FedEgo: Privacy-preserving Personalized Federated Graph Learning with Ego-graphs
Abstract.
As special information carriers containing both structure and feature information, graphs are widely used in graph mining, e.g., Graph Neural Networks (GNNs). However, in some practical scenarios, graph data are stored separately in multiple distributed parties, which may not be directly shared due to conflicts of interest. Hence, federated graph neural networks are proposed to address such data silo problems while preserving the privacy of each party (or client). Nevertheless, different graph data distributions among various parties, which is known as the statistical heterogeneity, may degrade the performance of naive federated learning algorithms like FedAvg. In this paper, we propose FedEgo, a federated graph learning framework based on ego-graphs to tackle the challenges above, where each client will train their local models while also contributing to the training of a global model. FedEgo applies GraphSAGE over ego-graphs to make full use of the structure information and utilizes Mixup for privacy concerns. To deal with the statistical heterogeneity, we integrate personalization into learning and propose an adaptive mixing coefficient strategy that enables clients to achieve their optimal personalization. Extensive experimental results and in-depth analysis demonstrate the effectiveness of FedEgo.
1. Introduction
Graph Neural Networks (GNNs) have shown incredible performance in distilling information from graph data and deriving expressive node embedding that facilitates downstream tasks such as node classification and link prediction. Nevertheless, previous GNN works focus on centralized node representation learning without taking into account the common existence of data silo problems in the real world. In a traditional data silo situation, the data are stored across several distributed parties and they’re only allowed to be accessed privately. As a result, how to collaborate separate graphs from local data owners while preserving privacy for the training of a high-quality graph-based model is a crucial problem.
Federated learning (FL), a technique that decouples the implementation of machine learning from the requirement for direct data sharing, has shown great promise in training models collaboratively while preserving data privacy (Li et al., 2020). The key idea of federated learning is to train a global model in a central server with the contribution of local data owners (or clients). When dealing with graph data, an intuitive idea is to combine naive federated algorithms with graph neural networks directly. Nevertheless, naive FL algorithms based on weight aggregation such as FedAvg does not benefit from the structure information in the graph data, thereby may have poor performance in graph mining. For an organic combination of GNN and FL that we term as federated graph learning, the structure information of graph data is meant to be fully utilized.
Moreover, federated graph learning suffers from the highly non-independent identically distributed (non-IID) problem. In the presence of the statistical heterogeneity among clients which commonly appears in the task of graph mining, a single global model might not generalize well on the local data of all clients (Jiang et al., 2019). As a consequence, it is necessary to integrate personalization into federated graph learning instead of training a single consensus model. That is to say, clients will adapt the global model to their own dataset and train their local models for personalization, which we term personalized federated graph learning.
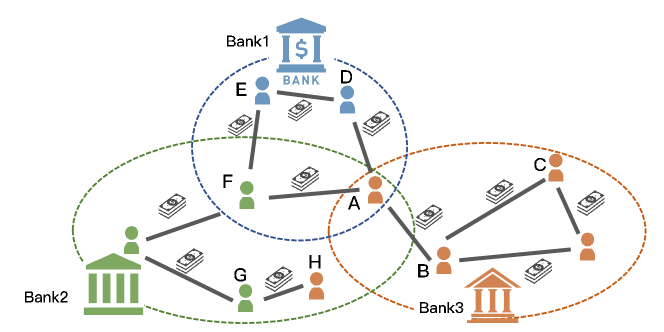
Take a practical problem in the financial system as an example. There are many banks in a city constituting the financial system, as shown in Fig. 1. The records of each bank are separately stored without sharing with others because of privacy concerns and conflicts of interest. With customers as nodes and transactions as edges, a local graph could be derived from the records stored in a bank’s database. Graph mining could be further applied and one of the most frequently applied tasks may be node classification such as distinguishing different kinds of customers. Furthermore, banks may also collaborate to improve the generalization ability of their local models. In many cases, however, various banks may target different markets and the distributed graph data are in a severe non-IID scenario, making the situation difficult. In other words, the local dataset of a bank can be regarded as a limited observation of the real world, and the key incentive for a bank to participate in collaboration is to reduce its local generalization error with the help of other banks’ data. In light of these observations, a bank needs to achieve the trade-off between the benefit from the collaboration and the disadvantage brought by the potentially statistical heterogeneity, which forms a typical personalized federated graph learning.
In general, this realistic scenario poses three main challenges in personalized federated graph learning:
-
Challenge 1: How to make full use of the structure information of graph data during federated training? Since topological information is an indispensable part of graph mining, it is important to integrate them into federated learning organically.
-
Challenge 2: How to mitigate the issue of the potentially non-IID graph data in the federated learning framework? Observations from different angles of the real dataset lead to severe non-IID graph data and prevent naive FL algorithms from performing well.
-
Challenge 3: How to achieve an optimal trade-off between the benefit and the disadvantages of the collaboration? Under the potential non-IID scenario, the ideal situation for a client is to utilize others’ data to compensate for its local dataset while minimizing the harm induced by the statistical heterogeneity among each other.
The challenges above motivate us to design FedEgo, a personalized federated graph learning system based on ego-graphs. FedEgo is capable of handling the challenges above and preserves privacy by keeping data anonymous in terms of structure and feature.
-
To address challenge 1, it is feasible to view the graph as a family of -hop ego-graphs with structures and node features. Ego-graph, a sampled subgraph with up to k-hop neighbors of the center node, is a kind of useful information carrier and enables message passing of structure and feature information during the graph mining. FedEgo extracts topological information from ego-graphs by applying GraphSAGE (Hamilton et al., 2017) over them. Furthermore, only the local topological information can be derived from the sampled ego-graphs and it is impossible to restore the original structure, which means that they are structure-anonymous.
-
To address challenge 2, we train a global model in the central server to handle the non-IID graph data. Taking consideration of challenge 1, we seek to develop a global model which is capable of capturing the structural information that ego-graphs contains. To this end, inspired by (Arivazhagan et al., 2019; Collins et al., 2021), we introduce a network that composes of reduction layers and personalization layers to exploit shared low-dimensional embeddings and perform personalized graph mining, respectively. In FedEgo, the clients’ model consists of both reduction layers and personalization layers for local training while the global model in the server consists of only the personalization layers for information distillation of the ego-graphs in the global dataset. By applying Mixup (Yoon et al., 2021; Zhang et al., 2017) within each batch in clients, mashed ego-graphs are generated, which are later sent to the server and form the global dataset. In the server, the ability of the global model to deal with non-IID graph data is developed by training over the uploaded mashed ego-graphs. The mashed ego-graphs, which contain only the mashed embedding and local structure, prevent the transmission of the raw data and protect privacy, and thus they are further feature-anonymous.
-
To address challenge 3, clients perform updates with the help of the global model. Clients will follow the vanilla algorithm of FedAvg (McMahan et al., 2017) in reduction layers to reach a consensus in encrypting the ego-graphs, and then mix the local and global weights in personalization layers according to an adaptive mixing coefficient. The mixing coefficient, which contributes to achieving better personalization for each client, is adaptively determined by the the difference between the distribution of local and global datasets.
We validate FedEgo on the real-world datasets in non-IID settings to better simulate the application scenarios. Experimental results show that FedEgo significantly outperforms baselines, which fully verifies the effectiveness of FedEgo. We summarized our main contribution as follows.
-
We introduce a novel personalized federated graph learning framework based on ego-graphs. FedEgo makes full use of structure information of graph data by applying GraphSAGE over ego-graphs.
-
We apply Mixup over ego-graphs for privacy concerns and develop the global model’s ability to capture structural information and deal with the non-IID graph data by training over the uploaded mashed ego-graphs.
