Adaptive Universal Generalized PageRank Graph Neural Network
Abstract
In many important graph data processing applications the acquired information includes both node features and observations of the graph topology. Graph neural networks (GNNs) are designed to exploit both sources of evidence but they do not optimally trade-off their utility and integrate them in a manner that is also universal. Here, universality refers to independence on homophily or heterophily graph assumptions. We address these issues by introducing a new Generalized PageRank (GPR) GNN architecture that adaptively learns the GPR weights so as to jointly optimize node feature and topological information extraction, regardless of the extent to which the node labels are homophilic or heterophilic. Learned GPR weights automatically adjust to the node label pattern, irrelevant on the type of initialization, and thereby guarantee excellent learning performance for label patterns that are usually hard to handle. Furthermore, they allow one to avoid feature over-smoothing, a process which renders feature information nondiscriminative, without requiring the network to be shallow. Our accompanying theoretical analysis of the GPR-GNN method is facilitated by novel synthetic benchmark datasets generated by the so-called contextual stochastic block model. We also compare the performance of our GNN architecture with that of several state-of-the-art GNNs on the problem of node-classification, using well-known benchmark homophilic and heterophilic datasets. The results demonstrate that GPR-GNN offers significant performance improvement compared to existing techniques on both synthetic and benchmark data. Our implementation is available online.111https://github.com/jianhao2016/GPRGNN
1 Introduction
Graph-centered machine learning has received significant interest in recent years due to the ubiquity of graph-structured data and its importance in solving numerous real-world problems such as semi-supervised node classification and graph classification (Zhu, 2005; Shervashidze et al., 2011; Lü & Zhou, 2011). Usually, the data at hand contains two sources of information: Node features and graph topology. As an example, in social networks, nodes represent users that have different combinations of interests and properties captured by their corresponding feature vectors; edges on the other hand document observable friendship and collaboration relations that may or may not depend on the node features. Hence, learning methods that are able to simultaneously and adaptively exploit node features and the graph topology are highly desirable as they make use of their latent connections and thereby improve learning on graphs.
Graph neural networks (GNN) leverage their representational power to provide state-of-the-art performance when addressing the above described application domains. Many GNNs use message passing (Gilmer et al., 2017; Battaglia et al., 2018) to manipulate node features and graph topology. They are constructed by stacking (graph) neural network layers which essentially propagate and transform node features over the given graph topology. Different types of layers have been proposed and used in practice, including graph convolutional layers (GCN) (Bruna et al., 2014; Kipf & Welling, 2017), graph attention layers (GAT) (Velickovic et al., 2018) and many others (Hamilton et al., 2017; Wijesinghe & Wang, 2019; Zeng et al., 2020; Abu-El-Haija et al., 2019).
However, most of the existing GNN architectures have two fundamental weaknesses which restrict their learning ability on general graph-structured data. First, most of them seem to be tailor-made to work on homophilic (associative) graphs. The homophily principle (McPherson et al., 2001) in the context of node classification asserts that nodes from the same class tend to form edges. Homophily is also a common assumption in graph clustering (Von Luxburg, 2007; Tsourakakis, 2015; Dau & Milenkovic, 2017) and in many GNNs design (Klicpera et al., 2018). Methods developed for homophilic graphs are nonuniversal in so far that they fail to properly solve learning problems on heterophilic (disassortative) graphs (Pei et al., 2019; Bojchevski et al., 2019; 2020). In heterophilic graphs, nodes with distinct labels are more likely to link together (For example, many people tend to preferentially connect with people of the opposite sex in dating graphs, different classes of amino acids are more likely to connect within many protein structures (Zhu et al., 2020) etc). GNNs model the homophily principle by aggregating node features within graph neighborhoods. For this purpose, they use different mechanisms such as averaging in each network layer. Neighborhood aggregation is problematic and significantly more difficult for heterophilic graphs (Jia & Benson, 2020).
Second, most of the existing GNNs fail to be “deep enough”. Although in principle an arbitrary number of layers may be stacked, practical models are usually shallow (including - layers) as these architectures are known to achieve better empirical performance than deep networks. A widely accepted explanation for the performance degradation of GNNs with increasing depth is feature-over-smoothing, which may be intuitively explained as follows. The process of GNN feature propagating represents a form of random walks on “feature graphs,” and under proper conditions, such random walks converge with exponential rate to their stationary points. This essentially levels the expressive power of the features and renders them nondiscriminative. This intuitive reasoning was first described for linear settings in Li et al. (2018) and has been recently studied in Oono & Suzuki (2020) for a setting involving nonlinear rectifiers.
We address these two described weaknesses by combining GNNs with Generalized PageRank techniques (GPR) within a new model termed GPR-GNN. The GPR-GNN architecture is designed to first learn the hidden features and then to propagate them via GPR techniques. The focal component of the network is the GPR procedure that associates each step of feature propagation with a learnable weight. The weights depend on the contributions of different steps during the information propagation procedure, and they can be both positive and negative. This departures from common nonnegativity assumptions (Klicpera et al., 2018) allows for the signs of the weights to adapt to the homophily/heterophily structure of the underlying graphs. The amplitudes of the weights trade-off the degree of smoothing of node features and the aggregation power of topological features. These traits do not change with the choice of the initialization procedure and elucidate the process used to combine node features and the graph structure so as to achieve (near)-optimal predictions. In summary, the GPR-GNN method can simultaneously learn the node label patterns of disparate classes of graphs and prevent feature over-smoothing.
The excellent performance of GPR-GNN is demonstrated empirically, on real world datasets, and further supported through a number of theoretical findings. In the latter setting, we show that the GPR procedure relates to general polynomial graph filtering, which can naturally deal with both high and low frequency parts of the graph signals. In contrast, recent GNN models that utilize Personalized PageRanks (PPR) with fixed weights (Wu et al., 2019; Klicpera et al., 2018; 2019) inevitably act as low-pass filters. Thus, they fail to learn the labels of heterophilic graphs. We also establish that GPR-GNN can provably mitigate the feature-over-smoothing issue in an adaptive manner even after large-step propagation (i.e., after a large number of propagation steps). Hence, the method is able to make use of informative large-step propagation.
To test the performance of GPR-GNN on homophilic and heterophilic node label patterns and determine the trade-off between node and topological feature exploration, we first describe the recently proposed contextual stochastic block model (cSBM) (Deshpande et al., 2018). The cSBM allows for smoothly controlling the “informativeness ratio” between node features and graph topology, where the graph can vary from being highly homophilic to highly heterophilic. We show that GPR-GNN outperforms all other baseline methods for the task of semi-supervised node classification on the cSBM consistently from strong homophily to strong heterophily. We then proceed to show that GPR-GNN offers state-of-the-art performance on node-classification benchmark real-world datasets which contain both homophilic and heterophilic graphs. Due to the space limit, we put all proofs, formal theorem statements, and the conclusion section in the Supplement.
2 Preliminaries
Let be an undirected graph with nodes and edges . Let denote the number of nodes, assumed to belong to one of classes. The nodes are associated with the node feature matrix where denotes the number of features per node. Throughout the paper, we use to indicate the row and to indicate the column of the matrix , respectively. The symbol is reserved for the Kronecker delta function. The graph is described by the adjacency matrix , while stands for the adjacency matrix for a graph with added self-loops. We let be the diagonal degree matrix of and denote the symmetric normalized adjacency matrix with self-loops.
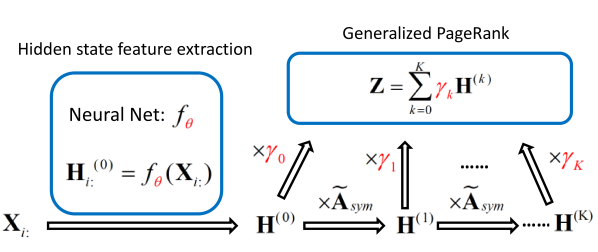
3 GPR-GNNs: Motivation and Contributions
Generalized PageRanks. Generalized PageRank (GPR) methods were first used in the context of unsupervised graph clustering where they showed significant performance improvements over Personalized PageRank (Kloumann et al., 2017; Li et al., 2019). The operational principles of GPRs can be succinctly described as follows. Given a seed node in some cluster of the graph, a one-dimensional feature vector is initialized according to . The GPR score is defined as , where the parameters , are referred to as the GPR weights. Clustering of the graph is performed locally by thresholding the GPR score. Certain PangRank methods, such as Personalized PageRank or heat-kernel PageRank (Chung, 2007), are associated with specific choices of GPR weights (Li et al., 2019). For an excellent in-depth discussion of PageRank methods, the interested reader is referred to (Gleich, 2015). The work in Li et al. (2019) recently introduced and theoretically analyzed a special form of GPR termed Inverse PR (IPR) and showed that long random walk paths are more beneficial for clustering then previously assumed, provided that the GPR weights are properly selected (Note that IPR was developed for homophilic graphs and optimal GPR weights for heterophilic graphs are not currently known).
Equivalence of the GPR method and polynomial graph filtering. If we truncate the infinite sum in the definition of GPR at some natural number , corresponds to a polynomial graph filter of order . Thus, learning the optimal GPR weights is equivalent to learning the optimal polynomial graph filter. Note that one can approximate any graph filter using a polynomial graph filter (Shuman et al., 2013) and hence the GPR method is able to deal with a large range of different node label patterns. Also, increasing allows one to better approximate the underlying optimal graph filter. This once again shows that large-step propagation is beneficial.
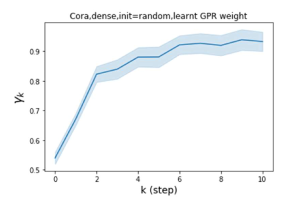
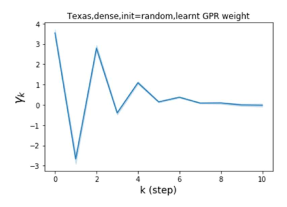
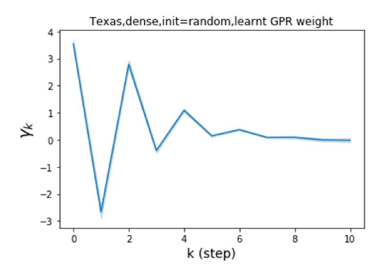
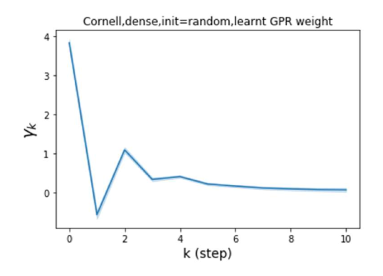
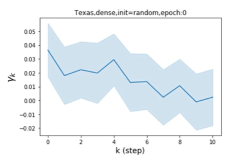
Universality with respect to node label patterns: Homophily versus heterophily. In their recent work, Pei et al. (2019) proposed an index to measure the level of homophily of nodes in a graph . Note that corresponds to strong homophily while indicates strong heterophily. Figures 1 (b) and (c) plot the GPR weights learnt by our GPR-GNN method on a homophilic (Cora) and heterophilic (Texas) dataset. The learnt GPR weights from Cora match the behavior of IPR (Li et al., 2019), which verifies that large-step propagation is indeed of great importance for homophilic graphs. The GPR weights learnt from Texas behave significantly differently from all known PR variants, taking a number of negative values. These differences in weight patterns are observed under random initialization, demonstrating that the weights are actually learned by the network and not forced by specific initialization. Furthermore, the large difference in the GPR weights for these two graph models illustrates the learning power of GPR-GNN and their universal adaptability.
