STrajNet: Multi-modal Hierarchical Transformer for Occupancy Flow Field Prediction in Autonomous Driving
Abstract
Forecasting the future states of surrounding traffic participants is a crucial capability for autonomous vehicles. The recently proposed occupancy flow field prediction introduces a scalable and effective representation to jointly predict surrounding agents’ future motions in a scene. However, the challenging part is to model the underlying social interactions among traffic agents and the relations between occupancy and flow. Therefore, this paper proposes a novel Multi-modal Hierarchical Transformer network that fuses the vectorized (agent motion) and visual (scene flow, map, and occupancy) modalities and jointly predicts the flow and occupancy of the scene. Specifically, visual and vector features from sensory data are encoded through a multi-stage Transformer module and then a late-fusion Transformer module with temporal pixel-wise attention. Importantly, a flow-guided multi-head self-attention (FG-MSA) module is designed to better aggregate the information on occupancy and flow and model the mathematical relations between them. The proposed method is comprehensively validated on the Waymo Open Motion Dataset and compared against several state-of-the-art models. The results reveal that our model with much more compact architecture and data inputs than other methods can achieve comparable performance. We also demonstrate the effectiveness of incorporating vectorized agent motion features and the proposed FG-MSA module. Compared to the ablated model without the FG-MSA module, which won place in the 2022 Waymo Occupancy and Flow Prediction Challenge, the current model shows better separability for flow and occupancy and further performance improvements.
I Introduction
Making robust and accurate predictions of future motions for multiple traffic participants (agents) in an efficient and scalable manner is one of the core capabilities of autonomous vehicles (AVs) [1, 2, 3]. However, motion prediction is an extremely difficult task due to a handful of challenges. First, the AV has to confront countless complicated traffic scenes, which consist of a varying number of heterogeneous traffic elements [4]. Second, the motion predictor should deal with not only the existing traffic elements’ observed states but also the underlying complicated interactions among them [5]. In addition, the prediction results are required to be robust to handle uncertainties [6], as the agent’s future motions may differ vastly even under the same situations.
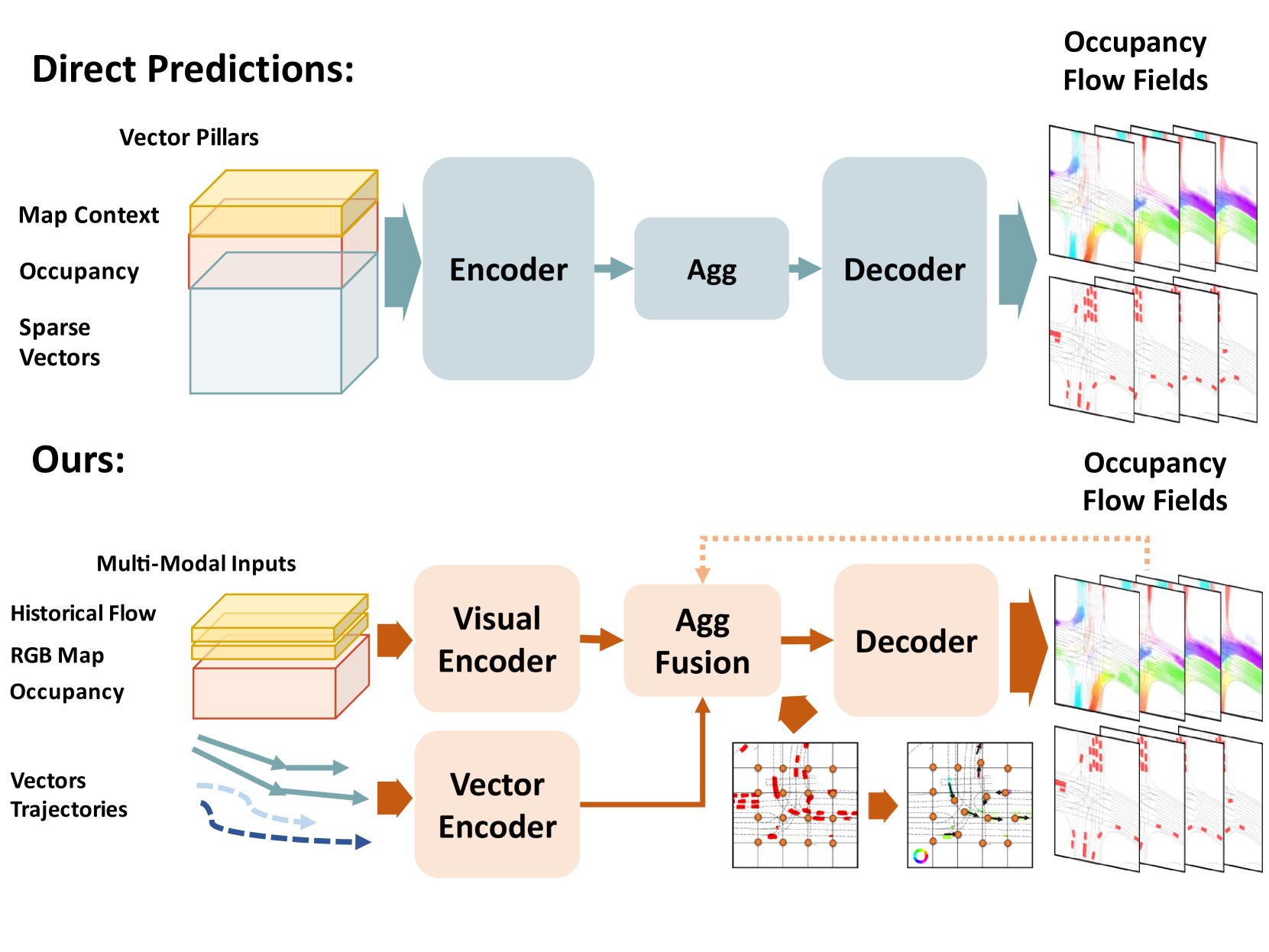
While most existing works on multi-agent prediction directly predict a sequence of future locations for each agent [10, 11, 12], the recently proposed occupancy flow field prediction [7] offers a more efficient and scalable prediction representation for multiple agents in a scene [13]. Specifically, the occupancy flow field is a spatial-temporal grid [9] that 1) simultaneously forecasts the occupancy probabilities for all agents (observed and occluded) on the grid, and 2) outputs a set of backward occupancy flow that predicts the warping (pixel shifting) between each occupancy grid for each occupied grid cell. It provides a competitive alternative prediction representation with better scalability and efficiency due to its ability to predict a varying amount of agents at once, better safety for downstream decision-making thanks to occluded (speculative) agent predictions, as well as dynamic tractability for each agent by the backward flow. However, current occupancy flow field prediction frameworks [7, 8] based on pillar-inspired [14] inputs are redundant and consume a large number of memory resources. Moreover, the direct prediction method (see Fig. 1) lacks separability for flow and occupancy features, which are mathematically related.
