A Unified Visual Information Preservation Framework for Self-supervised Pre-training in Medical Image Analysis
Abstract
Recent advances in self-supervised learning (SSL) in computer vision are primarily comparative, whose goal is to preserve invariant and discriminative semantics in latent representations by comparing siamese image views. However, the preserved high-level semantics do not contain enough local information, which is vital in medical image analysis (e.g., image-based diagnosis and tumor segmentation). To mitigate the locality problem of comparative SSL, we propose to incorporate the task of pixel restoration for explicitly encoding more pixel-level information into high-level semantics. We also address the preservation of scale information, a powerful tool in aiding image understanding but has not drawn much attention in SSL. The resulting framework can be formulated as a multi-task optimization problem on the feature pyramid. Specifically, we conduct multi-scale pixel restoration and siamese feature comparison in the pyramid. In addition, we propose non-skip U-Net to build the feature pyramid and develop sub-crop to replace multi-crop in 3D medical imaging. The proposed unified SSL framework (PCRLv2) surpasses its self-supervised counterparts on various tasks, including brain tumor segmentation (BraTS 2018), chest pathology identification (ChestX-ray, CheXpert), pulmonary nodule detection (LUNA), and abdominal organ segmentation (LiTS), sometimes outperforming them by large margins with limited annotations. Codes and models are available at https://github.com/RL4M/PCRLv2.
Index Terms:
Medical image analysis, Self-supervised learning, Transfer Learning, Context restoration, Feature pyramid.1 Introduction
It is usual to acquire a substantial amount of manually labeled data before training deep neural networks. This condition is easy to meet in natural images, where labor costs and labeling difficulties are tolerable. In medical image analysis, however, credible annotations are mainly derived from domain experts’ diagnoses, which are challenging to obtain due to the rarity of the target disease, the need to safeguard patient privacy, and the scarcity of medical resources. Against this background, self-supervised learning (SSL) has been widely accepted as a viable technique to learn medical image representations without specialistic annotations. We usually deploy SSL in the pre-training stage to obtain well-transferable features, which can be transferred to various downstream tasks for performance boosting.
Recent advances in SSL are mostly based on comparative learning [17, 8, 15, 10]. The rationale behind is to learn transferable latent representations with invariant and discriminative semantics by maximizing the mutual information between a pair of siamese images. One potential problem of these comparative methods is that they mainly focus on encoding high-level global semantics in representations but ignore the preservation of pixel-level information111In 3D medical images, we often use “voxel” to denote the same concept as the pixel does in 2D images. For simplicity, we use “pixel” to denote the smallest addressable element in both 2D and 3D images in the rest of this paper.. However, in medical image analysis, the latter type of information usually plays a vital role. For instance, in chest pathology detection, radiologists or clinicians are required to point out small lesions from a chest X-ray according to their textures. Sometimes, these areas of pathologies are so hard to identify that even medical experts have to check pixel-level details to tell where the lesions are. Another typical example lies in brain tumor segmentation, where the segmentation error of one voxel may cause irreparable harm to patients in brain surgeries, such as a permanent damage to the cochlear nerve when trying to remove the acoustic neuroma.
An intuitive way to preserve pixel-level information in learned features is to restore the pixel-level content from latent representations directly. This methodology, known as context restoration [29], has already been adopted as a surrogate task in pretext-based SSL for natural [29, 23, 44] and medical images [7, 49]. Specifically, these approaches first apply various data augmentation strategies to a given image to generate a corrupted input, based on which deep models are trained to restore original pixels. In this way, we explicitly require the latent representations to preserve information closely related to pixels. Although pure pixel-based features are not as transferable as those from comparative SSL [17, 48], we hypothesize it is still beneficial to explicitly preserve pixel-level information and global semantics, especially in medical image analysis where details matter a lot.
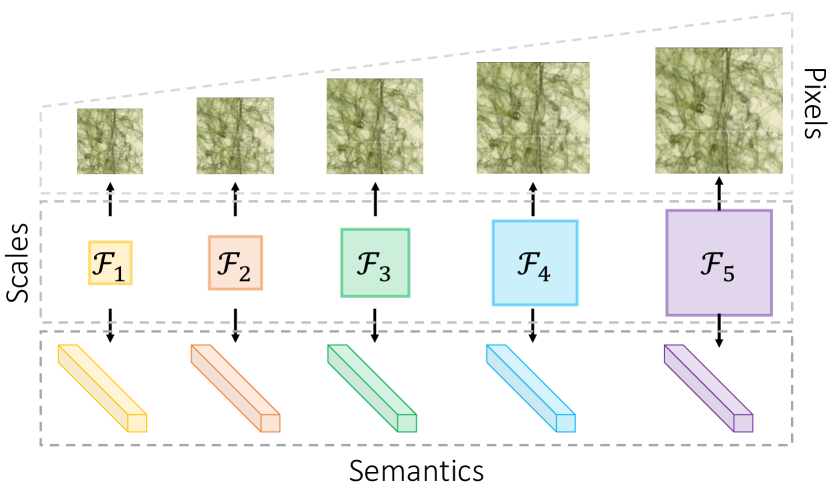
Besides semantics and pixels, introducing multi-scale representations has been proven to be quite helpful in aiding image understanding [12, 27, 39, 24, 26, 32]. The common practice of these methods is to construct a feature pyramid during training, testing, or both stages. Then, various tasks, such as detection, and segmentation, can be conducted on the basis of multi-scale features. The goal of building the feature pyramid is to endow image representations with the ability to recognize objects at different scales, which is also consistent with the law of human cognition [31]. However, the preservation of visual information at multiple scales is rarely mentioned in SSL. Thus, it is unclear whether introducing multi-scale self-supervised representations provides a stronger transfer learning ability.
