YOLO-FaceV2: A Scale and Occlusion Aware Face Detector
Abstract
In recent years, face detection algorithms based on deep learning have made great progress. These algorithms can be generally divided into two categories, i.e. two-stage detector like Faster R-CNN and one-stage detector like YOLO. Because of the better balance between accuracy and speed, one-stage detectors have been widely used in many applications. In this paper, we propose a real-time face detector based on the one-stage detector YOLOv5, named YOLO-FaceV2. We design a Receptive Field Enhancement module called RFE to enhance receptive field of small face, and use NWD Loss to make up for the sensitivity of IoU to the location deviation of tiny objects. For face occlusion, we present an attention module named SEAM and introduce Repulsion Loss to solve it. Moreover, we use a weight function Slide to solve the imbalance between easy and hard samples and use the information of the effective receptive field to design the anchor. The experimental results on WiderFace dataset show that our face detector outperforms YOLO and its variants can be find in all easy, medium and hard subsets. Source code in https://github.com/Krasjet-Yu/YOLO-FaceV2
Keywords— Face detection, YOLO, Scale-Aware, Loss function, Imbalance problem
1 Introduction
Face detection is an essential step in many face-related applications, such as face recognition, face verification and face attribute analysis, etc. With the booming of deep convolutional neural networks in recent years, the performance of face detectors has been greatly improved. Many high-performance face detection algorithms based on deep learning have been proposed. Generally, these algorithms can be divided into two branches. One branch of typical deep-learning-based face detection algorithms [1, 2, 3] uses cascading means of neural networks as feature extractors and classifiers to detect faces from coarse to fine. Despite their great success, it is important to note that cascade detectors suffer some drawbacks such as having difficulties in training and slow detection speed. The other branch is improved from general purpose object detection algorithms [4, 5, 6]. General purpose object detectors take into account more common features and broader characteristics of objects. Therefore, task-specific detectors can share these information and then enforce the spectacular properties by special designs. Some popular face detectors including YOLO [7, 8, 9, 10], Faster R-CNN [5] and RetinaNet [6] fall into this category. In this paper, inspired by YOLOv5 [11], TridentNet [12] and Attention Network in FAN [13], we propose a novel face detector that achieves the state-of-the-art in one-stage face detection.
Although deep convolutional networks have improved face detection remarkably, detecting faces with high variance in scale, pose, occlusion, expression, appearance, and illumination in realistic scenes remains great challenge. In our previous work, we proposed the YOLO-Face [14], an improved face detector based on YOLOv3 [9], which mainly focused on the problem of scale variance, design anchor ratios suitable for human face and utilized a more accurate regression loss function. The mAP of Easy, Medium, and Hard on the WiderFace [15] validation set reached 0.899, 0.872, and 0.693, respectively. Since then variety of new detectors have been presented and the face detection performance has been significantly improved. However, for small objects, the one-stage detectors have to divide the search space with a finer granularity, so it is apt to cause the problem of imbalance of positive and negative samples [16]. Furthermore, face occlusions [13] in complex scenes affects the accuracy of the face detector remarkably. Aimed to address the problems of varying face scales, easy and hard sample imbalance and face occlusion, we propose a YOLOv5-based face detection method called YOLO-FaceV2.
By carefully analyzing the difficulties encountered by face detectors and the shortcomings of YOLOv5 detector, we carry out the following solutions.
Multi scale fusion: In many scenarios, there are usually different scale faces existing in the images, which is really difficult for them all to be detected by the face detector. Therefore, solving different scale faces is a very important task for face algorithms. Currently, the main method to solve the problem of varying scales is constructing a pyramid to fuse the multi-scale features of faces [17, 18, 19, 20]. For example, in YOLOv5, FPN [20] fuses the features of P3, P4 and P5 layers. However, for small-scale objects, the information can be easily lost after multi-layer convolutions, and the pixel information retained is very little, even in the shallower P3 layer. Therefore, increasing the resolution of the feature map can undoubtedly benefit the detection of small objects.
Attention mechanism: In many complex scenes, face occlusion often occurs, which is one of the main reasons for the accuracy decline of face detectors. To address this problem, some researchers try to use attention mechanism to facial feature extraction. FAN [13] proposes a anchor-level attention. They suggest that the solution is to maintain the response value of the unobstructed region and to compensate the reduced response value of the obscured region through the attention mechanism. However, it doesn’t fully utilize the information between channels.
Hard Samples: In one-stage detectors, many bounding boxes are not been filtered out iterately. So the number of easy samples in one-stage detectors is very large. During training, their cumulative contribution dominates the update of the model, leading to the overfit of the model [16]. This is known as the problem of imbalanced samples. To deal with this problem, Lin et al. proposes Focal Loss to dynamically assign more weights to difficult sample examples [6]. Similar to focal loss, Gradient Harmonizing Mechanism (GHM) [21] suppresses the gradients from positive and negative simple samples to focus more on difficult samples. Prime Sample Attention (PISA) [22] proposed by Cao et al. assigns weights to positive and negative samples according to different criteria. However, current hard sample mining methods have too many hyperparameters to be set, which is very inconvenient in practice.
Anchor design: As pointed out in [23] a region in a CNN feature map has two types of receptive fields, the theoretical receptive field and the actual receptive field. It is experimentally shown that not all pixels in the receptive field respond equally, but obey a Gaussian distribution. This makes the anchor size based on the theoretical receptive field larger than its actual size, which makes it more difficult for the regression of bounding boxes. Zhang et. al designs the size of the anchors based on the effective receptive field in [24]. And FaceBoxes [25] designs the multiscale anchor to enrich the receptive fields and discretize anchors over different layers to handle faces of various scales. Therefore, the design of scales and ratios of the anchor boxes is very important which may greatly benefits the accuracy and convergence procedure of the model.
Regression Loss: Regression loss is used to measure the difference between the predicted bounding box and the ground truth bounding box. The commonly used regression loss functions in object detectors are L1/L2 loss, smooth L1 loss, IoU loss and its variants [26, 27, 28, 29]. YOLOv5 takes IoU loss as its objective regression function. However, the sensitivity of IoU varies greatly for objects of different scales. It is readily comprehensible that, for small targets, a slight position deviation leads to a significant IoU decrease. Wang et al. [30] proposes a small target evaluation method based on Wasserstein distance to effectively mitigate the effect of small target. However, their method performs not so significant for large targets.
In this paper, to address the aforementioned problems, we design a new face detector based on YOLOv5. Our aim is to find an optimal combinatorial detector that effectively solves the problems of small faces, large scale variations, occluded scenes and imbalanced hard and easy samples. First, we fuse P2 layer information of FPN to obtain more pixel-level information and compensate the information of small face. However, in this way, the detection accuracy of large and medium targets will be slightly reduced because the output feature map perceptual field becomes smaller. To ameliorate this situation, we design Receptive Field Enhancement (RFE) for the P5 layer, which increases the receptive field by using dilated convolution. Second, inspired by FAN and ConvMixer [31], we redesign a multi-head attention network to compensate for the loss of occluded face response values. In addition, we also introduce Repulsion Loss [32] to improve the recall of intra-class occlusions. Third, to mine hard samples, inspired by ATSS [33], we design the Slide weight function with adaptive thresholding to make the model focus more on hard samples during training. Fourth, in order to make the anchor more suitable for regression, we redesign the anchor size and proportion according to the effective receptive field and the proportion of the face. Fifth, we borrowed the Normalized Wasserstein Distance metric [30] and introduced it into the regression loss function to balance the shortage of IoU in predicting small faces.
In summary, we propose a new face detector YOLO-FaceV2, in which the highlighted contributions are as follows.