To tackle this challenge, we propose a multi-modal hierarchical Transformer-based framework for the spatial-temporal prediction task. First, a Swin-Transformer [15] visual encoder is utilized to fuse the information of visual modalities and capture the interactions among historical occupancy, backward flow, and dense road map. We also employ the vectorized representation of agent historical motions and encode them through a Transformer-based vector encoder considering interaction awareness. To model the mathematical relationships between future occupancy grids and backward flow, we design a flow-guided multi-head self-attention (FG-MSA) module for the high-level encoded grid cell that queries the warped grid cell by learnable flow offsets. It then outputs concatenated flow and occupancy grid cells for all future steps. To better associate occupancy grid cells with corresponding agent trajectories to capture their motion tendencies, we employ a cross-attention module that queries the encoded interaction trajectories of each grid cell across future steps. It should be noted that our proposed hierarchical Transformer framework is concise with simply three encoding stages, yet achieves state-of-the-art performance. The contributions of our proposed framework are summarized as:
-
1.
We propose a novel multi-modal hierarchical Transformer framework for the occupancy flow prediction task. It can fuse the rasterized and vectorized features of the scene and capture the underlying interactions.
-
2.
We design a flow-guided attention module that effectively queries the grid cell features warped by learnable flow offset, which shows better separability.
-
3.
We validate the framework on a large-scale real-world driving dataset, and the proposed model with a concise structure achieves state-of-the-art performance.
II Related Work
II-A Transformers for motion prediction
Due to the computational efficiency and effectiveness of the multi-head attention mechanism in time-series or graph-like interaction encoding, Transformer-based structures have gained great success in motion prediction tasks. Transformers have been widely adopted in vectorized scene encoding of both historical agent trajectories and high-fidelity map segments [16, 17]. On the other hand, with the help of the vision Transformer (ViT) [18], rasterized scene features can also be efficiently encoded with larger visual reception fields compared to CNN-based methods. In our method, we further utilize those two categories of scene representations during encoding and combine them using different types and stages of Transformer encoders, which shows improved performance. Another important factor for motion prediction is interaction modeling among the traffic agents and map information, and Transformers can well handle the interaction graphs through the attention mechanism. For example, VectorNet [16] firstly proposed to model the traffic elements as a fully-connected graph. SceneTransformer [10] further unified the interaction modeling across and within vectorized map and agent history sequences. In our work, we consider the interaction among occupancy grid cells and among the vectorized agent motions across different time steps, using self-attention Transformers modules to process them individually, as well as the interaction between these two kinds of modalities with cross-attention Transformer modules. Moreover, inspired by DAT [19] in object detection, we propose a flow-guided attention mechanism that is suitable for incorporating both flow and occupancy grid predictions, so that the grid cell features can be adaptively queried from the guidance of flow offsets.
II-B Occupancy flow field for motion prediction
Forecasting the future motions through occupancy grids can date back to ChauffeurNet [20], which predicts the future occupancy map to perform behavior planning in autonomous driving. StopNet [13] further utilizes this objective and improves the overall scene representation for efficient motion prediction. However, they ignore the tractability between time steps in the future, and [7] addresses this issue and makes the dynamic feature of each grid cell tractable by predicting the backward flow. Following the same representation, HOPE [8] proposed a hierarchical spatial-temporal predictor comprising a deep-level multi-stage encoder-decoder, as well as 3 layers of aggregators [21] for fusing high-level visual features. However, using the traditional spatial-temporal hierarchical structure costs a deeper model and much more model parameters, and requires pretraining the visual encoder [15]. Concurrent to our work, VectorFlow [22] instead fuses vector and visual features using cross-attention with a simple CNN-based encoder-decoder. However, it involves too much redundancy in vectorized inputs and the visual features are encoded with small reception fields. Different from the methods above, we instead design a more compact hierarchical Transformers structure that can deal with multi-modalities fusion with only 3 stages of encoding. In addition, a single layer aggregation of proposed flow-guided self-attention can also help improve the multi-task learning process and boost the final performance.
III Methodology
III-A Problem Formulation
Forecasting the occupancy flow field can be formulated as concurrently predicting a multi-task output that consists of the critical future frames of observed occupancy , occluded occupancy , and corresponding backward flow at each future step , conditioned on the past and current states of traffic agents and scene context inside a certain area. More specifically, the occupancy grid is modeled as a binary single-channel image , where represents the future occupancy of currently observed agents, and denotes the occluded ones that might occur in the future. The backward flow is regarded as a two-channel image-like tensor for the motion shifting of grids by occupied traffic agents along and axis: . The values of range from along each axis. Mathematically, given the warping function , flow-warped occupancy is defined as:
| (1) |
For the input representation X, it comprises multiple modalities with detailed formulations as follows:
1) Visual features: To acquire the spatial-temporal occupied status for traffic agents, we firstly build the historical and current occupancy grid ; dense road map that renders road networks (colored by categories) and traffic light states as a rasterized RGB image [23]. To facilitate the flow prediction, we also provide the historical backward flow built upon agent displacements in the occupancy grids between time steps: .
2) Vector features: For vectorized inputs, traffic agents currently occurred inside the grid area are collected to form a set of their historical trajectories , each denotes a motion sequence and each motion states is composed of . We also concatenate the one-hot encoding of the traffic agent’s type (vehicle, cyclist, or pedestrian) to the state. All of the representations above are normalized according to the current state of the ego vehicle.
