Wireless Deep Video Semantic Transmission
Abstract
In this paper, we design a new class of high-efficiency deep joint source-channel coding methods to achieve end-to-end video transmission over wireless channels. The proposed methods exploit nonlinear transform and conditional coding architecture to adaptively extract semantic features across video frames, and transmit semantic feature domain representations over wireless channels via deep joint source-channel coding. Our framework is collected under the name deep video semantic transmission (DVST). In particular, benefiting from the strong temporal prior provided by the feature domain context, the learned nonlinear transform function becomes temporally adaptive, resulting in a richer and more accurate entropy model guiding the transmission of current frame. Accordingly, a novel rate adaptive transmission mechanism is developed to customize deep joint source-channel coding for video sources. It learns to allocate the limited channel bandwidth within and among video frames to maximize the overall transmission performance. The whole DVST design is formulated as an optimization problem whose goal is to minimize the end-to-end transmission rate-distortion performance under perceptual quality metrics or machine vision task performance metrics. Across standard video source test sequences and various communication scenarios, experiments show that our DVST can generally surpass traditional wireless video coded transmission schemes. The proposed DVST framework can well support future semantic communications due to its video content-aware and machine vision task integration abilities.
Index Terms:
Semantic communications, video transmission, nonlinear transform, joint source-channel coding, rate-distortion.I Introduction
The task of video transmission in today’s wireless networks is largely separated into two steps: source coding and channel coding [1]. Source coding compresses the source video as sequences of bits, and channel coding represents sequences of bits as transmitted signals against impacts of imperfect wireless channels such as noise, fading, and interferences. This separation-based approach has been employed for a large variety of applications, as the binary representations of various source data can be seamlessly transmitted over arbitrary wireless channels by changing the underlying channel code. This paradigm has benefited a lot due to the independent optimization of each component.
However, the limits of the separation-based design begin to emerge with more demands on low-latency wireless video delivery applications such as virtual reality (VR). On the one hand, current wireless video transmission systems suffer from time-varying channel conditions, in which case the mismatch between communication rate and channel capacity leads to obvious cliff-effect, i.e., the performance breaks down when the channel capacity goes below communication rate. On the other hand, the widely-used entropy coding, which converts the source representation into sequences of bits, is quite sensitive to the variational estimate of the marginal distribution of the source latent representation. Small perturbations on this marginal can lead to catastrophic error propagation in entropy decoding [2]. In practice, the small perturbation can often be caused by floating point round-off error [3]. Unfortunately, this round-off operation depends heavily on hardware or software platforms, and in various data compression applications, the transceiver may well employ different platforms. This non-determinism issue in transmitter vs. receiver may finally lead to severe performance degradation.
To address this problem, it is very time to bridge source coding and channel coding together to boosting the end-to-end communication system capabilities. By this means, the channel transmission process can be aware of the source semantic features [4, 5, 6, 7, 8, 9, 10]. The paradigm aiming at the integrated design of source and channel processing was named joint source-channel coding (JSCC) [11], a classical topic in the information theory and coding theory. However, conventional JSCC schemes [11, 12, 13, 14] are based on explicit probabilistic models and handcrafted designs, whose optimization complexity is intractable for complex sources. In addition, they ignored the semantic aspects of source messages. As one modern version, recent deep learning methods for realizing JSCC have stimulated significant interest in both artificial intelligence (AI) and wireless communication communities [15, 16, 17, 18, 19]. By using artificial neural networks (ANNs), source data can be directly encoded as continuous-valued symbols to be transmitted over wireless channels. Deep JSCC can overcome the catastrophic degradation problem by using analog transmission without entropy coding. Current deep JSCC methods have shown end-to-end image transmission performance surpassing classical separation-based JPEG/JPEG2000/BPG source compression combined with ideal channel capacity-achieving code family, especially for sources of small dimensions, e.g., small CIFAR10 image data set [20].
However, one can observe that, in general, as the source dimension increases, e.g., large-scale images, the performance of deep JSCC degrades rapidly, which is even inferior to the classical separation-based coding schemes as demonstrated in [9]. Moreover, existing deep JSCC schemes cannot provide comparable coding gain as that of classical separated coding schemes, i.e., the slope of the performance curve slows down quickly with the increase of coding rate or the channel signal-to-noise ratio (SNR). This poor coding gain stems from the naive design of codec networks. Current deep JSCC works simply employ one highly-integrated ANN as the encoder function to achieve dimension reduction with respect to the raw source data. By adding the wireless channel as one non-trainable layer, the learned codec ANNs can also combat the impacts of imperfect wireless channels. Nevertheless, this light auto-encoder structured deep JSCC cannot provide sufficient model expression capability for large-scale source data, resulting in a prematurely saturated coding gain of deep JSCC. Compared to the image source, the video source further induces the time dimension. Above saturation phenomenon on the coding gain is more likely to appear on video sources that need higher dimensional representation. Thus, a naive application of deep JSCC for wireless video transmission cannot provide satisfactory performance.
Inspired by the emerging data compression methods adopted in computer vision (CV) communities, a high-dimensional source will first be converted as latent representations defined by variational latent-variable models. This procedure is referred to as nonlinear transform [21, 22, 23, 24, 25]. The richness of latent representations preserves almost all the source semantic features that can be used for either recovering source data or directly driving the downstream intelligent tasks. By training appropriately, many such nonlinear transform models successfully represent the source data quite compactly and may be called compression in a sense. For practical data compression tasks, the latent representation needs to be further compressed as binary sequences through entropy coding. However, because the employed ANNs in nonlinear transform are typically based on floating point math, and the transmission is over time-varying wireless channels, a direct combination of nonlinear transform with traditional source coding (entropy coding such as arithmetic coding [2]) and channel coding (such as low-density parity-check (LDPC) coding [26]) will be also vulnerable to catastrophic failures left by entropy decoding.
In this paper, to attain high-efficiency and robust end-to-end video transmission, we leverage the advantages of nonlinear transform and deep JSCC together to formulate a new powerful framework, named deep video semantic transmission (DVST). It is specifically targeted at video transmission over imperfect wireless channels and preventing catastrophic failures caused by sensitive entropy coding. By integrating the emerging conditional coding paradigm [27] with nonlinear transform and deep JSCC, the proposed DVST framework works on the principle: considering the strong temporal correlations among video frames, DVST encodes the current frame in an efficient manner to generate channel-input symbols through contextual nonlinear transform and contextual deep JSCC. The contextual semantic information is used as part of the input of both nonlinear transform and deep JSCC codec. Benefiting from the temporal prior provided by the semantic feature domain context, the learned nonlinear transform function becomes temporally adaptive, resulting in a richer and more accurate entropy model to indicate how to allocate channel bandwidth resources to transmit the current frame. Moreover, we leverage the context to carry rich information as prior to deep JSCC codec, which helps to reconstruct the semantic feature map for higher video quality or downstream task performance. The whole DVST design is formulated as an optimization problem whose goal is to minimize the end-to-end transmission rate-distortion (RD) performance under perceptual quality metrics or machine vision task performance metrics.
Specifically, the contributions of this paper can be summarized as follows.
-
(1)
DVST Framework: We propose a new end-to-end learnable framework for wireless video transmission, i.e., DVST, which integrates the advantages of nonlinear transform and deep JSCC. To the best of authors’ knowledge, this is the first work that establishes a temporally adaptive entropy model to customize deep JSCC for video. The proposed DVST framework exploits both nonlinear transform and conditional coding architecture for video semantic feature extraction, which contributes to higher efficiency and more robust wireless video transmission than traditional video coded transmission schemes.
