Hands-on Wireless Sensing with Wi-Fi: A Tutorial
Abstract.
With the rapid development of wireless communication technology, wireless access points (AP) and internet of things (IoT) devices have been widely deployed in our surroundings. Various types of wireless signals (e.g., Wi-Fi, LoRa, LTE) are filling out our living and working spaces. Previous researches reveal the fact that radio waves are modulated by the spatial structure during the propagation process (e.g., reflection, diffraction, and scattering) and superimposed on the receiver. This observation allows us to reconstruct the surrounding environment based on received wireless signals, called “wireless sensing”. Wireless sensing is an emerging technology that enables a wide range of applications, such as gesture recognition for human-computer interaction, vital signs monitoring for health care, and intrusion detection for security management. Compared with other sensing paradigms, such as vision-based and IMU-based sensing, wireless sensing solutions have unique advantages such as high coverage, pervasiveness, low cost, and robustness under adverse light and texture scenarios. Besides, wireless sensing solutions are generally lightweight in terms of both computation overhead and device size. This tutorial takes Wi-Fi sensing as an example. It introduces both the theoretical principles and the code implementation 111Code and data are available at http://tns.thss.tsinghua.edu.cn/wst and http://tns.thss.tsinghua.edu.cn/widar3.0. of data collection, signal processing, features extraction, and model design. In addition, this tutorial highlights state-of-the-art deep learning models (e.g., CNN, RNN, and adversarial learning models) and their applications in wireless sensing systems. We hope this tutorial will help people in other research fields to break into wireless sensing research and learn more about its theories, designs, and implementation skills, promoting prosperity in the wireless sensing research field.
1. Wireless Sensing Background
1.1. What is Wireless Sensing
Various sensors and sensor networks have thoroughly extended human perception of the physical world. Nowadays, numerous sensors have been deployed to complete various sensing tasks, resulting in a significant deployment and maintenance overhead. This problem becomes increasingly troublesome when a large sensing scale is in demand. Taking indoor person tracking as an example, a specialized tracking system only covers a room-level area, which is too small compared with the moving region during a person’s daily life. Multiple tracking systems are needed to achieve practical sensing coverage in realistic living environments, e.g., houses, campuses, markets, airports, and offices, and the cost inevitably ramps up.
Given the cost limitations of the sensors, many pioneers tried to figure out an alternative solution during the past decade. Nowadays, various types of signals (e.g., Wi-Fi, LoRa, LTE) are filling out our living and working spaces for wireless communication, which can be leveraged to capture the environmental changes without causing extra overhead. According to the electromagnetism theory, the radio signals emitted by the transmitter (Tx) experience various physical phenomena such as reflection, diffraction, and scattering during the propagation process and form into multiple propagation paths. In this way, the superimposed multipath signals collected by the receiver carry spatial information about the signal propagation environment. Relying only on the ambient wireless signals and ubiquitous communication devices, wireless sensing emerges as a novel paradigm for environment sensing.
In recent years, wireless sensing technology has attracted many research interests to bring wireless sensing from the imagination into reality, by boosting sensing granularity, improving system robustness, and exploring application scenarios. Many of their works on wireless sensing have been published in flagship conferences and journals, such as ACM SIGCOMM, ACM MobiCom, ACM MobiSys, IEEE INFOCOM, USENIX NSDI, IEEE/ACM ToN, IEEE JSAC, and IEEE TMC. In addition, many famous companies are also exploring the productization of sensorless sensing, launching various IoT devices for human-computer interaction, security monitoring, and health care.
1.2. Comparison of Wireless Sensing and Computer Vision
Typical RF signals (300 kHz - 300 GHz) and visible light signals (380 THz - 750 THz) are essentially electromagnetic (EM) waves. When propagating in our physical world, the EM waves experience a variety of physical phenomena such as reflection, diffraction, and scattering. Multipath signals are eventually superimposed and received by the receiver. Therefore, the received superimposed signals carry the physical information of the signal propagation space.
Both the RF-based and the vision-based sensing algorithms share similar processes. They first analyze the received signals (radio signal at the antenna or visible light at the camera lens), from which the features reflecting the propagation space are extracted and finally resolved by algorithms to realize the sensing of the surrounding environment.
Compared with vision-based sensing, wireless sensing solutions have unique advantages such as high coverage (Chi et al., 2021), pervasiveness, low cost, and robustness under adverse light and texture scenarios (Chi et al., 2022).

1.3. Wireless Sensing Applications
Wireless sensing systems are capable of perceiving changes in surrounding environments, objects, and human bodies. In this subsection, we take passive human sensing applications as an example, which refers to a human-centered sensing application that doesn’t require the user to carry any device. Therefore, such an sensing application is also termed as device-free sensing or non-invasive sensing. Passive human sensing enables a wide range of applications, including smart homes, security surveillance, and health care.
In smart home applications, passive human sensing recognizes a person’s behavior or intention based on the user’s physical locations, gestures, and postures. Passive human sensing brings a better user experience without imposing restrictions on the user. For example, users can remotely control electrical devices, e.g., television, computer, or washer, by merely performing gestures in the air (Zheng et al., 2019; Abdelnasser et al., 2015). Likewise, when playing video games, users can interact with the computer by performing different postures (Jiang et al., 2020).
In security surveillance applications, traditional methods adopt infrared or RGB cameras to monitor illegal invasions, protect valuable properties, and deal with emergencies. However, cameras are constrained by the limited field of view or blockage of opaque or metallic objects, rendering these methods to fail when the target is not in the Line-of-Sight (LoS) area of the surveillance camera or hidden behind other objects. In contrast to visual surveillance, wireless sensing technology leverages radio signals, which provide omnidirectional coverage around the wireless devices and are less prone to blockages. For example, wireless signals can be used to detect illegal intrusions (Wu et al., 2015; Qian et al., 2014). Besides, they can also be used to detect if properties have been moved from their original places.
In health care applications, passive human sensing can be leveraged to detect vital signals such as human respiration, heartbeat, gait, and accidental fall. Specifically, some researchers have exploited Wi-Fi signals to detect human respiration (Wang et al., 2016) for sleep monitoring. Some other works (Zhang et al., 2020; Wu et al., 2020) have extracted gait patterns from Wi-Fi signals to recognize human identity. Recently, Wi-Fi signals have been further used to detect accidental falls to relieve the need for wearable sensors (Hu et al., 2020; Palipana et al., 2019).
2. Understanding CSI
Channel state information (CSI) lays the foundation of most wireless sensing techniques, including Wi-Fi sensing, LTE sensing, and so on. CSI provides physical channel measurements in subcarrier-level granularity, and it can be easily accessed from the commodity Wi-Fi network interface controller (NIC).
CSI describes the propagation process of the wireless signal and therefore contains geometric information of the propagation space. Thus, understanding the mapping relationship between CSI and spatial geometric parameters lays the foundation for feature extraction and sensing algorithm design.
This section focuses on two mainstream CSI models: the ray-tracing model and the scattering model. The two models are based on two perspectives of understanding the signal propagation process. Thus, they have unique advantages and apply to different scenarios.