Suppose a prediction model with parameters , the occupancy flow field prediction task is formulated as:
| (2) | ||||
III-B Model Framework
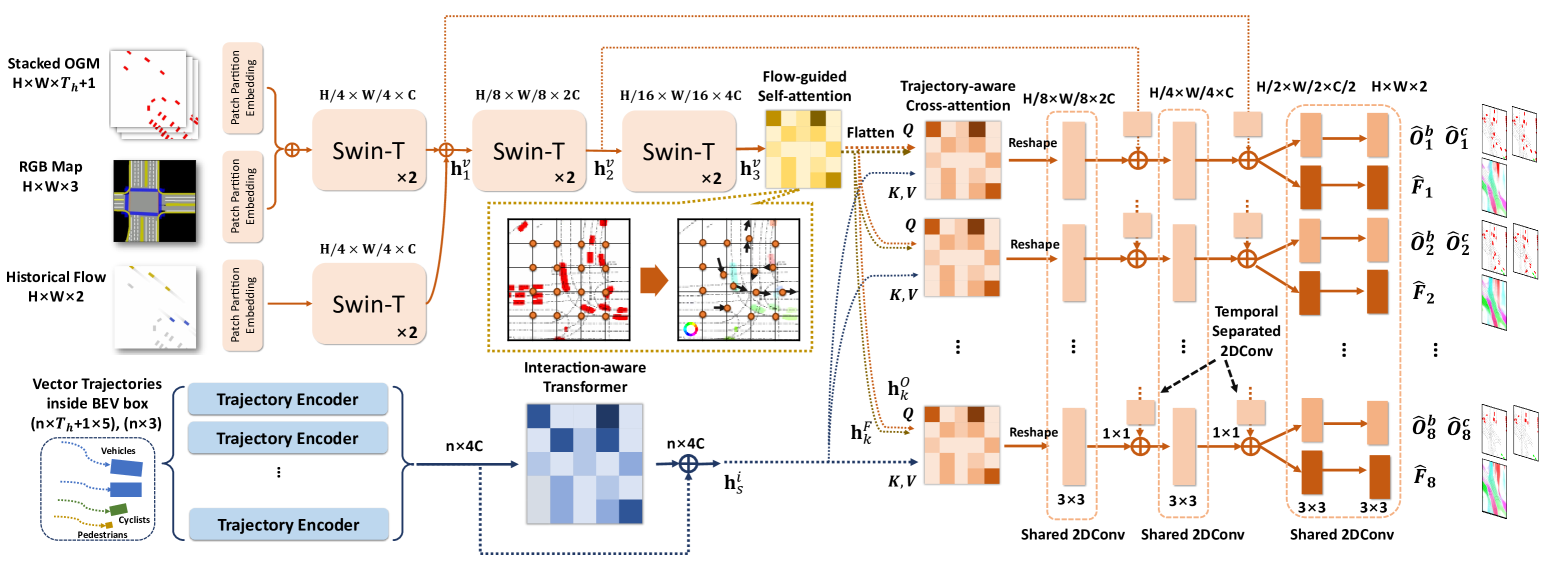
Fig. 2 shows the overall structure of our model, which encompasses three fundamental modules for occupancy flow field prediction. First, the multi-modalities inputs are separately encoded. Vectorized trajectories are encoded with trajectory encoder and interaction-aware Transformer to obtain the latent features . Visual features are early-fused and encoded into latent features with multiple scales through a Swin Transformer-based [15] encoder. Then, we adopt the proposed flow-guided attention to aggregate the flow and occupancy features from the highest-level visual latent feature . The obtained feature after the flow-guided attention layer is flattened and serves as queries to a temporally separated cross-attention module with as keys and values. Finally, a temporal-shared deconvolutional decoder with residual connections outputs a joint prediction of occupancy and flow .
III-C Multi-modal Encoder
1) Visual Encoder: The multi-modal visual inputs are encoded by a Swin-Transformer-based encoder, and a separate Swin-Transformer block is set for historical flow for information “shortcut" directly to future flow prediction. The occupancy map , dense road map , and flow are initially embedded and down-sampled into shape by separated convolution kernels with a stride of 4. We follow a concise setting of Swin-Transformer [15]. More specifically, each Swin-Transformer module is a two-layer Transformer with both window self-attention (W-SA) and shifted window self-attention (SW-SA). It enables global and intersected attention-based interaction modeling for visual features. Each attention module is multi-head attention with relative positional encoding bias B:
| (3) | |||
where the head numbers are as the module goes deeper, and is the dimension of the key token. The visual encoder outputs a set of visual features in varying scales: .
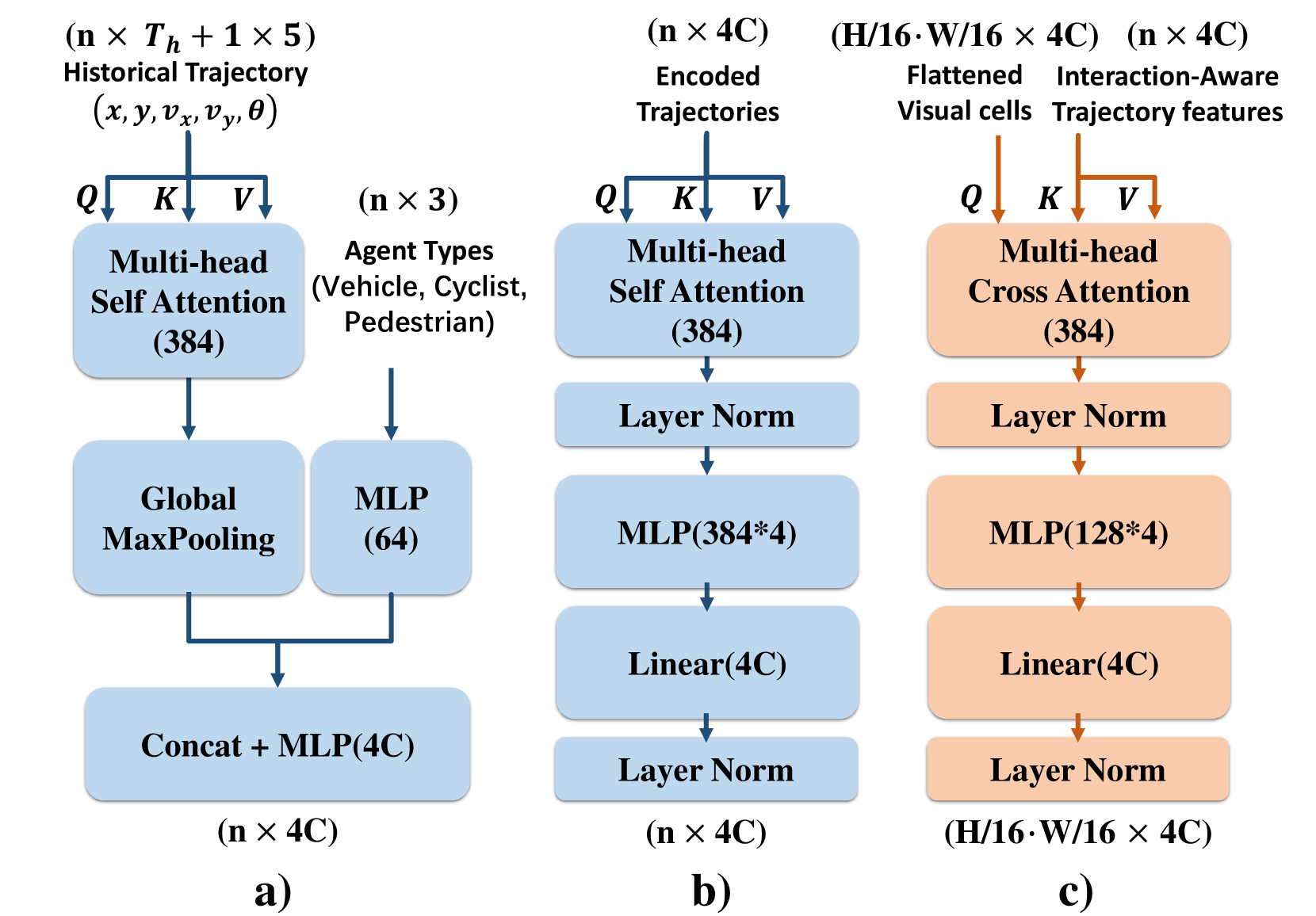
2) Vector Encoder: Vectorized trajectories are encoded considering interaction awareness. Historical motion vectors for agents are firstly aggregated across time by a shared trajectory encoder (Fig. 3(a)). It is a 4-head self-attention layer with global max-pooling, concatenated with its embedded agent type through a MLP layer. Next, a 6-head self-attention layer (Fig. 3(b)) with residual connection is introduced to build an interaction graph among all agents and outputs . The latent dimensions are kept the same as for all layers.
