VPAIR - Aerial Visual Place Recognition and Localization
in Large-scale Outdoor Environments
Abstract
Visual Place Recognition and Visual Localization are essential components in navigation and mapping for autonomous vehicles especially in GNSS-denied navigation scenarios. Recent work has focused on ground or close to ground applications such as self-driving cars or indoor-scenarios and low-altitude drone flights. However, applications such as Urban Air Mobility require operations in large-scale outdoor environments at medium to high altitudes. We present a new dataset named VPAIR. The dataset was recorded on board a light aircraft flying at an altitude of more than 300 meters above ground capturing images with a downwardfacing camera. Each image is paired with a high resolution reference render including dense depth information and 6-DoF reference poses. The dataset covers a more than one hundred kilometers long trajectory over various types of challenging landscapes, e.g. urban, farmland and forests. Experiments on this dataset illustrate the challenges introduced by the change in perspective to a bird’s eye view such as in-plane rotations. The dataset will be made publicly available under https://github.com/AerVisLoc/vpair.
I Introduction
Following the increased interest in autonomous vehicles research a number of datasets have been released that address Visual Place Recognition (VPR) and/or Visual Localization (VL) from the perspective of the self-driving car, e.g. [1, 2]. Other datasets were recorded from modalities such as ground robots [3], a railroad system [4] handheld-devices [5] or aerial platforms in indoor [6] or low-altitude-outdoor environments [7]. However, they all share a similar camera perspective where the scene is close to the camera’s position and the camera is oriented mostly in an upright manner.
On the other hand there is an increasing number of applications for autonomous flying vehicles in large-scale outdoor scenarios e.g. logistics [8], patrolling [9], inspection [10] and even personal transportation [11]. As regulatory bodies start to plan to integrate autonomous unmanned aerial vehicles into regular airspace by the end of the decade [12] there will be a need for alternatives to satellite-based navigation. One could argue that at high altitudes the reception quality of satellite signals would be favorable. However, global satellite navigation systems (GNSS) are very vulnerable to accidental or malicious radio frequency interruptions (jamming) or fake signals (spoofing) [13]. Safe aviation requires back up systems, especially without a human pilot. True autonomous flight thus can only become a reality at large scale if back up systems for GNSS-failure exist.
In VPR it is the goal to retrieve a coarse camera pose for a given image by querying a large database of geotagged images for instances of the same place. This can then be followed by a VL-based pose refinement step in a coarse to fine manner [14]. Both techniques together provide the capability to retrieve a drift-free 6-DoF global position estimate in absence of GNSS but require a database with precise reference imagery. The database is often built using traversals of the same place at different times. Similar to [15], we instead use publicly available geodata to render reference imagery and dense depth maps.
Matching query and reference imagery is challenging due to variation in appearance induced by illumination, weather and seasons, as well as viewpoint variations. Learned global and local image descriptors such as NetVLAD [16] and D2-Net [17] have shown promising performance in the context of large-scale autonomous navigation scenarios [18, 19]. Our experiments, however show, that the performance degrades drastically when faced with in-plane rotations, which is typical for an aerial setting with a downward-facing camera. Based on recent work by Parihar et al. [20] we show how rotation-robust features provide promising results both for VPR and VL highlighting the need to adapt current state-of-the-art techniques to the aerial scenario.
By releasing our dataset we hope to support the aerial robotics community in developing and extending VPR and VL techniques to the aerial scenario to enable safe autonomous flight in large-scale environments.
II Related Work
VPR and VL datasets usually follow a structure where a set of query images that capture the view of a device or a vehicle are accompanied by a set of geotagged reference images from one or multiple temporally separate traversals of the same spatial locations. Based on their geotags the reference images provide a coarse position estimate. These can subsequently be used as a starting point for a pose refinement step.
