22email: {chandra.thapa, chamikara.arachchige, seyit.camtepe}@data61.csiro.au
22email: lis221@lehigh.edu
SplitFed: When Federated Learning Meets Split Learning
Abstract
Federated learning (FL) and split learning (SL) are two popular distributed machine learning approaches. Both follow a model-to-data scenario; clients train and test machine learning models without sharing raw data. SL provides better model privacy than FL due to the machine learning model architecture split between clients and the server. Moreover, the split model makes SL a better option for resource-constrained environments. However, SL performs slower than FL due to the relay-based training across multiple clients. In this regard, this paper presents a novel approach, named splitfed learning (SFL), that amalgamates the two approaches eliminating their inherent drawbacks, along with a refined architectural configuration incorporating differential privacy and PixelDP to enhance data privacy and model robustness. Our analysis and empirical results demonstrate that (pure) SFL provides similar test accuracy and communication efficiency as SL while significantly decreasing its computation time per global epoch than in SL for multiple clients. Furthermore, as in SL, its communication efficiency over FL improves with the number of clients. Besides, the performance of SFL with privacy and robustness measures is further evaluated under extended experimental settings.
1 Introduction
Distributed Collaborative Machine Learning (DCML) is popular due to its default data privacy benefits [12]. Unlike the conventional approach, where the data is centrally pooled and accessed, DCML enables machine learning without having to transfer data from data custodians to any untrusted party. Moreover, analysts have no access to raw data; instead, the machine learning (ML) model is transferred to the data curator for processing. Besides, it enables computation on multiple systems or servers and distributed devices.
The most popular DCML approaches are federated learning [13, 19] and split learning [9]. Federated learning (FL) trains a full (complete) ML model on the distributed clients with their local data and later aggregates the locally trained full ML models to form a global model in a server. The main advantage of FL is that it allows parallel, hence efficient, ML model training across many clients.
Computational requirement at the client-side and model privacy during ML training in FL. The main disadvantage of FL is that each client needs to run the full ML model, and resource-constrained clients, such as available in the Internet of Things, could not afford to run the full model. This case is prevalent if the ML models are deep learning models. Besides, there is a privacy concern from the model’s privacy perspective during training because the server and clients have full access to the local and global models.
To address these concerns, split learning (SL) was introduced. SL splits the full ML model into multiple smaller network portions and train them separately on a server, and distributed clients with their local data. Assigning only a part of the network to train at the client-side reduces processing load (compared to that of running a complete network as in FL), which is significant in ML computation on resource-constrained devices [24]. Besides, a client has no access to the server-side model and vice-versa.
Training time overhead in SL. Despite the advantages of SL, there is a primary issue. The relay-based training in SL makes the clients’ resources idle because only one client engages with the server at one instance; causing a significant increase in the training overhead with many clients.
To address these issues in FL and SL, this paper proposes a novel architecture called splitfed learning (SFL). SFL considers the advantages of FL and SL, while emphasizing on data privacy, and robustness of the model. Refer to Table 1 for its abstract comparison with FL and SL. Our contributions are mainly two-fold: Firstly, we are the first to propose SFL. Data privacy and model’s robustness are enhanced at the architectural level in SFL by the differential privacy-based measures [1] and PixelDP [18]. Secondly, to demonstrate the feasibility of SFL, we present comparative performance measurements of FL, SL, and SFL by considering four standard datasets and four popular models. Based on our analyses and empirical results, SFL provides an excellent solution that offers better model privacy than FL, and it is faster than SL with a similar performance to SL in model accuracy and communication efficiency.
Overall, SFL is beneficial for resource-constrained environments where full model training and deployment are not feasible, and fast model training time is required to periodically update the global model based on a continually updating dataset over time (e.g., data stream). These environments characterize various domains, including health, e.g., real-time anomaly detection in a network with multiple Internet of Medical Things111The examples of the Internet of Medical Things include glucose monitoring devices, open artificial pancreas systems, wearable electrocardiogram (ECG) monitoring devices, and smart lenses. connected via gateways and finance, e.g., privacy-preserving credit card fraud detection.
Learning approach Model aggregation Model privacy advantage by splitted model Client-side training Distributed computing Access to raw data SL No Yes Sequential Yes No FL Yes No Parallel Yes No SFL Yes Yes Parallel Yes No
2 Background and Related Works
Federated learning [13, 19, 2] trains a complete ML network/algorithm at each client on its local data in parallel for a certain number of local epochs, and then the local updates are sent to the server for aggregation [19]. This way, the server forms a global model and completes one global epoch222When forward propagation and back-propagation are completed for all available datasets across all participating clients for one cycle, it is called one global epoch.. The learned parameters of the global model are then sent back to all clients to train for the next round. This process continues until the algorithm converges. In this paper, we consider the federated averaging (FedAvg) algorithm [19] for model aggregations in FL. FedAvg considers a weighted average of the gradients for the model updates.
Split learning [24, 9] splits a deep learning network into multiple portions, and these portions are processed and computed on different devices. In a simple setting, is split into two portions and , called client-side network and server-side network, respectively. The clients, where the data reside, commit only to the client-side portion of the network, and the server commits only to the server-side portion of the network. The communication involves sending activations, called smashed data, of the split layer, called cut layer, of the client-side network to the server, and receiving the gradients of the smashed data from the server-side operations. The synchronization of the learning process with multiple clients is done either in a centralized mode or peer-to-peer mode in SL [9].
Differential privacy (DP) is a privacy model that defines privacy in terms of stochastic frameworks [4, 3]. DP can be formally defined as follows:
Definition 1
A mechanism is considered to be -differential private if, for all adjacent datasets, and , and for all possible subsets of results, of the mechanism, the following holds:
Practically, the values of (privacy budget) and (probability of failure) should be kept as small as possible to maintain a high level of privacy. However, the smaller the values of and , the higher the noise applied to the input data by the DP algorithm.
3 The Proposed Framework
The framework SFL is presented in this section. We first give the overview of SFL. Then we detail three key modules: (1) the differentially private knowledge perturbation, (2) the PixelDP for robust learning, and (3) total cost analysis of SFL.
3.1 Overall Structure
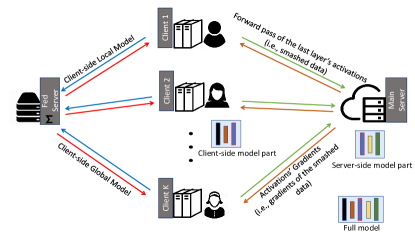
SFL combines the primary strength of FL, which is parallel processing among distributed clients, and the primary strength of SL, which is network splitting into client-side and server-side sub-networks during training. Refer to Fig. 1 for a representation of the SFL architecture. Unlike SL, all clients carry out their computations in parallel and engage with the main server and fed server. A client can be a hospital or an Internet of Medical Things with low computing resources, and the main server can be a cloud server or a researcher with high-performance computing resources. The fed server is introduced to conduct FedAvg on the client-side local updates. Moreover, the fed server synchronizes the client-side global model in each round of network training. The fed server’s computations, which is mainly computing FedAvg, are not costly. Hence, the fed server can be hosted within the local edge boundaries. Alternatively, if we implement all operations at the fed server over encrypted information, i.e., homomorphic encryption-based client-side model aggregation, then the main server can perform the operations of the fed server.
SFL workflow. All clients perform forward propagation on their client-side model in parallel, including its noise layer, and pass their smashed data to the main server. Then the main server processes the forward propagation and back-propagation on its server-side model with each client’s smashed data separately in (somewhat) parallel. It then sends the gradients of the smashed data to the respective clients for their back-propagation. Afterward, the server updates its model by FedAvg, i.e., weighted averaging of gradients that it computes during the back-propagation on each client’s smashed data. At the client’s side, after receiving the gradients of its smashed data, each client performs the back-propagation on their client-side local model and computes its gradients. A DP mechanism is used to make these gradients private and send them to the fed server. The fed server conducts the FedAvg of the client-side local updates and sends them back to all participating clients.
3.1.1 Variants of Splitfed Learning.
There can be several variants of SFL. We broadly divide them into two categories in the following:
Based on Server-side Aggregation.
This paper proposes two variants of SFL. The first one is called splitfedv1 (SFLV1), which is depicted in Algorithm 1 and 2. The next algorithm is called splitfedv2 (SFLV2), and it is motivated by the intuition of the possibility to increase the model accuracy by removing the model aggregation part in the server-side computation module in Algorithm 1. In Algorithm 1, the server-side models of all clients are executed separately in parallel and then aggregated to obtain the global server-side model at each global epoch. In contrast, SFLV2 processes the forward-backward propagations of the server-side model sequentially with respect to the client’s smashed data (no FedAvg of the server-side models). The client order is chosen randomly in the server-side operations, and the model gets updated in every single forward-backward propagation. Besides, the server receives the smashed data from all participating clients synchronously. The client-side operation remains the same as in the SFLV1; the fed server conducts the FedAvg of the client-side local models and sends the aggregated model back to all participating clients. These operations are not affected by the client order as the local client-side models are aggregated by the weighted averaging method, i.e., FedAvg. Some other SFL versions are available in the literature, but they are developed after and influenced by our approach [10, 7].
Based on Data Label Sharing.
Due to the split ML models in SFL, we can carry out ML in the two settings; (1) sharing the data labels to the server and (2) without sharing any data labels to the server. Algorithm 1 considers SFL with data label sharing. In cases without sharing data labels, the ML model in SFL can be partitioned into three parts, assuming a simple setup. Each client will process two client-side model portions; one with the first few layers of , and another with the last few layers of and loss calculations. The remaining middle layers of will be computed at the server-side. All possible configurations of SL, including vertically partitioned data, extended vanilla, and multi-task SL [24], can be carried out similarly in SFL as its variants.
3.2 Privacy Protection
The inherent privacy preservation capabilities of SFL are due to two reasons: firstly, it adopts the model-to-data approach, and secondly, SFL conducts ML over a split network. A network split in ML learning enables the clients/fed server and the main server to maintain the full model privacy by not allowing the main server to get the client-side model updates and vice-versa. The main server has access only to the smashed data (i.e., activation vectors of the cut layer). The curious main server needs to invert all the client-side model parameters, i.e., weight vectors, to infer data and client-side model. The possibility of inferring the client-side model parameters and raw data is highly unlikely if we configure the client-side ML networks’ fully connected layers with sufficiently large numbers of nodes [9]. However, for a smaller client-side network, the possibility of this issue can be high. This issue can be controlled by modifying the loss function at the client-side [23]. Due to the same reasons, the clients (having access only to the gradients of the smashed data from the main server) and the fed server (having access only to the client-side updates) cannot infer the server-side model parameters. Since there is no network split and separate training on the client-side and server-side in FL, SFL provides superior architectural configurations for enhanced privacy for an ML model during training compared to FL.
3.2.1 Privacy Protection at the Client-side.
We discuss the inherent privacy of the proposed model in the previous section. However, there can be an advanced adversary exploiting the underlying information representations of the shared smashed data or parameters (weights) to violate data owners’ privacy. This can happen if any server/client becomes curious though still honest. To avoid these possibilities, we apply two measures in our studies; (i) differential privacy to the client-side model training and (ii) PixelDP noise layer in the client-side model.
3.2.2 Privacy Protection on Fed Server.
Considering Algorithm 2, we present the process for implementing differential privacy at a client . We assume the following: represents the noise scale, and represents the gradient norm bound. Now, firstly, after time, the client receives the gradients from the server, and with this, it calculates client-side gradients for each of its local sample , and
| (1) |
Secondly, the -norm of each gradient is clipped according to the following equation:
| (2) |
Thirdly, calibrated noise is added to the average gradient:
| (3) |
Finally, the client-side model parameters of client are updated as follows; .
We apply calibrated noise iteratively until the model converges or reaches a specified number of iterations. As the iterations progress, the final convergence will exhibit a privacy level of - differential privacy, where is the overall privacy cost of the client-side model.
Differential privacy is used to enforce strict privacy to the client-side model training algorithm based on Abadi et al.’s approach [1]. Equation 2 (norm clipping) guarantees that is preserved when . This step also guarantees that scaled down to when . This step also helps clipping out the effect of Equation 5 on the gradients. Hence, norm clipping step allows bounding the influence of each individual example on in the process of guaranteeing differential privacy. It was shown that, the corresponding noise addition (refer to Equation 3) provides -DP for each step of (), if we choose (noise scale) to be [5]. Hence, at the end of steps, this will result in -DP. As shown by Abadi et al., for any and , by choosing , the privacy can be maintained at -DP [1]. Moments accountant (a privacy accountant) is used to track and maintain . Hence, at the end of , a client model guarantees -DP. With the strict assumption that all clients work on IID data, we can confirm that all clients maintain and guarantee -DP while client-side model training and synchronization.
3.2.3 Privacy Protection on Main Server.
The above DP measures do not stop potential leakage from the smashed data to the main server though it has some effect on the smashed data after the first global epoch. Thus, to avoid privacy leakage and further strengthen data privacy and model robustness against potential adversarial ML settings, we integrate a noise layer in the client-side model based on the concepts of PixelDP [18].
This extended measure utilizes the noise application mechanism involved in differential privacy to add a calibrated noise to the output (e.g., activation vectors) of a layer at the client-side model while maintaining utility. In this process, firstly, we calculate the sensitivity of the process. The sensitivity of a function is defined as the maximum change in output that can be produced by a change in the input, given some distance metrics for the input and output (p-norm and q-norm, respectively):
| (4) |
Secondly, Laplacian noise with scale is applied to randomize any data as follows:
| (5) |
where, represents a private version of , and is the privacy budget used for the Laplacian noise. This method enables forwarding private versions of the smashed data to the main server; hence, preserving the privacy of smashed data. The private version of the smashed data is due to the post-processing immunity of the DP mechanism applied at the noise layer in the client-side model. The noisy smashed data is more private than the original data due to the calibrated noise. Moreover, PixelDP not only can provide privacy for smashed data, but also can improve the robustness of the model against adversarial examples. However, detailed analysis and mathematical guarantees are kept for future work to preserve the main focus of the proposed work.
Robustness via PixelDP.
The primary intuition behind using random DP mechanism to robust ML against adversarial examples is to create a DP scoring function. For example, feeding any data sample through the DP scoring function, the outputs are DP with regards to the features of the input. Then, stability bounds for the expected output of the DP function are given by the following Lemma [18]:
Lemma 1
Suppose a randomized function , with bounded output , satisfies ()-DP. Then the expected value of its output meets the following property:
| (6) |
where is the -norm ball, and the expectation is taken over the randomness in .
Combined with Equation, , the bounds provide a rigorous certification for robustness to adversarial examples.
3.3 Total Cost Analysis
This section analyzes the total communication cost and model training time for FL, SL, and SFL under a uniform data distribution. Assume be the number of clients, be the total data size, be the size of the smashed layer, be the communication rate, be the time taken for one forward and backward propagation on the full model with dataset of size (for any architecture), is the time required to perform the full model aggregation (let be the aggregation time for an individual server), be the size of the full model, and be the fraction of the full model’s size available in a client in SL/SFL, i.e., . The term in communication per client is due to the download and upload of the client-side model updates before and after training, respectively, by a client. The result is presented in Table 2. As shown in the table, SL can become inefficient when there is a large number of clients. Besides, we see that when increases, the total training time cost increases in the order of SFLV2SFLV1SL. Also, we observe this in our empirical results.
Method Comms. per client Total comms. Total model training time FL SL SFLV1 SFLV2
4 Experiments
Experiments are carried out on uniformly distributed and horizontally partitioned image datasets among clients. All programs are written in python 3.7.2 using the PyTorch library (PyTorch 1.2.0). For quicker experiments and developments, we use the High-Performance Computing (HPC) platform that is built on Dell EMC’s PowerEdge platform with partner GPUs for computation and InfiniBand networking. We run clients and servers on different computing nodes of the cluster provided by HPC. We request the following resources for one slurm job on HPC: 10GB of RAM, one GPU (Tesla P100-SXM2-16GB), one computing node with at most one task per node. The architecture of the nodes is x86_64. In our setup, we consider that all participants update the model in each global epoch (i.e., during training). We choose ML network architectures and datasets based on their performance and their need to include proportionate participation in our studies. The learning rate for LeNet is maintained at 0.004 and 0.0001 for the remainder of network architectures (AlexNet, ResNet, and VGG16). We choose the learning rate based on the models’ performance during our initial observations. For example, for LeNet on FMNIST, we observed train and test accuracy of 94.8% and 92.1% with a learning rate of 0.004, whereas 87.8% and 87.3% with a learning rate of 0.0001 in 200 global epochs. We set up a similar computing environment for comparative analysis.
We use four public image datasets in our experiments, and these are summarized in Table 3. HAM10000 dataset is a medical dataset, i.e., the Human Against Machine with 10000 training images [22]. It consists of colored images of pigmented skin lesions, and has dermatoscopic images from different populations, acquired and stored by different modalities. It has seven cases of important diagnostic categories of lesions: Akiec, bcc, bkl, df, mel, nv, and vasc. MNIST, Fashion MNIST, and CIFAR10 are standard datasets, all with 10 classes.
Dataset Training samples Testing samples Image size HAM10000 [22] MNIST [16] FMNIST [25] CIFAR10 [14]
In regard to ML models, we consider four popular architectures in our experiments. These four architectures fall under Convolutional Neural Network (CNN) architectures and are summarized in Table 4. We restrict our experiments to CNN architectures to maintain the cohesiveness of our work proposed in this paper. We will conduct further experimental evaluations on other architectures such as recurrent neural networks in future work.
For all experiments in SL, SFLV1, and SFLV2, the network layers are split at the following layer: second layer of LeNet (after 2D MaxPool layer), second layer of AlexNet (after 2D MaxPool layer), fourth layer of VGG16 (after 2D MaxPool layer), and third layer (after 2D BatchNormalization layer) of ResNet18. For a fair comparison, while performing the comparative evaluations of SFLV1 and SFLV2 with FL and SL, we do not consider the addition of differential privacy-based measures and PixelDP in SFLV1 and SFLV2.
4.1 Performance of FL, SL, SFLV1 and SFLV2
We consider the results under normal learning (centralized learning) as our benchmark. Table 5 summarizes our first result, where the observation window is 200 global epochs with one local epoch, batch size of 1024, and five clients for DCML. The table shows the best accuracy observed in 200 global epochs. Moreover, the test accuracy is averaged over all clients in the DCML setup at each global epoch.
Architecture No. of parameters Layers Kernel size LeNet [17] thousands , AlexNet [15] million , , VGG16 [20] million ResNet18 [11] 11.7 million ,
Dataset Architecture Normal FL SL SFLV1 SFLV2 HAM10000 ResNet18 79.3% 77.5% 79.1% 79% 79.2% HAM10000 AlexNet 80.1% 75 % 73.8% 70.5% 74.9% FMNIST LeNet 92.7% 91.9 % 90.4% 89.6% 90.4% FMNIST AlexNet 90.5% 89.7% 84.7% 86% 81% CIFAR10 LeNet 72.1% 69.4 % 62.7% 62.6% 63.8% MNIST AlexNet 98.8% 98.7 % 95.1% 96.9% 92% MNIST ResNet18 99.3% 99.2 % 99.2% 99% 99.2%
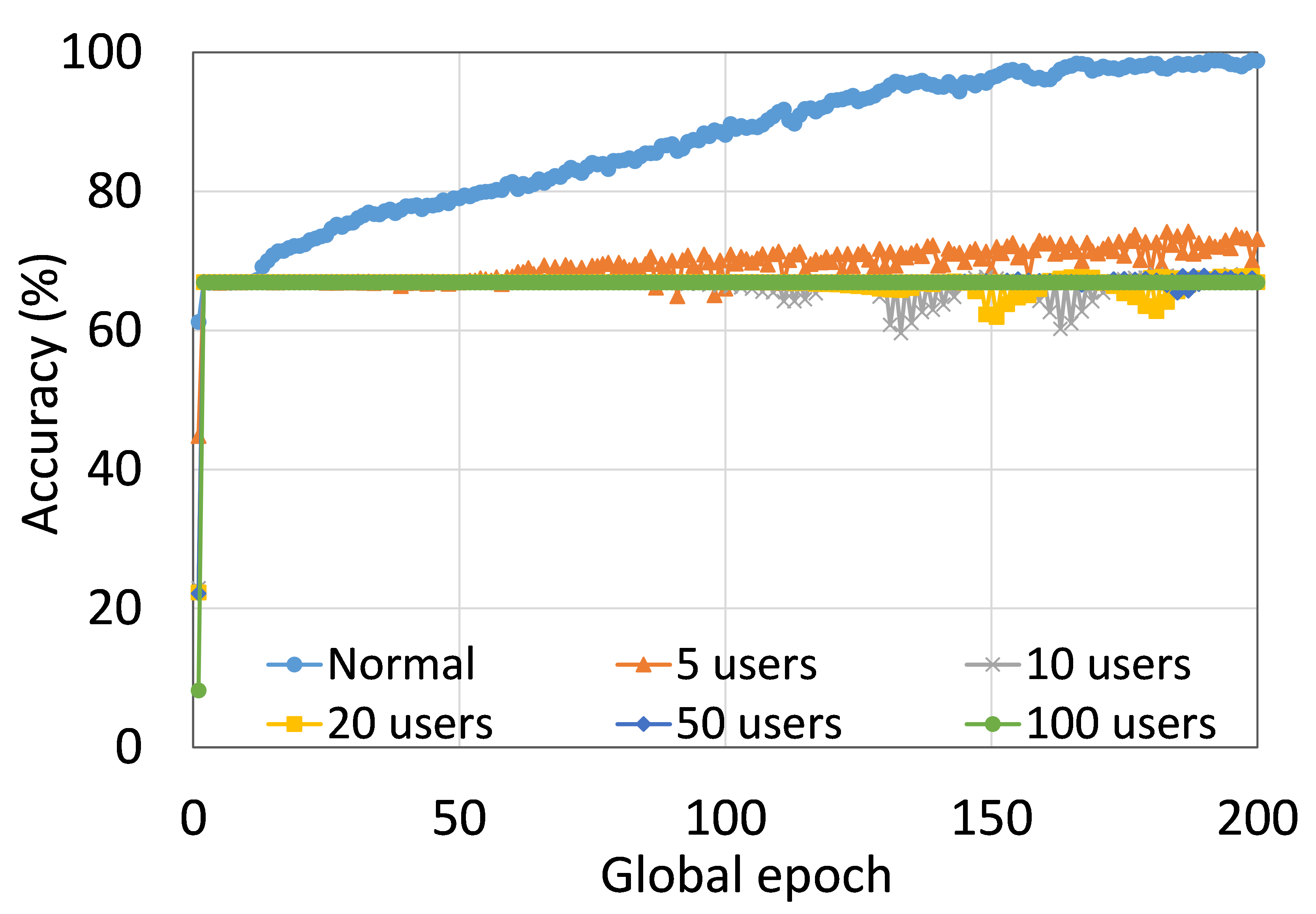
As presented in Table 5, SL and SFL (both versions) performed well under the proposed experimental setup. However, we also observed that among DCML, FL shows better learning performance in most cases, possibly due to the FedAvg of the full models at each global epoch. Based on the results, we can observe that SFLV1 and SFLV2 have inherited the characteristics of SL. In a separate experiment, we noticed that VGG16 on CIFAR10 did not converge in SL, which was the same for both versions of splitfed learning, although there were around 66% and 67% of training and testing accuracies, respectively, for FL. We assume that this was because of the unavailability of certain other factors such as hyper-parameters tuning or change in data distribution or additional regularization terms in the loss function, which are beyond the scope of this paper.
