Adversarial T-shirt!
Evading Person Detectors in A Physical World
Abstract
It is known that deep neural networks (DNNs) are vulnerable to adversarial attacks. The so-called physical adversarial examples deceive DNN-based decision makers by attaching adversarial patches to real objects. However, most of the existing works on physical adversarial attacks focus on static objects such as glass frames, stop signs and images attached to cardboard. In this work, we propose Adversarial T-shirts, a robust physical adversarial example for evading person detectors even if it could undergo non-rigid deformation due to a moving person’s pose changes. To the best of our knowledge, this is the first work that models the effect of deformation for designing physical adversarial examples with respect to non-rigid objects such as T-shirts. We show that the proposed method achieves 74% and 57% attack success rates in the digital and physical worlds respectively against YOLOv2. In contrast, the state-of-the-art physical attack method to fool a person detector only achieves 18% attack success rate. Furthermore, by leveraging min-max optimization, we extend our method to the ensemble attack setting against two object detectors YOLO-v2 and Faster R-CNN simultaneously.
frame 5
frame 30
frame 60
frame 90
frame 120
frame 150
pattern
Ours (digital)
adversarial T-shirt






 Ours (physical):
Ours (physical):
Adversarial T-shirt






 Affine (non-TPS)
Affine (non-TPS)
adversarial T-shirt






 Baseline physical attack
Baseline physical attack







1 Introduction
The vulnerability of deep neural networks (DNNs) against adversarial attacks (namely, perturbed inputs deceiving DNNs) has been found in applications spanning from image classification to speech recognition [18, 33, 35, 6, 32, 2]. Early works studied adversarial examples only in the digital space. Recently, some works showed that it is possible to create adversarial perturbations on physical objects and fool DNN-based decision makers under a variety of real-world conditions [28, 13, 1, 14, 25, 7, 30, 5, 21]. The design of physical adversarial attacks helps to evaluate the robustness of DNNs deployed in real-life systems, e.g., autonomous vehicles and surveillance systems. However, most of the studied physical adversarial attacks encounter two limitations: a) the physical objects are usually considered being static, and b) the possible deformation of adversarial pattern attached to a moving object (e.g., due to pose change of a moving person) is commonly neglected. In this paper, we propose a new type of physical adversarial attack, adversarial T-shirt, to evade DNN-based person detectors when a person wears the adversarial T-shirt; see the second row of Fig. 1 for illustrative examples.
Related work
Most of the existing physical adversarial attacks are generated against image classifiers and object detectors. In [28], a face recognition system is fooled by a real eyeglass frame designed under a crafted adversarial pattern. In [13], a stop sign is misclassified by adding black or white stickers on it against the image classification system. In [21], an image classifier is fooled by placing a crafted sticker at the lens of a camera. In [1], a so-called Expectation over Transformation (EoT) framework was proposed to synthesize adversarial examples robust to a set of physical transformations such as rotation, translation, contrast, brightness, and random noise. Compared to attacking image classifiers, generating physical adversarial attacks against object detectors is more involved. For example, the adversary is required to mislead the bounding box detector of an object when attacking YOLOv2 [26] and SSD [24]. A well-known success of such attacks in the physical world is the generation of adversarial stop sign [14], which deceives state-of-the-art object detectors such as YOLOv2 and Faster R-CNN [27].
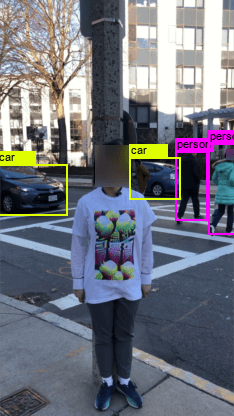
The most relevant approach to ours is the work of [30], which demonstrates that a person can evade a detector by holding a cardboard with an adversarial patch. However, such a physical attack restricts the adversarial patch to be attached to a rigid carrier (namely, cardboard), and is different from our setting here where the generated adversarial pattern is directly printed on a T-shirt. We show that the attack proposed by [30] becomes ineffective when the adversarial patch is attached to a T-shirt (rather than a cardboard) and worn by a moving person (see the fourth row of Fig. 1). At the technical side, different from [30] we propose a thin plate spline (TPS) based transformer to model deformation of non-rigid objects, and develop an ensemble physical attack that fools object detectors YOLOv2 and Faster R-CNN simultaneously. We highlight that our proposed adversarial T-shirt is not just a T-shirt with printed adversarial patch for clothing fashion, it is a physical adversarial wearable designed for evading person detectors in the real world.
Our work is also motivated by the importance of person detection on intelligent surveillance. DNN-based surveillance systems have significantly advanced the field of object detection [17, 16]. Efficient object detectors such as faster R-CNN [27], SSD [24], and YOLOv2 [26] have been deployed for human detection. Thus, one may wonder whether or not there exists a security risk for intelligent surveillance systems caused by adversarial human wearables, e.g., adversarial T-shirts. However, paralyzing a person detector in the physical world requires substantially more challenges such as low resolution, pose changes and occlusions. The success of our adversarial T-shirt against real-time person detectors offers new insights for designing practical physical-world adversarial human wearables.
Contributions
We summarize our contributions as follows:
-
•
We develop a TPS-based transformer to model the temporal deformation of an adversarial T-shirt caused by pose changes of a moving person. We also show the importance of such non-rigid transformation to ensuring the effectiveness of adversarial T-shirts in the physical world.
-
•
We propose a general optimization framework for design of adversarial T-shirts in both single-detector and multiple-detector settings.
-
•
We conduct experiments in both digital and physical worlds and show that the proposed adversarial T-shirt achieves 74% and 57% attack success rates respectively when attacking YOLOv2. By contrast, the physical adversarial patch [30] printed on a T-shirt only achieves 18% attack success rate. Some of our results are highlighted in Fig. 1.
2 Modeling Deformation of A Moving Object by Thin Plate Spline Mapping
In this section, we begin by reviewing some existing transformations required in the design of physical adversarial examples. We then elaborate on the Thin Plate Spline (TPS) mapping we adopt in this work to model the possible deformation encountered by a moving and non-rigid object.
Let be an original image (or a video frame), and be the physical transformer. The transformed image under is given by
| (1) |
Existing transformations.
In [1], the parametric transformers include scaling, translation, rotation, brightness and additive Gaussian noise; see details in [1, Appendix D]. In [23], the geometry and lighting transformations are studied via parametric models. Other transformations including perspective transformation, brightness adjustment, resampling (or image resizing), smoothing and saturation are considered in [29, 9]. All the existing transformations are included in our library of physical transformations. However, they are not sufficient to model the cloth deformation caused by pose change of a moving person. For example, the second and third rows of Fig. 1 show that adversarial T-shirts designed against only existing physical transformations yield low attack success rates.