Based on the modality from which the query and reference images were captured these datasets can be categorized into ground-to-ground, aerial-to-aerial or aerial-to-ground datasets. Ground-to-ground datasets such as [21, 1, 3, 4, 5] use the same sensor setup to collect query and reference images. The same is true for aerial-to-aerial VPR datasets such as [6, 7]. More recently aerial-to-ground datasets have introduced the idea of using external geodata for geolocating ground vehicles from aerial imagery such as orthophotos. External geodata provides access to a vast amount of georeferenced imagery with city-wide [22] or even nation-wide geographic coverage [15]. We adopt the same idea but use it for a high altitude aerial-to-aerial scenario. Most related to ours is the work by Zaffar et al. [23]. It investigates an aerial-to-aerial dataset and poses the question whether off-the-shelf VPR-techniques can cope with the viewpoint variation imposed by the 6-DoF movement of aerial platforms compared to the lateral movement of ground platforms. Its scope, however, is limited to scenarios with low-altitude drone flight at building level. In contrast to the previously published VPR datasets, ours centers around images taken from a vantage point hundreds of meters above ground with a downwardfacing camera which opens up a new research direction for VPR and VL dealing with challenges induced by the large distance to the scene and in-plane rotations.
III The VPaiR Dataset
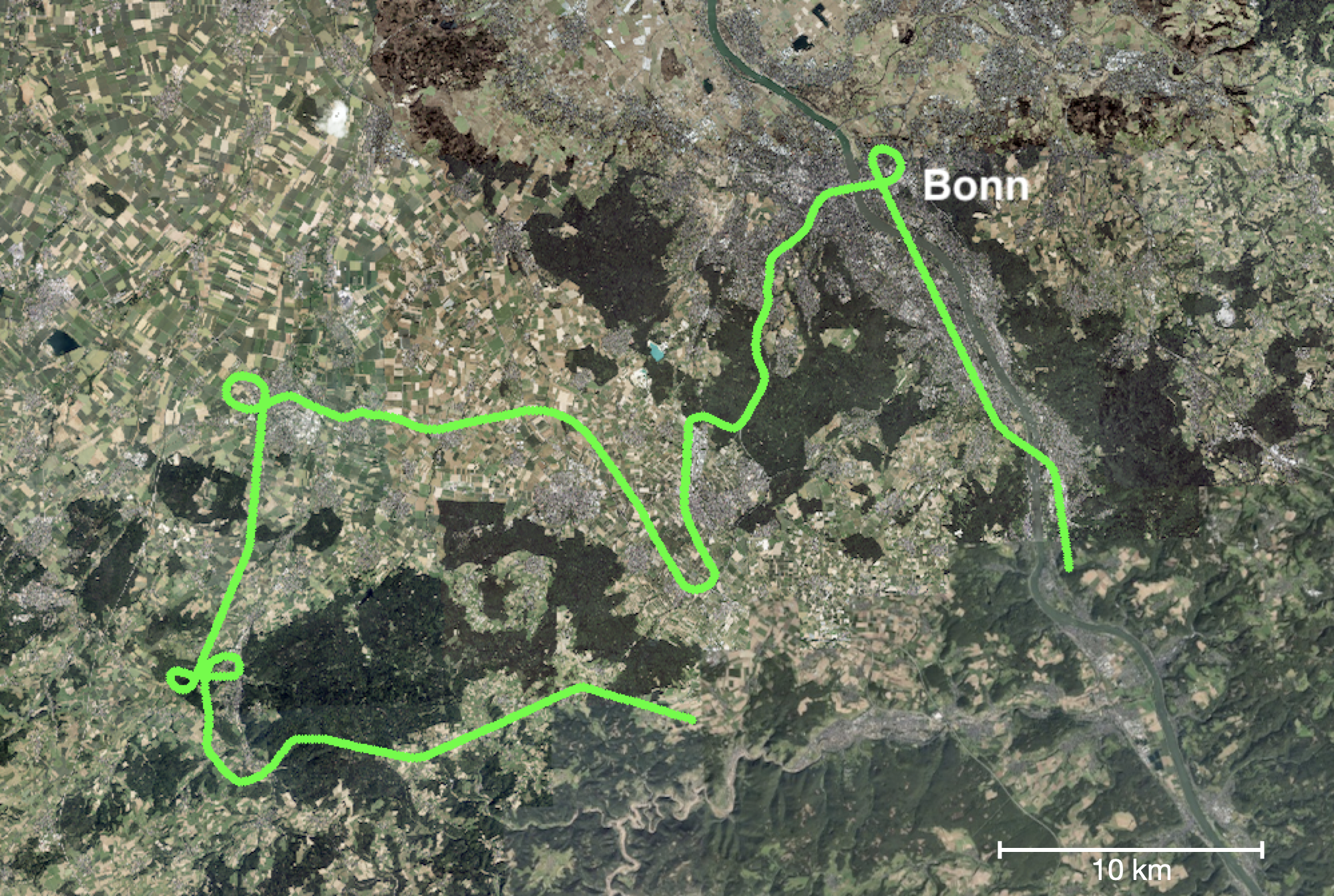
