Federated Learning Meets Multi-objective Optimization
Abstract
Federated learning has emerged as a promising, massively distributed way to train a joint deep model over large amounts of edge devices while keeping private user data strictly on device. In this work, motivated from ensuring fairness among users and robustness against malicious adversaries, we formulate federated learning as multi-objective optimization and propose a new algorithm FedMGDA+ that is guaranteed to converge to Pareto stationary solutions. FedMGDA+ is simple to implement, has fewer hyperparameters to tune, and refrains from sacrificing the performance of any participating user. We establish the convergence properties of FedMGDA+ and point out its connections to existing approaches. Extensive experiments on a variety of datasets confirm that FedMGDA+ compares favorably against state-of-the-art.
Keywords Pareto optimization, Distributed algorithms, Federated learning, Edge computing, Machine learning, Neural networks.
1 Introduction
Deep learning has achieved impressive successes on a number of domain applications, thanks largely to innovations on algorithmic and architectural design, and equally importantly to the tremendous amount of computational power one can harness through GPUs, computer clusters and dedicated software and hardware. Edge devices, such as smart phones, tablets, routers, car devices, home sensors, etc., due to their ubiquity and moderate computational power, impose new opportunities and challenges for deep learning. On the one hand, edge devices have direct access to privacy sensitive data that users may be reluctant to share (with say data centers), and they are much more powerful than their predecessors, capable of conducting a significant amount of on-device computations. On the other hand, edge devices are largely heterogeneous in terms of capacity, power, data, availability, communication, memory, etc., posing new challenges beyond conventional in-house training of machine learning models. Thus, a new paradigm, known as federated learning (FL) (McMahan et al.,, 2017) that aims at harvesting the prospects of edge devices, has recently emerged. Developing new FL algorithms and systems on edge devices has since become a hot research topic in machine learning.
From the beginning of its birth, FL has close ties to conventional distributed optimization. However, FL emerged from the pressing need to address news challenges in the mobile era that existing distributed optimization algorithms were not designed for per se. We mention the following characteristics of FL that are most relevant to our work, and refer to the excellent surveys (Li et al.,, 2019; Yang et al.,, 2019; Kairouz et al.,, 2019) and the references therein for more challenges and applications in FL.
-
•
Non-IID: Each user’s data can be distinctively different from every other user’s, violating the standard iid assumption in statistical learning and posing significant difficulty in formulating the goal in precise mathematical terms (Mohri et al.,, 2019). The distribution of user data is often severely unbalanced.
-
•
Limited communication: Communication between each user and a central server is constrained by network bandwidth, device status, user participation incentive, etc., demanding a thoughtful balance between computation (on each user device) and communication.
-
•
Privacy: Protecting user (data) privacy is of uttermost importance in FL. It is thus not possible to share user data (even to a cloud arbitrator), which adds another layer of difficulty in addressing the previous two challenges.
-
•
Fairness: As argued forcibly in recent work (e.g., Mohri et al., 2019; Li et al., 2020b ), ensuring fairness among users has become another serious goal in FL, as it largely determines users’ willingness to participate and ensures some degree of robustness against malicious user manipulations.
-
•
Robustness: FL algorithms are eventually deployed in the wild hence subject to malicious attacks. Indeed, adversarial attacks (e.g., Bagdasaryan et al., 2020; Sun et al., 2019; Bhagoji et al., 2019) have been constructed recently to reveal vulnerabilities of FL systems against malicious manipulations at the user side.
In this work, motivated from the last two challenges above, i.e.fairness and robustness, we propose a new algorithm FedMGDA+ that complements and improves existing FL systems. FedMGDA+ is based on multi-objective optimization and is guaranteed to converge to Pareto stationary solutions. FedMGDA+ is simple to implement, has fewer hyperparameters to tune, and most importantly refrains from sacrificing the performance of any participating user. We demonstrate the superior performance of FedMGDA+ under a variety of metrics including accuracy, fairness, and robustness.
We summarize our contributions as follows:
-
•
In §3, based on the proximal average we provide a novel, unifying and revealing interpretation of existing FL practices.
-
•
In §4, we summarize some background on multi-objective optimization and point out its connections to existing FL algorithms. We believe this new perspective will yield more fruitful exchanges between the two fields in the future.
-
•
In §5, we propose FedMGDA+ that complements existing FL systems while taking robustness and fairness explicitly into its algorithmic design. We prove that FedMGDA+ converges to a Pareto stationary solution under mild assumptions.
-
•
In §6, we perform extensive experiments to validate the competitiveness of FedMGDA+ under a variety of desirable metrics, and to illustrate the respective pros and cons of our and alternative algorithms.
We discuss more related work in §2 and we conclude in §7 with some future directions.
To facilitate reproducibility, we have released our code at: https://github.com/watml/Fed-MGDA.
2 Related Work
In this section we give a brief review of some recent work that is directly related to ours and put our contributions in context. To start with, McMahan et al., (2017) proposed the first FL algorithm known as “Federated Averaging” (a.k.a., FedAvg), which is a synchronous update scheme that proceeds in several rounds. At each round, the central server sends the current global model to a subset of users, each of which then uses its respective local data to update the received model. Upon receiving the updated local models from users, the server performs aggregation, such as simple averaging, to update the global model. For more discussion on different averaging schemes, see Li et al., (2020). Li et al., 2020a extended FedAvg to better deal with non-i.i.d. distribution of data, by adding a “proximal regularizer” to the local loss functions and minimizing the Moreau envelope function for each user. The resulting algorithm FedProx, as pointed out in §3, is a randomized version of the proximal average algorithm in Yu, (2013) and reduces to FedAvg when regularization diminishes.
Analysing FedAvg has been a challenging task due to its flexible updating scheme, partial user participation, and non-iid distribution of client data Li et al., 2020a . The first theoretical analysis of FedAvg for strongly convex and smooth problems with iid and non-iid data appeared in Stich, (2019) and Li et al., (2020), respectively, where the effect of different sampling and averaging schemes on the convergence rate of FedAvg was also investigated, leading to the conclusion that such effect becomes particularly important when the dataset is unbalanced and non-iid distributed. In Huo et al., (2020), FedAvg was analyzed for non-convex problems, where FedAvg was formulated as a stochastic gradient-based algorithm with biased gradients, and the convergence of FedAvg with decaying step sizes to stationary points was proved. Moreover, Huo et al., (2020) proposed FedMom, a server-side acceleration based on Nesterov’s momentum, and proved again its convergence to stationary points. Lately, Reddi et al., (2020) proposed and analyzed federated versions of several popular adaptive optimizers (e.g. ADAM). They generalize the framework of FedAvg by decoupling the FL update scheme into server optimizer and client optimizer. Interestingly, same as us, Reddi et al., (2020) also observed the importance of learning rate decays on both clients and server.
Recently, an interesting work by Pathak and Wainwright, (2020) demonstrated theoretically that fixed points reached by FedAvg and FedProx (if exist) need not be stationary points of the original optimization problem, even in convex settings and with deterministic updates. To address this issue, they proposed FedSplit to restore the correct fixed points. It still remains open, though, if FedSplit can still converge to the correct fixed points under asynchronous and stochastic user updates, both of which are widely adopted in practice and studied here.
Ensuring fairness among users has become a serious goal in FL since it largely determines users’ willingness to participate in the training process. Mohri et al., (2019) argued that existing FL algorithms can lead to federated models that are biased toward different users. To solve this issue, Mohri et al., (2019) proposed agnostic federated learning (AFL) to improve fairness among users. AFL considers the target distribution as a weighted combination of the user distributions and optimizes the centralized model for the worse-case realization, leading to a saddle-point optimization problem which was solved by a fast stochastic optimization algorithm. On the other hand, based on fair resource allocation in wireless networks, Li et al., 2020b proposed q-fair federated learning (q-FFL) to achieve more uniform test accuracy across users. Li et al., 2020b further proposed q-FedAvg as a communication efficient algorithm to solve q-FFL. However, both AFL and q-FedAvg do not explicitly encourage user participation and they suffer from adversarial attacks while our algorithm FedMGDA+ is designed to be fair among participants and robust against both additive and multiplicative attacks.
