DBT-Net: Dual-branch federative magnitude and phase estimation with attention-in-attention transformer for monaural speech enhancement
Abstract
The decoupling-style concept begins to ignite in the speech enhancement area, which decouples the original complex spectrum estimation task into multiple easier sub-tasks (i.e., magnitude-only recovery and the residual complex spectrum estimation), resulting in better performance and easier interpretability. In this paper, we propose a dual-branch federative magnitude and phase estimation framework, dubbed DBT-Net, for monaural speech enhancement, aiming at recovering the coarse- and fine-grained regions of the overall spectrum in parallel. From the complementary perspective, the magnitude estimation branch is designed to filter out dominant noise components in the magnitude domain, while the complex spectrum purification branch is elaborately designed to inpaint the missing spectral details and implicitly estimate the phase information in the complex-valued spectral domain. To facilitate the information flow between each branch, interaction modules are introduced to leverage features learned from one branch, so as to suppress the undesired parts and recover the missing components of the other branch. Instead of adopting the conventional RNNs and temporal convolutional networks for sequence modeling, we employ a novel attention-in-attention transformer-based network within each branch for better feature learning. More specially, it is composed of several adaptive spectro-temporal attention transformer-based modules and an adaptive hierarchical attention module, aiming to capture long-term time-frequency dependencies and further aggregate intermediate hierarchical contextual information. Comprehensive evaluations on the WSJ0-SI84 + DNS-Challenge and VoiceBank + DEMAND dataset demonstrate that the proposed approach consistently outperforms previous advanced systems and yields state-of-the-art performance in terms of speech quality and intelligibility.
Index Terms:
speech enhancement, decoupling-style, magnitude spectrum estimation, complex-spectrum purification, attention-in-attention transformer.I Introduction
Various types of environmental interference may greatly degrade the performance of telecommunication, automatic speech recognition (ASR), and hearing aids in real scenarios. In this regard, monaural speech enhancement (SE) is often necessary, aiming at recovering clean speech from its noise-contaminated mixture to improve speech quality and intelligibility [1]. With the renaissance of deep neural networks (DNNs), a plethora of DNN-based approaches have been proposed to ignite the development of SE algorithms for their more powerful capability in suppressing highly non-stationary noise than conventional statistical signal processing-based approaches [2], particularly under low signal-to-noise ratio (SNR) conditions.
Conventional supervised SE methods based on DNNs usually aim to estimate mask functions or directly predict the spectral magnitude of clean speech in the time-frequency (T-F) domain [3, 4], where the noisy phase remains unaltered when reconstructing the time-domain waveform. This is because that phase information was regarded as unimportant for a long time for the SE task [5]. Moreover, it is intractable to accurately estimate the phase distribution of clean speech, due to its highly nonstructural characteristic. However, recent studies reported that the unprocessed phase severely degrades the speech perceptual quality especially under low SNR conditions [6]. To this end, numerous phase-aware SE approaches have been proposed to tackle the phase estimation problem in the time domain or complex-valued spectral domain. For the former category, the raw waveform is directly used to regenerate enhanced speech without using any T-F representation [7, 8, 9, 10], which diverts around the explicit phase estimation problem. For example, SEGAN [11] proposed a generative adversarial network-based SE method, where a denoising generator directly maps the raw waveform of the clean speech from the mixed raw waveform by adversarial training. For the latter category, researchers handle the phase estimation in the complex-valued spectral domain [12, 13, 14, 15], which can be divided into two main streams, namely masking-based and mapping-based. For the first type, a multitude of complex-valued DNN-based algorithms have been proposed to estimate the complex-valued ratio mask (CRM), which can be then applied to real and imaginary (RI) parts of the complex spectrum, so as to recover the magnitude and phase simultaneously [12, 13, 14]. The second type has leveraged complex spectral mapping networks to directly predict the RI components of the clean complex spectrum [15]. For example, in [15], real-valued convolutional recurrent networks (CRN) were leveraged to directly map the RI components of target speech, where the enhanced RI components were decoded by two decoders respectively. More recently, a handful of multi-stage decoupling-style methods have thrived in the SE area and were demonstrated to achieve a remarkable performance [16, 17, 18, 19]. Instead of packing the mapping process into only one black box in the previous single-stage paradigm, these multi-stage methods decoupled the original complex spectrum estimation into optimizing magnitude and phase stage by stage, and alleviated the implicit compensation effect between two targets [20]. Specifically, due to the apparent spectral regularity of magnitude spectra, only the magnitude estimation was involved in the first stage. Subsequently, the complex spectrum refinement was conducted with residual learning in the second stage, which could also implicitly refine the phase.
Motivated by the aforementioned multi-stage studies, we decompose the complex spectrum estimation in parallel and propose a dual-branch framework involved with a novel transformer-based network, dubbed DBT-Net. From the complementary perspective, DBT-Net takes full advantage of magnitude spectrum-based and complex spectrum-based SE methods to explore the overall spectrum estimation. Specifically, two core branches are elaborately devised in parallel to facilitate the overall spectrum recovery, namely a Magnitude Estimation Branch (MEB) and an auxiliary Complex spectrum Purification Branch (CPB). Due to the apparent spectral regularity of the magnitude spectrum, we seek to construct the filtering system with MEB to coarsely suppress the dominant noise components in the magnitude domain. In parallel, we establish a refining system with CPB to compensate for the lost spectral details and phase mismatch effect in the complex-valued spectral domain. With information interaction between each branch, two branches can flow information and collaboratively facilitate the overall spectrum recovery.
Generally, mainstream SE models leveraged an encoder-decoder structure based on recurrent neural networks (RNN) or convolution neural networks (CNN), which ignored the long-range contextual information during modeling the speech sequences and led to limited denoising performance. Besides, CNN requires more convolutional layers to enlarge the receptive field for model long-term speech sequences, while RNNs suffer from high computational complexity and cannot perform parallel processing. Subsequently, convolutional recurrent networks (CRNs) [21] and temporal convolutional networks (TCNs) [22] were proposed for more effective sequence modeling in the SE area, due to their capability of further extracting high-level features and enlarging receptive fields. However, they still lacked sufficient capacity to capture the global contextual information [9, 23, 24, 25]. Additionally, most of them only worked in the time axis, which neglected the correlations among different frequency sub-bands. In this respect, transformer-based approaches have thrived in speech sequence-to-sequence domains for their remarkable performance in capturing the long-term dependency on natural language processing tasks [26]. In the speech separation and enhancement task, dual-path transformer-based networks were employed for extracting contextual information along both the time and frequency axes [9, 23, 25]. Nevertheless, they ignored the long-range hierarchical contextual information during sequence modeling, and thus the intermediate feature maps were not fully and effectively exploited.
To this end, we employ an attention-in-attention transformer network dubbed AIAT within each branch to funnel the global sequence modeling process, which integrates four adaptive time-frequency attention (ATFA) transformers and an adaptive hierarchical attention (AHA) module to form an “attention-in-attention” (AIA) structure. To be specific, the ATFA transformers can capture the local and global contextual information in the both time and frequency dimension, while the AHA module can flexibly aggregate all the output feature maps of ATFA modules together by a global attention weight.
The major contributions of this paper are summarized as follows.
-
•
We propose a dual-branch SE framework to simultaneously recover magnitude and phase information of the clean complex spectrum in parallel, and an attention-in-attention transformer-based network is adopted for sequence modeling. From a complementary perspective, these two core branches can collaboratively obtain the coarse- and fine-grained regions of clean speech, i.e., spectral magnitude and missing details.
-
•
Considering the complementary associations between spectral magnitude and complex spectral details, we introduce information interaction between the two branches, in which the external knowledge is extracted from the magnitude-based branch as assistance to facilitate the residual complex spectral estimation, and vice versa.
-
•
Comprehensive experiments on two public corpora show that DBT-Net achieves remarkable results and consistently outperforms the state-of-the-art baselines, while incurring a relatively small model parameter size.
The remainder of the paper is organized as follows. In Section II, the target formulation is described in detail. In Section III, the proposed network architecture is illustrated in detail. The experimental setup is presented in Section IV, while Section V gives the results and analysis. Finally, some conclusions are drawn in Section VI.

II Target Formulation
II-A Signal model
Given a monaural mixture, the noisy signal , clean speech and noise signals can be formulated as:
| (1) |
where denotes the discrete-time index. With the short-time Fourier transform (STFT), Eq. (1) can be transformed into:
| (2) |
where , and denote the T-F representations of noisy, clean and noise signals in the bin index. Note that we omit the time and frequency indices for brevity. In the Cartesian coordinates, Eq. (2) can also be written as:
| (3) |
where and denote the real and imaginary parts of the noisy complex spectrum , respectively, with . and have the similar definitions as and , as well as and .
II-B Dual-branch strategy
The overall diagram of the proposed system is illustrated in Fig. 1. It is mainly comprised of two branches, namely a magnitude spectrum estimation branch (MEB) and a complex spectrum purification branch (CPB), which aim at collaboratively estimating the magnitude and phase information of clean speech in parallel. To be specific, we first neglect the intractable phase estimation and only focus on the magnitude estimation. In the MEB path, we feed the magnitude of noisy spectrum into the network to estimate a gain function , which aims at coarsely filtering out dominant noise and recovering the magnitude of the target speech, i.e., . Then the coarsely denoised spectral magnitude is coupled with the corresponding noisy phase to derive the coarse-estimated RI components of the target spectrum, i.e., .
As a supplement, we leverage CPB to purify the fine-grained spectral structures which may be lost in the MEB path. That is to say, CPB aims at tackling the residual noise components as well as simultaneously recovering the phase information of the target spectrum. Instead of explicitly estimating the whole complex spectrum, CPB is designed for residual mapping in the complex-valued spectral domain, which can alleviate the overall burden of the network. Finally, we sum the coarse-denoised RI components and the fine-grained complex spectral details together to reconstruct the target complex spectrum. Note that the final output involves both magnitude estimation and complex residual mapping, indicating that the two branches contribute to the target estimation collaboratively. In a nutshell, the whole procedure can be formulated as:
| (4) | |||
| (5) | |||
| (6) | |||
| (7) | |||
| (8) |
where denote the output residual RI components of CPB and denote the final merged estimation of clean RI components. is the element-wise multiplication operator. The input features of MEB and CPB are denoted as and , respectively. Here is the number of frames and is the number of frequency bins.
III Proposed Architecture
In this section, the details of the proposed framework are described. As shown in Fig. 1 (a), MEB consists of three major components, namely a densely convolutional encoder, an AIAT for sequence modeling, and a masking decoder for magnitude spectral gain estimation. More specifically, the proposed AIAT module consists of four adaptive time-frequency attention transformer-based (ATFAT) modules and an adaptive hierarchical attention (AHA) module, as illustrated in Fig. 2, where ATFAT aims to capture long-range correlations separately along the temporal and spectral axes and AHA attempts to integrate different intermediate feature maps during sequence modeling. Note that the output range of the spectral gain is truncated into (0, 1) with the sigmoid activation function.
The overall topology of CPB is similar to that of MEB, which includes a densely convolutional encoder, an AIAT and two densely decoders, aiming at estimating the residual real and imaginary parts of the target complex spectrum, respectively. To interact and complement information during sequence modeling, we elaborately design the interaction modules between the two branches, where MEB can better guide the feature learning procedure with the information transformed by CPB, and vice versa. The detailed parameter setup is summarized in Table I, while the MEB and CPB share the same configuration except for the number of decoders, where MEB employs only one mask decoder and CPB employs two decoders for the real and imaginary parts of the residual target complex spectrum.
| layer name | input size | hyperparameters | output size | |
| Encoder | 2-D Conv | , , | ||
| DenseBlock_1 | , , , | |||
| DenseBlock_2 | , , , | |||
| DenseBlock_3 | , , , | |||
| DenseBlock_4 | , , , | |||
| 2-D Conv | , , | |||
| 2-D Conv (merge) | , , | |||
| ATFA Transformers ATAB | reshape | - | ||
| MHSA | - | |||
| Bi-GRU | 128 | |||
| Linear | 64 | |||
| reshape | - | |||
| AFAB | reshape | - | ||
| MHSA | - | |||
| Bi-GRU | 128 | |||
| Linear | 64 | |||
| reshape | - | |||
| 2-D Conv | , , | |||
| AHA module | - | |||
| Real/Imag Decoder | DenseBlock_1 | , , , | ||
| DenseBlock_2 | , , , | |||
| DenseBlock_3 | , , , | |||
| DenseBlock_4 | , , , | |||
| Sub-pixel Conv | , , | |||
| 2-D Conv | , , | |||
| Masking Decoder | DenseBlock_1 | , , , | ||
| DenseBlock_2 | , , , | |||
| DenseBlock_3 | , , , | |||
| DenseBlock_4 | , , , | |||
| Sub-pixel Conv | , , | |||
| 2-D Conv | , , | |||
| 2-D Conv_mask1 | , , | |||
| 2-D Conv_mask2 | , , | |||
| 2-D Conv | , , |
III-A Densely convolutional encoder
As illustrated in Fig. 1 (b), given the input features or , the densely convolutional encoder in each branch is composed of two 2-D convolutional layers, followed by layer normalization (LN) and parametric ReLU (PReLU) activation. Between these two convolutional layers, a DenseNet [27] with four dilated convolutional layers is employed, in which the dilation rates are . The output channel of the first 2-D convolutional layer is set to 64 and keeps unaltered, with kernel size and stride being (1, 1), while the second 2-D convolutional layer halves the dimension of the frequency axis, and sets kernel size and stride to (1, 3) and (1, 2), respectively. The detailed parameter setups for MEB and CPB are presented in Table I, where the real/imaginary decoder and masking decoder are employed in CPB and MEB paths, respectively.
