Exploiting symmetry in variational quantum machine learning
Abstract
Variational quantum machine learning is an extensively studied application of near-term quantum computers. The success of variational quantum learning models crucially depends on finding a suitable parametrization of the model that encodes an inductive bias relevant to the learning task. However, precious little is known about guiding principles for the construction of suitable parametrizations. In this work, we holistically explore when and how symmetries of the learning problem can be exploited to construct quantum learning models with outcomes invariant under the symmetry of the learning task. Building on tools from representation theory, we show how a standard gateset can be transformed into an equivariant gateset that respects the symmetries of the problem at hand through a process of gate symmetrization. We benchmark the proposed methods on two toy problems that feature a non-trivial symmetry and observe a substantial increase in generalization performance. As our tools can also be applied in a straightforward way to other variational problems with symmetric structure, we show how equivariant gatesets can be used in variational quantum eigensolvers.
The advent of quantum devices that come close to outperforming classical computers in certain computational tasks [1, 2] has sparked a wealth of investigations into the capabilities of noisy intermediate-scale quantum (NISQ) devices [3]. These endeavors are aimed at exploiting the computational power of quantum computers without quantum error correction that make use of relatively short quantum circuits. A particular emphasis is put on hybrid quantum-classical approaches that use the quantum device to implement subroutines in otherwise largely classical algorithms [4].
Important areas of applications intended for these hybrid approaches include problems in quantum chemistry, classical combinatorial optimization and machine learning [5, 6]. Symmetries have always played a very important role in the analysis of physical systems, due to their frequent admitting of conserved quantities. Combining this with Noether’s theorem informs us that conserved quantities correspond to symmetries of the underlying system. In quantum chemistry, for example, solutions to ground state problems or electronic structure calculations have to respect conserved quantities such as the global particle number or the parity of fermion number and hence admit non-trivial symmetries.
The usefulness of symmetries is not limited to the domain of physical systems, however, and their role in the context of classical machine learning must not be understated. Symmetries have been pivotal in the development of successful models for image recognition that sparked a revolution in learning with artificial neural networks [7]. More recent breakthroughs, like the development of the transformer model [8], are also linked to a better understanding of the underlying symmetries of the learning task. Consequently, the rigorous treatment of symmetries in machine learning has recently culminated in the creation of the sub-field of geometric deep learning [9].
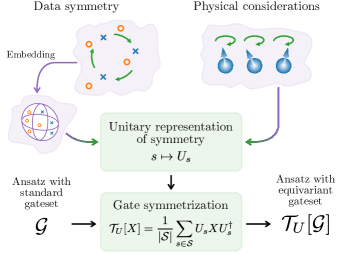
In this work, we explore how symmetries of a learning task can be exploited to create quantum learning models whose output is invariant under symmetry transformations on the level of the data. The fact that classical data has to be embedded into the Hilbert space of a quantum system makes it difficult to directly transfer ideas from the classical world to the construction of variational quantum learning models. As our main contribution, we show how to embed data in a way that enables us to build invariant learning models for which we give both a general blueprint and mathematical tools for their design.
In Sec. II, we exhibit data embeddings that give rise to meaningful representations of practically relevant data symmetries on the level of the Hilbert space, both for discrete and continuous symmetries. The trainable parts of variational quantum learning models are usually constructed using gates from a standard gateset. In Sec. III we show how the representation on the level of the Hilbert space can be exploited to symmetrize the generators of such a gateset to give rise to an equivariant gateset. We especially detail which pitfalls should be avoided when constructing an equivariant gateset. In Sec. IV we show how these building blocks can be combined to construct variational quantum data re-uploading models that make invariant predictions and thus include a meaningful inductive bias.
To elaborate on how our approaches are applied and to showcase the increase in performance, we conduct a number of numerical experiments in Sec. V. We consider the classification of games of tic-tac-toe as a paradigmatic learning task with non-trivial symmetry and show a significant increase in generalization performance that even generically holds for random constructions in the equivariant gateset. We further consider a learning task with similar symmetry properties that is inspired by a problem from the automotive industry and which can, as soon as the quantum computational resources become available, be scaled up to address the actual task. For this task, concerned with the classification of the criticality of driving scenarios for autonomous vehicles, we reach the same conclusions as for the tic-tac-toe example. We also argue that the idea of equivariant gatesets itself is not limited to applications in quantum machine learning. This is why we additionally provide numerical investigations into ground state problems of the transverse-field Ising model, the Heisenberg model and a toy model based on the longitudinal-transverse-field Ising model that exhibits the same symmetries as the tic-tac-toe problem. For these kinds of problems, equivariant ansätze usually help, but the benefit is less apparent than in the case of quantum machine learning models.
There is already a substantial amount of literature on the application of symmetries in the context of variational quantum algorithms. Explicit constructions of ansätze and gadgets for quantum chemistry problems can be found in Refs. [10, 11, 12, 13, 14, 15, 16, 17]. Another approach has been chosen by the authors of Refs. [18, 19] where symmetries were imposed through classical post-processing. An approach in the same direction as the one we outline in this work has been proposed in Ref. [20], where it has been suggested to simply remove generators that violate the symmetry or fix the parameters of the gates.
Here, we are reaching the same goal via a distinctly different route, as we propose to alter the set of generators used in the construction of the ansatz. Further works that treat symmetry-enhanced variational methods are found in Refs. [21, 22, 23]. Another possibility outside of altering the ansatz itself to enforce symmetries is to enforce them through the optimizer via the use of additional terms in the cost function that penalize asymmetric states as in Refs. [24, 25, 26]. In a different direction, Ref. [27] proposes a quantum model that closely follows the geometric deep learning blueprint [9] by having first a symmetry equivariant quantum “layer”, followed by a symmetry invariant classical “aggregator”. In particular, they propose a model for graph-based learning tasks, so the symmetry they consider is the permutation (or relabeling) of the graph nodes. Also specifically for graphs, Ref. [28] included a recipe for building permutation invariant models inspired by graph convolutional neural networks [9]. In Ref. [29], the authors look at the construction of group-equivariant ansatz states to learn quantum states. Ref. [30] proposes a construction of covariant quantum kernels that evaluate data that already comes with a group structure.
I Preliminaries
Variational quantum algorithms
Variational quantum algorithms (VQAs) [5] are a major research direction in the study of the capabilities of near-term quantum devices to solve practically relevant problems. In these hybrid quantum-classical approaches [4], a quantum device uses a parametrized quantum circuit (PQC) as an ansatz to prepare a parametrized quantum state vector . After the preparation of the state, measurements are performed in order to estimate the expectation values of a set of observables . These expectation values are then used to compute a cost function that encodes the problem of interest. Particularly prominent applications are the variational quantum eigensolver (VQE) where the cost function is given by the expectation value of a Hamiltonian whose ground state is to be approximated and the quantum approximate optimization algorithm (QAOA) which combines a specific ansatz construction with VQE to approximate solutions to classical optimization problems. As variational quantum algorithms offer an extremely flexible paradigm to tackle problems, such algorithms have been proposed for a wide variety of different problems beyond that [6].
Variational quantum learning models
With the current success of machine learning, especially neural-network based deep learning, the interest into possible gains from applying quantum computers to learning problems has come into focus, sparking the field of quantum machine learning (QML). Variational approaches as outlined above can be used to construct variational quantum learning models (VQLMs), see e.g. Refs. [31, 32, 33]. In such circuit-based models, the ansatz state does not only depend on variational parameters but also on the input data, and predictions are encoded in expectation values of observables
| (1) |
Because of the no-cloning theorem, it is important for the expressivity of quantum learning models to embed the data into the quantum circuit multiple times, a process dubbed data re-uploading [34, 35, 36]. In the following, we will therefore consider VQLMs where a fixed data-embedding unitary is interleaved with parametrized quantum circuits as
| (2) |
Symmetry groups
Symmetries are commonly captured by groups. A group is a set of objects together with a composition rule – usually called “multiplication” – so that for all . The multiplication is also required to be associative, i.e. . Furthermore, there is an identity element so that for all and that for all there exists a unique inverse element so that . A simple example of a group is where the composition is given by addition modulo 2. If a restriction of to some subset is itself a group under the composition rule of , we call this subset a subgroup.
The concept of groups also extends to continuous sets in the form of Lie groups. A real Lie group is a group which is also a smooth manifold and the composition rule and inversion are smooth maps. One example of a (non-compact) Lie group is the set of all invertible linear operators . Lie groups that are a subgroup of and can hence be expressed in terms of matrices are called matrix Lie groups and we will focus on these in the following. An example of a matrix Lie group are the unitary matrices acting on , denoted as .
Lie groups are intimately related to Lie algebras which can be seen as the generators of elements of the Lie group. For a matrix Lie group , we can define the associated algebra as
| (3) |
This is motivated by the fact that for two group elements we can understand the group multiplication on the level of the Lie algebra via the Baker-Campbell-Hausdorff formula
| (4) |
For and close to the identity element, we have that the norm of and are small in which case their commutator gives the first correction. It is actually part of the formal definition of a Lie algebra and is called the Lie bracket.
A representation of a group is a map that is compatible with the composition rule: . If the space is equipped with a scalar product and the linear maps are unitary, we call this a unitary representation.
II Symmetries induced by data embeddings
Symmetries play an important role all across physics and problems that are of interest in near-term applications are no different in this respect. A symmetry group acts on an -qubit Hilbert space through a unitary representation for .
In ground state problems – as they are encountered in the variational quantum eigensolver [37] – symmetries are usually derived from physical considerations. An example of such a symmetry, which is encountered for example in the Heisenberg-model, is that the energy of a state does not change if all spins are flipped, i.e. when the operator is applied. This can be understood as a representation of the symmetry group . Further symmetries include joint unitary transformations of all spins () or translation symmetry (). Such symmetries have already been extensively studied in the context of VQE, with a particular focus towards building symmetry-preserving ansätze for quantum chemistry applications [10, 11, 12, 13, 14, 15, 16, 17].
