Out of distribution detection for skin and malaria images
Abstract
Deep neural networks have shown promising results in disease detection and classification using medical image data. However, they still suffer from the challenges of handling real-world scenarios especially reliably detecting out-of-distribution (OoD) samples. We propose an approach to robustly classify OoD samples in skin and malaria images without the need to access labeled OoD samples during training. Specifically, we use metric learning along with logistic regression to force the deep networks to learn much rich class representative features. To guide the learning process against the OoD examples, we generate ID similar-looking examples by either removing class-specific salient regions in the image or permuting image parts and distancing them away from in-distribution samples. During inference time, the K-reciprocal nearest neighbor is employed to detect out-of-distribution samples. For skin cancer OoD detection, we employ two standard benchmark skin cancer ISIC datasets as ID, and six different datasets with varying difficulty levels were taken as out of distribution. For malaria OoD detection, we use the BBBC041 malaria dataset as ID and five different challenging datasets as out of distribution. We achieved state-of-the-art results, improving 5% and 4% in TNR TPR95% over the previous state-of-the-art for skin cancer and malaria OoD detection respectively.
keywords:
Skin cancer, Malaria, Out of distribution, Unsupervised approach, Tuplet loss, K-reciprocal neighbors1 Introduction
Recent years have witnessed tremendous success in applying deep neural networks to diagnose and analyze several diseases including skin cancer [2, 15, 39] and malaria [5, 6, 7]. Skin cancer is one of the most common types of cancer. There are around 1.19 million new cases of skin cancer only in 2020 [33]. An early diagnosis, including the detection of cancer and its correct classification, has been correlated to a high rate of overall survival. Similarly, according to the World Health Organization, only in 2019, 229 million cases of malaria occurred worldwide with 409,000 deaths globally due to malaria [26]. Therefore, it is very important to develop a computer-aided diagnosis system where computational methods can be used to assist medical practitioners in the early detection of different diseases including skin cancer and malaria.
One of the key advantages of deep learning models is their capability to generalize i.e., the ability to perform well on the testing data with several variations. These variations occur due to the different image capturing sensors, lighting conditions, and resolutions. Although having remarkable performance, deep neural networks exhibit overconfident incorrect predictions on images that are outside the training distribution. Experiments have shown that adding small noise to an image causes the network to incorrectly predict with high probability [17]. Similarly, as shown in [27], the image containing a dog can wrongly be classified as a skin cancer image using recent CNN architectures such as DenseNet, MobileNet, ResNet, and VGGNet, etc. This may result in catastrophic failures in real-world applications, especially in healthcare systems. For example, a network that is trained to detect a predefined number of classes is forced to classify a new type of disease into one of the predefined classes. Therefore, for reliable diagnosis and treatment of diseases through images, deep neural networks must be able to avoid such wrong overconfident predictions for such samples. Secure and reliable deployment of a healthcare system demands that the model should be accurate and vigorous to distribution change. This drives the necessity for methods that can efficiently detect out-of-distribution (OoD) samples.
The distribution that generates the training data is known as In-Distribution (ID), while the ones that do not belong to training distribution are called Out-of-Distribution (OoD) samples. Enabling deep networks to reliably raise a flag if the sample during test time is coming from a different distribution other than training distribution is important to detect new types of diseases. Attempts have been made to detect OoD samples using deep learning [17, 24, 19, 31] but, despite being extremely useful, little progress has been made in the medical domain [1]. During model deployment, OoD samples occur due to images from unrelated tasks, wrongly acquired images, and the appearance of a new class of disease [9]. Many recent methods [24, 22] develop supervised OoD approaches in which they assume the availability of manually annotated OoD samples during the training. However, manually annotated OoD samples are hard to collect and difficult to annotate especially when dealing with different medical disease images. Most importantly, since any example that is not part of ID can be considered OoD, therefore any finite sampled data will not be a complete representation of the OoD.
In this paper, we propose an approach to robustly classify OoD samples in skin and malaria images without needing to access labeled OoD samples during training. The proposed approach fine-tunes the existing classification network for learning representation such that intra-class variations are minimized. To discriminatively train the network and address the limitation of unavailability of OoD data during the training, we introduce OoD surrogate examples employing distribution examples. Chen et al., [10] has extensively explored different families of augmentation and reported that some augmentation techniques lead to learning better representation and some can degrade the performance as well. Furthermore, authors in [34] suggested that such performance degrading augmentations (e.g., rotation), can be used for OoD detection by considering them as negative. Inspired by [34] and noting the fact that skin and malaria images contain different visual information, we propose two approaches to generate OoD surrogates. For skin OoD detection, a novel class saliency-based OoD surrogate generation method, HideCam, is designed, to create OoD datasets from ID samples. Our strategy results in the OoD images whose non-salient regions are similar to the non-salient regions of ID images and this could be assumed to be on the boundary of the skin classes in the feature space. Similarly, for malaria OoD detection, OoD surrogates are generated using permuting different parts of an image. After that, a tuplet loss-based metric learning is employed to achieve two goals. First to bring ID samples close to each in the feature space. Second to map such OoD images away from the class boundaries of ID images. This tight mapping of the ID samples over to the latent space, allows us to employ a retrieval strategy for identifying OoD samples. Furthermore, to maintain the discriminative power of the classifier, classification loss is employed. Finally, instead of thresholding distance to the naive nearest neighbor, inspired by K-reciprocal nearest neighbors [40], we introduce a new robust OoD samples ranking strategy. We have compared the proposed approach with five state-of-the-art approaches on six OoD datasets [27] for skin cancer and five OoD datasets for malaria detection and have obtained promising results on all evaluation metrics. In summary, the proposed approach has the following contributions:
-
•
The proposed approach neither requires the network to be trained from scratch nor does it has any specific hyperparameters to tune on the labeled OoD set.