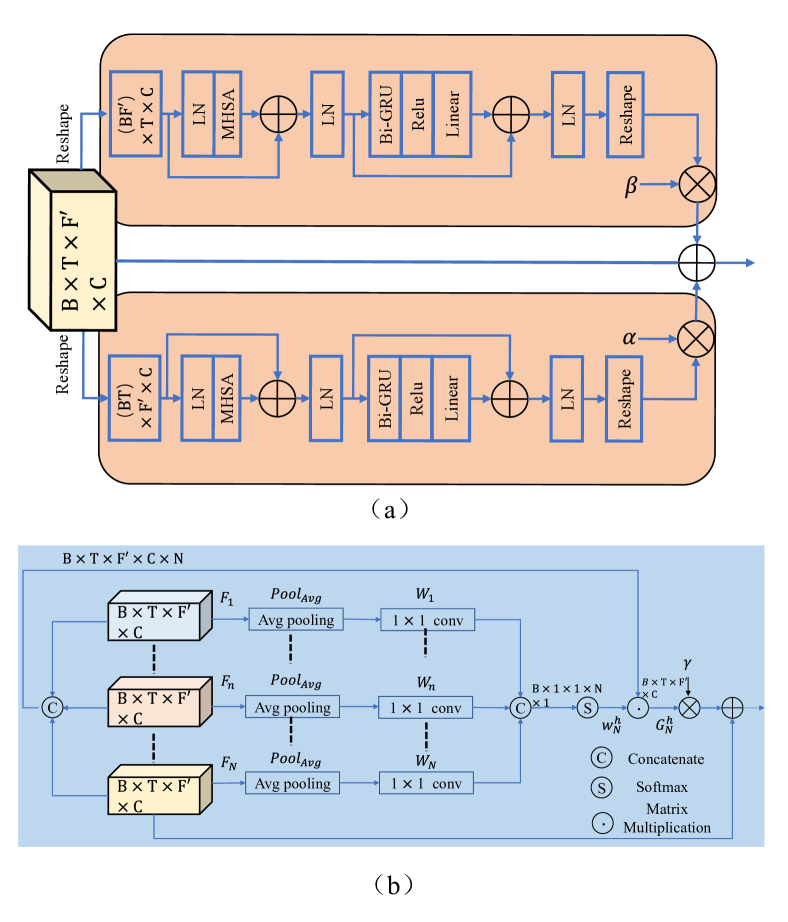
III-B Attention-in-attention transformer
Compared with recurrent neural network (RNN) or convolution neural network (CNN), transformer-based neural network can effectively resolve the long-dependency problem by modeling the speech sequences directly conditioning on context and also operate well in parallel, which has shown remarkable performance in speech enhancement area [9, 23, 24, 25]. In our attention-in-attention transformer (AIAT), we only utilize the encoder part in the original transformer [26], which consists of multi-head scaled dot-product self-attention and position-wise feedforward network similar to [9, 23].
Before feeding the compressed features into the AIAT in each branch, we concatenate the outputs from two branches in the channel axis and use a 2-D convolution to merge information, followed by PReLU activation. The proposed AIAT module consists of four adaptive time-frequency attention transformer-based (ATFAT) modules and an adaptive hierarchical attention (AHA) module, as illustrated in Fig. 2. Each ATFAT can strengthen the long-range spectro-temporal dependencies with relatively low computational cost and the AHA module can aggregate different intermediate features to capture global multi-scale contextual information, as pointed out in [28, 29, 30]. The ATFAT and AHA modules cooperate to form an “attention-in-attention” structure, which indicates that the output of ATFAT can be further enhanced and integrated by AHA depending on adaptive attention weights.
III-B1 Adaptive time-frequency attention Transformer
To alleviate the heavy computational complexity of conventional self-attention, we introduce an adaptive time-frequency attention (ATFA) mechanism as a lightweight solution to capture long-range correlations exhibited in the temporal and spectral axes, as described in [31, 28]. As illustrated in Fig. 2(a), the ATFAT is divided into two sub-branches in the time and frequency axes, namely an adaptive temporal attention branch (ATAB) and an adaptive frequency attention branch (AFAB), which can capture global dependencies along the temporal and spectral dimensions in parallel with two adaptive weights and . In each branch, different from the vanilla transformer, a GRU-based improved transformer [9] is employed, which is comprised of multi-head self-attention (MHSA) and GRU-based position-wise network, followed by residual connections and LN. Multi-head self-attention has been widely used in the natural language processing and speech processing areas, because it can leverage the contextual information in the feature maps [26, 32, 31, 28]. In MHSA modules, the input features are first mapped with different linear projections times to get queries , keys and values representations, where indicates the number of heads in MHSA modules. Then, the scaled dot-product attention is operated on each head to obtain a weighted sum of the values, where the weight is obtained by an attention function of the query and the corresponding keys. Finally, the attentions of all heads are concatenated and linearly transformed to obtain the final output. Given the input features , the attention block in ATAB can be written as:
| (9) |
where denotes the reshaped input of ATAB, , and are the linearly mapped queries, keys and values, respectively. and are linear transformation matrices. Here, , , and denote the batch size, the frame number, the compressed frequency dimension and the channel number, respectively. In our model, the number of heads is set to 4. Subsequently, inspired by the effectiveness of GRU-based transformer in speech separation and denoising tasks [9, 23], we replace the first fully connected layer of the feedforward network in the vanilla transformer with a bi-directional GRU. The final output is calculated by feeding the output from multi-head attention block into GRU-based feedforward network, followed by the residual connections and layer normalization:
| (10) |
where denotes the output of the GRU-based position-wise feedforward network, denotes the linear transformation, and denotes the bias. Here, and is set to 64 in this module. Then, we reshape the final output of ATAB to the original size, i.e., . Analogously, we reshape the compressed input features into vectors with dimension and feed it into AFAB to calculate the output, i.e., , along the frequency axis in parallel. Finally, the output features of the two branches and the original features are then combined by two learnable adaptive weights and to obtain the final output of the ATFA module, followed by a PReLU activation and 2-D convolutional layer, which can be formulated as:
| (11) |
where and are initialized to 1 and automatically assigned to suitable values. After each ATFAT module, a PReLU activation and a 2-D convolutional layer are employed, with kernel size and stride set to (1, 1).
III-B2 Adaptive hierarchical attention module
Given all ATFAT modules’ outputs , the proposed AHA module aims at integrating different intermediate feature maps depending on the global context. Here, is the number of ATFAT that is set to 4 in the paper. In the AHA module, we first cascade all the intermediate output of each ATFAT (i.e., ) to obtain a global feature map . The superscript denotes the adaptive hierarchical attention. For each output feature of ATFAT, we employ an average pooling layer and a convolutional layer to squeeze each ATFAT’s output feature into a global representation: , and then cascade all the pooled outputs as . After that, we apply a softmax function to derive the hierarchical attention map , which can be defined as:
| (12) |
where denotes the attention weights for the th pooled output with . Subsequently, we perform the global contextual information modeling by operating a matrix multiplication between and the hierarchical attention weights , which can be given by:
| (13) |
where denotes the th intermediate output of ATFAT, denotes the convolutional layer and denotes the combined global hierarchical feature. The final output can be obtained by a linear combination of the last ATFAT module output and the global contextual feature map , i.e., :
| (14) |
where is a learnable scalar coefficient with zero initialization. During the training process, this adaptive learning weight can automatically learn to assign a suitable value to merge more global contextual information.
III-C Interaction module
In DBT-Net, the MEB and CPB paths are designed to estimate the spectral magnitude and residual complex spectral details separately, which suggests that these two branches collaboratively facilitate the spectrum restoration. To better guide the sequence modeling process within each branch, we further design an interaction module to exchange information between MEB and CPB. In this way, external information from MEB as assistance can be leveraged to guide CPB to concentrate more on the spectral details which might be lost in the MEB path, and vice versa.
The structure of the interaction module is shown in Fig. 1 (e). Taking the interaction of the MEB path as an example, we first concatenate the intermediate feature from MEB (i.e., ) with that from CPB (i.e.,). Then, the concatenated feature is fed into the mask module to derive a gain function , which is comprised of 2-D convolution, layer normalization and sigmoid function. To be specific, the gain function automatically learns to filter and preserve different areas of . A filtered representation is then obtained by multiplying with elementally. Finally, we add the intermediate feature of the MEB path and the filtered feature of the CPB path to get the final interacted feature of the MEB path, which is subsequently fed into the next sequence modeling block in MEB. Analogously, we concatenate the intermediate feature from CPB (i.e., ) with that from MEB (i.e.,) together, and then feed it into the interaction module to obtain the interacted feature of the CPB path. Note that in Fig. 1 (e), for the interaction operation in the MEB path, “Branch-2 Features” denotes the compressed features from the magnitude branch, and “Branch-1 Features” denotes those from the complex branch, and vice versa in the CPB path. The whole process is calculated by:
| (15) | ||||
where denotes the concatenation in the channel axis, convolution, layer normalization and sigmoid operations. denotes element-wise multiplication. In our model, we employ four interaction modules between each ATAFT.
III-D Masking decoder
In the MEB path, a masking decoder makes use of the output features from AIAT to obtain the gain function in the magnitude domain for noise suppression. Note that the range of the oracle amplitude mask is considered as unbounded, i.e., , which is intractable to accurately estimate. In this regard, we employ the sigmoid function to scale the value of the spectral gain into , and the remaining regions with mask values over 1 can be further compensated by CPB.
The structure of the masking decoder is presented in Fig. 1 (d), which mainly consists of a dilated dense block with dilation rates , a sub-pixel 2-D convolutional layer with the upsampling factor 2, and a dual-path mask module. The sub-pixel convolution is utilized to upsample the compressed features, which has demonstrated its effectiveness in both image and speech processing fields [33]. Then, a dual-path mask module is performed to obtain the magnitude spectral gain by a 2-D convolution and a dual-path tanh/sigmoid nonlinearity operation, followed by a 2-D convolution and sigmoid activation. The final masked spectral magnitude is obtained by the element-wise multiplication between the input noisy spectral magnitude and the estimated spectral gain. The filtered magnitude in MEB is then coupled with its corresponding noisy phase to obtain a coarse estimation of the clean complex spectrum.
III-E Complex decoder
In CPB, two decoders are designed to reconstruct the residual RI components in parallel, which aims at refining spectral details in the complex-valued spectral domain. As illustrated in Fig. 1(c), both the real and imaginary decoders are composed of a dilated dense block with dilation rates , a sub-pixel 2-D convolution, and a 2-D convolution. The upsampling factor of the sub-pixel 2-D convolutional layer in the complex decoders is set to 2, with kernel size (1, 3). The output residual RI components of the CPB path are then incorporated with the coarse-denoised complex spectrum in MEB to obtain the final estimated spectrum.
III-F Loss function
The loss function of the proposed two-branch model is calculated by the final estimated complex spectrum, which can be expressed as:
| (16) | |||
| (17) | |||
| (18) |
where and denote the loss functions toward magnitude and RI constraints, respectively. denotes the mean squared error (MSE) loss. Here, represent the RI parts of the estimated speech spectrum, while represent the RI parts of the clean speech spectrum. In Eq. (18), the full loss function is a linear combination of the magnitude and RI loss functions, as it is reported that these two terms together improve the speech quality [34, 17, 35]. With the internal trial, we empirically set in the following experiments.