2.1. Ray-tracing Model
In typical indoor environments, a signal sent by the transmitter arrives at the receiver via multiple paths due to the reflection of the radio wave. Along each path, the signal experiences a certain attenuation and phase shift. The received signal is the superimposition of multiple alias versions of the transmitted signal. Therefore, the complex baseband signal strength measured at the receiver at a specific time can be written as follows (Yang et al., 2013):
| (1) |
where and are the amplitude and phase of the multipath component (note that the modulation scheme of the signal is implicitly considered), and is the total number of components. On this basis, the recieve signal strength indicator (RSSI) can be written as the received power in decibels (dB):
| (2) |
As the superimposition of multipath components, RSSI not only varies rapidly with propagation distance changing at the order of the signal wavelength but also fluctuates over time, even for a static link. A slight change in specific multipath components may result in significant constructive or destructive multipath components, leading to considerable fluctuations in RSSI.
The essential drawback of RSSI is the failure to reflect the multipath effect. The wireless channel is modeled as a linear temporal filter to fully characterize individual paths, known as channel impulse response (CIR). Under the time-invariant assumption, CIR is represented as:
| (3) |
where , , and are the complex antenuation, phase, and time delay of the path, respectively. is the total number of multipath and is the Dirac delta function. Each impulse represents a delayed multipath component, multiplied by the corresponding amplitude and phase.
In the frequency domain, the multipath causes frequency-selective fading, which is characterized by channel frequency response (CFR). CFR is essentially the Fourier transform of CIR. It consists of both the amplitude response and the phase response. Fig. 2 demonstrate a multipath scenario, the transmitted signal, the received signal, and the illustrative channel responses. Both CIR and CFR depict a small-scale multipath effect and are used for fine-grained channel measurement. Note that the complex amplitudes and antennuation are concerned in CIR and CFR, while another pair of parameters in terms of the signal power is Power Delay Profile (PDP) and Power Spectrum Density (PSD).
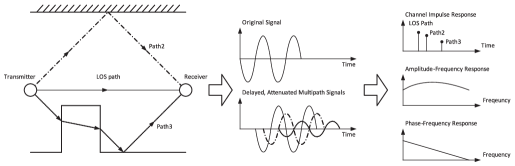
CIR and CFR are measured by decoupling the transmitted signal from the received signal. Specifically, in the time domain, the received signal is the convolution of transmitted signal and channel impulse response :
| (4) |
which indicates the recieved signal is generated from the transmit signal after it propagating from multipath channel.
Similarly, in the frequency domain, the received signal spectrum is the multiplication of the transmitted signal spectrum and the channel frequency response :
| (5) |
Note that the and are the Fourier transform of the recieved signal and the transmitted signal respectively. In this way, Eqn. 4 and Eqn. 5 forms a beautiful “symmetric” relationship.
As demonstrated in Eqn. 4 and Eqn. 5, CIR can be derived from the deconvolution operation of received and transmitted signals, and CFR can be treated as the ratio of the received and the transmitted spectrums. Compared with multiplication, the convolution operation is generally time-consuming. Therefore, in most cases, the device focuses on calculating the CFR, and the CIR can be further derived from the CFR using the inverse Fourier transform (Patwari and Kasera, 2007):
| (6) |
where denotes the inverse Fourier transform, is the conjugate operator, and approximates the transmitted signal power.
Although the derivation of CIR and CFR is independent of the modulation scheme, it could be more convenient to implement the process on commercial devices with specific modulation schemes. For the wireless standard where the orthogonal frequency division modulation (OFDM) is adopted (e.g., 802.11a/g/n/ac/ax), the amplitude and phase sampled on each subcarrier can be treated as a sampled version of the signal spectrum . On this basis, a sampled version of can be easily get from the OFDM receivers.
Recent advances in the wireless community make it possible to get the sampled version of CFR from commercial-off-the-shelf (COTS) Wi-Fi NICs. The extracted CFR are often refered to as a series of complex numbers, which depicts the amplitude and phase of each subcarrier:
| (7) |
where is a sample at the subcarrier, with denotes its phase. Most research paper treat the CFR at sampled at different subcarriers as the CSI data, which can be written as , where denotes the total number of subcarriers.
The ray-tracing model establishes the relationship between geometric properties of the signal propagation space and the CSI data. Theoretically, by analyzing the multipath signal, various types of geometric information (e.g., the propagation distance, the reflection points) can be derived. Therefore, the ray-tracing model is widely adopted in wireless localization and tracking tasks. In addition, many wireless detection and sensing systems also extract geometric features based on the ray-tracing models, and further put them into machine learning models for regression or classification.
A significant drawback of the ray-tracing model is that it is based on a simple environmental assumption. Therefore, in a complex environment where the signal undergoes diffraction or is disturbed by various types of noise, it becomes difficult to accurately recover all the spatial information by only limited CSI data.
2.2. Scattering Model
The above-mentioned ray-tracing model characterizes signals with multiple propagation paths, which may not apply to rich-scattering environments. To enable wireless sensing in more complex scenarios, some works (Zhang et al., 2018; Wu et al., 2020) establish the scattering model for CSI measurements with Wi-Fi.
The CSI data reported by commodity Wi-Fi NIC can be modeled as:
| (8) |
where is the total number of reflection paths, is the amplitude attenuation of path , is the corresponding phase.
As shown in Fig. 3, the scattering model treats all the objects in indoor environments as scatterers that diffuse the signals to all directions. The CSI observed by the receiver is added up with the portions contributed by the static (furniture, walls, etc.) and dynamic (arms, legs, etc.) scatterers. Intuitively, each scatter is deemed as a virtual Tx. Such modeling can be applied to typical indoor scenarios, where the rooms are crowded with furniture, and signals could propagate in almost all directions. On this basis, we can dismiss the specific signal propagation path and only statistically investigate the relationship between the observed CSI and the moving speed.
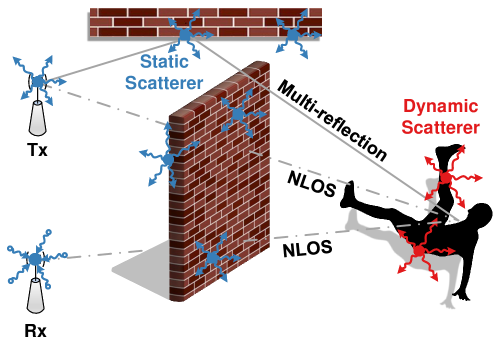
We decompose the observed CSI into the portions contributed by individual scatterers:
| (9) |
where and are the sets of static and dynamic scatterers, is the portion of observed CSI contributed by dynamic scatterer. For each scatterer, the diffused components undergo anonymous propagation processes and eventually add up at the receiver. Try to a three-dimensional coordinate with its origin at the scatterer and its z-axis align with the scatterer’s moving direction, the representation of is further decomposed as follows (Zhang et al., 2018):
| (10) |
where and is the signal wavelength, is the speed of the dynamic scatterer, and are the azimuth and elevation angles, represents the phase shift of the signal on direction . is the portion of observed CSI contributed by scatterer on direction . Inherited from the physical properties of EM waves (Hill, 2009), can be viewed as a circularly-symmetric Gaussian random variable. For and , is independent of .
Based on Eqn. 9 and Eqn. 10, we are able to derive the statistical property by analyzing the autocorrelation function (ACF) of (Hill, 2009):
| (11) |
where is the covariance between two random variables, is the variance of , , and is the time lag.
For some human activities like fall and walking, we can assume that the dynamic scatterers are mainly on the torso and have similar speeds . Thus, Eqn. 11 is approximated with a much simpler form: . Using this formulation, we have quantitatively established the relationship between the huamn speed and the ACF of CSI. In practice, the speed is extracted by matching the first peak of the function and the first peak of ACF:
| (12) |
where is the constant value representing the location of the first peak of function, is the time lag corresponding to the first peak of the ACF.