 (a)
(b)
(c)
(d)
(a)
(b)
(c)
(d)
TPS transformation for cloth deformation.
A person’s movement can result in significantly and constantly changing wrinkles (aka deformations) in her clothes. This makes it challenging to develop an adversarial T-shirt effectively in the real world. To circumvent this challenge, we employ TPS mapping [4] to model the cloth deformation caused by human body movement. TPS has been widely used as the non-rigid transformation model in image alignment and shape matching [19]. It consists of an affine component and a non-affine warping component. We will show that the non-linear warping part in TPS can provide an effective means of modeling cloth deformation for learning adversarial patterns of non-rigid objects.
TPS learns a parametric deformation mapping from an original image to a target image through a set of control points with given positions. Let denote the 2D location of an image pixel. The deformation from to is then characterized by the displacement of every pixel, namely, how a pixel at on image changes to the pixel on image at , where and , and and denote the pixel displacement on image along direction and direction, respectively.
Given a set of control points with locations on image , TPS provides a parametric model of pixel displacement when mapping to [8]
| (2) |
where and are the TPS parameters, and represents the displacement along either or direction.
Moreover, given the locations of control points on the transformed image (namely, ), TPS resorts to a regression problem to determine the parameters in (2). The regression objective is to minimize the distance between and along the direction, and the distance between and along the direction, respectively. Thus, TPS (2) is applied to coordinate and separately (corresponding to parameters and ). The regression problem can be solved by the following linear system of equations [10]
| (3) |
where the th element of is given by , the th row of is given by , and the th elements of and are given by and , respectively.
Non-trivial application of TPS
The difficulty of implementing TPS for design of adversarial T-shirts exists from two aspects: 1) How to determine the set of control points? And 2) how to obtain positions and of control points aligned between a pair of video frames and ?
To address the first question, we print a checkerboard on a T-shirt and use the camera calibration algorithm [15, 34] to detect points at the intersection between every two checkerboard grid regions. These successfully detected points are considered as the control points of one frame. Fig. 2-(a) shows the checkerboard-printed T-shirt, together with the detected intersection points. Since TPS requires a set of control points aligned between two frames, the second question on point matching arises. The challenge lies in the fact that the control points detected at one video frame are different from those at another video frame (e.g., due to missing detection). Fig. 2-(a) v.s. (b) provides an example of point mismatch. To address this issue, we adopt a 2-stage procedure, coordinate system alignment followed by point aliment, where the former refers to conducting a perspective transformation from one frame to the other, and the latter finds the matched points at two frames through the nearest-neighbor method. We provide an illustrative example in Fig. 2-(c). We refer readers to Appendix A for more details about our method.
3 Generation of Adversarial T-shirt: An Optimization Perspective
In this section, we begin by formalizing the problem of adversarial T-shirt and introducing notations used in our setup. We then propose to design a universal perturbation used in our adversarial T-shirt to deceive a single object detector. We lastly propose a min-max (robust) optimization framework to design the universal adversarial patch against multiple object detectors.
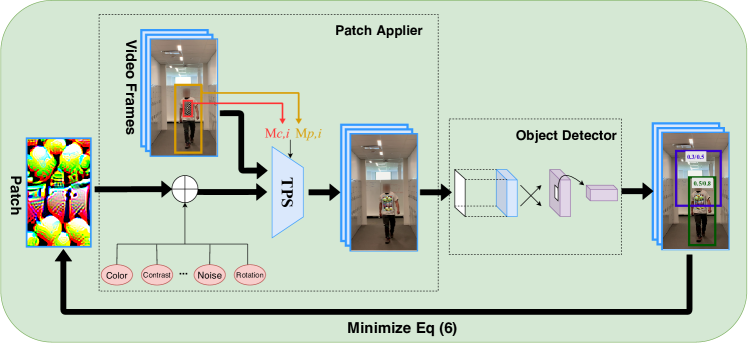
Let denote video frames extracted from one or multiple given videos, where denotes the th frame. Let denote the universal adversarial perturbation applied to . The adversarial T-shirt is then characterized by , where is a bounding box encoding the position of the cloth region to be perturbed at the th frame, and denotes element-wise product. The goal of adversarial T-shirt is to design such that the perturbed frames of are mis-detected by object detectors.
Fooling a single object detector.
We generalize the Expectation over Transformation (EoT) method in [3] for design of adversarial T-shirts. Note that different from the conventional EoT, a transformers’ composition is required for generating an adversarial T-shirt. For example, a perspective transformation on the bounding box of the T-shirt is composited with an TPS transformation applied to the cloth region.
Let us begin by considering two video frames, an anchor image (e.g., the first frame in the video) and a target image for 111 denotes the integer set .. Given the bounding boxes of the person () and the T-shirt () at , we apply the perspective transformation from to to obtain the bounding boxes and at image . In the absence of physical transformations, the perturbed image with respect to (w.r.t.) is given by
| (4) |
where the term denotes the background region outside the bouding box of the person, the term is the person-bounded region, the term erases the pixel values within the bounding box of the T-shirt, and the term is the newly introduced additive perturbation. In (4), the prior knowledge on and is acquired by person detector and manual annotation, respectively. Without taking into account physical transformations, Eq. (4) simply reduces to the conventional formulation of adversarial example .
Next, we consider three main types of physical transformations: a) TPS transformation applying to the adversarial perturbation for modeling the effect of cloth deformation, b) physical color transformation which converts digital colors to those printed and visualized in the physical world, and c) conventional physical transformation applying to the region within the person’s bounding box, namely, . Here denotes the set of possible non-rigid transformations, is given by a regression model learnt from the color spectrum in the digital space to its printed counterpart, and denotes the set of commonly-used physical transformations, e.g., scaling, translation, rotation, brightness, blurring and contrast. A modification of (4) under different sources of transformations is then given by
| (5) |
for , , and . In (5), the terms A, B and C have been defined in (4), and denotes a brightness transformation to model the environmental brightness condition. In (5), is an additive Gaussian noise that allows the variation of pixel values, where is a given smoothing parameter and we set it as in our experiments such that the noise realization falls into the range . The randomized noise injection is also known as Gaussian smoothing [11], which makes the final objective function smoother and benefits the gradient computation during optimization.