-
(2)
Context-Driven Semantic Feature Modeling: We exploit a simple yet efficient method using temporal context to enhance the entropy model in nonlinear transform as well as the deep JSCC codec. We design ANN architectures to realize each module of DVST, in which the definition, usage, and learning manner of contextual semantic features as conditions are all clearly given.
-
(3)
Rate-Adaptive Semantic Feature Transmission: In light of the temporally adaptive entropy model on semantic features, we develop a method to improve the coding gain of video deep JSCC. In particular, we introduce a variable-length transmission mechanism for each embedding vector in the latent representation. The resulting DVST model learns to allocate the limited channel bandwidth within and among video frames to maximize the overall performance.
-
(4)
Performance Validation: We verify the performance of our DVST system across standard video source sequences. We show that for wireless video transmission, our DVST can achieve much better coding gain and RD performance on various established metrics such as PSNR and MS-SSIM. Equivalently, achieving identical end-to-end wireless transmission performance, the proposed DVST method can save up to 50% channel bandwidth cost, compared to classical H.264/H.265 combined with LDPC and digital modulation schemes. For task-oriented machine-type semantic communications, experimental results verify the effectiveness of DVST, which can better support machine vision tasks, meanwhile holds higher perceptual fidelity for human vision.
The remainder of this paper is organized as follows. In the next section II, we first review the system model of wireless video transmission, and propose the DVST framework. Then, in section III, we propose ANN architectures for realizing DVST, as well as key methods to guide the optimization of the DVST model. Section IV provides a direct comparison of a number of methods to quantify the performance gain of the proposed method. Finally, section V concludes this paper.
Notational Conventions: Throughout this paper, lowercase letters (e.g., ) denote scalars, bold lowercase letters (e.g., ) denote vectors. In some cases, denotes the elements of , which may also represent a subvector of as described in the context. Bold uppercase letters (e.g., ) denote matrices, and denotes an -dimensional identity matrix. denotes the natural logarithm, and denotes the logarithm to base . denotes a probability density function (pdf) with respect to the continuous-valued random variable , and denotes a probability mass function (pmf) with respect to the discrete-valued random variable . In addition, denotes the statistical expectation operation, and denotes the real number set. Finally, denotes a Gaussian function, denotes a Laplace function, and stands for a uniform distribution centered on with the range from to .
II The Proposed Method
In this section, we first present the system model of wireless video transmission. Then, we describe the whole framework of DVST. After that, we introduce the contextual entropy model for rate-adaptively transmit the latent representations, followed by the learning methods of the context. Finally, we derive the optimization goal of DVST system.
II-A System Model
Consider a wireless video transmission problem. Given a video sequence , where the frame at time step is modeled as a vector of pixel intensities . The transmitter encodes the video frame sequence as a sequence of variable-length continuous-valued channel input symbols , where denote the -dimensional channel input vector at time step . We usually have , and is defined as the channel bandwidth ratio (CBR) [28] denoting the average coding rate of . Then, the sequence is successively sent over the wireless channel. This channel introduces random corruptions denoted as a transfer function , where denotes the channel parameters. The received sequence is with the transition probability . In this paper, we mainly consider the widely used additive white Gaussian noise (AWGN) channel such that the transfer function is where each component of the noise vector is independently sampled from a time-invariant multidimensional Gaussian distribution, i.e., , where is the average noise power. Other channel models can also be similarly incorporated by changing the channel transition function. The receiver comprises a series of inverse operation which aims to recover from the corrupted signal or executes the downstream intelligent task.
We consider video transmission over the noisy wireless channel in a low-latency manner, i.e., the video sequence is transmitted to and reconstructed in the receiver frame-by-frame. We encapsulate consecutive frames as one group-of-pictures (GOP). A typical video coding algorithm first divides into a stack of GOPs. Each GOP begins with an intra-coded picture (I-frame or keyframe) as a reference, followed by predictive coded frames (P-frames), which contain the motion compensated difference information for bitrate saving. In this paper, we exploit the classical GOP structure for end-to-end transmission. Since the transmission of I-frame is equivalent to that of image, which has been well studied in [17, 28, 18, 19], we concentrate on the transmission of P-frame.
II-B The Framework of DVST
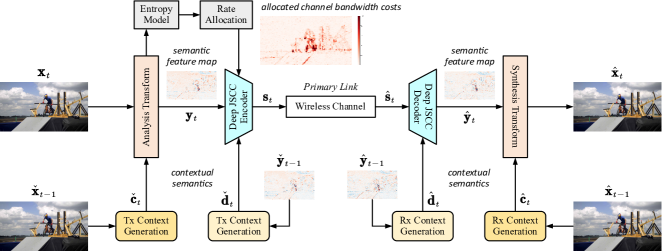
We propose the DVST as a new learnable model for end-to-end wireless video transmission, which integrates the advantages of nonlinear transform and deep JSCC. Our DVST framework is illustrated in Fig. 1. To encode the current frame efficiently, the transmitter adopts contextual analysis transform and contextual deep JSCC encoder as two critical modules. The analysis transform converts the source frame in pixel domain to the latent representation in semantic feature domain. Guided by the variational entropy modeling on the latent representation, a rate control module is added to achieve variable-length encoding in deep JSCC. For video source, there exists temporal correlation. Thus, the above two modules also employ the semantic feature domain context and the deep JSCC codeword domain context as the temporal prior. That makes nonlinear transform and deep JSCC modules temporally adaptive, resulting in a higher efficient video transmission framework.
As illustrated in Fig. 1 and Fig. 2, and functions in nonlinear transform of the current frame are conditioned on the contextual semantic features and , respectively. and functions in deep JSCC are conditioned on the contextual codewords and , respectively. The primary link of DVST system is formulated as
| (1) |
In our DVST design, we use ANN to realize each function in (1) except for the channel transfer function . In terms of the context information, transmitter (Tx) contexts and are obtained from the reference frame and the reference feature map , respectively. These two references are generated at the transmitter by simulating the DVST process without passing over the wireless channel, i.e.,
| (2) |
where the codeword is obtained from (1) by substituting the time step . Receiver (Rx) contexts and are obtained from the reference synthesized frame and the reference decoded feature map , respectively. These two references are directly obtained by taking out records from the receiver buffer at the time step . Details about how to use context as conditions to formulate ANN-based functions will be introduced in the next section.
Specifically, in the transmitter, for the current frame at time step , extracts the source semantic features as a lower-dimensional latent representation , operates on this latent space. Consider the inter frame correlation in video sources, the analysis transform is formulated as
| (3) |
denotes the function to generate context for the analysis transform, is therefore referred to as the contextual analysis transform. After that, the latent representation is fed into the contextual deep JSCC encoder to generate the channel-input sequence as
| (4) |
denotes the function of generating context for deep JSCC encoder. To provide rich and more correlated information for encoding , the context is in the semantic feature domain with higher dimensions, and the context is in the deep JSCC codeword space.
Then, the analog codeword sequence is directly sent over the wireless communication channel. As aforementioned, we consider the AWGN channel such that the received sequence is with . The receiver comprises a contextual deep JSCC decoder to reconstruct the corrupted signal as , i.e.,
| (5) |
denotes the function of generating context for deep JSCC decoder. The contextual synthesis transform function is then performed on to recover the current frame, i.e.,
| (6) |
denotes the function to generate context for the synthesis transform.
