A Benchmark of Medical Out of Distribution Detection
Abstract
Motivation: Deep learning models deployed for use on medical tasks can be equipped with Out-of-Distribution Detection (OoDD) methods in order to avoid erroneous predictions. However it is unclear which OoDD method should be used in practice.
Specific Problem: Systems trained for one particular domain of images cannot be expected to perform accurately on images of a different domain. These images should be flagged by an OoDD method prior to diagnosis.
Our approach: This paper defines 3 categories of OoD examples and benchmarks popular OoDD methods in three domains of medical imaging: chest X-ray, fundus imaging, and histology slides.
Results: Our experiments show that despite methods yielding good results on some categories of out-of-distribution samples, they fail to recognize images close to the training distribution.
Conclusion: We find a simple binary classifier on the feature representation has the best accuracy and AUPRC on average. Users of diagnostic tools which employ these OoDD methods should still remain vigilant that images very close to the training distribution yet not in it could yield unexpected results.
1 Introduction
A safe system for medical diagnosis should withhold diagnosis on cases outside its validated expertise. For machine learning (ML) systems, the expertise is defined by the validation score on the distribution of data used during training, as the performance of the system can be validated on samples drawn from the same distribution (as per PAC learning (Valiant, 1984)). This restriction can be translated into the task of Out-of-Distribution Detection (OoDD), the goal of which is to distinguish between samples in and out of the training distribution of the diagnosis system (abbreviated to In and Out data).
In contrast to natural image analysis, medical image analysis must often deal with orientation invariance (e.g. in cell images), high variance in feature scale (in X-ray images), and locale specific features (e.g. CT) (Razzak et al., 2017). A systematic evaluation of OoDD methods for applications specific to medical image domains remains absent, leaving practitioners blind as to which OoDD methods perform well and under which circumstances. This paper fills this gap by benchmarking many current OoDD methods under four medical image types (frontal and lateral chest X-ray, fundus imaging, and histology). Our empirical studies show that current OoDD methods perform poorly when detecting correctly acquired images that are not represented in the training data. We also find that some simple methods such as a binary classifier on features trained on In data performed on par with more complex methods (see Figure 4). We hope that this work can inspire more discussion and future work on the unique challenges of OoDD in medical image domains.
2 Defining OoD in Medical Data
Given an In distribution dataset, how should we define what constitutes Out data? To address this, we identify three distinct out-of-distribution categories:
-
•
use-case 1 Reject inputs that are unrelated to the evaluation. This includes obviously-wrong images from a different domain (e.g. MRI images processed using a model trained on X-ray images) and less obviously-wrong images (e.g. wrist X-ray image processed using a model trained with chest X-rays).
-
•
use-case 2 Reject inputs which are incorrectly prepared For example, in the case of chest X-ray images: blurry images, poor contrast, incorrect view of the anatomy (lateral views processed using a model trained with frontal views), images with the incorrect file format or pre-processing applied), or changes in data acquisition protocol.
-
•
use-case 3 Reject inputs that are unseen due to a selection bias in training data (e.g. image with an unseen disease), which may yield unexpected results.
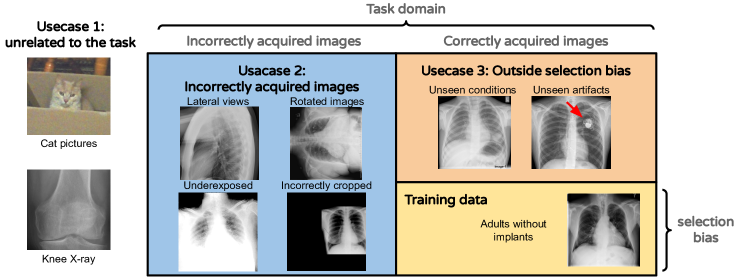
We justify these use-cases by enumerating different types of mistakes or biases that can occur at different stages of the data acquisition. This is visually represented in Figure 1. We construct our experiments to evaluate OoDD methods’ performance on each category.
Example 1
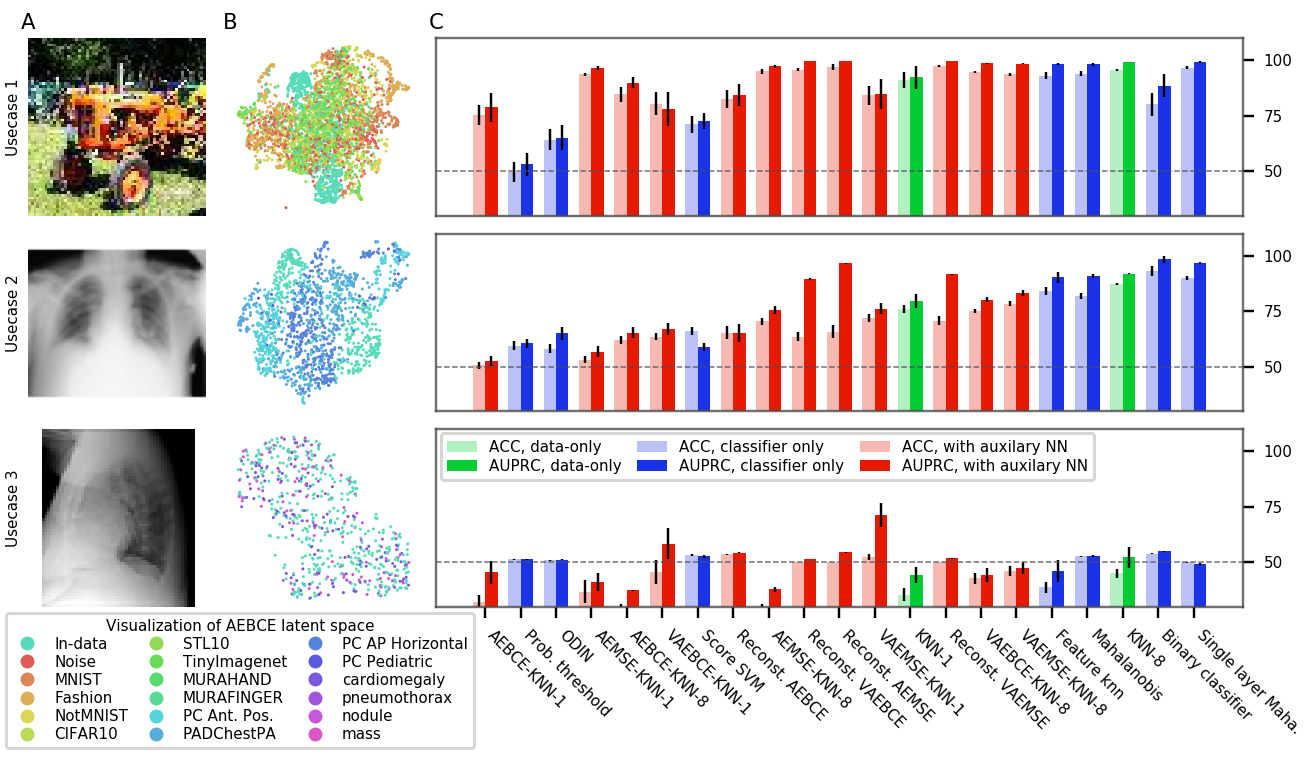
