Contrastive Behavioral Similarity
Embeddings for Generalization in
Reinforcement Learning
Abstract
Reinforcement learning methods trained on few environments rarely learn policies that generalize to unseen environments. To improve generalization, we incorporate the inherent sequential structure in reinforcement learning into the representation learning process. This approach is orthogonal to recent approaches, which rarely exploit this structure explicitly. Specifically, we introduce a theoretically motivated policy similarity metric (PSM) for measuring behavioral similarity between states. PSM assigns high similarity to states for which the optimal policies in those states as well as in future states are similar. We also present a contrastive representation learning procedure to embed any state similarity metric, which we instantiate with PSM to obtain policy similarity embeddings (PSEs111Pronounce ‘pisces’.). We demonstrate that PSEs improve generalization on diverse benchmarks, including LQR with spurious correlations, a jumping task from pixels, and Distracting DM Control Suite. Source code is available at agarwl.github.io/pse.
1 Introduction
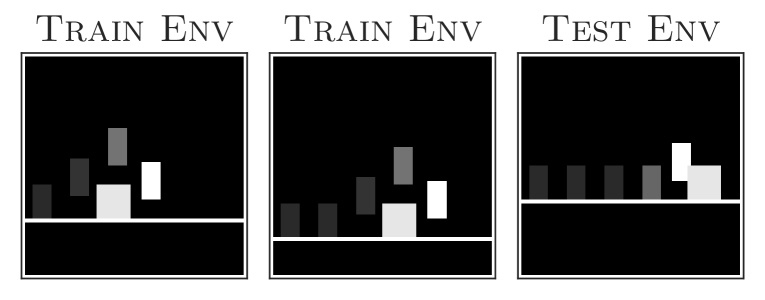
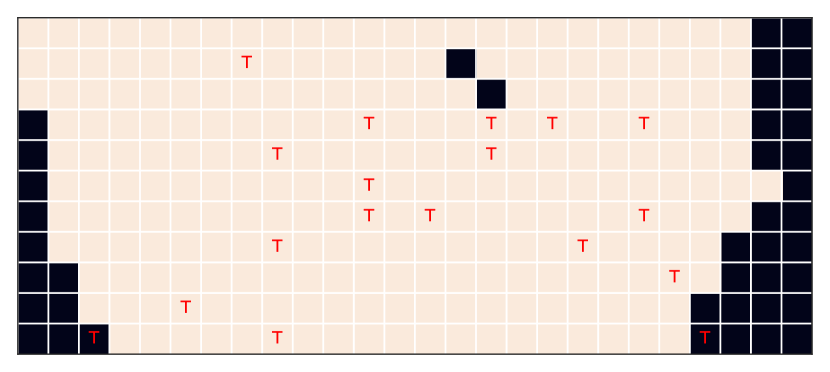
Current reinforcement learning (RL) approaches often learn policies that do not generalize to environments different than those the agent was trained on, even when these environments are semantically equivalent (Tachet des Combes et al., 2018; Song et al., 2019; Cobbe et al., 2019). For example, consider a jumping task where an agent, learning from pixels, needs to jump over an obstacle (Figure 1). Deep RL agents trained on a few of these jumping tasks with different obstacle positions struggle to successfully jump in test tasks where obstacles are at previously unseen locations.
Recent solutions to circumvent poor generalization in RL are adapted from supervised learning, and, as such, largely ignore the sequential aspect of RL. Most of these solutions revolve around enhancing the learning process, including data augmentation (e.g., Kostrikov et al., 2020; Lee et al., 2020a), regularization (Cobbe et al., 2019; Farebrother et al., 2018), noise injection (Igl et al., 2019), and diverse training conditions (Tobin et al., 2017); they rarely exploit properties of the sequential decision making problem such as similarity in actions across temporal observations.
Instead, we tackle generalization by incorporating properties of the RL problem into the representation learning process. Our approach exploits the fact that an agent, when operating in environments with similar underlying mechanics, exhibits at least short sequences of behaviors that are similar across these environments. Concretely, the agent is optimized to learn an embedding in which states are close when the agent’s optimal policies in these states and future states are similar. This notion of proximity is general and it is applicable to observations from different environments.
Specifically, inspired by bisimulation metrics (Castro, 2020; Ferns et al., 2004), we propose a novel policy similarity metric (PSM). PSM (Section 3) defines a notion of similarity between states originated from different environments by the proximity of the long-term optimal behavior from these states. PSM is reward-agnostic, making it more robust for generalization compared to approaches that rely on reward information. We prove that PSM yields an upper bound on suboptimality of policies transferred from one environment to another (Theorem 1), which is not attainable with bisimulation.
We employ PSM for representation learning and introduce policy similarity embeddings (PSEs) for deep RL. To do so, we present a general contrastive procedure (Section 4) to learn an embedding based on any state similarity metric. PSEs are the instantiation of this procedure with PSM. PSEs are appealing for generalization as they encode task-relevant invariances by putting behaviorally equivalent states together. This is unlike prior approaches, which rely on capturing such invariances without being explicitly trained to do so, for example, through value function similarities across states (e.g., Castro & Precup, 2010), or being robust to fixed transformations of the observation space (e.g., Kostrikov et al., 2020; Laskin et al., 2020a).
PSEs lead to better generalization while being orthogonal to how most of the field has been tackling generalization. We illustrate the efficacy and broad applicability of our approach on three existing benchmarks specifically designed to test generalization: (i) jumping task from pixels (Tachet des Combes et al., 2018) (Section 5), (ii) LQR with spurious correlations (Song et al., 2019) (Section 6.1), and (iii) Distracting DM Control Suite (Stone et al., 2021) (Section 6.2). Our approach improves generalization compared to a wide variety of approaches including standard regularization (Farebrother et al., 2018; Cobbe et al., 2019), bisimulation (Castro & Precup, 2010; Castro, 2020; Zhang et al., 2021), out-of-distribution generalization (Arjovsky et al., 2019) and state-of-the-art data augmentation (Kostrikov et al., 2020; Laskin et al., 2020a; Lee et al., 2020a).
2 Preliminaries
We describe an environment as a Markov decision process (MDP) (Puterman, 1994) , with a state space , an action space , a reward function , transition dynamics , and a discount factor . A policy maps states to distributions over actions. Whenever convenient, we abuse notation and write to describe the probability distribution , treating as a vector. In RL, the goal is to find an optimal policy that maximizes the cumulative expected return starting from an initial state .
We are interested in learning a policy that generalizes across related environments. We formalize this by considering a collection of MDPs, sharing an action space but with disjoint state spaces. We use and to denote the state spaces of specific environments, and write , for the reward and transition functions of the MDP whose state space is , and for its optimal policy, which we assume unique without loss of generality. For a given policy , we further specialize these into and , the reward and state-to-state transition dynamics arising from following in that MDP.
We write for the union of the state spaces of the MDPs in . Concretely, different MDPs correspond to specific scenarios in a problem class (Figure 1), and is the space of all possible configurations. Used without subscripts, , , and refer to the reward and transition function of this “union MDP”, and a policy defined over ; this notation simplifies the exposition. We measure distances between states across environments using pseudometrics222Pseudometrics are generalization of metrics where the distance between two distinct states can be zero. on ; the set of all such pseudometrics is , and is the set of metrics on probability distributions over .
In our setting, the learner has access to a collection of training MDPs , drawn from . After interacting with these environments, the learner must produce a policy over the entire state space , which is then evaluated on unseen MDPs from . Similar in spirit to the setting of transfer learning (Taylor & Stone, 2009), here we evaluate the policy’s zero-shot performance on .
Our policy similarity metric (Section 3) builds on the concept of -bisimulation (Castro, 2020). Under the -bisimulation metric, the distance between two states, and , is defined in terms of the difference between the expected rewards obtained when following policy . The -bisimulation metric satisfies a recursive equation based on the 1-Wasserstein metric , where is the minimal cost of transporting probability mass from to (two probability distributions on ) under the base metric (Villani, 2008). The recursion is
| (1) |
To achieve good generalization properties, we learn an embedding function that reflects the information encoded in the policy similarity metric; this yields a policy similarity embedding (Section 4). We use contrastive methods (Hadsell et al., 2006; Oord et al., 2018) whose track record for representation learning is well-established. We adapt SimCLR (Chen et al., 2020), a popular contrastive method for learning embeddings of image inputs. Given two inputs and , their embedding similarity is , where denotes the cosine similarity function. SimCLR aims to maximize similarity between augmented versions of an image (e.g., crops, colour changes) while minimizing its similarity to other images. The loss used by SimCLR for two versions of an image, and a set containing other images is:
| (2) |
where is an inverse temperature hyperparameter. The overall SimCLR loss is then the expected value of , when , , and are drawn from some augmented training distribution.