VPAIR is a dataset for evaluating visual place recognition and localization in a large-scale aerial environment. Our goal was to collect data over a wide area of surface types to be challenging and representative. The VPAIR dataset was recorded with a light aircraft over a region between the city of Bonn, Germany, and the Eifel mountain range at 300 to 400 meters above ground covering a distance of 107 kilometers. For a depiction of the flight path see Fig. 1. The dataset includes camera images from a downward-facing camera and timestamped reference poses recorded with a precise satellite and inertial navigation system (GNSS/INS). The sensor data was recorded on October 13, 2020 in a single pass. It is complemented with high resolution 3D rendered and geotagged reference imagery for the geolocalization task, dense depth maps and metadata that describes the dominant surface type visible in the image for evaluation purposes. In total there are 2788 query images and 12788 database images.
III-A Sensor Setup
The data was collected onboard a lightweight 2-seat fixed-wing aircraft with a nominal cruise speed of around 150 km/h. The payload consists of a monocular color camera recording with 1600x1200 resolution at 25 Hz and a dual antenna Ellipse-D GNSS/INS navigation system from SBG which provides accurate 6-DoF poses with an expected uncertainty of 0.05∘ in rotation and less than one meter in position. The image data is downsampled to 800x600 pixels and 1 Hz for this dataset to limit the total file size and increase its practicality while maintaining visual coverage of the full trajectory.
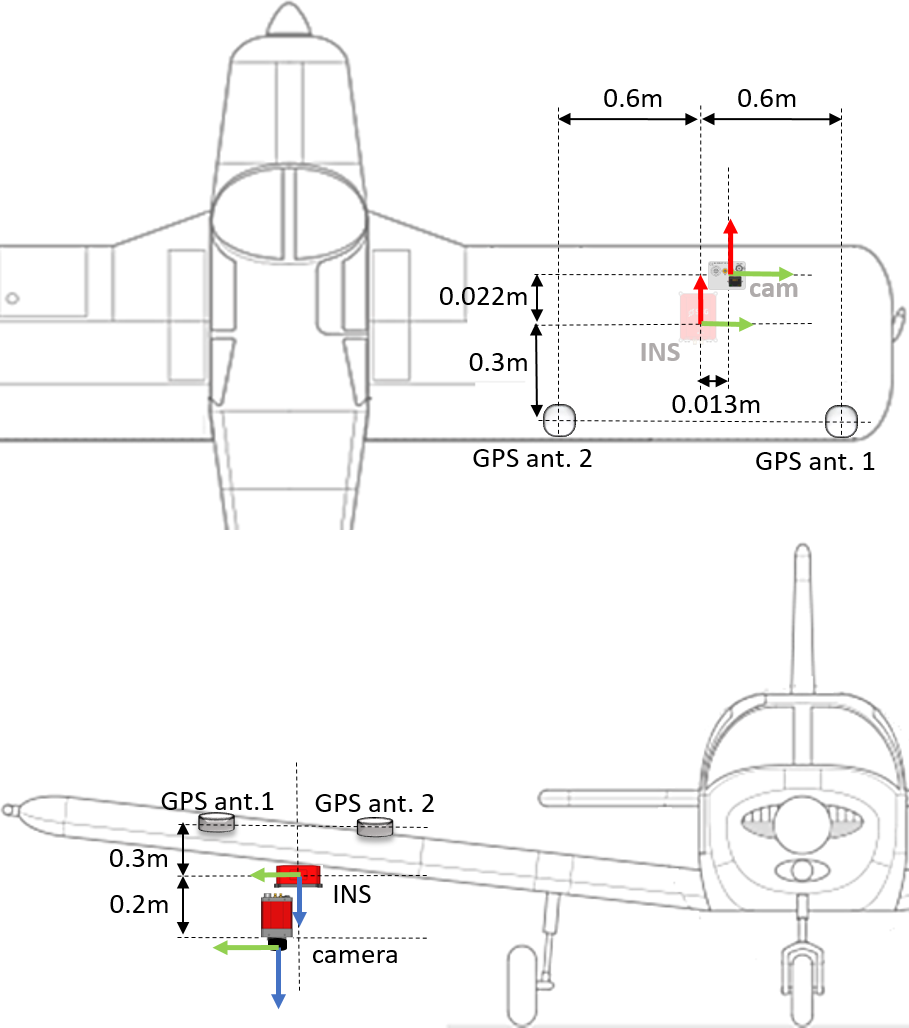
All items of the payload were placed close to each other below the wing with the camera facing down except for the GNSS antennas which were mounted on the top of the wing. We measured the distances between all parts of the payload carefully and provide a schematic in Fig. 2.