FedAvg relies on a coordinate-wise averaging of local models to update the global model. According to Wang et al., 2020b , in neural network (NN) based models, such coordinate-wise averaging might lead to sub-optimal results due to the permutation invariance of NN parameters. To address this issue, Yurochkin et al., (2019) proposed probabilistic federated neural matching (PFNM), which is only applicable to fully connected feed-forward networks. The recent work (Wang et al., 2020b, ) proposed federated matched averaging (FedMA) as a layer-wise extension of PFNM to accommodate CNNs and LSTMs. However, the Bayesian non-parametric mechanism in PFNM and FedMA may be vulnerable to model poisoning attack (Bagdasaryan et al.,, 2020; Bhagoji et al.,, 2019; Wang et al., 2020a, ), while some simple defences, such as norm thresholding and differential privacy, were discussed in Sun et al., (2019). We note that these ideas are complementary to FedMGDA+ and we plan to investigate possible integrations of them in future work.
Lastly, we note that there is significant interest in standardizing the benchmarks, protocols and evaluations in FL, see for instance (Caldas et al.,, 2018; He et al.,, 2020). We have spent significant efforts in adhering to the suggested rules there, by reporting on common datasets, open sourcing our code and including all experimental details.
3 Problem Setup
We recall the federated learning (FL) framework of McMahan et al., (2017) and point out a simple interpretation that seemingly unifies different implementations. We consider FL with users (edge devices), where the -th user is interested in minimizing a function , defined on a shared model parameter . Typically, each user function also depends on the respective user’s local (private) data . The main goal in FL is to collectively and efficiently optimize individual objectives while meeting challenges such as those mentioned in the Introduction (§1): non-iid distribution of user data, limited communication, user privacy, fairness, robustness, etc..
McMahan et al., (2017) proposed FedAvg to optimize the arithmetic average of individual user functions:
| (1) |
The weights need to be specified beforehand. Typical choices include the dataset size at each user, the “importance” of each user, or simply uniform, i.e.. FedAvg works as follows: At each round, a (random) subset of users is selected, each of which performs epochs of local (full or minibatch) gradient descent:
| (2) |
and then the weights are averaged at the server side:
| (3) |
which is finally broadcast to the users in the next round. The number of local epochs turns out to be a key factor. Setting amounts to solving (1) by the usual gradient descent algorithm, while setting (and assuming convergence for each local function ) amounts to (repeatedly) averaging the respective minimizers of ’s. We now give a new interpretation of FedAvg that yields insights on what it optimizes with an intermediate .
Our interpretation is based on the proximal average (Bauschke et al.,, 2008). Recall that the Moreau envelope and proximal map of a convex111For nonconvex functions, similar results hold once we address multi-valuedness of the proximal map, see Yu et al., (2015). function is defined respectively as:
| (4) | ||||
| (5) |
Given a set of convex functions and positive weights that sum to 1, we define the proximal average as the unique function such that In other words, the proximal map of the proximal average is the average of proximal maps. More concretely, Bauschke et al., (2008) gave the following explicit, albeit complicated, formula for the proximal average:
| (6) | ||||
| (7) |
From the above formula we can easily derive that
Interestingly, we can now interpret FedAvg in two extreme settings as minimizing the proximal average:
-
•
FedAvg with local step is exactly the same as minimizing the proximal average with . This is clear from the objective (1) of FedAvg (as our notation already suggests).
-
•
FedAvg with local steps is exactly the same as minimizing the proximal average with . Indeed,
(8) where the right-hand side decouples and hence at optimality is a minimizer of (recall that ).
Therefore, we may interpret FedAvg with an intermediate as minimizing with an intermediate . More interestingly, if we apply the PA-PG algorithm in Yu, (2013, Algo. 222) to minimize , we obtain the simple update rule
| (9) |
where the proximal maps are computed in parallel at the user’s side. We note that the recent FedProx algorithm (Li et al., 2020a, ) is essentially a randomized version of (9). Crucially, we do not need to evaluate the complicated formula (6) as the update (9) only requires its proximal map, which by definition is the average of the individual proximal maps (computed by each user separately). Moreover, the difference between the proximal average and the arithmetic average can be uniformly bounded using the Lipschitz constant of each function (Yu,, 2013). Thus, for small step size , FedAvg (with any finite ) and FedProx all minimize some approximate form of the arithmetic average in (1).
How to set the weights in FedAvg has been a major challenge. In FL, data is distributed in a highly non-iid and unbalanced fashion, so it is not clear if some chosen arithmetic average in (1) would really satisfy one’s actual intention. A second issue with the arithmetic average in (1) is its well-known non-robustness against malicious manipulations, which has been exploited in recent adversarial attacks (Bhagoji et al.,, 2019). Instead, Agnostic FL (AFL (Mohri et al.,, 2019)) aims to optimize the worst-case loss:
| (10) |
where the set might cover reality better than any specific and provide some minimum guarantee for all users (hence achieving mild fairness). On the other hand, the worst-case loss in (10) is perhaps even more non-robust against adversarial attacks. For instance, adding a positive constant to some loss can make it dominate the entire optimization process. The recent work q-FedAvg (Li et al., 2020b, ) proposes an norm interpolation between FedAvg (essentially norm) and AFL (essentially norm). By tuning , q-FedAvg can achieve better compromise than FedAvg or AFL.
4 Multi-objective Minimization (MoM)
Multi-objective minimization (MoM) refers to the setting where multiple scalar objective functions, possibly incompatible with each other, need to be minimized simultaneously. It is also called vector optimization (Jahn,, 2009) because the objective functions can be combined into a single vector-valued function. In mathematical terms, MoM can be written as
| (11) |
where the minimum is defined wrt the partial ordering:
| (12) |
(We remind that algebraic operations such as and , when applied to a vector with another vector or scalar, are always performed component-wise.) Unlike single objective optimization, with multiple objectives it is possible that
| (13) |
in which case we say and are not comparable.
We call a Pareto optimal solution of (11) if its objective value is a minimum element (wrt the partial ordering in (12)), or equivalently for any , implies . In other words, it is not possible to improve any component objective in without compromising some other objective. Similarly, we call a weakly Pareto optimal solution if there does not exist any such that , i.e., it is not possible to improve all component objectives in . Clearly, any Pareto optimal solution is also weakly Pareto optimal but the converse may not hold.
We point out that the optimal solutions in MoM are usually a set (in general of infinite cardinality) (Mukai,, 1980), and without additional subjective preference information, all Pareto optimal solutions are considered equally good (as they are not comparable against each other). This is fundamentally different from the single objective case.
From now on, for simplicity we assume all objective functions are continuously differentiable but not necessarily convex (to accommodate deep models). Finding a (weakly) Pareto optimal solution in this setting is quite challenging (already so in the single objective case). Instead, we will contend with Pareto stationary solutions, namely those that satisfy an intuitive first order necessary condition:
Definition 1 (Pareto-stationarity, Mukai, 1980).
We call Pareto-stationary iff some convex combination of the gradients vanishes, i.e.there exists some such that and .
Lemma 1 (Mukai, 1980).
Any Pareto optimal solution is Pareto stationary. Conversely, if all functions are convex, then any Pareto stationary solution is weakly Pareto optimal.
Needless to say, the above results reduce to the familiar ones for the single objective case ().
There exist many algorithms for finding Pareto stationary solutions. We briefly review three popular ones that are relevant for us, and refer the reader to the excellent monograph (Miettinen,, 1998) for more details.
Weighted approach. Let (the simplex) and consider the following single, weighted objective:
| (14) |
This is essentially the approach taken by FedAvg, with any (global) minimizer of (14) being weakly Pareto optimal (in fact, Pareto optimal if all weights are positive). From Definition 1 it is clear that any stationary solution of the weighted scalar problem (14) is a Pareto stationary solution of the original MoM (11). Note that the scalarization weights , once chosen, are fixed throughout. Different leads to different Pareto stationary solutions.
-constraint. Let , and consider the following constrained scalar problem:
| (15) | ||||
| (16) |
Assuming the constraints are satisfiable, then any (global) minimizer of (15) is again weakly Pareto optimal. The -constraint approach is closely related to the weighted approach above, through the usual Lagrangian reformulation. Both require fixing an dimensional parameter in advance ( vs. ), though.
Chebyshev approach. Let and consider the minimax problem (where recall that is the simplex constraint):
| (17) |
Again, any (global) minimizer is weakly Pareto optimal. Here is a fixed vector that ideally lower bounds . This is essentially the approach taken by AFL (Mohri et al.,, 2019) with .
5 FL as Multi-objective Minimization
Having introduced both FL and MoM, and observed some connections between the two, it is very natural to treat each user function in FL as a separate objective in MoM and aim to optimize them simultaneously as in (11). This will be the main approach we follow below, which, to the best of our knowledge, has not been formally explored before (despite of the apparent connections that we saw in the previous section, perhaps retrospectively). In particular, we will extend the multiple gradient descent algorithm (Mukai,, 1980) in MoM to FL, draw connections to existing FL algorithms, and prove convergence properties of our extended algorithm FedMGDA+. Very importantly, the notion of Pareto optimality and stationarity immediately enforces fairness among users, as we are discouraged from improving certain users by sacrificing others.