The prior work, e.g., [28, 12], established a non-printability score (NPS) to measure the distance between the designed perturbation vector and a library of printable colors acquired from the physical world. The commonly-used approach is to incorporate NPS into the attack loss through regularization. However, irt becomes non-trivial to find a proper regularization parameter, and the nonsmoothness of NPS makes optimization for the adversarial T-shirt difficult. To circumvent these challenges, we propose to model the color transformer using a quadratic polynomial regression. The detailed color mapping is showed in Appendix B.
With the aid of (5), the EoT formulation to fool a single object detector is cast as
| (7) |
where denotes an attack loss for misdetection, is the total-variation norm that enhances perturbations’ smoothness [14], and is a regularization parameter. We further elaborate on our attack loss in problem (7). In YOLOv2, a probability score associated with a bounding box indicates whether or not an object is present within this box. Thus, we specify the attack loss as the largest bounding-box probability over all bounding boxes belonging to the ‘person’ class. For Faster R-CNN, we attack all bounding boxes towards the class ‘background’. The more detailed derivation on the attack loss is provided in Appendix C. Fig. 3 presents an overview of our approach to generate adversarial T-shirts.
Min-max optimization for fooling multiple object detectors.
Unlike digital space, the transferability of adversarial attacks largely drops in the physical environment, thus we consider a physical ensemble attack against multiple object detectors. It was recently shown in [31] that the ensemble attack can be designed from the perspective of min-max optimization, and yields much higher worst-case attack success rate than the averaging strategy over multiple models. Given object detectors associated with attack loss functions , the physical ensemble attack is cast as
| (9) |
where are known as domain weights that adjust the importance of each object detector during the attack generation, is a probabilistic simplex given by , is a regularization parameter, and following (7). In (9), if , then the adversarial perturbation is designed over the maximum attack loss (worst-case attack scenario) since , where at a fixed . Moreover, if , then the inner maximization of problem (9) implies , namely, an averaging scheme over attack losses. Thus, the regularization parameter in (9) strikes a balance between the max-strategy and the average-strategy.
4 Experiments
In this section, we demonstrate the effectiveness of our approach (we call advT-TPS) for design of the adversarial T-shirt by comparing it with attack baseline methods, a) adversarial patch to fool YOLOv2 proposed in [30] and its printed version on a T-shirt (we call advPatch222For fair comparison, we modify the perturbation size same as ours and execute the code provided in [30] under our training dataset.), and b) the variant of our approach in the absence of TPS transformation, namely, in (5) (we call advT-Affine). We examine the convergence behavior of proposed algorithms as well as its Attack Success Rate333ASR is given by the ratio of successfully attacked testing frames over the total number of testing frames. (ASR) in both digital and physical worlds. We clarify our algorithmic parameter setting in Appendix D.
Prior to detailed illustration, we briefly summarize the attack performance of our proposed adversarial T-shirt. When attacking YOLOv2, our method achieves 74% ASR in the digital world and 57% ASR in the physical world, where the latter is computed by averaging successfully attacked video frames over all different scenarios (i.e., indoor, outdoor and unforeseen scenarios) listed in Table 2. When attacking Faster R-CNN, our method achieves 61% and 47% ASR in the digital and the physical world, respectively. By contrast, the baseline advPatch only achieves around 25% ASR in the best case among all digital and physical scenarios against either YOLOv2 or Faster R-CNN (e.g., 18% against YOLOv2 in the physical case).
4.1 Experimental Setup
Data collection.
We collect two datasets for learning and testing our proposed attack algorithm in digital and physical worlds. The training dataset contains videos ( video frames) from different scenes: one outdoor and three indoor scenes. each video takes - seconds and was captured by a moving person wearing a T-shirt with printed checkerboard. The desired adversarial pattern is then learnt from the training dataset. The test dataset in the digital space contains videos captured under the same scenes as the training dataset. This dataset is used to evaluate the attack performance of the learnt adversarial pattern in the digital world. In the physical world, we customize a T-shirt with the printed adversarial pattern learnt from our algorithm. Another test videos (Section 4.3) are then collected at a different time capturing two or three persons (one of them wearing the adversarial T-shirt) walking a) side by side or b) at different distances. An additional control experiment in which actors wearing adversarial T-shirts walk in an exaggerated way is conducted to introduce large pose changes in the test data. In addition, we also test our adversarial T-shirt by unforeseen scenarios, where the test videos involve different locations and different persons which are never covered in the training dataset. All videos were taken using an iPhone X and resized to 416 416. In Table A2 of the Appendix F, we summarize the collected dataset under all circumstances.
Object detectors.
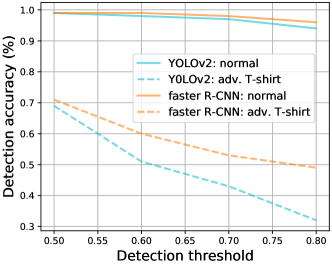
We use two state-of-the-art object detectors: Faster R-CNN [27] and YOLOv2 [26] to evaluate our method. These two object detectors are both pre-trained on COCO dataset [22] which contains 80 classes including ‘person’. The detection minimum threshold are set as 0.7 for both Faster R-CNN and YOLOv2 by default. The sensitivity analysis of this threshold is performed in Fig. A4 Appendix D.
4.2 Adversarial T-shirt in the digital world
Convergence performance of our proposed attack algorithm.
In Fig. 4, we show ASR against the epoch number used by our proposed algorithm to solve problem (7). Here the success of our attack at one testing frame is required to meet two conditions, a) misdetection of the person who wears the adversarial T-shirt, and b) successful detection of the person whom dresses a normal cloth. As we can see, the proposed attack method covnerges well for attacking both YOLOv2 and Faster R-CNN. We also note that attacking Faster R-CNN is more difficult than attacking YOLOv2. Furthermore, if TPS is not applied during training, then ASR drops around compared to our approach by leveraging TPS.