-
We design a strategy to adaptively learn a personalized model for a trade-off between the benefit and disadvantage of the collaboration.
-
We conduct extensive experiments on widely used datasets and empirically demonstrate the superior performance of FedEgo under non-IID scenarios.
2. Related Work
2.1. Federated Learning on Graphs
Recently, federated learning on graphs have raised great interest and several federated graph frameworks have been proposed by leveraging the power of federated learning and graph neural networks (Chen et al., 2021; Zhang et al., 2021; He et al., 2021; Wang et al., 2020; Xie et al., 2021; Pei et al., 2021). GraphFL (Wang et al., 2020) is a model-agnostic meta learning approach designed for few-shot learning and D-FedGNN (Pei et al., 2021) is a distributed federated graph framework which allows collaboration among clients without a centralized server. FedSage+ (Zhang et al., 2021), which trains a missing neighbor generator to recover the missing edges cross clients, mainly targets distributed subgraph systems that are not very common in practice. FedGL (Chen et al., 2021) uploads the prediction results and embeddings for global information of nodes and FedGCN (Yao and Joe-Wong, 2022) exchanges average information about the node’s neighbors among clients. Both of them suffer from severe privacy problems since others know whether a specific node is in a certain client’s local dataset. FedEgo, by contrast, preserves privacy for node classification tasks in a realistic setting by keeping the data anonymous in terms of structure and feature.
2.2. Personalized Federated learning
Personalization in federated learning has attracted much attention and has been widely explored in recent approaches (Arivazhagan et al., 2019; Jiang et al., 2019; Deng et al., 2020; Hanzely and Richtárik, 2020; Mansour et al., 2020). (Arivazhagan et al., 2019) proposes a neural network with base layers for federated averaging and personalization layers for personalization. (Collins et al., 2021) is a further extension of (Arivazhagan et al., 2019) and obtains low-dimensional embedding which accelerates the convergence speed of the training process. Some other works (Jiang et al., 2019; Chen et al., 2018) borrow ideas from MAML and (Jiang et al., 2019) considers federated learning as an instance of MAML. Moreover, (Wang et al., 2020) introduces MAML into federated graph learning framework and designs GraphFl for few-shot learning. Furthermore, it is proved effective to improve the performance of the personalized model by using a mixture of global model and local model (Deng et al., 2020; Mansour et al., 2020), multi-task learning (Smith et al., 2017) and adding proximal terms to perform local fine-tuning (Hanzely and Richtárik, 2020). Different from existing work, herein we discuss how to achieve better personalization based on the difference of local and global distributions with theoretical justification.
3. Preliminaries
3.1. Ego-Graph
Let be a graph with nodes, where denotes the node set and denotes the edge set. Following (Bai and Hancock, 2016; Zhu et al., 2020), we have the definition of a -hop ego-graph.
Definition 3.1.
(-hop ego-graph). A graph is called a -hop ego-graph centered at node if it has a -layer centroid expansion such that the greatest shortest path rooted from has length , i.e., , where is the shortest path from to and denotes the length of the path.
Given , a depth-based representation of the graph can be described as a family of ego-graphs (Bai and Hancock, 2016; Zhu et al., 2020). The label of each node is retained in the ego-graph, which is represented as a one-hot vector. As useful information carriers, ego-graphs will be sampled in each client for the training in FedEgo. In practice, we follow the method in GraphSAGE (Hamilton et al., 2017) and sample a fixed-size set of neighbors in each layer for the nodes. Note that the sampled ego-graphs will be in a fixed shape and can be trained independently of the original graph.
When training with the family of ego-graphs, we do not concern about the concrete information in the original graph but only the local property. In this sense, there is no way of knowing where the center node is located in the original graph and one could not restore the original graph through the sampled ego-graphs. Therefore, the sampled ego-graphs are structure-anonymous.
3.2. GraphSAGE
GraphSAGE (Hamilton et al., 2017) is a method applicable to inductive graph learning, with which we could enable the information flow in ego-graphs. It focus on the local property of the target node and aggregates feature from the neighborhood to obtain embedding for downstream tasks. Let denotes the embedding of node in the layer and the convolution layer with a mean aggregator can be defined as
| (1) |
with as the weight matrix and as the 1-hop neighbors of . In paricular, denotes the input features. For supervised node classification tasks, we use cross-entropy as the loss function. Let denotes the node samples with feature and label, be the map function from feature space to the label space , be the indicator function of label , be the weight in the whole model. Then the cross-entropy loss could be formulated as
| (2) |
where represents the probability vector of data distribution and . The distribution vector can be further obtained by following formula.
| (3) |
where is the one-hot vector of label and is the number of nodes.
3.3. Federated Learning
In federated learning, the main objective is to learn a global model by clients’ collaboration and a typical implementation is FedAvg (McMahan et al., 2017). In FedAvg, clients perform local updates and global averages iteratively and finally learn a global model. Formally, we assume that there are clients with as the local weight of client . In a training epoch, the server first broadcasts the latest global weight to all the clients. Subsequently, clients load the weight and then perform local updates several times:
| (4) |
After that, the server averages the uploaded local parameters and obtain the new global model:
| (5) |
The process is repeated for convergence and a global model is learned for prediction. FedAvg aggregates information from models whereas it ignores the difference between clients. Previous works show that it may perform poorly when it comes to severe non-IID situation (Xie et al., 2021).
3.4. Mixup
Mixup (Zhang et al., 2017) is a data augmentation technique that apply linear combination over data samples to generate additional data. In the federated framework, Yoon et al. (Yoon et al., 2021) propose FedMix and apply Mixup over samples within each batch. Formally, given a batch of data samples , FedMix constructs augmented data sample by averaging features and labels:
| (6) |

4. Proposed method: FedEgo
In FedEgo, we expect the server to be capable of capturing both structural and feature information of non-IID graph data from clients. And then with the help of the global model, clients update their local model for better personalization. To this end, there are different network architectures between clients and the server. Specifically, a client’s local model consists of reduction layers and personalization layers, whereas there are only personalized layers in the server. Reduction layers are designed to exploit shared low-dimensional embeddings among clients while personalization layers are used for personalized graph mining. To extend GraphSAGE over the ego-graphs, we follow (Hamilton et al., 2017) and sample a fixed-size set of neighbors for each given node. And then the training of FedEgo can be mainly divided into local stage and global stage. (1) In the Local Stage, clients feed their local ego-graphs into reduction layers and obtain the low-dimensional embedding. Subsequently, Mixup is applied over ego-graphs to generate mashed ego-graph within each batch. Then the embedding obtained from reduction layers will be further fed into personalization layers. Eventually, each client calculates the loss and updates the parameters in reduction layers and personalization layers. (2) In the Global Stage, clients upload parameters in reduction layers and the mashed ego-graphs to the server for collaboration. The server aggregates the parameters by applying FedAvg algorithm and updates the global personalization layers by training over the mashed ego-graphs. After that, all the parameters are sent back to clients. Clients will then load the reduction layers and update their personalization layers by mixing the local and global weight. The framework of FedEgo is illustrated in Fig. 3 and Algorithm 1 demonstrates the training process.