In Figure 1, we illustrate the motivation of the proposed unified visual information preservation framework for SSL. The introduced framework addresses the preservation of information in self-supervised visual representations from three aspects: pixels, semantics, and scales. Firstly, to retain pixel-level information in latent representations, our framework involves a reconstruction branch in the self-supervised model to rebuild uncorrupted images from corrupted inputs. Specifically, we ask the self-supervised model to restore pixels from feature maps of randomly corrupted inputs during training. As a result, information closely associated with pixels can be explicitly encoded into the latent representations. In practice, this type of information would enhance the ability of self-supervised representations to recognize and differentiate textures. Apart from pixel-level information, preserving invariant and discriminative semantics in visual representations is also necessary. Towards this end, we adopt the existing comparative SSL to encode invariant semantic information by comparing high-level representations of siamese image patches [10]. We empirically found the siamese SSL not only produces comparably (sometimes more) transferable medical image representations but also is much easier to implement in comparison to the typical contrastive manner [17]. Last but not the least, the proposed unified framework introduces multi-scale latent representations by conducting pixel restoration and feature comparison in a range of scales. To achieve this goal, we propose a non-skip U-Net (nsUNet) that constructs a feature pyramid upon the U-shape architecture [32]. In practice, nsUNet effectively avoids the production of shortcut solutions when performing the context restoration task. On the basis of nsUNet, we conduct pixel-level context restoration and siamese feature comparison in each level (i.e., scale) of the feature pyramid. In this way, the proposed framework helps improve the ability of self-supervised representations to recognize objects (e.g., lesions and organs in medical images) at different sizes and scales.
We summarize the contributions of this paper as follows:
-
•
We present an information preservation framework for advancing SSL in medical image analysis. In this framework, we unify the preservation of visual information in latent representations from three aspects: pixels, semantics, and scales. Towards this end, pixel restoration and feature comparison are conducted at different feature scales.
-
•
We introduce non-skip U-Net (nsUNet) to construct the feature pyramid. Compared to the typical U-shape models in medical imaging [32, 11], nsUNet maintains more feature scales and eliminates the usage of the widely adopted skip connections to avoid shortcut solutions to pixel restoration.
-
•
Inspired by multi-crop [5], we propose sub-crop to compare global volumes against local volumes. In order to mitigate the problem of the reduced mutual information between global and local views in 3D space, sub-crop restricts the cropping of local views within the 3D minimum bounding box of global views. Experiments on 3D medical images found that sub-crop is more effective than multi-crop in various downstream tasks.
-
•
We conduct extensive and comprehensive experiments to validate the effectiveness of the proposed framework. We show that the unification of pixels, semantics, and scales can provide impressive performance under the pre-training/fine-tuning protocol. Specifically, the proposed framework outperforms both self-supervised and supervised counterparts in chest pathology classification, pulmonary nodule detection, abdominal organ segmentation, and brain tumor segmentation by substantial margins.
The conference version of this paper (PCRLv1) was presented in [47], which demonstrates the benefits of incorporating more pixel-level information besides the invariant and discriminative semantics obtained by contrastive learning. In this paper, we made significant and substantial modifications to PCRLv1, and we name the improved framework as PCRLv2 (i.e., Preservational Comparative Representation Learning). The modifications and improvements in PCRLv2 include but are not limited to (i) Besides local pixel-level and global semantic information, scale information is also preserved in self-supervised visual representations. The motivation behind is that although multiple feature scales have been considered in various vision tasks, they have not drawn much attention in SSL. PCRLv2 shows that introducing multi-scale latent representations can boost the transfer learning performance of SSL in downstream tasks. (ii) PCRLv2 simplifies the attentional pixel restoration and hybrid feature contrast operations of PCRLv1 into a concise multi-task optimization problem. As a result, PCRLv2 is simpler and easier to implement while achieving better performance, thus more practical. (iii) Compared to PCRLv1 that relies on the plain U-Net architecture [32], PCRLv2 conducts SSL on top of a new backbone, i.e., non-skip U-Net (nsUNet). There are two inherent advantages of nsUNet. First, the feature pyramid of nsUNet allows performing multi-scale pixel-level context restoration and semantic feature comparison. As a result, the unification of pixels, semantics, and scales produces more transferable visual representations. Second, nsUNet can effectively avoid the production of shortcut solutions, providing obvious performance gains over the use of the typical skip connections. (iv) We integrate the idea of multi-crop [5] in PCRLv2. Moreover, in 3D medical imaging, we propose sub-crop to produce reliable local views with increased mutual information by randomly cropping multiple local volumes within the 3D minimum bounding box of global views. In practice, we found that the proposed sub-crop has better pre-training performance than multi-crop. (v) In 5 classification/segmentation tasks, PCRLv2 provides more transferable pre-trained visual representations, not only surpassing previous self-supervised and supervised counterparts by substantial margins but also obviously outperforming PCRLv1 in all experiments.
