Collaboration of Experts: Achieving 80%
Top-1 Accuracy on ImageNet with 100M FLOPs
Abstract
In this paper, we propose a Collaboration of Experts (CoE) framework to assemble the expertise of multiple networks towards a common goal. Each expert is an individual network with expertise on a unique portion of the dataset, contributing to the collective capacity. Given a sample, delegator selects an expert and simultaneously outputs a rough prediction to trigger potential early termination. For each model in CoE, we propose a novel training algorithm with two major components: weight generation module (WGM) and label generation module (LGM). It fulfills the co-adaptation of experts and delegator. WGM partitions the training data into portions based on delegator via solving a balanced transportation problem, then impels each expert to focus on one portion by reweighting the losses. LGM generates the label to constitute the loss of delegator for expert selection. CoE achieves the state-of-the-art performance on ImageNet, 80.7% top-1 accuracy with 194M FLOPs. Combined with PWLU and CondConv, CoE further boosts the accuracy to 80.0% with only 100M FLOPs for the first time. Furthermore, experiment results on the translation task also demonstrate the strong generalizability of CoE. CoE is hardware-friendly, yielding a 36x acceleration compared with existing conditional computation approaches.
1 Introduction
From simple systems to complicated ones, the accomplishment of various tasks relies on the collaboration of multiple individuals. Similarly, a wise combination of models with different properties could yield improved performance on a specific task compared to only deploying one individual model. There are many approaches for model collaboration, among which ensemble learning (Hansen & Salamon, 1990; Wen et al., 2020; Wenzel et al., 2020) is a popular one. Ensemble learning uses a consensus scheme to decide the collective result by vote. However, it requires multiple forward passes, leading to a significant runtime cost. MIMO (Havasi et al., 2021) draws inspiration from model sparsity (Frankle & Carbin, 2019) and tries to ensemble several subnetworks within one regular network. It only needs one single forward pass of the regular network but is incompatible with compact models. Conditional computation methods (Cheng et al., 2020; Yan et al., 2015) adopt the delegation scheme for model collaboration, conditionally assigning one or several, rather than all models, to make the prediction. Some recently proposed conditional computation methods (Yang et al., 2019; Zhang et al., 2021) have achieved remarkable performance based on dynamic convolution. Nonetheless, they usually have high memory access cost (MAC) and a low degree of parallelism, increasing the real latency (Ma et al., 2018).
Motivated by this, we propose the Collaboration of Experts (CoE) framework to both eliminate the need for multiple forward passes and keep hardware-friendly. CoE consists of one delegator and multiple experts. Firstly, delegator gives a rough prediction and makes the expert selection. If the rough prediction is unreliable, the selected expert will make the refined prediction. Otherwise, the procedure will be early terminated to save FLOPs. Moreover, we only need to load the selected expert into memory, thus keeping the ratio of MAC to FLOPs as a constant. By contrast, dynamic convolution methods (Zhang et al., 2020, 2021) need to load a large number of parameters, namely basis models or experts, to synthesize the input-dependent ones. It enlarges MAC and reduces the degree of parallelism, resulting in a significant deceleration.

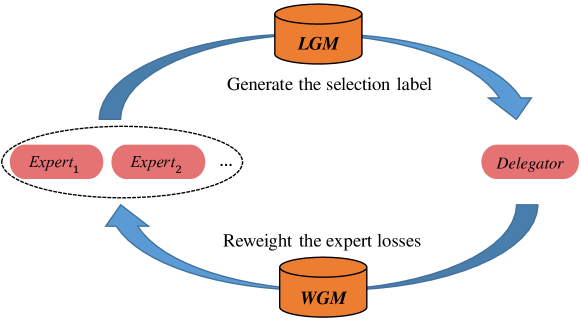
To make each model in CoE play its role, we propose a novel training algorithm (as shown in Fig.1) which consists of two major components: weight generation module (WGM) and label generation module (LGM). LGM generates the label (selection label) to constitute the loss of delegator for expert selection. Selection label is a one-hot vector, indicating the suitable expert for each given input. It is obtained by solving a balanced transportation problem (BTP, Shore 1970). Based on delegator, WGM partition the training data into portions by maximizing the summed selection probability via solving BTP as well. Then expert losses are reweighted so that each expert can focus on one portion. As shown in Fig.2, this fulfills the co-adaptation of experts and delegator. The co-adaptation manner makes CoE generalize well to the validation set. Due to the random initialization of experts, selection labels are irregular in the early training stage. Nonetheless, delegator tends to learn generalizable patterns first, since networks learn gradually more complex hypotheses during training (Arpit et al., 2017). Therefore, WGM can partition the training data into portions based on generalizable patterns with delegator as the bridge. It makes selection labels more regular in return, thus delegator avoids overfitting to the irregular labels.
We conduct the main experiments on ImageNet classification task. CoE achieves 78.2/80.7% top-1 accuracy with only 100/194M FLOPs, while the accuracy for ensembled models (Hansen & Salamon, 1990) is only 79.6% with 920M FLOPs. Compared with the widely-used gate-value-based optimization method (Shazeer et al., 2017; Fedus et al., 2021), our proposed training algorithm improves 1.2% accuracy for CoE, indicating the training effectiveness. Compared with dynamic network approaches, CoE is more hardware-friendly. It not only outperforms the SOTA dynamic method BasisNet which achieves 80.0% accuracy with 198M FLOPs (Zhang et al., 2021), but also accomplishes a 3.1x speedup on hardware. Besides, CoE can be equipped with CondConv and further improve the accuracy to 79.2/81.5% with 102/214M FLOPs. Moreover, we further boost the accuracy to 80.0% with only 100M FLOPs for the first time by using PWLU activation function (Zhou et al., 2021). Experiment results on the translation task also demonstrate the strong generalizability of CoE.
The contributions of this paper can be summarized as follows:
-
•
We propose a collaboration framework named Collaboration of Experts (CoE). The core advantage of it is the inference efficiency. Compared with other conditional computation methods, CoE has low memory access cost and a high degree of parallelism, which are two important factors for real latency.
-
•
We present a novel optimization strategy for CoE that fulfills the co-adaptation of experts and delegator. Experiment results demonstrate its superiority over the widely-used gate-value-based optimization method.
-
•
CoE updates the state-of-the-art on ImageNet for mobile setting, achieving 80.7% top-1 accuracy on ImageNet with less than 200M FLOPs for the first time as far as we know.
-
•
Since the expert selection is done at the model level, CoE can take advantage of existing techniques like conditional convolution and PWLU activation function to push the performance to a new level, namely, 80.0% accuracy on ImageNet with only 100M FLOPs.
2 Related Work
2.1 Ensemble Learning and Model Selection
Ensemble learning (Hansen & Salamon, 1990) aims at combining the predictions from several models to get a more robust one. Some recently proposed literatures (Wen et al., 2020; Wenzel et al., 2020) demonstrate that significant gains can be achieved with negligible additional parameters compared to the original model. However, these methods still require multiple (typically, 4-10) forward passes for prediction, leading to a significant runtime cost. Differently, CoE utilizes a delegator to select only one expert for the refined prediction, thus at most two forward passes are needed. MIMO (Havasi et al., 2021) draws inspiration from model sparsity (Frankle & Carbin, 2019) and holds the view that multiple independent subnetworks can be concurrently trained within one regular network because of the heavy parameter redundancy. Therefore, those subnetworks can be ensembled with a single forward pass of the regular model. However, MIMO cannot be applied to compact models which have already been pruned or the ones constructed by AutoML methods (Cai et al., 2020; Zhong et al., 2018). It is because these models have few redundant parameters. By contrast, CoE is free from the compactness of experts since expert selection is done at the model level. Recently, some works about model selection are proposed (Li et al., 2021b; You et al., 2021). These methods are concerned with ranking a number of pre-trained models and finding the one transfers best to a downstream task of interest. Therefore, they select models task-wisely. By contrast, CoE aims at improving the task performance via selecting the most suitable expert for each sample instance-wisely.
