Semantic Communications: Principles and Challenges
(Invited Paper)
Abstract
Semantic communication, regarded as the breakthrough beyond the Shannon paradigm, aims at the successful transmission of semantic information conveyed by the source rather than the accurate reception of each single symbol or bit regardless of its meaning. This article provides an overview on semantic communications. After a brief review of Shannon information theory, we discuss semantic communications with theory, framework, and system design enabled by deep learning. Different from the symbol/bit error rate used for measuring conventional communication systems, performance metrics for semantic communications are also discussed. The article concludes with several open questions in semantic communications.
Index Terms:
Deep learning, semantic communication, semantic theory, task-oriented communication.I Introduction
Around 70 years ago, Weaver [1] categorized communications into three levels: transmission of symbols, semantic exchange, and effects of semantic exchange. The first level communications, transmission of symbols, has been well studied and delivered in conventional communication systems, which are approaching to the Shannon capacity limit. However, in many situations, the ultimate goal of communications is to exchange semantic information, such as natural languages, while the communication medium, such as optical fiber, electromagnetic wave, and cable, can only transmit physical signals. Recently, semantic communication111In this article, semantic communications refer to Level 2 and Level 3, also called task/goal-oriented communications. has attracted extensive attention from industry and academia [2, 3], and has been identified as a core challenge for the sixth generation (6G) of wireless networks.
In contrast to the Shannon paradigm, semantic communications only transmit necessary information relevant to the specific task at the receiver [1], which leads to a truly intelligent system with significant reduction in data traffic. Fig. 1 demonstrates the concept of semantic communications, where the transmission task is image recognition. Instead of transmitting bit sequences representing the whole image, a semantic transmitter extracts features relevant to recognize the object, i.e., dog, in the source. The irrelevant information, such as image background, will be omitted to minimize the transmitted data without degrading performance. As a result, the demands on energy and wireless resources will be lowered significantly, leading to a more sustainable communication network.
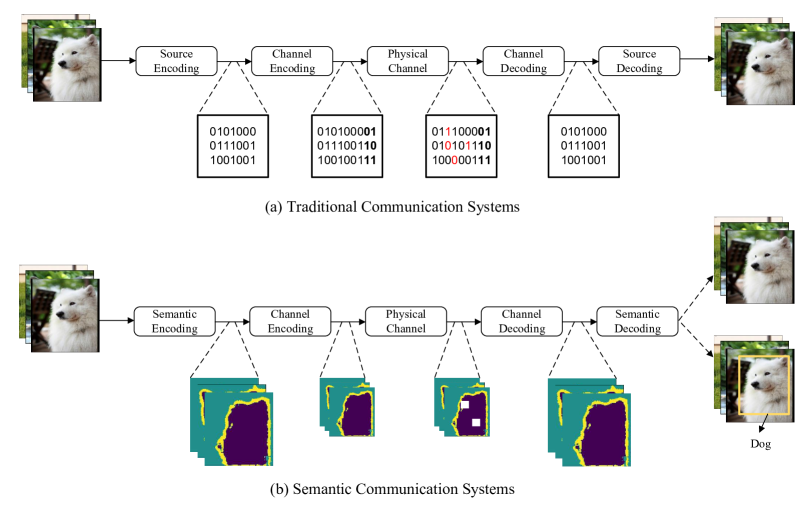
For many applications in the age of 6G and artificial intelligence (AI), the agent, such as smart terminals, robot, and smart surveillance, is able to understand the scene and executes the instruction automatically. Hence, the core of the task-oriented semantic communication is deep semantic level fidelity rather than shallow bit-level accuracy. Such a semantic communication framework will be widely used in Industrial Internet, smart transportation, video conference, online education, augmented reality (AR), and virtual reality (VR), to name a few.
Since the masterpiece from Shannon [1], the remarkable progress has been made in understanding the mathematical foundation of symbol transmission without considering semantics of the transmitted symbols or bits. Bar-Hillel and Carnap [4] revisited the bypassed semantic problem in Shannon’s work, and offered a preliminary definition of semantic information. Bao et al. [5] clarified the concepts of semantic noise and semantic channel. A semantic communication framework [6] was proposed to minimize semantic errors. These pioneering works are based on logical probability and are mainly designed for textual processing. Due to the lack of a general mathematical model to represent semantics, the development of semantic communications is still in its infancy after seven decades since it was first introduced.
Recent advancements in deep learning (DL) and its applications, such as natural language processing (NLP), speech recognition, and computer vision provide significant insights on developing semantic communications [3, 7]. Hwang [8] discussed intelligence transmission in the analysis and design of communication systems. Moreover, Chattopadhyay et al. [9] quantified semantic entropy and the complexity for semantic compression. Joint source-channel coding (JSCC) schemes [10, 11] were proposed to capture and transmit semantic features, in which the semantic receiver executes the corresponding actions directly rather than recovering the source messages. More recently, a series of semantic communication frameworks have been developed [12, 13, 14, 15] for multimodal data transmission, which have attracted extensive attention.
So far, there have been several tutorials and surveys on semantic communications. Tong et al. [3] identified two semantic communication related critical challenges faced by AI and 6G, including its mathematical foundations and the system design. Kalfa et al. [16] discussed semantic transformations of different sources for popular tasks in the field, and presented the semantic communication system design for different types of sources. Strinati et al. [17] indicated the role of semantic communications in 6G. Lan et al. [18] classified semantic communications into human-to-human (Level 2), human-to-machine (Level 2 and Level 3), and machine-to-machine (Level 3) communications. Various potential applications of semantic communications are presented. Furthermore, many researchers have dedicated to designing new frameworks [19, 20, 21, 22] for semantic communications in the format of terse and forceful magazine articles. By summarizing the highly related works, they serve as a good start to step into the area.
In this article, we will provide a comprehensive overview on principles and challenges of semantic communications. We first review Shannon information theory and summarize the development of semantic theory. After clarifying the critical difference between conventional and semantic communications, we introduce principles, frameworks, and performance metrics of semantic communications. Next, we present the developments of DL-enabled semantic communications for multimodal data transmission, including text, image, and audio. We conclude the article with research challenges to pave the pathway to semantic communications. This tutorial article tries to provide insights on answering the following common questions:
-
•
How to understand the semantic meaning of bit sequences?
-
•
Where is the gain from in semantic communications?
-
•
Is there a theoretic limitation for semantic communication systems?
This article will present readers a clear picture of semantic communications. The rest of the article is structured as follows. Section II compares conventional and semantic communication systems and theories. Section III presents semantic communication system components, semantic noise, and performance metrics. The recent advancements on DL-enabled semantic communication systems for transmitting multimodal data are discussed in Section IV. This article concludes with open questions in Section V.
II From Information Theory to Semantic Theory
In this section, we first discuss the critical difference between conventional and semantic communications. Then we briefly introduce information theory and semantic theory.
II-A Difference between Conventional and Semantic Communications
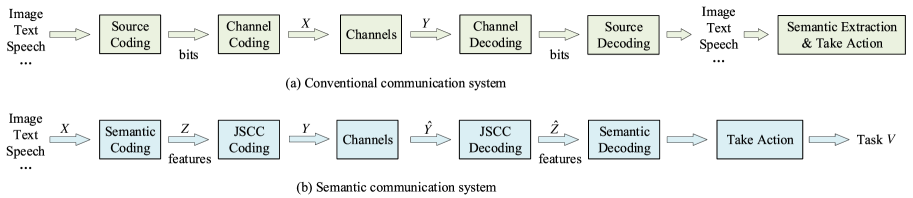
Since research in semantic communications is still in its preliminary stage, there is no consistent definition of semantic communications yet. In Fig. 2, we compare conventional and semantic communications. In a conventional communication system, the source is converted into bit sequences to process. At the receiver, the bit sequence representing the source is recovered accurately. In a conventional communication system, the bit/symbol transmission rate is bounded by Shannon capacity. Semantic communications transmit semantic meaning of the source. One of the critical difference is the introduction of semantic coding, which captures the semantic features, depending on tasks or actions to be executed at the receiver. Only those semantic features will be transmitted, which reduces the required communication resources significantly. Tasks at the receiver could be data reconstruction or some more intelligent tasks, such as image classification and language translation. Note that in semantic communications, data are not processed at the bit level, but the semantic level. Semantic communications could be described by semantic theory.
The following starts with a brief review of information theory. We then present semantic theory developed in past decades though it is not well established yet.
II-B Information Theory
In 1948, Shannon introduced the concept of information entropy [1], which exploits uncertainty to measure the information content in terms of bits.
Definition 1
Given the source, , with probabilities , the source entropy measures the average number of bits per symbol to be reconstructed without loss, which is defined as
| (1) |
Theorem 1
For transmission over noisy channels, described by , channel capacity is given by
| (2) |
where is the mutual information between the input, , and the output, , of the channel, and is the conditional entropy of for a given as shown in Fig. 2(a).
With the channel capacity, Shannon further developed the source-channel coding theorem.
