Machine Unlearning of Federated Clusters
Abstract
Federated clustering (FC) is an unsupervised learning problem that arises in a number of practical applications, including personalized recommender and healthcare systems. With the adoption of recent laws ensuring the “right to be forgotten”, the problem of machine unlearning for FC methods has become of significant importance. We introduce, for the first time, the problem of machine unlearning for FC, and propose an efficient unlearning mechanism for a customized secure FC framework. Our FC framework utilizes special initialization procedures that we show are well-suited for unlearning. To protect client data privacy, we develop the secure compressed multiset aggregation (SCMA) framework that addresses sparse secure federated learning (FL) problems encountered during clustering as well as more general problems. To simultaneously facilitate low communication complexity and secret sharing protocols, we integrate Reed-Solomon encoding with special evaluation points into our SCMA pipeline, and prove that the client communication cost is logarithmic in the vector dimension. Additionally, to demonstrate the benefits of our unlearning mechanism over complete retraining, we provide a theoretical analysis for the unlearning performance of our approach. Simulation results show that the new FC framework exhibits superior clustering performance compared to previously reported FC baselines when the cluster sizes are highly imbalanced. Compared to completely retraining -means++ locally and globally for each removal request, our unlearning procedure offers an average speed-up of roughly x across seven datasets. Our implementation for the proposed method is available at https://github.com/thupchnsky/mufc.
1 Introduction
The availability of large volumes of user training data has contributed to the success of modern machine learning models. For example, most state-of-the-art computer vision models are trained on large-scale image datasets including Flickr (Thomee et al., 2016) and ImageNet (Deng et al., 2009). Organizations and repositories that collect and store user data must comply with privacy regulations, such as the recent European Union General Data Protection Regulation (GDPR), the California Consumer Privacy Act (CCPA), and the Canadian Consumer Privacy Protection Act (CPPA), all of which guarantee the right of users to remove their data from the datasets (Right to be Forgotten). Data removal requests frequently arise in practice, especially for sensitive datasets pertaining to medical records (numerous machine learning models in computational biology are trained using UK Biobank (Sudlow et al., 2015) which hosts a collection of genetic and medical records of roughly half a million patients (Ginart et al., 2019)). Removing user data from a dataset is insufficient to ensure sufficient privacy, since training data can often be reconstructed from trained models (Fredrikson et al., 2015; Veale et al., 2018). This motivates the study of machine unlearning (Cao & Yang, 2015) which aims to efficiently eliminate the influence of certain data points on a model. Naively, one can retrain the model from scratch to ensure complete removal, yet retraining comes at a high computational cost and is thus not practical when accommodating frequent removal requests. To avoid complete retraining, specialized approaches have to be developed for each unlearning application (Ginart et al., 2019; Guo et al., 2020; Bourtoule et al., 2021; Sekhari et al., 2021).
At the same time, federated learning (FL) has emerged as a promising approach to enable distributed training over a large number of users while protecting their privacy (McMahan et al., 2017; Chen et al., 2020; Kairouz et al., 2021; Wang et al., 2021; Bonawitz et al., 2021). The key idea of FL is to keep user data on their devices and train global models by aggregating local models in a communication-efficient and secure manner. Due to model inversion attacks (Zhu et al., 2019; Geiping et al., 2020), secure local model aggregation at the server is a critical consideration in FL, as it guarantees that the server cannot get specific information about client data based on their local models (Bonawitz et al., 2017; Bell et al., 2020; So et al., 2022; Chen et al., 2022). Since data privacy is the main goal in FL, it should be natural for a FL framework to allow for frequent data removal of a subset of client data in a cross-silo setting (e.g., when several patients request their data to be removed in the hospital database), or the entire local dataset for clients in a cross-device setting (e.g., when users request apps not to track their data on their phones). This leads to the largely unstudied problem termed federated unlearning (Liu et al., 2021; Wu et al., 2022; Wang et al., 2022). However, existing federated unlearning methods do not come with theoretical performance guarantees after model updates, and often, they are vulnerable to adversarial attacks.
Our contributions are summarized as follows. 1) We introduce the problem of machine unlearning in FC, and design a new end-to-end system (Fig. 1) that performs highly efficient FC with privacy and low communication-cost guarantees, which also enables, when needed, simple and effective unlearning. 2) As part of the FC scheme with unlearning features, we describe a novel one-shot FC algorithm that offers order-optimal approximation for the federated -means clustering objective, and also outperforms the handful of existing related methods (Dennis et al., 2021; Ginart et al., 2019), especially for the case when the cluster sizes are highly imbalanced. 3) For FC, we also describe a novel sparse compressed multiset aggregation (SCMA) scheme which ensures that the server only has access to the aggregated counts of points in individual clusters but has no information about the point distributions at individual clients. SCMA securely recovers the exact sum of the input sparse vectors with a communication complexity that is logarithmic in the vector dimension, outperforming existing sparse secure aggregation works (Beguier et al., 2020; Ergun et al., 2021), which have a linear complexity. 4) We theoretically establish the unlearning complexity of our FC method and show that it is significantly lower than that of complete retraining. 5) We compile a collection of datasets for benchmarking unlearning of federated clusters, including two new datasets containing methylation patterns in cancer genomes and gut microbiome information, which may be of significant importance to computational biologists and medical researchers that are frequently faced with unlearning requests. Experimental results reveal that our one-shot algorithm offers an average speed-up of roughly x compared to complete retraining across seven datasets.

2 Related Works
Due to space limitations, the complete discussion about related works is included in Appendix A.
Federated clustering. The goal of this learning task is to perform clustering using data that resides at different edge devices. Most of the handful of FC methods are centered around the idea of sending exact (Dennis et al., 2021) or quantized client (local) centroids (Ginart et al., 2019) directly to the server, which may not ensure desired levels of privacy as they leak the data statistics or cluster information of each individual client. To avoid sending exact centroids, Li et al. (2022) proposes sending distances between data points and centroids to the server without revealing the membership of data points to any of the parties involved, but their approach comes with large computational and communication overhead. Our work introduces a novel communication-efficient secure FC framework, with a new privacy criterion that is intuitively appealing as it involves communicating obfuscated point counts of the clients to the server and frequently used in FL literature (Bonawitz et al., 2017).
Machine unlearning. Two types of unlearning requirements were proposed in previous works: exact unlearning (Cao & Yang, 2015; Ginart et al., 2019; Bourtoule et al., 2021; Chen et al., 2021) and approximate unlearning (Guo et al., 2020; Golatkar et al., 2020a; b; Sekhari et al., 2021; Fu et al., 2022; Chien et al., 2022). For exact unlearning, the unlearned model is required to perform identically as a completely retrained model. For approximate unlearning, the “differences” in behavior between the unlearned model and the completely retrained model should be appropriately bounded. A limited number of recent works also investigated data removal in the FL settings (Liu et al., 2021; Wu et al., 2022; Wang et al., 2022); however, most of them are empirical methods and do not come with theoretical guarantees for model performance after removal and/or for the unlearning efficiency. In contrast, our proposed FC framework not only enables efficient data removal in practice, but also provides theoretical guarantees for the unlearned model performance and for the expected time complexity of the unlearning procedure.
3 Preliminaries
We start with a formal definition of the centralized -means problem. Given a set of points in arranged into a matrix , and the number of clusters , the -means problem asks for finding a set of points that minimizes the objective
| (1) |
where denotes the Frobenius norm of a matrix, denotes the norm of a vector, and records the closest centroid in to each data point (i.e., ). Without loss of generality, we make the assumption that the optimal solution is unique in order to facilitate simpler analysis and discussion, and denote the optimum by . The set of centroids induces an optimal partition over , where . We use to denote the optimal value of the objective function for the centralized -means problem. With a slight abuse of notation, we also use to denote the objective value contributed by the optimal cluster . A detailed description of a commonly used approach for solving the -means problem, -means++, is available in Appendix B.
In FC, the dataset is no longer available at the centralized server. Instead, data is stored on edge devices (clients) and the goal of FC is to learn a global set of centroids at the server based on the information sent by clients. For simplicity, we assume that there exists no identical data points across clients, and that the overall dataset is the union of the datasets arranged as on device . The server will receive the aggregated cluster statistics of all clients in a secure fashion, and generate the set . In this case, the federated -means problem asks for finding global centroids that minimize the objective
| (2) |
where records the centroids of the induced global clusters that data points on client belong to. Note that the definition of the assignment matrix for the centralized -means is different from that obtained through federated -means : the -th row of only depends on the location of while the row in corresponding to depends on the induced global clusters that belongs to (for a formal definition see 3.1). In Appendix L, we provide a simple example that further illustrates the difference between and . Note that the notion of induced global clusters was also used in Dennis et al. (2021).
Definition 3.1.
Suppose that the local clusters at client are denoted by , and that the clusters at the server are denoted by . The global clustering equals where is the centroid of on client . Note that forms a partition of the entire dataset , and the representative centroid for is defined as .
Exact unlearning. For clustering problems, the exact unlearning criterion may be formulated as follows. Let be a given dataset and a (randomized) clustering algorithm that trains on and outputs a set of centroids , where is the chosen space of models. Let be an unlearning algorithm that is applied to to remove the effects of one data point . Then is an exact unlearning algorithm if . To avoid confusion, in certain cases, this criterion is referred to as probabilistic (model) equivalence.