IV Experiments
IV-A Datasets
We first compare the proposed models with several state-of-the-art baselines on a widely used dataset simulated on VoiceBank + DEMAND, and further evaluate our model on the WSJ0-SI84 dataset + DNS challenge.
VoiceBank + DEMAND: The dataset used in this work is publicly available as proposed in [36], which is a selection of the VoiceBank corpus [37] with 28 speakers for training and another 2 unseen speakers for testing. The training set includes 11,572 noisy-clean pairs, while the test set contains 824 pairs. For the training set, the audio samples are mixed with one of the 10 noise types, (including two artificial noise processes, i.e., babble and speech shaped noise, and eight real recording noise processes taken from the Demand database [38]) at four SNRs, i.e., . The test utterances are created with 5 unseen noise taken from the Demand database at SNRs of .
WSJ0-SI84 + DNS challenge: We also investigate the performance of the proposed framework on the WSJ0-SI84 corpus [39], which consists of 7138 clean utterances by 83 speakers (42 males and 41 females). We randomly choose 5,428 training utterances and 957 validation utterances from 77 speakers, respectively. In addition, two types of test sets are provided, each of which includes 150 utterances spoken by 6 untrained speakers (3 males and 3 females). To generate the noisy-clean pairs, we randomly select around 20,000 environmental noises from Interspeech 2020 DNS-Challenge [40] as noise set, whose duration is around 55 hours. During the mixing process, a random noise cut is extracted and then mixed with a randomly sampled utterance under a SNR selected from -5dB to 0dB with the interval 1dB. As a result, we totally generate around 150,000 and 10,000 noisy-clean pairs for training and validation. The total duration of the training set is around 300 hours. For model evaluation, two challenging untrained noise processes are employed to demonstrate the model generalization capability, namely babble, and factory1 from NOISEX92 [41]. Four SNR cases are set, i.e., , and 150 noisy-clean pairs are generated for each case.
IV-B Implementation setup
All the utterances are resampled at 16 kHz and chunked to 3 and 4 seconds respectively for VoiceBank and WSJ0-SI84 datasets, respectively. The Hanning window of length 20 ms is selected, with 50% overlap between consecutive frames. The 320-point STFT is utilized and 161-dimension spectral features can be obtained. Due to the efficacy of the compressed magnitude/complex spectrum in dereverberation and denoising tasks [18, 42], we conduct the power compression toward the magnitude while remaining the phase unaltered, and the optimal compression coefficient is set to 0.5, i.e., as input, as target. All the models are optimized using Adam [43] with the learning rate of 8e-4. For VoiceBank + DEMAND benchmark, 80 epochs are conducted for network training in total, while 40 epochs are conducted on WSJ0-SI84 + DNS Challenge benchmark with batch size 4 at the utterance level. We provide enhanced speech samples processed by different models online, and the source code and pretrained model are also released.111https://github.com/yuguochencuc/DBT-Net
IV-C Baselines
In this study, we first compare our model with various advanced systems on WSJ0-SI84 + DNS dataset. For fair comparison, we re-implement all the baselines with non-causal setting, namely BiLSTM [44], BiCRN [21], GRN [45], DCN [46], AECNN [47], ConvTasNet [48] (Non-causal version), DPRNN [8] (Non-causal version), TSTNN [9], BiDCCRN [49], BiGCRN [15] and CTS-Net [17] (Non-causal version), where BiLSTM, BiCRN, DPRNN (Non-causal version) and BiGCRN are similar to LSTM, CRN, original DPRRN and GCRN, respectively, and the only difference is that all the LSTM layers are replaced by their bidirectional versions. Note that for fair comparisons, all the baselines are re-implemented with non-causal configurations.
BiLSTM and BiCRN are two magnitude-based methods, where the former introduces a bi-directional RNN-based SE model and the latter adopts a typical convolutional recurrent network (CRN) with encoder-decoder architecture. BiGCRN is an advanced complex spectral mapping network with CRN, where RI components are estimated for magnitude and phase recovery, and all the regular convolutions in the encoder and decoder are replaced by gated linear units (GLUs) [50]. Both GRN and DCN are based on fully convolutional networks (FCNs), which incorporate dilated GLUs [51] and residual connections for magnitude recovery. AECNN is an advanced time-domain model, where the time-domain samples are directly estimated by a typical 1-D U-Net. DPRNN and TSTNN are two dual-path state-of-the-art time-domain methods, where the former employs a dual-path recurrent neural network and the latter employs a dual-path transformer to model the long sequences. Note that to further improve the performance of DPRNN, we attempt the case of phase-constrained (PCM) loss instead of the original time-domain SI-SNR loss, which was proposed in [52] and demonstrated better performance than SI-SNR loss. All the baselines are trained with the best parameter configurations mentioned in the reported literature, except that several following modifications are set. Firstly, for BiCRN, except for RI loss, we also introduce the magnitude constraint for better objective performance, which is reported to alleviate the magnitude distortion [34]. Secondly, for AECNN, the frame size for input and output is 16384 samples with 50% frame overlap, i.e., around 1-second contexts can be leveraged for each frame. Besides, in addition to using the reported frequency loss in [47], we also add a time-domain loss as multi-task learning and better performance can be achieved empirically. Finally, we extend ConvTasNet and DPRNN to the sampling rate of 16 kHz for model comparison, while both of them originally work for the sampling rate of 8 kHz in the speech separation task.
For the comparison on VoiceBank + DEMAND benchmark, we further adopt several state-of-the-art (SOTA) SE baselines, which includes six time-domain methods (e.g., SEGAN [11], SERGAN [53], MHSA-SPK [54], TSTNN [9], DEMUCS [7] and SE-Conformer [55]) and ten T-F domain methods(i.e., MMSEGAN [56], MericGAN [57], DCCRN [49], CRGAN [58], RDL-Net [59], T-GSA [60], PHASEN [61], GaGNet [19] and MetricGAN+ [62]). SEGAN, SERGAN, MMSEGAN, MetricGAN, CRGAN and MetricGAN+ are all based on generative adversarial networks (GANs), in which a generator () aims to conduct the enhancement process and a discriminator () aims to distinguish between the generated speech features and the real clean ones. Note that MetricGAN and MetricGAN+ optimize the generator with respect to one or multiple evaluation metrics such as PESQ and STOI by a pretrained metric-related discriminator. MHSA-SPK, T-GSA, TSTNN and SE-Conformer all employ multi-head self-attention mechanisms to capture long-term temporal sequence information for better performance, where the latter three models are conducted on transformer-based networks. RDL-Net introduces a novel residual-dense lattice network incorporated into a Deep Xi-MMSE-LSA based framework [63, 64] to estimate a priori SNR. DEMUCS is a SOTA real-time SE model working on the raw waveform domain, which introduces the time-domain L1 loss together with a multi-resolution STFT loss over the spectral magnitude. PHASEN and GaGNet both belong to advanced two-branch phase-aware SE methods, where both magnitude and phase are recovered simultaneously.
| Metrics | id | Feat. | AIA structure | Inter. | Para. | MACs | TBT | PESQ | ESTOI(%) | SDR(dB) | ||||||||||||
| SNR(dB) | ATAB | AFAB | AHA | (M) | (G/s) | (s) | -3 | 0 | 3 | Avg. | -3 | 0 | 3 | Avg. | -3 | 0 | 3 | Avg. | ||||
| Unprocessed | - | - | - | - | - | - | - | - | - | 1.58 | 1.76 | 1.97 | 1.77 | 33.37 | 42.43 | 52.18 | 42.66 | -2.92 | 0.04 | 3.04 | 0.16 | |
| Magnitude-branch models | ||||||||||||||||||||||
| MEB-Net | 1 | Mag | ✓ | ✗ | ✗ | - | 0.64 | 8.04 | 0.60 | 2.32 | 2.48 | 2.72 | 2.51 | 60.17 | 66.32 | 72.21 | 66.23 | 4.58 | 7.12 | 9.67 | 7.12 | |
| MEB-Net | 2 | Mag | ✗ | ✓ | ✗ | - | 0.64 | 7.99 | 0.53 | 2.38 | 2.57 | 2.78 | 2.58 | 62.01 | 69.56 | 76.09 | 69.22 | 5.78 | 8.03 | 10.56 | 8.12 | |
| MEB-Net | 3 | Mag | ✓ | ✓ | ✗ | - | 0.90 | 9.71 | 1.35 | 2.47 | 2.71 | 2.92 | 2.70 | 63.91 | 72.01 | 77.89 | 71.27 | 6.42 | 8.86 | 11.02 | 8.77 | |
| MEB-Net | 4 | Mag | ✓ | ✓ | ✓ | - | 0.90 | 9.72 | 1.38 | 2.52 | 2.76 | 3.00 | 2.76 | 64.48 | 72.24 | 78.55 | 71.76 | 6.99 | 9.05 | 11.14 | 9.06 | |
| Complex-branch models | ||||||||||||||||||||||
| CPB-Net | 1 | RI | ✓ | ✗ | ✗ | - | 0.91 | 10.22 | 0.66 | 2.48 | 2.74 | 3.01 | 2.74 | 64.27 | 71.16 | 78.01 | 71.14 | 7.03 | 9.68 | 11.02 | 9.24 | |
| CPB-Net | 2 | RI | ✗ | ✓ | ✗ | - | 0.91 | 10.17 | 0.58 | 2.54 | 2.81 | 3.06 | 2.80 | 66.16 | 73.68 | 79.51 | 73.12 | 7.79 | 10.03 | 11.61 | 9.81 | |
| CPB-Net | 3 | RI | ✓ | ✓ | ✗ | - | 1.18 | 11.89 | 1.43 | 2.63 | 2.89 | 3.12 | 2.88 | 68.23 | 75.46 | 81.03 | 74.91 | 8.47 | 10.82 | 12.04 | 10.44 | |
| CPB-Net | 4 | RI | ✓ | ✓ | ✓ | - | 1.18 | 11.89 | 1.47 | 2.70 | 2.97 | 3.18 | 2.95 | 69.56 | 76.78 | 82.22 | 76.19 | 9.34 | 11.21 | 12.79 | 11.11 | |
| Dual-branch models | ||||||||||||||||||||||
| DCB-Net | 1 | RI + RI | ✓ | ✓ | ✓ | ✓ | 3.18 | 42.76 | 2.27 | 2.74 | 3.02 | 3.22 | 2.99 | 70.28 | 76.93 | 82.69 | 76.63 | 9.56 | 11.71 | 13.49 | 11.59 | |
| DBT-Net♠ | 1 | Mag + RI | ✓ | ✓ | ✓ | ✓ | 2.91 | 40.59 | 2.20 | 2.83 | 3.06 | 3.27 | 3.05 | 72.60 | 79.43 | 84.47 | 78.83 | 9.97 | 11.99 | 13.85 | 11.94 | |
| DBT-Net (D=2) | 1 | Mag + RI | ✓ | ✓ | ✓ | ✓ | 2.98 | 23.65 | 1.54 | 2.73 | 2.98 | 3.19 | 2.96 | 71.34 | 78.84 | 84.02 | 78.07 | 9.29 | 11.64 | 13.62 | 11.52 | |
| DBT-Net (D=3) | 2 | Mag + RI | ✓ | ✓ | ✓ | ✓ | 3.08 | 12.48 | 0.96 | 2.65 | 2.86 | 3.12 | 2.88 | 69.01 | 75.94 | 81.51 | 76.25 | 8.59 | 10.47 | 12.71 | 10.76 | |
| DBT-Net (D=4) | 3 | Mag + RI | ✓ | ✓ | ✓ | ✓ | 3.18 | 6.92 | 0.62 | 2.57 | 2.79 | 3.03 | 2.79 | 67.82 | 74.65 | 80.78 | 74.42 | 8.13 | 10.21 | 12.17 | 10.17 | |
| DBT-Net | 1 | Mag + RI | ✓ | ✗ | ✗ | ✗ | 2.08 | 27.67 | 1.46 | 2.62 | 2.90 | 3.09 | 2.87 | 68.28 | 76.32 | 80.99 | 75.20 | 8.62 | 10.93 | 12.19 | 10.58 | |
| DBT-Net | 2 | Mag + RI | ✗ | ✓ | ✗ | ✗ | 2.08 | 27.49 | 1.29 | 2.66 | 2.92 | 3.11 | 2.90 | 70.19 | 76.83 | 82.04 | 76.35 | 9.31 | 11.12 | 12.85 | 11.09 | |
| DBT-Net | 3 | Mag + RI | ✓ | ✓ | ✗ | ✗ | 2.80 | 40.12 | 2.06 | 2.74 | 3.01 | 3.16 | 2.97 | 71.16 | 77.69 | 83.87 | 77.57 | 9.53 | 11.65 | 13.42 | 11.53 | |
| DBT-Net | 4 | Mag + RI | ✓ | ✓ | ✓ | ✗ | 2.81 | 40.13 | 2.13 | 2.87 | 3.10 | 3.29 | 3.09 | 74.32 | 80.56 | 85.09 | 79.99 | 10.49 | 12.37 | 14.06 | 12.31 | |
| DBT-Net | 5 | Mag + RI | ✓ | ✓ | ✓ | ✓ | 2.91 | 40.59 | 2.19 | 2.89 | 3.13 | 3.32 | 3.11 | 75.07 | 81.11 | 85.55 | 80.57 | 10.60 | 12.57 | 14.36 | 12.51 | |
IV-D Evaluation metrics
In the evaluation on WSJ0-SI84 + DNS benchmark, we use perceptual evaluation of speech quality (PESQ) [65], extended short-time objective intelligibility (ESTOI) [66] and SDR [67] as the objective metrics to evaluate the enhancement performance of different models. PESQ is used to evaluate perceptual speech quality, whose score ranges from to . Note that we use the narrow-band version recommended in ITU-T P.862.2 for WSJ0-SI84 + DNS dataset. ESTOI is the extended version of STOI to measure speech intelligibility [68], where the mutual independence assumption among frequency bands is canceled. The ESTOI score ranges from 0 to 1. SDR is widely used in blind speech separation and evaluates the level of speech distortion in the waveform. For VoiceBank + DEMAND corpus, we use wide-band PESQ (WB-PESQ), STOI, and three MOS metrics [69] (i.e., CSIG, CBAK, and COVL) to evaluate the speech quality. Here, CSIG, CBAK and COVL are designed to measure signal distortion, the background noise quality and the overall audio quality evaluation, respectively. All three MOS scores range from 1 to 5. Besides the aforementioned intrusive metrics, DNSMOS is also adopted to evaluate the perceptual speech quality [70], which is a robust non-intrusive perceptual speech quality metric serving as a proxy for subjective scores, ranging from 1 to 5. Higher values of all aforementioned metrics indicate better speech quality.