2.2 Dynamic Networks
Dynamic networks achieve high performance with low computation cost by conditionally varying the network parameters (Zhang et al., 2020; Yang et al., 2019) or network architectures (Yuan et al., 2020). HD-CNN (Yan et al., 2015) and HydraNet (Mullapudi et al., 2018) select branches based on the category, they cluster all categories into n groups, where n is the number of branches. While CoE learns the model selection pattern automatically, it can be based on any property, rather than limited to the category. MoE (Shazeer et al., 2017) and Switch Transformer (Fedus et al., 2021) select experts at the layer level with a router. The output feature of each expert will be scaled with the gate-value predicted by router, thus router becomes trainable. This gate-value-based optimization manner is heuristic while CoE trains the delegator more reasonably. Since expert selection for CoE is done across models, we can use protocols like True Class Probability (TCP, Corbière et al. 2019) to measure the suitability of each expert without bias. Based on expert suitabilities, the labels to supervise delegator for expert selection can be obtained. Additionally, CoE takes more advantage of conditional computation as the whole network is selected, rather than only some particular layers. The recently proposed Dynamic Convolution methods (Zhang et al., 2020; Yang et al., 2019; Chen et al., 2020) share the similar idea and achieve remarkable performance with low FLOPs but high latency. It is because these methods need to load many basis models or experts to synthesize the dynamic parameters, causing high MAC and low degree of parallelism (Ma et al., 2018). By contrast, CoE only needs to load the selected expert into memory, avoiding these problems. Finally yet importantly, batch processing is an important method to enhance the degree of parallelism. Because of the input-dependent parameters (Shazeer et al., 2017; Zhang et al., 2021) or architectures (Yuan et al., 2020), these methods cannot process samples in batch. Differently, CoE supports batch processing because the number of experts is limited and each one of them corresponds to many test samples.
3 Method
CoE consists of a delegator and experts, a total of individual neural networks. Given a sample, delegator will select an expert and simultaneously output a rough prediction to trigger potential early termination. Since the inference of delegator is conducted all the time, we prefer to make delegator more lightweight than expert. Delegator consists of three modules: feature extractor, task predictor and expert selector as shown in Fig.3. Based on the feature derived from feature extractor, task predictor and expert selector output the probabilities for classification and expert selection respectively. In the following subsections, we will describe the inference procedure and training strategy of CoE comprehensively. The number of samples and experts are denoted as and .

3.1 Inference Procedure
CoE firstly uses delegator to obtain the rough prediction and determine the selected expert for each sample. Afterward, Maximum Class Probability (MCP, Corbière et al. 2019) of rough prediction is calculated. It is the probability of predicted class. Then, the final recognition results for samples with MCP larger than a given threshold are derived from the rough predictions. Other samples are partitioned into groups based on which expert is selected. Subsequently, batch processing can be conducted within each group to obtain refined predictions. This procedure is shown in Fig.4. The averaged FLOPs/Instance of CoE ranges from to by varying from 0 to 1, and are FLOPs of delegator and experts. Therefore, the value of is directly determined by target FLOPs.

3.2 Label Generation Module (LGM)
Since expert selection for CoE is done across models, we can measure the suitability of each expert without bias. Based on this, labels to supervise delegator for expert selection can be obtained. This label-based training method for delegator is more reasonable than the widely-used gate-value-based method (Shazeer et al., 2017; Fedus et al., 2021) which enables the training of routing function by using its predicted gate-value to scale the output of each expert. Next, we firstly introduce how to measure the suitability of each expert, then illustrate how to obtain the selection label.
Model accuracy can be measured by True Class Probability (TCP, Corbière et al. 2019):
| (1) |
where, is the j-th sample, and are the predicted and true class. But accuracy is not the only factor for suitability. For example, when models are of different sizes, the larger one usually has a higher TCP. But it may not be more suitable, due to the large inference cost. Given that our concern is not the optimization of network architecture, we can suppose no expert is superior to others (No Superiority Assumption, NSA). Motivated by NSA, we leverage the standardized TCP as the metric for sutability:
| (2) |
where, and are mean value and standard deviation for TCPs of on samples.
Selection labels can be denoted by a binary matrix , where each row is a selection label. According to NSA, each expert should be assigned the same number of samples, thus the sum of each colum vector of should be same, i.e. for . Therefore, can be obtatined by maximizing :
| (3) |
This problem can be modeled as the balanced transportation problem (BTP, Shore 1970), where each sample is a supply source with a supply of one, each expert is a demand source with a demand of . is the per-unit transportation cost from the j-th supply source to the k-th demand source. We solve this problem via Vogel approximation method (VAM, Shore 1970) as introduced in Appendix A.1, which is a short-cut approach to invariably obtain a good solution.
3.3 Weight Generation Module (WGM)
To maximize the collective capacity of CoE, the dataset needs to be partitioned into portions then each expert only focuses on one portion. This is achieved by WGM which reweights the losses of experts. The partition can be indicated by an assignment matrix , with one-hot row vectors. means the j-th sample is assigned to the k-th expert, thus the loss weight for gets larger than other experts on .
A naive partition can be based on expert suitability, namely, partitioning the training data with selection labels . However, it results in a poor generalization to delegator as shown in Fig.5(a). Assuming is suitable on a sample , thus . Due to , the loss weight for gets larger than other experts on , making more suitable in return. Therefore selection labels cannot be updated and the irregularity for them caused by random initialization will be preserved. Consequently, delegator gradually overfits to irregular labels, yielding a poor generalization. This is also verified in Section 4.4, where the expert-suitability-based partition results in a terrible performance for CoE.


Since networks learn gradually more complex hypotheses during training (Arpit et al., 2017), delegator tends to learn generalizable patterns first. Therefore, the partition can be based on generalizable patterns with delegator as the bridge, namely, partition based on the output of delegator. In this way, selection labels get more regular in return due to the reweighting of expert losses. As shown in Fig.5(b), delegator avoids overfitting to the irregular labels.
Delegator outputs a probability matrix , whose element represents the probability of selecting the k-th expert on the j-th sample. As analyzed above, it is better to partition the training data based on , thus is obtained by maximizing . Moreover, according to NSA, the number of samples assigned to each expert should be same, i.e. . Thus, is optimized by:
| (4) |
This problem can also be modeled as BTP, and solved via VAM as described in section 3.2. In the early training stage, the models in CoE are underfitted. Thus we cannot trust and need to make the gap between loss weights for different experts smaller to warm up. We achieve this by smoothing to with Eq.5, where grows linearly from 0.2 to 0.8 with the training going on,
| (5) |
Finally, the output of WGM (i.e. ) is obtained by normalizing with the coefficient :
| (6) |
3.4 Training Details
The training framework of CoE is shown in Fig.1, which consists of three major losses: , and .
is the cross-entropy loss for the rough prediction of delegator. To avoid the repeated training of delegator, we use to train the feature extractor and task predictor (Fig.3) first of all. Then these two modules are fixed, only expert selector and experts are jointly optimized with , is set as 0.8 in this paper.
is used to optimize the expert selector. Based on the selection label , we can get the cross-entropy loss for the j-th sample. Because the final recognition result of CoE is not always sensitive to expert selection, should be attached various importance. For example, when experts have similar suitabilities (Eq.2) on the j-th sample, expert selection will have little influence to final performance of CoE, therefore the weight for gets smaller. Considering the similarity of suitabilities can be measured by the standard deviation , we set the loss weight for as . Finally,
| (7) |
is used to optimize the experts. Based on the class labels of m samples, we can get cross-entropy losses , where is the cross-entropy loss for the -th expert on the -th sample. Then is obtained by the weighted sum of with weights output by WGM:
| (8) |
We use either four or sixteen experts in this paper. When using sixteen experts, we decompose the task into four subtasks, each of which involves four experts as described in Appendix A.2. This reduces the memory cost for training.