Privacy-accuracy-efficiency trilemma. How to trade-off data privacy, model performance, communication and computational efficiency is a long-standing problem in distributed learning (Acharya & Sun, 2019; Chen et al., 2020; Gandikota et al., 2021) that also carries over to FL and FC. Solutions that simultaneously address all these challenges in the latter context are still lacking. For example, Dennis et al. (2021) proposed a one-shot algorithm that takes model performance and communication efficiency into consideration by sending the exact centroids of each client to the server in a nonanonymous fashion. This approach may not be desirable under stringent privacy constraints as the server can gain information about individual client data. On the other hand, privacy considerations were addressed in Li et al. (2022) by performing -means Lloyd’s iterations anonymously via distribution of computations across different clients. Since the method relies on obfuscating pairwise distances for each client, it incurs computational overheads to hide the identity of contributing clients at the server and communication overheads due to interactive computations. None of the above methods is suitable for unlearning applications. To simultaneously enable unlearning and address the trilemma in the unlearning context, our privacy criterion involves transmitting the number of client data points within local client clusters in such a manner that the server cannot learn the data statistics of any specific client, but only the overall statistics of the union of client datasets. In this case, computations are limited and the clients on their end can perform efficient unlearning, unlike the case when presented with data point/centroid distances.
Random and adversarial removal. Most unlearning literature focuses on the case when all data points are equally likely to be removed, a setting known as random removal. However, adversarial data removal requests may arise when users are malicious in unlearning certain points that are critical for model training (i.e., boundary points in optimal clusters). We refer to such a removal request as adversarial removal. In Section 5, we provide theoretical analysis for both types of removal.
4 Federated Clustering with Secure Model Aggregation
The block diagram of our FC (Alg. 1) is depicted in Fig. 1. It comprises five components: a client-side clustering, client local information processing, secure compressed aggregation, server data generation, and server-side clustering module. We explain next the role of each component of the system.
For client- and server-side clustering (line and of Alg. 1), we adopt -means++ as it lends it itself to highly efficient unlearning, as explained in Section 5. Specifically, we only run the -means++ initialization procedure at each client but full -means++ clustering (initialization and Lloyd’s algorithm) at the server.
Line and of Alg. 1 describe the procedure used to process the information of local client clusters. As shown in Fig. 1, we first quantize the local centroids to their closest centers of the quantization bins, and the spatial locations of quantization bins naturally form a tensor, in which we store the sizes of local clusters. A tensor is generated for each client , and subsequently flattened to form a vector . For simplicity, we use uniform quantization with step size for each dimension (line 3 of Alg. 1, with more details included in Appendix H). The parameter determines the number of quantization bins in each dimension. If the client data is not confined to the unit hypercube centered at the origin, we scale the data to meet this requirement. Then the number of quantization bins in each dimension equals , while the total number of quantization bins for dimensions is .
Line of Alg. 1 describes how to aggregate information efficiently at the server without leaking individual client data statistics. This scheme is discussed in Section 4.1. Line pertains to generating points for the -th quantization bin based on its corresponding spatial location. The simplest idea is to choose the center of the quantization bin as the representative point and assign weight to it. Then, in line , we can use the weighted -means++ algorithm at the server to further reduce the computational complexity.
A simplified version of Alg. 1 is discussed in Appendix I, for applications where the privacy criterion is not an imperative.
4.1 SCMA at the Server
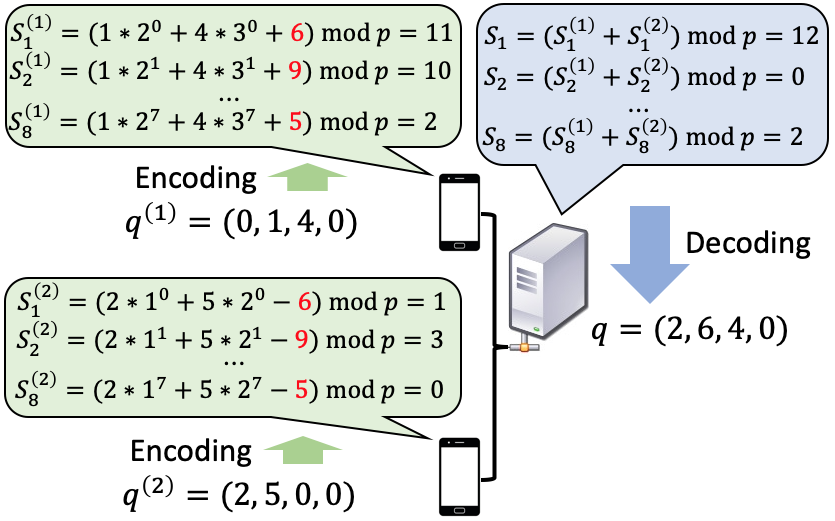
Once the vector representations of length for client are generated (line of Alg. 1), we can use standard secure model aggregation methods (Bonawitz et al., 2017; Bell et al., 2020; So et al., 2022) to sum up all securely and obtain the aggregated results at the server. However, since the length of each vector is , securely aggregating the whole vector would lead to an exponential communication complexity for each client. Moreover, each is a sparse vector since the number of client centroids is much smaller than the number of quantization bins (i.e., ). It is inefficient and unnecessary for each client to send out the entire with noisy masks for aggregation. This motivates us to first compress the vectors and then perform the secure aggregation, and we refer to this process as SCMA (Alg. 2), with one example illustrated in Fig. 2.
By observing that there can be at most nonzero entries in and at most nonzero entries in , we invoke the Reed-Solomon code construction (Reed & Solomon, 1960) for designing SCMA. Let be a finite field of prime order . We treat the indices of the quantization bins as distinct elements from the underlying finite field, and use them as evaluation points of the encoder polynomial. In addition, we treat a nonzero entry in vector as a substitution error at the -th entry in a codeword. Then, we use our SCMA scheme shown in Alg. 2, where the messages that the clients send to server can be treated as syndromes in Reed-Solomon decoding. Note that in our scheme, the server does not know beyond the fact that , which fits into our privacy criterion. This follows because is uniformly distributed over and independently chosen for different . For details, please refer to Appendix J.
4.2 Performance Analysis
Theorem 4.1.
Suppose that we performed uniform quantization with step size in Algorithm 1. Then we have
The performance guarantee in Theorem 4.1 pertains to two terms: the approximation of the optimal objective value and the quantization error (line of Alg. 1). For the first term, the approximation factor is order-optimal for one-shot FC algorithms since one always needs to perform two rounds of clustering and each round will contribute a factor of . To make the second term a constant w.r.t. , we can choose , which is a good choice in practice for the tested datasets as well. The above conclusions hold for any distribution of data across clients. Note that SCMA does not contribute to the distortion as it always returns the exact sum, while other methods for sparse secure aggregation based on sparsification (Han et al., 2020) may introduce errors and degrade the FC objective. See Appendix D for more details.
4.3 Complexity Analysis
5 Machine Unlearning via Specialized Seeding
We first describe an intuitive exact unlearning mechanism (Alg. 3) for -means clustering in the centralized setting, which will be used later on as the unlearning procedure on the client-sides of the FC framework described in Section 5.3. The idea behind Alg. 3 is straightforward: one needs to rerun the -means++ initialization, corresponding to retraining only if the current centroid set contains at least one point requested for removal. This follows from two observations. First, since the centroids chosen through -means++ initialization are true data points, the updated centroid set returned by Alg. 3 is guaranteed to contain no information about the data points that have been removed. Second, as we will explain in the next section, Alg. 3 also satisfies the exact unlearning criterion (defined in Section 3).
5.1 Performance Analysis
To verify that Alg. 3 is an exact unlearning method, we need to check that is probabilistically equivalent to the models generated by rerunning the -means++ initialization process on , the set of point remaining after removal. This is guaranteed by Lemma 5.1, and a formal proof is provided in Appendix E.
5.2 Complexity Analysis
We present next analytical results for the expected time complexity of removing a batch of data points simultaneously by our Alg. 3. For this, we consider both random and adversarial removal scenarios. While the analysis for random removal is fairly straightforward, the analysis for adversarial removal requests requires us to identify which removals force frequent retraining from scratch. In this regard, we state two assumptions concerning optimal cluster sizes and outliers, which will allow us to characterize the worst-case scenario removal setting.
Assumption 5.2.
Let be a constant denoting cluster size imbalance, where equals the size of the smallest cluster in the optimal clustering; when , all clusters are of size .
Assumption 5.3.
Assume that is a fixed constant. An outlier in satisfies and .
Under Assumptions 5.2 and 5.3, we arrive at an estimate for the expected removal time presented in Theorem 5.4 below. Notably, the expected removal time does not depend on the data set size .
Theorem 5.4.
Assume that the number of data points in is and the probability of the data set containing at least one outlier is upper bounded by . Algorithm 3 supports removing points within one single request with expected time for random removals, and expected time in expectation for adversarial removals. The complexity for complete retraining equals .
Remark.
Due to the distance-based -means++ initialization procedure, the existence of outliers in the dataset inevitably leads to higher retraining probability. This is the case since outliers are more likely to lie in the initial set of centroids. Hence, for analytical purposes, we assume in Theorem 5.4 that the probability of the data set containing at least one outlier is upper bounded by . This is not an overly restrictive assumption as there exist many different approaches for removing outliers before clustering Chawla & Gionis (2013); Gan & Ng (2017); Hautamäki et al. (2005), which effectively make the probability of outliers negligible.