2 Related Work
This section reviews related work in comparative SSL, including contrastive and non-contrastive methods, and lists SSL approaches that use context restoration as the pretext task. In the third part, we collect papers that emphasize the incorporation of multi-scale features in SSL.
Comparative SSL methodologies. One of the core ideas behind comparative SSL is to extract and encode invariant and discriminative semantics into representations via feature-level comparison. Hjelm et al. [20] proposed Deep InfoMax to maximize the mutual information between global and local feature vectors of the same input image using InfoNCE [28]. Bachman et al. [3] augmented InfoMax by conducting a global-local comparison on feature vectors of independently-augmented versions of each input. Tian et al. [36] increased the number of augmented views of each input and extended InfoNCE to multiple views. He et al. [17] presented Momentum Contrast (MoCo), which comprises a momentum encoder to maintain the consistency among positive and negative feature vectors. Different from [20, 3], MoCo performs InfoNCE on top of global feature vectors only. Compared to MoCo, SimCLR removes the momentum architecture and defines InfoNCE on the output of a MLP with one hidden layer. Inspired by SimCLR, Chen et al. [9] proposed MoCov2, which improves MoCo with an additional MLP head and more augmentations. SwAV [5] replaces the feature vectors in InfoNCE with cluster assignments and introduces the multi-crop strategy to increase the number of views of an image with affordable computational overhead. Grill et al. [15] proposed BYOL (bootstrap your own latent), which eliminates the use of InfoNCE in SSL by distilling semantics from positive pairs only. Based on BYOL, Chen et al. [10] further removed the restriction of the momentum architecture and introduced a simple siamese learning framework named SimSiam. In practice, SimSiam produces comparable results to MoCov2 in various downstream tasks. Recently, Zbontar et al. [42] simplified SimSiam by measuring the cross-correlation matrix between the siamese global feature vectors and trying to make this matrix close to the identity.
Comparative SSL, especially InfoNCE-based methodology, has also been widely adopted in medical image analysis. Zhou et al. [48] proposed to integrate mixup [43] into MoCov2, increasing the diversity of both positive and negative samples in InfoNCE. Taleb et al. [34] developed 3D versions of existing SSL techniques and compared 2D and 3D SSL approaches on downstream tasks. Azizi et al. [2] incorporated multi-instance learning into SimCLR, which helps utilize multiple views of each patient. Around the same time, Vu et al. [37] developed a method to select positive pairs coming from views of the same patient and used this strategy to improve MoCov2. There are also a number of approaches [6, 40, 41] that tailored comparative SSL for semi-supervised medical image segmentation.
However, the methodologies mentioned above fail to address the importance of integrating pixel-level information into the high-level representations with rich semantics, which is the primary focus of the proposed PCRL.
Context restoration for preserving pixel-level information. Restoring original context has been treated as an important pretext task in SSL. Pathak et al. [29] first time conducted self-supervised feature learning by recovering masked input images. Larsson et al. [23] and Zhang et al. [44] performed SSL on pixels via predicting RGB color values. For medical images, Chen et al. [7] extended the approach in [29] with swapped image patches. Zhou et al. [49] showed that adding more augmentations to input images brings benefits to SSL. Tao et al. [35] presented a volume-wise context transformation for 3D medical images. Different from the approaches mentioned above, Henaff [19] proposed to predict the next context feature vectors following an auto-regressive manner.
We can see that context restoration is more prevalent in medical imaging than in natural images from the above. The underlying reason is that medical imaging tasks require more pixel-level information to make fine-grained yet accurate decisions. On the other hand, we observe that comparative SSL can produce representations with richer semantics. Thus, it can be beneficial to build a SSL framework that simultaneously integrates pixel-level and semantic information. As far as we are concerned, none of these context restoration based approaches incorporate such a combination.
Multi-scale features in SSL. Although multi-scale features have not drawn much attention in existing SSL research, it has already been treated as an implicit yet effective regularization method for SSL in some methodologies. Deep InfoMax [20] contrasts high-level feature vectors with low-level feature maps using InfoNCE. To improve Deep InfoMax, Bachman et al. [3] proposed to contrast global and local feature vectors on multiple levels. In medical image analysis, preserving scale information becomes essential, as pathologies may show different characteristics on different scales. In [6], a local contrastive loss is introduced to learn distinctive representations of local regions that are helpful to per-pixel segmentation. At the same time, global feature vectors are used to distill discriminative semantics for classification tasks. A similar idea has also been used in image registration [25] and one-shot segmentation [46], where global and local feature vectors are employed to provide information on semantics and position, respectively.
