WeNet: Production Oriented Streaming and Non-streaming End-to-End Speech Recognition Toolkit
Abstract
In this paper, we propose an open source speech recognition toolkit called WeNet, in which a new two-pass approach named U2 is implemented to unify streaming and non-streaming end-to-end (E2E) speech recognition in a single model. The main motivation of WeNet is to close the gap between the research and deployment of E2E speech recognition models. WeNet provides an efficient way to ship automatic speech recognition (ASR) applications in real-world scenarios, which is the main difference and advantage to other open source E2E speech recognition toolkits. We develop a hybird connectionist temporal classification (CTC)/attention architecture with transformer or conformer as encoder and an attention decoder to rescore th CTC hypotheses. To achieve streaming and non-streaming in a unified model, we use a dynamic chunk-based attention strategy which allows the self-attention to focus on the right context with random length. Our experiments on the AISHELL-1 dataset show that our model achieves 5.03% relative character error rate (CER) reduction in non-streaming ASR compared to a standard non-streaming transformer. After model quantification, our model achieves reasonable RTF and latency at runtime. The toolkit is publicly available at https://github.com/mobvoi/wenet.
Index Terms: WeNet, Production oriented, U2
1 Introduction
End-to-end (E2E) automatic speech recognition (ASR) models have gained more and more attention over the last few years, such as connectionist temporal classification (CTC) [1, 2], recurrent neural network transducer (RNN-T), [3, 4, 5, 6] and attention based encoder-decoder (AED) [7, 8, 9, 10, 11]. Compared with the conventional hybrid ASR framework, the most attractive merit of E2E models is the extremely simplified training procedure.
Recent work [12, 13, 14] also shows that E2E systems have surpassed conventional hybrid ASR systems in the standard of word error rate (WER). Considering the foregoing mentioned advantages of E2E models, deploying the emerging ASR framework into real-world productions becomes necessary. However, deploying an E2E system is not easy and there are a lot of practical problems to be solved.
First, the streaming problem. Streaming inference is essential for many scenarios that require the ASR system to respond quickly with low latency. However, it is difficult for some E2E models to run in a streaming manner, such as LAS [8] and Transformer [15]. Either great effort is required or obvious accuracy loss is introduced to make such model work in the streaming fashion [16, 17, 18].
Second, unifying streaming and non-streaming modes. Streaming and non-streaming systems are usually developed separately. Unifying streaming and non-streaming in a single model can reduce the development effort, training cost as well as deployment cost, which is also preferred for production adoption [19, 20, 21, 22].
Third, the production problem, which is the most important problem we care about during the WeNet design. Great efforts are required to promote the E2E model into a real production application. So we have to carefully design the inference workflow in terms of model architecture, applications and runtime platforms. Due to the working manner of autoregressive beam search decoding, the workflow of most E2E model architecture is extremely complicated. Also, the cost of computation and memory should be considered during the model deployment on edge devices. As for runtime platforms, although there are various platforms can be used to do neural network inference, such as ONNX (Open Neural Network Exchange), LibTorch in Pytorch, TensorRT[23], OpenVINO, MNN[24] and NCNN, it still requires both speech processing and advanced deep learning optimization knowledge to select the best one for specific applications.
In this work, we present WeNet to address the above problems. “We” in WeNet is inspired by “WeChat”111WeChat is the most popular instant messaging platform on mobile devices in Chinese society., which means connection and share, and “Net” is from Espnet [25] since we have referred to a lot of excellent designs in Espnet. Espnet is the most popular open source platform for end-to-end speech research. It mainly focuses on end-to-end ASR, and adopts widely-used dynamic neural network toolkits Chainer and PyTorch as the main deep learning engine. By contrast, the main motivation of WeNet is to close the gap between research and production of E2E speech recognition models. On the production oriented principles, WeNet adopts the following implementations. First, we propose a new two-pass framework namely U2 to solve the unified streaming and non-streaming problem. Second, from model training to deployment, WeNet only depends on PyTorch and it’s ecosystem. The key advantages of WeNet are as follows.
Production first and production ready: The Python code of WeNet meets the requirements of TorchScript, so the model trained by WeNet can be directly exported by Torch Just In Time (JIT) and LibTorch is used for inference. There is no gap between research and production models.