4 Experiments
We conduct the main experiments on ImageNet classification task. After comparing with some popular efficient models, we verify the superiority of CoE over the existing model collaboration methods: model ensemble and category-based model selection. Afterward, the effectiveness of training strategy is analyzed by the comparison with the widely-used gate-value-based training method and the elaborated ablations. Moreover, we try to generalize CoE to the translation task and re-evaluate CoE using Reassessed Labels (ReaL) (Beyer et al., 2020). Finally, we try to analyze the reasonability of learned expert selection patterns. Statistics on referenced baselines in section 4.2.1&4.2.2 are directly cited from original papers, others are implemented with the following setting unless otherwise stated.
4.1 Implementation Details
We conduct experiments with two settings: CoE-Small and CoE-Large. For CoE-Small, we take TinyNet-E (Han et al., 2020b) with 24M FLOPs as the feature extractor of delegator by removing the last fully connected layer. We use OFA-110 (Cai et al., 2020) with 110M FLOPs as the expert. For CoE-Large, MobileNetV3-Small (Howard et al., 2019) with 56M FLOPs is adopted to construct the delegator by analogy. We use OFA-230 with 230M FLOPs as the expert. We have also tried to introduce CondConv (Zhang et al., 2020) and PWLU activation fuction (Zhou et al., 2021) to achieve the extreme performance. More details are illustrated in Appendix B.1.
4.2 Results and Analysis
4.2.1 Accuracy and Computation Cost
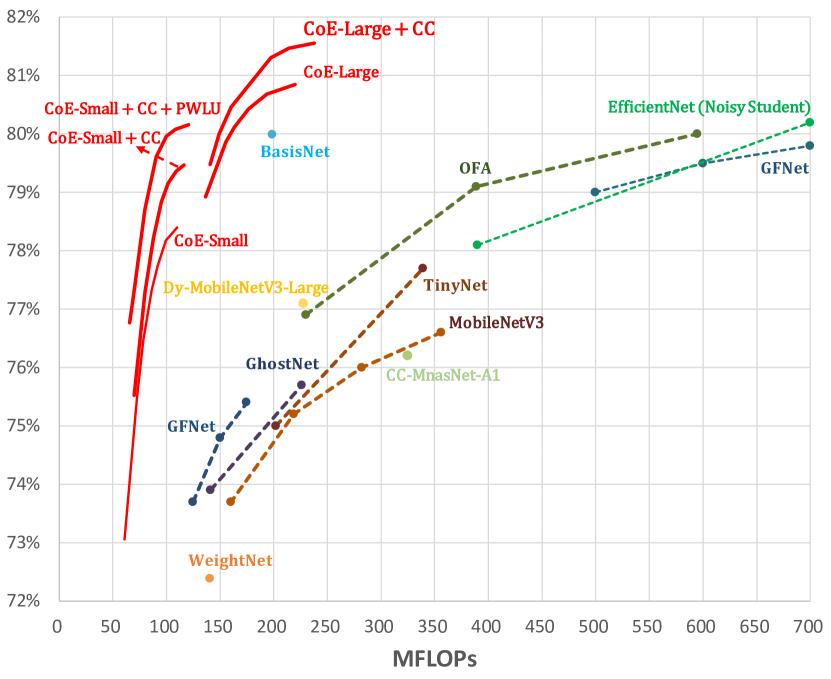
By varying the threshold of early termination, the accuracy curves for CoE are obtained. We show them in Fig. 6, then pick out a point from each curve to compare with some efficient models in Table 1. CoE achieves 78.2% and 80.7% accuracy with 16 experts and the averaged FLOPs/Instance are 100M and 194M respectively. Compared with OFA, CoE reduces the FLOPs from 230M to 100M and from 595M to 194M, with better top-1 accuracy. Though dynamic networks like GFNet, CondConv and BasisNet are more efficient than traditional networks, CoE still has significantly higher accuracy with smaller FLOPs. Compared with these approaches, CoE improves the accuracy by 2.2/2.4/0.7% respectively. When combined with CondConv, CoE achieves 79.2% and 81.5% accuracy with only 102M and 214M FLOPs, indicating that CoE is complementary to dynamic networks like CondConv. On the contrary, as CondConv and BasisNet share similar essence, namely using a group of basis to dynamically synthesize the input-dependent convolution kernel, the combination of them only arouses little collaborative benefit with the accuracy as 80.5%. Moreover, CoE achieves 80.0% accuracy with 100M FLOPs for the first time by further using PWLU.
| Method | FLOPs | TOP-1 Acc |
| WeightNet (2020) | 141M | 72.4% |
| DS-MBNet-M†‡(2021a) | 319M | 72.8% |
| GhostNet 1.0x (2020a) | 141M | 73.9% |
| MobileNetV3-Large (2019) | 219M | 75.2% |
| OFA-230 (2019) | 230M | 76.9% |
| TinyNet-A (2020b) | 339M | 77.7% |
| CondConv-EfficientNet-B0 (2019) | 413M | 78.3% |
| GFNet (2020) | 400M | 78.5% |
| CoE-Small | 100M | 78.2% |
| CoE-Small + CondConv | 102M | 79.2% |
| CoE-Small + CondConv + PWLU | 100M | 80.0% |
| BasisNet (2021) | 198M | 80.0% |
| OFA-595 (2019) | 595M | 80.0% |
| EfficientNet-B2 (2019) | 1.0B | 80.1% |
| EfficientNet-B1(Noisy Student) (2020) | 700M | 80.2% |
| BasisNet (2021) | 290M | 80.3% |
| FBNetV3-C (2020) | 557M | 80.5% |
| BasisNet + CondConv (2019) | 308M | 80.5% |
| CoE-Large | 194M | 80.7% |
| CoE-Large + CondConv | 214M | 81.5% |
4.2.2 Inference Speed and Memory Cost
The core advantage of CoE is the inference efficiency. To verify this advantage, we analyze the inference latency on hardware. The experiments are conducted on CPU platform (Intel(R) Xeon(R) CPU E5-2699 v4 @ 2.20GHz) with PyTorch version as 1.8.0. We report the averaged latency on the ImageNet validation set in Table 2. We notice the discrepancy between FLOPs and real speed. For example, OFA-230 has 1.6x FLOPs compared with GhostNet 1.0x, but the speed is 1.2x faster. Moreover, this discrepancy can be enlarged by CondConv. CondConv-EfficientNet-B0 has similar FLOPs with the original EfficientNet-B0, but the speed is 1.7x slower. BasisNet synthesizes the dynamic parameters all at once, rather than the “layer by layer” fashion like CondConv, thus is more efficient. However, it still needs to load a large number of parameters for this synthesis, which brings a large MAC. This is why CoE (16 experts) can reduce 14.09% latency than BasisNet even when the mini-batch size is one. Finally yet importantly, BasisNet and CondConv do not support batch processing, while CoE (16 experts) can take advantage of it to further achieve a 3.1/6.1x speedup compared with them. We analyze the memory cost from two perspectives: the number of parameters and MAC. As can be seen from Table 2, the accuracy of CoE-Large (4 experts) is no worse than BasisNet and CondConv-EfficientNet-B0 when using similar parameters. Besides, the averaged MAC/Instance of CoE is much smaller than theirs.