-
•
We have employed novel ways to generate OoD surrogates from ID samples.
-
•
The method does not require access to any real OoD data during training.
-
•
We have used a unique way to improve the OoD score using K-reciprocal neighbors.
-
•
Our thorough analysis reveals that the proposed approach has encouraging results when compared with the several competitive baselines.
The organization of the paper is as follows: Section 2 describes related work, section 3 contains our proposed methodology, section 4 provides details about datasets and experiments and section 5 concludes the paper.
2 Related work
Several methods have been developed recently for automatic skin and malaria detection using deep learning and computer vision. Yu et al., [39] and Codella et al., [13] have shown that combining deep features with local hand-crafted descriptors yields better skin classification results. Similarly, Codella et al., [13] and Gessert et al., [16] demonstrated the use of an ensemble of many networks for lesion classification. The recent public release of International Skin Imaging Collaboration (ISIC) archive [11, 35, 12] further facilitates research in skin cancer classification. Similarly, there is a huge need for improvement for worldwide deadly malaria disease detection. Although efforts have been made by researchers using different techniques [3, 23, 14], malaria detection is still a challenging task because of mosquito ecology and disease transmission cycle [41].
One of the straightforward ways of detecting OoD samples is to utilize the difference of prediction probability of OoD and ID examples [17]. This method is considered to be treated as a baseline approach for all other methods. The core idea is the hypothesis that ID samples will have a higher maximum softmax probability than OoD samples. Liang et al., [24] introduced a supervised OoD detection approach (ODIN) that widens the gap between maximum softmax scores of ID and OoD samples by fine-tuning the hyperparameters on the OoD datasets. Hsu et al., [19] further improved ODIN by making it independent of OoD samples while using a probabilistic perspective of decomposition of confidence of predicted class probabilities. Similarly, Lee et al., [22] proposed another supervised approach which models pre-trained features on every layer as a class conditional Gaussian. A sample on the test time is then evaluated based on its Mahalanobis distance with class conditional means and variances. Similar to [24], this approach uses input pre-processing and requires OoD samples to tune hyperparameters. In several recent works, this approach is named ‘Mahalanobis’. Similarly, Uwimana et al., [36] used Mahalanobis distance-based confidence score for OoD sample detection in classifying malaria cells.
Hendrycks et al., [18] demonstrated that an auxiliary OoD dataset can be used to discriminate between ID and OoD samples. Similarly, Tacket al., [34] interestingly proposed that certain augmentations of the same image could be considered as borderline cases of OoD samples, and treating them differently from original images should lead to more robust features for the OoD detection. Recently, Sastry et al., [31] posed an interesting observation that joint patterns of activation and class labels assigned at the output layer should lead us to recognize class level patterns. Any sample that followed other than the already defined pattern for a class should then be considered as an OoD sample. They found this pattern using different orders of gram matrices. Pachecho et al., [27] builds upon Gram OoD [31] and detected OoD samples for skin cancer. In their work, layer-wise deviation of a sample’s feature from its distribution is considered to be an indication of OoD and they have shown reasonable results on skin cancer-related OoD datasets.
Due to the recent use of self-supervised learning along with contrastive loss in several applications, attempts have been made to use contrastive learning to detect OoD samples. Winkens et al., [37] uses a famous method SIMCLR [10] for contrastive training. It treated different augmentations as positive and every other image as negative to learn semantically rich features. Once the network is trained, they fit Gaussian distributions to the activations on the training data to every layers’ features and use Mahalanobis distance at test time to see if the sample is OoD or not. Tack et al., [34] interestingly proposes that certain augmentations of the same image could be treated as OoD samples. These augmentations are supposed to be borderline cases of OoD samples and making it different from original images should lead to more robust features for the detection of OoD examples. They also used SIMCLR for contrastive learning. In comparison to the above-mentioned methods, the proposed approach is generic and could be applied to different diseases (such as malaria and skin cancer), does not require OoD samples during training, introduce a new way of OoD ranking, and have good OoD classification results as compared to several competitive baselines.

3 Methodology
Our proposed approach to tackle the challenging problem of OoD detection is based on three observations: (1) the proposed approach should make the compact clusters of ID samples while preserving each class discriminability, (2) due to the unavailability of OoD samples during training, we need to devise some mechanism to generate OoD surrogates to train a discriminative OoD detector, (3) finally, due to limitation of K-nearest neighbors for large datasets, we should have employ better distance metric to rank OoD samples. Below, we provide details of each step of our approach.
We propose to employ class-aware metric learning such that the samples belonging to the same class are mapped closer to each other than the samples from the other class. This minimization of intra-class variance and maximization of inter-class variance is a desired property of many clustering algorithms as well. For a pre-trained network on skin cancer or malaria dataset, we finetune it using tuplet margin loss [38]. Tuplet loss can be seen as an extension to triplet loss where a tuplet contains multiple negative samples with the anchor and positive. The negatives are then weighted according to a scale factor. In our context, the loss for ID samples is defined as:
| (1) |
where is the scaling factor for weights, is the number of classes, , represents anchor and positive samples from the same class, whereas are samples from the other classes. Finally, and is the angle between the samples and and samples and respectively.