Unified solution for streaming and non-streaming ASR: WeNet adopts the U2 framework to achieve an accurate, fast and unified E2E model, which is favorable for industry adoption.
Portable runtime: Several runtimes are provided to show how to host WeNet trained models on different platforms, including server (x86) and embedded (ARM in Android platforms).
Light weight: WeNet is designed specifically for E2E speech recognition with clean and simple code and all based on PyTorch and its ecosystem. So it has no dependencies on Kaldi[26], which simplifies installation and usage.
Our experiments has shown that, WeNet is a easy-learned speech recognition toolkit with an end-to-end solution from research to production. In this paper, we will describe the model architecture, system design and runtime benchmark including real-time factor (RTF) and latency.
2 WeNet
2.1 Model Architecture
As we aim to address the streaming, unifying and production problem, the solution should be simple and easy to build and convenient to be applied at runtime, while keeping good performance.
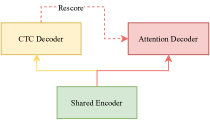
U2, a unified two-pass joint CTC/AED model gives a good solution to the problems. As shown in Figure 1, U2 consists of three parts, Shared Encoder, CTC Decoder and Attention Decoder. The Shared Encoder consists of multiple Transformer [15] or Conformer [27] layers which only takes limited right contexts into account to keep a balanced latency. The CTC Decoder consists of a linear layer, which transforms the Shared Encoder output to the CTC activation while the Attention Decoder consists of multiple Transformer decoder layers. During the decoding process, the CTC Decoder runs in a streaming mode in the first pass and the Attention Decoder is used in the second pass to give a more accurate result.
2.1.1 Training
The CTC loss and AED loss are combined in the training of U2:
| (1) |
where is the acoustic feature, is the corresponding label, and are the CTC and AED loss respectively while is a hyperparameter which balances the importance of CTC and AED loss.
As described before, our U2 can work in streaming mode when the Shared Encoder doesn’t need information of the full utterance. We adopt a dynamic chunk training technique to unify the non-streaming and streaming model. Firstly, the input is split into several chunks by a fixed chunk size with inputs and every chunk attends on itself and all the previous chunks, so the whole latency for the CTC Decoder in the first pass only depends on the chunk size. When the chunk size is limited, it works in a streaming way; otherwise it works in a non-streaming way. Secondly, the chunk size is varied dynamically from 1 to the max length of the current training utterance in the training, so the trained model learns to predict with arbitrary chunk size. Empirically, a larger chunk size gives better results with higher latency, so we can easily balance the accuracy and latency by tuning the chunk size during the runtime.
2.1.2 Decoding
To compare and evaluate different parts of the joint CTC/AED model during the Python based decoding process in the research stage, WeNet supports four decoding modes as follows:
-
•
attention: apply standard autoregressive beam search on the AED part of the model.
-
•
ctc_greedy_search: apply CTC greedy search on the CTC part of the model, CTC greedy search is super faster than other modes.
-
•
ctc_prefix_beam_search: apply CTC prefix beam search on the CTC part of the model, which can give the n-best candidates.
-
•
attention_rescoring: first apply CTC prefix beam search on the CTC part of the model to generate n-best candidates, and then rescore the n-best candidates on the AED decoder part with corresponding encoder output.
During the development runtime stage, WeNet supports the attention_rescoring decodeing mode only since it’s our ultimate solution for production.
2.2 System Design
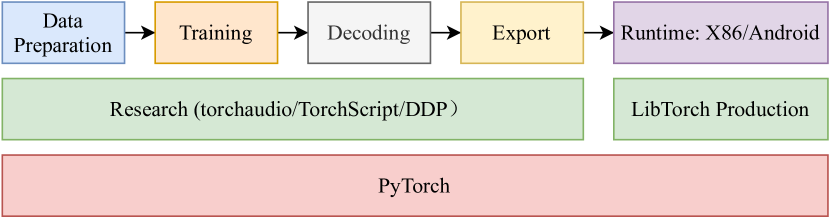
The overall design stack of WeNet is shown in Figure 2. Note that the bottom stack is fully based on PyTorch and it’s ecosystem. The middle stack consists of two parts. When we develop a research model, TorchScript is used for developing models, Torchaudio is used for on-the-fly feature extraction, Distributed Data Parallel (DDP) is used for distributed training, torch Just In Time (JIT) is used for model exportation, PyTorch quantization is used to quantize model, and LibTorch is used for production runtime. LibTorch Production is for hosting production model, which is designed to support various hardwares and platforms like CPU, GPU (CUDA) Linux, Android, and iOS. The top stack shows typical research to production pipeline in WeNet. The following subsections will go through the detailed design of these modules.