|
ASR of adversarial T-shirts in various attack settings.
We perform a more comprehensive evaluation on our methods by digital simulation. Table 1 compares the ASR of adversarial T-shirts generated w/ or w/o TPS transformation in 4 attack settings: a) single-detector attack referring to adversarial T-shirts designed and evaluated using the same object detector, b) transfer single-detector attack referring to adversarial T-shirts designed and evaluated using different object detectors, c) ensemble attack (average) given by (9) but using the average of attack losses of individual models, and d) ensemble attack (min-max) given by (9). As we can see, it is crucial to incorporate TPS transformation in the design of adversarial T-shirts: without TPS, the ASR drops from 61% to 34% when attacking faster R-CNN and drops from 74% to 48% when attacking YOLOv2 in the single-detector attack setting. We also note that the transferability of single-detector attack is weak in all settings. And faster R-CNN is consistently more robust than YOLOv2, similar to the results in Fig. 4. Compared to our approach and advT-Affine, the baseline method advPatch yields the worst ASR when attacking a single detector. Furthermore, we evaluate the effectiveness of the proposed min-max ensemble attack (9). As we can see, when attacking faster R-CNN, the min-max ensemble attack significantly outperforms its counterpart using the averaging strategy, leading to improvement in ASR. This improvement is at the cost of degradation when attacking YOLOv2.
method model target transfer ensemble(average) ensemble(min-max) advPatch[30] 22% 10% N/A N/A advT-Affine Faster R-CNN 34% 11% 16% 32% advT-TPS(ours) 61% 10% 32% 47% advPatch[30] 24% 10% N/A N/A advT-Affine YOLOv2 48% 13% 31% 27% advT-TPS(ours) 74% 13% 60% 53%
4.3 Adversarial T-shirt in the physical world
We next evaluate our method in the physical world. First, we generate an adversarial pattern by solving problem (7) against YOLOv2 and Faster R-CNN, following Section 4.2. We then print the adversarial pattern on a white T-shirt, leading to the adversarial T-shirt. For fair comparison, we also print adversarial patterns generated by the advPatch [30] and advT-Affine in Section 4.2 on white T-shirts of the same style. It is worth noting that different from evaluation by taking static photos of physical adversarial examples, our evaluation is conducted at a more practical and challenging setting. That is because we record videos to track a moving person wearing adversarial T-shirts, which could encounter multiple environment effects such as distance, deformation of the T-shirt, poses and angles of the moving person.
In Table 2, we compare our method with advPatch and advT-Affine under specified scenarios, including the indoor, outdoor, and unforeseen scenarios444Unforeseen scenarios refer to test videos that involve different locations and actors, never seen in the training dataset., together with the overall case of all scenarios. We observe that our method achieves 64% ASR (against YOLOv2), which is much higher than advT-Affine (39%) and advPatch (19%) in the indoor scenario. Compared to the indoor scenario, evading person detectors in the outdoor scenario becomes more challenging. The ASR of our approach reduces to 47% but outperforms advT-Affine (36%) and advPatch (17%). This is not surprising since the outdoor scenario suffers more environmental variations such as lighting change. Even considering the unforeseen scenario, we find that our adversarial T-shirt is robust to the change of person and location, leading to 48% ASR against Faster R-CNN and 59% ASR against YOLOv2. Compared to the digital results, the ASR of our adversarial T-shirt drops around in all tested physical-world scenarios; see specific video frames in Fig. A5.
method model indoor outdoor new scenes average ASR advPatch[30] 15% 16% 12% 14% advT-Affine Faster R-CNN 27% 25% 25% 26% advT-TPS(ours) 50% 42% 48% 47% advPatch[30] 19% 17% 17% 18% advT-Affine YOLOv2 39% 36% 34% 37% advT-TPS(ours) 64% 47% 59% 57%
4.4 Ablation Study
In this section, we conduct more experiments for better understanding the robustness of our adversarial T-shirt against various conditions including angles and distances to camera, camera view, person’s pose, and complex scenes that include crowd and occlusion. Since the baseline method (advPatch) performs poorly in most of these scenarios, we focus on evaluating our method (advT-TPS) against advT-Affine using YOLOv2. We refer readers to Appendix E for details on the setup of our ablation study.
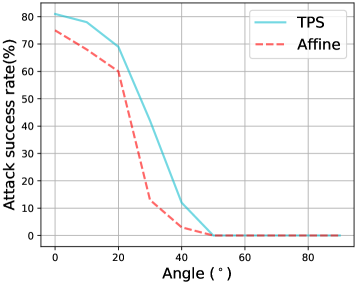
Angles and distances to camera.
In Fig. 5, we present ASRs of advT-TPS and advT-Affine when the actor whom wears the adversarial T-shit at different angles and distances to the camera. As we can see, advT-TPS works well within the angle and the distance m. And advT-TPS consistently outperforms advT-Affine. We also note that ASR drops significantly at the angle since it induces occlusion of the adversarial pattern. Further, if the distance is greater than m, the pattern cannot clearly be seen from the camera.