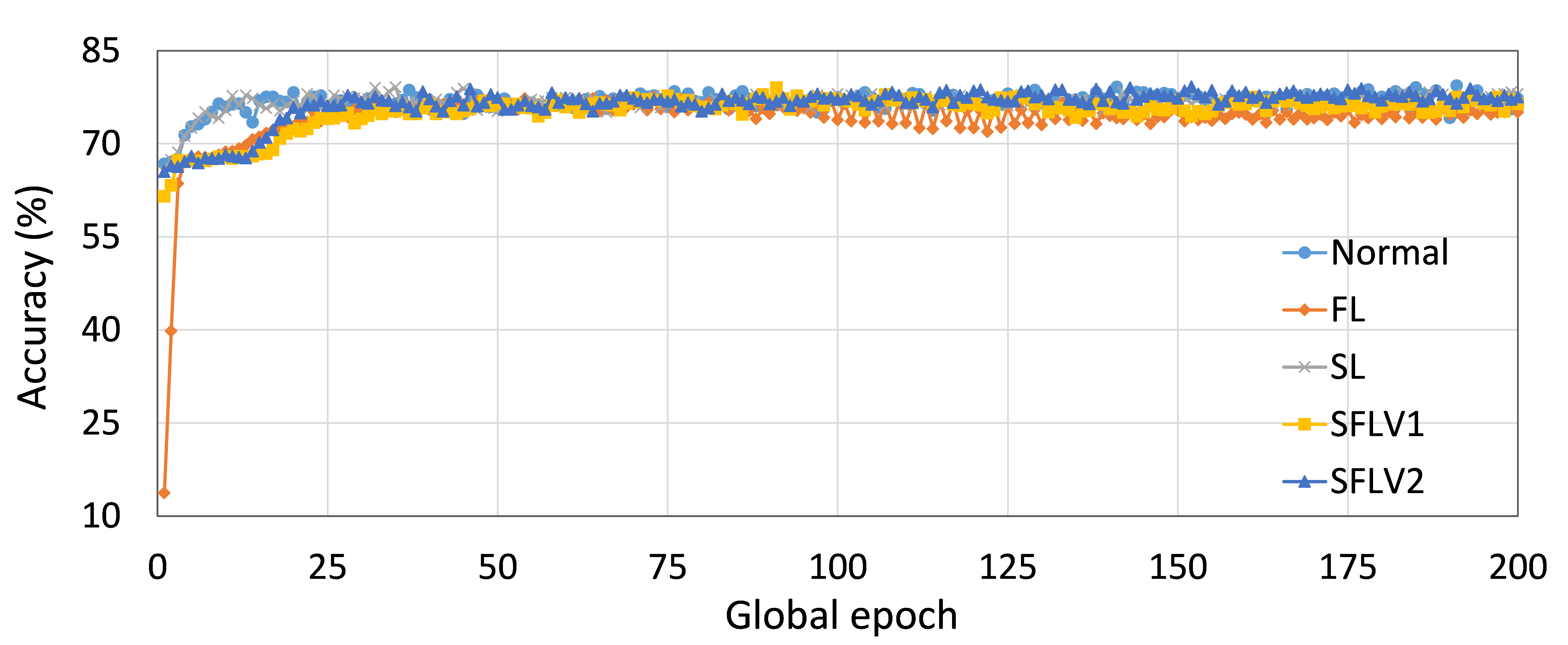
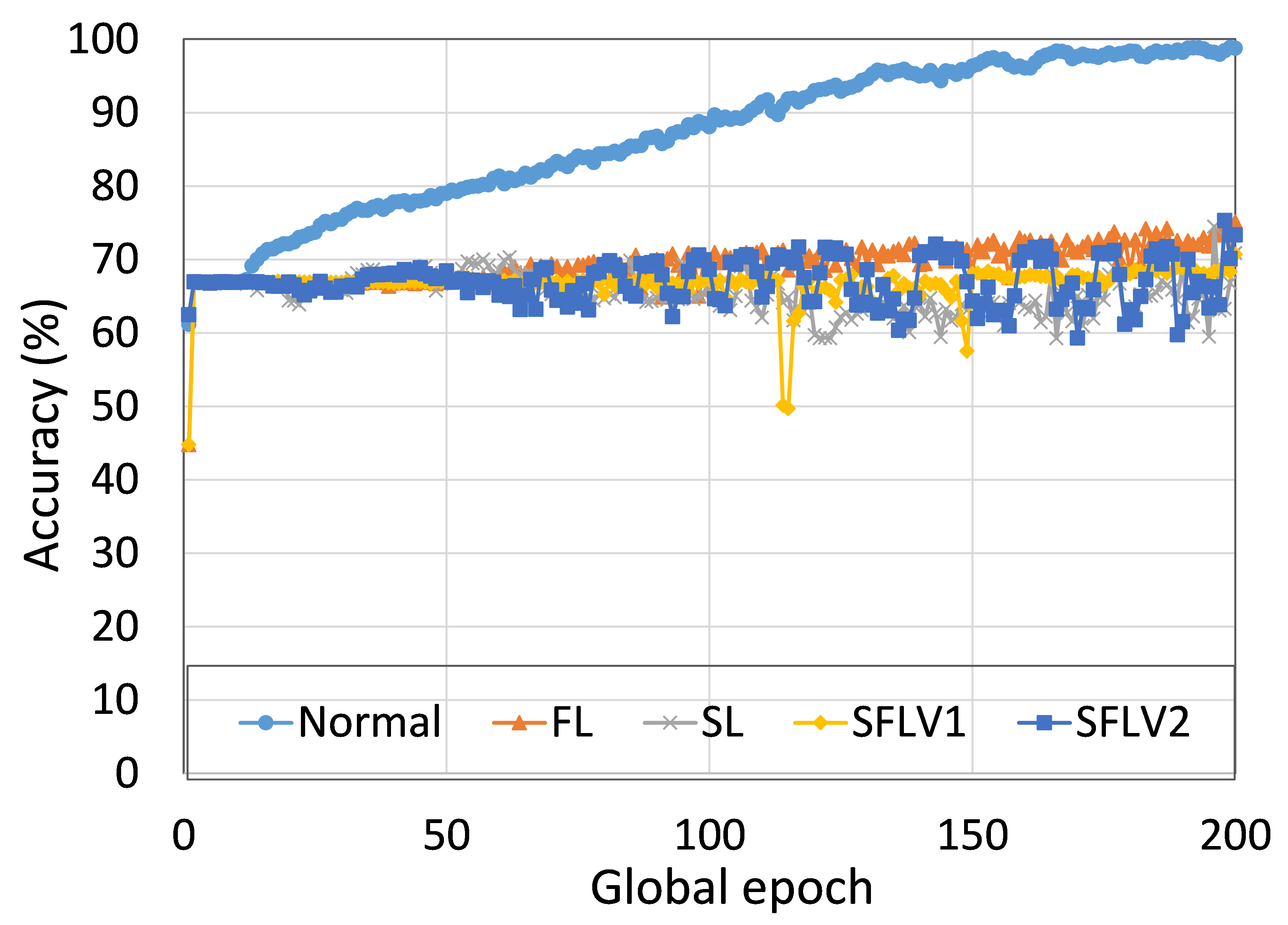
Further diving into individual cases, as an example, we present the performance of ResNet18 on the HAM10000 dataset for normal (centralized learning), FL, SL, SFLV1, and SFLV2, under similar settings. For ResNet18 on HAM10000, the test accuracy convergence was almost the same for FL, SL, SFLV1, and SFLV2, and they reached around 76% in the observation window of 200 global epochs (refer to Fig. 2). However, SFLV1 and SFLV2 struggled to converge if SL failed to converge. This was observed for the case of VGG16 on CIFAR10 in our separate experiments.
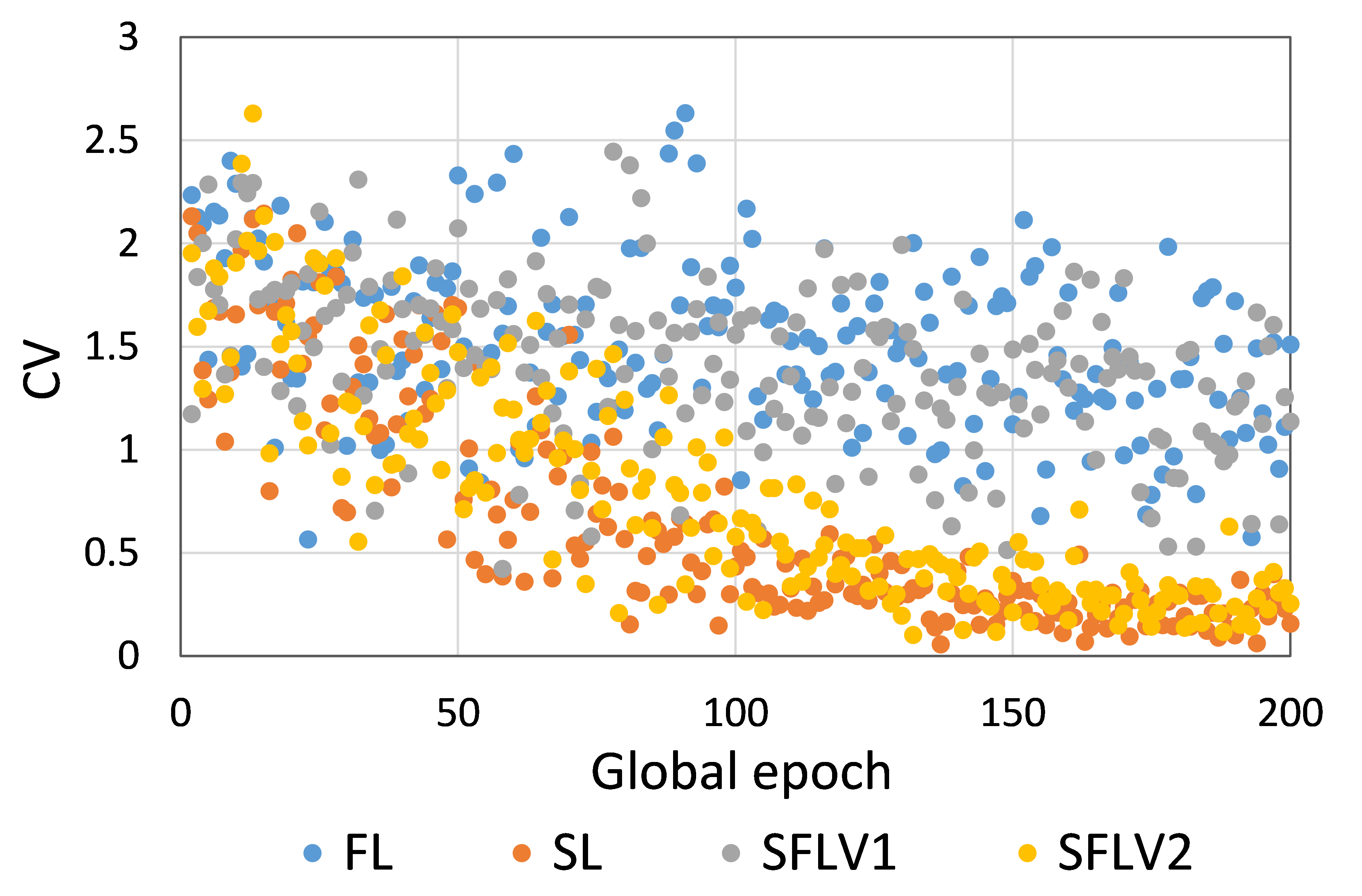
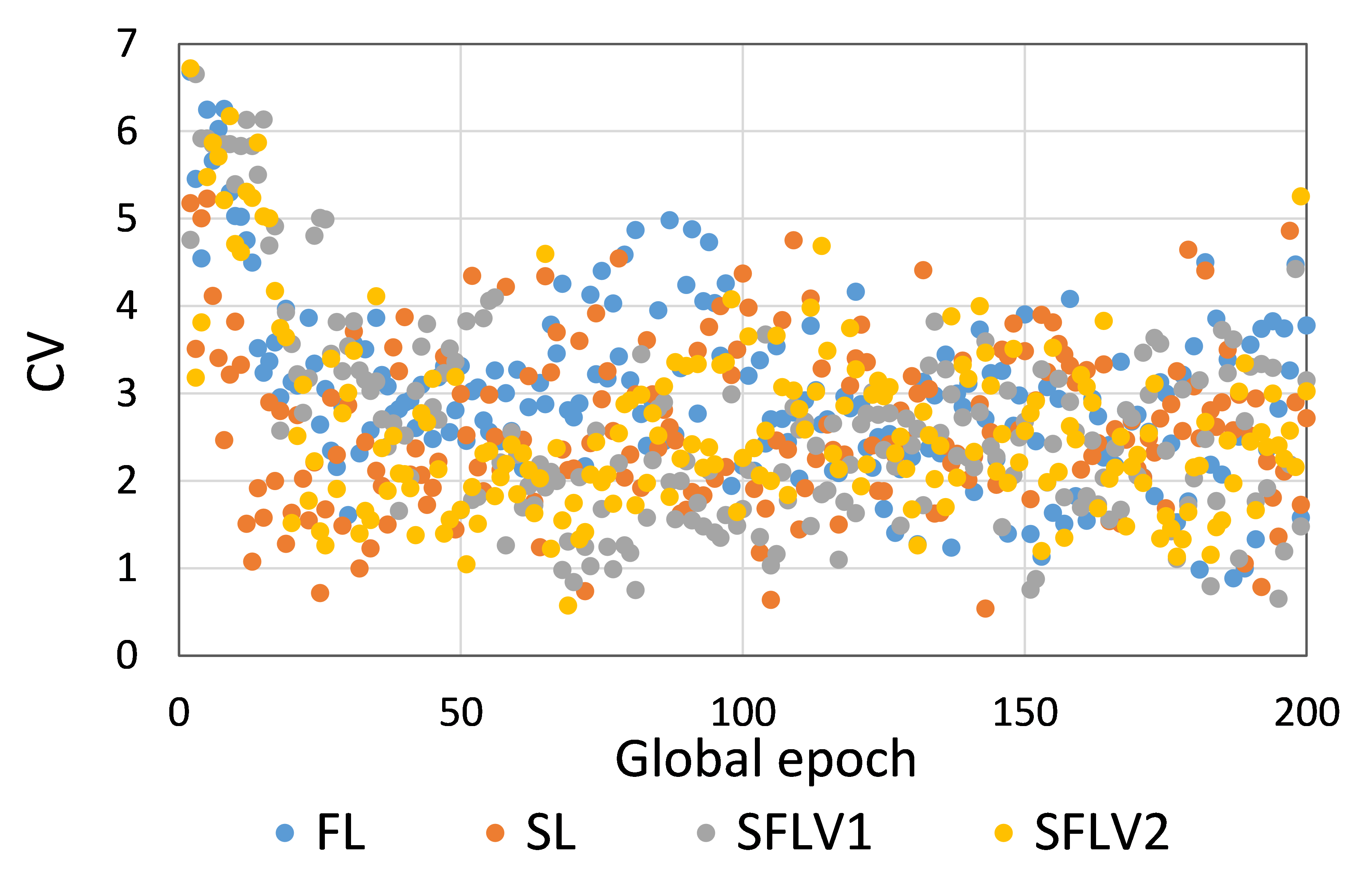
So far, we considered the testing mean accuracy in our results. Fig. 4 illustrates the variations of the performance (i.e., accuracy) over five clients at each global epoch. In this regard, we compute the coefficient of variation (CV), which is a ratio of the standard deviation to the mean, and it measures the dispersion. Moreover, we calculate the CV over the five accuracies generated by the five clients at each global epoch. Based on our results for ResNet18 on HAM10000, the CVs for SL, FL, SFLV1, and SFLV2 are bounded between 0.06 and 2.63 while training, and 0.54 and 6.72 while testing after epoch 2; at epoch 1, the CV is slightly higher. The results indicate uniform individual client-level performance across the clients, as the CV coefficient values below 10 are considered a good range in literature.
In some datasets and architectures, the training/testing accuracy of the model was still improving and showing better performance at higher global epochs than 200. For example, going from 200 epochs to 400 epochs, we noticed training and testing accuracy increment from around 83% to around 86% for FL with LeNet on FMNIST with 100 users. However, we limited our observation window to 100 or 200 global epochs as some network architecture such as AlexNet on HAM10000 in FL was taking an extensive amount of training time on the HPC (a shared resource).