1. For detecting multiscale faces, the perceptive field and resolution are key factors. Therefore, we design a receptive field enhancement module (called RFE) to learn different receptive fields of the feature map and enhance the feature pyramid representation.
2. We classify the face occlusions into two categories, i.e., the occlusion between different faces, and the occlusion of faces by other objects. The former makes the detection accuracy very sensitive to NMS thresholds which leads to missed detection. We use Repulsion Loss to face detection which penalizes the predicted box for shifting to the other ground-truth objects and requires each predicted box to keep away from the other predicted boxes with different designated targets to make the detection results less sensitive to NMS. The latter causes feature disappearance leading to inaccurate localization, and we design the attention module SEAM to enhance the learning of face features.
3. To address the problem of imbalance between hard and easy samples, we weight the easy and hard samples according to the IoU. To reduce hyperparameter tuning, we set the mean value of IoU of all candidate positive samples with ground-truth as the dividing line between positive and negative samples. And we design a weighted function named Slide to give higher weight to hard samples which is helpful for the model to learn more difficult features. The details of this function will be presented in sections 3-5.
The rest of the paper is arranged as follows: in Section 2 we review the related literature in this area; in Section 3 we describe the model structure in detail, and the main improvisions including the receptive field enhancement module, the attention module, the adaptive sample weighting function, the anchor design, the Replusion Loss and the Normalized Gaussian Wasserstein Distance (NWD) Loss, respectively; in Section 4 we describe the experiments and the according analysis of the results, including ablation experiments and comparisons with other models; and in Section 5 we summarize our work and give some advice about future research.
2 Related Works
Face Detection. Face detection has been a hot research area in computer vision for decades. In the early years of deep learning, face detection algorithms usually use neural networks to automatically extract image features for classification. CascadeCNN [1] proposes a cascaded structure with three stages of carefully designed deep convolutional networks that predicts face and landmark location in a coarse-to-fine manner. MTCNN [2] develops a similar cascade architecture to jointly align the face landmarks and detect the face locations. PCN [3] uses an angle prediction network to correct faces and improve the face detection accuracy. But early deep-learning-based face detection algorithms have some drawbacks such as tedious training, local optimum, slow detection speed, and low detection accuracy, etc.
Current face detection algorithms are mainly improved by inheriting the advantages of generic object detection algorithms, such as SSD [4], Faster R-CNN [5], RetinaNet [6], etc. CMS-RCNN [34] uses Faster R-CNN as backbone and introduces contextual information and multi-scale features to detect faces. Zhang et al. [25] designs a lightweight network based on SSD structure, named FaceBoxes, to quickly shrink the feature size by 32x down-sampling, and uses a multi-scale network module to enhance the features in both network width and depth dimensions. SRN [35], which is improved on the generic object detection algorithm RefineDet [36] and RetinaNet [6], achieves high performance by introducing two-stage classification and regression, and designs a multi-branch module to enhance the effect of receptive fields.
Scale-invariance. As one of the most challenging problems in face detection, large face scale variations in complex scenes has an important impact on the accuracy of the detector. The multi-scale detection capability mainly depends on the scale-invariance features, and many works address this problem to extract features more accurately and effectively [13, 24, 37, 38]. For small objects detection, using fewer down-sampling layers and dilated convolution can significantly improve the detection performance [39, 40]. Another way to bridge this problem is using more anchors. Anchor can provide good priori information, thus using denser anchors and corresponding matching strategies can effectively improve the quality of object proposals [24, 25, 37, 40]. Multi-scale training can be helpful to construct the image pyramids and increase the sample diversity, which is a simple but effective method to improve the performance of multi-scale object detection. On the other hand, the receptive fields will increase and the semantic information get richer accordingly, however, the spatial information may be missing correspondingly. A natural idea is to fuse deep semantic information with shallow features, such as [20, 41, 42]. Besides, SNIP [43] and TridentNet [12] also provide new ideas to solve the multi-scale problem, which will be discussed in detail in the following sections.
Occlusion problem. Crowding faces and the following occlusion problem give rise to partial data and lack of information about the occluded faces, because some regions are invisible or the boundaries are blurred, which can easily cause missed detection and low recalls. Some works have demonstrated that contextual information is helpful for face detection to alleviate the occlusion problem. SSH [37] uses means of simple convolution layers to incorporates context by enlarging the window around the candidate proposals. FAN [13] proposes an anchor-level attention to detect the occluded faces by highlighting the features from the face region. PyramidBox [44] designs a context-sensitive predict module in which they replace the convolution layers of context module in SSH by the residual prediction module of DSSD. RetinaFace [45] applies independent context modules on five feature pyramid levels to increase the receptive field and enhance the rigid context modelling power. The above methods have achieved good results in the occlusion problem. Therefore, using context information to improve the effectiveness of the occluded regions is a feasible direction which is worth further exploration.
Imbalance of easy and hard samples. For one-stage face detection, the number of easy samples is very large, and they dominate the variation of losses so that the model can only learn the features of easy samples and ignores the learning of hard samples. To address this problem, the OHEM [46] algorithm selects the difficult samples according to the sample loss and applies the loss of difficult samples to the training in stochastic gradient descent. In response to the problem of ignoring easy samples in the OHEM algorithm, Focal Loss [6] makes better use of all samples by weighting them and obtains higher accuracy. This idea is also followed by SRN [35]. Faceboxes [25] sorts the samples according to their IoU loss, and controls the ratio of positive to negative samples to be less than 1:3. Although the above methods can effectively solve the problem of sample imbalance, they also artificially introduce some hyperparameters, which increase the difficulty of adjusting. Therefore, we design a sample balance function with adaptive parameters.
3 YOLO-FaceV2
3.1 Network Architecture
YOLOv5 is an excellent general object detector. We introduce YOLOv5 into the face detection field and try to solve the problems of small faces and face occlusion, etc.
The architecture of our YOLO-FaceV2 detector is shown in Figure 1. It consists of three parts: the backbone structure, the neck and the heads. We take CSPDarknet53 as our backbone and replace the Bottleneck with RFE module in P5 layer to fuse multi-scale features. In the neck part, we maintain the structure of SPP [47] and PAN [48]. In addition, in order to improve the ability of target position perception, we also integrate the P2 layer into the PAN. The heads are used to classify the category and regress the location of the target. We also add a special branch into the heads to enhances the model’s ability of occlusion detection.