|
Human Pose.
In Table 3 (left), we evaluate the effect of pose change on advT-TPS, where videos are taken for an actor with some distinct postures including crouching, siting and running in place; see Fig. 6 for specific examples. To alleviate other latent effects, the camera was made to look straight at the person at a fixed distance of about m away from the person. As we can see, advT-TPS consistently outperforms advT-Affine. However, it is worth noting that the sitting posture remains challenging for both methods as the larger occlusion is the worse ASR is. To delve into this problem, Fig. A6 presents how well our adversarial T-shirt can handle occlusion by partially covering the T-shirt by hand. Not surprisingly, both advT-Affine and advT-TPS may fail when occlusion becomes quite large. Thus, occlusion is still an interesting problem for physical adversaries.
Complex scenes.
In Table 3 (right), we test our adversarial T-shirt in several complex scenes with cluttered backgrounds, including a) an office with multiple objects and people moving around; b) a parking lot with vehicles and pedestrians; and c) a crossroad with busy traffic and crowd. We observe that compared to advT-Affine, advT-TPS is reasonably effective in complex scenes without suffering a significant loss of ASR. Compared to the other factors such as camera angle and occlusion, cluttered background and even crowd are probably the least of a concern for our approach. This is explainable, as our approach works on object proposals directly to suppress the classifier.
crouching
sitting
running
advT-Affine