Theorem 2
If for , satisfies the asymptotic equipartition property (AEP) and , there exists a source-channel code with probability of error . Conversely, there will be a positive probability of error if .
Conventional communication systems are based on Shannon’s separation theorem including two stages: i) compress source data into its most efficient form; and ii) map the sequence of source coding into channel coding.
Theorem 1 provides an upper bound for distortion-less transmission. For a given distortion , the minimum transmission information rate can be described by rate distortion theory, also known as the lossy source coding theorem.
Theorem 3
For a given maximum average distortion , the rate distortion function is the lower bound of the transmission bit-rate [23]
| (3) |
where is the distortion, is the distortion metric with if . As , .
Information theory is a rich subject nowadays and it is impossible to introduce it within a couple of pages. The above are only theorems and definitions that are highly related to the semantic theory in the subsequent discussions.
II-C Semantic Theory
Entropy in Shannon information theory measures the information content by the uncertainty of the source. However, how to measure the amount of semantic information, or the importance of information, for a specific transmission task is yet to be determined. The transmission task refers to the task, such as classification, recognition, and device configuration, to be performed at the receiver after the source information is received in conventional communications.
Definition 2
Given a transmission task, , the semantic information, , is the information relevant to in the source, .
The uncertainty in is less than that in , which indicates the following relationship:
| (4) |
The semantic information, , is extracted from , which can be regarded as the lossy compression of . However, from the view of , is the lossless compression of since the task, , could be fully served by it. With different tasks, the required semantic representation, , will be different as shown in Fig. 2.(b).
With the transmission task, , it is possible to measure the importance of information, say semantic information. For example, for image classification tasks, the receiver is only interested in the objects in an image rather than the original image. Therefore, the objects are considered as essential information while the others are non-essential. Similarly, for text transmission, the receiver requires the meaning of text instead of lossless text recovery.
II-C1 Semantic Entropy
In the past decades, researchers have worked hard to find a way to quantify semantic entropy by following the path of information entropy developed by Shannon. However, it is still an active research area with huge space to investigate.
Based on logical probability, many different definitions of semantic entropy have been developed. Carnap and Bar-Hillel [4] measured the semantic information by the degree of confirmation, which is expressed as
| (5) |
where is defined as the degree of confirmation of hypothesis on the evidence, . For example, could be a new message and could refer to the knowledge. Bao et al. [5] defined semantic entropy of a message or sentence as
| (6) |
where the logical probability of is given by
| (7) |
Here, is the symbol set of a classical source, is the proposition satisfaction relation, and is the sets of models for , i.e., the space in which is true. Here, is the probability of . If there is no background available, . The conditional entropy with background knowledge is also defined by extending the above definition.
In fuzzy systems, semantic entropy is defined by introducing the concept of matching degree with the membership degree [24]. Membership degree is a concept in fuzzy set theory and is usually difficult to measure analytically. Therefore, it is defined manually by following expert intuition and experience. Liu et al. [24] defined as a semantic concept, which could be treated as the transmission task, and as the membership degree for each ,where is the set of . For the class, , the matching degree, , characterizes the semantic entropy of on the concept, . Note that the definition of matching degree shares similarity as that defined in (7). With the matching degree, semantic entropy on class is defined as
| (8) |
The overall semantic entropy over could be obtained by summing up that of all classes. The basic properties of semantic entropy defined above are similar to those of information entropy. The difference is the membership degree. It is related to the semantic concept or the transmission task, which characterizes the semantic information.
The above definitions of semantic entropy assume that there exists a way to measure semantic information. All theorems are developed based on the assumption of available semantic representation without providing the specific approach to quantifying semantic information. A group of statisticians [9] is working on an active project to develop an information-theoretic framework for quantifying semantic information content in multimodal data, where semantic entropy is defined as the minimum number of semantic enquires about the source , whose answers are sufficient to predict the transmission task, . By doing so, the approach to finding semantic entropy becomes to find the minimal representation of for serving the task, . However, it is still under investigation and how to apply such a framework to practical scenarios is to be clarified.
II-C2 Semantic Channel
For communication over a noisy channel, the received message is usually with distortion. From the Shannon theorem, such errors caused by distortion can be measured by bit-error rate (BER) or symbol-error rate (SER), which is the engineering problem. From the semantic view, such errors can be measured by semantic mismatch. Bao et al. [5] introduced two kinds of semantic errors from logic probability, 1) Unsoundness: the sent message is true but the received message is false, 2) Incompleteness: the sent message is false but the received message is true. However, there is yet a definition of the semantic error/noise, which will be further discussed in Section III.A.
II-C3 Semantic Channel Capacity
In addition to (6), Bao et al. [5] further developed the following theorem for semantic channel capacity, which can be regarded as counterpart of Theorem 1.
Theorem 4
The semantic channel capacity of a discrete memoryless channel is expressed as
| (9) |
where is the mutual information between the source, , and the transmission task, . is the conditional probabilistic distribution that refers to a semantic coding strategy with the source, , encoded into its semantic representation, , and means the semantic ambiguity of the coding. , , is the average logical information of the received messages for the task V.
Note that higher means higher semantic ambiguity caused by the semantic coding while higher leads to strong ability for the receiver to interpret received messages. The semantic channel capacity could be either higher or lower than the Shannon channel capacity , dependent on the semantic coding strategy and the receiver’s ability to interpret received messages.
Two cases are provide here for better understanding. Given the source sentence “She parked Jame’s car on the ground floor of the building, which has 13 floors with 120 sqm on each floor and is called Smith Building due to the creator, William Smith.” The receiver want to know where is Jame’s car.
-
•
Case 1: , which means that the receiver can handle the semantic ambiguity. The source sentence can be compressed as “the ground floor of Smith Building.” Compared with the source sentence, the semantic ambiguity is higher, which means that increases. However, the receiver can answer the question with the received sentence, thus the receiver can handle the semantic ambiguity. The semantic compression can achieve higher transmission rate. is higher than Shannon capacity in this case.
-
•
Case 2: , which means that the receiver cannot solve the semantic ambiguity. The source sentence can be compressed as “She parked Jame’s car on the building.” The receiver cannot find the car based on the received sentence, thus the receiver cannot handle the semantic ambiguity, in which is lower than Shannon capacity.
II-C4 Semantic Rate Distortion and Information Bottleneck
Similar to (3), the rate distortion in semantic communication system is formulated as [25]
| (10) |
where is the semantic distortion between source, , and recovered information, , at the receiver, and is the distortion between semantic representation, , and received semantic representation, . Note that (10) considers the distortion caused by both semantic compression and channel noise.
Information bottleneck is an approach to finding the optimal tradeoff between compression and accuracy, which is to solve the following problem [26]
| (11) |
where V is the desired semantic representation. As its extension, Sana et al. [27] designed a new loss function as
| (12) |
where and are the parameters to adjust the weights of the mutual information term and the inference term. The compression term represents the average number of bits required for . The inference term is the Kullback-Leibler (KL) divergence between the posterior probability at the encoder, , and the one captured by the decoder, . Note that the upper bound of (12) is
| (13) |
which is the loss function designed in [12] to be detailed in Section VI.
Though it is not yet possible to quantify semantic communication systems as Shannon did for conventional communication systems, understanding the above concepts could provide us important insights, especially on the loss function design for DL-enabled semantic communications.
III Components, Semantic Noise, and Performance Metrics
As we can see from Section II, semantic theory is still in its infancy. But it does not prevent us from developing practical semantic communication systems. This section introduces main components, semantic noise, and performance metrics for semantic communication systems.
III-A Semantic Communication System Components
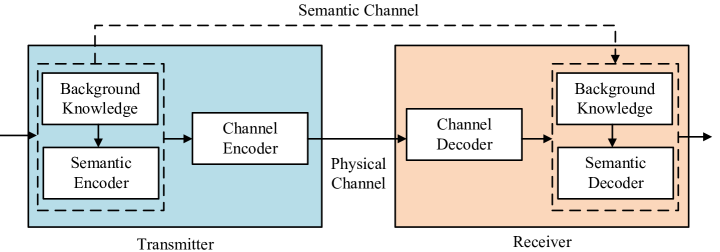
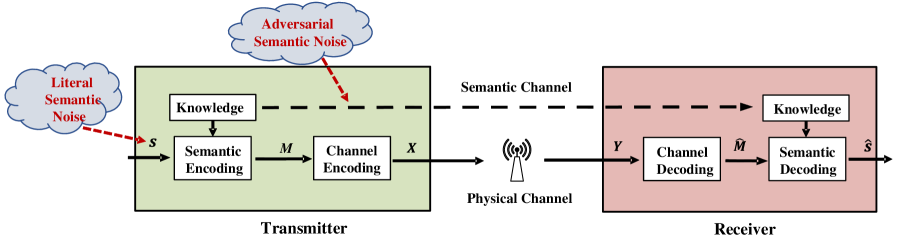
As shown in Fig. 3, a semantic communication system includes semantic level and transmission level. The semantic level addresses semantic information processing to obtain semantic representation, which is performed by the semantic encoder and decoder. Here, the semantic information refers to that useful for serving the intelligent tasks at the receiver. The transmission level guarantees the successful reception of symbols at the receiver after going through the transmission medium, which are normally proceeded by the channel encoder and decoder. The semantic transmitter and receiver are equipped with certain background knowledge to facilitate semantic feature extraction, where the background knowledge could be different for various applications.