However, most of these methods only perform SSL on two scales, i.e., one global and one local, which cannot fully capture multi-scale information. Besides, although these approaches emphasize the benefit of introducing local information to SSL, they do not exploit pixel-level information that is helpful to encode locality. In contrast, this paper proposes a unified framework that can simultaneously preserve semantic, pixel-level, and scale information.
3 Methodology
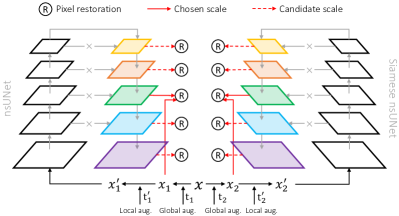
We provide an overview of PCRLv2 in Fig. 2. Suppose denotes a batch of input images. We introduce cascaded augmentations to distort in global and local views, respectively. To be specific, the first-stage augmentations ( and in Fig. 2) mainly consist of global transformations, such as flip and rotation, whose goal is to distort the semantics of input images from a global perspective. In comparison, the second-stage augmentations ( and in Fig. 2) comprise local pixel-level transformations, such as random noise and gaussian blur, which are leveraged to perturb the local semantics. After two-stage augmentations, the finally augmented images and are passed to siamese networks to perform pixel restoration and feature comparison, while the results of applying and to , i.e., and , serve as the ground truth targets for the pixel restoration task (as shown in Fig. 2a).
We perform SSL on the feature pyramid to encode multi-scale visual representations. Following the standard practice in medical image processing, we build feature pyramids using a U-shape model named non-skip U-Net (nsUNet). Compared to the typical U-Net architecture [32, 11], nsUNet has more feature scales and completely removes skip connections, both of which we empirically found helpful in producing better pre-trained representations. During the training stage, one scale is first randomly chosen from all five feature scales, after which we conduct pixel restoration and feature comparison on the siamese feature maps at the chosen scale. After the pre-training stage, we fine-tune the encoder of nsUNet on various downstream tasks.
3.1 Feature pyramid in non-skip U-Net
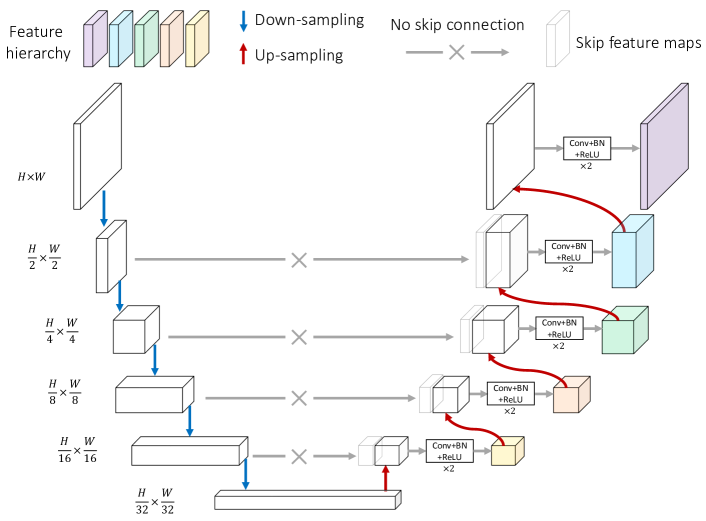
U-Net and its series [32, 11, 22] have been known in medical imaging for their abilities to handle image segmentation tasks. The most distinctive characteristic of these models is the skip connection that connects equal-resolution low- and high-level feature maps. The critical insight is to recover the spatial information lost in down-sampling operations of the encoder network, such as strided pooling or convolution. U-shape models use a feature pyramid to progressively incorporate multi-scale details brought by skip connections into high-level semantics, making the U-shape architecture an ideal choice for conducting context restoration.
In this paper, we explore the potential of U-shape architecture in SSL from two perspectives: deeply fusing semantic and pixel-level information by removing the skip connections and introducing multi-scale latent representations by conducting SSL on the feature pyramid. For the first perspective, we empirically found that skip connections provide shortcuts for context restoration, as the low-level feature maps contain rich, high-resolution pixel-level details. This characteristic does contribute to the restoration of context. However, it may prevent the high-level latent representations (with rich semantics) from incorporating more pixel-level information because the task of providing pixel-level details is assigned to low-level feature maps. To address this point, we remove the skip connections in U-shape architecture and propose non-skip U-Net (nsUNet). nsUNet relies on high-level representations without any skip connections to restore pixel-level details. In this way, the semantic and pixel-level information can be deeply fused. Meanwhile, the inherent multi-scale feature maps of nsUNet offer the opportunity to construct a feature pyramid, on top of which SSL can be conducted in multiple scales simultaneously.