The Camera and INS are synchronized through hardware triggering ensuring accurate timestamps. The camera’s timestamps correspond to the beginning of exposure. The exposure time was fixed to 5 ms at the day of capture. We used the official ROS implementations of the sensor drivers and adapted them for timestamp synchronization. The camera intrinsics and the extrinsics between IMU and camera were obtained by using the Kalibr calibration toolbox [24].
III-B Reference Imagery
Each image from the onboard camera is paired with a spatially aligned reference image, dense metric depth map and metadata describing the dominant type of land cover (i.e. urban, agricultural, forestry). The reference images and depth maps are rendered using a self implemented 3D engine in OpenGL in conjunction with publicly available orthophoto imagery and 3D surface models. The latter are provided by Geobasis NRW, a state funded geodata repository, that is accessible with a permissive open data license and covers the complete territory of the state of Nordrhein-Westfalen, Germany111Data was accessed via https://www.geoportal.nrw and is redistributed according to Data license Germany - Zero - Version 2.0 http://www.govdata.de/dl-de/zero-2-0. Land cover information is also obtained via Geobasis. The surface model is represented by a 3D point cloud with approximately 0.5 m accuracy of not only the ground but also vegetation and buildings derived from airborne laser scans. The orthophotos were captured between 2019 and 2021 and are provided with a ground resolution of 0.1 m per pixel.

The 3D point cloud is processed by the 3D rendering engine to a mesh and then textured using the orthophotos. Given a 6-DoF pose and an intrinsic camera model the engine is then able to output a perspective image that very closely mirrors the original view. When creating the reference imagery for this dataset, however, we disregard roll, pitch and yaw by setting them to a constant angle resembling a perfectly downwardfacing camera where the top of the image is facing in north direction. In addition to the image pairs we include 10.000 distractor images, that were sampled from a geographically separate region in a grid pattern within an area of 400 km2 near the city of Duesseldorf.
IV Experimental Setup
Given a query image from an onboard camera the goal of VPR is to recognize images of the same place within a large collection of georeferenced images. Based on this match we are then provided with a course location estimate. Proceeding with a coarse position estimate and information about the 3D scene structure it is then the goal of VL to refine the estimate and provide a 6-DoF pose. We use the off-the-shelf rotation-robust descriptors (RoRD) from Parihar et al. [20] for both the VPR and VL task and compare them to NetVLAD and SIFT/D2-Net respectively.
IV-A Visual Place Recognition
Each reference image in the dataset is described by a set of local descriptors which are then all stored in a database. For each query we retrieve the nearest neighbors of each query’s feature descriptors. The retrieved features are then associated with their source images. Finally, a ranking can be computed based on the occurrence of retrieved features per database image. The highest ranking reference images constitute the place candidates.
We compare this VPR pipeline based on local features against a widely used off-the-shelf technique NetVLAD [16] which has exhibited favorable performance in aerial [23] and large-scale autonomous navigation scenarios [18] in the past. We use the standard Recall@ metric for evaluating the VPR techniques with a distance threshold of 100 m.
