A Loss Curvature Perspective on Training Instability in Deep Learning
Abstract
In this work, we study the evolution of the loss Hessian across many classification tasks in order to understand the effect the curvature of the loss has on the training dynamics. Whereas prior work has focused on how different learning rates affect the loss Hessian observed during training, we also analyze the effects of model initialization, architectural choices, and common training heuristics such as gradient clipping and learning rate warmup. Our results demonstrate that successful model and hyperparameter choices allow the early optimization trajectory to either avoid—or navigate out of—regions of high curvature and into flatter regions that tolerate a higher learning rate. Our results suggest a unifying perspective on how disparate mitigation strategies for training instability ultimately address the same underlying failure mode of neural network optimization, namely poor conditioning. Inspired by the conditioning perspective, we show that learning rate warmup can improve training stability just as much as batch normalization, layer normalization, MetaInit, GradInit, and Fixup initialization.
1 Introduction
Optimization of neural networks can easily fail. While recent architectural advances such as skip connections [8] and Batch Normalization [11] have been applied successfully to produce architectures and hyperparameters that reliably train well, even small changes to a trainable configuration can easily result in training that diverges. More generally, producing a configuration that strikes the right balance between stable training and rapid optimization progress on a new domain can be difficult—practitioners and researchers have few reliable heuristics to guide them through the process. As a result, the specific hyperparameter tuning protocol has an outsized influence on the results [3, 28] and successes often rely on large hyperparameter searches [20]. Developing a principled understanding of what makes general architectures trainable would allow researchers to more reliably navigate this process and has the potential to dramatically accelerate research into finding better, more scalable architectures.
The focus of the empirical investigation of this work is to better understand what limits the maximum trainable learning rate for deep learning models trained with the typical minibatch stochastic gradient descent (SGD) family algorithms. As part of this investigation, we examine several methods developed by the deep learning community that have enabled training at larger learning rates and improved performance. Many methods have been developed that can achieve this goal, notably normalization, learning rate warmup, gradient clipping [22], and better model initializations such as Fixup [37], MetaInit [5], and GradInit [38]. While these methods are certainly not exactly equivalent, a key property they all have in common is that they can enable training at larger learning rates when applied to certain models (see for example Figure 1).
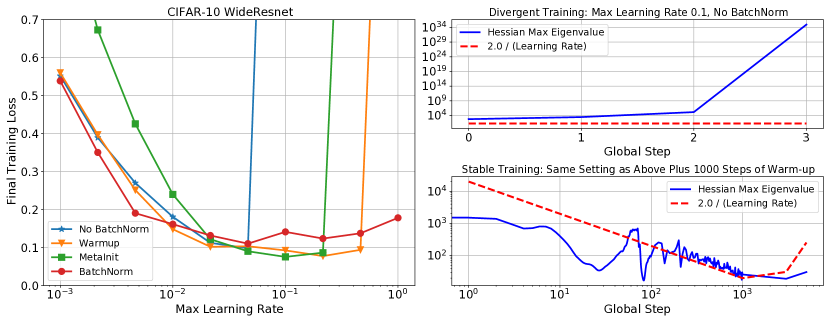
A natural hypothesis is that methods which enable training at larger learning rates do so through reducing the sharpness111Throughout this work we will use the term sharpness to refer to the maximum eigenvalue of the loss Hessian, denoted as . of the loss surface during training. Indeed, this hypothesis has already been proposed as one of the beneficial effects of Batch Normalization [6, 26] and residual connections [17], and quadratic models of the loss surface predict that optimization with SGD is unstable when [30]. However, recent empirical investigations into the relevance of quadratic stability bounds to neural network training have either focused on smaller models, focused on full batch training at small learning rates, and do not investigate connections between sharpness, model initialization and learning rate warmup [4, 13].
In this work, we design a series of large scale experiments studying the evolution of the loss sharpness as we vary the learning rate, warmup period, initialization, and architectural choices. Our results demonstrate the central role that plays in neural network optimization—maintaining sufficiently small during optimization is a necessary condition for successful training at large learning rates. Consequently, reducing is a primary benefit of proper tuning of a number of architecture and optimization hyperparameters: including model initialization, location of normalization, and warmup schedule. Specifically, we show the following:
-
•
We provide large scale empirical confirmation that training of neural networks with SGD+momentum is stable only when the optimization trajectory primarily resides in a region of parameter space where , where denotes the learning rate. This corroborates the theoretical predictions in Wu et al. [30] and recent empirical observations of Jastrzebski et al. [13] and Cohen et al. [4].
-
•
We demonstrate that several successful initialization strategies for architectures without normalization operate primarily by reducing curvature early in training, enabling training at larger learning rates.
-
•
We show that learning rate warmup gradually reduces during training, offering similar benefits to better model initialization. We connect the mechanism by which warmup operates to the dynamical stability model of Wu et al. [30].
-
•
We show that learning rate warmup is a simple yet competitive baseline for research into better model initialization. We demonstrate that key progress in this area from Dauphin and Schoenholz [5], Zhang et al. [37], Zhu et al. [38] can be matched by the application of learning rate warmup alone.
-
•
Finally, we show that large loss curvature can result in poor scaling at large batch sizes and interventions designed to improve loss conditioning can drastically improve the model’s ability to leverage data parallelism.
2 Related Work
Understanding BatchNorm The loss Hessian has been a central object of study for understanding optimization of neural networks. Santurkar et al. [26] argues that an important benefit of Batch Normalization is improved smoothness of the loss surface, while Lewkowycz et al. [16] notes that this is improved smoothness is only observed when higher learning rates are used in combination with Batch Normalization. Our results are generally consistent with this current understanding of Batch Normalization, however some of our experiments provide additional nuance—notably we observe several instances where models suffer from training instability (and high loss curvature) early in training despite using Batch Normalization (see Section 4).
Evolution of the loss Hessian Recent research has closely studied the interaction between sharpness and learning rate. Cohen et al. [4] observed that for full batch training, the loss curvature demonstrates “progressive sharpening”, where it increases until . In our experiments we observe that progressive sharpening of the loss occurs for models trained with SGD, with a notable exception of Transformer models on LM1B. Lewkowycz et al. [16] provides a theoretical model predicting that some architectures initialized at point with and trained with an MSE loss may enter a “catapult” regime—where the loss increases early until a flatter region of the loss surface is found, with divergence occurring in cases where greatly exceeds . Our experimental setup violates many assumptions from this work, though it is noteworthy that some of the behavior we observe is consistent with catapult dynamics—we observed that models can consistently be trained even when at initialization, resulting in brief initial training instability until optimization enters a flatter region. However, we observe some cases where models diverge despite being initialized at a point where , which is not predicted by this theoretical model.