But ground state problems are not the only problems of interest in near-term applications that can have a symmetric structure. Indeed, many learning problems encountered in the context of quantum machine learning also have some symmetry: A prototypical example is the labeling of images. Even if we move all the pixels of a cat photo to the right or rotate it, the photo still depicts a cat. More formally, consider a task where a prediction should be associated to data points . We say that the prediction is invariant under a symmetry group with representation if
| (5) |
Notions like this have recently sparked the subfield of geometric deep learning [9] which abstractly reasons about these symmetries and their implementation in learning models, particularly in artificial neural networks. The geometric reasoning also elucidates the early success of convolutional neural networks [7] which use building blocks that respect the translation symmetry present in typical image classification tasks and the success of transformer models [8]. It is also intuitive to expect that building symmetry-invariant models comes with advantages: By definition, a symmetry-invariant model does not see any difference between data points that are related by a symmetry transformation which effectively reduces the number of possible predictions the learning model can make. Such a model has lower complexity and is thus expected to be easier to train. Furthermore, these models only produce predictions that respect the symmetry already present in the learning problem and are thus expected to generalize better to unseen data.
In the following, we will show how to construct quantum circuits that embed classical data in a way that induces a meaningful unitary representation of the symmetry on the level of the Hilbert space. These embeddings are then used as building blocks in the construction of symmetry-invariant data re-uploading models.
Introductory example
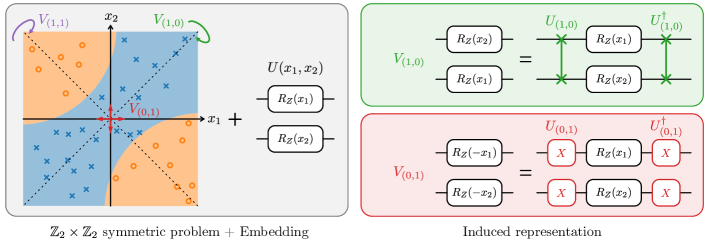
We first consider an introductory example that is given in Figure 2. Assume we have data points and the prediction – for example a classification – has the following symmetries
| (6) |
which correspond to an exchange of the coordinates and a simultaneous sign flip. The associated symmetry group, famously known as Klein’s four-group, is given by
| (7) |
with the group operation being entry-wise addition modulo 2. In this abstract definition of the symmetry group, the first component could be understood as the boolean answer to the question “do we exchange?”, and the second component as the boolean answer to the question “do we flip?”.
The representation on the level of the data is given by
ll
V_(0,0) = [1 00 1], &
V_(1,0) = [0 11 0] ,
V_(0,1) = [-1 00 -1],
V_(1,1) = [0 -1-1 0] .
If we use an embedding unitary
| (8) |
then the symmetry operations can be represented on the level of the Hilbert space as
| (9) | ||||
| (10) | ||||
| (11) | ||||
| (12) |
where we have used the fact that . Note that we could have equivalently used in the above example, so the operations are not necessarily unique.
We can use the intuition we gathered from the example to generalize the concept of an induced representation: We call a data encoding unitary equivariant with respect to the data symmetry 111We choose equivariant over the synonymous covariant as this is the terminology used in geometric deep learning. if
| (13) |
for a unitary representation of . The representation induced by our above example is then
ll
U_(0,0) = ⊗,&
U_(1,0) = ,
U_(0,1) = X ⊗X,
U_(1,1) = (X ⊗X).
In the following, we will show how we can construct data encodings which are equivariant with respect to the most important symmetry classes encountered in real-world learning tasks.
Permutation symmetries
Most data encountered in contemporary learning tasks, like images or time series data, has a discrete structure. Symmetry transformations of the data, like translating or rotating an image or translating a time series, can thus be captured by a permutation of the different data features. This means that in many relevant scenarios with symmetry, the symmetry group will be a subgroup of the permutation group (or symmetric group) of the different data features .
The elements of the symmetric groups are all possible reshufflings of the data features
| (14) |
Every permutation can be constructed by concatenating transpositions, which are exchanges of two data features at a time. We will write a transposition as such that for all we have that for some transpositions . Note that a product of transpositions is usually considered to be implemented from right to left.
In the previous section, we already saw how to construct a data encoding which is equivariant with respect to the permutation of two elements, and the construction directly generalizes to higher dimensions, needing qubits for -dimensional data. We complement this with a related construction that allows using approximately qubits but still retains equivariance. The natural construction is to embed every data feature via a Pauli rotation on a separate qubit, the choice of the generator is not relevant, so we settle for , to get
| (15) |
This encoding is obviously equivariant with respect to the permutations of the qubits and induces a representation of which is given by
| (16) |
where swaps the two qubits corresponding to the features swapped by . This embedding actually allows us to go even further than the permutation group and also equivariantly embed sign-flips of the -th coordinate by conjugating with Pauli on the -th qubit, thus generalizing to .222 This new group is the semidirect product which captures the intuition that every element can be written as the product of one permutation and a number of sign-flips .
With this strategy, we need as many qubits as data features. A natural question is whether it is possible to do better, namely if we could find a different encoding gate that embedded features in less than qubits and still be equivariant with respect to the permutation group. If we want to add another Pauli-word as a generator to the above set of local operators, we are limited by the fact that this generator has to be invariant under all operations between qubits because these should by definition only exchange the associated coordinates and not the newly added one. This means the only operator we can add is , yielding one additional data feature we could in principle encode with this strategy. In this case, the representation for exchanging the -th coordinate with the -st coordinate is a multi- gate where the -th qubit controls a simultaneous application of on the rest of the qubits.
Note that we could in principle employ a different set of mutually commuting Pauli words as any set of independent, mutually commuting Pauli words are interchangeable via Clifford-gates [38]. One example would be the set of generators which could equivalently be replaced by , which would constitute a more “balanced” encoding strategy as the operators are of similar weight. For this set of operators, the permutations are generated by the transpositions
| (17) | ||||
| (18) | ||||
| (19) |
where is a generalization of the Hadamard operator given by .
The encoding based on local -rotations is very intimately related to the IQP encoding proposed in Ref. [39]. We can use their inspiration to also include higher monomials of the data features like for example . If we embed such a monomial with a generator , where is a local acting on the -th qubit, then we see that a permutation of the features can be realized by a permutation of the qubits. An equivariant embedding of the data is then achieved by simultaneously embedding all possible permutations of monomial like , , and so on using the operators , , etc. The number of terms needed for this construction grows rather quickly because all possible permutations have to be considered. On the other, this means that we can expect to have to embed fewer terms if we only wish to realize a subgroup of the permutation group. If we consider only translations that map to , we only need to embed all possible translations of the monomial which is linear in the number of features.
While the above strategy for embedding data is straightforward to implement, we can in principle embed exponentially many data features in an equivariant way. One strategy to do so is to assign every state of the computational basis as the collection of all identified by the binary representation of the integer a generator
| (20) |
This generates unitaries which only put a phase on the amplitudes of the -th computational basis state. The transposition of features and is then easily seen to be achieved by
| (21) |
which induces a representation of the permutation group for a number of data features up to . However, contrary to the simple rotations in the example above, these rotations are very difficult to implement, as they mostly correspond to operations controlled on nearly all qubits. Furthermore, as we will see in Sec. III, if all of the available basis states are used, only trivial operations will respect the symmetry of the system.
The above example motivates that the construction of equivariant embeddings should be possible with relatively few qubits, but at the cost of very complicated gates that need to be implemented. This reduces the practicality of such an approach, especially in the NISQ era. The other extreme is the 1-local embedding proposed at the beginning of this section, which essentially only allows us to embed as many data features as there are qubits but which can be implemented very easily. It is therefore an interesting direction for future research what kind of embeddings can be defined that interpolate between these two regimes and allow to embed more data features than the 1-local embedding while still being sufficiently implementable.
Continuous symmetries
While many cases of practical interest display discrete symmetries, we need not constrain ourselves to this case. Especially when looking at possible applications in the natural sciences we can also encounter continuous symmetries, if for example rotating spatial data points around a certain axis does not alter predictions. The framework for dealing with continuous symmetries is given by Lie groups which are continuous groups with a differentiable structure.
Representation theory tells us that any compact Lie group can be expressed as a subgroup of a suitably large unitary group [40], and as any unitary group can be embedded in a larger special unitary group every Lie group can be represented on a suitably large quantum system. However, it is not a priori clear which Lie groups admit embeddings that induce a faithful unitary representation. We will show how we can construct an embedding that is equivariant with respect to the special orthogonal group in dimensions, , and show how we can extend this to the full orthogonal group . We then outline how the general task can be understood mathematically.
and
The group is made of all possible rotations of a sphere centered at the origin. For elements of the special orthogonal group, we will use lower case letters to distinguish them from their quantum counterparts. Any element can be constructed by successively applying one of the three canonical rotations about the axes of the coordinate system which we denote as and . In the following, we will use the parametrization in terms of the Euler angles given by
| (22) |
We now define an equivariant embedding of a data point as
| (23) |
where we defined the vector of Pauli operators . We can now exploit that this is essentially a mapping from data points to the Bloch sphere, of which we know that conjugation with a Pauli rotation generates the associated rotation of the Bloch sphere to obtain the induced representation. We only need that
| (24) | ||||
| (25) | ||||
| (26) |
to deduce that
| (27) | ||||
| (28) | ||||
| (29) | ||||
At this point, we recall that there is a parametrization for arbitrary unitaries , also in terms of three angles . Using this, we arrive at the desired induced representation
| (30) |
The full group of all orthogonal (i.e. length-preserving) transformations on , , is made of not only rotations but also reflections about any plane that passes through the origin. Luckily, reflections about different planes can be related by the rotation that maps the planes to one another. This means one fixed reflection, together with the three canonical rotations is enough to span the whole group . We pick the plane perpendicular to the vector , which realizes an inflection about the origin . As we have seen that we have already exhausted to represent this can not be possible using an embedding with only a single qubit. However, we can actually straightforwardly realize this inflection if we add an additional qubit and use the embedding
| (31) |
The rotations of are embedded in the same way as before on the first qubit, but now the inflection can also be realized as
| (32) | ||||
| (33) | ||||
| (34) | ||||
| (35) |
In this way, we can generate the entire group .
