Anomaly Detection in 3D Point Clouds
using Deep Geometric Descriptors
Abstract
We present a new method for the unsupervised detection of geometric anomalies in high-resolution 3D point clouds. In particular, we propose an adaptation of the established student-teacher anomaly detection framework to three dimensions. A student network is trained to match the output of a pretrained teacher network on anomaly-free point clouds. When applied to test data, regression errors between the teacher and the student allow reliable localization of anomalous structures. To construct an expressive teacher network that extracts dense local geometric descriptors, we introduce a novel self-supervised pretraining strategy. The teacher is trained by reconstructing local receptive fields and does not require annotations. Extensive experiments on the comprehensive MVTec 3D Anomaly Detection dataset highlight the effectiveness of our approach, which outperforms the next-best method by a large margin. Ablation studies show that our approach meets the requirements of practical applications regarding performance, runtime, and memory consumption.
1 Introduction
In recent years, significant progress has been made in the field of 3D computer vision in various research areas such as 3D classification, 3D semantic segmentation, and 3D object recognition. Many new methods build on earlier achievements in their counterparts in 2D, which operate with natural image data. However, the transition from 2D to 3D poses additional challenges, e.g., the need to deal with unordered point clouds and sensor noise. This has led to the development of new network architectures and training protocols specific to three dimensions.
We consider the challenging task of unsupervised anomaly detection and localization in 3D point clouds. The goal is to detect data points that deviate significantly from a training set of exclusively anomaly-free samples. This problem has important applications in various fields, such as industrial inspection (Bergmann et al., 2021, 2022; Carrera et al., 2017; Song and Yan, 2013), autonomous driving (Blum et al., 2019; Hendrycks et al., 2019), and medical imaging (Bakas et al., 2017; Baur et al., 2019; Menze et al., 2015). It has received considerable attention in 2D, where models are typically trained on color or grayscale images with established and well-studied architectures based on convolutional neural networks. In 3D, this problem is still comparatively unexplored and only a small number of methods exists. In this work, following approaches in other computer vision areas, we draw inspiration from recent advances in 2D anomaly detection to devise a powerful 3D method.
More specifically, we build on the success of using descriptors from pretrained neural networks for unsupervised anomaly detection in 2D. An established protocol is to extract these descriptors as intermediate features from networks trained on the ImageNet (Krizhevsky et al., 2012) dataset. Models based on pretrained features were shown to perform better than ones trained with random weight initializations (Bergmann et al., 2020; Burlina et al., 2019; Cohen and Hoshen, 2020). In particular, they outperform methods based on convolutional autoencoders or generative adversarial networks.
So far, there is no established pretraining protocol for unsupervised anomaly detection in 3D point clouds. Existing work addresses the extraction of local 3D features that are highly task-specific. For point cloud registration, feature extractors often heavily downsample the input data or operate only on a small number of input points. This makes them ill-suited for anomaly localization in 3D. In this work, we develop a novel approach for pretraining local geometric descriptors that transfer well to this task. We then use this pretraining strategy to introduce a new method that outperforms existing approaches in the localization of geometric anomalies in high-resolution 3D point clouds. In particular, our key contributions are:
-
We present 3D Student-Teacher (3D-ST), the first method for unsupervised anomaly detection that operates directly on 3D point clouds. Our method is trained only on anomaly-free data and it localizes geometric anomalies in high-resolution test samples with a single forward pass. We propose an adaptation of a student-teacher framework for anomaly detection to three dimensions. A student network is trained to match deep local geometric descriptors of a pretrained teacher network. During inference, anomaly scores are derived from the regression errors between the student’s predictions and the teacher’s targets. Our method sets a new state of the art on the recently introduced MVTec 3D-AD dataset. It performs significantly better than existing methods that use voxel grids and depth images.
-
We develop a self-supervised training protocol that allows the teacher network to learn generic local geometric descriptors that transfer well to the 3D anomaly detection task. The teacher extracts a geometric descriptor for each input point by aggregating local features within a limited receptive field. A decoder network is trained to reconstruct the local geometry encoded by the descriptors. Our pretraining strategy provides explicit control over the receptive field and dense feature extraction for a large number of input points. This allows us to compute anomaly scores for high-resolution point clouds without the need for intermediate subsampling.
2 Related Work
Our work touches on several aspects of computer vision, namely unsupervised detection of anomalies in two and three dimensions and extraction of deep local geometric descriptors for 3D data.
2.1 Anomaly Detection in 2D
There is a large body of work on the unsupervised detection of anomalies in two dimensions, i.e., in RGB or grayscale images. Ehret et al. (2019) and Pang et al. (2021) give comprehensive overviews. Some of the existing methods are trained from scratch with random weight initialization, in particular, those based on convolutional autoencoders (AEs) (Bergmann et al., 2019; Hong and Choe, 2020; Liu et al., 2020; Venkataramanan et al., 2020; Wang et al., 2020) or generative adversarial networks (GANs) (Carrara et al., 2021; Potter et al., 2020; Schlegl et al., 2019).
A different class of methods leverage descriptors from pretrained networks for anomaly detection (Bergmann et al., 2020; Cohen and Hoshen, 2020; Defard et al., 2021; Gudovskiy et al., 2022; Mishra et al., 2020; Reiss et al., 2021; Rippel et al., 2021). The key idea behind these approaches is that anomalous regions produce descriptors that differ from the ones without anomalies. These methods tend to perform better than methods trained from scratch, which motivates us to transfer this idea to the 3D domain.
Bergmann et al. (2020) propose a student-teacher framework for 2D anomaly detection. A teacher network is pretrained on the ImageNet dataset to output descriptors represented by feature maps. Each descriptor captures the content of a local region within the input image. For anomaly detection, an ensemble of student networks is trained on anomaly-free images to reproduce the descriptors of the pretrained teacher. During inference, anomalies are detected when the students produce increased regression errors and predictive variances. Closely following this idea, Salehi et al. (2021) train a single student network to match multiple feature maps of a single teacher.
2.2 Anomaly Detection in 3D
To date, there are very few methods that address the task of unsupervised anomaly detection in 3D data. None of them leverages the descriptiveness of feature vectors from pretrained networks.