The over-smoothing problem. One of the key components in most GNN models is the graph convolutional layer, described by
where and represents the trainable weight matrix for the layer. The key issue that limits stacking multiple layers is the over-smoothing phenomenon: If one were to remove ReLU in the above expression, where each row of only depends on the degree of the corresponding node, provided that the graph is irreducible and aperiodic. This shows that the model looses discriminative information provided by the node features as the number of layers increases.
Mitigating graph heterophily and over-smoothing issues with the GPR-GNN model. GPR-GNN first extracts hidden state features for each node and then uses GPR to propagate them. The GPR-GNN process can be mathematically described as:
| (1) |
where represents a neural network with parameter set that generates the hidden state features . The GPR weights are trained together with in an end-to-end fashion. The GPR-GNN model is easy to interpret: As already pointed out, GPR-GNN has the ability to adaptively control the contribution of each propagation step and adjust it to the node label pattern. Examining the learnt GPR weights also helps with elucidating the properties of the topological information of a graph (i.e., determining the optimal polynomial graph filter), as illustrated in Figure 1 (b) and (c).
Placing GPR-GNNs in the context of related prior work. Among the methods that differ from repeated stacking of GCN layers, APPNP (Klicpera et al., 2018) represents one of the state-of-the-art GNNs that is related to our GPR-GNN approach. It can be easily seen that APPNP as well as SGC (Wu et al., 2019) are special cases of our model since APPNP fixes , while SGC removes all nonlinearities with , respectively. These two weight choices correspond to Personalized PageRank (PPR) (Jeh & Widom, 2003), which is known to be suboptimal compared to the IPR framework when applied to homophilic node classification (Li et al., 2019). Fixing the GPR weights makes the model unable to adaptively learn the optimal propagation rules which is of crucial importance: As we will show in Section 4, the fixed PPR weights corresponds to low-pass graph filters which makes them inadequate for learning on heterophilic graphs. The recent work (Klicpera et al., 2018) showed that fixed PPR weights (APPNP) can also provably resolve the over-smoothing problem. However, the way APPNP prevents over-smoothing is independent on the node label information. In contrast, the escape of GPR-GNN from over-smoothing is guided by the node label information (Theorem 4.2). A detailed discussion of this phenomena along with illustrative examples is delegated to the Supplement.
Among the GCN-like models, JK-Net (Xu et al., 2018) exhibits some similarities with GPR-GNN. It also aggregates the outputs of different GCN layers to arrive at the final output. On the other hand, the GCN-Cheby method (Defferrard et al., 2016; Kipf & Welling, 2017) is related to polynomial graph filtering, where each convolutional layer propagates multiple steps and the graph filter is related to Chebyshev polynomials. In both cases, the depth of the models is limited in practice (Klicpera et al., 2018) and they are not easy to interpret as our GPR-GNN method. Some prior work also emphasizes adaptively learning the importance of different steps (Abu-El-Haija et al., 2018; Berberidis et al., 2018). Nevertheless, none of the above works is applicable for semi-supervised learning with GNNs and considers heterophilic graphs.
4 Theoretical properties of GPR-GNNs
Graph filtering aspects of GPR-GNNs. As mentioned in Section 3, the GPR component of the network may be viewed as a polynomial graph filter. Let be the eigenvalue decomposition of . Then, the corresponding polynomial graph filter equals , where is applied element-wise and . We established the following result.
Theorem 4.1 (Informal).
Assume that the graph is connected. If , and such that , then is a low-pass graph filter. Also, if and is large enough, then is a high-pass graph filter.
By Theorem 4.1 and from our discussion in Section 3, we know that both APPNP and SGC will invariably suppress the high frequency components. Thus, they are inadequate for use on heterophilic graphs. In contrast, if one allows to be negative and learned adaptively the graph filter will pass relevant high frequencies. This is what allows GPR-GNN to perform exceptionally well on heterophilic graphs (see Figures 1).
GPR-GNN can escape from over-smoothing. As already emphasized, one crucial innovation of the GPR-GNN method is to make the GPR weights adaptively learnable, which allows GPR-GNN to avoid over-smoothing and trade node and topology feature informativeness. Intuitively, when large-step propagation is not beneficial, it increases the training loss. Hence, the corresponding GPR weights should decay in magnitude. This observation is captured by the following result, whose more formal statement and proof are delegated to the Supplement due to space limitations.
Theorem 4.2 (Informal).
Assume the graph is connected and the training set contains nodes from each of the classes. Also assume that is large enough so that the over-smoothing effect occurs for which dominate the contribution to the final output . Then, the gradients of and are identical in sign for all .
Theorem 4.2 shows that as long as over-smoothing happens, will approach for all when we use an optimizer such as stochastic gradient descent (SGD) which has a suitable learning rate decay. This reduces the contribution of the corresponding steps in the final output . When the weights are small enough so that no longer dominates the value of the final output , the over-smoothing effect is eliminated.
5 Results for new cSBM synthetic and real-world datasets
Synthetic data. In order to test the ability of label learning of GNNs on graphs with arbitrary levels of homophily and heterophily, we propose to use cSBMs (Deshpande et al., 2018) to generate synthetic graphs. We consider the case with two equal-size classes. In cSBMs, the node features are Gaussian random vectors, where the mean of the Gaussian depends on the community assignment. The difference of the means is controlled by a parameter , while the difference of the edge densities in the communities and between the communities is controlled by a parameter . Hence and capture the “relative informativeness” of node features and the graph topology, respectively. Moreover, positive s correspond to homophilic graphs while negative s correspond to heterophilic graphs. The information-theoretic limits of reconstruction for the cSBM are characterized in Deshpande et al. (2018). The results show that, asymptotically, one needs to ensure a vanishing ratio of the misclassified nodes and the total number of nodes, where and as before denotes the dimension of the node feature vector.
Note that given a tolerance value , is an arc of an ellipsoid for which and . To fairly and continuously control the extent of information carried by the node features and graph topology, we introduce a parameter . The setting indicates that only node features are informative, while indicates that only the graph topology is informative. Moreover, corresponds to strongly homophilic graphs while corresponds to strongly heterophilic graphs. Note that the values and convey the same amount of information regarding graph topology. This is due to the fact that . Ideally, GNNs that are able to optimally learn on both homophilic and heterophilic graph should have similar performances for and . Due to space limitation we refer the interested reader to (Deshpande et al., 2018) for a review of all formal theoretical results and only outline the cSBM properties needed for our analysis. Additional information is also available in the Supplement.
Our experimental setup examines the semi-supervised node classification task in the transductive setting. We consider two different choices for the random split into training/validation/test samples, which we call sparse splitting () and dense splitting (), respectively. The sparse splittnig is more similar to the original semi-supervised setting considered in Kipf & Welling (2017) while the dense setting is considered in Pei et al. (2019) for studying heterophilic graphs. We run each experiment times with multiple random splits and different initializations.
Methods used for comparisons. We compare GPR-GNN with baseline models: MLP, GCN (Kipf & Welling, 2017), GAT (Velickovic et al., 2018), JK-Net (Xu et al., 2018), GCN-Cheby (Defferrard et al., 2016), APPNP (Klicpera et al., 2018), SGC (Wu et al., 2019), SAGE (Hamilton et al., 2017) and Geom-GCN (Pei et al., 2019). For all architectures, we use the corresponding Pytorch Geometric library implementations (Fey & Lenssen, 2019). For Geom-GCN, we directly use the code provided by the authors222https://github.com/graphdml-uiuc-jlu/geom-gcn. We could not test Geom-GCN on cSBM and other datasets not originally tested in the paper due to a preprocessing subroutine that is not publicly available (Pei et al., 2019).
The GPR-GNN model setup and hyperparameter tuning. We choose random walk path lengths with and use a -layer (MLP) with hidden units for the NN component. For the GPR weights, we use different initializations including PPR with , or and the default random initialization in pytorch. Similarly, for APPNP we search the optimal within . For other hyperparameter tuning, we optimize the learning rate over and weight decay for all models. For Geom-GCN, we use the best variants in the original paper for each dataset. Finally, we use GPR-GNN(rand) to describe the results obtained with random initialization of the GPR weights. Further experimental settings are discussed in the Supplement.
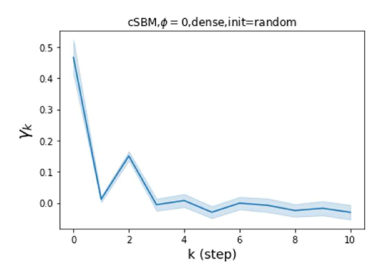
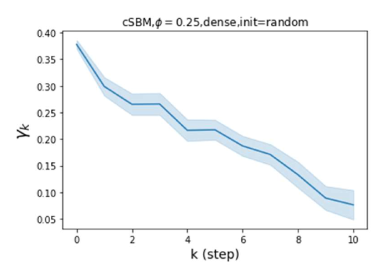
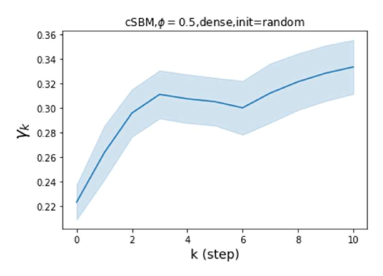
Results. We examine the robustness of all baseline methods and GPR-GNN using cSBM-generated data with , which includes graphs across the heterophily/homophily spectrum. The results are summarized in Figure 2. For both the sparse and dense setting, GPR-GNN significantly outperforms all other baseline models whenever (heterophilic graphs). On the other hand, all baseline GNNs can be worse then simple MLP when the graph information is weak (). This shows that existing GNNs cannot apply to arbitrary graphs, while GPR-GNN is clearly more robust. APPNP methods have the worst performance on strongly heterophilic graphs. This is in agreement with the result of Theorem 4.1 which asserts that APPNP intrinsically acts a low-pass filter and is thus inadequate for strong heterophily settings. JKNet, GCN-Cheby and SAGE are the only three baseline models that are able to learn strongly heterophilic graphs under dense splitting. This is also to be expected since JKNet is the only baseline model that combines results from different steps at the last layer, which is similar to what is done in GPR-GNN. GCN-Cheby uses multiple steps in each layers which allows it to partially adapt to heterophilic settings as each layer is related to a polynomial graph filter of higher order compared to that of GCN. SAGE treats ego-embeddings and embeddings from neighboring nodes differently and does not simply average them out. This allows SAGE to adapt to the heterophilic case since the ego-embeddings prevent nodes from being overwhelmed by information from their neighbors. Nevertheless, JKNet, GCN-Cheby and SAGE are not deep in practice.