III-D Aggregation and Fusion
1) Flow-guided Multi-head Self-attention (FG-MSA): To better aggregate the flow and occupancy features, we designed the FG-MSA module. The core idea is to use learnable flow offsets across future time steps to guide the flow-warped occupancy features via the MSA mechanism at once, so that both flow and flow-warped occupancy features for all future steps can be simultaneously aggregated.
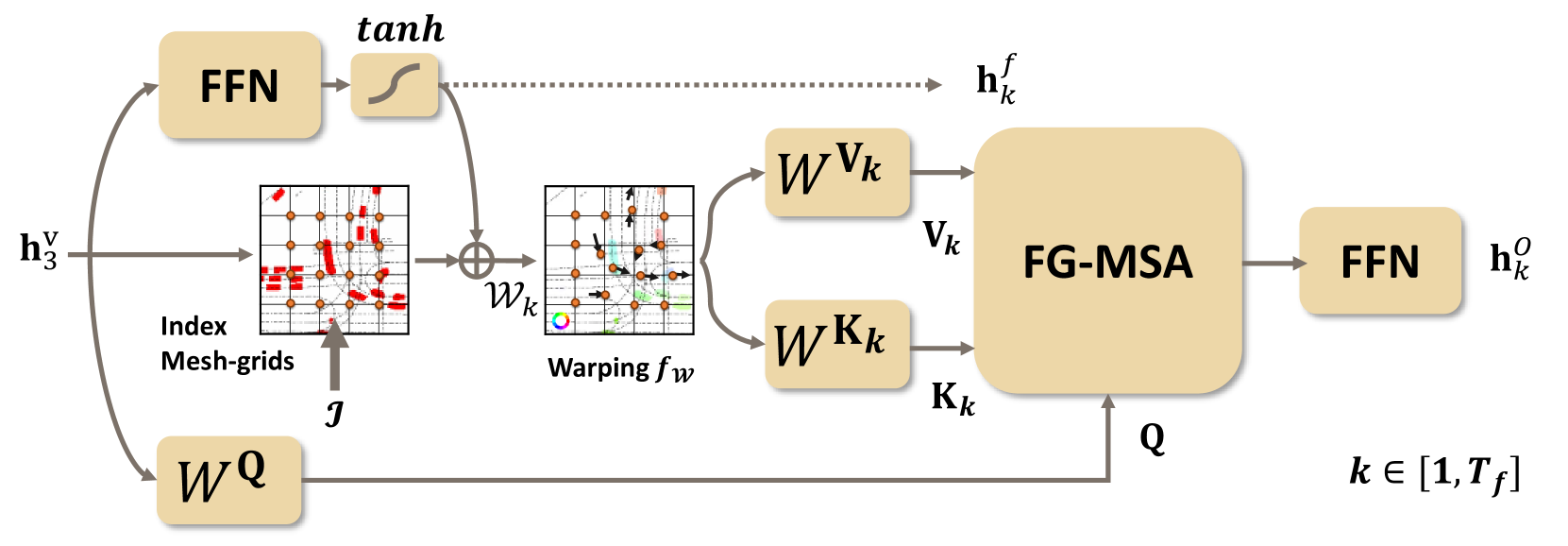
Given the latent visual feature , flow offsets are projected using the tanh-normalized feed-forward network (FFN): . Then, given the index mesh-grids , the warped indices become . We use bilinear interpolation as the warping function:
| (4) |
where . Then, the key and value are projected from flow-guided queries:
| (5) |
Finally, we utilize an MSA module to enable each head to deal with each future timestep:
| (6) | |||
The flow-guided occupancy features are then obtained through a standard FFN.
2) Trajectory-aware Cross-attention: The purpose of this module is to associate each grid cell with trajectory information of presented agents, so that the information is more directed and no longer constrained by patches or nearby features. As shown in Fig. 3(c), we use the aggregated occupancy and flow features as queries, and keys and values are vectorized agent motion features . We implement 8 cross-attention modules for different future timesteps and the outputs are reshaped back to original shape of the visual feature.
III-E Decoder
A feature pyramid network (FPN) [24] decoder is employed to decode occupancy and flow from the fusion feature. As shown in Fig. 2, 2D-CNNs (kernel size ) are shared across future time steps, and separated 2D-CNNs (kernel size ) are used to process the information from the residual path. We select the dimensions of pyramid decoder as . We also split decoding heads for occupancy and flow to enable varying projections from the shared features and direct information paths. The output of the occupancy head for timestep is a two-dimensional vector for each grid cell denoting observed and occluded occupancy, while the output of the flow head is also a two-dimensional vector denoting the flow along and directions for .
