A duplication-free quantum neural network for universal approximation
Abstract
The universality of a quantum neural network refers to its ability to approximate arbitrary functions and is a theoretical guarantee for its effectiveness. A non-universal neural network could fail in completing the machine learning task. One proposal for universality is to encode the quantum data into identical copies of a tensor product, but this will substantially increase the system size and the circuit complexity. To address this problem, we propose a simple design of a duplication-free quantum neural network whose universality can be rigorously proved. Compared with other established proposals, our model requires significantly fewer qubits and a shallower circuit, substantially lowering the resource overhead for implementation. It is also more robust against noise and easier to implement on a near-term device. Simulations show that our model can solve a broad range of classical and quantum learning problems, demonstrating its broad application potential.
I Introduction
Machine learning (ML) is a powerful data-analyzing tool that has generated a series of impactful results in image recognition [1, 2, 3], natural language processing [4, 5, 6], self-driving [7, 8, 9], etc. Meanwhile, quantum machine learning has become an emerging interdisciplinary subject combining machine learning with quantum computing. It studies two fundamental questions [10], one on applications of classical ML to quantum problems [11, 12, 13, 14, 15, 16], and the other on implementations of ML algorithms on a quantum processor. Recent works point out that implementing ML algorithms on a quantum computer to process quantum data requires exponentially fewer experiments than dealing with the same task on a classical computer [17]. In addition, it has been shown that many ML algorithms can be implemented on a quantum machine with certain levels of advantage, ranging from data fitting [18], support vector machine [19], nearest neighbors [20], principle component analysis [21], and linear regression [22], to PageRank algorithm [23], reinforcement learning [24, 25, 26], anomaly detection [27] and Boltzmann machine [28]. For other ML topics, especially the quantum neural networks (QNNs), the existence of quantum advantage is largely unknown [29], although an interesting result on the prediction advantage for QNNs has been recently achieved [30].
A neural network (NN) is a parameterized composite mapping comprised of activation functions and is very powerful in data fitting. A QNN is an NN implemented on a quantum computer [31] and there are various proposals to design it, such as the variational QNN [32, 33]. Besides quantum advantage, designing an effective and efficient QNN is also important. Not every QNN design effectively solves the given ML problem, and the concept of universal approximation is introduced to explain why some neural networks fail to work [34, 35]. Universal approximation, or the universality of an NN, refers to its ability to approximate arbitrary functions. For classical NNs, universality is easy to achieve; for QNNs, a smart design is required to make them universal and practical. In fact, the universality of NNs is closely related to the nonlinear activation functions, and the key point of designing a universal QNN is to generate the desired nonlinearity for function fitting. One method is to construct the quantum neurons, which are the building blocks of some QNNs [36, 37, 38, 39, 40, 41]; the other method is to construct a variational QNN from a parameterized quantum circuit, and the nonlinearity can be achieved by duplicating the quantum data into a tensor product of multiple copies [42, 43]. Examples of the latter method include the quantum circuit learning (QCL) algorithm [32] and the circuit-centric quantum classifiers (CCQ) algorithm [33]. So far, the universality of the QCL algorithm has been proved using the Weierstrass theorem, while the universality of the CCQ algorithm remains open. For both QCL and CCQ, approximating a highly-nonlinear function would require a tensor product of many data-encoding subsystems, resulting in a large overall system size with a considerable circuit complexity, conflicting with the principle of NISQ computing where a relatively small quantum system with a shallow circuit is preferred.
To address this problem, we propose a duplication-free quantum neural network (DQNN) based on a variational quantum circuit and rigorously prove its universality. Our model utilizes the classical sigmoid function to generate nonlinearity without duplicating the quantum data into a tensor product of multiple copies. Compared with the CCQ or QCL algorithms, our DQNN significantly reduces the system size and gate complexity, and hence the overall noise effect. Therefore, it is more likely to be implemented on near-term devices. Numerical simulations show that our DQNN outperforms the other two variational QNN algorithms with better performance on typical regression and classification problems and is more robust against noise. In addition, through solving a broad range of classical and quantum learning problems, our model has well demonstrated its wide application potential.