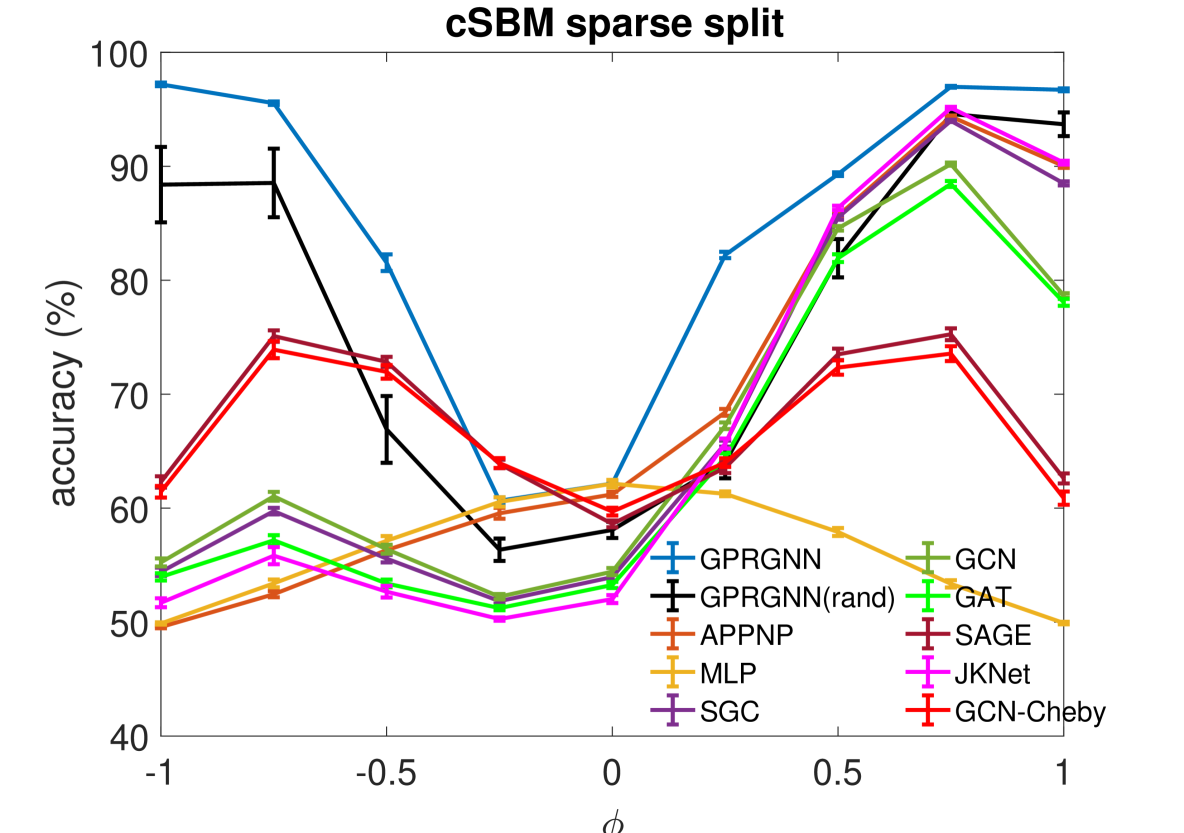
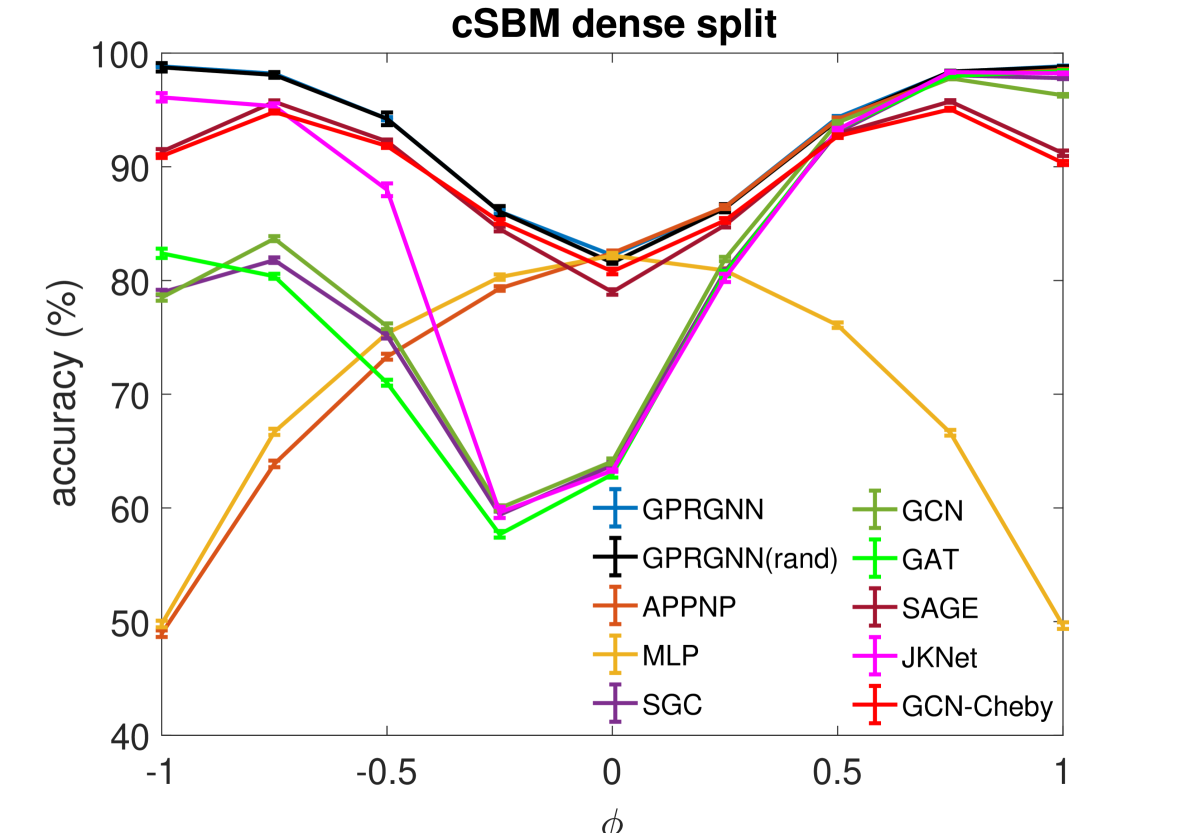
Moreover, JKNet fails to learn under the sparse splitting model while GCN-Cheby and SAGE fail to learn well when the graph information is strong (), again under the sparse splitting model.
Also, we observe that random initialization of our GPR weights only results in slight performance drops under dense splitting. The drop is more evident for sparse splitting setting but our method still outperforms baseline models by a large margin for strongly heterophilic graphs. This is also to be expected as we have less label information in the sparse splitting setting where the implicit bias provided by good GPR initialization is helpful. The implicit bias becomes irrelevant for the dense splitting setting, since the label information is sufficiently rich.
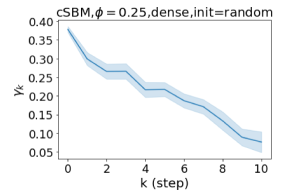
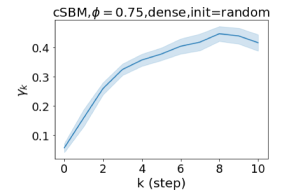
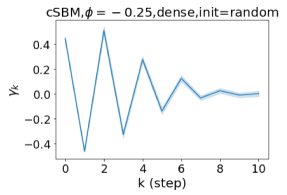
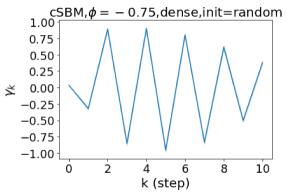
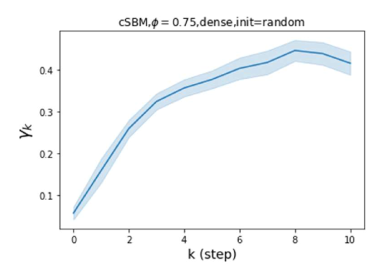
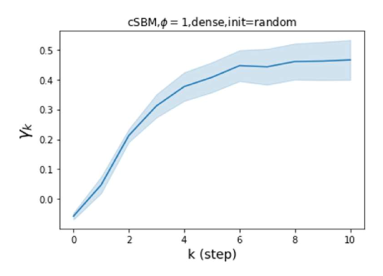
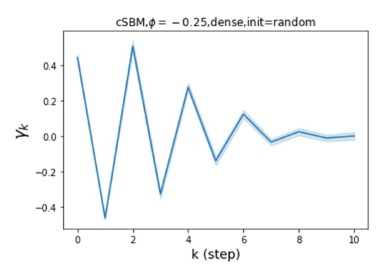
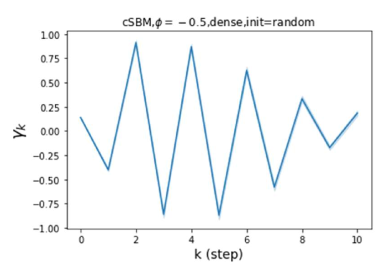
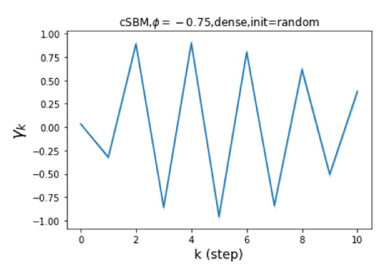
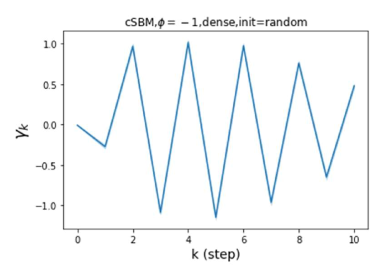
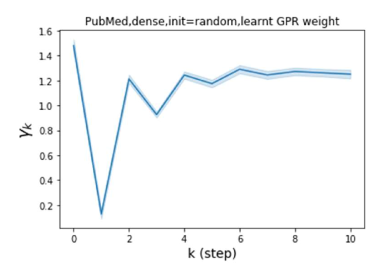
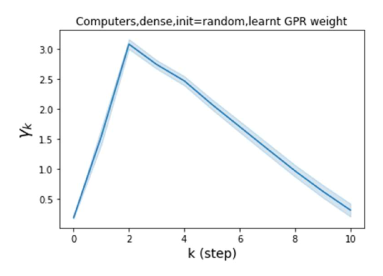
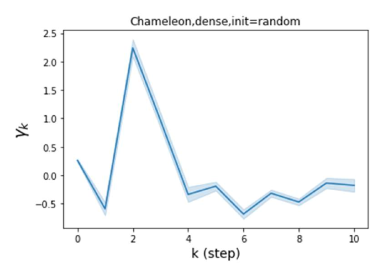
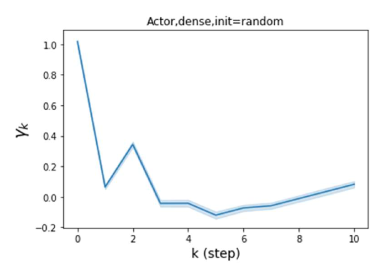
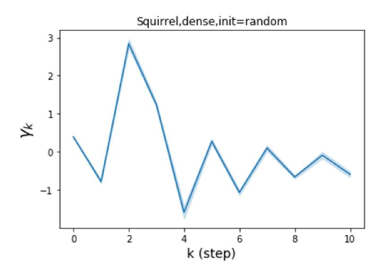
Besides the strong performance of GPR-GNN, the other benefit is its interpretability. In Figure 3, we demonstrate the learnt GPR weights by our GPR-GNN on cSBM with random initialization. When the graph is weak homophilic (), the learnt GPR weights are decreasing. This is similar to the PPR weights used in APPNP, despite that the decaying speed is different. When the graph is strong homophilic (), the learnt GPR weights are increasing which is significantly different from the PPR weights. This result matches the recent finding in Li et al. (2019) and behave similar to IPR proposed by the authors. On the other hand, the learnt GPR weights have zig-zag shape when the graph is heterophilic. This again validates Theorem 4.1 as GPR weights with alternating signs correspond to a high-pass filter. Interestingly, when the magnitude of learnt GPR weight is decreasing. This is because the graph information is weak and the node feature information is more important in this case. It makes sense that the learnt GPR weight focus on the first few steps. Hence, we have validated the interpretablity of GPR-GNN. In practice, one can use the learnt GPR weights to better understand the graph structured data at hand. We showcase this benefit in the results of real world benchmark datasets.