2.2.1 Data Preparation
There is no need for any offline feature extraction in the data preparation stage since we use on-the-fly feature extraction in training. WeNet just needs a Kaldi format transcript, a wave list file and a model unit dictionary to create input file.
2.2.2 Training
The training stage in WeNet has the following key features.
On-the-fly feature extraction: this is based on Torchaudio which can generate the same Mel-filter banks feature as Kaldi does. Since the feature is extracted on-the-fly from the raw PCM data, we can perform data augmentation on raw PCM at both time and frequency levels, and finally feature level at the same time, which enrich the diversity of data.
Joint CTC/AED training: joint training speeds up the convergence of the training, improves the stability of the training as well as gives better recognition results.
Distributed training: WeNet supports multiple GPUs training with DistributedDataParallel in PyTorch in order to make full use of multi-worker multi-gpu resources to achieve a higher linear speedup.
2.2.3 Decoding
A set of Python tools are provided to recognize wave files and compute accuracy in different decode modes. These tools help users to validate and debug the model before deploying it in production. All the decoding algorithms in Section 2.1.2 are supported.
2.2.4 Export
As a WeNet model is implemented in TorchScript, it can be exported by torch JIT to the production directly and safely. Then the exported model can be hosted by using the LibTorch library in runtime while both float-32 model and quantized int-8 model are supported. Using a quantized model can double the inference speed or even more when hosted on embedd devices such as ARM based Android and iOS platform.
2.2.5 Runtime
Currently, we support hosting WeNet production model on two mainstream platforms, namely x86 as server runtime and Android as on-device runtime. A C++ API Library and runnable demos for both platforms are provided while the users can also implement their customized system by using the C++ library. We carefully evaluated the three key metrics of an ASR system, which are accuracy, real-time factor (RTF), and latency. The results reported in Section 3.2 will show that WeNet is suitable for many ASR applications including service API and on-device voice assistants.
3 Experiments
We carry out our experiments on the open-source Chinese Mandarin speech corpus AISHELL-1 [28], which contains a 150-hour training set, a 10-hour development set and a 5-hour test set. The test set contains 7,176 utterances in total. As for acoustic features, the 80-dimensional log Mel-filter banks (FBANK) are computed on-the-fly by Torchaudio with a 25ms window and a 10ms shift. Besides, SpecAugment [29] is applied 2 frequency masks with maximum frequency mask (), and 2 time masks with maximum time mask () to alleviate over-fitting. Two convolution sub-sampling layers with kernel size 3*3 and stride 2 are used in the front of the encoder. For model parameters, we use 12 transformer layers for the encoder and 6 transformer layers for the decoder. Adam optimizer is used with a learning rate schedule with 25,000 warm-up steps. Moreover, we obtain our final model by averaging the top-K best models which have a lower loss on the development set during training.
3.1 Unified model evaluation
We first evaluate a non-streaming model (M1) as our baseline which is trained and inferenced by full attention and another unified model (M2) with a dynamic chunk strategy. M2 is inferenced with different chunk sizes (full/16/8/4) at decoding, where full means full attention non-streaming case and 16/8/4 is for the streaming case.
| decoding method | M1 | M2 | |||
|---|---|---|---|---|---|
| full | 16 | 8 | 4 | ||
| attention | 5.69 | 6.04 | 6.35 | 6.45 | 6.70 |
| ctc_greedy_search | 5.92 | 6.28 | 6.99 | 7.39 | 7.89 |
| ctc_prefix_beam_search | 5.91 | 6.28 | 6.98 | 7.40 | 7.89 |
| attention_rescoring | 5.30 | 5.52 | 6.05 | 6.28 | 6.62 |
As shown in Table 1, the unified model not only shows comparable results to the non-streaming model on the full attention case but also gives promising results on the streaming case with limited chunk size 16/8/4, which verifies the effectiveness of the dynamic chunk training strategy.