II Two types of designs for universal approximation
Before we discuss the DQNN design, let’s briefly review two common types of designs for the universal approximation of a classical NN. It turns out that universality is closely related to different kinds of convergence. Type I approximation relies on pointwise convergence; a typical example is the polynomial approximation, using the Weierstrass theorem and polynomials to approximate arbitrary functions; Type II approximation depends on the convergence in Lebesgue integration, e.g., -norm convergence. For polynomial approximation, there are several limitations. First, the Weierstrass theorem is only valid on a compact set, while many NN problems are defined on unbounded set, on which polynomials could fail to approximate a Lebesgue integrable function. For example, the function defined on can not be well approximated by polynomials since the latter diverges to while vanishes as . Second, polynomial approximation has a numerical problem called Runge’s phenomenon [44] when the polynomial order becomes very large, which is why using high-order polynomials for function fitting is not favored in practical use. Due to these limitations, polynomials are ineffective in designing universal NNs. It has been proved that the necessary and sufficient condition for a universal feedforward NN is that its activation functions are not polynomial [35]. In comparison, Type II approximation utilizes basis functions such as the hat function in finite-element method [45] or the sigmoid/ReLU function composite with linear function in neural networks [46]. Usually, the optimal approximation is the solution to a minimization problem, and the error is evaluated in a suitable function norm. In particular, universal NNs based on -norm approximation are widely applied and found to be very effective. Such examples include the ones with activation functions, such as the sigmoid or the ReLU functions. Hence, this work aims to discuss how to construct a universal and effective QNN based on approximation, using the trick analogous to the sigmoid function instead of the polynomials. We expect that such QNN is effective in a broad range of applications compared to the QNN based on polynomial approximation.
III DQNN and its universality
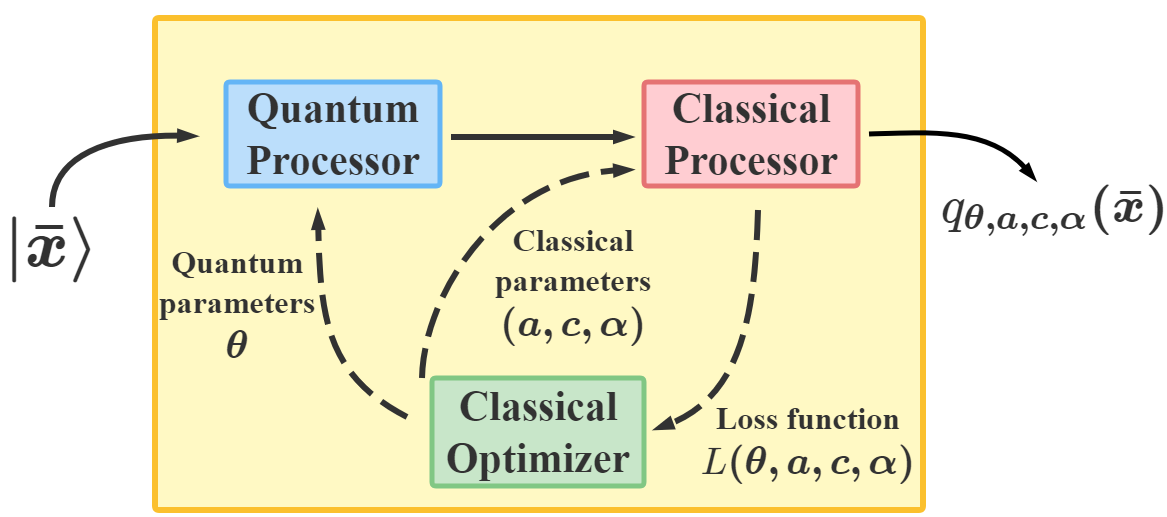
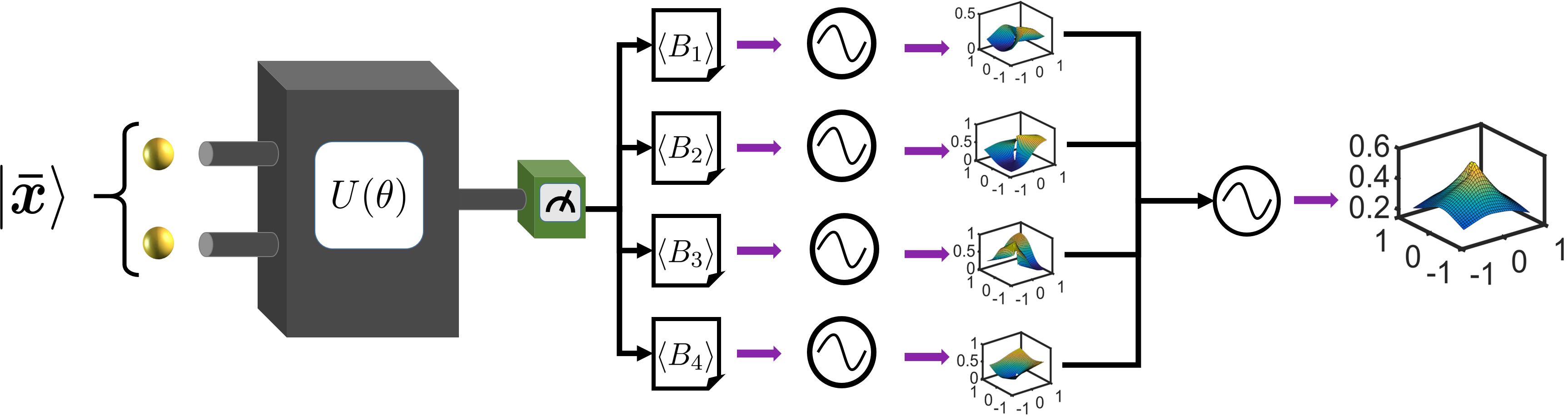
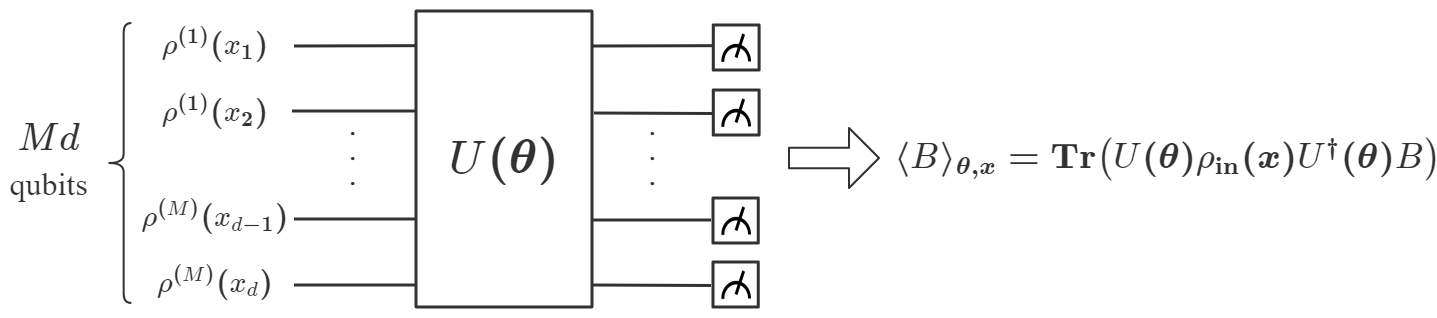
Mathematically, a variational QNN is a mapping built on a parameterized quantum circuit . It involves a hybrid quantum-classical algorithm that utilizes a quantum processor to generate the output for each input , and a classical processor to optimize to solve learning problems. Specifically, given an unknown function , and a data set , where is the label of , the aim of QNN is to find an optimal such that best approximates the target function . Our DQNN model consists of three parts, a quantum processor, a classical processor and a classical optimizer, as illustrated in Fig. 1(a). First, each data point is encoded into a state of an -qubit register ():
| (1) |
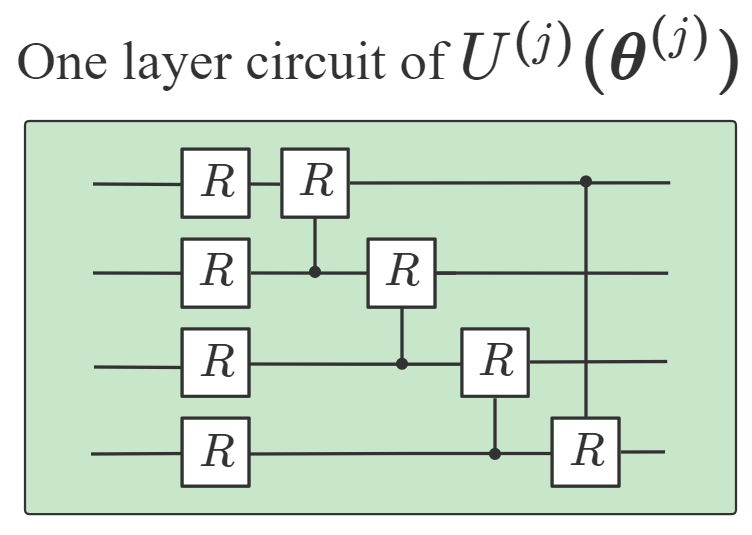
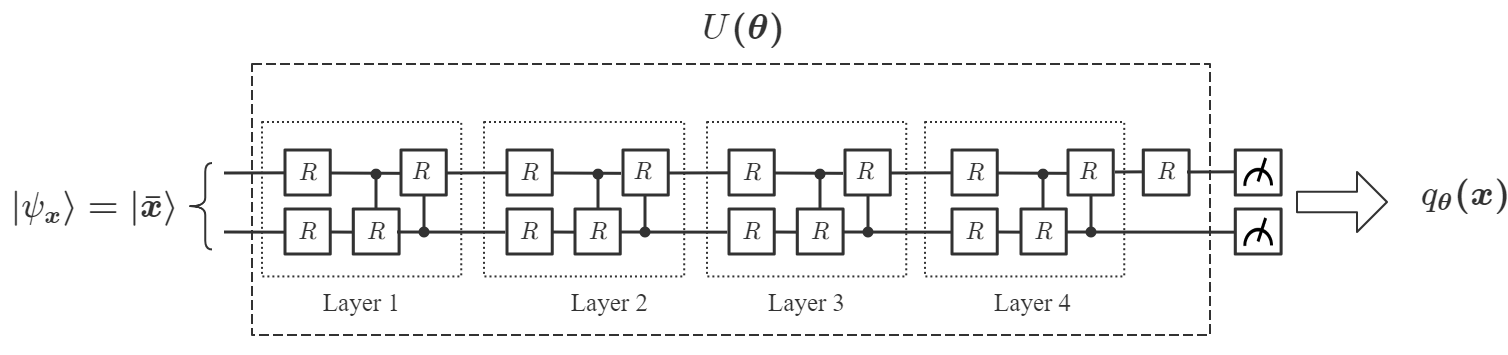
using the amplitude encoding method [47], where is a padding term chosen by the user and is a normalization factor (Appendix A). After initial state preparation, we apply to a series of variational quantum circuits according to , followed by measurements of a set of observables , to obtain the outcomes . The choices of are not unique and they can be chosen randomly from the generalized Pauli basis where with , and are the Pauli matrices. comprises -layers of quantum circuits. Each layer consists of parameterized -rotations (with one on each qubit), and parameterized controlled- gates, as shown in Fig. 1, with
Notice that the order of the gates in each layer is not unique and can be chosen randomly [33]. Next, based on and the sigmoid function , the classical processor computes and obtains the output:
| (2) |
with , where and are parameters to be trained. The entire process from to is summarized in Fig. 1. Finally, one can find the optimal values of to solve the given learning problem, through gradient-based optimization using algorithms such as SGD [48], ADAM [49] or BFGS [50]. The benefit of such construction is that DQNN can be proved to be universal based on approximation, which is summarized in the following theorem:
Theorem 1.