5.3 Unlearning Federated Clusters
We describe next the complete unlearning algorithm for the new FC framework which uses Alg. 3 for client-level clustering. In the FL setting, data resides on client storage devices, and thus the basic assumption of federated unlearning is that the removal requests will only appear at the client side, and the removal set will not be known to other unaffected clients and the server. We consider two types of removal requests in the FC setting: removing points from one client (cross-silo, single-client removal), and removing all data points from clients (cross-device, multi-client removal). For the case where multiple clients want to unlearn only a part of their data, the approach is similar to that of single-client removal and can be handled via simple union bounds.
The unlearning procedure is depicted in Alg. 4. For single-client data removal, the algorithm will first perform unlearning at the client (say, client ) following Alg. 3. If the client’s local clustering changes (i.e., client reruns the initialization), one will generate a new vector and send it to the server via SCMA. The server will rerun the clustering procedure with the new aggregated vector and generate a new set of global centroids . Note that other clients do not need to perform additional computations during this stage. For multi-client removals, we follow a similar strategy, except that no client needs to perform additional computations. Same as centralized unlearning described in Lemma 5.1, we can show that Alg. 4 is also an exact unlearning method.
Removal time complexity. For single-client removal, we know from Theorem 5.4 that the expected removal time complexity of client is and for random and adversarial removals, respectively. denotes the number of data points on client . Other clients do not require additional computations, since their centroids will not be affected by the removal requests. Meanwhile, the removal time complexity for the server is upper bounded by , where is the maximum number of iterations of Lloyd’s algorithm at the server before convergence. For multi-client removal, no client needs to perform additional computations, and the removal time complexity for the server equals .
6 Experimental Results
To empirically characterize the trade-off between the efficiency of data removal and performance of our newly proposed FC method, we compare it with baseline methods on both synthetic and real datasets. Due to space limitations, more in-depth experiments and discussions are delegated to Appendix M.
Datasets and baselines. We use one synthetic dataset generated by a Gaussian Mixture Model (Gaussian) and six real datasets (Celltype, Covtype, FEMNIST, Postures, TMI, TCGA) in our experiments. We preprocess the datasets such that the data distribution is non-i.i.d. across different clients. The symbol in Fig. 3 represents the maximum number of (true) clusters among clients, while represents the number of true clusters in the global dataset. A detailed description of the data statistics and the preprocessing procedure is available in Appendix M. Since there is currently no off-the-shelf algorithm designed for unlearning federated clusters, we adapt DC-Kmeans (DC-KM) from Ginart et al. (2019) to apply to our problem setting, and use complete retraining as the baseline comparison method. To evaluate FC performance on the complete dataset (before data removals), we also include the K-FED algorithm from Dennis et al. (2021) as the baseline method. In all plots, our Alg. 1 is referred to as MUFC. Note that in FL, clients are usually trained in parallel so that the estimated time complexity equals the sum of the longest processing time of a client and the processing time of the server.
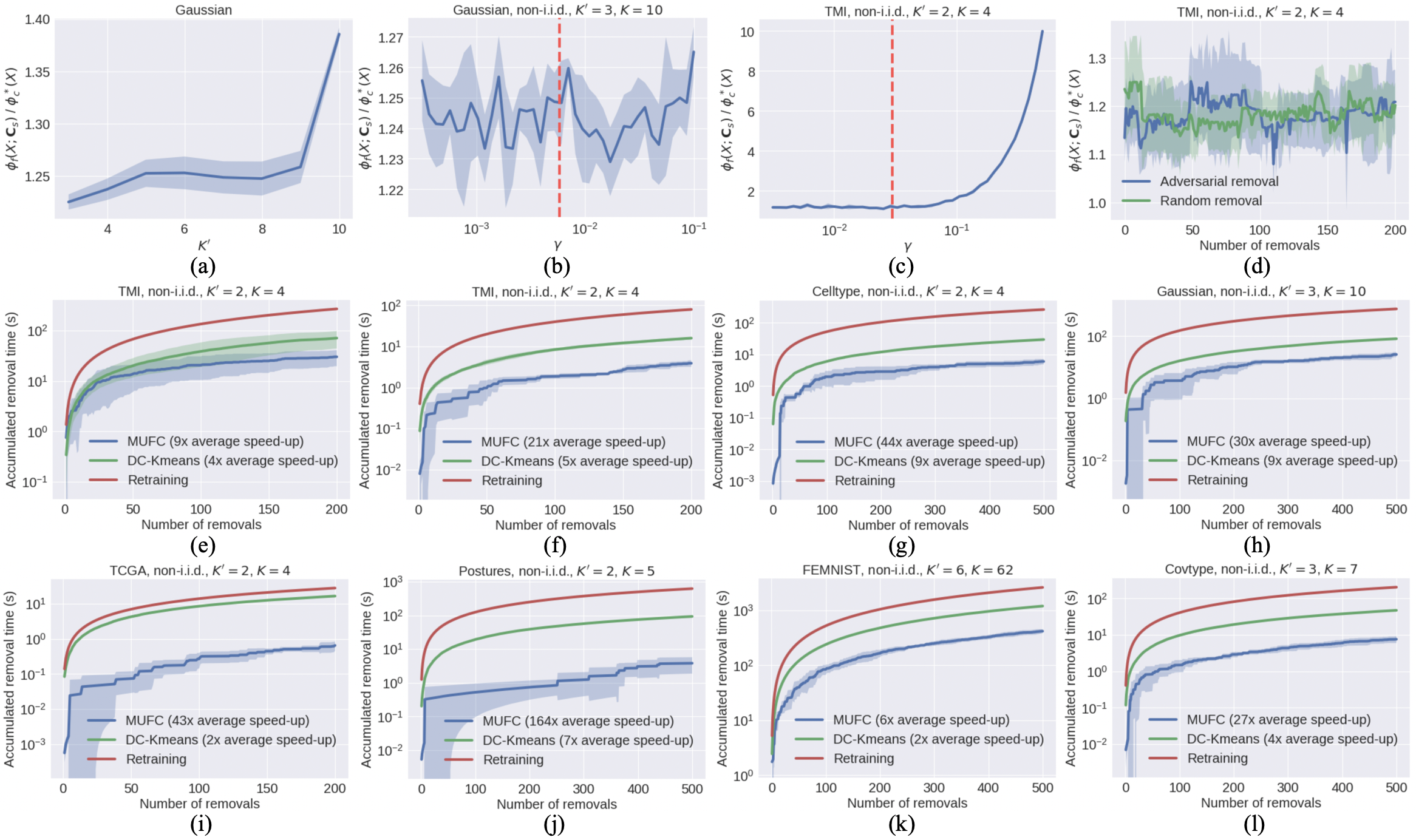
Clustering performance. The clustering performance of all methods on the complete dataset is shown in the first row of Tab. 1. The loss ratio is defined as 111 is approximated by running -means++ multiple times and selecting the smallest objective value., which is the metric used to evaluate the quality of the obtained clusters. For the seven datasets, MUFC offered the best performance on TMI and Celltype, datasets for which the numbers of data points in different clusters are highly imbalanced. This can be explained by pointing out an important difference between MUFC and K-FED/DC-KM: the quantized centroids sent by the clients may have non-unit weights, and MUFC is essentially performing weighted -means++ at the server. In contrast, both K-FED and DC-KM assign equal unit weights to the client’s centroids. Note that assigning weights to the client’s centroids based on local clusterings not only enables a simple analysis of the scheme but also improves the empirical performance, especially for datasets with highly imbalanced cluster distributions. For all other datasets except Gaussian, MUFC obtained competitive clustering performance compared to K-FED/DC-KM. The main reason why DC-KM outperforms MUFC on Gaussian data is that all clusters are of the same size in this case. Also note that DC-KM runs full -means++ clustering for each client while MUFC only performs initialization. Although running full -means++ clustering at the client side can improve the empirical performance on certain datasets, it also greatly increases the computational complexity during training and the retraining probability during unlearning, which is shown in Fig. 3. Nevertheless, we also compare the performance of MUFC with K-FED/DC-KM when running full -means++ clustering on clients for MUFC in Appendix M.
We also investigated the influence of and on the clustering performance. Fig. 3(a) shows that MUFC can obtain a lower loss ratio when , indicating that data is non-i.i.d. distributed across clients. Fig. 3(b) shows that the choice of does not seem to have a strong influence on the clustering performance of Gaussian datasets, due to the fact that we use uniform sampling in Step 6 of Alg. 1 to generate the server dataset. Meanwhile, Fig. 3(c) shows that can have a significant influence on the clustering performance of real-world datasets, which agrees with our analysis in Theorem 4.1. The red vertical line in both figures indicates the default choice of , where stands for the number of total data points across clients.
