Heterogeneity for the Win: One-Shot Federated Clustering
Abstract
In this work, we explore the unique challenges—and opportunities—of unsupervised federated learning (FL). We develop and analyze a one-shot federated clustering scheme, k-FED, based on the widely-used Lloyd’s method for -means clustering. In contrast to many supervised problems, we show that the issue of statistical heterogeneity in federated networks can in fact benefit our analysis. We analyse k-FED under a center separation assumption and compare it to the best known requirements of its centralized counterpart. Our analysis shows that in heterogeneous regimes where the number of clusters per device is smaller than the total number of clusters over the network , , we can use heterogeneity to our advantage—significantly weakening the cluster separation requirements for k-FED. From a practical viewpoint, k-FED also has many desirable properties: it requires only one round of communication, can run asynchronously, and can handle partial participation or node/network failures. We motivate our analysis with experiments on common FL benchmarks, and highlight the practical utility of one-shot clustering through use-cases in personalized FL and device sampling.
1 Introduction
Federated learning (FL) aims to perform machine learning over large, heterogeneous networks of devices such as mobile phones or wearables (McMahan et al., 2017). While significant attention has been given to the problem of supervised learning in such settings, the problem of unsupervised federated learning has been relatively unexplored (Kairouz et al., 2019). In this work, we show that unsupervised learning presents unique opportunities for FL, specifically for the task of clustering data that resides in a federated network.
Clustering is a crucial first step in many learning tasks. In the case of federated learning, clustering has found applications in client-selection (Cho et al., 2020), personalization (Ghosh et al., 2020) and exploratory data analysis. While many works have explored techniques for distributed clustering (Section 2), most do not take into account the unique challenges of federated learning, such as statistical heterogeneity, systems heterogeneity, and stringent communication constraints (Li et al., 2020a)111Privacy, while an important concern for many federated applications, is not the main focus of our work. However, a possible benefit of the one-shot nature of k-FED is that it requires significantly fewer messages to be shared over the network relative to standard iterative techniques such as distributed -means.. These challenges can complicate analyses, reduce efficiency, and lead to practical issues with stragglers and device failures. In this work, we study communication-efficient distributed clustering in settings where the data is non-identically distributed across the network (i.e., heterogeneous), and devices can join and leave the network abruptly. For such settings, we develop and analyse a one-shot clustering scheme, k-FED, based on the classical Lloyd’s heuristic (Lloyd, 1982) for clustering.
The method we propose, k-FED, requires only one round of communication with a central server. Each device, indexed by , solves a local -means problem and then communicates its local cluster means via a message of size . As we show in Section 3, this allows for device failures, only requiring that there are enough devices available in the network such that target clusters exist in the data. Moreover, it is possible to cluster points in previously unavailable devices via a simple recomputation at the central server.
Beyond the practical benefits of k-FED, our work is unique in rigorously demonstrating a problem setting where possible benefits of statistical heterogeneity exist for federated learning. In particular, in supervised learning, many works have highlighted detrimental effects of statistical heterogeneity, observing that heterogeneity can lead to poor convergence for federated optimization methods (McMahan et al., 2017; Li et al., 2020b), result in unfair models (Mohri et al., 2019), or necessitate novel forms of personalization (Smith et al., 2017; Mansour et al., 2020). In contrast to these works, we show that for the specific notion of heterogeneity considered herein (provided in Definition 3.2 and motivated by the application of clustering), heterogeneity can in fact have measurable benefits for our approach.
More specifically, similar to many works in clustering (Kumar & Kannan (2010); Awasthi & Sheffet (2012) and references therein), we analyse k-FED under a center-separation assumption; that is, we assume that the mean of the clusters are well separated. We also consider a specific notion of heterogeneity: given a target clustering with clusters that we wish to recover from the data, we assume that each device contains data from only of these target clusters. For instance, for clustering data generated by a mixture of well separated Gaussians, we assume that each device contains data from component Gaussians. In this regime, we show that our separation requirement is similar to that of the centralized counterpart. Further, while the centralized setting requires all pairs of cluster centers to satisfy a center separation requirement, the federated approach can handle a large fraction of cluster pairs only satisfying a weaker separation requirement. This is the first result we are aware of that analyzes the benefits of heterogeneity in the context of federated clustering.
Contributions. We propose and analyze a one-shot communication scheme for federated clustering. Our proposed method, k-FED, addresses common practical concerns in federated settings, such as high communication costs, stragglers, and device failures. Theoretically, we show that k-FED performs similarly to centralized clustering in regimes where each device only has data from at most clusters with a similar center separation requirement. Moreover, in contrast to the centralized setting, we show that a large number of cluster pairs need only a weaker separation assumption in heterogeneous networks, thus allowing a broader class of problems to be solved in this setting compared with centralized clustering. We demonstrate our method through experiments on common FL benchmarks, and explore the applicability of k-FED to problems in personalized federated learning and device sampling. Our work highlights that heterogeneity can have distinct benefits for a subset of problems in federated learning.
2 Background and Related Work
Centralized Clustering. Clustering is one of the most widely-used unsupervised learning tasks, and has been extensively studied in both centralized and distributed settings. Although a variety of clustering methods exist, Lloyd’s heuristic (Lloyd, 1982) remains popular due in part to its simplicity. In Lloyd’s method, we start with an initial set of centers. We then assign each point to its nearest center and reassign the centers to be the mean of all the points assigned to it, continuing this process till termination. While it is easy to show that this method terminates, it is also known that this process can take superpolynomial time to converge (Arthur & Vassilvitskii, 2006). However, under suitable assumptions and careful choice of the initial centers, it can be shown to converge in polynomial time (Arthur & Vassilvitskii, 2006; Ostrovsky et al., 2013; Kumar & Kannan, 2010; Awasthi & Sheffet, 2012).
The method we propose, k-FED (Section 3.2), is a simple, communication-efficient distributed variant of these classical techniques. k-FED runs a variant of Lloyd’s method for -means clustering locally on each device, and then performs one round of communication to aggregate and assign clusters. Our work builds on the analysis of a variant of Lloyd’s algorithm developed by Kumar & Kannan (2010) and later improved in Awasthi & Sheffet (2012) for the problem of clustering data from mixture distributions and other related results (e.g., McSherry, 2001; Ostrovsky et al., 2013). These works develop a deterministic framework with no generative assumptions on the data. Our analysis follows this framework and does not make any generative assumptions on the data.
Parallel and Distributed Clustering. Many works have explored parallel or distributed implementations of centralized clustering techniques (Dhillon & Modha, 2002; Tasoulis & Vrahatis, 2004; Datta et al., 2005; Bahmani et al., 2012; Xu et al., 1999). Unlike the one-shot communication scheme explored herein, these methods are typically direct parallel implementations of methods such as Lloyd’s heuristic or DBSCAN (Ester et al., 1996), and require numerous rounds of communication. Another line of work has considered communication-efficient distributed clustering variants that require only one or two rounds of communication (e.g., Kargupta et al., 2001; Januzaj et al., 2004; Feldman et al., 2012; Balcan et al., 2013; Bateni et al., 2014; Bachem et al., 2018). These works are mostly empirical, in that there are no provable guarantees on the approximation quality of the distributed schemes; the works of Balcan et al. (2013); Bateni et al. (2014); Bachem et al. (2018) differ by providing communication-efficient distributed coreset methods for clustering, along with provable approximation guarantees. However, these works do not explore the federated setting or potential benefits of heterogeneity.