As a straightforward example, we let a volunteer to walk and fall in a heavily furnished room and extract the speed with the CSI collected from a Wi-Fi link located in another room. As is shown in Fig. 4, even with non-line-of-sight (NLoS) occlusions and multipath pollution, the walking speed and fall speed are estimated consistently, demonstrating its robustness to environmental diversity.
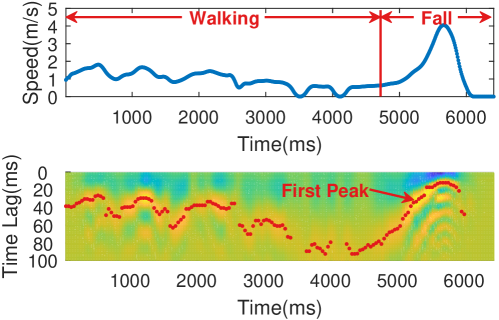
The scattering model is generally applicable to various speed-oriented sensing The scattering model generally applies to various speed-oriented sensing tasks such as intrusion detection and fall detection. As a statistical model, it has unique advantages in complex scenarios.
However, the scattering model fails to construct a correspondence between CSI and geometric parameters directly, and thus is generally not applicable to precise localization and tracking tasks.
3. CSI Data Collection
CSI data collection is the first step toward the implementation of a practical wireless sensing system. This section introduces one of the most famous Wi-Fi sensing datasets, the Widar3 dataset, so that beginners can quickly get start with wireless sensing with minimal effort. This section also introduces three of the most famous CSI collection tools that researchers can use to try out collecting CSI data with COTS NICs.
3.1. Widar3 Dataset
Open datasets are essential to provide comprehensive knowledge for model training and a unified benchmark for model comparison. Open datasets are even more necessary in the wireless sensing field because RF signals are more sensitive to devices and deployment environments. However, the absence of high-quality and large-scale datasets has become the bottleneck that hindered the progress of wireless sensing technology. Existing wireless sensing datasets suffer from small scales and limited scenarios in 2019 when we started to build the Widar3 dataset. Widar3222http://tns.thss.tsinghua.edu.cn/widar3.0 is a wireless sensing dataset for human activity recognition. It is collected from commodity Wi-Fi NICs in the form of RSSI and CSI. It consists of 258,000 instances of hand gestures with a duration of 8,620 minutes and from 75 domains. Widar3 is so far the largest and most comprehensive dataset in this field and receives widespread attention from researchers all over the world. Widar3 dataset is publicly available at IEEE DataPort (official data repository) and continues evolving to contain more types of activities.
3.2. PicoScenes Platform
PicoScenes (Jiang et al., 2021) is a versatile and powerful middleware for CSI-based Wi-Fi sensing research. It is one of the very few tools that support the latest 802.11ac/ax protocols. It supports many prevalent commercial NICs, including Qualcomm Atheros AR9300 (QCA9300), Intel Wireless Link 5300 (IWL5300), Intel AX200 and Intel AX210. PicoScenes supports up to 27 NICs to work concurrently for packet injection and CSI measurement.
PicoScenes is architecturally versatile and flexible. It encapsulates all the low-level features into unified and hardware-independent APIs and exposes them to the upper-level plugin layer. As a result, users can quickly prototype their own measurement plugins.
The data reported by PicoScenes can be parsed in MATLAB as a struct, containing the CSI data of different packets, subcarriers, and antennas. The struct also includes other helpful information such as timestamps, RSSI, and the signal-to-noise ratio (SNR).
The homepage333https://ps.zpj.io of this tool can be accessed for more detailed information.
3.3. Intel 5300 NIC CSI Tool
This CSI Tool (Halperin et al., 2011) is built upon the Intel WiFi Wireless Link 5300 802.11n MIMO radios, using a modified firmware and the open-source Linux wireless driver. It includes all the software and scripts required to collect, read, and parse CSI.
The IWL5300 provides 802.11n CSI of 30 subcarrier groups. Each group contains 2 adjacent subcarriers given 20 MHz bandwidth or 4 given 40 MHz bandwidth. Each CSI sample is a complex number, with a signed 8-bit resolution for both real and imaginary parts. One CSI record is a matrix, where is the number of pairs of transmitting and receiving antennas.
The homepage444https://dhalperi.github.io/linux-80211n-csitool of this tool can be accessed for detailed information.
3.4. Atheros CSI Tool
Atheros CSI Tool (Xie et al., 2018) is an open-source 802.11n measurement and experimentation tool. It enables the extraction of detailed PHY wireless communication information from the Atheros WiFi NICs, including the Channel State Information (CSI), the received packet payload, and other information (the time stamp, the RSSI of each antenna, the data rate, etc.). Atheros-CSI-Tool is built on top of ath9k, an open-source Linux kernel driver supporting Atheros 802.11n PCI/PCI-E chips. Thus, this tool theoretically supports all types of Atheros 802.11n WiFi chipsets. We have tested it on Atheros AR9580, AR9590, AR9344, and QCA9558. Furthermore, Atheros CSI Tool is open source, and all functionalities are implemented in software without any modification to the firmware. Therefore, one can extend the functionalities of Atheros CSI Tool with their own codes under the GPL license.
Atheros-CSI-Tool works on various Linux distributions, e.g., Ubuntu, OpenWRT, Linino, etc.. Different Linux distribution works with different hardware. Ubuntu works for personal computers like laptops or desktops. OpenWRT works for embedded devices such as WiFi routers. Linino works for IoT devices, such as Arduino YUN. The official website provides the source code for the Ubuntu version and OpenWRT version of the Atheros CSI tool.
The homepage555https://wands.sg/research/WiFi/AtherosCSI of this tool can be accessed for detailed information.
4. CSI Feature Extraction
The CSI features lay the fundation of wireless sensing. In particular, for different sensing tasks, choosing the most appropriate features can effectively improve the system performance. In addition, the quality of the extracted features determines the effectiveness of the sensing system.
For ease of illustration, code implementation used for feature extraction is provided below, which is a main function to call different function in the following subsections.
4.1. Time of Flight
ToF is the time duration the signal propagates from the transmitter to the receiver along a specific path. Given the frequency , the phase shift introduced by the ToF is:
| (13) |
As the superimposition of multipath signals, CSI can be represented based on the ray-tracing model:
| (14) |
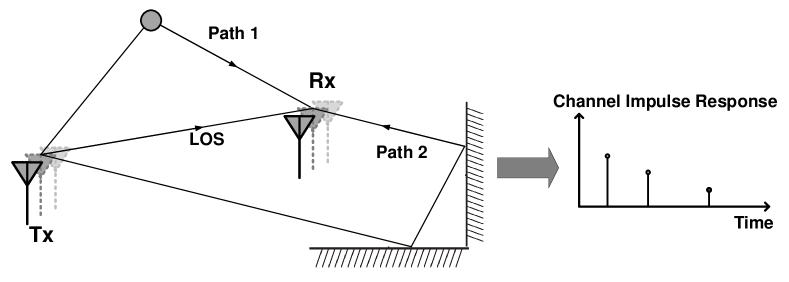
where is the total number of multipath, and and are the complex attenuation factor and time of flight (ToF) for the path, respectively. Theoretically, the ToF of all paths can be identified in CIR, which can be calculated by applying the inverse Fourier transform to CSI samples of all subcarriers. However, since the transmitter and the receiver lack synchronization, non-zero temporal shifts exist in CIR, and the absolute ToF is typically not accurate enough. The limited bandwidth also constrains the time resolution, causing meter-level ToF ambiguity The relationship between signal propagation path, ToF, and CIR is shown in Figure 5.