As running example, we will use our first evaluation where the In data consists of frontal chest X-rays. The In data contains 10 pulmonary conditions in the NIH Chest X-ray dataset (Wang et al., 2017). In use-case 1 we include natural images, images of symbols and text, and skeletal X-ray images. use-case 2 contains lateral view, dorsal view, and pediatric chest x-rays. Finally, use-case 3 include frontal chest X-rays of four pulmonary conditions that were not present in In data.
3 Task Formulation
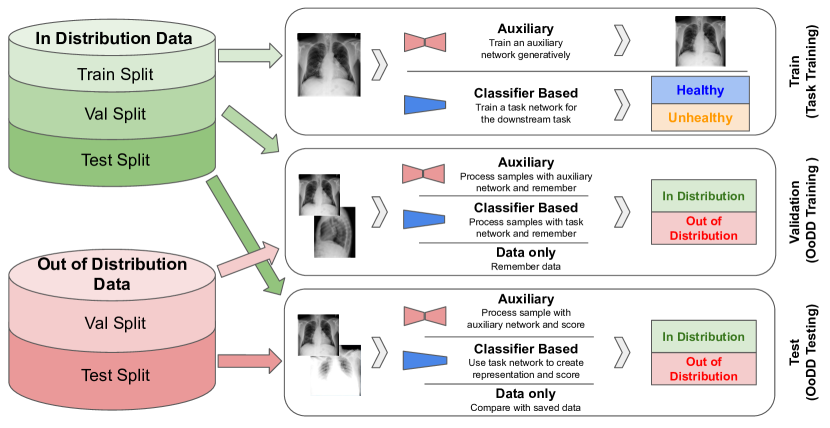
In this paper, we will assume that the downstream task is to perform classification using a deep neural network, which we call the task network. Let us denote a sample of In data used to train the task network as . Auxiliary models, as required by some OoDD methods, are also be trained on . Then, an OoDD method is trained on a “validation set” , a union of In and Out samples (labeled as “in” or “out”). may also use the features learned by the task network, thereby also making use of . Finally, is evaluated on the test set , also composed of In and Out samples. Each tuple constitutes an experiment. This three step process is illustrated in figure 2.
3.1 Methods of OoDD ()
We consider three classes of OoDD methods. Data-only methods do not rely on any pre-trained models and are learned directly on . Classifier-only methods assume access to a downstream classifier trained for classification on In data (). Methods with auxiliary models requires pre-training of a neural network that on In data using other objectives such as image reconstruction.
Data-only methods
The most simple and easy to implement data-only baseline is k-Nearest-Neighbors (KNN) which only needs to observe the training data. This is performed on images as a baseline for our evaluations. For speed only 1000 samples are used from to calculate neighbor distance. A threshold is determined using samples from .
Classifier-only methods
Classifier-only methods make use of the downstream classifier for performing OoDD. Compared to data-only methods they require less storage, however their applicability is constrained to cases with classification as downstream tasks. Probability Threshold (Hendrycks and Gimpel, 2017) uses a threshold on the prediction confidence of the classifier to perform OoDD. Score SVM trains an SVM on the logits of the classifier as features, generalizing probability threshold. Binary Classifier trains on the features of the penultimate layer of the classifier. Feature KNN uses the same features as the binary classifier, but constructs a KNN classifier in place of logistic regression. ODIN (Liang et al., 2017) is a probability threshold method that preprocesses the input by taking a gradient step of the input image to increase the difference between the In and Out data. Mahalanobis (Lee et al., 2018) models the features of a classifier of In data as a mixture of Gaussians, preprocesses the data as ODin, and thresholds the likelihood of the feature.
Methods with Auxiliary Models
OoDD methods in this section require an auxiliary model trained on In data. This results in extra setup time and resources when the downstream classifier is readily available. However, this could also be advantageous when the downstream task is not classification (such as regression) where methods may be difficult to adapt. Autoencoder Reconstruction thresholds the reconstruction loss of the autoencoder to achieve OOD detection. Intuitively, the autoencoder is only optimized for reconstructing In data, and hence reconstruction quality of Out data is expected to be poor due to the bottleneck in the autoencoder. In this work we consider three variants of autoencoders: standard autoencoder (AE) trained with reconstruction loss only, variational autoencoder trained with a variational lower bound (VAE) (Kingma and Welling, 2014), and decoder+encoder trained with an adversarial loss (ALI (Dumoulin et al., 2016), BiGAN (Donahue et al., 2017)). Furthermore, we include two different reconstruction loss functions in the benchmark: mean-squared error (MSE) and binary cross entropy (BCE). Finally, AE KNN constructs a KNN classifier on the features output by the encoder.