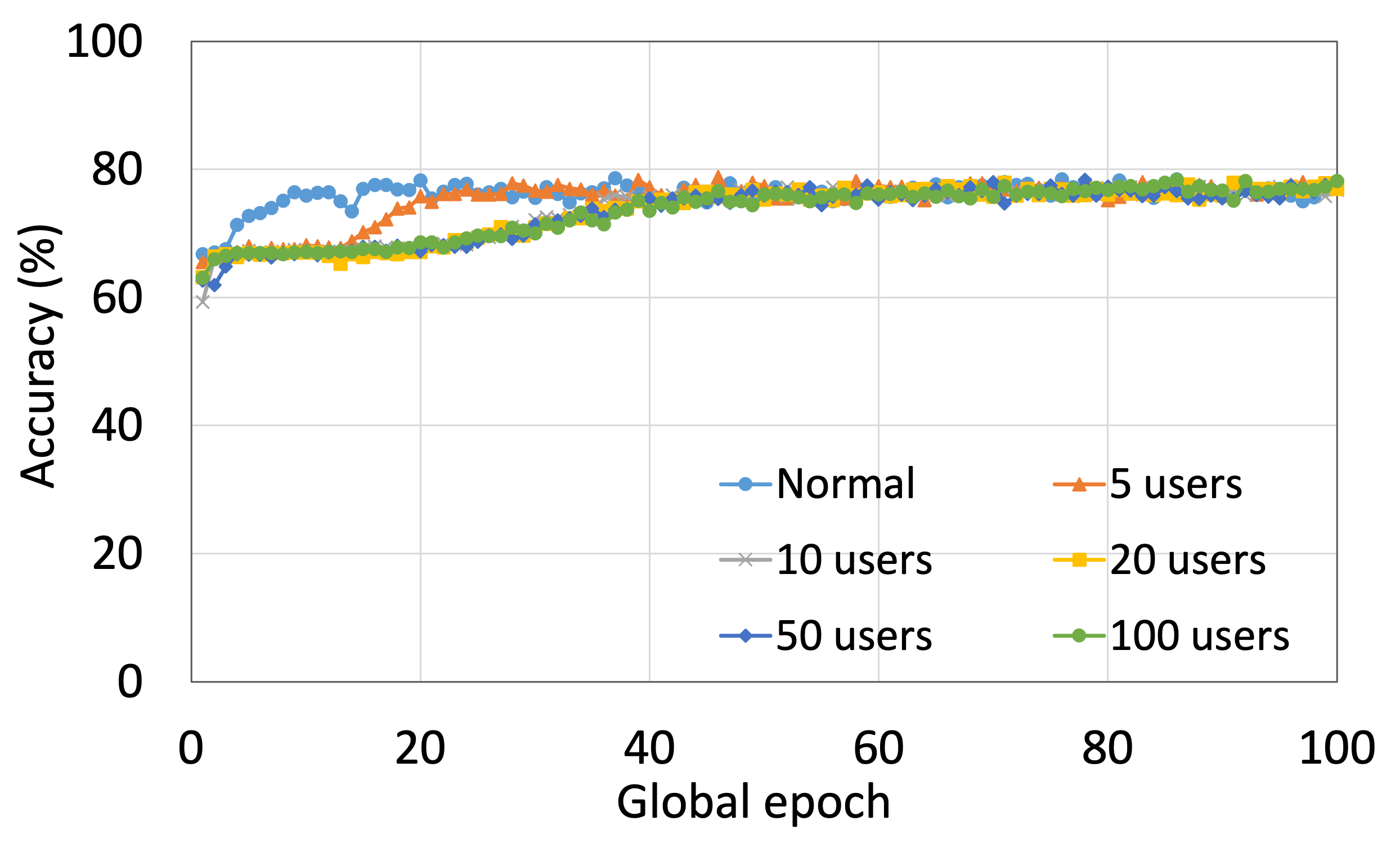
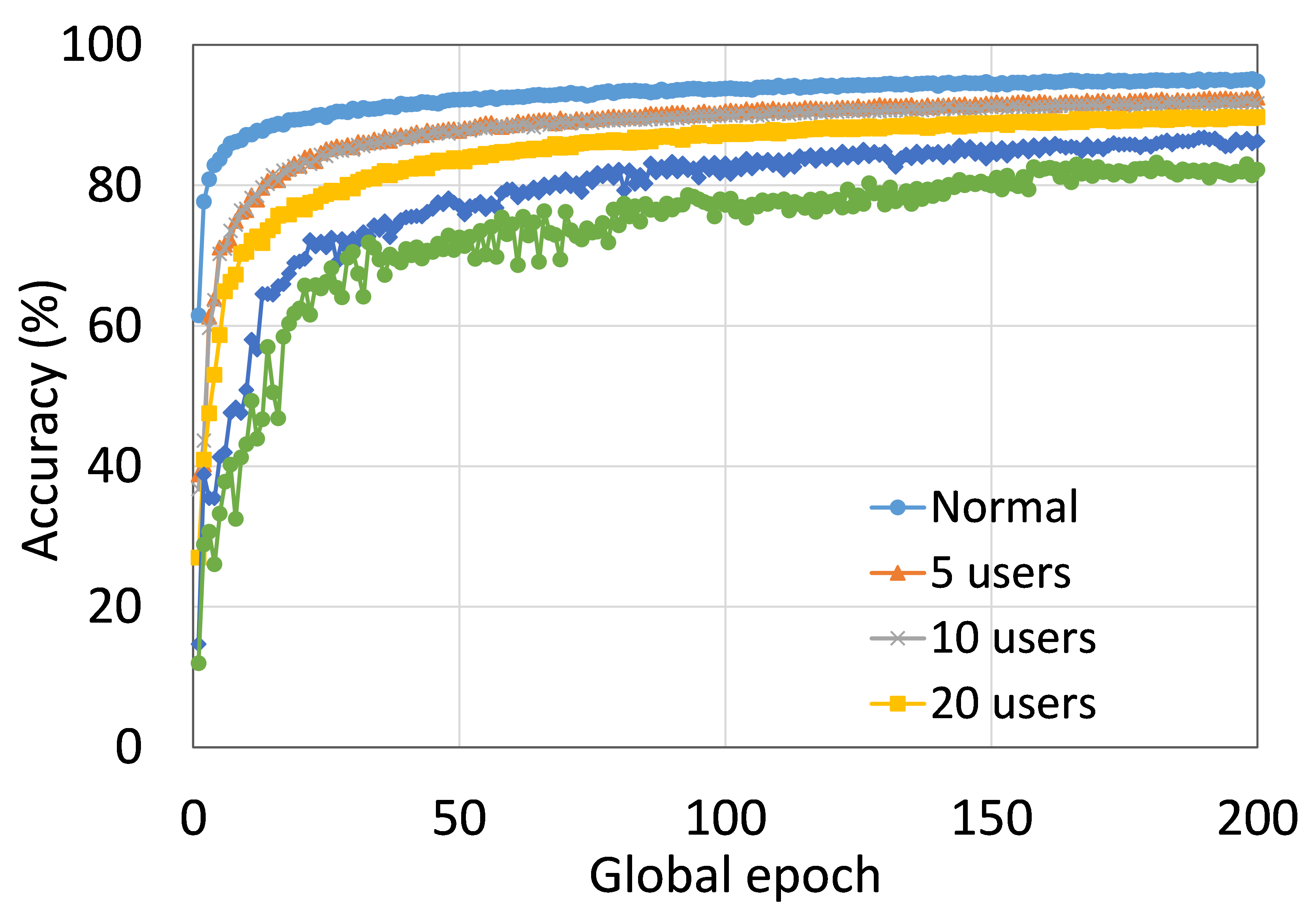
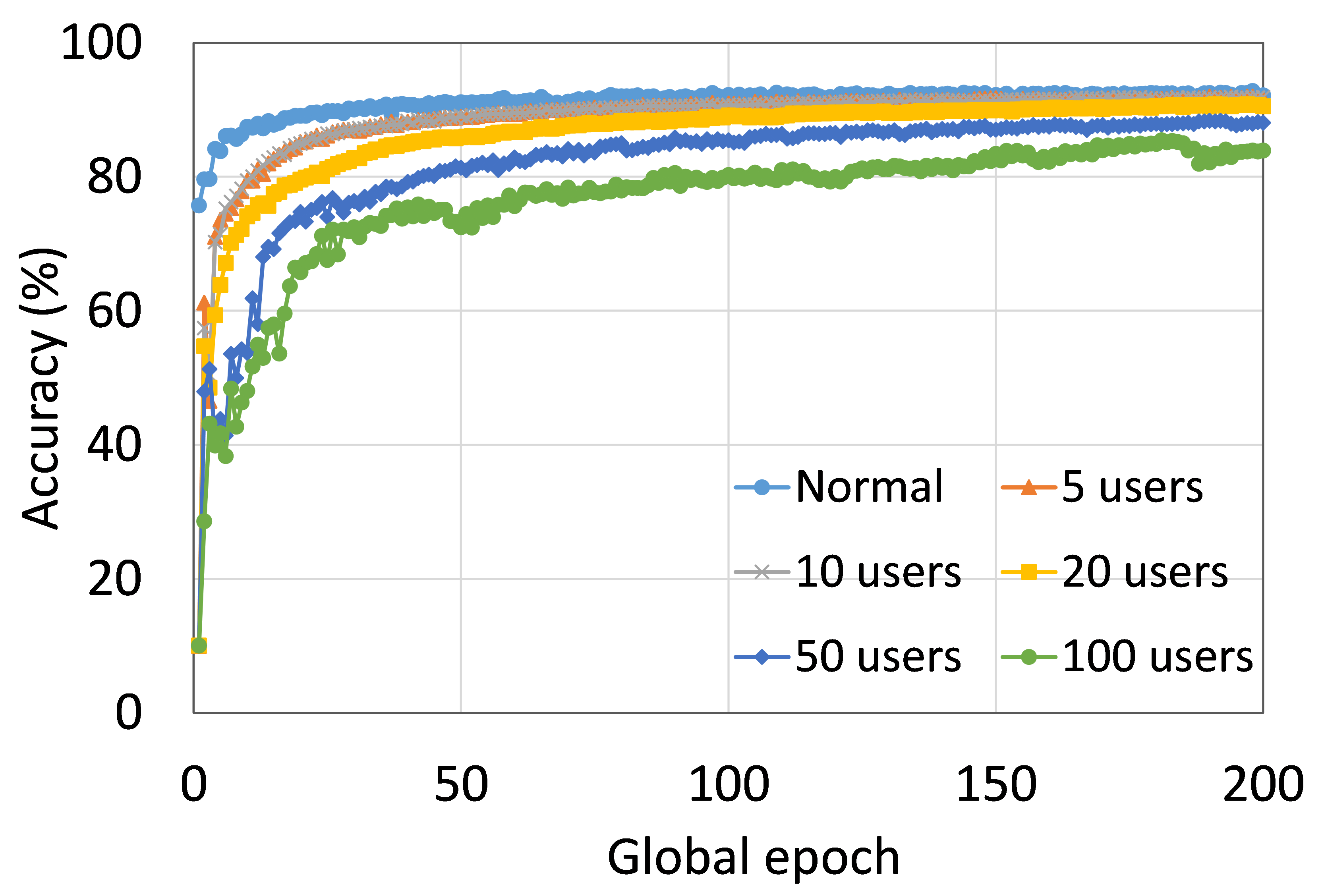
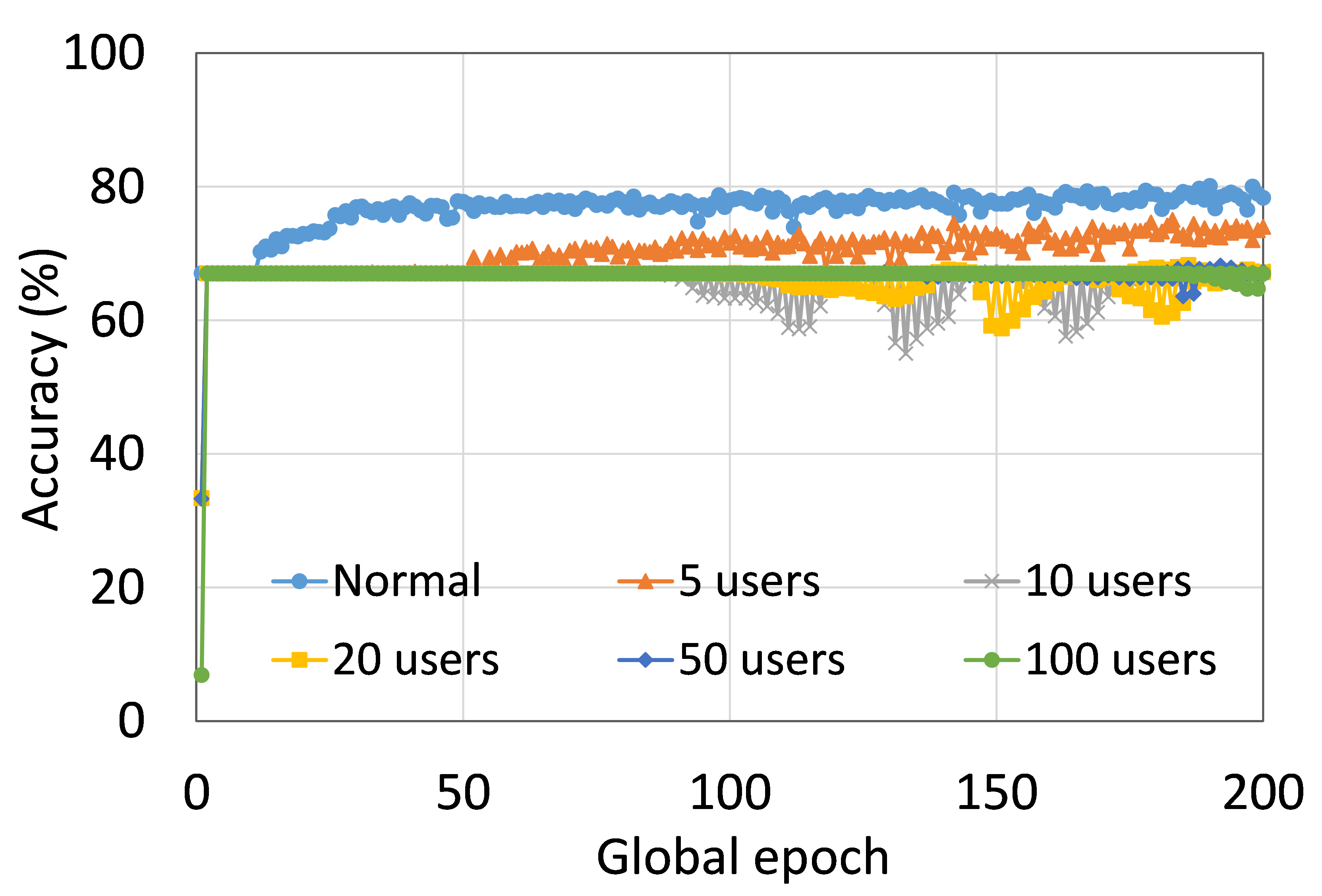
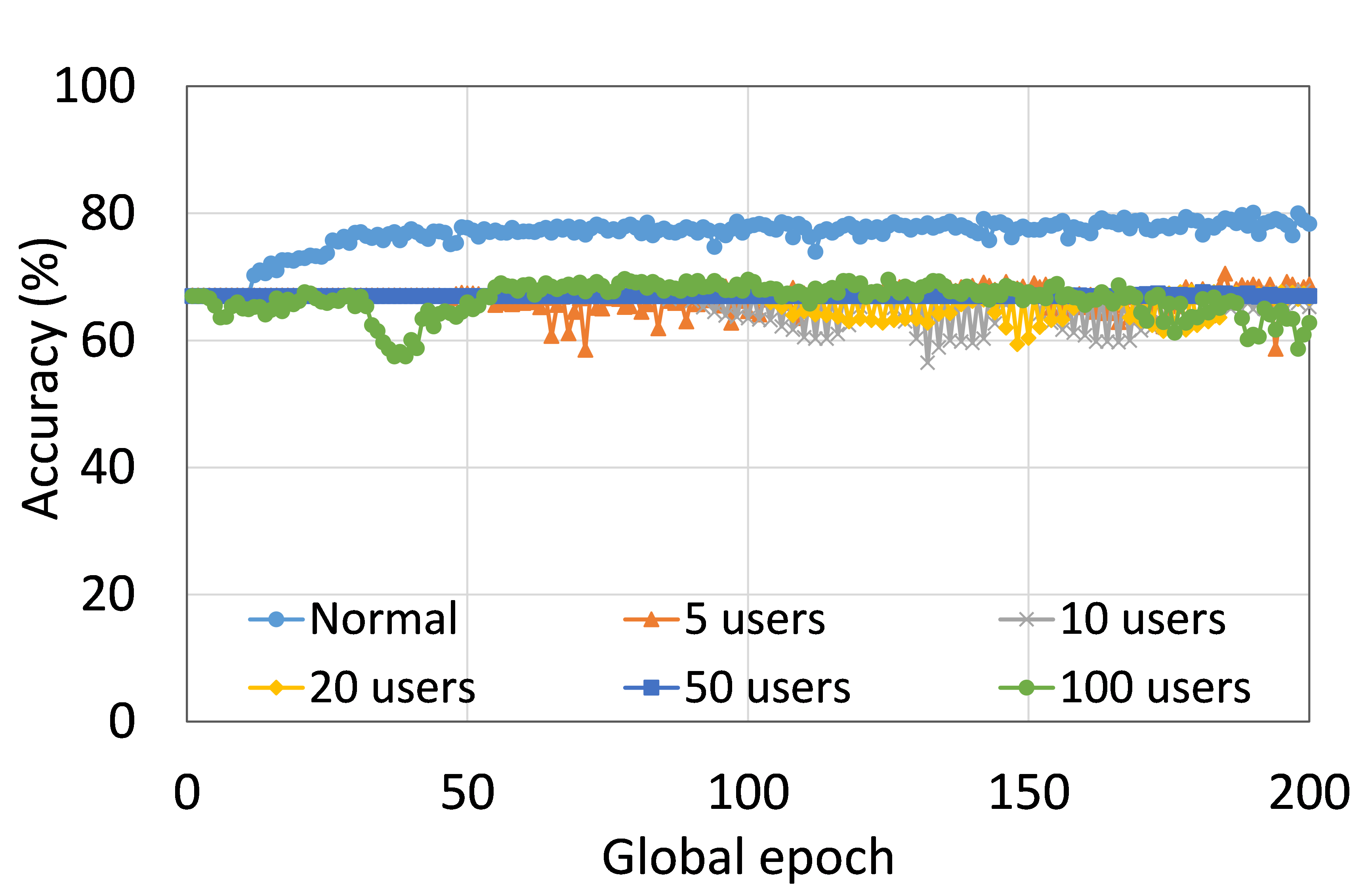
4.2 Effect of Number of Users on the Performance
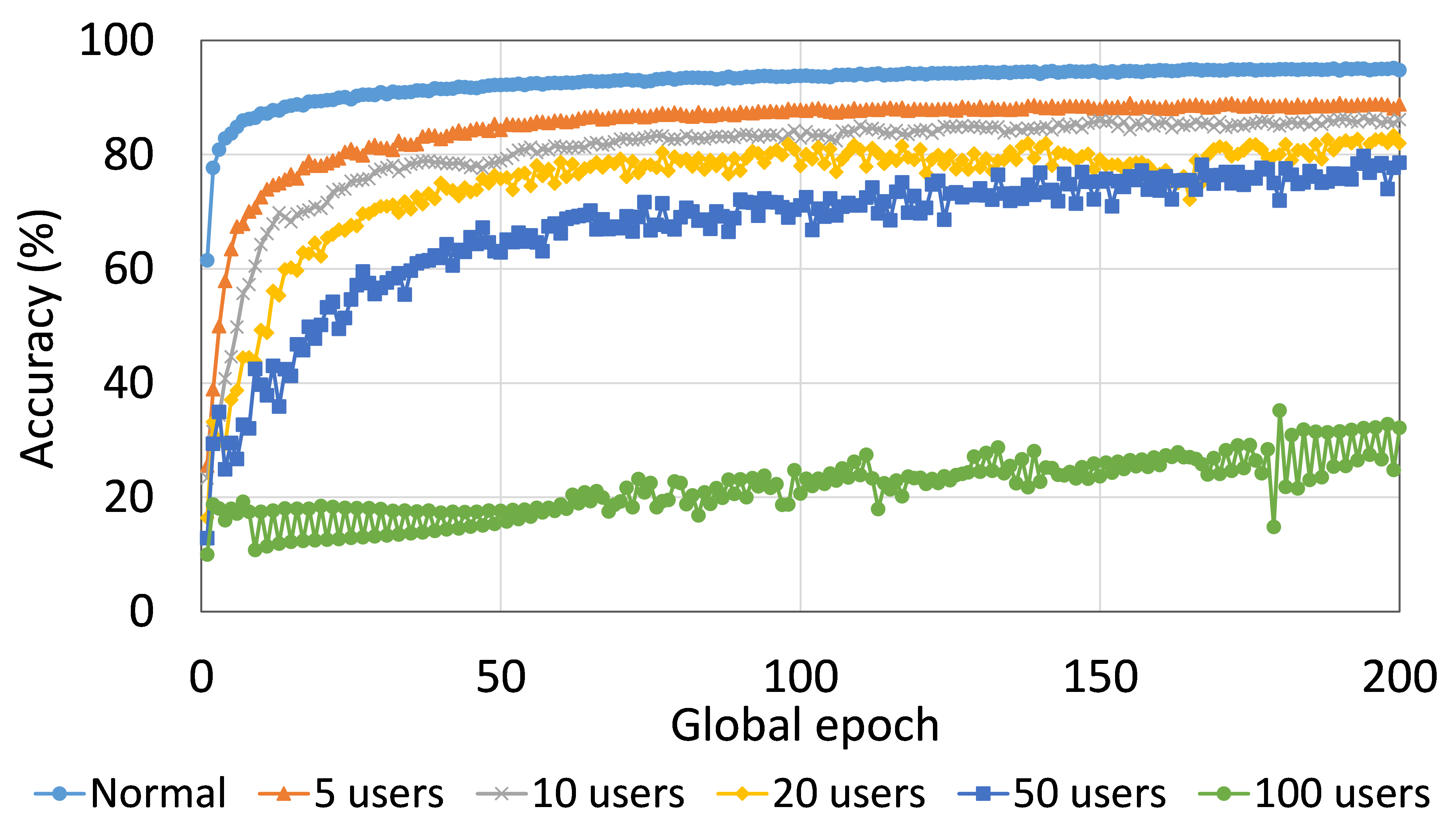
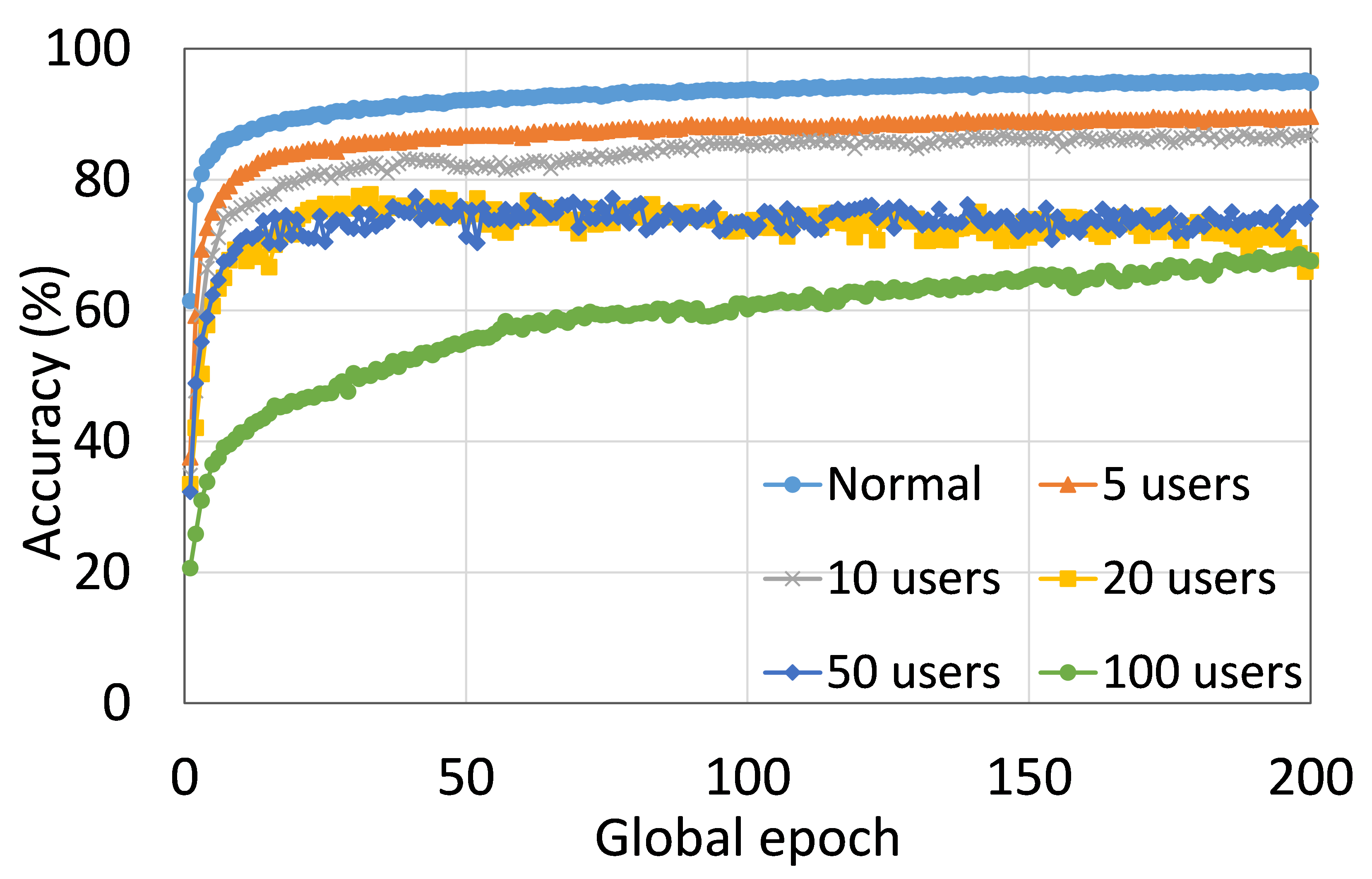
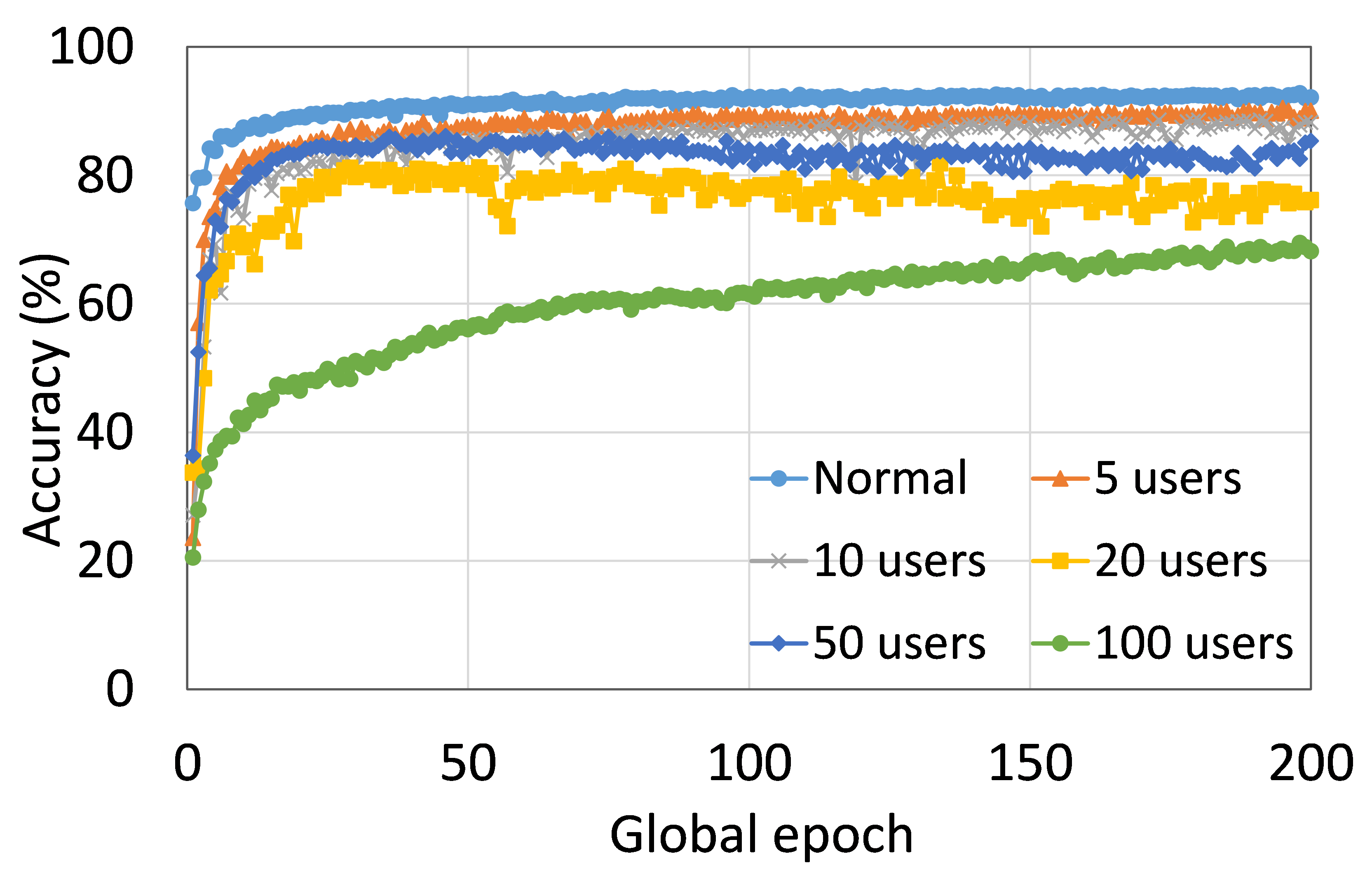
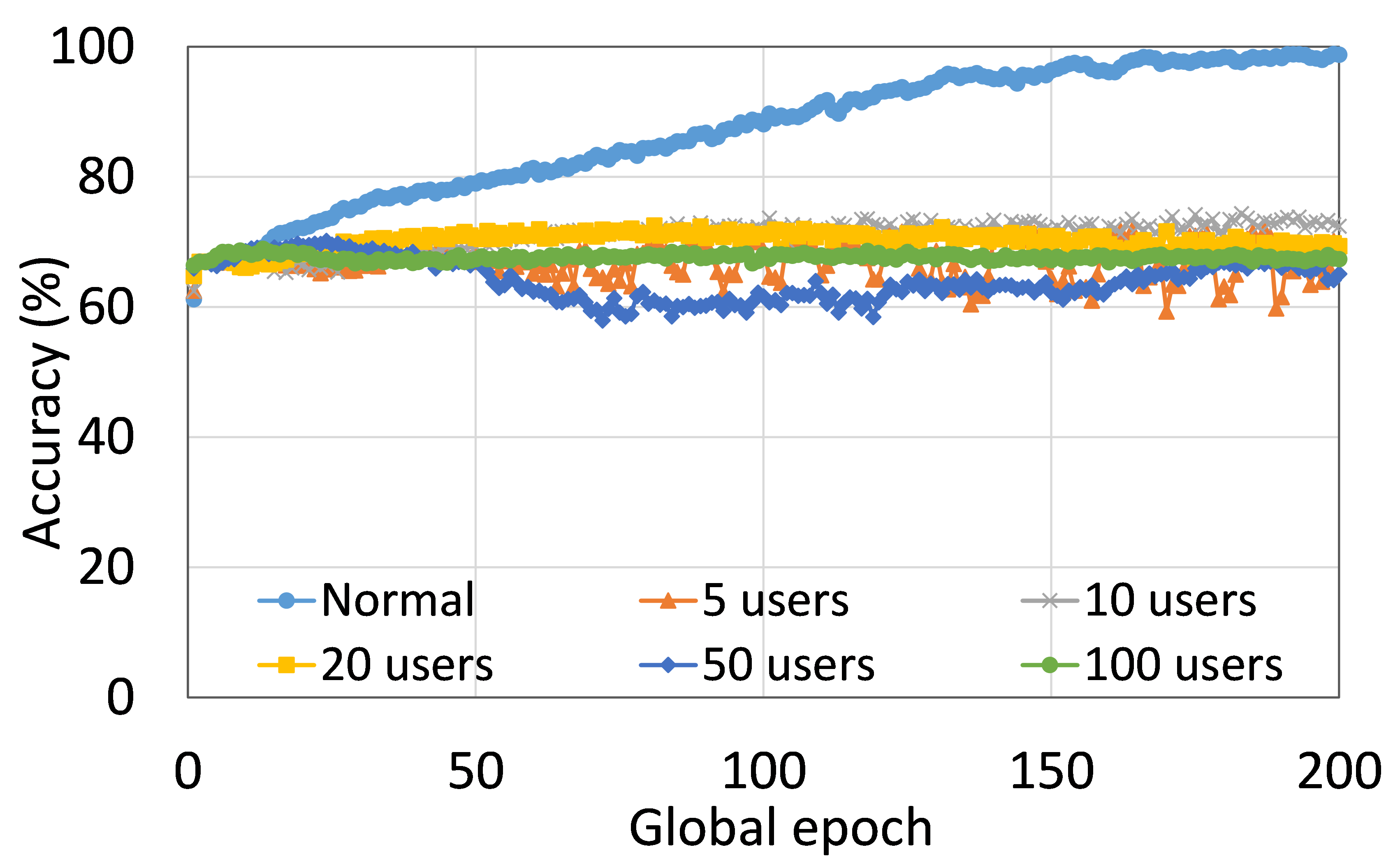
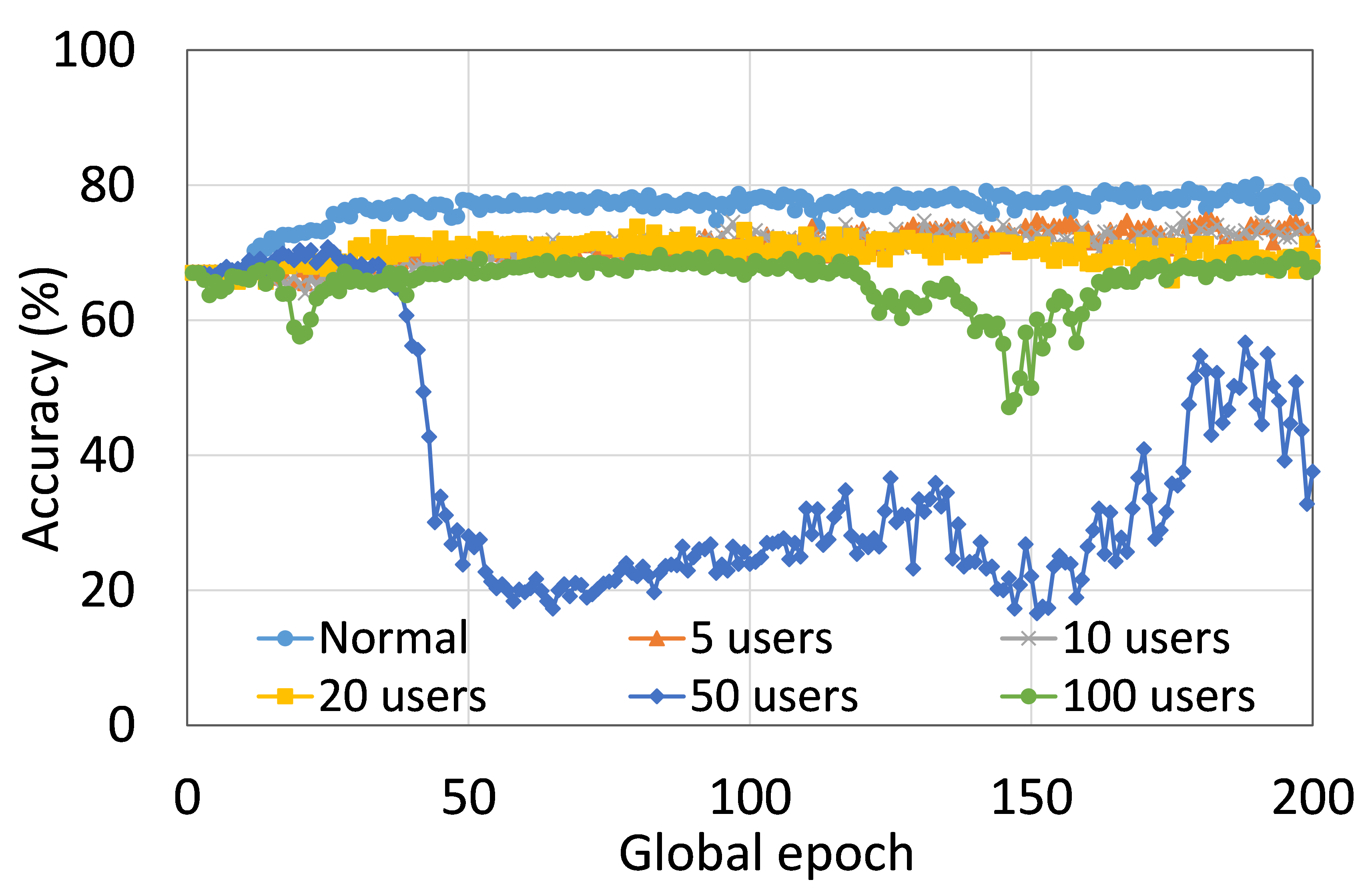
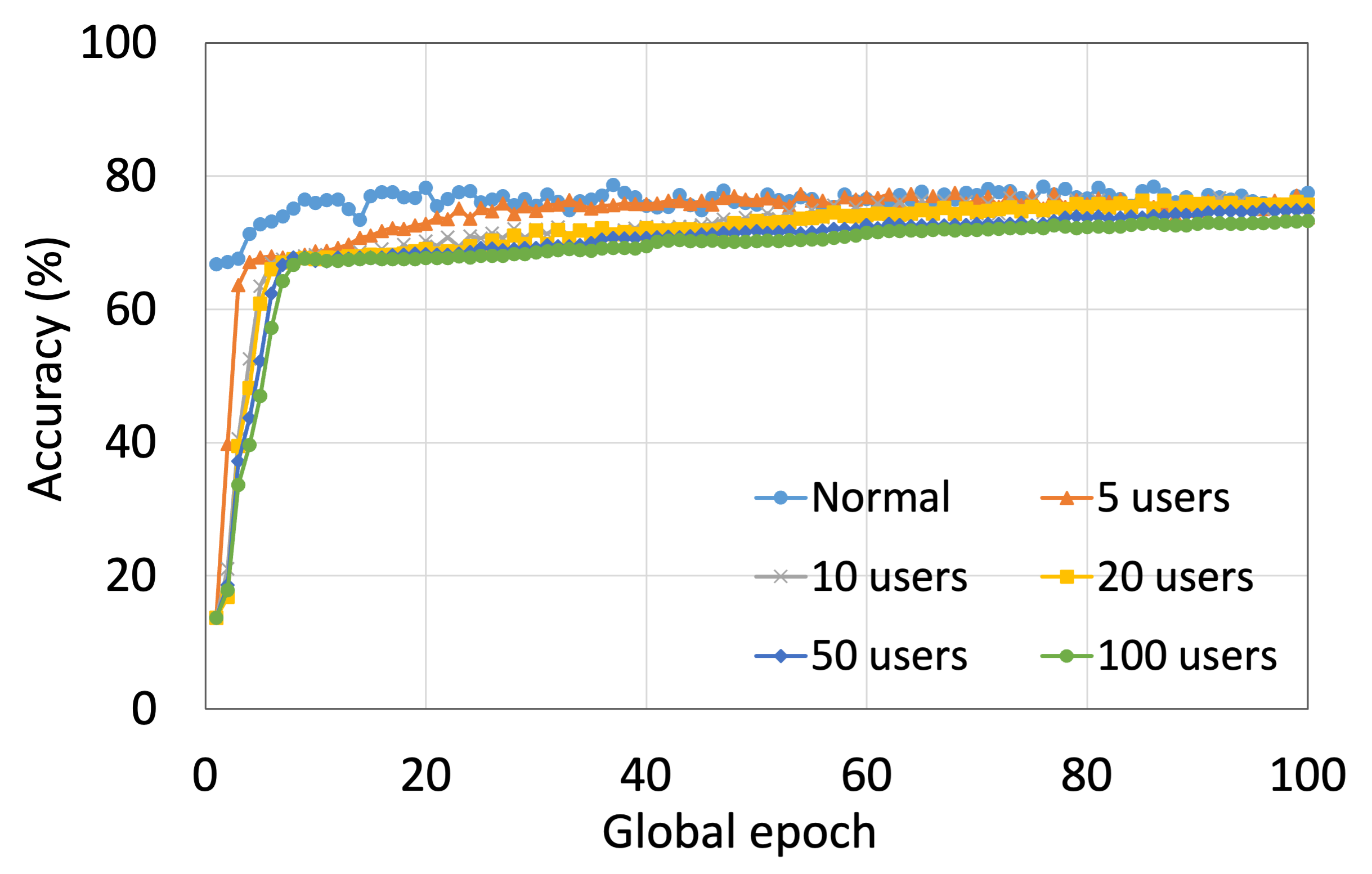
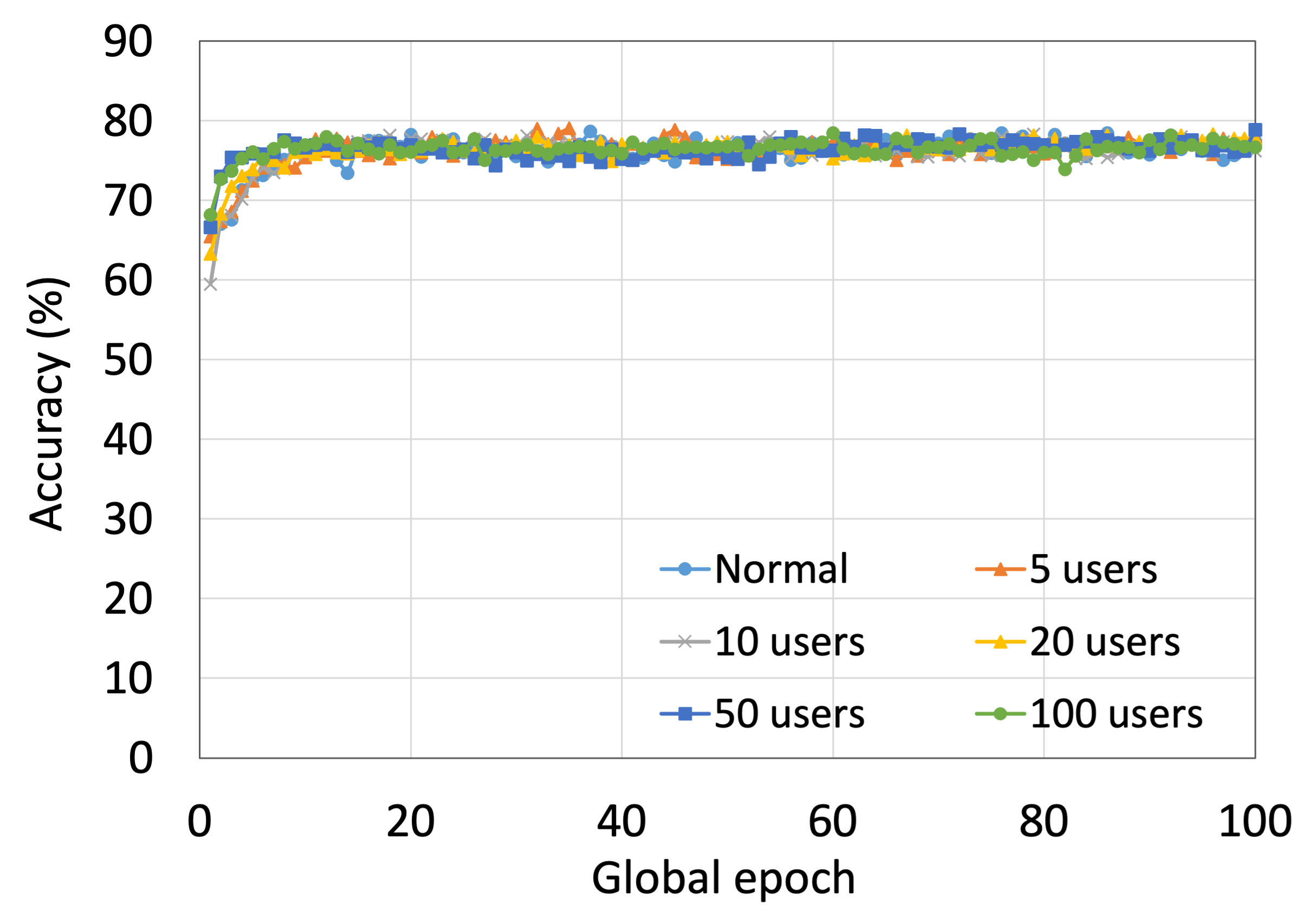
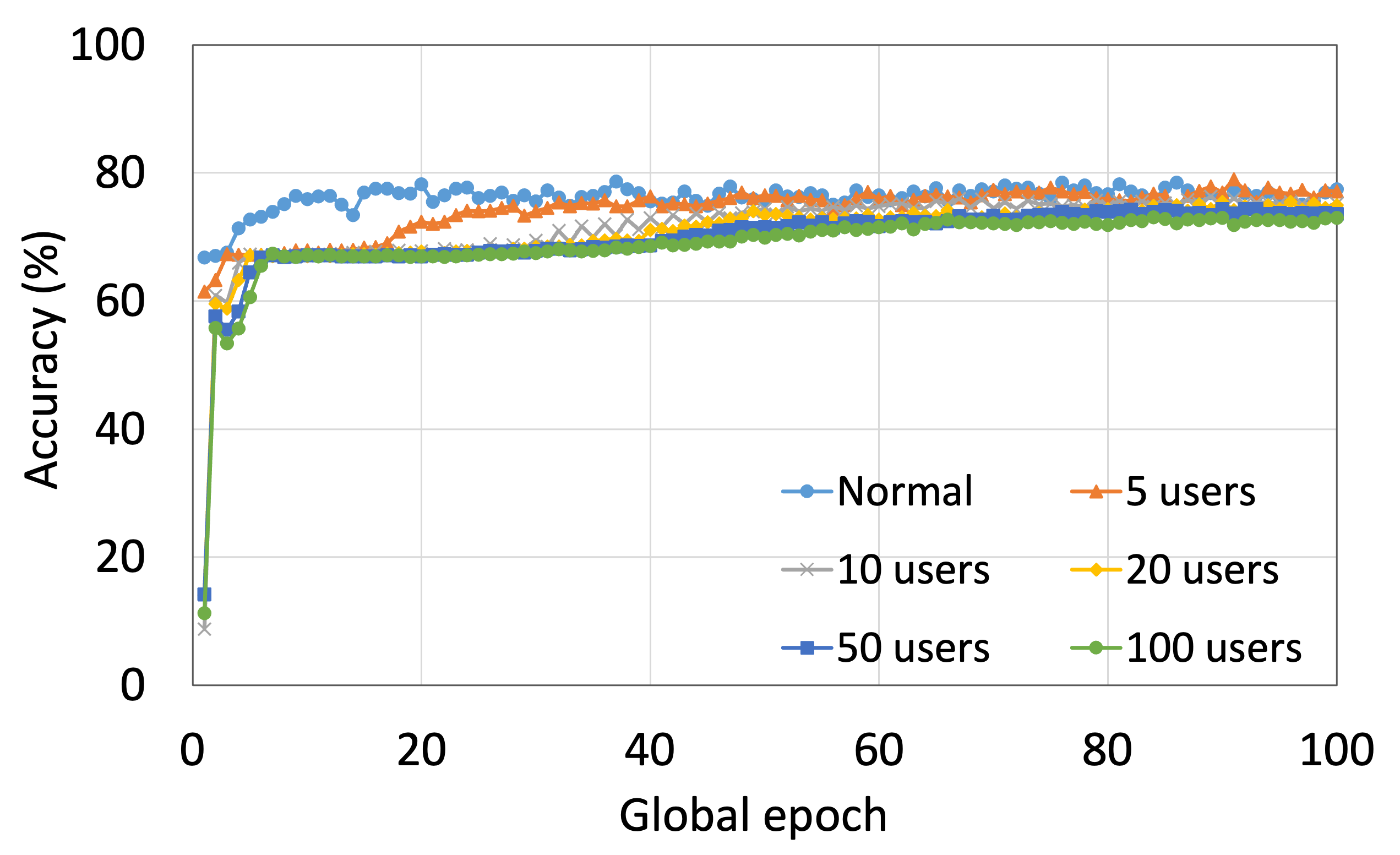
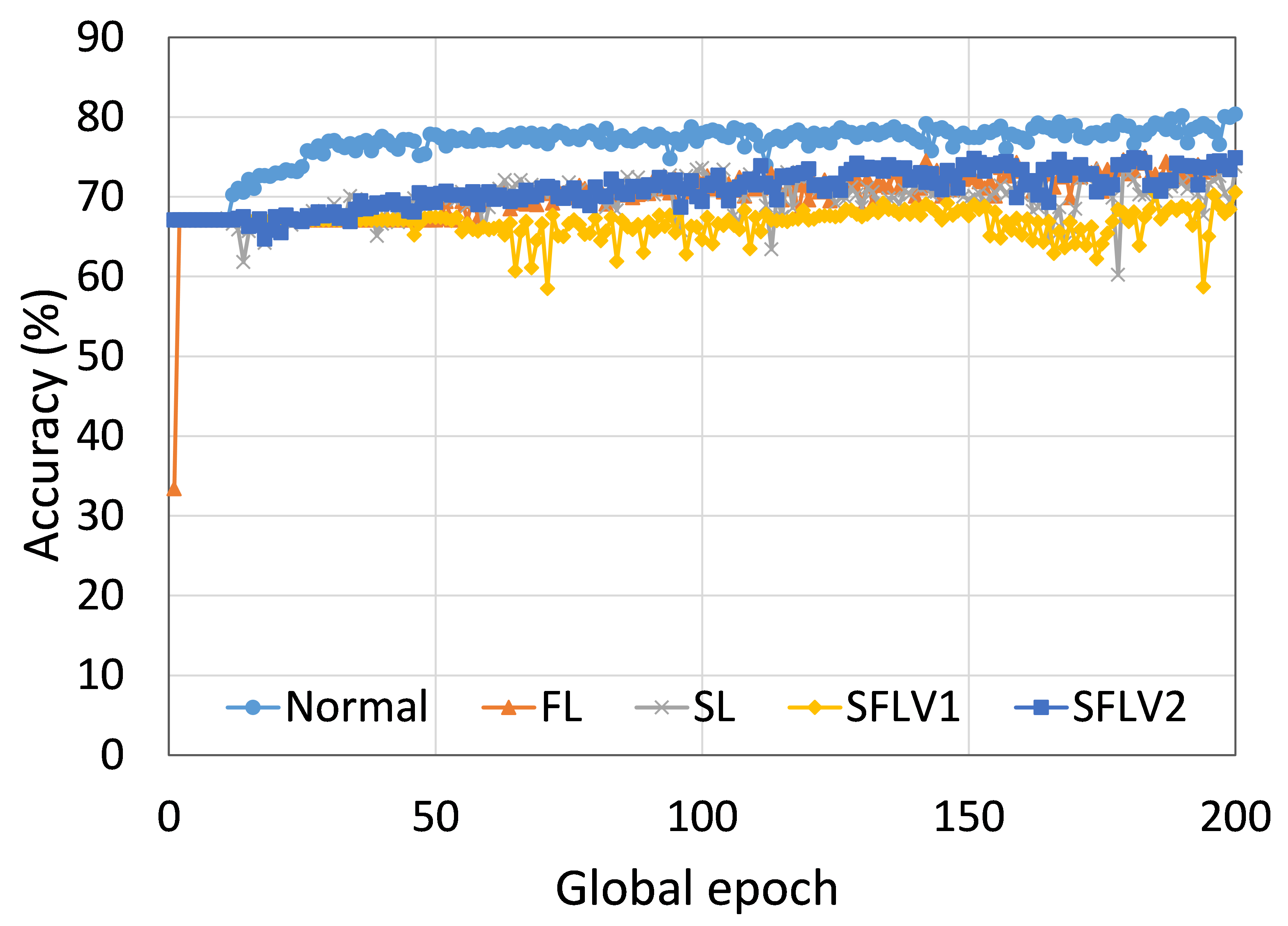
This section presents the analysis of the effect of the number of users for ResNet18 on HAM10000. We observed that up to 100 clients (clients ranging from 5 to 100), the training and testing curves for all numbers of clients followed a similar pattern in each plot. Moreover, they achieved a similar level of accuracy within each of our DCMLs. We got comparative average test accuracies of around 74% (FL), 77% (SL), 75% (SFLV1), and 77% (SFLV2) at 100 global epochs. While training, only SL and SFLV2 achieved the centralized training (normal learning) accuracy at around 100 global epochs. In contrast, FL and SFLV1 could not achieve this result even at 200 global epochs. The experimental results for clients ranging from five to hundred showed a negligible effect on the performance due to the increase in the number of clients in FL, SL, SFLV1, and SFLV2 (for example, refer to Fig. 3). However, this observation was not the case in general. For LeNet on FMNIST with fewer clients, the testing performances of FL and SL were close to the normal learning. Moreover, for SL with AlexNet on HAM10000, the performance degraded and even failed to converge