The following function naive_tof intends to extract the ToF of the strongest path (typically the shortest path) based on inverse Fourier transform.
4.2. Angle of Arrival and Angle of Departure
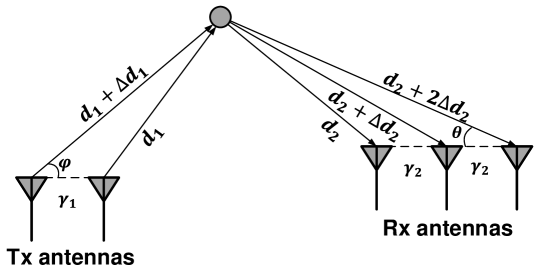
When a NIC equipes with multiple antennas, a local coordinate at the device can be created. As shown in Figure 6, for a transmitter, the angle of departure (AoD) represents the direction in the local coordinate along which the transmitted signal is emitted. For a receiver, the angle of arrival (AoA) represents the direction in the local coordinate along which the received signal is captured. Since the antennas are spatially separated, non-zero phase shifts between antennas are introduced. The phase shifts depend on the AoA/AoD. Specifically, suppose the relative location between two antennas is and the unit direciton vector of AoA is , the phase shift between the two antennas is:
| (15) |
Then CSI can be modeled as:
| (16) |
where represents the antenna at the receiver. The same model applies to the AoD at the trasmitter side and the 3D space with azimuth and elevation angles.
In practice, algorithms such as Capon (Capon, 1969) and MUSIC (Schmidt, 1986) can be used to estimate the AoA/AoD of multiple paths from the CSI of the antenna array.
MUSIC analyses the incident signals on multiple antennas to find out the AoA of each signal. Specifically, suppose signals arrive from directions at antennas. The received signal at the antenna element, denoted as , is a linear combination of the incident wavefronts and noise :
or
| (17) |
where is the array steering vector that characterizes added phase (relative to the first antenna) of each receiving component at the antenna. is the matrix of steer vectors. As shown in Figure 6, for a linear antenna array with elements well synchronized,
| (18) |
Suppose , and is a wide-sense stationary process with zero mean value, the covariance matrix of the received signal vector is:
| (19) | ||||
where is the covariance matrix of transmission vector . The notation represents conjugate transpose and represents expectation.
The covariance matrix has eigenvalues associated with eigenvectors . Sorted in a non-descending order, the smallest eigenvalues correspond to the noise while the rest correspond to the incident signals. In other word, the -dimension space can be divided into two orthogonal subspace, the noise subspace expanded by eigenvectors , and the signal subspace expanded by eigenvectors (or equivalently array steering vector ).
To solve for the array steering vectors (thus AoA), MUSIC plots the reciprocal of squared distance for points along the continue to the noise subspace as a function of :
| (20) |
This yields peaks in at the bearing of incident signals. It is similar to apply MUSIC algorithm for AoD spectrum estimation.
The following function naive_aoa intends to estimate the 3D AoA based on the phase difference, which is similar to Eqn. 15. Note that the following algorithm only considers one path, and thus cannot be applied to mutlipath signals.
4.3. Phase Shift Spectrum
Non-zero phase shift across different packets is caused by the relative movement of the transmitter, receiver, or objects in the propagation path of the signal. It equals the changing rate of the path length of the signal. When multiple packets are received in sequence, the CSI corresponding to the received packet is:
| (21) |
where is the phase of the path (Chi et al., 2022). Extract the phase of the the path in packet and respectively, and calculate the phase shift as:
| (22) |
Intuitively, the phase difference indicates the distance change of the path between two consecutive packets: .
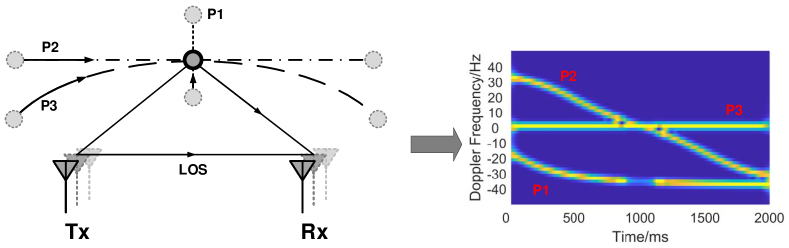
Take a step further, and apply the short-time Fourier transform (STFT) within a sliding window, we can get the spectrum as shown in Figure 7. The frequency axis reveals the change rate of consecutive CSI data, and implicitly contains the path length change rate. Figure 7 demonstrates the phase shift spectrum (or the Doppler Spectrum) for three different moving paths.
The following function naive_stft calculates the short-time Fourier transform of a series of CSI data. The generated spectrum can be used effectively for many wireless sensing tasks, like gesture recognition and fall detection.
4.4. Body-coordinate Velocity Profile
The limitation of the aforementioned spectrum is that, even the spectrum corresponding to the same activity will be different when the user moves at different locations or orientations relative to the Wi-Fi links. To resolve this problem, Widar3.0 (Zheng et al., 2019) proposes a domain-independent signal feature BVP (body-coordinate velocity profile) to characterize human activities.
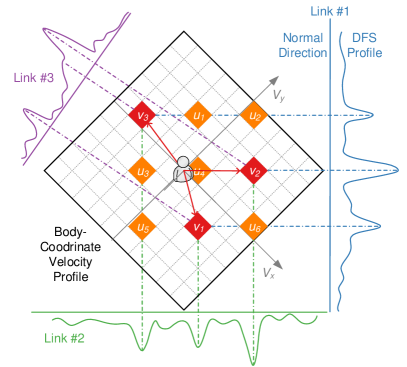
The basic idea of BVP is shown in Fig. 8. A BVP is quantized as a discrete matrix with dimension as velocity components decomposed along each axis of the body coordinates. For convenience, we establish the local body coordinates whose origin is the location of the person and positive x-axis aligns with the orientation of the person. The person’s location and orientation should be provided manually. Currently, it is assumed that the global location and orientation of the person are available. Then the known global locations of wireless transceivers can be transformed into the local body coordinates. Thus, for better clarity, all locations and orientations used in the following derivation are in the local body coordinates. Suppose the locations of the transmitter and the receiver of the link are , , respectively, then any velocity components around the human body (i.e., the origin) will contribute its signal power to some frequency component, denoted as , in the Doppler spectrum of the link (Qian et al., 2017):
| (23) |
and are coefficients determined by locations of the transmitter and the receiver:
| (24) | |||
where is the wavelength of Wi-Fi signal. As static components with zero Doppler spectrum (e.g., the line of sight signals and dominant reflections from static objects) are filtered out before the Doppler spectrum are calculated, only signals reflected by the person are retained. Besides, when the person is close to the Wi-Fi link, only signals with one-time reflection have prominent magnitudes (Qian et al., 2018). Thus, Eqn. 23 holds valid for the gesture recognition scenario. From the geometric view, Eqn. 23 means that the 2-D velocity vector is projected on a line whose direction vector is . Suppose the person is on an ellipse curve whose foci are the transmitter and the receiver of the link, then is indeed the average direction of the ellipse at the person’s location. Fig. 8 shows an example where the person generates three velocity components , and projection of the velocity components on the Doppler spectrum of three links.