Similar to the general structure shown in Fig. 3, a task-oriented semantic signal processing framework has been proposed [16]. Moreover, semantic-aware active sampling [21, 22] allows each smart device to control its traffic, in which samples are generated if the sampler is triggered for serving a specific task.
Note that there are two types of channels to deal with in semantic communication systems. The first type of channels are the physical channels, which introduce channel impairments, such as noise, fading, and inter-symbol interference, to the transmitted symbols. In the past, the majority of efforts on wireless communications have been made to combat the physical channel impairments. The second type of channels are the semantic channels, which could be contaminated by semantic noise caused by misunderstanding, interpretation errors, or disturbance in the estimated information.
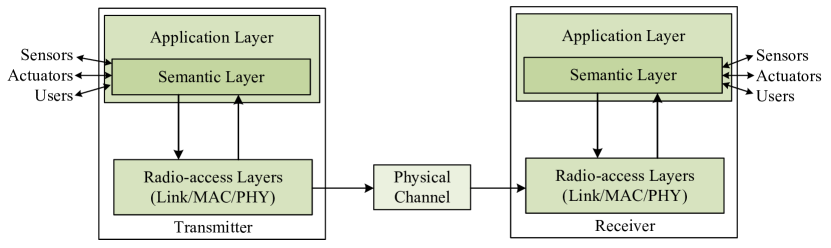
To support semantic communications, a semantic Open System Interconnection (OSI) model was introduced [18]. As shown in Fig. 4, it allows the semantic layer to interface with sensors or actuators and to access algorithms and data for specific tasks. In the semantic layer, semantic coding is performed to transmits semantic encoded data to lower layers. Moreover, the radio-access layer aims at improving the system transmission performance, which transmits control signals to the semantic layer over a control channel. Those control signals are exploited by the semantic layer to remove semantic noise for semantic symbol error correction or to control computing at the application layer. Similarly, Zhang et al. [20] proposed a new semantic system model with different layers as a comprehensive system to replace the existing OSI model.
III-B Semantic Noise
Semantic noise refers to the disturbance that affects the interpretation of the message, which could be treated as the semantic information mismatch between the transmitter and the receiver in semantic communications. Fig. 5 illustrates the semantic noise as the two parties interpret the word “earth” in different ways.

There is yet a general formulation of semantic noise. For semantic communications, we categorize it into two types as shown in Fig. 6. The first type of semantic noise refers to semantic ambiguity introduced to the source. For example, minor changes to letters or words in the sentence, for instance, replace the synonym or reverse the alphabetical order randomly, could make it hard to understand the semantic meaning by the machine, which leads to wrong decision making [28]. In particular, Peng et al. [29] developed a robust semantic communication system for text transmission to deal with such type of semantic noise.
Another type is the adversarial semantic noise that misleads the DL model. Due to the discrete nature of text, it is impossible to add perturbation to text without being noticed by human. However, some modifications added to images are so subtle that human can hardly notice. A typical example of adversarial example in the image domain is shown in Fig. 7, in which the adversarial samples are added. We could see that the image with adversarial noise will mislead the DL models for classification but look the same as the original image if observed by human. Moreover, the sample-dependent and sample-independent semantic noise are investigated in [30], which both mislead the DL model.
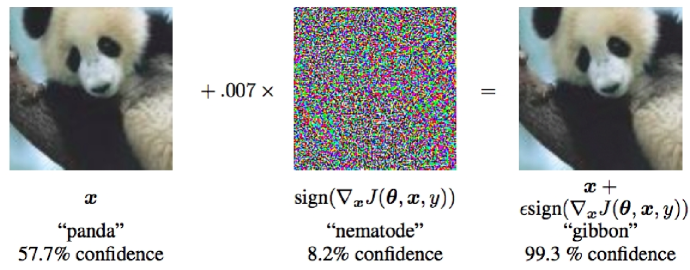
Some prior works have studied adversarial example generation. Goodfellow et al. [31] proposed a fast gradient sign method to generate perturbation by using the gradient of the loss function. Miyato et al. [32] developed a fast gradient method to generate adversarial examples. The role of adversarial examples for DL has two effects. First, it can be used to prevent machine learning system from attacks. Secondly, it is beneficial to improve the robustness of a DL-based system. Note that all the aforementioned adversarial examples are generated by human. To investigate whether there are adversarial samples in nature, a mobile phone camera is used to photograph adversarial samples [33], which have showed that images obtained by taking pictures of the adversarial samples will also be misclassified.
III-C Performance Metrics
In the conventional communication systems, BER and SER are usually adopted as the performance metrics. However, they are not applicable to measure semantic communication systems any more as the focus of communications is shifted from accurate symbol transmission to effective semantic information exchange. At the moment, a general metric is still missing for semantic communications. In the following of this section, We will discuss metrics for different sources, including text, image, and speech, in the literature.
III-C1 Text Semantic Similarity
Word-error rate (WER) is used to measure the semantic text transmission [34, 10], which is not applicable for semantic text transmission as two sentences with different words may share high semantic similarity. The bilingual evaluation understudy (BLEU) score is a commonly used metric to measure the quality of text after machine translation [35], which has been exploited to measure semantic communication systems for text transmission [12, 14]. The BLEU score between the transmitted sentence and the received sentence is calculated by
| (14) |
where and are the word length of and , respectively, defines the weights of the -grams, and is the -grams score defined as
| (15) |
where is the frequency count function for the -th element in the -th gram. BELU score counts the difference of -grams between two sentences, where -grams refer to the number of words in a word group for comparison. For example, for sentence “This is a dog”, the word groups are “this”, “is”, “a” and “dog” for -gram. For -grams, the word groups include “this is”, “is a” and “a dog”. The same rule applies for the rest.
The range of BLEU score falls between 0 and 1. The higher the score, the higher similarity between the two sentences. However, few human translations will attain the score of 1 since sentences with different expressions or words may refer to the same meaning. For example, sentences “my bicycle was stolen” and “my bike was stolen” share same meaning but the BLEU score is not 1 since they are different when compared word by word.
To characterize such a feature, sentence similarity [12] was proposed as a new metric to measure the semantic similarity level of two sentences, which is expressed as
| (16) |
where is the BERT model [36] to map a sentence to its semantic vector space, which is a pre-trained model with billions of sentences. Instead of comparing two sentences directly, we compare their semantic vectors obtained by the BERT model. Sentence similarity ranges from 0 to 1. The higher the value, the higher similarity between the two sentences.
To achieve a tradeoff between the transmission accuracy and the number of symbols used for each message, a metric [27] has been designed as
| (17) |
where is the number of symbols per message and is the semantic error between and . Note that could be in various formats, such as BLEU score and mean-squared error (MSE), which is dependent on the transmission task at the receiver.
Moreover, some other metrics have also been introduced recently, i.e., average bit consumption per sentence measures the system from a communication perspective [34].
III-C2 Image Semantic Similarity
The similarity of two images, and , is measured as
| (18) |
where is the image embedding function mapping an image to a point in the Euclidean space. The image embedding function is the essential part for finding the image semantic similarity. Note that the commonly used metrics, such as peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM), are shallow functions and fail to count many nuances of human perception. Moreover, traditional image similarity metrics are built on the top of hand designed features, such as Gabor filter and scale-invariant feature transform (SIFT). Their performance is heavily limited by the representation power of features.
Image semantic similarity metric depends on the high-order image structure, which is usually context dependent. DL-based image similarity metrics could achieve promising results, as the convolutional neural network (CNN) encodes high invariance and captures image semantics. It is discovered that deep CNNs trained on a high-level image classification task are often remarkably useful as a representational space. For example, we can measure the distance of two images in VGG feature space as the perceptual loss for image regression problems [37]. They define two perceptual loss functions based on a VGG network, . The feature reconstruction loss encourages the two images with similar feature representations computed by . Let be the activation function of the th layer, which is of shape . The feature reconstruction loss is calculated by
| (19) |
The style reconstruction loss penalizes differences in colors, textures, and common patterns. It is the difference between the Gram matrices, , of the two images given by
| (20) |
The effectiveness of deep features in similarity measuring is not restrict to VGG architecture. Richard et al. [38] evaluated deep features across different architectures and tasks, which showed significant performance gain compared to all previous metrics and coincided with human perception. Furthermore, a deep ranking model proposed in [39] characterizes the image similarity relationship within a set of triplets: a query image, a positive image, and a negative image. The image similarity relationship is characterized by the relative similarity ordering in triplets. Moreover, metrics, including adversarial loss [40], inception score (IS), and Fréchet inception distance (FID) [41], have also been proposed to measure the similarity between images generated from generative adversarial networks (GAN) and natural images, from a image distribution perspective.