Federated Clustering. Several works have explored clustering in the context of supervised FL as a way to better model non-IID data (Smith et al., 2017; Ghosh et al., 2019, 2020; Sattler et al., 2020). These works differ from our own by clustering specifically in terms of devices, focusing on the downstream supervised learning task, and using either iterative (Smith et al., 2017; Ghosh et al., 2020; Sattler et al., 2020) or centralized (Ghosh et al., 2019) clustering schemes. Though not the main of focus of our work, in Section 4 we demonstrate the applicability of one-shot clustering by showing how k-FED can be used as a simple pre-processing step to deliver personalized federated learning—achieving similar or superior performance relative to the recent iterative approach for clustered FL proposed in Ghosh et al. (2020).
More recently, a distributed matrix factorization based clustering approach was explored in Wang & Chang (2020) for the purposes of unsupervised learning. However, while the authors consider the impact of statistical heterogeneity on their convergence guarantees, the focus is not on one-shot clustering or on showing distinct benefits of heterogeneity in their analyses.
3 k-FED: Preliminaries and Main Results
In this section, we begin by discussing some preliminaries and existing results in clustering related to Lloyd-type methods. In Section 3.1, we present the deterministic framework of Awasthi & Sheffet (2012) for centralized clustering, which we build upon. We present our method k-FED and state our theoretical results in Section 3.2. We provide detailed proofs in Appendix A.
3.1 Centralized -means
In the standard (centralized) -means problem, we are given a matrix where each row is a data point in . We are also given a fixed positive integer , and our objective is to partition the data points into disjoint partitions, so as to minimize the -means cost:
| (1) |
Here we use as an operator to indicate the mean of the points indexed by , i.e., . To ease notation, we simplify this as , when is unambiguous.
While the k-means problem as stated here does not specify any generative model for the data points , a popular setting to consider is when the data is sampled from a mixture of -distributions in -dimensions (). For instance, we could imagine the data points as being sampled from a mixture of Gaussian distributions. This generative model also introduces a notion of a target clustering, where the set contains all points generated by the -th component distribution. Many distribution dependent results are known for the problem of clustering distributions (see Kumar & Kannan (2010)). In general, they can be stated as: If the means of the distributions are standard deviations apart, then we can cluster the data in polynomial time. Kumar & Kannan (2010) introduce a deterministic (distribution independent) framework that encompasses many of these known results. This work was later simplified and improved by Awasthi & Sheffet (2012). We state the main results of this framework here, after stating the notation we use. We emphasis that in our analysis we make no assumptions on how the data is generated; all relevant quantities only depend on the provided data.
Notation. We now introduce several definitions and notations that will be used throughout the paper. Let denote the spectral norm of a matrix , defined as , and let denote the norm of a vector . For consistency, we index individual rows of with and . Moreover, when a target clustering is fixed, we index clusters with , e.g., is the matrix of points indexed by . For notational convenience, we let to denote the cluster index for data point such that, . For some set of points , and another point say , let denote the distance of to the set , defined as . Finally, let be a matrix with each row . For cluster with , we define
| (2) |
Here the quantity can be thought of as a deterministic analogue of the standard deviation; it measures the maximum average variance along any direction. Thus instead of reasoning about the separation between two clusters and in terms of the standard deviation, we will use . In particular, we say that the two clusters and are well separated if for large enough constant , their means satisfy:
| (3) |
Again, we can interpret this as saying that two clusters are well separated if their means are -standard-deviations apart.222 Any is sufficient for our arguments (see Lemma 5). Using the center separation assumption in (3), Awasthi & Sheffet (2012) show that for a target clustering satisfying the separation assumption, the variant of Lloyd’s algorithm presented in Algorithm-1 when applied to the centralized clustering problem correctly clusters all but a small fraction of the data points. We state their result formally in Lemma 1, but before that we define a proximity condition, that will be used to precisely characterize the misclassified points.
Definition 3.1.
A point for some is said to satisfy the proximity condition, if for every , the projection of onto the line connecting and , denoted by satisfies
Thus a point for satisfies the proximity condition if its projection on the line connecting and is closer to by . We refer to points that do not satisfy the proximity condition as ‘bad points’. We now state the main result from Awasthi & Sheffet (2012) in the following lemma.
Lemma 1 (Awasthi-Sheffet, 2011).
Let be the target clustering. Assume that each pair of clusters and are well separated. Then, after step 2 of Algorithm-1, for every , it holds that . Moreover, if the number of bad points is , then (a) the clustering misclassifies no more than points and (b) . Finally, if then all points are correctly assigned.
When we say misclassify, we mean with respect to and up to a permutation of labels. Lemma 1 tells us that the cluster means, , are not very far away from the target cluster means, . Note that there are no distribution dependent terms in this statement; all relevant quantities are defined in terms of the data matrix and .
3.2 k-FED: Method and Main Result
We now turn our attention to clustering data in a federated network. In our setting, we assume that all the devices in the network can communicate with a central server. Our clustering method k-FED, described in Algorithm 2, can be thought of as working in two stages. In the first stage, each device solves a local clustering subproblem and computes the cluster means for this subproblem. In the second stage, the central server accumulates and aggregates the results to compute the final clustering.
Notation. Let be an data matrix of all the data points in our network. We index individual devices by and thus, we denote the data-matrix for any particular device by , where is the number of data points on the device. Let . Note that is some subset of rows of . Let be a clustering of all the data, referred to as a target clustering. For a fixed , let be subsets of our target clustering that reside on a device . Note that some could be empty. Let be the number of non-empty subsets on device and let . Our notion of heterogeneity is formally defined based on the value of , as described below.
Definition 3.2 (Heterogeneity of Clustering).
In the context of clustering, we say that a federated network with sufficient data is heterogeneous if . The lower the ratio between and , the more heterogeneity exists in the network.
Intuitively, this definition of heterogeneity states that—in contrast to the data from the total clusters being partitioned in an IID fashion across the network—the data are partitioned in an non-IID fashion, such that only data from a small number of clusters (at most ) exists on each device. Such non-IID partitioning is reasonable to expect in heterogeneous federated networks with a large number of clusters, since the distribution of data on each device may differ, and it is not possible to actively re-distribute data across the network. For instance, consider identifying interests of mobile phone users based on the interaction data on an application. Here the interaction data is generated by the user on their particular device, and will reflect the tastes of individual. While the total number of ‘tastes’ (clusters) over the entire network could be quite large, a typical user will be interested in only a small number of them. With this definition in mind, we next describe our one-shot clustering method, k-FED, and analyze it in heterogeneous regimes.
Method Description.
Similar to the centralized case (Section 3.1), let be a matrix of the local cluster means, i.e. of . Consider a non-empty susbset of cluster on some device and let . We assume that there is a constant , such that for all . We will use this quantity to ensure that individual devices have ‘enough’ points. Let,
| (4) |
In the first step of k-FED (Algorithm-2), each (available) device runs Algorithm-1 locally and solves a local clustering problem with their local dataset and parameter . We assume that is known. This stage outputs device cluster centers and cluster assignments, for each device . At this stage, note that even though each device has classified its own points into clusters, we do not yet have a clustering for points across devices. The central server attempts to create this clustering by aggregating the device cluster centers and separating them into sets, . These sets induce a clustering of the data on the network as defined here:
Definition 3.3 (k-FED induced clustering).