Since coefficients and only depend on the location of the link, the relation of projection of the BVP on the link is fixed. Specifically, an assignment matrix can be defined:
| (25) |
where is the frequency sampling point in the Doppler spectrum, and is velocity component corresponding to the element of the vectorized BVP . Thus, the relation between Doppler spectrum profile of the link and the BVP can be modeled as:
| (26) |
where is the scaling factor due to propagation loss of the reflected signal.
Due to the sparsity of BVP, compressed sensing (Donoho, 2006) technique can be adopted to formulate the estimation of BVP as an optimization problem:
| (27) |
where is the number of Wi-Fi links. The sparsity of the number of the velocity components is coerced by the term , where represents the sparsity coefficients and is the number of non-zero velocity components.
is the Earth Mover’s Distance (Rubner and Tomasi, 2001) between two distributions. The selection of EMD rather than Euclidean distance is mainly due to two reasons. First, the quantization of BVP introduces approximation error, i.e., projection of velocity components to the Doppler spectrum bin might be adjacent to the true one. Such quantization error can be relieved by EMD, which takes the distance between bins into consideration. Second, there are unknown scaling factors between the BVP and Doppler spectrum, making the Euclidean distance inapplicable.
5. CSI Sanitization
The wireless sensing models and features described in previous sections are consistent with the EM propagation theory and geometry. However, they don’t consider the various types of noise caused by imperfect implementations of transceiver hardware (Xie et al., 2018; Xie et al., 2019). This section focuses on various CSI error sources and the corresponding error cancellation algorithms.
For ease of illustration, code implementation for sanitization is provided, which is a main function to call different error cancellation functions and test their performance.
5.1. Nonlinear Amplitude and Phase
The nonlinear amplitude and phase errors are caused by the imperfect analog domain filter implementation inside the hardware. Specifically, it causes the extracted CSI amplitude and phase to be equivalently processed by a nonlinear function. Let and be the nonlinear modes of CSI amplitude and phase, respectively, the errorous CSI can be written as:
| (28) |
Specifically, during the OFDM modulation process, each subcarrier of should have the same gain. In other words, the amplitude-frequency characteristic of CSI should be a horizontal straight line when a coaxial cable is used to connect the transceiver ports. However, actual measurements show that even without the multipath radio channel, there is still a similar ”frequency selective fading” characteristic, i.e., the gain of each frequency band is different, showing an M-shaped amplitude-frequency characteristic curve. Similarly, when using a coaxial cable to connect the transceiver port, the CSI phase-frequency characteristics obtained by the NIC are not an ideal straight line with slope, but an S-shaped curve with certain nonlinearity.
After extensive research and experiments, we have observed two facts.
-
•
First, for a specific type of NIC, the nonlinear amplitude/phase error of CSI is fixed. This means that the correction task can be accomplished if we use a known length coaxial cable connected to the transceiver port. Before performing the sensing task, measure a representative set of CSI amplitude and phase, record the nonlinear characteristics, and eliminate the nonlinearity in the subsequent steps.
-
•
Second, we observe that the middle part of the subcarrier is free of nonlinear errors, and the nonlinear characteristics of both sides are also fixed.
Therefore, the function below the code performs the following steps to tackle the CSI nonlinearity:
-
(1)
Read in a set of CSI data measured using a coaxial cable.
-
(2)
Get its amplitude and phase.
-
(3)
Normalize its amplitude and record it as the amplitude template.
-
(4)
Unwrap the phases, then perform a linear fit to the middle part of its subcarriers. Subtract the linear fit result to obtain the nonlinear phase error template.
Finally, the nonlinear amplitude and nonlinear phase components are saved in the form of , which indicates the nonlinear error template of a specific type of NIC.
After getting the nonlinear error template, the sanitization process begins. For the raw CSI data csi_data collected in real time, we divide it by the error template csi_calib. This operation is equivalent to “dividing the original amplitude by the normalized nonlinear amplitude” and “subtracting the original phase from the nonlinear phase”, so that the returned CSI data csi_proc has sanitized amplitude and phase.
5.2. Automatic Gain Control Uncertainty
Automatic gain control (AGC) induces a random gain in each received CSI packet.
| (29) |
There are two ways to eliminate the AGC error: 1) Disable the AGC function of the wireless driver; 2) Compensate the amplitude of the measured CSI based on the reported AGC.
5.3. Radio Chain Offset
Radio chain offset (RCO) is the random phase variation introduced between different Tx/Rx chains (transceiver antenna pairs). The RCO is reset each time the NIC is powered up.
| (30) |
RCO induces a biast of the phase-frequency characteristic curve. It undermines the accuracy of features such as AoA or ToF. Fortunately, we found that this type of phase deviation is consistent between each successive packet sent and therefore doesn’t affect the performance of temporal tracking or sensing, and that this type of error can be eliminated by the following steps:
-
(1)
Once the NIC power-up, connect the transceiver port using a coaxial cable of known length and record the phase information calib_phase.
-
(2)
during subsequent measurements, subtracting this phase information from the measured phase csi_phase.
5.4. Central Frequency Offset
Central frequency offset (CFO), which is caused by the frequency desynchronization on both sides of the transceiver, leads to random frequency shift of each received CSI.
| (31) |
The CFO induces an extra bias (i.e., an overall up and down shift) of the phase-frequency characteristic curve.
To eliminate CFO, we need to insert multiple HT-LTFs in the same PPDU (Wi-Fi data frame), and therefore obtaining multiple CSI measurements. Since the time interval between multiple HT-LTFs is strictly controlled to according to the 802.11 protocol, the phase difference between two HT-LTFs is induced by the CFO within . Thus, the approximate value of the CFO can be recovered.
5.5. Sampling Frequency Offset and Packet Detection Delay
The sampling frequency offset (SFO), which appears to be an error in frequency domain, are generally considered as an equivalent time shift due to frequency asynchrony. The packet detection delay (PDD) is a time delay. Therefore, despite their distinct causes, they are often discussed together as a “time offset” together.
| (32) |
This type of error is critical because the time delay can be confused with real ToF and thus affect the accuracy of the ranging accuarcy. Specifically, this deviation will be characterized in the phase-frequency characteristic curve as a change in slope, since this time deviation causes different phase changes with different sub-bands .
Currently, there is no “perfect algorithm” to solve this type of error. Conjugate multiplication and division are the only two methods to eliminate the SFO and PDD. The code of both of them are listed below. By appling the conjugate multiplication or division, the is eliminated, at the cost of losing absolute ToF measurement.
To sum up, there are various forms of errors in Wi-Fi CSI measurements, including fixed bias and random errors. Each of them have different impacts on the localization, tracking, and sensing tasks. The erroneous CSI form can be finally written as:
| (33) |
6. Wireless Sensing with Deep Learning
This section introduces a series of learning algorithms, especially the prevalent deep neural network models such as CNN and RNN, and their applications in wireless sensing. This section also proposes a complex-valued neural network to accomplish learning and inference based on wireless features efficiently.