Visual semantic embedding is another way to assess the image semantic similarity [42]. As mentioned earlier, the concepts from different images can be extracted and compared. The visual translation embedding (VTransE) network [43] maps the visual features of objects and predication into a low-dimensional semantic space. Therefore, the semantic similarity can be measured. The relationship detection model in [44] learns a module to map features from the vision and semantic modalities into a shared space, where the matched feature pairs should be discriminative against those unmatched ones and maintaining close distances to semantically similar ones. As a result, the model can represent semantic similarity of images well at the relationship level. Semantic embedding has been widely used in scene graph generation (SGG), image captioning, and image retrieval. Hence, it is with great potential to be exploited in semantic communication systems.
III-C3 Speech Quality Measurement
The transmission goal of semantic commutations can be categorized into full data reconstruction and task execution. To achieve the speech reconstruction, the global speech semantic information, such as the voice of a speaker, text information, and speech delay, are transmitted and recovered at the receiver. Therefore, the metrics, such as perceptual evaluation of speech quality (PESQ) [45], short-time objective intelligibility (STOI) [46], and perceptual objective listening quality assessment (POLQA) [47], can be adopted to measure the global semantic content of speech signals, which comprehensively evaluate the reconstructed speech signals. In [13], PESQ is adopted as the performance metric in a semantic communication system for speech transmission.
However, to serve intelligent tasks, i.e., speech synthesis, the speech signals are synthesized at the receiver based on the text and speaker’s information, which omits some content of semantic information, e.g., speech delay. Therefore, unconditional Fréchet deep speech distance (FDSD) and unconditional kernel deep speech distance (KDSD) are utilized to assess the quality of synthesized speech, which first extracts the features of the speech signals and feeds these features into an assessment model to measure their similarity.
Denote the extracted features of the original speech samples and the synthesized ones as and , respectively, the FDSD is defined as
| (21) |
where and represent the averages of and , respectively, while and denote their covariance matrices.
KDSD [48] is given by
| (22) |
where is the kernel function.
From the above, for semantic communications serving different tasks, the performance metric is heavily dependent on the chosen “semantic language” for the application. Such a semantic language could be a typical natural language, the scene graph for image processing, truth tables from Carnap et al. [4], or the customized graph-based language from Kalfa et al. [16]. The metrics will have to be adapted to these languages.
IV Deep Semantic Communications for Text, Speech, and Image/Video
Though semantic theory has been investigated for decades, the lack of a general mathematical tool limits its applications. Thanks to the advancements of DL, some interesting works have been developed for semantic communications in recent years. This section presents the latest work on the deep semantic communication system design for text, image, speech, and multimodal data.
IV-A Text Processing
The advancement on NLP [49] enables text coding to consider the semantic meaning of text, which motivates us to re-design the transceiver for achieving successful semantic information transmission. For the system shown in Fig. 3, neural networks are used to represent the transmitter and receiver in DL-enabled semantic communications. The core of DL-enabled semantic communication is to design semantic coding, which can understand and extract semantic information. Those semantic features are then compressed. Moreover, the channel decoder is trained to combat the channel impairment. Another core task is to design a proper loss function to minimize semantic errors and channel impairments. If the system is designed for serving a specific task at the receiver, the loss function should be adjusted accordingly to capture features relevant to the task.
For erasure channels, Farsad et al. [10] developed a long short-term memory (LSTM) enabled JSCC for text transmission. The cross entropy is adopted as the loss function and WER is used for performance metric. It shows the great potential of DL-enabled JSCC compared to the conventional communication system. Though the concept of semantic communication was not mentioned in [10], it inspired subsequent research greatly.
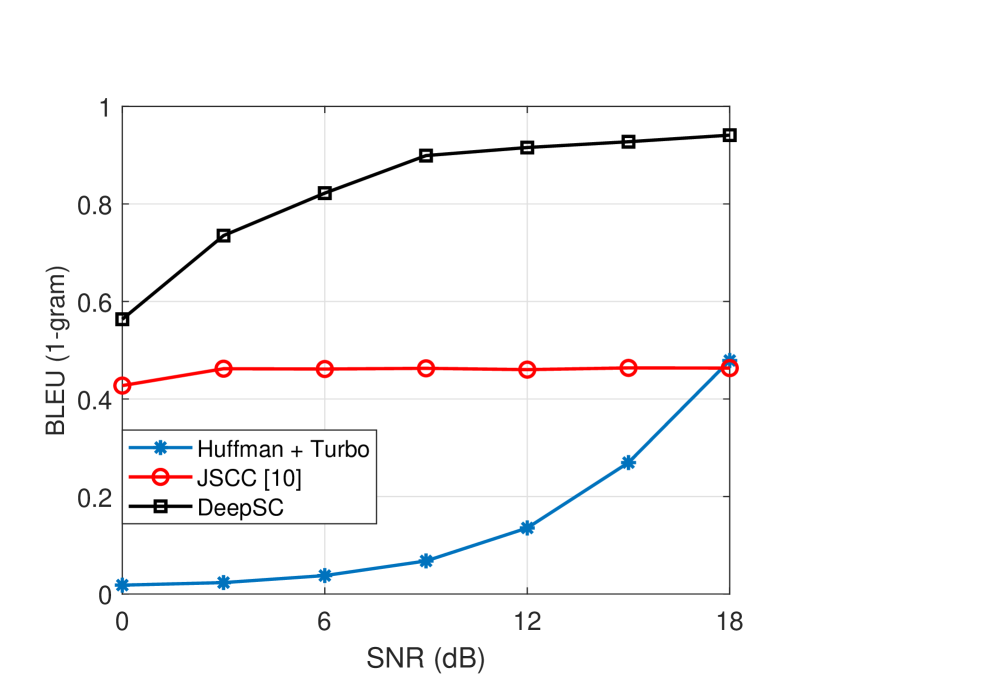
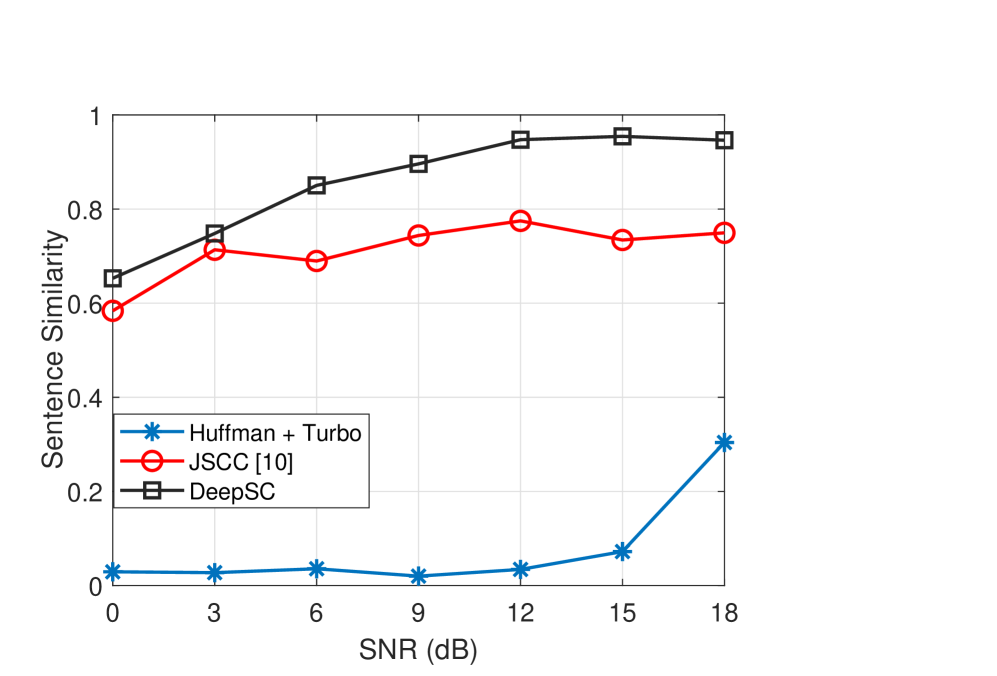
Afterwards, Xie et al. [12] developed a Transformer based joint semantic-channel coding for an end-to-end semantic communication system, named DeepSC. In such an end-to-end system, the block structure of the conventional communication system has been merged [7]. In particular, a new loss function given by (13) was provided, which counts the cross entropy for better understanding texts and the mutual information for higher data rates [12]. By designing such semantic coding and channel coding layers, DeepSC is capable of extracting semantic features and guaranteeing their accurate transmission. It has been verified that DeepSC outperforms typical communication systems significantly, especially when channel conditions are poor. For instance, the BLEU score in Fig. 8 is improved by 800% compared to the conventional method with Huffman coding and Turbo codes when SNR = 9 dB. When measured by sentence similarity defined in (13), we could also see the significant performance gap between DeepSC and the conventional method. Note that when SNR = 12 dB, the BLEU score is less than 0.2, which makes the received sentence almost impossible to read by human beings. It could be reflected by the sentence similarity which is almost 0 with SNR = 12 dB.