with the increase in the number of clients, and we saw a similar effect on the SFLV2. Overall, the convergence of the learning and performance slowed down (sometimes failed to progress) with the increase in the number of clients (in our DCML techniques) due to the resource limitations and other constraints, such as the change in data distribution among the clients with the increase in its number, and a regular global model aggregation to synchronize the model across the multiple clients.
4.3 SFL with Differential Privacy at the Client-side Model with a PixelDP Noise Layer
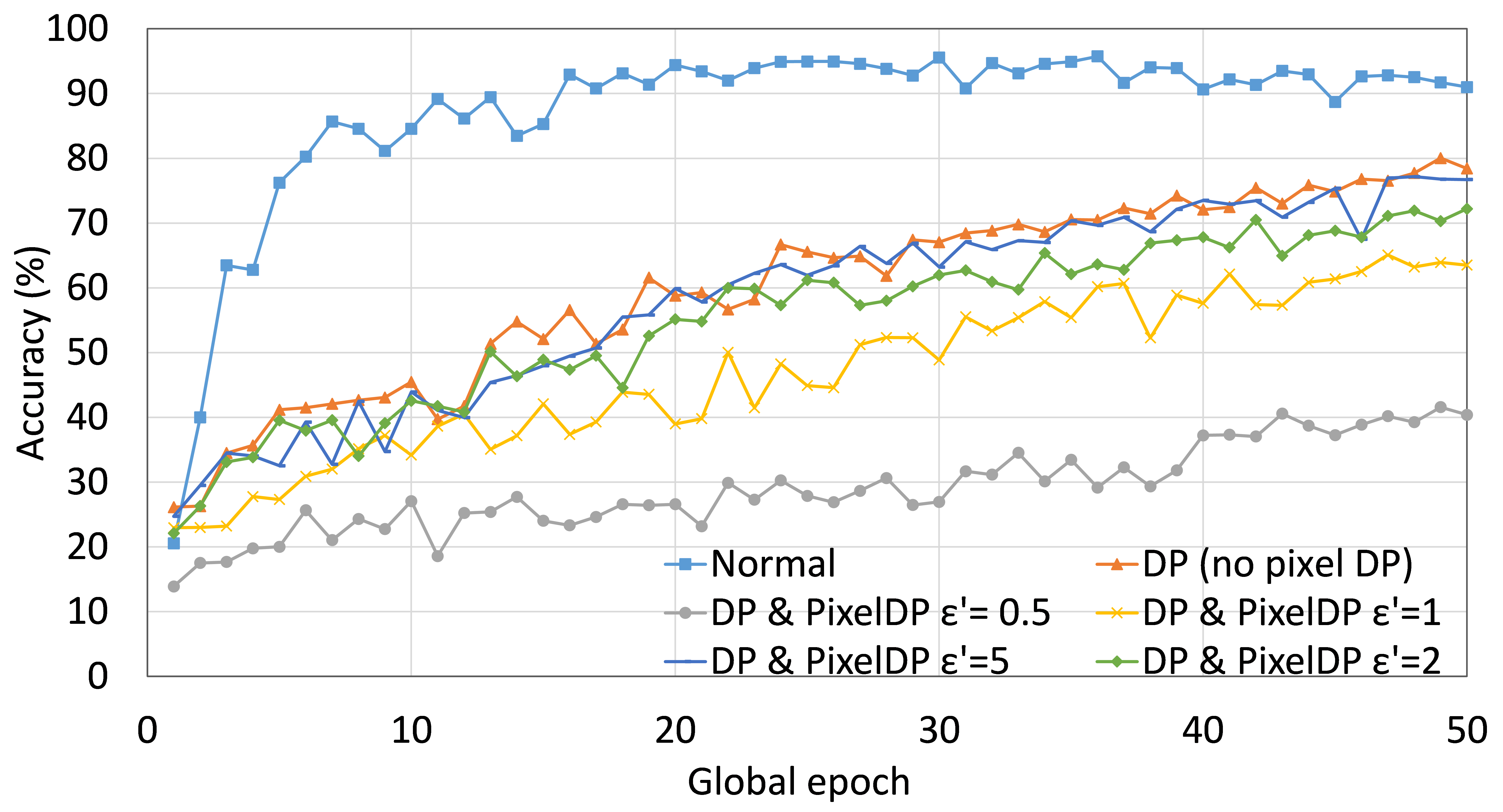
We implemented the differential privacy measures as described in Section “Privacy Protection.” For illustration, experiments were performed for SFLV1 with AlexNet on MNIST data distributed over five clients. For 50 global epochs with 5 local epochs at each client per global epoch, the testing accuracy curves converged as shown in Fig. 5. Besides, as for illustration, we change the values of , which is the privacy budget used by the PixelDP noise layer placed after the first convolution layer of AlexNet, to see the effect on the overall performance. Moreover, we maintain at 0.5 (privacy budget of client-side model training) during all experiments to examine the behavior of SFLV1 under strict client-side model privacy. As expected, the convergence of accuracy curves with DP measures is gradual and slow compared to non-differentially private training. Besides, testing accuracy of around 40%, 64%, 73%, 77%, and 78% are observed at global epoch 50 for equal to , and no PixelDP, respectively. Clearly, the accuracy increases with the increase in the privacy budget, i.e., . Overall, the utility is decreased with a decrease in the privacy budget. As the client-side architecture in SFLV2 is the same as in SFLV1, the application of differential privacy in SFLV2 can be done in the same way as in SFLV1.