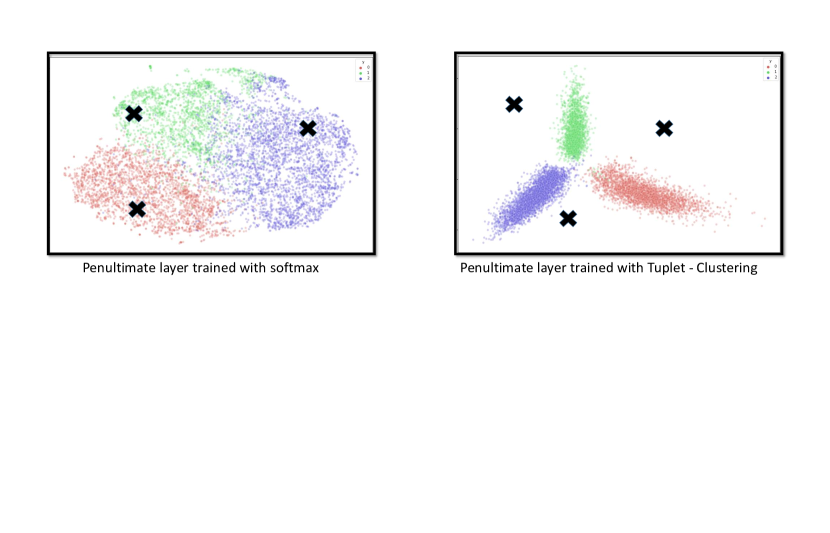
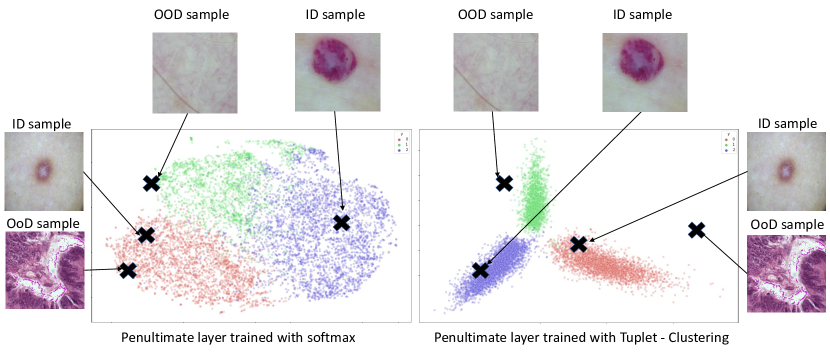
Minimizing the loss (Eq. 1) results in compactness of space over which samples belonging to one class are mapped while increasing the inter-class separability. It can be seen in Figure 2 that features obtained through training a network using tuplet loss are more useful for OoD detection as compared to the features trained using only cross-entropy loss. Since the loss function is only looking at the ID samples, the mapping can still result in ID and OoD samples being near to each other in latent space.
3.1 Generating OoD surrogates
(Eq. 1) clusters the in-distribution (ID) samples, however it does not contain any knowledge about out-of-distribution (OoD) samples. Therefore, to mitigate the shortcoming of the (Eq. 1), we propose to generate OoD samples with the help of existing ID samples. These surrogates will enable us to learn a boundary between ID and OoD data.
OoD sample space is extremely large, consisting of all the possible distributions that are not part of ID. Therefore instead of creating a dataset that could capture all these possible variations, we concentrate on generating OoD examples by manipulating the ID samples to capture the boundary of the ID manifold.
We generate OoD surrogates in two ways i.e., HideCam for skin cancer and Image-parts-Permutation [34] for malaria. Skin cancer images contain dense confined regions representing cancerous class, therefore, our proposed method HideCam removes class salient regions to make OoD. On the other hand, malaria images do not contain any such dense pattern, however, the overall structural information is important. Therefore, we employ image part-based permutation to generate OoD for malaria images. Below, we provide the details of both surrogate generation techniques.
-
(A)
HideCam: We generate the class-dependent surrogate images. Inspired from the observations of [18] and [29], we create surrogate OoD samples such that non-salient information is preserved and class representative information is removed.
We used gradient-based class activation maps (CAM) [32] from the pre-trained network, to identify the regions that are class salient. Gradient-based CAM highlights the region of importance pertaining to the specific class. Once we have the information about the spatial position of cancer (or any other class for that matter), we crop the healthy region from the same image and overwrite the cancerous regions with these healthy crops. The resulted images are used as OoD surrogates for skin cancer.
-
(B)
Image-Parts-Permutation: Since certain transformations/augmentations of the image can lead to good representatives of OoD data [34], we generate new images through image-parts based permutations. Specifically, to generate an OoD image for malaria, the image is simply divided into n equal regions, and then those regions are randomly shuffled. Intuitively, this shifts the input distribution.
The samples for HideCam and Image-Parts-Permutation are shown in Figure 3. Similar to Eq 1, tuplet loss is applied using ID samples and OoD surrogates to bring ID samples close to each other and OoD samples far from each other in the feature space.
3.2 Objective function
Given a network trained for classification task, we fine-tune last few layers using the following loss function:
| (2) | ||||
Similar to Eq. 1 represent anchor, positive and negative of the tuplet respectively. represents OoD surrogates created from the method described in section 3.1. is cross-entropy loss. and represents tuplet loss with ID only and with ID + OoD surrogates respectively. In this equation, the first term is a tuplet loss where positives and negatives come from the same and different classes with respect to the anchor. In the second term, generated surrogate OoD samples constitute negatives in the tuplet. This term is responsible for the separation of OoD surrogates from ID samples. This second term is the most important one since clustering classwise samples alongside distancing OoD surrogates is what makes the identification of OoD easier. The third term ensures that, in addition to OoD detection, the classifier learns to discriminate between different classes.

3.3 Inference - OoD score
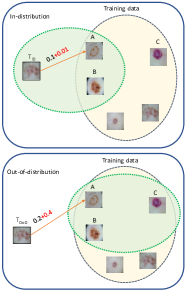
Instead of relying on the output of the softmax layer to classify the OoD, we use the consistency in the retrieval result as the parameter to identify OoD. A simple OoD score for an input sample could be obtained by finding its nearest neighbors in the training set, and deciding if the sample and nearest neighbors have a distance less than some specific threshold or not. Due to the sensitivity of naive nearest neighbors scoring to outliers and lower accuracy when dealing with high dimensional large dataset [4, 8], we propose to use distance based on K-reciprocal neighbors [28], employing a combination of Jaccard and Euclidean distance [40].