The general case
We have found an encoding that is equivariant with respect to transformations, but the immediate question arising from this construction is if it can be generalized to arbitrary Lie groups acting on the data. To this end, we will mathematically formalize the process that leads to an equivariant embedding. Note that it is required that the symmetry must have non-trivial finite-dimensional unitary representations which rules out interesting groups like as they are not compact groups.
We assume that the embedding of the data is of the form
| (36) |
which means that we effectively embed the data into the Lie algebra of the quantum system . We will further assume that the map from the data to the Lie algebra is linear. We model the symmetry transformation on the level of the data as a representation of the symmetry Lie group given by . Our aim is to find a map , such that the following diagram commutes:
Here, is a transformation that implements the symmetry transformation on the level of the Lie algebra in an equivariant way. This means it needs to be a conjugation by a unitary
| (37) |
for some that represents the symmetry group acting on the data. The above is nothing but the adjoint action of , which if , is generated by the adjoint action on the level of the Lie algebra
| (38) |
where . Looking back to the data space, we can use that is a matrix representation of a Lie group and that we can write for some element of the Lie algebra of , . Making the diagram commute then enforces
| (39) |
which can be quickly verified to be the case if
| (40) |
In other words, this means that, to construct an equivariant embedding for a given Lie group representation acting on the data, we need to find a subspace of – which is then the image of – such that the restriction of the adjoint representation of to this subspace is identical to the representation of the symmetry Lie algebra acting on the data, .
This elucidates why we were able to construct an embedding equivariant with respect to . It is because the fundamental representation of the Lie algebra which acts on the data is equal to the adjoint representation of . Additional to this, we can also see that there always exists a trivial embedding which induces a trivial representation of the Lie algebra. From the above reasoning, we also see that it is not enough to find a sub Lie algebra isomorphic to the one acting on the data, we really have to make sure that there is an appropriate subrepresentation of the adjoint representation of identical to the representation of on the data space. As we think that the realization of embeddings equivariant with respect to symmetries more exotic than is a topic of limited interest we leave the classification of equivariant embeddings that can be realized in this setup as a topic of further investigation.
III Gate symmetrization
As we have seen above, symmetries arise naturally in variational quantum learning models if an equivariant embedding is used. In these applications, it is paramount to construct the trainable parts of the model in a way that encodes an inductive bias suitable to the problem at hand. The problem we face is that the knowledge of the relation between parametrized quantum circuits and the associated inductive bias is not really understood, leaving us with precariously little to inform our construction of learning models. Symmetries provide a first avenue to the construction of better quantum learning models as they allow us to include knowledge about the underlying data into the model in a meaningful way. They furthermore allow us to reduce the complexity of the ansatz as measured by the number of free parameters and thus also save resources. The same holds true for other variational applications, e.g. in the search for ground states. There, the goal is not a better generalization capability but a better expressivity in the relevant parts of the Hilbert space.
In this section, we explain how we can use elementary group theory to construct an equivariant gateset from a standard gateset used in ansatz constructions, where, as we will make formal below, we define equivariant as commuting with the symmetry representation. This allows us to take an existing ansatz and to make it equivariant by replacing every gate by its equivariant counterpart. We will also explore why this approach has its advantages but is no panacea as there are several pitfalls to avoid. This sometimes makes it advisable to not build equivariance with respect to the full symmetry group into the model but to only consider subgroups thereof.
Equivariant gatesets
We will focus on gates generated by a fixed generator as
| (41) |
as they are usually encountered in ansatz constructions for variational approaches. When constructing an ansatz, gates are picked with generators from a fixed gateset .
We call a gate equivariant with respect to the symmetry embodied by a unitary representation of if the order of applying the symmetry operation and the gate itself does not matter, so that
| (42) |
This can only be the case if the generator itself commutes with the representation which is captured by the following proposition.
Proposition 1 (Commuting generators).
For a given gate we have that
| (43) |
if and only if for all .
Proof.
First, we show that the condition is necessary. For this consider the expansion of to first order
| (44) | ||||
| (45) | ||||
| (46) | ||||
| (47) |
as this relation needs to be valid also for infinitesimally small . The condition is obviously sufficient as implies that all powers of and hence the full exponential commutes with . ∎
Luckily for us, there is a straightforward way to ensure that a generator does commute with a given representation – we can make use of the twirling formula.
Proposition 2 (Twirling formula [41]).
Let be a unitary representation of . Then,
| (48) |
defines a projector onto the set of operators commuting with all elements of the representation, i.e., for all and .
The same holds true for Lie groups if we replace the uniform average with an integration over the Haar measure ,
| (49) |
We use this approach to associate to any gateset an equivariant gateset
| (50) |
Note that this approach also directly extends to gates which are not parametrized, as these gates can either be directly symmetrized via the twirling formula or they can be written as a parametrized gate with fixed evolution angle as in Eq. (41).
Ansatz symmetrization
We can now use the aforementioned gate symmetrization technique to convert a complete ansatz (or trainable block) to an equivariant ansatz (or equivariant trainable block) by replacing the ansatz’ gateset with its equivariant counterpart. The computation of the equivariant gateset can for practical purposes usually be done efficiently beforehand.
To make this more palpable, let us return to our example with an exchange symmetry on two qubits. Assume an ansatz is made up of local rotation gates generated by the Pauli operators, , and entangling gates generated by a interaction, all of which we consider as trainable. In this case, the gateset is
| (51) |
where the index identifies the qubit the Pauli is acting on. The gate already commutes with the swap operation, which means we can focus on the local operations only.
In our example, the symmetry group is , where the symmetries were generated by (exchange ) and (sign flip ). We will first consider the symmetrization over the two subgroups only to synergize afterwards.
The generator already commutes with the swap operations and thus stays invariant under symmetrization. If we apply the symmetrization with respect to the exchange symmetry to , we obtain
| (52) | ||||
| (53) | ||||
| (54) | ||||
| (55) | ||||
| (56) |
The symmetrization proceeds analogously for the other operators. We see that and map to the same operator upon symmetrization – hence, the symmetrized gateset has a lower cardinality. This means that, as expected, the subspace of symmetry-preserving unitaries is smaller than the full space of unitaries and that upon symmetrization, we reduce the number of parameters, and hence the complexity, of the ansatz. The gateset equivariant with respect to the exchange symmetry is then given by symmetric entangling gates and simultaneous Pauli rotations on the two qubits that share the same angle,
| (57) |
Now, let us look at the sign flip symmetry. Again, already commutes with and stays invariant under symmetrization. The situation is again different for the local gates. It is quite straightforward that and commute with , but this is not true for the other gates as
| (58) | ||||
| (59) | ||||
| (60) | ||||
| (61) |
where we have used the fact that . The calculation goes analogously for and also for and because . This means that the sign flip equivariant gateset looks rather different than the one for the exchange symmetry, as in this case we are only allowed local Pauli rotations
| (62) |
Due to the commuting nature of the group, we can obtain the fully equivariant gateset by applying either symmetrization procedure to the other gateset which yields
| (63) |
We see that taking into account the full symmetry greatly reduces the amount of available operations, but which comes at a cost of reduced expressivity as we will also detail further in the next section.
Pitfalls to avoid
Making an ansatz equivariant through symmetrization can bring considerable advantages but is by no means a panacea. There are important considerations and a series of pitfalls that one should be aware of.
First and foremost, there is always a trade-off between the gain in equivariance and therefore specialization to the relevant subspace and the reduction in expressivity of the ansatz. This is the point where quantum machine learning and ground state problems arguably differ the most: In machine learning applications, maximal expressivity is almost always a bad thing, as it leads to overfitting and therefore bad generalization performance. Depending on the amount of available data and the specifics of the learning model, the regime of overfitting can also be reached relatively quickly. In this case, equivariant models offer a clear advantage as they not only reduce the expressivity but they do so in a way that ensures that generalization improves. For the preparation of ground states with a given symmetry, the picture looks somewhat different. In this case, there exists no phenomenon of overfitting per se, as a lower energy is preferred even if the prepared state does not have the same symmetry as the ground state.
We can conclude that the trade-off between expressivity and equivariance should always be kept in mind. To fine-tune this trade-off, it can also be advised to only realize a subset of all existing symmetries of the problem. In our example above, one could for example opt to only respect the exchange symmetry of the problem. Another way to fine-tune expressivity of the model is by including a limited number of explicitly symmetry-breaking gates, as was for example argued in Ref. [23]. This can be especially advisable if we do not know the symmetry sector the ground state is in, so that we have to have the ability to change the sector which is impossible with purely equivariant circuits. It can furthermore happen that an equivariant circuit has an unfavorable loss landscape which can sometimes be alleviated by adding some symmetry-breaking operations.
During the symmetrization process itself, there are further pitfalls to avoid: First, we have already seen that the symmetrization procedure can trivialize certain generators. One example is the representation of given by and . We can express every single-qubit unitary as a decomposition which corresponds to using the gateset . However, neither of these generators is equivariant with respect to this representation, i.e., , leaving us with no gates, even though we started from a universal parametrization. This is in contrast to the fact that we have a set of unitaries compatible with the symmetries which is generated as . If we had chosen, for example , the trivialization would not have occurred.
Second, depending on the gates that were used to construct the ansatz it can lose universality. This can happen if the gates involved do not generate the full set of unitaries compatible with the symmetry. In the context of quantum chemistry and fermi-to-qubit mappings, 3-local unitaries are necessary to generate all possible symmetry-preserving transformations [14, 42]. If one would naively symmetrize an ansatz built from the customary single- and two-qubit gates one would loose universality.
Third, the circuit depth could increase dramatically under symmetrization. This would happen when the symmetry induces interactions which are non-local with respect to the underlying hardware and which have to be realized by extensive SWAP-chains.