Unlearning performance. Since K-FED does not support data removal, has high computational complexity, and its empirical clustering performance is worse than DC-KM (see Tab. 1), we only compare the unlearning performance of MUFC with that of DC-KM. For simplicity, we consider removing one data point from a uniformly at random chosen client at each round of unlearning. The second row of Tab. 1 records the speed-up ratio w.r.t. complete retraining for one round of MUFC unlearning (Alg. 4) when the removed point does not lie in the centroid set selected at client . Fig. 3(e) shows the accumulated removal time on the TMI dataset for adversarial removals, which are simulated by removing the data points with the highest contribution to the current value of the objective function at each round, while Fig. 3(f)-(l) shows the accumulated removal time on different datasets for random removals. The results show that MUFC maintains high unlearning efficiency compared to all other baseline approaches, and offers an average speed-up ratio of x when compared to complete retraining for random removals across seven datasets. We also report the change in the loss ratio of MUFC during unlearning in Fig. 3(d). The loss ratio remains nearly constant after each removal, indicating that our unlearning approach does not significantly degrade clustering performance. Similar conclusions hold for other tested datasets, as shown in Appendix M.
| TMI | Celltype | Gaussian | TCGA | Postures | FEMNIST | Covtype | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Loss ratio | MUFC | |||||||||
| K-FED | ||||||||||
| DC-KM | ||||||||||
|
x | x | x | x | x | x | x | |||
Ethics Statement
The seven datasets used in our simulations are all publicly available. Among these datasets, TCGA and TMI contain potentially sensitive biological data and are downloaded after logging into the database. We adhered to all regulations when handling this anonymized data and will only release the data processing pipeline and data that is unrestricted at TCGA and TMI. Datasets that do not contain sensitive information can be downloaded directly from their open-source repositories.
Reproducibility Statement
Our implementation is available at https://github.com/thupchnsky/mufc. Detailed instructions are included in the source code.
Acknowledgment
This work was funded by NSF grants 1816913 and 1956384. The authors thank Eli Chien for the helpful discussion.
References
- Acharya & Sun (2019) Jayadev Acharya and Ziteng Sun. Communication complexity in locally private distribution estimation and heavy hitters. In International Conference on Machine Learning, pp. 51–60. PMLR, 2019.
- Ailon et al. (2009) Nir Ailon, Ragesh Jaiswal, and Claire Monteleoni. Streaming k-means approximation. Advances in neural information processing systems, 22, 2009.
- Beguier et al. (2020) Constance Beguier, Mathieu Andreux, and Eric W Tramel. Efficient sparse secure aggregation for federated learning. arXiv preprint arXiv:2007.14861, 2020.
- Bell et al. (2020) James Henry Bell, Kallista A Bonawitz, Adrià Gascón, Tancrède Lepoint, and Mariana Raykova. Secure single-server aggregation with (poly) logarithmic overhead. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, pp. 1253–1269, 2020.
- Berlekamp (1968) Elwyn R. Berlekamp. Algebraic coding theory. In McGraw-Hill series in systems science, 1968.
- Blackard & Dean (1999) Jock A Blackard and Denis J Dean. Comparative accuracies of artificial neural networks and discriminant analysis in predicting forest cover types from cartographic variables. Computers and electronics in agriculture, 24(3):131–151, 1999.
- Bonawitz et al. (2021) Kallista Bonawitz, Peter Kairouz, Brendan McMahan, and Daniel Ramage. Federated learning and privacy: Building privacy-preserving systems for machine learning and data science on decentralized data. Queue, 19(5):87–114, 2021.
- Bonawitz et al. (2017) Keith Bonawitz, Vladimir Ivanov, Ben Kreuter, Antonio Marcedone, H Brendan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth. Practical secure aggregation for privacy-preserving machine learning. In proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, pp. 1175–1191, 2017.
- Bourtoule et al. (2021) Lucas Bourtoule, Varun Chandrasekaran, Christopher A Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. Machine unlearning. In 2021 IEEE Symposium on Security and Privacy (SP), pp. 141–159. IEEE, 2021.
- Caldas et al. (2018) Sebastian Caldas, Sai Meher Karthik Duddu, Peter Wu, Tian Li, Jakub Konečnỳ, H Brendan McMahan, Virginia Smith, and Ameet Talwalkar. LEAF: A Benchmark for Federated Settings. arXiv preprint arXiv:1812.01097, 2018.
- Cao & Yang (2015) Yinzhi Cao and Junfeng Yang. Towards making systems forget with machine unlearning. In 2015 IEEE Symposium on Security and Privacy, pp. 463–480. IEEE, 2015.
- Chawla & Gionis (2013) Sanjay Chawla and Aristides Gionis. k-means–: A unified approach to clustering and outlier detection. In Proceedings of the 2013 SIAM international conference on data mining, pp. 189–197. SIAM, 2013.
- Chen et al. (2021) Min Chen, Zhikun Zhang, Tianhao Wang, Michael Backes, Mathias Humbert, and Yang Zhang. Graph unlearning. arXiv preprint arXiv:2103.14991, 2021.
- Chen et al. (2020) Wei-Ning Chen, Peter Kairouz, and Ayfer Ozgur. Breaking the communication-privacy-accuracy trilemma. Advances in Neural Information Processing Systems, 33:3312–3324, 2020.
- Chen et al. (2022) Wei-Ning Chen, Christopher A Choquette Choo, Peter Kairouz, and Ananda Theertha Suresh. The fundamental price of secure aggregation in differentially private federated learning. In International Conference on Machine Learning, pp. 3056–3089. PMLR, 2022.
- Chien et al. (2022) Eli Chien, Chao Pan, and Olgica Milenkovic. Certified graph unlearning. In NeurIPS 2022 Workshop: New Frontiers in Graph Learning, 2022. URL https://openreview.net/forum?id=wCxlGc9ZCwi.
- Chien et al. (2023) Eli Chien, Chao Pan, and Olgica Milenkovic. Efficient model updates for approximate unlearning of graph-structured data. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=fhcu4FBLciL.
- Chung et al. (2022) Jichan Chung, Kangwook Lee, and Kannan Ramchandran. Federated unsupervised clustering with generative models. In AAAI 2022 International Workshop on Trustable, Verifiable and Auditable Federated Learning, 2022.
- Cohen et al. (2017) Gregory Cohen, Saeed Afshar, Jonathan Tapson, and Andre Van Schaik. EMNIST: Extending MNIST to handwritten letters. In 2017 international joint conference on neural networks (IJCNN), pp. 2921–2926. IEEE, 2017.
- Deng et al. (2009) Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pp. 248–255. Ieee, 2009.
- Dennis et al. (2021) Don Kurian Dennis, Tian Li, and Virginia Smith. Heterogeneity for the win: One-shot federated clustering. In International Conference on Machine Learning, pp. 2611–2620. PMLR, 2021.
- Eisinberg & Fedele (2006) Alfredo Eisinberg and Giuseppe Fedele. On the inversion of the vandermonde matrix. Applied mathematics and computation, 174(2):1384–1397, 2006.
- Ergun et al. (2021) Irem Ergun, Hasin Us Sami, and Basak Guler. Sparsified secure aggregation for privacy-preserving federated learning. arXiv preprint arXiv:2112.12872, 2021.
- Fredrikson et al. (2015) Matt Fredrikson, Somesh Jha, and Thomas Ristenpart. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC conference on computer and communications security, pp. 1322–1333, 2015.
- Frikken (2007) Keith Frikken. Privacy-preserving set union. In International Conference on Applied Cryptography and Network Security, pp. 237–252. Springer, 2007.
- Fu et al. (2022) Shaopeng Fu, Fengxiang He, and Dacheng Tao. Knowledge removal in sampling-based bayesian inference. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=dTqOcTUOQO.
- Gan & Ng (2017) Guojun Gan and Michael Kwok-Po Ng. K-means clustering with outlier removal. Pattern Recognition Letters, 90:8–14, 2017.
- Gandikota et al. (2021) Venkata Gandikota, Daniel Kane, Raj Kumar Maity, and Arya Mazumdar. vqsgd: Vector quantized stochastic gradient descent. In International Conference on Artificial Intelligence and Statistics, pp. 2197–2205. PMLR, 2021.
- Gardner et al. (2014a) Andrew Gardner, Christian A Duncan, Jinko Kanno, and Rastko Selmic. 3D hand posture recognition from small unlabeled point sets. In 2014 IEEE International Conference on Systems, Man, and Cybernetics (SMC), pp. 164–169. IEEE, 2014a.
- Gardner et al. (2014b) Andrew Gardner, Jinko Kanno, Christian A Duncan, and Rastko Selmic. Measuring distance between unordered sets of different sizes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 137–143, 2014b.
- Geiping et al. (2020) Jonas Geiping, Hartmut Bauermeister, Hannah Dröge, and Michael Moeller. Inverting gradients-how easy is it to break privacy in federated learning? Advances in Neural Information Processing Systems, 33:16937–16947, 2020.
- Ghosh et al. (2020) Avishek Ghosh, Jichan Chung, Dong Yin, and Kannan Ramchandran. An efficient framework for clustered federated learning. Advances in Neural Information Processing Systems, 33:19586–19597, 2020.
- Ginart et al. (2019) Antonio Ginart, Melody Guan, Gregory Valiant, and James Y Zou. Making AI forget you: Data deletion in machine learning. Advances in neural information processing systems, 32, 2019.
- Golatkar et al. (2020a) Aditya Golatkar, Alessandro Achille, and Stefano Soatto. Eternal sunshine of the spotless net: Selective forgetting in deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9304–9312, 2020a.