 advT-TPS
advT-TPS








crouching siting running advT-Affine 27% 26% 52% advT-TPS 53% 32% 63% office parking lot crossroad advT-Affine 69% 53% 51% advT-TPS 73% 65% 54%


|
5 Conclusion
In this paper, we propose Adversarial T-shirt, the first successful adversarial wearable to evade detection of moving persons. Since T-shirt is a non-rigid object, its deformation induced by a person’s pose change is taken into account when generating adversarial perturbations. We also propose a min-max ensemble attack algorithm to fool multiple object detectors simultaneously. We show that our attack against YOLOv2 can achieve 74% and 57% attack success rate in the digital and physical world, respectively. By contrast, the advPatch method can only achieve 24% and 18% ASR. Based on our studies, we hope to provide some implications on how the adversarial perturbations can be implemented in physical worlds.
References
- [1] Athalye, A., Engstrom, L., Ilyas, A., Kwok, K.: Synthesizing robust adversarial examples. In: Dy, J., Krause, A. (eds.) Proceedings of the 35th International Conference on Machine Learning. vol. 80, pp. 284–293 (10–15 Jul 2018)
- [2] Athalye, A., Carlini, N., Wagner, D.: Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. arXiv preprint arXiv:1802.00420 (2018)
- [3] Athalye, A., Engstrom, L., Ilyas, A., Kwok, K.: Synthesizing robust adversarial examples. In: International Conference on Machine Learning. pp. 284–293 (2018)
- [4] Bookstein, F.L.: Principal warps: Thin-plate splines and the decomposition of deformations. IEEE Transactions on pattern analysis and machine intelligence 11(6), 567–585 (1989)
- [5] Cao, Y., Xiao, C., Yang, D., Fang, J., Yang, R., Liu, M., Li, B.: Adversarial objects against lidar-based autonomous driving systems. arXiv preprint arXiv:1907.05418 (2019)
- [6] Carlini, N., Wagner, D.: Audio adversarial examples: Targeted attacks on speech-to-text. In: 2018 IEEE Security and Privacy Workshops (SPW). pp. 1–7. IEEE (2018)
- [7] Chen, S.T., Cornelius, C., Martin, J., Chau, D.H.P.: Shapeshifter: Robust physical adversarial attack on faster r-cnn object detector. In: Joint European Conference on Machine Learning and Knowledge Discovery in Databases. pp. 52–68. Springer (2018)
- [8] Chui, H.: Non-rigid point matching: algorithms, extensions and applications. Citeseer (2001)
- [9] Ding, G.W., Lui, K.Y.C., Jin, X., Wang, L., Huang, R.: On the sensitivity of adversarial robustness to input data distributions. In: International Conference on Learning Representations (2019)
- [10] Donato, G., Belongie, S.: Approximate thin plate spline mappings. In: European conference on computer vision. pp. 21–31. Springer (2002)
- [11] Duchi, J.C., Bartlett, P.L., Wainwright, M.J.: Randomized smoothing for stochastic optimization. SIAM Journal on Optimization 22(2), 674–701 (2012)
- [12] Evtimov, I., Eykholt, K., Fernandes, E., Kohno, T., Li, B., Prakash, A., Rahmati, A., Song, D.: Robust physical-world attacks on machine learning models. arXiv preprint arXiv:1707.08945 (2017)
- [13] Eykholt, K., Evtimov, I., Fernandes, E., Li, B., Rahmati, A., Xiao, C., Prakash, A., Kohno, T., Song, D.: Robust physical-world attacks on deep learning visual classification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 1625–1634 (2018)
- [14] Eykholt, K., Evtimov, I., Fernandes, E., Li, B., Rahmati, A., Tramer, F., Prakash, A., Kohno, T., Song, D.: Physical adversarial examples for object detectors. In: 12th USENIX Workshop on Offensive Technologies (WOOT 18) (2018)
- [15] Geiger, A., Moosmann, F., Car, Ö., Schuster, B.: Automatic camera and range sensor calibration using a single shot. In: 2012 IEEE International Conference on Robotics and Automation. pp. 3936–3943. IEEE (2012)
- [16] Girshick, R.: Fast r-cnn. In: Proceedings of the IEEE international conference on computer vision. pp. 1440–1448 (2015)
- [17] Girshick, R., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 580–587 (2014)
- [18] Goodfellow, I.J., Shlens, J., Szegedy, C.: Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572 (2014)
- [19] Jaderberg, M., Simonyan, K., Zisserman, A., et al.: Spatial transformer networks. In: Advances in neural information processing systems. pp. 2017–2025 (2015)
- [20] Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
- [21] Li, J., Schmidt, F., Kolter, Z.: Adversarial camera stickers: A physical camera-based attack on deep learning systems. In: International Conference on Machine Learning. pp. 3896–3904 (2019)
- [22] Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
- [23] Liu, H.T.D., Tao, M., Li, C.L., Nowrouzezahrai, D., Jacobson, A.: Beyond pixel norm-balls: Parametric adversaries using an analytically differentiable renderer. In: International Conference on Learning Representations (2019), https://openreview.net/forum?id=SJl2niR9KQ
