Efficient algorithms for quantum information bottleneck
Abstract
The ability to extract relevant information is critical to learning. An ingenious approach as such is the information bottleneck, an optimisation problem whose solution corresponds to a faithful and memory-efficient representation of relevant information from a large system. The advent of the age of quantum computing calls for efficient methods that work on information regarding quantum systems. Here we address this by proposing a new and general algorithm for the quantum generalisation of information bottleneck. Our algorithm excels in the speed and the definiteness of convergence compared with prior results. It also works for a much broader range of problems, including the quantum extension of deterministic information bottleneck, an important variant of the original information bottleneck problem. Notably, we discover that a quantum system can achieve strictly better performance than a classical system of the same size regarding quantum information bottleneck, providing new vision on justifying the advantage of quantum machine learning.
1 Introduction
Learning is a task of eminent importance to the contemporary world. As such, it has always been of top priority to quest powerful tools for learning information. Information bottleneck [32] stands as an excellent example, with many useful applications including deep learning [33, 28, 8], video processing [16], clustering [29] and polar coding [30]. Concretely, information bottleneck is a method to extract a piece of information with respect to the system from the system , and is formulated as the minimization problem of the difference with a positive parameter , where is the mutual information between and . In particular, we are interested in the case when is classical. By design, information bottleneck achieves an irreversible compression, by extracting essential information about and simultaneously removing unessential information contained in .

As we are stepping into the age of quantum information, the demand is growing for a method that efficiently learns information on a quantum system. For this purpose, let us consider the setup of quantum information bottleneck (QIB), demonstrated in Fig. 1. Similar as its classical counterpart, the aim of QIB is to compress into a smaller system while preserving the correlation with when some of these systems are quantum systems. Prior to this work, QIB has been discussed in several recent works [9, 24, 6, 14, 2] and has been applied to quantum information theory [6, 14] and quantum machine learning [2]. On the other hand, the fundamental properties of QIB such as convergence have not been analysed, which hinders its application in more practical tasks. Quantum information bottleneck is first proposed as a quantum extension of information bottleneck method in [9]. It also derived a necessary condition for the solution of the minimization problem (see [9, Appendix A]) by using Lagrange multiplier method in the same way as [1, 4]. Using the obtained condition, it also proposed an iterative algorithm to find a solution to satisfy the necessary condition [9, Appendix C]. Then, the reference [24] considered QIB in the quantum communication scenario. 111The reference [24, Appendix A] derived a necessary condition for the solution of the minimization problem by using Lagrange multiplier method in the same way as [1, 4]. Using the obtained condition, it also proposed an iterative algorithm to find a solution to satisfy the necessary condition [24, The end of Appendix C]. However, no study discusses the behaviour of the iterative algorithm, i.e., it is not known whether the algorithm monotonically reduces the objective function [32, 31, 9, 24]. It was also claimed in [9, Appendix B] that there is no advantage of using a quantum if are both classical.
In this work, we conduct a systematic study on quantum information bottleneck, focusing on the case when the system is classical. Compared to existing works [9, 24, 6, 14, 2], our work makes significant contributions in several directions:
First, we provide throughout analyses on two critical properties – efficiency and convergence – of QIB. Motivated by a recent generalization [22] of the Arimoto-Blahut algorithm [1, 4], we introduce a new quantum information bottleneck algorithm with an acceleration parameter that can make the value of QIB converges much faster than before when chosen properly. We prove rigorous criteria for our algorithm to converge and to achieve a minimum. In particular, we prove that the choice of plays an important role in convergence.
Second, in contrast to the claim in Refs. [9, 24], we provide concrete examples where using a quantum instead of classical could reduce the minimal value of QIB. Notably, our result justifies a genuine quantum advantage in quantum machine learning [34, 27, 3], where the employment of quantum circuits has been prevalent [26, 11, 5, 17, 20, 25] but the quantum advantage was rarely justified.
Last but not least, we generalise QIB by considering a general target function with parameters , which reduces to the standard QIB when . By doing so, the generalised QIB contains QDIB, i.e., the quantum version of deterministic information bottleneck [31], by setting . We show that our analyses and our algorithm hold for this generalised setting and, in particular, to QDIB. Then, we clarify that QDIB can be used to find a good approximate sufficient statistics for for , which requires a smaller entropy and larger mutual information . We justify our finding via a numerical example, where QDIB extracts a good approximate sufficient statistics over information about a quantum ensemble.
In summary, our work addresses several critical issues of QIB, including convergence, efficiency, choice of parameters, and the quantum advantage. We also extend QIB to a generalised setting and introduce the notion of QDIB. Our results consist of both rigorous analytical analyses and numerical experiments that justifies the importance of QIB and QDIB in fundamental tasks of learning.
The remaining part of this paper is organized as follows. Section 2 introduces our algorithm for quantum information bottleneck, and discusses its convergence and dependence of the parameter . Section 3 discusses our algorithm when our memory system is classical. Section 4 presents examples that realizes a smaller value of the target function by quantum memory than by classical memory . Section 5 discusses an application of our QIB algorithm in data classification. Section 6 proposes our algorithm for quantum deterministic information bottleneck, and studies its properties. Section 7 applies it to the extraction of approximate sufficient statistics, and numerically verifies its efficiency in an example. Section 8 makes discussion and conclusion.
2 The quantum information bottleneck (QIB) problem
2.1 Problem definition
Consider a classical-quantum joint system composed of and with the joint state
| (1) |
where is a classical system and is a quantum system. Our quantum information bottleneck (QIB) problem aims at constructing an information processor, modelled by a c-q channel from to (which prepares a quantum state when the classical register is ), that extracts efficient information from with respect to the quantum system . After the action of the information processor, the joint state becomes:
| (2) |
To this aim, the QIB problem concerns constructing a classical-quantum channel that minimizes the information bottleneck function, consisting of entropic quantities defined with respect to the joint state :
| (3) |
where denotes the entropy of 222For convenience, the notation stands for the Shannon entropy when the system is classical and for the von Neumann entropy when is quantum., denotes the conditional entropy of on , and stands for the mutual information between and .
That is, our aim is the calculation of the following value:
| (4) |
In the information bottleneck (2.1), and are positive real variables modelling the objective of the task. In the original proposal of information bottleneck [32] . Another common choice of is , and the task is called a deterministic QIB (whose classical counterpart was discussed in Ref. [31]). The parameter controls the tradeoff between faithfulness and compression. For instance, in a deterministic information bottleneck, a larger would make more prominent in the objective function, forcing the information processor to preserve more information about , whereas a smaller would signify the role of , prompting the information processor to do more compression in .