Let be the clustering of device centers returned by Algorithm 2. Define,
Then, form a disjoint partition of the entire data, called the k-FED induced clustering.
For our analysis comparing the quality of the k-FED induced clustering, , to our target clustering , we require two different separation assumptions. We refer to them as active and inactive separation and introduce them through the following two definitions.
Definition 3.4 (Active/Inactive cluster pairs).
A pair of clusters are said to be an active pair if there exists at least one device that contains data points from both and . If no device has data points from both clusters and , we refer to the cluster pair as an inactive pair.
Definition 3.5.
We say that two clusters and satisfies the active separation requirement if, , for some large enough constant . Similarly, we say that they satisfy the inactive separation requirement if .
Intuitively, these notions capture the difficulty in clustering two different types of clusters pairs—active and inactive cluster pairs. If no device has data from both and (i.e. an inactive pair), then the clustering sub-problems individual devices have to solve is easier since they never involve data from both of these clusters simultaneously. Thus the separation requirement for inactive cluster pairs is weaker than that for an active cluster pair. We now state our main theorem, which characterizes the performance of k-FED. We provide a detailed proof in Appendix A.
Theorem 3.1 (Main theorem).
Let be a fixed target clustering of the data on a federated network. Let be such that, for all and for all . Assume that each active cluster pairs and satisfy the active separation requirement, i.e.,
Further, assume that for each inactive cluster pairs ,
Then, at termination of k-FED all but points are correctly classified. Moreover, if for each device , the data points satisfy the proximity condition (Definition 3.1) for its local problem, then all points are classified correctly.
As before, by classified we mean that the clustering produced by k-FED and agree on all but points, up to permutation of labels of . Note that when , our active separation requirement is stricter than that required in centralized clustering vs . Further, as one would expect, as the number of points per cluster on each device decreases, the local clustering becomes harder. This is highlighted by our adverse dependency on .
However, in contrast to the general distributed learning framework where each device typically has a random subset of the data, the data residing on the devices in federated networks are typically generated locally and thus the partition of data among the devices is non-identically distributed. Specifically, in practice, the number of subsets of target clusters that reside on a device may be much smaller than the total number of clusters. Thus, as outlined in Definition 3.2, we look at the cases where . Observe that in such settings, our active separation requirement reduces to that of the centralized -means problem (with an additional penalty) and our inactive separation requirement weakens to . We state this formally in Corollary 1.1.
Corollary 1.1.
Assuming , an active cluster pair satisfies the active separation requirement if
Similarly, an inactive cluster pair satisfies the inactive separation requirement if
Thus in this setting of , k-FED recovers the target partitions in only one round of communication. Moreover, inactive cluster pairs need only satisfy our separation requirement as opposed to the separation that all cluster pairs need to satisfy in the centralized setting for Lemma 1 to hold. This highlights that there exists a benefit of heterogeneity in the context of running k-FED over federated networks.
Practical benefits of k-FED.
Finally, we highlight several practical benefits of the k-FED method:
-
•
One-shot: k-FED only requires one round of communication for each device: one outgoing message to send the local clustering results and one incoming message to receive cluster identity information.
-
•
No network-wide synchronization: Classical parallel implementations of Lloyd’s heuristic and variants (e.g., Dhillon & Modha, 2002), require a network wide synchronization/initialization step. Unlike these methods, each device in k-FED works independently does not require an initialization/synchronization step.
-
•
New devices/Device Failures: Assuming we have already performed clustering on the current network, for any new device entering the network, either from a previous failure or as a new participant, computing the clustering information can be done without involving any other device in the network. As we show in Theorem 3.2 (below), simply assigning any new local cluster center from the new device , to the nearest device cluster mean in sufficient. The central server only has to maintain cluster means to perform this update.
Theorem 3.2.
Steps 2-8 of k-FED take pairwise distance computations to terminate. Further, after the set in Step 6 has been computed, new local cluster centers from a yet unseen device can be correctly assigned in distance computations.
As we show in Section 4, these properties of k-FED make it an ideal candidate for being used as an inexpensive heuristic for clustering in federated networks, either for data exploration or as part of a preprocessing step for another algorithm, even in settings where the separation requirements are not formally satisfied.
4 Applications and Experiments
We now present experimental evaluation of k-FED. We first specialize the theory to the special case where data is drawn from a mixture of Gaussians in Section 4.1 to validate our theory on synthetic data. In Section 4.2, we evaluate k-FED on real datasets—presenting experimental evidence that highlights the benefit of heterogeneity and the communication efficiency of k-FED. We further present two applications of k-FED, in client selection as well as personalization. The dataset details for each experiment can be found in the corresponding section. Implementation of k-FED and experimental setup details can be found at: http://github.com/metastableB/kfed/.
4.1 Separating Mixture of Gaussians
We first specialize our theorem to the case of separating data generated from a mixture of Gaussians . Let be the mean of the mixture component and let be the mixing weights. Finally, let be the minimum mixing weight. Let be the maximum variance along any direction among all the component distributions. Assume this data resides over our devices such that no single device has data from more than components. We state the following theorem (proved in Appendix A) that specifies the conditions required for this setup to satisfy our separation assumptions:
Theorem 4.1.
Let the total number of data pints, . Then any active cluster pairs satisfy the active separation requirement with high probability if;
Further, an inactive cluster pairs satisfy the inactive separation requirement with high probability if
Finally, with this separation in place, all points satisfy the proximity condition with high probability.
Concretely, in this setup k-FED recovers the target clustering exactly with high probability. To empirically evaluate our theory, we instantiate an simplified instance of the above setup as follows:
| Parameters | Accuracy |
|---|---|
Setup. Again consider the Gaussian components , and define the set of integers . These sets thus can be used to index the Gaussian components . For each , construct a set of data points by sampling samples from each component for . Thus the set contains samples . Pick and for each set of data points , distribute the data among devices such that each device receives exactly samples. We now run k-FED on this setup and measure the quality of the clustering averaged over 10 runs, (shown in Table 1). As one would expect, the clustering produced by k-FED agrees strongly with the target clustering. Note that by construction all devices with data from the same set contain data from the same set of Gaussian components. Further, devices with data from different sets have no common Gaussian component. Thus all cluster pairs within the same set are active cluster pairs and there are such pairs. Moreover, any pair such that , form an inactive cluster pair and there are such pairs. These need only satisfy the weaker inactive separation requirement.