Example 1 (cont.)
We will use Autoencoder Reconstruction with VAE trained using MSE Loss(Reconst. VAEMASE) as the OoDD method of our running example. In the first stage, we train the auxiliary VAE on by maximizing the evidence lower bound (ELBO) under MSE criteria as evidence. Then, in the second stage, we compute the reconstruction loss on samples of and calibrate a threshold value on reconstruction loss for separating In and Out samples. Finally, we evaluate on by predicting its label (“in” or “out” ) according to the reconstruction loss and comparing to the ground truth.
3.2 In Datasets ()
| Domain | Eval | In data | use-case 1 Out data | use-case 2 Out data | use-case 3 Out data |
| Chest X-ray | 1 | NIH (In split) | UC-1 Common, MURA | PC-Lateral, PC-AP, PC-PED, PC-AP-Horizontal | NIH-Cardiomegaly, NIH-Nodule, NIH-Mass, NIH-Pneumothorax |
| 2 | PC-Lateral (In split) | UC-1 Common, MURA | PC-AP, PC-PED, PC-AP-Horizontal, PC-PA | PC-Cardiomegaly, PC-Nodule, PC-Mass, PC-Pneumothorax | |
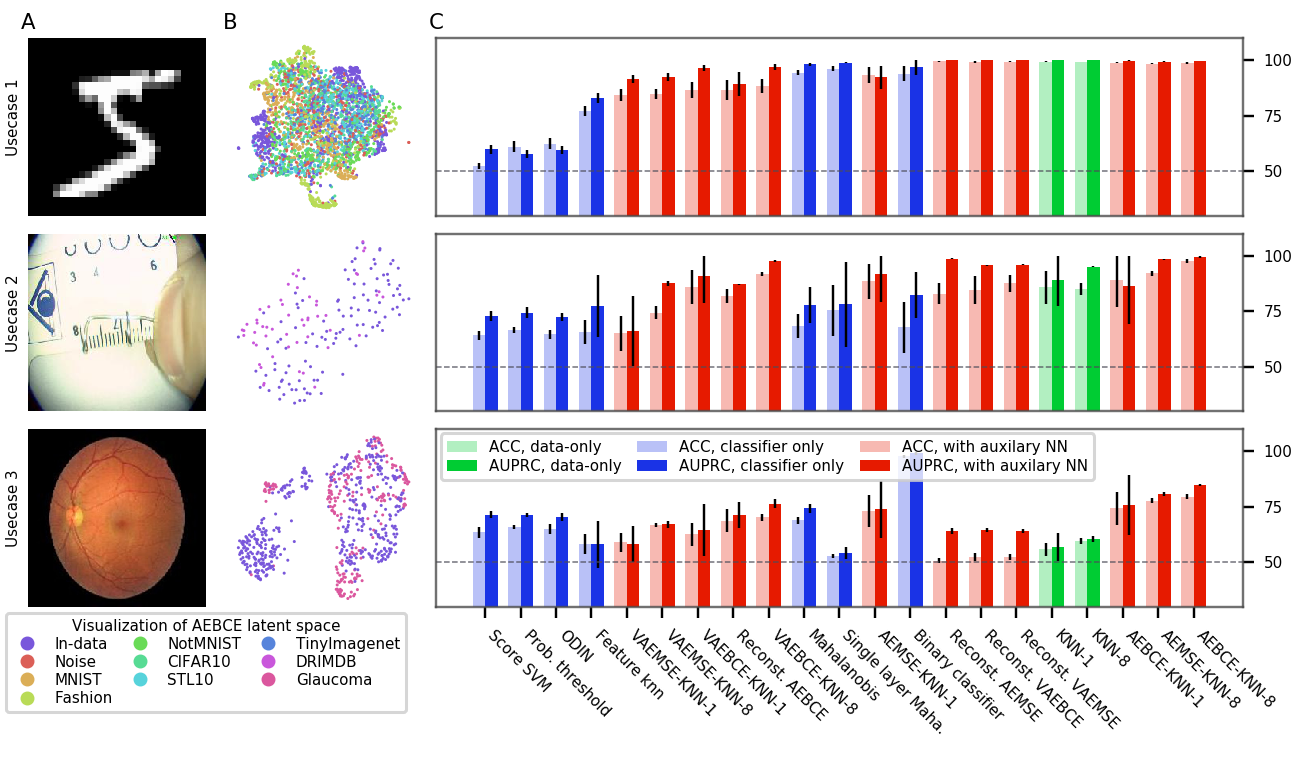
| Fundus Imaging | 3 | DRD | UC-1 Common | DRIMDB | RIGA |
| Histology | 4 | PCAM | UC-1 Common, Malaria | ANHIR, IDC | None |
For , we select from four medical datasets ranging over three modalities of medical imaging. Each dataset has been randomly split three ways for use in , , and . Each dataset also contains a classification task. As most ML applications only deal with one image type (i.e. an medical application wouldn’t simultaneous diagnose chest conditions and diabetic retinopathy), we consider each In distribution dataset as distinct evaluations and do not consider their combinations. The In datasets of each evaluation are:
-
1.
Frontal view chest X-ray images. The task is to predict 10 of the 14 radiologcal findings defined by the NIH Chest-X-Ray dataset (Wang et al., 2017). The remaining conditions are held-out for use-case 3.
-
2.
Lateral view chest X-ray images (PC-Lateral). The task is the same as evaluation 1, but the data is from lateral view images in the PADChest (PC) dataset (Bustos et al., 2019). Remaining conditions are also held-out for use-case 3.