Fig. 3 presents the architecture of nsUNet. The feature pyramid in nsUNet comprises five levels, ranging from low resolution (the down-sampling rate is 32) to full resolution (no down-sampling). For 2D input data, we use ResNet-18 [18] as the encoder, while for 3D input volumes, we build the encoder following [11]. As illustrated in Fig. 3, the decoder of nsUNet maintains a shared architecture across all pyramid levels, which can be summarized as:
| (1) | ||||
where . denotes the output of the bottleneck block, which has the lowest spatial resolution (down-sampling rate=32). Up represents the up-sampling operation. Conv-BN-ReLU stands for a sequence of operations, including convolution (kernel size=3), batch normalization (BN), and ReLU activation. As a result, the bag of feature maps is then forwarded to following task-dependent heads to perform pixel restoration and feature comparison, respectively and simultaneously.
3.2 Multi-scale pixel restoration
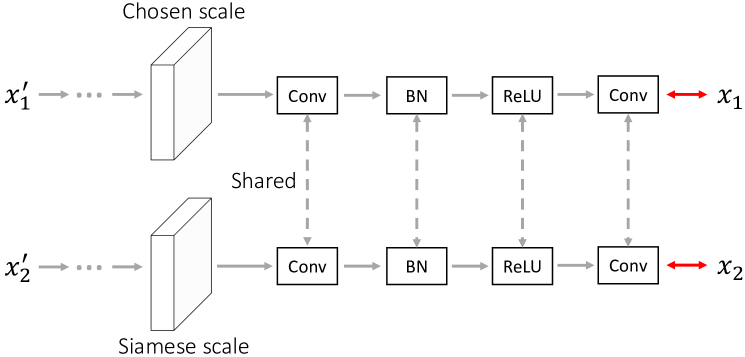
As the name implies, multi-scale pixel restoration aims to preserve pixel-level and scale information in latent visual representations simultaneously. To achieve this goal, we ask the network to recover the exact pixel-level details across different scales, where each pair of siamese feature maps share one pixel restoration head. In contrast, PCRLv1 only restores pixel details at the full resolution, which inevitably loses multi-scale properties in learned representations.
As shown in Fig. 4a, the input images and are intentionally corrupted via various pixel-level augmentations, such as guassian blur and random noise. For each training iteration, we first randomly choose a feature scale from . Then, we pass to the pixel restoration head for the -th scale, whose internal processing procedure can be summarized as:
| (2) | ||||
where all convolution layers use a kernel size of 3 and a stride of 2. Similarly, we apply the shared pixel restoration head to the paired siamese feature map to acquire the prediction output :
| (3) | ||||
Lastly, we employ the mean square error (MSE) loss to measure the reconstruction errors between and . For the siamese feature pyramid, we apply MSE loss to and . The cost function of the pixel restoration task in each training iteration (with mini-batch optimization) is as follows:
| (4) | ||||
where denotes the number of scales in each feature pyramid. stands for the scale index. is an indicator function, which is equal to 1 when == is true (otherwise, 0). The explanation of can be summarized as: (i) randomly choose a feature scale from all five scales; (ii) pass and its siamese feature map to the shared task head ; (iii) calculate the MSE loss between the outputs of and uncorrupted images . By reconstructing the same targets / across different feature scales, can encode the pixel-level information into multi-scale latent visual representations.
3.3 Multi-scale feature comparison
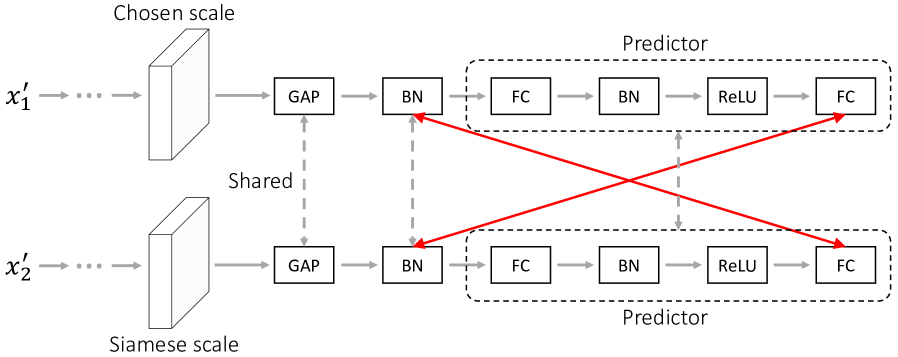
PCRLv1 employs a hybrid way to conduct contrastive learning with the help of the momentum encoder [17] and mixup [43]. However, this contrastive deployment is complex, making PCRLv1 heavy, thus troublesome to implement and improve. To address these issues, PCRLv2 replaces the hybrid contrastive strategies in PCRLv1 with the multi-scale comparison. Inspired by [10], multi-scale comparison conducts SSL with siamese learning, whose key operation is to attract the same image’s siamese views. Different from [10] that conducts feature comparison on one scale, we propose to preserve the discriminative semantics across different feature scales, which forces the model to preserve multi-scale self-supervised representations. In the following, we provide technical details of performing the multi-scale comparison.