Jastrzebski et al. [13] describes several preconditioning benefits of using large learning rates with SGD, namely smaller observed and larger during training. Our results provide large scale empirical evidence for the conjecture that larger learning rates result in flatter curvature during training. Additionally, we demonstrate that learning rate warmup and gradient clipping leverage this mechanism to reduce even further, as some models can be trained with even larger learning rates when these two techniques are adopted.
3 Experimental Setup
We investigate models trained on several benchmarks: CIFAR-10 [15] and ImageNet [25] for image classification, LM1B [2] for Language Modeling, and WMT for Neural Machine Translation (NMT). On CIFAR-10 we consider the WideResnet [34] and DenseNet [10] architectures, both with and without Batch Normalization. When training without Batch Normalization we consider several initialization strategies including the default “LeCun Normal” initialization, and running MetaInit. As a way to artificially induce worse initializations, we also consider experiments where we scale every variable produced by the default initialization by a constant factor . The NMT models are trained on the WMT’16 EN-DE training set, tuned for hyper-parameters on the WMT’16 EN-DE validation set and evaluated on the WMT’14 EN-DE test set for BLEU scores. For NMT and LM1B Language Modeling, we train 6 layer Transformer models [29]. Inspired from Xiong et al. [31], we experiment with three Layer Norm settings: pre-Layer Norm, post-Layer Norm [18] and no Layer Norm for the transformer models.
Each model is trained with various learning rates using cosine decay (unless mentioned explicitly). For warmup experiments we use linear warmup which starts at 0 and scales linearly to a max value before applying cosine decay. To measure the max eigenvalue of the loss Hessian we use the Lanczos method where the number of iterations varied as needed depending on the architecture (details provided in the appendix).
4 Early Training Instability and the Loss Hessian
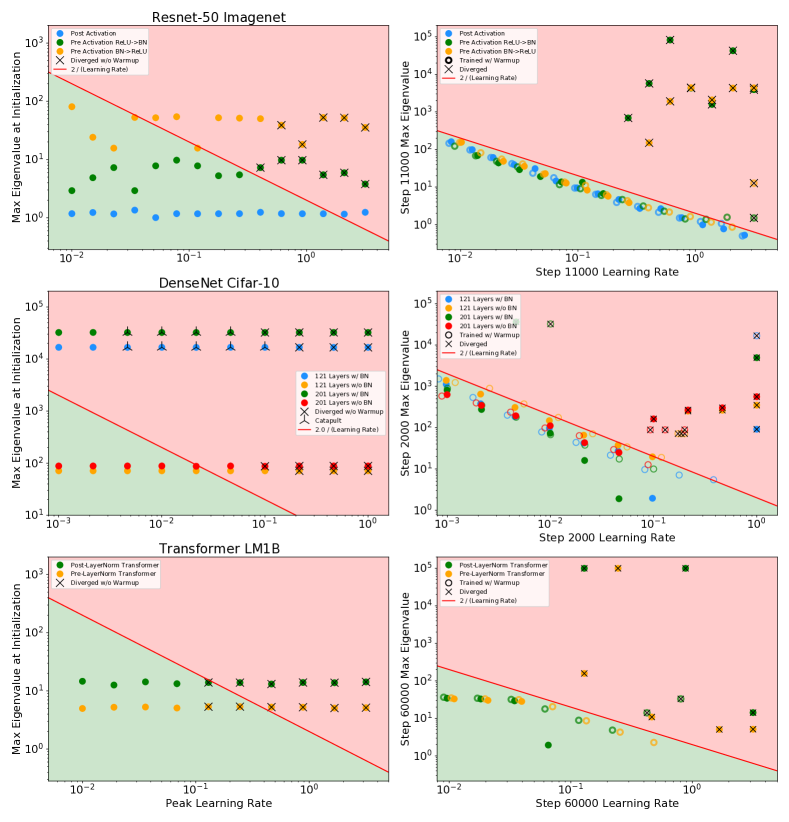
In Figure 2 we plot the curvature at initialization and during training for a series of models trained on different datasets (plots showing final performance for all models can be found in the appendix). Each row indicates a different base model, the left column plots the curvature of the model at initialization and indicates with an ‘X’ whether or not the model diverges when trained without warmup. On the right we plot the measured curvature and learning rate at a specified point during training. We observe across all datasets that successful training occurs only when optimization enters a region of parameter space where , and that divergent models are outside this region shortly before divergence. At initialization, some models can be successfully trained even when they start out in the unstable region and generally speaking, divergence is more likely for models deeper in the unstable region.
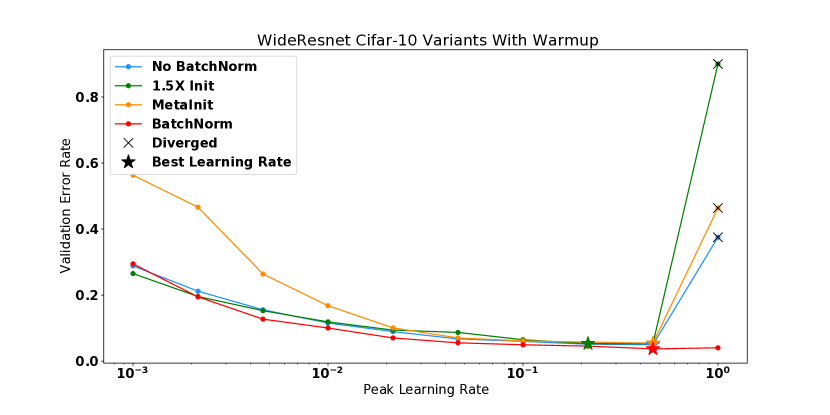
These experiments also visualize how different methods unlock training at higher learning rates. For CIFAR-10 WideResnet, removing batch norm results in a model with higher curvature at initialization and results in divergent models when trained with a learning rate . Scaling the WideResnet initialization up by a factor of exacerbates the problem, resulting in even higher curvature at initialization and divergence when . MetaInit starts the model out at a point with very small , and allows training without Batch Normalization at higher learning rates than the default initialization. We also observed that higher learning rates can be unlocked when the models are trained with learning rate warmup, and that we are able to match the performance of MetaInit using warmup and starting with the bad initialization. Warmup was particularly effective for models which exhibit large either at initialization or early in training. Other models such as the post activation Resnet-50, and WideResnet w/ Batch Normalization did not benefit from warmup at the considered learning rates.