V Results and Analysis
V-A Ablation study on WSJ0-SI84 + DNS Challenge
For the ablation study, we create a smaller dataset on WSJ0-SI84 + DNS Challenge. For training, we establish a 15000, 1500 noisy-clean pairs also at the SNR range of for training and validation, respectively. The total duration for the training set is about 30 hours. For testing, three SNR cases are set with factory1 noise from NOISEX92 on both seen and unseen speakers, i.e., , and 150 noisy-clean pairs are generated for each case. The results of the ablation study are presented in Table II, which studies the impacts of different AIA structures, the dual-branch strategy and the interaction modules. To be specific, MEB-Net (1)-(4) only estimate the spectral gain in the magnitude domain and retains the phase information unaltered, while CPB-Net (1)-(4) estimate the RI parts of the clean complex spectrum. The configurations of MEB-Net and CPB-Net are similar to those presented in Table I. MEB-Net adopts a densely convolutional encoder, an AIAT without information interaction, and a magnitude masking decoder. CPB-Net adopts a similar encoder, an AIAT, and two separate decoders to decode RI components of the clean complex spectrum. By merging MEB-Net and CPB-Net, DBT-Net (1)-(5) aim at estimating the magnitude spectral gain and the residual RI components of the clean complex spectrum in parallel. Additionally, another two dual-branch models are implemented to investigate the effectiveness of separately estimating the spectral magnitude and residual complex spectral details. Specifically, we employ a dual-branch CPB-Net, dubbed DCB-Net, to estimate the RI components and the residual complex spectral details, which can be formulated as:
| (19) | |||
| (20) |
where denote the estimated RI components by the first branch in DCB-Net and denote the estimated residual RI components by the second branch. denote the final RI estimation by DCB-Net. Then, we implement another dual-branch network, dubbed DBT-Net♠, to estimate the spectral magnitude and the whole RI components of the clean complex spectrum instead of the residual RI components in parallel. In DBT-Net♠, the magnitude branch (i.e., MEB♠) aims at estimating the spectral magnitude while the complex branch (i.e., CPB♠) aims at restoring the whole RI components of the clean complex spectrum instead of estimating the residual complex spectrum as in our proposed reconstruction strategy. Finally, we average the spectral magnitude estimated by MEB♠ and CPB♠ and use the estimated phase by CPB♠ to obtain the final RI components of the clean complex spectrum. The whole procedure can be formulated as:
| (21) | |||
| (22) | |||
| (23) | |||
| (24) |
where denote the output RI components of the CPB♠ path. and represent the estimated spectral magnitude of MEB♠ and CPB♠. and denote the final output spectral magnitude and phase of the clean complex spectrum, respectively.
We also investigate different attention mechanisms in single-branch and dual-branch approaches. For example, MEB-Net (1) and (2) only adopt the adaptive temporal attention branch (ATAB) or the adaptive temporal attention branch (AFAB) in the proposed transformer-based network, while MEB-Net (3) utilizes the combination of ATAB and ATFB as the ATFA modules. Then, we merge the ATFA modules and the AHA module as the attention-in-attention structure in MEB-Net (4). CPB-Net (1)-(4) and DBT-Net (1)-(4) utilize the same attention mechanisms as in MEB-Net (1)-(4), respectively. Finally, we add the interaction modules in DBT-Net (5) to investigate the impact of information interaction. Moreover, we implement another three dual-branch frameworks similar to DBT-Net (5), namely DBT-Net (D=2), DBT-Net (D=3) and DBT-Net (D=4), to investigate the impact of using more downsampling layers in our model. Specifically, DBT-Net (D=2) utilizes two 2-D convolutional downsampling layers in the encoder and two symmetrical 2-D convolutional upsampling layers in the decoder, which is set to 1 in DBT-Net (1)-(5). That is to say, the frequency dimension of the encoded features is downsampled to 40 in DBT-Net (D=2). Analogously, DBT-Net (D=3) and DBT-Net (D=4) employ three and four 2-D convolutional downsampling layers in the encoders, respectively. The values are averaged upon both seen and unseen speaker conditions.
V-A1 Effect of AIA structure
We first analyze the effect of different attention mechanisms in our sequence modeling network. As shown in Table II, taking the magnitude-based methods (MEB-Net) as an example, the objective performance of the enhanced speech is severely limited. When combining ATAB and AFAB to capture both spectro-temporal dependencies, MEB-Net (3) dramatically outperforms MEB-Net (1) and MEB-Net (2) in terms of PESQ, ESTOI and SDR. For example, from MEB-Net (1) to MEB-Net (3), around 0.19, 5.04% and 1.65dB score improvements are obtained for PESQ, ESTOI and SDR, averaging under seen and unseen speaker conditions. Similar results are also observed in the complex-path models (CPB-Net(1)-(3)) and dual-branch models (DBT-Net (1)-(3)). This indicates the merit of simultaneously capturing spectro-temporal contextual information in parallel. Then, by adding the adaptive hierarchical attention (AHA) module as an attention-in-attention topology, consistently better speech performance can be obtained in all metrics. For example, MEB-Net (4) yields average 0.06 PESQ, 0.49% ESTOI and 0.29dB SDR improvements over MEB-Net (3) with nearly same parameter burden. A similar tendency is also observed for CPB-Net and DBT-Net. This verifies the effectiveness of the proposed AIA structure in improving speech quality and intelligibility.
V-A2 Effect of dual-branch strategy
We then investigate the impact of the dual-branch strategy, i.e., magnitude estimation path and complex refining path. First, when using the single branch, the complex spectrum mapping approaches, i.e., CPB-Nets, consistently surpass the magnitude spectrum estimate approaches, i.e, MEB-Nets. This indicates the importance of phase recovery in improving speech quality and intelligibility. However, although phase recovery is involved, the performance of single-branch methods is limited. The latent reason is that when directly estimating the whole RI components, the phase is implicitly optimized and the magnitude may deviate from its optimal optimization path, leading to sub-optimal solutions. When federatively merging the magnitude estimation branch and complex refining branch, DBT-Nets dramatically outperform the single-branch approaches. For example, DBT-Net (4) provides average 0.21, 3.80% and 1.87dB score improvements over CPB-Net (4) for PESQ, ESTOI and SDR, averaging under seen and unseen speaker conditions. Subsequently, when compared with other dual-branch models (i.e., DCB-Net and DBT-Net♠), the proposed dual-branch model achieves consistently better performance. When only estimating the RI components of the clean complex spectrum directly, DCB-Net obtains relatively marginal improvements over the single-branch CPB-Nets, which indicates the effectiveness of decoupling the magnitude and phase recovery in two heads. Meanwhile, DBT-Net (5) considerably surpasses DBT-Net♠ in terms of all metrics, while suffering a similar model computational cost. This verifies the superiority of the dual-branch strategy, i.e., eliminating the dominant noise in the magnitude domain and restoring the residual complex details by two branches.
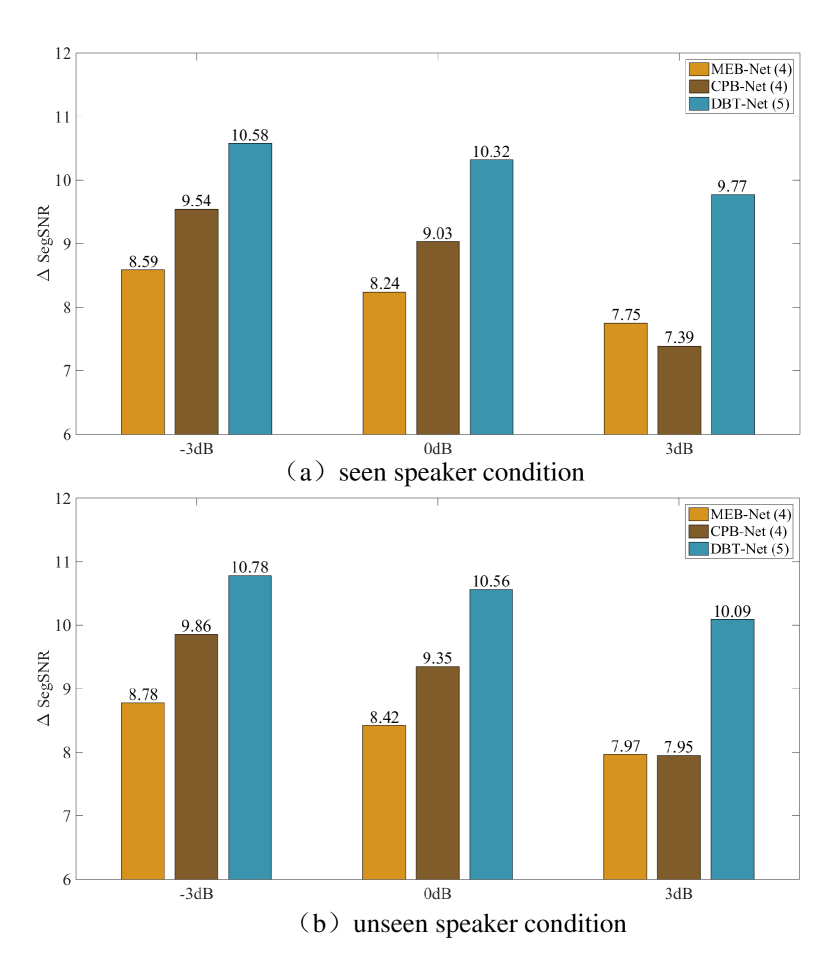
In addition, we provide the segmental SNR improvements (SegSNR) [71] of the single-branch (MEB-Net (4) and CPB-Net (4)) and dual-branch methods (i.e., DBT-Net (5)) over the unprocessed mixtures in both seen and unseen speaker conditions, as shown in Fig. 3 (a) and (b). One can observe that DBT-Net produces significantly larger SegSNR improvements than the single-branch baselines, with which a more than average 10dB SegSNR improvement is achieved at -3dB, 0dB, 3dB SNR cases. These observations fully emphasize the remarkable superiority of the proposed dual-branch strategy in speech quality and intelligibility.