To further motivate our development, let us compare to the objective in AFL (Mohri et al.,, 2019):
| (18) |
where denotes the simplex222To be precise, AFL restricted to a subset . We simply set to ease the discussion.. By optimizing the worst loss than the average loss in FedAvg, AFL provides some guarantee to all users hence achieving some form of fairness. However, note that AFL’s objective (18) is not robust against adversarial attacks. In fact, if a malicious user artificially “inflates” its loss (e.g., even by adding/multiplying a constant), it can completely dominate and mislead AFL to solely focus on optimizing its performance. The same issue applies to q-FedAvg (Li et al., 2020b, ), albeit with a less dramatic effect if is small.
AFL’s objective (18) is very similar to the Chebyshev approach in MoM (see Section 4), which inspires us to propose the following iterative algorithm for solving (11):
| (19) |
where we adaptively “center” the user functions using function values from the previous iteration. When the functions are smooth, we apply the quadratic bound to obtain:
| (20) |
where is the Jacobian and is the step size. Crucially, note that does not appear in the above bound (20) since we subtracted it off in (19). Since (20) is convex in and concave in we can swap min with max and obtain the dual:
| (21) |
Solving by setting its derivative to we arrive at:
| (22) | |||
| (23) |
Note that is precisely the minimum-norm element in the convex hull of the columns (i.e., gradients) in the Jacobian , and finding amounts to solving a simple quadratic program. The resulting iterative algorithm in (22) is known as multiple gradient descent algorithm (MGDA), which has been (re)discovered in Mukai, (1980); Fliege and Svaiter, (2000); Désidéri, (2012) and recently applied to multitask learning in Sener and Koltun, (2018); Lin et al., (2019) and to training GANs in Albuquerque et al., (2019). Our concise derivation here reveals some new insights about MGDA, in particular its connection to AFL.
To adapt MGDA to the federated learning setting, we propose the following extensions.
Balancing user average performance and fairness. We observe that the MGDA update in (22) resembles FedAvg, with the crucial difference that MGDA automatically tunes the dual weighting variable in each step while FedAvg pre-sets based on a priori information about the user functions (or simply uniform in lack of such information). Importantly, the direction found in MGDA is a common descent direction for all participating objectives:
| (24) |
where the first inequality follows from familiar smoothness assumption on while the second inequality follows simply from plugging in (20) and noting that by definition can only decrease (20) even more. It is clear that equality is attained iff , i.e., is Pareto-stationary (see Section 4). In other words, MGDA never sacrifices any participating objective to trade for more sizable improvements over some other objective, something FedAvg with a fixed weighting might attempt to do. On the other hand, FedAvg with a fixed weighting may achieve higher average performance under the weighting . It is natural to introduce the following trade-off between average performance and fairness:
| (25) |
Clearly, setting recovers FedAvg with a priori weighting while setting recovers MGDA where the weighting variable is tuned without any restriction to achieve maximal fairness. In practice, with an intermediate we may strike a desirable balance between the two (sometimes) conflicting goals. Moreover, even with the uninformative weighting , using an intermediate allows us to upper bound the contribution of each user function to the common direction hence achieve some form of robustness against malicious manipulations.
Robustness against malicious users through normalization. Existing work (e.g., Bhagoji et al.,, 2019; Xie et al.,, 2019) has demonstrated that the average gradient in FedAvg can be easily manipulated by even a single malicious user. While more robust aggregation strategies are studied recently (see e.g., Blanchard et al.,, 2017; Yin et al.,, 2018; Diakonikolas et al.,, 2019), they do not necessarily maintain the convergence properties of FedMGDA+ (e.g.finding a common descent direction and converging to a Pareto stationary solution). Instead, we propose to simply normalize the gradients from each user to unit length, based on the following considerations: (a) Normalizing the (sub)gradient is common for specialists in nonsmooth and stochastic optimization (Anstreicher and Wolsey,, 2009) and sometimes eases step size tuning. (b) Solving the weights in (22) with normalized gradients still guarantees fairness, i.e., the resulting direction is descending for all participating objectives (by a completely similar reasoning as the remark after (5)). (c) Normalization restores robustness against multiplicative “inflation” from any malicious user, which, combined with MGDA’s built-in robustness against additive “inflation” (see Equation 19), offers reasonable robustness guarantees against adversarial attacks.
Balancing communication and on-device computation. Communication between user devices and the central server is heavily constrained in FL, due to a variety of reasons mentioned in §3. On the other hand, modern edge devices are capable of performing reasonable amount of on-device computations. Thus, we allow each user device to perform multiple local updates before communicating its update , namely the difference between the initial and the final , to the central server. The server then calls the (extended) MGDA to perform a global update, which will be broadcast to the next round of user devices. We note that similar strategy was already adopted in many existing FL systems (e.g., McMahan et al.,, 2017; Li et al., 2020b, ; Li et al., 2020a, ).
Subsampling to alleviate non-iid and enhance throughput. Due to the massive number of edge devices in FL, it is not realistic to expect most devices to participate at each or even most rounds. Consequently, the current practice in FL is to select a (different) subset of user devices to participate in each round (McMahan et al.,, 2017). Moreover, randomly subsampling user devices can also help combat the non-iid distribution of user-specific data (e.g., McMahan et al.,, 2017; Li et al.,, 2020). Here we point out an important advantage of our MGDA-based algorithm: its update is along a common descending direction (see (5)), meaning that the objective of any participating user can only decrease. We believe this unique property of MGDA provides strong incentive for users to participate in FL. To our best knowledge, existing FL algorithms do not provide similar algorithmic incentives. Last but not the least, subsampling also solves a degeneracy issue in MGDA: when the number of participating users exceeds the dimension , the Jacobian has full row-rank hence (22) achieves Pareto-stationarity in a single iteration and stops making progress. Subsampling removes this undesirable effect and allows different subsets of users to be continuously optimized.
With the above extensions, we summarize our extended algorithm FedMGDA+ in Algorithm 1, and we prove the following convergence guarantees (precise statements and proofs can be found in Appendix A):
Theorem 1a.
Let each user function be -Lipschitz smooth and -Lipschitz continuous, and choose step size so that and , where with
| (26) | ||||
| (27) |
Then, with we have:
| (28) |
Here is the number of local updates and is the number of minibatches in each local update. The convergence rate depends on how quickly the “variance” term of the stochastic common descent direction diminishes (if at all), which in turn depends on how aggressively we subsample users or how heterogeneous the users are.
For deterministic gradient updates, we can prove convergence even with more local updates (i.e.):
Theorem 1b.
Let each user function be -Lipschitz smooth and -Lipschitz continuous. For any number of local updates , if the global step size with , local learning rate and , then we have:
| (29) |
Please refer to Appendix A for the precise statement of the theorem and its proof. We note that one natural approach to bound the deviation is by applying the -constrained version of FedMGDA. For example, if , and is bounded, then is also bounded. Thus, when . Moreover, when , we do not need the local learning rate to decay for convergence; in addition, if (e.g. in FedAvg), then our convergence guarantee reduces to the usual one for gradient descent, which is expected since we know FedAvg with is the same as centralized gradient descent. Lastly, we note that when , local learning rate must vanish in order to obtain convergence. This importance of local learning rate decay is also pointed out in Reddi et al., (2020).
When the functions are convex, we can derive a finer result:
Theorem 2.
Suppose each user function is convex and -Lipschitz continuous. Suppose at each round FedMGDA+ includes a strongly convex user function whose weight is bounded away from 0. Then, with the choice and , we have
| (30) |
and almost surely, where is the nearest Pareto stationary solution to and is some constant.
A slightly stronger result where we also allow some user functions to be nonconvex can be found in Appendix A. The same results hold if the gradient normalization is bounded away from 0 (otherwise we are already close to Pareto stationarity). For , using a similar argument as in §3, we expect FedMGDA+ to optimize some proxy problem (such as the proximal average), and we leave the thorough theoretical analysis for future work.