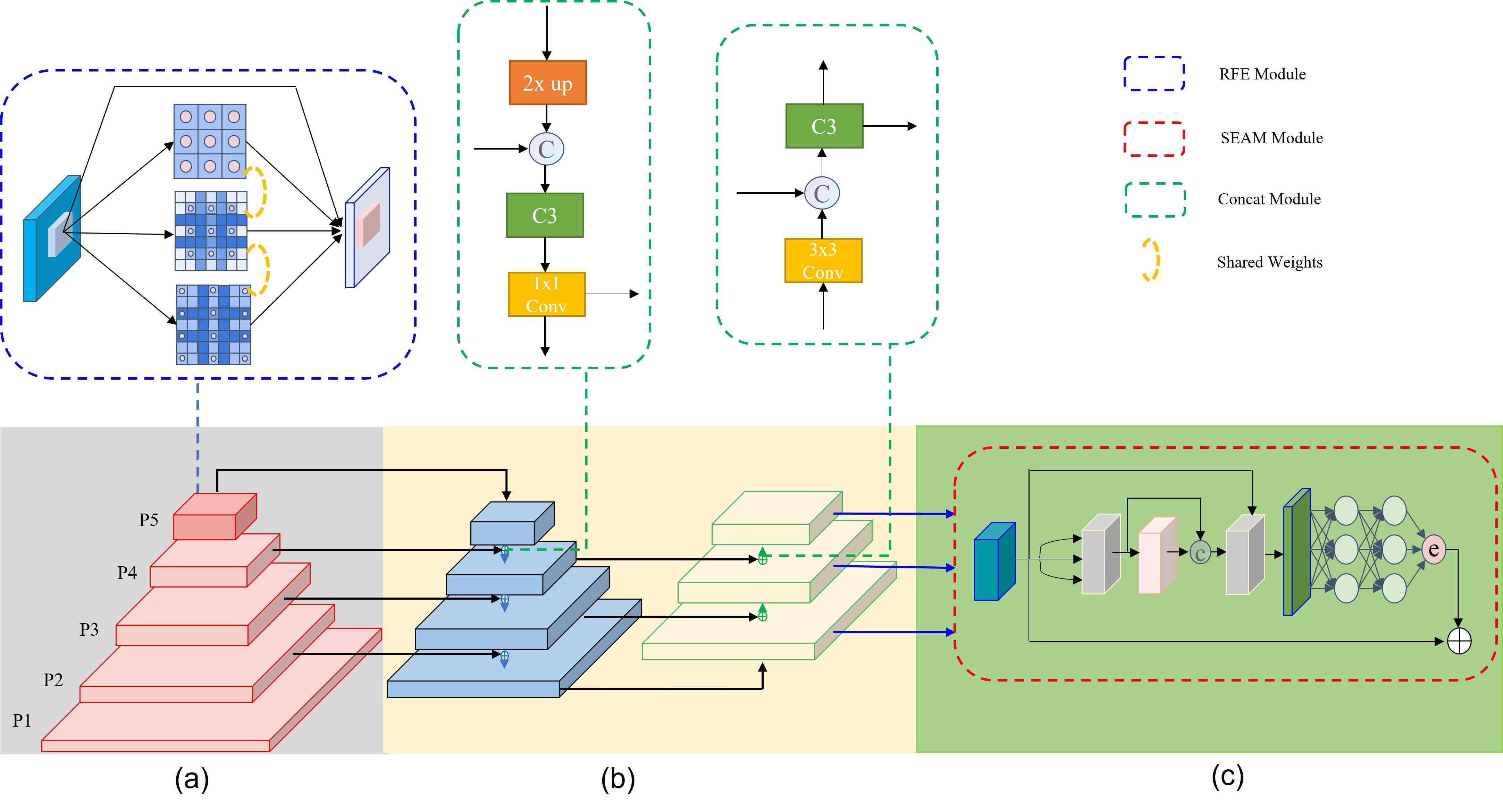
In Figure 1 (a), the red part on the left is the backbone of the detector, which is composed of CSP blocks and CBS blocks. It is mainly used to extract the features of the input images. And the RFE module is added to expand the effective receptive field and enhance the fusion capability of multi-scale in the P5 layer. In Figure 1 (b), the blue and yellow parts on the right are called neck layers, which consists of SPP and PAN. We additionally fuse the features of the P2 layer to improve the ability of more accurate target localization. In Figure 1 (c), we introduce the separated and enhancement attention module(SEAM) to strengthen the responsiveness of occluded faces after the output part of the neck layer.
3.2 Scale-Aware RFE Model
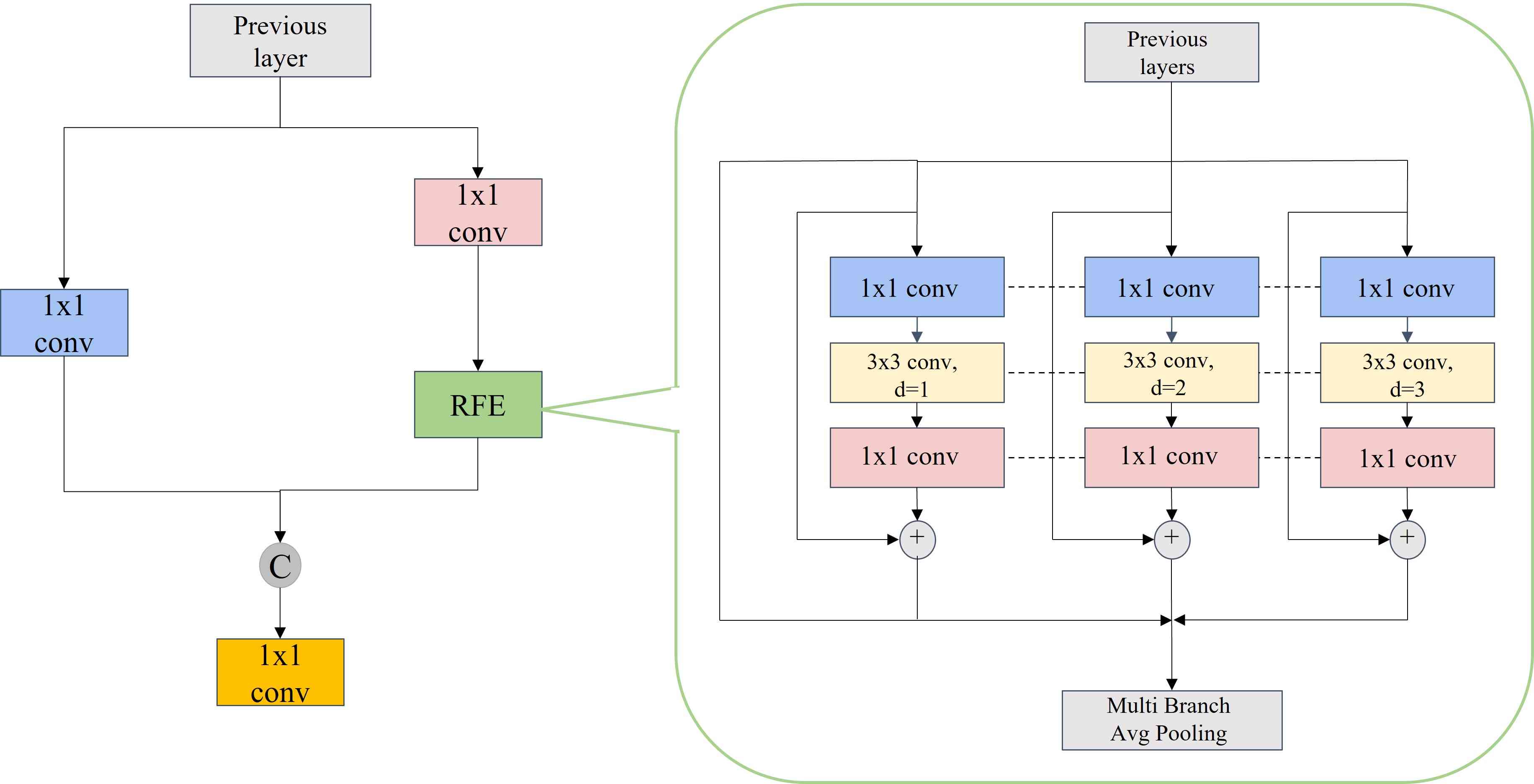
Since different size of receptive fields means different capability of capturing long-range dependency, we design the RFE module to sufficiently make use of the advantage of receptive fields in the feature map by using dilated convolution. Inspired by TridentNet, we use four branches of different rates of dilated convolution to capture multi-scale information and different ranges of dependency. All the branches have sharing weights, the only difference is their distinctive receptive fields. On the one hand, it reduces the amount of parameters and thus the risk of potential overfitting. On the other hand, it can make full use of each sample. The proposed RFE module can be divided into two parts: multi branches based on dilated convolutions and the gathering & weighting layer, as shown in Figure 2. The multi-branch part takes 1,2 and 3 as the rates of different dilated convolutions separately, which all use fixed convolutional kernel size 3x3. Furthermore, we add a residual connection to prevent the problem of gradient explosion and disappearance during training. The gathering and weighting layer is used to gather information from different branches and weight every branch of the features. The weighting operation is used to balance the representation of different branches.