Although this section addresses the case with quantum systems and , the case with a classical system and a quantum can be contained as a special case by considering the diagonal densities . On the other hand, the case with a classical system is a different problem from the case with a quantum system because we need to discuss a different minimization problem, which has a different range for the minimizing variable. Fortunately, our algorithm for a quantum system , presented in the next subsection, can be applied to the case with a classical system . Section 3 discusses the case of being classical. We remark that the case where both and are classical has been widely studied in classical information theory and machine learning; see, e.g., Refs. [32, 33, 31, 28].
2.2 QIB algorithm for
The paper [9] discussed this problem when are quantum systems and , extending the classical information bottleneck [32] to the quantum regime. It derived a necessary condition for to achieve the minimum (4). The necessary condition with quantum systems and a classical system is written as
| (5) |
where is a normalizing constant and
| (6) | ||||
| (7) | ||||
| (8) |
Since this condition is self-consistent, using this condition, the paper [9] proposed the following iterative algorithm with the following update rule:
| (9) |
2.3 The acceleration parameter
Next, we propose an extension of the iterative algorithm in [9]. First, we introduce a new parameter and rewrite the condition (5) as:
| (10) |
where
| (11) |
Using (10), we can derive another iterative algorithm as
| (12) |
In this way, we can easily generalize the iterative algorithm (9) by [9]. However, it is not trivial to find the suitable value for , which, as we show later, is critical to the efficiency of our iterative algorithm. Although many papers [32, 31, 9, 24] discussed the iterative algorithm given by (9) including the classical case, no preceding study showed the convergence of the iterative algorithm by (9). In addition, the discussion above focuses on the case of and does not include the case of deterministic information bottleneck (). Therefore, to make an efficient algorithm, we need to discuss the choice of the parameter for generic .
2.4 QIB algorithm with general and convergence
To analyze the convergence of the algorithm (12), we introduce a two-input variable function based on the idea in Ref. [22, Section III-B], whereas the method in Ref. [22, Section III-B] was obtained as a generalization of the Arimoto-Blahut algorithm [1, 4]. The idea is that, instead of directly solving the minimization of , which is often too difficult, we find a continuous function with two variables . Then we can update these two input variables alternately to decrease . Finally, if the function satisfies
| (13) |
the minimum of will be close to the minimum of the IB function.
The above type of functions can be constructed if we find an operator to satisfy
| (14) |
In this paper, we employ the following function:
| (15) |
Then, the condition (14) is satisfied.
Using this function, we can define , which satisfies the condition (13). However, it is difficult to optimize two input variables alternately in the function . Instead, for , we introduce the following function
| (16) | ||||
| (17) |
where and denotes the relative entropy.
Next, we need to specify the rules of the alternatively updating . Crucially, we need to ensure that is non-increasing under the updating rules. To this purpose, we first introduce the following condition:
- (A1)
-
and satisfy the relation
(18)
In fact, the condition (A1) is rewritten as by defining as
| (19) |
This quantity is evaluated as
| (20) |
because the relation
| (21) |
implies the relation
| (22) |
To state our updating rules, we define
| (23) | ||||
| (24) | ||||
| (25) |
In particular, when , the operator is simplified as
| (26) |
Theorem 1
Under the condition (A1), we have
| (27) | ||||
| (28) |
Also, we have
| (30) |
where , , and follow from (17), (23), and (25), respectively. Finally, from Eq. (30) we can see that the minimum of is achieved when , since the first term of (30) is non-negative (with equality achieved when ) and the second term is independent of . Hence, we obtain (28).
Corollary 2
When , the following chain of inequalities hold: . Hence, the monotonicity of the information bottleneck under the updating rules is also guaranteed, as long as is sufficiently large. Finally, we propose the following algorithm with a fixed and general :
As mentioned, when satisfies the condition (A1) in all iteration steps, i.e., when is sufficiently large, Theorem 1 guarantees the monotonicity of the information bottleneck function:
| (32) |
Since consists of bounded entropic quantities (assuming the system to be finite), it is a bounded quantity. Therefore, the sequence in our Algorithm converges. In addition, we can show that the sequence of c-q channels converges as well:
Theorem 3
When , the sequence converges.
In particular, since , the sequence converges with .
Proof: Since is monotonically decreasing for , we have
| (33) |
Using (30), we have
| (34) |
Thus, we have
| (35) |
Since due to (33) and (35), the sequence is a Cauchy sequence, it converges.
We remark that it is free to choose the convergence criterion in Algorithm 1.
In Algorithm 1, is fixed to be a large enough value. Intuitively (see the next paragraph for more detailed discussion), (or, more precisely, ) is an acceleration parameter that makes the algorithm converge faster if chosen to be a smaller value.
To begin with, we show the role of in convergence of the algorithm. Denote by the convergence point of . The performance of our algorithm can be characterized by the decreasing speed of the average divergence between and , which is evaluated as
| (36) |
where , , and follow from the combination of (23) and (25), (30), and (27), respectively.
The above discussion manifests that if , making smaller makes the average divergence between and decrease faster. On the other hand, making too small leads to a risk of violating the condition (18) (and, consequently, breaking the monotonicity of ).
Remark 1
The reference [22, Section III] considered a general setting. If is a single density matrix, our method can be considered as a special case of their setting. However, since is classical-quantum channel in our case, our analysis is not a special case of their setting.
Remark 2
The references [9, Appendix A] [24, Appendix A] considered the case when the systems are quantum systems and . They derived a necessary condition for the solution of the minimization problem by using Lagrange multiplier method in the same way as [1, 4]. Using the obtained condition, they [9, Appendix C] [24, Appendix C] also proposed an iterative algorithm to find a solution to satisfy the necessary condition. It seems that their necessary condition is the same as (31) with . However, they did not discuss the convergence to a local minimizer in their algorithm.
2.5 Numerics on the effects of different
To see the effect of different , let us take a look at a concrete example: Consider a single-qubit quantum system and a classical register with size . Then, we assume that is the uniform distribution over , and the density is given as , where
| (37) |
where is the Pauli- matrix. The parameters and are randomly chosen.
Then, the ensemble we consider admits the following joint density matrix:
| (38) |
with given by Eq. (37).
Now, we apply our QIB algorithm (i.e., Algorithm 1) to the ensemble (38). We consider a classical whose size is the square root of (i.e., ). We set , and . Our focus will be the effects of different choices of the acceleration parameter . As shown in Fig. 2, the choice of is crucial for the performance, more specifically, the efficiency and the convergence, of the QIB algorithm.