5 Conclusion
By bringing federated learning (FL) and split learning (SL) together, we proposed a novel distributed machine learning approach, named splitfed learning (SFL). SFL offered model privacy by network splitting and differential private client-side model updates. It is faster than SL by performing parallel processing across clients. Our results demonstrate that SFL provides similar performance in terms of model accuracy compared to SL. Thus, being a hybrid approach, it supports machine learning with resource-constrained devices (enabled by network splitting as in SL) and fast training (enabled by handling clients in parallel as in FL). The performance of SFL with privacy and robustness measures based on differential privacy and PixelDP was further analyzed to investigate its feasibility towards data privacy and model robustness. Studies related to the detailed trade-off analysis of privacy and utility, and integration of homomorphic encryption [8] for guaranteed data privacy are left for future works.
References
- [1] Abadi, M., Chu, A., Goodfellow, I., McMahan, H.B., Mironov, I., Talwar, K., Zhang, L.: Deep learning with differential privacy. In: Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. pp. 308–318 (2016)
- [2] Bonawitz, K., Eichner, H., Grieskamp, W., Huba, D., Ingerman, A., Ivanov, V., Kiddon, C., Konecný, J., Mazzocchi, S., McMahan, H.B., Overveldt, T.V., Petrou, D., Ramage, D., Roselander, J.: Towards federated learning at scale: System design. In: Proc. SysML Conference. pp. 1–15 (2019), https://mlsys.org/Conferences/2019/doc/2019/193.pdf
- [3] Dwork, C., McSherry, F., Nissim, K., Smith, A.D.: Calibrating noise to sensitivity in private data analysis. J. Priv. Confidentiality 7(3), 17–51 (2016). https://doi.org/10.29012/jpc.v7i3.405, https://doi.org/10.29012/jpc.v7i3.405
- [4] Dwork, C., Roth, A.: The algorithmic foundations of differential privacy. Foundations and Trends in Theoretical Computer Science 9(3-4), 211–407 (2014)
- [5] Dwork, C., Roth, A., et al.: The algorithmic foundations of differential privacy. Foundations and Trends in Theoretical Computer Science 9(3-4), 211–407 (2014)
- [6] Gao, Y., Kim, M., Abuadbba, S., Kim, Y., Thapa, C., Kim, K., Camtepe, S.A., Kim, H., Nepal, S.: End-to-end evaluation of federated learning and split learning for internet of things. In: Proc. SRDS (2020), https://arxiv.org/pdf/2003.13376.pdf
- [7] Gao, Y., Kim, M., Thapa, C., Abuadbba, S., Zhang, Z., Camtepe, S., Kim, H., Nepal, S.: Evaluation and optimization of distributed machine learning techniques for internet of things. CoRR abs/2103.02762 (2021), https://arxiv.org/abs/2103.02762
- [8] Gentry, C.: A fully homomorphic encryption scheme. Ph.D. thesis, Stanford University, Stanford, California (Sept 2009)
- [9] Gupta, O., Raskar, R.: Distributed learning of deep neural network over multiple agents. J. Network and Computer Applications 116, 1–8 (2018). https://doi.org/10.1016/j.jnca.2018.05.003
- [10] Han, D.J., amd Jungmoon Lee, H.I.B., Moon, J.: Accelerating federated learning with split learning on locally generated losses. In: Proc. FL-ICML (2021)
- [11] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proc. IEEE CVPR. pp. 770–778 (June 2016). https://doi.org/10.1109/CVPR.2016.90
- [12] Kairouz, P., McMahan, H.B., et al.: Advances and open problems in federated learning. CoRR abs/1912.04977 (2019), http://arxiv.org/abs/1912.04977
- [13] Konecný, J., McMahan, B., Ramage, D.: Federated optimization: Distributed optimization beyond the datacenter. arxiv (2015), https://arxiv.org/pdf/1511.03575.pdf
- [14] Krizhevsky, A., Nair, V., Hinton, G.: Cifar-10 (canadian institute for advanced research) Http://www.cs.toronto.edu/ kriz/cifar.html
- [15] Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. In: Proc. NIPS’12 - Vol. 1. pp. 1097–1105. USA (2012)
- [16] Lecun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. In: Proc. of the IEEE. vol. 86, pp. 2278–2324 (Nov 1998). https://doi.org/10.1109/5.726791
- [17] Lecun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proc. of the IEEE 86(11), 2278–2324 (Nov 1998)
- [18] Lecuyer, M., Atlidakis, V., Geambasu, R., Hsu, D., Jana, S.: Certified robustness to adversarial examples with differential privacy. In: 2019 IEEE Symposium on Security and Privacy (SP). pp. 656–672. IEEE (2019)
- [19] McMahan, B., Moore, E., Ramage, D., Hampson, S., y Arcas, B.A.: Communication-efficient learning of deep networks from decentralized data. In: Proc. AISTATS. pp. 1273–1282 (2017)
- [20] Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: Proc. 3rd ICLR (2015), http://arxiv.org/abs/1409.1556
- [21] Singh, A., Vepakomma, P., Gupta, O., Raskar, R.: Detailed comparison of communication efficiency of split learning and federated learning. arxiv (2019), https://arxiv.org/abs/1909.09145
- [22] Tschandl, P.: The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions (2018), doi:10.7910/DVN/DBW86T
- [23] Vepakomma, P., Gupta, O., Dubey, A., Raskar, R.: Reducing leakage in distributed deep learning for sensitive health data. In: Proc. ICLR (2019)
- [24] Vepakomma, P., Gupta, O., Swedish, T., Raskar, R.: Split learning for health: Distributed deep learning without sharing raw patient data. arxiv (2018), http://arxiv.org/abs/1812.00564
- [25] Xiao, H., Rasul, K., Vollgraf, R.: Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arxiv (2017), http://arxiv.org/abs/1708.07747
Appendix
Appendix 0.A Threat Model
In this work, for federated learning (FL), split learning (SL), and splitfed learning (SFL), we consider the fed server and the main server of the system model are honest-but-curious adversaries. They perform the tasks as specified but can be curious about the local private data of the clients and the full model. Moreover, the attack scenario for the servers are considered here is passive, where they only observe the updates and possibly do some calculations to get the information, but they do not maliciously modify their own inputs or parameters for the attack purpose. Besides, the servers and clients are non-colluding with each other. Regarding clients, they are considered as curious adversaries; behave honestly while training, but can input adversarial inputs only during inference (testing).