4.1. Local Stage
4.1.1. Reduction Layers: Multi-Layer Perception
In the federated framework, data distribution between clients is in a severe non-IID situation, which gives rise to the difficulty to train a central model. However, these heterogeneous data may share a common representation despite having various labels (Collins et al., 2021) and hence reduction layers are proposed to capture the common low-dimensional embeddings across clients, as shown in the green part of Fig. 3. And the embedding obtained by reduction layers, which we term reduction embedding, may facilitate subsequent calculations while also protecting data privacy due to the reduction of dimensionality. Besides, it has been observed that deeply stacking the layers often results in significantly worse performance for GNNs, which is called over-smoothing (Cai and Wang, 2020). To avoid such a problem, herein we dig out the reduction embedding using a multi-layer perception since 2-layer GNN will be applied in personalization layers for graph mining. Formally, consider as the -dimension raw feature of node and a layers perception, the hidden embedding can be calculated as:
| (7) |
where and is the weight and the bias of layer respectively, is the activation function and represents the hidden embedding of node obtained by layer . Specifically, we take the raw feature as input of the reduction layers and we have . The final embedding is regarded as the reduction embedding. For convenience, we term the whole reduction layers as .
4.1.2. Mashed Ego-graphs: Mixup within Each Batch
In FedEgo, clients will generate mashed ego-graphs for the training of the global model and further send them to the server rather than raw data. All mashed ego-graphs uploaded are structure-anonymous, which means that the server has no way of knowing the structure of the original graphs and whether a specific node exists in the local dataset of a certain client. The mashed ego-graphs are in the same shape as the ego-graphs and can be obtained by mixing up the reduction embedding of ego-graphs within each batch. As a popular data augmentation technique for traditional data, Mixup, however, is not directly applicable to graph data because of the alignment problem. The feature matrices of traditional data samples share the same dimension and can be used for element-wise operations while the irregularity of structures in graph data limits the element-wise calculation and various ways to mix up may give rise to different impacts on the training.
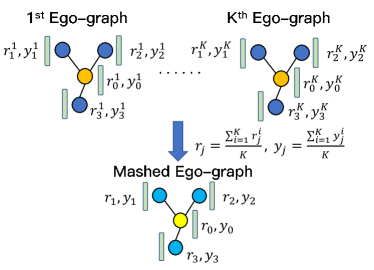
Mixup, on the other hand, is relatively easy to be applied over ego-graphs in the fixed shape. The number of -hop neighbors in such ego-graphs is only determined by and the size of the neighbors set . For convenience, we sort the nodes based on its layer to assign each node a specific position and obtain the position sets in the -th layers, i.e., , , and so on. The node in a specific position connects to its corresponding neighbors in the next layer. For example, the neighbors of node in the second layer can be represented as . The position within the same layer can be assigned arbitrarily as long as the special connectivity between layers is maintained. To apply Mixup over ego-graphs, we could first align the center nodes, i.e., the node of all the ego-graphs within a batch together and then recursively extend their neighbors to assign each node a specific position in its corresponding layer. Then the embedding of each position in the mashed ego-graph can be obtained by simply averaging the embedding of the corresponding nodes according to the alignment, which is illustrated in Fig 2b. Formally, given the embedding and the one-hot label of the -th position in the -th ego-graphs and according to the alignment, we obtain the mashed embedding as well as the label of the nodes in the mashed ego-graphs.
| (8) |
The mashed ego-graphs average the reduction embedding to prevent privacy leakage, making them feature-anonymous in addition to structure-anonymous. Besides, there are lots of ways to align ego-graphs though, all of them have the same effect on a specific GNN model according to Theorem 4.1.
Theorem 4.1.
Mashed ego-graphs generated from all sorts of alignments are equivalent for the training of linear GraphSAGE layers without activation functions. If there are two different alignments and , the final embedding of the center node after aggregation under alignment and will be the same.
The detailed proof of Theorem 4.1 is provided in Appendix. As Theorem 4.1 shows, linear GraphSAGE layers avoid the impact that different alignments bring, and hence they could be used as the personalization layers without incuring bias. However, the unbiased estimate of the embedding may not always guarantee better performance when dealing with complex scenarios, such as the distribution of highly non-IID data among clients. Due to the high statistical heterogeneity, activation function may be preferable in the personalization layers since it empowers the model’s ability to learn complex patterns while also introduces bias that will alleviate the severe non-IID issues. In developments test we found a slight improvement of GraphSAGE with activation over the linear one and thus focus on the former for the rest of our experiments.
4.1.3. Personalization Layers: GraphSAGE over Ego-graphs and Classification
Once obtained the reduction embedding, we further feed the ego-graph into linear GraphSAGE layers to forward implement graph mining, as can be seen in the pink part of Fig. 3. Formally, we have the personalization layers
| (9) |
where represents the hidden embedding of node obtained by layer . And we have , i.e., using the reduction embedding as input. Moreover, it is worth noting that we use linear GraphSAGE layers without activation functions between them. After that, predictions are generated by a subsequent linear classifier with a softmax function, and the loss is calculated eventually. For convenience, we term the whole personalization layer as .
4.2. Global Stage
4.2.1. Global training
In the global stage, the server trains a global model over the mashed ego-graphs uploaded by clients and updates the parameters in the global model. There exist the same personalization layers in the server as in clients and we have GNN layers defined like Eq. (9) with a classifier in the global model.
| (10) |
where denotes the -th layer global personalization layers weight.
When considering the commnication cost, another variant of FedEgo is to replace the reduction layers with GNN and the personalization layers with MLP. An incentive in this variant is that clients simply need to upload their reduction embedding of the center nodes instead of the structure in the mashed ego-graphs. However, the information flow of topological structure is implicit in the form of the reduction embedding, making it rather challenging for the server to train especially in the case of highly non-IID data. Averaging the GNN parameters in the reduction layers may also be inappropriate since different data distribution among clients contributes to various node connection patterns. Consequently, clients will receive limited or even negative help because of the poor collaboration.
When using the GNN layers as the personalization layers, the generalization ability of the global model is obviously better than any local one because of the access to the encrypted data among all clients. After that, clients perform the following updates to enhance the performance of their local models.
4.2.2. Averaging in Reduction Layers
Aiming at exploiting shared representations among clients, the parameters in reduction layers are updated by coordinate-wise weight averaging. Formally, we have the following update in reduction layers.
| (11) |
| (12) |
where represents the reduction layers in client and denotes avgeraged one. With the update in reduction layers, clients reach a consensus to some degree even if graph data from their datasets are potentially non-IID. In other words, clients encrypt their raw data in the same way and project their data into a low-dimensional space.
4.2.3. Mixing in Personalization Layers
When updating parameters in personalization layers, clients will mix local and global weight to achieve the trade-off of advantages and drawbacks of the global model. Given a mixing coefficient for client , we update the personalization layers as follows.
| (13) |
where represents the personalization layers in client and denotes global one. Intuitively, the strategy to select mixing coefficient hinges on the diversity between local and global distributions. With great diversity, the mixing coefficient is expected to be large in that the client tends to gain more from the global model to correct its deviations and reduce the local generalization error. Otherwise, needs to be small for better personalization of the local model.
4.2.4. Adaptive Mixing Coefficient for Each Client
It is obvious that a fixed is inappropriate for all the clients due to the potential statistical heterogeneity. We further propose an adaptive strategy to select with theoretical analysis, thereby adjusting for each client to achieve better personalization. For convenience, we termed the model weights in clients and the server as local and global weight, respectively. First, following (Zhao et al., 2018), a metric is designed in Definition 4.2 to measure the distance between local and global weights. We only analyze the personalization layers here since the reduction layers are frozen by averaging. Then we bound the weight divergence in Theorem 4.3.
Definition 4.2.
Let denotes the local weight in personalization layers on client , denotes the global one, then the weight divergence is defined as the distance between local and global weight: .
Theorem 4.3.