Simarro Viana et al. (2021) propose Voxel f-AnoGAN, which is an extension of the 2D f-AnoGAN model (Schlegl et al., 2019) to 3D voxel grids. A GAN is trained on anomaly-free data samples. Afterwards, an encoder is trained to predict the latent vectors of anomaly-free voxel grids that, when passed through the generator network, reconstruct the input data. During inference, anomaly scores are derived by a per-voxel comparison of the input to the reconstruction. Bengs et al. (2021) introduce a method based on convolutional autoencoders that also operates on 3D voxel grids. A variational autoencoder is trained to reconstruct input samples through a low-dimensional bottleneck. Again, anomaly scores are derived by comparing each voxel element of the input to its reconstruction.
Recently, Bergmann et al. (2022) introduced MVTec 3D-AD, a comprehensive dataset for the evaluation of 3D anomaly detection algorithms. So far, this is the only public dataset specifically designed for this task. They show that the existing methods do not perform well on challenging high-resolution point clouds and that there is a need for the development of new methods for this task.
2.3 Learning Deep 3D Descriptors
Geometric feature extraction is commonly used in 3D applications such as 3D registration or 3D pose estimation. The community has recently shifted from designing hand-crafted descriptors (Salti et al., 2014; Tombari et al., 2010) to learning-based approaches.
One line of work learns low-dimensional descriptors on local 3D patches cropped from larger input point clouds. In 3DMatch (Zeng et al., 2017) and PPFNet (Deng et al., 2018b), supervised metric learning is used to learn embeddings from annotated 3D correspondences. PPF-FoldNet (Deng et al., 2018a) pursues an unsupervised strategy where an autoencoder is trained on point pair features extracted from the local patches. Similarly, Kehl et al. (2016) introduce an autoencoder that is trained on patches of RGB-D images to obtain local features. These methods have the disadvantage that a separate patch needs to be cropped and processed for each feature. This quickly becomes computationally intractable for a large number of points.
To mitigate this problem, recent 3D feature extractors attempt to densely compute features for high-resolution inputs. Choy et al. (2019) propose FCGF, a fully convolutional approach to local geometric feature extraction for 3D registration. They design a network with sparse convolutions to efficiently processes high-resolution voxel data. Given a large number of precisely annotated local correspondences, their approach is trained using contrastive losses that encourage matching local geometries to be close in feature space. PointContrast (Xie et al., 2020) learns descriptors for 3D registration in a self-supervised fashion and does not rely on human annotations. Correspondences are automatically derived by augmenting a pair of overlapping views from a single 3D scan. While being computationally efficient, these methods require a prior voxelization that can lead to discretization inaccuracies. Furthermore, all of the discussed methods are designed to produce feature spaces that are ideally invariant to 3D rotations of the input data. In unsupervised anomaly detection, however, anomalies can manifest themselves precisely through locally rotated geometric structures. Such differences should therefore be reflected in the extracted feature vectors. This calls for the development of a different pretraining strategy that is sensitive to local rotations.
3 Student-Teacher Anomaly Detection in Point Clouds
In this section, we introduce 3D Student-Teacher (3D-ST), a versatile framework for the unsupervised detection and localization of geometric anomalies in high-resolution 3D point clouds. We build on the recent success of leveraging local descriptors from pretrained networks for anomaly detection and propose an adaptation of the 2D student-teacher method (Bergmann et al., 2020) to 3D data.
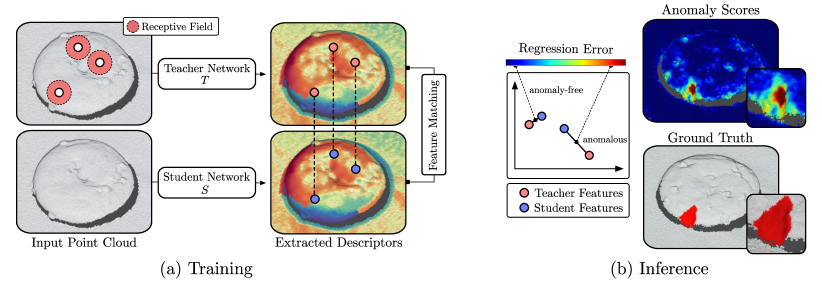
Given a training dataset of anomaly-free input point clouds, our goal is to create a model that can localize anomalous regions in test point clouds, i.e., to assign a real-valued anomaly score to each point. To achieve this, we design a dense feature extraction network , called teacher network, that computes local geometric features for arbitrary point clouds. For anomaly detection, a student network is trained on the anomaly-free point clouds against the descriptors obtained from . During inference, increased regression errors between and indicate anomalous points. An overview of our approach is illustrated in Figure 2.
To pretrain the teacher, we present a self-supervised protocol. It works on any generic auxiliary 3D point cloud dataset and requires no human annotations.
3.1 Self-Supervised Learning of Dense Local Geometric Descriptors
We begin by describing how to construct a descriptive teacher network . An overview of our pretraining protocol is displayed in Figure 3. Given an input point cloud containing 3D points, its purpose is to produce a -dimensional feature vector for every . The vector describes the local geometry around the point , i.e., the geometry within its receptive field.
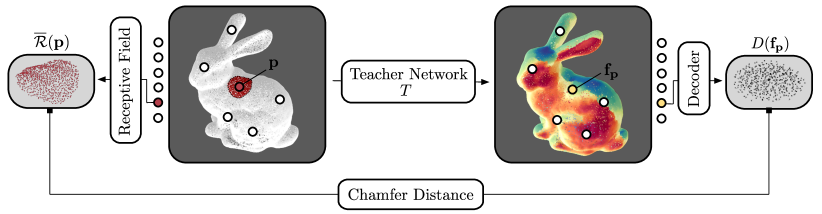
Local Feature Aggregation.
The network architecture of has two key requirements. First, it should be able to efficiently process high-resolution point clouds by computing a feature vector for each input point without downsampling the input data. Second, it requires explicit control over the receptive field of the feature vectors. In particular, it has to be possible to efficiently compute all points within the receptive field of an output descriptor.
To meet these requirements, we construct the -nearest neighbor graph of the input point cloud and initialize . We then pass the input sample through a series of residual blocks, where each block updates the feature vector of each 3D point from to . These blocks are inspired by RandLA-Net (Hu et al., 2020, 2021), an efficient and lightweight neural architecture for semantic segmentation of large-scale point clouds. In semantic segmentation tasks, the absolute position of a point is often related to its class, e.g., in autonomous driving datasets. Here, we want our model to produce features that describe the local geometry of an object independent of its absolute location. We therefore make the residual blocks translation-invariant by removing any dependency on absolute coordinates. This significantly increases the performance when used for anomaly detection as underlined by the results of our experiments in Section 4.