Two interesting phenomena are manifested by our numerics: For one thing, choosing a smaller will accelerate the course of convergence. As shown in Fig. 2, by choosing a suitably smaller value of (e.g., or ), our QIB algorithm achieves convergence faster than the existing QIB algorithm [9, 24], which corresponds to Algorithm 1 with . For the other, choosing a too small will ruin the convergence property of the QIB algorithm. For instance, when is chosen to be , jumps up after a few iterations and ends up in a much larger value than its initial value.
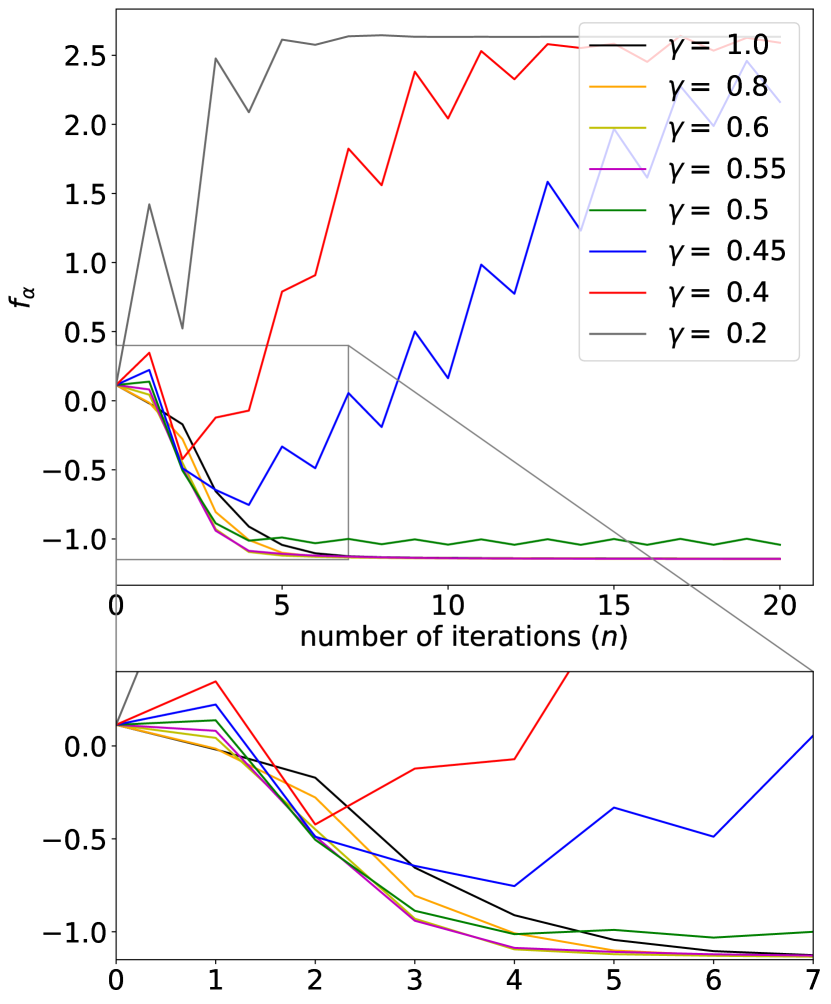
In conclusion, the numerics has justified our theoretical analysis (see Section 2.4) on the importance of choosing a suitable . We emphasize that our contribution in this direction is twofold:
-
1.
We proposed a method of accelerating the QIB algorithm, making it converge within fewer rounds of iteration, by introducing a new parameter and setting it to be smaller than one.
-
2.
We showed that the QIB algorithm cannot achieve the desired minimal value of if is too small.
2.6 Choice of
The output of our QIB algorithms depend not only on [cf. (1)] but also on the choice of and . Intuitively, a larger improves the faithfulness (as it makes more significant in ), while a smaller leads to more compression (as it makes more significant in ). Somehow surprisingly, the choice of is not completely free: In the following, we show that the QIB algorithm will yield a trivial if is too small.
To consider the relation between the choice of and the resultant information on , we introduce the following condition for a subset , where is the the set of all c-q channels from to , i.e., the set :
- (A2)
-
For any two distinct elements ,
The condition (A2) is unitarily invariant, i.e., the pair satisfies the condition (A2), if and only if the pair satisfies the condition (A2) for any unitary on . Hence, we choose as a unitarily invariant subset.
Theorem 4
Assume that a unitarily invariant subset satisfies (A2). Let be the solution to the QIB problem. When belongs to , is the maximally mixed state on for any .
If is the maximally mixed state for every , is uncorrelated with and does not contain any meaningful information. In other words, when the assumption for Theorem 4 holds, the solution of the QIB problem is not useful. Hence, we need to choose the parameters such that condition (A2) does not hold.
Now we discuss how to avoid the condition (A2). The LHS of (A2) is evaluated as
| (39) |
where . Since , the coefficient of is a negative value. Hence, a smaller has a possibility to satisfy the condition (A2). That is, to obtain a useful solution, we need to choose to be a sufficiently large value.
3 Classical system
Next, we consider the case when is constrained to be a classical system. We stress that this is a different minimization from the previously discussed one with a quantum system , whose minimum may not be attainable with a classical . Instead, our objective function now is
| (42) |
Therefore, we need to re-examine the validity of our previous analyses.
Let us start with the form of QIB algorithm. Fortunately, our algorithm with a quantum system can be applied to this case, simply with the adaptation that the states are limited to diagonal density matrices with respect to the basis of . Under this condition, the states are also diagonal density matrices. Therefore, when we set the initial state as diagonal density matrices, Algorithm 1 works for this case.
The above discussion leads to an interesting observation as follows. The convergent with initial diagonal satisfies the condition (10) and it is also diagonal. That is, if the minimum with classical is strictly larger than the minimum with quantum , the minimum with classical is an example for the following statement: A solution of the condition (10) does not necessarily give the minimum of with quantum . This fact shows the possible risk that a solution to (10) might be a saddle point or a local minimum rather than the global minimum for with quantum .
When the states are limited to diagonal density matrices with respect to the basis of , is commutative with so that we can define . Then, is simplified as follows.
| (43) |
The notion of unitary invariance is reduced to invariance under permutations on , and the condition (A2) is invariant under permutations on . Then, Theorem 4 can be rewritten as follows.
Theorem 5
Assume that a subset satisfies (A2) and is invariant under any permutation on . Let be the minimizer of . When belongs to , is the uniform distribution over for any .
In this case, we can make a more precise discussion for the condition (A2). For this purpose, we consider the maximum ratio
| (44) |
The inequality follows from the information processing inequality for the map . In this condition, is written as by using a distribution . Then, the LHS of (A2) is simplified as
| (45) |
When the condition holds, the LHS of (A2) is positive for . Hence, to extract useful , we need to choose to satisfy the condition with . In fact, even when , there is a possibility that a permutation-invariant subset satisfies (A2). Due to Theorem 5, when a permutation-invariant subset satisfies (A2), a useful solution does not belong to the subset . Hence, to obtain a useful solution, we need to choose sufficiently large beyond the above condition with .