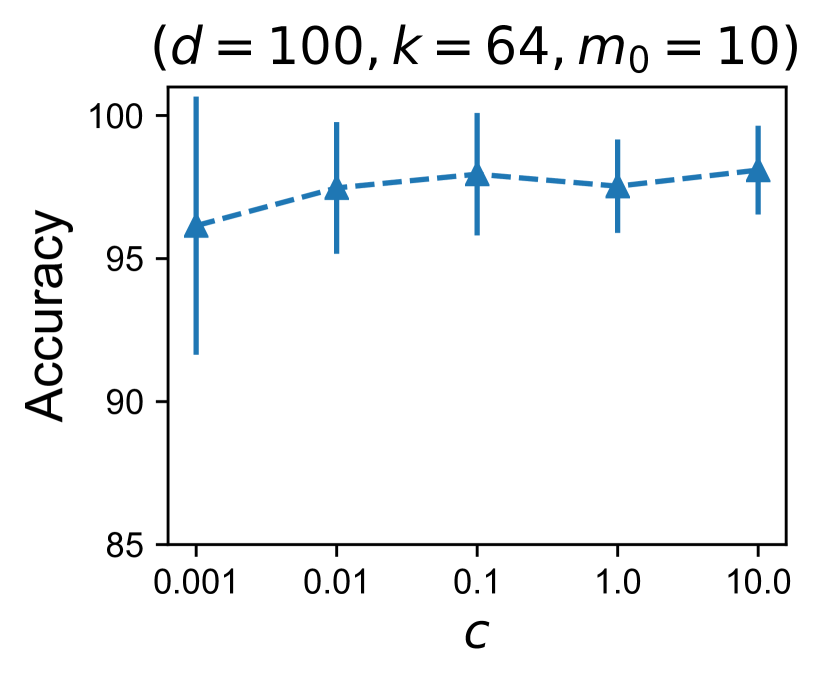
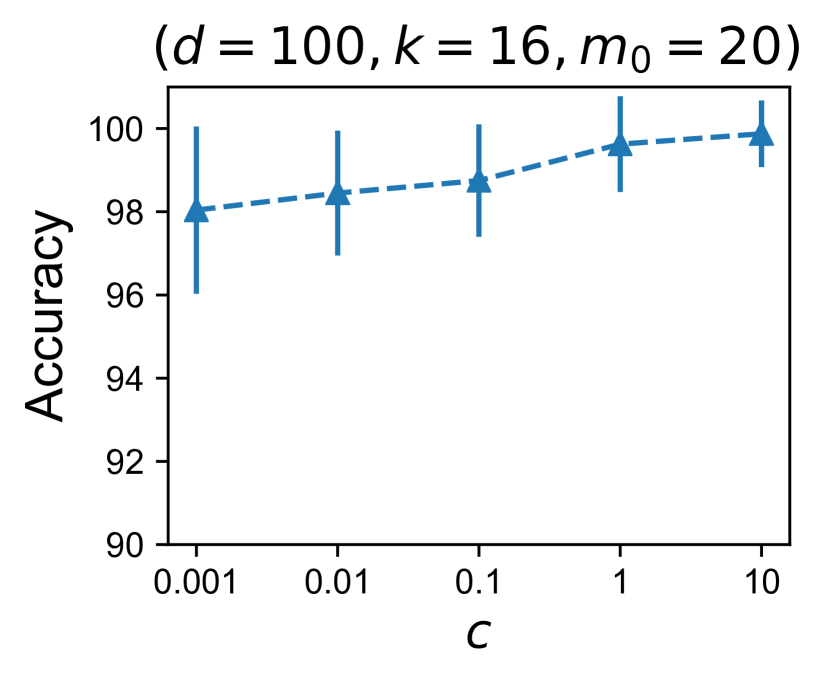
Note that while we prescribe for our arguments to hold, Figure 1 demonstrates that clustering can be recovered even in settings where is much smaller.
4.2 Empirical Evaluation on Real Data
In this section, we empirically explore k-FED and the related analyses from Section 3. First, we validate our theoretical results, showing that clustering over structured (heterogeneous) partitions can improve clustering performance relative to clustering over random, IID partitioned data. Second, we explore the effect of one-shot clustering relative to more communication-intensive baselines. Finally, we investigate practical applications of one-shot clustering in terms of client sampling and personalized federated learning.
4.2.1 Properties of k-FED
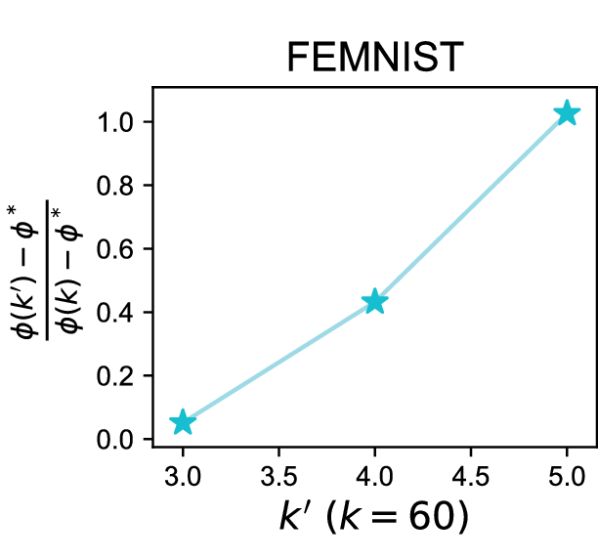
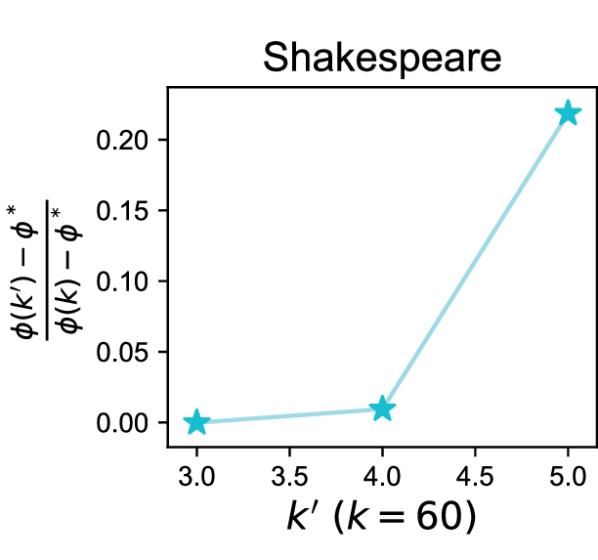
Benefits of Heterogeneity (Def. 3.2). We compare the performance of k-FED on two different partitions of data among devices: (i) one with IID random partitions, and (ii) another with structured partitions. To generate the underlying structured partition for this experiment we use the following heuristic. First, we cluster all the data into clusters for a range of values of . For each , we take the clustering we have as the target clustering , and construct the data matrix and the matrix of centers . Finally, for each pair of cluster means , we compute the quantity , the ratio of the actual separation of the cluster mean to the required active separation. We pick a value of at which a large number of clusters are reasonably well separated (see Appendix B, Figure 5). We call this our oracle clustering. Now to generate the IID partition for (i), we randomly distribute this data among devices. To generate the structured partition for (ii), we divide the data among devices such that each device receives only data from a random subset of no more than clusters. For each value of , we cluster the data for both cases over the devices using k-FED and compute the -means cost. Let denotes the -means cost of the original oracle clustering. Let denote the -means cost when clusters are assigned to each device. Figure 2 presents the relative cost ratio between the cost change in structured partitions () and random partitions ().
We perform this experiment on the FEMNIST and Shakespeare datasets (Caldas et al., 2018) (see Appendix B for details). It can be seen from the results plotted in Figure 2 that clustering on structured splits achieves a cost closer to that of the oracle partition compared to the cost achieved on the IID random partition. We note that the separation achieved in real datasets is much smaller than required even with this careful construction (Appendix B). Even still, our experiments demonstrate that heterogeneity can benefit federated clustering on common benchmarks.