3 Policy Similarity Metric
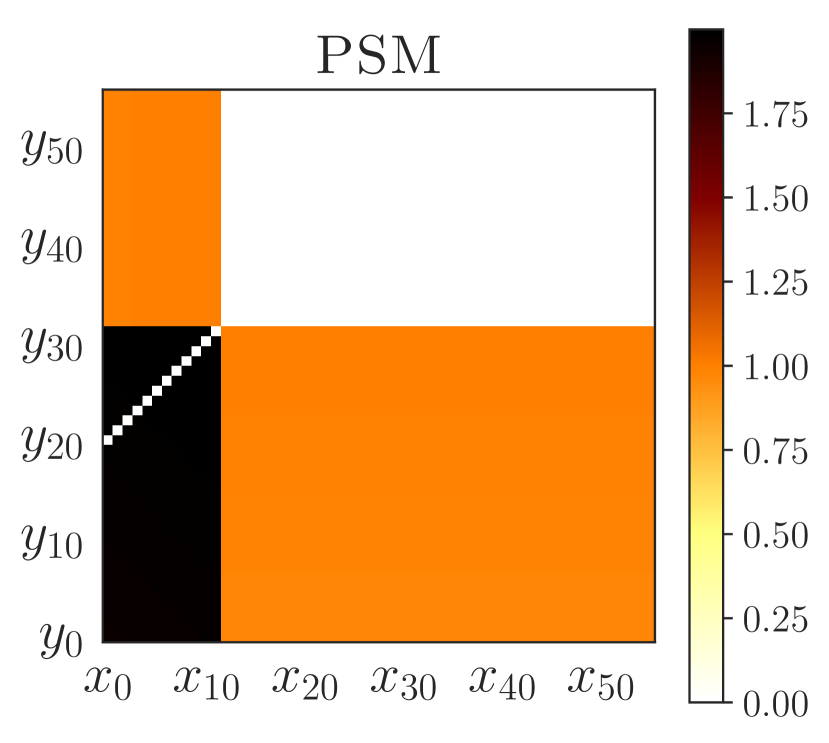
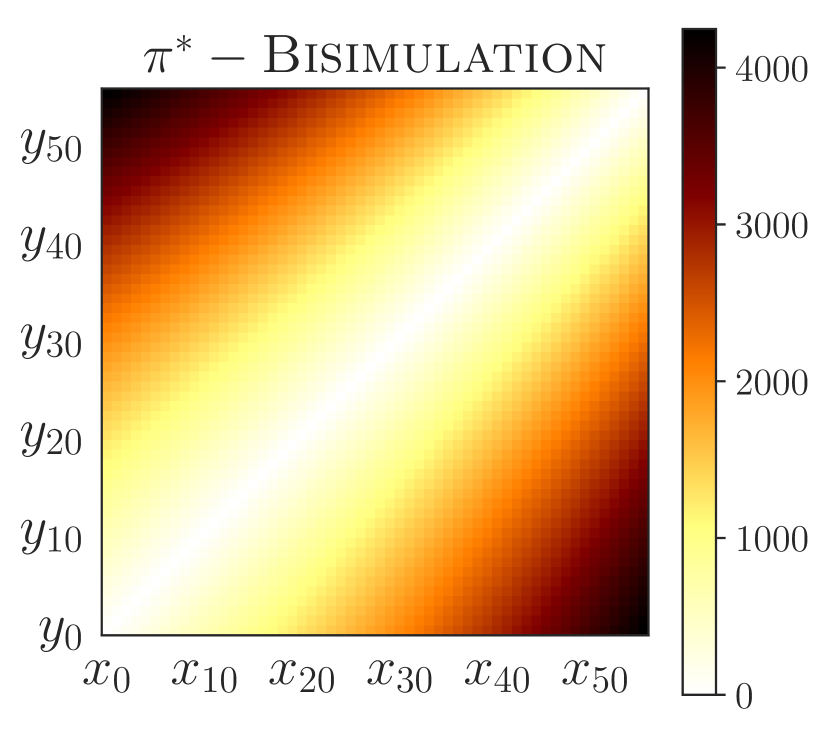
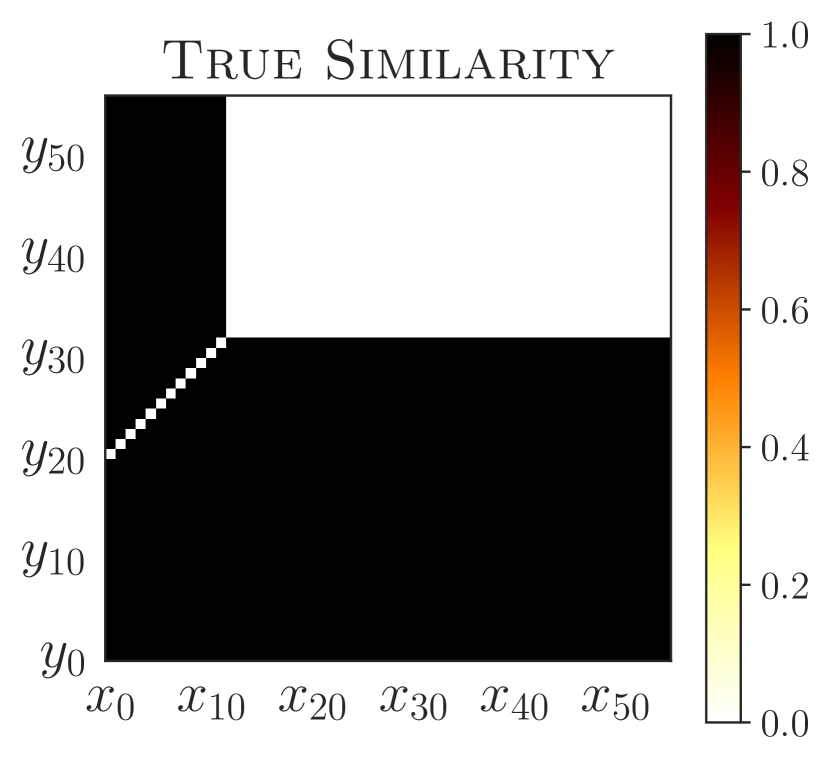
A useful tool in learning a policy that generalizes is to understand which states result in similar behavior, and which do not. To be maximally effective, this similarity should go beyond the immediately chosen action and consider long-term behavior. In this regards, the -bisimulation metrics are interesting as they are based on the full sequence of future rewards received from different states. However, considering rewards can be both too restrictive (when the policies are the same, but the obtained rewards are not; see Figure 2) or too permissive (when the policies are different, but the obtained rewards are not; see Figure 5(a)). In fact, -bisimulation metrics actually lead to poor generalization in our experiments (Sections 5.1 and 5.2).
To address this issue, we instead consider the similarity between policies themselves. We replace the absolute reward difference by a probability pseudometric between policies, denoted Dist. Additionally, since we would like to perform well in unseen environments, we are interested in similarity in optimal behavior. We thus use as the grounding policy. This yields the policy similarity metric (PSM), for which states are close when the optimal policies in these states and future states are similar. For a given Dist, the PSM satisfies the recursive equation
| (3) |
The Dist term captures the difference in local optimal behavior (A) while captures long-term optimal behavior difference (B); the exact weights assigned to the two are given by the discount factor. Furthermore, when Dist is bounded, is guaranteed to be finite. While there are technically multiple PSMs (one for each Dist), we omit this distinction whenever clear from context. A proof of the uniqueness of is given in Proposition A.1.
Our main use of PSM will be to compare states across environments. In this context, we identify the terms in Equation 3 with specific environments for clarity and write (despite its technical inaccuracy)
PSM is applicable to both discrete and continuous action spaces. In our experiments, Dist is the total variation distance () when is discrete, and we use the distance between the mean actions of the two policies when is continuous. PSM can be computed iteratively using dynamic programming (Ferns et al., 2011) (more details in Section C.1). Furthermore, when is unavailable on training environments, we replace it by an approximation to obtain an approximate PSM, which is close to the exact PSM depending on the suboptimality of (Proposition C.3).
Despite resembling -bisimulation metrics in form, the PSM possesses different characteristics which are better suited to the problem of generalizing a learned policy. To illustrate this point, consider the following simple nearest-neighbour scheme: Given a state , denote its closest match in by . Suppose that we use this scheme to transfer to , in the sense that we behave according to the policy . We can then bound the difference between and , something that is not possible if is replaced by a -bisimulation metric.
Theorem 1.
[Bound on policy transfer] For any , let define the sequence of random states encountered starting in and following policy . We have:
The proof is in the Appendix (Section A). Theorem 1 is non-vacuous whenever . In particular, implies that the transferred policy is optimal. Although this scheme is not practical (computing requires knowledge of ), it shows that meaningful policy generalization can be obtained if we can find a mapping that generalizes across . Put another way, PSM gives us a principled way of lifting generalization across inputs (a supervised learning problem) to generalization across environments. We now describe how to employ PSM for learning representations that put together states in which the agent’s long-term optimal behavior is similar.
4 Learning Contrastive Metric Embeddings
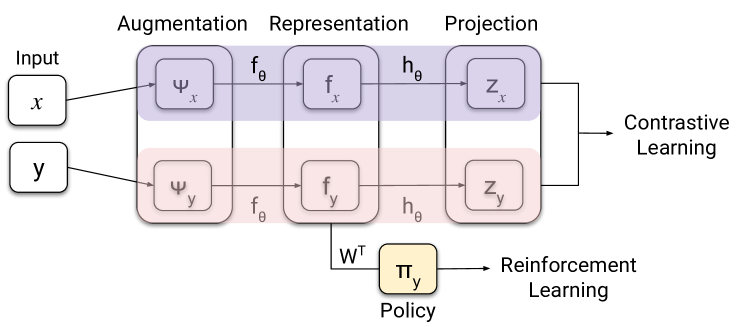
To generalize a learned policy to new environments, we build on the success of contrastive representations (Section 2). Given a state similarity metric , we develop a general procedure (Algorithm 1) to learn contrastive metric embeddings (CMEs) for . We utilize the metric for defining the set of positive and negative pairs, as well as assigning importance weights to these pairs in the contrastive loss (Equation ).
We first apply a transformation to convert to a similarity measure , bounded in [0, 1] for “soft” similarities. In this work, we transform using the Gaussian kernel with a positive scale parameter , that is, . controls the sensitivity of the similarity measure to .
Second, we select the positive and negative pairs given a set of states and from MDPs respectively. For each anchor state , we use its nearest neighbor in based on the similarity measure to define the positive pairs , where . The remaining states in , paired with , are used as negative pairs. This choice of pairs is motivated by Theorem 1, which shows that if we transfer the optimal policy in to the nearest neighbors defined using PSM, its performance in has suboptimality bounded by PSM.
Next, we define a soft version of the SimCLR contrastive loss (Equation 2) for learning the function , which maps states (usually high-dimensional) to embeddings. Given a positive state pair , the set , and the similarity measure , the loss (pseudocode provided in Section I.2) is given by
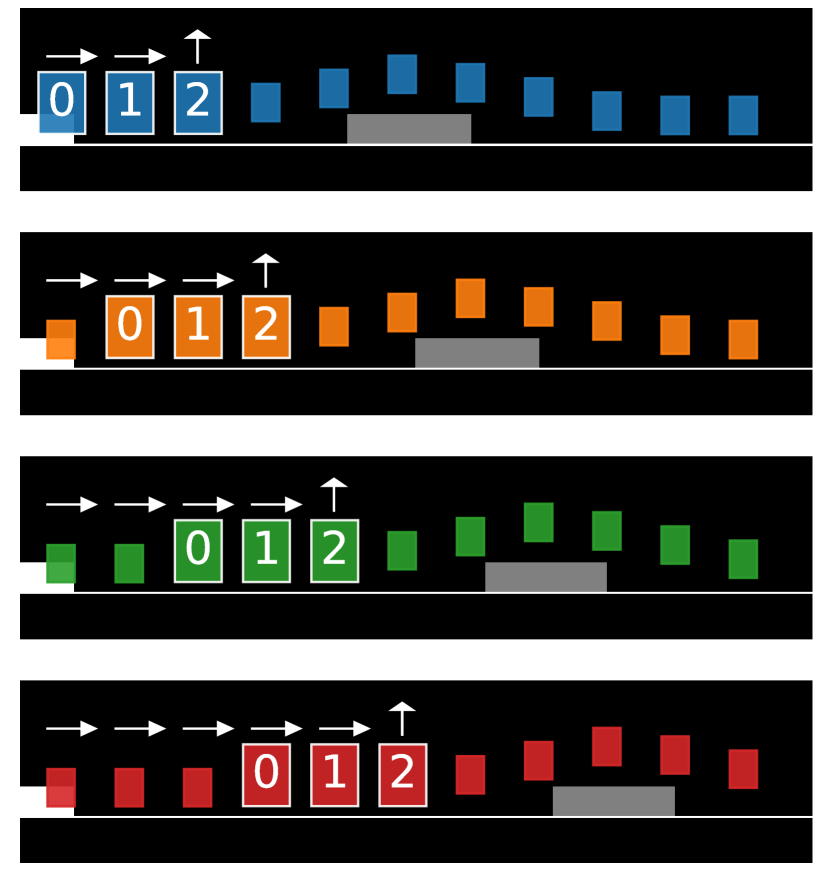
where we use the same notation as in Equation 2. Following SimCLR, we use a non-linear projection of the representation as (Figure 3). The agent’s policy is an affine function of the representation.