- Golatkar et al. (2020b) Aditya Golatkar, Alessandro Achille, and Stefano Soatto. Forgetting outside the box: Scrubbing deep networks of information accessible from input-output observations. In European Conference on Computer Vision, pp. 383–398. Springer, 2020b.
- Guha et al. (2003) Sudipto Guha, Adam Meyerson, Nina Mishra, Rajeev Motwani, and Liadan O’Callaghan. Clustering data streams: Theory and practice. IEEE transactions on knowledge and data engineering, 15(3):515–528, 2003.
- Guo et al. (2020) Chuan Guo, Tom Goldstein, Awni Hannun, and Laurens Van Der Maaten. Certified data removal from machine learning models. In Hal Daumé III and Aarti Singh (eds.), Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pp. 3832–3842. PMLR, 13–18 Jul 2020.
- Han et al. (2020) Pengchao Han, Shiqiang Wang, and Kin K Leung. Adaptive gradient sparsification for efficient federated learning: An online learning approach. In 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS), pp. 300–310. IEEE, 2020.
- Han et al. (2018) Xiaoping Han, Renying Wang, Yincong Zhou, Lijiang Fei, Huiyu Sun, Shujing Lai, Assieh Saadatpour, Ziming Zhou, Haide Chen, Fang Ye, et al. Mapping the mouse cell atlas by microwell-seq. Cell, 172(5):1091–1107, 2018.
- Hartigan & Wong (1979) John A Hartigan and Manchek A Wong. Algorithm as 136: A k-means clustering algorithm. Journal of the royal statistical society. series c (applied statistics), 28(1):100–108, 1979.
- Hautamäki et al. (2005) Ville Hautamäki, Svetlana Cherednichenko, Ismo Kärkkäinen, Tomi Kinnunen, and Pasi Fränti. Improving k-means by outlier removal. In Scandinavian conference on image analysis, pp. 978–987. Springer, 2005.
- Hutter & Zenklusen (2018) Carolyn Hutter and Jean Claude Zenklusen. The Cancer Genome Atlas: Creating Lasting Value beyond Its Data. Cell, 173(2):283–285, 2018.
- Kairouz et al. (2021) Peter Kairouz, H Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Kallista Bonawitz, Zachary Charles, Graham Cormode, Rachel Cummings, et al. Advances and open problems in federated learning. Foundations and Trends® in Machine Learning, 14(1–2):1–210, 2021.
- Kedlaya & Umans (2011) Kiran S Kedlaya and Christopher Umans. Fast polynomial factorization and modular composition. SIAM Journal on Computing, 40(6):1767–1802, 2011.
- Kissner & Song (2005) Lea Kissner and Dawn Song. Privacy-preserving set operations. In Annual International Cryptology Conference, pp. 241–257. Springer, 2005.
- Lee et al. (2017) Euiwoong Lee, Melanie Schmidt, and John Wright. Improved and simplified inapproximability for k-means. Information Processing Letters, 120:40–43, 2017.
- Li et al. (2022) Songze Li, Sizai Hou, Baturalp Buyukates, and Salman Avestimehr. Secure federated clustering. arXiv preprint arXiv:2205.15564, 2022.
- Liu et al. (2021) Gaoyang Liu, Xiaoqiang Ma, Yang Yang, Chen Wang, and Jiangchuan Liu. Federaser: Enabling efficient client-level data removal from federated learning models. In 2021 IEEE/ACM 29th International Symposium on Quality of Service (IWQOS), pp. 1–10. IEEE, 2021.
- Lloyd (1982) Stuart Lloyd. Least squares quantization in pcm. IEEE transactions on information theory, 28(2):129–137, 1982.
- Mahajan et al. (2012) Meena Mahajan, Prajakta Nimbhorkar, and Kasturi Varadarajan. The planar k-means problem is np-hard. Theoretical Computer Science, 442:13–21, 2012.
- Mansour et al. (2020) Yishay Mansour, Mehryar Mohri, Jae Ro, and Ananda Theertha Suresh. Three approaches for personalization with applications to federated learning. arXiv preprint arXiv:2002.10619, 2020.
- Massey (1969) James Massey. Shift-register synthesis and bch decoding. IEEE transactions on Information Theory, 15(1):122–127, 1969.
- McMahan et al. (2017) Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics, pp. 1273–1282. PMLR, 2017.
- Pan et al. (2023) Chao Pan, Eli Chien, and Olgica Milenkovic. Unlearning graph classifiers with limited data resources. In The Web Conference, 2023.
- Peterson et al. (2009) Jane Peterson, Susan Garges, Maria Giovanni, Pamela McInnes, Lu Wang, Jeffery A Schloss, Vivien Bonazzi, Jean E McEwen, Kris A Wetterstrand, Carolyn Deal, et al. The NIH Human Microbiome Project. Genome research, 19(12):2317–2323, 2009.
- Reed & Solomon (1960) Irving S Reed and Gustave Solomon. Polynomial codes over certain finite fields. Journal of the society for industrial and applied mathematics, 8(2):300–304, 1960.
- Sattler et al. (2020) Felix Sattler, Klaus-Robert Müller, and Wojciech Samek. Clustered federated learning: Model-agnostic distributed multitask optimization under privacy constraints. IEEE transactions on neural networks and learning systems, 32(8):3710–3722, 2020.
- Sekhari et al. (2021) Ayush Sekhari, Jayadev Acharya, Gautam Kamath, and Ananda Theertha Suresh. Remember what you want to forget: Algorithms for machine unlearning. Advances in Neural Information Processing Systems, 34:18075–18086, 2021.
- Seo et al. (2012) Jae Hong Seo, Jung Hee Cheon, and Jonathan Katz. Constant-round multi-party private set union using reversed laurent series. In International Workshop on Public Key Cryptography, pp. 398–412. Springer, 2012.
- So et al. (2022) Jinhyun So, Corey J Nolet, Chien-Sheng Yang, Songze Li, Qian Yu, Ramy E Ali, Basak Guler, and Salman Avestimehr. Lightsecagg: a lightweight and versatile design for secure aggregation in federated learning. Proceedings of Machine Learning and Systems, 4:694–720, 2022.
- Sudlow et al. (2015) Cathie Sudlow, John Gallacher, Naomi Allen, Valerie Beral, Paul Burton, John Danesh, Paul Downey, Paul Elliott, Jane Green, Martin Landray, et al. Uk biobank: an open access resource for identifying the causes of a wide range of complex diseases of middle and old age. PLoS medicine, 12(3):e1001779, 2015.
- Thomee et al. (2016) Bart Thomee, David A Shamma, Gerald Friedland, Benjamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and Li-Jia Li. Yfcc100m: The new data in multimedia research. Communications of the ACM, 59(2):64–73, 2016.
- Vassilvitskii & Arthur (2006) Sergei Vassilvitskii and David Arthur. k-means++: The advantages of careful seeding. In Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms, pp. 1027–1035, 2006.
- Veale et al. (2018) Michael Veale, Reuben Binns, and Lilian Edwards. Algorithms that remember: model inversion attacks and data protection law. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 376(2133):20180083, 2018.
- Wang et al. (2021) Jianyu Wang, Zachary Charles, Zheng Xu, Gauri Joshi, H Brendan McMahan, Maruan Al-Shedivat, Galen Andrew, Salman Avestimehr, Katharine Daly, Deepesh Data, et al. A field guide to federated optimization. arXiv preprint arXiv:2107.06917, 2021.
- Wang et al. (2022) Junxiao Wang, Song Guo, Xin Xie, and Heng Qi. Federated unlearning via class-discriminative pruning. In Proceedings of the ACM Web Conference 2022, pp. 622–632, 2022.
- Wu et al. (2022) Chen Wu, Sencun Zhu, and Prasenjit Mitra. Federated unlearning with knowledge distillation. arXiv preprint arXiv:2201.09441, 2022.
- Zhu et al. (2019) Ligeng Zhu, Zhijian Liu, and Song Han. Deep leakage from gradients. Advances in neural information processing systems, 32, 2019.
Appendix A Related Works
Federated clustering. The idea of FC is to perform clustering using data that resides at different edge devices. It is closely related to clustered FL (Sattler et al., 2020), whose goal is to learn several global models simultaneously, based on the cluster structure of the dataset, as well as personalization according to the cluster assignments of client data in FL (Mansour et al., 2020). One difference between FC and distributed clustering (Guha et al., 2003; Ailon et al., 2009) is the assumption of data heterogeneity across different clients. Recent works (Ghosh et al., 2020; Dennis et al., 2021; Chung et al., 2022) exploit the non-i.i.d nature of client data to improve the performance of some learners. Another difference pertains to data privacy. Most previous methods were centered around the idea of sending exact (Dennis et al., 2021) or quantized client (local) centroids (Ginart et al., 2019) to the server, which may not be considered private as it leaks the data statistics or cluster information of all the clients. To avoid sending exact centroids, Li et al. (2022) proposes sending distances between data points and centroids to the server without revealing the membership of data points to any of the parties involved. Note that there is currently no formal definition of computational or information-theoretic secrecy/privacy for FC problems, making it hard to compare methods addressing different aspects of FL. Our method introduces a simple-to-unlearn clustering process and new privacy mechanism that is intuitively appealing as it involves communicating obfuscated point counts of the clients to the server.