Given clients with samples of nodes drawn i.i.d from local data distribution for client and the global data distribution . Let train epochs for clients and server be the same . Consider the update in personalization layers as a separate step and it is conducted every steps. The local weight of client and the global weight in the -th step of the -th epoch are denoted as and , respectively. Let is -Lipschitz for each class and the mixing coefficient , then the bound of weight divergence after -th update is formulated as follows.
where .
The proof is provided in Appendix B. The second part on the right side includes the difference between the distribution of local and global datasets that is mainly reflected in , which is termed as earth mover distance (). EMD is correlated with and thus we can fine-tune to affect the impact of EMD and optimize the weight divergence. When the difference of local and global distribution is large (larger ), a larger should be selected to pull the client closer to the global model. Otherwise, should be small to fully achieve the personalization. Both the local distribution vector and the global one can be calculated by Eq. (3) even though there are only averaged data in the server. Then we can obtain of client .
| (14) |
We further provide a formula to adaptively select by introducing a hyperparameter in Eq. (15). It ensures to be negative correlated with and varies from 0 to 1 with increases within its range.
| (15) |
5. Experiment
5.1. Datasets and experimental settings
We conduct our experiments on four real datasets: Cora (Sen et al., 2008), Citeseer (Sen et al., 2008), CoraFull (Bojchevski and Günnemann, 2017), and Wiki (Mernyei and Cangea, 2020). Table 1 shows the details of the datasets and the relevant settings. In our experiments, we construct a local dataset for each client and a global dataset for final test, which are used for verifying the personalization and the generalization ability of the model, respectively. We first sample nodes for global testing and delete them from the original dataset, leaving the remaining nodes for clients’ local dataset. To construct a label distribution skew scenario, the nodes are divided into different sets depending on their labels. Then each client randomly selects 3 labels as its major node labels and sample nodes from the corresponding sets to compose nodes in its local dataset. Random unselected nodes will be added as the remaining nodes. In each client, 300 nodes are sampled for testing and 20% nodes for validating, leaving other nodes for training. We choose 2 hop neighbors for each node and set the number of neighbors to be 6 when sampling ego-graphs.
| Dataset | —V— | —E— | #C | N | |||
|---|---|---|---|---|---|---|---|
| Cora | 2708 | 5429 | 7 | 5 | 0.3 | 0.3 | 0.01 |
| Citeseer | 3312 | 4715 | 6 | 5 | 0.3 | 0.3 | 0.01 |
| Wiki | 17716 | 52867 | 4 | 10 | 0.3 | 0.2 | 0.0003 |
| CoraFull | 19793 | 63421 | 70 | 10 | 0.3 | 0.3 | 0.01 |
5.2. Comparison Methods
We compare FedEgo with the following methods:
-
Local Only: In this method, each client trains its model by feeding local data independently.
-
FedAvg: FedAvg (McMahan et al., 2017) applies the averaging method over the weight parameters to obtain a global model. It is a simple but effective way to cope with the non-IID scenario. In this method, the parameters are averaged in both the reductions and the personalization layers.
-
FedProx: FedProx (Li et al., 2020) tackles data heterogeneity by adding a proximal term to the loss. We apply the adaptive FedProx loss coefficient in [0.001,0.01, 0.1,1] based on the fluctuation of the loss.
-
GraphFL: GraphFL (Wang et al., 2020) is a method designed for few-shot learning based on model-agnostic meta-learning (MAML) and addresses the problem of non-IID graph data between clients. We follow the original setting in (Wang et al., 2020) and use 100 nodes for both the support and query set in GraphFL.
-
D-FedGNN: D-FedGNN (Pei et al., 2021) is a distributed federated graph framework based on the weighted communication topology among clients. We follow the setting in (Pei et al., 2021) and use the standard ring network for aggregation.
-
FedGCN: In FedGCN (Yao and Joe-Wong, 2022), clients communicate with each other to exchange average information about the node’s neighbors. It suffers from severe privacy problems since others know the nodes in a certain client’s local dataset. We follow the original setting in (Yao and Joe-Wong, 2022) and 2 GCN layers for FedGCN.
The models are in the same structure with 1 layer MLP as the reduction layers, 2 layers GraphSAGE with activation function as the personalization layers followed by 1 fully connected layer as the classifier. We choose Relu as the activation function, and Adam as the optimizer. Besides, the amount of the mashed ego-graphs and the additional communication cost are both strongly influenced by batch size, which is preferred to be 32 based on development test observations 5.7. During the clients’ training, nodes will be trained in 5 mini-batches for epochs each round. In FedEgo, the server will utilize ego-graphs uploaded by clients for training for epochs each round. We execute all experiments 4 times and the averaged results are reported 111Code available at https://github.com/FedEgo/FedEgo.
5.3. Overall Perforamance
5.3.1. Personalization ability
The F1 score in the local test given in Table 3 illustrates the personalization ability of each method under severe non-IID scenarios. It is a clear finding that the result in the local test is much higher compared to the global test, primarily because of the same distribution of the testing and training data. Furthermore, FedEgo, FedAvg, FedProx, and D-FedGNN benefit from the collaboration on all datasets and enhance the personalization ability of local models. D-FedGNN performs better than FedAvg since the average merely with local neighbors mitigates the issues of non-IID to some degree. For FedEgo, there is only a slight performance improvement than FedAvg, which is caused by the label skew scenario and the information from others only compensates for a client’s training to a limited extent. Interestingly, GraphFL performs worse than other FL methods in all cases, owing to the fact that it is designed for few-shot learning and does not extract enough useful information under the severe label distribution skew scenario. Similarly, FedGCN is not suitable for non-IID scenarios and is no match for the local training when it comes to enormous data, as the results on Wiki and CoraFull demonstrate.
5.3.2. Generalization ability
As can be seen from the result in Table 2, the most striking observation emerging from the comparison is that FedEgo consistently outperforms other methods and improves the generalization ability of clients’ local models. With the update in reduction and personalization layers, clients gain about 11%-15% improvement in performance than local training. The remarkable improvement indicates that FedEgo is able to accomplish the collaboration of clients and tackle the non-IID graph data.
Similar to FedProx, FedAvg provides a boost to some amount, whereas it still falls short of FedEgo. Clients benefit from collaboration in the reduction and personalization layers, as evidenced by the gap between FedAvg and local training. Besides, D-FedGNN performs slightly better than FedAvg due to its unique aggregation. Compared to FedAvg, FedEgo is a personalized pattern rather than averaging updates in personalization layers. FedEgo significantly exceeds FedAvg and D-FedGNN, implying that a mixture of the local and global models is far superior to a naive average in the severe non-IID scenario. As for GraphFL and FedGCN, they suffer from the same issue as mentioned above and perform poorly in all cases.