We assume that our approaches splitfedv1 (SFLV1) and splitfedv2 (SFLV2) adhere to the standard client-server security model where the clients and servers establish a certain level of trust before starting the network model training. For example, in the health domain, the hospitals (clients) only allow platform (server) and researchers (model owners) that have a level of trust. Hospitals opt out if the corresponding platform has malicious clients or servers. Besides, we assume that all communications between the participating entities (e.g., exchange of smashed data and gradients between clients and the main server) are performed in an encrypted form. Compared with the threat model of FL, SFL has an extra honest-but-curious and non-colluding fed server at the client-side (similar to the case of SL in centralized mode). The fed server and clients in SFL have access only to the gradients/weights of the client-side model portions only. In FL, the main server has access to the entire model. In contrast, the main server has access only to the server-side portion of the model and the smashed data (i.e., activation vectors of the cut layer) from the client in SL and SFL.
Appendix 0.B Total Cost Measurement
In addition to our theoretical analyses of the communication cost and the model training time cost of FL, SL, SFLV1, and SFLV2 learning, we perform the empirical test on communication and training time. These results complement our analysis in Section “Total Cost Analysis.”
0.B.1 Communication Measurement
The amount of data uploaded and downloaded by a client indicates the operability of a Distributed Collaborative Machine Learning (DCML) approach in a resource-constrained environment. High data communication slows down the machine learning (ML) training and testing process, and the clients need to have sufficient resources to handle the high communication cost. In this regard, we measure the amount of data communication in our experiments and present the relative performance of the four DCML techniques. To make the experimental setup normalized for different numbers of clients, we run our program under the following configurations: The main server’s and fed server’s programs run in two different HPC nodes, and clients’ programs run in five separate nodes (except for experiment with one client). Each client HPC node runs one, two, and four clients (client-side programs) for five, ten, and twenty client cases. We record the total communication for the observation window of 11 global epochs with one local epoch and a batch size of 256. The results were then averaged over all global epochs and clients to obtain the communication cost per client per global epoch. Refer to Fig. 6 for the communication load of ResNet18 on HAM10000 and AlexNet on MNIST.
Recent works have shown that SL is more communication efficient than FL while increasing the number of clients or model size [21]. In contrast, FL is preferred if the amount of data samples is increased by keeping the number of clients or model size low [21, 6].
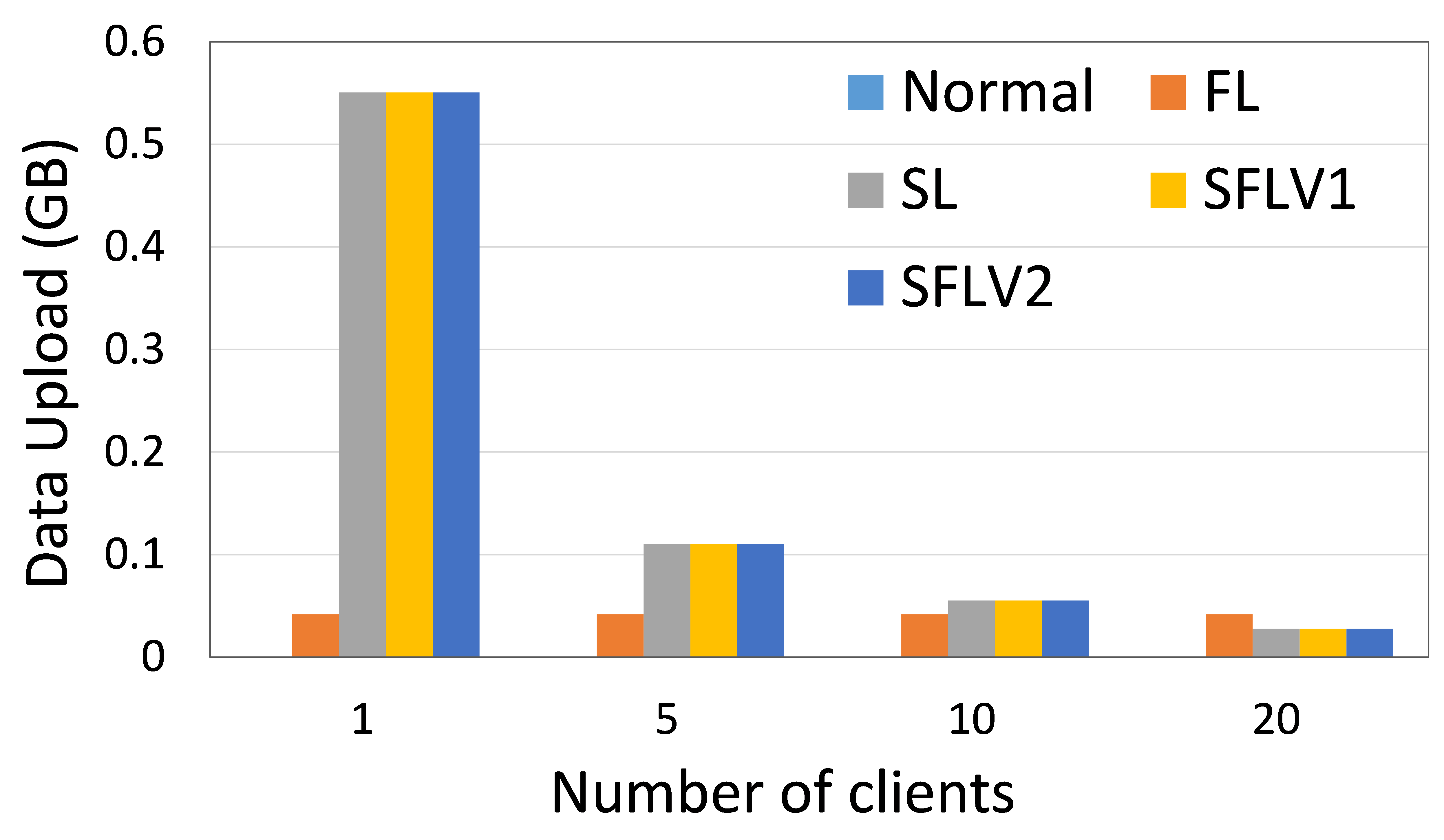
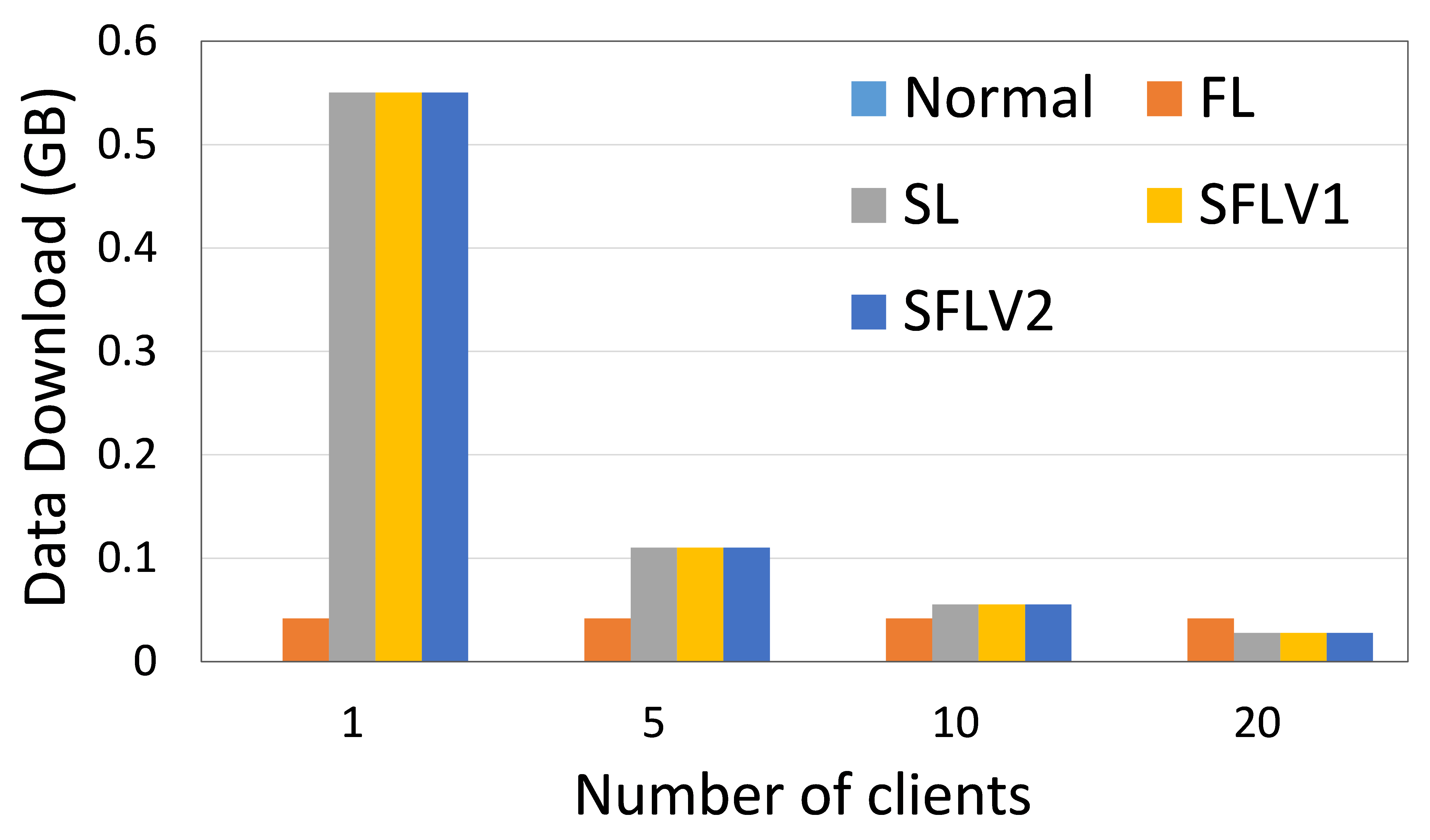
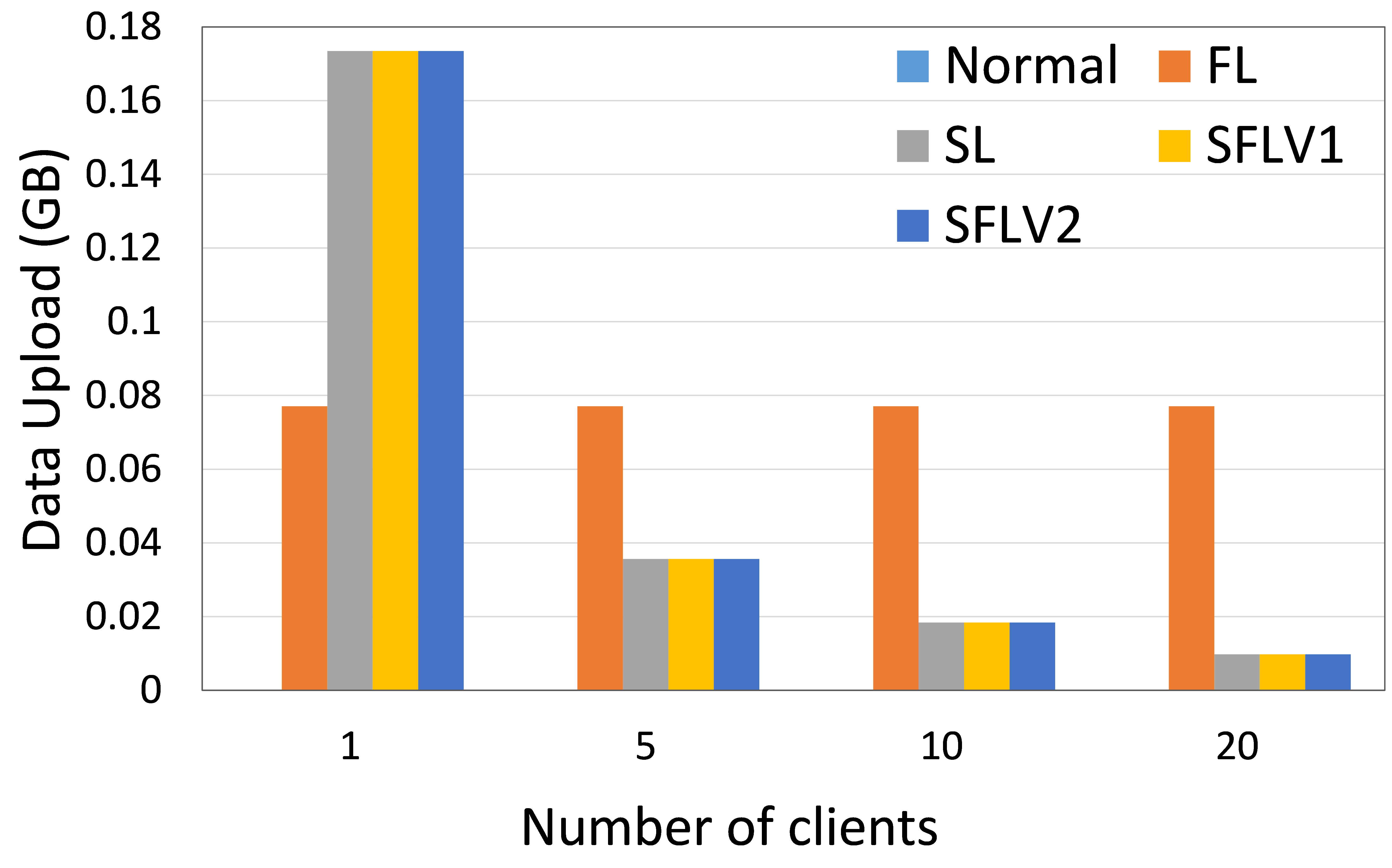
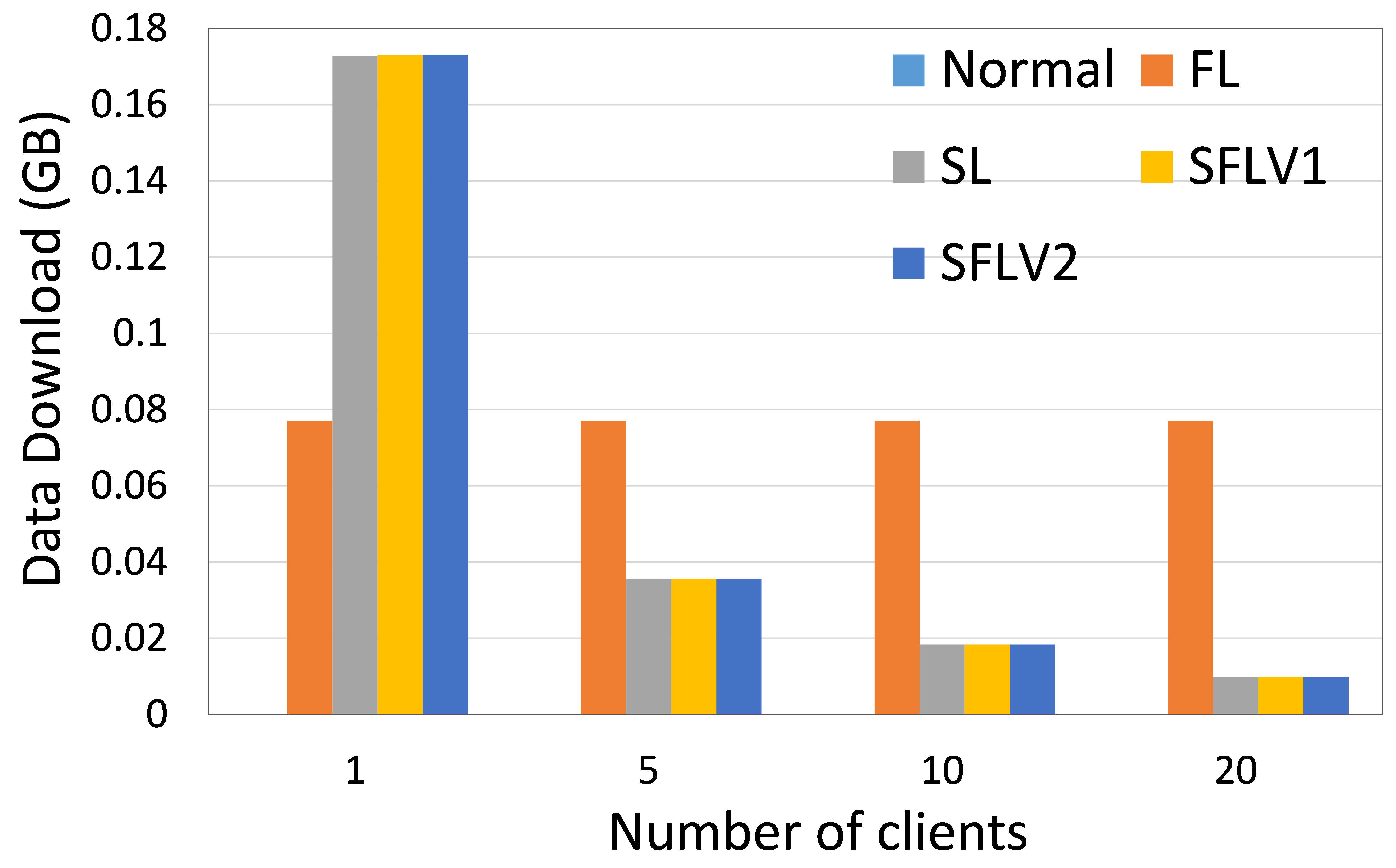
0.B.2 Time Measurement
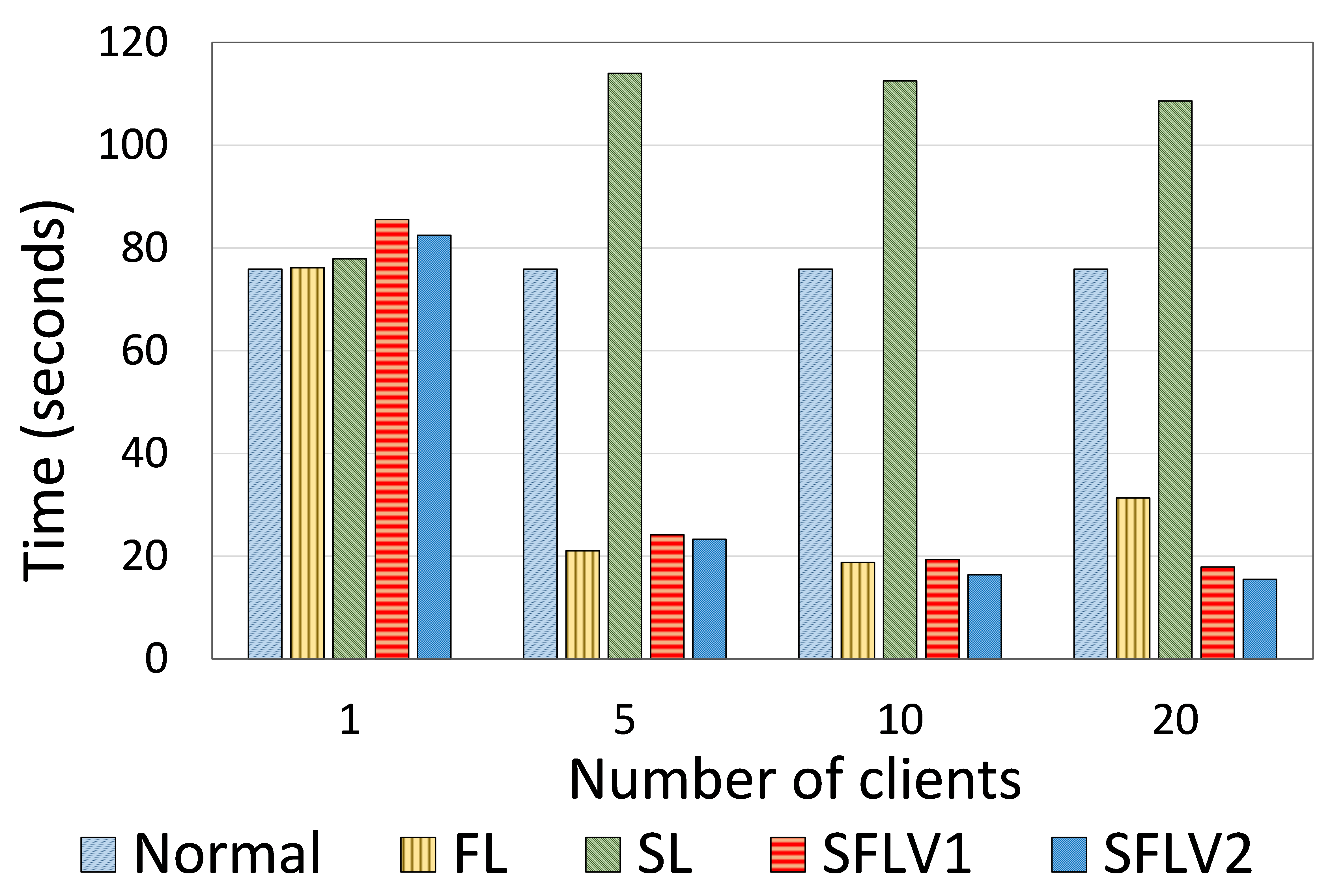
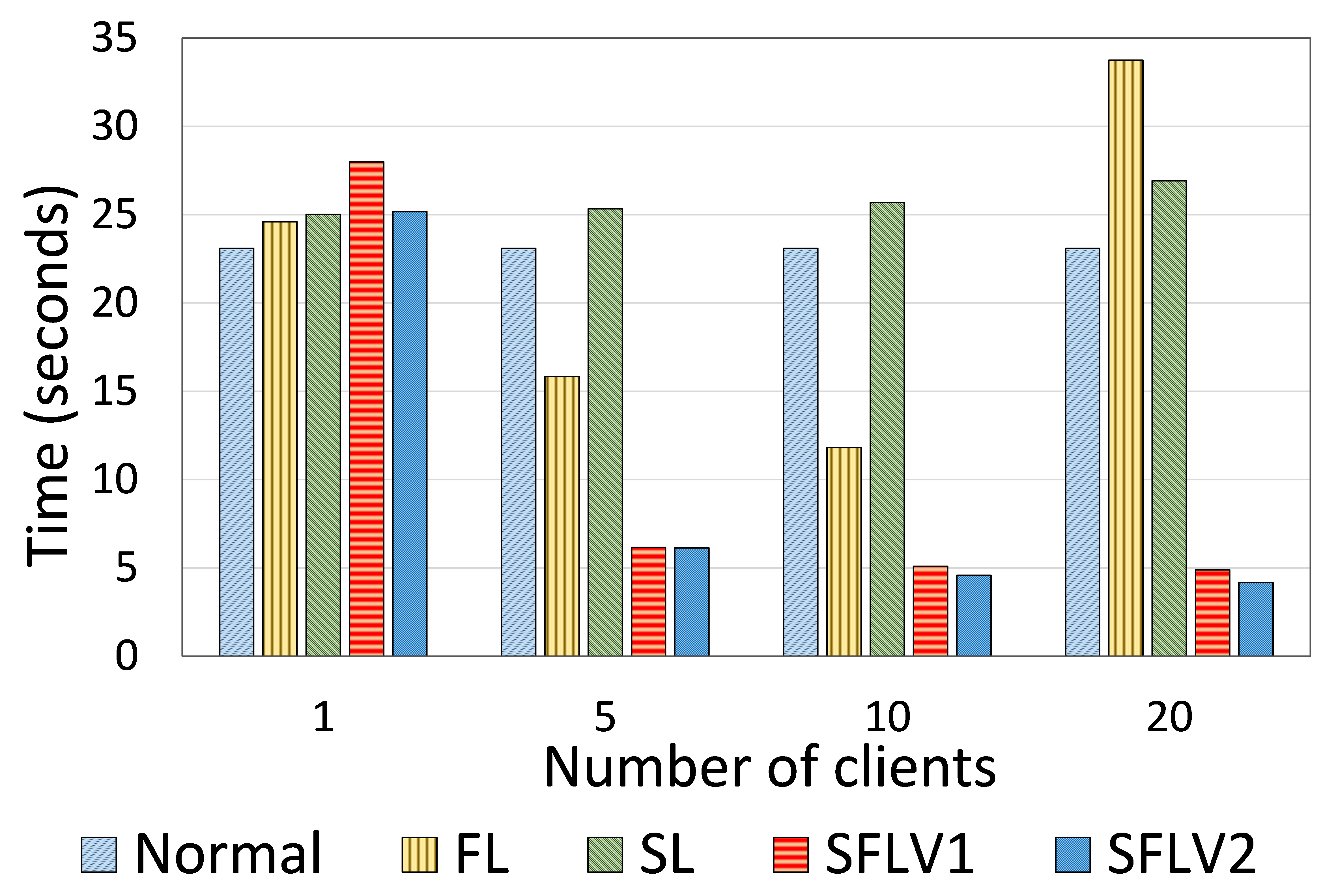
To show the time efficiency of SFLV1 and SFLV2 compared to SL, we analyze the training time taken for one global epoch. Considering Section “Total Cost Analysis,” Algorithm 1 and 2, it is not difficult to see the following: For SL, the main overhead is due to the client-side model upload and download by each client, and for a global epoch, it is a multiple of the total number of clients (). In contrast, there are no such product terms while calculating the time in SFLV1 and SFLV2 because the server can be a supercomputing resource and processes all clients in parallel. Consequently, SFL (both versions) is faster than SL for multiple clients. Besides, this also shows that the training time measurement depends not only on the implementation but also on the algorithm. For our experiments in SFL, we implemented a multithreaded python program for the main server. Using the same experimental setup (which was used to measure the communication cost), we ran each experiment for eleven global epochs and recorded the time for each global epoch. Unlike in the communication measurement setup, the training time was averaged by considering the time from the second global epoch onward for all clients after running each experiment ten times. The time for the first global epoch was excluded because it included the time taken by clients to connect to the server, i.e., the initial connection overhead (in our setup, all clients got connected to the server at first and kept the connection during the experiment). We ran each experiment ten times - different HPC slurm jobs in each instance - to exclude the effects of the change in the computing environment in each run.
Based on our observations on ResNet18 on HAM10000 and AlexNet on MNIST, the time statistics for the cases with multiple clients indicated that SFLV1 and SFLV2 were significantly faster - by four to six times - than SL. It had a similar or even better speed than FL (refer to Fig. 7). For the single client case, SL and FL approaches spent similar time; SFLV1 and SFLV2 spent slightly more time than the other.
Appendix 0.C Additional Empirical Results
0.C.1 Performance of FL, SL, SFLV1, and SFLV2
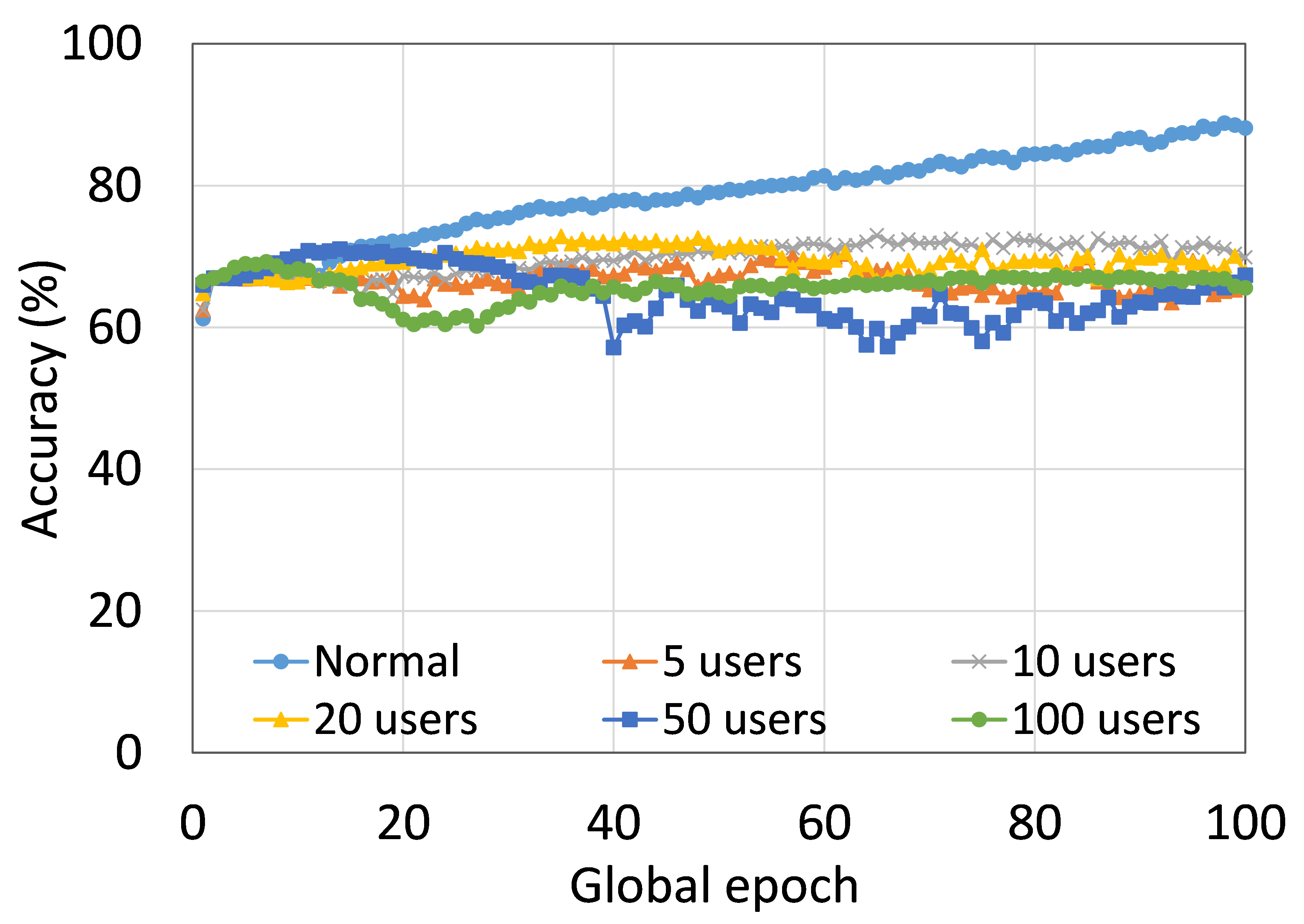
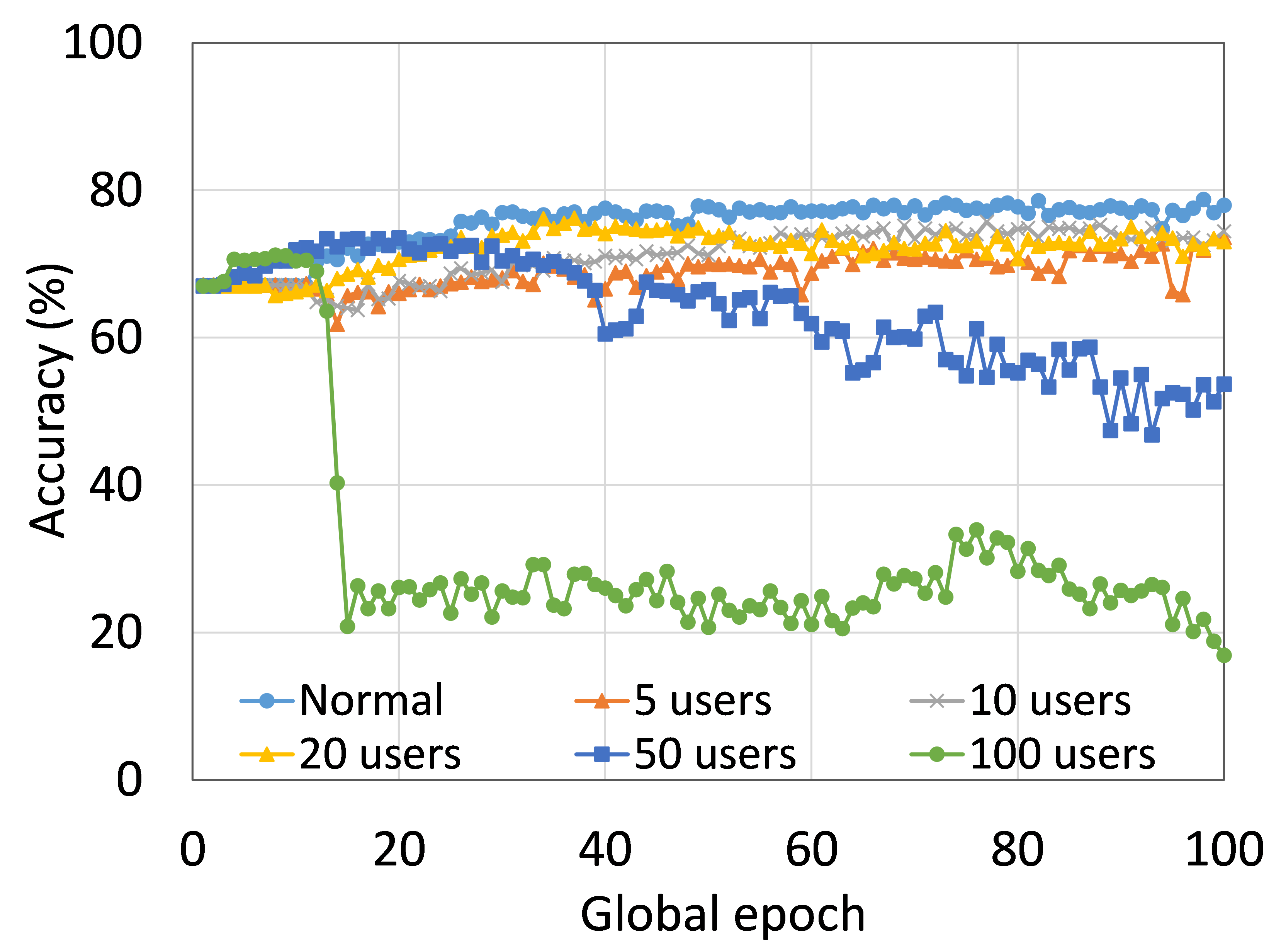
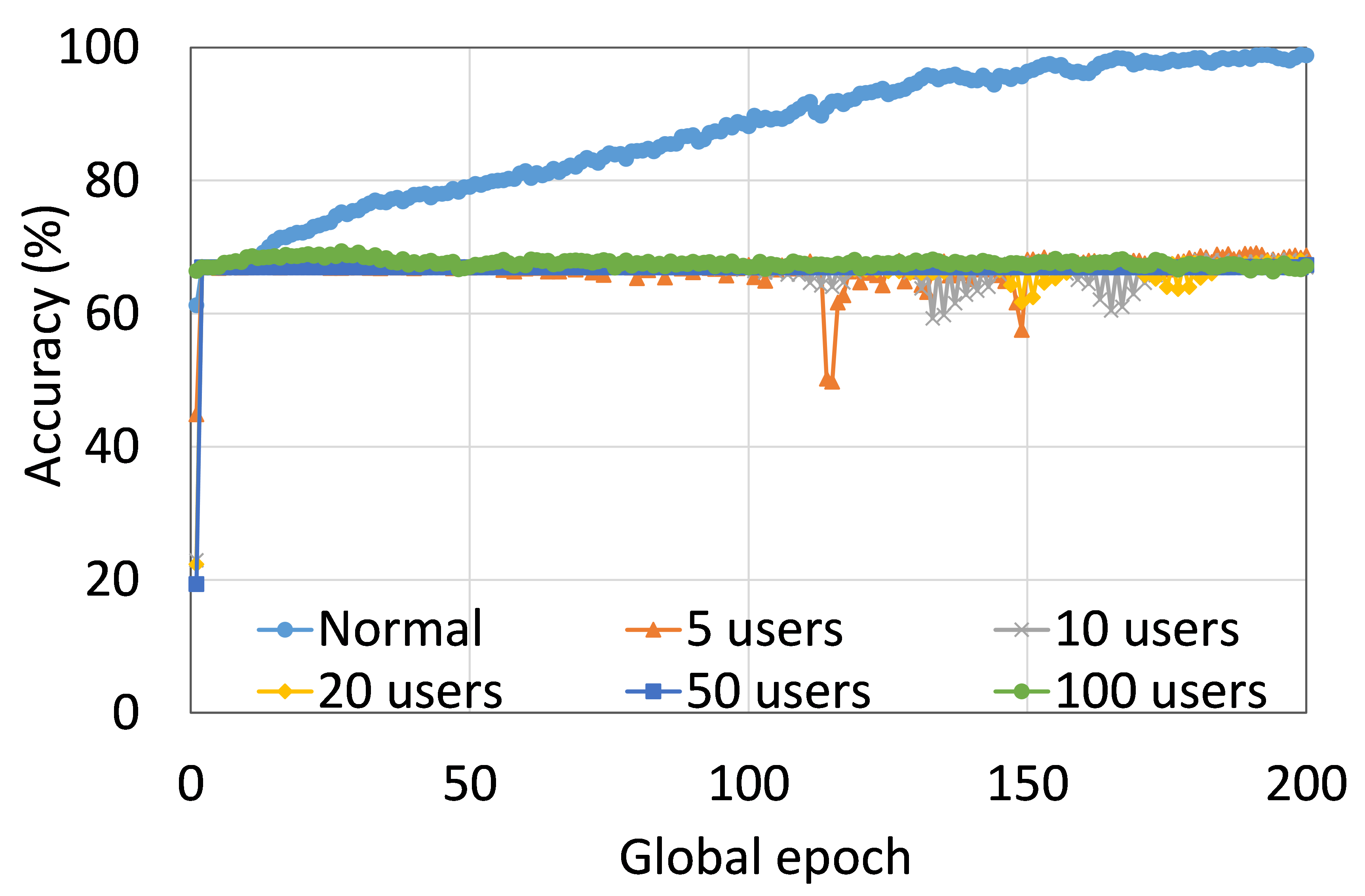
This section presents the training and testing convergence plots of normal (centralized) learning, FL, SL, SFLV1, and SFLV2. The experiments are performed considering five clients and using AlexNet on HAM10000, ResNet18 on MNIST, AlexNet on MNIST, LeNet5 on FMNIST, AlexNet on FMNIST, LeNet5 on CIFAR10, and VGG16 on CIFAR10. We present the training and testing results to demonstrate both the pictures of training and testing instances.
The main observation from these results is that FL, SL, SFLV1 and SFLV2 behave similar characteristics while training and testing in most of the cases. Besides, the best performance of an individual approach depends on the dataset. There can be the worst cases, where, for some cases, some approaches may not learn in a naive implementation. For example, SL, SFLV1, and SFLV2 can suffer from no learning in VGG16 on CIFAR10 (see Fig. 8(m) and 8(n)). This requires further investigation. In other cases, our DCML approaches learn in an expected way. For some datasets like CIFAR10, FL performs well compared to others in a similar setting; however, SL, SFLV1, and SFLV2 have advantages due to split network architecture, like low computation requirements at the client-side and model privacy, over FL. Furthermore, among SFLV1 and SFLV2, the FedAvg at the server-side network is not always efficient; for example, AlexNet on HAM10000 (see Fig. 8(b); most of the cases, FedAvg (in FL and SFLV1) is contributing towards promising results.