| Models | CPU Latency/Instance (ms) | FLOPs | MAC | Params | Accuracy | |
| Batchsize=1 | Batchsize=64 | |||||
| MobileNetV3-Small | 14.77 | 4.18 | 56M | 2.5M | 2.5M | 67.4% |
| GhostNet 1.0x | 39.91 | 16.50 | 141M | 5.2M | 5.2M | 73.9% |
| TinyNet-B | 34.58 | 19.44 | 202M | 3.7M | 3.7M | 75.0% |
| MobileNetV3-Large | 31.55 | 18.43 | 219M | 5.4M | 5.4M | 75.2% |
| GhostNet 1.3x | 43.94 | 29.70 | 226M | 7.3M | 7.3M | 75.7% |
| OFA-230 | 33.52 | 15.21 | 230M | 5.8M | 5.8M | 76.9% |
| EfficientNet-B0 | 49.12 | 35.21 | 391M | 5.3M | 5.3M | 77.2% |
| TinyNet-A | 45.76 | 23.71 | 339M | 5.1M | 5.1M | 77.7% |
| CondConv-EfficientNet-B0 | 81.81 | - | 413M | 24.0M | 24.0M | 78.3% |
| BasisNet | 40.61 | - | 198M | 24.9M | 24.9M | 80.0% |
| CoE-Large (4 experts) | 38.67 | 15.02 | 220M | 6.6M | 25.7M | 79.9% |
| CoE-Large (16 experts) | 34.89 | 13.30 | 194M | 6.0M | 95.3M | 80.7% |
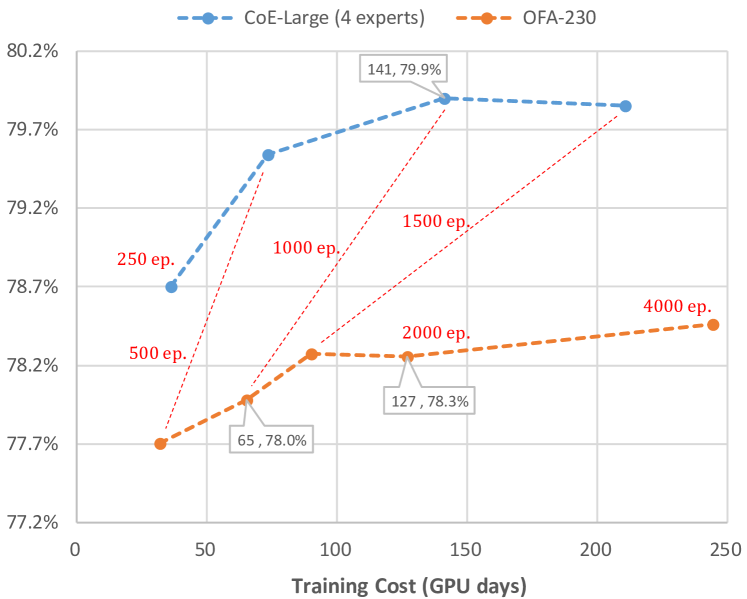
4.2.3 Analysis of the training cost
To achieve superior performance with fewer inference FLOPs and latency, CoE may consume more training time. For example, the applying of CoE (4 experts) on OFA-230 improves the accuracy from 78.0% to 79.9%, but at the expense of a 2.2x training cost. To verify whether the improvement still exists with similar training cost, we get a series of accuracies by varying the number of training epochs as shown in Fig.7, where 32 GPUs (Tesla-V100-PCIe-16GB) are used. It is seen that CoE boosts the performance from 78.3% to 79.9% even when the training cost is similar.
4.3 Comparison with Existing Approaches
4.3.1 Comparison with Model Ensemble
We train four OFA-230 models with different initialization seeds as shown in Table 3. The random initialization usually causes minor variety in accuracy for ImageNet classification but leads models to fall into different local minima, yielding the diversity of output. This diversity enables the ensembled models to achieve an improvement of 1.6% in accuracy. We adopt the naive ensemble here, i.e. averaging the output of each model. As shown in Wen et al. (2020); Chen et al. (2019), though simple, naive ensemble has a competitive performance in terms of accuracy. However, CoE still achieves 1.1% higher accuracy than it. Recently proposed ensemble methods (Havasi et al., 2021) mainly focus on reducing the computation cost with a little drop of accuracy than naive ensemble, but the computation cost is always larger than the one of a base model. By contrast, CoE reduces the FLOPs to 0.84 of the base model, indicating the superiority of CoE in terms of FLOPs as well.
| Method | FLOPs | Acc. | |
| OFA-230 | Seed1 | 230M | 78.1% |
| Seed2 | 230M | 78.0% | |
| Seed3 | 230M | 78.1% | |
| Seed4 | 230M | 78.0% | |
| Ensemble | 920M | 79.6% | |
| CoE-Large | 4 Experts | 194M | 79.8% |
| 16 Experts | 194M | 80.7% | |
4.3.2 Comparison with Category-Based Method
HD-CNN and HydraNets select branches based on the category. Despite their methods are originally designed to select a specific block, we apply them to the model level. To select expert based on category, the categories should be partitioned into n groups, where n is the number of experts. We try two schemes: random partition and clustering-based partition. Then, expert can be selected according to the rough prediction of delegator. During the training procedure, we also reweight losses of each expert based on the assignment matrix with Eq.5&6. Here, is obtained directly based on the rough prediction. The results with 4 experts are shown in Table 4, demonstrating a better collaboration pattern is learned by CoE.
| Method | FLOPs | Top-1 Acc. | |
| Category-Based | RP | 220M | 78.3% |
| CBP | 220M | 77.5% | |
| CoE-Large | - | 220M | 79.9% |
4.3.3 Comparison with Gate-Value-Based Training Method
MoE and Switch Transformer adopt the gate-value-based training method for routing function. They enable the training of router by using its predicted gate-value to scale the output of each expert. This optimization manner is heuristic while CoE trains the delegator more reasonably. Since expert selection for CoE is done across models, we can measure the suitability of each expert without bias. Thereafter, selection labels can be obtained to supervise delegator. Despite the gate-value-based method is originally designed to select a specific layer, we apply it to the model level. We compare with both the soft gate-value and the hard gate-value. For hard gate-value, it is a one-hot vector generated by replacing the softmax in expert selector (Fig.3) with gumbel softmax (Jang et al., 2017). The results with 4 experts are shown in Table 5, where CoE achieves better performance, indicating the effectiveness of our training method.
| Method | FLOPs | Top-1 Acc. | |
| Gate-Value-Based | Soft Gate-Value | 220M | 78.7% |
| Hard Gate-Value | 220M | 78.9% | |
| CoE-Large | - | 220M | 79.9% |
4.4 Ablation Studies for CoE
We have conducted elaborated ablations, including ablations for each element of our proposed training method, ablations for the training tricks, ablations for expert number and early termination. We mainly introduce the ablations for our proposed training method here, others are discussed in Appendix B.2.