V-A3 Effect of interaction modules
We finally investigate the effect of the information interaction modules between two branches. After introducing the information flow between the MEB path and the CPB path, One can observe that DBT-Net (5) consistently surpasses DBT-Net (4) with only a little increased parameter size. For example, from DBT-Net (4) to DBT-Net (5), around 0.02, 0.58% and 0.20dB score improvements are obtained for PESQ, ESTOI and SDR, averaging under seen and unseen speaker conditions. These results show that the interaction modules indeed facilitate the simultaneous magnitude estimation and complex spectral details refinement, resulting in better spectrum restoration.
V-A4 Model Complexity Discussion
In Table II, we provide detailed model complexity comparisons in terms of the number of parameters, the multiply-accumulate operations (MACs) per second, and the training batch time (TBT) among models. Specifically, we measure the MACs using an utterance with a duration of one second, and the TBT is evaluated with one-second utterances and the batch size of 4 on Tesla M40 with 24 GB of RAM. From Table II, we can observe that although the proposed DBT-Net achieves low trainable parameters, the MACs are relatively high, leading to a large computational cost. This is because, to better model the dependencies along the different frequency bands by adaptive frequency attention branch (AFAB), we only employ one downsampling layer along with the frequency axis, leading to relatively high frequency-dimension encoded features and large MACs.
Then we investigate the trade-off between the computational cost and objective performance improvements. As shown in Table II, when using more downsampling operations in the encoder, DBT-Net (D=2), (D=3) and (D=4) can effectively reduce the MACs and TBT with a slightly increased parameter size. However, due to the insufficient sequence modeling in the frequency axis caused by the decreased frequency dimension of features, DBT-Net (D=2)-(D=4) also decrease the speech enhancement performance with the increasing number of downsampling layers along the frequency axis. For example, DBT-Net (D=2) decreases around 0.15 PESQ, 1.51% ETOI and 0.99dB SDR scores by DBT-Net (5), while decreasing around 16.94 G/s MACs. This indicates that utilizing more downsampling layers can reduce the computation cost with somewhat increased parameter burden, and meanwhile, it decreases the speech enhancement performance. In practical applications, we can balance parameter number and computation cost flexibly by adjusting the number of downsampling layers and convolutional kernels according to different equipment requirements. In the following experiments, to achieve the best performance with a small model size, all the models only employ the downsampling-upsampling operation once in the densely encoder-decoder, and the frequency dimension is set to 80 during the sequence modeling. For practical applications, it is often desired to reduce the parameter burden and computational complexity, which can be studied in future research.
| Metrics | Cau. | Feat. | PESQ | ESTOI(%) | SDR(dB) | |||||||||||||
| SNR(dB) | -3 | 0 | 3 | 6 | Avg. | -3 | 0 | 3 | 6 | Avg. | -3 | 0 | 3 | 6 | Avg. | |||
| Babble Noise | Noisy | - | - | 1.72 | 1.88 | 2.06 | 2.25 | 1.98 | 34.76 | 43.27 | 51.95 | 61.61 | 47.90 | -2.94 | 0.04 | 3.03 | 6.03 | 1.54 |
| BiLSTM [44] | ✗ | Mag | 2.41 | 2.68 | 2.90 | 3.09 | 2.77 | 67.20 | 75.22 | 80.26 | 84.39 | 76.77 | 4.86 | 7.33 | 9.53 | 11.66 | 8.35 | |
| BiCRN [21] | ✗ | Mag | 2.38 | 2.64 | 2.84 | 3.04 | 2.73 | 66.05 | 73.67 | 79.10 | 83.63 | 75.61 | 4.90 | 7.36 | 9.52 | 11.78 | 8.39 | |
| GRN [45] | ✗ | Mag | 2.16 | 2.37 | 2.54 | 2.70 | 2.44 | 59.92 | 68.20 | 74.35 | 79.74 | 70.55 | 4.37 | 6.82 | 9.05 | 11.25 | 7.87 | |
| DCN [46] | ✗ | Mag | 2.15 | 2.41 | 2.62 | 2.82 | 2.50 | 57.38 | 66.26 | 72.99 | 78.59 | 68.81 | 4.16 | 6.75 | 9.03 | 11.21 | 7.79 | |
| AECNN [47] | ✗ | waveform | 2.30 | 2.63 | 2.90 | 3.13 | 2.74 | 64.84 | 73.49 | 79.62 | 84.14 | 75.52 | 7.16 | 9.84 | 11.96 | 13.95 | 10.73 | |
| ConvTasNet [48] | ✗ | Waveform | 2.67 | 2.96 | 3.18 | 3.35 | 3.04 | 74.97 | 81.67 | 85.81 | 88.82 | 82.82 | 9.51 | 12.21 | 14.20 | 15.98 | 12.96 | |
| DPRNN [8] | ✗ | Waveform | 2.86 | 3.14 | 3.33 | 3.47 | 3.20 | 78.09 | 81.67 | 86.25 | 88.33 | 83.59 | 10.09 | 12.21 | 14.04 | 15.98 | 13.08 | |
| TSTNN [9] | ✗ | Waveform | 2.62 | 2.92 | 3.17 | 3.38 | 3.02 | 72.23 | 74.99 | 83.62 | 88.01 | 79.71 | 9.01 | 12.18 | 13.48 | 15.21 | 12.37 | |
| BiGCRN [15] | ✗ | RI | 2.59 | 2.88 | 3.11 | 3.28 | 2.97 | 70.12 | 77.90 | 83.09 | 86.58 | 79.42 | 7.62 | 10.14 | 12.23 | 14.17 | 11.04 | |
| BiDCCRN [49] | ✗ | RI | 2.46 | 2.77 | 2.99 | 3.22 | 2.86 | 65.62 | 73.04 | 79.81 | 86.06 | 76.13 | 7.36 | 9.78 | 12.21 | 14.39 | 10.93 | |
| CTS-Net [17] | ✗ | Mag+RI | 2.76 | 3.05 | 3.24 | 3.39 | 3.11 | 74.94 | 81.33 | 85.22 | 88.23 | 82.43 | 9.16 | 11.61 | 13.46 | 15.14 | 12.34 | |
| MEB-Net(Pro.) | ✗ | Mag | 2.53 | 2.82 | 3.06 | 3.27 | 2.92 | 67.93 | 75.56 | 81.36 | 86.19 | 77.76 | 7.24 | 8.86 | 11.28 | 13.26 | 10.16 | |
| CPB-Net(Pro.) | ✗ | RI | 2.69 | 2.98 | 3.17 | 3.39 | 3.06 | 72.79 | 75.95 | 84.37 | 88.49 | 80.40 | 8.81 | 11.37 | 12.88 | 14.69 | 11.94 | |
| DBT-Net(Pro.) | ✗ | Mag+RI | 2.89 | 3.18 | 3.38 | 3.55 | 3.25 | 78.22 | 83.78 | 87.51 | 90.01 | 84.06 | 10.57 | 12.72 | 14.50 | 16.20 | 13.50 | |
| Factory1 Noise | Noisy | - | Mag | 1.60 | 1.78 | 1.99 | 2.20 | 1.89 | 34.76 | 43.73 | 54.04 | 63.90 | 49.11 | -2.92 | 0.05 | 3.04 | 6.03 | 1.55 |
| BiLSTM [44] | ✗ | Mag | 2.53 | 2.75 | 2.96 | 3.14 | 2.85 | 68.40 | 75.18 | 80.54 | 84.78 | 77.23 | 5.89 | 8.03 | 10.20 | 12.19 | 9.08 | |
| BiCRN [21] | ✗ | Mag | 2.48 | 2.70 | 2.90 | 3.07 | 2.79 | 66.10 | 73.16 | 79.12 | 83.87 | 75.56 | 5.73 | 7.96 | 10.21 | 12.31 | 9.05 | |
| GRN [45] | ✗ | Mag | 2.26 | 2.43 | 2.58 | 2.70 | 2.49 | 62.06 | 69.70 | 76.09 | 81.25 | 72.28 | 5.60 | 7.86 | 10.07 | 12.10 | 8.91 | |
| DCN [46] | ✗ | Mag | 2.32 | 2.55 | 2.74 | 2.92 | 2.63 | 59.47 | 68.05 | 74.67 | 80.18 | 70.59 | 5.60 | 7.85 | 10.02 | 12.03 | 8.88 | |
| AECNN [47] | ✗ | Waveform | 2.44 | 2.72 | 2.97 | 3.16 | 2.82 | 64.12 | 72.74 | 78.86 | 83.54 | 74.82 | 8.14 | 10.26 | 12.14 | 13.92 | 11.11 | |
| ConvTasNet [48] | ✗ | Waveform | 2.79 | 3.02 | 3.20 | 3.36 | 3.09 | 75.11 | 81.04 | 85.20 | 88.39 | 82.43 | 10.16 | 12.14 | 13.96 | 15.64 | 12.97 | |
| DPRNN [8] | ✗ | Waveform | 2.91 | 3.13 | 3.30 | 3.43 | 3.19 | 77.03 | 81.85 | 86.21 | 89.15 | 83.56 | 10.46 | 12.72 | 14.08 | 15.74 | 13.25 | |
| TSTNN [9] | ✗ | Waveform | 2.72 | 2.94 | 3.21 | 3.42 | 3.08 | 71.46 | 76.23 | 82.62 | 87.82 | 79.53 | 9.82 | 11.67 | 13.75 | 15.03 | 12.57 | |
| BiGCRN [15] | ✗ | RI | 2.69 | 2.95 | 3.16 | 3.31 | 3.02 | 69.24 | 77.11 | 82.63 | 86.45 | 78.86 | 7.78 | 10.20 | 12.21 | 14.05 | 11.06 | |
| BiDCCRN [49] | ✗ | RI | 2.49 | 2.82 | 3.07 | 3.26 | 2.91 | 65.07 | 74.37 | 81.25 | 87.02 | 76.93 | 8.01 | 10.71 | 12.43 | 14.37 | 11.38 | |
| CTS-Net [17] | ✗ | Mag+RI | 2.80 | 3.03 | 3.21 | 3.36 | 3.10 | 73.90 | 80.02 | 84.27 | 87.60 | 81.45 | 9.60 | 11.56 | 13.33 | 14.99 | 12.37 | |
| MEB-Net(Pro.) | ✗ | Mag | 2.63 | 2.88 | 3.11 | 3.32 | 2.98 | 67.06 | 74.82 | 80.58 | 85.76 | 77.06 | 7.31 | 9.29 | 11.36 | 13.46 | 10.35 | |
| CPB-Net(Pro.) | ✗ | RI | 2.74 | 3.00 | 3.21 | 3.41 | 3.09 | 71.86 | 76.67 | 83.54 | 88.01 | 80.02 | 9.73 | 11.64 | 13.50 | 14.99 | 12.47 | |
| DBT-Net(Pro.) | ✗ | Mag+RI | 2.92 | 3.15 | 3.33 | 3.49 | 3.22 | 77.11 | 82.62 | 86.48 | 89.69 | 83.98 | 10.68 | 12.57 | 14.28 | 15.99 | 13.38 | |
| Metrics | Cau. | Feat. | PESQ | ESTOI(%) | SDR(dB) | |||||||||||||
| SNR(dB) | -3 | 0 | 3 | 6 | Avg. | -3 | 0 | 3 | 6 | Avg. | -3 | 0 | 3 | 6 | Avg. | |||
| Babble Noise | Noisy | - | - | 1.64 | 1.82 | 2.01 | 2.23 | 1.93 | 31.51 | 39.66 | 48.21 | 57.74 | 44.28 | -2.93 | 0.05 | 3.03 | 6.03 | 1.55 |
| BiLSTM [44] | ✗ | Mag | 2.30 | 2.58 | 2.79 | 2.99 | 2.67 | 63.26 | 71.51 | 77.17 | 85.02 | 74.24 | 4.92 | 7.29 | 9.41 | 11.48 | 8.28 | |
| BiCRN [21] | ✗ | Mag | 2.25 | 2.55 | 2.77 | 2.97 | 2.64 | 61.51 | 70.71 | 76.73 | 81.98 | 72.73 | 4.73 | 7.42 | 9.76 | 12.08 | 8.50 | |
| GRN [45] | ✗ | Mag | 2.08 | 2.32 | 2.54 | 2.72 | 2.42 | 56.52 | 65.57 | 72.66 | 78.85 | 68.39 | 4.21 | 6.76 | 9.18 | 11.62 | 7.94 | |