| Dataset | Local Only | FedAvg | FedProx | GraphFL | D-FedGNN | FedGCN | FedEgo |
|---|---|---|---|---|---|---|---|
| Cora | 0.691 | 0.769 | 0.77 | 0.739 | 0.776 | 0.681 | 0.794 |
| Citeseer | 0.634 | 0.701 | 0.701 | 0.649 | 0.712 | 0.655 | 0.727 |
| Wiki | 0.7 | 0.785 | 0.784 | 0.677 | 0.795 | 0.439 | 0.818 |
| CoraFull | 0.501 | 0.544 | 0.549 | 0.35 | 0.576 | 0.486 | 0.653 |
| Dataset | Local Only | FedAvg | FedProx | GraphFL | D-FedGNN | FedGCN | FedEgo |
|---|---|---|---|---|---|---|---|
| Cora | 0.851 | 0.952 | 0.954 | 0.861 | 0.954 | 0.884 | 0.959 |
| Citeseer | 0.757 | 0.917 | 0.915 | 0.766 | 0.917 | 0.894 | 0.920 |
| Wiki | 0.874 | 0.922 | 0.924 | 0.789 | 0.915 | 0.819 | 0.926 |
| CoraFull | 0.639 | 0.874 | 0.875 | 0.479 | 0.883 | 0.838 | 0.901 |
5.4. The Effort of Statistical Heterogeneity
The performance of FedAvg and FedEgo is heavily influenced by the statistical heterogeneity among clients that is controlled by the major node rate. With a larger major node rate, clients tend to have more nodes in the same classes, leading to a higher statistical heterogeneity. According to this, we vary the major node rate and provide the results in Table 4. Unsurprisingly, the generalization ability of both FedEgo and FedAvg reduces as the major node rate becomes larger. Perhaps more surprisingly, the increase in major node rate improves the personalization ability to some level. In this case, more nodes in the local dataset will share the same labels and the pattern of interconnections between nodes becomes relatively constant and easy to learn.
| Global Test | Local Test | |||||
|---|---|---|---|---|---|---|
| Major Node Rate | 0.0 | 0.3 | 0.8 | 0.0 | 0.3 | 0.8 |
| FedAvg | 0.803 | 0.800 | 0.785 | 0.907 | 0.906 | 0.922 |
| FedEgo | 0.823 | 0.826 | 0.818 | 0.903 | 0.907 | 0.926 |
5.5. Ablation Study
To verify the effectiveness of Mixup, we undertake a comparison method called FedEgo w/o Mixup wherein clients upload the first ego-graph within a batch to the server rather than the mashed ego-graphs. Note that it is not feasible to do so in real scenarios since the transmission of raw ego-graphs may result in the risk of privacy leakage. We also compare FedEgo with its linear variant, denoted as FedEgo-Linear, in order to evaluate the impact of the activation function in the personalization layers. FedEgo-Linear guarantees unbiased estimate of the center nodes’ embedding, whereas FedEgo applies activation function to learn more complex patterns in the data.
As the result in Table 5 indicates, Mixup improves both the generalization ability and personalization ability of the model while preserving privacy. The reason is that the graph data among clients are severely non-IID and the virtual samples generated by Mixup can be considered as the clients’ exploration of the unknown distribution in the real world dataset, thereby improving the robustness of the model. By comparing FedEgo with FedEgo w/o Mixup, we can also infer that structural information are still highly retained in the mashed ego-graphs after Mixup is applied. The averaging operation in Mixup extracts essential part of the structural information, which facilitates the training in the server and results in better performance of the model. Further, we observe that the performance marginally decreases without activation function in the personalization layers, which indicates that the model does not necessarily suffer from the bias introduced by the activation function, paricularly in the case of extremely non-IID scenario.
| Global Test | Local Test | |||
| Dataset | Cora | Citeseer | Cora | Citeseer |
| FedEgo w/o Mixup | 0.783 | 0.717 | 0.951 | 0.912 |
| FedEgo-Linear | 0.793 | 0.717 | 0.958 | 0.918 |
| FedEgo | 0.794 | 0.727 | 0.959 | 0.920 |
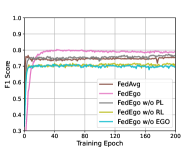
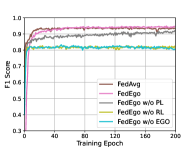
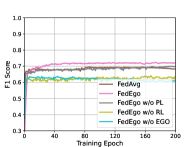
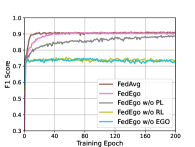
To further figure out whether it is worthwhile to build ego-graphs and verify the effectiveness of reduction layers and personalization layers, we compare FedEgo with three ablation methods: (1) FedEgo w/o EGO: In this method, we replace the reduction layers with GNN and the personalizationn layers with MLP. In this case, graph mining is performed locally and only the reduction embedding need to be uploaded rather than the explict structure of the mashed ego-graphs. (2) FedEgo w/o RL: In this method, clients will only update their personalization layers without performing the averaging updates in reduction layers. In this case, clients will encrypt the graph data in various ways, making it difficult to train the global model in the server. (3) FedEgo w/o PL: In this method, clients will only update their reduction layers without performing the mixing update in personalization layers. In this case, clients will not receive the help of the global model but only benefit from averaging update in reduction layers. Moreover, we also include FedAvg since FedAvg is an averaging version of Fedego w/o PL compared to FedEgo.
The poor performance of FedEgo w/o EGO, as can be seen from Fig. 4, demonstrates the necessity to upload mashed ego-graphs for structural information flow in the federated framework. Without the mashed ego-grpahs, it is rather difficult for the server to capture the structural information solely from the reduction embedding and further provide proper help for clients. Moreover, it is evidently clear that reduction layers play a more important part in enhancing the performance. Unsurprisingly, the removal of the averaging update in reduction layers hinders clients from encrypting the ego-graphs in the same way, and the mashed ego-graphs uploaded may be even harmful to the global model in early training. Besides, there is still a significant difference between FedEgo w/o PL and FedEgo, demonstrating the effectiveness of mixing updates in personalization layers. In the case of FedAvg, it requires the lowest convergence time due to its simple aggregation pattern. The slight gap between FedAvg and FedEgo w/o PL verifies the benefit brought by the averaging update in personalization layers, whereas the performance of FedAvg begins to decline after around 15 epochs before stabilizing in the global test. In the local test, however, the F1 score of FedAvg continues to increase until the end. As a result, FedAvg is inclined to improve clients’ personalization ability at the expense of generalization ability. And finally, the observed difference between FedAvg and FedEgo in the local test is limited while there is a large gap in the global test, as we have discussed before.
5.6. Parameter Study
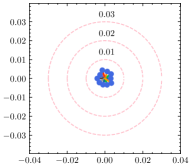
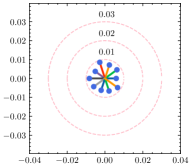
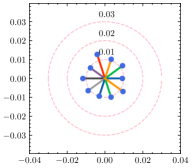
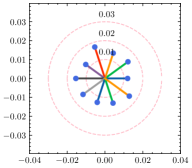
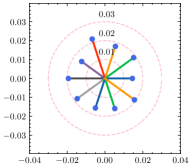
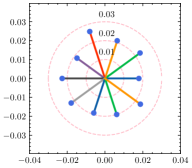
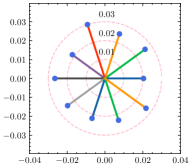
To have a better understanding of the hyperparameter , we estimate the weight divergence of each client with the varying . As shown in Fig. 5, the global weight is fixed at the center of the circle while scattered points represent the local weight of clients, and the distance to the center indicates the weight divergence. Circles with the same center but different radii are also plotted for reference. As we can see from the result, the weight divergence is affected by and becomes larger as increases. According to Eq. (15), is negatively correlated with , and thus the weight divergence increases as decreases, which is plausible support of Theorem 4.1. In addition to the visualization of weight divergence, we provide the F1 score over different values of in Table 6. With a fine-tuned , the adaptive strategy is capable of discovering the best for each client. Note that the optimal for the generalization ability and the personalization ability are not always the same due to the statistical heterogeneity. With a relatively large deviation from the global ground-truth, reducing clients’ generalization error will likely degrade their performance in the local dataset.