Sparse secure aggregation. Sparse secure aggregation aims to securely aggregate local models in a communication-efficient fashion for the case that the local models are high-dimensional but sparse. Existing works on sparse secure aggregation (Beguier et al., 2020; Ergun et al., 2021) either have a communication complexity that is linear in the model dimension, or they can only generate an approximation of the aggregated model based on certain sparsification procedures (Han et al., 2020). In comparison, our SCMA scheme can securely recover the exact sum of the input sparse models with a communication complexity that is logarithmic in the model dimension.
Private set union. The private set union (Kissner & Song, 2005; Frikken, 2007; Seo et al., 2012) is a related but different problem compared to sparse secure aggregation. It requires multiple parties to communicate with each other to securely compute the union of their sets. In SCMA we aggregate multisets, which include the frequency of each element that is not considered in the private set union problem. In addition, our scheme includes only one round of communication from the clients to the server, while there is no server in the private set union problem but multi-round client to client communication is needed.
Machine unlearning. For centralized machine unlearning problems, two types of unlearning requirements were proposed in previous works: exact unlearning and approximate unlearning. For exact unlearning, the unlearned model is required to perform identically as a completely retrained model. To achieve this, Cao & Yang (2015) introduced distributed learners, Bourtoule et al. (2021) proposed sharding-based methods, Ginart et al. (2019) used quantization to eliminate the effect of removed data in clustering problems, and Chen et al. (2021) applied sharding-based methods to Graph Neural Networks. For approximate unlearning, the “differences” in behavior between the unlearned model and the completely retrained model should be appropriately bounded, similarly to what is done in the context of differential privacy. Following this latter direction, Guo et al. (2020) introduced the inverse Newton update for linear models, Sekhari et al. (2021) studied the generalization performance of approximately unlearned models, Fu et al. (2022) proposed an MCMC unlearning algorithm for sampling-based Bayesian inference, Golatkar et al. (2020a; b) designed model update mechanisms for deep neural networks based on Fisher Information and Neural Tangent Kernel, while Chien et al. (2022; 2023); Pan et al. (2023) extended the analysis to Graph Neural Networks. A limited number of recent works also investigated data removal in the FL settings: Liu et al. (2021) proposed to use fewer iterations during retraining for federated unlearning, Wu et al. (2022) introduced Knowledge Distillation into the unlearning procedure to eliminate the effect of data points requested for removal, and Wang et al. (2022) considered removing all data from one particular class via inspection of the internal influence of each channel in Convolutional Neural Networks. These federated unlearning methods are (mostly) empirical and do not come with theoretical guarantees for model performance after removal and/or for the unlearning efficiency. In contrast, our proposed FC framework not only enables efficient data removal in practice, but also provides theoretical guarantees for the unlearned model performance and for the expected time complexity of the unlearning procedure.
Appendix B -means++ Initialization
The -means problem is NP-hard even for , and when the points lie in a two-dimensional Euclidean space (Mahajan et al., 2012). Heuristic algorithms for solving the problem, including Lloyd’s (Lloyd, 1982) and Hartigan’s method (Hartigan & Wong, 1979), are not guaranteed to obtain the global optimal solution unless further assumptions are made on the point and cluster structures (Lee et al., 2017). Although obtaining the exact optimal solution for the -means problem is difficult, there are many methods that can obtain quality approximations for the optimal centroids. For example, a randomized initialization algorithm (-means++) was introduced in Vassilvitskii & Arthur (2006) and the expected objective value after initialization is a -approximation to the optimal objective (). -means++ initialization works as follows: initially, the centroid set is assumed to be empty. Then, a point is sampled uniformly at random from for the first centroid and added to . For the following rounds, a point from is sampled with probability for the new centroid and added to . Here, denotes the minimum distance between and the centroids in chosen so far. After the initialization step, we arrive at initial centroids in used for running Lloyd’s algorithm.
Appendix C Complexity Analysis of Algorithm 1
Computational complexity of client-side clustering. Client-side clustering involves running -means++ initialization procedure, which is of complexity .
Computational complexity of server-side clustering. Server-side clustering involves running -means++ initialization procedure followed by Lloyd’s algorithm with iterations, which is of complexity .
Computational complexity of SCMA at the client end. The computation of on client requires at most multiplications over . The total computational complexity equals multiplication and addition operations over .
Computational complexity of SCMA at the server end. The computational complexity at the server is dominated by the complexity of the Berlekamp-Massey decoding algorithm (Berlekamp, 1968; Massey, 1969), factorizing the polynomial over (Kedlaya & Umans, 2011), and solving the linear equations with known , . The complexity of Berlekamp-Massey decoding over is . The complexity of factorizing a polynomial over using the algorithm in Kedlaya & Umans (2011) is operations over . The complexity of solving for equals that of finding the inverse of a Vandermonde matrix, which takes operations over (Eisinberg & Fedele, 2006). Hence, the total computational complexity at the server side is operations over .
Communication complexity of SCMA at the client end. Since each can be represented by bits, the information sent by each client can be represented by bits. Note that there are at most -ary vectors of length . Hence, the cost for communicating from the client to server is at least bits, which implies that our scheme is order-optimal w.r.t. the communication cost. Note that following standard practice in the area, we do not take into account the complexity of noise generation in secure model aggregation, as it can be done offline and independently of the Reed-Solomon encoding procedure.
Appendix D Proof of Theorem 4.1
Proof.
We first consider the case where no quantization is performed (Algorithm 5). The performance guarantees for the federated objective value in this setting are provided in Lemma D.1.
Lemma D.1.
Suppose that the entire data set across clients is denoted by , and the set of server centroids returned by Algorithm 5 is . Then we have
Proof.
Let denote the optimal set of centroids that minimize the objective (1) for the entire dataset , let be the matrix that records the closest centroid in to each data point, the set of centroids returned by Alg. 1, and the matrix that records the corresponding centroid in for each data point based on the global clustering defined in Definition 3.1. Since we perform -means++ initialization on each client dataset, for client it holds
| (3) |
where records the closest centroid in to each data point in , is the optimal solution that can minimize the local -means objective for client , and denotes the row in that corresponds to client . Summing up (D) over all clients gives
| (4) |
At the server side the client centroids are reorganized into a matrix . The weights of the client centroids are converted to replicates of rows in . Since we perform full -means++ clustering at the server, it follows that
| (5) |
where is the optimal solution that minimizes the -means objective at the server. It is worth pointing out that is different from , as they are optimal solutions for different optimization objectives. Note that we still keep the expectation on RHS for . The randomness comes from the fact that is obtained by -means++ initialization, which is a probabilistic procedure.
Combining (4) and (D) results in
| (6) |
For , we have
| (7) |
Replacing (D) into (D) shows that , which completes the proof.
If we are only concerned with the performance of non-outlier points over the entire dataset, we can upper bound the term by
| (8) |
Here, we used the fact that rows of are all real data points sampled by the -means++ initialization procedure. For each data point , it holds that , where . In this case, we arrive at , where corresponds to all non-outlier points. ∎
Remark.
In Theorem 4 of Guha et al. (2003) the authors show that for the distributed -median problem, if we use a -approximation algorithm (i.e., ) for the -median problem with subdatasets on distributed machines, and use a -approximation algorithm for the -median problem on the centralized machine, the overall distributed algorithm achieves effectively a -approximation of the optimal solution to the centralized -median problem. This is consistent with our observation that Alg. 5 can offer in expectation a -approximation to the optimal solution of the centralized -means problem, since -means++ initialization achieves a -approximation on both the client and server side.
We also point out that in Dennis et al. (2021) the authors assume that the exact number of clusters from the global optimal clustering on client is known and equal to , and propose the -FED algorithm which performs well when . The difference between and represents the data heterogeneity across different clients. With a slight modifications of the proof, we can also obtain , when is known for each client beforehand, and perform -means++ on client instead of -means++ in Alg. 1. For the extreme setting where each client safeguards data of one entire cluster (w.r.t. the global optimal clustering ()), the performance guarantee for Alg. 1 becomes , which is the same as seeding each optimal cluster by a data point sampled uniformly at random from that cluster. From Lemma 3.1 of Vassilvitskii & Arthur (2006) we see that we can indeed have , where the approximation factor does not depend on . This shows that data heterogeneity across different clients can benefit the entire FC framework introduced.
Next we show the proof for Theorem 4.1. Following the same idea as the one used in the proof of Lemma D.1, we arrive at
| (9) |
where is the quantized version of . The first term can be upper bounded in the same way as in Lemma D.1. For the second term, the distortion introduced by quantizing one point is bounded by , if we choose the center of the quantization bin as the reconstruction point. Therefore,
| (10) |
The third term can be bounded as
| (11) |
Replacing (10) and (D) into (9) leads to
which completes the proof. Similar as in Lemma D.1, we can have that for non-outlier points , . ∎
Appendix E Proof of Lemma 5.1
Proof.
Assume that the number of data points in is , the size of is , and the initial centroid set for is . We use induction to prove that returned by Alg. 3 is probabilistically equivalent to rerunning the -means++ initialization on .