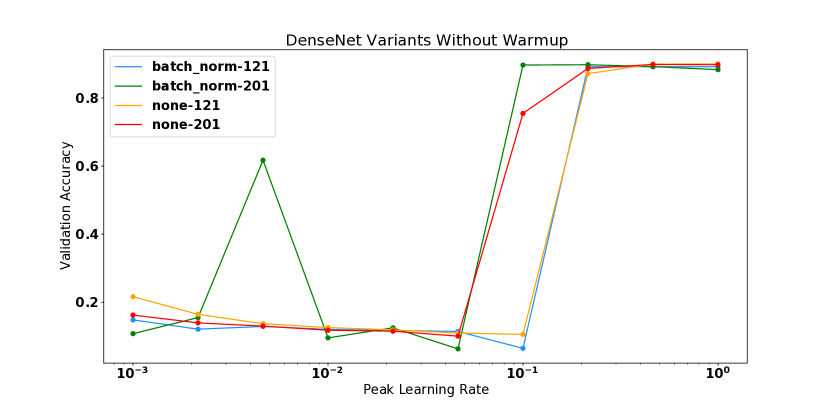
For the DenseNet experiments, it is noteworthy that the models with Batch Normalization actually start out with higher curvature than the non-BN variants. This is contrary to the generally accepted narrative that Batch Normalization improves the smoothness of the loss surface [6, 26], though not without precedent as Yang et al. [32] demonstrates settings for which Batch Normalization can cause exploding gradients. We found that the Batch Normalization models were more unstable than the non-BN variants here, as some models diverged at smaller learning rates. However, when combined with warmup the BN models were trainable at learning rates , whereas this did not hold for the non-BN variants, which diverge both with and without warmup at these learning rates. This result suggests that BN still offers training stability for this model, and flatter curvature mid training if trained with warmup and a higher learning rate, however no smoothness benefits are observed at initialization.
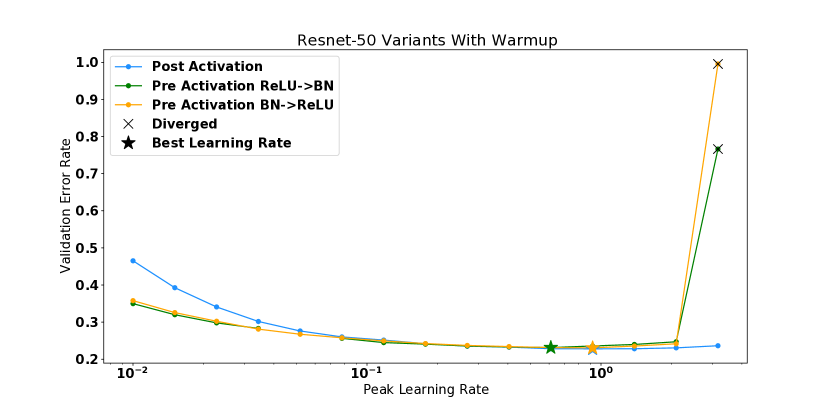
For Resnet-50 trained on ImageNet we compare two different residual blocks: the preactivation block [9] and the more commonly used post activation block [8]. For the preactivation block, we also consider flipping the order of the ReLU activation and batch normalization, as was considered in Brock et al. [1]. We find that both preactivation models start out in a region of higher curvature relative to the post activation variant, and that these models diverge when whereas the post activation variant is trainable with learning rates as large at .
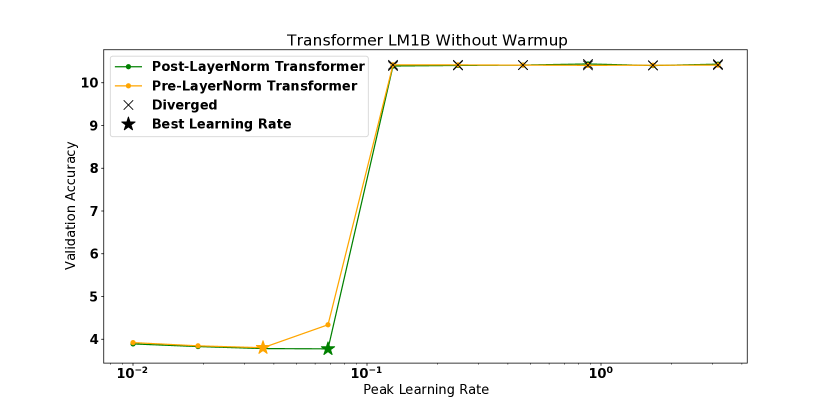
Notably, there are several models in our experiments which diverge despite starting out in a region where . This occurs for both the pre and post layernorm transformer, and the WideResnet model initialized with MetaInit. We found for these divergent models that the curvature rapidly increases in the initial steps of training, which is partially visible in the mid training plot where we plot the final observed curvature before divergence. Full training curves for these models can be found in the appendix. These examples are noteworthy because it demonstrates that measuring smoothness at model initialization is not always sufficient to predict whether or not the model will be easily trained. Currently, some architectural innovations are motivated by an analysis of either gradient statistics or smoothness at initialization [18]—a more robust analysis would consider the evolution of these statistics under SGD.