The total contrastive loss for and utilizes the optimal trajectories and , where and . We set and define
We refer to CMEs learned with policy similarity metric as policy similarity embeddings (PSEs). PSEs can trivially be combined with data augmentation by using augmented states when computing state embeddings. We simultaneously learn PSEs with the RL agent by adding (Algorithm 1) as an auxiliary objective during training. Next, we illustrate the benefits from this auxiliary objective.
5 Jumping Task from Pixels: A Case Study
Task Description. The jumping task (Tachet des Combes et al., 2018) (Figure 1) captures, using well-defined factors of variations, whether agents can learn the correct invariances required for generalization, directly from image inputs. The task consists of an agent trying to jump over an obstacle. The agent has access to two actions: right and jump. The agent needs to time the jump precisely, at a specific distance from the obstacle, otherwise it will eventually hit the obstacle. Different tasks consist in shifting the floor height and/or the obstacle position. To generalize, the agent needs to be invariant to the floor height while jump based on the obstacle position. The obstacle can be in 26 different locations while the floor has 11 different heights, totaling 286 tasks.
Problem Setup. We split the problem into 18 seen (training) and 268 unseen (test) tasks to stress test generalization using a few changes in the underlying factors of variations seen during training. The small number of positive examples333We have 18 different trajectories with several examples for the action right, but only one instance of jump action per trajectory, leading to just 18 total instances of the action jump. results in a highly unbalanced classification problem with low amounts of data, making it challenging without additional inductive biases. Thus, we evaluate generalization in regimes with and without data augmentation. The different grids configurations (Figure 4) capture different types of generalization: the “wide” grid tests generalization via “interpolation”, the “narrow” grid tests out-of-distribution generalization via “extrapolation”, and the random grid instances evaluate generalization similar to supervised learning where train and test samples are drawn i.i.d. from the same distribution.
We used RandConv (Lee et al., 2020a), a state-of-the-art data augmentation for generalization. For hyperparameter selection, we evaluate all agents on a validation set containing 54 unseen tasks in the “wide” grid (Figure 4(a)) and pick the parameters with the best validation performance. We use these fixed parameters for all grid configurations to show the robustness of PSEs to hyperparameter tuning. We first compute the optimal trajectories in the training tasks. Using these trajectories, we compute PSM using dynamic programming (Section C.1). We train the agent by imitation learning, combined with an auxiliary loss for PSEs (Section 4). More details are in Section F.
| Data Augmentation | Method | Grid Configuration (%) | ||
|---|---|---|---|---|
| “Wide” | “Narrow” | Random | ||
| ✗ | Dropout and reg. | 17.8 (2.2) | 10.2 (4.6) | 9.3 (5.4) |
| Bisimulation Transfer4 | 17.9 (0.0) | 17.9 (0.0) | 30.9 (4.2) | |
| PSEs | 33.6 (10.0) | 9.3 (5.3) | 37.7 (10.4) | |
| ✓ | RandConv | 50.7 (24.2) | 33.7 (11.8) | 71.3 (15.6) |
| RandConv + -bisimulation | 41.4 (17.6) | 17.4 (6.7) | 33.4 (15.6) | |
| RandConv + PSEs | 87.0 (10.1) | 52.4 (5.8) | 83.4 (10.1) | |
5.1 Evaluating Generalization on Jumping Task
We show the efficacy of PSEs compared to common generalization approaches such as regularization (e.g., Cobbe et al., 2019; Farebrother et al., 2018), and data augmentation (e.g., Lee et al., 2020a; Laskin et al., 2020a), which are quite effective on pixel-based RL tasks. We also contrast PSEs with bisimulation transfer (Castro & Precup, 2010), a tabular state-based transfer approach based on bisimulation metrics which does not do any learning and bisimulation preserving representations (Zhang et al., 2021), showing the advantages of PSM over a prevalent state similarity metric.
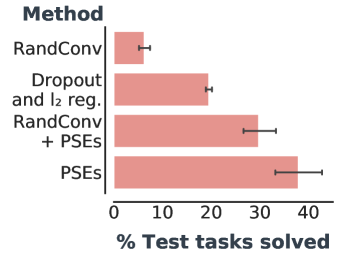
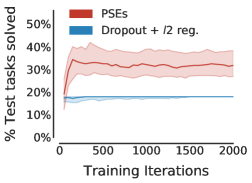
We first investigated how well PSEs generalize over existing methods without incorporating additional domain knowledge during training. Table 1 summarizes, in the setting without data augmentation, the performance of these methods in different train/test splits (c.f. Figure 4 for a detailed description). PSEs, with only 18 examples, already leads to better performance than standard regularization.
PSEs also outperform bisimulation transfer in the “wide” and random grids. Although bisimulation transfer is impractical444Bisimulation transfer assumes oracle access to dynamics and rewards on unseen environments as well as tabular state space to compute the exact bisimulation metric (Section B). when evaluating zero-shot generalization, we still performed this comparison, unfair to PSEs, to highlight their efficacy. PSEs perform better because, in contrast to bisimulation, PSM is reward agnostic (c.f. Proposition C.1) – the expected return of the jump action is quite different depending on the obstacle position (c.f. Figure F.2 for a visual juxtaposition of PSM and bisimulation). Overall, these results are promising because they place PSEs as an effective generalization method that does not rely on data augmentation.
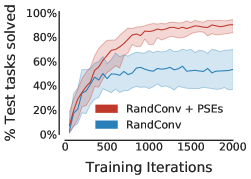
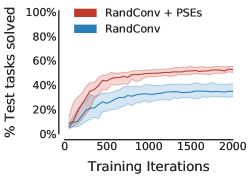
Nevertheless, PSEs are complementary to data augmentation, which consistently improves generalization in deep RL. We compared RandConv combined with PSEs to simply using RandConv. Domain-specific augmentation also succeeds in the jumping task. Thus, it is not surprising that RandConv is so effective compared to techniques without augmentation. Table 1 ( row) shows that PSEs substantially improve the performance of RandConv across all grid configurations. Moreover, Table 1 ( row) illustrates that when combined with RandConv, bisimulation preserving representations (Zhang et al., 2021) diminish generalization by relative to PSEs.
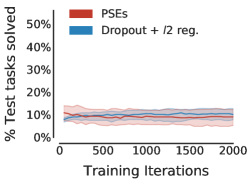
Notably, Table 1 ( row) indicates that learning-based methods are ineffective on the “narrow” grid without data augmentation. That said, PSEs do work quite well when combined with RandConv. However, even with data augmentation, generalization in “narrow” grid happens only around the vicinity of training tasks, exhibiting the challenge this grid poses for learning-based methods. We believe this is due to the poor extrapolation ability of neural networks (e.g., Haley & Soloway, 1992; Xu et al., 2020), which is more perceptible without prior inductive bias from data augmentation.
5.2 Understanding gains from PSEs: Ablations and Visualizations


| Metric / Embedding | -embeddings | CMEs |
|---|---|---|
| -bisimulation | 41.4 (17.6) | 23.1 (7.6) |
| PSM | 17.5 (8.4) | 87.0 (10.1) |
PSEs are contrastive metric embeddings (CMEs) learned with PSM. We investigate the gains from CMEs (Section 4) and PSM (Section 3) by ablating them. CMEs can be learned with any state similarity metric – we use -bisimulation (Castro, 2020) as an alternative. Similarly, PSM can be used with any metric embedding – we use -embeddings (Section D) as an alternative, which Zhang et al. (2021) employed with -bisimulation for learning representations in a single task RL setting. For a fair comparison, we tune hyperparameters for 128 trials for each ablation entry in Table 2.
Table 2 show that PSEs ( PSM + CMEs) generalize significantly better than -bisimulation with CMEs or -embeddings, both of which significantly degrade performance ( and , respectively). This is expected, as -bisimulation imposes the incorrect invariances for the jumping task (c.f. Figures 2(a) and 2(d)). Additionally, looking at the rows of Table 2, CMEs are superior than -embeddings for PSM while inferior for -bisimulation. This result is in line with the hypothesis that CMEs better enforce the invariances encoded by a similarity metric compared to -embeddings (c.f. Figures 5(b) and 5(c)).
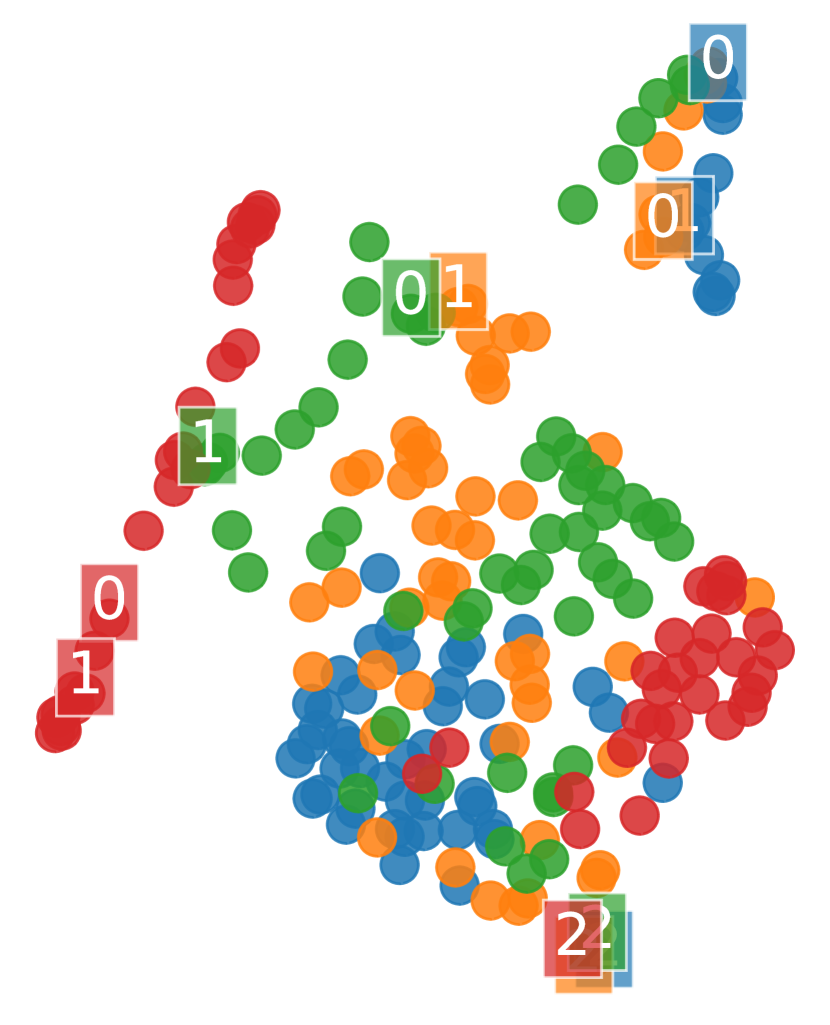
Visualizing learned representations. We visualize the metric embeddings in the ablation above by projecting them to two dimensions with UMAP (McInnes et al., 2018), a popular visualization technique for high dimensional data which better preserves the data’s global structure compared to other methods such as t-SNE (Coenen & Pearce, 2019).