The base case of induction amounts to investigating the removal process for , the first point selected by -means++. There are two possible scenarios: and . In the first case, we will rerun the initialization process over , which is equivalent to retraining the model. In the second case, since we know , the probability of choosing from as the first centroid equals the conditional probability
Next suppose that , . The centroids returned by Alg. 3 can be viewed probabilistically equivalent to the model obtained from rerunning the initialization process over for the first rounds. Then we have
where holds based on the definition of , indicating that the -th centroid is not in . Therefore, the centroid returned by Alg. 3 can be seen as if obtained from rerunning the initialization process over in the -th round. Again based on the definition of , it is clear that for , are the centroids chosen by the -means++ procedure over . This proves our claim that returned by Alg. 3 is probabilistic equivalent to the result obtained by rerunning the -means++ initialization on .
Theorem 1.1 of Vassilvitskii & Arthur (2006) then establishes that
| (12) |
which completes the proof. ∎
Appendix F Proof of Theorem 5.4
Proof.
We first analyze the probability of rerunning -means++ initialization based on Alg. 3. Assumptions 5.2 and 5.3 can be used to derive an expression for the probability of (where is the point that needs to be unlearned), which also equals the probability of retraining.
Lemma F.1.
Assume that the number of data points in is and that the probability of the data set containing at least one outlier is upper bounded by . Let be the centroid set obtained by running -means++ on . For an arbitrary removal set of size , we have
| for random removals: | |||
| for adversarial removals: |
Proof.
Since outliers can be arbitrarily far from all true cluster points based on definition, during initialization they may be sampled as centroids with very high probability. For simplicity of analysis, we thus assume that outliers are sampled as centroids with probability if they exist in the dataset, meaning that we will always need to rerun the -means++ initialization when outliers exist in the complete dataset before any removals.
For random removals, where the point requested for unlearning, , is drawn uniformly at random from , it is clear that , since contains distinct data points in .
For adversarial removals, we need to analyze the probability of choosing as the -th centroid, given that the first centroids have been determined and . For simplicity we first assume that there is no outlier in . Then we have
| (13) |
For the denominator , the following three observations are in place
Therefore,
| (14) |
where are the closest centroid in and to , respectively. Here, is a consequence of the fact that . Since is not an outlier for based on our assumption, we have
Consequently,
| (15) |
For , it hold . Thus, (F) can be lower bounded by
| (16) |
Combining (16) and (F) we obtain
Using this expression in (13) results in
| (17) |
which holds for . Thus, the probability can be computed as
| (18) |
Here, we assumed that .
For the case where outliers are present in the dataset, we have
which completes the proof for the adversarial removal scenario. Finally, by union bound we can have that for the removal set of size ,
| random removals: | |||
| adversarial removals: |
Also, the probability naturally satisfies that
∎
Next we show the proof for Theorem 5.4. The expected removal time for random removals can be upper bounded by
Following a similar argument, we can also show that the expected removal time for adversarial removals can be upper bounded by . And based on our Algorithm 3, the unlearning complexity for both types of removal requests would be always upper bounded by the retraining complexity as well, which completes the proof. ∎
Appendix G Comparison between Algorithm 3 and Quantized -means
In Ginart et al. (2019), quantized -means were proposed to solve a similar problem of machine unlearning in the centralized setting. However, that approach substantially differs from Alg. 3. First, the intuition behind quantized -means is that the centroids are computed by taking an average, and the effect of a small number of points is negligible when there are enough terms left in the clusters after removal. Therefore, if we quantize all centroids after each Lloyd’s iteration, the quantized centroids will not change with high probability when we remove a small number of points from the dataset. Meanwhile, the intuition behind Alg. 3 is as described in Lemma F.1. Second, the expected removal time complexity for quantized -means equals , which is high since one needs to check if all quantized centroids remain unchanged after removal at each iteration, where denotes the maximum number of Lloyd’s iteration before convergence and is some intrinsic parameter. In contrast, Alg. 3 only needs even for adversarial removals. Also note that the described quantized -means algorithm does not come with performance guarantees on removal time complexity unless it is randomly initialized.
Appendix H Quantization
For uniform quantization, we set , where 222We can also add random shifts during quantization as proposed in Ginart et al. (2019) to make the data appear more uniformly distributed within the quantization bins.. The parameter determines the number of quantization bins in each dimension. Suppose all client data lie in the unit hypercube centered at the origin, and that if needed, pre-processing is performed to meet this requirement. Then the number of quantization bins in each dimension equals , while the total number of quantization bins for dimensions is .
In Section 4, we remarked that one can generate points by choosing the center of the quantization bin as the representative point and endow it with a weight equal to . Then, in line , we can use the weighted -means++ algorithm at the server to further reduce the computational complexity, since the effective problem size at the server reduces from to . However, in practice we find that when the computational power of the server is not the bottleneck in the FL system, generating data points uniformly at random within the quantization bins can often lead to improved clustering performance. Thus, this is the default approach for our subsequent numerical simulations.
Appendix I Simplified Federated -means Clustering
When privacy criterion like the one stated in Section 3 is not enforced, and as done in the framework of Dennis et al. (2021), one can skip line 3-6 in Alg. 1 and send the centroid set obtained by client along with the cluster sizes directly to the server. Then, one can run the weighted -means++ algorithm at the server on the aggregated centroid set to obtain . The pseudocode for this simplified case is shown in Alg. 5. It follows a similar idea as the divide-and-conquer schemes of Guha et al. (2003); Ailon et al. (2009), developed for distributed clustering.
In line 5 of Alg. 5, weighted -means++ would assign weights to data points when computing the sampling probability during the initialization procedure and when computing the average of clusters during the Lloyd’s iterations. Since the weights we are considering here are always positive integers, a weighted data point can also be viewed as there exist identical data points in the dataset with multiplicity equals to the weight.
Appendix J The Uniqueness of the Vector given
To demonstrate that the messages generated by Alg. 2 can be uniquely decoded, we prove that there exists a unique that produces the aggregated values at the server. The proof is by contradiction. Assume that there exist two different vectors and that result in the same . In this case, we have the following set of linear equations . Given that and represent at most unknowns and coefficients, the linear equations can be described using a square Vandermonde matrix for the coefficients, with the columns of the generated by the indices of the nonzero entries in . This leads to a contradiction since a square Vandermonde matrix with different column generators is invertible, which we show below. Hence, the aggregated values must be different for different . Similarly, the sums are distinct for different choices of vectors , , .
If two vectors and result in the same , then for all . Let be the set of integers such that at least one of and is nonzero for . Note that . Rewrite this equation as
| (26) |
Since , we take the first equations in (26) and rewrite them as
where
is a square Vandermonde matrix and
is a nonzero vector since . It is known that the determinant of a square Vandermonde matrix is given by , which in our case is nonzero since all the are different. Therefore, is invertible and does not admit a non-zero solution, which contradicts the equation .
Appendix K A Deterministic Low-Complexity Algorithm for SCMA at the Server
In the SCMA scheme we described in Alg. 1, the goal of the server is to reconstruct the vector , given values for . To this end, we first use the Berlekamp-Massey algorithm to compute the polynomial . Then, we factorize over the finite field using the algorithm described in Kedlaya & Umans (2011). The complexity referred to in Section 4.3 corresponds to the average complexity (finding a deterministic algorithm that factorizes a polynomial over finite fields with worst-case complexity is an open problem). The complexity referred to in Appendix C for the SCMA scheme represents an average complexity.
We show next that the SCMA scheme has small worst-case complexity under a deterministic decoding algorithm at the server as well. To this end, we replace the integer in Alg. 2 with a large number such that is larger than the largest possible and there is no overflow when applying the modulo operation on . It is known (Bertrand’s postulate) that there exists a prime number between any integer and , and hence there must be a prime number lower-bounded by and twice the lower bound . However, since searching for a prime number of this size can be computationally intractable, we remove the requirement that is prime. Correspondingly, is not necessarily a finite field. Then, instead of sending , client , will send to the server, , where random keys are independently and uniformly distributed over and hidden from the server. After obtaining , , the server can continue performing operations over the field of reals since there is no overflow in computing . We note that though is exponentially large, the computation of and , and is still manageable, and achieved by computing and storing and using floating point numbers, instead of computing and storing in a single floating point number. Note that can be computed using floating point numbers with complexity almost linear in (i.e., for some constant ).
We now present a low complexity secure aggregation algorithm at the server. After reconstructing , we have . The server switches to computations over the real field. First, it uses the Berlekamp-Massey algorithm to find the polynomial (the algorithm was originally proposed for decoding of BCH codes over finite fields, but it applies to arbitrary fields). Let be the degree of . Then . The goal is to factorize over the field of reals, where the roots are known to be integers in and the multiplicity of each root is one.
If the degree of is odd, then and . Then we can use bisection search to find a root of , which requires polynomial evaluations of , and thus multiplication and addition operations of integers of size at most . After finding one root , we can divide by and start the next root-finding iteration.
If the degree of is even, then the degree of is odd, and the roots of are different and confined to . We use bisection search to find a root of . If , then we use bisection search on to find a root of and start a new iteration as described above when the degree of is odd. If , then and . We use bisection search to find another root of in . Note that for every two roots and () of satisfying and we can always find another root of in . We keep iterating the search for every two such roots until we find a list of roots of such that for odd in and for even . Then we can run bisection search on the sets , to find roots of . Note that during the iteration we need bisection search iterations to find the roots for and bisection search iterations to find roots for .
The total computations complexity is hence at most evaluations of polynomials with degree at most and at most polynomial divisions, which requires at most multiplications and additions for integers of size at most . This results in an overall complexity of for some constant .