To make our paper self-contained, below we describe K-reciprocal neighbors in detail. Suppose, we represent K-nearest neighbors of the sample by , then K-reciprocal neighbors of can be written as:
| (3) |
where is an image from training set which is neighbor of query image and query image also appears in the neighbor’s list of . It can be easily seen that K-reciprocal neighbors is more stringent than naive nearest neighbors in the sense that mutual neighborhood is required for being a K-reciprocal neighbors. Furthermore, the Jaccard distance between two samples and can now be defined as:
| (4) |
where stands for Jaccard distance and where represents the locally expanded neighborhood created from [40]. The local query expansion is the process of expanding the neighborhood of a sample beyond the naive nearest neighbors. It does so by taking the nearest neighbors of query sample and taking the union of the original neighbors of query and neighbors of the neighbors. It can be observed that for the samples having mutual K-reciprocal neighbors, will be smaller. Therefore, for two samples to have a lower distance, it must be the case that their neighborhoods are mutual which is hard to achieve if the sample is far away from the training sample.
Finally, we compute the distance of testing sample with training sample is computed using using the following equation:
| (5) |
where is the weighted summation of (Jaccard distance) and (Euclidean distance). is higher when is not in the neighborhood of . Intuitively, it will enlarge the distance of sample which is far away from training sample . The demonstration of this idea is depicted in Figure 4 and Figure 5.
For robustness, the OoD score of a sample , (x), is computed by taking the median distance of nearest neighbors i.e.,
| (6) |
where shows the closest neighbor of based on and is set to 15 in experiments.
4 Experiments
The goal of our experiments is to thoroughly evaluate the proposed approach on skin and malaria OoD datasets over the different evaluation metrics and analyze different components of our approach.
4.1 Datasets
4.1.1 ISIC 2019 Dataset
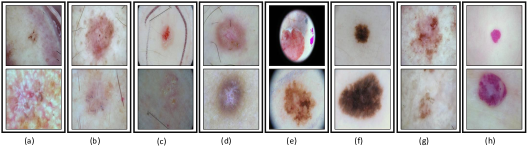
We evaluate our approach using the setup proposed by [27], where two standard skin cancer datasets, ISIC 2018 and ISIC 2019 [11, 35, 12] are used as ID data. ISIC 2019 dataset contains 25,331 images of eight skin cancer classes i.e., Melanoma (MEL), Melanocytic nevus (NV), Basal cell carcinoma (BCC), Actinic keratosis (AK), Benign keratosis (BKL), Dermatofibroma (DF), Squamous cell carcinoma (SCC) and Vascular lesion Squamous cell carcinoma (VASC). The samples of each of them are shown in Figure 6.
We use six different OoD datasets [27] for the model trained on skin images of ISIC. The details of each of them are as follows:
-
•
Imagenet contains 3000 randomly selected images from orignal ImageNet dataset.
-
•
NCT contains 1350 colorectal cancer images randomly selected from NCT-CRC-HE-7K [21].
-
•
BBOX contains 2025 ISIC 2019 images where the lesion is covered by a black bounding box.
-
•
BBOX 70 is the same as BBOX except that this dataset has atleast 70% of the lesion covered by a black bounding box.
-
•
Derm-skin represents dermoscopic 1,565 healthy skin images which are taken from ISIC 2019.
-
•
Clinical comprises 723 clinical healthy skin images.
4.1.2 BBBC041 Malaria Dataset
This dataset is taken from Broad Bioimage Benchmark Collection [25] and contains 1328 images with almost 80,000 cells. Blood smears were stained with Giemsa reagent and images were captured using a microscopic camera. Finally, the infected cells were annotated by a team of experts. The data consists of two classes of healthy cells (i.e. red blood cells and leukocytes) and four classes of malaria-infected cells i.e. gametocytes (125 images), rings (418 images), trophozoites (1270 images), and schizonts (1270 images). The data has a heavy imbalance towards healthy red blood cells as compared to healthy leukocytes and malaria-infected cells where healthy cells making up over 95% of all cells. Some samples of this are shown in the second row of Figure 7. Similar to [27], we introduce the following OoD datasets for malaria. The details of each of them are as follows:
-
•
Imagenet contains 3000 randomly selected images from original ImageNet dataset.
-
•
NCT contains 1350 colorectal cancer images randomly selected from NCT-CRC-HE-7K [21].
-
•
Coin fusion contains 500 blended images of coin and healthy red blood cells. A coin and cell are fused using the Laplacian of Gaussian pyramids.
-
•
Flag fusion contains 192 blended images of flags (of different countries) with healthy red blood cells. The process of creating these was similar to coin fusion.
-
•
Healthy red blood cell contains 3868 healthy red blood samples from the BBBC041 dataset. This is the most difficult case of all.

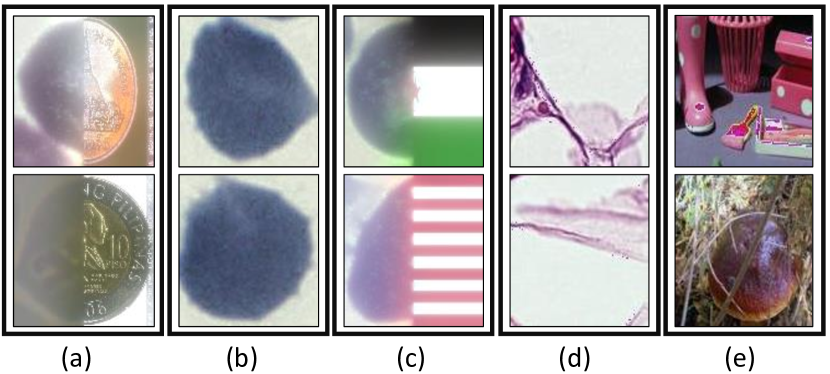
The samples of these different OoD samples for skin and malaria are shown in Figure 8 and Figure 9 respectively. In addition to evaluating the model on the aforementioned OoD datasets, we also explored the efficacy of the approach by leaving one class at a time as an OoD class. This means that we train the network on seven (for example in the skin dataset) classes and consider the eighth as an OoD class.