III-F Loss Functions
For better performance of joint occupancy and flow predictions, we modify the loss function in [7], but keep the binary probabilistic losses for occluded occupancy and observed occupancy . Because the ground-truth samples are heavily imbalanced around zero (unoccupied area), we replace the cross-entropy loss with the focal loss [25]. For the flow-warped loss , we use the ground-truth occupancy instead of the predicted one to stabilize flow training. The final multi-task learning objective sums up the following loss terms averaged by the height, width, and length of timesteps of the output:
| (7) |
| Evalutation Metrics | Observed Occupancy | Occluded Occupancy | Flow | Combined | |||
|---|---|---|---|---|---|---|---|
| Model | AUC | Soft-IOU | AUC | Soft-IOU | EPE | FT-AUC | FT-Soft-IOU |
| HorizonOccFlow(HOPE) [8] | 0.803 | 0.235 | 0.165 | 0.017 | 3.672 | 0.839 | 0.633 |
| Look Around [26] | 0.801 | 0.234 | 0.139 | 0.029 | 2.619 | 0.825 | 0.549 |
| Temp-Q | 0.757 | 0.393 | 0.171 | 0.041 | 3.308 | 0.778 | 0.465 |
| VectorFlow [22] | 0.755 | 0.488 | 0.174 | 0.045 | 3.583 | 0.767 | 0.531 |
| 3D-STCNN [27] | 0.691 | 0.412 | 0.115 | 0.021 | 4.181 | 0.733 | 0.468 |
| Motionnet [28] | 0.694 | 0.411 | 0.141 | 0.032 | 4.275 | 0.732 | 0.469 |
| FTLS | 0.618 | 0.318 | 0.085 | 0.019 | 9.612 | 0.689 | 0.431 |
| Ours | 0.778 | 0.491 | 0.178 | 0.045 | 3.204 | 0.785 | 0.531 |
IV Experiments
IV-A Experimental Setup
We employ the Waymo Open Motion dataset (WOMD) [29] in the experiments, which consists of over 500,000 samples covering diverse real-world driving scenarios and dynamical interactions among traffic agents including vehicles, cyclists, and pedestrians. The historical agent states are sampled at 10Hz for the past one second (), and the objective is to predict the occupancy and flow over the future 8 seconds at 1Hz (). The rasterized image resolution for input and the output is , representing an area of in the real world; Hidden dimension is kept as ; The vector inputs are sorted according to their current distances to the ego vehicle, and we keep a maximum of agents. The WOMD splits 485,568 samples for training and some scenarios of interest for validation and testing (4,400 each).
To fairly evaluate the performance of our method, we follow the standard metrics proposed in the challenge [7]. 1) Occupancy metrics: for and , we measure AUC for the pair of precision-recall area values, and Soft-IOU for the overlapped area with ground-truth. 2) Flow metrics: EPE measures the mean L2 pixel distances of flow end-point error by . 3) Combined metrics: we measures the AUC and Soft-IOU for flow-traced occupancy according to Eq. 1 (FT-AUC, FT-Soft-IOU).
IV-B Implementation details
We choose GELU as the activation function in all encoders and ELU in the pyramid decoder. To mitigate over-fitting, dropout is added after each MLP layer and also in the image encoder, all with a dropout rate of 0.1. Due to the numerous size of data inputs and predictions, we use a distributed training strategy on 4 Tesla V100 GPUs with a total batch size of 16. Adam optimizer is used with an initial learning rate of 1e-4, and the learning rate decays by a factor of 50% every 3 epochs. The total training epochs are set to 10.
IV-C Quantitative Results
1) Performance on the benchmark: Table I reports the testing performances of our proposed method against other state-of-the-art methods on the Waymo prediction benchmark. As of Aug 2022, our method has achieved three best metrics, i.e., Soft-IOU for both observed and occluded occupancy predictions, as well as the AUC for occluded occupancy. Moreover, our method achieves comparable performance to large pre-trained models, i.e., HOPE (Honorable Mention) [8] and Look Around ( place) [26], which both use very large image encoders pre-trained on ImageNet [15, 30]. Compared with the similar framework VectorFlow ( place) [22], which also uses flattened visual features to attend to the vector features, our method performs better across a variety of metrics, i.e., over 2% improvement in terms of occupancy metrics and 8% for the flow prediction errors, as well as better combined metrics. Overall, the superior testing results of our method indicate that: 1) our method shows excellent capabilities in detecting the occurrence of traffic agents (Soft-IOU for detection); 2) the framework is more adaptive and capable of predicting the occluded (speculative) agents (high AUC), which cloud enhance the safety of downstream planning; 3) the proposed FG-MSA module described in Section III-D could improve the learning pipeline for flow and occupancy predictions.