IV-B Visual Localization
Assuming that the correct image was retrieved the pose is refined based on a PnP solver. Given a set of 2D-3D point correspondences it estimates a 6-DoF pose by minimizing the reprojection error in the camera plane. Our VL pipeline works as follows. First 2D-2D matches between query and reference image are obtained with the rotation robust descriptors. Then, similar to [15] we retrieve 3D scene information by back-projecting the rendered image based on dense metric depth maps thereby obtaining the 3D global scene coordinates for each matched keypoint. Finally, the PnP solver provides the 6-DoF pose. We compare the usage of RoRD against two off-the-shelf baselines, namely SIFT and D2-Net evaluating on the absolute pose error metric [19].
V Results
Table I and II show that the VPR-technique based on off-the-shelf local descriptors compares favorably to the global image descriptor NetVLAD. Performance is generally better in scenes that depict urban environments which might be less subject to appearance change than scenes depicting agricultural environments or forests. Table III compares the place recognition performance when controlling for the difference in heading. NetVLAD suffers drastically from in-plane rotation while RoRD-VPR’s performance drop is less significant.
We note that our VPR pipeline based on local features requires hundreds of retrieval operations per image compared to a single one when using global image descriptors like NetVLAD. The runtime and memory requirements are therefore impractical with a large database especially on constrained mobile platforms. This highlights the need for rotation robust global image descriptors.
Finally, Table IV shows that RoRD outperforms D2-Net and SIFT in the visual localization task. D2-Net is a learned image descriptor that is based on the same architecture but not rotation robust. SIFT is rotation-invariant but suffers from the appearance change between query and reference images.
| R@1 | R@5 | R@20 | |
|---|---|---|---|
| NetVLAD | 10.2 | 22.6 | 35.7 |
| RoRD-VPR | 38.7 | 50.1 | 58.8 |
| urban | agricultural | forestry | |
|---|---|---|---|
| NetVLAD | 31.1 | 15.6 | 5.5 |
| RoRD-VPR | 77.4 | 27.4 | 16.9 |
| Heading difference | 0∘ | 30∘ | 90∘ | 135∘ |
|---|---|---|---|---|
| NetVLAD | 66.1 | 34.4 | 23.3 | 17.7 |
| RoRD-VPR | 71.4 | 69.4 | 56.9 | 51.2 |
| 25m/5∘ | 50m/10∘ | |
|---|---|---|
| SIFT | 6.2 | 15.9 |
| D2-Net | 2.9 | 7.0 |
| RoRD-VL | 10.6 | 27.8 |
VI Conclusions
We propose VPAIR - a challenging dataset for aerial visual place recognition and localization. Experiments based on off-the-shelf image descriptors highlight the need for rotation robust and runtime efficient VPR and VL techniques. By releasing the dataset to the community we hope to foster research in large-scale aerial geolocalisation.
References
- [1] F. Warburg, S. Hauberg, M. Lopez-Antequera, P. Gargallo, Y. Kuang, and J. Civera, “Mapillary street-level sequences: A dataset for lifelong place recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2020, pp. 2626–2635.
- [2] W. Maddern, G. Pascoe, C. Linegar, and P. Newman, “1 Year, 1000km: The Oxford RobotCar Dataset,” Int. J. Robot. Res., vol. 36, no. 1, pp. 3–15, 2017.
- [3] M. Leyva-Vallina, N. Strisciuglio, M. Lopez-Antequera, R. Tylecek, M. Blaich, and N. Petkov, “Tb-places: A data set for visual place recognition in garden environments.” IEEE Access, vol. 7, no. 52277-52287, p. 2, 2019.
- [4] D. Olid, J. M. Fácil, and J. Civera, “Single-view place recognition under seasonal changes,” arXiv preprint arXiv:1808.06516, 2018.
- [5] H. Taira, M. Okutomi, T. Sattler, M. Cimpoi, M. Pollefeys, J. Sivic, T. Pajdla, and A. Torii, “InLoc: Indoor visual localization with dense matching and view synthesis,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018.
- [6] M. Burri, J. Nikolic, P. Gohl, T. Schneider, J. Rehder, S. Omari, M. W. Achtelik, and R. Siegwart, “The euroc micro aerial vehicle datasets,” Int. J. Robot. Res., 2016.