To make it clear, we replace the bottleneck of C3 module in YOLOv5 with RFE module to increase the receptive field of feature map, so as to improve the accuracy of multi-scale target detection and recognition, as shown in Figure 2.
3.3 Occlusion-Aware Repulsion Loss
Intra class occlusion may cause face A contains the features of face B, resulting in a higher false detection rate. The introduction of the repulsion loss can effectively alleviate this problem through repulsion. The repulsion loss is divided into two parts: RepGT and RepBox. The function of RepGT Loss is to make the current bounding box as far away from the surrounding ground truth box as possible. The surrounding ground truth box here refers to the face label with the largest IoU with the face except for the object to be returned by the bounding box itself. The formula of RepGT loss function is as follows:
| (1) |
where
| (2) |
P in the formula is the face prediction frame, is the ground truth with the largest IoU around the face. The overlap between P and is defined as intersection over ground truth (IoG): and . is (0, 1) a continuously differentiable. ln function, is a smoothing parameter to adjust the sensitivity of repulsion loss to outliers.
The purpose of RepBox loss is to make the prediction frame as far away from the surrounding prediction frame as possible and reduce the IOU between them, so as to avoid one of the prediction frames belonging to two faces being suppressed by NMS. We divide the prediction frame into multiple groups. Assuming there are g individual faces, the division form is shown in Eqn 3. The prediction frames between the same groups return to the same face label, and the prediction frames between different groups correspond to different face labels.
| (3) |
Then, for the prediction box between different groups and , we hope that we get the smaller the overlap area between and . RepBox also uses as an optimization function. The overall loss function is as follows:
| (4) |
3.4 Occlusion-Aware Attention Network
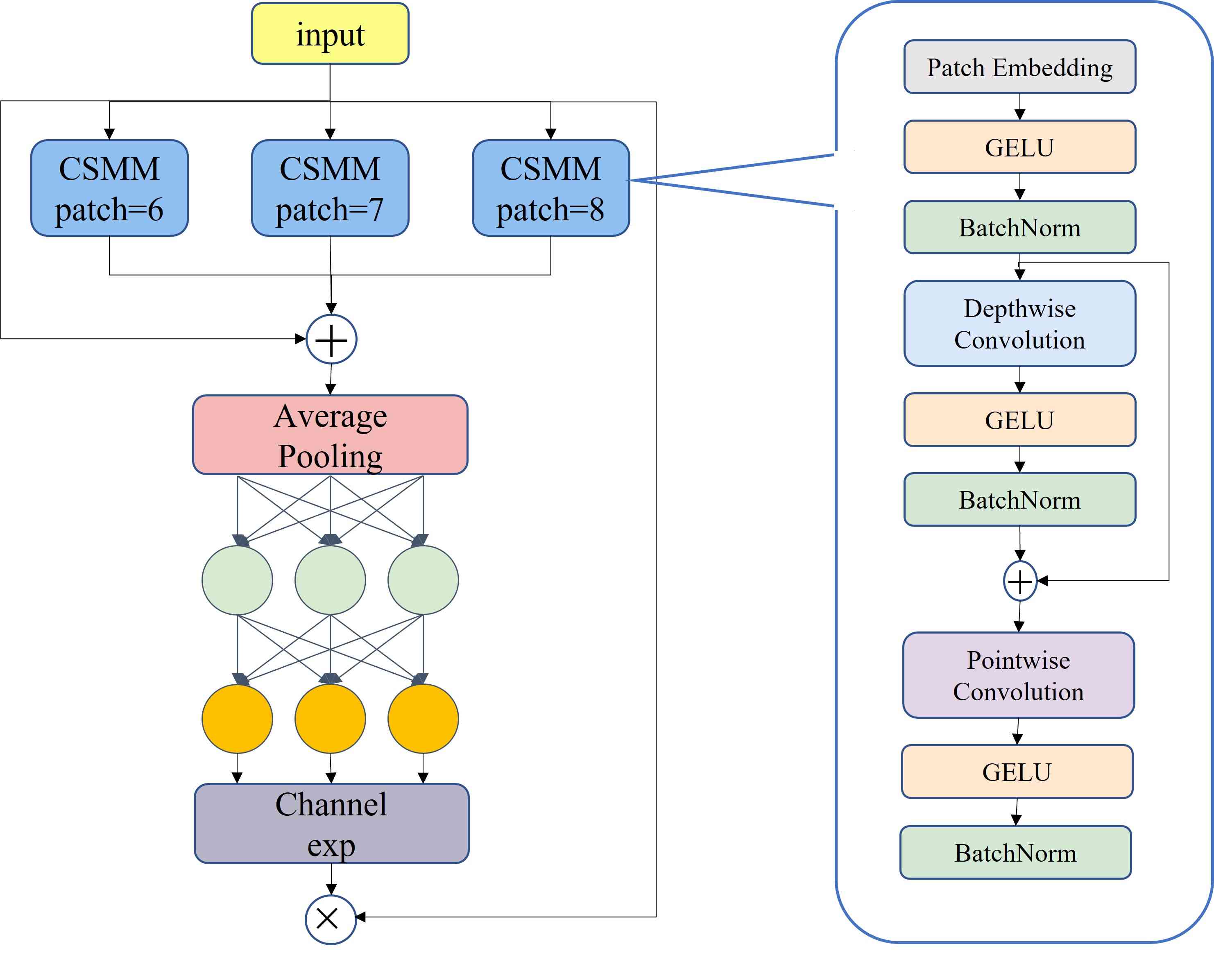
Inter class occlusion will cause alignment error, local aliasing and feature missing. We add the multi head attention network, namely the SEAM module (see Figure 3), in which we have three purposes: realize multi-scale face detection, emphasize the face area in the image and weaken the background area oppositely. The first part of SEAM is the depth separable convolution with residual connection. Depth separable convolution is operated depth by depth, that is, the convolution separated channel by channel. Although depth separable convolution can learn the importance of different channels and reduce the amount of parameters, it ignores the information relationship between channels. To make up for this loss, the outputs of different depth convolutions are subsequently combined by point-by-point (1x1) convolutions. Then a two-layer full connection network is used to fuse the information of each channel, so that the network can strengthen the connection between all channels. It is hoped that this model can make up for the aforementioned loss under occlusion scenarios through the relationship between the occluded face and the unobstructed face learned in the previous step. The output logits learned by the full connection layer is then processed by an exponential function to expand the value range from [0, 1] to [1, e]. This exponential normalization provides a monotonic mapping relationship that makes the results more tolerant to position error. Finally, the output of the SEAM module is used as attention that is multiplied by the original features, so that the model can deal with the face occlusion more effectively.