- [24] Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.Y., Berg, A.C.: Ssd: Single shot multibox detector. In: European conference on computer vision. pp. 21–37. Springer (2016)
- [25] Lu, J., Sibai, H., Fabry, E.: Adversarial examples that fool detectors. arXiv preprint arXiv:1712.02494 (2017)
- [26] Redmon, J., Farhadi, A.: Yolo9000: better, faster, stronger. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7263–7271 (2017)
- [27] Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time object detection with region proposal networks. In: Advances in neural information processing systems. pp. 91–99 (2015)
- [28] Sharif, M., Bhagavatula, S., Bauer, L., Reiter, M.K.: Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. In: Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. pp. 1528–1540. ACM (2016)
- [29] Sitawarin, C., Bhagoji, A.N., Mosenia, A., Mittal, P., Chiang, M.: Rogue signs: Deceiving traffic sign recognition with malicious ads and logos. arXiv preprint arXiv:1801.02780 (2018)
- [30] Thys, S., Van Ranst, W., Goedemé, T.: Fooling automated surveillance cameras: adversarial patches to attack person detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. pp. 0–0 (2019)
- [31] Wang, J., Zhang, T., Liu, S., Chen, P.Y., Xu, J., Fardad, M., Li, B.: Beyond adversarial training: Min-max optimization in adversarial attack and defense. arXiv preprint arXiv:1906.03563 (2019)
- [32] Xu, K., Chen, H., Liu, S., Chen, P.Y., Weng, T.W., Hong, M., Lin, X.: Topology attack and defense for graph neural networks: An optimization perspective. In: International Joint Conference on Artificial Intelligence (IJCAI) (2019)
- [33] Xu, K., Liu, S., Zhao, P., Chen, P.Y., Zhang, H., Fan, Q., Erdogmus, D., Wang, Y., Lin, X.: Structured adversarial attack: Towards general implementation and better interpretability. In: International Conference on Learning Representations (2019)
- [34] Zhang, Z.: A flexible new technique for camera calibration. IEEE Transactions on pattern analysis and machine intelligence 22 (2000)
- [35] Zhao, P., Xu, K., Liu, S., Wang, Y., Lin, X.: Admm attack: an enhanced adversarial attack for deep neural networks with undetectable distortions. In: Proceedings of the 24th Asia and South Pacific Design Automation Conference. pp. 499–505. ACM (2019)
Appendix
In the supplement, we provide details on the thin plate spline (TPS) transformation, the formulation of attack loss, the setting of algorithmic parameters, and the additional experiments of the adversarial T-shirt in the physical world.
Appendix A How to construct TPS transformation?
| frame 1 in Fig.2a | frame 2 in Fig.2b |
|---|---|
 |
|
We first manually annotate four corner points (see blue markers in Figure A1) to conduct a perspective transformation between two frames at different time instants. This perspective transformation is used to align the coordinate system of anchor points used for TPS transformation between two frames.
Ideally, the checkerboard detection tool [15, 34] always outputs a grid of corner points detected. In most cases, it can locate all the points on the checkerboard perfectly, so no additional effort is needed to establish the point correspondences between two images. In the case when there are corner points missing in the detection, we use the following method to match two images. We perform a point matching procedure (see Algorithm 1) to align the anchor points (see red markers in Figure A1) detected by the checkerboard detection tool. The data matching procedure selects the set of matched anchor points used for constructing TPS transformation.
Appendix B Color transformation
As shown in Figure A2, we generate the training dataset to map a digital color palette to the same one printed on a T-shirt. With the aid of color cell pairs. We learn the weights of the quadratic polynomial regression by minimizing the mean squared error of the predicted physical color (with the digital color in Figure A2(a) as input) and the ground-truth physical color provided in Figure A2(b). Once the color transformer is learnt, we then incorporate it into (5).
 |
 |
 |
| (a) | (b) | (c) |
Appendix C Formulation of attack loss
There are two possible options to formulate the attack loss to fool person detectors. First, is specified as the misclassification loss, commonly-used in most of previous works. The goal is to misclassify the class ‘person’ to any other incorrect class. However, our work consider a more advanced disappearance attack, which enforces the detector even not to draw the bounding box of the object ‘person’. For YOLOv2, we minimize the confidence score of all bounding boxes corresponding to the class ‘person’. For Faster R-CNN, we attack all bounding boxes towards the class ‘background’. Let be a perturbed video frame, the attack loss in (6) is then given by