Comparing the four different decoding modes, the attention_rescoring mode can always improve on the CTC results in both the non-streaming mode and the unified mode. The ctc_greedy_search and ctc_prefix_beam_search have almost the same performance, and they degrade significantly as the chunk size decreases. The attention_rescoring mode alleviates the performance degradation of the ctc_prefix_beam_search results while the attention mode degrades the performance slightly.
The attention_rescoring mode is faster and has a better RTF than the attention mode since the attention mode is an autoregressive procedure while the attention_rescoring mode is not. Overall, the attention_rescoring mode not only shows promising results but also has a lower RTF. As a result, the dynamic chunk based unified model with attention_rescoring decoding is our choice for production. So only the attention_rescoring mode is supported at runtime.
3.2 Runtime benchmark
This section will show the quantization, RTF, and latency benchmarks on the unified model M2 described above. We finished benchmarks on a server x86 platform and an on-device ARM Android platform respectively.
For the cloud x86 platform, the CPU is 4 cores Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz with 16G memory in total. Only one thread is used for CPU threading and TorchScript inference 222https://pytorch.org/docs/stable/notes/cpu_threading_torchscript_inf
erence.html for each utterance since the cloud service requires parallel processing, and a single thread avoids performance degradation in parallel processing. For the on-device Android, the CPU is 4 cores Qualcomm Snapdragon 865 with 8G memory and a single thread is used for the on-device inference.
3.2.1 Quantization
Here we just compare CER before and after quantization. As shown in Table 2, CER is comparable before and after quantization. CER of the float model is slightly different from what we listed in Table 1 because the result in Table 1 is evaluated by Python research tools while that in Table 2 here is evaluated by runtime tools.
| quantization/decoding_chunk | full | 16 | 8 | 4 |
|---|---|---|---|---|
| NO (float32) | 5.58 | 6.03 | 6.27 | 6.60 |
| YES (int8) | 5.59 | 6.06 | 6.28 | 6.64 |
3.2.2 RTF
As shown in Table 3, RTF increases as the chunk size decreases since smaller chunk requires more iterations for forward computation. Further, quantization can bring about 2 times speedup on on-device (Android) and a slight improvement on server (x86).
| model/decoding_chunk | full | 16 | 8 | 4 |
|---|---|---|---|---|
| server (x86) float32 | 0.079 | 0.095 | 0.128 | 0.186 |
| server (x86) int8 | 0.072 | 0.081 | 0.098 | 0.134 |
| on-device (Android) float32 | 0.164 | 0.251 | 0.350 | 0.505 |
| on-device (Android) int8 | 0.082 | 0.114 | 0.130 | 0.201 |
3.2.3 Latency
For latency benchmark, we create a WebSocket server/client to simulate a real streaming application because this benchmark is only carried out on the server x86 platform. The average latency we evaluated is described here. Model latency (L1): the waiting time introduced by the model structure. For our chunk based decoding, the average waiting time is half of the chunk theoretically. And the total model latency of our model is (ms), where 4 is the subsampling rate, 6 is the lookahead introduced by the first two CNN layers in the encoder and 10 is the frame shift. Rescoring cost (L2): the time cost on the second pass attention rescoring. Final latency (L3): the user (client) perceived latency, which is the time difference between the user stopping speaking and getting the recognition result. When our ASR server receives the speech ending signal, it first forwards the left speech for CTC searching, and then does the second pass attention rescoring, so rescoring cost is part of the final latency. The network latency also should be taken into account for a real production but it is negligible, since we test the server/client on the same machine.
| decoding_chunk | L1 (ms) | L2 (ms) | L3 (ms) |
|---|---|---|---|
| 16 | 380 | 115 | 142 |
| 8 | 220 | 115 | 135 |
| 4 | 140 | 114 | 130 |
As shown in Table 4, the rescoring costs are almost the same for different chunk sizes and this is reasonable since rescoring computation is invariant to chunk size. Besides, the final latency is dominated by the rescoring cost which means we can further reduce the final latency by reducing the rescoring cost. At last, the final latency increases slightly as the decoding chunk varies from 4 to 8 and from 8 to 16.