For the contextual analysis transform , we use a network to automatically learn the correlation between and , which does not remove the redundancy through handcrafted subtraction operation like traditional residual video coding [29]. Herein, the context comes from the reference frame . In this way, the contextual analysis transform becomes adaptive which generates the latent representation by selectively extracting semantic features from and [27]. Due to the motion in video, for old contents in that can find a good reference from , still forces to generate its patch embeddings from the residue. For new contents in that cannot find a good reference from , tends to generate its patch embeddings from itself. The contextual nonlinear transform inherently learns to adaptively utilize the condition for semantic extraction. In addition, the context is not only used for generating the latent representation, but also utilized to construct the entropy model, which will be introduced in the subsequent subsection.
For the contextual deep JSCC encoder , we use a network to automatically learn the correlation between and . Note that the context comes from the reconstructed reference feature map , thus, the contextual deep JSCC encoder also becomes adaptive to generate the channel-input codewords. If patch embeddings in can find a good reference from , inclines to transmit these embeddings with smaller channel bandwidth. In contrast, for patch embeddings in that cannot find a good reference from , tends to allocate more channel bandwidth to transmit these embeddings. In this way, the contextual deep JSCC codec learns to adaptively utilize the condition for high-efficiency transmission. Moreover, the context is not only used for generating the channel-input codeword, but also utilized to learn a rate-allocation function that controls the scaling rule from entropy value to channel bandwidth cost. Details will be introduced in the subsequent subsection.
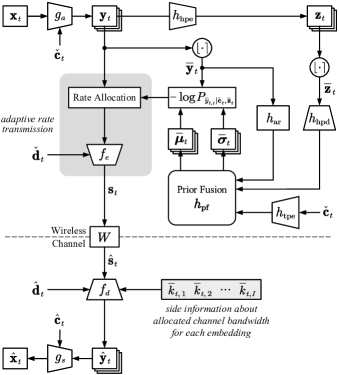
II-C Entropy Model for Rate-Adaptive Transmission
In order to improve the coding gain of DVST, a variable-length transmission mechanism should be developed for each embedding of the semantic feature map . To this end, we estimate the entropy distribution on , and the channel bandwidth cost for transmitting can be accordingly determined. Therefore, our target is to design an entropy model which can accurately estimate the probability distribution of the latent representation .
Our entropy model is illustrated in Fig. 2. Following the work of [27], the latent representation is variationally modeled as the Laplace distribution, where each embedding is of varying distribution parameters. In this paper, the hyperprior entropy model learns both the hierarchical prior [23] and the spatial prior [24]. In addition, our entropy model fuses the temporal prior provided by the context . Specifically, the entropy of each embedding is computed as
| (7) |
where denotes the quantized version of by using the uniform scalar quantization function (rounding to integers). denotes a tensor consisting of quantized embeddings with . The quantized hyperprior is obtained by stacking the hyperprior encoder network on .
In order to use the gradient descent methods to optimize the entropy model, Ballé et al. have proposed a relaxed method for addressing the zero gradient problem caused by quantization [21]. A proxy “uniformly-noised” representation is adopted to replace the quantized representation during model training, i.e., with . Each is variationally modeled as a Laplace distribution with learned parameters and such that
| (8) | ||||
where “” is the convolutional operation, denotes the path embedding index, and the proxy hyperprior is obtained by performing the hyperprior encoder network on and adding the uniformly sampled random offset , i.e., . Since we do not have prior beliefs about the hyperprior , it can be modeled as non-parametric fully factorized density [23], i.e.,
| (9) |
where encapsulates all the parameters of . During model testing, the entropy model is established by taking discrete values from the learned entropy model by substituting as . denotes the hyperprior decoder network to provide the hierarchical prior. represents the auto regressive network to provide the spatial prior. denotes the temporal prior encoder network to provide additional side information. denotes the prior fusion network operating on the above three types of prior information. During model testing, the entropy model in (7) will be established by taking discrete values from the learned entropy model by substituting and as and , respectively.
As stated in NTC [25], the probabilistic model of can be conditioned on some other vector like [23] or its preceding dimensions as that in [24]. The former corresponds to forward adaptation (FA) of the density model, and the latter is backward adaptation (BA). In this paper, due to the auto-regressive computation in (8), our entropy model is established under the BA mode. One can also use the FA mode, where relies only on the hierarchical prior and the context, i.e., . Herein, the FA mode in DVST however cannot harvest the gain of better codec parallelism while it incurs performance degradation. The reason is that the auto-regressive computations of BA in our DVST are only used in entropy modeling to estimate the probability. The following deep JSCC codec runs in parallel for each embedding . In comparison, traditional codec relying on arithmetic coding also adopts regressive computations in the BA mode which leads to higher latency. Therefore, we advertise the BA mode in our DVST framework.
With the learned entropy model , the allocated channel bandwidth cost to transmit the embedding is formulated as
| (10) |
where the scaling factor denotes the proportion from the entropy of embedding to the number of channel symbols. In particular, the physical meaning of can be interpreted as , where is the channel capacity (bits per channel symbol), and denotes an efficiency factor representing the capability of deep JSCC codec. Accordingly, stands for the ideal JSCC codec that is of the same performance as entropy-achieving source coding combined with capacity-achieving channel coding.
Following the aforementioned entropy model, the channel bandwidth cost of the primary link for transmitting semantic features is derived as
| (11) | ||||
II-D Motion Transmission and Context Learning
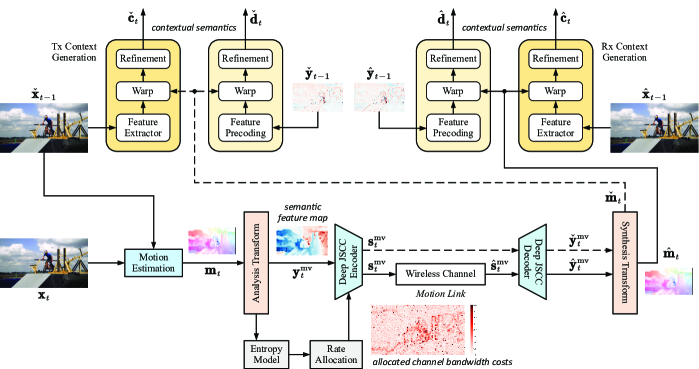
As for context learning functions , , , and , inspired by [27], we also adopt the idea of motion estimation and motion compensation (MEMC) to formulate specific forms of these functions. Different from conventional MEMC applied in source pixel domain, we perform MEMC in semantic feature domain to generate contexts , and in deep JSCC codeword domain to generate contexts , . This paradigm utilizes rich information density in feature/codeword domain to fascinate high-efficiency video transmission over wireless channels with limited bandwidth.
As shown in Fig. 3, the motion vector (MV) is generated by using the flow estimation network [30] performed between the current frame and the reconstructed reference frame . This MV is then transmitted over the wireless channel, which is referred to as the motion link. The whole process copies from the primary link without using context, i.e.,
| (12) | |||
In our DVST design, we use ANN to realize each function in (12) except for the channel transfer function . The reference MV used at the transmitter is generated by simulating the motion link without passing over the wireless channel, i.e.,
| (13) |
where the codeword is obtained from (12).