Given the feature maps at a randomly chosen scale , we pass them through a global average pooling layer and a shared batch normalization layer (as shown in Fig. 4b) to acquire 1D representations :
| (5) |
We can get by processing the siamese feature maps in a similar way.
Next, we forward to the shared predictor , whose architecture is displayed in Fig. 4b and can be summarized as:
| (6) |
where FC denotes the fully-connected layer. FC-BN-ReLU stands for a sequence of layers, which are the fully-connected layer, batch normalization layer, and ReLU activation. Similarly, we can acquire by passing to the same predictor.
We measure the similarity between siamese feature vectors with the cosine similarity:
| (7) | ||||
where denotes the L2 normalization. Symmetrically, we calculate as follows:
| (8) | ||||
Finally, the cost function of multi-scale feature comparison can be summarized as:
| (9) | ||||
denotes the number of feature scales. stands for the scale index. Following [10], we apply the stop-gradient operation (denoted as sg) in Eq. 9 to prevent the network optimizer from finding shortcut solutions.
Minimizing requires the model to maximize the similarity between siamese latent features across all feature scales. In this way, scale invariance can be implicitly incorporated into the preserved latent semantics.
3.4 From multi-crop to sub-crop
Multi-crop [5] has been known as a helpful strategy to improve SSL performance in natural images, which increases the number of input views by sampling several standard resolution crops and more low-resolution crops from the original input. One key insight behind multi-crop is to capture relations between parts of a scene or an object, while low-resolution views ensure a controllable increase in the computational cost.
When applied to medical images, multi-crop works well in 2D X-ray data but leads to the non-convergence of the model in 3D volume data (such as CT and MRI). After careful investigation, we found the root of this problem lies in the contradiction between the limited input size and many candidate crops in three-dimensional space. Specifically, on the one hand, we cannot afford large-sized 3D inputs because processing them with 3D deep models often costs dramatic GPU memory. On the other hand, if we overly reduce the size of 3D inputs, the sampled views would be too dispersed to guarantee the model capture the local-global associations.
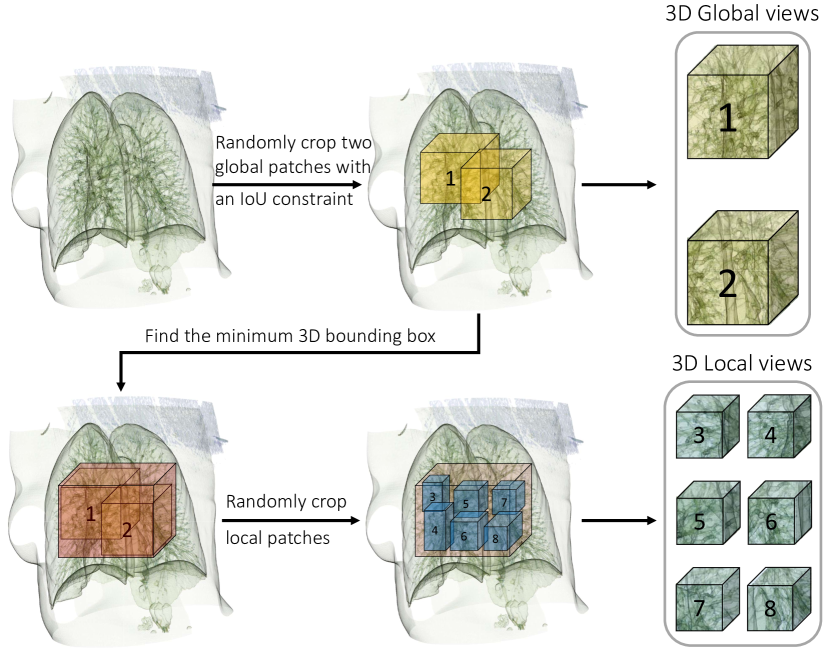
To mitigate the above issue, we introduce sub-crop to replace multi-crop in 3D medical images. The core idea of sub-crop is straightforward: reducing the sampling space. As illustrated in Fig. 5, sub-crop mainly consists of three steps: (i) randomly crop two extensive global views with an IoU constraint; (ii) find the minimum 3D bounding box over the cropped global patches; (iii) randomly crop multiple local patches within the 3D bounding box. There are two critical operations in sub-crop: the constraint of IoU on global views and the sampling of local patches within the minimum bounding box. In practice, the first operation guarantees the global-global association by ensuring the overlap between large patches larger than a fixed threshold. The second operation mitigates the disperse problem of local views and helps the model to discover local-global relations.