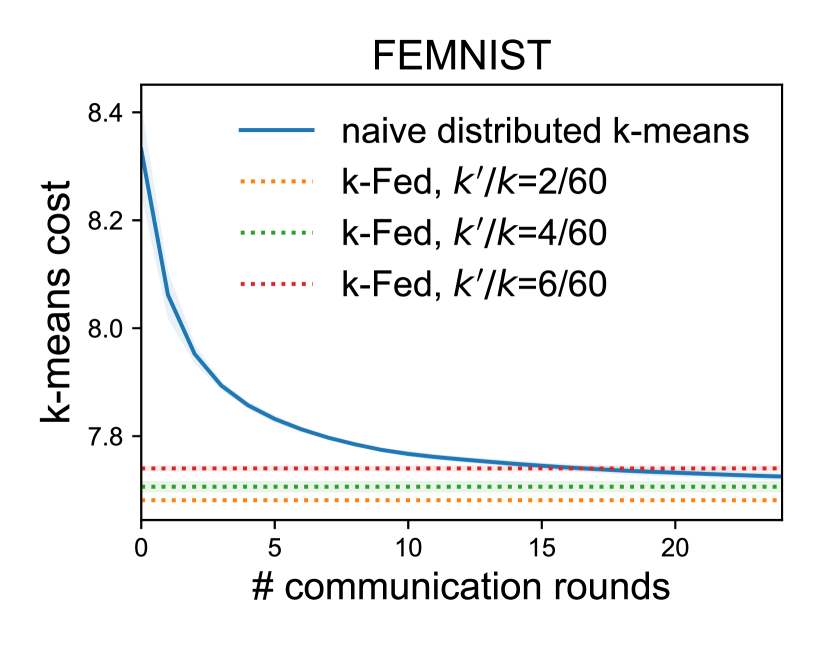
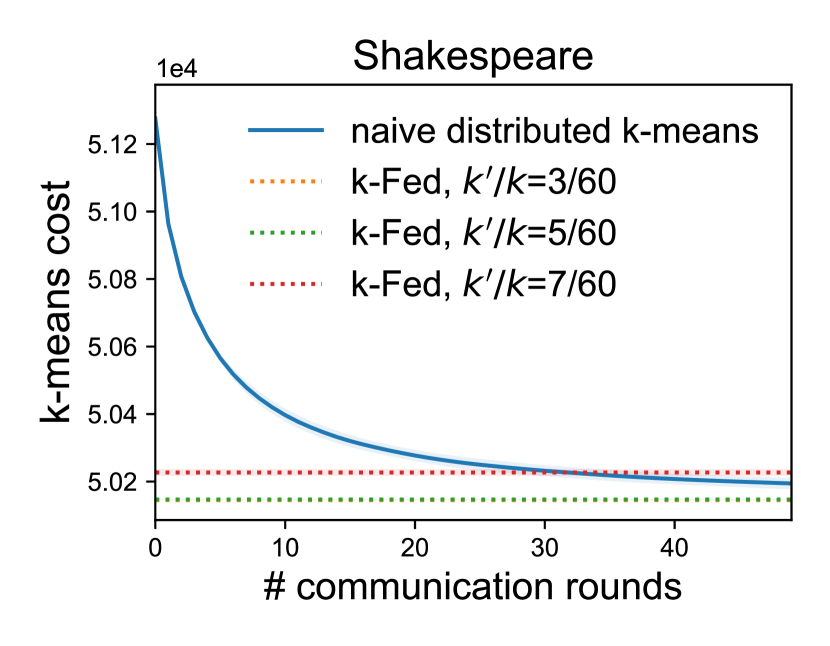
Communication-Efficiency. One advantage of the proposed method is that it requires only a single round of communication. Given this, it is natural to wonder how the performance of k-FED would compare with other, more communication-intensive clustering baselines. In particular, a common way to solve -means in distributed settings is to simply parallelize the cluster assignment and cluster mean calculations at each step. Here, we show that for different partitions of the dataset with multiple values of , our one-shot method -FED is able to produce similar clustering outputs (in terms of the -means cost; lower is better) as naive distributed -means, which requires multiple communication rounds. Here we use the same oracle clustering as the previous experiment to construct our device data.
4.2.2 Applications of -Fed
Personalized FL. Compared with fitting a single global model to data across all device, jointly learning personalized (separate but related) models can boost the effective sample size while adapting to the heterogeneity in federated networks (e.g., Smith et al., 2017; Mansour et al., 2020).
Ghosh et al. (2020) recently proposed an algorithm to learn models over federated networks where devices are partitioned into clusters when the clustering information is unavailable. Consider a supervised learning problem that each cluster of devices want to solve and assume the number of clusters is known. Their method, the Iterative Federated Clustering Algorithm (IFCA), in its first step initializes models , one for each cluster. At the start of each round, all models are sent to the devices. Each device picks the model that minimizes a loss function on its locally available data. The device can be configured to now either compute and transmit the gradient of the loss function of this model or it can perform a few model updates locally and send the updated model to the central server. As the last step of the round, for each model , all the devices that picked this model are identified. All these devices are assigned cluster id . Model then is updated by either model averaging or gradient averaging using the information sent by devices in cluster .
| Global | IFCA | -FED | |
|---|---|---|---|
| 100 devices () | 95.0 | 98.0 | 98.0 |
| 200 devices () | 94.5 | 97.2 | 97.8 |
| 100 devices () | 95.3 | 95.6 | 97.1 |
| 200 devices () | 94.5 | 95.1 | 96.4 |
We instantiate IFCA on the problem of learning personalized models for clusters. As in (Ghosh et al., 2020), we use the MNIST dataset for this experiment. We construct clusters by and degree rotations and distribute them among devices. Note that in the setup for IFCA, each device only contains data from a single cluster (since we are clustering devices and not individual data points). Thus we set and compare IFCA with a simple k-FED based method: We first perform one-shot clustering to obtain an initial clustering and then we use FedAvg (McMahan et al., 2017) to learn one model per cluster. As a baseline, we also learn a single global model and include it for comparison. As can be seen from the test accuracies in Table 2 (), k-FED is competitive with IFCA. Moreover, k-FED has the additional advantage that once the cluster identities have been assigned, we only need to transmit one model instead of the models that are transmitted with IFCA.
Since k-FED clusters data, the k-FED + FedAvg approach can also handle cases where there are data from multiple clusters on the same device. Table 2 () shows the test accuracy on such a partition. Here we observe the performance of IFCA degrade when compared to k-FED.
Client Selection. Finally, we demonstrate that the clustering information produced by -FED is a useful prior for client selection applications (Cho et al., 2020). In practice, cross-device federated optimization algorithms need to tolerate partial device participation (Kairouz et al., 2019). Intuitively, incorporating information from ‘representative’ devices at each communication round may speed up the convergence of learning tasks over federated networks as opposed to randomly sampling devices. When randomly sampling, similar and potentially redundant clients can be selected. A recent device selection method proposes to additionally select the devices with large training losses among those randomly-selected subset of devices (Cho et al., 2020) to help with convergence speed. We combine -FED with this approach by further filtering out the devices coming from the same clusters. Note that -FED does not add significant additional overhead to the baseline algorithm as it only requires running one-shot clustering before training. The results are shown in Figure 4. We see that leveraging the underlying structure learnt by -FED can boost convergence on these realistic federated benchmarks.