In analogue to the primary link, by using the learned entropy model on , the allocated channel bandwidth cost to transmit the embedding is formulated as
| (14) |
The channel bandwidth cost of the motion link for transmitting MV semantic features is derived as
| (15) |
The hyperprior is obtained as , and the entropy model of the quantized hyperprior can be obtained similar to (9).
As illustrated in Fig. 3, at the transmitting end, the feature domain context generation function is formulated as
| (16) |
where the reference frame is obtained as (2). We use the feature extractor network to convert the reference frame to its feature domain representation. The reference MV guides where to extract feature domain context by using the warping function [33]. The refinement network is used to restore the spatial discontinuity problem caused by warping operation.
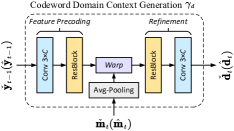
As for the codeword context , its generation function is formulated as
| (17) |
The precoding network operates on the reference semantic feature map which preprocesses the data before warping it. denotes the refinement network.
II-E Optimization Goal
The optimization goal of our DVST system is to use the least channel bandwidth cost to get the best video reconstruction quality or downstream task performance. Given the reference frame, the loss function at the current time step is formulated as a rate-distortion (RD) form, i.e.,
| (18) |
where controls the trade-off between the total channel bandwidth cost and the distortion .
Due to the conditional coding architecture, the performance of a previous frame will affect its subsequent frame. Therefore, during the training phase of DVST, we take into account the correlations of frames within a GOP. The DVST model can thus learn to allocate channel bandwidth resources within one frame and among various frames. Thus, the overall training loss function is formulated as
| (19) |
The training procedure details will be introduced in the subsequent subsection.
For machine-type semantic communications, our DVST can directly drive the downstream machine vision tasks while preserving the advantages of signal level reconstruction. Different from the functional transmission mode adopted in [19], this paper aims to transmit videos friendly to both human vision and machine analytics [34]. Therefore, we incorporate the low-level signal distortion and the loss of high-level tasks, thus, the distortion term is reformulated as , where denotes the reconstruction loss and denotes the loss of downstream task.
III Architectures and Implementations
In this section, we present details of the adopted network architectures to implement our DVST. Then, we introduce the progressive training strategy to enable a stable model learning.
III-A Network Architectures
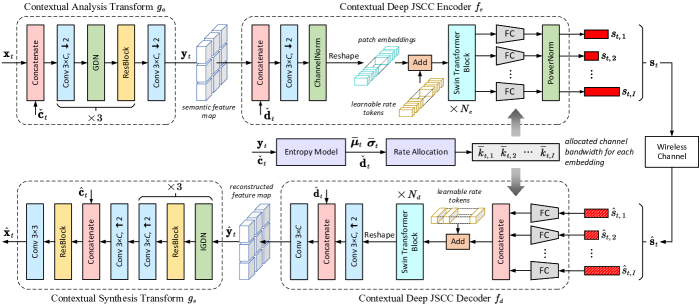
We illustrate ANN implementation details of the primary link in Fig. 4, including the contextual nonlinear transform modules and the contextual deep JSCC modules. For brevity, we do not repeat the structure of the motion link since it has almost the same architecture as the primary link except that the MV is of two channels, and the contextual operations are removed.
| (20) | ||||
| (21) | ||||
III-A1 Contextual Nonlinear Transform
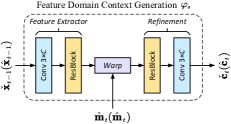
The proposed DVST drives the current frame in terms of the context extracted from MV rather than relying on a handcrafted subtraction operation. Fig. 5(a) illustrates the context generation network in semantic feature domain, which consists of feature extractor, warp, and refinement operation. After that, the analysis transform concatenates the Tx context with the current frame to learn a compact latent representation in semantic feature domain. To estimate the spatial varying mean values and standard deviations of , we follow the hyperprior entropy model in [27], which fuses hierarchical prior, spatial prior, and temporal prior. The contextual synthesis transform has a symmetric architecture with except that it uses the Rx context generated from which is of the same structure with .
III-A2 Contextual Deep JSCC
Contextual deep JSCC module exploits the codeword contexts extracted from and to collaboratively transmit the current latent representation . It is of variable rates in accordance to the estimated entropy. In particular, the structure of codeword context generator is shown in Fig. 5(b). Before the wrapping operation [33], we align the MV with the precoded feature by using an average pooling operation with stride 16. By using the learned entropy model, we pre-allocate the channel bandwidth cost of each spatial position as (11). Accordingly, the encoder fuses the with the context and partitions the fused feature map into patch embedding sequence , where each embedding is an -dimensional feature vector. After that, the practical channel bandwidth cost for transmitting is determined as . Herein, denotes a scalar quantization whose range includes () integers, and the quantization value set is related to the scaling factor and the Lagrange multiplier in the RD loss function. In this way, we inform the receiver which rate is allocated to each embedding by transmitting predetermined bits as extra side information.
Instead of naively training deep JSCC networks, we exploit the dynamic neural network structure to realize variable rate transmission. As shown in Fig. 4, consists of a powerful shared backbone to extract the contextual dependencies among , and light FC layers to encode into the given dimension . In particular, we employ a group of FC layers with different output dimensions , and each FC layer is invoked on demand. As a result, during the model forward pass, some FC layers may not be used while others may be used more than once. Additionally, to enhance the capacity of deep JSCC and extract the global and long-term correlations, we employ Swin Transformer blocks as the network backbone [35]. Inspired by the application of positional embeddings in vision Transformer, we develop a group of rate tokens to indicate the CBR information. The rate tokens can be viewed as learnable parameters within Transformer. As shown in Fig. 4, each embedding will be added with its corresponding rate token before fed into Transformer blocks. Hence, the output patch embeddings can get a better trade-off between fidelity and robustness. As a result, the following FC layer can efficiently rescale the dimensions of channel-input symbols .
III-B Progressive Training Strategy
As aforementioned, the goal of DVST is to minimize a compromise between channel bandwidth cost (including primary link and motion link) and end-to-end distortion (reconstruction error or downstream task accuracy). Starting from a pretrained optical flow estimation network, the training procedure consists of the following steps:
-
(1)
Pretrain the nonlinear transform components of the motion link, including the motion estimation network, , , and the entropy model. In this step, we use the lossless previous frame as reference. The pretraining loss function of this step is formulated as (20), where denotes uniformly sampled random quantization offsets.
-
(2)
Taking the wireless transmission error of the motion link into account, based on the previous step, deep JSCC codec , , and the rate adaptation module are jointly trained with nonlinear transform components to execute an MV transmission task. We also add the pretraining distortion terms to make the training process stable. The training loss function of this step is formulated as
(22) where the reconstructed MV is obtained as (12) by passing over wireless channel, and the channel bandwidth cost of the motion link is obtained from (15).
-
(3)
Pretrain the nonlinear transform components of the primary link and context generation networks and meanwhile freezing the parameters of motion link. Similar to the pretraining process of motion link, we still employ the ideal lossless previous frame as reference, i.e., we manually set . In practice, following [27], we temporally remove the bitcost terms and readd them after several training epoches. This strategy helps model to generate useful contexts and exploit them, which actually accelerates the convergence. The training loss of this step is formulated as (21), where the generation of feature domain context and can refer to (16).
-
(4)
Based on the previous step, train the whole framework except the freezing motion link. The training loss of this step is formulated as
(23) where the reconstructed frame is derived from (1), and the channel bandwidth cost of the primary link is obtained as (11). In this step, model learns to transmit current frame efficiently with the help of context in JSCC codeword space. Also, for stable training, the end-to-end distortion is added.