Figure 5 shows that PSEs partition the states into two sets: (1) states where a single suboptimal action leads to failure (all states before jump) and (2) states where actions do not affect the final outcome (states after jump). Additionally, PSEs align the labeled states in the first set, which have a PSM distance of zero. These aligned states have the same distance from the obstacle, the invariant feature that generalizes across tasks. On the other hand, -embeddings (Zhang et al., 2021) with PSM do not align states with zero PSM except the state with the jump action – poor generalization, as observed empirically, is likely due to states with the same optimal behavior ending up with distant embeddings. CMEs with -bisimulation align states with -bisimulation distance of zero – such states are equidistant from the start state and have different optimal behavior for any pair of tasks with different obstacle positions (Figure 2(c)).
5.3 Effect of Policy Suboptimality on PSEs
To understand the sensitivity of learning effective PSEs to the quality of the policies, we compute PSEs using -suboptimal policies on the jumping task, which take the optimal action with probability and the subopotimal action with probability .
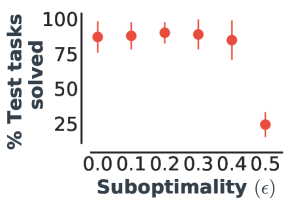
We evaluate the generalization performance of PSEs for increasingly suboptimal policies, ranging from the optimal policy () to the uniform random policy (). To isolate the effect of suboptimality on PSEs, the agent still imitates the optimal actions during training for all .
Figure 6 shows that PSEs show near-optimal generalization with while degrade generalization with an uniform random policy. This result is well-aligned with Proposition C.3, which shows that for policies with decreasing suboptimality, the PSM approximation becomes more accurate, resulting in improved PSEs. Overall, this study confirms that the utility of PSEs for generalization is robust to suboptimality. One reason for this robustness is that PSEs are likely to align states with similar long-term greedy optimal actions, resulting in good performance even with suboptimal policies that preserve these greedy actions.
5.4 Jumping Task with Colors: Where Task-dependent Invariance Matters
The task-dependent invariances captured by PSEs are usually orthogonal to task-agnostic invariances from data augmentation. This difference is important because, for certain RL tasks, data augmentation can erroneously alias states with different optimal behavior. Domain knowledge is often required to select appropriate augmentations, otherwise augmentations can even hurt generalization. In contrast, PSEs do not require any domain knowledge but instead exploit the inherent structure of the RL tasks.
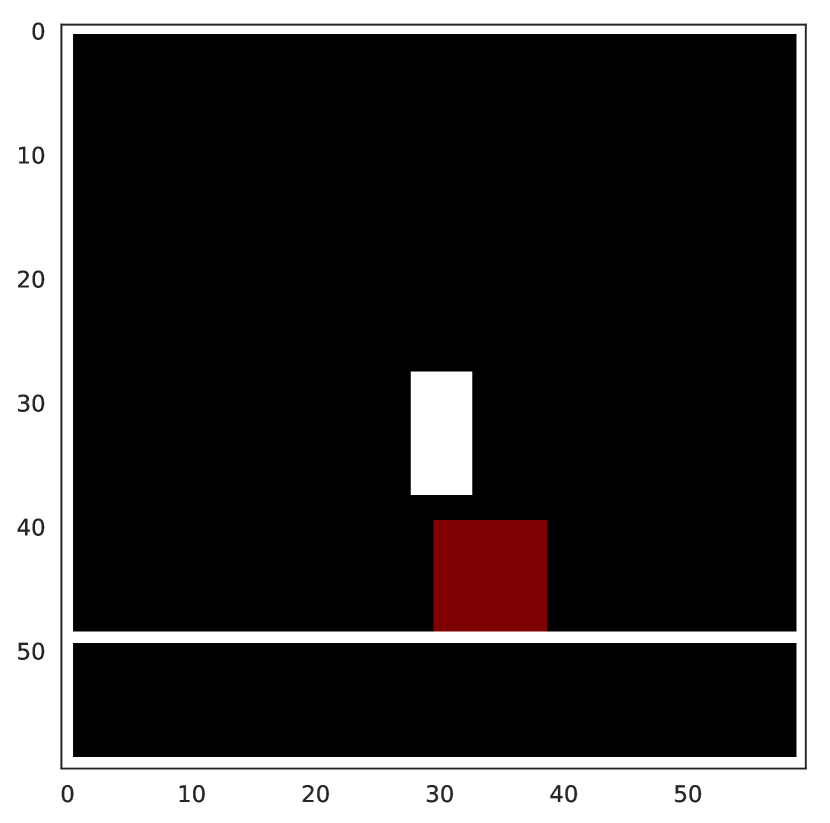
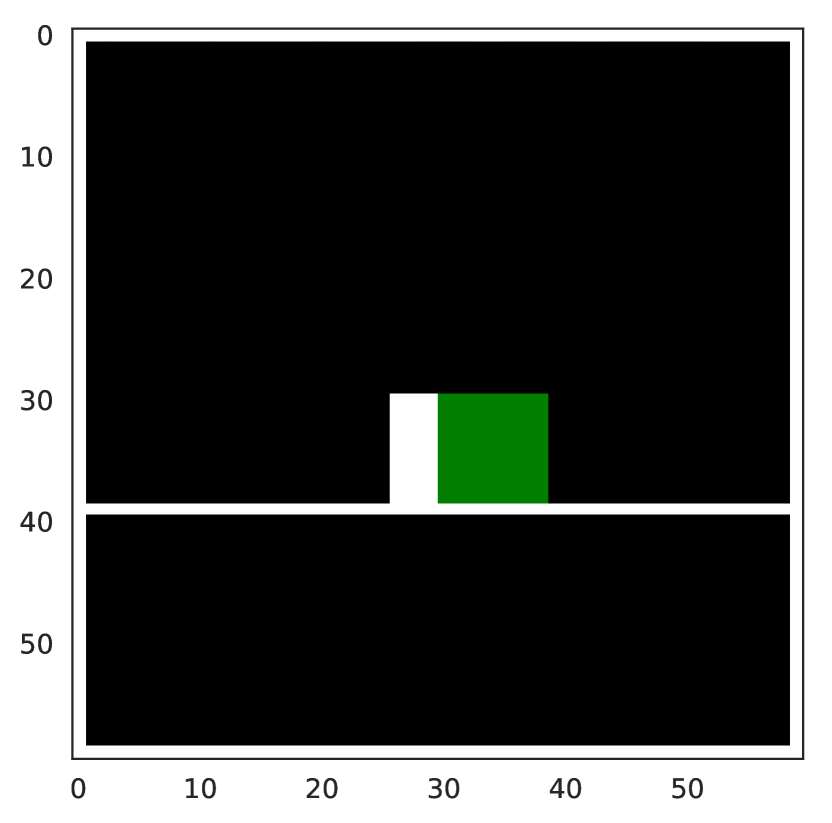
To demonstrate the difference between PSEs and data augmentation, we simply include colored obstacles in the jumping task (see Figure F.5). In this modified task, the optimal behavior of the agent depends on the obstacle color: the agent needs to jump over the red obstacle but strike the green obstacle to get a high return. The red obstacle task has the same difficulty as the original jumping task while the green obstacle task is easier. We jointly train the agent with 18 training tasks each, for both obstacle colors, on the “wide” grid and evaluate generalization on unseen red tasks.
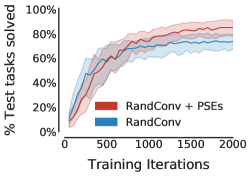
Figure 7 shows the large performance gap between PSEs and data augmentation with RandConv. All methods solve the green obstacle tasks (Table F.1). As opposed to the original jumping task (c.f. Table 1), data augmentation inhibits generalization since RandConv forces the agent to ignore color, conflating the red and green tasks (Figure F.6). PSEs still outperform regularization and data augmentation. Furthermore, data augmentation performs better when combined with PSEs. Thus, PSEs are effective even when data augmentation hurts performance.
6 Additional Empirical Evaluation
In this section, we exhibit that PSM ignores spurious information for generalization using a LQR task (Song et al., 2019) with non-image inputs. Then, we demonstrate the scalability of PSEs without explicit access to optimal policies in an RL setting with continuous actions, using Distracting DM Control Suite (Stone et al., 2021).
6.1 LQR with Spurious Correlations
We show how representations learned using PSM, when faced with semantically equivalent environments, can learn the main factors of variation and ignore spurious correlations that hinder
generalization. We use LQR with distractors (Song et al., 2019; Sonar et al., 2020) to assess generalization in a feature-based RL setting with linear function approximation. The distractors are input features that are spuriously correlated with optimal actions and can be used for predicting these actions during training, but hurt generalization. The agent learns a linear policy using 2 environments with fixed distractors. This policy is evaluated on environments with unseen distractors.
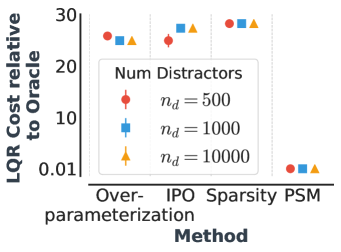
We aggregate state pairs in training environments with near-zero PSM. We contrast this approach with (i) IPO (Sonar et al., 2020), a policy optimization method based on IRM (Arjovsky et al., 2019) for out-of-distribution generalization, (ii) overparametrization, which leads to better generalization via implicit regularization (Song et al., 2019), and (iii) weight sparsity using -regularization since the policy weights which generalize in this task are sparse.
All methods optimally solve the training environments; however, the baselines perform abysmally in terms of generalization compared to state aggregation with PSM (Figure 8), indicating their reliance on distractors. PSM obtains near-optimal generalization which we corroborate through this conjecture (Section G.1): Assuming zero state aggregation error with PSM, the policy learned using gradient descent is independent of the distractors. Refer to Section G for a detailed discussion.