| (11) |
where denotes the confidence score of the th bounding box for YOLOv2 or the probability of the ‘person’ class at the th bounding box for Faster R-CNN, is a confidence threshold, the use of enforces the optimizer to minimize the bounding boxes of high probability (greater than ), is the th bounding box, is the known bounding box encoding the person’s region, the quantity represents the intersection between and , is the cardinality function, and is the indicator function, which returns if has at least -overlapping with , and otherwise. In Eq.(11), the quantity characterizes the bounding box of our interest with both high probability and large overlapping with . And the eventual loss in Eq.(11) gives the largest probability for detecting a bounding box of the object ‘person’.
Appendix D Hyperparameter setting
When solving Eq. (7), we use Adam optimizer [20] to train 5,000 epochs with the initial learning rate, . The rate is decayed when the loss ceases to decrease. The regularization parameter for total-variation norm is set as . In Eq. (9), we set as 1, and solve the min-max problem by 6000 epochs with the initial learning rate . In Eq. (5), the details of transformations are shown in Table A1.
| Transformation | Minimum | Maximum |
|---|---|---|
| Scale | 0.5 | 2 |
| Brightness | -0.1 | 0.1 |
| Contrast | 0.8 | 1.2 |
| Random uniform noise | -0.1 | 0.1 |
| Blurring | average pooling/filter size = 5 | |
In experiments, we find that the hyperparameter strikes a balance between the fine-gained perturbation pattern and its smoothness. As we can see in Figure A3, when is smallest (namely, ), the perturbation can achieve the best ASR (82% ) against YOLOv2 in the digital space, however when we test the digital pattern in the physical world, the attacking performance drops to 51% (worse than the case of ) as the non-smooth (sharp) perturbation pattern might not be well captured by a real-world camera. In our experiments, we choose for the best tradeoff between digital and physical results.
| 1 | 3 | 5 | |
 |
|
 |
|
| digital | 82% | 74% | 69% |
| physical | 51% | 57% | 55% |
For a real-world deployment of a person detector, the minimum detection threshold needs to be empirically determined to obtain a good tradeoff between detection accuracy and false alarm rates. In our physical-word testing, we set the threshold to 0.7 for Faster R-CNN and YOLOv2, at which both of them achieve detection accuracy over 97% on person wearing normal clothing. The sensitivity analysis of this threshold is provided in Figure A4.
 |
Appendix E Dataset details
| videos (frames) | indoor | outdoor | overall | |||
| office | elevator | hallway | street1 | street2 | ||
| single-person | 4 (177) | 4 (135) | 4 (230) | 4 (225) | 4 (240) | 20 (1007) |
| multi-persons | 4 (162) | 4 (132) | 4 (245) | 4 (230) | 4 (227) | 20 (996) |
| train | 6 (245) | 6 (180) | 6 (335) | 6 (344) | 6 (365) | 30 (1469) |
| test (digital) | 2 (94) | 2 (87) | 2 (140) | 2 (111) | 2 (102) | 10 (534) |
| unseen | elevator | hallway | street3 | |||
| test (physical) | 6 (236) | 6 (184) | 6 (220) | 6 (288) | 24 (928) | |
In Section 4.4 for ablation study on parameter sensitivity and generalization to more complex testing scenarios, we further collected some new test data. Specifically, we considered the scenario of five people (two females and three males) for ablation study and none of them appeared in the original training and testing datasets. We recorded multiple videos by using two cameras (one iPhone X and one iPhone XI) and reported the resulting ASR in average.
Appendix F More experimental results
In Figure A5, we demonstrate our physical-world attack results in two scenarios: a) adversarial T-shirts generated by advT-TPS, advT-Affine and advPatch in an outdoor scenario (the first three rows), b) adversarial T-shirts generated by advT-TPS and advT-Affine in an unseen scenario (at a location never seen in the training dataset). As we can see, our method outperforms affine and baseline. In the absence of TPS, adversarial T-shirts generated by affine and baseline fail in most of cases, implying the importance of TPS to model the T-shirt deformation. When a person whom wears the adversarial T-shirt walks towards the camera, as expected, the detector also becomes easier to be attacked.
advT-TPS






 advT-Affine
advT-Affine






 advPatch
advPatch






 advT-TPS
advT-TPS




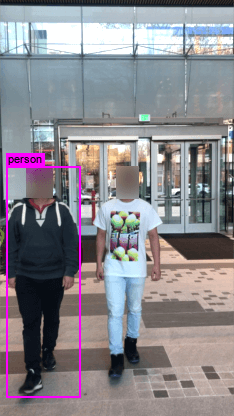

 advT-Affine
advT-Affine







| advT-Affine | advT-TPS | ||||
|---|---|---|---|---|---|

|

|

|

|

|

|