We remark that convergence rate for MGDA, even when restricted to the deterministic case, was only derived recently in Fliege et al., (2019). The stochastic case (that we consider here) is much more challenging and our theorems provide one of the first convergence guarantees for FedMGDA+. We wish to emphasize that FedMGDA+ is not just an alternative algorithm for FL practitioners; it can be used as a post-processing step to enhance existing FL systems or combined with existing FL algorithms (such as FedProx or q-FedAvg). This is particularly appealing with nonconvex user functions as MGDA is capable of converging to all Pareto stationary points while approaches such as FedAvg do not necessarily enjoy this property even when we enumerate the weighting (Miettinen,, 1998). Furthermore, it is possible to find multiple or even enumerate all Pareto optimal solutions (i.e.the Pareto front). For instance, we may run FedMGDA+ multiple times with different random seeds or initializations. As shown by Lin et al., (2019), we could also incorporate additional linear constraints in (22) to encode one’s preference and encourage more diverse solutions. However, these techniques become less effective in higher dimensions (i.e.when the number of users is large) and in communication limited settings. Practically, the server may dynamically adjust the linear constraints in (22) to steer the algorithm to a more desirable Pareto stationary solution.
Lastly, we mention that finding the common descent direction (i.e.Line 6 of Algorithm 1) is a standard quadratic programming (QP) problem that is solved only at the server side. For moderate number of (sampled) users, it suffices to employ a generic QP solver while for large number of users we could also solve efficiently using for instance the conditional gradient algorithm (Sener and Koltun,, 2018), with per-step complexity proportional to the model dimension and the number of participating users. For our experiments below, we used a generic QP sovler and we observed that this overhead is negligible, resulting almost the same overall running time for FedAvg and FedMGDA.
6 Experiments
6.1 Experimental setups
| Dataset | Train Clients | Train samples | Test clients | Test samples | Batch size |
|---|---|---|---|---|---|
| CIFAR-10 (Krizhevsky,, 2009) | |||||
| F-MNIST (Xiao et al.,, 2017) | |||||
| FEMNIST (Caldas et al.,, 2018) | |||||
| Shakespeare (Li et al., 2020a, ) | |||||
| Adult (Dua and Graff,, 2017) |
| Layer | Output Shape | of Trainable Parameters | Activation | Hyper-parameters |
|---|---|---|---|---|
| Input | ||||
| Conv2d | ReLU | kernel size =; strides= | ||
| MaxPool2d | pool size= | |||
| LocalResponseNorm | size= | |||
| Conv2d | ReLU | kernel size =; strides= | ||
| LocalResponseNorm | size= | |||
| MaxPool2d | pool size= | |||
| Flatten | ||||
| Dense | ReLU | |||
| Dense | ReLU | |||
| Dense | softmax | |||
| Total |
| Layer | Output Shape | of Trainable Parameters | Activation | Hyper-parameters |
|---|---|---|---|---|
| Input | ||||
| Conv2d | ReLU | kernel size =; strides= | ||
| MaxPool2d | pool size= | |||
| Conv2d | ReLU | kernel size =; strides= | ||
| MaxPool2d | pool size= | |||
| Dropout2d | ||||
| Flatten | ||||
| Dense | ReLU | |||
| Dropout | ||||
| Dense | softmax | |||
| Total |
| Layer | Output Shape | of Trainable Parameters | Activation | Hyper-parameters |
|---|---|---|---|---|
| Input | ||||
| Conv2d | kernel size =; strides= | |||
| Conv2d | ReLU | kernel size =; strides= | ||
| MaxPool2d | pool size= | |||
| Dropout | ||||
| Flatten | ||||
| Dense | ||||
| Dropout | ||||
| Dense | softmax | |||
| Total |
| Name | Parameters |
|---|---|
| AFL | |
| q-FedAvg | , |
| FedMGDA+ | , and |
| FedAvg-n | , and |
| FedProx | |
| MGDA-Prox | , , and |
In this subsection we provide experimental details including dataset descriptions, sampling schemes, model configurations and hyper-parameter settings. A quick summary of the datasets that we use can be found in Table 1. We have two parameters in FedMGDA+ to control the total number of local updates in each communication round: , the number of local epochs, and , the number of updates in each local epoch. Here is the number of samples at each user (assumed the same for simplicity) while is the minibatch size for each local update. As observed by, e.g., McMahan et al., (2017) (Table 2), having a larger is similar as having a smaller (or equivalently a larger ), in terms of total number of local updates. Moreover, with a suitable usually leads to satisfying performance while very large can result in plateau or divergence. Thus, in our experiments we fix while vary to reduce the total number of hyperparameters. This corresponds to a single pass of the local data at each user in every communication round.
6.1.1 CIFAR-10 (Krizhevsky,, 2009) and Fashion MNIST (Xiao et al.,, 2017) datasets
In order to create a non-i.i.d. dataset, we follow a similar sampling procedure as in McMahan et al., (2017): first we sort all data points according to their classes. Then, they are split into shards, and each user is randomly assigned shards of data. By considering users, this procedure guarantees that no user receives data from more than classes and the data distribution of each user is different from each other. The local datasets are balanced–all users have the same amount of training samples. The local data is split into train, validation, and test sets with percentage of %, %, and %, respectively. In this way, each user has data points for training, for test, and for validation. We use a CNN model which resembles the one in McMahan et al., (2017), with two convolutional layers followed by three fully connected layers. The details are included in Table 2 for CIFAR-10 and in Table 3 for Fashin MNIST. To update the local models at each user using its local data, we apply stochastic gradient descent (SGD) with local batch size , local epoch , and local learning rate , or , , and . To model the fact that not all users may participate in each communication round, we employ a parameter to control the fraction of participating users: is the default setting which means that only % of users participate in each communication round.
6.1.2 Federated EMNIST dataset (Caldas et al.,, 2018)
For this experimental setup, we use the same dataset, model, and hyper-parameters as Reddi et al., (2020). We use the federated EMNIST dataset of Caldas et al., (2018). The dataset consists of images of digits, and English characters—both lower and upper cases, with 62 classes in total. The images are partitioned by their authors in a way that naturally makes the dataset heterogeneous and unbalanced. We use the model described in Table 4 and the following hyper-parameters: local learning rate and selecting clients per communication round as recommended. The only difference between our setup and the one in (Reddi et al.,, 2020) is that we use local epoch for all algorithms.
6.1.3 Shakespeare dataset (Li et al., 2020a, )
For experiments on the Shakespeare dataset, we use the same model, data pre-processing and sampling procedure as in q-FedAvg paper (Li et al., 2020b, ). The dataset is built from The Complete Works of William Shakespeare, where each role in the play represents one user. Following Li et al., 2020a , we subsample users to train a neural language model for next character prediction. Each character is embedded in an -dimensional space and the sequence length is characters. The model we use is a two-layer LSTM (with hidden size ) followed by one dense layer (McMahan et al.,, 2017; Li et al., 2020a, ). Joint hyper-parameters that are shared by all algorithms include: total communication rounds , local batch size , local epoch , and local optimizer being SGD, unless otherwise stated.
6.1.4 Adult dataset (Dua and Graff,, 2017)
Following the setting in AFL (Mohri et al.,, 2019), we split the Adult dataset into two non-overlapping domains based on the education attribute—phd domain and non-phd domain. The resulting FL setting consists of two users each of which has data from one of the two domains. Further, data is pre-processed as in Li et al., 2020b to have binary features. We use a logistic regression model for all FL algorithms mentioned in the main paper. Local data is split into train, validation, and test sets with percentage of %, %, and %, respectively. In each round, both users participate and the server aggregates their losses and gradients (or weights). Joint hyper-parameters that are shared by all algorithms include: total communication rounds , local batch size , local epoch , local learning rate , and local optimizer being SGD without momentum, unless otherwise stated. Algorithm-specific hyper-parameters will be mentioned in the appropriate places below. One important note is that the phd domain has only samples while the non-phd domain has samples, so the split is very unbalanced while training only on the phd domain yields inferior performance on all domains due to the insufficient sample size.
6.1.5 Hyper-parameters
We evaluate the performance of different algorithms with a wide range of hyper-parameters, summarized in Table 5. In particular, following Anstreicher and Wolsey, (2009) we tried sublinear and exponential decay learning rates on the server, and a fixed local learning rate for client updates. Eventually we settled on decaying by a factor of every steps: , where and is the total number of communication rounds (with e.g. decay = ). We note that Reddi et al., (2020) also found exponential decay to be most effective in their experiments. We use grid search to choose suitable local learning rates for all algorithms.