CoE consists of 2 major components: LGM and WGM. Apart from directly removing one component, we also try to alter some elements inside them. We propose several modified versions of CoE for ablation as below:
-
•
CoELGM: Remove LGM from CoE. Thus, CoE collapses to a single expert with delegator to trigger the early termination.
- •
-
•
CoEWGM: Remove WGM from CoE. Thus, losses of experts have identical weights for each sample.
-
•
CoE: WGM partitions the training data based on expert suitability, thus the assignment matrix in WGM equals to the output matrix of LGM.
- •
-
•
CoE: Abandon the progressive sharpening for in WGM. Specifically, set in Eq.5 as a constant 0.8, instead of linearly increasing it.
-
•
CoESR: Abandon the reweighting for losses of expert selection (), namely set in Eq.7 as a constant .
The results for those CoE versions with the CoE-Large setting and 4 experts are shown in Table 6, which demonstrates the significance of each element of the training method.
| Method | Experts | FLOPs | Acc. |
| CoE-Large | 4 | 220M | 79.9% |
| CoE-LargeLGM | 4 | 220M | 78.0% |
| CoE-Large | 4 | 220M | 79.4% |
| CoE-LargeWGM | 4 | 220M | 78.1% |
| CoE-Large | 4 | 220M | 77.0% |
| CoE-Large | 4 | 220M | 79.2% |
| CoE-Large | 4 | 220M | 79.4% |
| CoE-LargeSR | 4 | 220M | 79.5% |
4.5 Analysis of the Generalization
To verify the generalizability, we conduct two extra experiments: generalizing CoE to translation task and using Reassessed Labels (ReaL) (Beyer et al., 2020) to re-evaluate CoE. We mainly introduce the first one here, another one are discussed in Appendix B.3.
To generalize CoE to translation task, we build a CoE-Transformer model based on Transformer (base model) (Vaswani et al., 2017). CoE-Transformer has four decoders, given a sentence, one decoder will be selected to decode the features extracted by encoder. To select the decoder, an extra constant token is added at the beginning of each sentence, whose feature extracted by encoder is input to the expert selector (Fig.3) for expert selection. During training, the TCP of a sentence is obtained by averaging the TCPs of each token. The architecture of CoE-Transformer are shown in Fig. 8.
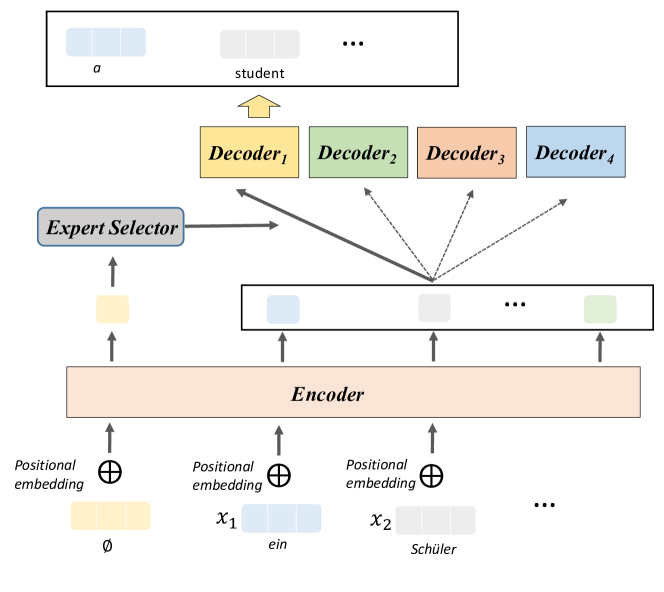
Following (Vaswani et al., 2017; Ott et al., 2019), CoE-Transformer is trained on the standard WMT 2014 English-German dataset. As mentioned, an extra token will be added to this vocabulary. We adopt the same training and evaluating setting as (Ott et al., 2019), more details are shown in Appendix B.4. From Table 7 we can see, CoE-Transformer outperforms Transformer (base model) by a large margin and achieves similar performance as Transformer (big) with much less MAC and parameters.
| Model | MAC | Parameters | BLEU |
| Transformer (base) | 62.4M | 62.4M | 28.1 (2019) |
| Transformer (big) | 213.0M | 213.0M | 29.3 (2019) |
| CoE-Transformer | 62.5M | 138.2M | 29.4 |
4.6 Analysis of the Learned Expert Selection Patterns
We also conduct experiments to analyze the expert selection patterns of CoE and find them quite reasonable. When experts have different architectures, the delegator tends to assign easy samples to smaller experts and complex samples to heavier experts. When experts share the same architecture, delegator learns the expert selection patterns automatically, it can be based on any property (e.g. whether humans are contained), rather than limited to the category. We introduce the experiment when experts have various architectures here, more details are illustrated in Appendix B.5.
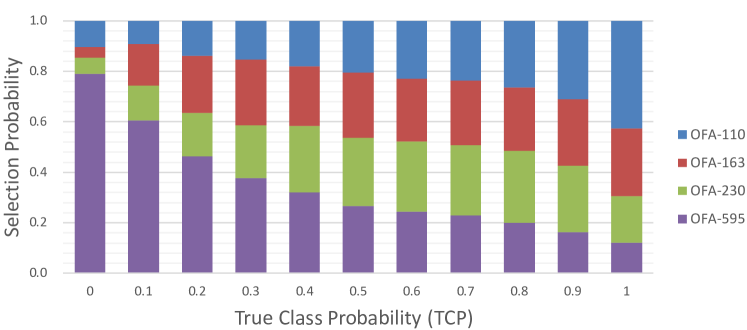
Considering TCP (Corbière et al., 2019) measures the complexity of a given sample if the inference model is fixed, namely, the more complex is the sample, the smaller TCP will be. We can analyze the relationship between sample complexity and expert selection. We take four architectures searched via OFA (Cai et al., 2020) as the experts, i.e. OFA-110, OFA-163, OFA-230 and OFA-595. OFA-xx indicates the FLOPs is xx. The delegator is also MobileNetV3-small as described in section 4.1. We obtain the TCP value for each sample based on the delegator. We count the selection probability for each expert at different TCP values on the validation set. As shown in Fig.9, the selection probability for heavier model increases with the input sample getting more complex (with the decrease of TCP). It demonstrates that CoE can learn reasonable expert selection patterns automatically.
5 Conclusion
We propose a CoE framework to pool together the expertise of multiple networks towards a common aim. Experiments in this paper demonstrate the superiority of CoE on both accuracy and real speed. We also analyze the collaboration patterns and find them have interpretability. In the future, CoE will be extended to the trillion parameters level. Meanwhile, we will try to implement CoE to more tasks and verify its compatibility with quantification and other technologies. Besides, CoE has the potential to solve problems of lifelong learning by updating experts.
References
- Arpit et al. (2017) Arpit, D., Jastrzębski, S., Ballas, N., Krueger, D., Bengio, E., Kanwal, M. S., Maharaj, T., Fischer, A., Courville, A., Bengio, Y., and Lacoste-Julien, S. A closer look at memorization in deep networks. In Precup, D. and Teh, Y. W. (eds.), Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pp. 233–242. PMLR, 06–11 Aug 2017. URL https://proceedings.mlr.press/v70/arpit17a.html.
- Beyer et al. (2020) Beyer, L., Hénaff, O. J., Kolesnikov, A., Zhai, X., and van den Oord, A. Are we done with imagenet? CoRR, abs/2006.07159, 2020.