| Dataset | Metric | Baseline[US] | ODIN[S] | Mahalanobis[S] | Gram-OoD[US] | Gram-OoD*[US] | Ours [US] |
| Derm-skin | TNR @ TPR 95% | 22.8 | 46.2 | 81.47 | 78.0 | 76.1 | 95.59 |
| AUROC | 74.4 | 86.8 | 96.2 | 96.5 | 95.8 | 98.66 | |
| Detection acc | 67.3 | 78.3 | 89.7 | 90.9 | 89.3 | 96.50 | |
| Clinical | TNR @ TPR 95% | 18.5 | 25.2 | 81.7 | 82.8 | 83.1 | 85.33 |
| AUROC | 72.5 | 69.5 | 96.1 | 96.6 | 96.6 | 95.59 | |
| Detection acc | 67.3 | 65.8 | 90.8 | 91.1 | 90.9 | 90.27 | |
| Imagenet | TNR @ TPR 95% | 9.30 | 50.0 | 99.9 | 80.7 | 88.4 | 90.86 |
| AUROC | 59.1 | 83.8 | 99.9 | 97.0 | 97.7 | 97.17 | |
| Detection acc | 56.6 | 78.1 | 99.1 | 92.0 | 97.9 | 94.15 | |
| BBOX | TNR @ TPR 95% | 27.9 | 68.8 | 94.8 | 88.0 | 88.1 | 97.60 |
| AUROC | 77.3 | 90.6 | 98.3 | 98.1 | 97.5 | 98.89 | |
| Detection acc | 69.8 | 83.7 | 95.3 | 94.5 | 94.0 | 98.33 | |
| BBOX-70 | TNR @ TPR 95% | 36.6 | 99.3 | 100 | 99.9 | 100 | 100 |
| AUROC | 89.4 | 99.8 | 100 | 99.7 | 99.9 | 100 | |
| Detection acc | 84.9 | 98.1 | 99.9 | 99.0 | 100 | 100 | |
| NCT | TNR @ TPR 95% | 1.44 | 32.5 | 98.7 | 98.9 | 99.9 | 99.30 |
| AUROC | 36.7 | 82.0 | 98.9 | 99.4 | 99.7 | 99.85 | |
| Detection acc | 50.1 | 75.0 | 98.7 | 97.1 | 98.5 | 92.10 | |
| Average (S) | TNR @ TPR 95% | - | 53.67 | 92.75 | - | - | 94.79 |
| AUROC | - | 85.42 | 98.23 | - | - | 98.36 | |
| Detection acc | - | 79.83 | 95.47 | - | - | 96.41 | |
| Average (US) | TNR @ TPR 95% | 19.42 | - | - | 88 | 89.27 | 94.79 |
| AUROC | 68.23 | - | - | 97.9 | 97.87 | 98.36 | |
| Detection acc | 66.0 | - | - | 94.1 | 94.97 | 96.41 |
| OoD Class | TNR @ TPR 95% | AUROC | Detection accuracy |
| BKL | 20.60 | 67.29 | 63.90 |
| AK | 14.30 | 62.40 | 62.35 |
| BCC | 36.14 | 74.24 | 69.90 |
| DF | 12.61 | 65.59 | 63.25 |
| MEL | 12.40 | 66.25 | 62.67 |
| NV | 7.36 | 70.14 | 67.21 |
| SCC | 17.43 | 61.80 | 61.84 |
| VASC | 9.74 | 61.97 | 59.53 |
| OoD dataset | TNR @ TPR 95% | AUROC | Detection accuracy |
| Derm-skin | 100 | 100 | 100 |
| Clinical | 100 | 99.90 | 99.90 |
| Imagenet | 99.30 | 99.70 | 99.30 |
| BBOX | 99.80 | 99.80 | 99.70 |
| BBOX-70 | 100 | 100 | 100 |
| NCT | 99.60 | 99.90 | 99.60 |
| Average | 99.78 | 99.88 | 99.75 |
| Standard dev | 0.0029 | 0.0012 | 0.0027 |
4.1.3 Evaluation Metrics
To measure the efficiency of our approach to differentiate between ID and OoD examples, we use three evaluation metrics which are described below for completeness.
-
•
TNR@95TPR is the likelihood that an OoD sample is accurately identified with the true positive rate (TPR) as high as 95%. The true positive rate can be computed as TPR = TP/(TP + FN), where TP and FN represent true positive and false negative respectively [30].
-
•
Detection Accuracy measures the maximum achievable classification accuracy across all possible thresholds in distinguishing among ID and OoD samples [30].
-
•
AUROC is the measure of the area under the curve of true positive rate vs false positive rate [30].
4.2 Implementation details
In this section, we provide implementation details of our approach. The proposed approach is divided into two stages. In the first phase, we train DenseNet-121 [20] on the ID data (ISIC and malaria) for classification purposes. For both datasets, we use the weighted cross-entropy loss function to account for class imbalance i.e., minority classes were given higher weight depending upon the frequency. The model is trained for around 100 epochs with early stopping. As an optimizer, stochastic gradient descent is employed with a learning rate of 0.001 and weight decay of 0.001. The above-mentioned settings were the same for both skin and malaria datasets. Due to the large class imbalance in the malaria dataset, we augment the minority class (gametocytes) samples with rotations of different angles. In the second phase, we took the network trained in the first phase and trained it further with the loss function given by Equation 2. We used HideCam to generate OoD surrogates for skin cancer and Image-Parts-Permutation for malaria-related experiments. We finetuned the network in this phase for around 200 epochs. We used the default margin of 5.73 for tuplet loss and use a learning rate of .