We also want to note that making the ansatz equivariant is not the only way to make use of symmetries. One way to do so is to use penalty terms, which are additional parts of the cost function that increase the cost of states that have low symmetry [26, 25, 43]. This is comparable to the use of regularization terms in classical machine learning. Penalty terms can be constructed for arbitrary symmetry representations and have the charm that they act through the optimizer instead of the ansatz, which means they can be generically included to partially alleviate problems with uninformed ansätze.
IV Invariant re-uploading models
In this section, we want to summarize the construction of invariant re-uploading models. We repeat the definition of a generic data re-uploading model in our sense. We prepare an ansatz state vector consisting of repeated applications of trainable blocks and a data-encoding unitary as
| (64) |
A prediction is then obtained from the expectation value
| (65) |
of an observable. We wish to construct the quantum learning model in a way that the prediction is invariant under the action of a symmetry group acting through a representation for in the sense that
| (66) |
As we have argued in Sec. II, we can do so for quantum learning models if the data embedding is equivariant with respect to the symmetry in the sense that it induces a unitary representation of the symmetry group on the Hilbert space according to
| (67) |
If the data embedding is not equivariant we have little hope to build invariant quantum learning models as the symmetry is not meaningfully represented on the level of the Hilbert space. Under an equivariant embedding, the parts of the re-uploading model transform like
| (68) |
We can make this construction equivariant by enforcing that the trainable block is equivariant with respect to the unitary representation of , mathematically formulated as
| (69) |
As argued in Sec. III, the representation gives us a direct recipe to enforce equivariance of the trainable blocks. This is because the twirling formula
| (70) |
is a projector onto all operators that commute with the symmetry representation (a projection onto the commutant) and are thus equivariant. We use the fact that ansätze are constructed from parametrized gates with generators a gateset to define an equivariant gateset , which consists of the twirled generators of the standard gateset. The equivariant gateset now contains building blocks that can be freely combined to construct equivariant trainable blocks. Combining data embeddings equivariant with respect to the data symmetry with trainable blocks that are equivariant with respect to the induced symmetry on the Hilbert space gives rise to an equivariant circuit
| (71) |
We have so far shown how to construct equivariant circuits. To reach invariance of the final prediction, we also need an invariant initial state vector
| (72) |
As this equivalently implies that
| (73) |
If we now apply an equivariant circuit to an invariant initial state, we obtain an equivariant ansatz
| (74) | ||||
| (75) | ||||
| (76) | ||||
| (77) |
Finally, if we combine an equivariant ansatz with an invariant observable
| (78) |
we obtain an invariant re-uploading model
| (79) | ||||
| (80) | ||||
| (81) | ||||
| (82) |
Note that the conditions for invariance of the observable in Eq. (78) the condition for the equivariance of the trainable blocks in Eq. (69) are actually the same if spelled out. The reason for this apparent contradiction is that both objects are operators, but they do different things: the trainable block performs a transformation of states, but the initial state and the final observable act like objects that are transformed. The picture becomes more clear if we look at the operations in terms of their action on density matrices, i.e. if we understand them as quantum channels. Then, equivariance of a trainable block manifests as
| (83) |
whereas invariance of an observable is still realized as in Eq. (78). Both pictures come together in the fact that conjugation with an invariant object (in our case the unitary representing the trainable block) constitutes an equivariant transformation.
The construction outlined above can be viewed as the “adjoint” or “two-sided” version of the geometric deep learning blueprint where we have to start from an invariant object, the initial state, apply equivariant operations and then evaluate the expectation value again on an invariant object.
V Numerical experiments
In this section, we report on the results of numerical experiments we undertook to compare the performance of invariant learning models with their non-invariant counterparts on two selected toy problems with non-trivial symmetry. We observe that invariant learning models under-perform on the training data but have a much better generalization performance than learning models that do not respect the symmetry considerations. To ensure that the symmetrization procedure proposed in Sec. III helps generically and we did not cherry-pick a working edge-case, we also performed simulations where we randomized over the layouts of the trainable parts of our learning models that confirm our main numerics and show a generic advantage in generalization.
We have further investigated the performance of equivariant ansätze for ground state problems at the hands of the transverse-Field Ising model, the Heisenberg model and a longitudinal-transverse-field Ising model that shares the same symmetries as our learning toy problems. For these problems, and in the ansatz constructions we have studied, equivariant ansätze produce better ground state approximations on average while needing fewer iterations to converge. We further show that equivariant ansätze can mitigate the barren plateaus problem. We note, however, that the applicability picture is not as clear as in the quantum machine learning application and that equivariant ansätze can also have downsides which we discuss in detail.
Tic-tac-toe
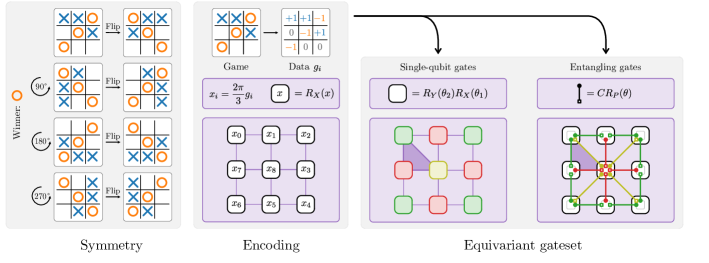
To showcase the methods outlined above we start by considering a simple training task based on the well-known game of tic-tac-toe. The goal will be to train a variational quantum learning model to classify games into the categories “cross won” (), “circle won” () or “draw” (). This classification problem has a non-trivial symmetry group, as rotating the board and reflecting the board about an axis does not change the outcome. It also has the advantage that it can be realized with equivariant embeddings on a modest number of nine qubits. The symmetries of the tic-tac-toe game are depicted on the left of Fig. 3.
The symmetry group of this learning task is given by the dihedral group , which is equivalent to all operations that map a square to itself. The dihedral group can be generated by a counter-clockwise rotation of 90 degrees and a flip about the vertical axis through the center. The group has order , so has a total of elements. The group induces equivalence classes of fields of the tic-tac-toe board, as corners of the board will always be mapped to corners, edges to edges and the center will always stay the same. These three equivalence classes will also be mirrored in the equivariant gateset.
We note that the task of labeling games of tic-tac-toe is easily solved by a classical deterministic algorithm, and in fact, only a finite number of games are even possible. The goal of this numerical example is to showcase a possible end-to-end implementation of our symmetrization procedure and to compare equivariant with standard gatesets. Furthermore, in some of the following sections, we discuss how this example can be taken as a paradigm to tackle other, potentially more useful problems.
Dataset
The first process is mapping a game of tic-tac-toe to classical data. As shown in the second column of Fig. 3, we do so by mapping the nine fields of the board to elements of a vector where represents a cross, a circle and an empty field. The labels of the game are encoded in a one-hot fashion in a vector where a value of is assigned to the correct label and to the other two entries. The number of distinct tic-tac-toe games is sufficiently small so that we were able to generate all possible valid games. In our dataset, we also allow for unfinished games, which are labeled as “draw”. The training and test data sets were then constructed by choosing a subset of all possible games of tic-tac-toe at random, with the constraint that each outcome is equally represented.
Learning model
To address the tic-tac-toe learning task, we will make use of a data re-uploading model with an equivariant embedding as described in Secs. I and II. The equivariant embedding is constructed by encoding the different numerical values that represent a game via a Pauli- rotation on separate qubits that we view in a planar grid. To distribute the three data features equidistantly, we use a multiple of for the rotation angle, again as shown in the second column of Fig. 3.
The equivariance of the embedding ensures that symmetry transformations are realized by unitary conjugation. For example, a reflection along the vertical axis is implemented by in the numbering of Fig. 3. The advantage of permutation-type symmetries on the level of qubits is that they can easily be understood on a visual level. The qubits lie in equivalence classes under the symmetry operation. Single-qubit gates then have to act on all qubits of the same equivalence class equally. This is how we get the type of equivariant single-qubit layer that is depicted in the third column of Fig. 3 where single-qubit unitaries applied that share the same parameters when acting on corners (c), on edges (e) or on the middle (m). The same reasoning can also be applied to two-qubit gates. An entangling operation that connects, for example, a corner with the edge next to it has to act in the same way on all pairs of neighboring corners and edges. This is how we obtain the equivariant layers of entangling gates used for our learning models, which perform controlled rotations from corners to neighboring edges (o), edges to the middle (i) and from the middle to the corners (d), as depicted in the fourth column of Fig. 3. We chose for parametrized rotations.
The learning model starts with all qubits initialized in the state vector, which is invariant under the problem’s symmetry. Then a number of layers are applied, each made up of one data encoding followed by a sequence of parametrized layers. The default parametrized layer was chosen to be “cemoid”, which corresponds to one application of the single-qubit gates followed by the entangling gates, both visible in Fig. 3. The prediction of a label is obtained in a one-hot-encoding by measuring the expectation values of three invariant observables
| (84) | ||||
| (85) | ||||
| (86) |
as . A prediction for a given data point is obtained by selecting the class for which the observed expectation value is the largest.
Training
We train the learning model using an -loss function, which for a set of games with associated one-hot label vectors is given by
| (87) |
We ran optimizations with 100 epochs, each consisting of 30 steps. At each step, the gradient was computed using 15 data points representing a tic-tac-toe game. The size of the training set is then the product of these two numbers . The training set is shuffled after each epoch is completed. The test set was composed of 600 games chosen randomly for each training run with the same constraint as above but kept fixed throughout the run. The above hyper-parameters were chosen empirically.
The quantum learning model was implemented with the PennyLane library [44] for quantum machine learning. Using the PyTorch interface provided by PennyLane, we trained the PQC by gradient descent as implemented by the Adam PyTorch optimizer [45].