The architecture of our residual blocks is visualized in Figure 4(a). The input features are first passed through a shared MLP, followed by two local feature aggregation (LFA) blocks. The output features are added to the input after processing both by an additional shared MLP. The features are transformed by a series of residual blocks and a final shared MLP with a single hidden layer that maintains the dimension of the descriptors, i.e., .
The purpose of the LFA block is to aggregate the geometric information from the local vicinity of each input point. To this end, it computes the nearest neighbors of all and a set of local geometric features for each point pair defined by
| (1) |
The operator denotes the concatenation operation and denotes the -norm. Since only depends on the difference vectors between neighboring points, our network is by design invariant to translations of the input data. Our experiments show that this invariance of our local feature extractor is crucial for anomaly detection performance. Therefore, we make this small but important change to the LFA block. A schematic description of such a block is given in Figure 4(b).
For each LFA block, the set of geometric features is passed through a shared MLP producing feature vectors of dimension . These are concatenated with the set of input features . The output feature vector of the LFA block is obtained by an average-pooling operation of the concatenated features, yielding a feature vector of dimension .
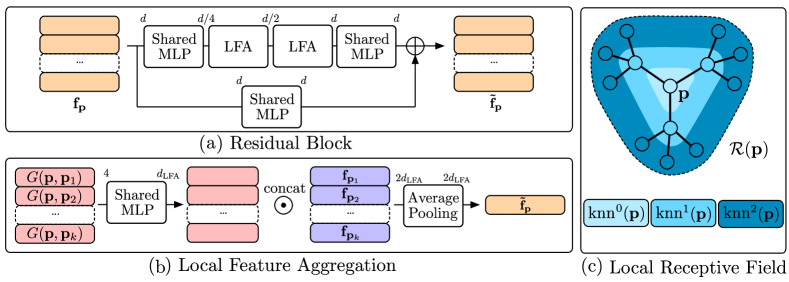
Reconstructing Local Receptive Fields.
To pretrain in a self-supervised fashion, we propose to employ a network that decodes the local receptive field of a feature vector.
The design of our network architecture allows an efficient computation of all points within the receptive field of a point , i.e., all points that affect the feature vector . Each LFA block depends on the features of the surrounding nearest neighbors . Whenever an LFA block is executed, grows by one hop in the nearest-neighbor graph. The receptive field can therefore be obtained by iteratively traversing the nearest neighbor graph:
| (2) |
and . denotes the total number of LFA blocks in the network. Figure 4(c) visualizes this definition of the receptive field.
The decoder upsamples a feature vector to produce 3D points by applying an MLP. For pretraining, we extract descriptors from an input point cloud by passing it through the local feature extractor. We then randomly sample a set of points from the input point cloud. For each , we compute the receptive fields and pass their respective feature vectors through the decoder. To train , we minimize the Chamfer distance (Barrow et al., 1977) between the decoded points and the receptive fields. Since our network architecture is not aware of the absolute coordinates of , we additionally compute the mean of all and subtract it from each point, yielding the set . The loss function for our self-supervised training procedure can then be written as:
| (3) |
Data Normalization.
In order for our teacher network to be applied to any point cloud not included in the pretraining dataset, some form of data normalization is required. Since our network operates on the distance vectors of neighboring points, we choose to normalize the input data with respect to these distances. More specifically, we compute the average distance between each point and its nearest neighbors over the entire training set, i.e.,
| (4) |
We then scale the coordinates of each data sample in the pretraining dataset by . This allows us to apply the teacher network to arbitrary point cloud datasets, as long as the same data normalization technique is used.
3.2 Matching Geometric Features for 3D Anomaly Detection
Finally, we describe how to employ the pretrained teacher network to train a student network for anomaly detection. Given a dataset of anomaly-free point clouds, we first calculate the scaling factor for this dataset as defined in (4). The weights of remain constant during the entire anomaly detection training. exhibits the identical network architecture as and is initialized with uniformly distributed random weights. Each training point cloud is passed through both networks, and , to compute dense features and for all , respectively. The weights of are optimized to reproduce the geometric descriptors of by computing the feature-wise -distance:
| (5) |
We transform the teacher features to be centered around with unit standard deviation. This requires the computation of the component-wise means and standard deviations of all teacher features over the whole training set. We denote the inverse of the diagonal matrix filled with the entries of by .
During inference, anomaly scores are derived for each point in a test point cloud . They are given by the regression errors between the respective features of the student and the teacher network, i.e., . The intuition behind this is that anomalous geometries produce features that the student network has not observed during training, and is hence unable to reproduce. Large regression errors indicate anomalous geometries.
4 Experiments
To demonstrate the effectiveness of our approach, we perform extensive experiments on the recently released MVTec 3D Anomaly Detection (MVTec 3D-AD) dataset (Bergmann et al., 2022). This dataset was designed to evaluate methods for the unsupervised detection of geometric anomalies in point cloud data (PCD). Currently, this is the only publicly available comprehensive dataset for this task. It contains over 4000 high-resolution 3D scans of 10 object categories of industrially manufactured products. The task is to train a model on anomaly-free samples and to localize anomalies that occur as defects on the manufactured products during inference.
4.1 Experiment Setup
We benchmark the performance of our 3D-ST method against existing methods for unsupervised 3D anomaly detection. In particular, we follow the initial benchmark on MVTec 3D-AD and compare 3D-ST against the Voxel f-AnoGAN, the Voxel Autoencoder, and the Voxel Variation Model. The benchmark also includes their respective counterparts that process depth images instead of voxel grids by exchanging 3D with 2D convolutions. The GAN- and autoencoder-based methods derive anomaly scores by a per-pixel or per-voxel comparison of their reconstructions to the input samples. The Variation Model is a shallow machine learning model that computes the per-pixel or per-voxel means and standard deviations over the training set. During inference, anomaly scores are obtained by computing the per-pixel or per-voxel Mahalanobis distance from a test sample to the training distribution. We employ the same training and evaluation protocols and hyperparameters setting as listed in (Bergmann et al., 2022).
Teacher Pretraining.
To pretrain the teacher network of our method (cf. Section 3.1), we generate synthetic 3D scenes using objects of the ModelNet10 dataset (Wu et al., 2015). It consists of over 5000 3D models divided into 10 different object categories.