Let be a subset of the complex sphere in , and be an arbitrary square-integrable function on . We define the following parameterized functions:
| (3) |
and denote as the set of all such functions, where , , , , and . Then is dense in in the following sense: for any ,
| (4) |
The detailed proof of Theorem 1 can be found in Appendix B. It turns out that any in Eq. (3) can be generated as the output of the DQNN in Eq. (2). Specifically, given the parameters , we can design a DQNN with a single observable , , and a series of quantum circuits such that . Then the output of the DQNN in Eq. (2) is reduced to:
| (5) |

Thus we have proved the following corollary:
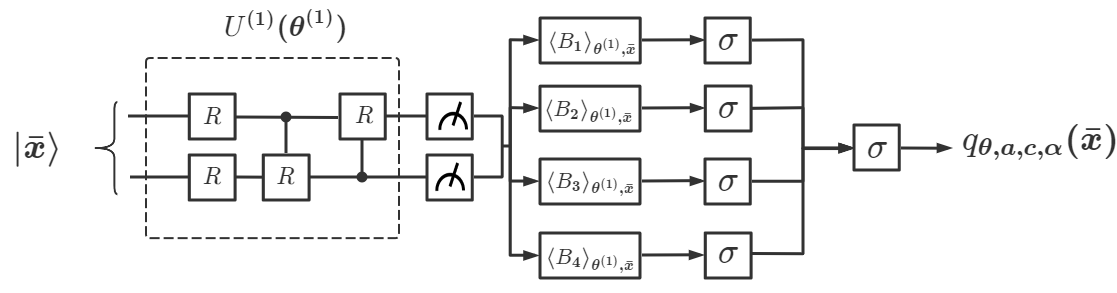
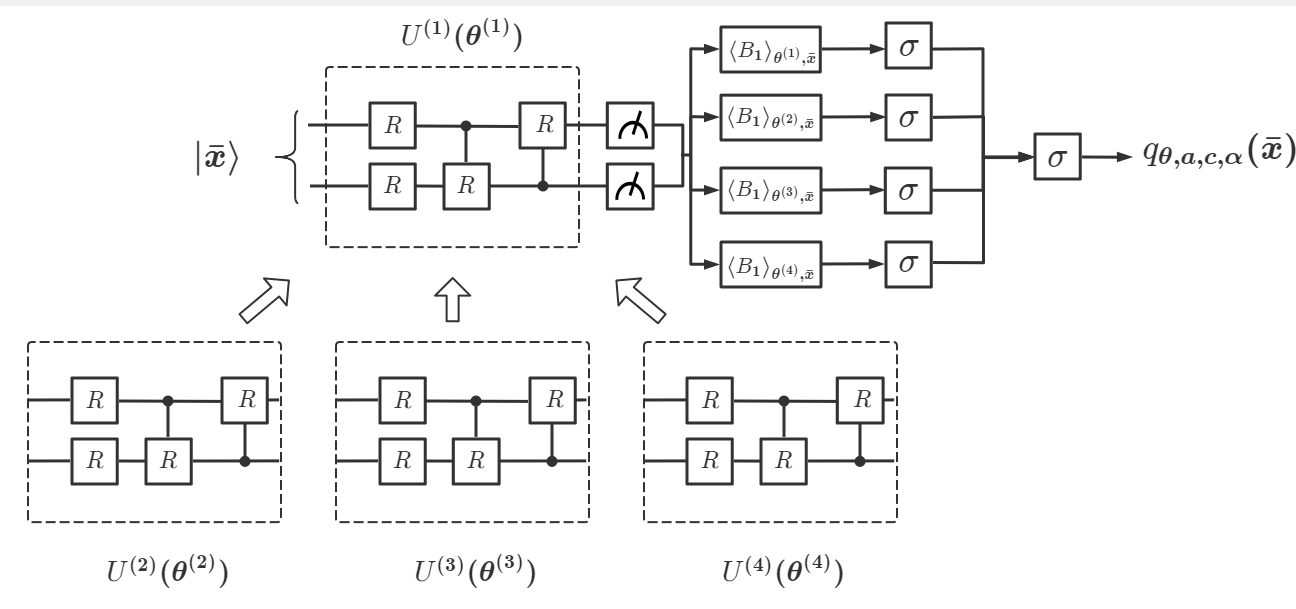
Notice that choosing multiple and a single observable is only a sufficient condition to prove the universality in Corollary 1. In practice, we often design a DQNN with a single () and a set of as the first trial to solve the given problem. If it is not good enough, we then construct a new DQNN with a larger . It turns out a DQNN with is often sufficient for most learning problems we have studied. In addition, in the proof of Corollary 1, we have assumed that the variational circuits with can be generated by our designed multi-layer variational circuits as shown in Fig. 1 (b). More layers in will make it more powerful to approximate arbitrary unitary gate, but will also make the optimization process computationally more expensive. Hence, in practice, we often construct a DQNN starting from a single consisting of one or two layers. In the following, we will study the performance of DQNN with different values of , and for simplicity, we will denote the corresponding network as DQNN.
IV Performance comparison among QNN models
In Section II, we have mentioned that universality serves as a necessary condition to build an effective QNN, and among the two types of universal design, an NN with convergence using sigmoid basis functions works more effectively in a broader range of applications. As shown above, the nonlinearity and the universality of DQNN originates essentially from the convergence of sigmoids functions, which is distinctive from other polynomial-approximation-based QNN models, including the CCQ [33] and the QCL [32], whose nonlinearity is mainly generated by duplicating the same data-encoding state into a tensor product of multiple subsystems. In this way, DQNN has significantly reduced the number of qubits required to construct a universal QNN. In the following, we will demonstrate the advantages of DQNN by comparing its performance with those of the two well-established QNN models, the CCQ and the QCL.
For an -qubit QNN model, we define its complexity as , where denotes the number of quantum gates and denotes the number of quantum measurements. Notice that given a measurement precision, is proportional to the number of measurement observables . Hence, with a further assumption that the QNN variational circuit can be efficiently generated, i.e., , the overall complexity of the QNN then becomes . We hope to figure out the numbers of qubits and observables required to approximate an -order polynomial function with using CCQ, QCL and DQNN respectively. We denote by the number of qubits in the data-encoding register, and by the number of copies of the data-encoding register used in a QNN model. To approximate such , CCQ requires duplicates of the data-encoding register such that the amplitude of the input state, , is an -order polynomial of . After applying a circuit , we measure the expectation values of a given observable according to . The output of the CCQ is an -order polynomial of . Then the goal of CCQ is to find the best value through optimization such that is the optimal function to approximate . The number of qubits in the data-encoding register is and the number of observables is . Hence the total complexity of CCQ is equal to . For QCL, a -dimensional classical data is encoded into a -qubit data-encoding register as using several single-qubit rotation gates. In order to generate an -order polynomial, is duplicated into identical copies in a tensor product as . Applying a circuit to , we measure the expectation value of a given observable . The outcome is an -order polynomial of . Through optimization, we can find the best value such that will well approximate . The total number of qubits in QCL is and the number of observables is . Hence the total complexity of QCL is .
Different from the above two duplication-based QNN models, DQNN only uses qubits to encode as . We sequentially apply a set of variational quantum circuits to and measure the expectation for a set of chosen observables . Next we apply the parameterized classical sigmoid function and derive the final output . Through the optimization, we can find the optimal values to approximate the function . The number of measurement observables is determined by . Hence the total complexity of DQNN is . The comparison is summarized in Table 1. It can be seen that for large and large , our DQNN can significantly reduce the total complexity to generate nonlinearity. More details can be found in Appendix C.
| Algorithm | Complexity | ||
|---|---|---|---|
| QCL | |||
| CCQ | |||
| DQNN |
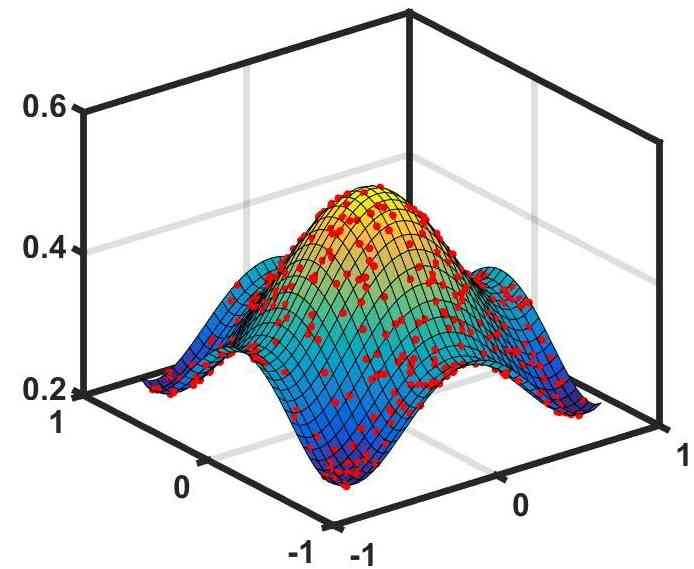
To demonstrate that our DQNN has advantage in solving classical ML problems and in reducing circuit complexity, we apply DQNN, QCL, and CCQ to two typical supervised learning problems, a regression problem and a classification problem, and compare their performance. The first problem is learning from a data set to approximate a highly nonlinear polynomial with (Fig. 2). For input , the output of the QNN is denoted as . One can define the relative error to measure the performance of the QNN in solving regression problems. A tiny relative error implies that the QNN approximates the target function well. First, we run the hybrid optimization process for each model based on the data set. To show the effectiveness of the three QNN models, we choose different values of the number of layers for each model so that their circuit complexity is similar in size. We use the same definition of as in the above section. Then, we compare the optimal relative errors achieved for each model. We choose two types of DQNN to solve the regression problem. One has a single-layer variational quantum circuit and multiple observables. We name it DQNN. The other has single-layer variational quantum circuits and one observable. We name it DQNN. We find that, with no duplicate, , the relative error achieved by DQNN is substantially lower than those achieved by QCL and CCQ, as shown in Table 2(a). If we add one more duplicate to both the QCL and the CCQ models, their optimal relative error will decrease, but their complexity will increase and surpass that of the DQNN. In addition, we implement such comparison for a few other examples, and simulation results suggest that DQNN can prominently reduce the circuit complexity to approximate highly nonlinear functions compared with QCL and CCQ. The approximation process of the DQNN with observables is shown in Fig. 2, and more details of the comparison can be found in Appendix D.