| DCN [46] | ✗ | Mag | 2.03 | 2.32 | 2.57 | 2.79 | 2.43 | 53.19 | 63.17 | 70.81 | 77.49 | 66.17 | 3.92 | 6.71 | 9.14 | 11.56 | 7.83 | |
| AECNN [47] | ✗ | Waveform | 2.24 | 2.59 | 2.86 | 3.10 | 2.69 | 62.64 | 72.11 | 78.37 | 83.57 | 74.18 | 6.26 | 9.90 | 12.12 | 14.20 | 10.62 | |
| ConvTasNet [48] | ✗ | Waveform | 2.58 | 2.89 | 3.12 | 3.30 | 2.97 | 72.36 | 79.81 | 84.49 | 87.94 | 81.14 | 9.50 | 12.00 | 14.08 | 16.00 | 12.89 | |
| DPRNN [8] | ✗ | Waveform | 2.82 | 3.07 | 3.31 | 3.43 | 3.16 | 76.86 | 82.45 | 86.51 | 87.94 | 83.44 | 10.19 | 12.74 | 14.13 | 15.86 | 13.23 | |
| TSTNN [9] | ✗ | Waveform | 2.59 | 2.93 | 3.12 | 3.36 | 3.00 | 71.97 | 74.64 | 82.37 | 87.95 | 79.23 | 9.98 | 12.63 | 14.03 | 15.79 | 13.11 | |
| BiGCRN [15] | ✗ | RI | 2.55 | 2.85 | 3.08 | 3.27 | 2.94 | 68.41 | 76.68 | 82.16 | 86.38 | 78.41 | 7.77 | 10.42 | 12.55 | 14.60 | 11.34 | |
| BiDCCRN [49] | ✗ | RI | 2.41 | 2.71 | 2.96 | 3.19 | 2.82 | 63.47 | 71.94 | 77.93 | 84.92 | 74.56 | 7.31 | 9.86 | 12.37 | 14.55 | 11.02 | |
| CTS-Net [17] | ✗ | Mag+RI | 2.68 | 3.00 | 3.22 | 3.39 | 3.07 | 73.11 | 80.10 | 84.49 | 87.76 | 81.37 | 9.34 | 11.74 | 13.70 | 15.51 | 12.57 | |
| MEB-Net(Pro.) | ✗ | Mag | 2.50 | 2.78 | 3.02 | 3.25 | 2.89 | 66.90 | 74.42 | 80.60 | 86.37 | 77.07 | 7.31 | 9.32 | 11.42 | 13.59 | 10.41 | |
| CPB-Net(Pro.) | ✗ | RI | 2.62 | 2.97 | 3.21 | 3.41 | 3.05 | 72.47 | 75.15 | 83.85 | 88.34 | 79.95 | 9.16 | 11.83 | 13.64 | 15.24 | 12.47 | |
| DBT-Net(Pro.) | ✗ | Mag+RI | 2.91 | 3.18 | 3.39 | 3.57 | 3.26 | 77.74 | 83.47 | 87.37 | 90.13 | 84.68 | 11.09 | 13.23 | 15.01 | 16.81 | 14.03 | |
| Factory1 Noise | Noisy | - | - | 1.55 | 1.75 | 1.96 | 2.17 | 1.86 | 31.97 | 41.13 | 50.32 | 59.78 | 45.80 | -2.92 | 0.04 | 3.04 | 6.03 | 1.55 |
| BiLSTM [44] | ✗ | Mag | 2.43 | 2.65 | 2.86 | 3.04 | 2.75 | 64.51 | 71.81 | 77.68 | 82.01 | 74.00 | 5.96 | 8.04 | 10.03 | 11.91 | 8.99 | |
| BiCRN [21] | ✗ | Mag | 2.40 | 2.63 | 2.84 | 3.01 | 2.72 | 62.72 | 70.76 | 77.02 | 81.81 | 73.08 | 5.90 | 8.20 | 10.39 | 12.57 | 9.26 | |
| GRN [45] | ✗ | Mag | 2.24 | 2.44 | 2.61 | 2.75 | 2.51 | 59.86 | 68.38 | 74.89 | 80.01 | 70.79 | 5.78 | 8.08 | 10.31 | 12.46 | 9.16 | |
| DCN [46] | ✗ | Mag | 2.26 | 2.51 | 2.73 | 2.90 | 2.60 | 56.89 | 66.11 | 73.40 | 78.94 | 68.84 | 5.67 | 8.05 | 10.31 | 12.42 | 9.11 | |
| AECNN [47] | ✗ | Waveform | 2.40 | 2.69 | 2.94 | 3.13 | 2.79 | 62.09 | 71.23 | 78.00 | 82.54 | 73.47 | 8.30 | 10.42 | 12.35 | 14.14 | 11.30 | |
| ConvTasNet [48] | ✗ | Waveform | 2.73 | 2.98 | 3.17 | 3.33 | 3.06 | 73.12 | 79.68 | 84.39 | 87.42 | 81.15 | 10.32 | 12.31 | 14.04 | 15.72 | 13.10 | |
| DPRNN [8] | ✗ | Waveform | 2.85 | 3.11 | 3.17 | 3.38 | 3.13 | 75.92 | 81.53 | 85.63 | 88.32 | 82.85 | 10.84 | 12.89 | 14.32 | 15.85 | 13.47 | |
| TSTNN [9] | ✗ | Waveform | 2.70 | 2.94 | 3.21 | 3.40 | 3.08 | 71.01 | 76.18 | 83.05 | 87.29 | 79.38 | 10.01 | 12.07 | 13.80 | 15.27 | 12.81 | |
| BiGCRN [15] | ✗ | RI | 2.65 | 2.93 | 3.14 | 3.30 | 3.01 | 66.94 | 76.06 | 81.90 | 85.77 | 77.67 | 8.19 | 10.54 | 12.61 | 14.42 | 11.44 | |
| BiDCCRN [49] | ✗ | RI | 2.45 | 2.78 | 3.04 | 3.23 | 2.88 | 64.54 | 73.87 | 80.81 | 86.38 | 76.39 | 8.37 | 10.92 | 12.81 | 14.98 | 11.77 | |
| CTS-Net [17] | ✗ | Mag+RI | 2.78 | 3.02 | 3.22 | 3.37 | 3.09 | 72.72 | 78.33 | 83.95 | 87.07 | 80.52 | 9.92 | 11.92 | 13.68 | 15.35 | 12.72 | |
| MEB-Net(Pro.) | ✗ | Mag | 2.61 | 2.85 | 3.08 | 3.26 | 2.95 | 65.48 | 74.41 | 79.22 | 86.68 | 76.45 | 7.76 | 9.61 | 11.91 | 14.16 | 10.86 | |
| CPB-Net(Pro.) | ✗ | RI | 2.75 | 3.00 | 3.22 | 3.42 | 3.10 | 71.17 | 78.50 | 84.11 | 88.05 | 80.46 | 9.94 | 11.98 | 13.81 | 15.25 | 12.74 | |
| DBT-Net(Pro.) | ✗ | Mag+RI | 2.97 | 3.19 | 3.37 | 3.51 | 3.26 | 77.01 | 82.62 | 86.64 | 89.53 | 83.95 | 11.35 | 13.20 | 14.88 | 16.51 | 13.99 | |
V-B Performance comparison with baselines using WSJ0-SI84 + DNS Challenge dataset
Based on previous ablation studies, DBT-Net (5) is selected as the default configuration of the proposed framework. Besides, we also evaluate the two proposed single-branch methods with their best performance as shown in Table II (i.e., MEB-Net (4) and CPB-Net (4)) as the reference. Then we compare the performance of the proposed methods with advanced non-causal time and T-F domain baselines in terms of PESQ, ESTOI and SDR, whose objective results are presented in Tables III and IV. From the results in Tables III and IV, one can have several observations.
First, we focus on the comparison of magnitude-based methods. When compared with advanced magnitude-based methods, our proposed MEB-Net outperforms other baselines consistently. Taking the performance under the seen speaker case as an example, MEB-Net provides average 0.19 PESQ, 2.15% ESTOI and 1.77dB SDR score improvements than BiCRN on Babble noise, while average 0.21 PESQ, 1.50% ESTOI and 1.30dB SDR score improvements are provided on factory1 noise. It fully demonstrates the superiority of the proposed AIA transformer in speech quality and intelligibility.
Second, when focusing on complex-spectrum-based methods, we can observe that most complex-spectrum-based baselines consistently surpass magnitude-based approaches. Take BiCRN and BiGCRN as an example, we find that average 0.30 PESQ, 5.68% ESTOI and 2.84dB SDR score improvements are provided in the unseen speakers on babble noise. It indicates the importance of phase recovery to improve speech quality and intelligibility. Meanwhile, our proposed CPB-Net also outperforms most single-stage complex-spectrum-based methods, which all aim at optimizing magnitude and phase in a single stage. For example, in the seen speaker condition, CPB-Net provides average 0.20 PESQ, 4.27% ESTOI and 1.01dB SDR score improvements than BiDCCRN on Babble noise, while average 0.18 PESQ, 3.09% ESTOI and 1.11dB SDR score improvements are provided on factory1 noise. A similar tendency is also observed in the unseen speaker case.
Third, when the magnitude estimation and phase recovery are decoupled into two stages, consistently better performance can be obtained than single-stage complex spectrum estimation methods. For example, when babble noise is given in the seen speaker, CTS-Net achieves average 0.14, 3.01%, and 1.30dB score improvements over BiGCRN in terms of PESQ, ESTOI, and SDR, respectively. For factory1 noise in the seen speaker, the improvements are 0.08 PESQ, 2.59% ESTOI and 1.31dB SDR, respectively. Under the unseen speaker condition, similar improvements can be also obtained. This indicates the notable advantage of decoupling-based methods over single-stage methods in the complex-valued spectral domain. Then, one can see that when the magnitude and complex spectral details are optimized in parallel instead of in the cascaded pipeline, DBT-Net dramatically surpasses CTS-Net by a considerable margin. For instance, for babble noise condition in the unseen speaker case, DBT-Net achieves average 0.19, 3.31%, and 1.46dB score improvements over CTS-Net in terms of PESQ, ESTOI, and SDR, respectively. This indicates the merit and effectiveness of the proposed dual-branch pipeline in improving speech quality and intelligibility in the complex-valued spectral domain.
Finally, we compare our proposed method with the advanced time-domain systems. From Tables III and IV, one can find that in both seen and unseen speaker cases, DBT-Net considerably outperforms AECNN in terms of all metrics, e.g., around 0.49, 9.67%, and 2.80dB average improvements in PESQ, ESTOI, and SDR are observed for babble and factory1 noises in both seen and unseen speaker cases. This demonstrates that our proposed approach in the complex-spectrum domain enjoys significant performance superiority over the previous time-domain system. Additionally, when compared with other advanced dual-path time-domain methods, one can get that DBT-Net consistently achieves better performance in terms of all metrics, indicating the superiority of the proposed dual-branch strategy and the attention-in-attention transformer-based network. For example, for the factory1 noise in the seen speaker case, DBT-Net achieves average 0.14, 4.45%, and 0.82dB score improvements over TSTNN in terms of PESQ, ESTOI, and SDR, respectively.