3.5 Sample weighting function
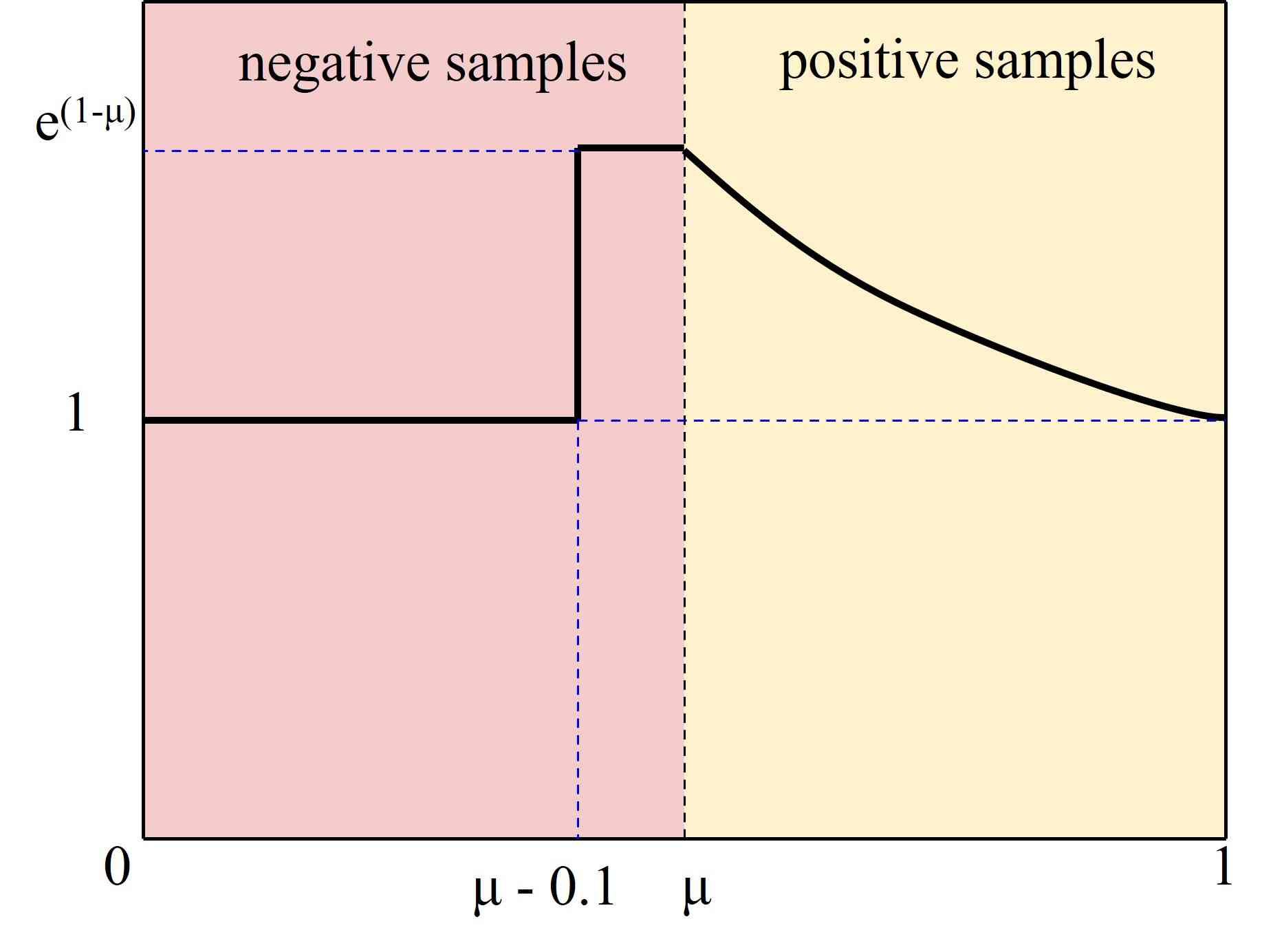
The sample imbalance problem, i.e., in most cases the number of easy samples are quite large while hard samples are relatively sparse, has attracted a lot of attention. In our work, we design a Slide Loss function which looks like a "slide" to address this problem. The distinction between easy and hard samples is based on the IoU size of the prediction box and groundtruth box. To reduce hyperparameters, we take the average of the IoU value of all bounding boxes as threshold value , those less than are taken as negative samples, and positive samples for the values greater than . However, samples near the boundaries often suffer from large losses due to unclear classifications. We hope that the model can learn to optimize these samples and use these samples more sufficiently to train the network. Nevertheless, the number of such samples is relatively small. Therefore, we try to assign higher weights to the difficult samples. We first divide the samples into positive and negative samples by the parameter . Then, we emphasis on the samples at the boundary by a weighting function Slide, as shown in Figure 4. The Slide weighting function can be expressed as Eqn 5.
| (5) |
3.6 Anchor Design Strategy
| Layer | Stride | Ratio | Anchor |
| P2 | 4 | 1.2 | [16, 20.16, 25.40] |
| P3 | 8 | 1.2 | [32, 40.32, 50.80] |
| P4 | 16 | 1.2 | [64, 80.63, 101.59] |
Anchor design strategy is critical in face detection. In our model, each of the three detection heads is associated with a specific anchor scale. The design of anchors includes the ratio of width to height and the size of anchors which are designed according to the stride of P2, P3 and P4(see Table 1). For the ratio of width to height, we calculate the statistics from the WiderFace train set based on the ground-truth face ratio. Here in face detection, we set the aspect ratio to 1:1.2 according to the statistics. For the size of anchors, we design it according to the receptive field of each layer, which can be calculated by the number of convolution and pooling layers. However, not every pixels in the theoretical receptive field contributes the same to the final output. In general, the central pixel has a greater influence than the peripheral pixel, as shown in Figure 5 (a). In other words, only a small part of the area has an effective influence on the output value. The actual effect can be equivalent to an effective receptive field. According to this hypothesis, in order to match the effective receptive field, the anchor should be significantly smaller than the theoretical receptive field (see the specific example in Figure 5 (b)). Therefore, we redesigned the initial anchor size as shown in the Table 1.

3.7 Normalized Gaussian Wasserstein Distance
Normalized Wasserstein Distance named NWD is a new evaluation method for small target detection. Firstly, the bounding box is modeled as a two-dimensional Gaussian distribution, and the similarity between the predicted target and the real target is calculated through their corresponding Gaussian distribution, that is, the normalized wasserstein distance between them is calculated according to Eqn 6. For the detected targets, whether they overlap or not, they can be measured by the distribution similarity. The NWD is not sensitive to the scale of the targets and thus is more suitable for measuring the similarity between small targets. In our regression loss function, we add a NWD Loss to make up for the disadvantage of the IoU loss for small target detection. But we still keep the IoU loss because it is suitable for large object detection.
| (6) |
| (7) |
Where C is a constant closely related to the data set, is a distance measure, and and are Gaussian distributions modeled by and .
4 Experiments
In this part, we conduct comprehensive ablations of our proposed method, including the effectiveness of our attention module, multi-scale fusion pyramid structure and loss function design. Then, we compare the performances between our proposed detector and other SOTA face detectors.
4.1 Dataset
We evaluated our model on the WiderFace dataset, which has 32203 images, including more than 400k faces. It consists of three parts: 40% for training set, 10% for verification set and 50% for test set. The results of training set and verification set can be obtained from the official website of WiderFace. According to the difficulties, the dataset can be divided into three parts: easy, medium and hard. Among them, hard subset is the most challenging, and its performance can better reflect the effectiveness of face detector. We trained our model on the WiderFace training set and evaluated it on the validation set and test set.
4.2 Training
We use YOLOv5 as our baseline and the methods are implemented by PyTorch.The optimizer we used is SGD with momentum. The initial learning rate is set to 1e-2, the final learning rate is 1e-3, and the weight decay is set to 5e-3. A momentum 0.8 is used in first 3 warming-up epochs. After that, the momentum is 0.937. The IoU for the NMS is set to 0.5. We train the model on 1080ti which have 4 CPU workers. The fine-tuning consumes 100 iterations with a batch size of 16 images.