6.2 Distracting DM Control Suite

Finally, we demonstrate scalability of PSEs on the Distracting DM Control Suite (DCS) (Stone et al., 2021), which tests whether agents can ignore high-dimensional visual distractors irrelevant to the RL task. Since we do not have access to optimal training policies, we use learned policies as proxy for for computing PSM as well as collecting data for optimizing PSEs. Even with this approximation, PSEs outperform state-of-the-art data augmentation.
DCS extends DM Control (Tassa et al., 2020) with visual distractions. We use the dynamic background distractions (Stone et al., 2021; Zhang et al., 2018b) where a video is played in the background from a specific frame. The video and the frame are randomly sampled every new episode. We use 2 videos during training (Figure 9) and evaluate generalization on 30 unseen videos (Figure H.1).
All agents are built on top of SAC (Haarnoja et al., 2018) combined with DrQ (Kostrikov et al., 2020), an augmentation method with state-of-the-art performance on DM control. Without data augmentation on DM control, SAC performs poorly, even during training (Kostrikov et al., 2020). We augment DrQ with an auxiliary loss for learning PSEs and compare it with DrQ (Table 3). Orthogonal to DrQ, PSEs align representations of different states across environments based on PSM (c.f. Figure 3). All agents are trained for 500K environment steps with random crop augmentation. For computing PSM, we use policies learned by DrQ pretrained on training environments for 500K steps.
| Initialization | Method | BiC-catch | C-swingup | C-run | F-spin | R-easy | W-walk |
|---|---|---|---|---|---|---|---|
| Random | DrQ | 74728 | 58242 | 22012 | 64654 | 93114 | 54983 |
| DrQ + PSEs | 82117 | 74919 | 30812 | 77949 | 95510 | 78928 | |
| Pretrained | DrQ | 74830 | 68922 | 21910 | 76448 | 94310 | 70929 |
| DrQ + PSEs | 80525 | 75313 | 2828 | 80319 | 96211 | 82921 |
First, we investigate how much better PSEs generalize relative to DrQ, assuming the agent is provided with PSM beforehand. The agent’s policy is randomly initialized so that additional gains over DrQ can be attributed to the auxiliary information from PSM. The substantial gains in Table 3 indicate that PSEs are more effective than DrQ for encoding invariance to distractors.
Since PSEs utilize PSM approximated using pretrained policies, we also compare to a DrQ agent where we initialize it using these pretrained policies. This comparison provides the same auxiliary information to DrQ as available to PSEs, thus, the generalization difference stems from how they utilize this information. Table 3 demonstrates that PSEs outperform DrQ with pretrained initialization, indicating that the additional pretraining steps are more judiciously utilized for computing PSM as opposed to just longer training with DrQ. More details, including learning curves, are in Section H.
7 Related Work
PSM (Section 3) is inspired by bisimulation metrics (Section B). However, different than traditional bisimulation (e.g., Larsen & Skou, 1991; Givan et al., 2003; Ferns et al., 2011), PSM is more tractable as it defined with respect to a single policy similar to the recently proposed -bisimulation (Castro, 2020; Zhang et al., 2021). However, in contrast to PSM, bisimulation metrics rely on reward information and may not provide a meaningful notion of behavioral similarity in certain environments (Section 5). For example, states similar under PSM would have similar optimal policies, yet can have arbitrarily large -bisimulation distance between them (Proposition C.1).
PSEs (Section 4) use contrastive learning to encode behavior similarity (Section 3) across MDPs. Previously, contrastive learning has been applied for imposing state self-consistency (Laskin et al., 2020b), capturing predictive information (Oord et al., 2018; Mazoure et al., 2020; Lee et al., 2020b) or encoding transition dynamics (van der Pol et al., 2020; Stooke et al., 2020; Schwarzer et al., 2020) within an MDP. These methods can be integrated with PSEs to encode additional invariances. Interestingly, in a similar spirit to PSEs, Pacchiano et al. (2020); Moskovitz et al. (2021) explore comparing behavioral similarity between policies to guide policy optimization within an MDP.
PSEs are complementary to data augmentation methods (Kostrikov et al., 2020; Lee et al., 2020a; Raileanu et al., 2020; Ye et al., 2020), which have recently been shown to significantly improve agents’ generalization capabilities. In fact, we combine PSEs to state-of-the-art augmentation methods including random convolutions (Lee et al., 2020a; Laskin et al., 2020a) in the jumping task and DrQ (Kostrikov et al., 2020) on Distracting Control Suite, leading to performance improvement. Furthermore, for certain RL tasks, it can be unclear what an optimality invariant augmentation would look like (Section 5.4). PSM can quantify the invariance of such augmentations (Proposition C.2).
8 Conclusion
This paper advances generalization in RL by two contributions: (1) the policy similarity metric (PSM) which provides a new notion of state similarity based on behavior proximity, and (2) contrastive metric embeddings, which harness the benefits of contrastive learning for representations based on a similarity metric. PSEs combine these two ideas to improve generalization. Overall, this paper shows the benefits of exploiting the inherent structure in RL for learning effective representations.
References
- Agarwal et al. (2019) Rishabh Agarwal, Chen Liang, Dale Schuurmans, and Mohammad Norouzi. Learning to generalize from sparse and underspecified rewards. In ICML, 2019.
- Arjovsky et al. (2019) Martín Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk minimization. CoRR, abs/1907.02893, 2019.
- Arora et al. (2019) Sanjeev Arora, Nadav Cohen, Wei Hu, and Yuping Luo. Implicit regularization in deep matrix factorization. In Advances in Neural Information Processing Systems, pp. 7413–7424, 2019.
- Balaji et al. (2018) Yogesh Balaji, Swami Sankaranarayanan, and Rama Chellappa. Metareg: Towards domain generalization using meta-regularization. In Advances in Neural Information Processing Systems, pp. 998–1008, 2018.
- Castro (2020) Pablo Samuel Castro. Scalable methods for computing state similarity in deterministic Markov decision processes. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2020.
- Castro & Precup (2010) Pablo Samuel Castro and Doina Precup. Using bisimulation for policy transfer in MDPs. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2010.
- Chen et al. (2020) Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey E. Hinton. A simple framework for contrastive learning of visual representations. CoRR, abs/2002.05709, 2020.
- Cobbe et al. (2019) Karl Cobbe, Oleg Klimov, Christopher Hesse, Taehoon Kim, and John Schulman. Quantifying generalization in reinforcement learning. In Proceedings of the International Conference on Machine Learning (ICML), 2019.
- Coenen & Pearce (2019) Andy Coenen and Adam Pearce. Understanding umap, 2019. URL https://pair-code.github.io/understanding-umap/.
- Farebrother et al. (2018) Jesse Farebrother, Marlos C. Machado, and Michael Bowling. Generalization and regularization in DQN. In NeurIPS Deep Reinforcement Learning Workshop, 2018.
- Ferns et al. (2004) Norm Ferns, Prakash Panangaden, and Doina Precup. Metrics for finite Markov decision processes. In Proceedings of the Conference in Uncertainty in Artificial Intelligence (UAI), 2004.
- Ferns et al. (2006) Norm Ferns, Pablo Samuel Castro, Doina Precup, and Prakash Panangaden. Methods for computing state similarity in Markov decision processes. In Proceedings of the 22nd Conference on Uncertainty in Artificial Intelligence, UAI ’06. AUAI Press, 2006.
- Ferns et al. (2011) Norm Ferns, Prakash Panangaden, and Doina Precup. Bisimulation metrics for continuous markov decision processes. SIAM Journal on Computing, 40(6):1662–1714, 2011.
- Ferns & Precup (2014) Norman Ferns and Doina Precup. Bisimulation metrics are optimal value functions. In The 30th Conference on Uncertainty in Artificial Intelligence, pp. 10, 2014.
- Finn et al. (2017) Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning (ICML), 2017.
- Givan et al. (2003) Robert Givan, Thomas Dean, and Matthew Greig. Equivalence notions and model minimization in markov decision processes. Artificial Intelligence, 147(1-2):163–223, 2003.
- Golovin et al. (2017) Daniel Golovin, Benjamin Solnik, Subhodeep Moitra, Greg Kochanski, John Karro, and D Sculley. Google vizier: A service for black-box optimization. In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, pp. 1487–1495, 2017.
- Gunasekar et al. (2017) Suriya Gunasekar, Blake E Woodworth, Srinadh Bhojanapalli, Behnam Neyshabur, and Nati Srebro. Implicit regularization in matrix factorization. In Advances in Neural Information Processing Systems, pp. 6151–6159, 2017.
- Haarnoja et al. (2018) Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. arXiv preprint arXiv:1801.01290, 2018.
- Hadsell et al. (2006) Raia Hadsell, Sumit Chopra, and Yann LeCun. Dimensionality reduction by learning an invariant mapping. In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), volume 2, pp. 1735–1742. IEEE, 2006.
- Haley & Soloway (1992) Pamela J Haley and DONALD Soloway. Extrapolation limitations of multilayer feedforward neural networks. In [Proceedings 1992] IJCNN International Joint Conference on Neural Networks, volume 4, pp. 25–30. IEEE, 1992.
- Igl et al. (2019) Maximilian Igl, Kamil Ciosek, Yingzhen Li, Sebastian Tschiatschek, Cheng Zhang, Sam Devlin, and Katja Hofmann. Generalization in reinforcement learning with selective noise injection and information bottleneck. In Advances in Neural Information Processing Systems, pp. 13978–13990, 2019.
- Jin et al. (2020) Wengong Jin, Regina Barzilay, and Tommi Jaakkola. Domain extrapolation via regret minimization. arXiv preprint arXiv:2006.03908, 2020.
- Juliani et al. (2019) Arthur Juliani, Ahmed Khalifa, Vincent-Pierre Berges, Jonathan Harper, Ervin Teng, Hunter Henry, Adam Crespi, Julian Togelius, and Danny Lange. Obstacle Tower: A generalization challenge in vision, control, and planning. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), 2019.
- Justesen et al. (2018) Niels Justesen, Ruben Rodriguez Torrado, Philip Bontrager, Ahmed Khalifa, Julian Togelius, and Sebastian Risi. Illuminating generalization in deep reinforcement learning through procedural level generation. arXiv preprint arXiv:1806.10729, 2018.
- Killian et al. (2017) Taylor W. Killian, George Dimitri Konidaris, and Finale Doshi-Velez. Robust and efficient transfer learning with hidden parameter Markov decision processes. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), pp. 4949–4950, 2017.
- Kostrikov et al. (2020) Ilya Kostrikov, Denis Yarats, and Rob Fergus. Image augmentation is all you need: Regularizing deep reinforcement learning from pixels. CoRR, abs/2004.13649, 2020.