6.1. Convolutional Neural Network
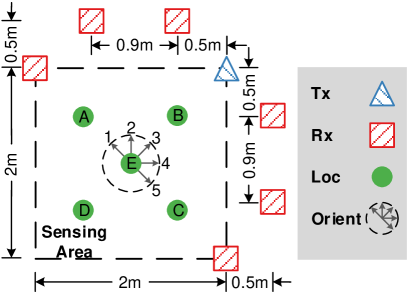
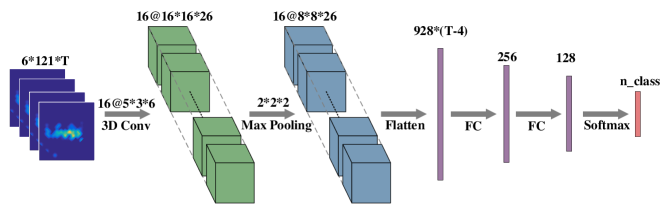
Convolutional Neural Network (CNN) contributes to the recent advances in understanding images, videos, and audios. Some works (Zhao et al., 2018; Zheng et al., 2019; Jiang et al., 2020) have exploited CNN for wireless signal understanding in wireless sensing tasks and achieved promising performance. This section will present a working example to demonstrate how to apply CNN for wireless sensing. Specifically, we use commodity Wi-Fi to recognize six human gestures. The gestures are illustrated in Fig. 9. We deploy a Wi-Fi transmitter and six receivers in a typical classroom, and the device setup is sketched in Fig. 10. The users are asked to perform gestures at the five marked locations and to five orientations. The data samples can be found in our released dataset (Yang et al., 2020). We extract DFS from raw CSI signals and feed them into a CNN network. The network architecture is shown in Fig. 11.

We now introduce the implementation code in detail.
First, some necessary packages are imported. We use Keras (Chollet et al., 2015) API with TensorFlow as the backend to demonstrate how to implement the neural network.
Then we define some parameters, including the hyperparameters and the data path. The fraction of testing data is defined as 0.1. To simplify the problem, we only use six gesture types in the widar3.0 dataset.
The program begins with loading data with the predefined function load_data. The loaded data are split into train and test by calling the API function train_test_split. The labels of the training data are encoded into the one-hot format with the predefined function onehot_encoding.
After loading and formatting the training and testing data, we defined the model with the predefined function build_model. After that, we train the model by calling the API function fit. The input data and label are specified in the parameters. The fraction of validation data is specified as 0.1.
After the training process, we evaluate the model with the test dataset. The predictions are converted from one-hot format to integers and are used to calculate the confusion matrix and accuracy.
The predefined onehot_encoding function convert the label to one-hot format.
The predefined load_data function is used to load all data samples and labels from a directory. Each file in the directory corresponds to a single data sample. Each data sample is normalized with the predefined normalize_data function. It is worth noting that the data samples have different time durations. We use a predefined zero_padding function to make their durations the same as the longest one.
The normalize_data function is used to normalize the loaded data samples. Each data sample has a dimension of , in which the number ”6” represents the number of Wi-Fi receivers, the number ”121” represents the frequency bins, and the ”T” represents the time durations. To normalize a sample, we scale the data to be in the range of for each time snapshot.
The zero_padding function is used to align all the data samples to have the same duration. The padded length is specified by the parameter T_MAX.
In this function, we define the network structure. The input layer is specified with the API function Input, which has the parameters to define the input shape, data type, and the layer name. Following the input layer, we use a three-dimensional convolutional layer, a max-pooling layer, and two fully connected layers. The output layer is specified with the API function Output, which has the parameters to define the activation function, the dimension, and the name. At last, we finalize the model with the API function Model and compile. The optimizer is specified to RMSprop, and the loss is specified to categorical_crossentropy.
6.2. Recurrent Neural Network
Recurrent Neural Network (RNN) is designed for modeling temporal dynamics of sequences and is commonly used for time series data analysis like speech recognition and natural language processing. Wireless signals are highly correlated over time and can be processed with RNN. Some works (Zheng et al., 2019; Jiang et al., 2020) have demonstrated the potential of RNN for wireless sensing tasks. In this section, we will present a working example of combining CNN and RNN to perform gesture recognition with Wi-Fi. The experimental settings are the same as in Sec. 6.1. We also extract DFS from the raw CSI as the input feature of the network. The network architecture is shown in Fig. 12.
We now introduce the implementation code in detail.
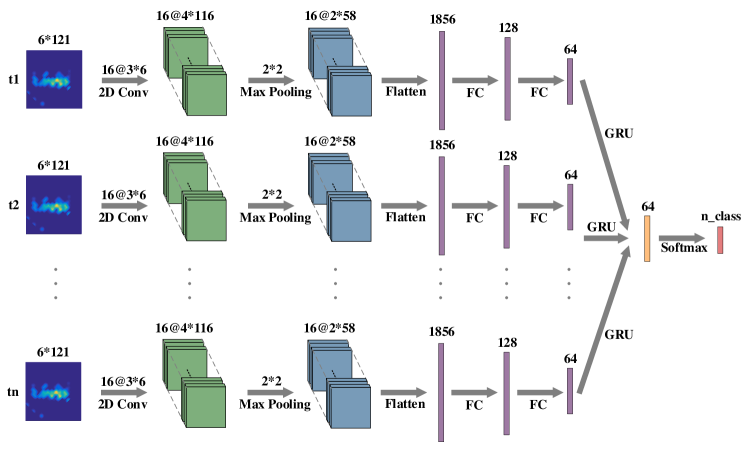
Most of the code is the same as in Sec. 6.1 except for the model definition. To define the model, we use two-dimensional convolutional layer and max-pooling layer on the dimensional except for the time dimension of the data. We adopt the GRU layer as the recurrent layer.
6.3. Adversarial Learning
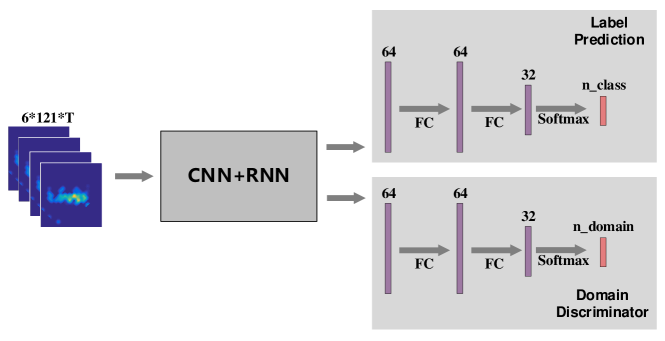
Except for the basic neural network components, some high-level network architectures also play essential roles in wireless sensing. Similar to computer vision tasks, wireless sensing also suffer from domain misalignment problem. Wireless signals can be reflected by the surrounding objects during propagation and will be flooded with target-irrelevant signal components. The sensing system trained in one deployment environment can hardly be applied directly in other settings without adaptation. Some works (Jiang et al., 2018) try to adopt adversarial learning techniques to tackle this problem and achieve promising performance. This section will give an example of how to apply this technique in wireless sensing tasks. Specifically, we build a gesture recognition system with Wi-Fi, similar to that in Sec. 6.1. We try to achieve consistent performance across different human locations and orientations. The network architecture is shown in Fig. 13.
We now introduce the implementation code in detail.
In the Widar3.0 dataset (Yang et al., 2020), we collect gesture data when the users stand at different locations. As discussed in Sec. 4.3, human locations have significant impact on the DFS measurements. To mitigate this impact, we treat human locations as different domains and build an adversarial learning network to recognize gestures irrespective of domains. In the program, we first load data, labels, and domains from the dataset and split them into train and test. Both label and domain are encoded into the one-hot format.