We evaluate our algorithm FedMGDA+ on several public datasets: CIFAR-10 (Krizhevsky,, 2009), F-MNIST (Xiao et al.,, 2017), Federated EMNIST (Caldas et al.,, 2018), Shakespeare (Li et al., 2020a, ) and Adult (Dua and Graff,, 2017), and compare to existing FL systems including FedAvg (McMahan et al.,, 2017), FedProx (Li et al., 2020a, ), q-FedAvg (Li et al., 2020b, ), and AFL333Experiments of AFL in the original work (Mohri et al.,, 2019) and later work that compare with it (e.g. (Li et al., 2020b, )) was reported on datasets with very few clients ( or ), possibly due to applicability reasons. We followed this convention in our work. (Mohri et al.,, 2019). In addition, from the discussions in §5, one can envision several potential extensions of existing algorithms to improve their performance. So, we also compare to the following extensions: FedAvg-n which is FedAvg with gradient normalization, and MGDA-Prox which is FedMGDA+ with a proximal regularizer added to each user’s loss function.444One can also apply the gradient normalization idea to q-FedAvg; however, we observed from our experiments that the resulting algorithm is unstable particularly for large values. We distinguish between FedMGDA+ and FedMGDA which is a vanilla extension of MGDA to FL.
We point out that FL algorithms are to be deployed on smart devices with moderate computational capabilities. Thus, the models we chose to experiment on are medium-sized (see Tables 2, 3 and 4 for details), with similar complexity to the ones in FedAvg, q-FedAvg and AFL. Due to space limits we only report some representative results in the main paper, and defer the full set of experiments to Appendix B.
6.2 Experimental results
In this subsection we report experimental results about our proposed algorithm FedMGDA+ and compare it with state-of-the-art (SOTA) alternatives under a variety of performance metrics, including accuracy, robustness and fairness. We remind that the accuracy metric is exactly what FedAvg aims to optimize during training, and hence it has some advantage in this metric over other alternative algorithms such as FedMGDA+, AFL, and q-FedAvg, which all aim to bring some fairness among users, perhaps at some occasional, and hopefully small, loss of accuracy.
6.2.1 Recovering FedAvg
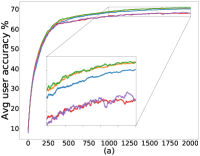
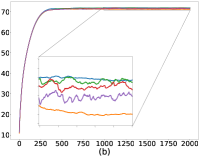
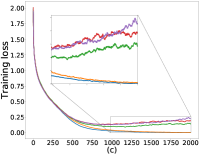
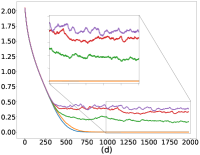
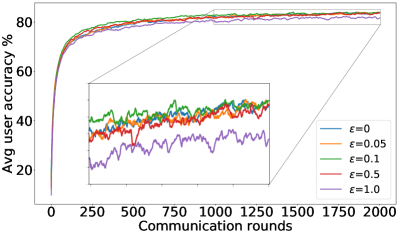
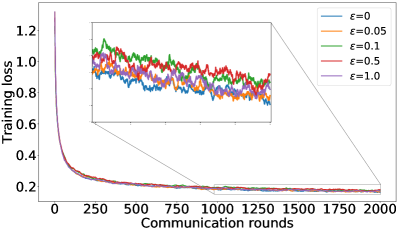
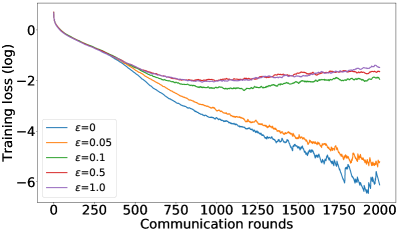
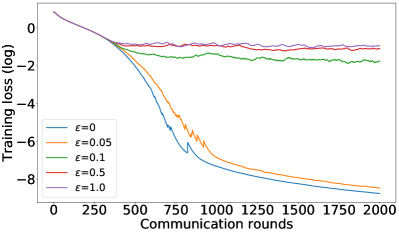
As mentioned in §5, we can control the balance between the user average performance and fairness by tuning the -constraint in Equation 25. Setting recovers FedAvg while setting recovers FedMGDA. To verify this empirically, we run (25) with different , and report results on CIFAR-10 in Figure 1 for both iid and non-iid distributions of data (for results on F-MNIST, see Section B.1). These results confirm that changing from to yields an interpolation between FedAvg and FedMGDA, as expected. Since FedAvg essentially optimizes the (uniformly) averaged training loss, it naturally performs the best under this metric (Figure 1 (c) and (d)). Nevertheless, it is interesting to note that some intermediate values actually lead to better user accuracy than FedAvg in the non-iid setting (Figure 1 (a)).

6.2.2 Robustness
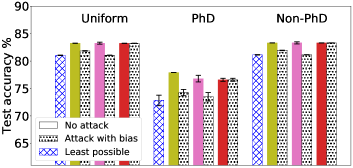
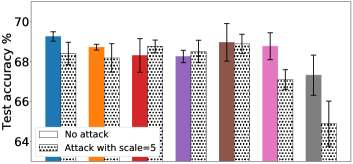
We discussed earlier in §5 that the gradient normalization and MGDA’s built-in robustness allow FedMGDA+ to combat against certain adversarial attacks in practical FL deployment. We now empirically evaluate the robustness of FedMGDA+ against these attacks. We run various FL algorithms in the presence of a single malicious user who aims to manipulate the system by inflating its loss. We consider an adversarial setting where the attacker participates in each communication round and inflates its loss function by (i) adding a bias to it, or (ii) multiplying it by a scaling factor, termed the bias and scaling attack, respectively. In the first experiment, we simulate a bias attack on the Adult dataset by adding a constant bias to the underrepresented user, i.e. the PhD domain, since it’s more natural to expect an attacker to be consisted of a small number of users. In this setup, the worst performance we can get is bounded by training the model using PhD data only. Results under the bias attack are presented in Figure 2 (Left); also see Section B.2 for more results. We observe that AFL and q-FedAvg perform slightly better than FedMGDA+ without the attack; however, their performances deteriorate to a level close to the worst case scenario under the attack. In contrast, FedMGDA+ is not affected by the attack with any bias, which empirically supports our claim in §5. Note that we did not include FedAvg in this comparison since from its definition it is clear that FedAvg, like FedMGDA+, is not affected by the bias attack. Figure 2 (Right) shows the results of different algorithms on CIFAR-10 with and without an adversarial scaling. As mentioned earlier, q-FedAvg with gradient normalization is highly unstable particularly under the scaling attack, so we did not include its result here. From Figure 2 (Right) it is immediate to see that (i) the scaling attack affects all algorithms that do not employ gradient normalization; (ii) q-FedAvg is the most affected under this attack; (iii) surprisingly, FedMGDA+ and, to a lesser extent, MGDA-Prox actually converge to slightly better Pareto solutions, compared to their own results under no scaling attack. The above results empirically verify the robustness of FedMGDA+ under perhaps the most common bias and scaling attacks.
6.2.3 Fairness
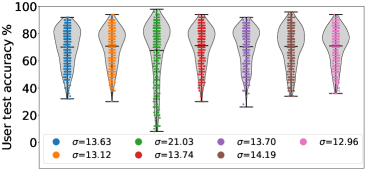
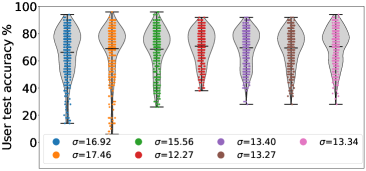
Lastly, we compare FedMGDA+ with existing FL algorithms using different notions of fairness on CIFAR-10. For the first experiment, we adopt the same fairness metric as (Li et al., 2020b, ), and measure fairness by calculating the variance of users’ test error. We run each algorithm with different hyperparameters, and among the results, we pick the best ones in terms of average accuracy to be shown in Figure 3; full table of results can be found in Section B.3. From this figure, we observe that (i) FedMGDA+ achieves the best average accuracy while its standard deviation is comparable with that of q-FedAvg; (ii) FedMGDA+ significantly outperforms FedMGDA, which clearly justifies our proposed modifications in Algorithm 1 to the vanilla MGDA; and (iii) FedMGDA+ outperforms FedAvg-n, which uses the same normalization step as FedMGDA+, in terms of average accuracy and standard deviation. These observations confirm the effectiveness of FedMGDA+ in inducing fairness. We perform the same experiment on the Federated EMNIST dataset, and observed similar results, which can be found in Table 6 and Section B.4.