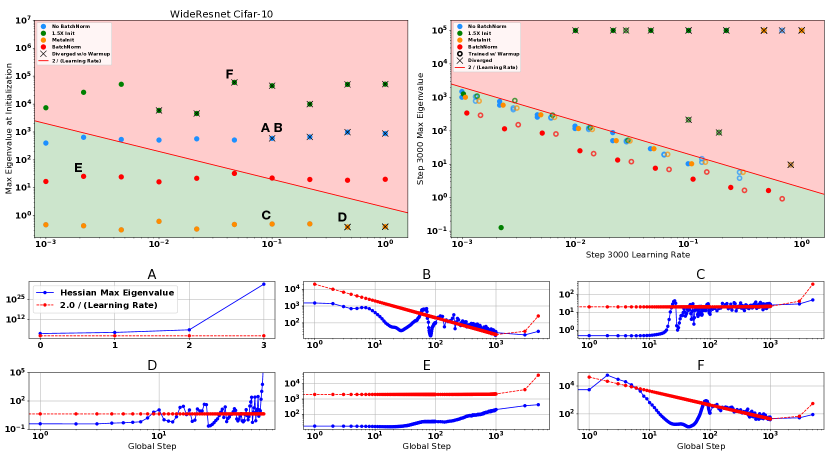
Bottom Row: Full time evolution of curvature and learning rate for select runs (labeled with letters in the top row). A: The non-BN variant diverges within 3 steps when trained at learning rate . B: Same configuration as (A), but when warmup is used the curvature gradually decreases during training allowing successful training with peak learning rate of . C: MetaInit allows training without warmup at learning rate by starting off optimization in a flatter region of parameter space. Despite starting out with very flat curvature, we observe progressive sharpening until the curvature fluctuates around the bound . D: An example of a model diverging despite starting out in the “stable” region. The curvature grows early and eventually diverges before step 100. E: An example of progressive sharpening when training with a small learning rate. F: Learning rate warmup recovers from an even poorer initialization (the same point diverges without warmup).
5 The Interaction between Learning Rate Warmup, Initialization and Curvature
The success of learning rate warmup is inconsistent with conventional optimization wisdom, which traditionally suggests adapting the step size to the curvature (see for example the discussion around equation 2.4 in [19]). However, with the understanding that is a dynamic quantity whose evolution is tightly coupled with the learning rate schedule, the benefits of a warmup period are more easily understood. We argue that the success of learning rate warmup follows naturally from two properties of training deep models:
-
1.
Models diverge when the learning rate is too large relative to the bound.
-
2.
When the learning rate only slightly exceeds optimization is unstable until the parameters move to a region with smaller [30, 16].
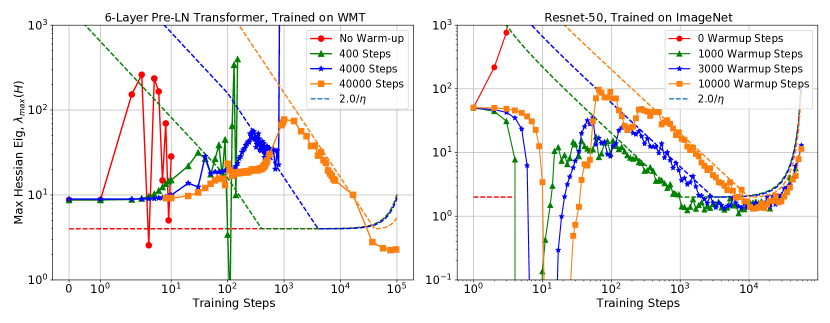
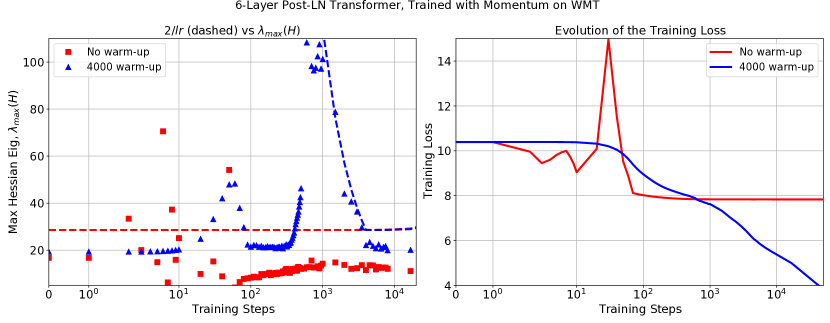
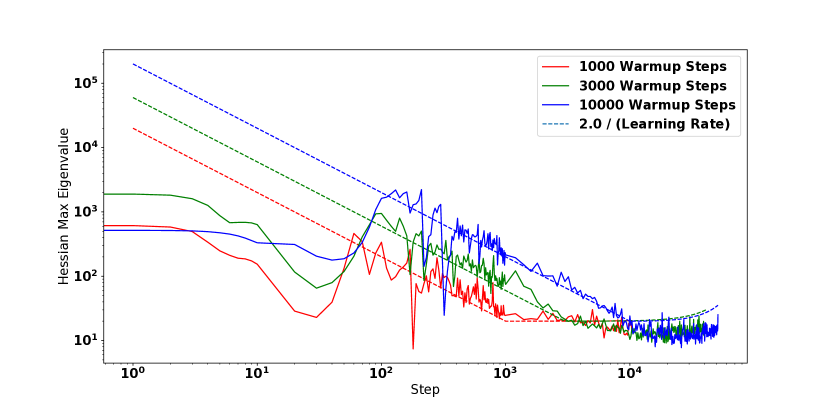
The first criteria implies that we can’t start off at too large of a value relative to at initialization. The second criteria implies that gradually increasing can gradually “push” the parameters to a region of parameter space where optimization is stable (with lower values of ). In Figure 4 there is clear evidence for this “pushing”, as during the warmup period the we see that holds for a large part of the warmup phase. Furthermore, this approximation holds even as we vary the length of the warmup period. Other examples can be seen in Figure 3 (B and F), and Figure 15 in the appendix.
Warmup is not the only method capable of reducing during training, one can instead initialize the model in a region where starts off small. Consider for example, the points A, B and C in Figure 3. Each point shows optimization of a non-BN WideResnet with peak learning rate of . In (A) we see the model diverges within 3 steps without warmup using the default initialization. In (B) we see that a linear warmup period results in progressively decreasing until the peak step size of is reached at step 1000, with no divergence occurring. Finally in (C) we initialize the same model with MetaInit, at which point is small at initialization, and the model can be trained at without warmup.