5.7. Communication Cost Analysis over Batch Size
In FedEgo, clients upload not only the parameters but also the mashed ego-graphs with reduction embedding, and hence whether the additional communication cost is affordable is an significant issue. A key factor that affects the communication cost and the quality of the mashed ego-graph is the batch size. With a low batch size, more mashed ego-graphs result in a larger communication cost, and more sensitive information of original data will pass over, yielding the problem of privacy leakage. However, in the other extreme, a large batch size leads to a significant amount of information loss. Based on the analysis above, appropriate batch size is exactly a tradeoff of privacy protection and client collaboration. Therefore, we conduct extensive experiments and evaluate the communication cost in terms of megabytes (MB). The results are provided under various batch sizes in Table 7.
The fact that smaller batches lead to higher performance and larger communication cost stands out in the results. The high quality of the uploaded mashed ego-graphs contributes to the improvement, while the communication cost and training over more data make the training time longer. The improvement of reducing batch size decreases as the batch size becomes smaller while the communication overhead, on the other hand, will be doubled due to more batches in the local training. Furthermore, a smaller batch size fails to meet the need for privacy protection. Therefore, we believe that selecting 32 as the batch size is a fair tradeoff based on the results. Additionally, the weight parameters mainly account for the communication cost with such an proper batch size, and it is acceptable to promote the performance at the expense of the additional cost.
| 0.125 | 0.25 | 0.375 | 0.5 | 0.625 | 0.75 | 0.875 | |
|---|---|---|---|---|---|---|---|
| Local Test | 0.899 | 0.901 | 0.9 | 0.901 | 0.899 | 0.902 | 0.899 |
| Global Test | 0.652 | 0.653 | 0.648 | 0.649 | 0.649 | 0.648 | 0.646 |
| Cora | Citeseer | |||||||||||
| FedAvg | FedEgo | FedAvg | FedEgo | |||||||||
| Batch Size | 32 | 8 | 16 | 32 | 64 | 128 | 32 | 8 | 16 | 32 | 64 | 128 |
| Global Test | 0.769 | 0.797 | 0.794 | 0.793 | 0.792 | 0.764 | 0.701 | 0.724 | 0.724 | 0.725 | 0.72 | 0.711 |
| Local Test | 0.952 | 0.958 | 0.959 | 0.958 | 0.955 | 0.945 | 0.917 | 0.92 | 0.919 | 0.918 | 0.918 | 0.917 |
| Time (mins) | 10.190 | 57.674 | 38.775 | 20.661 | 15.6 | 10.201 | 11.679 | 90.539 | 41.525 | 32.742 | 13.89 | 6.307 |
| Ego-graphs Cost (MB) | 0 | 6071 | 3055 | 1545 | 790 | 425 | 0 | 6895 | 3477 | 1769 | 899 | 471 |
| Parameters Cost (MB) | 6819 | 2801 | 2801 | 2801 | 2801 | 2801 | 11250 | 7234 | 7234 | 7234 | 7234 | 7234 |
| Total Cost (MB) | 6819 | 8872 | 5856 | 4346 | 3591 | 3226 | 11250 | 14129 | 10711 | 9003 | 8133 | 7705 |
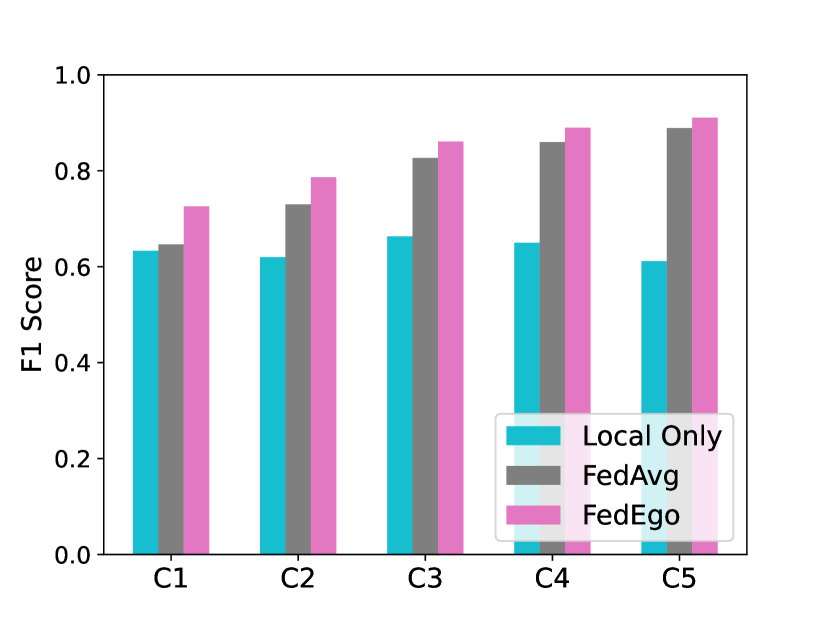
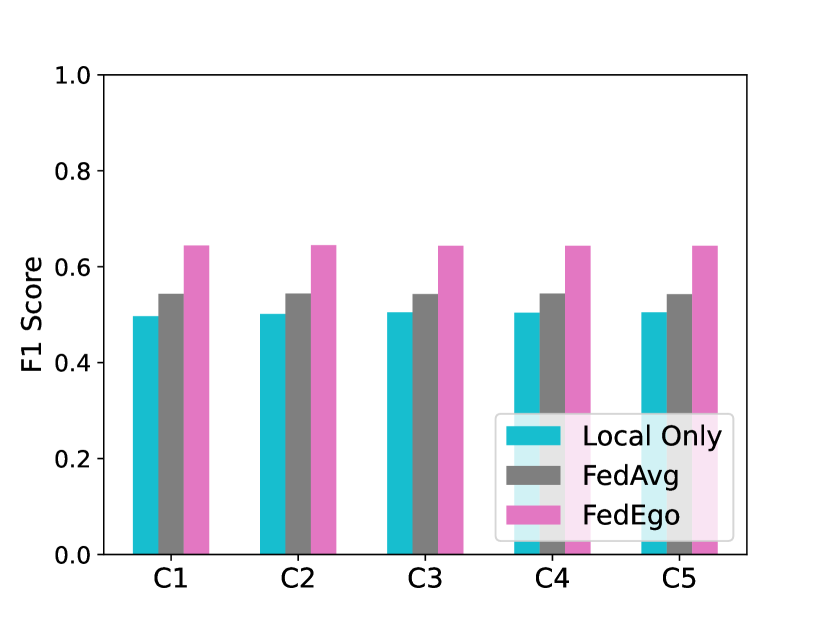
5.8. Improvements for each Client
To further explore how FedEgo improves the performance of a specific client, we provide the comparison results of each client in the local and the global test, as shown in Fig. 6. The results indicate that FedEgo enhances the generalization ability and the personalization ability of all the clients. Compared to FedAvg, FedEgo offers more substantial benefits for clients. Moreover, the performance of clients in the global test is relatively stable, even though the graph data are severe non-IID among clients. The stable and significant improvement in performance demonstrates the effect of FedEgo.
| Number of Clients | 5 | 10 | 15 | 20 | 25 | 30 | 35 |
|---|---|---|---|---|---|---|---|
| Local Test | 0.9261 | 0.9256 | 0.9245 | 0.9255 | 0.9254 | 0.9237 | 0.9247 |
| Global Test | 0.8179 | 0.8187 | 0.8175 | 0.8174 | 0.8169 | 0.8158 | 0.8157 |
5.9. Effort of Client Participation
In a real scenario, more clients in participation bring more information and data which may have a potential impact on the statistical heterogeneity. Therefore, we study the influence of client participation on FedEgo in this experiment. In particular, we select 5, 10, 15, 20, 30 and 35 clients to participate in each round on Wiki and the experimental results are reported in Table. 8. The personalization ability mainly depends on the client’s own dataset and thus slightly drops with an increase in clients due to the introduced bias. As for generalization ability, the global model will have capability to collect more graph data to better fit the real dataset and further develop the generalization ability with more clients participating. This is especially the case when the number of clients is small. However, with a large number of clients, the benefit of introducing new clients diminishes, and the training time increases. Redundant clients might not boost the model performance after there are enough clients is sufficient and the data is no longer in short supply.
