
- Goodfellow et al. (2014) Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems 27, pages 2672–2680. Curran Associates, Inc., 2014.
- Guo et al. (2017) Xifeng Guo, Long Gao, Xinwang Liu, and Jianping Yin. Improved deep embedded clustering with local structure preservation. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, IJCAI’17, pages 1753–1759. AAAI Press, 2017. ISBN 978-0-9992411-0-3.
- Joulin et al. (2010) A. Joulin, F. Bach, and J. Ponce. Discriminative clustering for image co-segmentation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), 2010.
- Kingma et al. (2014) Diederik P. Kingma, Shakir Mohamed, Danilo Jimenez Rezende, and Max Welling. Semi-supervised learning with deep generative models. In Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, December 8-13 2014, Montreal, Quebec, Canada, pages 3581–3589, 2014.
- Peyré et al. (2019) Gabriel Peyré, Marco Cuturi, et al. Computational optimal transport. Foundations and Trends® in Machine Learning, 11(5-6):355–607, 2019.
- Pollard (1982) David Pollard. Quantization and the method of k-means. IEEE Transactions on Information theory, 28(2):199–205, 1982.
- Salimans et al. (2018) Tim Salimans, Han Zhang, Alec Radford, and Dimitris Metaxas. Improving gans using optimal transport. arXiv preprint arXiv:1803.05573, 2018.
- Song et al. (2013) Chunfeng Song, Feng Liu, Yongzhen Huang, Liang Wang, and Tieniu Tan. Auto-encoder based data clustering. In José Ruiz-Shulcloper and Gabriella Sanniti di Baja, editors, Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications, pages 117–124, Berlin, Heidelberg, 2013. Springer Berlin Heidelberg.
- Xie et al. (2016) Junyuan Xie, Ross Girshick, and Ali Farhadi. Unsupervised deep embedding for clustering analysis. In Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48, ICML’16, pages 478–487. JMLR.org, 2016.
- Yang et al. (2017) Bo Yang, Xiao Fu, Nicholas D. Sidiropoulos, and Mingyi Hong. Towards k-means-friendly spaces: Simultaneous deep learning and clustering. In Doina Precup and Yee Whye Teh, editors, Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 3861–3870, International Convention Centre, Sydney, Australia, 06–11 Aug 2017. PMLR.
- Yang et al. (2016) Jianwei Yang, Devi Parikh, and Dhruv Batra. Joint unsupervised learning of deep representations and image clusters. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2016. doi: 10.1109/cvpr.2016.556.