Remark 3
We consider the case with classical and . The operator is simplified as follows.
| (46) |
In this case, the reference [31, (14) Section 3] proposed the following update rule:
| (47) |
where the operator is defined as
| (48) |
Since
| (49) |
we have
| (50) |
That is, the update rule (47) by [31, (14) Section 3] is the same as ours of this special case. In particular, the update rule (47) with coincides with the update rule by the reference [32].
Remark 4
When the system is classical and , the reference [9, Appendix B] claimed that there is no difference between the optimal value with quantum and the optimal value with classical . Since their algorithm works with of a fixed size, it can be considered that they claimed the above statement when the size of is fixed. However, their proof (see [9, Appendix B II]) contains a gap: The statement under Eq. (B23) that “the Lagrangian is invariant under a measurement of the memory in a chosen basis ” is not backed by a rigorous mathematical proof. It is thus unclear whether this statement and, consequently, the claim that there is no quantum advantage are correct. On the other hand, as we show next, the optimal value with quantum can be strictly smaller than the optimal value with classical . That is, the claim in [9, Appendix B] contradicts with our result of the next section.
4 Quantum advantage for
To see the advantage of quantum system over classical system , we discuss several examples with the strict inequality
| (51) |
We provide an analytical example in this section and a numerical example with application in quantum machine learning in Section 5.2 when the size of the system is fixed. Generally, to achieve the optimal performance, we need to choose the system as a sufficiently large dimensional system. However, in this section, to provide analytical examples, we fix the size of the system to a certain value.
Assume that is a classical system of size . The size of is times of the size of . We assume that is given as with and . The distribution of is assumed to be uniform. We focus on the quantum system with the dimension .
Lemma 6
When and , we have
| (52) |
Proof: First, we show a bound on the QIB for generic (quantum) . For any , we have . Hence, the relation implies . Hence, we have
| (53) |
Since and , we obtain
| (54) |
The above bound is tight. Indeed, we choose as the pure state . Then, we have . Also, . Therefore, .
Next, we focus on the case when is a classical system of dimension .
Lemma 7
Assume that with . When , we have
| (55) |
Proof: Any channel can be written as a probabilistic mixture of deterministic channels . That is, we have
| (56) |
Since is independent of and the random variable describing the choice of , we have
| (57) |
Also, we have
| (58) |
Then, we have
| (59) |
where follows from (53), and follows from (57) and (58). The minimization of equals the minimization of the same function under the condition that is a deterministic channel and depends only on .
Under this condition, we have , which implies the equality in at (59). Therefore, for the minimization, we can impose this condition, i.e., the variable is determined only by , which implies . In this case, we have . In the classical case, the maximum entropy among deterministic channels is achieved when the distribution as close as possible to the uniform distribution, i.e., . Hence, the maximum entropy is . Therefore, we obtain the desired statement.
5 Quantum feature maps with QIB
5.1 Information bottleneck in supervised learning
Supervised learning is a cornerstone of machine learning. Given a dataset sampled from an unknown probability distribution , a general supervised learning task is to find a classifier such that, for any testing data sampled from the same distribution , it predicts the label with as high accuracy as possible given .
Remarkably, recent studies [33, 28, 8] on the information bottleneck theory showed evidences that the training phase of deep learning can be divided into two stages. In the first stage, a representation of that faithfully encodes its correlation with is found, featured by increasing . In the second stage, the size of is compressed, featured by decreasing . This result suggests that finding an efficient and compressed representation of facilitates data classification.