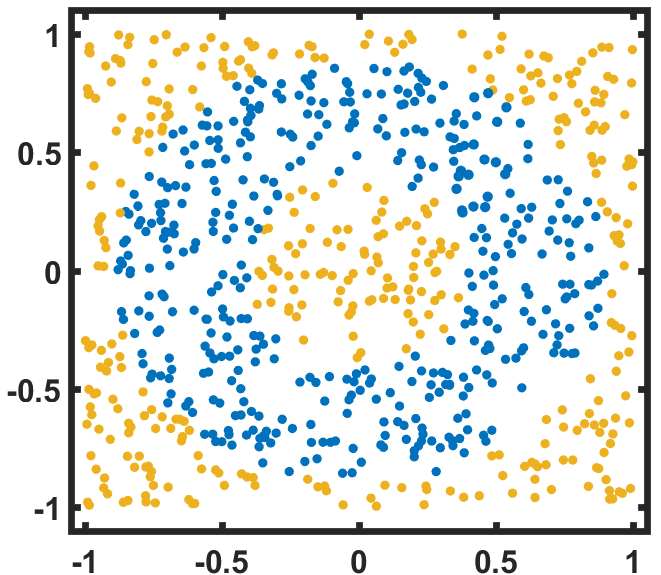
We apply the three models to a binary classification problem on a ring-shaped data set in the second task. The boundaries of the two sub-datasets are determined by six curves , , and (Fig. 2). One can use classification accuracy to quantify the performance of QNN model in solving classification problems, which is defined as where is the output of QNN, represents the label of and is the Dirac delta function [51]. Analogous to the first task, we choose the DQNN with one variational quantum circuit and multiple observables (DQNN) and the DQNN with variational quantum circuits and one observable (DQNN) for the classification task. We choose appropriate values for and , so that the circuit complexity of the three models is similar in size. After optimizing the three QNN models, we find that accuracy achieved by the DQNN is substantially higher than those achieved by QCL and CCQ. In addition, increasing the number of duplicates does help QCL and CCQ to improve their optimal accuracy, but even a -copy model (with 12 qubits) for QCL or CCQ cannot perform equally well as a DQNN with only two qubits (Table 2(b)). Next, we implement such a comparison for a few other examples. Simulation results suggest that DQNN can prominently reduce the circuit complexity compared to QCL and CCQ, but maintain a good performance in solving classification problems.
| Model | Copy number () | # Qubits () | # Layers () | # Observables () | Relative error | ||
| DQNN | 2 | 1 | 2 | 1 | 4 | 48 | 6.79% |
| DQNN | 2 | 1 | 2 | 1 | 1 | 48 | 5.46% |
| QCL | 2 | 1 | 2 | 4 | 1 | 48 | 8.21% |
| CCQ | 2 | 1 | 2 | 4 | 1 | 51 | 12.92% |
| QCL | 2 | 2 | 4 | 5 | 1 | 120 | 7.35% |
| CCQ | 2 | 2 | 4 | 4 | 1 | 99 | 4.74% |
| Model | Copy number () | # Qubits () | # Layers () | # Observables () | Accuracy | ||
| DQNN | 2 | 1 | 2 | 1 | 20 | 240 | 91.40% |
| DQNN | 2 | 1 | 2 | 1 | 1 | 48 | 97.63% |
| QCL | 2 | 2 | 4 | 5 | 2 | 240 | 74.18% |
| CCQ | 2 | 2 | 4 | 10 | 1 | 243 | 75.20% |
| QCL | 2 | 6 | 12 | 10 | 2 | 1440 | 76.93% |
| CCQ | 2 | 6 | 12 | 10 | 1 | 723 | 80.63% |
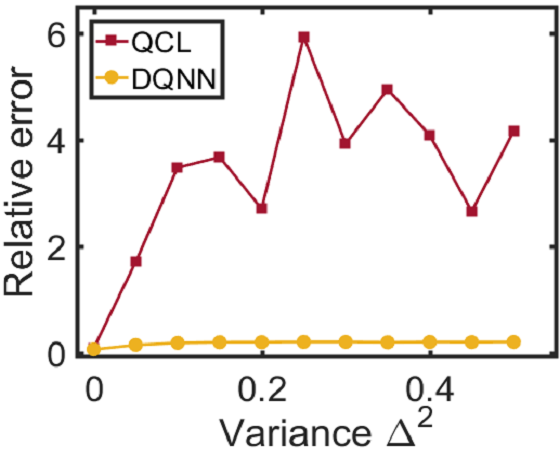
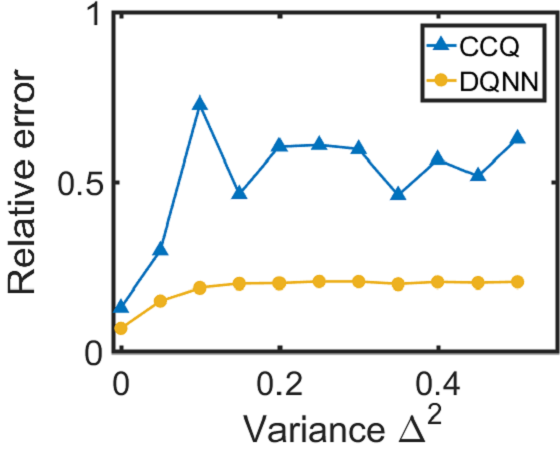
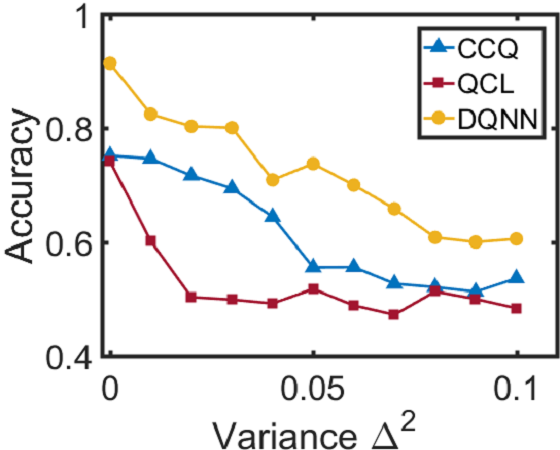
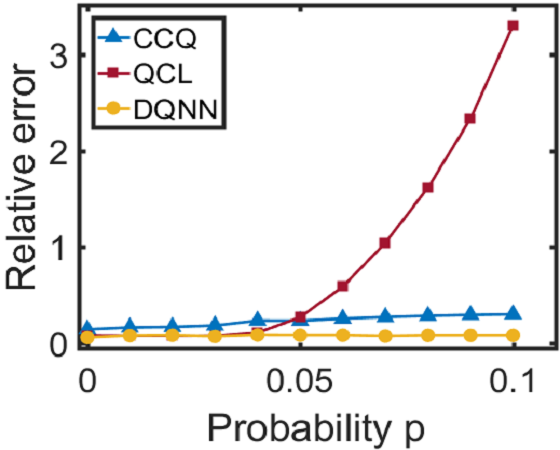
Since the DQNN can reduce the circuit complexity, we expect that it can achieve a better performance in the presence of noise, and hence is easier to be implemented on NISQ devices. We will consider two types of noise in this work: one is the coherent noise caused by the imprecision of the classical control on the parameter values in the QNN circuits; the other is the decoherence generated by interactions between the quantum register and its environment. We add a coherent noise to the -th parameter, , in the variational circuit according to when we train the three QNN models, and test their performance under the noisy environment. The coherent noise is generated by sampling from a Gaussian distribution, where indicates the noise intensity. It can be seen from Fig. 3 and 3 that for the regression task, the DQNN achieves lower relative error than QCL and CCQ when we increase the coherent noise. Meanwhile, for the classification task (as shown in Fig. 3), DQNN is more robust than the other two when the coherent noise increases. In addition to the coherent noise, we further apply the decoherence, , to the two-qubit control gates, , contained in the quantum circuits according to where indicates the complete Pauli basis and represents the probability of decoherence occurrence. From Fig. 3, we can find that, in the regression task, the DQNN has a significantly lower relative error than QCL and CCQ as the probability of decoherence increases. These numerical results demonstrate that the DQNN can decrease the influence of noise accumulation in the training process and is more likely to be implemented on near-term devices.
Besides the comparison among three QNN models over two supervised learning problems, we further demonstrate the performance of the different QNNs in solving the typical real-world machine learning problem based on the handwritten digits data set, MNIST [52]. In this task, a QNN is first trained with figures, each of which has a number ranging from to , and then is tested with new figures to generate the classification accuracy. A figure in the MNIST data set is reshaped to be a -dimensional vector and encoded into an -qubit quantum state by using the amplitude encoding method. Since the QCL needs qubits to encode the classical data, it is intractable to implement the QCL in solving this task and we only compare the performance of the DQNN and the CCQ. For our DQNN, we use -layer variational circuits and one observable . The classification accuracy over new figures can achieve . For the CCQ, we use one variational quantum circuit and a set of POVM operators to generate the final output. We adopt different layers for the variational quantum circuit, however, the performance of the CCQ is still significantly lower than the DQNN. For instance, the CCQ with a -layer variational quantum circuit only achieves accuracy. The result demonstrates that the QNN without a strict universality guarantee will fail in solving machine learning problems.