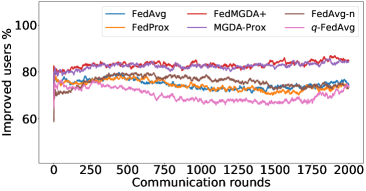
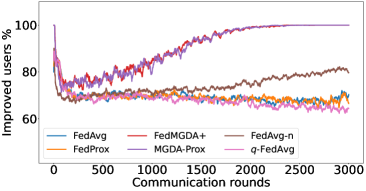
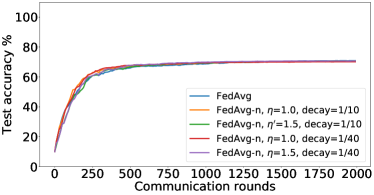
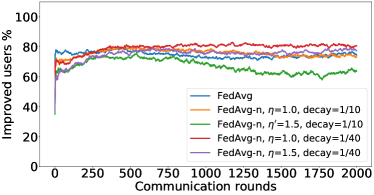
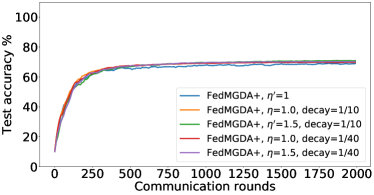
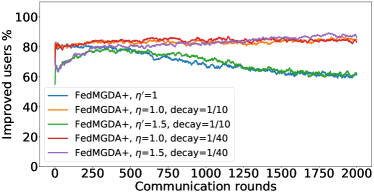
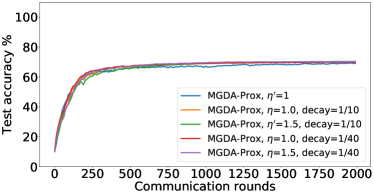
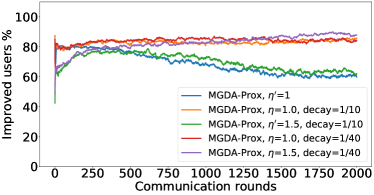
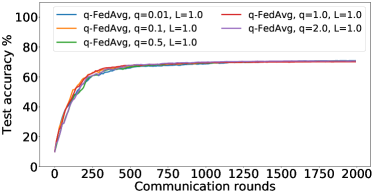
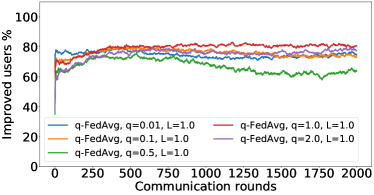
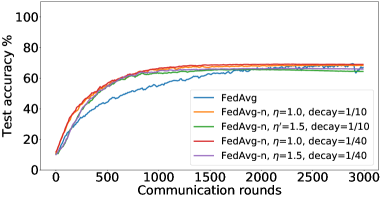
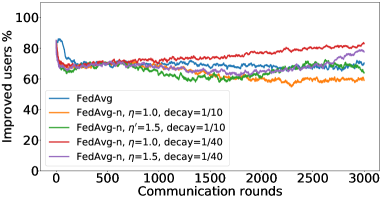
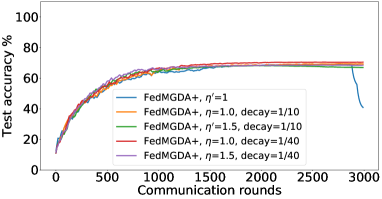
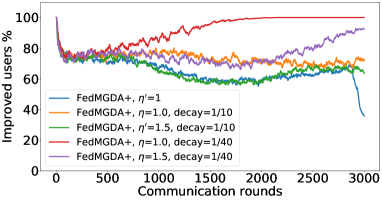
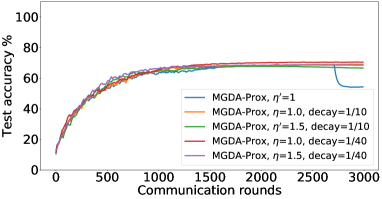
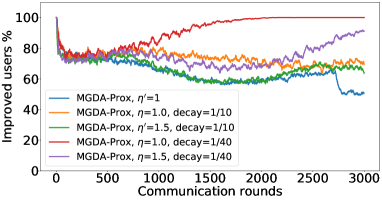
In the next experiment, we show that FedMGDA+ not only yields a fair final solution but also maintains fairness during the entire training process in the sense that, in each round, it refrains from sacrificing the performance of any participating user for the sake of improving the overall performance. To the best of our knowledge, “fairness during training” has not been investigated before, in spite of having great practical implications—it encourages user participation. To examine this fairness, we run several experiments on CIFAR-10 and measure the percentage of improved participants in each communication round. Specifically, we measure the training loss before and after each round for all participating users, and report the percentage of those improved or stay unchanged.555The percentage of improved users at time is defined as where is the selected users at time , and is the indicator function of an event . Figure 4 shows the percentage of improved participating users in each communication round in terms of training loss for two representative cases; see Section B.5 for full results with different hyperparameters.
We can see that FedMGDA+ consistently outperforms other algorithms in terms of percentage of improved users, which means that by using FedMGDA+, fewer users’ performances get worse after each participation. Furthermore, we notice from Figure 4 (Left) that, with local batch size , the percentage of improved users is less than %, which can be explained as follows: for small batch sizes (i.e., where represents a local dataset), the received updates from users are not the true gradients of users’ losses given the global model (i.e., ); they are noisy estimates of the true gradients. Consequently, the common descent direction calculated by MGDA is noisy and may not always work for all participating users. To remove the effect of this noise, we set which allows us to recover the true gradients from the users. The results are presented in Figure 4 (Right), which confirms that, when step size decays (less overshooting), the percentage of improved users for FedMGDA+ reaches towards % during training, as is expected.
| Algorithm | Average (%) | Std. (%) |
|---|---|---|
| FedMGDA | ||
| FedMGDA+ | ||
| MGDA-Prox | ||
| FedAvg | ||
| FedAvg-n | ||
| FedProx | ||
| q-FedAvg |
7 Conclusion
We have proposed a novel algorithm FedMGDA+ for federated learning. FedMGDA+ is based on multi-objective optimization and aims to converge to Pareto stationary solutions. FedMGDA+ is simple to implement, has fewer hyperparameters to tune, and complements existing FL systems nicely. Most importantly, FedMGDA+ is robust against additive and multiplicative adversarial manipulations and ensures fairness among all participating users. We established preliminary convergence guarantees for FedMGDA+, pointed out its connections to recent FL algorithms, and conducted extensive experiments to verify its effectiveness. In the future we plan to formally quantify the tradeoff induced by multiple local updates and to establish some privacy guarantee for FedMGDA+.
Acknowledgment
Resources used in preparing this research were provided, in part, by the Province of Ontario, the Government of Canada through CIFAR, and companies sponsoring the Vector Institute. We gratefully acknowledge funding support from NSERC, the Canada CIFAR AI Chairs Program, and Waterloo-Huawei Joint Innovation Lab. We thank NVIDIA Corporation (the data science grant) for donating two Titan V GPUs that enabled in part the computation in this work.
References
- Albuquerque et al., (2019) Albuquerque, I., Monteiro, J., Doan, T., Considine, B., Falk, T., and Mitliagkas, I. (2019). Multi-objective training of Generative Adversarial Networks with multiple discriminators. In ICML.
- Anstreicher and Wolsey, (2009) Anstreicher, K. M. and Wolsey, L. A. (2009). Two “well-known” properties of subgradient optimization. Mathematical Programming, 120(1):213–220.
- Bagdasaryan et al., (2020) Bagdasaryan, E., Veit, A., Hua, Y., Estrin, D., and Shmatikov, V. (2020). How To Backdoor Federated Learning. In AISTATS, Proceedings of Machine Learning Research, pages 2938–2948.
- Bauschke et al., (2008) Bauschke, H. H., Goebel, R., Lucet, Y., and Wang, X. (2008). The Proximal Average: Basic Theory. SIAM Journal on Optimization, 19(2):766–785.
- Bhagoji et al., (2019) Bhagoji, A. N., Chakraborty, S., Mittal, P., and Calo, S. (2019). Analyzing Federated Learning through an Adversarial Lens. In ICML, pages 634–643.
- Blanchard et al., (2017) Blanchard, P., El Mhamdi, E. M., Guerraoui, R., and Stainer, J. (2017). Machine Learning with Adversaries: Byzantine Tolerant Gradient Descent. In NeurIPS.
- Caldas et al., (2018) Caldas, S., Wu, P., Li, T., Konecny, J., McMahan, H. B., Smith, V., and Talwalkar, A. (2018). Leaf: A benchmark for federated settings. arXiv:1812.01097.
- Désidéri, (2012) Désidéri, J.-A. (2012). Multiple-gradient descent algorithm (MGDA) for multiobjective optimization. Comptes Rendus Mathematique, 350(5):313–318.