Results
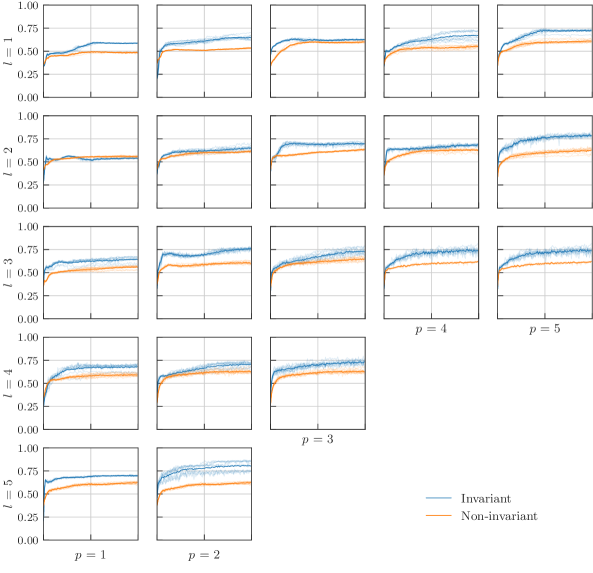
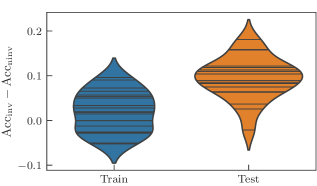
In all our numerics, we compare invariant with non-invariant models where the parameter sharing indicated in Fig. 3 is not imposed. The non-invariant models therefore have more independent parameters and hence a higher expressivity. To evaluate the performance of the models, we record the classification accuracy for the training and the test set. The general trend we observe is that invariant models built from equivariant circuits achieve the same or lower accuracy on the training set, but consistently higher accuracy on the test set which indicates their better generalization capabilities.
We first verify that this is the case for circuits of different sizes. Fig. 4 compares the results of invariant and non-invariant models composed of layers, each of which consists of one data encoding followed by independent repetitions of the layout “cemoid”. We refer to the different architectures with the pair , and we sweep over the range . Due to limited computational resources, we were unable to record the results for the values . In this experiment, the parametrized entangling gates were chosen to be , but similar experiments with different controlled Pauli rotations produce comparable results.
The difference in accuracy on the training set should not come across as odd, since invariant models only express a subset of the output mappings of the non-invariant ones. For non-invariant models, high training accuracy and low test accuracy are clear witnesses of the overfitting regime. On the contrary, for invariant models we see that the price we pay by lowering the expressivity returns a very similar performance on both previously seen and unseen data, hinting at the sweet spot in the bias-variance trade-off. Formally, we say the empirical generalization gap of invariant models is much smaller than that of non-invariant ones, which confirms our expectations.
As a sanity check, and to make sure we did not cherry-pick a working example, we studied the performance of other variational layouts different from “cemoid”. We did so by fixing the number of layers to , where after encoding the data with “t” we take three consecutive random permutations of “cemoid” without contiguous repetitions. An example of such a layout is “tdomiececiodmdmoiec”, which we then repeat three times. In total, 20 different layouts were generated and simulated. The summary of results in Fig. 5 reveals that the test performance of the invariant models is consistently higher across different layer layouts, with few exceptions. This confirms our expectations that making learning models invariant helps more or less generically to enhance generalization performance.
Classifying autonomous vehicle scenarios
The tic-tac-toe task provides an intuitive example of how we can exploit symmetry in learning, but it does not connect to a relevant real-world learning scenario. In this section, we want to outline how we can use the intuition developed in the tic-tac-toe example and apply it to a toy model of a task that is of actual relevance in the automotive industry and shows a clear way of connecting to a real-world scenario.
Autonomous driving is a future-oriented field of the automotive industry, for which two main challenges interact. First, the vehicle must be able to recognize and automatically evaluate its surroundings to deduce possible driving maneuvers to reach a goal. Second, the automated evaluation performed by the car requires verification and testing along the development cycle of the car. To meet these challenges, scenario-based development is state of the art [46]. We define a scenario as a concatenation of a scene (snapshot of the surrounding) and actions (destination goals and values). Therefore a scenario is a specific description of a driving situation, taking into account dynamic and static components which are determined by the sensor systems of the vehicle, map data, and others [47]. In the development process of the vehicle different pre-defined scenarios are classified with respect to their safety relevance according to a criticality metric. This classification will then be used to evaluate the requirements for testing, in the field or in simulation. The Pegasus Project [48] classifies the scenarios into different levels. In this publication, we concentrate on street level 1, which includes geometry and topology of the streets, in order to demonstrate our concept. Driving-maneuver classification is investigated using classical machine learning tools among other approaches [49, 50]. We again want to emphasize that, for the purpose of this paper, the original classification task is reduced to a simple version that can be simulated with the computational resources available to us. It is however clear how larger resources in terms of quantum computational hardware would allow us to address parts of the actual question as soon as it becomes available.
Dataset
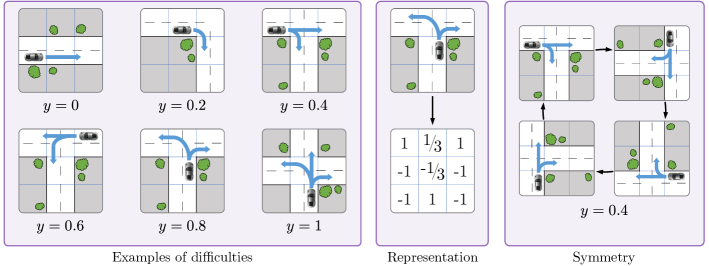
In the following, we derive driving scenarios at different street intersections, deduce the geometric symmetries and build a classification of the possible actions according to their safety relevance. Since relevant scenarios include behavior at intersections, traffic circles, and traffic jams [51], we consider the following simplified street situations, using a grid. Each tile of this grid can be either part of a road or be impassable, and a car is placed on one of the road tiles. With this encoding, we are able to represent different geometries from a straight road to a more complicated intersection. The symmetries of these scenarios are a subset of the Tic-Tac-To case as a scenario can always be rotated by 90°(see the right panel of Fig. 6), but not necessarily mirrored in all instances as left turns have a different difficulty than right turns. We translate this into a array , where a road tile is encoded with 1, an impassable tile with -1, the car with -1/3, and the orientation of the car with 1/3. An example of this can be seen in the middle panel of Fig. 6.
We rate the level of difficulty with regards to a simplified criticality metric as follows: Forward: 0; Right or left curve: 0.2; Forward and right (T-crossing, intersection of three streets): 0.4; Forward and left (T-crossing, intersection of three streets): 0.6; Left and right (T-crossing, intersection of three streets): 0.8; Forward, left and right (X-crossing, intersection of four streets): 1. Examples of the possible difficulties are visualized in the left panel of Fig. 6 alongside a representation of the data encoding and a demonstration of the symmetry.
The different scenarios were generated by first hand placing various road layouts (T-intersection, left curve, X-intersections…), generating all their images under rotations and reflections and then putting the car on every possible road tile. Additionally, every possible orientation of a placed car is iterated. This process creates the total set of possible scenarios and their associated difficulty .
As for the tic-tac-toe games, training and test data sets were constructed by choosing a subset of scenarios at random, with the constraint that each difficulty level is equally represented.
Learning model
The general circuit construction is essentially the same as in the tic-tac-toe case and follows the data re-uploading models as described in Secs. I and II. The different numerical values that represent a scene are encoded via a Pauli-X rotation on the separate qubits where the rotation angle is given by a multiple of the array value as in the tic-tac-toe case. The key difference to the tic-tac-toe case is the missing mirror symmetry, rendering the actual symmetry group to instead of . This only affects the outer layer (o) and splits it into two distinct sub-layers: one where controlled operations are performed clockwise with shared parameters and one where controlled operations are performed counter-clockwise with shared parameters.
As in the tic-tac-toe case, all qubits are initialized in the state and layers of data-encoding followed by parametrized gates are applied. The default topology for the parametrized blocks was again chosen to be “cemoid”, where it is understood that the outer layer (o) splits into two sub-layers as explained above. The model’s prediction of difficulty is obtained by measuring and normalizing the Pauli-Z expectation value of the middle qubit
| (88) |
A hard prediction for a given scenario is obtained by rounding to the nearest difficulty in .
Training
The learning model is trained using an -loss function which is, for a set of games , given by
| (89) |
No epochs were used in this case and optimizations were run with 30 steps. At each step, the gradient was computed for the same 60 scenes. As the limited grid size of only allowed four difficulty 1 [X-Crossing] scenarios, random copies were created to ensure an equal distribution (ten games of each difficulty). After each step, the accuracy on the training data and the test data, which consisted of 130 unique games, was evaluated by calculating the fraction of correctly classified inputs. The above hyper-parameters were again chosen empirically. The numerical experiments have been performed using the PennyLane library [44]. For the two-qubit gates, only the -gate has been implemented. All optimizations have been executed using the PyTorch L-BFGS-optimizer [45].
Results
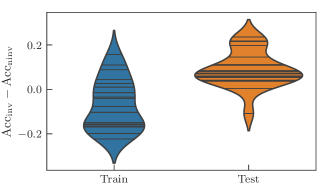
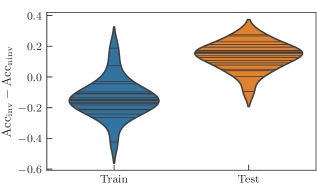
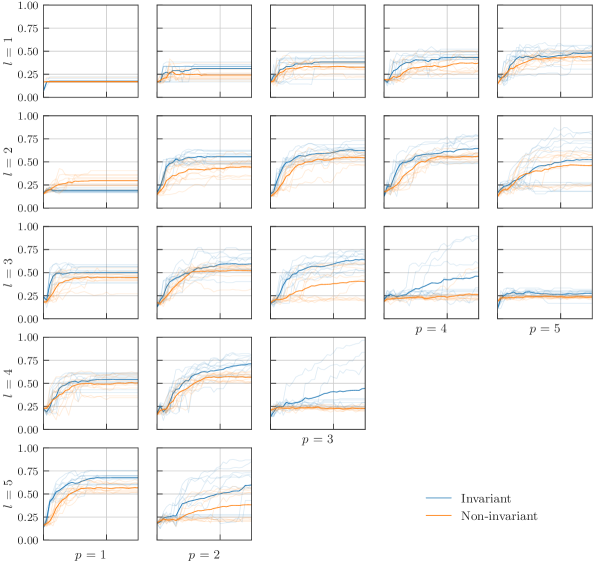
We repeat the experiments we designed for the tic-tac-toe learning task, now with this different dataset. As expected, we observe the same general trend. We repeat that we compare an invariant model with the non-invariant model obtained from the invariant one where the parameter sharing indicated in Fig. 3 is not imposed. The non-invariant models therefore have more independent parameters and hence a higher expressivity. To evaluate the performance of the models, we record the classification accuracy for the training and the test set.