For inference, we compute the distance of the test sample with every training sample using Equation 5. As suggested in [40], for K-reciprocal, we use the 15 nearest neighbors to be considered for a query and 6 nearest neighbors for the process of local query expansion. Finally, we use = 0.3. These values were kept the same for both skin and malaria-related experiments which shows that the algorithm is not heavily dependent on finetuning these hyper-parameters.
In addition to testing on the OoD dataset introduced in section 4.1, we took 25% of samples from original ISIC and BBBC401 datasets as testing ID samples. Following [27], TNR @ TPR 95%, AUROC, Detection accuracy are used as evaluation metrics.
| Dataset | Metric | Baseline[US] | ODIN[S] | Mahalanobis[S] | Gram-OOD[US] | Gram-OOD*[US] | Ours[US] |
| RBC Healthy | TNR @ TPR 95% | 2.68 | 23.97 | 49.35 | 58.59 | 41.9 | 78.30 |
| AUROC | 48.95 | 78.71 | 90.05 | 82.64 | 91.8 | 94.05 | |
| Detection acc | 53.18 | 73.45 | 83.17 | 78.18 | 86.61 | 90.19 | |
| Coin fusion | TNR @ TPR 95% | 29.06 | 83.33 | 100 | 95.49 | 98.81 | 95.20 |
| AUROC | 87.8 | 96.09 | 100 | 98.72 | 98.67 | 96.86 | |
| Detection acc | 81.8 | 90.36 | 100 | 95.64 | 98.05 | 95.58 | |
| Flag fusion | TNR @ TPR 95% | 18.75 | 83.33 | 100 | 97.72 | 99.58 | 84.60 |
| AUROC | 85.95 | 97.25 | 100 | 99.36 | 99.12 | 95.28 | |
| Detection acc | 80.51 | 91.51 | 100 | 97.02 | 98.49 | 91.56 | |
| Imagenet | TNR @ TPR 95% | 18.44 | 73.82 | 100 | 88.82 | 98.21 | 97.60 |
| AUROC | 84.21 | 92.65 | 99.97 | 97.74 | 98.8 | 99.07 | |
| Detection acc | 79.3 | 86.88 | 99.7 | 92.22 | 97.28 | 96.79 | |
| NCT | TNR @ TPR 95% | 18.08 | 71.09 | 100 | 95.94 | 98.51 | 99.48 |
| AUROC | 77.78 | 92.98 | 99.97 | 99.16 | 98.94 | 99.10 | |
| Detection acc | 73.08 | 85.65 | 99.7 | 95.56 | 97.44 | 98.020 | |
| Average (S) | TNR @ TPR 95% | - | 67.11 | 89.87 | - | - | 91.04 |
| AUROC | - | 91.53 | 97.9 | - | - | 96.31 | |
| Detection acc | - | 85.57 | 96.5 | - | - | 94.42 | |
| Average (US) | TNR @ TPR 95% | 17.4 | - | - | 73.03 | 87.40 | 91.04 |
| AUROC | 76.93 | - | - | 92.08 | 97.47 | 96.31 | |
| Detection acc | 73.57 | - | - | 88.38 | 95.57 | 94.42 |
| OoD Class | TNR @ TPR 95% | AUROC | Detection accuracy |
| Ring | 5.98 | 81.44 | 78.37 |
| Schizont | 34.76 | 84.06 | 78.55 |
| Gametocyte | 36.57 | 82.37 | 75.47 |
| Trophozoite | 76.25 | 91.94 | 86.27 |
4.3 Comparison with the State-of-the-art
We compare the proposed unsupervised OoD detection approach with supervised OoD detection approaches (ODIN [24] and Mahalanobis [22]) and unsupervised OoD detection approaches (Maximum softmax probability [17], Gram OoD [31] and Gram OoD* [27]). Note that supervised approaches assume access to labeled OoD samples during training and unsupervised approach (including ours) assume that labeled OoD training data is unavailable.
4.3.1 OoD detection for Skin cancer
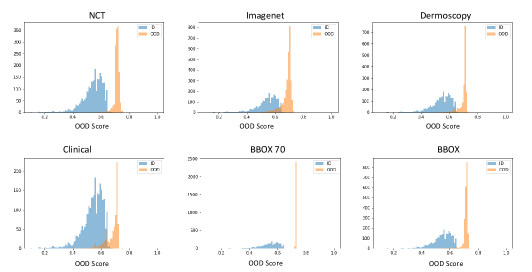
The quantitative results in Table 1 demonstrate that, on all evaluation metrics, our unsupervised OoD detection approach significantly outperforms the recently published unsupervised and supervised OoD approaches. A clear improvement in the last column demonstrates the usefulness of our approach and enforces that clustered representation (using tuplet loss) and OoD surrogates are essential for robust OoD detection. Table 2 shows the results when one class is kept as OoD and the whole model is trained on the remaining seven classes. Since this case is extremely difficult, as the OoD (the class which is not included in the training) and ID samples look very similar, the numbers are not as good as in the case of other OoD samples as shown in Table 1. Experimental results on the ISIC-2018 dataset are shown in Table 3. In Figure 10, we demonstrate the histogram of OoD score (Eq. ) for ID test set (ISIC-2019) and six different OoD datasets. The histogram demonstrates the discriminative nature of the OoD score between OoD and ID samples.