We generate a scene of our pretraining dataset by randomly selecting samples from ModelNet10 and scaling the longest side of their bounding box to . The objects are rotated around each 3D axis with angles sampled uniformly from the interval . Each object is placed at a random location sampled uniformly from . Point clouds are created by selecting points from the scene using farthest point sampling (Moenning and Dodgson, 2003). The training and validation dataset consist of and point clouds, respectively. Our experiments show that using such a synthetic dataset for pretraining yields local descriptors that are well suited for 3D anomaly detection. In our ablation studies, we additionally investigate the use of real-world datasets from different domains for pretraining, namely Semantic KITTI (Behley et al., 2019; Geiger et al., 2012), MVTec ITODD (Drost et al., 2017), and 3DMatch (Zeng et al., 2017).
The teacher network consists of residual blocks and processes input points. We perform experiments using two different feature dimensions . The shared MLPs in all network blocks are implemented with a single dense layer, followed by a LeakyReLU activation with a negative slope of . The input and output dimensions of each shared MLP are given in Figure 4. For local feature aggregation, a nearest neighbor graph with neighbors is constructed. The pretraining runs for epochs using the Adam optimizer with an initial learning rate of and a weight decay of . At each training step, a single input sample is fed through the teacher network. To generate reconstructions of local receptive fields, randomly selected descriptors from the output of are passed through the decoder network , which is implemented as an MLP with input dimension , two hidden layers of dimension , and an output layer that reconstructs points. Each hidden layer is followed by a LeakyReLU activation with negative slope of . After the training, we select the model with the lowest validation error as the teacher network.
| bagel |
|
carrot | cookie | dowel | foam | peach | potato | rope | tire | mean | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Voxel | GAN | 0.440 | 0.453 | 0.825 | 0.755 | 0.782 | 0.378 | 0.392 | 0.639 | 0.775 | 0.389 | 0.583 | ||
| AE | 0.260 | 0.341 | 0.581 | 0.351 | 0.502 | 0.234 | 0.351 | 0.658 | 0.015 | 0.185 | 0.348 | |||
| VM | 0.453 | 0.343 | 0.521 | 0.697 | 0.680 | 0.284 | 0.349 | 0.634 | 0.616 | 0.346 | 0.492 | |||
| Depth | GAN | 0.111 | 0.072 | 0.212 | 0.174 | 0.160 | 0.128 | 0.003 | 0.042 | 0.446 | 0.075 | 0.143 | ||
| AE | 0.147 | 0.069 | 0.293 | 0.217 | 0.207 | 0.181 | 0.164 | 0.066 | 0.545 | 0.142 | 0.203 | |||
| VM | 0.280 | 0.374 | 0.243 | 0.526 | 0.485 | 0.314 | 0.199 | 0.388 | 0.543 | 0.385 | 0.374 | |||
| PCD | 3D-ST64 | 0.939 | 0.440 | 0.984 | 0.904 | 0.876 | 0.633 | 0.937 | 0.989 | 0.967 | 0.507 | 0.818 | ||
| 3D-ST128 | 0.950 | 0.483 | 0.986 | 0.921 | 0.905 | 0.632 | 0.945 | 0.988 | 0.976 | 0.542 | 0.833 |
Anomaly Detection.
The student network in our 3D-ST method has the same network architecture as the teacher. It is trained for epochs on the anomaly-free training split of the MVTec 3D-AD dataset. We train with a batch size of . This is equivalent to processing a large number of local patches per iteration due to the limited receptive field of the employed networks. We use Adam with an initial learning rate of and weight decay . Each point cloud is reduced to input points using farthest point sampling. For inference, we select the student network with the lowest validation error.
The evaluation on MVTec 3D-AD requires to predict an anomaly score for each pixel in the original images. To do this, we apply harmonic interpolation (Evans, 2010) to the pixels that were not assigned anomaly scores by our method. We follow the standard evaluation protocol of MVTec 3D-AD and compute the per-region overlap (PRO) (Bergmann et al., 2021) and the corresponding false positive rate for successively increasing anomaly thresholds. We then report the area under the PRO curve (AU-PRO) integrated up to a false positive rate of . We normalize the resulting values to the interval .
4.2 Experiment Results
Table 1 shows quantitative results of each evaluated method on every object category of MVTec 3D-AD. The top three rows list the performance of the voxel-based methods. The following three rows list the performance of the respective methods on 2D depth images. The bottom two rows show the performance of our 3D-ST method on 3D point cloud data, evaluated for two different descriptor dimensions . Our method performs significantly better than all other methods on every dataset category. Increasing the descriptor dimension from to yields a slight overall improvement of percentage points. The latter outperforms the previously leading method by points.
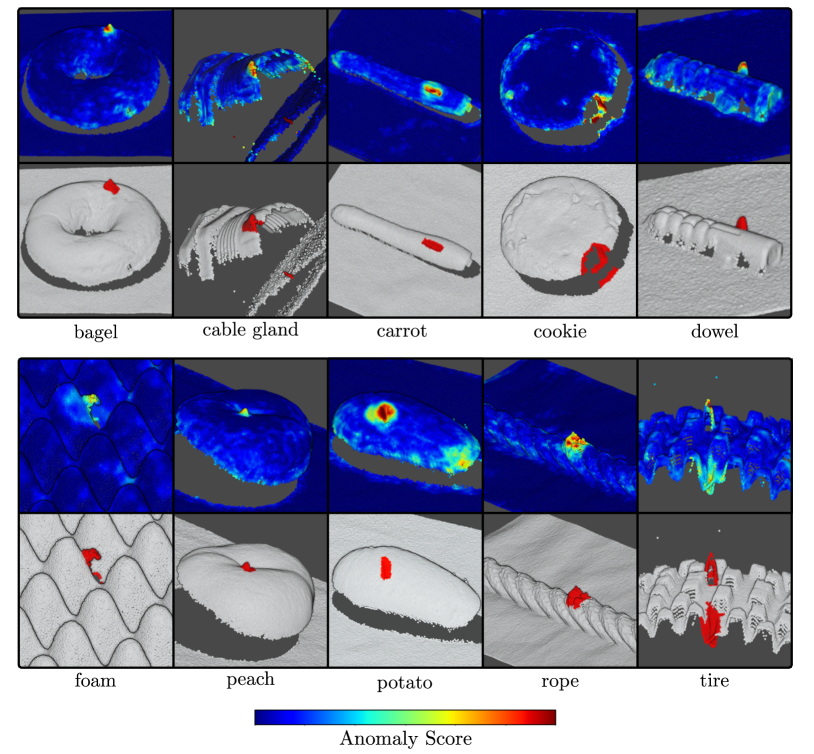
Qualitative results of our method are shown in Figure 1. 3D-ST manages to localize anomalies over a range of different object categories, such as the crack in the bagel, the contamination on the rope and the tire, or the cut in the foam and the potato. Additional qualitative results for each object category are shown in Section B.