-
3.
Fundus/retinal (back of the eye) images. The task is to detect diabetic retinopathy in the retina defined by the DRD (Diabetic Retinopathy Detection) dataset. (Kaggle and EyePacs, 2015)
-
4.
H&E stained histology slides of lymph nodes. The task is to predict if image patches contain cancerous tissue defined by the PCAM dataset (Veeling et al., 2018).
3.3 Out Datasets ( and )
We select Out datasets according to use-cases described in section 2. As users may be independently interested in a particular use-case, we evaluate the OoDD methods per use-case. Clearly, characteristics of each use-case are defined relative to the In distribution, hence we may need to select different Out datasets for each In dataset.
For and under use-case 1, we take a combination of natural image and symbols datasets which we call UC-1 Common. This is used for every In data. For use-case 2, we use datasets of the same modality of the In distribution, but incorrectly captured. For example, different views (e.g. lateral vs frontal) of the chest area are used as and for evaluations 1 and 2. Finally, for use-case 3, we use images of different conditions/diseases as Out data. For evaluations 1 and 2, the four held-out conditions are used as use-case 3 Out data. We did not include a use-case 3 Out dataset for histology slides due to lack of available data. Table 1 summarizes our roster of In and Out datasets. Each Out dataset is split 50/50 for and . Subsampling is used to balance the number of In and Out samples in and .
It remains to be determined how to split Out data between and . A common but overly optimistic assumption is that Out data are similar to each other, hence the OoDD method is trained and evaluated on different splits of the same OoD dataset. In our running example, this entails calibrating the threshold for reconstruction loss on NIH Chest data vs MNIST training-split, and then evaluate on NIH chest data vs MNIST testing split. On the other extreme, the assumption is that we have no access to out-of-distribution data, turning the task into that of one-class classification where no Out data is used except for testing. In a realistic setting, the developer would train the OoDD method on a number of various datasets to cover different modes of OoD data, but the data seen at deploy time possesses variability not accounted for by those selected by the developer. Hence, for each use-case, we select a subsample of datasets for training the OoDD method, and use the remaining datasets for evaluation.
Example 1. (cont.)
For use-case 1 of the running example, we split the Out data in to 14 partitions (9 datasets in UC-1 Common, and 5 areas of the body in the MURA skeletal X-ray dataset). We sample without replacement 3 partitions for , and use the rest in . In use-case 2, we have lateral-view, pediatric (PED), dorsal-view (AP), and horizontal dorsal-view (AP-Horizontal) as four Out splits. We randomly select one as and use the remaining for . We do the same for use-case 3, which also has four Out splits.
4 Experiments and Results
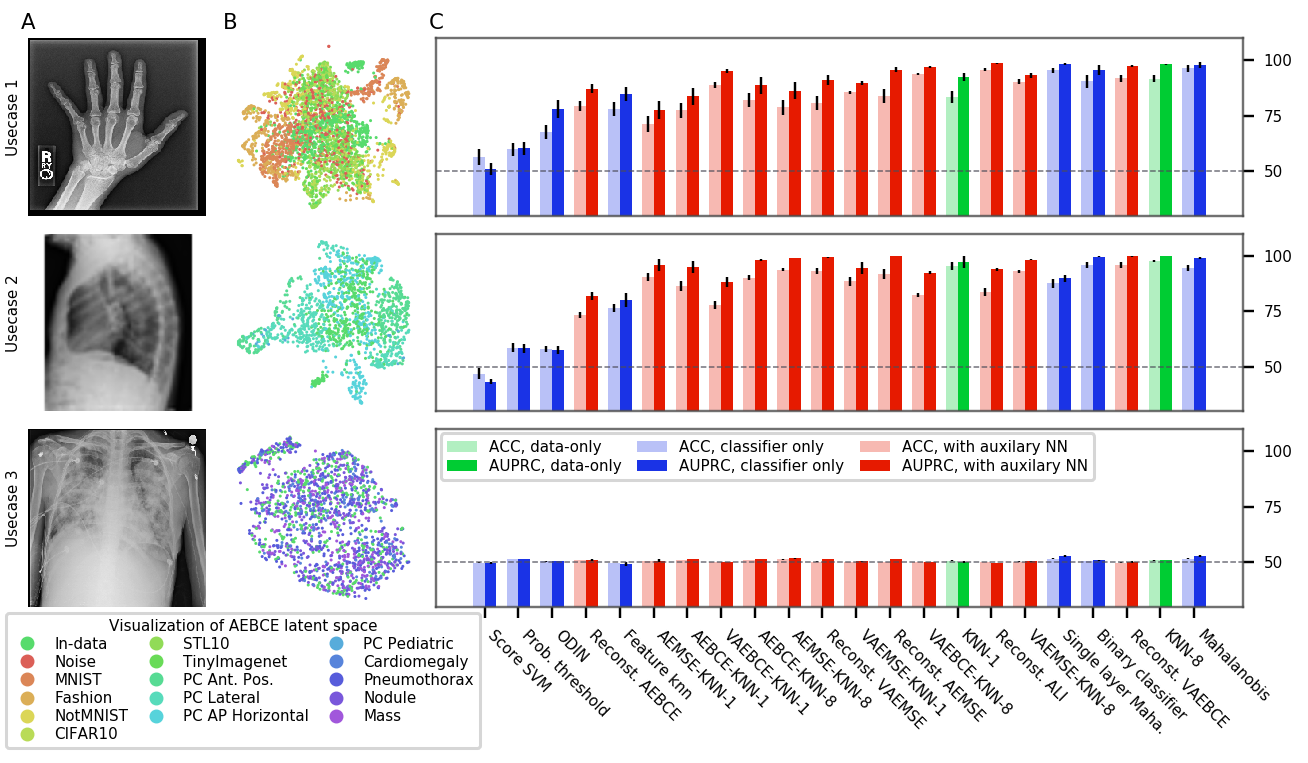
In this benchmark, we report the performance of each OoDD method on every evaluation and use-case. We measure the accuracy and Area Under Precision-Recall Curve (AUPRC) on , totaling at 11 pairs of performance numbers per method. Since is class-balanced, accuracy provides an unbiased representation of type I and type II errors. AUPRC characterizes the separability of In and Out samples in predicted value (the value that we threshold to obtain classification). Details of experimental setup are in Appendix B.