V Comparison with classical neural networks
To demonstrate that our DQNN can perform at least as effectively as the classical NN, we apply the DQNN to solve three typical real-world classification problems and further compare its performance with the classical NN in the minimum parameters required the number of iterations to achieve a similar classification accuracy. Since our DQNN is essentially with a single hidden layer, we will choose a single-hidden-layer classical neural network for the comparison. On the handwritten digits data set, MNIST [52], we implement a binary classification (MNIST) to distinguish the digits and , and a -target classification (MNIST) to recognize the digits , , . Each sample is reshaped into a -dimensional vector and taken as the input of DQNN and classical NN. Meanwhile, we implement two more classification tasks based on the Wine data set [53] and the Breast Cancer data set [53]. We use a -qubit state to store the -dimensional classical data for the Wine problem, and a -qubit state to store the dimensional data for the Breast Cancer problem. As shown in Table 3, the DQNN performs as well as the classic neural networks in discovering complex patterns hidden in real-world data sets. Notice that DQNN uses fewer parameters to achieve similar accuracy than the classical counterpart but is at the extra cost of required iterations in some cases.
| Model | Task | # Parameters | # Iterations | ||||
| DQNN | MNIST | ||||||
| Classical NN | MNIST | ||||||
| DQNN | MNIST | ||||||
| Classical NN | MNIST | ||||||
| DQNN | Wine | ||||||
| Classical NN | Wine | ||||||
| DQNN | Breast Cancer | ||||||
| Classical NN | Breast Cancer |
VI Quantum phase recognition
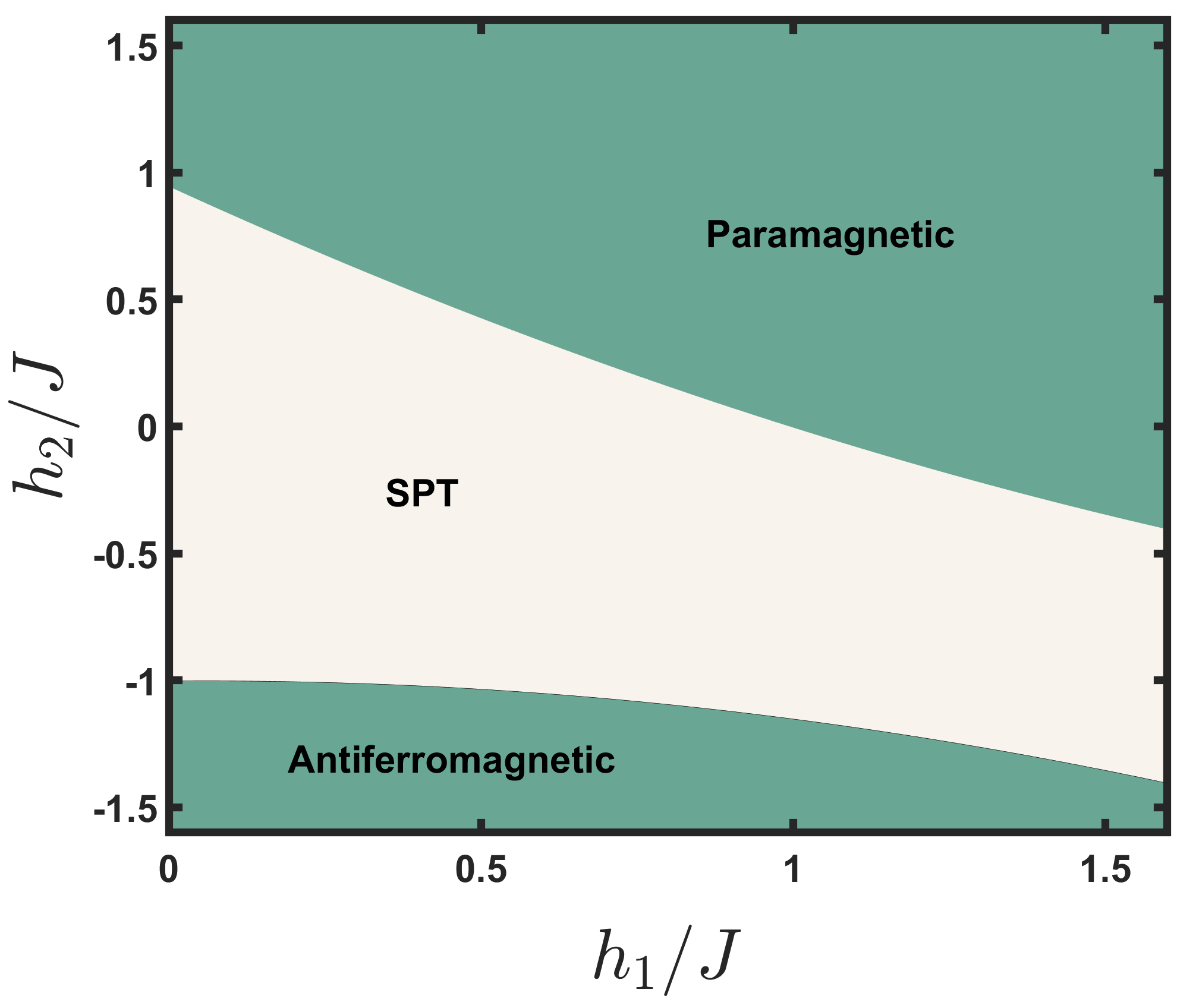
Besides the classical ML problems, our DQNN model can solve ML problems on quantum data sets. In the following, we concentrate on a class of quantum phase recognition problems, the discrimination of the symmetry-protected topological (SPT) phase on a Haldane chain [54]. The ground state of the Hamiltonian,
has three topological phases, the SPT phase, the paramagnetic phase and the antiferromagnetic phase, where and are parameters. Our goal is to identify whether a given state sampled from the phase diagram in Fig. 4 belongs to the SPT phase. To complete such a task, we take equally spaced points from and as the training set and equally spaced points as the test set. If the ground state belongs to the SPT phase, it is labeled ; otherwise, it is labeled . We numerically implement the DQNN with a single -qubit variational quantum circuit with parameters and observables. After training, the accuracy of the DQNN on the test data achieves . It indicates that our DQNN model has solved the quantum phase recognition problem with good performance. However, the training set to train the DQNN is larger than the training set to train the quantum convolutional neural network [55] for phase recognition task. The reason for the difference is that the DQNN used in the comparison is only a prototype, while the quantum convolutional neural network in [55] has been optimized for this task, with a stronger ability to analyze the local information of quantum states. Hence, as a future work, we hope to improve the DQNN design to optimize its performance for the given ML problem.
VII Conclusion
There have been many successes in achieving larger scale and higher fidelity of the NISQ devices. These improvements provide the quantum neural network with the opportunity to deal with larger data sets and even outperform the classical counterpart. This paper presents a duplication-free quantum neural network model, DQNN, to solve machine learning problems. Meanwhile, we provide it with the universal guarantee to approximate any arbitrary continuous function using several variational quantum circuits, multiple measurement observables and the classical parameterized sigmoid function. We can enhance the expressibility of DQNN by increasing the number of quantum circuits and the number of observables without requiring auxiliary qubits. This property for the number of qubits makes DQNN more likely to be implemented on intermediate-scale quantum computers.
Unlike other variational QNN proposals, DQNN utilizes the classical computer in the hybrid system to generate nonlinearity. Without duplicates, DQNN significantly reduces the number of required qubits and decreases circuit complexity compared with two well-known QNN models. Our simulation results demonstrate that, compared with QCL and CCQ, DQNN uses fewer qubits and fewer quantum gates to outperform the other two QNN models and hence weaken the influence of the circuit noise. Furthermore, DQNN requires fewer parameters than the classical counterpart but is at an extra cost of the iterations in some cases. DQNN can also be used to solve quantum problems. These results indicate that the DQNN is an efficient QNN model which can find the patterns hidden in the classical and quantum data sets.
Like the classical naive neural network, DQNN can be considered a subroutine to construct more complex quantum deep learning models. In addition, DQNN can also be improved by optimizing its structure for the given ML problem. For example, DQNN can be combined with the concept of recurrent neural network to efficiently solve the natural language processing tasks, or integrated into a quantum reinforcement learning framework. Moreover, due to its simple design, DQNN is relatively easy to be implemented on NISQ devices for QNN demonstration.
Acknowledgements
The authors gratefully acknowledge the grant from the National Key R&D Program of China, Grant No. 2018YFA0306703. We also thank Chu Guo, Bujiao Wu, Yusen Wu, Shaojun Wu, Yuhan Huang, Donghong Han, Yingli Yang and Yi Tian for helpful discussions.