5.2 Quantum feature maps
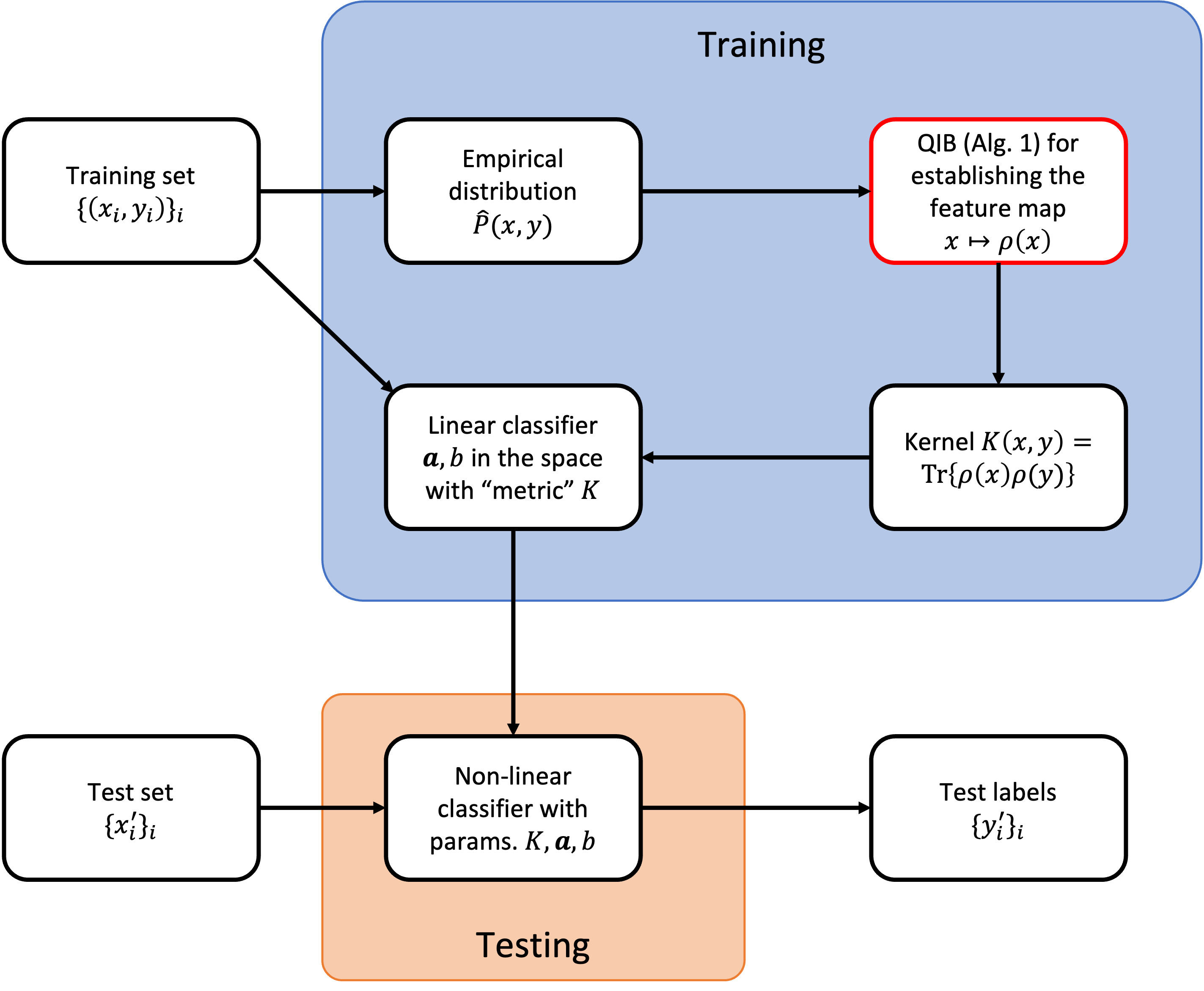
Following the above intuition, we propose a classical-quantum hybrid algorithm of data classification, by combining the QIB algorithm with the kernel method. The idea is illustrated in the flowchart in Fig. 3. Given a training dataset , the algorithm first identifies an efficient representation of by minimising the information bottleneck . Then a classifier is constructed that yields a prediction based on the state in corresponding to the value of . For simplicity, we consider for now the case when is binary. In the first step, we set the representation to be a quantum state that depends on the data , and we obtain via Algorithm 1. In the second step, we use a linear classifier
| (60) |
where is a Hermitian operator and . We further consider that can be expressed as a linear combination , and the classifier has the reduced form
| (61) |
where is the kernel function, in our case given by the Hilbert-Schmidt (HS) inner product of quantum states and can be evaluated by performing the SWAP test on a quantum computer:
| (62) |
The algorithm is summarised as follows:
We remark that the quantum kernel method, where a mapping is constructed for better classification, has been a hot topic recently (see, e.g., [26, 11, 5, 17, 20, 25]). The key distinction between existing works and our present method is the following: In existing works, the parameter is passed to a parametrised (a.k.a. variational) quantum circuit that prepares the state . One needs to train the circuit parameters on a quantum computer to obtain a good mapping , which is called a feature map. In the near term, this method might be subject to the physical limitations of quantum devices. In contrast, in our present method is directly computed via a simple iterative algorithm. Therefore, there are two possible ways of realizing our present method, i.e., Algorithm 2. In the near term, we can regard Algorithm 2 as a “quantum-inspired” classical algorithm, and evaluate everything on a classical computer. When large-scale quantum computing becomes feasible, Algorithm 2 can be readily “quantised”. Indeed, the evaluation of in each iteration requires subroutines that compute matrix powers and logarithm and solve linear systems, which have already been developed in Refs. [10, 19, 18, 7].
5.3 Numerical experiments
As a proof-of-principle experiment, we tested the performance of our QIB classifier on a dataset on , generated in the following way: First, we define the discrete sets and , with and . To apply our classification method, we arbitrarily choose permutation , and generate independent and identically distributed data for as follows. We independently generate according to the following distribution
| (63) |
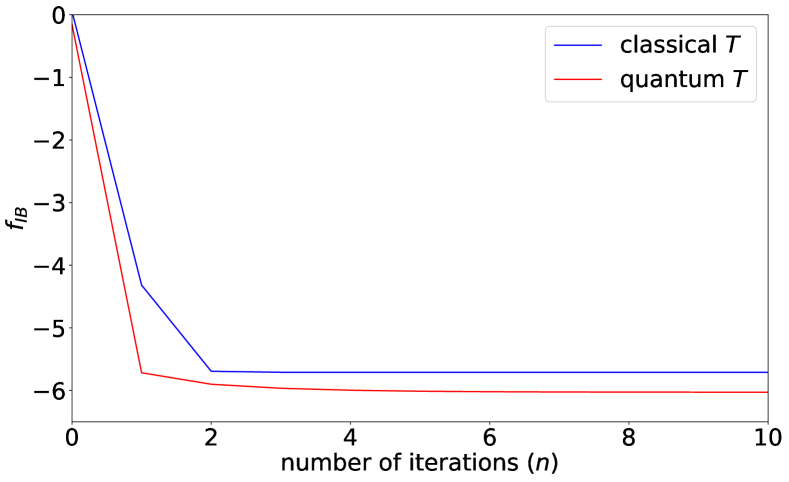
where is the uniform distribution over , , , and . Next, we generate the random variables , where the random variable is subject to the uniform distribution in the interval unless nor , it is subject to the uniform distribution in the interval otherwise. Then, using the obtained data with , we define its empirical distribution . We apply Algorithm 1 to the distribution as Fig. 4. In the case with the distribution , Algorithm 1 with quantum can realize a smaller than Algorithm 1 with classical , which shows the advantage of quantum over classical .
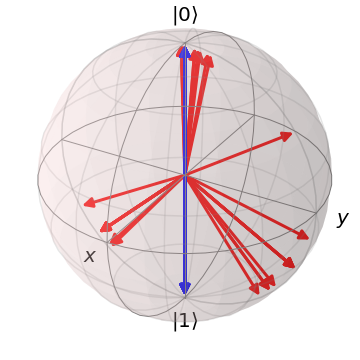
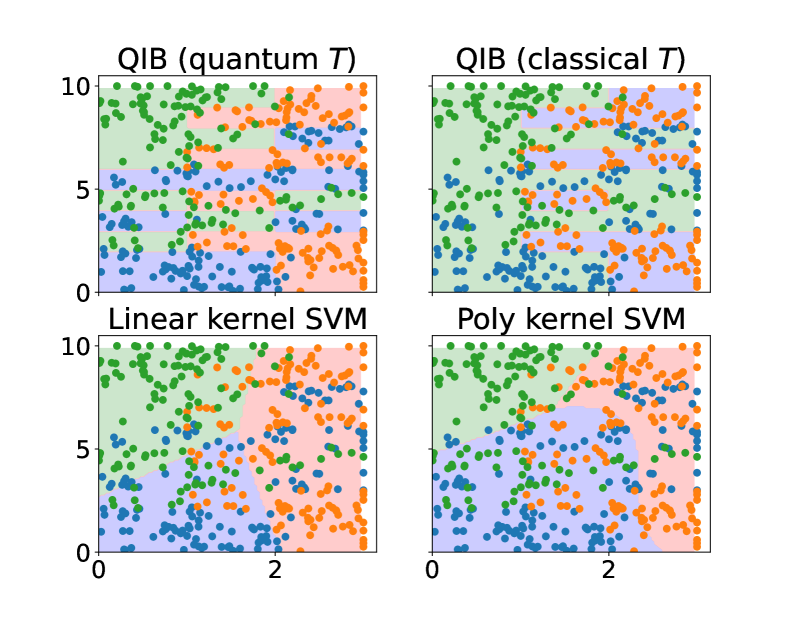
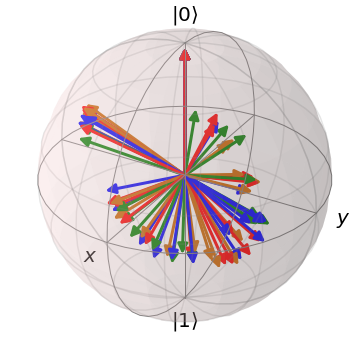
In the classification experiment, of the data are used as the training set and the rest are used as the testing set. The kernel is constructed with Algorithm 2 with , a single-qubit register , and 10 iterations. We consider both when is a generic qubit system and when is restricted to a binary classical system, and we compare their performance. As can be seen from Fig. 4, the case of quantum has lower IB value than the case of classical . The final feature map for the quantum case suffers from certain degree of dispersion due to the random noise , but the quantum features still form 3 clusters. In contrast, the final in the classical case maps different values of into two clusters.