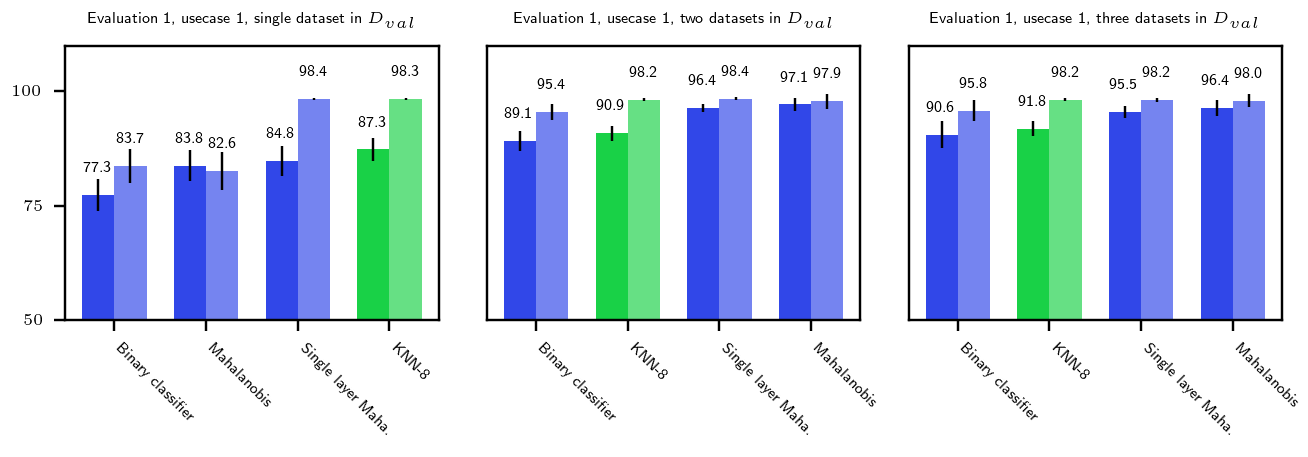
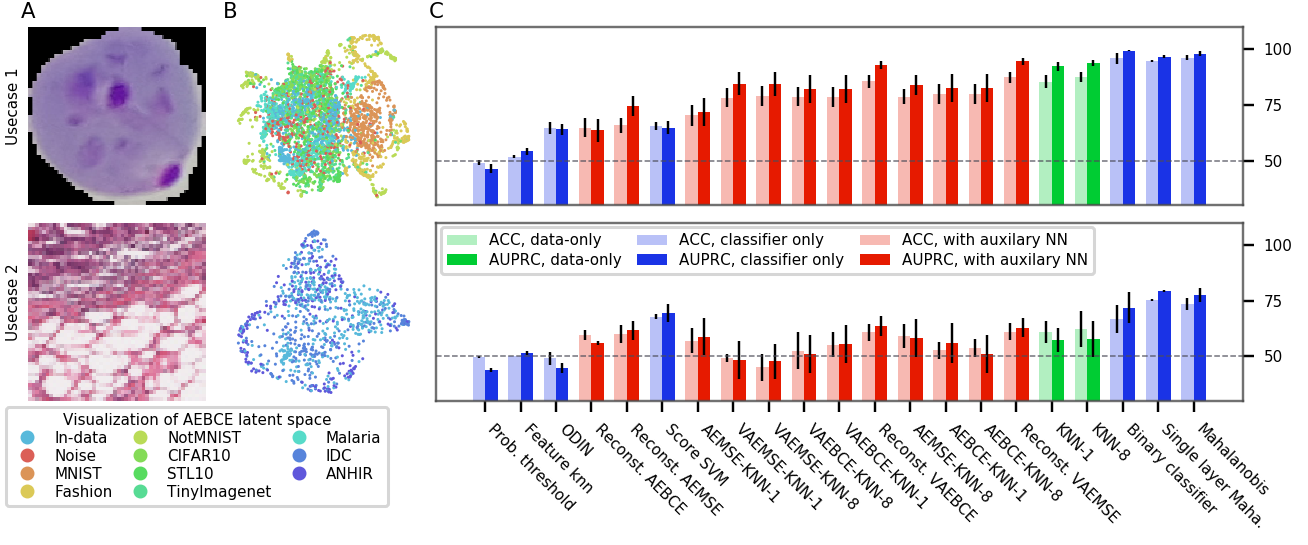
Figures 3, 6, 7, and 8 show the performance of OoDD methods on the four evaluations. Generally, we observe that our choice of datasets create a range of simple to hard test cases for OoDD methods. While many methods can solve use-case 1 and use-case 2 adequately in evaluations 1-3, use-case 3 proves difficult for all methods tested. This is reflected in the UMAP visualization of the AE latent spaces (column B of figures 3 to 7), in which we observe that the In data points are easily separable from Out data in use-cases 1 and 2, but well-mixed with Out data in use-case 3. It is surprising that no method achieved significantly better accuracy than random in use-case 3 of evaluations 1 and 2 across all repeated trials. This illustrates the extreme difficulty of detecting unseen/nouveau diseases, which corroborates the findings of Ren et al. (2019).