Appendix A Amplitude encoding method
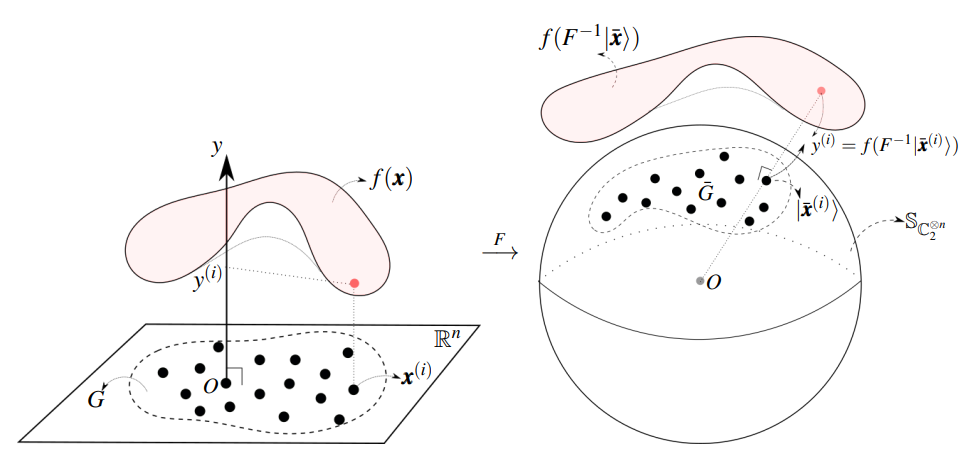
Suppose of the data set is contained in a subset of . Without loss of generality, we can choose an appropriate coordinate frame through translation such that and every satisfies with constants and . In order to apply variational QNN, we encode the classical data into the states of a quantum register. In this work, we define the encoding mapping such that is an -qubit state in the Hilbert space with :
| (6) |
where , . It is easy to validate that and
| (7) |
with . Such encoding method is called amplitude encoding, since the classical information is encoded into the amplitudes of , as illustrated in Fig. 5. Therefore, approximating is equivalent to the approximation of .
Appendix B Proof of Theorem 1
It suffices to show is dense in . We will prove it by contradiction. Assume that the closure . By the Hahn-Banach theorem [56], there exists a bounded linear functional on such that and . By the Riesz representation theorem [57], there exists a function such that the linear functional can be represented as
| (8) |
Note that implies on . Therefore, the following two sets and are measurable and at least one of them has a positive measure. Without loss of generality, we assume that almost everywhere in an open subset with . Substituting into above equation, and in view of , we have:
| (9) |
As the open set contains a small ball , we will show that, by choosing large enough and , the function tends to in a smaller ball and vanishes quickly outside of , which leads to a contradiction to Eq. (9).
Since is a real subset of the unit sphere,
| (10) |
which implies that is equivalent to one of the following two cases:
| (11) |
For , case (i) means is sufficiently close to , and (ii) means is sufficiently close to , but the latter case is impossible. Specifically, for sufficiently close to , and a given value , we can choose such that , and together with Eq. (7), we have:
| (12) |
If (ii) were true, then by , we would find , contradictory to Eq. (12). Hence case (ii) is impossible. Therefore, when , is only equivalent to case (i). Passing to the limit , we get
| (13) |
with . Taking sufficiently close to , we have , and from Eq. (9) we obtain
| (14) | ||||
| (15) |
which is a contradiction. Hence, we conclude that is dense in . Thus for any and , there exists a such that
| (16) |
which proves Theorem 1.
Remark 1.
If is a ReLU-type function, then the conclusion still holds. In fact, instead of Eq.(13), we have for all and otherwise, which leads to the contradiction:
Appendix C Introduction to other variational QNN models
In order to compare the performance of DQNN with other models, in this section, we will present a brief introduction to two established variational QNN models, circuit-centric quantum classifier (CCQ) [33] and quantum circuit learning (QCL) [32], and will apply these models to solve the following quantum learning problem: constructing a QNN to approximate an -order polynomial : , where is an even number.
First, we consider the CCQ model, where the classical data with is mapped into a -qubit register with , using the following encoding scheme:
| (17) |
where is a padding term chosen by the user, and is the normalization factor. Notice that alone is not sufficient as an input to generate the desired nonlinearity, and an input state as a tensor product of copies of is required to generate the high-order terms in . Specifically, to approximate the polynomial , the input state of CCQ is chosen as:
| (18) | ||||
| (19) |
where . Here we have chosen the number of copies of in to be .
Denoting the variational quantum circuit in CCQ by , the output state becomes:
| (20) |
where each amplitude of is an -order polynomial of . Hence, for a chosen observable , the measurement outcome is an -order polynomial of . Then the goal of CCQ is to choose an appropriate and to find the best value through quantum-classical hybrid optimization such that is the optimal function to approximate . The quantum circuit for CCQ is presented in Fig. 6.
Next, we consider the QCL model, where the data point is encoded into a -qubit data-encoding pure-state density operator:
| (21) |
where represents a Pauli- rotation on the -th qubit. Analogous to the CCQ case, along is not sufficient as an input to generate the desired nonlinearity. In order to generate an -order polynomial, is duplicated into identical copies in a tensor product. Specifically, the input state of QCL is chosen as:
| (22) |
Applying a parameterized quantum circuit to , followed by a measurement of a chosen observable , we obtain the measurement outcome as the output of QCL:
| (23) |
Define as a set of generalized Pauli operators. Due to Eq. (22), can be expanded in terms of :
| (24) |
where , , are polynomials with respect to all variables. Assuming is unitarily diagonalized as
| (25) |
we substitute Eq. (24) and Eq. (25) into Eq. (23) and obtain:
where is the set of computational basis. Thus, the task of QCL is to choose an appropriate observable and to find the best value through quantum-classical hybrid optimization such that will well approximate . The quantum circuit for QCL is given in Fig. 7.
In summary, to prepare the desired initial state to solve the same polynomial approximation problem, it requires qubits for CCQ, and qubits for QCL. In comparison, it only requires qubits for DQNN to prepare the input state as in Eq. (17). This is a significant reduction for large and large . Specifically, for DQNN, after we prepare the input state , we sequentially apply a series of variational quantum circuits, , and quantum measurement to derive the measurement outcome for a set of chosen observables . Next, we apply a parameterized classical sigmoid function to each to construct the final output . Finally, we implement the hybrid optimization to find the optimal values of to approximate the target polynomial, where , , are parameters used to construct the final output , with details in the following.
Appendix D Solving regression problems using DQNN, CCQ and QCL
In the following, we aim to solve a regression task of approximating a highly nonlinear function:
| (26) |
using DQNN, QCL and CCQ. The data set is of size , with randomly chosen from the square , and each label is calculated according to . The goal of a QNN is to generate a nonlinear function to approximate by optimizing over the parameters of the QNN.
First, we use the DQNN model to solve this problem. We choose two cases for DQNN in the task. Case (DQNN) is based on a -qubit single-layer variational quantum circuit, , and four measurement observables, , randomly chosen the generalized Pauli basis on two qubits, as shown in Fig. 8(a). Case (DQNN) is based on four -qubit single-layer variational quantum circuits, , and one measurement observable , as shown in Fig. 8(b). Through state reparation, each data point is encoded into the input state:
| (27) |
where and . Then we sequentially apply the variational circuit and quantum measurement to obtain the measurement outcome :
| (28) |
Denoting the sigmoid function as , with
| (29) |
for DQNN, we obtain
| (30) |
and finally derive
| (31) |
where the parameter comes from the quantum circuit , while the parameters come from the classical processing after . For DQNN, we obtain
| (32) |
and derive
| (33) |
Finally, through optimization, we can find the optimal values of parameters that correspond to the optimal approximation to the target function .
Second, we consider the CCQ model. For any data point , can be encoded into a 2-qubit state as in Eq. (17). For the input state in Eq. (19), the number of copies can be chosen to be . Here we consider two cases, and . For , we design in CCQ to be a -qubit -layer variational quantum circuit; for , in CCQ is chosen to be a -qubit -layer circuit. The circuit depth of is in the former case, and in the latter case. Correspondingly, the input state is either a 2-qubit state or a 4-qubits state, as shown in Fig. 9. After input state preparation in each case, we apply and a measurement to , and derive the measurement outcome
| (34) |
where the observable is chosen as , the local Pauli-Z gate on the first qubit. Then we derive the following output
| (35) |
Through optimization, we can find the optimal value that correspond to the best approximated to the target function .