- [7] F. Maffra, Z. Chen, and M. Chli, “Viewpoint-tolerant place recognition combining 2d and 3d information for uav navigation,” in IEEE Int. Conf. Robot. Autom. (ICRA). IEEE, 2018, pp. 2542–2549.
- [8] J. Scott and C. Scott, “Drone delivery models for healthcare,” in Proc. 50th Hawaii Int. Conf. Syst. Sci., 2017.
- [9] A. Girard, A. Howell, and K. Hedrick, “Border patrol and surveillance missions using multiple unmanned air vehicles,” in 43rd IEEE Conf. Decision and Contr. (CDC), vol. 1. IEEE, 2004, pp. 620–625.
- [10] J. Nikolic, M. Burri, J. Rehder, S. Leutenegger, C. Huerzeler, and R. Siegwart, “A uav system for inspection of industrial facilities,” in IEEE Aerosp. Conf. IEEE, 2013, pp. 1–8.
- [11] P. Planing and Y. Pinar, “Acceptance of air taxis - a field study during the first flight of an air taxi in a european city,” Dec 2019.
- [12] S. J. Undertaking, “European atm master plan: Roadmap for the safe integration of drones into all classes of airspace,” SESAR Joint Undertaking, Publications office of the European Union, 2018.
- [13] M. Harris, “Military tests that jam and spoof gps signals are an accident waiting to happen,” IEEE Spectr., vol. 58, no. 2, pp. 22–27, 2021.
- [14] P.-E. Sarlin, C. Cadena, R. Siegwart, and M. Dymczyk, “From coarse to fine: Robust hierarchical localization at large scale,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 12 716–12 725.
- [15] A. Vallone, F. Warburg, H. Hansen, S. Hauberg, and J. Civera, “Danish airs and grounds: A dataset for aerial-to-street-level place recognition and localization,” arXiv preprint arXiv:2202.01821, 2022.
- [16] R. Arandjelovic, P. Gronat, A. Torii, T. Pajdla, and J. Sivic, “Netvlad: Cnn architecture for weakly supervised place recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2016, pp. 5297–5307.
- [17] M. Dusmanu, I. Rocco, T. Pajdla, M. Pollefeys, J. Sivic, A. Torii, and T. Sattler, “D2-net: A trainable cnn for joint detection and description of local features,” arXiv preprint arXiv:1905.03561, 2019.
- [18] M. Zaffar, S. Garg, M. Milford, J. Kooij, D. Flynn, K. McDonald-Maier, and S. Ehsan, “Vpr-bench: An open-source visual place recognition evaluation framework with quantifiable viewpoint and appearance change,” International Journal of Computer Vision, vol. 129, no. 7, pp. 2136–2174, 2021.
- [19] T. Sattler, W. Maddern, C. Toft, A. Torii, L. Hammarstrand, E. Stenborg, D. Safari, M. Okutomi, M. Pollefeys, J. Sivic et al., “Benchmarking 6dof outdoor visual localization in changing conditions,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018, pp. 8601–8610.
- [20] U. S. Parihar, A. Gujarathi, K. Mehta, S. Tourani, S. Garg, M. Milford, and K. M. Krishna, “Rord: Rotation-robust descriptors and orthographic views for local feature matching,” in 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, pp. 1593–1600.
- [21] A. Torii, J. Sivic, T. Pajdla, and M. Okutomi, “Visual place recognition with repetitive structures,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2013, pp. 883–890.
- [22] T.-Y. Lin, Y. Cui, S. Belongie, and J. Hays, “Learning deep representations for ground-to-aerial geolocalization,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2015, pp. 5007–5015.
- [23] M. Zaffar, A. Khaliq, S. Ehsan, M. Milford, K. Alexis, and K. McDonald-Maier, “Are state-of-the-art visual place recognition techniques any good for aerial robotics?” arXiv preprint arXiv:1904.07967, 2019.
- [24] J. Rehder, J. Nikolic, T. Schneider, T. Hinzmann, and R. Siegwart, “Extending kalibr: Calibrating the extrinsics of multiple imus and of individual axes,” in IEEE Int. Conf. Robot. Autom. (ICRA). IEEE, 2016, pp. 4304–4311.