Moreover, Table I provides an snapshot of the received sentences after they pass through Rayleigh fading channels, in which the traditional methods exhibit some spelling mistakes. Note that the performance metrics, such as BLEU score and sentence similarity, cannot be used as the loss function in DeepSC as it will cause gradient disappearance for the transceiver training.
| Transmitted sentence | it is an important step towards equal rights for all passengers. |
| DeepSC | it is an important step towards equal rights for all passengers. |
| JSCC[10] | it is an essential way towards our principles for democracy. |
| Huffman + Turbo | rt is a imeomant step tomdrt equal rights for atp passurerrs. |
Since then, several variants of DeepSC have been developed. Specifically, Jiang et al. [34] combines semantic coding with Reed Solomon coding and hybrid automatic repeat request for improving the reliability of text semantic transmission. A similarity detection network was proposed to detect meaning errors. Moreover, Sana et al. [27] defined a new loss function (12) to capture the effect of semantic distortion, which can dynamically trade semantic compression loss for semantic fidelity. Note that (12) is upper bounded by (13), but it is hard to use (12) as the loss function for neural network training. Another contribution from [27] is the introduction of adaptive number of symbols used for each word for further performance gain in terms of the metric defined in (17). The performance gain becomes obvious when the maximum number of symbols for each word is large, but it also increases the size of data to be transmitted. To make the trained model affordable for capacity-limited IoT devices, Xie et al. [14] developed a lite model of DeepSC by pruning and quantizing the trained DeepSC models, which could achieve 40x compression ratio without performance degradation.
IV-B Image Processing
In this part, we first introduce different approaches of image semantic extraction. DL-based image compression and semantic communications for image transmission are then discussed.
IV-B1 Non-Structural Image Semantic Representation
The representation of pixel-level images usually lacks of high-level semantic information. Classical machine learning methods utilize hand-crafted features for image representation. Later on, sparse coding [50] was introduced to represent image patches as a combination of overcomplete basis elements, also known as a codebook. However, the representation power of shallow features is usually limited.
After the breakthrough of convolutional neural networks (CNN), powerful deep features become available. In a CNN, each layer generates a successively higher-level abstraction of the input data, named a feature map, to keep essential yet unique information. By employing a very deep hierarchy of layers, modern CNNs achieve superior performance in image semantic representation and content understanding. Although these approaches have achieved advanced performance in visual feature extraction, there is still a gap between visual features and semantics.
To narrow the gap, some researchers focus on extracting image utilizing context information. The deep semantic feature matching approach proposed in [51] incorporates convolutional feature pyramids and activation guided feature selection. Promising results have been obtained in estimating correspondences across different instances and scenes of the same semantic category. Huang [52] proposed an image and sentence matching approach by utilizing the image global context to learn semantic concepts, such as objects, properties, and actions. The description of image regions is generated in [53], where the visual-semantic alignment model infers the alignment between segments of sentences and the region of the image described by those text segments. Shi et al. [54] proposed a semantic representation for person re-identification, where semantic attributes include the color and category of clothes as well as different parts of the body.
Some researchers tried to extract concise representation for image semantics, such as semantic segmentation map, sketch, object skeleton, and facial landmark. These semantic labels describe the layout of those objects. For instance, each pixel in semantic segmentation is labeled with the class of its enclosing object or region. Object skeleton describes the symmetry axis, which is widely used in object recognition/detection. Facial landmarks are used to localize and represent salient regions of the face, i.e., eyes and nose, which are applied to various tasks, such as face alignment, head pose estimation, and face swapping, to name a few.
IV-B2 Structural Image Semantic Representation
The efforts of structural image semantic representation have been concentrated on using graph-based machine learning techniques to reduce semantic gap between the low-level image features and the profusion of high-level human perception to images. With the power of graph representation, the solution space is reduced, which results in faster optimization convergence and higher accuracy in the representation learning. Graph based methods have demonstrated effective performance in image segmentation, annotation, and retrieval. In this way, the gap between image vision content and the semantic tags can be bridged.
Scene graph [55] has been regarded as a typical representation of the semantic graph, which is a data structure to describe objects and their relationship in a real scene. As shown in Fig. 9, a complete scene graph could represent the detailed semantics of scenes, which can be used to encode 2D/3D images/videos into semantic features. Scene graph is a new content for scene description, which has been widely adopted in inference tasks, such as question answering, image retrieval, and image captioning.
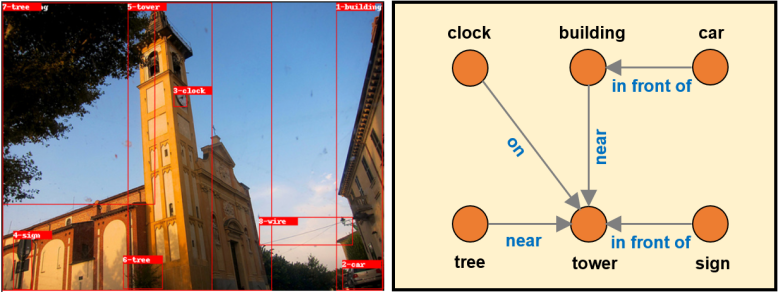
Scene Graph Generation (SGG) is developed to build a more complete scene graph. Particularly, VTransE places objects in a low-dimension relation space where the relationship can be modeled as a simple translation vector () [43]. Note that elements of visual scenes have strong structural regularity, thus some structural repetitions in scene graphs can be examined. MOTIFNET [56] divides SGG into the stage predicting bounding boxes, object labels, and relationships. Moreover, Causal-TDE [57], which is based on causal inference other than the conventional likelihood, introduced a causal graph of SGG to remove the effect from the undesired bias by counterfactual causality.
IV-B3 Deep Learning based Image Compression
Traditional image compression projects an image into its sparse domain and reconstructs the image under the guidance of pixel level accuracy. They suffer from blocky and ringing artifact at low bit rate and the reconstructed image is not visually pleasant. It is the frontier that machine learning based image compression methods transform the traditional pixel reconstruction into semantic reconstruction. Content understanding is considered as the core of next generation image coding.
Deep autoencoder encodes the image into a low dimensional latent code thus achieves highly efficient compression. Various end-to-end deep autoencoder based image compression architectures were proposed in [58, 59, 60]. To deal with the non-differential rounding based quantization, differentiable alternatives have been proposed for the quantization and entropy rate estimation. Based on the fact that local information content of an image is spatially variant, a content-aware bit rate allocation method was proposed in [61].
Moreover, GAN is used to produce visually pleasing reconstruction for very low bit rates. The pioneering work [62] introduced GAN to compression and proposed a real-time adaptive image compression method. By utilizing an autoencoder feature pyramid to downsample an image and a generator to reconstruct it, the compressor typically produces files 2.5 times smaller than the typical image compression method, such as JPEG. Agustsson et al. [63] introduced the GAN based extreme learned image compression, which obtains visually pleasing results at an extremely low bit rate. Furthermore, if a semantic label map is available, the non-essential regions in the decoded image can be fully synthesized. Wu et al. [64] proposed a GAN-based tunable image compression system, in which the important map is learned to guide the bit allocation.
IV-B4 Semantic Communications for Image/Video
Fig. 10 illustrates a structure for image semantic communications, which utilizes the aforementioned image processing but is beyond that. The semantic encoder extracts the low-dimensional semantic information, in the form of visual-semantic embedding, semantic label, or semantic graph. Machine learning techniques are adopted to design an efficient semantic encoder. The next stage is the channel encoder, which can be jointly trained with the semantic encoder.
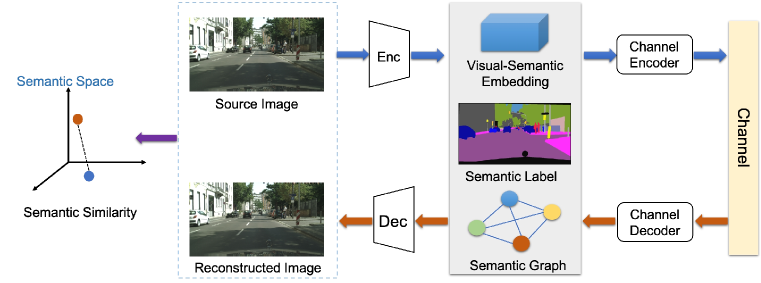
Particularly, Kurka et al. proposed DeepJSCC [65, 66] for adaptive-bandwidth wireless transmission of images. It exploits the channel output feedback signal and outperfoms separation-based schemes. DeepJSCC performs well in the low SNR and small bandwidth regimes with slight degradation. At the receiver, the semantic decoder usually adopts a GAN based architecture to map semantic information into its vision space. Such an under-determined image reconstruction training task is optimized using the criterion of semantic similarity.