The effect of the above distinction is made apparent in the classification performance. In Fig. 5, the performance of the classifiers constructed from the kernels are illustrated via their decision regions. It can be seen that, since the classical- feature map groups into two clusters, its resultant classifier gives a binary prediction on any input data, giving up the least possible label. In stark contrast, the quantum- feature map utilizes the full Bloch ball to generate 3 clusters, leading to a much higher accuracy of prediction. The advantage of a genuinely quantum feature map is thus manifested by this numerical example.
For reference, in Fig. 5, we also plot the performance of two standard methods of classical feature maps. The referential methods (linear kernel and polynomial kernel) achieve accuracies (defined by the ratio of correct predictions in the testing set) and , which is slightly higher than the classical- information bottleneck kernel () but much lower than the QIB kernel (). This further justifies the superior performance of our QIB method in classification.
6 Quantum deterministic information bottleneck (QDIB)
Considering the limit , the paper [31] proposed deterministic IB, which minimize . Now, we consider this minimization with quantum systems and classical system . First, we define
| (64) |
where is the projection to the maximum eigenvalue of the operator .
Given an initial point , we propose the following update rule
| (65) |
As shown below, each step of this algorithm improves the value of the target function .
The operator is characterized as
| (66) |
Since Theorem 1 and (20) guarantee
| (67) |
the limit in (67) implies
| (68) |
which shows that each step of this algorithm improves the value of the target function .
| (69) |
7 Approximate sufficient statistics from DIB
7.1 Task formulation
Next, we discuss how DIB can be used for the extraction of useful information under a classical-quantum (c-q) joint system composed of and with the joint state , where is a classical system and is a quantum system. For example, assume that our interest is in the quantum phenomena in the quantum system . This quantum system is correlated to the classical system . However, there is a possibility that the classical system contains redundant information. In this case, it is useful to extract essential information from to describe the behavior of the quantum phenomena in the quantum system . To discuss the essential information, we introduce the concept of -(approximate) sufficient statistics of the classical system with respect to the quantum system while the papers [36, 12] discussed this concept when system is a classical system.
A function from to is called a sufficient statistics of for the quantum system when there exists a conditional distribution such that
| (70) |
The above condition is equivalent to the condition
| (71) |
while in general we have the inequality .
However, when we use sufficient statistics, we cannot remove a small correlation generated by a noise. As an example, suppose that the classical system is composed of two classical systems and . Assume that we have a c-q state with two classical systems and .
We assume that we have already known the distribution but we do not know . Also, we assume that we generate this state several times and apply the state estimation to the generated state. As a result, we obtain our estimate
| (72) |
Since our estimate always has small error, is not exactly the same as , but it is close to . In this case, this difference should be considered as a noise. That is, the dependence of is not essential. It is better to consider that the correlation is given as so that our estimate of is given as .
For , a function is called an -sufficient statistics when the inequality
| (73) |
holds. Hence, a sufficient statistics with of small size and an -sufficient statistics can be considered as compressed data of with respect to .
In the above example, is a sufficient statistics for . When is sufficiently small for , is close to , i.e., is an -sufficient statistics. Hence, we can remove non-essential information . In fact, if is disturbed by a random permutation , it will be non-trivial to extract essential information. To cover such a non-trivial case, we need a systematic approach to find such a function with a small-size . For this aim, we can use the information bottleneck algorithm.
To extract approximate sufficient statistics , we focus on two requirements. The mutual information should be larger, and the entropy should be smaller. To handle these requirements, we simply minimize by using deterministic information bottleneck algorithm with . Since the algorithm minimizes , and the conditional distribution in the solution is deterministic, the support of in the solution is expected to be smaller than the original set .
7.2 Numerics
To demonstrate the above idea, let us take a look at a concrete example, which is a modification of the example in Section 2.5. Consider a single-qubit quantum system and a classical register that encodes information about . The register is further split into two sub-registers and that take values in the sets and . Then, we assume that is the uniform distribution over , and the density is given as with (37). The parameters and depend on as
| (74) |
Obviously, the quantum system depends only on and contains no information about the quantum system. An experimentalist who has access to the ensemble, however, does not know this. To extract information about the quantum system, for each pair of , the experimentalist estimates its density matrix by repetitively (for times) making a suitable measurement on . According to quantum state estimation theory [15, 13], the estimate has an inaccuracy proportional to . Taking this into account, we model the estimated density matrix as when the actual density matrix is , where
| (75) | ||||
| (76) |
and characterise the estimation errors. The estimated ensemble then admits the density matrix given in (72) with , which is given by Eqs. (37), (75), and (76). Notice that now the register is correlated with in the estimated joint state , even if the estimation-induced noise follows a distribution that does not depend on the value of .
Now, the task is to compress the register , by constructing a map from to a smaller classical register . Here we take to be the same size as . One intuitive approach is to discard the register because contains much more information about the qubit state than . Nevertheless, such a simple map does not exist in more general cases. For instance, if the values of in Eq. (72) are permuted, discarding will not result in faithful compression. To see this, we further apply a arbitrary chosen unknown reshuffling to the classical register in Eq. (72). The ensemble then admits the following joint density matrix:
| (77) |
with given by Eqs. (75) and (76). The goal is to extract an approximate sufficient statistics by constructing a map .