- Cai et al. (2020) Cai, H., Gan, C., Wang, T., Zhang, Z., and Han, S. Once-for-all: Train one network and specialize it for efficient deployment. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=HylxE1HKwS.
- Chen et al. (2019) Chen, Q., Zhang, W., Yu, J., and Fan, J. Embedding complementary deep networks for image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- Chen et al. (2020) Chen, Y., Dai, X., Liu, M., Chen, D., Yuan, L., and Liu, Z. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11030–11039, 2020.
- Cheng et al. (2020) Cheng, A.-C., Lin, C. H., Juan, D.-C., Wei, W., and Sun, M. Instanas: Instance-aware neural architecture search. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pp. 3577–3584, 2020.
- Corbière et al. (2019) Corbière, C., THOME, N., Bar-Hen, A., Cord, M., and Pérez, P. Addressing failure prediction by learning model confidence. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper/2019/file/757f843a169cc678064d9530d12a1881-Paper.pdf.
- Cubuk et al. (2019) Cubuk, E. D., Zoph, B., Mane, D., Vasudevan, V., and Le, Q. V. Autoaugment: Learning augmentation strategies from data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 113–123, 2019.
- Dai et al. (2020) Dai, X., Wan, A., Zhang, P., Wu, B., He, Z., Wei, Z., Chen, K., Tian, Y., Yu, M., Vajda, P., et al. Fbnetv3: Joint architecture-recipe search using neural acquisition function. arXiv preprint arXiv:2006.02049, 2020.
- Fedus et al. (2021) Fedus, W., Zoph, B., and Shazeer, N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. arXiv preprint arXiv:2101.03961, 2021.
- Frankle & Carbin (2019) Frankle, J. and Carbin, M. The lottery ticket hypothesis: Finding sparse, trainable neural networks. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=rJl-b3RcF7.
- Gontijo-Lopes et al. (2021) Gontijo-Lopes, R., Smullin, S., Cubuk, E. D., and Dyer, E. Tradeoffs in data augmentation: An empirical study. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=ZcKPWuhG6wy.
- Han et al. (2020a) Han, K., Wang, Y., Tian, Q., Guo, J., Xu, C., and Xu, C. Ghostnet: More features from cheap operations. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1577–1586, 2020a. doi: 10.1109/CVPR42600.2020.00165.
- Han et al. (2020b) Han, K., Wang, Y., Zhang, Q., Zhang, W., Xu, C., and Zhang, T. Model rubik’s cube: Twisting resolution, depth and width for tinynets. In NeurIPS, 2020b.
- Hansen & Salamon (1990) Hansen, L. K. and Salamon, P. Neural network ensembles. IEEE transactions on pattern analysis and machine intelligence, 12(10):993–1001, 1990.
- Havasi et al. (2021) Havasi, M., Jenatton, R., Fort, S., Liu, J. Z., Snoek, J., Lakshminarayanan, B., Dai, A. M., and Tran, D. Training independent subnetworks for robust prediction. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=OGg9XnKxFAH.
- He et al. (2016) He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
- Howard et al. (2019) Howard, A., Sandler, M., Chu, G., Chen, L.-C., Chen, B., Tan, M., Wang, W., Zhu, Y., Pang, R., Vasudevan, V., et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1314–1324, 2019.
- Huang et al. (2016) Huang, G., Sun, Y., Liu, Z., Sedra, D., and Weinberger, K. Q. Deep networks with stochastic depth. In European conference on computer vision, pp. 646–661. Springer, 2016.
- Jang et al. (2017) Jang, E., Gu, S., and Poole, B. Categorical reparameterization with gumbel-softmax. In ICLR, 2017.
- Li et al. (2021a) Li, C., Wang, G., Wang, B., Liang, X., Li, Z., and Chang, X. Dynamic slimmable network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8607–8617, June 2021a.
- Li et al. (2021b) Li, Y., Jia, X., Sang, R., Zhu, Y., Green, B., Wang, L., and Gong, B. Ranking neural checkpoints. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2663–2673, June 2021b.
- Ma et al. (2018) Ma, N., Zhang, X., Zheng, H.-T., and Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European conference on computer vision (ECCV), pp. 116–131, 2018.
- Ma et al. (2020) Ma, N., Zhang, X., Huang, J., and Sun, J. Weightnet: Revisiting the design space of weight networks. CoRR, abs/2007.11823, 2020.
- Mullapudi et al. (2018) Mullapudi, R. T., Mark, W. R., Shazeer, N., and Fatahalian, K. Hydranets: Specialized dynamic architectures for efficient inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8080–8089, 2018.
- Ott et al. (2019) Ott, M., Edunov, S., Baevski, A., Fan, A., Gross, S., Ng, N., Grangier, D., and Auli, M. fairseq: A fast, extensible toolkit for sequence modeling. In Proceedings of NAACL-HLT 2019: Demonstrations, 2019.
- Shazeer et al. (2017) Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., and Dean, J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017.
- Shore (1970) Shore, H. H. The transportation problem and the vogel approximation method. Decision Sciences, 1(3-4):441–457, 1970.
- Tan & Le (2019) Tan, M. and Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning, pp. 6105–6114. PMLR, 2019.
- Vaswani et al. (2017) Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attention is all you need. In NIPS, pp. 6000–6010, 2017. URL http://papers.nips.cc/paper/7181-attention-is-all-you-need.
- Wang et al. (2020) Wang, Y., Lv, K., Huang, R., Song, S., Yang, L., and Huang, G. Glance and focus: a dynamic approach to reducing spatial redundancy in image classification. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M. F., and Lin, H. (eds.), Advances in Neural Information Processing Systems, volume 33, pp. 2432–2444. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper/2020/file/1963bd5135521d623f6c29e6b1174975-Paper.pdf.
- Wen et al. (2020) Wen, Y., Tran, D., and Ba, J. Batchensemble: an alternative approach to efficient ensemble and lifelong learning. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=Sklf1yrYDr.
- Wenzel et al. (2020) Wenzel, F., Snoek, J., Tran, D., and Jenatton, R. Hyperparameter ensembles for robustness and uncertainty quantification. arXiv preprint arXiv:2006.13570, 2020.
- Xie et al. (2020) Xie, Q., Luong, M.-T., Hovy, E., and Le, Q. V. Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10687–10698, 2020.
- Xie et al. (2017) Xie, S., Girshick, R., Dollar, P., Tu, Z., and He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
- Yan et al. (2015) Yan, Z., Zhang, H., Piramuthu, R., Jagadeesh, V., DeCoste, D., Di, W., and Yu, Y. Hd-cnn: hierarchical deep convolutional neural networks for large scale visual recognition. In Proceedings of the IEEE international conference on computer vision, pp. 2740–2748, 2015.
- Yang et al. (2019) Yang, B., Bender, G., Le, Q. V., and Ngiam, J. Condconv: Conditionally parameterized convolutions for efficient inference. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
- You et al. (2021) You, K., Liu, Y., Wang, J., and Long, M. Logme: Practical assessment of pre-trained models for transfer learning. In Meila, M. and Zhang, T. (eds.), Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp. 12133–12143. PMLR, 18–24 Jul 2021. URL https://proceedings.mlr.press/v139/you21b.html.
- Yuan et al. (2020) Yuan, K., Li, Q., Chen, D., Zhou, A., and Yan, J. Dynamic graph: Learning instance-aware connectivity for neural networks. arXiv preprint arXiv:2010.01097, 2020.
- Zhai et al. (2019) Zhai, X., Oliver, A., Kolesnikov, A., and Beyer, L. S4l: Self-supervised semi-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2019.