4.3.2 OoD detection for malaria detection
Similar to experiments on the skin OoD dataset, we evaluate the OoD detection approach on five different malaria OoD datasets. The quantitative results of those are shown in Table 4. As can be seen that our approach significantly outperforms the baselines in the most difficult case, i.e. healthy red blood cells. On average, for TNR @ TPR 95%, the proposed approach has around 4% better results as compared to the baselines and has comparative results for AUROC and Detection accuracy. One possible reason for comparative performance on AUROC and Detection accuracy might be the fact that these metrics consider every possible threshold and there might be some thresholds where baseline models are working well. TNR metric basically works on one stringent and specific threshold which has a lot more importance and our model might be working better because we aim to work well on the case where we want good performance for detecting both in-distribution and OOD samples.
4.4 Ablation studies
We analyze different components of the proposed approach to verify their effectiveness. The experimental results in Table 6 on the skin ISIC 2019 dataset show that each component of our approach is important and contributes toward final accuracy.
| Loss | TNR @ TPR 95% | AUROC | Detection accuracy |
| w/o ID tuplet | 81.34 | 93.14 | 88.87 |
| w/o OoD tuplet | 69.14 | 88.38 | 85.82 |
| w/o CE | 79.62 | 92.95 | 89.69 |
| w/o K-reciprocal | 90.07 | 96.80 | 92.60 |
| Complete Approach | 94.79 | 98.36 | 96.41 |
5 Discussion and Concluding remarks
Deep neural networks have generally proven to be erroneous when it comes to detecting if a sample is coming from training distribution or not. This leads to reliability issues in deployment, especially for medical applications. We propose to tackle this by learning a representation that is not only inter-class discriminative but also has large intra-class similarities. Decreasing tuplet loss over OoD surrogates, generated from the ID dataset, helps to map out-of-distribution samples away from the class boundary. For robust OoD score estimation, we use the median over the K-reciprocal neighbors’ distances. We have demonstrated the efficacy of the approach by obtaining state-of-the-art results on different pairs of ID and OoD datasets. We took skin cancer and malaria-contained cell images as ID and evaluated the approach on varying OoD datasets. We achieved state-of-the-art results, improving 5% and 4% in TNR TPR95% over the previous state-of-the-art for skin cancer and malaria detection respectively. In the future, we aim to generalize this approach to make it applicable to a wide variety of clinical datasets.
Acknowledgement:
The project is partially supported by an unrestricted gift from Facebook, USA. The
opinions, findings, and conclusions or recommendations expressed in this publication are those of the author(s) and do
not necessarily reflect those of Facebook.
References
- Gao et al. [2020] Gao, L., Wu, S., 2020. Response score of deep learning for out-of-distribution sample detection of medical images. Journal of Biomedical Informatics 107, 103442.
- Harangi et al. [2020] Harangi, B., 2018. Skin lesion classification with ensembles of deep convolutional neural networks. Journal of Biomedical Informatics 86, 25-32.
- Baroni et al. [2020] Baroni, L., Salles, R.,Salles, S.,Guedes, G., Porto, F.,Bezerra, E., Barcellos, C.,Pedroso, M.,Ogasawara, E., 2020. An analysis of malaria in the Brazilian Legal Amazon using divergent association rules. Journal of Biomedical Informatics 108, 103512.
- Díaz et al. [2020] Xu, Z., Shen, D.,Nei, T.,Kou, Y., 2020. A hybrid sampling algorithm combining M-SMOTE and ENN based on Random forest for medical imbalanced data. Journal of Biomedical Informatics 107, 103465.
- Díaz et al. [2020] Díaz, G., González, S.,F.,Romero, E., 2009. A semi-automatic method for quantification and classification of erythrocytes infected with malaria parasites in microscopic images. Journal of Biomedical Informatics 42, 296-307.
- Lee et al. [2021] Lee, Y.W., Choi, J.W., Shin, E.H., 2021. Machine learning model for predicting malaria using clinical information. Computers in Biology and Medicine 129, 104151.
- Santosh et al. [2020] Santosh, T., Ramesh, D., Reddy, D., 2020. Lstm based prediction of malaria abundances using big data. Computers in Biology and Medicine 124, 103859.
- Balsubramani et al. [2019] Balsubramani, A., Dasgupta, S., Freund, Y., Moran, S., 2019. An adaptive nearest neighbor rule for classification., in: NeurIPS.
- Cao et al. [2020] Cao, T., Huang, C., Hui, D.Y.T., Cohen, J.P., 2020. A benchmark of medical out of distribution detection. arXiv preprint arXiv:2007.04250 .
- Chen et al. [2020] Chen, T., Kornblith, S., Norouzi, M., Hinton, G., 2020. A simple framework for contrastive learning of visual representations, in: International conference on machine learning, PMLR. pp. 1597–1607.
- Codella et al. [2019] Codella, N., Rotemberg, V., Tschandl, P., Celebi, M.E., Dusza, S., Gutman, D., Helba, B., Kalloo, A., Liopyris, K., Marchetti, M., et al., 2019. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic). ICLR .
- [12] Codella, N.C., Gutman, D., Celebi, M.E., Helba, B., Marchetti, M.A., Dusza, S.W., Kalloo, A., Liopyris, K., Mishra, N., Kittler, H., et al., . Skin lesion analysis toward melanoma detection: A challenge at the 2017 international symposium on biomedical imaging (isbi), hosted by the international skin imaging collaboration (isic), in: 2018 IEEE 15th International Symposium on Biomedical Imaging.
- Codella et al. [2017] Codella, N.C., Nguyen, Q.B., Pankanti, S., Gutman, D.A., Helba, B., Halpern, A.C., Smith, J.R., 2017. Deep learning ensembles for melanoma recognition in dermoscopy images. IBM Journal of Research and Development .
- Davis et al. [2019] Davis, J.K., Gebrehiwot, T., Worku, M., Awoke, W., Mihretie, A., Nekorchuk, D., Wimberly, M.C., 2019. A genetic algorithm for identifying spatially-varying environmental drivers in a malaria time series model .