4.3 Ablation Study
In this section, we conduct comprehensive experiments of each module on the WiderFace dataset to evaluation their affections on the performance of the model. Then the modules are combined and analyzed one-by-one. Moreover, all the loss functions are also evaluated.
| SEAM | PAN+P2 | RFE | Slide | Anchor | NWD Loss | RPLoss | Easy | Medium | Hard | Params (M) | Flops (G) |
| 94.65 | 93.00 | 83.30 | 7.063 | 16.4 | |||||||
| 95.53 | 93.82 | 84.36 | 7.464 | 17.1 | |||||||
| 93.67 | 92.14 | 83.87 | 6.101 | 17.1 | |||||||
| 95.06 | 93.60 | 85.47 | 5.097 | 17.1 | |||||||
| 95.13 | 93.41 | 83.67 | - | 17.1 | |||||||
| 94.89 | 93.75 | 84.20 | - | - | |||||||
| 94.62 | 92.87 | 83.31 | - | - | |||||||
| 95.27 | 93.63 | 83.80 | - | - | |||||||
| 95.06 | 93.64 | 85.57 | 5.201 | 17.9 | |||||||
| 95.34 | 93.85 | 85.66 | |||||||||
| 96.22 | 94.79 | 85.82 | |||||||||
| 96.30 | 94.99 | 85.94 | |||||||||
| 98.78 | 97.39 | 87.75 | 18.2 |
4.3.1 SEAM Block
Our proposed SEAM block is the attention network. By using this block, we make up for the response loss of the occluded face by strengthening the response of unobstructed faces. The results are shown in the second row of Table 2. As we can see, the accuracy increases by 0.88, 0.82 and 1.06 on the easy, medium and hard subset validation sets respectively.
4.3.2 Multi-scale feature fusion
Firstly, we fuse P2 layer features on the basis of PAN, so that the fused feature map contains more information of small targets. According to the third row of Table 2, it can be observed that the hard subset has increased by 0.57. In order to make up for the shortage of limited receptive field in the output feature map of the neck layer, which leads to the decline of detection accuracy of large and medium-sized targets, we applied the designed receptive field enhancement module, and used dilated convolutions, whose dilating rate are 1, 2 and 3, respectively, to improve the effect of long range dependency. The effect is shown in the fourth row of Table 2. The accuracy has increased by 0.5, 0.6 and 2.17 respectively.
4.3.3 Slide Loss
The main purpose of the Slide loss function is to make the model focus more on hard samples. According to the results in the fifth row of the table, the Slide function slightly improves the model of the model on the medium and hard subsets.
4.3.4 Anchor Design
The ratio and size of anchor are closely related to the effective receptive field. Different models have different effective receptive fields. According to the effective receptive field and face shape characteristics, the performance impact of designed anchors is shown in the sixth row of Table 2. It improves by 0.24, 0.75, 0.9 on the easy, medium and hard datasets respectively. As we would expect, properly designed anchors can recall more small face targets.
4.3.5 NWD Loss