| Global Test | Local Test | |||
|---|---|---|---|---|
| Dataset | Cora | CoraFull | Cora | CoraFull |
| FedEgo w/o PL (Fixed ) | 0.7705 | 0.6173 | 0.9345 | 0.8488 |
| FedEgo (Fixed ) | 0.7843 | 0.6437 | 0.9585 | 0.9005 |
| FedEgo-Server (Fixed ) | 0.7921 | 0.6418 | 0.9535 | 0.8985 |
| FedEgo (Adaptive ) | 0.7939 | 0.6442 | 0.959 | 0.9012 |
5.10. Benefit of Adaptive Mixing Coefficient
We further conduct additional experiments on Cora and CoraFull to verify whether FedEgo benefits from the adaptive mixing coefficient . We compare adaptive with the following methods: (1) FedEgo w/o PL: As mentioned before, in this method clients would not performing the mixing update in the personalization layers. Thus, it can be considered as a variant when is fixed to be 0. (2) FedEgo (Fixed ): In this method, we fixed to be 0.5 when performing the mixing update in the personalization layers. (3) FedEgo-Server: In this method, clients entirely replace the personalization layers with the weight in the server for graph mining. Thus, it can be considered as a variant when is fixed to be 1.
As can be seen from Table 9, adaptive brings promotion for clients’ performance to some extent. In the fixed pattern, FedEgo w/o PL has the worst performance without help of the global model. In the other extreme, FedEgo-Server inferior to FedEgo with adaptive due to the absence of the personalization. With regard to the compromise strategy, however, the fixed may be too small for some clients with larger but too large for those with smaller , preventing clients from achieving better performance. By contrast, the adaptive allows clients to find their optimal level of participation in federated learning. With adaptive , clients perform better in the local test and achieve better personalization. Meanwhile, appropriate for each client also improves their F1 score in the global test, which indicates that the mixing coefficient in personalization layers has an significant influence on the generalization ability of the model.
5.11. Visulization
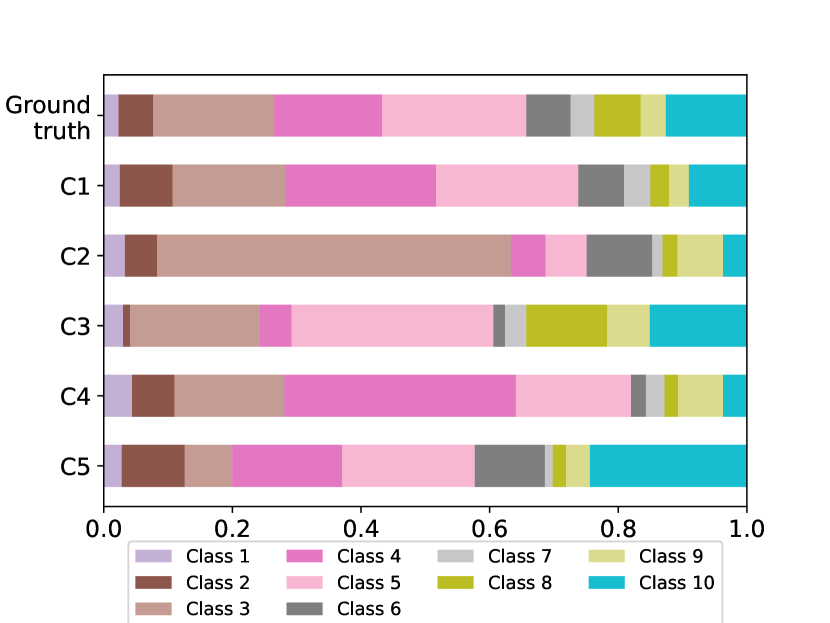
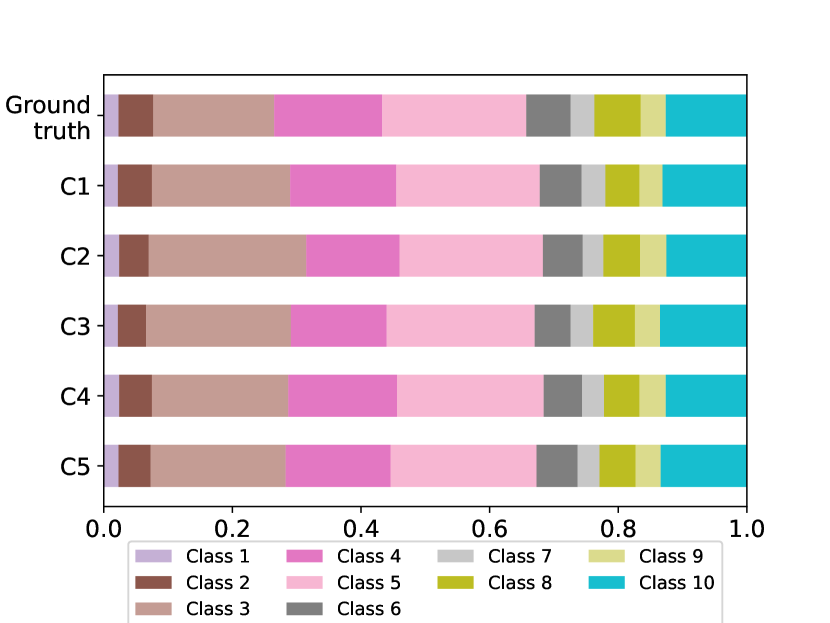
To comprehend how FedEgo improves the performance, we provide the original label distribution and the model prediction of FedEgo. The distribution of 5 local biased and the global testing datasets are shown in Fig. 7a. Despite the fact that the graph data are severely non-IID, FedEgo enables clients to effectively extract useful information from their biased local datasets and establish collaboration. As a result, clients are capable of making relatively correct predictions following the global groud-truth, as shown in Fig. 7b.
6. Conclusion
In this paper, we study the personalized federated node classification task on graphs and discuss three main challenges in a realistic setting. The proposed ego-graph-based federated framework FedEgo makes full use of structural information and tackles non-IID graph data by training a global model in the server. Moreover, clients adapt the global model to its local dataset by mixing the local and global weights. Besides, the Mixup technique is also applied for model robustness and privacy concern. Eventually, FedEgo outperforms baselines significantly with empirical evidence, showing its ability to address the difficult challenges in federated graph learning. Similar to existing FL methods, future work needs to be done to deal with communication cost for FedEgo, desirably about efficient compression method of ego-graphs and model weight.
References
- (1)
- Arivazhagan et al. (2019) Manoj Ghuhan Arivazhagan, Vinay Aggarwal, Aaditya Kumar Singh, and Sunav Choudhary. 2019. Federated learning with personalization layers. arXiv preprint arXiv:1912.00818 (2019).
- Bai and Hancock (2016) Lu Bai and Edwin R Hancock. 2016. Fast depth-based subgraph kernels for unattributed graphs. Pattern Recognition 50 (2016), 233–245.
- Bojchevski and Günnemann (2017) Aleksandar Bojchevski and Stephan Günnemann. 2017. Deep gaussian embedding of graphs: Unsupervised inductive learning via ranking. arXiv preprint arXiv:1707.03815 (2017).