- Esteva et al. [2017] Esteva, A., Kuprel, B., Novoa, R.A., Ko, J., Swetter, S.M., Blau, H.M., Thrun, S., 2017. Dermatologist-level classification of skin cancer with deep neural networks. nature .
- Gessert et al. [2020] Gessert, N., Nielsen, M., Shaikh, M., Werner, R., Schlaefer, A., 2020. Skin lesion classification using ensembles of multi-resolution efficientnets with meta data. MethodsX .
- Hendrycks and Gimpel [2017] Hendrycks, D., Gimpel, K., 2017. A baseline for detecting misclassified and out-of-distribution examples in neural networks. ICLR .
- Hendrycks et al. [2018] Hendrycks, D., Mazeika, M., Dietterich, T., 2018. Deep anomaly detection with outlier exposure, in: ICLR.
- Hsu et al. [2020] Hsu, Y.C., Shen, Y., Jin, H., Kira, Z., 2020. Generalized odin: Detecting out-of-distribution image without learning from out-of-distribution data, in: CVPR.
- Huang et al. [2018] Huang, G., Liu, Z., van der Maaten, L., Weinberger, K.Q., 2018. Densely connected convolutional networks. arXiv:1608.06993.
- Kather et al. [2019] Kather, J.N., Krisam, J., Charoentong, P., Luedde, T., Herpel, E., Weis, C.A., Gaiser, T., Marx, A., Valous, N.A., Ferber, D., et al., 2019. Predicting survival from colorectal cancer histology slides using deep learning: A retrospective multicenter study. PLoS medicine .
- Lee et al. [2018] Lee, K., Lee, K., Lee, H., Shin, J., 2018. A simple unified framework for detecting out-of-distribution samples and adversarial attacks, in: NeurIPS.
- Lee et al. [2016] Lee, K.Y., Chung, N., Hwang, S., 2016. Application of an artificial neural network (ann) model for predicting mosquito abundances in urban areas. Ecological Informatics 36, 172--180.
- Liang et al. [2018] Liang, S., Li, Y., Srikant, R., 2018. Enhancing the reliability of out-of-distribution image detection in neural networks. ICLR .
- Ljosa et al. [2012] Ljosa, V., Sokolnicki, K.L., Carpenter, A.E., 2012. Annotated high-throughput microscopy image sets for validation. Nature methods 9, 637--637.
- Organization et al. [2019] Organization, W.H., et al., 2019. World malaria report 2019 .
- Pacheco et al. [2020] Pacheco, A.G., Sastry, C.S., Trappenberg, T., Oore, S., Krohling, R.A., 2020. On out-of-distribution detection algorithms with deep neural skin cancer classifiers, in: CVPR Workshop.
- Qin et al. [2011] Qin, D., Gammeter, S., Bossard, L., Quack, T., Van Gool, L., 2011. Hello neighbor: Accurate object retrieval with k-reciprocal nearest neighbors, in: CVPR.
- Ren et al. [2019] Ren, J., Liu, P.J., Fertig, E., Snoek, J., Poplin, R., DePristo, M.A., Dillon, J.V., Lakshminarayanan, B., 2019. Likelihood ratios for out-of-distribution detection, in: NeurIPS.
- Sastry and Oore [2019] Sastry, C.S., Oore, S., 2019. Detecting out-of-distribution examples with in-distribution examples and gram matrices. arXiv preprint arXiv:1912.12510 .
- Sastry and Oore [2020] Sastry, C.S., Oore, S., 2020. Detecting out-of-distribution examples with gram matrices, in: International Conference on Machine Learning, PMLR.
- Selvaraju et al. [2017] Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D., 2017. Grad-cam: Visual explanations from deep networks via gradient-based localization, in: CVPR.
- Sung et al. [2021] Sung, H., Ferlay, J., Siegel, R.L., Laversanne, M., Soerjomataram, I., Jemal, A., Bray, F., 2021. Global cancer statistics 2020: Globocan estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA: a cancer journal for clinicians .
- Tack et al. [2020] Tack, J., Mo, S., Jeong, J., Shin, J., 2020. Csi: Novelty detection via contrastive learning on distributionally shifted instances, in: NeurIPS.
- Tschandl et al. [2018] Tschandl, P., Rosendahl, C., Kittler, H., 2018. The ham10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Scientific data .
- Uwimana and Senanayake [2021] Uwimana, A., Senanayake, R., 2021. Out of distribution detection and adversarial attacks on deep neural networks for robust medical image analysis, in: ICML 2021 Workshop on Adversarial Machine Learning. URL: https://openreview.net/forum?id=1iy7rdPCt_.
- Winkens et al. [2020] Winkens, J., Bunel, R., Roy, A.G., Stanforth, R., Natarajan, V., Ledsam, J.R., MacWilliams, P., Kohli, P., Karthikesalingam, A., Kohl, S., et al., 2020. Contrastive training for improved out-of-distribution detection. arXiv preprint arXiv:2007.05566 .
- Yu and Tao [2019] Yu, B., Tao, D., 2019. Deep metric learning with tuplet margin loss, in: CVPR.
- Yu et al. [2018] Yu, Z., Jiang, X., Zhou, F., Qin, J., Ni, D., Chen, S., Lei, B., Wang, T., 2018. Melanoma recognition in dermoscopy images via aggregated deep convolutional features. IEEE Transactions on Biomedical Engineering .
- Zhong et al. [2017] Zhong, Z., Zheng, L., Cao, D., Li, S., 2017. Re-ranking person re-identification with k-reciprocal encoding, in: CVPR.
- Zinszer et al. [2015] Zinszer, K., Kigozi, R., Charland, K., Dorsey, G., Brewer, T.F., Brownstein, J.S., Kamya, M.R., Buckeridge, D.L., 2015. Forecasting malaria in a highly endemic country using environmental and clinical predictors. Malaria journal 14, 1--9.