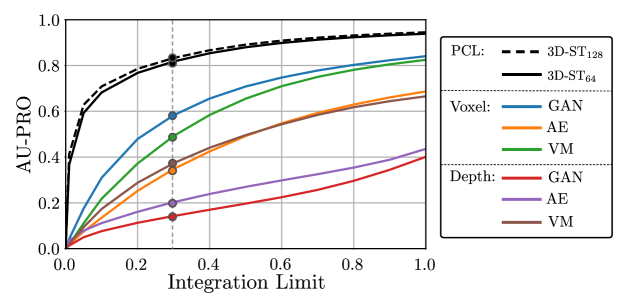
The MVTec 3D-AD paper states that real-world anomaly detection applications require particularly low false positive rates. We therefore report the mean performance of all evaluated methods when varying the integration limit of the PRO curve in Figure 5. Our method outperforms all other evaluated methods for any chosen integration limit. The relative difference in performance is particularly large for lower integration limits. This makes our approach well-suited for practical applications. Exact values for several integration limits can be found in Section A.
4.3 Ablation Studies
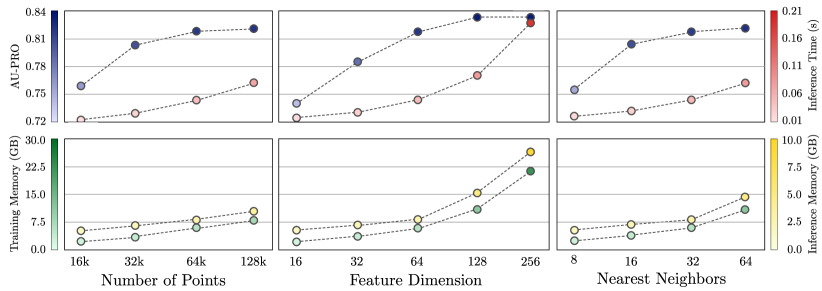
We additionally perform various ablation studies with respect to the key hyperparameters of our proposed method. Again, the exact values for each experiment can be found in Section A. Figure 6 shows the dependency of the mean performance of our method on the number of input points , the feature dimension , or the number of nearest neighbor points used for local feature aggregation. We additionally visualize the inference time and the memory consumption of each model during training and evaluation111All models were implemented using the PyTorch library (Paszke et al., 2019). Inference times and memory consumption were measured on an NVIDIA Tesla V100 GPU.. We find that our method is insensitive to the choice of each hyperparameter. In particular, the mean performance of each evaluated model outperforms the best performing competing model from the baseline experiments by a large margin. The mean performance of our model grows monotonically with respect to each considered hyperparameter. It eventually saturates, whereas the inference time and memory consumption continue to increase super-linearly.
Feature Space of the Teacher Network.
We depict the effectiveness of our pretraining strategy in Figure 7. The left bar plot shows the mean performance with respect to changes in the training strategy of our method. The first bar indicates how the performance changes when we initialize the teacher’s weights randomly and perform no pretraining. As expected, the performance drops significantly. The second bar shows the performance when concatenating the absolute point coordinates of each 3D point to the local feature aggregation function , as proposed in (Hu et al., 2020). This no longer makes our network translation invariant and decreases the performance. This indicates that translation invariance is indeed important for our network architecture and that our modification to the local feature aggregation module has a significant impact. The third bar shows the performance of our method when trying to additionally incorporate rotation invariance. We achieve this by augmentation of the training data with randomly sampled rotations such that locally rotated geometries are also considered as anomaly-free. In this setting, the performance is still significantly below our method, which indicates that sensitivity to local rotations is beneficial for 3D anomaly detection.
Pretraining Dataset.
In most of our experiments, we use synthetically generated scenes created from objects from the ModelNet10 dataset as described above. Our pretraining strategy does not require any human annotations and can operate on arbitrary input point clouds. We are thus interested in whether the performance varies when using different pretraining datasets. As first experiment, we randomly select training scenes from the Semantic KITTI autonomous driving dataset, which is captured with a LIDAR sensor. Secondly, we pretrain a teacher on all samples of 3DMatch, an indoor dataset originally designed for point cloud registration. Finally, we use all samples of the MVTec ITODD dataset, an industrial dataset originally designed for 3D pose estimation. The center bar chart in Figure 7 shows the mean performance of our method when using these three datasets for pretraining, compared to our baseline model. We find that our method does not strongly depend on the specific dataset chosen for pretraining when using ITODD or 3DMatch. We observe a slight performance gap for the KITTI dataset, which is likely due to the large domain shift.
Feature Extractor.
We additionally test the performance of our method when our pretrained teacher network is replaced by descriptors obtained from different feature extractors.
In particular, we compare against features obtained from PPFFold-Net (Deng et al., 2018a) and FCGF (Choy et al., 2019). For both, we use publicly available pretrained models.222https://github.com/XuyangBai/PPF-FoldNet
https://github.com/chrischoy/FCGF
PPF-FoldNet outputs a single -dimensional descriptor for patches cropped from a local neighborhood of points around each input point. Since it requires patch-based feature extraction, producing descriptors for a large number of input points becomes prohibitively slow. We therefore only extract descriptors for each point cloud with PPF-FoldNet.
FCGF outputs -dimensionsal descriptors and was pretrained in a supervised fashion on the 3DMatch dataset by finding correspondences for 3D registration. Since it requires a prior voxelization of the input data, we select a voxel size of mm and extract descriptors for points.
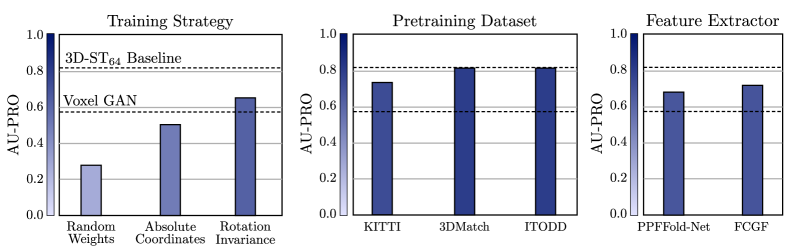
We train our student network to match the features extracted from these pretrained networks instead of our proposed teacher network. The feature dimension of the output layer of our student network is adapted to match the feature dimension of the descriptors. The results are shown in the right bar plot in Figure 7. Transferring the features of both networks yields better performance than the Voxel GAN, which is the previously best-performing method that was trained from scratch. This underlines the effectiveness of using pretrained geometric descriptors for 3D anomaly detection. Both extractors do not reach the performance of our proposed pretraining strategy that is specifically designed for the anomaly detection problem.