()
()
()
()
Real world benchmark datasets. We use homophilic benchmark datasets available from the Pytorch Geometric library, including the citation graphs Cora, CiteSeer, PubMed (Sen et al., 2008; Yang et al., 2016) and the Amazon co-purchase graphs Computers and Photo (McAuley et al., 2015; Shchur et al., 2018). We also use heterophilic benchmark datasets tested in Pei et al. (2019), including Wikipedia graphs Chameleon and Squirrel (Rozemberczki et al., 2021), the Actor co-occurrence graph, and webpage graphs Texas and Cornell from WebKB333http://www.cs.cmu.edu/afs/cs.cmu.edu/project/theo-11/www/wwkb. We summarize the dataset statistics in Table 1.
| Dataset | Cora | Citeseer | PubMed | Computers | Photo | Chameleon | Squirrel | Actor | Texas | Cornell |
|---|---|---|---|---|---|---|---|---|---|---|
| Classes | 7 | 6 | 5 | 10 | 8 | 5 | 5 | 5 | 5 | 5 |
| Features | 1433 | 3703 | 500 | 767 | 745 | 2325 | 2089 | 932 | 1703 | 1703 |
| Nodes | 2708 | 3327 | 19717 | 13752 | 7650 | 2277 | 5201 | 7600 | 183 | 183 |
| Edges | 5278 | 4552 | 44324 | 245861 | 119081 | 31371 | 198353 | 26659 | 279 | 277 |
| 0.825 | 0.718 | 0.792 | 0.802 | 0.849 | 0.247 | 0.217 | 0.215 | 0.057 | 0.301 |
Results on real-world datasets.
| Cora | Citeseer | PubMed | Computers | Photo | Chameleon | Actor | Squirrel | Texas | Cornell | |
|---|---|---|---|---|---|---|---|---|---|---|
| GPRGNN | 79.510.36 | 67.630.38 | 85.070.09 | 82.900.37 | 91.930.26 | 67.480.40 | 39.300.27 | 49.930.53 | 92.920.61 | 91.360.70 |
| APPNP | 79.410.38 | 68.590.30 | 85.020.09 | 81.990.26 | 91.110.26 | 51.910.56 | 38.860.24 | 34.770.34 | 91.180.70 | 91.800.63 |
| MLP | 50.340.48 | 52.880.51 | 80.570.12 | 70.480.28 | 78.690.30 | 46.720.46 | 38.580.25 | 31.280.27 | 92.260.71 | 91.360.70 |
| SGC | 70.810.67 | 58.980.47 | 82.090.11 | 76.270.36 | 83.800.46 | 63.020.43 | 29.390.20 | 43.140.28 | 55.181.17 | 47.801.50 |
| GCN | 75.210.38 | 67.300.35 | 84.270.01 | 82.520.32 | 90.540.21 | 60.960.78 | 30.590.23 | 45.660.39 | 75.160.96 | 66.721.37 |
| GAT | 76.700.42 | 67.200.46 | 83.280.12 | 81.950.38 | 90.090.27 | 63.90.46 | 35.980.23 | 42.720.33 | 78.870.86 | 76.001.01 |
| SAGE | 70.890.54 | 61.520.44 | 81.300.10 | 83.110.23 | 90.510.25 | 62.150.42 | 36.370.21 | 41.260.26 | 79.031.20 | 71.411.24 |
| JKNet | 73.220.64 | 60.850.76 | 82.910.11 | 77.800.97 | 87.700.70 | 62.920.49 | 33.410.25 | 44.720.48 | 75.531.16 | 66.731.73 |
| GCN-Cheby | 71.390.51 | 65.670.38 | 83.830.12 | 82.410.28 | 90.090.28 | 59.960.51 | 38.020.23 | 40.670.31 | 86.080.96 | 85.331.04 |
| GeomGCN | 20.371.13 | 20.300.90 | 58.201.23 | NA | NA | 61.060.49 | 31.810.24 | 38.280.27 | 58.561.77 | 55.591.59 |
We use accuracy (the micro-F1 score) as the evaluation metric along with a confidence interval. The relevant results are summarized in Table 2. For homophilic datasets, we provide results for sparse splitting which is more aligned with the original setting used in Kipf & Welling (2017); Shchur et al. (2018). For the heterophilic datasets, we adopt dense splitting which is used in Pei et al. (2019).
Table 2 shows that, in general, GPR-GNN outperforms all tested methods. On homophilic datasets, GPR-GNN achieves the state-of-the-art performance. On heterophilic datasets, GPR-GNN significantly outperforms all the other baseline models. It is important to point out that there are two different patterns to be observed among the heterophilic datasets. On Chameleon and Squirrel, MLP and APPNP perform worse then other baseline methods such as GCN and JKNet. In contrast, MLP and APPNP outperform the other baseline methods on Actor, Texas and Cornell. We conjecture that this is due to the fact that the graph topology information is strong and weak, respectively. Note that these two patterns match the results of the cSBM experiments for close to and , respectively (Figure 2). Furthermore, the homophily measure proposed by Pei et al. (2019) cannot characterize such differences in heterophilic datasets. We relegate the more detailed discussion of this topic along with illustrative examples to the Supplement.For fairness, we also repeated the experiment involving GeomGCN on homophilic datasets using a dense split - the observed performance pattern tends to be similar which can be found in Supplement.
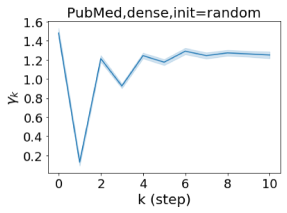
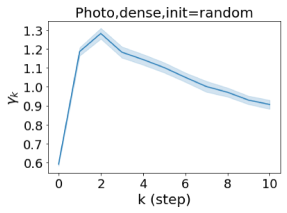
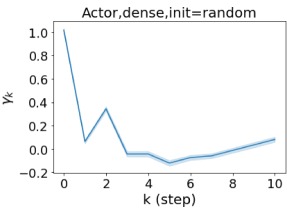
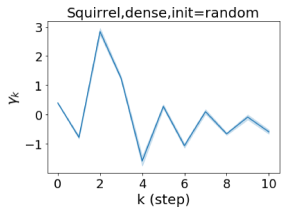
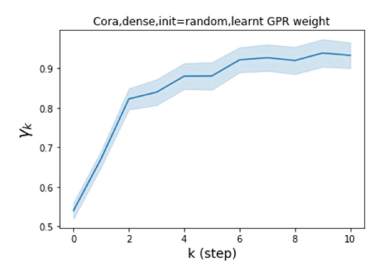
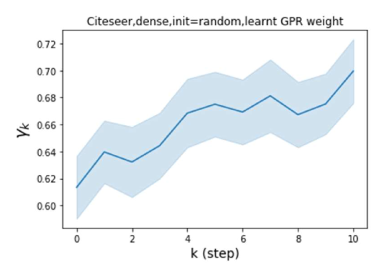
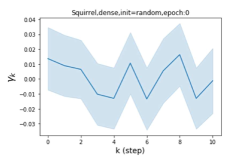
We also examined the learned GPR weights on real datasets in Figure 4. Due to space limitations, a more comprehensive GPR weight analysis for other datasets is deferred to the Supplement. We can see that learned GPR weights are all positive for homophilic datasets (PubMed and Photo). In contrast, some GPR weights learned from heterophilic datasets (Actor and Squirrel) are negative. These results agree with the patterns observed on cSBMs. Interestingly, the learned weight has the largest magnitude for the Actor dataset. This indicates that most of the information is contained in node features. From Table 2 we can also see that MLPs indeed outperforms most baseline GNNs (this is similar to the case of cSBM). On the other hand, GPR weights learned from Squirrel have a zig-zag pattern. This implies that graph topology is more informative for Squirrel compared to Actor. From Table 2 we also see that baseline GNNs also outperform MLPs on Squirrel.