More works have been designed for serving certain vision tasks, named task-oriented semantic communications. Specifically, Lee et al. [67] designed a joint transmission-classification system for images, in which the receiver outputs image classification results directly. It has been verified that such a joint design achieved higher classification accuracy than performing image recovery and classification separately. Kang et al. [68] proposed a scheme for joint image transmission and scene classification. Deep reinforcement learning was exploited to identify the most essential semantic features for serving the transmission task so as to achieve the best tradeoff between classification accuracy and transmission cost. Jankowski et al. [69] considered image based re-identification for persons or cars as the transmission task, and two schemes were proposed to improve the retrieval accuracy.
Moreover, video transmission is considered as a killing application of semantic communications, especially the video conference. In particular, Wang et al. [70] have developed a reinforcement learning enabled end-to-end framework for video transmission with variable bandwidth. It demonstrates superior performance compared to the conventional method. Wang et al. [71] have designed a JSCC scheme for video transmission over the air with to minimize the end-to-end transmission rate-distortion. Jiang et al. [72] have proposed a semantic transmission scheme for video conferencing with a novel semantic error detector. The photo of the speaker is shared as prior information to help reconstruct the motion of the speaker’s facial expression. The developed scheme lower the demands on wireless resource dramatically. Tao et al. [73] developed a mobile video transmission framework to guarantee the quality of experience (QoE). A large dataset has been built to find the relationship between the subjective QoE scores and the neural network parameters to guide the semantic video transmission. Moreover, Fried et al. [74] have proposed to edit talking-head video by editing text. Afterwards, Tandon et al. [75] have proposed to transmit text only rather than video, which dramatically lower the network traffic.
For image or video transmission, task-oriented semantic communications lower the network traffic significantly. However, as the system is trained for a specific task, the trained model should be updated or even re-trained if the transmission task varies.
IV-C Speech and Multimodal Data Processing
IV-C1 Semantic Communications for Speech
Semantic communication systems have also been designed for speech transmission [76, 77]. Weng et al. [13] proposed an extension of DeepSC for speech signals, named DeepSC-S. In particular, joint semantic-channel coding could deal with source distortion and channel effect. In this work, the bit-to-symbol transformation is not involved. MSE is adopted as the loss function to minimize the difference between the recovered speech signals and the input ones. In addition, signal-to-distortion ratio (SDR) and PESQ are adopted as two performance metrics to the quality of recovered speech signals. Tong et al. [77] extended it to a multi-user case and implemented federated learning to collaboratively train the CNN based encoder and decoder over multiple local devices and the server. MSE is also used as the loss function and performance metric, which hardly reflects the amount of semantic information at the receiver.
Inspired by the unprecedented demands of intelligent tasks, DeepSC-ST [76] utilized recurrent neural networks (RNNs) to extract the text-related semantic information from speech signals at the transmitter and to recover the text sequence at the receiver for speech synthesis. By doing so, only text semantic information is transmitted, which reduce the required transmission resource significantly. Connectionist temporal classification (CTC) [78] is adopted as the loss function, where character-error-rate (CER) and WER are adopted as two performance metrics to measure the accuracy of the recognized text information. The aforementioned FDSD and KDSD are exploited to measure the similarity between the real and synthesized speech signals.
IV-C2 Unified Semantic Communications for Multimodal Data and Multi-Task
Multimodal data processing has been considered as a critical task as shown in Fig. 11. For tasks, such as AR/VR and human sensing care system, the generated multimodal data are correlated in the context. By introducing new degrees of freedom, multimodal data improves the performance of intelligent tasks [79].
Semantic communications are promising to support multimodal data transmission. Xie et al. [15] developed MU-DeepSC for the visual question answering task, where text based questions about images are transmitted by one user and the enquiry images are transmitted from another user. Cross entropy is adopted as the loss function while the task related metric, i.e., answer accuracy rate, is used to measure the performance of MU-DeepSC. Different from all the aforementioned works for the point-to-point transmission, MU-DeepSC is designed for serving multi-user transmission. As an extension of DeepSC, a Transformer based framework [80] has been developed as a unique structure for serving different tasks. Various tasks have been tested in [80] to show its superiority.
Note that the aforementioned work still requires model training for each task, which limits the application. A unified deep learning enabled semantic communication system (U-DeepSC) [81] has been designed to serve various transmission tasks. To jointly serve these tasks in one model, domain adaptation is employed to lower the transmission overhead. Moreover, since each task is with different difficulty and requires different numbers of layers, a multi-exit architecture has been proposed to provide early-exit results for relatively simple tasks.
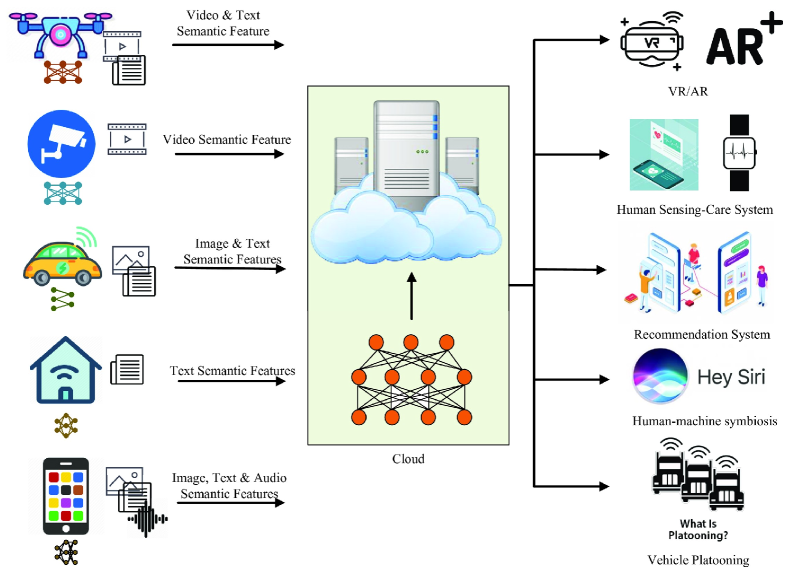
Note that the investigation on semantic commutations for multimodal data transmission is still at its infancy. But we could see the great potential of semantic communications to support multimodal data transmission for various applications, especially the great potential to lower the size of data to be transmitted by utilizing the correlations among data from different modalities.
V Research Challenges and Conclusions
We can now conclude that the semantic communication is a breakthrough of the conventional communication. However, its general structure and many related issues are not clear yet, which motivates us to investigate more in this area. To pave the way to semantic communications, the following open questions should be answered:
-
1.
Semantic theory: Though some researchers have tackled semantic theory in past decades, most of them are based on logical probability with limited application scenarios, which follows the framework of conventional information theory. It is still questionable whether we could follow a similar path to quantify semantic communications by semantic entropy, semantic channel capacity, semantic level rate-distortion theory, and the relationship between inference accuracy and transmission rate.
-
2.
Semantic transceiver: Semantics provide concise and effective representations, thus making the semantic communication an efficient system in terms of bandwidth saving and subsequent task processing. However, a general semantic level JSCC for different types of sources is not available yet. Moreover, it is a significant challenge to design a semantic noise robust communication system, incorporating machine learning techniques like adversarial training. Furthermore, proper loss functions without causing gradient disappearance are required.
-
3.
Semantic communications with reasoning: Inspired by the advances of System 2 that enables reasoning, planning, and handling exceptions, a semantic communication system with reasoning could significantly reduces the communication cost by sending only the most effective semantics as pointed out by Tong’s keynote and Seo et al. [82]. However, the investigated in this direction is still at its infancy, more efforts are expected to develop a more intelligent semantic communication system with reasoning.
-
4.
Resource allocation in semantic-aware network: In semantic-aware networks, it is essential to rethink resource allocation for semantic interference control. In contrast to resource allocation in conventional communications, which focuses on engineering issues, i.e., improving bit transmission rate, semantic-aware resource allocation aims to address both engineering and semantic issues. The objective of semantic-aware resource allocation is to improve communication efficiency in semantic domain. In particular, semantic spectrum efficiency has been proposed in [83, 84]. However, this issue still faces following challenges:
-
•
How to evaluate semantic communication efficiency, i.e., semantic transmission rate or semantic spectral efficiency?
-
•
How to formulate a general resource allocation problem for difference task-oriented semantic systems to optimize the resource allocation policy to maximize semantic communication efficiency?
-
•
-
5.
Performance metrics: Though several new performance metrics have been explored in semantic communication systems as aforementioned, it is more than desired to design more appropriate evaluation metrics for semantic communications, for instance, the metric to evaluate the amount of semantic information that has been preserved or missed. Moreover, a general performance metric, such as SER or BER for conventional communication systems, is required to measure different semantic communication systems.
-
6.
Applications: Apart from the extensive research interest in semantic communications, the killing applications are more then desired. We are witnessing extensive interest in semantic communications enabled AR/VR and video conference from both academia and industries. We are looking forward to seeing more potential applications of semantic communications in the near future.
References
- [1] C. E. Shannon and W. Weaver, The Mathematical Theory of Communication. The University of Illinois Press, 1949.
- [2] J. Hoydis, F. A. Aoudia, A. Valcarce, and H. Viswanathan, “Toward a 6G AI-native air interface,” arXiv preprint arXiv:2012.08285, Apr. 2021.