-
(5)
Unfreeze the motion link and train the whole DVST model according to subsection II-E. The final training loss for a GOP is formulated as
(24) where the pretraining distortion serves as a regularization term to improve the training stability. In this step, the model indeed learns a bandwidth cost trade-off between primary and motion links. Moreover, due to the integrated training within a whole GOP, the rate allocation between frames has also been optimized, which will be shown in the ablation study of the subsequent section.
IV Experimental Results
IV-A Experimental Setup
IV-A1 Datasets
Our DVST model is trained with the Vimeo-90k dataset [36], which consists of 89800 video clips with a large variety of scenes and actions. During the model training, the chunks are randomly cropped to pixels. We use unrolled frames as a GOP in the last step of the training procedure and disallow the gradients passing from the I-frame reconstruction to the P-frame. We evaluate the performance of DVST using the HEVC test dataset [37] and the UVG dataset. As widely used standards to measure video-related algorithms’ performance, they contain sequences of various content, frame rate, and resolution. In particular, the HEVC dataset includes Class A (), Class B (), Class C (), Class D (), Class E (). And the UVG dataset consists of videos with the resolution of . During model testing, we set the GOP size as , which is identical to the end-to-end wireless video transmission scheme in [38]. As for I-frame coding, we adopt our previous work of image semantic transmission using nonlinear transform source-channel coding [9].
IV-A2 Implementation Details
In all experiments, the channel dimension in Fig. 4 is set to 96 for the primary link and 128 for the motion link. In addition, the channel dimension in Fig. 5 is 96. As mentioned before, we employ the Swin Transformer [35] as the backbone of the contextual deep JSCC codec, which greatly reduces the computation complexity of vision Transformers by conducting multi-head self-attention (MHSA) within local windows or shifted windows. In this paper, the number of Swin Transformer blocks is set to , and we use 8 heads and window size in MHSA. In addition, the quantized channel bandwidth cost value set of primary link is chosen as , and the motion link . Hence, extra side information of total bits will be transmitted to inform the receiver of the CBR for each embedding. Since we adopt a large patch size of pixels, the side information cost is relatively trivial compared to video content. The composition of total CBR will be discussed in the ablation study.
For the reconstruction task, we optimize DVST in terms of the mean squared error (MSE) for the peak-signal-to-noise ratio (PSNR) metric, or multiscale structural similarity [39] (MS-SSIM) for perceptual quality. Multiple DVST models are trained with for MS-SSIM and for PSNR, thus achieving different RD tradeoffs. A smaller value of leads to a larger CBR. We denote these models as “DVST (PSNR)” and “DVST (MS-SSIM)”, respectively. For each model, we use the Adam optimizer [40] with a learning rate of . We use a mini-batch size of 8, and it takes about one week to train the whole DVST model on single RTX 3090 GPU.
IV-A3 Comparison Schemes

Following [38], we compare our DVST with classical video coded transmission schemes in current mainstream wireless communication systems. In particular, we employ the standard video codecs (H.264 [41] and H.265 [42]) for source coding combined with practical LDPC codes [26] or ideal capacity-achieving channel code family for channel coding. For brevity, we use “+” to concatenate the source coding and channel coding schemes, e.g., H.265 combined with capacity-achieving channel code is denoted as “H.265 + Capacity”. As we shall note, the ideal “H.264 + Capacity” or “H.265 + Capacity” scheme can be viewed as a performance upper bound on traditional separation-based source and channel coding schemes. The above simulations are implemented on the top of Sionna [43], an open-source library for the link-level simulation of digital communication systems. In addition, we refer to the configurations of H.264 and H.265 in [44], which adopt the typical ffmpeg settings for low-latency and veryfast mode. In practical implementation, to be aligned with previous works [17], we also convert two consecutive real symbols in as one complex channel-input symbol and add complex Gaussian noise.
IV-B Reconstruction Task Results
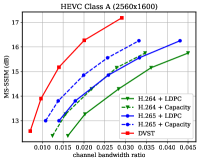
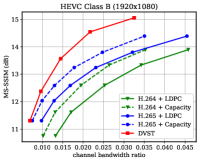
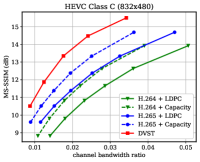
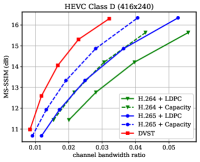
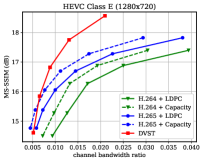


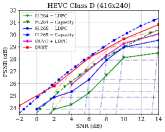

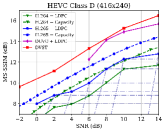
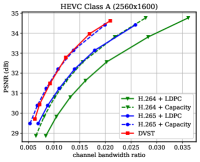
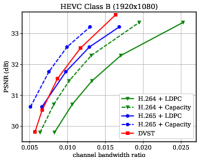
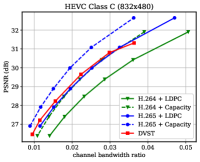
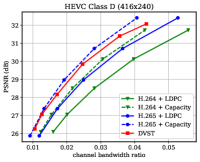
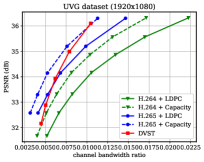
Fig. 6 shows the RD results under the PSNR metric among various test sequences over the AWGN channel with channel dB. For H.264 + LDPC and H.265 + LDPC, after traversing given combinations of LDPC coded modulation schemes, we exploit a rate LDPC code with 16-ary quadrature amplitude modulation (16QAM) to ensure reliable transmission and the highest efficiency [28]. We use the Gaussian capacity formula [1] to calculate the maximum transmission rate per channel symbol for the ideal H.264 + Capacity and H.265 + Capacity schemes. From Fig. 6, we can find that on most test sequences, the proposed DVST (PSNR) scheme can outperform the practical H.264 + LDPC scheme by a large margin for all CBRs, and the performance gap increases with the CBR which indicates a better coding gain achieved by our DVST method. Furthermore, the proposed DVST shows competitive performance to the H.265 + LDPC scheme and even performs close to H.265 + Capacity in some test sequences.
As for the coding gain that shows as the RD curve slope, by using the adaptive rate allocation and contextual transmission mechanism, our DVST model shows comparable coding gain as that of H.265/H.264 series in most cases. The coding gain generally increases with the resolution of the video sequence, which demonstrates the potential of DVST on transmitting higher resolution videos over wireless channels. However, we also note that DVST performs slightly worse than H.265 + LDPC on HEVC Class C and E. A possible reason is that many video sequences, e.g., BQMall, in these two Classes consist of complex foreground or various textures, which results in difficulty to the context generation in both semantic feature space and deep JSCC codeword space. As a comparison, our DVST performs better than H.265 + LDPC on HEVC Class A and D, which are of relatively flat foreground and simple textures.
Fig. 7 shows the RD performance in terms of MS-SSIM perceptual metric over the AWGN channel at dB. Since MS-SSIM yields values between 0 (worst) and 1 (best), and most values are higher than 0.9, we converted the MS-SSIM values in dB to improve the legibility. For semantic communications, this perceptual metric aligns better with human feeling. Results indicate that the proposed DVST method can outperform classical schemes by a large margin, and it achieves a greater improvement on high-resolution images and high CBR regions. Compared to the PSNR results in Fig. 6, we can find that traditional video coded transmission series are inferior to the learning-based DVST because traditional video compression is designed to be optimized for squared error with hand-selected constraints.