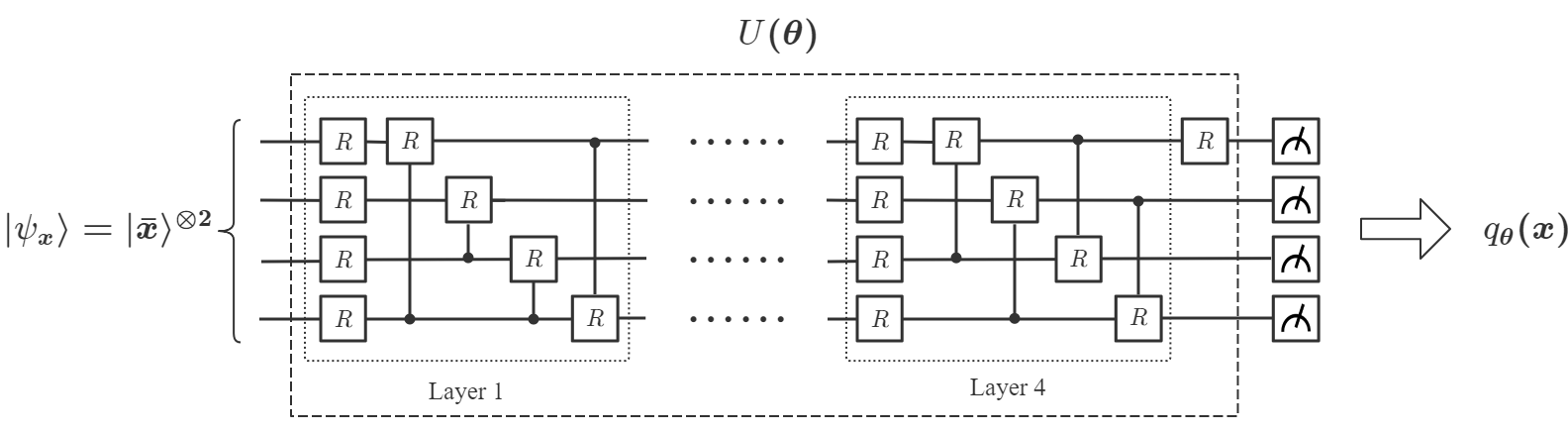
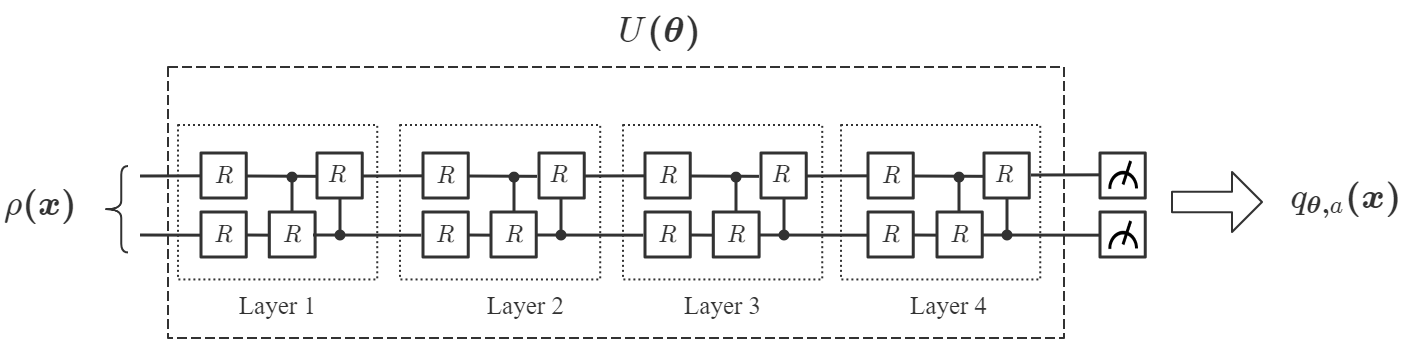
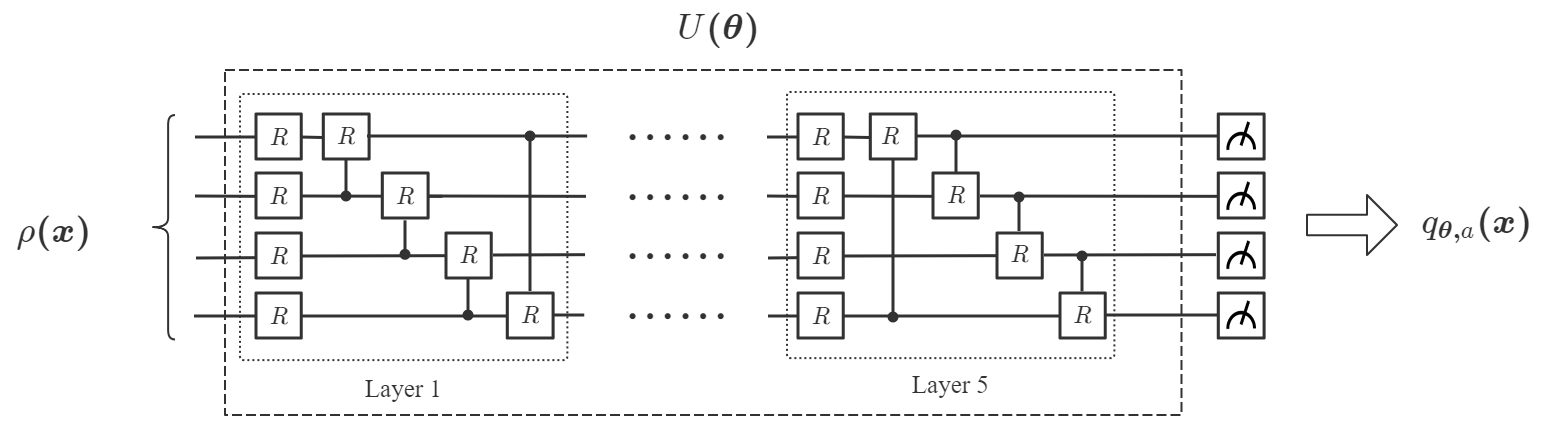
Finally, we apply QCL to solve the same problem. We also consider two cases where the classical data point is encoded into a 2-qubit state () and a 4-qubit state () respectively, as in Eq. (21):
| (36) |
The entire process from the input state to the final output of QCL is illustrated in Fig. 10. Notice that the variational quantum circuit is slightly different from the original suggestion in [32], as we find that our modified circuit has a better performance. After input state preparation in each case, we apply and a measurement to , and derive the measurement outcome
| (37) |
where the observable is chosen as . Then we obtain the final output of QCL:
| (38) |
where is a trainable parameter. Then, through optimization, we find the optimal values of the parameters that correspond to the best approximated to the target function .
References
- Zheng et al. [2017] H. Zheng, J. Fu, T. Mei, and J. Luo, Learning multi-attention convolutional neural network for fine-grained image recognition, in IEEE International Conference on Computer Vision (ICCV), edited by K. Ikeuchi, G. Medioni, and M. Pelillo (Venice, Italy, 2017) p. 5219.
- Shi et al. [2017] B. Shi, X. Bai, and C. Yao, An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition, IEEE Trans. Pattern Anal. Mach. Intell. 39, 2298 (2017).
- Albawi et al. [2017] S. Albawi, T. A. Mohammed, and S. Al-Zawi, Understanding of a convolutional neural network, in 2017 International Conference on Engineering and Technology (ICET), edited by O. Bayat, S. A. Aljawarneh, and H. F. Carlak (Akdeniz University, Antalya, Turkey, 2017) p. 1.
- Goldberg [2016] Y. Goldberg, A primer on neural network models for natural language processing, J. Artif. Intell. Res. 57, 345 (2016).
- Goldberg [2017] Y. Goldberg, Neural Network Methods for Natural Language Processing, Vol. 37 (Morgan & Claypool, 2017).
- Collobert and Weston [2008] R. Collobert and J. Weston, A unified architecture for natural language processing: Deep neural networks with multitask learning, in Proceedings of the 25th International Conference on Machine Learning, edited by W. Cohen, A. McCallum, and S. Roweis (Helsinki, Finland, 2008) p. 160.
- Nugraha et al. [2017] B. T. Nugraha, S. F. Su, and Fahmizal, Towards self-driving car using convolutional neural network and road lane detector, in International conference on automation, cognitive science, optics, micro electro-mechanical system, and information technology, edited by T. Arjon, H. Taufik, and K. D. Esti (Jakarta, Indonesia, 2017) p. 65.
- Do et al. [2018] T. D. Do, M. T. Duong, Q. V. Dang, and M. H. Le, Real-time self-driving car navigation using deep neural network, in International Conference on Green Technology and Sustainable Development, edited by D. T. Trung (Ho Chi Minh City, Vietnam, 2018) p. 7.
- Bojarski et al. [2017] M. Bojarski, P. Yeres, A. Choromanska, K. Choromanski, B. Firner, L. Jackel, and U. Muller, Explaining how a deep neural network trained with end-to-end learning steers a car (2017), arXiv e-prints, ArXiv:1704.07911.
- Biamonte et al. [2017] J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, and S. Lloyd, Quantum machine learning, Nature 549, 195 (2017).
- Carleo and Troyer [2017] G. Carleo and M. Troyer, Solving the quantum many-body problem with artificial neural networks, Science 355, 602 (2017).
- Deng et al. [2017] D. L. Deng, X. P. Li, and S. Das Sarma, Quantum entanglement in neural network states, Phys. Rev. X 7, 021021 (2017).