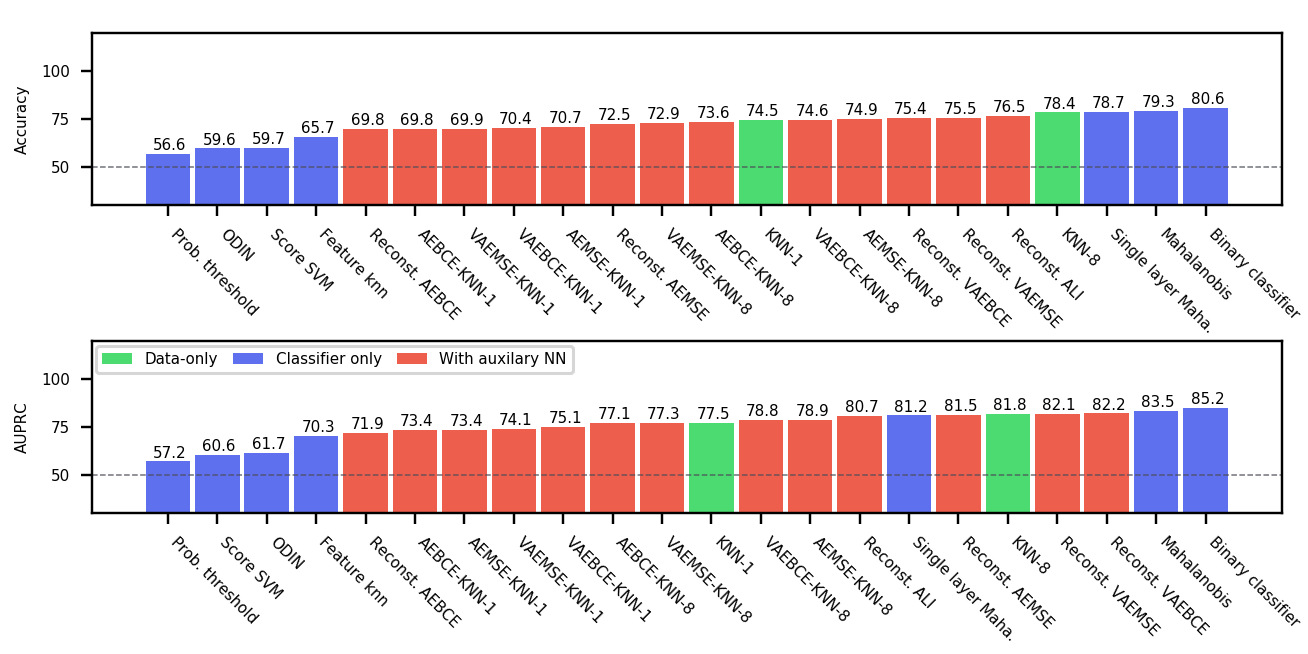
Overall Performance Across evaluations, the better performing classifier-only methods are competitive with the methods that use auxiliary models. When performance is aggregated across all evaluations (Figure 4), the best classifier-only methods (Mahalanobis and binary classifier) outperform auxiliary models in accuracy. The performance of binary classifier is strong despite the method’s simplicity. We suspect that this strong performance is due to the fact that we randomly sample 3 Out datasets when constructing as opposed to selecting a single Out dataset. This added variety in Out data improves generalization by enforcing more stable decision boundaries. We performed additional experiments with fewer Out datasets on a subset of methods and tasks. Results in appendix figure 9 shows that the gap between the top-4 methods quickly closing with more Out datasets in .
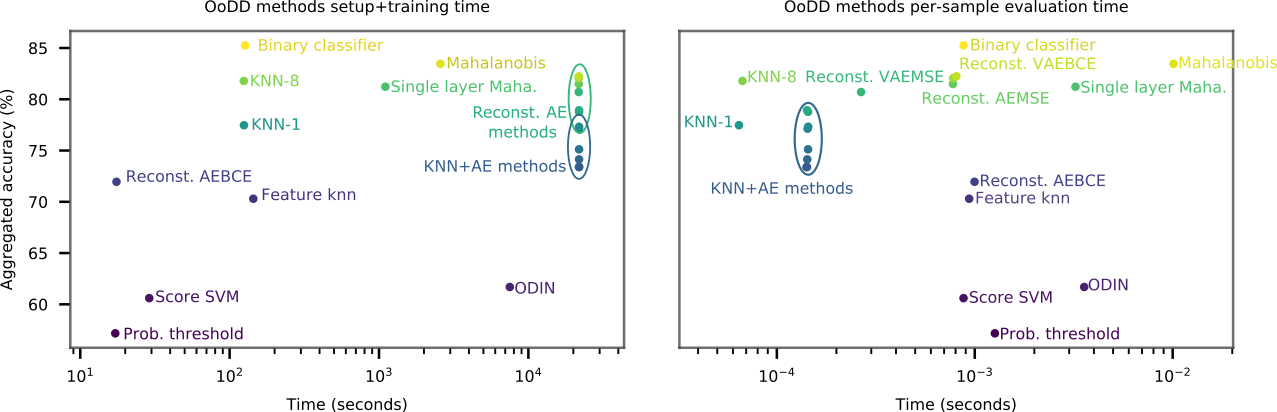
Computational Cost
We consider computational cost of each method in terms of setup time and run time. The setup time is measured as the wall-clock computation time taken for hyperparameter search and training. For methods with auxiliary models, the training time of auxiliary neural networks are also included in the setup-time. Run time is measured as the per-sample computation time (averaged over fixed batch size) at test time. Figure 5 plots the accuracy of models over their respective setup and run time. All methods can make predictions reasonably fast, allowing for potential online usage. Mahalanobis and its single layer variant take significantly more time to setup and run than other classifier methods. KNN-8 exhibits the best time vs performance trade-off with its low setup time and good performance. However, as it requires the storage of training images for predictions, it may be unsuitable for use on memory constrained platforms (e.g. mobile) or when training data privacy is of concern.