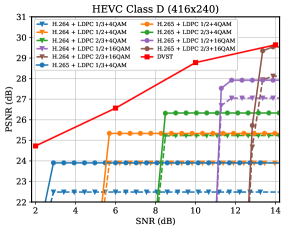
Fig. 8 provides the PSNR and MS-SSIM results versus the change of channel SNR, where the CBR constraint for HEVC Class A sequence is , and for Class D sequence. Since DVST learns an adaptive bandwidth allocation strategy depending on the video content and channel condition, it is difficult to strictly constrain the CBR to the predetermined value. In practice, based on the 10dB DVST models ( for PSNR, and for MS-SSIM), we finetune to meet the CBR constraint in different SNRs. For comparison schemes, we evaluate the performance using all possible combinations of , , and LDPC codes with 4QAM, 16QAM, and 64QAM modulations. The solid blue line presents the envelope of the best performing configurations of H.265 + LDPC at each SNR. In Fig. 8, we use the solid red line to illustrate the performance of the DVST model trained with channel SNR at 2dB, 2dB, 6dB, 10dB, and 14dB, where the testing SNR equals to the training SNR. We also provide the performance of mismatched training and testing as the red dashed lines, where two models are trained under channel SNR 6dB and 10dB, respectively, but tested for various SNRs. We can find that the proposed DVST brings considerable performance gain. Comparing the three red lines, we observe that our DVST model also shows reasonable performance improvement with the increase of when , and avoids catastrophic degradation when . In contrast, traditional separation-based video coded transmission schemes show significant cliff effect which are plotted as the PSNR-SNR curves of H.265 + LDPC in the blue dashdotted lines.
As for the slope of each curve in Fig. 8, our DVST shows better performance and comparable coding gain with that of H.264/H.265 series, especially on the high-resolution videos of HEVC Class A since it contains more high-frequency contents. Furthermore, we compare our DVST with the emerging neural video compression scheme DCVC [27] combined with LDPC codes for wireless transmission. For fair comparison, we use the same I-frame coding and GOP size and only compare the P-frame performance. Compared with DCVC + LDPC, we also achieve meaningful gain, which indicates our DVST can benefit from the good match between the learned deep JSCC and the nonlinear transform. Moreover, DVST does not rely on explicit entropy coding for compression and channel codes for error-correcting, which avoids the cliff effect and reduces the computational complexity, but DCVC + LDPC will also involve the cliff effect due to the use of entropy coding and left errors in LDPC decoding.
| Original | H.264 + LDPC | H.265 + LDPC | DVST |




















Next, we show the PSNR performance under the Rayleigh fading channel with CBR constraint in Fig. 9. In this case, we assume the Rayleigh fading channel gain vector , and it is known at the receiver with ideal channel estimation. Thus, the receiver first conducts channel equalization, such that the received signal can be equivalently written as , and then feed into DVST decoder. In practice, our DVST models of the Rayleigh fading channel are finetuned from baseline models learned under the AWGN channel with the same SNR. Apparently, classical separation schemes (H.264/H.265 + LDPC + QAM) are still inferior to our DVST, especially in the low SNR region.
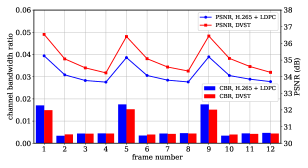
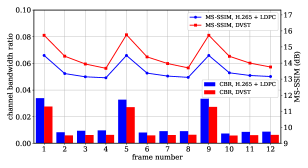
Fig. 10 shows a detailed comparison between DVST and H.265 + LDPC over the performance of a group of consecutive frames. It can be observed that the reconstruction quality of both schemes degrades with the increase of P-frame number within one GOP. In comparison, our DVST can spend fewer channel bandwidth costs while achieving much better reconstruction quality.
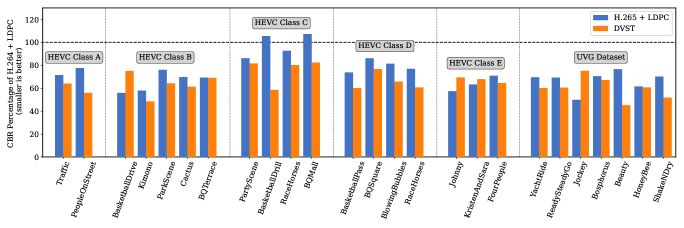
Furthermore, as shown in Fig. 11, we compute the BD rate reduction [45] relative to H.264 + LDPC for each video under AWGN channel at SNR = 10dB. Compared with H.264 + LDPC, the channel bandwidth cost of DVST is only 40% to 80% under the same reconstruction quality in terms of PSNR, which means a 60% to 20% the channel bandwidth can be saved. Compared with the results of H.265 + LDPC, DVST can still save more bandwidth in most videos ().
Fig. 12 and Fig. 13 provide illustrative examples to demonstrate the performance of DVST intuitively. Specifically, as shown in Fig. 12, we visualize the specific reconstructed frames of Fig. 6 and Fig. 7 in the two rows, respectively. From the two groups of examples, we can observe that our DVST model generates high fidelity reconstructions with lower CBR costs. Fig. 13 presents the reconstruction results versus the change of channel SNR under a limited CBR budget. It can be seen that the results of H.265 + LDPC + QAM scheme have artifacts and block effects in the low SNR region, while DVST generates a clear text.
| Ground Truth | H.264 + LDPC | H.265 + LDPC | DVST |





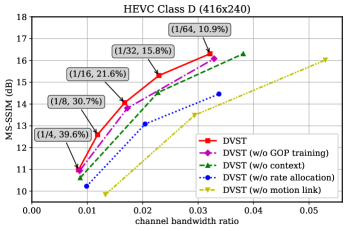
As for the ablation study, we verify the gains brought by proposed algorithms in Fig. 14, including the contextual model enhancement, rate-adaptive transmission, and GOP integrated training strategy. The bandwidth cost trade-offs between primary and motion links are also provided. When the becomes smaller, the DVST model tends to allocate more channel bandwidth to reduce the distortion in the primary link while the percentage of channel bandwidth in the motion link decreases. This result means it is more efficient to focus on the primary link in the high CBR region since this link can preserve more details. We verify the effectiveness of the GOP training strategy, which considers the influence of temporal correlations among adjacent frames. Comparing the results of DVST with that of DVST (without (w/o) GOP training), about 0.2dB reconstruction quality improvement can be seen. To verify the advantages of contextual video transmission, we remove the context generation network of DVST and adopt the traditional residual coding structure [44] as an alternative, which exploits MV to warp the reference frame and transmit the residual between the wrapped frame and the input frame. This contextual model enhancement method in DVST improves the whole performance compared to traditional residual coding structure. Finally, we invalidate the rate adaption module in , , , and by using a constant channel bandwidth cost for each patch embedding and deleting the additional rate tokens. Since the network can no longer learn a bandwidth cost trade-off between primary and motion links, the CBR proportion of the motion link is predetermined to . Given the channel bandwidth cost for each patch embedding, the total CBR is then fixed, so the loss function of DVST (w/o rate allocation) only has the distortion term. As shown in Fig. 14, our DVST overpasses the DVST (w/o rate allocation) by a large margin, especially in the high CBR region, verifying the coding gain brought by the proposed rate-adaptive transmission mechanism. Furthermore, we provide the ablation study about the motion link. The DVST (w/o motion link) extracts the context semantics solely from previous reconstructions. In this case, the whole system architecture can be vastly simplified. However, without the guidance of optical flow, it will be difficult for the context generation module to extract valuable information to exploit the spatio-temporal dependencies, resulting in significant performance degradation.