We again study different hyperparameters for the architecture of the learning model. Recall that we use layers consisting of a data encoding followed by repetitions of the atom “cemoid”. We sweep over the range except for the values , and . As can be seen in Fig. 7, most invariant learning models perform worse than non-invariant models on the training set and better on the test set. A straightforward explanation would be the position the different models take in the bias-variance trade-off: overfitting regime for non-invariant models, and sweet-spot for invariant models. The full data found in Fig. 15 in the appendix further supports this intuition as it shows a drop in accuracy for high values, where the expressivity of both models is found empirically to be too high for this task. This experiment crystallizes in the statement: invariant models generalize better than non-invariant models.
We also repeat the randomization experiment over the specific spelling of the trainable parts, with the results being reported in Fig. 8. We make circuits with a random layer repeated times. Random layers start with a data encoding followed by three consecutive random permutations of “cemoid”, such that there are no repeated letters adjacent. Again, in almost every case the invariant models outmatch the non-invariant ones.
Variational quantum eigensolvers
The gate symmetrization procedure proposed in this work only necessitates the existence of a unitary symmetry representation on the level of the Hilbert space. It can therefore also be applied to ground state problems where conserved quantities of the Hamiltonian yield representations of symmetries. This case is paradigmatically treated through a variational algorithm using the variational quantum eigensolver. In the following, we will conduct some numerical experiments that showcase the advantages and disadvantages of generic symmetrization in this context.
Transverse-field Ising model
We will first consider the transverse-field Ising model (TFIM) [52] as a paradigmatic example. The TFIM Hamiltonian with periodic boundary conditions on spins is given by
| (90) |
where we consider a transverse field strength .
The TFIM Hamiltonian has a symmetry as it commutes with the parity operator
| (91) |
The unitary representation is then given by for . The eigenvalues of the parity operator are either or . For the ground state is given by which has a parity of . Using the adiabatic theorem and the fact that for finite system size the ground state energy is not degenerate we can conclude that the parity of the ground state is the same for each . Therefore, if we want to force our ansatz state to encode this symmetry, we require that
| (92) |
Of course, it is not necessary for our ansatz to respect this property for all values of the parameters as long as it finds the correct ground state, but in many cases it can be beneficial to restrict the expressivity of the ansatz into a relevant part of the Hilbert space. If we do this, however, we have to assure that the ansatz does produce a state that is in the same symmetry sector as the true ground state. This can be assured by taking an initial state that has the correct symmetry, for example , and then only performing equivariant gates that can be obtained from the symmetrization procedure of Sec. III. We note again that one has to be attentive to the fact that symmetrization has to be executed with care as it can trivialize certain generators.
In our numerical experiments, we use the QAOA ansatz [53] which can be easily seen to be equivariant with respect to the parity symmetry,
| (93) | ||||
Here, is the number of QAOA layers. We compare it to a variant of the QAOA ansatz which we denote as QAOA’ where we add an additional mixer term involving Pauli- rotations increases the expressivity as
| (94) | ||||
As the gate symmetrization procedure of Sec. III will remove these Pauli- rotations and will yield the standard QAOA ansatz, which has been widely studied and shown [54, 55, 56, 57, 56] to provide a faithful ground state approximation for the TFIM when , while for the QAOA ansatz can only reach a variational energy which is above the ground state energy [55] due to light-cone arguments [54]. This behavior can also be observed in our experiments.
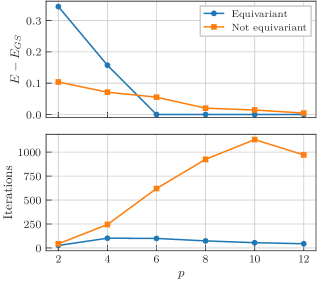
We compare the performance of the two ansätze using the TFIM with spins and different values for the number of QAOA layers . We optimize using the L-BFGS optimizer until convergence is reached. We perform the optimization for 20 random initializations of the circuit parameters and average the results to arrive at the statistics shown in Fig. 9. For all values of , the QAOA ansatz needs fewer iterations to converge. For small , we observe that the QAOA ansatz does not converge to a good approximation of the ground state which is in line with the aforementioned previous findings. In this regime, it is outperformed by the non-equivariant ansatz, highlighting the trade-off between expressivity and equivariance. If the circuit depth is large enough, the picture reverses and the equivariant QAOA ansatz reliably reaches the ground state whereas the non-equivariant QAOA’ ansatz converges to an energy above the ground state on average.
Heisenberg model
Another model that has a continuous symmetry group is given by the Heisenberg model [52] with periodic boundary conditions on an even number of spins captured by the Hamiltonian
| (95) |
We can understand this Hamiltonian as the alignment of two neighboring spins. Quite logically, if we rotate all spins simultaneously, the relative alignment will not change. The symmetry group of the model is thus represented by
| (96) |
As in the previous example, we initialize the quantum computer in a state that lies in the right symmetry sector, which in the case of the Heisenberg model is given by all states that have zero total spin, and we choose
| (97) |
For the Heisenberg model, we start from the non-equivariant ansatz
| (98) | ||||
where is an anisotropic Heisenberg Hamiltonian defined on the even lattice sites, i.e. ,
| (99) | ||||
The Hamiltonian is analogously defined but acts on the odd sites. For the even and odd Hamiltonians we have three parameters each, together with the parameter controlling the Pauli- rotation we have seven parameters per layer, yielding parameters in total. We note that since and are both linear combinations of commuting operators, we can decompose the corresponding unitaries using two-qubit gates.
The above ansatz is not equivariant, which means we need to apply the symmetrization procedure. The symmetrization procedure corresponds to a particular instance of a 2-design twirl
| (100) | ||||
| (101) |
These calculations can be straightforwardly performed using the Weingarten calculus (see, e.g. , Ref. [58]). The important fact for us is that any outcome of 2-design twirl will be a sum of identity and SWAP,
| (102) | ||||
| (103) |
where we have used the expansion of SWAP into Pauli words. Note that identity terms only generate global phases, which means that the effective symmetrized generator associated to can be taken to be
| (104) |
This generator gives rise to the particle-number conserving Givens rotations [59]. The additional Pauli- rotation in turn is trivialized by the symmetrization procedure
| (105) |
where we have exploited the formula associated to first moment operator [60].
The same argument holds for the other terms, which yields the equivariant ansatz
| (106) | ||||
where we have chosen and to be the isotropic variants given by . The equivariant ansatz we obtain with the symmetrization procedure has the same form as the Hamiltonian variational ansatz used in Ref. [57, 55]. Note that the equivariant ansatz has parameters in total compared to the of the non-symmetric ansatz.
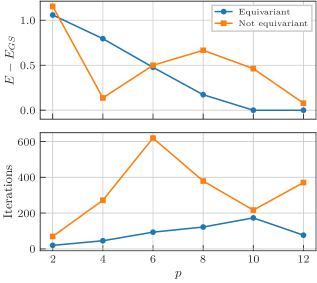
We compare the performance of the two ansätze using the Heisenberg model with spins and different values for the number of layers . As in the TFIM numerics, we optimize using the L-BFGS optimizer until convergence is reached and average the outcomes over 20 random initializations of the circuit parameters to arrive at the data shown in Fig. 10.
We see that the equivariant ansatz reaches its minimum energy faster across all depths. However, only for a large enough depth it can outperform the non-equivariant ansatz in terms of the energy expectation value. This nicely shows the trade-off between expressivity and symmetrization, as for small the increased expressivity of the non-equivariant ansatz is at an advantage over the equivariance of the symmetrized ansatz. However, as soon as the equivariant ansatz becomes sufficiently expressive, the picture reverses.
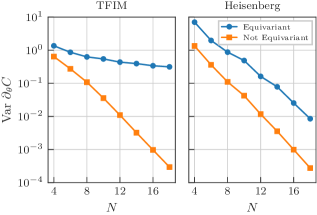
Barren plateaus
In a further numerical experiment that uses the same setups as above – TFIM and Heisenberg model – we analyze the influence of our symmetrization procedure on the barren plateaus phenomenon [61, 62]. Symmetrization reduces the expressivity of the ansatz by reducing the number of free parameters and additionally alters the dynamical Lie algebra associated with the ansatz generators, which is known to be intimately related to barren plateaus [63]. We therefore expect that the equivariant ansatz will have larger gradients in the applications studied here. In Fig. 11, we can indeed observe that the barren plateaus phenomenon is mitigated by the symmetrization procedure. For the transverse-field Ising model, the gradient decay of the equivariant ansatz is consistent with the polynomial scaling predicted by the reduced dimension of the dynamical Lie algebra found in Ref. [63], whereas the non-equivariant ansatz shows an exponential decay. In the case of the Heisenberg model, the equivariant ansatz shows an exponential decay like its non-equivariant counterpart, but the gradient magnitude is enhanced and we see signs of a slightly slower decay exponent.
Tic-tac-toe LTFIM
The last model we analyze is a variant of the longitudinal-transverse-field Ising model (LTFIM) defined on a two-dimensional lattice of nine sites. This model is constructed such that it has the same geometric symmetry as the tic-tac-toe example that we encountered above. We can write the Hamiltonian as
| (107) |
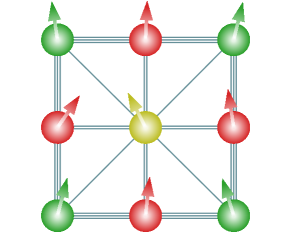
where determines the interaction of the spins. As shown in Fig. 12, we distinguish three families of edges through their interaction strength: those in the contour of the lattice (triple lines in the figure), those along the diagonals (single lines), and those at the inside (double lines).