We have first adopted NWD instead of IOU as the regression loss. However, the result is not improved. Therefore, we choose to retain the IoU Loss and improve the robustness of our model to small target detection by adjusting the proportional relationship between them. Because the experimental results show that for large and medium-sized targets, the effect measured by IoU is better than NWD, and NWD can effectively improve the detection accuracy of small targets. The result show in Table 3:
| IoU | NWD | Easy | Medium | Hard | Epochs |
| 1 | 0 | 94.4 | 92.74 | 82.91 | 20 |
| 0 | 1 | 81.13 | 84.4 | 75.77 | 20 |
| 0.5 | 0.5 | 94.62 | 92.87 | 83.31 | 20 |
| 0.4 | 0.6 | 91.13 | 90.38 | 80.11 | 20 |
| 0.6 | 0.4 | 92.87 | 91.39 | 80.91 | 20 |
4.3.6 Balance of RepGT and RepBox
Inspired by the solution of occlusion in pedestrian detection, we add the Repulsion Loss to face detection, and analyze the different face occlusion thresholds to make this loss function applicable to face detection. According to the results in the eighth row of the table, the repulsion loss function improves the model accuracy by 0.71, 0.63 and 0.5 on easy, medium and hard subsets.
4.4 Comparisons with Existing Face Detectors
| Method | Detector | Easy | Medium | Hard |
| Faster R-CNN | ||||
| CMS-RCNN | 0.899 | 0.874 | 0.624 | |
| HR | 0.925 | 0.91 | 0.806 | |
| Face R-CNN | 0.937 | 0.921 | 0.831 | |
| FDNet | 0.959 | 0.945 | 0.879 | |
| SSD | ||||
| SFD | 0.937 | 0.925 | 0.859 | |
| SSH | 0.931 | 0.921 | 0.845 | |
| PyramidBox | 0.961 | 0.95 | 0.889 | |
| DSFD | 0.966 | 0.957 | 0.904 | |
| SFDet | 0.954 | 0.945 | 0.888 | |
| RetinaNet | ||||
| FAN | 0.952 | 0.94 | 0.9 | |
| SRN | 0.964 | 0.952 | 0.901 | |
| DFS | 0.969 | 0.959 | 0.912 | |
| RetinaFace | 0.969 | 0.961 | 0.918 | |
| RefineFace | 0.971 | 0.962 | 0.92 | |
| YOLO | ||||
| YOLO-FaceV1 | 0.899 | 0.872 | 0.693 | |
| YOLO5Face | 0.963 | 0.956 | 0.913 | |
| YOLO-FaceV2 | 0.987 | 0.972 | 0.877 |
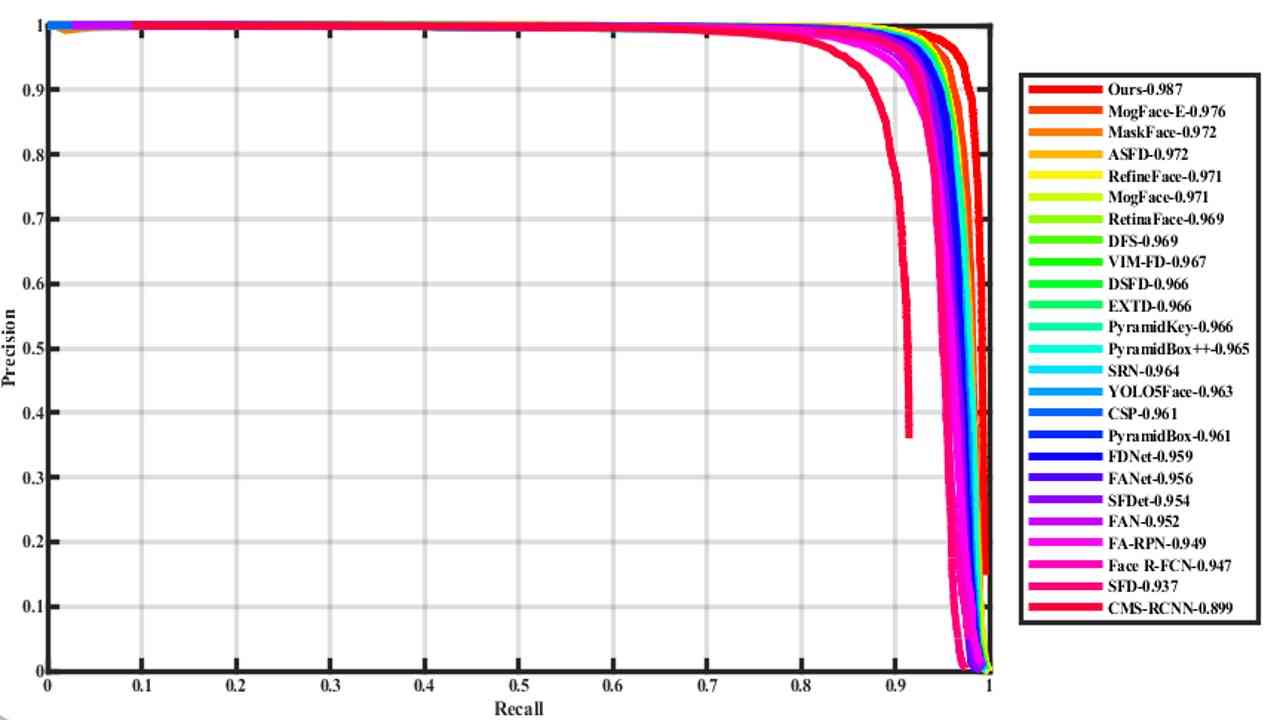
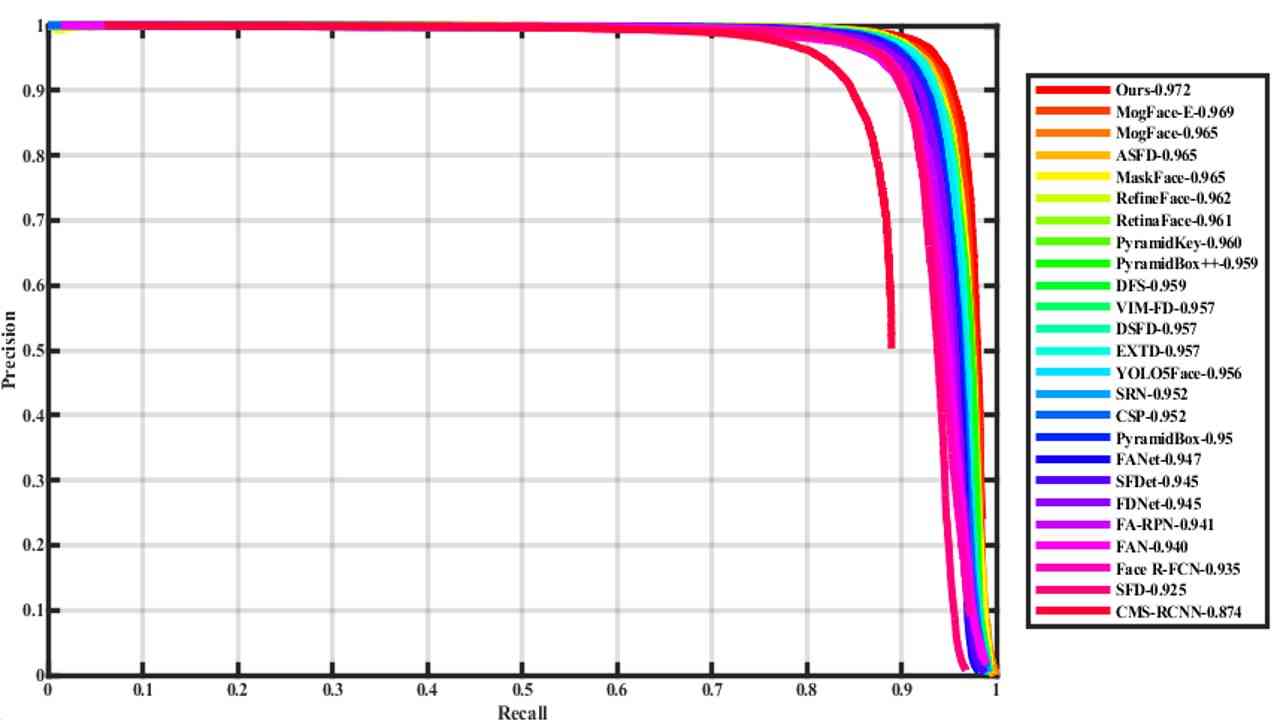
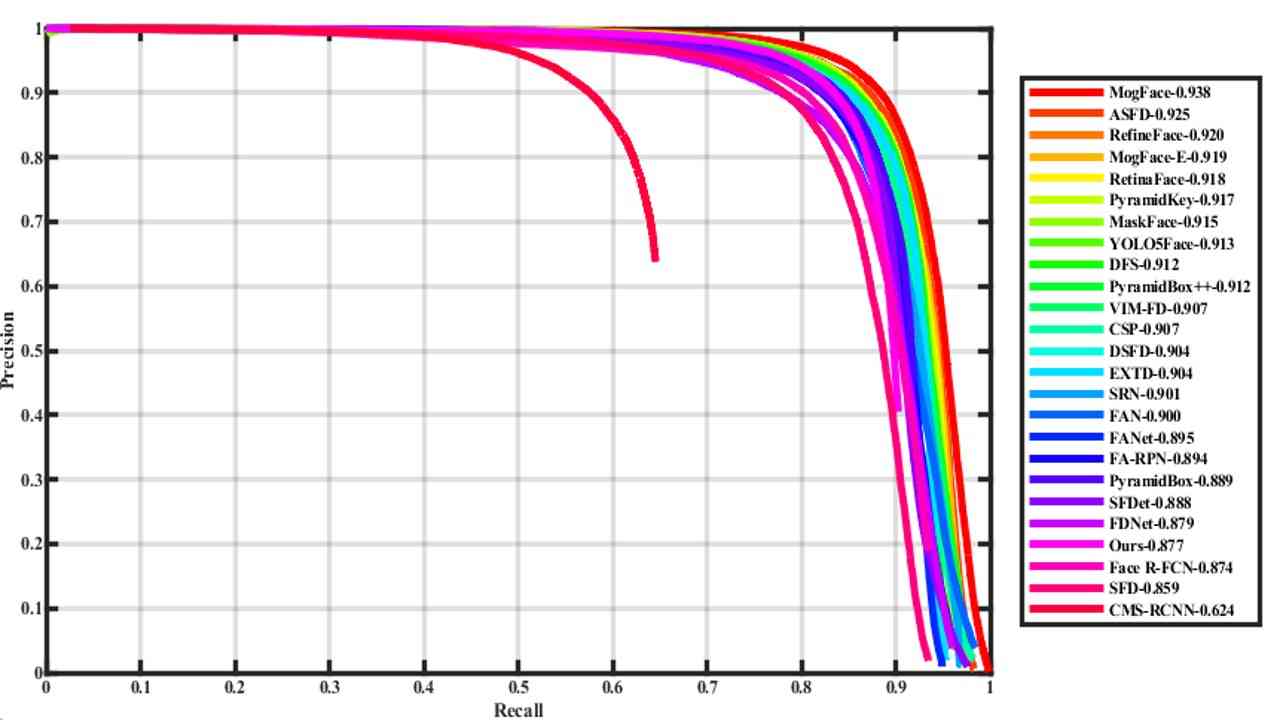
We mainly compare with various excellent face detectors presented recently. Table 4 is classified according to face detectors based on different general detectors, such as fast RCNN, SSD, Yolo, etc. The data in the table is obtained from the official website of WiderFace.
And the precision-recall (PR) curves of our YOLO-FaceV2 face detector, along with the competitors, are shown in Figure 6.
5 Conclusion
In this paper, aimed to address the problems of varying face scales, easy and hard sample imbalance and face occlusion, we propose a YOLOv5-based face detection method called YOLO-FaceV2. For the problems of varying face scales, we fuse the P2 layer into the feature pyramid to improve the resolution of small objects, design the RFE module to enhance the receptive field and use NWD Loss to improve the robustness of our model to small target detection. And we introduce Slide function to alleviate the easy and hard sample imbalance. For the face occlusion, we use SEAM module and Repulsion Loss to solve it. Beside, We use the information of the effective receptive field to design the anchor. Finally, we achieve close to or exceeding SOTA performance on the WiderFace validation Easy and Medium subsets.