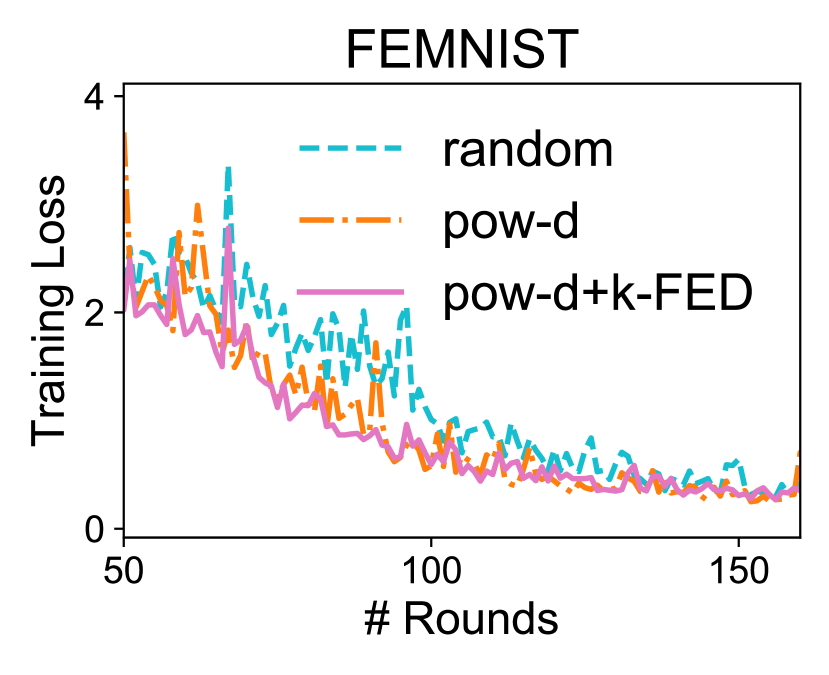
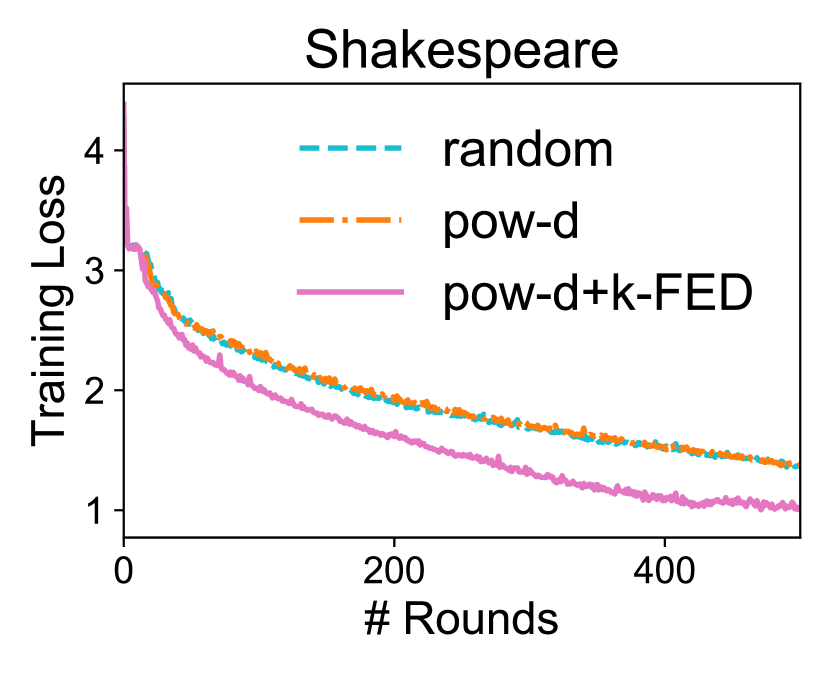
Similar to Cho et al. (2020), we also observe that for the experiments in Figure 4, the variance of test performance across all devices has been reduced using client selection strategies favoring more informative (potentially more underrepresented) clients compared with that of random selection. For instance, on FEMNIST, the variance of final test accuracies is reduced by 35% when using k-fed combined with pow-d instead of random selection. This may be useful in scenarios where we wish to impose notions fairness for federated learning (Mohri et al., 2019; Li et al., 2020c).
5 Conclusion
In this work, we provide an example of how heterogeneity in federated networks can be beneficial, by rigorously analyzing the effects of heterogeneity on a simple, one-shot variant of Lloyd’s algorithm for distributed clustering. Our proposed method, k-FED, addresses common practical concerns in federated settings, such as high communication costs, stragglers, and device failures. We believe that other, specific notions of heterogeneity—together with careful analyses—may provide benefits for a plethora of other problems in federated learning, which is an interesting direction of future work.
6 Acknowledgements
This work was supported in part by the National Science Foundation Grant IIS1838017, a Google Faculty Award, a Facebook Faculty Award, and the CONIX Research Center. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the National Science Foundation or any other funding agency.
References
- Arthur & Vassilvitskii (2006) Arthur, D. and Vassilvitskii, S. How slow is the k-means method? In Proceedings of the Twenty-Second Annual Symposium on Computational Geometry, 2006.
- Awasthi & Sheffet (2012) Awasthi, P. and Sheffet, O. Improved spectral-norm bounds for clustering. In Approximation, Randomization, and Combinatorial Optimization. Algorithms and Techniques. 2012.
- Bachem et al. (2018) Bachem, O., Lucic, M., and Krause, A. Scalable k-means clustering via lightweight coresets. In International Conference on Knowledge Discovery & Data Mining, 2018.
- Bahmani et al. (2012) Bahmani, B., Moseley, B., Vattani, A., Kumar, R., and Vassilvitskii, S. Scalable k-means+. Proceedings of the VLDB Endowment, 2012.
- Balcan et al. (2013) Balcan, M.-F., Ehrlich, S., and Liang, Y. Distributed -means and -median clustering on general topologies. In Advances in Neural Information Processing Systems, 2013.
- Bateni et al. (2014) Bateni, M., Bhaskara, A., Lattanzi, S., and Mirrokni, V. Distributed balanced clustering via mapping coresets. In Advances in Neural Information Processing Systems, 2014.
- Caldas et al. (2018) Caldas, S., Duddu, S. M. K., Wu, P., Li, T., Konečnỳ, J., McMahan, H. B., Smith, V., and Talwalkar, A. Leaf: A benchmark for federated settings. arXiv preprint arXiv:1812.01097, 2018.
- Cho et al. (2020) Cho, Y. J., Wang, J., and Joshi, G. Client selection in federated learning: Convergence analysis and power-of-choice selection strategies. arXiv preprint arXiv:2010.01243, 2020.
- Dasgupta et al. (2007) Dasgupta, A., Hopcroft, J., Kannan, R., and Mitra, P. Spectral clustering with limited independence. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, 2007.