- [3] W. Tong and G. Y. Li, “Nine challenges in artificial intelligence and wireless communications for 6G,” IEEE Wireless Commun., pp. 1–10, 2022.
- [4] R. Carnap, Y. Bar-Hillel et al., An Outline of A Theory of Semantic Information. RLE Technical Reports 247, Research Laboratory of Electronics, Massachusetts Institute of Technology., Cambridge MA, Oct. 1952.
- [5] J. Bao, P. Basu, M. Dean, C. Partridge, A. Swami, W. Leland, and J. A. Hendler, “Towards a theory of semantic communication,” in IEEE Network Science Workshop, West Point, NY, USA, Jun. 2011, pp. 110–117.
- [6] B. Guler, A. Yener, and A. Swami, “The semantic communication game,” IEEE Trans. Cogn. Commun. Netw., vol. 4, no. 4, pp. 787–802, Dec. 2018.
- [7] Z. Qin, H. Ye, G. Y. Li, and B.-H. F. Juang, “Deep learning in physical layer communications,” IEEE Wireless Commun., vol. 26, no. 2, pp. 93–99, Apr. 2019.
- [8] B. H. Juang, “Quantification and transmission of information and intelligence—history and outlook [DSP history],” IEEE Signal Process. Mag., vol. 28, no. 4, pp. 90–101, Jul. 2011.
- [9] A. Chattopadhyay, B. D. Haeffele, D. Geman, and R. Vidal, “Quantifying task complexity through generalized information measures,” https://openreview.net/pdf?id=vcKVhY7AZqK, 2021.
- [10] N. Farsad, M. Rao, and A. Goldsmith, “Deep learning for joint source-channel coding of text,” in Proc. IEEE Int. Conf. Acoustics Speech Signal Process (ICASSP), Calgary, Canada, Apr. 2018, pp. 2326–2330.
- [11] E. Bourtsoulatze, D. B. Kurka, and D. Gündüz, “Deep joint source-channel coding for wireless image transmission,” IEEE Trans. Cogn. Commun. Netw., vol. 5, no. 3, pp. 567–579, May 2019.
- [12] H. Xie, Z. Qin, G. Y. Li, and B.-H. Juang, “Deep learning enabled semantic communication systems,” IEEE Trans. Signal Process., vol. 69, pp. 2663–2675, Apr. 2021.
- [13] Z. Weng and Z. Qin, “Semantic communication systems for speech transmission,” IEEE J. Sel. Areas Commun., vol. 39, no. 8, pp. 2434–2444, Aug. 2021.
- [14] H. Xie and Z. Qin, “A lite distributed semantic communication system for Internet of Things,” IEEE J. Sel. Areas Commun., vol. 39, no. 1, pp. 142–153, Jan. 2021.
- [15] H. Xie, Z. Qin, and G. Y. Li, “Task-oriented multi-user semantic communications for VQA,” IEEE Wireless Commun. Lett., vol. 11, no. 3, pp. 553–557, Mar. 2022.
- [16] M. Kalfa, M. Gok, A. Atalik, B. Tegin, T. M. Duman, and O. Arikan, “Towards goal-oriented semantic signal processing: Applications and future challenges,” Digit. Signal Process., vol. 119, pp. 103–134, Dec. 2021.
- [17] E. C. Strinati and S. Barbarossa, “6G networks: Beyond shannon towards semantic and goal-oriented communications,” arXiv preprint arXiv:2011.14844, Feb. 2021.
- [18] Q. Lan, D. Wen, Z. Zhang, Q. Zeng, X. Chen, P. Popovski, and K. Huang, “What is semantic communication? A view on conveying meaning in the era of machine intelligence,” arXiv preprint arXiv:2110.00196, Oct. 2021.
- [19] G. Shi, Y. Xiao, Y. Li, and X. Xie, “From semantic communication to semantic-aware networking: Model, architecture, and open problems,” IEEE Commun. Mag., vol. 59, no. 8, pp. 44–50, Sep. 2021.
- [20] P. Zhang, W. Xu, H. Gao, K. Niu, X. Xu, X. Qin, C. Yuan, Z. Qin, H. Zhao, J. Wei, and F. Zhang, “Toward wisdom-evolutionary and primitive-concise 6G: A new paradigm of semantic communication networks,” Engineering, pp. 1–17, Nov. 2021.
- [21] M. Kountouris and N. Pappas, “Semantics-empowered communication for networked intelligent systems,” IEEE Commun. Mag., vol. 59, no. 6, pp. 96–102, Jun. 2021.
- [22] E. Uysal, O. Kaya, A. Ephremides, J. Gross, M. Codreanu, P. Popovski, M. Assaad, G. Liva, A. Munari, T. Soleymani, B. Soret, and K. H. Johansson, “Semantic communications in networked systems,” arXiv preprint arXiv:2103.05391, Jun. 2021.
- [23] P. Blanchart, “Fast learning methods adapted to the user specificities: Application to earth observation image information mining,” PhD thesis, Sep. 2011.
- [24] X. Liu, W. Jia, W. Liu, and W. Pedrycz, “Afsse: An interpretable classifier with axiomatic fuzzy set and semantic entropy,” IEEE Trans. Fuzzy Syst., vol. 28, no. 11, pp. 2825–2840, 2020.
- [25] J. Liu, W. Zhang, and H. V. Poor, “A rate-distortion framework for characterizing semantic information,” arXiv preprint arXiv:2105.04278, May 2021.
- [26] N. Tishby, F. C. Pereira, and W. Bialek, “The information bottleneck method,” arXiv preprint arXiv:0004057, Apr. 2000.
- [27] M. Sana and E. C. Strinati, “Learning semantics: An opportunity for effective 6G communications,” arXiv preprint arXiv:2110.08049, Oct. 2021.
- [28] W. Wang, L. Wang, R. Wang, Z. Wang, and A. Ye, “Towards a robust deep neural network in texts: A survey,” arXiv preprint arXiv:1902.07285, Feb. 2019.
- [29] X. Peng, Z. Qin, D. Huang, X. Tao, J. Lu, G. Liu, and C. Pan, “A robust deep learning enabled semantic communication system for text,” arXiv preprint arXiv:2206.02596, Jun. 2022.
- [30] Q. Hu, G. Zhang, Z. Qin, Y. Cai, G. Yu, and G. Y. Li, “Robust semantic communications with masked VQ-VAE enabled codebook,” arXiv preprint arXiv:2206.04011, Jun. 2022.
- [31] I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” arXiv preprint arXiv:1412.6572, Dec. 2014.
- [32] T. Miyato, A. M. Dai, and I. Goodfellow, “Adversarial training methods for semi-supervised text classification,” arXiv preprint arXiv:1605.07725, May 2016.
- [33] A. Kurakin, I. Goodfellow, and S. Bengio, “Adversarial examples in the physical world,” Proc. Int Conf. Learning Rep. workshop, May 2017.
- [34] P. Jiang, C.-K. Wen, S. Jin, and G. Y. Li, “Deep source-channel coding for sentence semantic transmission with HARQ,” arXiv preprint arXiv:2106.03009, Jun. 2021.
- [35] K. Papineni, S. Roukos, T. Ward, and W. Zhu, “BLEU: A method for automatic evaluation of machine translation,” in Proc. Annual Meeting Assoc. Comput. Linguistics (ACL), Philadelphia, PA, USA, Jul. 2002, pp. 311–318.
- [36] J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” in Proc. North American Chapter of the Assoc. for Comput. Linguistics: Human Language Tech. (NAACL-HLT), Minneapolis, MN, USA, Jun. 2019, pp. 4171–4186.
- [37] J. Johnson, A. Alahi, and L. Fei-Fei, “Perceptual losses for real-time style transfer and super-resolution,” in Proc. European Conf. Comput. Vis. (ECCV). Springer, Amsterdam, The Netherlands, Mar. 2016, pp. 694–711.
- [38] R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Salt Lake City, UT, USA, Jun. 2018, pp. 586–595.
- [39] J. Wang, Y. Song, T. Leung, C. Rosenberg, J. Wang, J. Philbin, B. Chen, and Y. Wu, “Learning fine-grained image similarity with deep ranking,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Columbus, OH, USA, Jun. 2014, pp. 1386–1393.
- [40] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial networks,” arXiv preprint arXiv:1406.2661, Jun. 2014.
- [41] T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford, and X. Chen, “Improved techniques for training GANs,” arXiv preprint arXiv:1606.03498, Jun. 2016.
- [42] A. Frome, G. S. Corrado, J. Shlens, S. Bengio, J. Dean, M. A. Ranzato, and T. Mikolov, “Devise: A deep visual-semantic embedding model,” in Proc. Advances Neural Inf. Processing Syst. (NIPS), vol. 26, Lake Tahoe., USA, Dec. 2013.
- [43] H. Zhang, Z. Kyaw, S.-F. Chang, and T.-S. Chua, “Visual translation embedding network for visual relation detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Honolulu, Hawaii., Jun. 2017, pp. 5532–5540.