- Larsen & Skou (1991) Kim G Larsen and Arne Skou. Bisimulation through probabilistic testing. Information and computation, 94(1):1–28, 1991.
- Laskin et al. (2020a) Michael Laskin, Kimin Lee, Adam Stooke, Lerrel Pinto, Pieter Abbeel, and Aravind Srinivas. Reinforcement learning with augmented data. CoRR, abs/2004.14990, 2020a.
- Laskin et al. (2020b) Michael Laskin, Aravind Srinivas, and Pieter Abbeel. Curl: Contrastive unsupervised representations for reinforcement learning. Proceedings of the 37th International Conference on Machine Learning, Vienna, Austria, PMLR 119, 2020b. arXiv:2003.06417.
- Lee et al. (2020a) Kimin Lee, Kibok Lee, Jinwoo Shin, and Honglak Lee. Network randomization: A simple technique for generalization in deep reinforcement learning. In The International Conference on Learning Representations (ICLR), 2020a.
- Lee et al. (2020b) Kuang-Huei Lee, Ian Fischer, Anthony Liu, Yijie Guo, Honglak Lee, John Canny, and Sergio Guadarrama. Predictive information accelerates learning in rl. arXiv preprint arXiv:2007.12401, 2020b.
- Li et al. (2018) Da Li, Yongxin Yang, Yi-Zhe Song, and Timothy M. Hospedales. Learning to generalize: Meta-learning for domain generalization. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2018.
- Mazoure et al. (2020) Bogdan Mazoure, Remi Tachet des Combes, Thang Long DOAN, Philip Bachman, and R Devon Hjelm. Deep reinforcement and infomax learning. Advances in Neural Information Processing Systems, 33, 2020.
- McInnes et al. (2018) L. McInnes, J. Healy, and J. Melville. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. ArXiv e-prints, February 2018.
- Moskovitz et al. (2021) Ted Moskovitz, Michael Arbel, Ferenc Huszar, and Arthur Gretton. Efficient wasserstein natural gradients for reinforcement learning. In International Conference on Learning Representations, 2021.
- Oh et al. (2017) Junhyuk Oh, Satinder P. Singh, Honglak Lee, and Pushmeet Kohli. Zero-shot task generalization with multi-task deep reinforcement learning. In Proceedings of the International Conference on Machine Learning (ICML), 2017.
- Oord et al. (2018) Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- Pacchiano et al. (2020) Aldo Pacchiano, Jack Parker-Holder, Yunhao Tang, Krzysztof Choromanski, Anna Choromanska, and Michael Jordan. Learning to score behaviors for guided policy optimization. In International Conference on Machine Learning, 2020.
- Packer et al. (2018) Charles Packer, Katelyn Gao, Jernej Kos, Philipp Krähenbühl, Vladlen Koltun, and Dawn Song. Assessing generalization in deep reinforcement learning. arXiv preprint arXiv:1810.12282, 2018.
- Perez et al. (2020) Christian F. Perez, Felipe Petroski Such, and Theofanis Karaletsos. Generalized hidden parameter mdps transferable model-based rl in a handful of trials. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2020.
- Pont-Tuset et al. (2017) Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Arbeláez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation. arXiv preprint arXiv:1704.00675, 2017.
- Puterman (1994) Martin L Puterman. Markov Decision Processes: Discrete Stochastic Dynamic Programming. John Wiley & Sons, Inc., 1994.
- Raileanu et al. (2020) Roberta Raileanu, Max Goldstein, Denis Yarats, Ilya Kostrikov, and Rob Fergus. Automatic data augmentation for generalization in deep reinforcement learning. arXiv preprint arXiv:2006.12862, 2020.
- Rajeswaran et al. (2017) Aravind Rajeswaran, Kendall Lowrey, Emanuel Todorov, and Sham M. Kakade. Towards generalization and simplicity in continuous control. In Advances in Neural Information Processing Systems (NeurIPS), 2017.
- Recht (2019) Benjamin Recht. A tour of reinforcement learning: The view from continuous control. Annual Review of Control, Robotics, and Autonomous Systems, 2019.
- Schwarzer et al. (2020) Max Schwarzer, Ankesh Anand, Rishab Goel, R Devon Hjelm, Aaron Courville, and Philip Bachman. Data-efficient reinforcement learning with momentum predictive representations. arXiv preprint arXiv:2007.05929, 2020.
- Sonar et al. (2020) Anoopkumar Sonar, Vincent Pacelli, and Anirudha Majumdar. Invariant policy optimization: Towards stronger generalization in reinforcement learning. arXiv preprint arXiv:2006.01096, 2020.
- Song et al. (2019) Xingyou Song, Yiding Jiang, Yilun Du, and Behnam Neyshabur. Observational overfitting in reinforcement learning. In The International Conference on Learning Representations (ICLR), 2019.
- Stone et al. (2021) Austin Stone, Oscar Ramirez, Kurt Konolige, and Rico Jonschkowski. The distracting control suite – a challenging benchmark for reinforcement learning from pixels. arXiv preprint arXiv:2101.02722, 2021.
- Stooke et al. (2020) Adam Stooke, Kimin Lee, Pieter Abbeel, and Michael Laskin. Decoupling representation learning from reinforcement learning. arXiv preprint arXiv:2009.08319, 2020.
- Tachet des Combes et al. (2018) Remi Tachet des Combes, Philip Bachman, and Harm van Seijen. Learning invariances for policy generalization. In Workshop track at the International Conference on Learning Representations (ICLR), 2018.
- Tang et al. (2020) Yujin Tang, Duong Nguyen, and David Ha. Neuroevolution of self-interpretable agents. arXiv preprint arXiv:2003.08165, 2020.
- Tassa et al. (2020) Yuval Tassa, Saran Tunyasuvunakool, Alistair Muldal, Yotam Doron, Siqi Liu, Steven Bohez, Josh Merel, Tom Erez, Timothy Lillicrap, and Nicolas Heess. dm_control: Software and tasks for continuous control. arXiv preprint arXiv:2006.12983, 2020.
- Taylor & Stone (2009) Matthew E. Taylor and Peter Stone. Transfer learning for reinforcement learning domains: A survey. Journal of Machine Learning Research, 10:1633–1685, 2009.
- Tobin et al. (2017) Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 23–30. IEEE, 2017.
- van der Pol et al. (2020) Elise van der Pol, Thomas Kipf, Frans A Oliehoek, and Max Welling. Plannable approximations to mdp homomorphisms: Equivariance under actions. In Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, pp. 1431–1439, 2020.
- Villani (2008) Cédric Villani. Optimal transport: old and new. Springer, 2008.
- Witty et al. (2018) Sam Witty, Jun Ki Lee, Emma Tosch, Akanksha Atrey, Michael Littman, and David Jensen. Measuring and characterizing generalization in deep reinforcement learning. In NeurIPS Critiquing and Correcting Trends in Machine Learning Workshop, 2018.
- Xu et al. (2020) Keyulu Xu, Jingling Li, Mozhi Zhang, Simon S Du, Ken-ichi Kawarabayashi, and Stefanie Jegelka. How neural networks extrapolate: From feedforward to graph neural networks. arXiv preprint arXiv:2009.11848, 2020.
- Ye et al. (2020) Chang Ye, Ahmed Khalifa, Philip Bontrager, and Julian Togelius. Rotation, translation, and cropping for zero-shot generalization. CoRR, abs/2001.09908, 2020.
- Zhang et al. (2018a) Amy Zhang, Nicolas Ballas, and Joelle Pineau. A Dissection of Overfitting and Generalization in Continuous Reinforcement Learning. CoRR, abs/1806.07937, 2018a.
- Zhang et al. (2018b) Amy Zhang, Yuxin Wu, and Joelle Pineau. Natural environment benchmarks for reinforcement learning. arXiv preprint arXiv:1811.06032, 2018b.
- Zhang et al. (2020) Amy Zhang, Clare Lyle, Shagun Sodhani, Angelos Filos, Marta Kwiatkowska, Joelle Pineau, Yarin Gal, and Doina Precup. Invariant causal prediction for block mdps. In Proceedings of the International Conference on Machine Learning (ICML), 2020.
- Zhang et al. (2021) Amy Zhang, Rowan McAllister, Roberto Calandra, Yarin Gal, and Sergey Levine. Learning invariant representations for reinforcement learning without reconstruction. The International Conference on Learning Representations (ICLR), 2021.
- Zhang et al. (2018c) Chiyuan Zhang, Oriol Vinyals, Rémi Munos, and Samy Bengio. A study on overfitting in deep reinforcement learning. CoRR, abs/1804.06893, 2018c.
Appendix
Appendix A Proofs
We begin by defining some notation which will be used throughout these results:
-
•
We denote
-
•
For any , let , where .
-
•
.
We now proceed with some technical lemmas necessary for the main result.
Lemma 1.
Given any two pseudometrics555Pseudometrics are generalization of metrics where the distance between two distinct states can be zero. and probability distributions where , we have:
Proof.
Note that the dual of the linear program for computing is given by
Using the dual formulation subject to the constraints above, can be written as
∎
Lemma 2.
Given any , we have:
Proof.
∎
Lemma 3.
Given any , if , we have:
Proof.
Note that we have the following equality, where is a vector of zeros:
which is the same form as the primal LP for . By assumption, we have that
This implies that is a feasible solution to :
and the result follows. ∎
Proposition A.1.
The operator given by:
is a contraction mapping and has a unique fixed point for a bounded .
Proof.
We first prove that is contraction mapping. Then, a simple application of the Banach Fixed Point Theorem asserts that has a unique fixed point. Note that for all pseudometrics , and for all states , ,
Thus, , so that is a contracting mapping for and has an unique fixed point . ∎
See 1
Proof.
We will prove this by induction. Assuming that the bound holds for , we prove the bound holds for . The base case for follows from . Note that since the distance per time-step can be at most 1.
Let denote the probability of ending in state after steps when following policy and starting from state . We then have:
Thus, by induction, it follows that for all :
which completes the proof. ∎
Appendix B Bisimulation metrics
Notation. We use the notation as defined in Section 2.
Bisimulation metrics (Givan et al., 2003; Ferns et al., 2011) define a pseudometric where is defined in terms of distance between immediate rewards and next state distributions. Define by
| (B.1) |
then, has a unique fixed point which is a bisimulation metric. uses the 1-Wasserstein metric . The 1-Wasserstein distance under the pseudometric can be computed using the dual linear program:
Since we are only interested in computing the coupling between the states in and , the above formulation assumes that for all and for all . The computation of is expensive and requires a tabular representation of the states, rendering it impractical for large state spaces. On-policy bisimulation (Castro, 2020) (e.g., -bisimulation) is tied to specific behavior policies and is much easier to approximate than bisimulation.