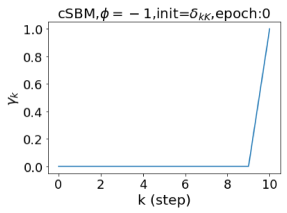
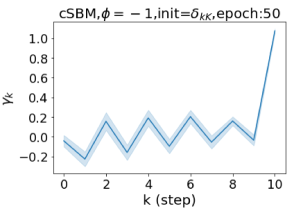
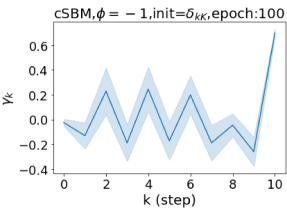
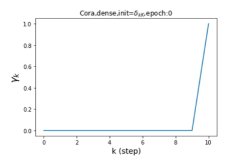
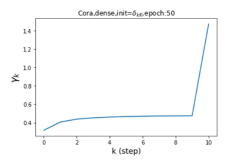
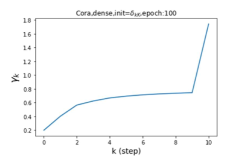
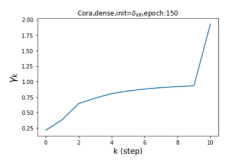
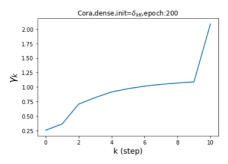
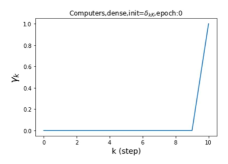
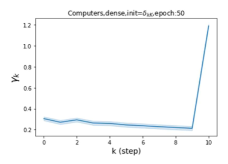
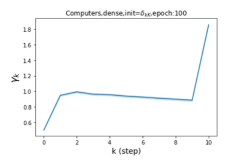
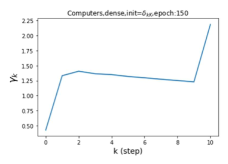
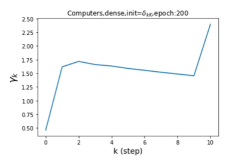
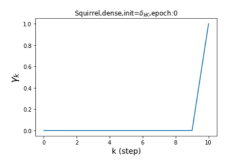
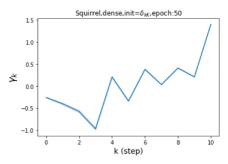
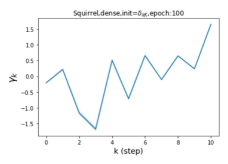
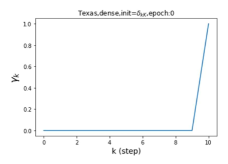
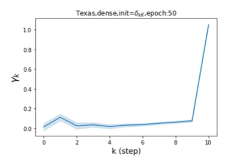
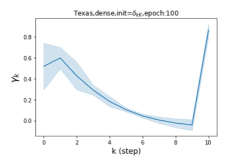
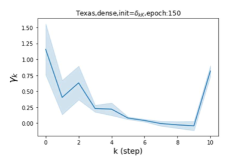
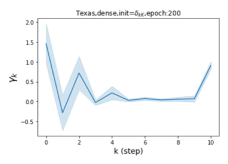
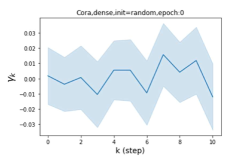
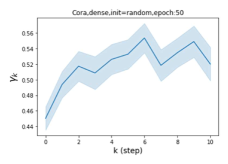
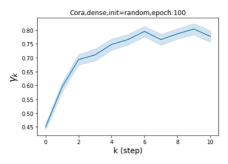
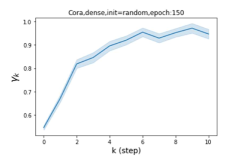
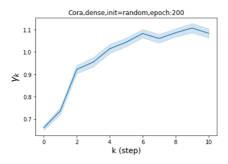
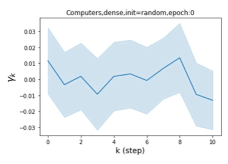
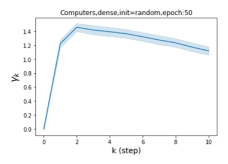
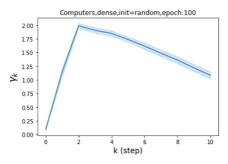
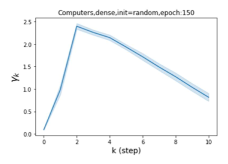
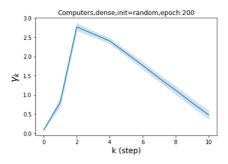
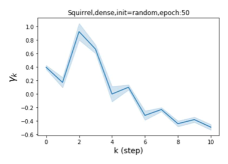
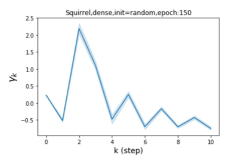
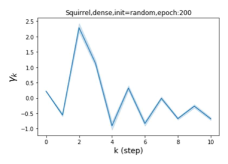
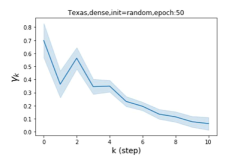
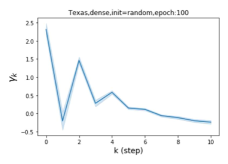
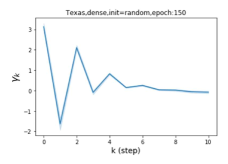
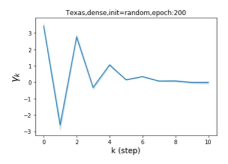
Escaping from over-smoothing and dynamics of learning GPR weights. To demonstrate the ability of GPR-GNNs to escape from over-smoothing, we choose the initial GPR weights to be . This ensures that over-smoothing effects are present with high probability at the very beginning of the learning process. On cSBM with dense splitting, we find that for out of runs, GPR-GNN predicts the same labels for all nodes at epoch , which implies that over-smoothing indeed occurs immediately. The final prediction is accurate which is much larger than the initial accuracy of at epoch . Similar results can be observed for other datasets and this verifies our theoretical findings. We plot the dynamics of the learned GPR weights in Figure 4(e)-(h), which shows that the peak at last step is indeed reduced while the GPR weights for other steps are significantly increased in magnitude. More results on the dynamics of learning GPR weights may be found in the Supplement.
| Cora | Pubmed | Computers | Chameleon | Actor | Squirrel | Texas | |
|---|---|---|---|---|---|---|---|
| GPRGNN | 17.62ms / 3.74s | 20.19ms / 5.53s | 39.93ms / 11.40s | 16.74ms / 3.40s | 19.31ms / 4.49s | 25.28ms / 5.12s | 17.56ms / 3.55s |
| APPNP | 17.16ms / 4.00s | 18.47ms / 6.29s | 39.59ms / 20.00s | 17.01ms / 3.44s | 16.32ms / 4.04s | 22.93ms / 4.63s | 15.96ms / 3.24s |
| MLP | 4.14ms / 0.92s | 5.43ms / 2.86s | 5.33ms / 2.77s | 3.41ms / 0.69s | 4.84ms / 0.98s | 5.19ms / 1.05s | 3.81ms / 1.04s |
| SGC | 3.31ms / 3.31s | 3.81ms / 3.81s | 4.36ms / 4.36s | 3.13ms / 3.13s | 3.98ms / 1.00s | 4.79ms / 4.79s | 2.86ms / 2.09s |
| GCN | 9.25ms / 1.97s | 14.11ms / 4.17s | 32.45ms / 16.29s | 13.83ms / 2.79s | 12.39ms / 2.50s | 27.11ms / 5.56s | 10.22ms / 2.06s |
| GAT | 14.78ms / 3.42s | 21.52ms / 6.70s | 61.45ms / 24.28s | 16.63ms / 3.63s | 18.91ms / 3.86s | 47.46ms / 10.05s | 15.50ms / 3.13s |
| SAGE | 12.06ms / 2.44s | 28.82ms / 6.32s | 171.36ms / 71.94s | 64.43ms / 13.02s | 27.95ms / 5.65s | 343.47ms / 69.38s | 6.08ms / 1.28s |
| JKNet | 18.97ms / 4.41s | 24.48ms / 6.61s | 35.02ms / 14.96s | 20.03ms / 5.15s | 23.52ms / 4.75s | 29.89ms / 6.67s | 19.67ms / 4.01s |
| GCN-cheby | 22.96ms / 4.75s | 45.76ms / 12.02s | 218.82ms / 96.58s | 89.41ms / 18.06s | 43.94ms / 8.88s | 440.55ms / 88.99s | 12.34ms / 3.08s |
Efficiency analysis. We also examine the computational complexity of GPR-GNNs compared to other baseline models. We report the empirical training time in Table 3. Compared to APPNP, we only need to learn additional GPR weights for GPR-GNN, and usually (i.e. we choose in our experiments). This additional computations are dominated by the computations performed by the neural network module . We can observe from Table 3 that indeed GPR-GNN has a running time similar to that of APPNP. It is nevertheless worth pointing out that the authors of Bojchevski et al. (2020) successfully scaled APPNP to operate on large graphs. Whether the same techniques may be used to scale GPR-GNNs is an interesting open question.
6 Conclusions
We addressed two fundamental weaknesses of existing GNNs: Failing to act as universal learners by not generalizing to heterophilic graphs and making use of large number of propagation steps. We developed a novel GPR-GNN architecture which combines adaptive generalized PageRank (GPR) scheme with GNNs. We theoretically showed that our method does not only mitigates feature over-smoothing but also works on highly diverse node label patterns. We also tested GPR-GNNs on both homophilic and heterophilic node label patterns, and proposed a novel synthetic benchmark datasets generated by the contextual stochastic block model. Our experiments on real-world benchmark datasets showed clear performance gains of GPR-GNN over the state-of-the-art methods. Moreover, we showed that GPR-GNN has desirable interpretability properties which is of independent interest.
Acknowledgments
The work was supported in part by the NSF Emerging Frontiers of Science of Information Grant 0939370 and the NSF CIF 1618366 Grant. The authors thank Mohamad Bairakdar for helpful comments on an earlier version of the paper.
References
- Abbe (2017) Emmanuel Abbe. Community detection and stochastic block models: recent developments. The Journal of Machine Learning Research, 18(1):6446–6531, 2017.
- Abu-El-Haija et al. (2018) Sami Abu-El-Haija, Bryan Perozzi, Rami Al-Rfou, and Alexander A Alemi. Watch your step: Learning node embeddings via graph attention. In Advances in Neural Information Processing Systems, pp. 9180–9190, 2018.
- Abu-El-Haija et al. (2019) Sami Abu-El-Haija, Bryan Perozzi, Amol Kapoor, Nazanin Alipourfard, Kristina Lerman, Hrayr Harutyunyan, Greg Ver Steeg, and Aram Galstyan. Mixhop: Higher-order graph convolutional architectures via sparsified neighborhood mixing. In International Conference on Machine Learning, pp. 21–29, 2019.
- Battaglia et al. (2018) Peter W Battaglia, Jessica B Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, et al. Relational inductive biases, deep learning, and graph networks. arXiv preprint arXiv:1806.01261, 2018.