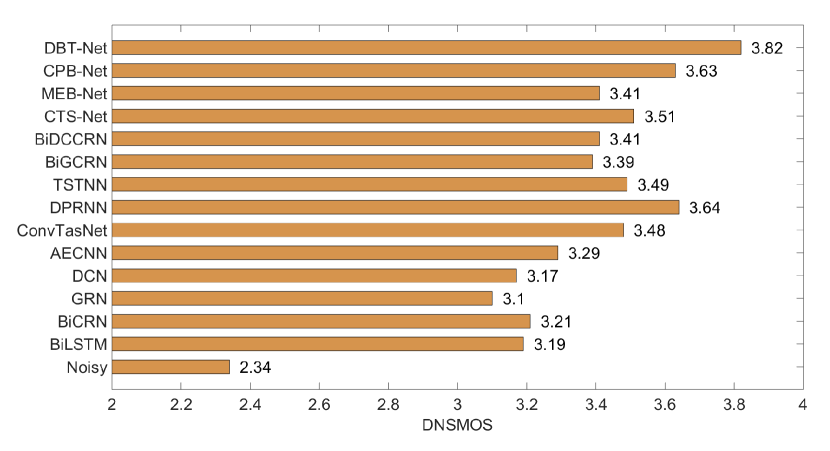
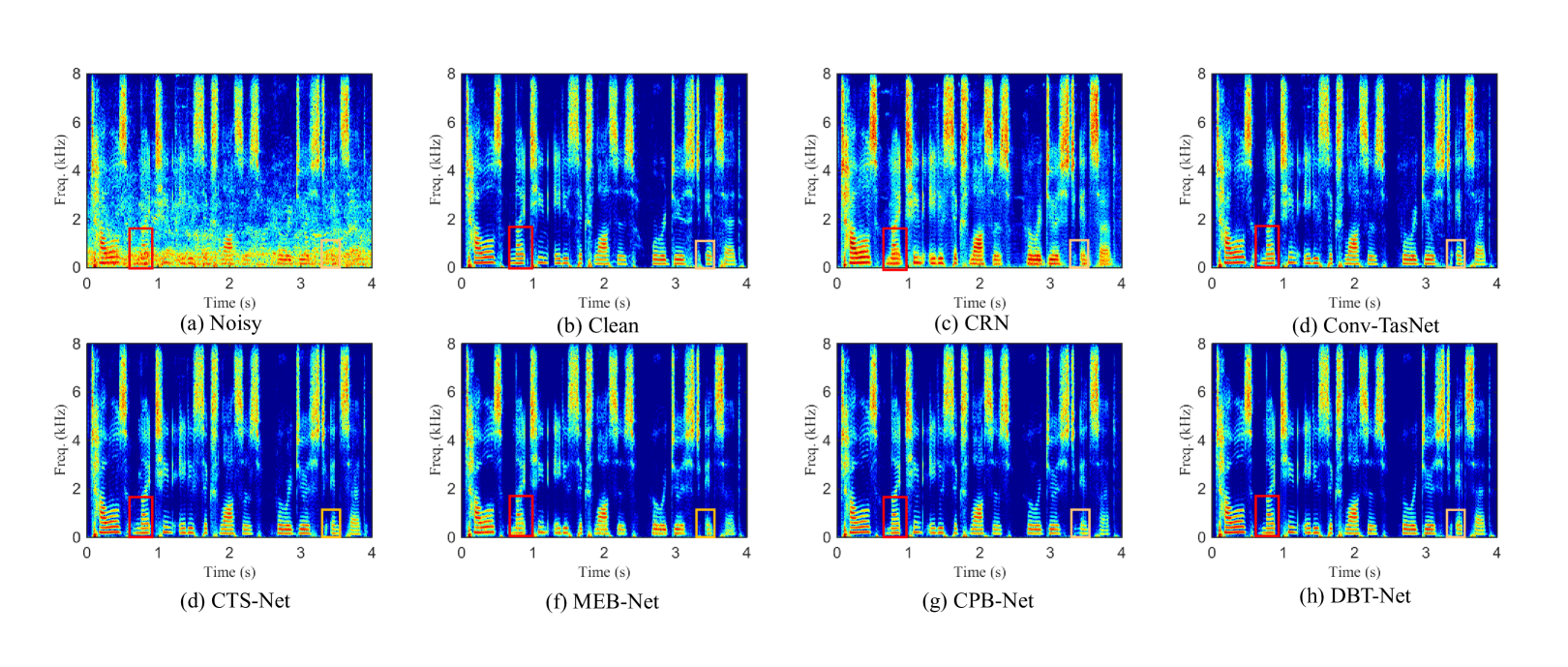
Besides, the perceptual evaluation on DNSMOS, a non-intrusive perceptual metric, is also provided in Fig. 4. One can find that the proposed approach outperforms all the advanced baselines by a significant margin, which also demonstrates the superiority of DBT-Net in improving subjective perceptual speech quality. Moreover, an example of spectrograms of clean utterance, noisy utterance the enhanced utterances by the CRN, ConvTasNet, CTS-Net, MEB-NET, CPB-Net and DBT-Net are presented in Fig. 5 (a)-(h). It is obvious that DBT-NET outperforms other baselines in terms of restoring spectral details and suppressing background noise. Focusing on the red and orange boxes in Fig. 5 (f) and (g), one can see that MEB-Net suppresses more background noise than CPB-Net, while CPB-Net can estimate more lost fine-gained spectral details. By merging these two branches, DBT-Net can encourage strengths and bypass the weakness of each branch from a complementary aspect, resulting in better spectrum estimating than the single-branch paradigm, as illustrated in Fig. 5 (h).
V-C Performance comparison with baselines using VoiceBank + DEMAND dataset
| Methods | Year | Param. | PESQ | STOI(%) | CSIG | CBAK | COVL |
| Noisy | – | – | 1.97 | 92.1 | 3.35 | 2.44 | 2.63 |
| SOTA time and T-F Domain approaches | |||||||
| SEGAN [11] | 2017 | 43.2 M | 2.16 | 92.5 | 3.48 | 2.94 | 2.80 |
| MMSEGAN [56] | 2018 | – | 2.53 | 93.0 | 3.80 | 3.12 | 3.14 |
| SERGAN [53] | 2019 | 43.2 M | 2.16 | 92.5 | 3.48 | 2.94 | 2.80 |
| MetricGAN [57] | 2019 | 1.86 M | 2.86 | – | 3.99 | 3.18 | 3.42 |
| CRGAN [58] | 2020 | – | 2.92 | 94.0 | 4.16 | 3.24 | 3.54 |
| DCCRN [49] | 2020 | 3.70 M | 2.68 | 93.7 | 3.88 | 3.18 | 3.27 |
| RDL-Net [59] | 2020 | 3.91 M | 3.02 | 93.8 | 4.38 | 3.43 | 3.72 |
| PHASEN [61] | 2020 | – | 2.99 | – | 4.21 | 3.55 | 3.62 |
| MHSA-SPK [54] | 2020 | – | 2.99 | – | 4.15 | 3.42 | 3.53 |
| T-GSA [60] | 2020 | – | 3.06 | 93.7 | 4.18 | 3.59 | 3.62 |
| TSTNN [9] | 2021 | 0.92 M | 2.96 | 95.0 | 4.17 | 3.53 | 3.49 |
| DEMUCS [7] | 2021 | 128 M | 3.07 | 95.0 | 4.31 | 3.40 | 3.63 |
| CTS-Net [17] | 2021 | 4.35 M | 2.92 | – | 4.25 | 3.46 | 3.59 |
| GaGNet [19] | 2021 | 5.94 M | 2.94 | 94.7 | 4.26 | 3.45 | 3.59 |
| MetricGAN+ [62] | 2021 | – | 3.15 | – | 4.14 | 3.16 | 3.64 |
| SE-Conformer [55] | 2021 | – | 3.13 | 95 | 4.45 | 3.55 | 3.82 |
| Proposed approaches | |||||||
| MEB-Net | 2021 | 0.90 M | 3.11 | 94.9 | 4.45 | 3.60 | 3.79 |
| CPB-Net | 2021 | 1.18 M | 3.15 | 94.7 | 4.48 | 3.54 | 3.81 |
| DBT-Net | 2021 | 2.91 M | 3.30 | 95.7 | 4.59 | 3.75 | 3.92 |
Besides the WSJ0-SI84 corpus, we also conduct the experiments on another public benchmark, i.e., VoiceBank + DEMAND, to further validate the superiority of the proposed approach with other SOTA baselines, whose results are presented in Table V. From the results in Table V, one can have the following observations. First, when only the magnitude estimation branch (MEB-Net) or the complex spectral mapping branch (CPB-Net) is adopted, the proposed frameworks achieve competitive performance compared with most existing advanced single-branch based baselines in the magnitude or complex spectrum domain. For example, from RDL-Net to MEB-Net, average 0.09, 1.1%, 0.07, 0.17 and 0.07 improvements are achieved in terms of PESQ, STOI, CSIG, CBAK and COVL, respectively. Similarly, CPB-Net provides average 0.09 PESQ, 1.0%STOI, 0.30 CSIG, and 0.19 COVL improvements over T-GSA. This verifies the effectiveness of the proposed attention-in-attention transformer-based network in improving speech quality. In addition, when only the single-branch topology is adopted, one can observe that CPB-Net yields better performance in PESQ, CSIG and COVL than MEB-Net, while MEB-Net achieves a higher score in CBAK. This indicates that MEB-Net can better eliminate noise, while CPB-Net conducts better speech overall quality. Second, by simultaneously adopting two branches in parallel, DBT-Net yields significant improvements in terms of all metrics than the single-branch methods. This verifies that the proposed dual-branch method can collaboratively facilitate the complex spectrum recovery from the complementary perspective. Compared with other existing single-stage and decoupling-style SOTA methods, DBT-Net achieves consistently better speech performance. For example, from the previous decoupling-style approach, i.e., GaGNet, to DBT-Net, average 0.36, 0.33, 0.30 and 0.33 improvements can be observed in terms of PESQ, CSIG, CBAK and COVL respectively. Third, compared with previous SOTA time-domain baselines, the proposed DBT-Net also achieves better performance in all objective metrics. For example, DBT-Net provides average 0.17, 0.14, 0.20, and 0.10 improvements over SE-Conformer in terms of PESQ, CSIG, CBAK and COVL, respectively.
Additionally, we also provide a comparison of the number of parameters between our methods and some reported SOTA methods. The proposed method has a relatively low parameter burden, i.e., 2.91 M, when compared with the most advanced time-domain and T-F domain methods.
VI Conclusions
In this paper, we propose a dual-branch transformer-based framework to federatively facilitate clean spectrum estimation from the complementary perspective. Specifically, a magnitude spectrum estimation branch (MEB) is designed to coarsely filter out the dominant noise components in the magnitude domain, while the residual spectral details are derived by a complex spectrum purification branch (CPB) in parallel. To leverage the information exchange between two branches, the interaction block is proposed to guide the sequence modeling by the information learned from the other branch. Within each branch, we introduce a novel attention-in-attention transformer-based (AIAT) module between a densely encoder-decoder architecture for contextual information modeling, which aims to strengthen long-term spectro-temporal dependencies and aggregate global hierarchical intermediate information. Experimental results on two public datasets, namely WSJ0-SI84 + DNS Challenge and VoiceBank + DEMAND, demonstrate that the proposed method achieves state-of-the-art performance over previous advanced approaches remarkably in various objective and subjective metrics.
References
- [1] P. C. Loizou, Speech enhancement: theory and practice, CRC press, 2013.
- [2] D. L. Wang and J. Chen, “Supervised speech separation based on deep learning: An overview,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 26, no. 10, pp. 1702–1726, 2018.
- [3] Y. Wang, A. Narayanan, and D. L. Wang, “On training targets for supervised speech separation,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 22, no. 12, pp. 1849–1858, 2014.
- [4] Y. Xu, J. Du, L-R. Dai, and C-H. Lee, “A regression approach to speech enhancement based on deep neural networks,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 23, no. 1, pp. 7–19, 2014.
- [5] D. Wang and J. Lim, “The unimportance of phase in speech enhancement,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 30, no. 4, pp. 679–681, 1982.
- [6] K. Paliwal, K. Wójcicki, and B. Shannon, “The importance of phase in speech enhancement,” Speech Commun., vol. 53, no. 4, pp. 465–494, 2011.
- [7] A. Defossez, G. Synnaeve, and Y. Adi, “Real time speech enhancement in the waveform domain,” in Proc. Interspeech, 2020, pp. 3291–3295.
- [8] Y. Luo, Z. Chen, and T. Yoshioka, “Dual-Path RNN: efficient long sequence modeling for time-domain single-channel speech separation,” in Proc. ICASSP. IEEE, 2020, pp. 46–50.
- [9] K. Wang, B. He, and W. P. Zhu, “TSTNN: Two-stage transformer based neural network for speech enhancement in the time domain,” in Proc. ICASSP. IEEE, 2021, pp. 7098–7102.
- [10] K. Kinoshita, T. Ochiai, M. Delcroix, and T. Nakatani, “Improving noise robust automatic speech recognition with single-channel time-domain enhancement network,” in Proc. ICASSP. IEEE, 2020, pp. 7009–7013.
- [11] S. Pascual, A. Bonafonte, and J. Serra, “SEGAN: Speech enhancement generative adversarial network,” in Proc. Interspeech, 2017, pp. 3642–3646.
- [12] D. S. Williamson, Y. Wang, and D. Wang, “Complex ratio masking for monaural speech separation,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 24, no. 3, pp. 483–492, 2015.