So we choose to be
| (108) |
where every term is a sum of the interactions for the given set of edges
| (109) |
This model has clear geometric symmetries which are the same we have used in the tic-tac-toe learning task. In Fig. 12, we have represented the qubits that are equivalent under symmetry transformation with the same colors. Note that we have three independent families of qubits and also of edges.
For this model, we use an ansatz which is composed of repeated layers of entangling rotations for each edge in Fig. 12, Pauli- and Pauli- rotation on each qubit. The symmetrization procedure will enforce that the gate parameters of the gates are the same for equivalence classes of edges for the entangling gates and for equivalence classes of spins for the single-qubit gates. Thus in the non-symmetric case, we have free parameters in total, while in the symmetric one we have a reduction to free parameters. The invariant state vector is used as the initial state.
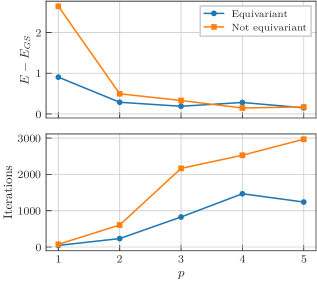
We numerically tested the performance of the two ansätze in a manner similar to that of previous models as shown in Fig. 13. We can conclude that in this model, the equivariant ansatz performs better on average than the non-equivariant one, both in achieved energy and number of needed iterations for the circuit depths we tested. However, we see that there is an uptick in the energy achieved by the equivariant ansatz for larger layers which probably indicates that this advantage is not stable against increasing the depth of the circuit. This underscores the fact that symmetrization is usually expected to be helpful, but it still is a tool that needs to be treated with care as it is no panacea.
Discussion
In the examples shown above, we examined different figures of merit, such as the final energy, the required iterations for the optimizer, and barren plateaus, to see if the use of an equivariant ansatz can yield better performance. We verified that in some cases it actually does, especially in the number of iterations necessary to reach a solution. We attribute this to the reduction in the number of free parameters of the model, which simplifies the underlying optimization problem. However, the picture is less clear when looking at the achievable minimal energy. In our numerics, we observed the trade-off between the gain in equivariance of the ansatz on one hand and the reduction in expressivity on the other hand. Especially at small circuit depths, it can be advantageous to have a non-equivariant ansatz that can explore larger portions of the Hilbert space, whereas at larger circuit depths the restriction of the expressivity to the relevant subspace of the Hilbert space can help.
This further motivates the use of carefully engineered symmetry-breaking in conjunction with equivariant ansätze, especially at small circuit depths as was explored in Ref. [23]. A theoretical underpinning to this reasoning was given in Ref. [64], where it was shown that an ansatz that preserves parity symmetry, such as QAOA with a shallow circuit, may be an obstacle for the preparation of the ground state of certain Hamiltonians. It is therefore of essence to further clarify the conditions under which an equivariant ansatz can lead to better performance in ground state preparation problems.
VI Summary and outlook
In this work, we have laid the foundations for the construction of variational quantum learning models that make predictions invariant under a symmetry transformation of the data. We have shown that the embedding of the data into the Hilbert space of the quantum system plays a crucial role and that it has to be chosen suitably to induce a meaningful unitary representation of the data symmetry on the level of the Hilbert space. We have provided embeddings that allow doing this for the most important symmetries encountered in contemporary learning scenarios, namely permutation-type symmetry, and also embeddings that induce a meaningful representation of the Lie group of orthogonal spatial transformations.
With the unitary representation of the symmetry at hand, we show how elementary results from representation theory can be used to construct equivariant gatesets from standard gatesets used for the construction of variational quantum learning models. Armed with these gatesets, the construction of invariant re-uploading models becomes possible: alternating layers of equivariant data embeddings and equivariant trainable blocks applied to a symmetry-invariant initial state yield invariant predictions when evaluated on a symmetry-invariant observable. In this way, we give both a blueprint and tools for the construction of invariant variational quantum machine learning models. Moreover, using equivariant gatesets is a much needed building block that allows us to inform decisions about how to construct quantum learning models which is a first step to a solution of the quantum model selection problem. To increase the applicability of these tools, we also outlined the pitfalls that one should avoid when using them.
The numerical experiments we have conducted on the tic-tac-toe toy example and the autonomous vehicles toy problem have confirmed our expectation that invariant learning models indeed have better generalization capabilities, as their expressivity is constrained to a set of output functions that include some knowledge about the underlying data. We have also ensured that we did not cherry-pick the results by comparing random invariant model architectures with their non-invariant counterparts where we have observed the same results.
As the existence of a unitary symmetry representation is sufficient for the construction of equivariant gatesets, these can also be applied to problems outside the realm of variational quantum machine learning. We paradigmatically explore this possibility by comparing equivariant with non-equivariant ansatz circuits for ground state type problems where conserved quantities of the Hamiltonian give rise to a symmetry. Our analysis on the transverse-field Ising model, the Heisenberg model and a variant of the longitudinal-transverse-field Ising model with geometric symmetry allow us to conclude that equivariant ansätze can be helpful in this application as well. They often allow to reach a better energy estimate in fewer iterations and help to alleviate the problem of barren plateaus. Nevertheless, the picture is not as clear as in the learning scenario which we discussed in detail.
We have studied the question of equivariant quantum embeddings for the case of . But there is no fundamental reason why other Lie groups that constitute a data symmetry should not also be amenable to equivariant quantum embeddings. While this is a somewhat exotic direction from the perspective of real-world learning tasks, we expect that future research into the interplay between data embeddings in the quantum system’s Lie algebra and unitary representations of the symmetry on the level of the Hilbert space will allow us to learn much more about the inner workings of variational quantum learning models.
Another interesting direction for future research is to prove rigorous results about the generalization capabilities of invariant quantum machine learning models, with the aim to find quantitative expressions of how much exploiting a particular symmetry helps to better solve the learning task at hand. One should also note that we have only run numerical experiments on maximally nine qubits for the learning problems, as our computational resources have been limited. In the future, it will be interesting to compare invariant variational quantum learning models to classical models on more realistic learning tasks.
Finally, it is our hope that this work stimulates further research efforts aimed at exploiting symmetry in variational quantum algorithms in the context of quantum machine learning and beyond.
Acknowledgments
The authors would like to thank Hakop Pashayan and Regina Kirschner for insightful discussions and Matthias Caro, Simon Marshall, Sergi Masot, Franz Schreiber, Adrián Pérez-Salinas, and Andrea Skolik for useful comments on an earlier version of this manuscript. F. A. acknowledges the support of the Alexander von Humboldt Foundation. We thank the BMBF (Hybrid), the BMWK (PlanQK), the QuantERA (HQCC), the Munich Quantum Valley (K8) and the Einstein Foundation (Einstein Research Unit on Quantum Devices) for their support. We also thank the Porsche Digital GmbH.
Author contributions
J. J. M. conceived and supervised the project. J. J. M. E. G. F. and F. A. developed the theory for equivariant embeddings and gate symmetrization. M. M. and F. A. conducted the quantum machine learning experiments based on ideas by F. A., M. M., A. W. A. A. M. conceived and conducted the ground state search experiments. A. W. and J. E. supported research and development. All authors contributed to the writing of the manuscript under the lead of J. J. M.
Data availability
Code for implementations and data of the numerical experiments conducted in this work will be made available upon reasonable request.
Note added
During the finalization of this manuscript, Ref. [65] was published which has conceptual overlap with our work, especially in the definition of invariant and equivariant models. However, the authors of Ref. [65] consider a different setting, where learning is performed on quantum states rather than classical data, and focus on binary classification. Our work discusses how and when symmetries on the level of the quantum system arise when dealing with classical data symmetries and how we can then exploit these to construct invariant learning models. As our techniques can also be readily applied to the setting of Ref. [65], we give a way of constructing equivariant architectures as left as a future direction in their work.
References
- Arute et al. [2019] F. Arute et al., Nature 574, 505 (2019).
- Wu et al. [2021] Y. Wu, W.-S. Bao, S. Cao, F. Chen, M.-C. Chen, X. Chen, T.-H. Chung, H. Deng, Y. Du, D. Fan, et al., Phys. Rev. Lett. 127, 180501 (2021).
- Preskill [2018] J. Preskill, Quantum 2, 79 (2018).
- McClean et al. [2016] J. R. McClean, J. Romero, R. Babbush, and A. Aspuru-Guzik, New J. Phys. 18, 023023 (2016).
- Cerezo et al. [2021] M. Cerezo, A. Arrasmith, R. Babbush, S. C. Benjamin, S. Endo, K. Fujii, J. R. McClean, K. Mitarai, X. Yuan, L. Cincio, et al., Nature Reviews Physics 3, 625 (2021).
- Bharti et al. [2022] K. Bharti, A. Cervera-Lierta, T. H. Kyaw, T. Haug, S. Alperin-Lea, A. Anand, M. Degroote, H. Heimonen, J. S. Kottmann, T. Menke, et al., Rev. Mod. Phys. 94, 015004 (2022).
- LeCun et al. [1989] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel, Neural Computation 1, 541 (1989).
- Vaswani et al. [2017] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, in Advances in Neural Information Processing Systems (Curran Associates, Inc., 2017), vol. 30.
- Bronstein et al. [2021] M. M. Bronstein, J. Bruna, T. Cohen, and P. Veličković, Geometric deep learning: Grids, groups, graphs, geodesics, and gauges (2021), arXiv:2104.13478.
- Liu et al. [2019] J.-G. Liu, Y.-H. Zhang, Y. Wan, and L. Wang, Phys. Rev. Res. 1, 023025 (2019).