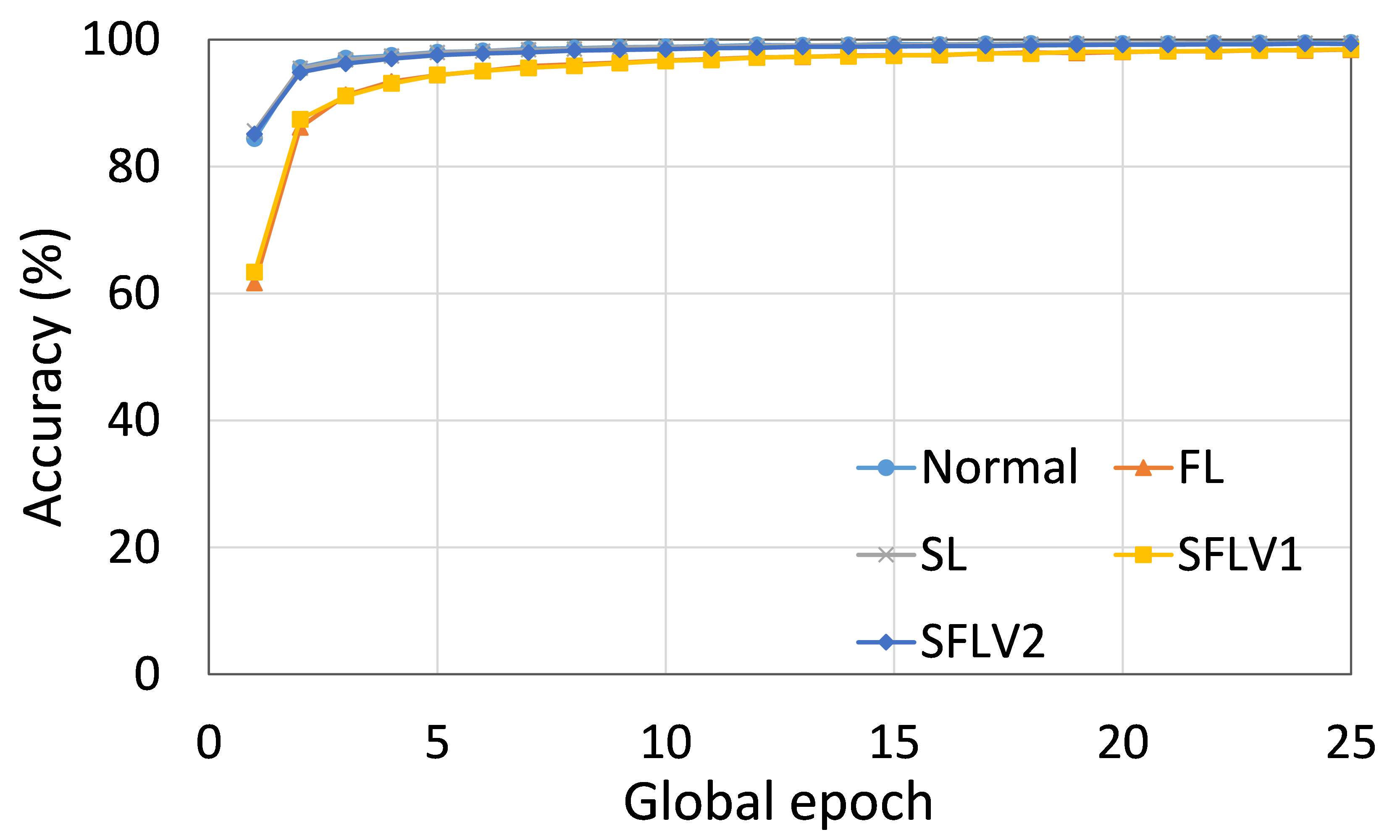
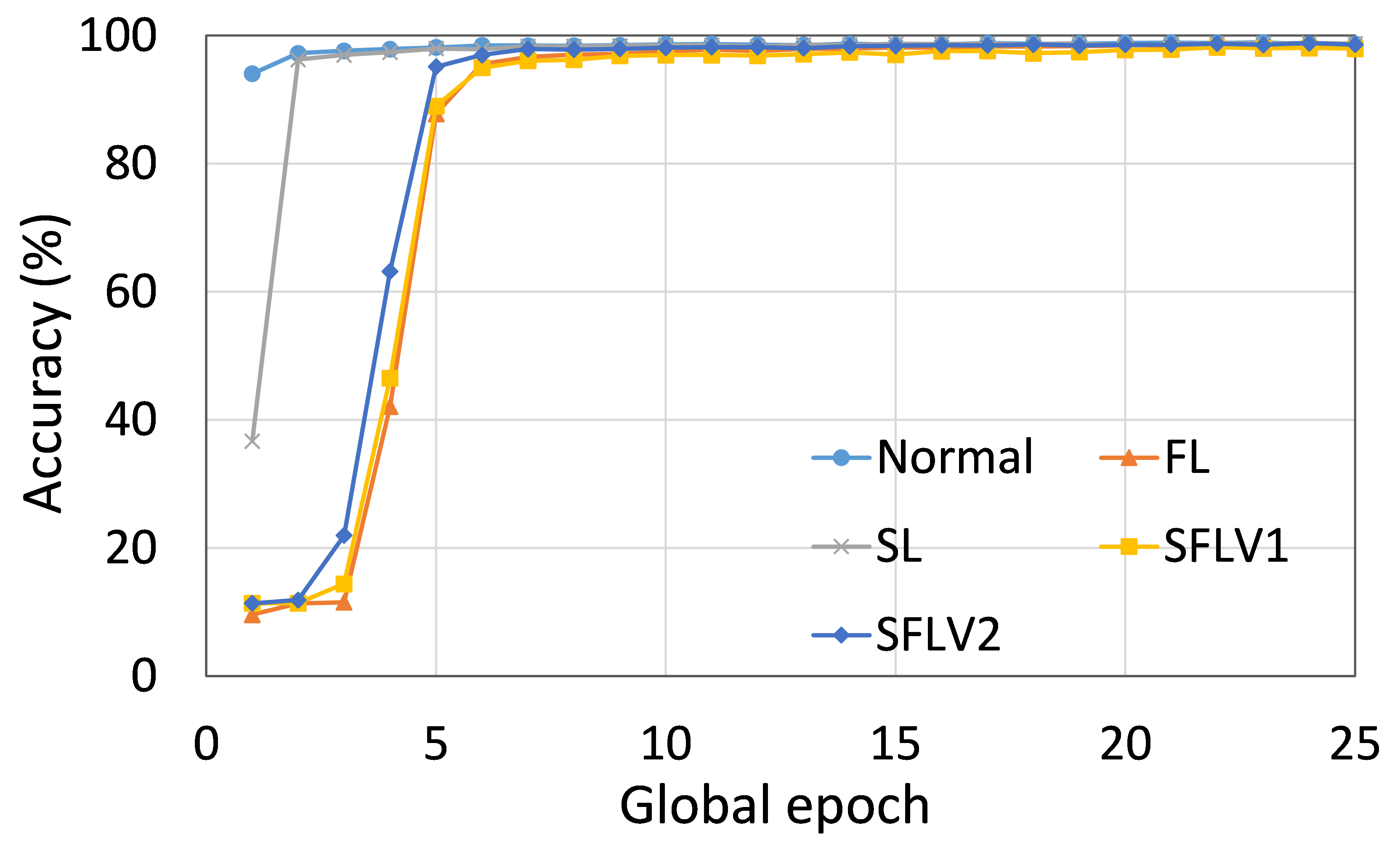
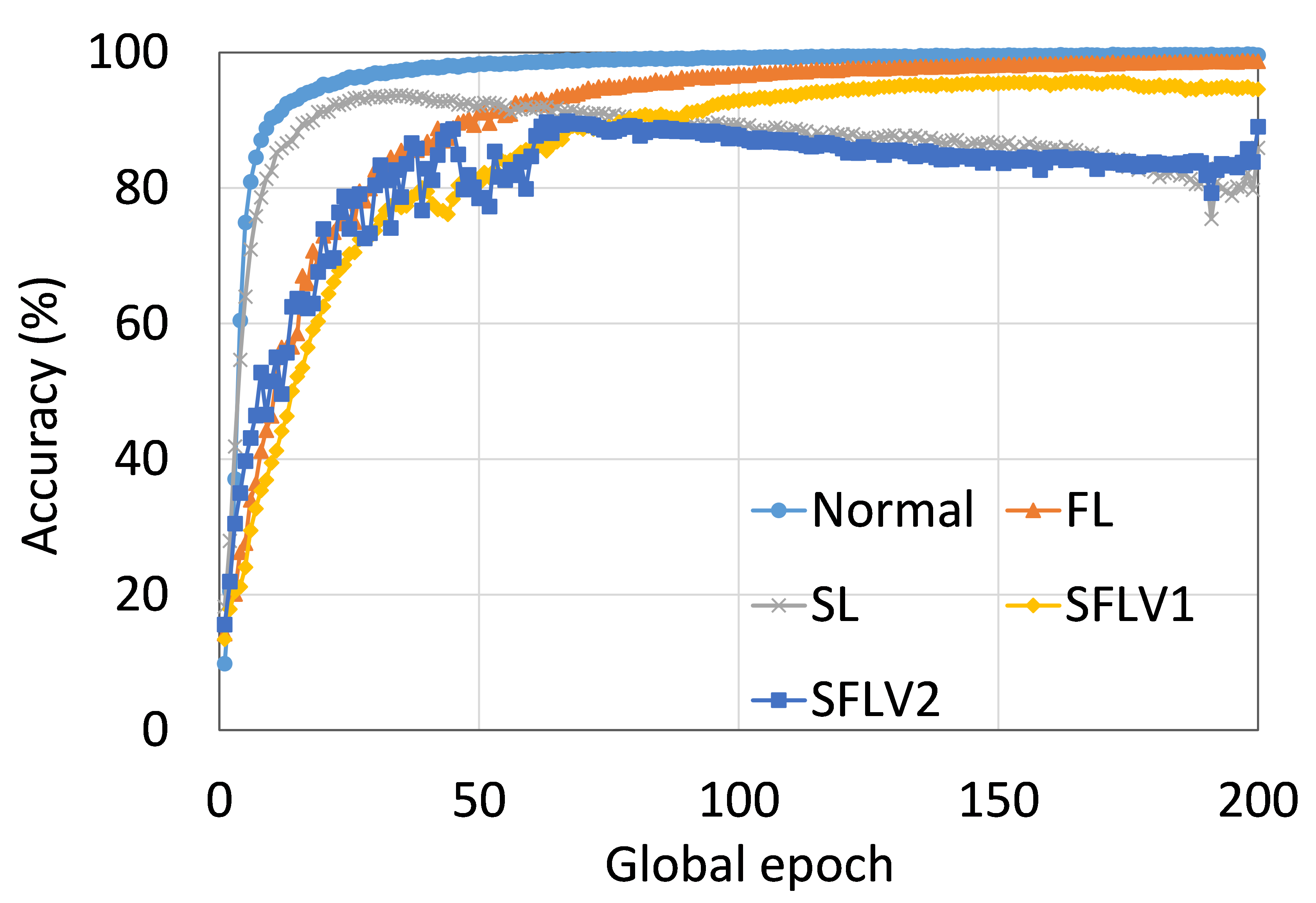
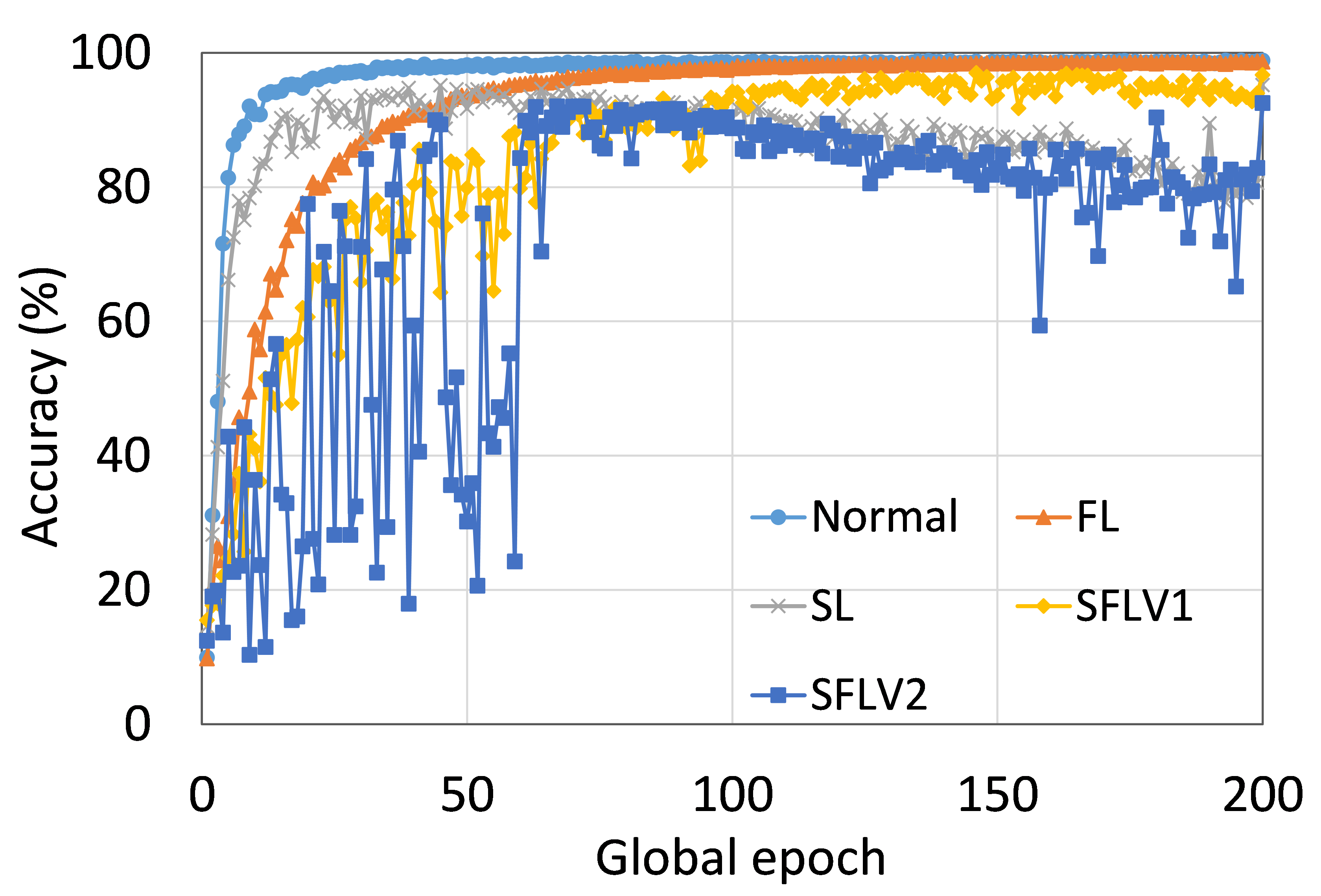
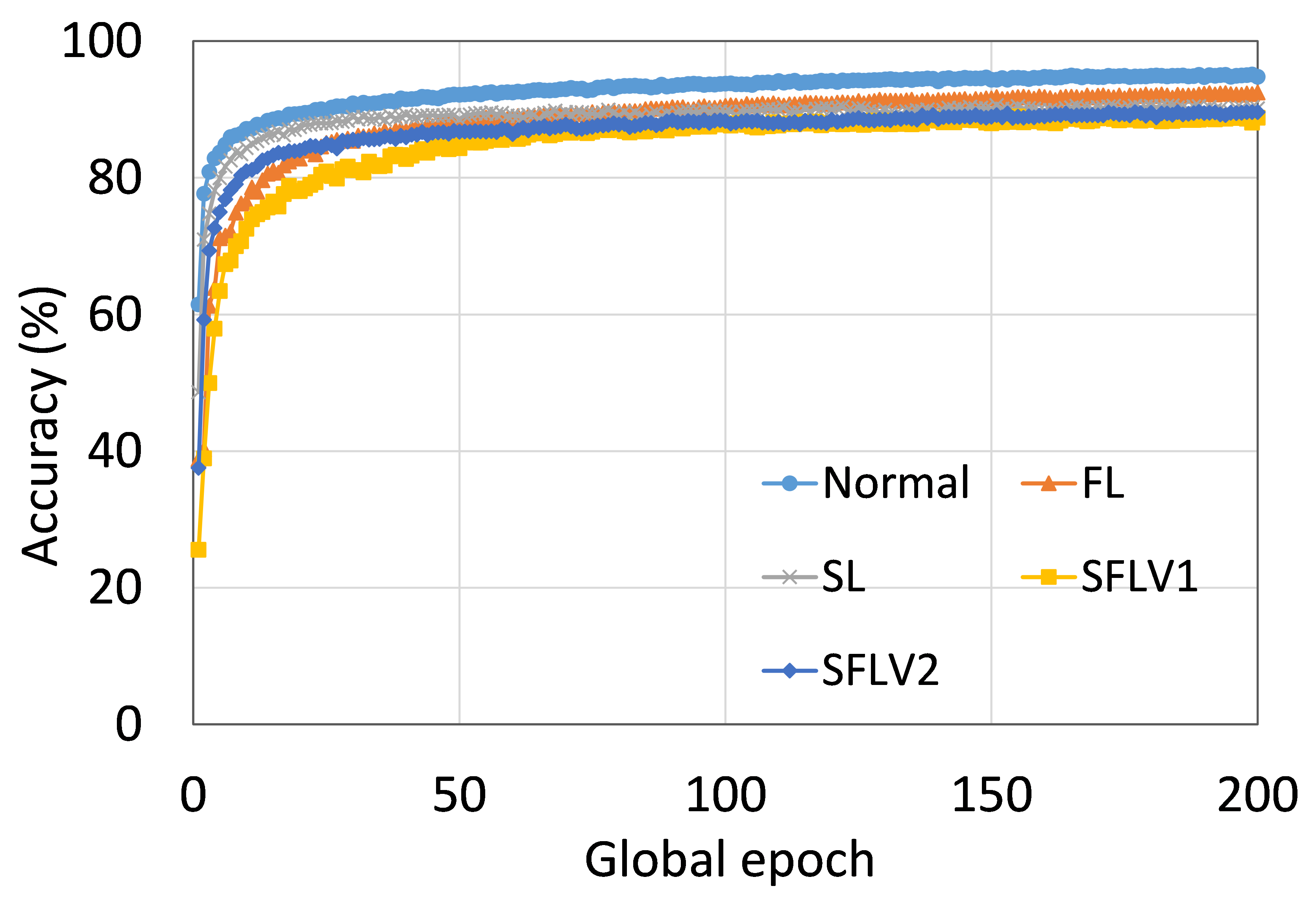
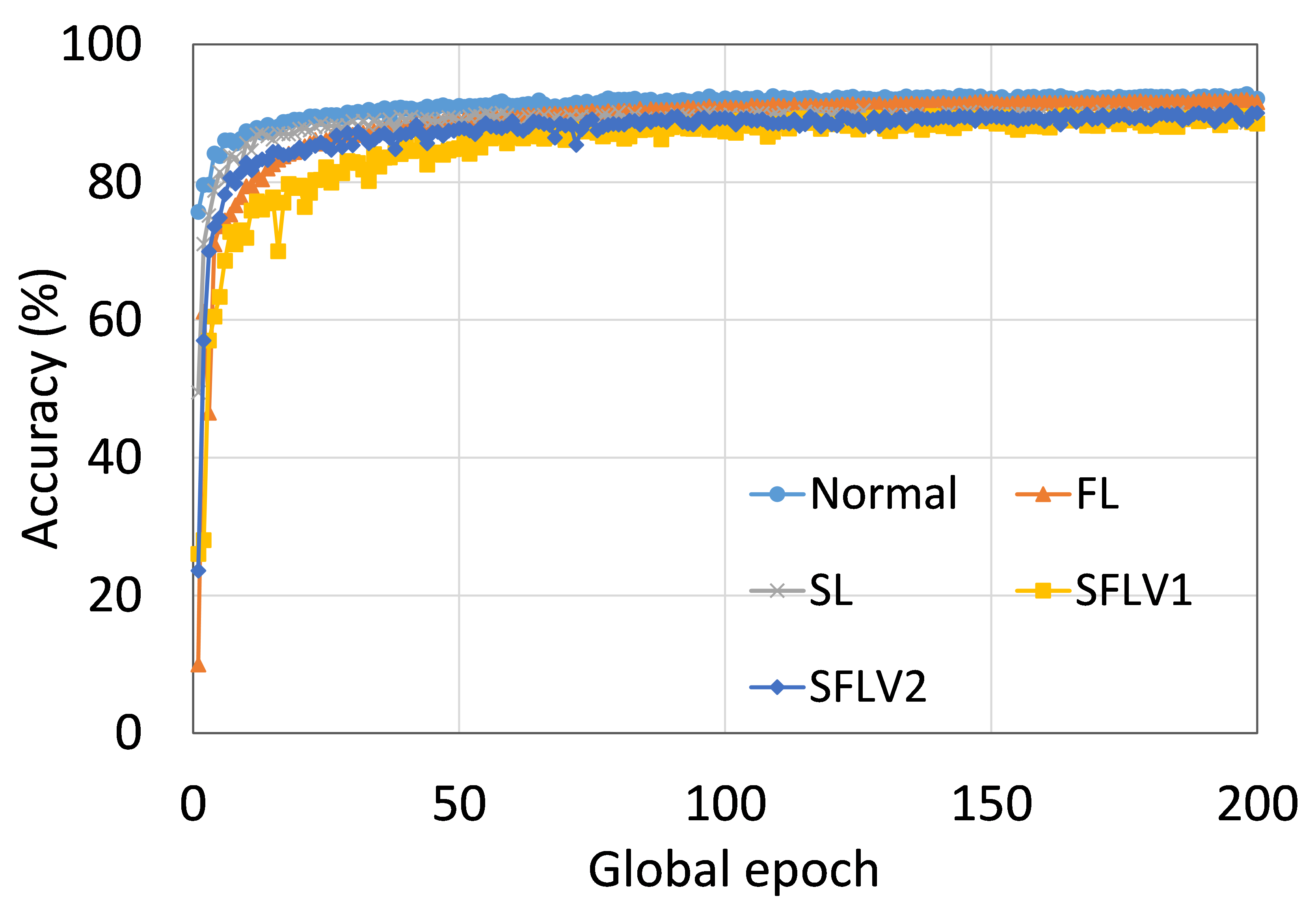
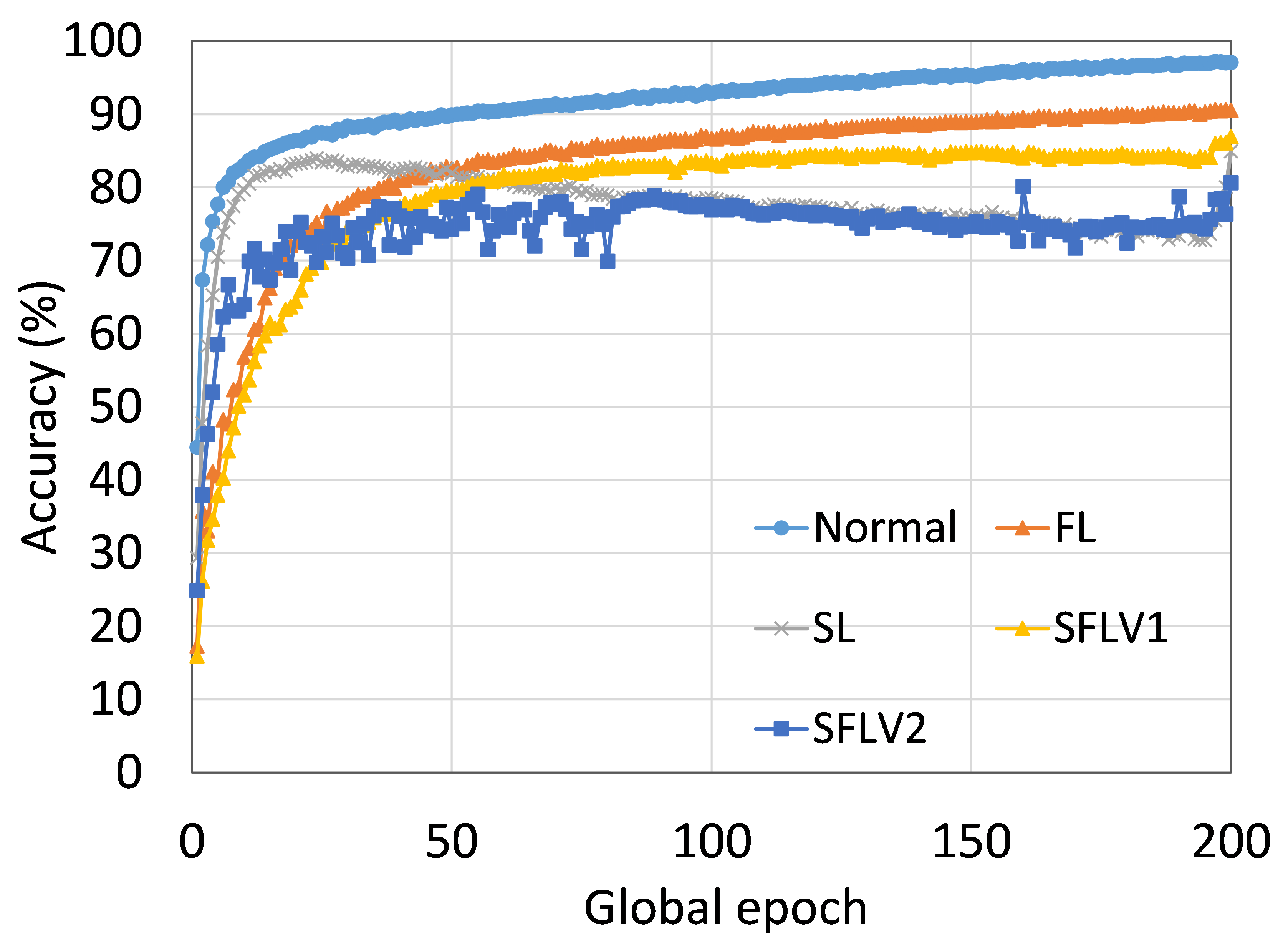

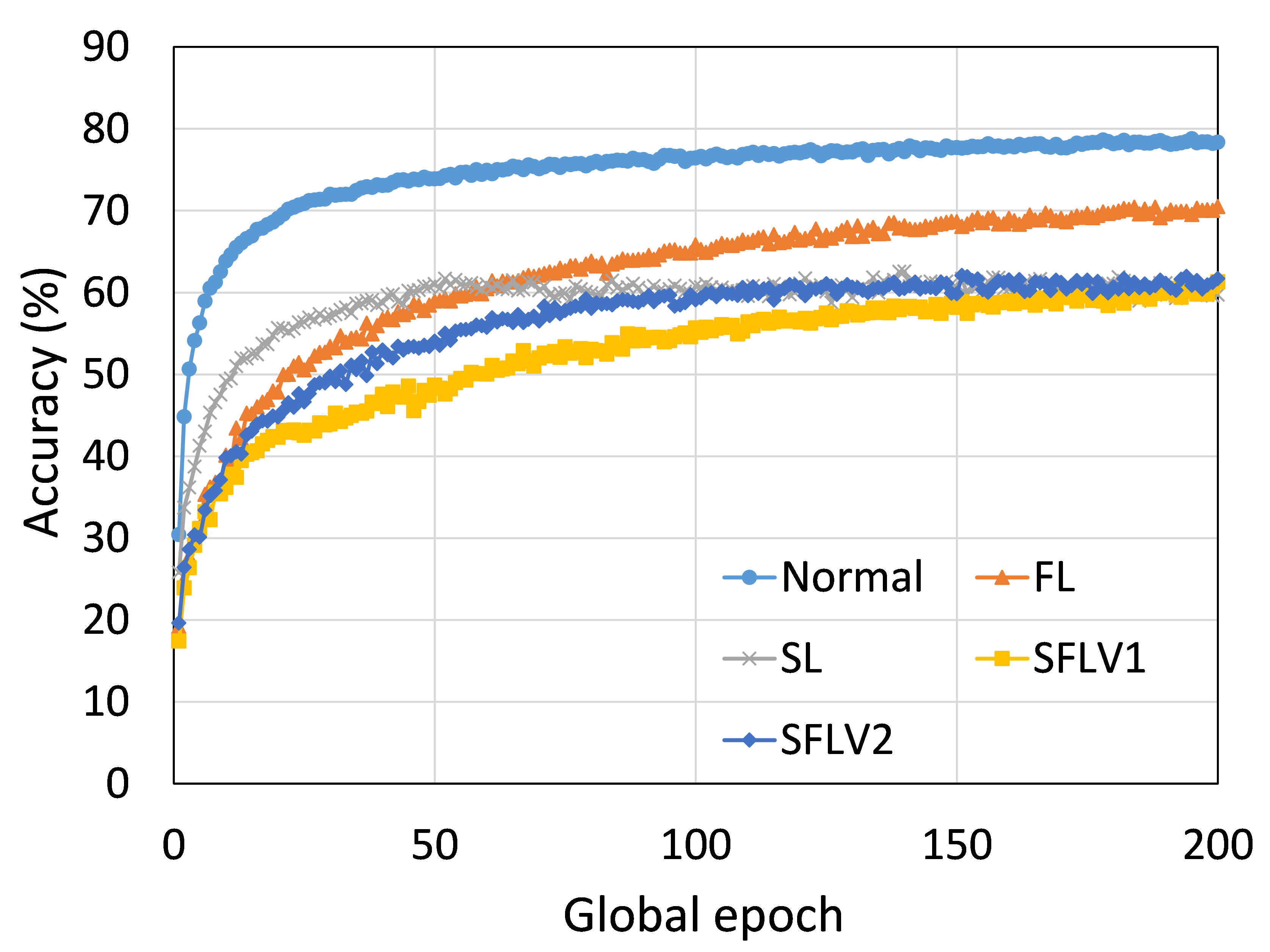
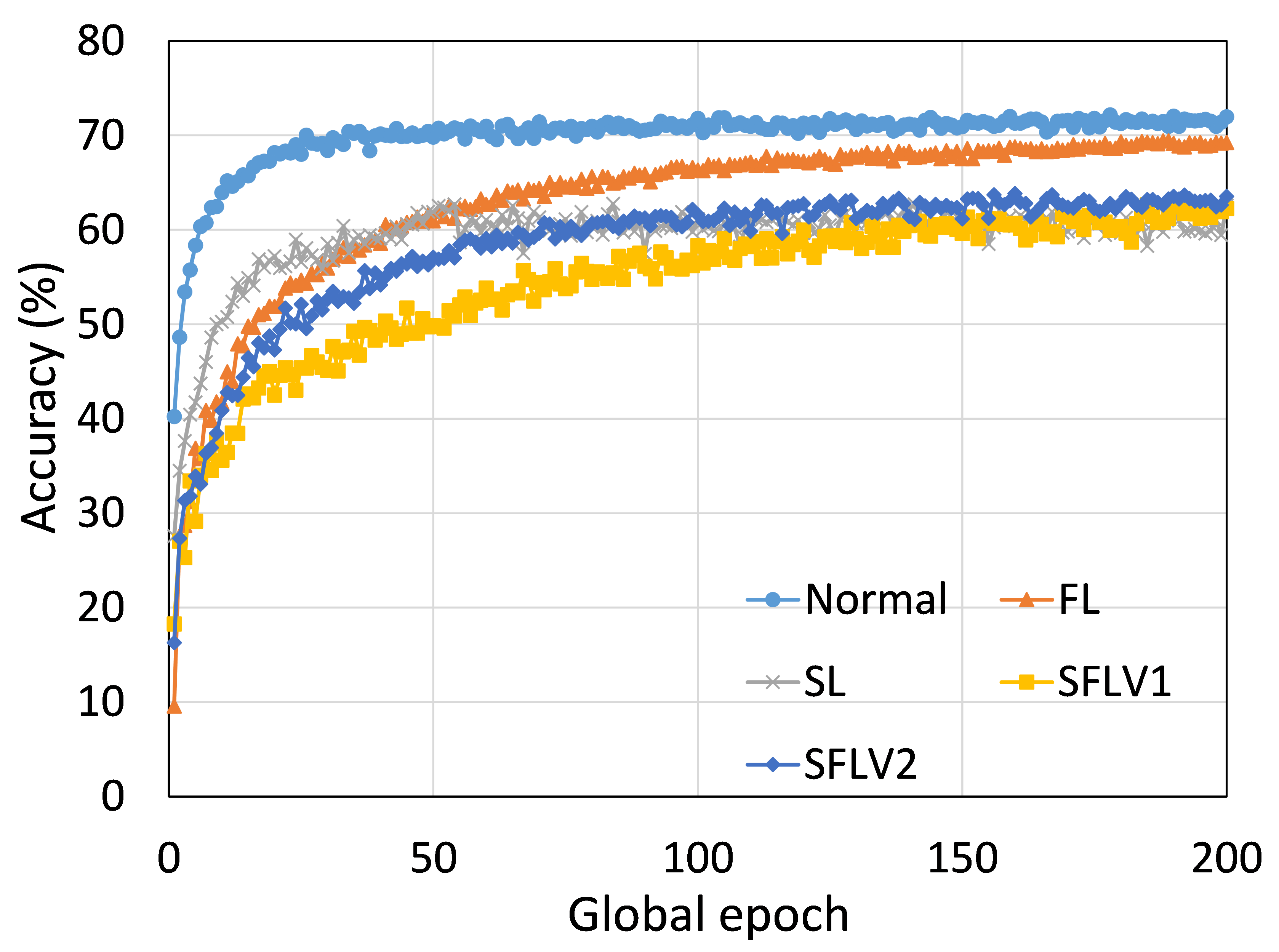
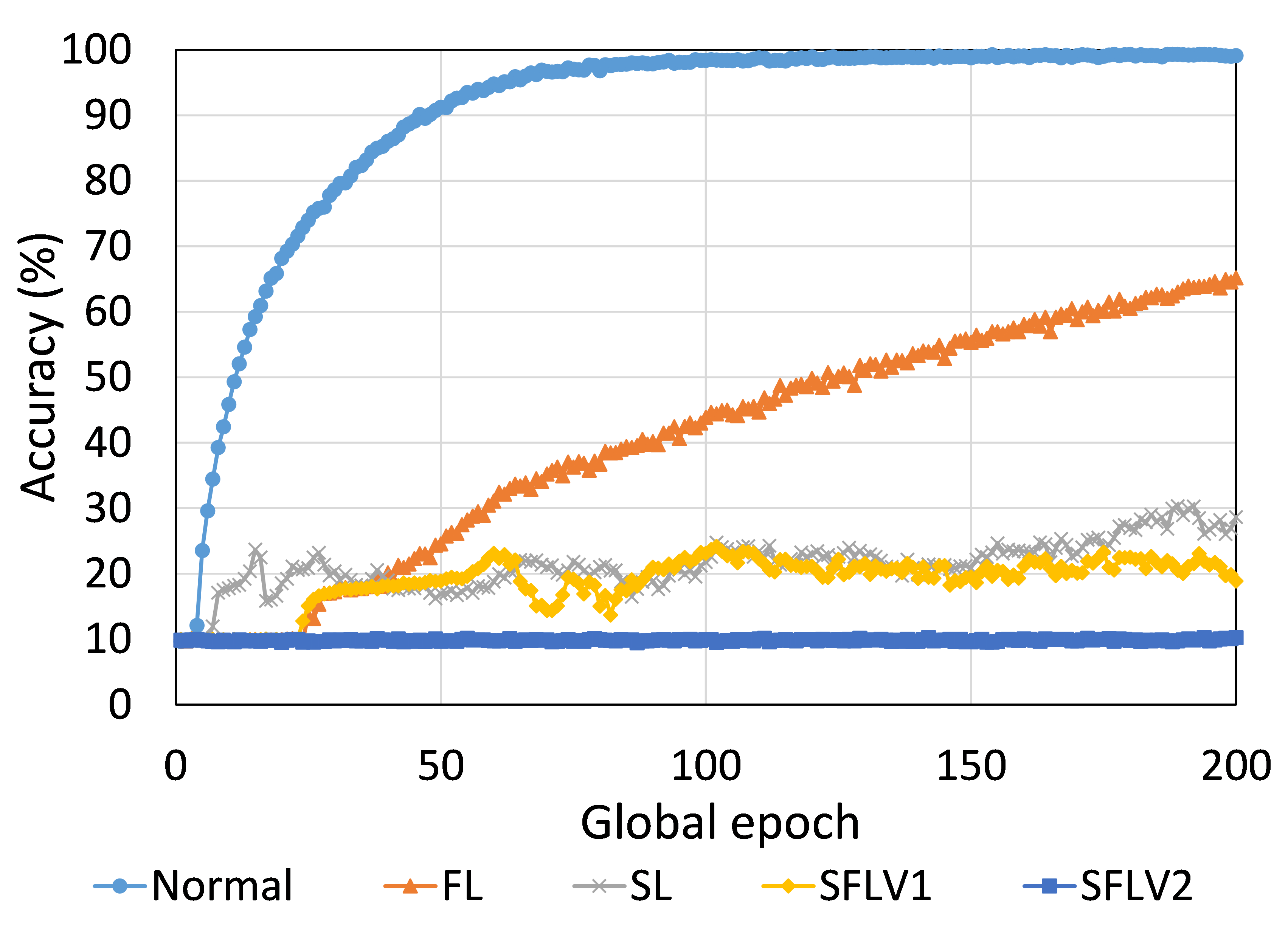
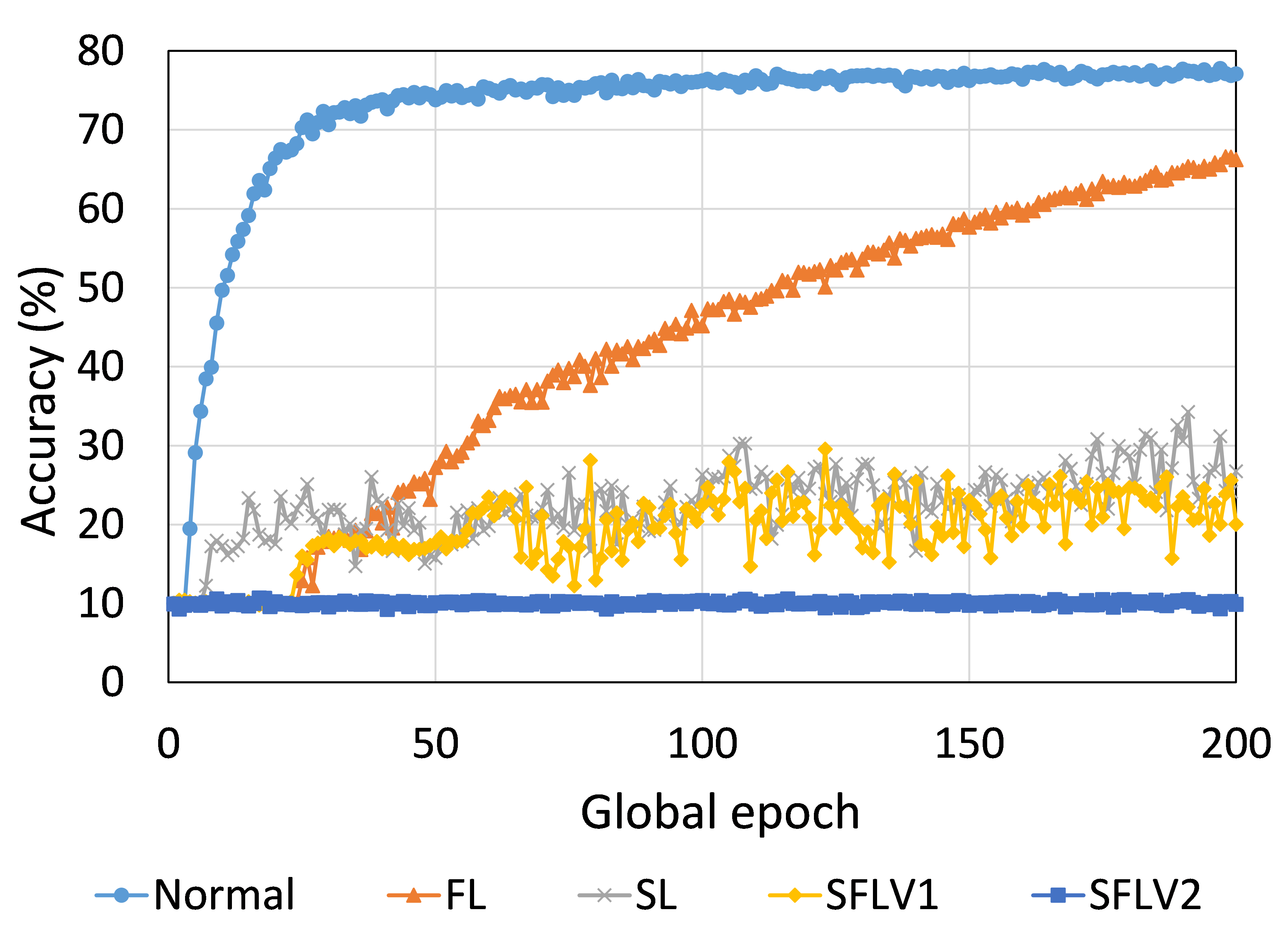
0.C.2 Effects of Number of Users on the Performance
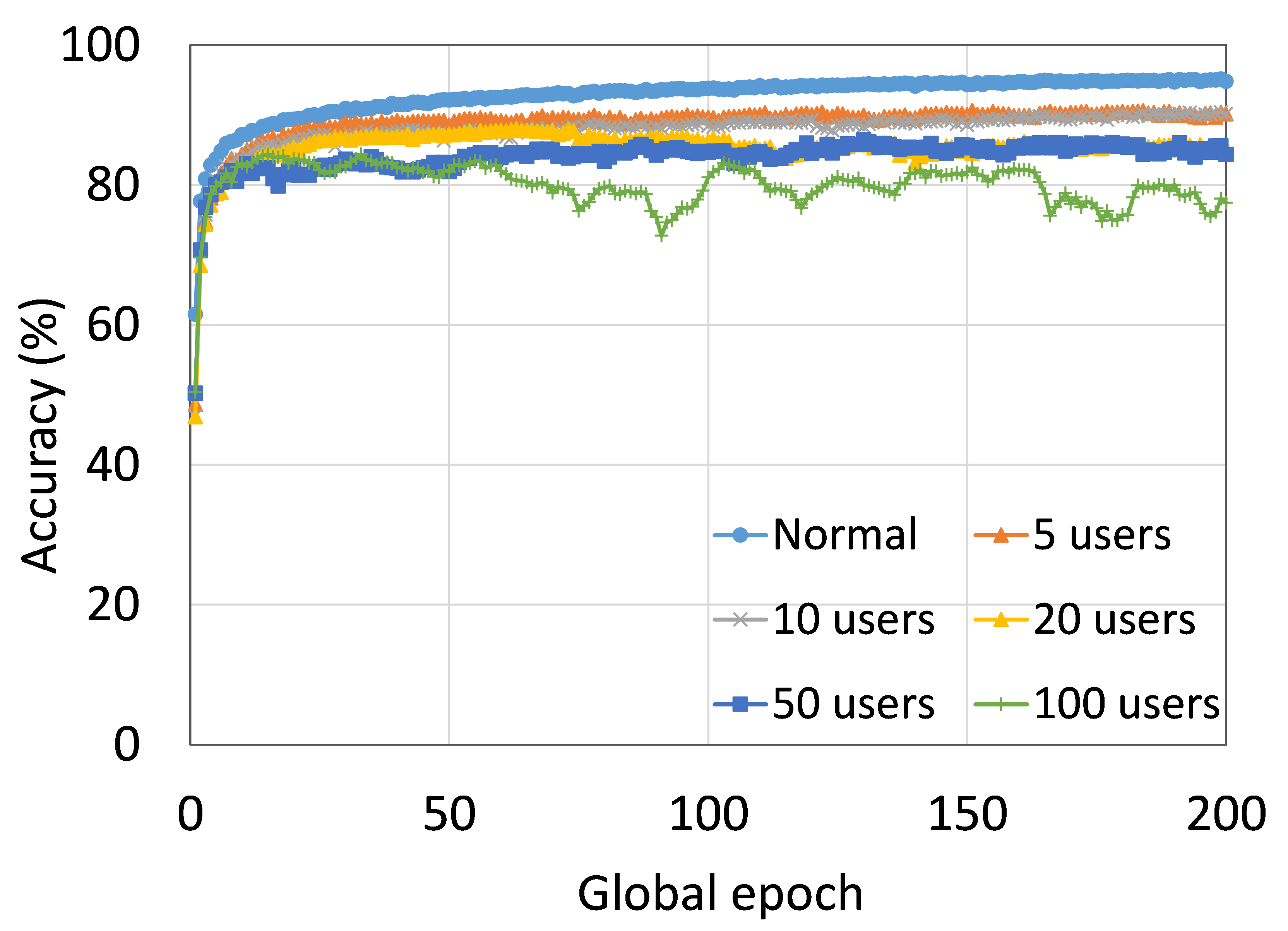
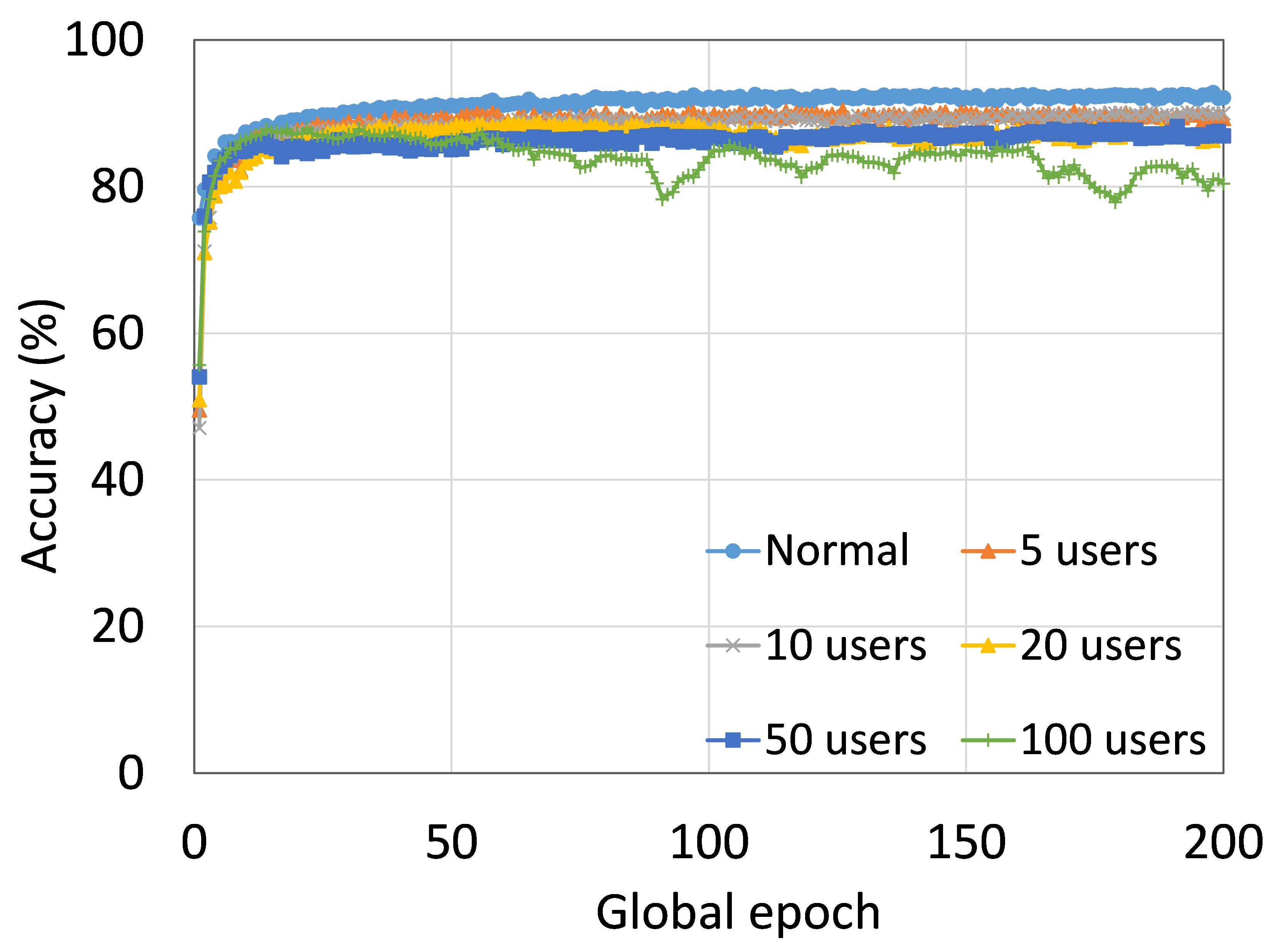
This section presents the training and testing convergence plots of normal (centralized) learning, SL, FL, SFLV1, and SFLV2. The experiments are performed considering a various number of clients ranging from 5 to 100. Moreover, we consider LeNet5 on FMNIST and AlexNet on HAM10000.
Our main observation is that usually, the convergence slows down, and performance degrades with the increase in the number of users (see Fig. 9 (b), (d), (f), and (h)) within the observation window of the global epochs. Furthermore, all our DCML approaches show similar behavior over the various number of users (clients). However, there are some cases with SL, where, despite model learning well during training, there exists a sharp fall in testing performance, for example, SL with AlexNet on HAM10000 with 100 users (see Fig. 9(l)). Similarly, SFLV2, which acts similarly to the SL at the server-side operations, also shows a similar fall, but for 50 users. This particular case requires further investigation.