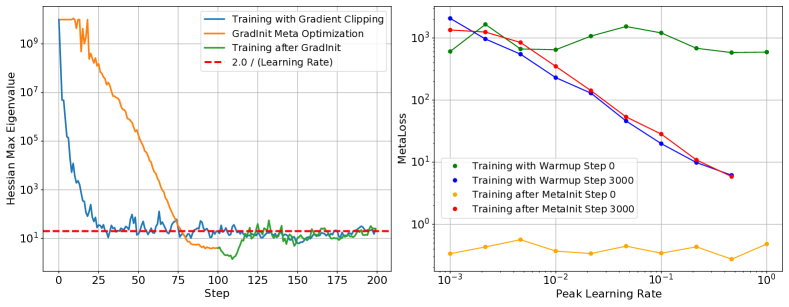
Similar to the aforementioned MetaInit, the success of related initialization strategies can be explained by reduced early in training. In Figure 5 (left) we look at the evolution of during the GradInit meta optimization process and compare this with simply training the same model using gradient clipping222Similar to warmup, gradient clipping reduces the step size in regions of large curvature.. Both methods result in decreasing dramatically, after which hovers around . Notably, GradInit starts regular training off at significantly below the bound, however the curvature quickly increases within a few steps. Given that initialization and warmup serve similar roles in reducing , we expect to be able to achieve similar performance using the two methods. As shown in Tables 1 and 2 we can easily match key advances in this field by applying learning rate warmup alone (see Appendix for experimental details).
Beyond controlling mid-training, the learning rate controls more general conditioning measures of the loss surface. For example, in Figure 5 we observe that even the MetaInit gradient quotient—the conditioning measure directly optimized by this initialization strategy—is controlled by mid training. This again provides further evidence that the primary benefit of this initialization method is to reduce at initialization. As shown, any gains by optimizing the more general gradient quotient must be short lived as the initialization has no control over the long term value.
| Model | Method | |||
|---|---|---|---|---|
| DenseNet-100 | Kaiming-Clip 1.0 | 35.43 | 93.97 | |
| DenseNet-100 | GradInit | 37.19 | 94.85 | |
| DenseNet-100 | Kaiming-Clip 6.0 | 39.0 | 94.65 |
| Model | Dataset | Method | ||
|---|---|---|---|---|
| WideResnet 28-10 (w/o BN) | CIFAR-10 | Warmup 1000 | 97.2 | |
| WideResnet 28-10 (w/o BN) | CIFAR-10 | MetaInit | 97.1 | |
| Resnet-50 (w/o BN) | ImageNet | Fixup | 76.0 | |
| Resnet-50 (w/o BN) | ImageNet | MetaInit | 76.0 | |
| Resnet-50 (w/o BN) | ImageNet | GradInit | 76.2 | |
| Resnet-50 (w/o BN) | ImageNet | Warmup 1000 | 76.2 | |
| Transformer 6L (w/o LN) | WMT | Warmup + Clip + .25x Init | 27.10 (BLEU) | |
| Transformer 6L (w/ LN) | WMT | LayerNorm | 27.01 (BLEU) |
6 The Effects of Curvature on Batch Size Scaling
So far, we discussed how large loss curvature limits the range of stable learning rates for training. In this section, we highlight how these limits on usable learning rates affect the model’s ability to effectively leverage larger batch sizes. Previous research has studied the interplay of the loss curvature and batch size scaling from various different perspectives. Most notably, Shallue et al. [27] observe that increasing the batch size yields consistent improvements in training speed until a (problem-dependent) critical batch size is reached; increasing the batch size beyond this threshold yields diminishing improvements in training speed. Zhang et al. [35] observe that a simple Noisy Quadratic Model (NQM) is able to capture the empirical behavior observed in [27]. Similarly, McCandlish et al. [19] use quadratic approximations to the loss to provide a closed form expression for the critical batch size as a function of the loss Hessian and the covariance of the stochastic gradient. We contribute to this literature by highlighting the role of in the batch size scaling behavior of the model.
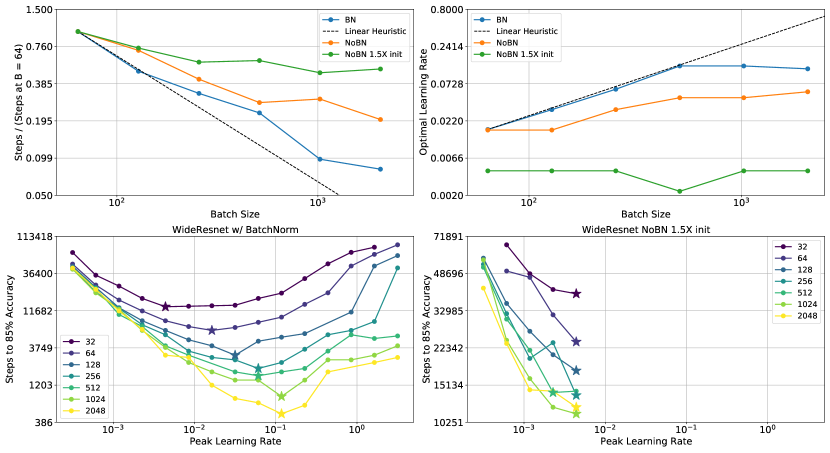
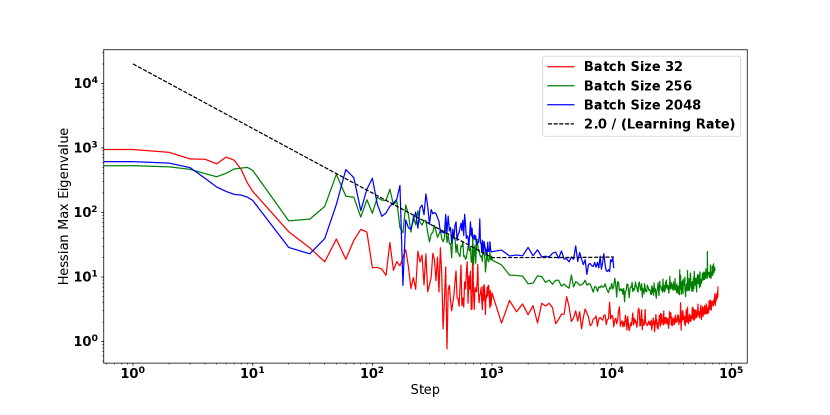
For this analysis, we focus on three of the WideResnet variants considered in Figure 2—the BatchNorm model (a low curvature model), the non BatchNorm model (with moderate curvature), and the non BatchNorm model with 1.5X init scaling (with high curvature). We train these models while sweeping both the learning rate and the batch size. 333We sweep for the optimal learning rate on a log-scale grid between and . For batch size, we sweep over powers of 2 from to . We then measure the number of training steps required to reach validation accuracy, and the optimal learning rate found for each batch size. Similar to [27], we normalize the plotted steps to accuracy by the value measured at batch size .