- Datta et al. (2005) Datta, S., Giannella, C., Kargupta, H., et al. K-means clustering over peer-to-peer networks. In International Workshop on High Performance and Distributed Mining, 2005.
- Dhillon & Modha (2002) Dhillon, I. S. and Modha, D. S. A data-clustering algorithm on distributed memory multiprocessors. In Large-Scale Parallel Data Mining. 2002.
- Ester et al. (1996) Ester, M., Kriegel, H.-P., Sander, J., Xu, X., et al. A density-based algorithm for discovering clusters in large spatial databases with noise. In International Conference on Knowledge Discovery & Data Mining, 1996.
- Feldman et al. (2012) Feldman, D., Sugaya, A., and Rus, D. An effective coreset compression algorithm for large scale sensor networks. In International Conference on Information Processing in Sensor Networks, 2012.
- Ghosh et al. (2019) Ghosh, A., Hong, J., Yin, D., and Ramchandran, K. Robust federated learning in a heterogeneous environment. arXiv preprint arXiv:1906.06629, 2019.
- Ghosh et al. (2020) Ghosh, A., Chung, J., Yin, D., and Ramchandran, K. An efficient framework for clustered federated learning. Advances in Neural Information Processing Systems, 2020.
- Januzaj et al. (2004) Januzaj, E., Kriegel, H.-P., and Pfeifle, M. Dbdc: Density based distributed clustering. In International Conference on Extending Database Technology, 2004.
- Kairouz et al. (2019) Kairouz, P., McMahan, H. B., Avent, B., Bellet, A., Bennis, M., Bhagoji, A. N., Bonawitz, K., Charles, Z., Cormode, G., Cummings, R., et al. Advances and open problems in federated learning. arXiv preprint arXiv:1912.04977, 2019.
- Kargupta et al. (2001) Kargupta, H., Huang, W., Sivakumar, K., and Johnson, E. Distributed clustering using collective principal component analysis. Knowledge and Information Systems, 2001.
- Kumar & Kannan (2010) Kumar, A. and Kannan, R. Clustering with spectral norm and the k-means algorithm. In Annual Symposium on Foundations of Computer Science, 2010.
- Li et al. (2020a) Li, T., Sahu, A. K., Talwalkar, A., and Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Processing Magazine, 2020a.
- Li et al. (2020b) Li, T., Sahu, A. K., Zaheer, M., Sanjabi, M., Talwalkar, A., and Smith, V. Federated optimization in heterogeneous networks. In Proceedings of Machine Learning and Systems, 2020b.
- Li et al. (2020c) Li, T., Sanjabi, M., Beirami, A., and Smith, V. Fair resource allocation in federated learning. In International Conference on Learning Representations, 2020c.
- Lloyd (1982) Lloyd, S. Least squares quantization in pcm. IEEE Transactions on Information Theory, 1982.
- Mansour et al. (2020) Mansour, Y., Mohri, M., Ro, J., and Suresh, A. T. Three approaches for personalization with applications to federated learning. arXiv preprint arXiv:2002.10619, 2020.
- McMahan et al. (2017) McMahan, B., Moore, E., Ramage, D., Hampson, S., and y Arcas, B. A. Communication-efficient learning of deep networks from decentralized data. In Artificial Intelligence and Statistics, 2017.
- McSherry (2001) McSherry, F. Spectral partitioning of random graphs. In Symposium on Foundations of Computer Science, 2001.
- Mohri et al. (2019) Mohri, M., Sivek, G., and Suresh, A. T. Agnostic federated learning. In International Conference on Machine Learning, 2019.
- Ostrovsky et al. (2013) Ostrovsky, R., Rabani, Y., Schulman, L. J., and Swamy, C. The effectiveness of lloyd-type methods for the k-means problem. Journal of the ACM, 2013.
- Sattler et al. (2020) Sattler, F., Müller, K.-R., and Samek, W. Clustered federated learning: Model-agnostic distributed multitask optimization under privacy constraints. IEEE Transactions on Neural Networks and Learning Systems, 2020.
- Smith et al. (2017) Smith, V., Chiang, C.-K., Sanjabi, M., and Talwalkar, A. S. Federated multi-task learning. In Advances in Neural Information Processing Systems, 2017.
- Tasoulis & Vrahatis (2004) Tasoulis, D. K. and Vrahatis, M. N. Unsupervised distributed clustering. In Parallel and Distributed Computing and Networks, 2004.
- Wang & Chang (2020) Wang, S. and Chang, T.-H. Federated clustering via matrix factorization models: From model averaging to gradient sharing. arXiv preprint arXiv:2002.04930, 2020.
- Xu et al. (1999) Xu, X., Jäger, J., and Kriegel, H.-P. A fast parallel clustering algorithm for large spatial databases. In High Performance Data Mining. 1999.
Appendix A Proofs
A.1 Proving Theorem 3.1 (Main Theorem)
Before we proceed to proving Theorem 3.1, we first establish a few preliminary results. Let be our target clustering and let be the subset of points of a cluster on device . For any point, on device , let denote the index of the cluster it belongs to. That is,
Also recall the definition of matrix , the matrix of means. Here the -th row of contains the mean of the cluster which contains data points , i.e. . Our first lemma bounds how far the ‘local’ cluster mean can deviate from .
Lemma 2 (Lemma 5.2 in Kumar & Kannan (2010)).
Let be a subset of on device . Let denote the mean of the points indexed by . Then,
Proof.
Let be the sub-matrix of on device and let be the corresponding sub-matrix of our matrix of means . Let be an indicator vector for points in . Observe that,
Here, for the last inequality, we note that contains a subset of rows of , and therefore . ∎
Now consider the local clustering problem on each device . The device has a data matrix , whose rows are a subset of . Let be subsets of on this device, such that no more than of them are non-empty. Construct a matrix , of the same dimensions as where for each row of , the corresponding row of contains the mean of the local cluster the point belongs to. That is, the -th row of contains . Using this next lemma, we bound the operator norm of the matrix , in terms of .
Lemma 3.
Let be subsets of target cluster that reside on a device such that of them are non-empty. Let be the corresponding data matrix. Let be the corresponding matrix of means; that is each row . Then,
Proof.
Let be an matrix where . First, consider a unit vector along the top singular direction and observe that:
Here for inequality we invoke Lemma 2. Also, noting that , we get,
∎
We prove Theorem 3.1 in four parts:
- 1.
- 2.
-
3.
In next step, we show that the process of picking initial centers in steps 2-6 of k-FED picks exactly one local cluster center for each cluster . That is, we pick local centers one corresponding to each target cluster. (Lemma 6)
-
4.
Finally, we argue that with this initialization, the clustering of local cluster centers produced has the property that, all local cluster centers corresponding the to the same cluster (say ) will be in the same set (say ). Moreover, no local cluster center corresponding to any , will be in . As we argue later, this is sufficient for the induced clustering produced by to agree with our target clustering up to permutation of labels and missclassifications incurred at the local clustering stage.
Lemma 4.
Let be cluster pairs such that, Let and be large subsets on device . Then,
Proof.