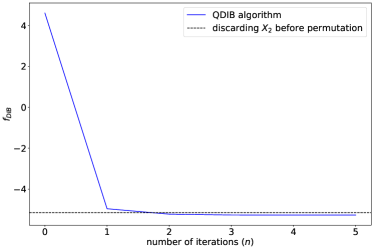
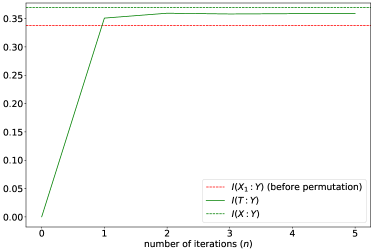
Our QDIB algorithm works as a more systematic and more efficient method to extract essential information and discard non-essential information, even in the presence of an arbitrary permutation. In the QDIB algorithm (Algorithm 3), we choose and . First, we consider the case when the ensemble admits the form (72), and the performance is summarised in Fig. 7. As one can see from the numerics, of applying our QDIB algorithm to drops lower than that of the “discarding after the inverse permutation ” approach within 5 iterations, and converges to a much lower value, suggesting a better compression performance. This is further justified in the second plot, where the faithfulness and the residual information are plotted. We can see that since our QDIB algorithm preserves almost as much information about as the original variable , it compresses a considerably larger portion of information about the original register .
8 Discussion and conclusion
We have proposed a generalized algorithm for QIB with an acceleration parameter and an additional parameter , and have derived a necessary condition for the monotonic decrease of the objective function with quantum systems and classical system when we extract information with respect to from . We have also showed its convergence under the same condition and that a wisely-chosen parameter can accelerate the convergence. Our numerical calculation has further justified the above analysis as follows. In our numerical experiment, making smaller accelerates the convergence, but if is made smaller than a threshold the algorithm will fail to converge. In addition, we have provided examples that quantum system have an advantage over classical system even when and are classical.
Next, taking the limit , we have proposed an iterative algorithm for QDIB that minimizes the objective function . We have shown that this iterative algorithm always decreases the objective function monotonically. QDIB can be applied to find an approximate sufficient statistics because it realizes a smaller entropy and a larger mutual information . Then, we have numerically demonstrated that our QDIB algorithm works well as an approximate sufficient statistics.
An important application we show in this work is that our QIB algorithm yields a new approach of constructing quantum feature maps for classification. In our numerical example, quantum system realizes a smaller value of the objective function than classical system . This numerical analysis shows the advantage of using quantum memory for the classification. Despite significant recent progress [34, 27, 3, 26, 11, 5, 17, 20, 25], the advantage of quantum machine learning over its classical counterpart has not been discussed much. Our work provides a new angle of attacking this issue, shedding light on a new proposal to rigorously justify and quantify quantum supremacy in the world of learning.
An open question left for future study is how to extend our result to the case where is also a quantum system, which covers, for instance,the scenario of compressing a quantum system while keeping its correlation with a classical label [21, 23, 35, 36, 37, 38]. Remarkably, in such a scenario, it has been shown that, if is classical, some correlation will be lost regardless of its size [37]. Therefore, we anticipate that the advantage of a quantum might persist or grow even stronger for QIB with a quantum .
Finally, we remark that currently there is no efficient method to compute the restriction on in Theorem 3. Resolving this important issue in a future work will accelerate the convergence of our information bottleneck algorithm.
Acknowledgement
MH is supported in part by the National Natural Science Foundation of China (Grant No. 62171212) and Guangdong Provincial Key Laboratory (Grant No. 2019B121203002). YY is supported by Guangdong Basic and Applied Basic Research Foundation (Project No. 2022A1515010340), and by the Hong Kong Research Grant Council (RGC) through the Early Career Scheme (ECS) grant 27310822.
References
- Arimoto [1972] S. Arimoto. An algorithm for computing the capacity of arbitrary discrete memoryless channels. IEEE Transactions on Information Theory, 18(1):14–20, 1972. doi: 10.1109/TIT.1972.1054753.
- Banchi et al. [2021] Leonardo Banchi, Jason Pereira, and Stefano Pirandola. Generalization in quantum machine learning: A quantum information standpoint. PRX Quantum, 2:040321, Nov 2021. doi: 10.1103/PRXQuantum.2.040321.
- Biamonte et al. [2017] Jacob Biamonte, Peter Wittek, Nicola Pancotti, Patrick Rebentrost, Nathan Wiebe, and Seth Lloyd. Quantum machine learning. Nature, 549(7671):195–202, 2017. doi: 10.1038/nature23474.
- Blahut [1972] R. Blahut. Computation of channel capacity and rate-distortion functions. IEEE Transactions on Information Theory, 18(4):460–473, 1972. doi: 10.1109/TIT.1972.1054855.
- Blank et al. [2020] Carsten Blank, Daniel K Park, June-Koo Kevin Rhee, and Francesco Petruccione. Quantum classifier with tailored quantum kernel. npj Quantum Information, 6(1):1–7, 2020. doi: 10.1038/s41534-020-0272-6.
- Datta et al. [2019] Nilanjana Datta, Christoph Hirche, and Andreas Winter. Convexity and operational interpretation of the quantum information bottleneck function. In 2019 IEEE International Symposium on Information Theory (ISIT), pages 1157–1161, 2019. doi: 10.1109/ISIT.2019.8849518.
- Gilyén et al. [2019] András Gilyén, Yuan Su, Guang Hao Low, and Nathan Wiebe. Quantum singular value transformation and beyond: exponential improvements for quantum matrix arithmetics. In Proceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing, pages 193–204, 2019. doi: 10.1145/3313276.3316366.
- Goldfeld and Polyanskiy [2020] Ziv Goldfeld and Yury Polyanskiy. The information bottleneck problem and its applications in machine learning. IEEE Journal on Selected Areas in Information Theory, 1(1):19–38, 2020. doi: 10.1109/JSAIT.2020.2991561.
- Grimsmo and Still [2016] Arne L. Grimsmo and Susanne Still. Quantum predictive filtering. Phys. Rev. A, 94:012338, Jul 2016. doi: 10.1103/PhysRevA.94.012338.
- Harrow et al. [2009] Aram W Harrow, Avinatan Hassidim, and Seth Lloyd. Quantum algorithm for linear systems of equations. Physical review letters, 103(15):150502, 2009. doi: 10.1103/PhysRevLett.103.150502.
- Havlíček et al. [2019] Vojtěch Havlíček, Antonio D Córcoles, Kristan Temme, Aram W Harrow, Abhinav Kandala, Jerry M Chow, and Jay M Gambetta. Supervised learning with quantum-enhanced feature spaces. Nature, 567(7747):209–212, 2019. doi: 10.1038/s41586-019-0980-2.
- Hayashi and Tan [2018] Masahito Hayashi and Vincent Y. F. Tan. Minimum rates of approximate sufficient statistics. IEEE Transactions on Information Theory, 64(2):875–888, 2018. doi: 10.1109/TIT.2017.2775612.