5 Discussion
The necessity of OoDD is supported by two considerations. First of which is usability. As we transition Machine Learning tools from research labs to the hands of the end user, usability of these tools becomes pivotal to their success. One common characteristic of good usability is to fail gracefully when handling user errors. In ML assisted diagnostic tools, this means equipping the tool with the capacity to reject predictions on erroneous input data, thereby preventing the “garbage-in, garbage-out” scenario. For ML tools facing users outside the computer science community, this clarity is particularly important. The second reason why OoDD is necessary is the requirement for safety. In applications like ML assisted diagnosis, the performance of the system is directly tied to the safety of the patients. A well documented failure mode for Machine learned predictors is when the predictor attempts to extrapolate on inputs outside the distribution of its training data. OoDD provides a safety mechanism that prevents failures of the predictor from harming the user through inaccurate predictions.
6 Conclusion
Overall, the top three classifier-only methods obtain better accuracy than all methods with auxiliary models except for fundus imaging. Binary classifier has the best accuracy and AUPRC on average, and is simple to implement. Hence, we recommend binary classifier as the default method for OoDD in the domain of medical images. The methods we find to work best are almost opposite that of Shafaei et al. (2018) despite using the same code for overlapping methods. The main difference between these studies is that they evaluate on natural images instead of medical images. We performed an extensive hyperparameter search on all methods and conclude that this discrepancy is due to the specific data and tasks we have defined. While use-case 1 and 2 are easily solved with non-complicated models, the failure of most models in almost all tasks to significantly solve use-case 3 is consistent with the finding of Ahmed and Courville (2019). Users of diagnostic tools which employ these OoDD methods should still remain vigilant that images very close to the training distribution yet not in it (and a false negative for use-case 3) could yield unexpected results. In the absence of OoDD methods which have good performance on use-case 3, another approach is to develop methods which will systematically generalize to these examples.
Acknowledgments
We thank Tobias Würfl, Faruk Ahmed, and Ronald Summers for their useful comments. This work utilized the supercomputing facilities managed by Compute Canada and Calcul Quebec. We thank AcademicTorrents.com for making data available for our research.
References
- Ahmed and Courville (2019) Faruk Ahmed and Aaron Courville. Detecting semantic anomalies. In Association for the Advancement of Artificial Intelligence, aug 2019. URL http://arxiv.org/abs/1908.04388.
- Bustos et al. (2019) Aurelia Bustos, Antonio Pertusa, Jose-Maria Salinas, and Maria de la Iglesia-Vayá. PadChest: A large chest x-ray image dataset with multi-label annotated reports. arXiv preprint, jan 2019. URL http://arxiv.org/abs/1901.07441.
- Donahue et al. (2017) Jeff Donahue, Philipp Krähenbühl, and Trevor Darrell. Adversarial Feature Learning. In International Conference on Learning Representations (ICLR), 2017. URL http://arxiv.org/abs/1605.09782.
- Dumoulin et al. (2016) Vincent Dumoulin, Ishmael Belghazi, Ben Poole, Olivier Mastropietro, Alex Lamb, Martin Arjovsky, and Aaron Courville. Adversarially Learned Inference. International Conference on Learning Representations, 2016. URL http://arxiv.org/abs/1606.00704.
- Hendrycks and Gimpel (2017) Dan Hendrycks and Kevin Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural networks. In International Conference on Learning Representations, 2017.
- Huang et al. (2017) Gao Huang, Zhuang Liu, Laurens van der Maaten, and Kilian Q. Weinberger. Densely Connected Convolutional Networks. In Computer Vision and Pattern Recognition, 2017. URL https://arxiv.org/abs/1608.06993.
- Kaggle and EyePacs (2015) Kaggle and EyePacs. Kaggle diabetic retinopathy detection, jul 2015. URL https://www.kaggle.com/c/diabetic-retinopathy-detection/data.
- Kingma and Welling (2014) Diederik P Kingma and Max Welling. Auto-Encoding Variational Bayes. In International Conference on Learning Representations, 2014. URL http://arxiv.org/abs/1312.6114.
- Lee et al. (2018) Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks. jul 2018. URL http://arxiv.org/abs/1807.03888.
- Liang et al. (2017) Shiyu Liang, Yixuan Li, and R. Srikant. Enhancing The Reliability of Out-of-distribution Image Detection in Neural Networks. jun 2017. URL http://arxiv.org/abs/1706.02690.
- Razzak et al. (2017) Muhammad Imran Razzak, Saeeda Naz, and Ahmad Zaib. Deep learning for medical image processing: Overview, challenges and the future. Classification in BioApps, page 323–350, Nov 2017. ISSN 2212-9413. doi: 10.1007/978-3-319-65981-7˙12. URL http://dx.doi.org/10.1007/978-3-319-65981-7_12.
- Ren et al. (2019) Jie Ren, Peter J. Liu, Emily Fertig, Jasper Snoek, Ryan Poplin, Mark A. DePristo, Joshua V. Dillon, and Balaji Lakshminarayanan. Likelihood ratios for out-of-distribution detection, 2019.
- Shafaei et al. (2018) Alireza Shafaei, Mark Schmidt, and James J. Little. Does Your Model Know the Digit 6 Is Not a Cat? A Less Biased Evaluation of ”Outlier” Detectors. arxiv, sep 2018. URL http://arxiv.org/abs/1809.04729.
- Valiant (1984) L. G. Valiant. A theory of the learnable. In Proceedings of the Annual ACM Symposium on Theory of Computing, pages 436–445. Association for Computing Machinery, dec 1984. ISBN 0897911334. doi: 10.1145/800057.808710.