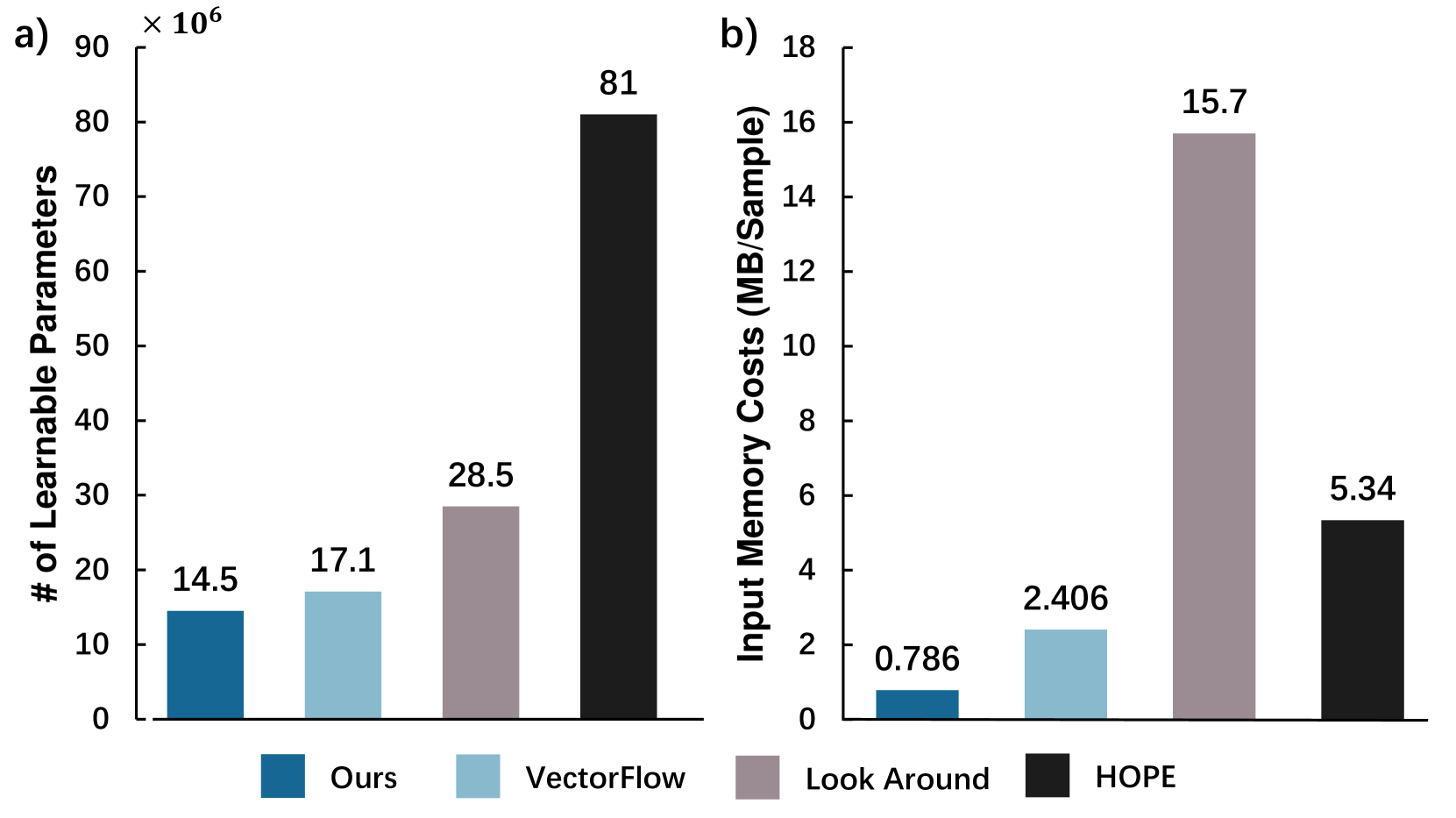
2) Computation efficiency: To evaluate the computation efficiency of existing methods, we report the number of network parameters (Fig. 5(a)) and roughly calculate the memory usage of input tensors per sample (Fig. 5(b)) for each method. The calculation of tensor memory usage is explained as follows. We count 1 bit for occupancy at each grid cell (boolean type), 2 bytes for int type data, and 4 bytes for vectorized inputs (float type) per unit. The results in Fig. 5(b) show the outstanding memory efficiency of the proposed method, only 32% of VectorFlow [22] and 5% of Look Around [26] in terms of memory usage. Likewise, in Fig. 5(a), comparing the number of network parameters of ours (full model) with other SOTA methods (encoders only), our model is much more concise, i.e., 18% of HOPE [8] and 51% of Look Around [26], but is able to deliver competitive performance. Therefore, we can conclude that: 1) using unified large tensors combining all features consumes much more memory, and the proposed model can tackle this issue by combining visual images of occupancy and vectorized trajectories; 2) it is not necessary to use deep layers and encoding stages in visual encoders for the occupancy flow field prediction task, as our proposed method can deliver competitive results with only a few encoding stages.
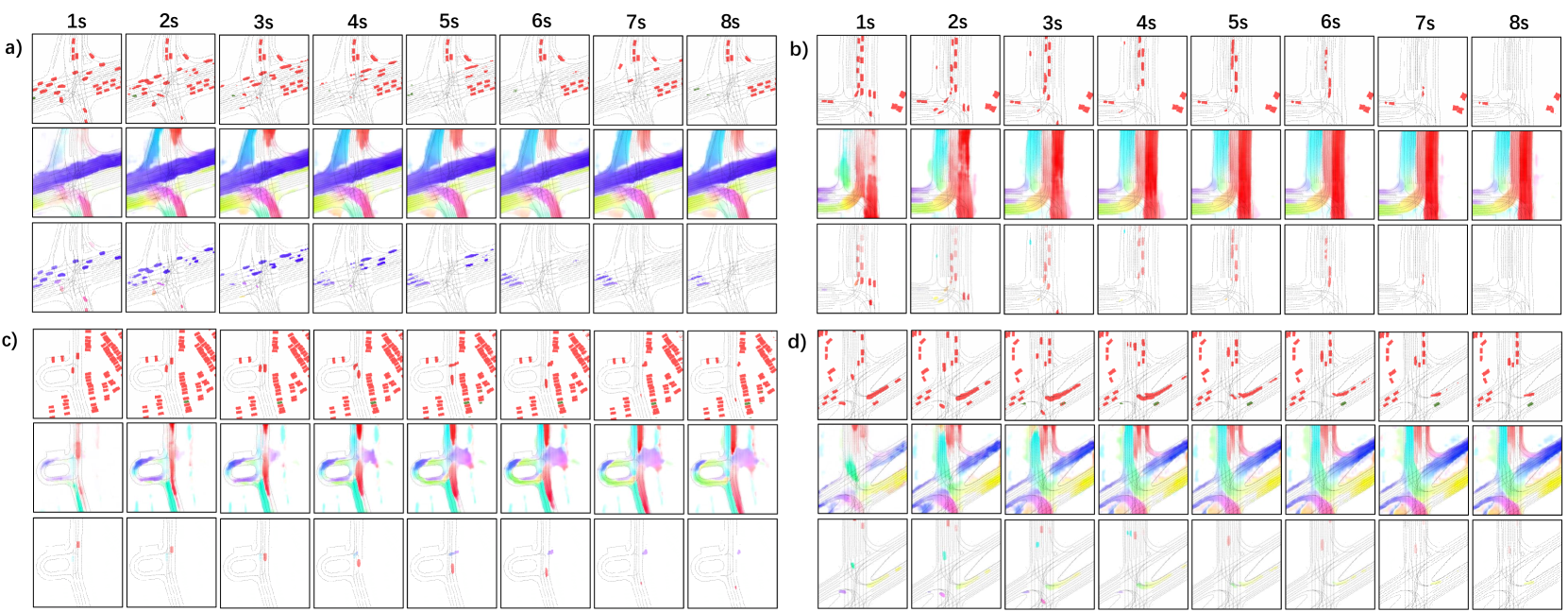
IV-D Qualitative Results
To intuitively evaluate the performance of our method, we visualize the testing results from several representative driving scenarios in Fig. 6. The results demonstrate that our method can perform effective and accurate occupancy forecasting for both dynamic (a, b, d) and static (c) traffic agents. Occlusion awareness is also manifested (a, c, d) even for popped-up agents (c, d). The flow-traced occupancy predictions further ensure the tractability of dynamic agents.