5 Conclusion
We propose 3D-ST, a new method for the challenging problem of unsupervised anomaly detection in 3D point clouds. Our approach is trained exclusively on anomaly-free samples. During inference, it localizes geometric structures that deviate from the ones present in the training set. Existing methods such as convolutional autoencoders or generative adversarial networks are trained from random weight initializations. In contrast to this, our method leverages the descriptiveness of deep local geometric features extracted from a network pretrained on an auxiliary 3D dataset. In particular, we propose an adaptation of student-teacher anomaly detection from 2D to 3D. To address the lack of pretraining protocols for 3D anomaly detection, we introduce a self-supervised strategy. This way, we create teacher networks that produce dense local geometric descriptors for arbitrary 3D point clouds. The teacher network is pretrained by reconstructing local receptive fields. For anomaly detection, a student network matches the geometric descriptors of the teacher on anomaly-free data. During inference, anomaly scores are derived for each 3D point by computing the regression error between its associated student and teacher descriptors. Extensive experiments on the MVTec 3D Anomaly Detection dataset show that our method outperforms all existing methods by a large margin. We performed various ablation studies that additionally showed that our method is computationally efficient, and robust to the choice of hyperparameters and pretraining datasets used.
Acknowledgements.
We would like to thank Bertram Drost, Carsten Steger, Markus Glitzner, and the entire research team at MVTec Software GmbH for valuable discussions.
References
- Bakas et al. (2017) S. Bakas, H. Akbari, A. Sotiras, M. Bilello, M. Rozycki, J. S. Kirby, et al. Advancing the cancer genome atlas glioma MRI collections with expert segmentation labels and radiomic features. Scientific Data, 4(1), 2017. doi: 10.1038/sdata.2017.117.
- Barrow et al. (1977) H. G. Barrow, J. M. Tenenbaum, R. C. Bolles, and H. C. Wolf. Parametric correspondence and chamfer matching: Two new techniques for image matching. In IJCAI, pages 659–663, 1977.
- Baur et al. (2019) C. Baur, B. Wiestler, S. Albarqouni, and N. Navab. Deep Autoencoding Models for Unsupervised Anomaly Segmentation in Brain MR Images. In A. Crimi, S. Bakas, H. Kuijf, F. Keyvan, M. Reyes, and T. van Walsum, editors, Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries, pages 161–169, Cham, 2019. Springer International Publishing.
- Behley et al. (2019) J. Behley, M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, and J. Gall. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. In Proc. of the IEEE/CVF International Conf. on Computer Vision (ICCV), 2019.
- Bengs et al. (2021) M. Bengs, F. Behrendt, J. Krüger, R. Opfer, and A. Schlaefer. Three-dimensional deep learning with spatial erasing for unsupervised anomaly segmentation in brain MRI. International Journal of Computer Assisted Radiology and Surgery, 16, 2021. doi: 10.1007/s11548-021-02451-9.
- Bergmann et al. (2019) P. Bergmann, S. Löwe, M. Fauser, D. Sattlegger, and C. Steger. Improving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders. In A. Tremeau, G. Farinella, and J. Braz, editors, 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, volume 5: VISAPP, pages 372–380, Setúbal, 2019. Scitepress.
- Bergmann et al. (2020) P. Bergmann, M. Fauser, D. Sattlegger, and C. Steger. Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4182–4191, 2020.
- Bergmann et al. (2021) P. Bergmann, K. Batzner, M. Fauser, D. Sattlegger, and C. Steger. The MVTec Anomaly Detection Dataset: A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection. International Journal of Computer Vision, 129(4):1038–1059, 2021. doi: 10.1007/s11263-020-01400-4.
- Bergmann et al. (2022) P. Bergmann, X. Jin, D. Sattlegger, and C. Steger. The MVTec 3D-AD Dataset for Unsupervised 3D Anomaly Detection and Localization. In 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, volume 5: VISAPP, Setúbal, 2022. Scitepress.
- Blum et al. (2019) H. Blum, P.-E. Sarlin, J. Nieto, R. Siegwart, and C. Cadena. Fishyscapes: A Benchmark for Safe Semantic Segmentation in Autonomous Driving. In 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), pages 2403–2412, 2019. doi: 10.1109/ICCVW.2019.00294.
- Burlina et al. (2019) P. Burlina, N. Joshi, and I.-J. Wang. Where’s Wally Now? Deep Generative and Discriminative Embeddings for Novelty Detection. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- Carrara et al. (2021) F. Carrara, G. Amato, L. Brombin, F. Falchi, and C. Gennaro. Combining GANs and AutoEncoders for efficient anomaly detection. In 2020 25th International Conference on Pattern Recognition (ICPR). IEEE, 2021. doi: 10.1109/icpr48806.2021.9412253.
- Carrera et al. (2017) D. Carrera, F. Manganini, G. Boracchi, and E. Lanzarone. Defect Detection in SEM Images of Nanofibrous Materials. IEEE Transactions on Industrial Informatics, 13(2):551–561, 2017. doi: 10.1109/TII.2016.2641472.
- Choy et al. (2019) C. Choy, J. Park, and V. Koltun. Fully convolutional geometric features. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 8957–8965, 2019. doi: 10.1109/ICCV.2019.00905.
- Cohen and Hoshen (2020) N. Cohen and Y. Hoshen. Sub-image anomaly detection with deep pyramid correspondences. arXiv preprint arXiv:2005.02357, 2020.
- Defard et al. (2021) T. Defard, A. Setkov, A. Loesch, and R. Audigier. Padim: A patch distribution modeling framework for anomaly detection and localization. In A. Del Bimbo, R. Cucchiara, S. Sclaroff, G. M. Farinella, T. Mei, M. Bertini, H. J. Escalante, and R. Vezzani, editors, Pattern Recognition. ICPR International Workshops and Challenges, pages 475–489. Springer International Publishing, 2021. ISBN 978-3-030-68799-1.
- Deng et al. (2018a) H. Deng, T. Birdal, and S. Ilic. PPF-FoldNet: Unsupervised Learning of Rotation Invariant 3D Local Descriptors. In Proceedings of the European Conference on Computer Vision (ECCV), 2018a.
- Deng et al. (2018b) H. Deng, T. Birdal, and S. Ilic. PPFNet: Global Context Aware Local Features for Robust 3D Point Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018b.