- Veeling et al. (2018) Bastiaan S. Veeling, Jasper Linmans, Jim Winkens, Taco Cohen, and Max Welling. Rotation Equivariant CNNs for Digital Pathology. In Medical Image Computing & Computer Assisted Intervention (MICCAI), jun 2018. URL http://arxiv.org/abs/1806.03962.
- Wang et al. (2017) Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mohammadhadi Bagheri, and Ronald M. Summers. ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases. In Computer Vision and Pattern Recognition, 2017. doi: 10.1109/CVPR.2017.369. URL http://arxiv.org/abs/1705.02315.
A Description of Datasets
The following datasets are used in UC-1 Common:
-
•
MNIST111http://yann.lecun.com/exdb/mnist/ 28x28 black and white hand written digits data. Original test split is used in UC-1 Common.
-
•
notMNIST 222http://yaroslavvb.blogspot.com/2011/09/notmnist-dataset.html Letters A-J in various fonts. Black and white with resolution of 28x28. Test split is used.
-
•
CIFAR10 and CIFAR100333https://www.cs.toronto.edu/ kriz/cifar.html 32x32 natural images. Original test split used in UC-1 Common.
-
•
TinyImagenet444https://tiny-imagenet.herokuapp.com/ 96x96 downsampled subset of ILSVRC2012. Validation split used in UC-1 Common.
-
•
FashionMNIST555https://www.kaggle.com/zalando-research/fashionmnist Grayscale 28x28 images of clothes and shoes. Validation split is used in UC-1 Common.
-
•
STL-10 666https://ai.stanford.edu/ acoates/stl10/ Natural image dataset of size 96x96. 8000 testing images are used in UC-1 Common.
-
•
Noise White noise generated at any desired resolution.
The following medical datasets are used:
-
•
ANHIR 777https://anhir.grand-challenge.org/ Automatic Non-rigid Histological Image Registration Challenge. Microscopy images of histopathology tissue samples stained with different dyes. Images of intestine and kidney tissue were used in evaluation 4, use-case 2.
-
•
DRD 888https://www.kaggle.com/c/diabetic-retinopathy-detection/data High-resolution retina images with presence of diabetic retinopathy in each image labeled on a scale of 0 to 4. We convert this into a classification task where 0 corresponds to healthy and 1-4 corresponds to unhealthy.
-
•
DRIMDB Fundus images of various qualities labeled as good/bad/outlier. We use the images labeled as bad/outlier in evaluation 3, use-case 2.
-
•
Malaria 999https://lhncbc.nlm.nih.gov/publication/pub9932 Image of cells in blood smear microscopy collected from healthy persons and patients with malaria. Used in evaluation 4 use-case 1.
-
•
MURA 101010https://stanfordmlgroup.github.io/competitions/mura/ MUsculoskeletal RAdiographs is a large dataset of skeletal X-rays. We use its validation split in evaluation 1 and 2’s use-case 1. Images are grayscale and the square cropped.
-
•
NIH Chest 111111https://www.kaggle.com/nih-chest-xrays/data This NIH Chest X-ray Dataset is comprised of 112,120 X-ray images with 14 condition labels. The x-rays images are in posterior-anterior view (X-tray traverses back to front).
-
•
PAD Chest 121212https://bimcv.cipf.es/bimcv-projects/padchest/ This is a large scale chest X-ray dataset. It is labeled with 117 radiological findings - we use the subset with correspondence to the 14 condition labels in the NIH Chest dataset. Images are in 5 different views: posterior-anterior (PA), anterior-posterior (AP), lateral, AP horizontal, and pediatric.
-
•
PCAM 131313https://github.com/basveeling/pcam Patch Camelyon dataset is composed of histopathologic scans of lymph node sections. Images are labeled for presence of cancerous tissue.
-
•
RIGA Fundus imaging dataset for glaucoma analysis. Images are marked by physicians for regions of disease. We use this dataset for evaluation 3, use-case 3.
B Details of Experimental Procedure
B.1 Network training
For classifier models, we use a DenseNet-121 architecture (Huang et al., 2017) with Imagenet pretrained weights. The last layer is re-initialized and the full network is finetuned on . As the NIH and PC-Lateral datasets only contain grayscale images, the pretrained weights of features in the first layer are averaged across channels prior to finetuning.
For all of the autoencoders, we use a 12-layer CNN architecture with a bottleneck dimension of 512 for all evaluations. Due to computational constraints, all images are downsampled to when fed to an autoencoder. These AEs are trained from scratch on their respective with MSE loss and BCE loss. We also trained VAEs with the same architectures, except that the bottleneck dimension is doubled to 1024 to allow the code to be split into means and variances.
In addition, we explore the potential benefits of training encoder+decoder using ALI in evaluation 1. We use the same network architecture as proposed in Dumoulin et al. (2016), with weights pretrained on Imagenet and finetuned on NIH In classes. Due to the added complexity of training GANs and the lack of significant improvements in OoDD performance over regular AEs (see §4), we did not train ALI models for the other three evaluations.
In order to gauge training progress and overfitting, we hold out of as validation set. We select the training checkpoint with the lowest error on for use in OoDD methods.
B.2 OoDD Method Training
When training the OoDD methods for use-case 1, three Out datasets are randomly selected for while the rest is used for . For use-cases 2 and 3, we enumerate over configurations where each Out dataset is used as with the rest as . and are class-balanced by subsampling equal numbers of In and Out samples. Additionally, some methods (ODIN and Mahalanobis) require additional hyper-parameter selection. Hence, we further subdivide in to a ‘training’ split and a ‘validation’ split; methods are trained/optimized on the ‘training’ split with early-stopping/calibration on the ‘validation’ split. Hyperparameter sweep is carried out where needed. 10 repeated trials, with re-sampled and , are performed for each evaluation.
C Additional Results