- Helstrom [1969] Carl W Helstrom. Quantum detection and estimation theory. Journal of Statistical Physics, 1(2):231–252, 1969. doi: 10.1007/BF01007479.
- Hirche and Winter [2020] Christoph Hirche and Andreas Winter. An alphabet-size bound for the information bottleneck function. In 2020 IEEE International Symposium on Information Theory (ISIT), pages 2383–2388, 2020. doi: 10.1109/ISIT44484.2020.9174416.
- Holevo [2011] Alexander S Holevo. Probabilistic and statistical aspects of quantum theory, volume 1. Springer Science & Business Media, 2011. doi: 10.1007/978-88-7642-378-9.
- Hsu et al. [2006] Winston H. Hsu, Lyndon S. Kennedy, and Shih-Fu Chang. Video search reranking via information bottleneck principle. MM ’06, pages 35–44, New York, NY, USA, 2006. Association for Computing Machinery. ISBN 1595934472. doi: 10.1145/1180639.1180654.
- Lloyd et al. [2020] Seth Lloyd, Maria Schuld, Aroosa Ijaz, Josh Izaac, and Nathan Killoran. Quantum embeddings for machine learning. arXiv preprint arXiv:2001.03622, 2020. doi: 10.48550/arXiv.2001.03622.
- Low and Chuang [2017] Guang Hao Low and Isaac L Chuang. Hamiltonian simulation by uniform spectral amplification. arXiv preprint arXiv:1707.05391, 2017. doi: 10.48550/arXiv.1707.05391.
- Low and Chuang [2019] Guang Hao Low and Isaac L Chuang. Hamiltonian simulation by qubitization. Quantum, 3:163, 2019. doi: 10.22331/q-2019-07-12-163.
- Pérez-Salinas et al. [2020] Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, and José I Latorre. Data re-uploading for a universal quantum classifier. Quantum, 4:226, 2020. doi: 10.22331/q-2020-02-06-226.
- Plesch and Bužek [2010] Martin Plesch and Vladimír Bužek. Efficient compression of quantum information. Physical Review A, 81(3):032317, 2010. doi: 10.1103/PhysRevA.81.032317.
- Ramakrishnan et al. [2021] Navneeth Ramakrishnan, Raban Iten, Volkher B. Scholz, and Mario Berta. Computing quantum channel capacities. IEEE Transactions on Information Theory, 67(2):946–960, 2021. doi: 10.1109/TIT.2020.3034471.
- Rozema et al. [2014] Lee A Rozema, Dylan H Mahler, Alex Hayat, Peter S Turner, and Aephraim M Steinberg. Quantum data compression of a qubit ensemble. Physical Review Letters, 113(16):160504, 2014. doi: 10.1103/PhysRevLett.113.160504.
- Salek et al. [2019] Sina Salek, Daniela Cadamuro, Philipp Kammerlander, and Karoline Wiesner. Quantum rate-distortion coding of relevant information. IEEE Transactions on Information Theory, 65(4):2603–2613, 2019. doi: 10.1109/TIT.2018.2878412.
- Schuld [2021] Maria Schuld. Supervised quantum machine learning models are kernel methods. arXiv preprint arXiv:2101.11020, 2021. doi: 10.48550/arXiv.2101.11020.
- Schuld and Killoran [2019] Maria Schuld and Nathan Killoran. Quantum machine learning in feature Hilbert spaces. Physical Review Letters, 122(4):040504, 2019. doi: 10.1103/PhysRevLett.122.040504.
- Schuld et al. [2015] Maria Schuld, Ilya Sinayskiy, and Francesco Petruccione. An introduction to quantum machine learning. Contemporary Physics, 56(2):172–185, 2015. doi: 10.1080/00107514.2014.964942.
- Shwartz-Ziv and Tishby [2017] Ravid Shwartz-Ziv and Naftali Tishby. Opening the black box of deep neural networks via information. arXiv preprint arXiv:1703.00810, 2017. doi: 10.48550/arXiv.1703.00810.
- Slonim and Tishby [2000] Noam Slonim and Naftali Tishby. Document clustering using word clusters via the information bottleneck method. SIGIR ’00, pages 208–215, New York, NY, USA, 2000. Association for Computing Machinery. ISBN 1581132263. doi: 10.1145/345508.345578.
- Stark et al. [2018] Maximilian Stark, Aizaz Shah, and Gerhard Bauch. Polar code construction using the information bottleneck method. In 2018 IEEE Wireless Communications and Networking Conference Workshops (WCNCW), pages 7–12, 2018. doi: 10.1109/WCNCW.2018.8368978.
- Strouse and Schwab [2017] DJ Strouse and David J. Schwab. The Deterministic Information Bottleneck. Neural Computation, 29(6):1611–1630, 06 2017. ISSN 0899-7667. doi: 10.1162/NECO_a_00961.
- Tishby et al. [1999] N. Tishby, F. C. Pereira, and W. Bialek. The information bottleneck method. In The 37th annual Allerton Conference on Communication, Control, and Computing, pages 368–377. Univ. Illinois Press, 1999. doi: 10.48550/arXiv.physics/0004057.
- Tishby and Zaslavsky [2015] Naftali Tishby and Noga Zaslavsky. Deep learning and the information bottleneck principle. In 2015 IEEE information theory workshop (ITW), pages 1–5. IEEE, 2015. doi: 10.1109/ITW.2015.7133169.
- Wittek [2014] Peter Wittek. Quantum machine learning: what quantum computing means to data mining. Academic Press, 2014. doi: 10.1016/C2013-0-19170-2.
- Yang et al. [2016a] Yuxiang Yang, Giulio Chiribella, and Daniel Ebler. Efficient quantum compression for ensembles of identically prepared mixed states. Physical Review Letters, 116(8):080501, 2016a. doi: 10.1103/PhysRevLett.116.080501.
- Yang et al. [2016b] Yuxiang Yang, Giulio Chiribella, and Masahito Hayashi. Optimal compression for identically prepared qubit states. Phys. Rev. Lett., 117:090502, Aug 2016b. doi: 10.1103/PhysRevLett.117.090502.
- Yang et al. [2018a] Yuxiang Yang, Ge Bai, Giulio Chiribella, and Masahito Hayashi. Compression for quantum population coding. IEEE Transactions on Information Theory, 64(7):4766–4783, 2018a. doi: 10.1109/TIT.2017.2788407.
- Yang et al. [2018b] Yuxiang Yang, Giulio Chiribella, and Masahito Hayashi. Quantum stopwatch: how to store time in a quantum memory. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 474(2213):20170773, 2018b. doi: 10.1098/rspa.2017.0773.