The results are shown in Figure 6. A few observations are in order: The low curvature model shows almost linear speedups in training speed as the batch size increases. In contrast, the high curvature model exhibits only minimal improvements in training speed with larger batch sizes. These scaling differences are closely mirrored by how the optimal learning rate changes with the batch size: for the low curvature model increases linearly with the batch size, while for the high curvature model is fixed around . Notably, for the high curvature model is almost always the largest non-divergent value—a clear indication that the high loss curvature slows down training by preventing larger values from being used.
A clear picture emerges from these observations. Previous research suggests that in order to effectively leverage larger batch sizes, one has to increase the learning rate in tandem with the batch size [12, 7, 27, 19]. Our results suggest that large values of place a sharp limit on the maximum the learning rate possible and therefore, limit the model’s ability to leverage data parallelism effectively. For the high curvature model the optimal learning rate is always close to the largest non-divergent learning rate—we believe this to be a useful diagnostic to detect if the training speed of a model is limited by being too large. In such scenario, our results from Section 5 suggest that learning rate warm-up or better initialization algorithms can be used to improve the model’s scaling behavior with respect to the batch size.
7 Limitations
Our analysis has focused primarily on models trained with SGD with momentum. This decision was motivated to reduce additional confounds that arise when using adaptive preconditioning. Notably, it is unclear what the analogue of should be for a model trained with Adam. In the appendix, we provide evidence that loss curvature adaption to the learning rate does occur even for Transformer models trained with Adam, and that learning rate warmup results in the similar effect of the optimization trajectory being “pushed” to flatter regions. However we leave a deeper analysis into this for future work.
Finally, while our experiments certainly raise questions about the efficacy better model initialization has on further accelerating training, our measurements has focused primarily on the (lack of) influence initialization has on mid training. It is possible that better initializations could have lasting influence on the broader Hessian eigenspectrum (for example improving the ration for smaller eigenvalues ) and that our analysis is missing such an effect.
8 Conclusion
Through extensive empirical experiments measuring the evolution of the loss sharpness during training, we have demonstrated how different methods such as initialization, learning rate warmup, and normalization all enable higher learning rates to be used (without causing divergence) by reducing during training. It is noteworthy that two of the most popular models we investigated (the popular variants of the Resnet-50 and WideResnet 28-10) did not benefit from learning rate warmup, and exhibited small values of throughout training at the learning rates we considered. Thus researchers and practitioners who primarily work with well-optimized architectures might never notice a benefit from using warmup. However, even seemingly trivial modifications to a working architecture can easily result in large values of and thus instability early in training—a naive response to such a situation would be to dramatically reduce the learning rate or, even worse, abandon the modification being investigated all together. We hope the perspective presented in this work can help future researchers better navigate such situations, either through investigating different initializations, applying warmup and gradient clipping, or changing the location of normalization layers in the model.
Perhaps the most striking feature of our results is how consistently adapts to the learning rate, both in cases where and where . While we are not the first to observe this adaptation, we have provided large scale empirical evidence for it under far less restrictive settings than prior work. This adaption of to the learning rate is in direct contradiction with conventional optimization wisdom, which would instead recommend choosing the step size based on measured values of . Moving forward, much more work is needed to better understand why this adaptation occurs and to further understand the implications it has for optimizer design, step size selection, and model initialization.
9 Societal Impact
Our results provide new understanding on neural network optimization that have the potential to accelerate research into better models through a more principled understanding of model tuning. While normalization free networks have been proposed recently, our work analyzes these methods from the lens of loss curvature, and enhances confidence in the working or failure modes of these networks. Normalization free networks improve power consumption at inference time, when deployed in large scale systems. We also suggest leveraging learning rate warmup as an alternative to computationally expensive initialization strategies, which require their own hyper parameter tuning. This would simplify the budget constraints, thereby reducing the environmental impact. While our efforts can potentially result in computational savings, this can actually sometimes lead to an increase in overall usage [33].
Our results required numerous experiments in order to reach useful conclusions, and these machine learning workloads can sometimes result in significant carbon emissions [23]. That said, the cloud computing resources we used run on carbon-free power,444https://www.gstatic.com/gumdrop/sustainability/24-7-explainer.pdf (although are not yet 24/7 carbon-free and still use some offsets).
Additionally, our work contributes to an increased understanding of machine learning methods, which have the potential to be used for benevolent or harmful purposes depending on the use case. Given the fundamental nature of our results, we do not believe the most likely uses are harmful.
References
- Brock et al. [2021] A. Brock, S. De, and S. L. Smith. Characterizing signal propagation to close the performance gap in unnormalized resnets. arXiv preprint arXiv:2101.08692, 2021.
- Chelba et al. [2013] C. Chelba, T. Mikolov, M. Schuster, Q. Ge, T. Brants, and P. Koehn. One billion word benchmark for measuring progress in statistical language modeling. INTERSPEECH, 2013.
- Choi et al. [2019] D. Choi, C. J. Shallue, Z. Nado, J. Lee, C. J. Maddison, and G. E. Dahl. On empirical comparisons of optimizers for deep learning. arXiv preprint arXiv:1910.05446, 2019.
- Cohen et al. [2021] J. M. Cohen, S. Kaur, Y. Li, J. Z. Kolter, and A. Talwalkar. Gradient descent on neural networks typically occurs at the edge of stability. arXiv preprint arXiv:2103.00065, 2021.
- Dauphin and Schoenholz [2019] Y. N. Dauphin and S. Schoenholz. Metainit: Initializing learning by learning to initialize. Advances in Neural Information Processing Systems, 32:12645–12657, 2019.
- Ghorbani et al. [2019] B. Ghorbani, S. Krishnan, and Y. Xiao. An investigation into neural net optimization via hessian eigenvalue density. In International Conference on Machine Learning, pages 2232–2241. PMLR, 2019.
- Goyal et al. [2017] P. Goyal, P. Dollár, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y. Jia, and K. He. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677, 2017.
- He et al. [2016a] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016a.
- He et al. [2016b] K. He, X. Zhang, S. Ren, and J. Sun. Identity mappings in deep residual networks. In European conference on computer vision, pages 630–645. Springer, 2016b.
- Huang et al. [2017] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4700–4708, 2017.
- Ioffe and Szegedy [2015] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning, pages 448–456. PMLR, 2015.
- Jastrzębski et al. [2017] S. Jastrzębski, Z. Kenton, D. Arpit, N. Ballas, A. Fischer, Y. Bengio, and A. Storkey. Three factors influencing minima in sgd. arXiv preprint arXiv:1711.04623, 2017.