- Gard et al. [2020] B. R. T. Gard, L. Zhu, G. S. Barron, N. J. Mayhall, S. E. Economou, and E. Barnes, npj Quant. Inf. 6, 1 (2020).
- Setia et al. [2020] K. Setia, R. Chen, J. E. Rice, A. Mezzacapo, M. Pistoia, and J. D. Whitfield, J. Chem. Th. Comp. 16, 6091 (2020).
- Anselmetti et al. [2021] G.-L. R. Anselmetti, D. Wierichs, C. Gogolin, and R. M. Parrish, New J. Phys. 23, 113010 (2021).
- Arrazola et al. [2021a] J. M. Arrazola, O. Di Matteo, N. Quesada, S. Jahangiri, A. Delgado, and N. Killoran, Universal quantum circuits for quantum chemistry (2021a).
- Vogt et al. [2021] N. Vogt, S. Zanker, J.-M. Reiner, M. Marthaler, T. Eckl, and A. Marusczyk, Quant. Sc. Tech. 6, 035003 (2021).
- Zhang et al. [2021] F. Zhang, N. Gomes, N. F. Berthusen, P. P. Orth, C.-Z. Wang, K.-M. Ho, and Y.-X. Yao, Phys. Rev. Res. 3, 013039 (2021).
- Barron et al. [2021] G. S. Barron, B. R. T. Gard, O. J. Altman, N. J. Mayhall, E. Barnes, and S. E. Economou, Phys. Rev. App. 16, 034003 (2021).
- Seki et al. [2020] K. Seki, T. Shirakawa, and S. Yunoki, Phys. Rev. A 101, 052340 (2020).
- Seki and Yunoki [2022] K. Seki and S. Yunoki, Phys. Rev. A 105, 032419 (2022).
- Herasymenko and O’Brien [2021] Y. Herasymenko and T. E. O’Brien, Quantum 5, 596 (2021).
- Selvarajan et al. [2022] R. Selvarajan, M. Sajjan, and S. Kais, Symmetry 14, 457 (2022).
- Lyu et al. [2022] C. Lyu, X. Xu, M.-H. Yung, and A. Bayat, Symmetry enhanced variational quantum eigensolver (2022), arXiv:2203.02444.
- Park [2021] C.-Y. Park, Efficient ground state preparation in variational quantum eigensolver with symmetry breaking layers (2021), arXiv:2106.02509.
- Bookatz et al. [2015] A. D. Bookatz, E. Farhi, and L. Zhou, Phys. Rev. A 92, 022317 (2015).
- Ryabinkin and Genin [2018] I. G. Ryabinkin and S. N. Genin, Symmetry adaptation in quantum chemistry calculations on a quantum computer (2018), arXiv:1812.09812.
- Kuroiwa and Nakagawa [2021] K. Kuroiwa and Y. O. Nakagawa, Phys. Rev. Res. 3, 013197 (2021).
- Mernyei et al. [2021] P. Mernyei, K. Meichanetzidis, and İ. İ. Ceylan, Equivariant quantum graph circuits (2021), arXiv:2112.05261.
- Verdon et al. [2019] G. Verdon, T. McCourt, E. Luzhnica, V. Singh, S. Leichenauer, and J. Hidary, Quantum graph neural networks (2019), arXiv:1909.12264.
- Zheng et al. [2021] H. Zheng, Z. Li, J. Liu, S. Strelchuk, and R. Kondor (2021), arXiv:2112.07611.
- Glick et al. [2021] J. R. Glick, T. P. Gujarati, A. D. Corcoles, Y. Kim, A. Kandala, J. M. Gambetta, and K. Temme, Covariant quantum kernels for data with group structure (2021), arXiv:2105.03406.
- Mitarai et al. [2018] K. Mitarai, M. Negoro, M. Kitagawa, and K. Fujii, Phys. Rev. A 98, 032309 (2018).
- Benedetti et al. [2019] M. Benedetti, E. Lloyd, S. Sack, and M. Fiorentini, Quant. Sc. Tech. 4, 043001 (2019).
- Schuld et al. [2020] M. Schuld, A. Bocharov, K. M. Svore, and N. Wiebe, Phys. Rev. A 101, 032308 (2020).
- Pérez-Salinas et al. [2020] A. Pérez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, and J. I. Latorre, Quantum 4, 226 (2020).
- Schuld et al. [2021] M. Schuld, R. Sweke, and J. J. Meyer, Phys. Rev. A 103, 032430 (2021).
- Jerbi et al. [2021] S. Jerbi, L. J. Fiderer, H. P. Nautrup, J. M. Kübler, H. J. Briegel, and V. Dunjko, Quantum machine learning beyond kernel methods (2021), arXiv:2110.13162.
- Peruzzo et al. [2014] A. Peruzzo, J. McClean, P. Shadbolt, M.-H. Yung, X.-Q. Zhou, P. J. Love, A. Aspuru-Guzik, and J. L. O’Brien, Nature Comm. 5, 4213 (2014).
- Aaronson and Gottesman [2004] S. Aaronson and D. Gottesman, Phys. Rev. A 70, 052328 (2004).
- Havlíček et al. [2019] V. Havlíček, A. D. Córcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, and J. M. Gambetta, Nature 567, 209 (2019).
- Folland [2016] G. B. Folland, A course in abstract harmonic analysis (Chapman and Hall/CRC, 2016), 0th ed.
- Helsen [2021] J. Helsen, Quantum information in the real world: Diagnosing and correcting errors in practical quantum devices (2021), PhD thesis, URL http://resolver.tudelft.nl/uuid:312b719d-32bc-4219-82bb-8e6febc2abcc.
- Oszmaniec and Zimborás [2017] M. Oszmaniec and Z. Zimborás, Phys. Rev. Lett. 119, 220502 (2017).
- Yen et al. [2019] T.-C. Yen, R. A. Lang, and A. F. Izmaylov, J. Chem. Phys. 151, 164111 (2019).
- Bergholm et al. [2020] V. Bergholm, J. Izaac, M. Schuld, C. Gogolin, M. S. Alam, S. Ahmed, J. M. Arrazola, C. Blank, A. Delgado, S. Jahangiri, et al. (2020), arXiv:1811.04968.
- Paszke et al. [2019] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, et al., in Advances in Neural Information Processing Systems 32, edited by H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett (Curran Associates, Inc., 2019), pp. 8024–8035.
- Menzel et al. [2018] T. Menzel, G. Bagschik, and M. Maurer, Scenarios for development, test and validation of automated vehicles (2018), arXiv:1801.08598.
- Geyer et al. [2014] S. Geyer, M. Baltzer, B. Franz, S. Hakuli, M. Kauer, M. Kienle, S. Kwee-Meier, T. Weigerber, K. Bengler, R. Bruder, et al., Intelligent Transport Systems, IET 8, 183 (2014).
- Steimle et al. [2021] M. Steimle, T. Menzel, and M. Maurer, IEEE Access 9, 147828 (2021).
- Sonka et al. [2017] A. Sonka, F. Krauns, R. Henze, F. Küçükay, R. Katz, and U. Lages, in 2017 IEEE Intelligent Vehicles Symposium (IV) (2017), pp. 97–102.
- Xie et al. [2018] J. Xie, A. R. Hilal, and D. Kulić, IEEE Sen. J. 18, 4777 (2018).
- Schwab [2019-05-10] A. Schwab (2019-05-10), Eine Methode zur Auswahl kritischer Fahrszenarien für automatisierte Fahrzeuge anhand einer objektiven Charakterisierung des Fahrverhaltens, URL https://mediatum.ub.tum.de/doc/1518844/1518844.pdf.
- Franchini [2017] F. Franchini, An introduction to integrable techniques for one-dimensional quantum systems (Springer International Publishing, 2017).
- Farhi et al. [2014] E. Farhi, J. Goldstone, and S. Gutmann, A quantum approximate optimization algorithm (2014), arXiv:1411.4028.
- Mbeng et al. [2019] G. B. Mbeng, R. Fazio, and G. Santoro, Quantum annealing: a journey through digitalization, control, and hybrid quantum variational schemes (2019), arXiv:1906.08948.
- Ho and Hsieh [2019] W. W. Ho and T. H. Hsieh, SciPost Phys. 6, 029 (2019).
- Wierichs et al. [2020] D. Wierichs, C. Gogolin, and M. Kastoryano, Phys. Rev. Res. 2, 043246 (2020).
- Wiersema et al. [2020] R. Wiersema, C. Zhou, Y. de Sereville, J. F. Carrasquilla, Y. B. Kim, and H. Yuen, PRX Quantum 1, 020319 (2020).
- Puchała and Miszczak [2017] Z. Puchała and J. Miszczak, Bulletin of the Polish Academy of Sciences Technical Sciences 65, 21 (2017).
- Arrazola et al. [2021b] J. M. Arrazola, O. Di Matteo, N. Quesada, S. Jahangiri, A. Delgado, and N. Killoran, Universal quantum circuits for quantum chemistry (2021b), arXiv:2106.13839.
- Kliesch and Roth [2021] M. Kliesch and I. Roth, PRX Quantum 2, 010201 (2021).
- Holmes et al. [2022] Z. Holmes, K. Sharma, M. Cerezo, and P. J. Coles, PRX Quantum 3, 010313 (2022).
- McClean et al. [2018] J. R. McClean, S. Boixo, V. N. Smelyanskiy, R. Babbush, and H. Neven, Nature Comm. 9, 4812 (2018).
- Larocca et al. [2021] M. Larocca, P. Czarnik, K. Sharma, G. Muraleedharan, P. J. Coles, and M. Cerezo, Diagnosing barren plateaus with tools from quantum optimal control (2021).
- Bravyi et al. [2020] S. Bravyi, A. Kliesch, K. R, and E. Tang, Phys. Rev. Lett. 125, 260505 (2020).
- Larocca et al. [2022] M. Larocca, F. Sauvage, F. M. Sbahi, G. Verdon, P. J. Coles, and M. Cerezo, Group-invariant quantum machine learning (2022), arXiv:2205.02261.
Appendix A Additional figures