After loading and formating data, we built the network and trained it from scratch. The training data, label, and domain are passed to the API function fit for training.
After the training process finishes, we evaluate the network with the test samples. Note that the adversarial network has both label and domain prediction outputs. We only use the label output for accuracy evaluation.
Different from that in Sec. 6.1, we load data, label, and domain in the load_data function. The domain is defined as the location of the human, which is embedded in the file name.
To define the network, we use a CNN layer and an RNN layer as the feature extractor, which is similar to that in Sec. 6.2. In the gesture recognizer and domain discriminator, we use two fully-connected layers and an output layer activated by softmax function, respectively. We use categorical cross-entropy loss for both label prediction and domain prediction outputs. The domain prediction loss is weighted with loss_weight_domain and subtracted from the label prediction loss.
The pre-defined custom_loss_label and custom_loss_domain are categorical crossentropy losses for both label prediction and domain prediction.
6.4. Complex-valued Neural Network
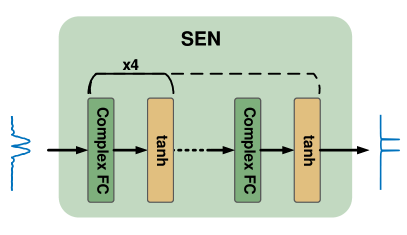
In this section, we will present a more complicated wireless sensing task with deep learning. Many wireless sensing approaches employ Fast Fourier Transform (FFT) on a time series of RF data to obtain time-frequency spectrograms of human activities. FFT suffers from errors due to an effect known as leakage, when the block of data is not periodic (the most common case in practice), which results in a smeared spectrum of the original signal and further leads to misleading data representation for learning-based sensing. Classical approaches reduce leakage by windowing, which cannot eliminate leakage entirely. Considering the significant fitting capability of deep neural networks, we can design a signal processing network to learn an optimal function to minimize or nearly eliminate the leakage and enhance the spectrums, which we call the Signal Enhancement Network (SEN).
The signal processing network takes as input a spectrogram transformed from wireless signals via STFT, removes the spectral leakage in the spectrogram, and recovers the underlying actual frequency components. Fig. 16 shows the training process of the network. As shown in the upper part of Fig. 16, we randomly generate ideal spectrums with 1 to 5 frequency components, whose amplitudes, phases, and frequencies are uniformly drawn from their ranges of interest. Then, the ideal spectrum is converted to the leaked spectrum following the process in the following equation to simulate the windowing effect and random complex noises:
| (34) |
where and are the ideal and estimated frequency spectrum, respectively, represents the additive Gaussian noise vector, and is the convolution matrix of the windowing function in the frequency domain. The column of is:
| (35) |
where represents the windowing function of FFT in time domain.
The amplitude of the noise follows a Gaussian distribution and its phase follows a uniform distribution in . The network takes the leaked spectrum as input and outputs the enhanced spectrum close to the ideal one. Thus, we minimize the loss during training. During inference, the spectrums measured from real-world scenarios are normalized to and fed into the network to obtain the enhanced spectrum.
We now present the implementation code in detail.


Different from previous sections, we use the PyTorch platform to implement the network. PyTorch provides the interface to implement custom layers, which makes the implementation of the CVNN much more convenient. We first import some necessary packages as follows.
Some parameters are defined in this part.
The program begins with the following code. We first generate the convolution matrix of the windowing function (Eqn. 35) with the pre-defined function generate_blur_matrix_complex, which will be introduced shortly. Then we define the SEN model and move it to the GPU processor with the API function cuda. After the model definition, we train the model with synthetic spectrograms, during which process we save the trained model every 500 epochs. The trained and saved model can be directly loaded and used to enhance spectrograms.
This generate_blur_matrix_complex function is used to generate the convolution matrix of the windowing function. The core idea behind this function is to enumerate all the frequencies, apply the window function on the sinusoid signal, and generate the corresponding spectrums with FFT. After obtaining the convolution matrix, we can bridge the gap between the ideal and the leaked spectrograms with Eqn. 34. In other words, we can directly get the leaked spectrograms by multiplying the idea spectrograms with the convolution matrix.
This function is to generate one batch of spectrograms in both the leaked form and the idea form. The process is the same as that illustrated in Eqn. 34.
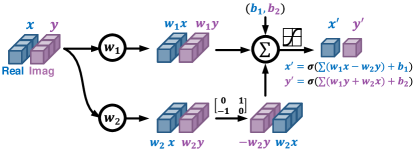
This part demonstrates the code on how to implement the SEN network. According to the API of PyTorch, both the __init__ and the forward interfaces should be implemented with customized algorithms. In the __init__ function, we defined five complex-valued fully-connected layers. In the forward function, we defined the network structure by concatenating the five FC layers and specifying the input and output layers.
This m_Linear class leverages the interface of PyTorch to define the customized complex-valued fully-connected layer, which is the implementation of the network structure illustrated in Fig. 14.
This loss_function defines the loss function of the SEN network. The loss is defined as the Euclidean distance between the idea spectrum and the netwrok predicted spectrum. Only the amplitude of the spectrums are considered.
In this train function, we implement the training process of SEN as that described in Fig. 16. In each epoch, we generate and train the network with multiple iterations. For each iteration, we generate a batch of synthetic spectrums in leaked format. Each leaked spectrum have an idea spectrum as the label.
This function converts the complex-valued arrays to double channel real-valued arrays. This is because the GPU only supports the calculations of real numbers. We use a little trick to implement the complex-valued network by separating the real and imaginary parts into two real arrays.
This function converts the double channel real-valued arrays into complex-valued arrays.
After training the SEN network with sufficient epochs, we test the performance with spectrograms collected from Wi-Fi.
First, we define some parameters. The STFT window width is set to 125, and the window type is set to “gaussian”. The path to the pre-trained model and the CSI file is selected.
The program begins with loading the pre-trained model. Then, the CSI data is loaded and transformed to spectrograms with the predefined function csi_to_spec. After that, the complex-valued spectrograms are transformed to double real-valued channel tensors and processed with the SEN model. The results and the raw spectrograms are stored in files.
This function first transforms the CSI data into spectrograms and crops the concerned frequency range between Hz. Then, it unwraps the frequency bins and performs normalizations.
This function transforms the time domain CSI data into frequency domain spectrograms with the API function scipy.signal.stft.
This function scales the spectrograms to normalize the values into .
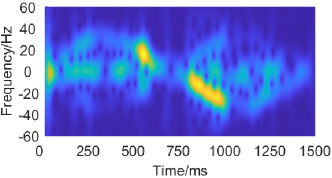
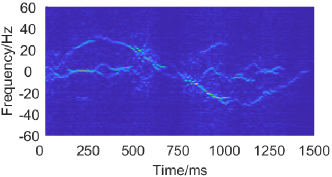
Fig. 17 demonstrates the raw and enhanced spectrograms of pushing and pulling gestures.
References
- (1)
- Abdelnasser et al. (2015) Heba Abdelnasser, Moustafa Youssef, and Khaled A Harras. 2015. Wigest: A ubiquitous wifi-based gesture recognition system. In Proceedings of the IEEE INFOCOM.