3.3 15,000-hour Task
| test set | Utt Dur (s) | Conformer | U2 | |
|---|---|---|---|---|
| full | 16 | |||
| AISHELL-1 | 5.01 | 3.96 | 3.70 | 4.41 |
| TV | 2.99 | 10.96 | 11.61 | 13.03 |
| Conversation | 2.69 | 12.84 | 13.86 | 15.07 |
We further train the proposed U2 model using a 15,000-hour Mandarin dataset collected from various domains which include talk show, TV play, podcast and radio broadcast to show our model’s ability on an industry-scale dataset. The model is evaluated on three test sets.
We use Conformer [27] as our shared encoder while the decoder is a transformer as same as the previous experiments. Conformer adds convolution module on the basis of transformer so it can capture both local and global context and get better results on different ASR tasks. Specially, the causal convolution is used for chunk training of Conformer and we add extra 3 dimensional pitch features concatenated with 80-dimensional FBANK. We keep the main structure of the encoder in previous experiments and only change the transformer layers to 12 conformer layers with multi-head attention (4 heads). Each conformer layer uses 384 attention dimension and 2048 feed forward dimension. Besides, accumulating grad is also used to stabilize training and we update parameters every 4 steps. Moreover, we obtain our final model by averaging the top-10 best models which have a lower loss on the evaluation set during training. We train a full context conformer CTC model and a U2 model using dynamic chunk training. Three test sets are used to evaluate these models, including AISHELL-1, TV domain and conversation domain. The U2 model works on attention_rescoring decoding mode while the conformer model works on the attention decoding mode. As shown in Table 5, we can see that U2 achieves comparable results with the Conformer baseline in general and even better results on AISHELL-1 test set when using full attention during inference. When the chunk size is 16, the CER does not get obviously worse.
To analyse why U2 model perform better on the AISHELL-1 task, we collect the average utterance duration in each test set shown in Table 5. Since the average utterance duration in AISHELL-1 is much longer than that in the other two test sets, AISHELL-1 task may need stronger global information modeling ability. The U2 model can use the attention decoder to rescore the CTC hypotheses, which makes it more favourable to the AISHELL-1 task.
4 Conclusions
We present a new open source production oriented E2E speech recognition toolkit named WeNet, providing a unified solution for streaming and non-streaming application. This paper introduces the model structure behind the toolkit, system design and benchmarks. The whole toolkit is well designed, lightweight and shows great performance on an open dataset and an internal large dataset. Wenet has already supported custom language model in runtime, by adopting n-gram ad WFST. In addition, Wenet has also supported gRPC-based speech recognition microservice framework applications. More featured functions will be updated in the future. Please stay tuned and visit our website https://github.com/wenet-e2e/wenet for more updates.
References
- [1] A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks,” in Proceedings of the 23rd international conference on Machine learning, 2006, pp. 369–376.
- [2] D. Amodei, S. Ananthanarayanan, R. Anubhai, J. Bai, E. Battenberg, C. Case, J. Casper, B. Catanzaro, Q. Cheng, G. Chen et al., “Deep speech 2: End-to-end speech recognition in english and mandarin,” in International conference on machine learning, 2016, pp. 173–182.
- [3] A. Graves, “Sequence transduction with recurrent neural networks,” arXiv preprint arXiv:1211.3711, 2012.
- [4] A. Graves, A.-r. Mohamed, and G. Hinton, “Speech recognition with deep recurrent neural networks,” in IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2013, pp. 6645–6649.
- [5] X. Wang, Z. Yao, X. Shi, and L. Xie, “Cascade RNN-Transducer: Syllable based streaming on-device mandarin speech recognition with a syllable-to-character converter,” in 2021 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2021, pp. 15–21.
- [6] S. Wang, P. Zhou, W. Chen, J. Jia, and L. Xie, “Exploring rnn-transducer for chinese speech recognition,” in 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC). IEEE, 2019, pp. 1364–1369.
- [7] J. Chorowski, D. Bahdanau, K. Cho, and Y. Bengio, “End-to-end continuous speech recognition using attention-based recurrent nn: First results,” in NIPS 2014 Workshop on Deep Learning, 2014.
- [8] W. Chan, N. Jaitly, Q. V. Le, and O. Vinyals, “Listen, attend and spell,” arXiv preprint arXiv:1508.01211, 2015.