- [44] J. Zhang, Y. Kalantidis, M. Rohrbach, M. Paluri, A. Elgammal, and M. Elhoseiny, “Large-scale visual relationship understanding,” in Proc. AAAI Conf. Artif. Intell., Jan. 2019, pp. 9185–9194.
- [45] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, “Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), Salt Lake City, UT, USA, May. 2001, pp. 749–752.
- [46] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “An algorithm for intelligibility prediction of time–frequency weighted noisy speech,” IEEE Trans. Audio, Speech, Language Process., vol. 19, no. 7, pp. 2125–2136, Sep. 2011.
- [47] J. G. Beerends, C. Schmidmer, J. Berger, M. Obermann, R. Ullmann, J. Pomy, and M. Keyhl, “Perceptual objective listening quality assessment (POLQA), the third generation ITU-T standard for end-to-end speech quality measurement part I—temporal alignment,” J. Audio Eng. Soc., vol. 61, no. 6, pp. 366–384, Jun. 2013.
- [48] M. Bińkowski, J. Donahue, S. Dieleman, A. Clark, E. Elsen, N. Casagrande, L. C. Cobo, and K. Simonyan, “High fidelity speech synthesis with adversarial networks,” arXiv preprint arXiv:1909.11646, Sep. 2019.
- [49] D. W. Otter, J. R. Medina, and J. K. Kalita, “A survey of the usages of deep learning for natural language processing,” IEEE Trans. Neural Netw. Learning syst., vol. 32, no. 2, pp. 604–624, 2020.
- [50] H. Bristow, A. Eriksson, and S. Lucey, “Fast convolutional sparse coding,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Portland, OR, USA, Jun. 2013, pp. 391–398.
- [51] N. Ufer and B. Ommer, “Deep semantic feature matching,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Honolulu, Hawaii., Nov. 2017, pp. 6914–6923.
- [52] Y. Huang, Q. Wu, C. Song, and L. Wang, “Learning semantic concepts and order for image and sentence matching,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Salt Lake City, UT, USA, Jun. 2018, pp. 6163–6171.
- [53] A. Karpathy and L. Fei-Fei, “Deep visual-semantic alignments for generating image descriptions,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Boston, MA, USA, Jun. 2015, pp. 3128–3137.
- [54] Z. Shi, T. M. Hospedales, and T. Xiang, “Transferring a semantic representation for person re-identification and search,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Boston, MA, USA, Jun. 2015, pp. 4184–4193.
- [55] J. Johnson, R. Krishna, M. Stark, L.-J. Li, D. Shamma, M. Bernstein, and L. Fei-Fei, “Image retrieval using scene graphs,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Boston, MA, USA, Jun. 2015, pp. 3668–3678.
- [56] R. Zellers, M. Yatskar, S. Thomson, and Y. Choi, “Neural motifs: Scene graph parsing with global context,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Salt Lake City, UT, Jun. 2018, pp. 5831–5840.
- [57] K. Tang, Y. Niu, J. Huang, J. Shi, and H. Zhang, “Unbiased scene graph generation from biased training,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Seattle, WA, USA, Jun. 2020, pp. 3716–3725.
- [58] L. Theis, W. Shi, A. Cunningham, and F. Huszár, “Lossy image compression with compressive autoencoders,” arXiv preprint arXiv:1703.00395, Mar. 2017.
- [59] Z. Cheng, H. Sun, M. Takeuchi, and J. Katto, “Deep convolutional autoencoder-based lossy image compression,” in IEEE Proc. Picture Coding Symposium (PCS), Sep. 2018, pp. 253–257.
- [60] J. Ballé, V. Laparra, and E. P. Simoncelli, “End-to-end optimized image compression,” arXiv preprint arXiv:1611.01704, Nov. 2016.
- [61] M. Li, W. Zuo, S. Gu, D. Zhao, and D. Zhang, “Learning convolutional networks for content-weighted image compression,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Salt Lake City, UT, USA, Jun. 2018, pp. 3214–3223.
- [62] O. Rippel and L. Bourdev, “Real-time adaptive image compression,” in PMLR Proc. Int. Conf. Mach. Learning (ICML), Sydney, Australia, May 2017, pp. 2922–2930.
- [63] E. Agustsson, M. Tschannen, F. Mentzer, R. Timofte, and L. V. Gool, “Generative adversarial networks for extreme learned image compression,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Seoul, Korea (South), Oct. 2019, pp. 221–231.
- [64] L. Wu, K. Huang, and H. Shen, “A GAN-based tunable image compression system,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Venice, Italy, Jun. 2020, pp. 2334–2342.
- [65] D. B. Kurka and D. Gündüz, “DeepJSCC-f: Deep joint source-channel coding of images with feedback,” IEEE J. Sel. Areas Inf. Theory, May 2020.
- [66] D. B. Kurka and D. Gündüz, “Bandwidth-agile image transmission with deep joint source-channel coding,” IEEE Trans. Wireless Commun., pp. 8081–8095, Jun. 2021.
- [67] C.-H. Lee, J.-W. Lin, P.-H. Chen, and Y.-C. Chang, “Deep learning-constructed joint transmission-recognition for Internet of Things,” IEEE Access, vol. 7, pp. 76 547–76 561, Jun. 2019.
- [68] X. Kang, B. Song, J. Guo, Z. Qin, and F. R. Yu, “Task-oriented image transmission for scene classification in unmanned aerial systems,” arXiv preprint arXiv: 2112.10948, Dec. 2021.
- [69] M. Jankowski, D. Gündüz, and K. Mikolajczyk, “Wireless image retrieval at the edge,” IEEE J. Select. Areas Commun., vol. 39, no. 1, pp. 89–100, Jan. 2021.
- [70] T.-Y. Tung and D. Gündüz, “Deepwive: Deep-learning-aided wireless video transmission,” arXiv preprint arXiv:2111.13034, Nov. 2021.
- [71] S. Wang, J. Dai, Z. Liang, K. Niu, Z. Si, C. Dong, X. Qin, and P. Zhang, “Wireless deep video semantic transmission,” arXiv preprint arXiv:2205.13129, 2022.
- [72] P. Jiang, C.-K. Wen, S. Jin, and G. Y. Li, “Wireless semantic communications for video conferencing,” arXiv preprint arXiv:2204.07790, 2022.
- [73] X. Tao, Y. Duan, M. Xu, Z. Meng, and J. Lu, “Learning QoE of mobile video transmission with deep neural network: A data-driven approach,” IEEE Journal on Selected Areas in Communications, vol. 37, no. 6, pp. 1337–1348, Jun. 2019.
- [74] O. Fried, A. Tewari, M. Zollhöfer, A. Finkelstein, E. Shechtman, D. B. Goldman, K. Genova, Z. Jin, C. Theobalt, and M. Agrawala, “Text-based editing of talking-head video,” ACM Trans. Graphics (TOG), vol. 38, no. 4, pp. 1–14, 2019.
- [75] P. Tandon, S. Chandak, P. Pataranutaporn, Y. Liu, A. M. Mapuranga, P. Maes, T. Weissman, and M. Sra, “Txt2Vid: Ultra-low bitrate compression of talking-head videos via text,” arXiv preprint arXiv:2106.14014, Jun. 2022.
- [76] Z. Weng, Z. Qin, X. Tao, C. Pan, G. Liu, and G. Y. Li, “Deep learning enabled semantic communications with speech recognition and synthesis,” arXiv preprint arXiv:2205.04603, May 2022.
- [77] H. Tong, Z. Yang, S. Wang, Y. Hu, O. Semiari, W. Saad, and C. Yin, “Federated learning for audio semantic communication,” Frontiers Commun. Netw., vol. 2, p. 43, Sep. 2021.
- [78] A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, “Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks,” in PMLR Proc. Int. Conf. Mach. Learning (ICML), Pittsburgh, USA, Jun. 2006, pp. 369–376.
- [79] D. Lahat et al., “Multimodal data fusion: An overview of methods, challenges, and prospects,” Proc. IEEE, vol. 103, no. 9, pp. 1449–1477, Apr. 2015.
- [80] H. Xie, Z. Qin, X. Tao, and K. B. Letaief, “Task-oriented multi-user semantic communications,” arXiv preprint arXiv:2112.10255, Dec. 2021.
- [81] G. Zhang, Q. Hu, Z. Qin, Y. Cai, and G. Yu, “A unified multi-task semantic communication system with domain adaptation,” arXiv preprint arXiv:2206.00254, Jun. 2022.
- [82] H. Seo, J. Park, M. Bennis, and M. Debbah, “Semantics-native communication with contextual reasoning,” arXiv preprint arXiv:2108.05681, Aug. 2021.
- [83] L. Yan, Z. Qin, R. Zhang, Y. Li, and G. Y. Li, “Resource allocation for semantic-aware networks,” arXiv preprint arXiv:2201.06023, Apr. 2022.
- [84] ——, “QoE-aware resource allocation for semantic communication networks,” arXiv preprint arXiv:2205.14530, May 2022.