- [13] H. S. Choi, J. H. Kim, J. Huh, A. Kim, J. W. Ha, and K. Lee, “Phase-aware speech enhancement with deep complex U-Net,” arXiv preprint arXiv:1903.03107, 2019.
- [14] G. Yu, Y. Wang, H. Wang, Q. Zhang, and C. Zheng, “A two-stage complex network using cycle-consistent generative adversarial networks for speech enhancement,” Speech Commun., vol. 134, pp. 42–54, 2021.
- [15] K. Tan and D. L. Wang, “Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 28, pp. 380–390, 2019.
- [16] Y. Sun, Y. Xian, W. Wang, and S. M. Naqvi, “Monaural source separation in complex domain with long short-term memory neural network,” IEEE Journal of Selected Topics in Signal Processing, vol. 13, no. 2, pp. 359–369, 2019.
- [17] A. Li, W. Liu, C. Zheng, C. Fan, and X. Li, “Two heads are better than one: A two-stage complex spectral mapping approach for monaural speech enhancement,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 29, pp. 1829–1843, 2021.
- [18] A. Li, W. Liu, X. Luo, G. Yu, C. Zheng, and X. Li, “A simultaneous denoising and dereverberation framework with target decoupling,” in Proc. Interspeech, 2021, pp. 2801–2805.
- [19] A. Li, C. Zheng, L. Zhang, and X. Li, “Glance and gaze: A collaborative learning framework for single-channel speech enhancement,” Applied Acoustics, vol. 187, pp. 108499, 2022.
- [20] Z.-Q. Wang, G. Wichern, and J. Le Roux, “On the compensation between magnitude and phase in speech separation,” IEEE Signal Processing Letters, vol. 28, pp. 2018–2022, 2021.
- [21] K. Tan and D. Wang, “A convolutional recurrent neural network for real-time speech enhancement.,” in Proc. Interspeech, 2018, pp. 3229–3233.
- [22] A. Pandey and D. Wang, “TCNN: Temporal convolutional neural network for real-time speech enhancement in the time domain,” in Proc. ICASSP. IEEE, 2019, pp. 6875–6879.
- [23] J. Chen, Q. Mao, and D. Liu, “Dual-path transformer network: Direct context-aware modeling for end-to-end monaural speech separation,” in Proc. Interspeech, 2020, pp. 2642–2646.
- [24] Y. Li, Y. Sun, and S. M. Naqvi, “U-shaped transformer with frequency-band aware attention for speech enhancement,” arXiv preprint arXiv:2112.06052, 2021.
- [25] Y. Fu, Y. Liu, J. Li, D. Luo, S. Lv, Y. Jv, and L. Xie, “Uformer: A unet based dilated complex & real dual-path conformer network for simultaneous speech enhancement and dereverberation,” in Proc. ICASSP. IEEE, 2022, pp. 7417–7421.
- [26] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in neural information processing systems, 2017, p. 5998–6008.
- [27] F. Iandola, M. Moskewicz, S. Karayev, R. Girshick, T. Darrell, and K. Keutzer, “DenseNet: Implementing efficient convnet descriptor pyramids,” arXiv preprint arXiv:1404.1869, 2014.
- [28] G. Yu, Y. Wang, C. Zheng, H. Wang, and Q. Zhang, “CycleGAN-based non-parallel speech enhancement with an adaptive attention-in-attention mechanism,” in Proc. Asia-Pacific Signal Inf. Process. Assoc. (APSIPA), 2021, pp. 523–529.
- [29] G. Yu, A. Li, Y. Wang, Y. Guo, H. Wang, and C. Zheng, “Dual-branch attention-in-attention transformer for single-channel speech enhancement,” in Proc. ICASSP. IEEE, 2022, pp. 7847–7851.
- [30] G. Yu, A. Li, Y. Wang, Y. Guo, C. Zheng, and H. Wang, “Joint magnitude estimation and phase recovery using Cycle-in-Cycle GAN for non-parallel speech enhancement,” in Proc. ICASSP. IEEE, 2022, pp. 6967–6971.
- [31] C. Tang, C. Luo, Z. Zhao, W. Xie, and W. Zeng, “Joint time-frequency and time domain learning for speech enhancement,” in Proc. IJCAI, 2020, pp. 3816–3822.
- [32] M. Sperber, J. Niehues, G. Neubig, S. Stüker, and A. Waibel, “Self-attentional acoustic models,” in Proc. Interspeech, 2018, pp. 3723–3727.
- [33] W. Shi, J. Caballero, F. Huszár, J. Totz, A. P. Aitken, D. Bishop, R.and Rueckert, and Z. Wang, “Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network,” in Proc. CVPR, 2016, pp. 1874–1883.
- [34] Z.-Q. Wang, P. Wang, and D. Wang, “Complex spectral mapping for single-and multi-channel speech enhancement and robust asr,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 28, pp. 1778–1787, 2020.
- [35] S. Wisdom, J. R. Hershey, K. Wilson, J. Thorpe, M. Chinen, B. Patton, and R. A. Saurous, “Differentiable consistency constraints for improved deep speech enhancement,” in Proc. ICASSP. IEEE, 2019, pp. 900–904.
- [36] C. Valentini-Botinhao, X. Wang, S. Takaki, and J. Yamagishi, “Investigating RNN-based speech enhancement methods for noise-robust text-to-speech,” in Proc. SSW, 2016, pp. 146–152.
- [37] C. Veaux, J. Yamagishi, and S. King, “The voice bank corpus: Design, collection and data analysis of a large regional accent speech database,” in Proc. O-COCOSDA/CASLRE. IEEE, 2013, pp. 1–4.
- [38] J. Thiemann, N. Ito, and E. Vincent, “The diverse environments multi-channel acoustic noise database: A database of multichannel environmental noise recordings,” JASA, vol. 133, no. 5, pp. 3591–3591, 2013.
- [39] D. Paul and J. Baker, “The design for the wall street journal-based csr corpus,” in Workshop on Speech and Natural Language, 1992, p. 357–362.
- [40] C. KA. Reddy, V. Gopal, R. Cutler, E. Beyrami, R.. Cheng, H. Dubey, S. Matusevych, R. Aichner, A. Aazami, S. Braun, et al., “The interspeech 2020 deep noise suppression challenge: Datasets, subjective testing framework, and challenge results,” in Proc. Interspeech, 2020, pp. 2492–2496.
- [41] A. Varga and H. JM. Steeneken, “Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems,” Speech Commun., vol. 12, no. 3, pp. 247–251, 1993.
- [42] A. Li, C. Zheng, R. Peng, and X. Li, “On the importance of power compression and phase estimation in monaural speech dereverberation,” JASA Express Letters, vol. 1, no. 1, pp. 014802, 2021.
- [43] D. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in Proc. ICLR, 2015.
- [44] J. Chen, Y. Wang, S. E. Yoho, D. Wang, and E. W. Healy, “Large-scale training to increase speech intelligibility for hearing-impaired listeners in novel noises,” JASA, vol. 139, no. 5, pp. 2604–2612, 2016.
- [45] K Tan, J. Chen, and D. Wang, “Gated residual networks with dilated convolutions for monaural speech enhancement,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 27, no. 1, pp. 189–198, 2018.
- [46] S. Pirhosseinloo and J. S. Brumberg, “Monaural speech enhancement with dilated convolutions.,” in Proc. Interspeech, 2019, pp. 3143–3147.
- [47] A. Pandey and D. Wang, “A new framework for CNN-based speech enhancement in the time domain,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 27, no. 7, pp. 1179–1188, 2019.
- [48] Y. Luo and N. Mesgarani, “Conv-TasNet: Surpassing ideal time–frequency magnitude masking for speech separation,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 27, no. 8, pp. 1256–1266, 2019.
- [49] Y. Hu, Y. Liu, S. Lv, M. Xing, and L. Xie, “DCCRN: Deep complex convolution recurrent network for phase-aware speech enhancement,” in Proc. Interspeech, 2020, pp. 2472–2476.
- [50] Y. N. Dauphin, A. Fan, M. Auli, and D. Grangier, “Language modeling with gated convolutional networks,” in Proc. ICML. PMLR, 2017, pp. 933–941.
- [51] F. Yu and V. Koltun, “Multi-scale context aggregation by dilated convolutions,” in Proc. ICLR, 2015.
- [52] A. Pandey and D. Wang, “Dense cnn with self-attention for time-domain speech enhancement,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 29, pp. 1270–1279, 2021.
- [53] D. Baby and S. Verhulst, “SERGAN: Speech enhancement using relativistic generative adversarial networks with gradient penalty,” in Proc. ICASSP. IEEE, 2019, pp. 106–110.
- [54] Y. Koizumi, K. Yatabe, M. Delcroix, Y. Masuyama, and D. Takeuchi, “Speech enhancement using self-adaptation and multi-head self-attention,” in Proc. ICASSP. IEEE, 2020, pp. 181–185.
- [55] E. Kim and H. Seo, “Se-Conformer: Time-domain speech enhancement using conformer,” in Proc. Interspeech, 2021, pp. 2736–2740.
- [56] M. H. Soni, N. Shah, and H. A. Patil, “Time-frequency masking-based speech enhancement using generative adversarial network,” in Proc. ICASSP. IEEE, 2018, pp. 5039–5043.
- [57] S.-W. Fu, C.-F. Liao, Y. Tsao, and S.-D. Lin, “MetricGAN: Generative adversarial networks based black-box metric scores optimization for speech enhancement,” in Proc. ICML. PMLR, 2019, pp. 2031–2041.
- [58] Z. Zhang, C. Deng, Y. Shen, D. S. Williamson, Y. Sha, Y. Zhang, H. Song, and X. Li, “On loss functions and recurrency training for gan-based speech enhancement systems,” in Proc. Interspeech, 2020, pp. 3266–3270.
- [59] M. Nikzad, A. Nicolson, Y. Gao, J. Zhou, K. K. Paliwal, and F. Shang, “Deep residual-dense lattice network for speech enhancement,” in Proc. AAAI, 2020, vol. 34, pp. 8552–8559.
- [60] J. Kim, M. El-Khamy, and J. Lee, “T-gsa: Transformer with Gaussian-weighted self-attention for speech enhancement,” in Proc. ICASSP. IEEE, 2020, pp. 6649–6653.
- [61] D. Yin, C. Luo, Z. Xiong, and W. Zeng, “PHASEN: A phase-and-harmonics-aware speech enhancement network,” in Proc. AAAI, 2020, vol. 34, pp. 9458–9465.
- [62] S.-W. Fu, C. Yu, T.-A. Hsieh, P. Plantinga, M. Ravanelli, X. Lu, and Y. Tsao, “MetricGAN+: An improved version of MetricGAN for speech enhancement,” in Proc. Interspeech, 2021, pp. 201–205.
- [63] A. Nicolson and K. K. Paliwal, “Deep learning for minimum mean-square error approaches to speech enhancement,” Speech Commun., vol. 111, pp. 44–55, 2019.
- [64] Q. Zhang, A. Nicolson, M. Wang, K. K. Paliwal, and C. Wang, “DeepMMSE: A deep learning approach to MMSE-based noise power spectral density estimation,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 28, pp. 1404–1415, 2020.
- [65] A. Rix, J. Beerends, M. Hollier, and A. Hekstra, “Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,” in Proc. ICASSP. IEEE, 2001, vol. 2, pp. 749–752.
- [66] J. Jensen and C. H. Taal, “An algorithm for predicting the intelligibility of speech masked by modulated noise maskers,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 24, no. 11, pp. 2009–2022, 2016.
- [67] E. Vincent, H. Sawada, P. Bofill, S. Makino, and J. P. Rosca, “First stereo audio source separation evaluation campaign: data, algorithms and results,” in International Conference on Independent Component Analysis and Signal Separation. Springer, 2007, pp. 552–559.
- [68] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “A short-time objective intelligibility measure for time-frequency weighted noisy speech,” in Proc. ICASSP. IEEE, 2010, pp. 4214–4217.
- [69] Y. Hu and P. C. Loizou, “Evaluation of objective quality measures for speech enhancement,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 16, no. 1, pp. 229–238, 2007.
- [70] C. K. Reddy, V. Gopal, and R. Cutler, “DNSMOS: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors,” in Proc. ICASSP. IEEE, 2021, pp. 6493–6497.
- [71] P. Mermelstein, “Evaluation of a segmental snr measure as an indicator of the quality of adpcm coded speech,” JASA, vol. 66, no. 6, pp. 1664–1667, 1979.