To compare the computational complexity of different video transmission systems, we measured the average encoding time of DVST on a Linux server with an Intel Xeon Gold 6226R CPU and a RTX 3090 GPU. Following the complexity analysis from [44, 27], we transmit five videos in the 1080P HEVC Class B dataset and measure the encoding speed. As a result, our DVST model spends 280ms to encode a single P-frame as channel-input symbols, which is one times faster than DCVC + LDPC, mainly due to the savings in arithmetic coding time. It is worth mentioning that the coding speed can be further improved by employing the latest deep model acceleration techniques, which is beyond the scope of this paper. As a comparison, the scheme of H.265 + LDPC runs at the speed from 1.5fps (frames per second) to 25fps with different coding settings (the trade-off between the coding efficiency and encoding speed), and the encoding speed of H.264 + LDPC is 8fps to 150fps. Note that, both H.264 and H.265 are implemented using commercial softwares with highly parallel framework and advanced assembly optimization techniques, while their official reference software runs hundreds of times slower [46].
IV-C Downstream Machine Vision Task Results
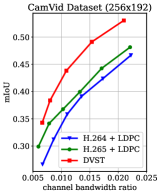
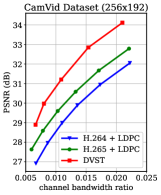
To potentially support future machine-type communications [34], we further optimize DVST for driving the downstream machine vision tasks while preserving the advantages of signal level reconstruction. Specifically, an analytics model is concatenated after the transmission framework to complete high-level semantics-related tasks based on the reconstructed frames. The transmission framework can be either a JSCC scheme like DVST or classical separated system like H.265 + LDPC. Herein, we take semantic segmentation as an example visual analytic task, employ HyperSeg [47] as a powerful analytics model to generate segmentation prediction, and evaluate the capacity of our DVST on the popular CamVid benchmark [48, 49]. CamVid is a road scene understanding dataset, which offers four video clips of driving scenes, and part of frames are densely semantic annotated. Following the training protocol of [47], we use 468 annotated images as the training set and the other 233 ones as the test set. Each video and the labeled images are resized to . To achieve a better rate-distortion-accuracy trade-off, we finetune the DVST (PSNR) model over the CamVid training set. The whole training loss extends (19) to achieve joint optimization of both video transmission and analysis. It is formulated as , where denotes the boot-strapped cross entropy loss [50] specialized for semantic segmentation. is the weighting parameter, we set to balance the importance among reconstruction and segmentation. During the evaluation on the test set, all frames are transmitted to the receiver to calculate signal level distortion in terms of PSNR, while only the labeled frame participates in the calculation of segmentation performance (the labeled frame evenly distributes in the second or last frame of GOP). We report the class mean intersection over union (mIoU) results, a standard evaluation metric for semantic image segmentation [47]. A higher mIoU score indicates a better match between prediction and ground truth, with a maximum value of 1.
The quantitative results are shown in Fig. 15. We observe that our DVST achieves better performance for both reconstruction and segmentation with various CBRs. It outperforms the two separated coding schemes and the gap increases with CBR. Hence, our DVST method can better support machine vision tasks and hold higher fidelity for human vision at the same time. In addition, we present a group of segmentation example in Fig. 16. The reconstruction of DVST preserves more semantic information for machine recognition, which leads to more accurate segmentation results.
V Conclusion
This paper has proposed a new class of high-efficiency deep JSCC methods to achieve end-to-end video transmission over wireless channels. It was collected under the name “DVST”. This DVST framework has exploited nonlinear transform and conditional coding architecture to adaptively extract semantic features across video frames, and transmit semantic features via a group of learned variable-length deep JSCC codecs and wireless channel. Benefiting from the strong temporal prior provided by the semantic feature domain context and the deep JSCC codeword domain context, the DVST framework works highly efficient and effective. The whole video transmission system design has been formulated as an optimization problem whose goal is to minimize the end-to-end transmission rate-distortion performance under established perceptual quality metrics or downstream task metrics, which well matches with the goal of end-to-end semantic communications. Extensive numerical results have shown that the proposed DVST method can generally surpass traditional wireless video coded transmission schemes. In a nutshell, this paper has proposed a promising method to attain a customized design of learning-based source-channel coding for video transmission in future semantic communications.
References
- [1] C. E. Shannon, “A mathematical theory of communication, 1948,” Bell System Technical Journal, vol. 27, no. 3, pp. 3–55, 1948.
- [2] J. Rissanen and G. Langdon, “Universal modeling and coding,” IEEE Transactions on Information Theory, vol. 27, no. 1, pp. 12–23, 1981.
- [3] J. Ballé, N. Johnston, and D. Minnen, “Integer networks for data compression with latent-variable models,” in Proceedings of the International Conference on Learning Representations, 2018.
- [4] P. Zhang, W. Xu, H. Gao, K. Niu, X. Xu, X. Qin, C. Yuan, Z. Qin, H. Zhao, J. Wei, et al., “Toward wisdom-evolutionary and primitive-concise 6G: A new paradigm of semantic communication networks,” Engineering, vol. 8, pp. 60–73, 2022.
- [5] H. Xie, Z. Qin, G. Y. Li, and B.-H. Juang, “Deep learning enabled semantic communication systems,” IEEE Transactions on Signal Processing, vol. 69, pp. 2663–2675, 2021.
- [6] Z. Qin, X. Tao, J. Lu, and G. Y. Li, “Semantic communications: Principles and challenges,” arXiv preprint arXiv:2201.01389, 2021.
- [7] H. Seo, J. Park, M. Bennis, and M. Debbah, “Semantics-native communication with contextual reasoning,” arXiv preprint arXiv:2108.05681, 2021.
- [8] J. Dai, P. Zhang, K. Niu, S. Wang, Z. Si, and X. Qin, “Communication beyond transmitting bits: Semantics-guided source and channel coding,” IEEE Wireless Communications, pp. 1–8, early access, 2022.
- [9] J. Dai, S. Wang, K. Tan, Z. Si, X. Qin, K. Niu, and P. Zhang, “Nonlinear transform source-channel coding for semantic communications,” IEEE Journal on Selected Areas in Communications, vol. 40, no. 8, pp. 2300–2316, 2022.
- [10] K. Niu, J. Dai, S. Yao, S. Wang, Z. Si, X. Qin, and P. Zhang, “A paradigm shift towards semantic communications,” IEEE Communications Magazine, pp. 1–7, early access, 2022.
- [11] M. Fresia, F. Perez-Cruz, H. V. Poor, and S. Verdu, “Joint source and channel coding,” IEEE Signal Processing Magazine, vol. 27, no. 6, pp. 104–113, 2010.
- [12] A. Guyader, E. Fabre, C. Guillemot, and M. Robert, “Joint source-channel turbo decoding of entropy-coded sources,” IEEE Journal on Selected Areas in Communications, vol. 19, no. 9, pp. 1680–1696, 2001.