- Jastrzebski et al. [2020] S. Jastrzebski, M. Szymczak, S. Fort, D. Arpit, J. Tabor, K. Cho, and K. Geras. The break-even point on optimization trajectories of deep neural networks. arXiv preprint arXiv:2002.09572, 2020.
- Kingma and Ba [2014] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Krizhevsky [2009] A. Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009.
- Lewkowycz et al. [2020] A. Lewkowycz, Y. Bahri, E. Dyer, J. Sohl-Dickstein, and G. Gur-Ari. The large learning rate phase of deep learning: the catapult mechanism. arXiv preprint arXiv:2003.02218, 2020.
- Li et al. [2017] H. Li, Z. Xu, G. Taylor, C. Studer, and T. Goldstein. Visualizing the loss landscape of neural nets. arXiv preprint arXiv:1712.09913, 2017.
- Liu et al. [2020] L. Liu, X. Liu, J. Gao, W. Chen, and J. Han. Understanding the difficulty of training transformers. arXiv preprint arXiv:2004.08249, 2020.
- McCandlish et al. [2018] S. McCandlish, J. Kaplan, D. Amodei, and O. D. Team. An empirical model of large-batch training. arXiv preprint arXiv:1812.06162, 2018.
- Nado et al. [2021] Z. Nado, J. Gilmer, C. J. Shallue, R. Anil, and G. E. Dahl. A large batch optimizer reality check: Traditional, generic optimizers suffice across batch sizes. CoRR, abs/2102.06356, 2021. URL https://arxiv.org/abs/2102.06356.
- Papyan [2018] V. Papyan. The full spectrum of deepnet hessians at scale: Dynamics with sgd training and sample size. arXiv preprint arXiv:1811.07062, 2018.
- Pascanu et al. [2013] R. Pascanu, T. Mikolov, and Y. Bengio. On the difficulty of training recurrent neural networks. In International conference on machine learning, pages 1310–1318. PMLR, 2013.
- Patterson et al. [2021] D. Patterson, J. Gonzalez, Q. Le, C. Liang, L.-M. Munguia, D. Rothchild, D. So, M. Texier, and J. Dean. Carbon emissions and large neural network training. arXiv preprint arXiv:2104.10350, 2021.
- Pearlmutter [1994] B. A. Pearlmutter. Fast exact multiplication by the hessian. Neural computation, 6(1):147–160, 1994.
- Russakovsky et al. [2015] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3):211–252, 2015.
- Santurkar et al. [2018] S. Santurkar, D. Tsipras, A. Ilyas, and A. Madry. How does batch normalization help optimization? arXiv preprint arXiv:1805.11604, 2018.
- Shallue et al. [2018] C. J. Shallue, J. Lee, J. Antognini, J. Sohl-Dickstein, R. Frostig, and G. E. Dahl. Measuring the effects of data parallelism on neural network training. arXiv preprint arXiv:1811.03600, 2018.
- Sivaprasad et al. [2020] P. T. Sivaprasad, F. Mai, T. Vogels, M. Jaggi, and F. Fleuret. Optimizer benchmarking needs to account for hyperparameter tuning. In H. D. III and A. Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 9036–9045. PMLR, 13–18 Jul 2020. URL http://proceedings.mlr.press/v119/sivaprasad20a.html.
- Vaswani et al. [2017] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30, 2017. URL https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf.
- Wu et al. [2018] L. Wu, C. Ma, and W. E. How sgd selects the global minima in over-parameterized learning: A dynamical stability perspective. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, pages 8289–8298, 2018.
- Xiong et al. [2020] R. Xiong, Y. Yang, D. He, K. Zheng, S. Zheng, C. Xing, H. Zhang, Y. Lan, L. Wang, and T. Liu. On layer normalization in the transformer architecture. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 of Proceedings of Machine Learning Research, pages 10524–10533. PMLR, 2020.
- Yang et al. [2019] G. Yang, J. Pennington, V. Rao, J. Sohl-Dickstein, and S. S. Schoenholz. A mean field theory of batch normalization. arXiv preprint arXiv:1902.08129, 2019.
- York [2006] R. York. Ecological paradoxes: William stanley jevons and the paperless office. Human Ecology Review, pages 143–147, 2006.
- Zagoruyko and Komodakis [2016] S. Zagoruyko and N. Komodakis. Wide residual networks. arXiv preprint arXiv:1605.07146, 2016.
- Zhang et al. [2019a] G. Zhang, L. Li, Z. Nado, J. Martens, S. Sachdeva, G. Dahl, C. Shallue, and R. B. Grosse. Which algorithmic choices matter at which batch sizes? insights from a noisy quadratic model. Advances in neural information processing systems, 32:8196–8207, 2019a.
- Zhang et al. [2017] H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412, 2017.
- Zhang et al. [2019b] H. Zhang, Y. N. Dauphin, and T. Ma. Fixup initialization: Residual learning without normalization. arXiv preprint arXiv:1901.09321, 2019b.
- Zhu et al. [2021] C. Zhu, R. Ni, Z. Xu, K. Kong, W. R. Huang, and T. Goldstein. Gradinit: Learning to initialize neural networks for stable and efficient training. arXiv preprint arXiv:2102.08098, 2021.
Appendix A Miscellaneous Figures

Appendix B Performance of models in Figure 2
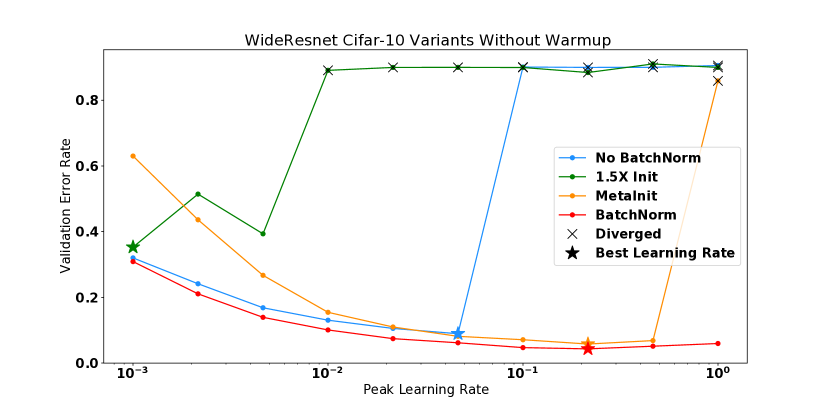
In this this section, we plot the performance vs learning rate for all of the models shown in Figure 2 of the main text. These are shown in Figures 9, 10, 11, and 12. For models which diverged, we plot the best test performance achieved before divergence. In all settings, high curvature affects the final performance by limiting the use of higher learning rates.