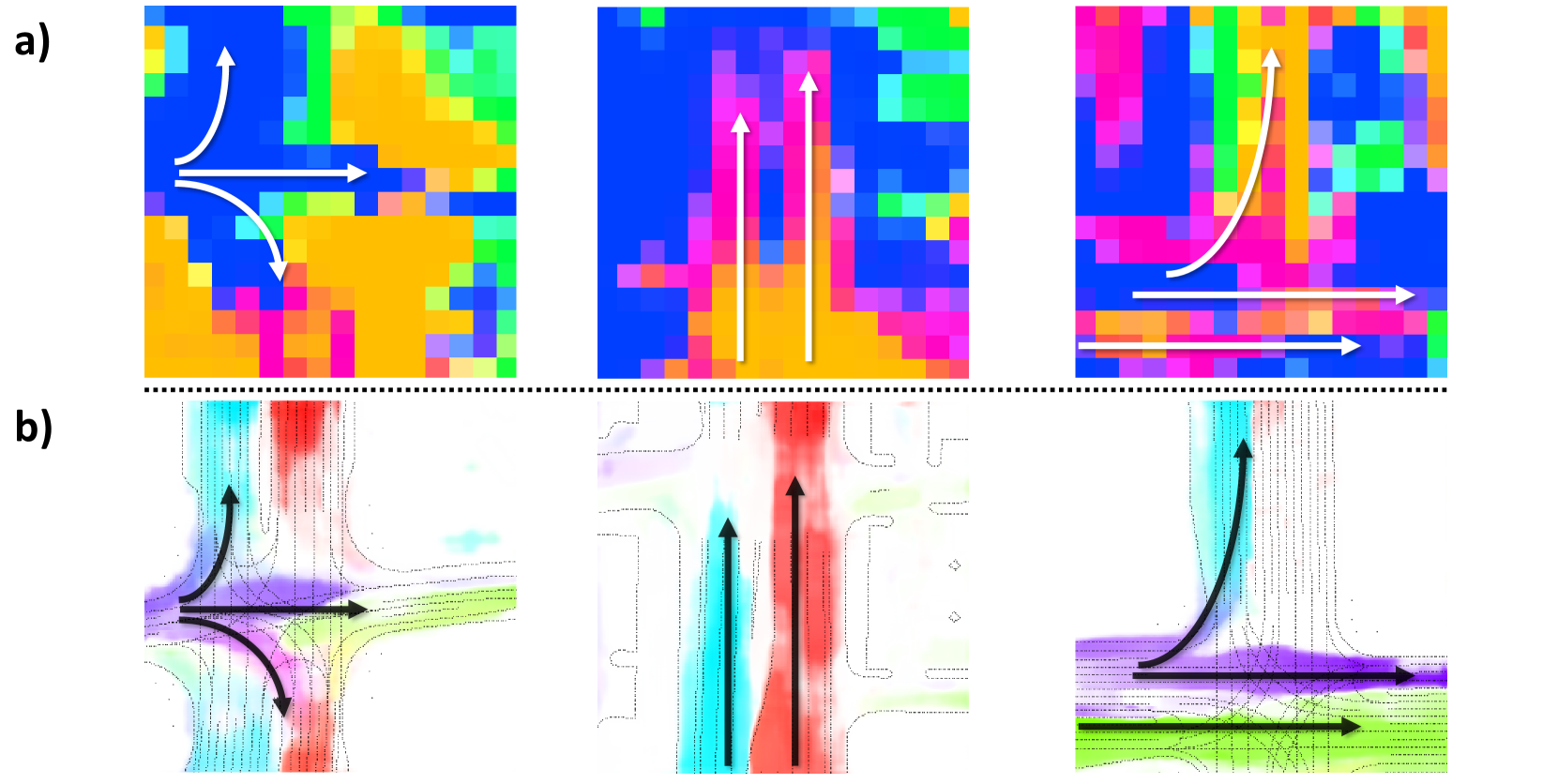
To investigate the performance improvement brought by the FG-MSA module, we compare the shape of the flow offsets inside the module (a) with flow outputs (b) in Fig. 7. The similar shapes of flow offsets and flow outputs suggest the function of the proposed FG-MSA module to guide the feature aggregation for both flow and occupancy.
IV-E Ablation Study
We conduct an ablation study to investigate the influences of key modules in our proposed framework, i.e., the FG-MSA module and vectorized trajectories encoding and fusion module. Therefore, we train two ablated versions without the FG-MSA module and the vector-encoding branch respectively, and all the ablated models are validated on the same testing set. We report the AUC of occupancy metrics and the flow EPE in Table II, which shows that there is an overall performance drop in the two ablated models. Using purely visual-based encoding models significantly worsens the prediction performance due to the lack of agent motion information. Incorporating sparse agent motion information in the visual image, like in other baseline methods, can help mitigate this issue but consume a large number of memory usage and computing resources. On the other hand, we propose to use vectorized motion information and temporal cross-attention to fuse the visual and vector features can bring comparable performance but much less memory and computation usage. Compared with the ablated model without the FG-MSA module ( place solution in the challenge), the current version shows significant improvements in observed AUC () and flow EPE (). Because the FG-MSA module can better separate and aggregate the features from occupancy and flow and explicitly represents their relations (Eq. 1), incorporating the FG-MSA module can further lift the model performance, especially for flow prediction.
| Vector | FG- | Observed | Occluded | FT- | Flow |
|---|---|---|---|---|---|
| Encoding | MSA | AUC | AUC | AUC | EPE |
| ✕ | ✕ | 0.741 | 0.138 | 0.751 | 3.712 |
| ✓ | ✕ | 0.751 | 0.161 | 0.777 | 3.586 |
| ✓ | ✓ | 0.778 | 0.178 | 0.785 | 3.204 |
V Conclusions
In this paper, we propose a multi-modal Hierarchical Transformer framework to forecast the occupancy flow field for autonomous driving. Multi-modal scene representation inputs, including visual features and vectorized motion trajectories, are separately encoded through carefully designed hierarchical Transformer modules, and both modalities are fused with temporal cross-attention. Moreover, the designed flow-guided attention module can better aggregate the flow and occupancy features via self-attention with explicit modeling of their mathematical relations. Comprehensive experiments conducted on the Waymo open dataset reveal the superior performance of the proposed method compared with SOTA models, even with a much smaller network. The ablation study indicates that adding the vectorized motion information fusion and flow-guided attention aggregation can significantly improve the prediction performance.