- Diakonikolas et al., (2019) Diakonikolas, I., Kamath, G., Kane, D., Li, J., Steinhardt, J., and Stewart, A. (2019). Sever: A Robust Meta-Algorithm for Stochastic Optimization. In ICML.
- Dua and Graff, (2017) Dua, D. and Graff, C. (2017). UCI Machine Learning Repository.
- Fliege and Svaiter, (2000) Fliege, J. and Svaiter, B. F. (2000). Steepest descent methods for multicriteria optimization. Mathematical Methods of Operations Research, 51(3):479–494.
- Fliege et al., (2019) Fliege, J., Vaz, A. I. F., and Vicente, L. N. (2019). Complexity of gradient descent for multiobjective optimization. Optimization Methods and Software, 34(5):949–959.
- He et al., (2020) He, C., Li, S., So, J., Zhang, M., Wang, H., Wang, X., Vepakomma, P., Singh, A., Qiu, H., Shen, L., et al. (2020). FedML: A research library and benchmark for federated machine learning. arXiv:2007.13518.
- Huo et al., (2020) Huo, Z., Yang, Q., Gu, B., Carin, L., and Huang, H. (2020). Faster On-Device Training Using New Federated Momentum Algorithm. arXiv:2002.02090.
- Jahn, (2009) Jahn, J. (2009). Vector optimization. Springer.
- Kairouz et al., (2019) Kairouz, P., McMahan, H. B., Avent, B., Bellet, A., Bennis, M., Bhagoji, A. N., Bonawitz, K., Charles, Z., Cormode, G., Cummings, R., D’Oliveira, R. G. L., Rouayheb, S. E., Evans, D., Gardner, J., Garrett, Z., Gascón, A., Ghazi, B., Gibbons, P. B., Gruteser, M., Harchaoui, Z., He, C., He, L., Huo, Z., Hutchinson, B., Hsu, J., Jaggi, M., Javidi, T., Joshi, G., Khodak, M., Konečný, J., Korolova, A., Koushanfar, F., Koyejo, S., Lepoint, T., Liu, Y., Mittal, P., Mohri, M., Nock, R., Özgür, A., Pagh, R., Raykova, M., Qi, H., Ramage, D., Raskar, R., Song, D., Song, W., Stich, S. U., Sun, Z., Suresh, A. T., Tramèr, F., Vepakomma, P., Wang, J., Xiong, L., Xu, Z., Yang, Q., Yu, F. X., Yu, H., and Zhao, S. (2019). Advances and Open Problems in Federated Learning. arXiv:1912.04977.
- Krizhevsky, (2009) Krizhevsky, A. (2009). Learning Multiple Layers of Features from Tiny Images. Technical report, University of Toronto.
- Li et al., (2019) Li, T., Sahu, A. K., Talwalkar, A., and Smith, V. (2019). Federated learning: Challenges, methods, and future directions. arXiv:1908.07873.
- (19) Li, T., Sahu, A. K., Zaheer, M., Sanjabi, M., Talwalkar, A., and Smith, V. (2020a). Federated Optimization in Heterogeneous Networks. In MLSys, pages 429–450.
- (20) Li, T., Sanjabi, M., Beirami, A., and Smith, V. (2020b). Fair Resource Allocation in Federated Learning. In ICLR.
- Li et al., (2020) Li, X., Huang, K., Yang, W., Wang, S., and Zhang, Z. (2020). On the Convergence of FedAvg on Non-IID Data. In ICLR.
- Lin et al., (2019) Lin, X., Zhen, H.-L., Li, Z., Zhang, Q.-F., and Kwong, S. (2019). Pareto Multi-Task Learning. In NeurIPS.
- McMahan et al., (2017) McMahan, B., Moore, E., Ramage, D., Hampson, S., and y Arcas, B. A. (2017). Communication-Efficient Learning of Deep Networks from Decentralized Data. In AISTATS, pages 1273–1282.
- Mercier et al., (2018) Mercier, Q., Poirion, F., and Désidéri, J.-A. (2018). A stochastic multiple gradient descent algorithm. European Journal of Operational Research, 271(3):808–817.
- Miettinen, (1998) Miettinen, K. M. (1998). Nonlinear Multiobjective Optimization. Springer.
- Mohri et al., (2019) Mohri, M., Sivek, G., and Suresh, A. T. (2019). Agnostic Federated Learning. In ICML, volume 97, pages 4615–4625.
- Mukai, (1980) Mukai, H. (1980). Algorithms for multicriterion optimization. IEEE Transactions on Automatic Control, 25(2):177–186.
- Pathak and Wainwright, (2020) Pathak, R. and Wainwright, M. J. (2020). FedSplit: An algorithmic framework for fast federated optimization. In NeurIPS.
- Reddi et al., (2020) Reddi, S., Charles, Z., Zaheer, M., Garrett, Z., Rush, K., Konečny, J., Kumar, S., and McMahan, H. B. (2020). Adaptive Federated Optimization. arXiv:2003.00295.
- Sener and Koltun, (2018) Sener, O. and Koltun, V. (2018). Multi-Task Learning as Multi-Objective Optimization. In NeurIPS.
- Stich, (2019) Stich, S. U. (2019). Local SGD converges fast and communicates little. In ICLR.
- Sun et al., (2019) Sun, Z., Kairouz, P., Suresh, A. T., and McMahan, H. B. (2019). Can You Really Backdoor Federated Learning? arXiv:1911.07963.
- (33) Wang, H., Sreenivasan, K., Rajput, S., Vishwakarma, H., Agarwal, S., Sohn, J.-y., Lee, K., and Papailiopoulos, D. (2020a). Attack of the Tails: Yes, You Really Can Backdoor Federated Learning. In NeurIPS, volume 33, pages 16070–16084.
- (34) Wang, H., Yurochkin, M., Sun, Y., Papailiopoulos, D., and Khazaeni, Y. (2020b). Federated Learning with Matched Averaging. In ICLR.
- Xiao et al., (2017) Xiao, H., Rasul, K., and Vollgraf, R. (2017). Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv:1708.07747.
- Xie et al., (2019) Xie, C., Koyejo, S., and Gupta, I. (2019). Fall of Empires: Breaking Byzantine-tolerant SGD by Inner Product Manipulation. In UAI.
- Yang et al., (2019) Yang, Q., Liu, Y., Chen, T., and Tong, Y. (2019). Federated Machine Learning: Concept and Applications. ACM Transactions on Intelligent Systems and Technology, 10(2).
- Yin et al., (2018) Yin, D., Chen, Y., Kannan, R., and Bartlett, P. (2018). Byzantine-Robust Distributed Learning: Towards Optimal Statistical Rates. In ICML.
- Yu, (2013) Yu, Y. (2013). Better Approximation and Faster Algorithm Using the Proximal Average. In NeurIPS.
- Yu et al., (2015) Yu, Y., Zheng, X., Marchetti-Bowick, M., and Xing, E. P. (2015). Minimizing Nonconvex Non-Separable Functions. In AISTATS, pages 1107–1115.
- Yurochkin et al., (2019) Yurochkin, M., Agarwal, M., Ghosh, S., Greenewald, K., Hoang, N., and Khazaeni, Y. (2019). Bayesian Nonparametric Federated Learning of Neural Networks. In ICML, pages 7252–7261.
Appendix A Proofs
Theorem 1a (full version).
Suppose each user function is -Lipschitz smooth (i.e., ) and -Lipschitz continuous. Then, with step size we have
| (31) |
where is the variance of the stochastic common direction. Moreover, if some user function is bounded from below, and it is possible to choose so that , then the left-hand side in (31) converges to 0.
Proof.
Let , where is the concatenation of stochastic gradients at each user, and
| (32) |
where for the latter we also constrain if the -th user is not participating in round . Then, applying the quadratic bound and the update rule (we remind that comparison between vector and scalar should be understood as component-wise):
| (33) | ||||
| (34) | ||||
| (35) |
where we used the Lipschitz continuity and the first-order optimality condition of so that
| (36) |
Letting , taking expectations and rearranging we obtain
| (37) |
where . ∎
Theorem 1b (full version).
Suppose each user function is -Lipschitz smooth (i.e., ) and -Lipschitz continuous. Then, for any number of local updates , with global learning rate , deterministic gradient update and local learning rate , we have
| (38) |
where is the deviation between the exact and approximate (dual) weightings. Moreover, if some user function is bounded from below, then the left-hand side in (38) converges to 0 as long as , and with .
Proof.
Let
| (39) |
and , where is the concatenation of accumulated updates at each user. Formally, , which denotes the difference between the initial and the final after local updates, for user . (Note that we have abused the notation and a bit for simplicity here, as they do not distinguish user . This is not a big problem since the context is clear.)