- [13] N. Ramzan, S. Wan, and E. Izquierdo, “Joint source-channel coding for wavelet-based scalable video transmission using an adaptive turbo code,” EURASIP Journal on Image and Video Processing, vol. 2007, pp. 1–12, 2007.
- [14] C. Chen, L. Wang, and F. CM Lau, “Joint optimization of protograph LDPC code pair for joint source and channel coding,” IEEE Transactions on Communications, vol. 66, no. 8, pp. 3255–3267, 2018.
- [15] N. Farsad, M. Rao, and A. Goldsmith, “Deep learning for joint source-channel coding of text,” in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2018, pp. 2326–2330.
- [16] K. Choi, K. Tatwawadi, A. Grover, T. Weissman, and S. Ermon, “Neural joint source-channel coding,” in Proceedings of the International Conference on Machine Learning. PMLR, 2019, pp. 1182–1192.
- [17] E. Bourtsoulatze, D. B. Kurka, and D. Gündüz, “Deep joint source-channel coding for wireless image transmission,” IEEE Transactions on Cognitive Communications and Networking, vol. 5, no. 3, pp. 567–579, 2019.
- [18] D. B. Kurka and D. Gündüz, “Bandwidth-agile image transmission with deep joint source-channel coding,” IEEE Transactions on Wireless Communications, vol. 20, no. 12, pp. 8081–8095, 2021.
- [19] M. Jankowski, D. Gündüz, and K. Mikolajczyk, “Wireless image retrieval at the edge,” IEEE Journal on Selected Areas in Communications, vol. 39, no. 1, pp. 89–100, 2020.
- [20] A. Krizhevsky, G. Hinton, et al., “Learning multiple layers of features from tiny images,” 2009.
- [21] J. Ballé, V. Laparra, and E. P. Simoncelli, “End-to-end optimized image compression,” in Proceedings of the International Conference on Learning Representations, 2017.
- [22] J. Ballé, “Efficient nonlinear transforms for lossy image compression,” in 2018 Picture Coding Symposium. IEEE, 2018, pp. 248–252.
- [23] J. Ballé, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, “Variational image compression with a scale hyperprior,” in Proceedings of the International Conference on Learning Representations, 2018.
- [24] D. Minnen, J. Ballé, and G. D Toderici, “Joint autoregressive and hierarchical priors for learned image compression,” Advances in Neural Information Processing Systems, vol. 31, 2018.
- [25] J. Ballé, P. A Chou, D. Minnen, S. Singh, N. Johnston, E. Agustsson, S. J. Hwang, and G. Toderici, “Nonlinear transform coding,” IEEE Journal of Selected Topics in Signal Processing, vol. 15, no. 2, pp. 339–353, 2020.
- [26] T. Richardson and S. Kudekar, “Design of low-density parity check codes for 5G new radio,” IEEE Communications Magazine, vol. 56, no. 3, pp. 28–34, 2018.
- [27] J. Li, B. Li, and Y. Lu, “Deep contextual video compression,” Advances in Neural Information Processing Systems, vol. 34, 2021.
- [28] D. B. Kurka and D. Gündüz, “DeepJSCC-f: Deep joint source-channel coding of images with feedback,” IEEE Journal on Selected Areas in Information Theory, vol. 1, no. 1, pp. 178–193, 2020.
- [29] G. Lu, W. Ouyang, D. Xu, X. Zhang, C. Cai, and Z. Gao, “DVC: An end-to-end deep video compression framework,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 11006–11015.
- [30] A. Ranjan and M. J Black, “Optical flow estimation using a spatial pyramid network,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 4161–4170.
- [31] F. Mentzer, G. D Toderici, M. Tschannen, and E. Agustsson, “High-fidelity generative image compression,” Advances in Neural Information Processing Systems, vol. 33, pp. 11913–11924, 2020.
- [32] J. Ballé, V. Laparra, and E. P Simoncelli, “Density modeling of images using a generalized normalization transformation,” in Proceedings of the International Conference on Learning Representations, 2016.
- [33] M. Jaderberg, K. Simonyan, A. Zisserman, and K. kavukcuoglu, “Spatial transformer networks,” in Advances in Neural Information Processing Systems, C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett, Eds. 2015, vol. 28, Curran Associates, Inc.
- [34] L. Duan, J. Liu, W. Yang, T. Huang, and W. Gao, “Video coding for machines: A paradigm of collaborative compression and intelligent analytics,” IEEE Transactions on Image Processing, vol. 29, pp. 8680–8695, 2020.
- [35] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10012–10022.
- [36] T. Xue, B. Chen, J. Wu, D. Wei, and W. T Freeman, “Video enhancement with task-oriented flow,” International Journal of Computer Vision, vol. 127, no. 8, pp. 1106–1125, 2019.
- [37] F. Bossen et al., “Common test conditions and software reference configurations,” JCTVC-L1100, vol. 12, no. 7, 2013.
- [38] T.-Y. Tung and D. Gündüz, “Deepwive: Deep-learning-aided wireless video transmission,” IEEE Journal on Selected Areas in Communications, vol. 40, no. 9, pp. 2570–2583, 2022.
- [39] Z. Wang, E. P Simoncelli, and A. C Bovik, “Multiscale structural similarity for image quality assessment,” in Proceedings of the The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers. IEEE, 2003, vol. 2, pp. 1398–1402.
- [40] D. P Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [41] T. Wiegand, G. J Sullivan, G. Bjontegaard, and A. Luthra, “Overview of the H. 264/AVC video coding standard,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 13, no. 7, pp. 560–576, 2003.
- [42] G. J Sullivan, J.-R. Ohm, W.-J. Han, and T. Wiegand, “Overview of the high efficiency video coding (HEVC) standard,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 22, no. 12, pp. 1649–1668, 2012.
- [43] J. Hoydis, S. Cammerer, F. Ait Aoudia, A. Vem, N. Binder, G. Marcus, and A. Keller, “Sionna: An open-source library for next-generation physical layer research,” arXiv preprint, Mar. 2022.
- [44] G. Lu, X. Zhang, W. Ouyang, L. Chen, Z. Gao, and D. Xu, “An end-to-end learning framework for video compression,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 10, pp. 3292–3308, 2021.
- [45] G. Bjontegaard, “Calculation of average PSNR differences between rd-curves,” ITU-T VCEG-M33, April, 2001, 2001.
- [46] G. Lu, X. Zhang, W. Ouyang, L. Chen, Z. Gao, and D. Xu, “An end-to-end learning framework for video compression,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 10, pp. 3292–3308, 2020.
- [47] Y. Nirkin, L. Wolf, and T. Hassner, “Hyperseg: Patch-wise hypernetwork for real-time semantic segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 4061–4070.
- [48] G. J Brostow, J. Shotton, J. Fauqueur, and R. Cipolla, “Segmentation and recognition using structure from motion point clouds,” in European Conference on Computer Vision. Springer, 2008, pp. 44–57.
- [49] G. J Brostow, J. Fauqueur, and R. Cipolla, “Semantic object classes in video: A high-definition ground truth database,” Pattern Recognition Letters, vol. 30, no. 2, pp. 88–97, 2009.
- [50] S. E Reed, H. Lee, D. Anguelov, C. Szegedy, D. Erhan, and A. Rabinovich, “Training deep neural networks on noisy labels with bootstrapping,” in Proceedings of the International Conference on Learning Representations (Workshop), 2015.