- Berberidis et al. (2018) Dimitris Berberidis, Athanasios Nikolakopoulos, and Georgios B Giannakis. Adaptive diffusions for scalable learning over graphs. In Mining and Learning with Graphs Workshop @ ACM KDD 2018, pp. 1, 8 2018.
- Bojchevski et al. (2019) Aleksandar Bojchevski, Johannes Klicpera, Bryan Perozzi, Martin Blais, Amol Kapoor, Michal Lukasik, and Stephan Günnemann. Is pagerank all you need for scalable graph neural networks? In ACM KDD, MLG Workshop, 2019.
- Bojchevski et al. (2020) Aleksandar Bojchevski, Johannes Klicpera, Bryan Perozzi, Amol Kapoor, Martin Blais, Benedek Rózemberczki, Michal Lukasik, and Stephan Günnemann. Scaling graph neural networks with approximate pagerank. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 2464–2473, 2020.
- Bruna et al. (2014) Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann Lecun. Spectral networks and locally connected networks on graphs. In International Conference on Learning Representations (ICLR2014), CBLS, April 2014, pp. http–openreview, 2014.
- Chung (2007) Fan Chung. The heat kernel as the pagerank of a graph. Proceedings of the National Academy of Sciences, 104(50):19735–19740, 2007.
- Dau & Milenkovic (2017) Hoang Dau and Olgica Milenkovic. Latent network features and overlapping community discovery via boolean intersection representations. IEEE/ACM Transactions on Networking, 25(5):3219–3234, 2017.
- Defferrard et al. (2016) Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. In Advances in Neural Information Processing Systems, pp. 3844–3852, 2016.
- Deshpande et al. (2018) Yash Deshpande, Subhabrata Sen, Andrea Montanari, and Elchanan Mossel. Contextual stochastic block models. In Advances in Neural Information Processing Systems, pp. 8581–8593, 2018.
- Fey & Lenssen (2019) Matthias Fey and Jan Eric Lenssen. Fast graph representation learning with pytorch geometric. arXiv preprint arXiv:1903.02428, 2019.
- Gilmer et al. (2017) Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. Neural message passing for quantum chemistry. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pp. 1263–1272. JMLR. org, 2017.
- Gleich (2015) David F Gleich. Pagerank beyond the web. Siam Review, 57(3):321–363, 2015.
- Hamilton et al. (2017) Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems, pp. 1024–1034, 2017.
- Jeh & Widom (2003) Glen Jeh and Jennifer Widom. Scaling personalized web search. In Proceedings of the 12th international conference on World Wide Web, pp. 271–279, 2003.
- Jia & Benson (2020) Junteng Jia and Austin Benson. Outcome correlation in graph neural network regression. arXiv preprint arXiv:2002.08274, 2020.
- Kingma & Ba (2014) Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Kipf & Welling (2017) Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations (ICLR), 2017.
- Klicpera et al. (2018) Johannes Klicpera, Aleksandar Bojchevski, and Stephan Günnemann. Predict then propagate: Graph neural networks meet personalized pagerank. In International Conference on Learning Representations, 2018.
- Klicpera et al. (2019) Johannes Klicpera, Stefan Weißenberger, and Stephan Günnemann. Diffusion improves graph learning. In Advances in Neural Information Processing Systems, pp. 13333–13345, 2019.
- Kloumann et al. (2017) Isabel M Kloumann, Johan Ugander, and Jon Kleinberg. Block models and personalized pagerank. Proceedings of the National Academy of Sciences, 114(1):33–38, 2017.
- Li et al. (2019) Pan Li, I Chien, and Olgica Milenkovic. Optimizing generalized pagerank methods for seed-expansion community detection. In Advances in Neural Information Processing Systems, pp. 11705–11716, 2019.
- Li et al. (2018) Qimai Li, Zhichao Han, and Xiao-Ming Wu. Deeper insights into graph convolutional networks for semi-supervised learning. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
- Lü & Zhou (2011) Linyuan Lü and Tao Zhou. Link prediction in complex networks: A survey. Physica A: statistical mechanics and its applications, 390(6):1150–1170, 2011.
- McAuley et al. (2015) Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel. Image-based recommendations on styles and substitutes. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 43–52, 2015.
- McPherson et al. (2001) Miller McPherson, Lynn Smith-Lovin, and James M Cook. Birds of a feather: Homophily in social networks. Annual review of sociology, 27(1):415–444, 2001.
- Oono & Suzuki (2020) Kenta Oono and Taiji Suzuki. Graph neural networks exponentially lose expressive power for node classification. In International Conference on Learning Representations, 2020.
- Pei et al. (2019) Hongbin Pei, Bingzhe Wei, Kevin Chen-Chuan Chang, Yu Lei, and Bo Yang. Geom-gcn: Geometric graph convolutional networks. In International Conference on Learning Representations, 2019.
- Rozemberczki et al. (2021) Benedek Rozemberczki, Carl Allen, and Rik Sarkar. Multi-Scale Attributed Node Embedding. Journal of Complex Networks, 9(2), 2021.
- Sen et al. (2008) Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. Collective classification in network data. AI magazine, 29(3):93–93, 2008.
- Shchur et al. (2018) Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, and Stephan Günnemann. Pitfalls of graph neural network evaluation. arXiv preprint arXiv:1811.05868, 2018.
- Shervashidze et al. (2011) Nino Shervashidze, Pascal Schweitzer, Erik Jan Van Leeuwen, Kurt Mehlhorn, and Karsten M Borgwardt. Weisfeiler-lehman graph kernels. Journal of Machine Learning Research, 12(77):2539–2561, 2011.
- Shuman et al. (2013) D. I. Shuman, S. K. Narang, P. Frossard, A. Ortega, and P. Vandergheynst. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains. IEEE Signal Processing Magazine, 30(3):83–98, 2013.
- Tsourakakis (2015) Charalampos Tsourakakis. Provably fast inference of latent features from networks: With applications to learning social circles and multilabel classification. In Proceedings of the 24th International Conference on World Wide Web, pp. 1111–1121, 2015.
- Velickovic et al. (2018) Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lia, and Yoshua Bengio. Graph attention networks. In International Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=rJXMpikCZ.
- Von Luxburg (2007) Ulrike Von Luxburg. A tutorial on spectral clustering. Statistics and computing, 17(4):395–416, 2007.
- Wijesinghe & Wang (2019) WOK Asiri Suranga Wijesinghe and Qing Wang. Dfnets: Spectral cnns for graphs with feedback-looped filters. In Advances in Neural Information Processing Systems, pp. 6007–6018, 2019.
- Wu et al. (2019) Felix Wu, Amauri Souza, Tianyi Zhang, Christopher Fifty, Tao Yu, and Kilian Weinberger. Simplifying graph convolutional networks. In International Conference on Machine Learning, pp. 6861–6871, 2019.
- Xu et al. (2018) Keyulu Xu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken-ichi Kawarabayashi, and Stefanie Jegelka. Representation learning on graphs with jumping knowledge networks. In International Conference on Machine Learning, pp. 5453–5462, 2018.
- Yang et al. (2016) Zhilin Yang, William W Cohen, and Ruslan Salakhutdinov. Revisiting semi-supervised learning with graph embeddings. In Proceedings of the 33rd International Conference on International Conference on Machine Learning-Volume 48, pp. 40–48, 2016.
- Zeng et al. (2020) Hanqing Zeng, Hongkuan Zhou, Ajitesh Srivastava, Rajgopal Kannan, and Viktor Prasanna. GraphSAINT: Graph sampling based inductive learning method. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=BJe8pkHFwS.
- Zhu et al. (2020) Jiong Zhu, Yujun Yan, Lingxiao Zhao, Mark Heimann, Leman Akoglu, and Danai Koutra. Generalizing graph neural networks beyond homophily. arXiv preprint arXiv:2006.11468, 2020.
- Zhu (2005) Xiaojin Jerry Zhu. Semi-supervised learning literature survey. Technical report, University of Wisconsin-Madison Department of Computer Sciences, 2005.
Appendix A Appendix
A.1 Detailed discussion on preventing over-smoothing.
As mentioned in Section 4, another method – APPNP – can also provably prevents over-smoothing Klicpera et al. (2018). The authors of this study use the fact that the PPR propagation will converge to , where is independent on the node label information provided in the training data. Each row of still depends on and thus APPNP will not suffer from the over-smoothing effect. However, since is independent of the label information, it can cause undesired consequences that we discuss in what follows.
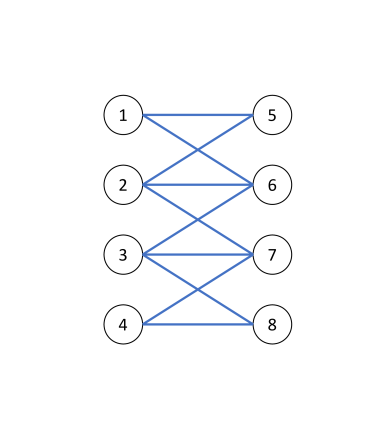
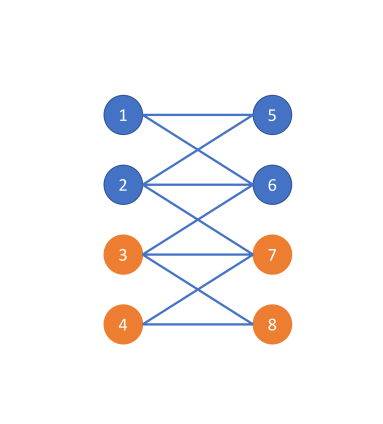
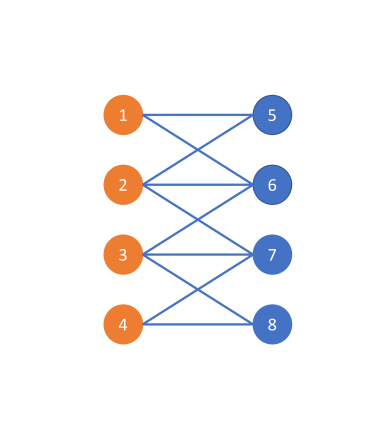
Let us consider a simple example shown in Figure 5 involving a connected and undirected graph (Figure 5 (a)). Consider two different node label assignments shown in Figure 5 (b) and Figure 5 (c). Obviously, the graph topologies depicted in Figure 5 (b) and (c) are identical and the only difference is the class label assignment. In Figure 5 (b), the graph is homophilic and hence the optimal graph filter should emphasize the low-frequency part of the graph signal. In contrast, in Figure 5 (c), the graph is heterophilic as the graph is bipartite with respect to the labels. Hence, the optimal graph filter should emphasize the high-frequency part of the graph signal. This example illustrates that the optimal graph filter should depend on both the graph topology and the node label information. Recall that the equivalent graph filter that APPNP uses in the asymptotic regime is which is independent on the node label information. Also, Theorem 4.1 established that APPNP intrinsically utilizes a low-pass filter. In contrast, GPR-GNN learns the GPR weights guided by the node label information which allows it to account for both cases (homophilic and heterophilic) shown.