- [9] J. K. Chorowski, D. Bahdanau, D. Serdyuk, K. Cho, and Y. Bengio, “Attention-based models for speech recognition,” in Advances in neural information processing systems, 2015, pp. 577–585.
- [10] H. Luo, S. Zhang, M. Lei, and L. Xie, “Simplified self-attention for transformer-based end-to-end speech recognition,” in 2021 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2021, pp. 75–81.
- [11] H. Miao, G. Cheng, C. Gao, P. Zhang, and Y. Yan, “Transformer-based online ctc/attention end-to-end speech recognition architecture,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6084–6088.
- [12] R. Prabhavalkar, K. Rao, T. N. Sainath, B. Li, L. Johnson, and N. Jaitly, “A comparison of sequence-to-sequence models for speech recognition.” in Interspeech, 2017, pp. 939–943.
- [13] T. N. Sainath, R. Pang, D. Rybach, Y. He, R. Prabhavalkar, W. Li, M. Visontai, Q. Liang, T. Strohman, Y. Wu et al., “Two-pass end-to-end speech recognition,” 2019, pp. 2773–2777.
- [14] S. Kim, T. Hori, and S. Watanabe, “Joint CTC-attention based end-to-end speech recognition using multi-task learning,” in IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2017, pp. 4835–4839.
- [15] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in neural information processing systems, 2017, pp. 5998–6008.
- [16] C. Raffel, M.-T. Luong, P. J. Liu, R. J. Weiss, and D. Eck, “Online and linear-time attention by enforcing monotonic alignments,” in International Conference on Machine Learning. PMLR, 2017, pp. 2837–2846.
- [17] C.-C. Chiu and C. Raffel, “Monotonic chunkwise attention,” in International Conference on Learning Representations, 2018.
- [18] H. Inaguma, M. Mimura, and T. Kawahara, “Enhancing monotonic multihead attention for streaming asr,” in Proc. Interspeech, 2020, pp. 2137–2141.
- [19] J. Yu, W. Han, A. Gulati, C.-C. Chiu, B. Li, T. N. Sainath, Y. Wu, and R. Pang, “Universal ASR: Unify and improve streaming asr with full-context modeling,” arXiv preprint arXiv:2010.06030, 2020.
- [20] A. Tripathi, J. Kim, Q. Zhang, H. Lu, and H. Sak, “Transformer transducer: One model unifying streaming and non-streaming speech recognition,” arXiv preprint arXiv:2010.03192, 2020.
- [21] K. Hu, T. N. Sainath, R. Pang, and R. Prabhavalkar, “Deliberation model based two-pass end-to-end speech recognition,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 7799–7803.
- [22] K. Hu, R. Pang, T. N. Sainath, and T. Strohman, “Transformer based deliberation for two-pass speech recognition,” in 2021 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2021, pp. 68–74.
- [23] H. Vanholder, “Efficient inference with tensorrt,” 2016.
- [24] X. Jiang, H. Wang, Y. Chen, Z. Wu, L. Wang, B. Zou, Y. Yang, Z. Cui, Y. Cai, T. Yu, C. Lv, and Z. Wu, “MNN: A universal and efficient inference engine,” in Machine Learning and Systems (MLSys), 2020.
- [25] S. Watanabe, T. Hori, S. Karita, T. Hayashi, J. Nishitoba, Y. Unno, N. E. Y. Soplin, J. Heymann, M. Wiesner, N. Chen et al., “Espnet: End-to-end speech processing toolkit,” arXiv preprint arXiv:1804.00015, 2018.
- [26] D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P. Motlicek, Y. Qian, P. Schwarz et al., “The Kaldi speech recognition toolkit,” in IEEE 2011 workshop on automatic speech recognition and understanding. IEEE Signal Processing Society, 2011.
- [27] A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y. Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y. Wu et al., “Conformer: Convolution-augmented transformer for speech recognition,” in Proc. Interspeech, 2020, pp. 5036–5040.
- [28] H. Bu, J. Du, X. Na, B. Wu, and H. Zheng, “Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline,” in 2017 20th Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment (O-COCOSDA). IEEE, 2017, pp. 1–5.
- [29] D. S. Park, W. Chan, Y. Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V. Le, “Specaugment: A simple data augmentation method for automatic speech recognition,” in Proc. Interspeech, 2019, pp. 2613–2617.