References
- [1] Haoxiang Li, Zhe Lin, Xiaohui Shen, Jonathan Brandt, and Gang Hua. A convolutional neural network cascade for face detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015.
- [2] K. Zhang, Z. Zhang, Z. Li, and Y. Qiao. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Processing Letters, 23(10):1499–1503, 2016.
- [3] X. Shi, S. Shan, M. Kan, S. Wu, and X. Chen. Real-time rotation-invariant face detection with progressive calibration networks. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018.
- [4] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Y. Fu, and A. C. Berg. Ssd: Single shot multibox detector. 2015.
- [5] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis & Machine Intelligence, 39(6):1137–1149, 2017.
- [6] T. Y. Lin, P. Goyal, R. Girshick, K. He, and P Dollár. Focal loss for dense object detection. IEEE Transactions on Pattern Analysis & Machine Intelligence, PP(99):2999–3007, 2017.
- [7] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. IEEE, 2016.
- [8] J. Redmon and A. Farhadi. Yolo9000: Better, faster, stronger. In IEEE Conference on Computer Vision & Pattern Recognition, pages 6517–6525, 2017.
- [9] J. Redmon and A. Farhadi. Yolov3: An incremental improvement. arXiv e-prints, 2018.
- [10] A. Bochkovskiy, C. Y. Wang, and Hym Liao. Yolov4: Optimal speed and accuracy of object detection. 2020.
- [11] Glenn Jocher. Yolov5. https://github.com/ultralytics/yolov5.
- [12] Y. Li, Y. Chen, N. Wang, and Z. Zhang. Scale-aware trident networks for object detection. IEEE, 2019.
- [13] J. Wang, Y. Yuan, and G. Yu. Face attention network: An effective face detector for the occluded faces. 2017.
- [14] Weijun Chen, Hongbo Huang, Shuai Peng, Changsheng Zhou, and Cuiping Zhang. Yolo-face: a real-time face detector. The Visual Computer, 37(4):805–813, 2021.
- [15] S. Yang, P. Luo, C. C. Loy, and X. Tang. Wider face: A face detection benchmark. IEEE, pages 5525–5533, 2016.
- [16] K. Oksuz, B. C. Cam, S. Kalkan, and E. Akbas. Imbalance problems in object detection: A review. IEEE Transactions on Pattern Analysis and Machine Intelligence, PP(99):1–1, 2020.
- [17] S. Liu, L. Qi, H. Qin, J. Shi, and J. Jia. Path aggregation network for instance segmentation. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- [18] M. Tan, R. Pang, and Q. V. Le. Efficientdet: Scalable and efficient object detection. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- [19] S. Qiao, L. C. Chen, and A. Yuille. Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. arXiv, 2020.
- [20] T. Y. Lin, P. Dollar, R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for object detection. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- [21] Min Chen, Xuemei Ren, and Zhanyi Yan. Real-time indoor object detection based on deep learning and gradient harmonizing mechanism. In 2020 IEEE 9th Data Driven Control and Learning Systems Conference (DDCLS), 2020.
- [22] Y. Cao, K. Chen, C. C. Loy, and D. Lin. Prime sample attention in object detection. 2019.
- [23] W. Luo, Y. Li, R. Urtasun, and R. Zemel. Understanding the effective receptive field in deep convolutional neural networks. 2017.
- [24] S. Zhang, X. Zhu, Z. Lei, H. Shi, X. Wang, and S. Z. Li. Sfd: Single shot scale-invariant face detector. In IEEE Computer Society, 2017.
- [25] S. Zhang, X. Zhu, Z. Lei, H. Shi, X. Wang, and S. Z. Li. Faceboxes: A cpu real-time face detector with high accuracy. 2017.
- [26] J. Yu, Y. Jiang, Z. Wang, Z. Cao, and T. Huang. Unitbox: An advanced object detection network. ACM, 2016.
- [27] H. Rezatofighi, N. Tsoi, J. Y. Gwak, A. Sadeghian, and S. Savarese. Generalized intersection over union: A metric and a loss for bounding box regression. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [28] Z. Zheng, P. Wang, W. Liu, J. Li, R. Ye, and D. Ren. Distance-iou loss: Faster and better learning for bounding box regression. arXiv, 2019.
- [29] Y. F. Zhang, W. Ren, Z. Zhang, Z. Jia, L. Wang, and T. Tan. Focal and efficient iou loss for accurate bounding box regression. 2021.
- [30] J. Wang, C. Xu, W. Yang, and L. Yu. A normalized gaussian wasserstein distance for tiny object detection. 2021.
- [31] A. Trockman and J Zico Kolter. Patches are all you need? arXiv e-prints, 2022.
- [32] X. Wang, T. Xiao, Y. Jiang, S. Shao, J. Sun, and C. Shen. Repulsion loss: Detecting pedestrians in a crowd. 2017.
- [33] S. Zhang, C. Chi, Y. Yao, Z. Lei, and S. Z. Li. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- [34] Chenchen Zhu, Yutong Zheng, Khoa Luu, and Marios Savvides. Cms-rcnn: Contextual multi-scale region-based cnn for unconstrained face detection. 2017.
- [35] C. Chi, S. Zhang, J. Xing, Z. Lei, S. Z. Li, and X. Zou. Selective refinement network for high performance face detection. 2018.
- [36] S. Zhang, L. Wen, X. Bian, Z. Lei, and S. Z. Li. Single-shot refinement neural network for object detection. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018.
- [37] M. Najibi, P. Samangouei, R. Chellappa, and L. Davis. Ssh: Single stage headless face detector. In 2017 IEEE International Conference on Computer Vision (ICCV), 2017.
- [38] S. Yang, Y. Xiong, C. L. Chen, and X. Tang. Face detection through scale-friendly deep convolutional networks. 2017.
- [39] Songtao Liu, Di Huang, et al. Receptive field block net for accurate and fast object detection. In Proceedings of the European conference on computer vision (ECCV), pages 385–400, 2018.
- [40] J. Li, Y. Wang, C. Wang, Y. Tai, J. Qian, J. Yang, C. Wang, J. Li, and F. Huang. Dsfd: Dual shot face detector. 2018.
- [41] Z. Li, P. Chao, Y. Gang, X. Zhang, and S. Jian. Detnet: A backbone network for object detection. 2018.
- [42] T. Kong, A. Yao, Y. Chen, and F. Sun. Hypernet: Towards accurate region proposal generation and joint object detection. IEEE, 2016.
- [43] B. Singh and L. S. Davis. An analysis of scale invariance in object detection - snip. 2017.
- [44] Xu Tang, Daniel K Du, Zeqiang He, and Jingtuo Liu. Pyramidbox: A context-assisted single shot face detector. In Proceedings of the European conference on computer vision (ECCV), pages 797–813, 2018.
- [45] J. Deng, J. Guo, Y. Zhou, J. Yu, I. Kotsia, and S. Zafeiriou. Retinaface: Single-stage dense face localisation in the wild. 2019.
- [46] A. Shrivastava, A. Gupta, and R. Girshick. Training region-based object detectors with online hard example mining. In IEEE Conference on Computer Vision & Pattern Recognition, pages 761–769, 2016.
- [47] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Transactions on Pattern Analysis & Machine Intelligence, 37(9):1904–16, 2014.
- [48] S. Liu, L. Qi, H. Qin, J. Shi, and J. Jia. Path aggregation network for instance segmentation. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.