- Zhang et al. (2021) Zhang, M., Chu, C.-T., Zhmoginov, A., Howard, A., Jou, B., Zhu, Y., Zhang, L., Hwa, R., and Kovashka, A. Basisnet: Two-stage model synthesis for efficient inference. arXiv preprint arXiv:2105.03014, 2021.
- Zhang et al. (2020) Zhang, Y., Zhang, J., Wang, Q., and Zhong, Z. Dynet: Dynamic convolution for accelerating convolutional neural networks. arXiv preprint arXiv:2004.10694, 2020.
- Zhong et al. (2018) Zhong, Z., Yan, J., Wu, W., Shao, J., and Liu, C.-L. Practical block-wise neural network architecture generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
- Zhou et al. (2021) Zhou, Y., Zhu, Z., and Zhong, Z. Learning specialized activation functions with the piecewise linear unit. CoRR, abs/2104.03693, 2021.
Appendix A Extra Details for Method
A.1 Introduction of Vogel Approximation Method (VAM)
In weight generation module (WGM) and label generation module (LGM), we need to solve the balanced transportation problem (BTP, (Shore, 1970)) via Vogel approximation method (VAM, (Shore, 1970)). We will introduce it in this section with the number of samples and experts as and respectively.
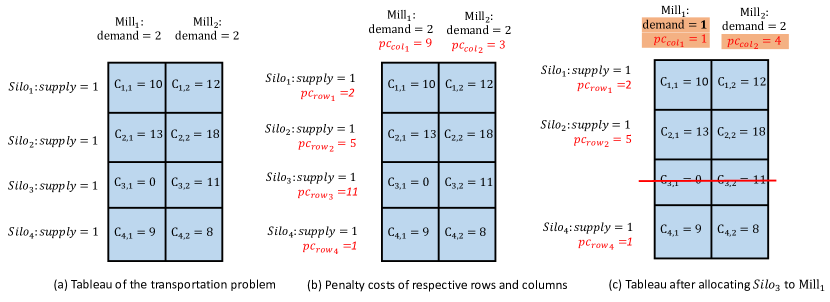
The BTP involved in WGM and LGM has supply sources, each of which is denoted as with a supply of one, as well as demand sources, each of which is denoted as with a demand of . is the per-unit transportation cost from to . Specifically, in WGM and in LGM. To make it clear, we illustrate this algorithm with a toy example, where the problem is simplified as Fig.10 (a) with , . In the first step, we calculate the penalty cost for each row and for each column of the tableau in Fig.10 (a). Penalty cost is determined by subtracting the lowest unit cost in the row (column) from the next lowest unit cost. The penalty costs of the respective rows and columns have been marked in red color for clarity in Fig.10 (b). Since the third row has the largest penalty cost ( =11) and is the lowest unit cost of that row, is allocated to , i.e. in WGM or in LGM. Then the corresponding row should be crossed out and the demand of should minus one, if this results in a zero demand, the first column will be crossed out as well. After adjusting penalty cost for each row and column, the tableau becomes Fig.10 (c), where the changed values are marked in orange. The described procedure will be looped until no rows remained.
Considering the calculation of is much more time-consuming compared with because in WGM and LGM, we modify VAM by only seeking lowest penalty cost among . We find this modification makes VAM more efficient while keeps the superiority of the solution. It is because the mechanics of VAM makes it meaningful to take into account only when the demand of is one, which rarely happens. Thus, we adopt this modification to promote efficiency in this paper.
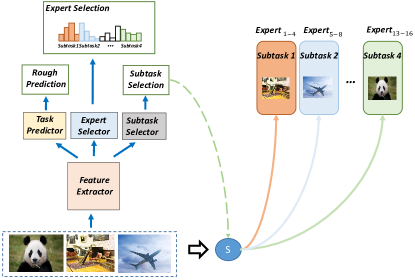
A.2 A Strategy for Task Decomposition
To fulfill task decomposition, we introduce a new module to delegator, named subtask selector as shown in Fig.11. The subtask selector is used to allocate the input samples into different subtasks. The expert selector outputs sixteen probabilities, which are partitioned into four groups as well. For each subtask, only one group of probabilities is visible. The experts within each subtask and the corresponding weights of the expert selector are jointly optimized. As for the feature extractor, task predictor, and subtask selector, their weights directly derive from the delegator trained with the setting of four experts and then fixed. During this procedure, the weights of subtask selector derive from the expert selector.
Appendix B Extra details for Experiments
B.1 Experiment details for the ImageNet classification task
To combine with CondConv, we replace the convolutions within each inverted residual block of the experts with CondConv (). To take advantage of PWLU, we replace all activation layers except those that have tiny input feature maps as illustrated in Zhou et al. (2021). Models are trained using SGD optimizer with 0.9 momentum. We use a mini-batch size of 4096, and a weight decay of 0.00002. Cosine learning rate decay is adopted and the number of training iterations is 313000. We use the augment policy searched by Cubuk et al. (2019) as well (fixed auto-augment). Similar as BasisNet, we use knowledge distillation with EfficientNet-B2 (Tan & Le, 2019; Xie et al., 2020) as the teacher. The learning rate is 0.8/1.6 for CoE-Small/Large and dropout rate is 0.2. The stochastic depth (Huang et al., 2016) is used except for TinyNet-E with a survival probability of 0.8. We think only when the overfitting problem is solved can task accuracy reflect model capacity exactly. Because this paper is concerned with improving the model capacity with limited computation cost, we use knowledge distillation, fixed auto-augment and stochastic depth to overcome the overfitting problem. Nonetheless, we also conduct ablations for them as shown in Appendix B.2.1
B.2 Ablation Studies for CoE
B.2.1 Ablation study for the training tricks
Knowledge distillation (KD), auto-augment (AA) and stochastic depth (SD) are widely-used strategies to overcome the overfitting problem. We think only when the overfitting problem is solved can task accuracy reflect model capacity exactly. Because this paper is concerned with improving the model capacity with limited computation cost, we use these strategies. Nonetheless, we conduct ablations for them in this section. We adopt the CoE-Large setting with 4 experts. Results are shown in Table 8. We find KD extremely important for CoE, it may indicate CoE is easy to be overfitted. In addition, SD decreases the accuracy of CoE. By removing SD, CoE-Large (4 experts) boosts the accuracy from 79.9% to 80.2%. Perhaps, it is because SD makes the capacity of delegator and each expert too tiny (Gontijo-Lopes et al., 2021).
| KD | AA | SD | Experts | FLOPs | TOP-1 Acc |
| 4 | 220M | 79.9% | |||
| 4 | 220M | 80.2% | |||
| 4 | 220M | 79.4% | |||
| 4 | 220M | 76.2% | |||
| 4 | 220M | 79.7% | |||
| 4 | 220M | 76.3% | |||
| 4 | 220M | 75.2% | |||
| 4 | 220M | 75.1% |
B.2.2 Effect of Expert Number
We analyze the number of experts in this section, including 1, 4, and 16 experts. The results are shown in Table 9. Using one expert brings little improvement compared with the original model. When increasing the number of experts, the accuracy becomes 1.9% better with four experts and 2.9% better with sixteen experts. It demonstrates CoE can make full use of multiple experts, leading to a large collaborative benefit. What‘s more, the accuracy also reaches 79.9% by combining CondConv with OFA-230. In this manner, CoE can further enhance the accuracy to 80.8/81.5% with 4/16 experts.