3.5 Overall training objective
After applying multi-crop/sub-crop to medical images, we can acquire two global views and local views . For clarification, we denote the associated inputs in notations of loss functions. For instance, means we calculate on top of the extracted siamese representations of two global views, where and can be regarded as a pair of siamese images. At last, the overall training objective of PCRLv2 can be formalized as follows:
| (10) | ||||
There are three terms in : , , and . The first term is designed to preserve pixel-level details in multi-scale learned representations. The second term addresses the importance of encoding multi-scale semantics into latent features. The last term aims to capture the multi-scale global-local semantic relations.
3.6 Short discussion: PCRLv2 vs. PCRLv1
Simpler. PCRLv1 combines the context restoration and comparative SSL via transformation-conditioned attention and cross-model mixup. These two components make the framework heavy, less intuitive, and not easy to implement. Compared to PCRLv1, PCRLv2 exploits a simpler yet more intuitive design to incorporate pixel-level and semantic information via multi-scale learning. As aforementioned, PCRLv2 can be formulated as a simple multi-task optimization problem whose objective function maximizes the preservation of multi-level information in latent visual representations. These characteristics make it easier for both implementation and potential expansion.
Faster. PCRLv1 makes heavy use of mixup (to both inputs and features) in its implementation, which is found to deliver performance gains. In PCRLv2, we eliminate mixup strategies and cut the training time in half. In addition, PCRLv2 requires less running memory in GPUs during the training stage, making it more practical in real-world scenarios.
4 Experiments
In this section, we first conduct thorough ablation studies to investigate the influence of different modules in PCRLv2. Then, we evaluate the effectiveness of PCRLv2 on both 2D and 3D medical imaging tasks, including chest pathology classification, pulmonary nodule detection, abdominal organ segmentation, and brain tumor segmentation. For model evaluation, we follow the pre-training (on source data)fine-tuning (on target data) protocol and employ two settings, which are semi-supervised learning and transfer learning. In the first setting, the source and target data come from the same dataset. Specifically, we first pre-train the model using all training data without labels, and then fine-tune the pre-trained model with limited annotations. As for transfer learning (the second setting), we pre-train and fine-tune the model on different datasets. Different from semi-supervised learning, we fine-tune the pre-trained model with both limited and full annotations in transfer learning.
4.1 Datasets
NIH ChestX-ray (2D) [38] is made up of 112,120 X-ray scans from 30,805 patients. There are fourteen different chest pathologies in NIH ChestX-ray, including atelectasis, cardiomegaly, consolidation, edema, effusion, emphysema, fibrosis, hernia, infiltration, mass, nodule, pleural thickening, pneumonia, and pneumothorax. The labels of radiographs were automatically extracted from associated radiology reports using natural language process (NLP) techniques. We use NIH ChestX-ray in semi-supervised learning in our experiments and treat it as the target dataset in transfer learning.
CheXpert (2D) [21] involves 224,316 chest radiographs from 65,240 patients for the presence of 14 common chest radiographic observations: no finding, enlarged cardio, cardiomegaly, lung opacity, lung Lesion, edema, consolidation, pneumonia, atelectasis, pneumothorax, pleural effusion, pleural other, fracture, and support devices. Similar to NIH ChestX-ray, an NLP labeler was developed to detect the presence of 14 observations in radiology reports automatically. In practice, CheXpert serves as the source data in transfer learning.
LUNA (3D) [33] was collected for the automatic detection of pulmonary nodules, which involves 888 annotated thoracic computed tomography (CT) scans. LUNA is a cherry-picked subset of LIDC-IDRI [1], which excludes scans with a slice thickness greater than 3mm, inconsistent slice spacing, or missing slices. In the 888 scans, a total of 5,855 annotations were made by the radiologists, where only nodules 3mm are categorized as relevant lesions, and at least one radiologist checks each nodule. On LUNA, we perform semi-supervised learning and transfer learning experiments. For transfer learning, LUNA is mainly used for self-supervised pre-training.
LiTS (3D) [4] releases 131 abdominal CT Volumes and associated annotations for training and validation. There are two types of labels in LiTS: the liver and tumor. In this paper, we only utilize the ground truth masks of the liver to evaluate the effectiveness of various SSL algorithms. The task on LiTS is abdominal organ segmentation, where LiTS is used for fine-tuning in transfer learning.
BraTS (3D) has been known as a series of challenges in brain tumor segmentation. In this paper, we perform experiments on the released 351 magnetic resonance imaging (MRI) scans of BraTS 2018. There are three classes in BraTS: whole tumor (WT), tumor core (TC), and enhancing tumor (ET). Similar to the role of LiTS, BraTS serves as the target data in transfer learning.
4.2 Baselines
A variety of SSL baselines are included in our extensive experiments, which can be roughly divided into three categories: 2D specific methods, 3D specific approaches, and generic (2D & 3D) methodologies. Details of baselines in each category are listed below.