- Drost et al. (2017) B. Drost, M. Ulrich, P. Bergmann, P. Härtinger, and C. Steger. Introducing MVTec ITODD — A Dataset for 3D Object Recognition in Industry. In IEEE International Conference on Computer Vision Workshops (ICCVW), pages 2200–2208, 2017. doi: 10.1109/ICCVW.2017.257.
- Ehret et al. (2019) T. Ehret, A. Davy, J.-M. Morel, and M. Delbracio. Image Anomalies: A Review and Synthesis of Detection Methods. Journal of Mathematical Imaging and Vision, 61(5):710–743, 2019.
- Evans (2010) L. C. Evans. Partial differential equations. American Mathematical Society, Providence, R.I., 2010. ISBN 9780821849743 0821849743.
- Geiger et al. (2012) A. Geiger, P. Lenz, and R. Urtasun. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 3354–3361, 2012.
- Gudovskiy et al. (2022) D. Gudovskiy, S. Ishizaka, and K. Kozuka. CFLOW-AD: Real-Time Unsupervised Anomaly Detection With Localization via Conditional Normalizing Flows. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 98–107, 2022.
- Hendrycks et al. (2019) D. Hendrycks, S. Basart, M. Mazeika, M. Mostajabi, J. Steinhardt, and D. Song. A Benchmark for Anomaly Segmentation. arXiv preprint arXiv:1911.11132, 2019.
- Hong and Choe (2020) E. Hong and Y. Choe. Latent feature decentralization loss for one-class anomaly detection. IEEE Access, 8:165658–165669, 2020. doi: 10.1109/ACCESS.2020.3022646.
- Hu et al. (2020) Q. Hu, B. Yang, L. Xie, S. Rosa, Y. Guo, Z. Wang, N. Trigoni, and A. Markham. RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020.
- Hu et al. (2021) Q. Hu, B. Yang, L. Xie, S. Rosa, Y. Guo, Z. Wang, N. Trigoni, and A. Markham. Learning semantic segmentation of large-scale point clouds with random sampling. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
- Kehl et al. (2016) W. Kehl, F. Milletari, F. Tombari, S. Ilic, and N. Navab. Deep Learning of Local RGB-D Patches for 3D Object Detection and 6D Pose Estimation. In B. Leibe, J. Matas, N. Sebe, and M. Welling, editors, Computer Vision – ECCV 2016, pages 205–220, Cham, 2016. Springer International Publishing. ISBN 978-3-319-46487-9.
- Krizhevsky et al. (2012) A. Krizhevsky, I. Sutskever, and G. E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems - Volume 1, pages 1097–1105, 2012.
- Liu et al. (2020) W. Liu, R. Li, M. Zheng, S. Karanam, Z. Wu, B. Bhanu, R. J. Radke, and O. Camps. Towards visually explaining variational autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- Menze et al. (2015) B. H. Menze, A. Jakab, S. Bauer, J. Kalpathy-Cramer, K. Farahani, J. Kirby, et al. The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS). IEEE Transactions on Medical Imaging, 34(10):1993–2024, 2015. doi: 10.1109/TMI.2014.2377694.
- Mishra et al. (2020) P. Mishra, C. Piciarelli, and G. L. Foresti. A neural network for image anomaly detection with deep pyramidal representations and dynamic routing. International Journal of Neural Systems, 30(10):2050060, 2020. doi: 10.1142/S0129065720500604.
- Moenning and Dodgson (2003) C. Moenning and N. A. Dodgson. Fast Marching farthest point sampling. In Eurographics 2003 - Posters. Eurographics Association, 2003. doi: 10.2312/egp.20031024.
- Pang et al. (2021) G. Pang, C. Shen, L. Cao, and A. V. D. Hengel. Deep learning for anomaly detection: A review. ACM Comput. Surv., 54(2), 2021. ISSN 0360-0300. doi: 10.1145/3439950.
- Paszke et al. (2019) A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems, volume 32, 2019.
- Potter et al. (2020) K. M. Potter, B. Donohoe, B. Greene, A. Pribisova, and E. Donahue. Automatic detection of defects in high reliability as-built parts using x-ray CT. In Applications of Machine Learning 2020, volume 11511, pages 120 – 136. International Society for Optics and Photonics, SPIE, 2020. doi: 10.1117/12.2570459.
- Reiss et al. (2021) T. Reiss, N. Cohen, L. Bergman, and Y. Hoshen. Panda: Adapting pretrained features for anomaly detection and segmentation. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2805–2813, 2021. doi: 10.1109/CVPR46437.2021.00283.
- Rippel et al. (2021) O. Rippel, A. Chavan, C. Lei, and D. Merhof. Transfer Learning Gaussian Anomaly Detection by Fine-Tuning Representations. arXiv preprint arXiv:2108.04116, 2021.
- Salehi et al. (2021) M. Salehi, N. Sadjadi, S. Baselizadeh, M. H. Rohban, and H. R. Rabiee. Multiresolution knowledge distillation for anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14902–14912, 2021.
- Salti et al. (2014) S. Salti, F. Tombari, and L. Di Stefano. SHOT: Unique signatures of histograms for surface and texture description. Computer Vision and Image Understanding, 125:251–264, 2014. ISSN 1077-3142. doi: 10.1016/j.cviu.2014.04.011.
- Schlegl et al. (2019) T. Schlegl, P. Seeböck, S. M. Waldstein, G. Langs, and U. Schmidt-Erfurth. f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks. Medical Image Analysis, 54:30–44, 2019. doi: 10.1016/j.media.2019.01.010.
- Simarro Viana et al. (2021) J. Simarro Viana, E. de la Rosa, T. Vande Vyvere, D. Robben, D. M. Sima, and CENTER-TBI Participants and Investigators. Unsupervised 3D Brain Anomaly Detection. In Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries, pages 133–142. Springer International Publishing, 2021. doi: 10.1007/978-3-030-72084-1.
- Song and Yan (2013) K. Song and Y. Yan. A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects. Applied Surface Science, 285:858–864, 2013. doi: 10.1016/j.apsusc.2013.09.002.
- Tombari et al. (2010) F. Tombari, S. Salti, and L. Di Stefano. Unique signatures of histograms for local surface description. In Proceedings of the 11th European Conference on Computer Vision: Part III, page 356–369, Berlin, Heidelberg, 2010. Springer-Verlag. ISBN 364215557X.