| Method | Experts | FLOPs | Acc. |
| OFA-230 | - | 230M | 78.0% |
| CoE-Large | 1 | 220M | 78.0% |
| 4 | 220M | 79.9% | |
| 16 | 220M | 80.9% | |
| CC-OFA-230 | - | 242M | 79.9% |
| CoE-Large + CC | 1 | 214M | 79.9% |
| 4 | 214M | 80.8% | |
| 16 | 214M | 81.5% |
B.2.3 Effect of Early Termination
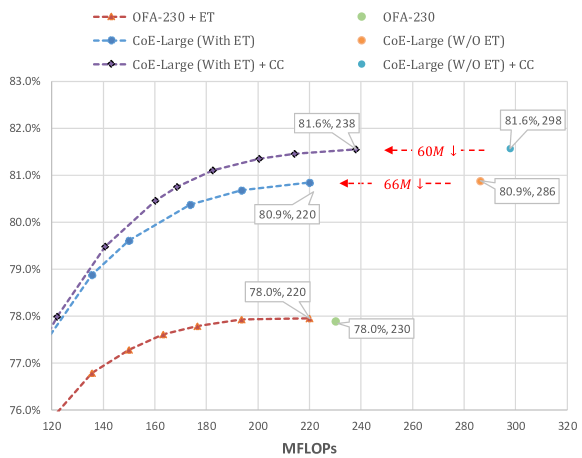
The original OFA-230 has 78.0% top-1 accuracy with 230M FLOPs. We can introduce a MobileNetV3-Small to conduct early termination. By varying the threshold, we get a series of accuracies and FLOPs as shown in Fig.12. It can seen that the accuracy becomes 78.0% with 220M FLOPs. This indicates the computation cost brought by MobileNetV3-Small is eliminated via early termination strategy. Inspired by this, we expect to eliminate the computation cost brought by delegator via early termination as well. It does reduce the computation cost by 60/66M FLOPs, demonstrating the effectiveness of early termination.
B.3 Re-evaluation with Reassessed Labels
As described in paper (Beyer et al., 2020), the validation set labels have a set of deficiencies that makes the recent progress on ImageNet classification benchmark suffer from overfitting to the artifacts. To verify the generalization, we use the Reassessed Labels (ReaL) (Beyer et al., 2020) to re-evaluate our method. The results are shown in Table 10. It can be seen that our method still has a remarkable performance, achieving higher accuracy than the compared methods with significantly smaller FLOPs.
| Method | FLOPs | ReaL Acc. | Ori. Acc. |
| OFA-595 (Cai et al., 2020) | 595M | 86.0% | 80.0% |
| S4L MOAM (Zhai et al., 2019) | 4B | 86.6% | 80.3% |
| ResNeXt-101 (Xie et al., 2017) | 16B | 85.2% | 79.2% |
| ResNet-152 (He et al., 2016) | 11B | 84.8% | 78.2% |
| CoE-Large | 194M | 86.5% | 80.7% |
| CoE-Large + CC | 214M | 86.9% | 81.5% |
B.4 Experiment details for the translation task
Following (Vaswani et al., 2017; Ott et al., 2019), CoE-Transformer is trained on the standard WMT 2014 English-German dataset, which has a shared source-target vocabulary of about 37000 tokens. As mentioned, an extra token will be added to this vocabulary. The default training setting is identical with the one described in (Vaswani et al., 2017), except for the batch size and learning rate becoming larger following (Ott et al., 2019). Moreover, the parameter in Eq.5 grows linearly from 0.1 to 0.4 with the training going on. We report BLEU on news2014 with a beam width of 4 and length penalty of 0.6 based on a single model obtained by averaging the last 5 checkpoints following (Vaswani et al., 2017; Ott et al., 2019).
B.5 Analysis of the Learned Expert Selection Patterns
B.5.1 Expert Selection Patterns when experts share the same architecture
We have analyzed the selection patterns when experts have different architectures, here we focus on the case that all experts share the same architecture. We adopt the CoE-Large setting with four experts.
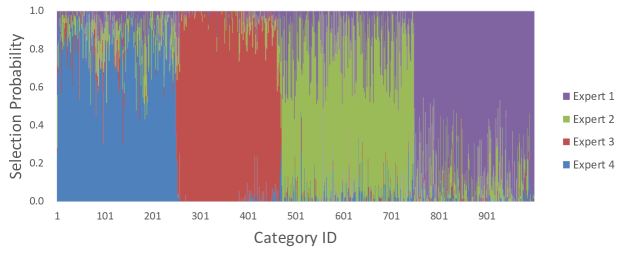
Considering many works (Yan et al., 2015; Mullapudi et al., 2018) select branches based on the category, we firstly experiment to observe the relationship between selection patterns and rough prediction of the delegator on ImageNet validation set. Based on the predicted class of rough prediction, the validation set can be partitioned into 1000 subsets. Then we calculate the probabilities to select each expert within each subset and get 1000 probability vectors. After clustering, we plot the probability vectors on Fig.13, where each column represents a probability vector. It can be seen that samples with the same rough prediction class are assigned to different experts. Therefore, we can conclude that the expert is not always selected based on category.
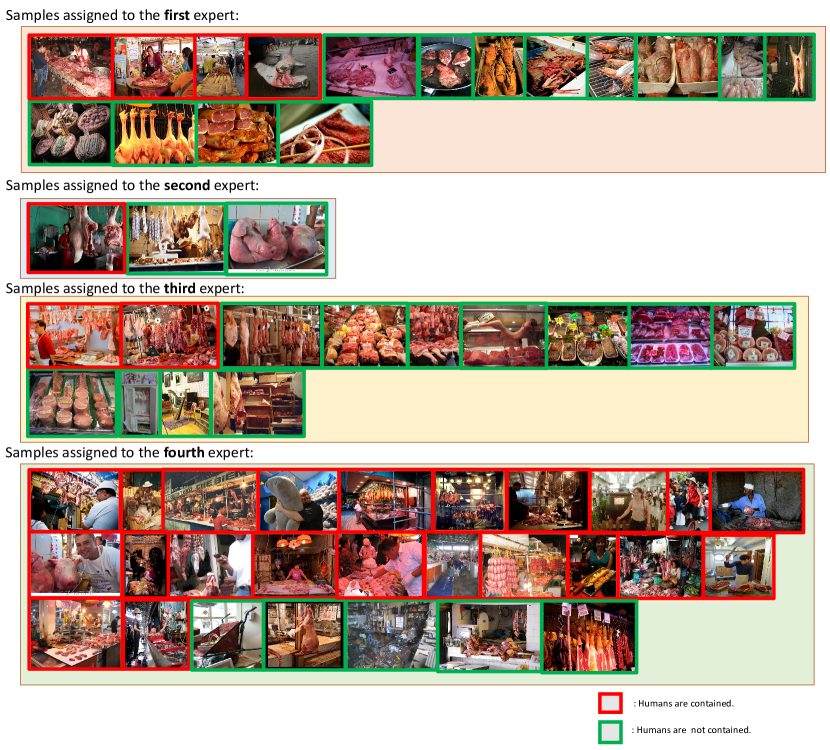
Besides, we further make qualitative analysis on the ImageNet validation set and find some interesting patterns. For example, we find that images predicted as “meat market” are most likely to be assigned to the fourth expert if humans are contained. We show those images in Fig.14. It can be seen, 27 images are assigned to the fourth expert, among which 22 images contain humans with a ratio of 81.5%. By contrast, among the 32 images assigned to other experts, only 7 images contain humans with a ratio of 21.9%. This indicates CoE learns the expert selection patterns automatically, it can be based on properties other than the category.