Appendix L Difference between the Assignment Matrices and
One example that explains the difference between these two assignment matrices is as follows. Suppose the global data sets and centroid sets are the same for the centralized and FC settings, i.e.,
Suppose that for , which is the first row of , we have
Then, the first row of equals . However, if resides on the memory of client and belongs to the local cluster , and the recorded local centroid satisfies
then the first row of is , even if . Here is the row concatenation of the matrices on client . This example shows that the assignment matrices and are different, which also implies that and are different.
Appendix M Experimental Setup and Additional Results
M.1 Datasets
In what follows, we describe the datasets used in our numerical experiments. Note that we preprocessed all datasets such that the absolute value of each element in the data matrix is smaller than . Each dataset has an intrinsic parameter for the number of optimal clusters, and these are used in the centralized -means++ algorithm to compute the approximation of the optimal objective value. We use in subsequent derivation to denote the objective value returned by the -means++ algorithm. Besides , we set an additional parameter for each client data so that the number of true clusters at the client level is not larger than . This non-i.i.d. data distribution across clients is discussed in Dennis et al. (2021). For small datasets (e.g., TCGA, TMI), we consider the number of clients as , and set for all other datasets.
Celltype [] (Han et al., 2018; Gardner et al., 2014b) comprises single cell RNA sequences belonging to a mixture of four cell types: fibroblasts, microglial cells, endothelial cells and mesenchymal stem cells. The data, retrieved from the Mouse Cell Atlas, consists of data points and each sample has feature dimensions, reduced from an original dimension of using Principal Component Analysis (PCA). The sizes of the four clusters333The clusters are obtained by running centralized -means++ clustering multiple times and selecting the one inducing the lowest objective value. are .
Postures [] (Gardner et al., 2014b; a) comprises images obtained via a motion capture system and a glove for different users performing five hand postures – fist, pointing with one finger, pointing with two fingers, stop (hand flat), and grab (fingers curled). For establishing a rotation and translation invariant local coordinate system, a rigid unlabeled pattern on the back of the glove was utilized. There are a total of samples in the dataset and the data dimension is . The sizes of the given clusters are .
Covtype [] (Blackard & Dean, 1999) comprises digital spatial data for seven forest cover types obtained from the US Forest Service (USFS) and the US Geological Survey (USGS). There are cartographic variables including slope, elevation, and aspect. The dataset has samples. The sizes of the seven clusters are .
Gaussian [] comprises ten clusters, each generated from a -variate Gaussian distribution centered at uniformly at random chosen locations in the unit hypercube. From each cluster, samples are taken, for a total of samples. Each Gaussian cluster is spherical with variance .
FEMNIST [] (Caldas et al., 2018) is a popular FL benchmark dataset comprising images of digits (0-9) and letters from the English alphabet (both upper and lower cases) from over users. It dataset is essentially built from the Extended MNIST repository (Cohen et al., 2017) by partitioning it on the basis of the writer of the digit/character. We extract data corresponding to different clients, each of which contributed at least data points. Each image has dimension . The size of the largest cluster is , and that of the smallest cluster is .
TCGA [] methylation consists of methylation microarray data for samples from The Cancer Genome Atlas (TCGA) (Hutter & Zenklusen, 2018) corresponding to four different cancer types: Low Grade Glioma (LGG), Lung Adenocarcinoma (LUAD), Lung Squamous Cell Carcinoma (LUSC) and Stomach Adenocarcinoma (STAD). The observed features correspond to a subset of values, representing the coverage of the methylated sites, at locations on the promoters of different genes (ATM, BRCA1, CASP8, CDH1, IGF2, KRAS, MGMT, MLH1, PTEN, SFRP5 and TP53). This subset of genes was chosen for its relevance in carcinogenesis. The sizes of the four clusters are .
TMI [] contains samples from human gut microbiomes. We retrieved human gut microbiome samples from the NIH Human Gut Microbiome (Peterson et al., 2009). Each data point is of dimension , capturing the frequency (concentration) of identified bacterial species or genera in the sample. The dataset can be roughly divided into four classes based on gender and age. The sizes of the four clusters are .
M.2 Baseline Setups.
We use the publicly available implementation of K-FED and DC-KM as our baseline methods. For DC-KM, we set the height of the computation tree to , and observe that the leaves represent the clients. Since K-FED does not originally support data removal, has high computational complexity, and its clustering performance is not comparable with that of DC-KM (see Tab. 1), we thus only compare the unlearning performance of MUFC with DC-KM. During training, the clustering parameter is set to be the same in both clients and server for all methods, no matter how the data was distributed across the clients. Experiments on all datasets except FEMNIST were repeated times to obtain the mean and standard deviations, and experiments on FEMNIST were repeated times due to the high complexity of training. Note that we used the same number of repeated experiments as in Ginart et al. (2019).
M.3 Enabling Complete Client Training for MUFC
Note that both K-FED and DC-KM allow clients to perform full -means++ clustering to improve the clustering performance at the server. Thus it is reasonable to enable complete client training for MUFC as well to compare the clustering performance on the full datasets. Although in this case we need to retrain affected clients and the server for MUFC upon each removal request, leading to a similar unlearning complexity as DC-KM, the clustering performance of MUFC is consistently better than that of the other two baseline approaches (see Tab. 2). This is due to the fact that we utilize information about the aggregated weights of client centroids.
| TMI | Celltype | Gaussian | TCGA | Postures | FEMNIST | Covtype | ||
|---|---|---|---|---|---|---|---|---|
| Loss ratio | MUFC | |||||||
| K-FED | ||||||||
| DC-KM |
M.4 Loss Ratio and Unlearning Efficiency
In Fig. 4 we plot results pertaining to the change of loss ratio after each removal request and the accumulated removal time when the removal requests are adversarial. The conclusion is consistent with the results in Section 6.
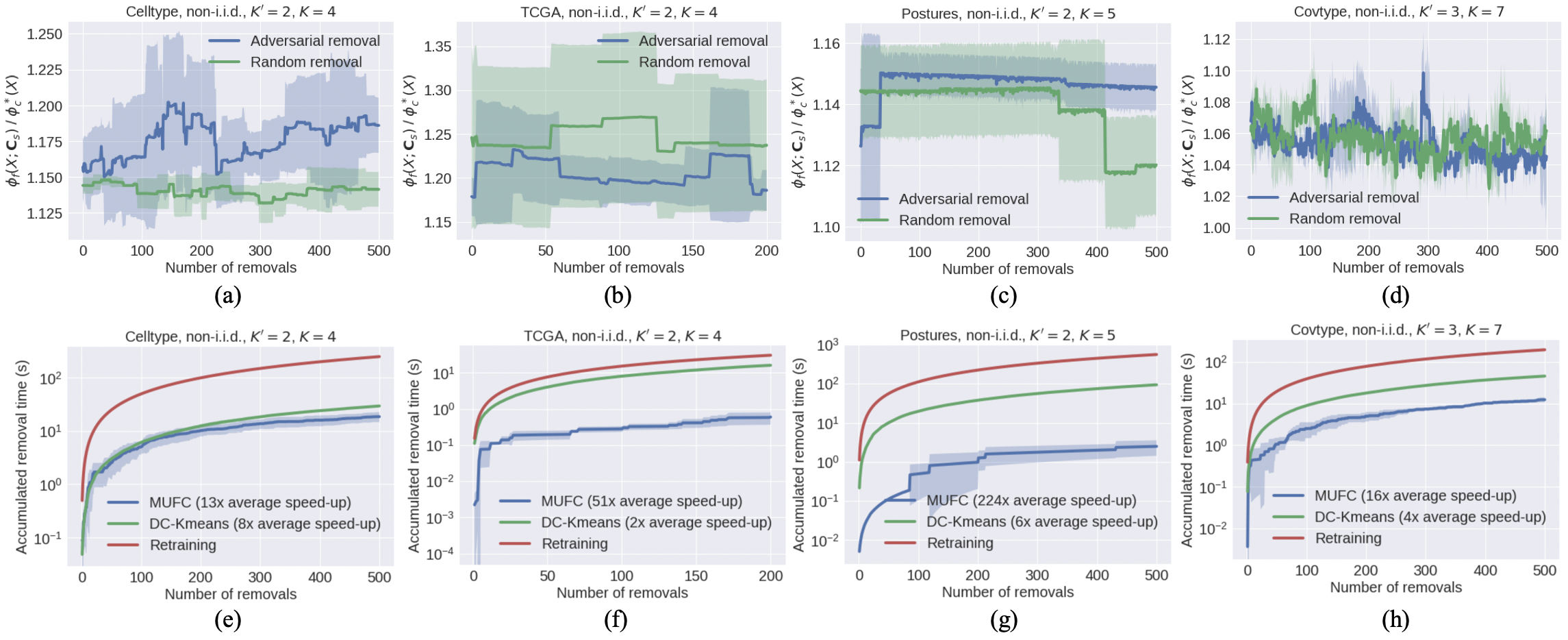
M.5 Batch Removal
In Fig. 5 we plot the results pertaining to removing multiple points within one removal request (batch removal). Since in this case the affected client is more likely to rerun the -means++ initialization for each request, it is expected that the performance (i.e., accumulated removal time) of our algorithm would behave more similar to retraining when we remove more points within one removal request, compared to the case in Fig. 3 where we only remove one point within one removal request.