Appendix C Policy Similarity Metric
C.1 Computing PSM
In general, PSM for a given Dist across MDPs and is given by
| (C.1) |
Since our main focus is showing the utility of PSM for generalization, we simply use environments where PSM can be computed using dynamic programming. Using a similar observation to Castro (2020), we assert that the recursion for takes the following form in deterministic environments:
| (C.2) |
where , are the next states from taking actions , from states respectively. Furthermore, we assume that Dist between terminal states from and is zero. Note that the form of Equation C.2 closely resembles the update rule in Q-learning, and as such, can be efficiently computed with samples using approximate dynamic programming. Given access to optimal trajectories and , where and , Equation C.2 can be solved using exact dynamic programming; we provide pseudocode in Section I.1.
There are other ways to approximate the Wasserstein distance in bisimulation metrics (e.g., Ferns et al., 2006; 2011; Castro, 2020; Zhang et al., 2021). That said, approximating bisimulation (or PSM) for stochastic environments remains an exciting research direction (Castro, 2020). Investigating other distance metrics for long-term behavior difference in PSM is also interesting for future work.
C.2 PSM Connections to Data Augmentation and Bisimulation
Connection to bisimulation. Although bisimulation metrics have appealing properties such as bounding value function differences (e.g., (Ferns & Precup, 2014)), they rely on reward information and may not provide a meaningful notion of behavioral similarity in certain environments. Proposition C.1 implies that states similar under PSM would have similar optimal policies yet can have arbitrarily large bisimulation distance between them.
Proposition C.1.
There exists environments and such that where , for any given .
For example, consider the two semantically equivalent environments in Figure 2 with and but different rewards respectively. Whenever , bisimulation metrics incorrectly imply that is more behaviorally similar to than .
For the MDPs shown in Figure 2, to determine which state is behaviorally equivalent to , we look at the distances computed by bisimulation metric and -bisimulation metric :
Thus, implies that as well as .
Connection to data augmentation. Data augmentation often assumes access to optimality invariant transformations, e.g., random crops or flips in image-based benchmarks (Laskin et al., 2020a; Kostrikov et al., 2020). However, for certain RL tasks, such augmentations can erroneously alias states with different optimal behavior and hurt generalization. For example, if the image observation is flipped in a goal reaching task with left and right actions, the optimal actions would also be flipped to take left actions instead of right and vice versa. Proposition C.2 states that PSMs can precisely quantify the invariance of such augmentations.
Proposition C.2.
For an MDP and its transformed version for the data augmentation , indicates the optimality invariance of for any .
C.3 PSM with Approximately-Optimal Policies
Generalized Policy Similarity Metric for arbitrary policies. For a given Dist, we define a generalized PSM where is the set of all policies over . satisfies the recursive equation:
| (C.3) |
Since Dist is assumed to be a pseudometric and is a probability metric, it implies that is a pseudometric as
(1) is non-negative, that is, , (2) is symmetric, that is, , and satisfies
the triangle inequality, that is, .
Using this notion of generalized PSM, we show that the approximation error in PSM from using a suboptimal policy is bounded by the policy’s suboptimality. Thus, for policies with decreasing suboptimality, the PSM approximation becomes more accurate, resulting in improved PSEs.
Proposition C.3.
[Approximation error in PSM] Let be the approximate PSM computed using a suboptimal policy defined over , that is, . We have:
Proof.
The PSM and approximate PSM are instantiations of the generalized PSM (Equation C.3) with both input policies as and respectively.
∎
Appendix D L2 Metric Embeddings
Another common choice (Zhang et al., 2021) for learning metric embeddings is to use the squared loss (i.e., -loss) for matching the euclidean distance between the representations of a pair of states to the metric distance between those states. Concretely, for a given and representation , the loss is minimized. However, it might be too restrictive to match the exact metric distances, which we demonstrate empirically by comparing metric embeddings with CMEs (Section 5.2).
Appendix E Extended Related Work
Generalization across different tasks used to be described as transfer learning. In the past, most transfer learning approaches relied on fixed representations and tackled different problem formulations (e.g., assuming shared state space). Taylor & Stone (2009) present a comprehensive survey of the techniques at the time, before representation learning became so prevalent in RL. Recently, the problem of performing well in a different, but related task, started to be seen as a problem of generalization; with the community highlighting that deep RL agents tend to overfit to the environments they are trained on (Cobbe et al., 2019; Witty et al., 2018; Farebrother et al., 2018; Juliani et al., 2019; Kostrikov et al., 2020; Song et al., 2019; Justesen et al., 2018; Packer et al., 2018).
Prior generalization approaches are typically adapted from supervised learning, including regularization (Cobbe et al., 2019; Farebrother et al., 2018), stochasticity (Zhang et al., 2018c), noise injection (Igl et al., 2019; Zhang et al., 2018a), more diverse training conditions (Rajeswaran et al., 2017; Witty et al., 2018) and self-attention architectures (Tang et al., 2020). In contrast, PSEs exploits behavior similarity (Section 3), a property related to the sequential aspect of RL.
Meta-learning is also related to generalization. Meta-learning methods try to find a parametrization that requires a small number of gradient steps to achieve good performance on a new task (Finn et al., 2017). In this context, various meta-learning approaches capable of zero-shot generalization have been proposed (Li et al., 2018; Agarwal et al., 2019; Balaji et al., 2018). These approaches typically consist in minimizing the loss in the environments the agent is while adding an auxiliary loss for ensuring improvement in the other (validation) environments available to the agent. Nevertheless, Tachet des Combes et al. (2018) has shown that meta-learning approaches fail in the jumping task which we also observed empirically. Others have also reported similar findings (e.g., Farebrother et al., 2018).
There are several other approaches for tackling zero-shot generalization in RL, but they often rely on domain-specific information. Some examples include knowledge about equivalences between entities in the environment (Oh et al., 2017) and about what is under the agent’s control (Ye et al., 2020). Causality-based methods are a different way of tackling generalization, but current solutions do not scale to high-dimensional observation spaces (e.g., Killian et al., 2017; Perez et al., 2020; Zhang et al., 2020).
Appendix F Jumping Task with Pixels


Detailed Task Description. The jumping task consists of an agent trying to jump over an obstacle on a floor. The environment is deterministic with the agent observing a reward of at each time step. If the agent successfully reaches the rightmost side of the screen, it receives a bonus reward of ; if the agent touches the obstacle, the episode terminates. The observation space is the pixel representation of the environment, as depicted in Figure 1. The agent has access to two actions: right and jump. The jump action moves the agent vertically and horizontally to the right.

Architecture. The neural network used for Jumping Task experiment is adapted from the Nature DQN architecture. Specifically, the network consists of 3 convolutional layers of sizes 32, 64, 64 with filter sizes , and and strides 4, 2, and 1, respectively. The output of the convnet is fed into a single fully connected layer of size 256 followed by ’ReLU’ non-linearity. Finally, this FC layer output is fed into a linear layer which computes the policy which outputs the probability of the jump and right actions.
Contrastive Embedding. For all our experiments, we use a single ReLU layer with units for the non-linear projection to obtain the embedding (Figure 3). We compute the embedding using the penultimate layer in the jumping task network. Hyperparameters are reported in Table F.2.
Total Loss. For jumpy world, the total loss is given by where is the imitation learning loss, is the auxiliary loss for learning PSEs with the coefficient .

F.1 Jumping Task from Colors
| Method | Red (%) | Green (%) | ||
|---|---|---|---|---|
| RandConv | 6.2 | (0.4) | 99.6 | (0.2) |
| Dropout and reg. | 19.5 | (0.2) | 100.0 | (0.0) |
| RandConv + PSEs | 29.8 | (1.3) | 99.6 | (0.2) |
| PSEs | 37.9 | (1.9) | 100.0 | (0.0) |

F.2 Hyperparameters
For hyperparameter selection, we evaluate all agents on a validation set containing 54 unseen tasks in the “wide” grid and pick the parameters with the best validation performance. The validation set (Figure F.7) was selected by using the environments nearby to the training environments whose floor height differ by 1 or whose obstacle position differ by 1.
| Hyperparameter | Value |
| Learning rate decay | 0.999 |
| Training epochs | 2000 |
| Optimizer | Adam |
| Batch size (Imitation) | 256 |
| Num training tasks | 18 |
| -scale Parameter () | 0.01 |
| Embedding size () | 64 |
| Batch Size () | 57 |
| 57 |

| Hyperparameter | Dropout and -reg. | PSEs | RandConv | RandConv + PSEs |
| Learning Rate | ||||
| -reg. coefficient | – | – | ||
| Dropout coefficient | – | – | – | |
| Contrastive Temperature () | – | – | ||
| Auxiliary loss coefficient () | – | – |
| Hyperparameter | Dropout and -reg. | PSEs | RandConv | RandConv + PSEs |
| Learning Rate | ||||
| -reg. coefficient | – | – | ||
| Dropout coefficient | – | – | – | |
| Contrastive Temperature () | – | – | ||
| Auxiliary loss coefficient () | – | – |
| Hyperparameter | PSM | -bisimulation | ||
|---|---|---|---|---|
| CMEs | -embeddings | CMEs | -embeddings | |
| Learning Rate | ||||
| Contrastive Temperature () | – | – | ||
| Auxiliary loss coefficient () | ||||
Please note that Table F.3 and Table F.4 correspond to two different tasks: one uses the standard jumping task with white obstacles, while the other uses colored obstacles where the optimal policies depend on color. For fair comparison, we tune hyperparameters for all the methods using Bayesian optimization (Golovin et al., 2017). We use the best parameters among these tuned hyperparameters and the ones found in Table F.3, leading to different parameters for both PSEs as well as RandConv. Evaluating PSEs with the jumping task hyperparameters from Table F.3 instead of the ones in Table F.4 leads to a small drop (-4%) on the jumping task with colors (Section 5.4). Nevertheless, PSEs still outperform other methods in Section 5.4.
Appendix G LQR: Additional Details
| Method | Number of Distractors () | ||
|---|---|---|---|
| 500 | 1000 | 10000 | |
| Overparametrization (Song et al., 2019) | 25.8 (1.5) | 24.9 (1.1) | 24.9 (0.4) |
| IPO (Sonar et al., 2020) (IRM + Policy opt.) | 32.6 (5.0) | 27.3 (2.8) | 24.8 (0.4) |
| Weight Sparsity (-reg.) | 28.2 (0.0) | 28.2 (0.0) | 28.2 (0.0) |
| PSM (State aggregation) | 0.03 (0.0) | 0.03 (0.0) | 0.02 (0.0) |
Optimal control with linear dynamics and quadratic cost, commonly known as LQR, has been increasingly used as a simplified surrogate for deep RL problems (Recht, 2019). Following Song et al. (2019); Sonar et al. (2020), we analyze the following LQR problem for assessing generalization:
| (G.1) |
where is the initial state distribution, is the (hidden) true state at time t, is the control action, and is the linear policy matrix. The agent receives the input observation , which is a linear transformation of the state . and are semi-orthogonal matrices to prevent information loss for predicting optimal actions. An environment corresponds to a particular choice of ; all other system parameters () are fixed matrices which are shared across environments and unknown to the agent. The agent learns the policy matrix using training environments based on Equation G.1. At test time, the learned policy is evaluated on environments with unseen .