- Venkataramanan et al. (2020) S. Venkataramanan, K.-C. Peng, R. V. Singh, and A. Mahalanobis. Attention guided anomaly localization in images. In A. Vedaldi, H. Bischof, T. Brox, and J.-M. Frahm, editors, Computer Vision – ECCV 2020, pages 485–503. Springer International Publishing, 2020. ISBN 978-3-030-58520-4.
- Wang et al. (2020) L. Wang, D. Zhang, J. Guo, and Y. Han. Image anomaly detection using normal data only by latent space resampling. Applied Sciences, 10(23), 2020. ISSN 2076-3417. doi: 10.3390/app10238660.
- Wu et al. (2015) Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, and J. Xiao. 3D ShapeNets: A Deep Representation for Volumetric Shapes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1912–1920, 2015.
- Xie et al. (2020) S. Xie, J. Gu, D. Guo, C. Qi, L. Guibas, and O. Litany. PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding. In ECCV, 2020.
- Zeng et al. (2017) A. Zeng, S. Song, M. Nießner, M. Fisher, J. Xiao, and T. Funkhouser. 3DMatch: Learning Local Geometric Descriptors from RGB-D Reconstructions. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 199–208, 2017. doi: 10.1109/CVPR.2017.29.
A Additional Information on Ablation Experiments
For reference, we provide numerical values of the results of our ablation studies that correspond to the line- and barplots in our main manuscript.
A.1 Lower Integration Limits
In our paper, quantitative results are reported as the AU-PRO where the PRO values are integrated over the false positive rates (FPR). In the majority of our experiments, we limit the FPR by an upper integration limit of . In order to enable a comparison at lower integration limits, we list the performance of our method at four different integration limits in Table 2. The first four row show the performance of our model with a descriptor dimension of . The bottom four rows show the corresponding performance of our model with feature dimension . These values are also depicted in the line plot shown in Figure 5.
|
bagel |
|
carrot | cookie | dowel | foam | peach | potato | rope | tire | mean | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.01 | 0.361 | 0.019 | 0.690 | 0.461 | 0.147 | 0.232 | 0.433 | 0.762 | 0.558 | 0.008 | 0.367 | |||||
| 0.05 | 0.718 | 0.095 | 0.909 | 0.699 | 0.481 | 0.428 | 0.735 | 0.934 | 0.841 | 0.083 | 0.592 | |||||
| 0.10 | 0.832 | 0.177 | 0.954 | 0.791 | 0.662 | 0.505 | 0.837 | 0.966 | 0.910 | 0.187 | 0.682 | |||||
| 0.20 | 0.910 | 0.322 | 0.977 | 0.869 | 0.815 | 0.578 | 0.909 | 0.983 | 0.952 | 0.364 | 0.768 | |||||
| 0.01 | 0.438 | 0.023 | 0.710 | 0.500 | 0.239 | 0.278 | 0.511 | 0.791 | 0.630 | 0.015 | 0.414 | |||||
| 0.05 | 0.776 | 0.114 | 0.917 | 0.741 | 0.581 | 0.456 | 0.773 | 0.933 | 0.876 | 0.113 | 0.628 | |||||
| 0.10 | 0.867 | 0.200 | 0.957 | 0.824 | 0.738 | 0.521 | 0.858 | 0.964 | 0.932 | 0.223 | 0.709 | |||||
| 0.20 | 0.927 | 0.352 | 0.979 | 0.891 | 0.858 | 0.584 | 0.920 | 0.982 | 0.965 | 0.399 | 0.786 |
A.2 Varying Key Model Hyperparameters
We analyzed the dependency of the anomaly detection performance of our method on the number of input points, the feature dimension of the geometric descriptors, and the number of nearest neighbors used for local feature aggregation. In Table 3, we provide the numerical values for this ablation study. The values correspond to the line plots in Figure 6.
| Performance | Number of Points | Feature Dimension | Nearest Neighbors | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | 16 | 32 | 64 | 128 | 16 | 32 | 64 | 128 | 256 | 8 | 16 | 32 | 64 | ||
|
0.759 | 0.803 | 0.818 | 0.821 | 0.740 | 0.785 | 0.818 | 0.833 | 0.833 | 0.755 | 0.804 | 0.818 | 0.821 | ||
|
0.014 | 0.026 | 0.049 | 0.080 | 0.017 | 0.028 | 0.049 | 0.093 | 0.189 | 0.020 | 0.030 | 0.049 | 0.080 | ||
|
2.29 | 3.33 | 5.89 | 7.87 | 2.06 | 3.54 | 5.89 | 10.98 | 21.13 | 2.43 | 3.98 | 5.89 | 10.86 | ||
|
1.71 | 2.15 | 2.71 | 3.47 | 1.75 | 2.24 | 2.71 | 5.14 | 8.81 | 1.79 | 2.28 | 2.71 | 4.76 | ||
A.3 Modifying the Training Strategy
We further experimented with different training strategies applied to our proposed approach. We tested a randomly initialized teacher network, adding absolute point coordinates to the model, and incorporating rotation invariance to the anomaly detection training. We then investigated different pretraining datasets and pretrained feature extractors. The numerical values for these experiments are listed in Table 4. These values correspond to the bar plots in Figure 7.
|
AU-PRO |
|
AU-PRO |
|
AU-PRO | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
0.278 | ITODD | 0.820 | FCGF | 0.719 | ||||||
|
0.505 | 3DMatch | 0.819 | PPF-FoldNet | 0.682 | ||||||
|
0.650 | KITTI | 0.735 | - | - |
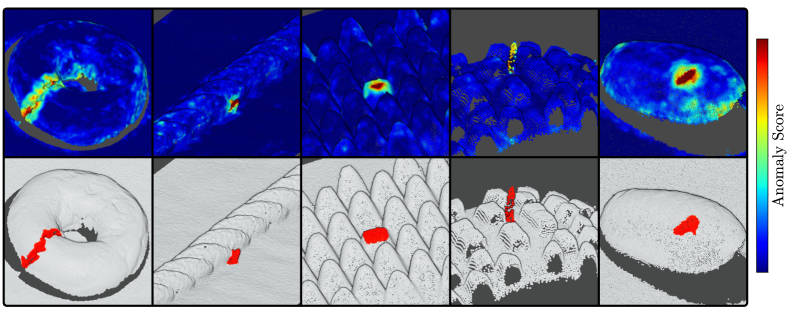
B Additional Qualitative Results
Figure 8 shows additional qualitative results of our method for each dataset category of the MVTec 3D-AD dataset for which our method reliably localizes anomalies.