- Garrido Torres et al. [2021] J. A. Garrido Torres, V. Gharakhanyan, N. Artrith, T. H. Eegholm, and A. Urban, Augmenting zero-kelvin quantum mechanics with machine learning for the prediction of chemical reactions at high temperatures, Nat. Commun. 12, 1 (2021).
- Schütt et al. [2019] K. Schütt, M. Gastegger, A. Tkatchenko, K.-R. Müller, and R. J. Maurer, Unifying machine learning and quantum chemistry with a deep neural network for molecular wavefunctions, Nat. Commun. 10, 1 (2019).
- Gao and Duan [2017] X. Gao and L. M. Duan, Efficient representation of quantum many-body states with deep neural networks, Nat. Commun. 8, 1 (2017).
- Paruzzo et al. [2018] F. M. Paruzzo, A. Hofstetter, F. Musil, S. De, M. Ceriotti, and L. Emsley, Chemical shifts in molecular solids by machine learning, Nat. Commun. 9, 1 (2018).
- Huang et al. [2022] H.-Y. Huang, M. Broughton, J. Cotler, S. Chen, J. Li, M. Mohseni, H. Neven, R. Babbush, R. Kueng, J. Preskill, and J. R. McClean, Quantum advantage in learning from experiments, Science 376, 1182 (2022).
- Wiebe et al. [2012] N. Wiebe, D. Braun, and S. Lloyd, Quantum algorithm for data fitting, Phys. Rev. Lett. 109, 050505 (2012).
- Rebentrost et al. [2014] P. Rebentrost, M. Mohseni, and S. Lloyd, Quantum support vector machine for big data classification, Phys. Rev. Lett. 113, 130503 (2014).
- Wiebe et al. [2015] N. Wiebe, A. Kapoor, and K. M. Svore, Quantum algorithms for nearest-neighbor methods for supervised and unsupervised learning, Quantum Info. Comput. 15, 316 (2015).
- Lloyd et al. [2014] S. Lloyd, M. Mohseni, and P. Rebentrost, Quantum principal component analysis, Nat. Phys. 10, 631 (2014).
- Schuld et al. [2016] M. Schuld, I. Sinayskiy, and F. Petruccione, Prediction by linear regression on a quantum computer, Phys. Rev. A 94, 022342 (2016).
- Paparo and Martin-Delgado [2012] G. D. Paparo and M. Martin-Delgado, Google in a quantum network, Sci. Rep. 2, 1 (2012).
- Dong et al. [2008] D. Y. Dong, C. L. Chen, H. X. Li, and T.-J. Tarn, Quantum reinforcement learning, IEEE Transactions on Systems, Man, and Cybernetics, Part B 38, 1207 (2008).
- Saggio et al. [2021] V. Saggio, B. E. Asenbeck, A. Hamann, T. Strömberg, P. Schiansky, V. Dunjko, N. Friis, N. C. Harris, M. Hochberg, D. Englund, S. Wölk, H. Briegel, and P. Walther, Experimental quantum speed-up in reinforcement learning agents, Nature 591, 229 (2021).
- Paparo et al. [2014] G. D. Paparo, V. Dunjko, A. Makmal, M. A. Martin-Delgado, and H. J. Briegel, Quantum speedup for active learning agents, Phys. Rev. X 4, 031002 (2014).
- Liu and Rebentrost [2018] N. Liu and P. Rebentrost, Quantum machine learning for quantum anomaly detection, Phys. Rev. A 97, 042315 (2018).
- Amin et al. [2018] M. H. Amin, E. Andriyash, J. Rolfe, B. Kulchytskyy, and R. Melko, Quantum boltzmann machine, Phys. Rev. X 8, 021050 (2018).
- Aaronson [2015] S. Aaronson, Read the fine print, Nat. Phys. 11, 291 (2015).
- Huang et al. [2021] H. Y. Huang, M. Broughton, M. Mohseni, R. Babbush, S. Boixo, H. Neven, and J. R. McClean, Power of data in quantum machine learning, Nat. Commun. 12 (2021).
- Schuld et al. [2014] M. Schuld, I. Sinayskiy, and F. Petruccione, The quest for a quantum neural network, Quantum Inf. Process 13, 2567 (2014).
- Mitarai et al. [2018] K. Mitarai, M. Negoro, M. Kitagawa, and K. Fujii, Quantum circuit learning, Phys. Lett. A 98, 032309 (2018).
- Schuld et al. [2020] M. Schuld, A. Bocharov, K. M. Svore, and N. Wiebe, Circuit-centric quantum classifiers, Phys. Lett. A 101, 032308 (2020).
- Hornik et al. [1989] K. Hornik, M. Stinchcombe, and H. White, Multilayer feedforward networks are universal approximators, Neural Networks 2, 359 (1989).
- Leshno et al. [1993] M. Leshno, V. Y. Lin, A. Pinkus, and S. Schocken, Multilayer feedforward networks with a nonpolynomial activation function can approximate any function, Neural Networks 6, 861 (1993).
- Cao et al. [2017] Y. D. Cao, G. G. Guerreschi, and A. Aspuru-Guzik, Quantum neuron: an elementary building block for machine learning on quantum computers (2017), arXiv e-prints, ArXiv:1711.11240.
- Yan et al. [2020] S. Yan, H. Qi, and W. Cui, Nonlinear quantum neuron: A fundamental building block for quantum neural networks, Phys. Lett. A 102, 052421 (2020).
- Tacchino et al. [2019] F. Tacchino, C. Macchiavello, D. Gerace, and D. Bajoni, An artificial neuron implemented on an actual quantum processor, npj Quantum Inf. 5, 1 (2019).
- Kristensen et al. [2021] L. B. Kristensen, M. Degroote, P. Wittek, A. Aspuru-Guzik, and N. T. Zinner, An artificial spiking quantum neuron, npj Quantum Inf. 7, 1 (2021).
- Torrontegui and García-Ripoll [2019] E. Torrontegui and J. J. García-Ripoll, Unitary quantum perceptron as efficient universal approximator, Europhys. Lett. 125, 30004 (2019).
- Beer et al. [2020] K. Beer, D. Bondarenko, T. Farrelly, T. J. Osborne, R. Salzmann, D. Scheiermann, and R. Wolf, Training deep quantum neural networks, Nat. Commun. 11, 1 (2020).
- Schuld et al. [2015] M. Schuld, I. Sinayskiy, and F. Petruccione, Simulating a perceptron on a quantum computer, Phys. Lett. A 379, 660 (2015).
- Wan et al. [2017] K. H. Wan, O. Dahlsten, H. Kristjánsson, R. Gardner, and M. Kim, Quantum generalisation of feedforward neural networks, npj Quantum Inf. 3, 1 (2017).
- Runge [1901] C. Runge, über empirische funktionen und die interpolation zwischen äquidistanten ordinaten, Zeitschrift für Mathematik und Physik 46, 224 (1901).
- Brenner and Scott [2007] S. C. Brenner and L. R. Scott, The Mathematical Theory of Finite Element Methods (Springer, 2007).
- Goodfellow et al. [2016] I. Goodfellow, Y. Bengio, and A. Courville, Deep Learning (MIT Press, 2016).
- Plesch and Brukner [2011] M. Plesch and Č. Brukner, Quantum-state preparation with universal gate decompositions, Phys. Rev. A 83, 032302 (2011).
- Bottou [2010] L. Bottou, Large-scale machine learning with stochastic gradient descent, Comput. Stat. , 177 (2010).
- Kingma and Ba [2015] D. Kingma and J. Ba, Adam: A method for stochastic optimization, in International Conference on Learning Representations, edited by Y. Bengio and Y. Lecun (San Diego, CA, 2015) p. 13.
- Buckley and LeNir [1985] A. Buckley and A. LeNir, Algorithm 630: Bbvscg–a variable-storage algorithm for function minimization, ACM Trans. Math. Softw. 11, 103 (1985).
- Bishop [2006] C. M. Bishop, Pattern Recognition and Machine Learning (Springer Press, Berlin, 2006).
- LeCun et al. [2010] Y. LeCun, C. Cortes, and C. Burges, Mnist handwritten digit database (2010), figshare http://yann.lecun.com/exdb/mnist (2010).
- Dua and Graff [2017] D. Dua and C. Graff, UCI machine learning repository (2017), http://archive.ics.uci.edu/ml (2017).
- Haldane [1983] F. D. M. Haldane, Nonlinear field theory of large-spin heisenberg antiferromagnets: semiclassically quantized solitons of the one-dimensional easy-axis néel state, Phys. Rev. Lett. 50, 1153 (1983).
- Cong et al. [2019] I. Cong, S. Choi, and M. D. Lukin, Quantum convolutional neural networks, Nat. Phys. 15, 1273 (2019).
- Hahn [1927] H. Hahn, Über lineare gleichungssysteme in linearen räumen., J. für die Reine und Angew. Math. 1927, 214 (1927).
- Fréchet [1907] M. Fréchet, Sur les ensembles de fonctions et les opérations linéaires, CR Acad. Sci. Paris 144, 1414 (1907).