References
- [1] S. Mozaffari, O. Y. Al-Jarrah, M. Dianati, P. Jennings, and A. Mouzakitis, “Deep learning-based vehicle behavior prediction for autonomous driving applications: A review,” IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 1, pp. 33–47, 2020.
- [2] Z. Huang, J. Wu, and C. Lv, “Driving behavior modeling using naturalistic human driving data with inverse reinforcement learning,” IEEE Transactions on Intelligent Transportation Systems, 2021.
- [3] Z. Huang, H. Liu, J. Wu, and C. Lv, “Differentiable integrated motion prediction and planning with learnable cost function for autonomous driving,” arXiv preprint arXiv:2207.10422, 2022.
- [4] X. Mo, Z. Huang, Y. Xing, and C. Lv, “Multi-agent trajectory prediction with heterogeneous edge-enhanced graph attention network,” IEEE Transactions on Intelligent Transportation Systems, 2022.
- [5] X. Mo, Y. Xing, and C. Lv, “Interaction-aware trajectory prediction of connected vehicles using cnn-lstm networks,” in IECON 2020 The 46th Annual Conference of the IEEE Industrial Electronics Society. IEEE, 2020, pp. 5057–5062.
- [6] N. Djuric, V. Radosavljevic, H. Cui, T. Nguyen, F.-C. Chou, T.-H. Lin, N. Singh, and J. Schneider, “Uncertainty-aware short-term motion prediction of traffic actors for autonomous driving,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2020, pp. 2095–2104.
- [7] R. Mahjourian, J. Kim, Y. Chai, M. Tan, B. Sapp, and D. Anguelov, “Occupancy flow fields for motion forecasting in autonomous driving,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 5639–5646, 2022.
- [8] Y. Hu, W. Shao, B. Jiang, J. Chen, S. Chai, Z. Yang, J. Qian, H. Zhou, and Q. Liu, “Hope: Hierarchical spatial-temporal network for occupancy flow prediction,” arXiv preprint arXiv:2206.10118, 2022.
- [9] S. Hoermann, M. Bach, and K. Dietmayer, “Dynamic occupancy grid prediction for urban autonomous driving: A deep learning approach with fully automatic labeling,” in 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018, pp. 2056–2063.
- [10] J. Ngiam, B. Caine, V. Vasudevan, Z. Zhang, H.-T. L. Chiang, J. Ling, R. Roelofs, A. Bewley, C. Liu, A. Venugopal et al., “Scene transformer: A unified architecture for predicting multiple agent trajectories,” arXiv preprint arXiv:2106.08417, 2021.
- [11] B. Varadarajan, A. Hefny, A. Srivastava, K. S. Refaat, N. Nayakanti, A. Cornman, K. Chen, B. Douillard, C. P. Lam, D. Anguelov et al., “Multipath++: Efficient information fusion and trajectory aggregation for behavior prediction,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 7814–7821.
- [12] J. Gu, C. Sun, and H. Zhao, “Densetnt: End-to-end trajectory prediction from dense goal sets,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 303–15 312.
- [13] J. Kim, R. Mahjourian, S. Ettinger, M. Bansal, B. White, B. Sapp, and D. Anguelov, “Stopnet: Scalable trajectory and occupancy prediction for urban autonomous driving,” arXiv preprint arXiv:2206.00991, 2022.
- [14] A. H. Lang, S. Vora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “Pointpillars: Fast encoders for object detection from point clouds,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 12 697–12 705.
- [15] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10 012–10 022.
- [16] J. Gao, C. Sun, H. Zhao, Y. Shen, D. Anguelov, C. Li, and C. Schmid, “Vectornet: Encoding hd maps and agent dynamics from vectorized representation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 525–11 533.
- [17] Z. Huang, X. Mo, and C. Lv, “Multi-modal motion prediction with transformer-based neural network for autonomous driving,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 2605–2611.
- [18] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [19] Z. Xia, X. Pan, S. Song, L. E. Li, and G. Huang, “Vision transformer with deformable attention,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 4794–4803.
- [20] M. Bansal, A. Krizhevsky, and A. Ogale, “Chauffeurnet: Learning to drive by imitating the best and synthesizing the worst,” arXiv preprint arXiv:1812.03079, 2018.
- [21] A. Hu, Z. Murez, N. Mohan, S. Dudas, J. Hawke, V. Badrinarayanan, R. Cipolla, and A. Kendall, “Fiery: Future instance prediction in bird’s-eye view from surround monocular cameras,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 273–15 282.
- [22] X. Huang, X. Tian, J. Gu, Q. Sun, and H. Zhao, “Vectorflow: Combining images and vectors for traffic occupancy and flow prediction,” arXiv preprint arXiv:2208.04530, 2022.
- [23] Z. Huang, X. Mo, and C. Lv, “Recoat: A deep learning-based framework for multi-modal motion prediction in autonomous driving application,” arXiv preprint arXiv:2207.00726, 2022.
- [24] T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2117–2125.
- [25] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár, “Focal loss for dense object detection,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2980–2988.
- [26] P. Dmytro, “Waymo open dataset occupancy and flow prediction challenge solution: Look around,” 2022. [Online]. Available: https://storage.googleapis.com/waymo-uploads/files/research/OccupancyFlow/Dmytro1.pdf
- [27] Z. He, C.-Y. Chow, and J.-D. Zhang, “Stcnn: A spatio-temporal convolutional neural network for long-term traffic prediction,” in 2019 20th IEEE International Conference on Mobile Data Management (MDM). IEEE, 2019, pp. 226–233.
- [28] Y. Wang, M. Long, J. Wang, and P. S. Yu, “Spatiotemporal pyramid network for video action recognition,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2017, pp. 1529–1538.
- [29] S. Ettinger, S. Cheng, B. Caine, C. Liu, H. Zhao, S. Pradhan, Y. Chai, B. Sapp, C. R. Qi, Y. Zhou et al., “Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9710–9719.
- [30] K. Sun, B. Xiao, D. Liu, and J. Wang, “Deep high-resolution representation learning for human pose estimation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 5693–5703.