- Capon (1969) J. Capon. 1969. High-resolution frequency-wavenumber spectrum analysis. Proc. IEEE (1969).
- Chi et al. (2021) Guoxuan Chi, Jingao Xu, Jialin Zhang, Qian Zhang, Qiang Ma, and Zheng Yang. 2021. Locate, Tell, and Guide: Enabling Public Cameras to Navigate the Public. IEEE Transactions on Mobile Computing (2021).
- Chi et al. (2022) Guoxuan Chi, Zheng Yang, Jingao Xu, Chenshu Wu, Jialin Zhang, Jianzhe Liang, and Yunhao Liu. 2022. Wi-drone: Wi-Fi-based 6-DoF Tracking for Indoor Drone Flight Control. In Proceedings of the ACM MobiSys.
- Chollet et al. (2015) François Chollet et al. 2015. Keras. https://github.com/fchollet/keras.
- Donoho (2006) David L Donoho. 2006. Compressed sensing. IEEE Transactions on information theory (2006).
- Halperin et al. (2011) Daniel Halperin, Wenjun Hu, Anmol Sheth, and David Wetherall. 2011. Tool release: Gathering 802.11 n traces with channel state information. ACM SIGCOMM computer communication review (2011).
- Hill (2009) David A. Hill. 2009. Electromagnetic fields in cavities: deterministic and statistical theories. John Wiley & Sons (2009).
- Hu et al. (2020) Yuqian Hu, Feng Zhang, Chenshu Wu, Beibei Wang, and K. J. Ray Liu. 2020. A WiFi-Based Passive Fall Detection System. In Proceedings of the IEEE ICASSP.
- Jiang et al. (2018) Wenjun Jiang, Chenglin Miao, Fenglong Ma, Shuochao Yao, Yaqing Wang, Ye Yuan, Hongfei Xue, Chen Song, Xin Ma, Dimitrios Koutsonikolas, Wenyao Xu, and Lu Su. 2018. Towards Environment Independent Device Free Human Activity Recognition. In Proceedings of ACM MobiCom.
- Jiang et al. (2020) Wenjun Jiang, Hongfei Xue, Chenglin Miao, Shiyang Wang, Sen Lin, Chong Tian, Srinivasan Murali, Haochen Hu, Zhi Sun, and Lu Su. 2020. Towards 3D Human Pose Construction Using Wifi. In Proceedings of the ACM MobiCom.
- Jiang et al. (2021) Zhiping Jiang, Tom H Luan, Xincheng Ren, Dongtao Lv, Han Hao, Jing Wang, Kun Zhao, Wei Xi, Yueshen Xu, and Rui Li. 2021. Eliminating the Barriers: Demystifying Wi-Fi Baseband Design and Introducing the PicoScenes Wi-Fi Sensing Platform. IEEE Internet of Things Journal (2021).
- Palipana et al. (2019) Sameera Palipana, David Rojas, Piyush Agrawal, and Dirk Pesch. 2019. FallDeFi: Ubiquitous Fall Detection Using Commodity Wi-Fi Devices. In Proceedings of the ACM IMWUT.
- Patwari and Kasera (2007) Neal Patwari and Sneha K. Kasera. 2007. Robust Location Distinction Using Temporal Link Signatures. In Proceedings of the ACM MobiCom.
- Qian et al. (2017) Kun Qian, Chenshu Wu, Zheng Yang, Yunhao Liu, and Kyle Jamieson. 2017. Widar: Decimeter-Level Passive Tracking via Velocity Monitoring with Commodity Wi-Fi. In Proceedings of the ACM MobiHoc.
- Qian et al. (2014) Kun Qian, Chenshu Wu, Zheng Yang, Yunhao Liu, and Zimu Zhou. 2014. PADS: Passive detection of moving targets with dynamic speed using PHY layer information. In Proceedings of the IEEE ICPADS.
- Qian et al. (2018) Kun Qian, Chenshu Wu, Yi Zhang, Guidong Zhang, Zheng Yang, and Yunhao Liu. 2018. Widar2.0: Passive human tracking with a single wi-fi link. Proceedings of the ACM MobiSys (2018).
- Rubner and Tomasi (2001) Yossi Rubner and Carlo Tomasi. 2001. The earth mover’s distance. In Perceptual Metrics for Image Database Navigation. Springer.
- Schmidt (1986) R. Schmidt. 1986. Multiple emitter location and signal parameter estimation. IEEE Transactions on Antennas and Propagation (1986).
- Wang et al. (2016) Hao Wang, Daqing Zhang, Junyi Ma, Yasha Wang, Yuxiang Wang, Dan Wu, Tao Gu, and Bing Xie. 2016. Human Respiration Detection with Commodity Wifi Devices: Do User Location and Body Orientation Matter?. In Proceedings of the ACM Ubicomp.
- Wu et al. (2015) Chenshu Wu, Zheng Yang, Zimu Zhou, Xuefeng Liu, Yunhao Liu, and Jiannong Cao. 2015. Non-Invasive Detection of Moving and Stationary Human With WiFi. IEEE Journal on Selected Areas in Communications (2015).
- Wu et al. (2020) Chenshu Wu, Feng Zhang, Yuqian Hu, and K. J. Ray Liu. 2020. GaitWay: Monitoring and Recognizing Gait Speed Through the Walls. IEEE Transactions on Mobile Computing (2020).
- Xie et al. (2018) Yaxiong Xie, Zhenjiang Li, and Mo Li. 2018. Precise power delay profiling with commodity Wi-Fi. IEEE Transactions on Mobile Computing (2018).
- Xie et al. (2019) Yaxiong Xie, Jie Xiong, Mo Li, and Kyle Jamieson. 2019. mD-Track: Leveraging multi-dimensionality for passive indoor Wi-Fi tracking. In Proceedings of the ACM MobiCom.
- Yang et al. (2020) Zheng Yang, Yi Zhang, Guidong Zhang, and Yue Zheng. 2020. Widar 3.0: WiFi-based Activity Recognition Dataset. https://doi.org/10.21227/7znf-qp86
- Yang et al. (2013) Zheng Yang, Zimu Zhou, and Yunhao Liu. 2013. From RSSI to CSI: Indoor Localization via Channel Response. ACM Comput. Surv. (November 2013), 25:1–25:32.
- Zhang et al. (2018) Feng Zhang, Chen Chen, Beibei Wang, and K. J. Ray Liu. 2018. WiSpeed: A Statistical Electromagnetic Approach for Device-Free Indoor Speed Estimation. IEEE Internet of Things Journal (2018).
- Zhang et al. (2020) Yi Zhang, Yue Zheng, Guidong Zhang, Kun Qian, Chen Qian, and Zheng Yang. 2020. GaitID: Robust Wi-Fi Based Gait Recognition. In Proceedings of the Springer WASA.
- Zhao et al. (2018) Mingmin Zhao, Yonglong Tian, Hang Zhao, Mohammad Abu Alsheikh, Tianhong Li, Rumen Hristov, Zachary Kabelac, Dina Katabi, and Antonio Torralba. 2018. RF-Based 3D Skeletons. In Proceedings of the ACM SIGCOMM.
- Zheng et al. (2019) Yue Zheng, Yi Zhang, Kun Qian, Guidong Zhang, Yunhao Liu, Chenshu Wu, and Zheng Yang. 2019. Zero-Effort Cross-Domain Gesture Recognition with Wi-Fi. In Proceedings of the ACM MobiSys.