A.2 Discussion on the insufficiency of homophily measure
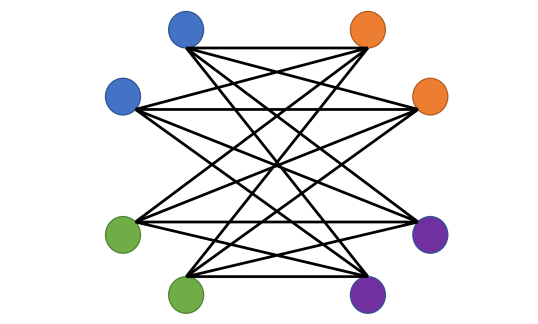
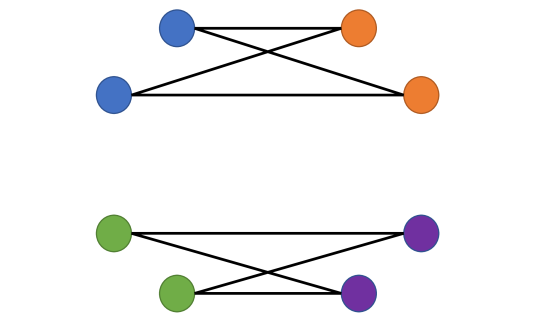
As mentioned in Section 5, the homophily measure is inadequate for characterizing whether a heterophilic graph topology is informative or not. Consider two simple examples depicted in Figure 6, where the color of the nodes indicates their label. In case 1, blue and green nodes link to all orange and purple nodes. In case 2, blue nodes only link to orange nodes and green nodes only link to purple nodes. From the definition of one can see that both cases have , since in both cases nodes do not link to other nodes of the same label. However, it is obvious that the graph topology carries more node label information in case 2 compared to case 1. In fact, for case 1 it is impossible to distinguish blue and green nodes merely from the graph topology (and the same is true of orange and purple nodes). One possible alternative for the homophily measure is the Chernoff-Hellinger divergence Abbe (2017) of the empirical edge probability matrix ; here is the empirical probability of an edge with one end node labeled and the other labeled . The intuition behind our suggestion lies in the fact that the Chernoff-Hellinger divergence characterizes the fundamental limit of SBMs. However, as many practical graph generative processes may significantly differ from SBMs, investigating alternative homophily/heterophily measures is another interesting open problem.
A.3 Proof of Theorem 4.1
We first state the formal version of Theorem 4.1.
Theorem A.1 (Formal version of Theorem 4.1).
Assume the graph is connected. Let be the eigenvalues of . If , and such that , then . Also, if and , then .
Note that implies that after applying the graph filter , the lowest frequency component (correspond to ) further dominates. Recall that in the unfiltered case, we do not multiply with . It can also be viewed as multiplying the identity matrix , where the eigenvalue ratio is . Hence acts like a low pass filter in this case. In contrast, implies that after applying the graph filter, the lowest frequency component (correspond to ) no longer dominates. This correspond to the high pass filter case.
Proof.
We start with the low pass filter result. From basic spectral analysis (Von Luxburg, 2007) we know that and . One can also find the analysis in the proof of our Lemma A.2 in the Supplement. Then by assumption we know that
Hence, proving Theorem A.1 is equivalent to show
This is obvious since is a polynomial of order with nonnegative coefficients. It is easy to check that . Combine with the fact that all ’s are nonnegative we have
Finally, note that the only possibility that the equality in (a) holds is since . However, by assumption and such that we know that this is impossible. Hence (a) is a strict inequality . Together we complete the proof for low pass filtering part.
For the high pass filter result, it is not hard to see that
where the last step is due to the fact that and thus . Thus we have
The strict inequalities (b) is from the fact that . Notably, happens at the boundary , which corresponds the the bipartite graph. It further shows that the graph filter with respect to the choice emphasizes high frequency components and thus it is indeed acting as a high pass filter. ∎
A.4 Proof of Theorem 4.2
We start by introducing some additional notation, lemmas and definition before we proceed to the formal statement of Theorem 4.2. The label matrix is denoted by , where each row is a one-hot vector. We use to denote the argmax of the vector : we have if and only if (ties are broken evenly), and otherwise. Let us replace the softmax with softmax, where we let stand for the softmax with a smooth parameter . Note that for we recover the standard softmax. With a slight abuse of notation, for the vector we write to denote element-wise exponentiation. We use to denote the standard Euclidean inner product. Also we use for the cross entropy loss where
Lemma A.2.
Assume that the nodes in an undirected and connected graph have one of labels. Then, for large enough, we have
| (2) |
For any and large enough , if the label prediction is dominated by , all nodes will have a representation proportional to . Hence, we will arrive at the same label for all nodes. This is what we refer to as the over-smoothing phenomenon.
Definition A.3 (The over-smoothing phenomenon).
First, recall that . If over-smoothing occurs in the GPR-GNN for sufficiently large, we have for some if and for some if .
Lemma A.4.
Let be the cross entropy loss and let be the training set. Under the same assumption as given in Lemma A.2, the gradient of for large enough is
Lemma A.5.
For any real vector and large enough, we have .
Now we are ready to state the formal version of Theorem 4.2.
Theorem A.6 (Formal version of Theorem 4.2).
Under the same assumptions as those listed in Lemma A.2, if the training set contains nodes from each class, then the GPR-GNN method can always avoid over-smoothing. More specifically, for large enough we have
| (3) | |||
| (4) |
Note that when , (3) when ignoring the term. The equality is achieved if and only if . This means that over-smoothing results in a prediction that perfectly aligns with the ground truth label in the training set. However, if our training set contains at least one node from each class then the equality can never be attained. Thus, the gradient of will always be positive when . Similarly when , (4) when ignoring the term. The equality is achieved if and only if . By the same reason we know that under the assumption on training set the equality can never be attained. Thus, the gradient of will always be negative when . Finally, it is not hard to check that the gradient is bounded in magnitude. Together we have shown that the gradient of and are of the same sign. This directly implies that will approach to until we escape from over-smoothing when we use a decreasing learning rate for the optimizer (i.e. SGD).
Proof.
First, let us assume the over-smoothing takes place and the for the dominate term. By Definition A.3, we know that for some and sufficiently large. By Lemma A.4 we have
| (5) | |||
| (6) |
where the last step follows from Definition A.3. Next, by Lemma A.5, we may approximate the softmax by the true argmax for large enough according to
| (7) | |||
| (8) | |||
| (9) |
The first equality is due to the fact that and . Recall that by Lemma A.2, . Since we have a self- loop for each node, and thus . For the case , the same analysis still valid until (7). Hence we have
| (10) | |||
| (11) | |||
| (12) |
Together we complete the proof.
∎
A.5 cSBM details
The cSBM adds Gaussian random vectors as node features on top of the classical SBM. For simplicity, we assume equally sized communities with node labels in . Each node is associate with a dimensional Gaussian vector where is the number of nodes, and has independent standard normal entries. The (undirected) graph in cSBM is described by the adjacency matrix defined as
Similar to the classical SBM, given the node labels the edges are independent. The symbol stands for the average degree of the graph. Also, recall that and control the information strength carried by the node features and the graph structure respectively.
One reason for using the cSBM to generate synthetic data is that the information-theoretic limit of the model is already characterized in Deshpande et al. (2018). This result is summarized below.
Theorem A.7 (Informal main result in Deshpande et al. (2018)).
Assume that , and . Then there exists an estimator such that is bounded away from if and only if .
In our experiment, we set and thus have . We vary and along the arc for some to ensure that we are in the achievable parameter regime. We also choose for all our experiment.
A.6 Proof of Lemma A.2
Note that the proof of Lemma A.2 reduces to a standard analysis of random walks on graph. We include it for completeness and refer the interested readers to the tutorial Von Luxburg (2007).
We start by showing that the symmetric graph Laplacian
| (13) |
is positive semi-definite. Let be any real vector of unit norm and , then we have
| (14) | |||
| (15) | |||
| (16) |
where the last step follows from the definition of the degree.
Next we show that is indeed an eigenvalue of associated with the unit eigenvector where .
Let be the all one vector. Then, a direct calculation reveals that
| (17) | |||
| (18) | |||
| (19) |
Combining this result with the positive semi-definite property of the Laplacian shows that is indeed the smallest eigenvalue of associated with the eigenvector . Moreover, from (16) and the assumption that the graph is connected, it is not hard to see that the multiplicity of the eigenvalue is exactly 1 (See Proposition 2 and 4 in Von Luxburg (2007) for more detail). Finally, from (13) it is obvious that the the largest eigenvalue of is , which correspond to the eigenvector . Hence all other eigenvalues of .
Next, we prove that . This can also be shown directly from (16). Note that
| (20) | |||
| (21) | |||
| (22) |
The inequality follows from an application of the Cauchy-Schwartz inequality. Consequently, the largest eigenvalue of is bounded by which means that . Note that equality holds if and only if the underlying graph is bipartite. However, this is impossible in our setting since we have added a self loop to each node. Hence . This means
| (23) |
Hence, for any we have
| (24) |
Note that this can also be written with the term as
| (25) |
This completes the proof.
A.7 Proof of Lemma A.4
Recall that our loss function equals
| (26) |
Then by taking the partial derivative of the loss function with respect to we have
| (27) |
Next, recall that for GPR-GNN we also have . Plugging this expression into the previous formula and applying the chain rule we obtain
| (28) | |||
| (29) |
Settin for large enough , it follows from Lemma A.2 that
| (30) | |||
| (31) | |||
| (32) | |||
| (33) |
Note that in (32) and (33) we used the definition of the soft prediction . This completes the proof.
A.8 Proof of Lemma A.5
Let . Then by the definition of softmax for we have
| (34) |
Note that when and when . Without loss of generality we assume that there are maxima in , where and let denote the set of indices of those maxima. Then, taking the limit we have
| (35) |
This implies that for large enough one has
| (36) |
The above result completes the proof.
A.9 Additional Experimental details
| 0.039 | 0.073 | 0.170 | 0.328 | 0.500 | 0.673 | 0.829 | 0.928 | 0.960 |
All experiments are performed on a Linux Machine with cores, GB of RAM, and a NVIDIA Tesla P100 GPU with GB of GPU memory. For the training set, we ensure that number of nodes from each class is approximately the same an keep the total number of training nodes close to . For the validation set, we randomly sample of the nodes and place the remaining ones into the test set.