Let and be the local optimization steps.
Then,
| (40) | ||||
| (41) | ||||
| (42) |
Thus, the difference between and gradient is bounded by:
| (44) | ||||
| (45) | ||||
| (46) |
Thus,
| (47) | ||||
| (48) | ||||
| (49) |
the last step comes from matrix norm inequality on the first term, and triangular inequality on the second term. Note that vanishes when and .
Then, applying the quadratic upper bound, we have
| (50) | ||||
| (51) | ||||
| (52) |
Finally, if and , then and hence the right-hand side in (38) when , in which case the left-hand side converges to as well. ∎
Theorem 2 (full version).
Suppose each user function is -strongly convex (i.e. ) and -Lipschitz continuous. Suppose at each round FedMGDA includes some function such that
| (54) |
where is the projection of to the Pareto stationary set of (11). Assume , then
| (55) |
where and . In particular,
-
•
if , then and converges to the Pareto stationarity set almost surely;
-
•
with the choice we have
(56)
Proof.
For each user , let us define the function
| (57) |
where the random variable indicates which user participates at a particular round. Clearly, we have . Therefore, our multi-objective minimization problem is equivalent as:
| (58) |
since positive scaling does not change Pareto stationarity. (If one prefers, we can also normalize the stochastic functions so that the unbiasedness property holds.)
We now proceed as in Mercier et al., (2018) and provide a slightly sharper analysis. Let us denote the projection of to the Pareto-stationary set of (58), i.e.,
| (59) |
Then,
| (60) | ||||
| (61) | ||||
| (62) |
To bound the middle term, we have from our assumption:
| (63) | ||||
| (64) |
where the second inequality follows from the definition of . Therefore,
| (65) | ||||
| (66) | ||||
| (67) | ||||
| (68) |
Continuing from (62) and taking conditional expectation:
| (69) |
where . Taking expectation we obtain the familiar recursion:
| (70) |
from which we derive
| (71) |
where and . Since , we know
| (72) |
if and .
Setting we obtain and by induction
| (73) |
whence
| (74) |
Using a standard supermartingale argument we can also prove that
| (75) |
The proof is well-known in stochastic optimization hence omitted (or see Mercier et al., (2018, Theorem 5) for details). ∎
Appendix B Full experimental results
In this section we provide additional results that are deferred from the main paper.
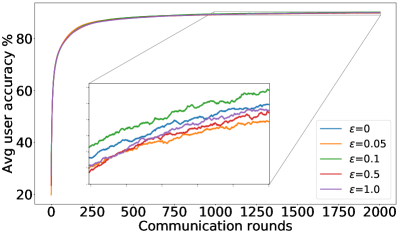
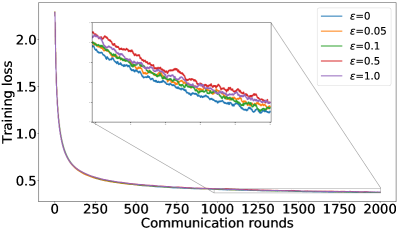
B.1 Recovering FedAvg full results: results on Fashion-MNIST and CIFAR-10
Complementary to the results shown in Figure 1, Figure 5 and Figure 6 summarize similar results on the F-MNIST dataset, while Figure 7 depicts the training losses on CIFAR-10 dataset in log-scale.
B.2 Robustness full results: bias attack on Adult dataset
| Name | Bias | Uniform | PhD | Non-PhD |
|---|---|---|---|---|
| AFL | ||||
| AFL | ||||
| AFL | ||||
| AFL | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| FedMGDA+ | Arbitrary | |||
| Baseline_PhD |
The hyper-parameter setting for Figure 2. Left: step sizes , , and bias for AFL; , and bias for q-FedAvg; , decay=, and arbitrary bias for FedMGDA+. Right: for FedProx; and for q-FedAvg; and decay= for FedMGDA+ and FedAvg-n. The simulations are run with % user participation () in each round which reduces the effectiveness of the adversary since it needs to participate in a bigger pool of users in comparison to our default setting .
B.3 Fairness full results: first experiment on CIFAR-10
Tables 8, LABEL:, 9, LABEL:, 10, LABEL: and 11 report the full results of the experiment presented in Figure 3 for different batch sizes and fractions of user participation.
| Algorithm | Average (%) | Std. (%) | Worst % (%) | Best % (%) | ||
| Name | decay | |||||
| FedMGDA | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| Name | decay | |||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| Name | decay | |||||
| FedAvg | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| Name | ||||||
| FedProx | ||||||
| FedProx | ||||||
| FedProx | ||||||
| Name | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| Algorithm | Average (%) | Std. (%) | Worst % (%) | Best % (%) | ||
| Name | decay | |||||
| FedMGDA | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| Name | decay | |||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| Name | decay | |||||
| FedAvg | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| Name | ||||||
| FedProx | ||||||
| FedProx | ||||||
| FedProx | ||||||
| Name | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| Algorithm | Average (%) | Std. (%) | Worst % (%) | Best % (%) | ||
| Name | decay | |||||
| FedMGDA | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| Name | decay | |||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| Name | decay | |||||
| FedAvg | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| Name | ||||||
| FedProx | ||||||
| FedProx | ||||||
| FedProx | ||||||
| Name | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| Algorithm | Average (%) | Std. (%) | Worst % (%) | Best % (%) | ||
| Name | decay | |||||
| FedMGDA | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| Name | decay | |||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| Name | decay | |||||
| FedAvg | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| Name | ||||||
| FedProx | ||||||
| FedProx | ||||||
| FedProx | ||||||
| Name | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
B.4 Fairness full results: first experiment on Federated EMNIST
Tables 12, LABEL: and 13 report the full results of the experiment presented in Table 6 for different batch sizes.
| Algorithm | Average (%) | Std. (%) | Worst % (%) | Best % (%) | ||
| Name | decay | |||||
| FedMGDA | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| Name | decay | |||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| Name | decay | |||||
| FedAvg | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| Name | ||||||
| FedProx | ||||||
| FedProx | ||||||
| FedProx | ||||||
| Name | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| Algorithm | Average (%) | Std. (%) | Worst % (%) | Best % (%) | ||
| Name | decay | |||||
| FedMGDA | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| Name | decay | |||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| Name | decay | |||||
| FedAvg | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| Name | ||||||
| FedProx | ||||||
| FedProx | ||||||
| FedProx | ||||||
| Name | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
B.5 Fairness full results: second experiment
Figures 8, LABEL: and 9 show the full results of the experiment presented in Figure 4 for different batch sizes.
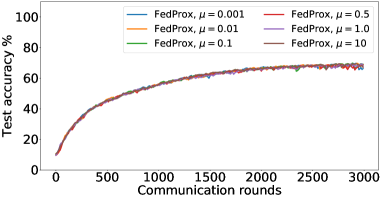
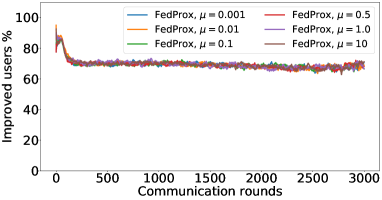
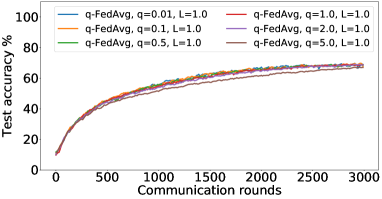
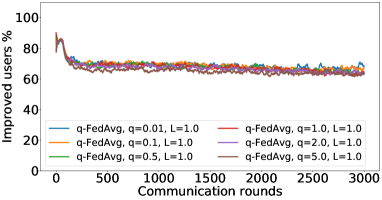
B.6 Results: Shakespeare dataset
| Algorithm | Avg (client) (%) | Avg (data) (%) | Std. (%) | Worst (%) | Best (%) | ||
| Name | momentum | ||||||
| FedAvg | |||||||
| FedAvg | |||||||
| FedAvg | |||||||
| FedAvg | |||||||
| FedAvg | |||||||
| Name | momentum | ||||||
| FedProx | |||||||
| FedProx | |||||||
| FedProx | |||||||
| FedProx | |||||||
| FedProx | |||||||
| Name | decay | ||||||
| FedMGDA+ | |||||||
| FedMGDA+ | |||||||
| FedMGDA+ | |||||||
| FedMGDA+ | |||||||
| Name | decay | ||||||
| FedAvg-n | |||||||
| FedAvg-n | |||||||
| FedAvg-n | |||||||
| FedAvg-n | |||||||