(Lemma 4) Using the triangle inequality, we have
| (5) |
using the active separation assumption. Now, expanding the terms can write the left hand side as
We first only consider the term . According to Lemma 3, . Using this we can bound as
Now recall that for large cluster subsets and thus . This means that we can bound term as,
We get a symmetric expression for term as well. Using this in equation 5, we get the desired result:
∎
Since Algorithm-1 is run locally on each device, it is unaffected by the inactive separation condition, as by definition, subsets of only active cluster pairs exist on each device. This implies that Algorithm-1 solves the local clustering problem successfully. Specifically on device containing data from some cluster , is not too far from . Showing this result is our second step and we state this formally in Lemma 5 below.
Lemma 5.
Let be the subsets of on some device such that no more than of them are non-empty. Moreover, assume all non-empty subsets are large, i.e. . Finally, assume that the active separation requirement is satisfied for all active cluster pairs on . Then, on termination of Algorithm-1, for each non-empty , we have
and,
Proof.
This means that for a fixed , all the received at the central server from devices are ‘close’ to .
The next step is to show that in the initial centers k-FED picks in steps 2-6, there is exactly one corresponding to each target cluster . We will show later that this is sufficient for the final step of the algorithm to correctly assign local cluster centers to the correct partition.
Lemma 6.
Let be our target clustering. Assume all active cluster pairs and inactive cluster pairs satisfy their separation requirements. Further let . Then at the end of step 6 of k-FED, for every target cluster , there exists an such that for some .
Before we proceed to proving this lemma, we state and prove a lower bound on how close a local cluster center can be to some cluster mean for :
Lemma 7.
Let . The for any , ,
Proof.
First, from the triangle inequality note that,
Using Lemma 5 and our inactive separation assumption we bound the right hand side further as,
as desired. ∎
Proof.
(Lemma 6) Let denote the set in step 2-6 of k-FED, after picking the first points . Let us denote the point k-FED selects in iteration as . That is,
We will show that the set contains points corresponding to different target clusters at every iteration . This invariant holds trivially at . Assume the statement first became false at some . Let the point correspond to a local cluster mean from cluster . Then there must exist some such that also correspond to a local cluster mean from . Further, there must exist some cluster such that for any .
Now by definition of , we have
| (6) |
Here inequality (a) follows from the triangle inequality and (b) follows from Lemma 5.
Now consider for any . Since no other local cluster center from is contained in , from Lemma 7 we conclude that for every ,
But this means that leading to a contradiction based on the definition of . This completes our argument. ∎
Now we are ready to prove our main Theorem 3.1.
Proof.
From Lemma 6, we know that the set at the end of step 6 of k-FED contains exactly one center corresponding to each target clustering. Let the local cluster center correspond to the cluster . Observe that for any ,
using Lemma 7. Further, for any ,
This means that for every and , is closer to the corresponding initial center than to any other initial center , . Let be the set of local cluster centers assigned to . Then it can be seen that only contains local cluster centers for all devices , i.e. contains all the device cluster centers corresponding to target cluster .
Now consider the definition of k-FED induced clustering (Definition 3.3), where we define
In this case, we know that only local cluster centers corresponding to cluster is contained in . Thus our induced cluster becomes,
Now from Lemma 1 we know that on each device the sets and only differ on at most . Summing this error over all devices , we see that our induced clustering and the target clustering differ only on points. Finally, if all the local points satisfy their respective proximity condition (Definition 3.1), then no points are missclassified. This concludes our proof. ∎
A.2 Running Time of k-FED and Handling New Devices
We now analyze the running time of k-FED steps 2-8. Since step 1 is running Algorithm-1 on individual devices, we do not include the running time of this step as part of our analysis. Note that with the separation assumptions in place, Algorithm-1 will converge in polynomial time. However, as observed in practise, Lloyd like methods typically only take a few iterations to terminate.
Theorem A.1.
Steps 2-8 of k-FED takes pairwise distance computations to terminate. Further, after the set in step 6 has been computed, new local cluster centers from a yet unseen device can be correctly assigned in distance computations.
Proof.
(Theorem 3.2) The proof of the first part follows from a simple step by step analysis. Step 1 can be performed in . Step 2-6 executes exactly times. At each iteration , , we compute the distance of all device cluster centers, of which there are most , to the points in . Thus at iteration , this can be implemented with distance computations. Summing over all , we see that steps 2-6 can run in distance computations. Finally, step 7 requires us to assign all the device cluster centers to one of the initial points in . This can be implemented in distance computations. Thus the overall complexity in terms of pairwise distance computations is .
The second part of the statement follows from noting that for each , the nearest point in set must be the initial center we picked as was demonstrated in the proof of Theorem 3.1. Thus every is assigned to the correct partition as required. ∎
A.3 Separating Data from Mixture of Gaussian
We now prove Theorem 4.1. Recall that we are working in the setting where . Our proof builds on results from Lemma 6.3, Kumar & Kannan (2010).
Proof.
First consider an active cluster pair . Based on our separation requirement, we have:
We further simplify the right hand to get,
Now note the number of points from each component is very close to with very high probability. Here is the mixing weight of component and is the number of data points. Using this, with high probability we have
Further, it can be shown that is with high probability (see (Dasgupta et al., 2007)). Thus we conclude that, with high probability
Thus the active separation requirement is satisfied. The proof for the inactive separation condition is similar. Finally, the proximity condition follows from the concentration properties of Gaussians. ∎
Appendix B Experimental Details
B.1 Datasets
For all experiments involving real data, we use the EMNIST, FEMNIST, and Shakespeare datasets. These datasets and their corresponding models are available at the LEAF benchmark: https://leaf.cmu.edu/. For client selection experiments, we manually partition a subset of FEMNIST (first 10 classes) by assigning 2 classes to each device. There are 500 devices in total. Both the number of training samples across all devices and the number of training samples per class within each device follow a power law. We use the natural partition of Shakespeare where each device corresponds to a speaking role in the plays of William Shakespeare. We randomly sample 109 users from the entire dataset. For personalization experiments, following Ghosh et al. (2020), we use a CNN-based model with one hidden layer and 200 hidden units trained with a learning rate of and local updates on each device.
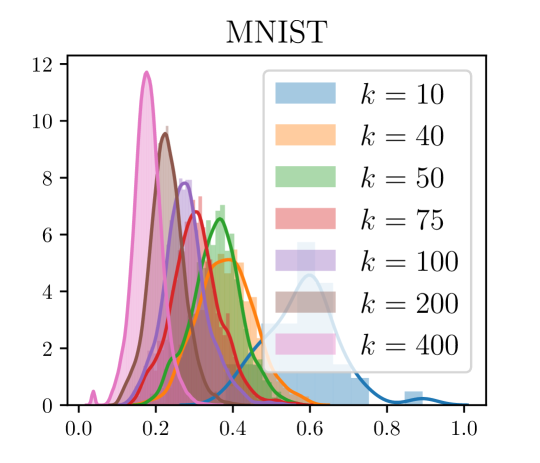
B.2 Choosing Based on Separation
As mentioned in Section 4.2, to create our oracle clustering, we compute the quantity for each cluster pairs , for every candidate value of we are considering. We construct a distribution plot of these . An example of such a plot for the MNIST dataset is provided in Figure 5. As can be seen here, for all values of , the relative separation is quite small. Thus even for this oracle clustering, the actual separation between cluster means is small. To pick a for our oracle clustering, we pick a fixed value (say ) and then pick the value of which leads to maximum fraction of cluster pairs to have .