For all baseline models, we directly use the implementation available in the Pytorch Geometric library Fey & Lenssen (2019).We use early stopping and a maximum number of epochs equal to for both real benchmark dataset and our cSBM synthetic datasets. All models use the Adam optimizer Kingma & Ba (2014). Note that the early stopping criteria is exactly the same as in Pytorch Geometric – when the epoch is greater than half of the maximum epoch, we check if the current validation loss is lower than the average over the past epochs. If it is not lower, we stop the training process.
For GCN, we use GCN layers with hidden units. For GAT, we use GAT convolutional layers, where the first layer has attention heads and each head has hidden units; the second layer has attention head and hidden units. For GCN-Cheby, we use steps propagation for each layer with hidden units. Note that the number of equivalent hidden units for each layer is for this case. For JK-Net, we use the GCN-based model with layers and hidden units in each layer. As for the layer aggregation part, we use a LSTM with channels and layers. For the MLP, we choose a -layer fully connected network with 4 hidden units. For APPNP we use the same -layer MLP with steps of propagation. Besides the GPR-GNN, we fix the dropout rate for the NN part to be as APPNP and optimize the dropout rate for the GPR part among . For Geom-GCN, we choose the datasets already tested in the paper were the method was first described (Pei et al., 2019). For SGC, we use the default layers after test among . For SAGE, we use SAGE convolutional layers with hidden units.
The heterophilic datasets used in (Pei et al., 2019). The graphs Chameleon, Actor, Squirrel, Texas and Cornell in their original form are directed graphs (see the github repository of (Pei et al., 2019)). Since the usual setting for semi-supervised node classifications involves undirected graph, we transformed the graphs into undirected to test them on all previously described benchmark methods. We keep the input graph directed for Geom-GCN as the method uses a fixed preprocessing scheme that was unfortunately not made public by the authors. Our homophily measure values in Table 1 are all based on undirected graphs and hence the numbers are different from those reported in (Pei et al., 2019).
A.10 Additional Experimental results
| GPRGNN | 97.190.16 | 95.540.15 | 81.540.73 | 60.650.31 | 62.160.23 | 68.830.28 | 89.310.16 | 96.980.08 | 96.710.13 |
| GPRGNN(random) | 88.393.31 | 88.543.01 | 66.912.93 | 56.350.98 | 58.090.71 | 64.011.39 | 81.931.68 | 94.590.29 | 93.691.04 |
| APPNP | 49.570.11 | 52.450.27 | 56.320.40 | 59.550.48 | 61.210.23 | 68.410.30 | 85.660.22 | 94.370.09 | 90.020.16 |
| MLP | 49.880.10 | 53.400.34 | 57.140.41 | 60.550.41 | 62.150.33 | 61.260.21 | 57.910.35 | 53.360.32 | 49.920.11 |
| SGC | 54.410.37 | 59.740.29 | 55.570.33 | 51.840.23 | 53.950.28 | 65.650.27 | 85.510.20 | 93.990.10 | 88.500.18 |
| GCN | 55.240.35 | 61.040.39 | 56.400.39 | 52.230.24 | 54.430.32 | 67.230.29 | 84.560.20 | 90.190.14 | 78.670.19 |
| GAT | 53.970.32 | 57.180.45 | 53.390.34 | 51.230.19 | 53.260.27 | 64.450.36 | 81.940.34 | 88.450.26 | 78.060.30 |
| SAGE | 62.300.50 | 75.100.50 | 72.840.44 | 63.880.37 | 58.620.30 | 63.550.47 | 73.500.50 | 75.260.52 | 62.610.44 |
| JKNet | 51.700.39 | 55.830.75 | 52.670.51 | 50.270.15 | 52.020.35 | 65.670.44 | 86.350.19 | 95.130.09 | 90.320.17 |
| GCN-Cheby | 61.440.51 | 73.910.75 | 71.960.6 | 63.960.43 | 59.700.34 | 64.000.38 | 72.340.63 | 73.560.65 | 60.880.58 |
| GPRGNN | 98.830.06 | 98.190.08 | 94.230.14 | 86.060.20 | 82.220.20 | 86.480.20 | 94.340.13 | 98.460.08 | 98.840.06 |
| GPRGNN(random) | 98.750.05 | 98.080.08 | 94.220.14 | 86.060.20 | 81.570.23 | 86.360.20 | 94.090.14 | 98.380.08 | 98.770.07 |
| APPNP | 48.940.29 | 63.870.29 | 73.300.26 | 79.300.20 | 82.410.23 | 86.470.18 | 94.200.14 | 97.960.10 | 98.530.08 |
| MLP | 49.790.29 | 66.690.27 | 75.360.26 | 80.300.24 | 82.190.24 | 80.880.22 | 76.070.24 | 66.610.25 | 49.650.29 |
| SGC | 78.950.23 | 81.790.24 | 75.150.25 | 59.400.28 | 63.750.26 | 80.810.22 | 93.040.15 | 98.050.08 | 97.800.09 |
| GCN | 78.500.28 | 83.680.22 | 75.980.25 | 59.980.25 | 64.090.26 | 81.890.19 | 93.910.12 | 97.780.08 | 96.290.11 |
| GAT | 82.390.41 | 80.370.22 | 71.010.26 | 57.680.29 | 62.950.28 | 80.610.24 | 93.260.14 | 97.990.08 | 98.400.09 |
| SAGE | 91.330.23 | 95.720.12 | 93.230.17 | 84.520.20 | 78.990.24 | 84.870.20 | 92.900.15 | 95.750.11 | 91.190.24 |
| JKNet | 96.110.37 | 95.330.25 | 87.980.56 | 59.610.49 | 63.280.10 | 80.230.36 | 93.280.15 | 98.330.07 | 98.220.07 |
| GCN-Cheby | 90.940.16 | 94.820.13 | 91.830.17 | 85.180.21 | 80.800.25 | 85.280.21 | 92.700.16 | 95.060.13 | 90.340.18 |
| Cora | Citeseer | PubMed | |
|---|---|---|---|
| GPRGNN | 88.650.28 | 80.010.28 | 89.180.15 |
| APPNP | 88.10.23 | 80.50.26 | 89.150.13 |
| MLP | 76.440.30 | 76.250.28 | 86.430.13 |
| SGC | 86.580.26 | 76.230.29 | 83.520.10 |
| GCN | 86.870.25 | 79.280.25 | 86.970.12 |
| GAT | 87.520.24 | 80.560.31 | 86.640.11 |
| SAGE | 86.580.26 | 78.240.30 | 86.850.11 |
| JKNet | 86.970.27 | 77.690.35 | 87.380.13 |
| GCN-Cheby | 86.460.26 | 78.660.26 | 88.20.09 |
| GeomGCN | 85.40.26 | 76.420.37 | 88.510.08 |
()
()
()
()
()
()
()
()
()
()
()
()
()
()
()
()
()
()
()
| Accuracy at epoch (%) | Accuracy at the final epoch(%) | Over-smoothing ratio(%) | |
|---|---|---|---|
| Cora | 12.75 | 88.25 | 84 |
| Computers | 9.41 | 85.93 | 89 |
| Squirrel | 19.87 | 52.06 | 97 |
| Texas | 21.05 | 90.05 | 100 |
epoch
epoch
epoch
epoch
epoch
epoch
epoch
epoch
epoch
epoch
epoch
epoch
epoch
epoch
epoch
epoch
epoch
epoch
epoch
epoch
| Cora | Citeseer | Pubmed | Computers | Photo | |
|---|---|---|---|---|---|
| GPRGNN | 17.62ms / 3.74s | 19.28ms / 3.89s | 20.19ms / 5.53s | 39.93ms / 11.40s | 21.61ms / 6.18s |
| APPNP | 17.16ms / 4.00s | 15.97ms / 3.26s | 18.47ms / 6.29s | 39.59ms / 20.00s | 20.10ms / 10.93s |
| MLP | 4.14ms / 0.92s | 5.30ms / 1.13s | 5.43ms / 2.86s | 5.33ms / 2.77s | 4.63ms / 2.72s |
| SGC | 3.31ms / 3.31s | 11.45ms / 2.31s | 3.81ms / 3.81s | 4.36ms / 4.36s | 19.12ms / 8.75s |
| GCN | 9.25ms / 1.97s | 17.46ms / 3.53s | 14.11ms / 4.17s | 32.45ms / 16.29s | 32.56ms / 11.33s |
| GAT | 14.78ms / 3.42s | 19.94ms / 4.47s | 21.52ms / 6.70s | 61.45ms / 24.28s | 24.57ms / 11.61s |
| SAGE | 12.06ms / 2.44s | 41.40ms / 8.36s | 28.82ms / 6.32s | 171.36ms / 71.94s | 108.88ms / 42.18s |
| JKNet | 18.97ms / 4.41s | 3.99ms / 3.99s | 24.48ms / 6.61s | 35.02ms / 14.96s | 3.66ms / 3.66s |
| GCN-cheby | 22.96ms / 4.75s | 23.16ms / 4.68s | 45.76ms / 12.02s | 218.82ms / 96.58s | 82.38ms / 30.48s |
| Chameleon | Squirrel | Actor | Texas | Cornell | |
|---|---|---|---|---|---|
| GPRGNN | 16.74ms / 3.40s | 25.28ms / 5.12s | 19.31ms / 4.49s | 17.56ms / 3.55s | 18.42ms / 3.72s |
| APPNP | 17.01ms / 3.44s | 22.93ms / 4.63s | 16.32ms / 4.04s | 15.96ms / 3.24s | 14.66ms / 3.09s |
| MLP | 3.41ms / 0.69s | 5.19ms / 1.05s | 4.84ms / 0.98s | 3.81ms / 1.04s | 3.46ms / 0.89s |
| SGC | 13.83ms / 2.79s | 27.11ms / 5.56s | 12.39ms / 2.50s | 10.22ms / 2.06s | 10.38ms / 2.10s |
| GCN | 16.63ms / 3.63s | 47.46ms / 10.05s | 18.91ms / 3.86s | 15.50ms / 3.13s | 13.67ms / 2.76s |
| GAT | 20.03ms / 5.15s | 29.89ms / 6.67s | 23.52ms / 4.75s | 19.67ms / 4.01s | 19.35ms / 3.91s |
| SAGE | 89.41ms / 18.06s | 440.55ms / 88.99s | 43.94ms / 8.88s | 12.34ms / 3.08s | 12.15ms / 2.69s |
| JKNet | 3.13ms / 3.13s | 4.79ms / 4.79s | 3.98ms / 1.00s | 2.86ms / 2.09s | 2.81ms / 1.18s |
| GCN-cheby | 64.43ms / 13.02s | 343.47ms / 69.38s | 27.95ms / 5.65s | 6.08ms / 1.28s | 6.05ms / 1.44s |