We also noted several models in Figure 2 which diverged despite training starting out in a stable region of parameter space. In Figure 13 we plot the evolution of the loss sharpness during training, showing that it quickly enters a region where before diverging around step 90.




Appendix C Details on Computing the Hessian Eigenspectrum via Lanczos
We use Lanczos iterations to estimate the top eigenvalue of the Hessian. Lanczos algorithm only requires Hessian-vector products which can be efficiently computed via Pearlmutter’s trick [24]. Previous research has demonstrated that this approach provides a robust and scalable framework to examine the eigenvalues of the Hessian for large neural networks [6, 21].
For our WMT / LM1B experiments, we run the algorithm for steps while for image models, we use steps. When monitoring the evolution of the top eigenvalue as a function of the number of Lanczos steps, in all cases except one, we observe that the algorithm converges. For the case of Resnet with ReLUBN ordering, due to a very small eigengap between the top eigenvalue and the bulk, the convergence is significantly slower. We use Lanczos steps in this case to alleviate the issue.
It is well-known that Lanczos algorithm can suffer from numerical instabilities caused by finite-precision arithmetic. To alleviate these issues, Lanczos vectors are stored in float64 accuracy and we perform reorthogonalized at each step of the algorithm.
Appendix D Training Details for Tables 1 and 2
D.1 Neural Machine Translation
Neural Machine Translation experiments are based on the Transformer models [29]. We use separate embeddings on encoder and decoder, and a common word piece vocabulary of size 32000. For depth, we use 6 layers on both encoder and decoder. For width, we experiment with two models, namely Transformer-Base and Transformer-Wide. For Transformer-Base, we use word embeddings with 512 dimensions, 8 heads and 2048 feed-forward dimension. For Transformer-Wide we use word embeddings with 1024 dimensions, 16 heads and 4096 feed-forward dimension. The experiments reported in Figures 3 and 5 use Transformer-Base. The experiments reported in Table 2 use Transformer-Wide models trained with Adam [14]. We sweep over warm-up, learning rate, gradient clipping and init_scaling and optimize for validation loss to evaluate performance on test set BLEU reported in Table 2. All the models are trained for 60 epochs at batch size of 1024 for Transformer-Base models, and batch size of 512 for Transformer-Big models. We use dropout of 0.1, label smoothing of 0.1 and no weight decay for all these models.
D.2 DenseNets
In Table 2 the ResNet-50 (w/o BN) architecture was trained for 100 epochs at batch size 512, with l2 regularization of 5e-5, dropout of .3. It was trained with SGD with nesterov momentum of .9 and learning rate of .2. We applied gradient clipping at global l2 norm of 5 and used linear learning rate warmup with warmup period of 1000 steps.
For Table 1, the DenseNet-100 model was trained using the Gradinit codebase 555https://github.com/zhuchen03/gradinit by modifying the supplied DenseNet script to apply gradient clipping of norm 6 and to use the default initialization instead of GradInit.
Appendix E Training Details for Figure 2
The WideResnet-28-10 models were trained with batch size of 1024 for 300 epochs. We applied the MixUp augmentation[36]. For learning rate warmup we used 1000 steps of linear warmup until the peak learning rate is achieved, at which point the learning rate is decayed according to the cosine schedule.
The DenseNet models were trained with batch size of 512 using the SGD optimizer with momentum of 0.9, weight decay of 5e-4, L2 regularization of 1e-4 and warmup of 1000 steps (for the models where warmup is used) followed by cosine decay. The models were trained for 200 epochs. For the DenseNet architecture we used growth_rate of 32 and reduction of 0.5.
The Resnet-50 models were trained with batch size of 2048 using the SGD optimizer with nesterov momentum of .9. The learning rate schedule was the same as in the WideResnet case, with linear warmup of 1000 steps followed by cosine decay. We applied label smoothing of .1 and used the standard flip plus crop for data augmentation.
The Transformer models on LM1B were trained at batch size 1024 using SGD with nesterov momentum of .9. We use embedding dimension of 512, 6 layers with 8 heads and MLP hidden dimension of 1024. The attention dropout rate was .1. The learning rate schedule followed the same recipe as in the Resnet cases.
Appendix F Curvature Adaptation with the Adam Optimizer
The discussion in the main text focused primarily on models trained with SGD and momentum. In this appendix, we briefly examine if similar conclusions hold for optimizers such as Adam that use preconditioning. It is unclear a priori whether or not curvature adapation to the learning rate should occur for optimizers which apply preconditioning. However, given that Adam is a diagonal preconditioner applied to a non-diagonal Hessian, there may be some similar effects observed.
Consider a simple quadratic loss
where optimization is performed via preconditioned gradient descent with a fixed diagonal preconditioning matrix :
As such, this simple model would suggest that the max eigenvalue of the following matrix may be related to training instability of models trained with Adam
| (1) |
While (1) does not take into the account the effects of adaptive preconditioning or momentum, we find some empirical evidence that this approximation provides understanding into the stability of the optimization.
Figure 14 below examines the evolution of for three Transformer models trained with Adam and different warm-up lengths. Here, is a diagonal matrix with . We observe that, similar to the models trained with momentum, the maximum (preconditioned) Hessian eigenvalue adapts to the warm-up schedule (green and red markers). We notice that –perhaps due to the effect of momentum or adaptive preconditioning – the threshold does not seem to be aligning with the data well. Instead, an empirically corrected threshold seems to fit the data better. We observe that instabilities in model training coincide exactly with crossing the empirically corrected threshold.
These observations suggest that some of the insights discussed in the main text seem to carry over to the case of adaptive optimizers. We leave further exploration of this more complex setting to future work.

Appendix G Compute Resources Used
Nearly all experiments utilized the Google Cloud Platform with v2 cloud TPUs except for the following: The Figure 2 Resnet-50 and Densenet experiments utilized the v3 cloud TPU, while the GradInit code was run on a cloud machine with a single V100 GPU. The Figure 2 experiments were done in parallel using up to 50 v2 TPUs concurrently over the period of a few days. Additionally, all the Machine Translation models were trained on v3 cloud TPUs.