- Cai and Wang (2020) Chen Cai and Yusu Wang. 2020. A note on over-smoothing for graph neural networks. arXiv preprint arXiv:2006.13318 (2020).
- Chen et al. (2021) Chuan Chen, Weibo Hu, Ziyue Xu, and Zibin Zheng. 2021. FedGL: federated graph learning framework with global self-supervision. arXiv preprint arXiv:2105.03170 (2021).
- Chen et al. (2018) Fei Chen, Mi Luo, Zhenhua Dong, Zhenguo Li, and Xiuqiang He. 2018. Federated meta-learning with fast convergence and efficient communication. arXiv preprint arXiv:1802.07876 (2018).
- Collins et al. (2021) Liam Collins, Hamed Hassani, Aryan Mokhtari, and Sanjay Shakkottai. 2021. Exploiting Shared Representations for Personalized Federated Learning. arXiv preprint arXiv:2102.07078 (2021).
- Deng et al. (2020) Yuyang Deng, Mohammad Mahdi Kamani, and Mehrdad Mahdavi. 2020. Adaptive personalized federated learning. arXiv preprint arXiv:2003.13461 (2020).
- Hamilton et al. (2017) Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems. 1024–1034.
- Hanzely and Richtárik (2020) Filip Hanzely and Peter Richtárik. 2020. Federated learning of a mixture of global and local models. arXiv preprint arXiv:2002.05516 (2020).
- He et al. (2021) Chaoyang He, Keshav Balasubramanian, Emir Ceyani, Carl Yang, Han Xie, Lichao Sun, Lifang He, Liangwei Yang, Philip S Yu, Yu Rong, et al. 2021. Fedgraphnn: A federated learning system and benchmark for graph neural networks. arXiv preprint arXiv:2104.07145 (2021).
- Jiang et al. (2019) Yihan Jiang, Jakub Konečnỳ, Keith Rush, and Sreeram Kannan. 2019. Improving federated learning personalization via model agnostic meta learning. arXiv preprint arXiv:1909.12488 (2019).
- Li et al. (2020) Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith. 2020. Federated optimization in heterogeneous networks. Proceedings of Machine Learning and Systems 2 (2020), 429–450.
- Mansour et al. (2020) Yishay Mansour, Mehryar Mohri, Jae Ro, and Ananda Theertha Suresh. 2020. Three approaches for personalization with applications to federated learning. arXiv preprint arXiv:2002.10619 (2020).
- McMahan et al. (2017) Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. 2017. Communication-efficient learning of deep networks from decentralized data. In Artificial Intelligence and Statistics. PMLR, 1273–1282.
- Mernyei and Cangea (2020) Péter Mernyei and Cătălina Cangea. 2020. Wiki-cs: A wikipedia-based benchmark for graph neural networks. arXiv preprint arXiv:2007.02901 (2020).
- Pei et al. (2021) Yang Pei, Renxin Mao, Yang Liu, Chaoran Chen, Shifeng Xu, Feng Qiang, and Blue Elephant Tech. 2021. Decentralized Federated Graph Neural Networks. In International Workshop on Federated and Transfer Learning for Data Sparsity and Confidentiality in Conjunction with IJCAI.
- Sen et al. (2008) Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. 2008. Collective classification in network data. AI magazine 29, 3 (2008), 93–93.
- Smith et al. (2017) Virginia Smith, Chao-Kai Chiang, Maziar Sanjabi, and Ameet Talwalkar. 2017. Federated multi-task learning. arXiv preprint arXiv:1705.10467 (2017).
- Wang et al. (2020) Binghui Wang, Ang Li, Hai Li, and Yiran Chen. 2020. Graphfl: A federated learning framework for semi-supervised node classification on graphs. arXiv preprint arXiv:2012.04187 (2020).
- Xie et al. (2021) Han Xie, Jing Ma, Li Xiong, and Carl Yang. 2021. Federated graph classification over non-iid graphs. Advances in Neural Information Processing Systems 34 (2021).
- Yao and Joe-Wong (2022) Yuhang Yao and Carlee Joe-Wong. 2022. FedGCN: Convergence and Communication Tradeoffs in Federated Training of Graph Convolutional Networks. arXiv preprint arXiv:2201.12433 (2022).
- Yoon et al. (2021) Tehrim Yoon, Sumin Shin, Sung Ju Hwang, and Eunho Yang. 2021. Fedmix: Approximation of mixup under mean augmented federated learning. arXiv preprint arXiv:2107.00233 (2021).
- Zhang et al. (2017) Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. 2017. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412 (2017).
- Zhang et al. (2021) Ke Zhang, Carl Yang, Xiaoxiao Li, Lichao Sun, and Siu Ming Yiu. 2021. Subgraph federated learning with missing neighbor generation. Advances in Neural Information Processing Systems 34 (2021).
- Zhao et al. (2018) Yue Zhao, Meng Li, Liangzhen Lai, Naveen Suda, Damon Civin, and Vikas Chandra. 2018. Federated learning with non-iid data. arXiv preprint arXiv:1806.00582 (2018).
- Zhu et al. (2020) Qi Zhu, Yidan Xu, Haonan Wang, Chao Zhang, Jiawei Han, and Carl Yang. 2020. Transfer learning of graph neural networks with ego-graph information maximization. arXiv preprint arXiv:2009.05204 (2020).
Appendix A Proof of Theorem 4.1
In this section, we provide the detailed proof of Theorem 4.1.
Proof.
Assume a batch of ego-graphs are in a fixed shape with hop neighbors and nodes in each layer extends neighbors. For convenience, we sort the nodes based on its layer to assign each node a specific position and obtain the position sets in the -th layers, i.e., , , and so on. The node in a specific position connects to its corresponding neighbors in the next layer. For example, the neighbors of node in the second layer can be represented as . The position of nodes within the same layer can be assigned arbitrarily as long as the special connectivity between layers is maintained. Then the sum of nodes’ embedding in a specific layer does not change for different alignment when generating mashed ego-graph. Formally, given a batch of ego-graphs and the mashed ego-graph under an alignment , let be the embedding of node in the mashed ego-graph, we have
| (16) |
where equals the sum of original embedding in the -th layer of the sampled batch ego-graphs.
Then a layer of GraphSAGE according to Eq. (9) can be written into the following format.
| (17) |
where is the embedding matrix, denotes the adjacency matrix of the mashed ego-graph and is a reparameterzed weight matrix by multiplication . In paricular, denotes the final embedding of the center node.
For convenience, we further expand and as follows.
| (18) |
We focus on the center node and compute its final embedding as follows.
| (21) |
Due to symmetry of the mashed ego-graph, given a layer , the weight of the edge between node and each node in layer should be the same in the final adjacency matrix . Thus we have
| (22) |
where is a constant that only depends on the and .
Appendix B Proof of Theorem 4.3
In this section, we provide the detailed proof of Theorem 4.3.
Proof.
According to the definition of the and , we further define the model of epoch after the -th update as and . For simplicity, the update in personalization layers is defined as the -th step after the -th update. The weight after the update in personalization layers can be written as:
| (24) |
And hence we have the change of weight divergence after single update in personalization layers:
| (25) | ||||
Now take the SGD update of the clients and the server into consideration. Given cross-entropy loss defined as Eq. (2), SGD update in the -th step perfoms:
| (26) |
Therefore, we have:
| (27) |
We next calculate the weight divergence as follows:
| (28) | ||||
The last inequality holds due to absolute value inequality.
For simplicity, we denotes the gradient of of label as , which only depends on model weight :
| (29) |
Since is -Lipschitz, we have
| (30) |