The generalization challenge in this setup is to ignore the distractors: represents the state features invariant across environments while is a high-dimensional distractor of size , respectively, such that . Furthermore, the policy matrix which generalizes across all environments is , where corresponds to the optimal LQR solution with access to state . However, for a single environment with distractor , multiple solutions exist, for instance, . Note that the distractors are an order of magnitude larger than the invariant features in and dependence on them is likely to cause the agent to act erratically on inputs with unseen distractors, resulting in poor generalization.
We use overparametrized policies with two linear layers, i.e., , where is the learned representation for observation . We learn using gradient descent using the combined cost on 2 training environments with varying number of distractors. We aggregate observation pairs with near-zero PSM by matching their representations using a squared loss. We use the open-source code released by Sonar et al. (2020) for our experiments.
| Parameter | Setting |
|---|---|
| A | Orthogonal matrix, scaled 0.8 |
| B | |
| 20 | |
| 20 | |
| Q | |
| R | |
| Orthogonal Initialization, scaled 0.001 | |
| Random semi-orthogonal matrix |
The reliance on distractors for IPO also highlights a limitation of IRM: if a model can achieve a solution with zero training error, then any such solution is acceptable by IRM regardless of its generalization ability – a common scenario with overparametrized deep neural nets (Jin et al., 2020).
G.1 Near-optimality of PSM Aggregation
Conjecture 1.
Assuming zero state aggregation error with policy similarity metric (PSM), the policy matrix learned using gradient descent is independent of the distractors.
Proof.
For LQR domains , an observation pair (, ) has zero PSM iff the underlying state is same for both the observations in the pair. This is true, as (a) both domains has the same transition dynamics, as specified by Equation G.1, and (b) the optimal policy is deterministic and is completely determined by the current state at any time .
Assume and for distractor semi-orthogonal matrices and , respectively. Furthermore, the representation is given by and respectively. Assume that where and and .
Zero state-aggregation error with squared loss implies that for pair (, ) corresponding to ,
| (G.2) |
As Equation G.2 holds for all states visited by the optimal policy in an infinite horizon LQR, it follows that .
Furthermore, it is well-known that gradient descent tends to find low-rank solutions due to implicit regularization (Arora et al., 2019; Gunasekar et al., 2017), e.g.,with small enough step sizes and initialization close enough to the origin, gradient descent on matrix factorization converges to the minimum nuclear norm solution for 2 layer linear networks (Gunasekar et al., 2017). Based on this, we conjecture that which we found to be true in practice. ∎
Appendix H Distracting Control Suite

We use the same setup as Kostrikov et al. (2020); Stone et al. (2021) for implementation details and training protocol. For completeness, we describe the details below.
Dynamic Background Distractions. In Distracting Control Suite (Stone et al., 2021), random backgrounds are projected from scenes of the DAVIS 2017 dataset (Pont-Tuset et al., 2017) onto the skybox of the scene. To make these backgrounds visible for all tasks and views, the floor grid is semi-transparent with transparency coefficient 0.3. We take the first 2 videos in the DAVIS 2017 training set and randomly sample a scene and a frame from those at the start of every episode. In the dynamic setting, the video plays forwards or backwards until the last or first frame is reached at which point the video is played backwards. This way, the background motion is always smooth and without “cuts”.
Soft Actor-Critic. Soft Actor-Critic (SAC) (Haarnoja et al., 2018) learns a state-action value function , a stochastic policy and a temperature to find an optimal policy for an MDP by optimizing a -discounted maximum-entropy objective. is used generically to denote the parameters updated through training in each part of the model. The actor policy is a parametric -Gaussian that given samples , where and and are parametric mean and standard deviation.
The policy evaluation step learns the critic network by optimizing a single-step of the soft Bellman residual
where is a replay buffer of transitions, is an exponential moving average of the weights. SAC uses clipped double-Q learning, which we omit for simplicity but employ in practice.
The policy improvement step then fits the actor policy network by optimizing the objective
Finally, the temperature is learned with the loss
where is the target entropy hyper-parameter that the policy tries to match, which in practice is usually set to .
H.1 Actor and Critic Networks
Following Kostrikov et al. (2020), we use clipped double Q-learning for the critic, where each -function is parametrized as a 3-layer MLP with ReLU activations after each layer except of the last. The actor is also a 3-layer MLP with ReLUs that outputs mean and covariance for the diagonal Gaussian that represents the policy. The hidden dimension is set to for both the critic and actor.
H.2 Encoder Network
We employ the encoder architecture from Kostrikov et al. (2020). This encoder consists of four convolution layers with kernels and channels. The ReLU activation is applied after each convolutional layer. We use stride to everywhere, except of the first convolutional layer, which has stride . The output of the convnet is feed into a single fully-connected layer normalized by LayerNorm. Finally, we apply tanh nonlinearity to the dimensional output of the fully-connected layer. We initialize the weight matrix of fully-connected and convolutional layers with the orthogonal initialization and set the bias to be zero. The actor and critic networks both have separate encoders, although we share the weights of the conv layers between them. Furthermore, only the critic optimizer is allowed to update these weights (i.e.,we stop the gradients from the actor before they propagate to the shared convolutional layers).
H.3 Contrastive Metric Embedding Loss
For all our experiments, we use a single ReLU layer with units for the non-linear projection to obtain the embedding (Figure 3). We compute the embedding using the penultimate layer in the actor network. For picking the hyperparameters, we used 3 temperatures and 3 auxiliary loss coefficients using “Ball In Cup Catch” as the validation environment. All other hyperparameters are the same as prior work (see Table H.2).
We approximate optimal policies with the policies obtained after training a DrQ agent for 500K environment steps. Since a given action sequence from this approximate policy has the same performance across different training environments, we compute the PSM across training environments, via dynamic programming (see Section I.1 for pseudo-code), using such action sequences.
Total Loss. The total loss is given by where is the reinforcement learning loss which combines , , and ), while is the auxiliary loss for learning PSEs with the coefficient .
H.4 Training and Evaluation Setup
For evaluation, we use the first 30 videos from the DAVIS 2017 validation dataset (see Figure H.1). Each checkpoint is evaluated by computing the average episode return over 100 episodes from the unseen environments. All experiments are performed with five random seeds per task used to compute means and standard deviations/errors of their evaluations. We use as prescribed by Kostrikov et al. (2020) for DrQ. Following Kostrikov et al. (2020) and Stone et al. (2021), we use a different action repeat hyper-parameter for each task, which we summarize in Table H.3. We construct an observational input as a -stack of consecutive frames (Kostrikov et al., 2020), where each frame is an RGB rendering of size from the th camera. We then divide each pixel by to scale it down to range. For data augmentation, we maintain temporal consistency by using the same crop augmentation across consecutive frames.
| Hyperparameter | Setting |
|---|---|
| Contrastive temperature () | 0.1 |
| Auxiliary loss coefficient () | 1.0 |
| -scale parameter () | 0.1 |
| Batch Size () | 128 |
| 1000 // Action Repeat |
| Parameter | Setting |
| Replay buffer capacity | |
| Seed steps | |
| Batch size (DrQ) | |
| Discount | |
| Optimizer | Adam |
| Learning rate | |
| Critic target update frequency | |
| Critic Q-function soft-update rate | |
| Actor update frequency | |
| Actor log stddev bounds | |
| Init temperature |
| Task name | Action repeat |
|---|---|
| Cartpole Swingup | |
| Reacher Easy | |
| Cheetah Run | |
| Finger Spin | |
| Ball In Cup Catch | |
| Walker Walk |
H.5 Generalization Curves
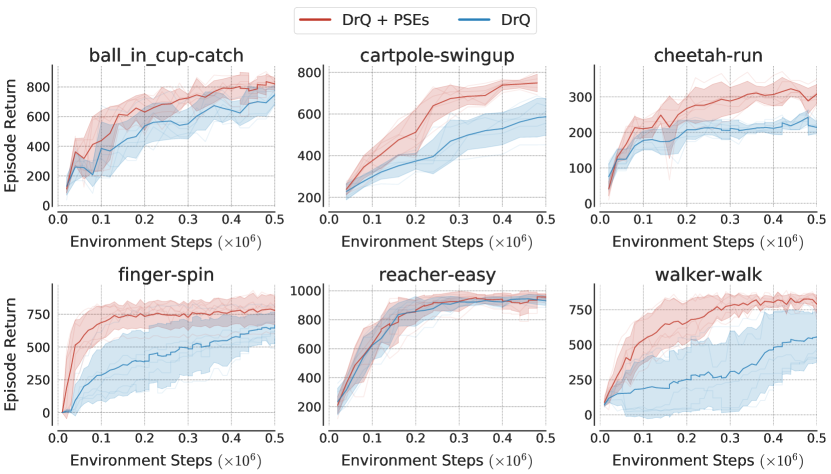
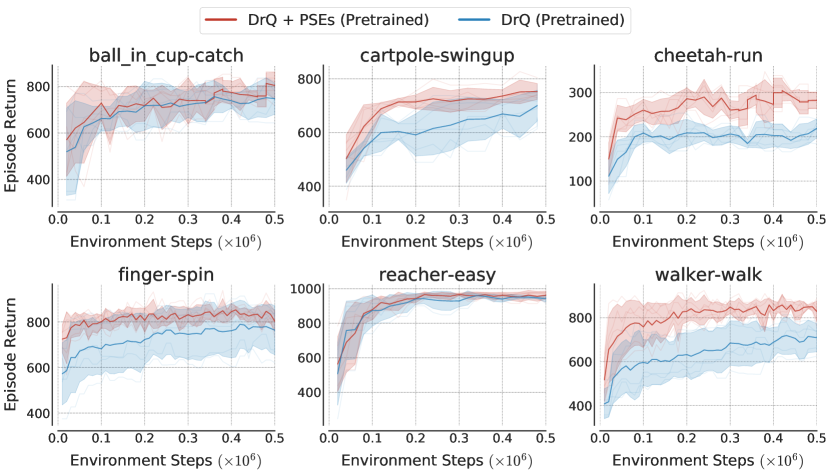
Appendix I Pseudo code
I.1 Dynamic Programming for Computing PSM
I.2 Contrastive Loss
a