2D specific SSL methodologies consist of ImageNet-based pre-training (IN) [14], Comparing to Learn (C2L) [48], and Simple Siamese Learning (SimSiam) [10]. IN is the most widely adopted pre-training methodology, which conducts supervised pre-training on one of the biggest natural image datasets, i.e., ImageNet [14]. C2L is a recently proposed SSL approach based on momentum contrast (i.e., MoCov1 [17] and MoCov2 [9]). SimSiam is a simple siamese SSL framework that eliminates the barrier of negative samples in contrastive learning and the use of a momentum encoder in BYOL [15]. Besides, we compare PCLRv2 against SimSiam to highlight the significance of the preserved pixel-level information and multi-scale features.
3D specific SSL methodologies include Rubik’s cube++ [35] and 3D-CPC [34]. Rubik’s cube++ is the most recent SSL approach built on top of context restoration for 3D medical images. It adopts a volume-wise transformation for context permutation. In comparison, 3D-CPC is based on contrastive predictive encoding [19], a variation of contrastive learning, and demonstrates the most superior performance among different SSL approaches investigated in [34].
Generic SSL methodologies involve train from scratch (TS), Model Genesis (MG) [49], TransVW [16], and PCRLv1 [47] (the conference version of our approach). MG resorts to aggressive augmentations to generate corrupted input images, based on which the model is asked to restore the original inputs. TransVW improves MG by appending an intermediate classification head to encode anatomical patterns explicitly. PCRLv1 first proposes simultaneously preserving semantic and pixel-level information in SSL.
4.3 Implementation details
Dataset pre-processing for pre-training. On NIH ChestX-ray and CheXpert, each input image is resized to 224224 after random crop. On LUNA, we randomly crop a volume from the whole CT scan with a random size from {646432, 969664, 969696, 11211264}. Each cropped volume is then resized to 646432. Each voxel’s Hounsfield Unit (HU) in the crop is truncated to [-1000,1000]. If a voxel’s HU is lower than -150, we regard it as a background voxel. In practice, if over 85% voxels within a crop belong to the background, we would not use this crop in pre-training.
Dataset pre-processing for fine-tuning. For NIH ChestX-ray and CheXpert, we follow the same pre-processing procedures as in the pre-training stage. On LUNA, we randomly crop a volume for each training iteration, and the size of each crop is 484848. On LiTS, we first localize the liver and expand the target volume by 30 slices on each axis. After random crop, the size of each crop is 25625664. Unlike LUNA, we truncate the HU of each voxel to [-200, 200]. For BraTS, the size of each random crop is 1121121124.
Data augmentation and multi-crop/sub-crop. As shown in Fig. 2, there are two types of augmentations, i.e., global and local augmentations. Specifically, for 2D tasks, the global augmentation includes random crop, random horizontal flip, and random rotation. The local augmentation involves random grayscale, gaussian blur, and cutout. In comparison, for 3D tasks, the global augmentation consists of random flip and random affine. Local augmentation strategies are applied, including Gaussian blur, random noise, random gamma, and random swap. Note that all 3D augmentations are implemented following [30]. As for multi-crop in 2D tasks, we resort to the scale factor of random crop222https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html to generate global and local views. Specifically, we set the range of scale to [0.3, 1] to generate two global views. For six local views, the scale range is set to [0.05, 0.3]. Both global and local views are resized to 224224. As for sub-crop in 3D tasks, we randomly sample two global views with a random size from {646432, 969664, 969696, 11211264}. The IoU constraint (i.e., threshold) between two global views is 0.3. Then, we find the minimum bounding box of global views, from which six local views are randomly cropped, each with a random size from {888, 161616, 323216, 323232}. After random crop, all 3D global views are resized to 646432, while all local views are resized to 161616.
| Datasets | w/o skip | w/ skip | Gain |
| NIH | 76.6 | 75.4 | 1.2 |
| BraTS | 73.0 | 71.5 | 1.5 |
| LiTS | 79.0 | 77.6 | 1.4 |
Training and evaluation details. We use stochastic gradient descent (SGD) with momentum as the default optimizer, where the momentum is set to 0.9. The initial learning rate is 1e-2, and we employ the cosine annealing strategy for learning rate decay. We set the weight decay to 1e-5. The number of training epochs is 240. The batch sizes of 2D pre-training and fine-tuning (on NIH ChestX-ray or CheXpert) are 256 and 512, respectively. As for 3D pre-training, the batch size (on LUNA) is 32. For 3D fine-tuning tasks, the batch sizes on LUNA, LiTS, and BraTS are 32, 4, and 4, respectively. The evaluation metric on NIH ChestX-ray, CheXpert, and LUNA is AUROC (Area Under the Receiver Operating Characteristics). For segmentation tasks on LiTS and BraTS, we use Dice similarity as the evaluation metric. We use 70%, 10%, and 20% of the whole dataset to build the training, validation, and test sets. In particular, for semi-supervised learning, we construct the pre-training set by removing a specific amount of data from the entire training set. At the same time, the remainder is used as the training set for fine-tuning. Binary cross-entropy loss is used for the fine-tuning of NIH ChestX-ray, CheXpert, and LUNA, while Dice loss is used for the fine-tuning of LiTS and BraTS.
4.4 Ablation studies
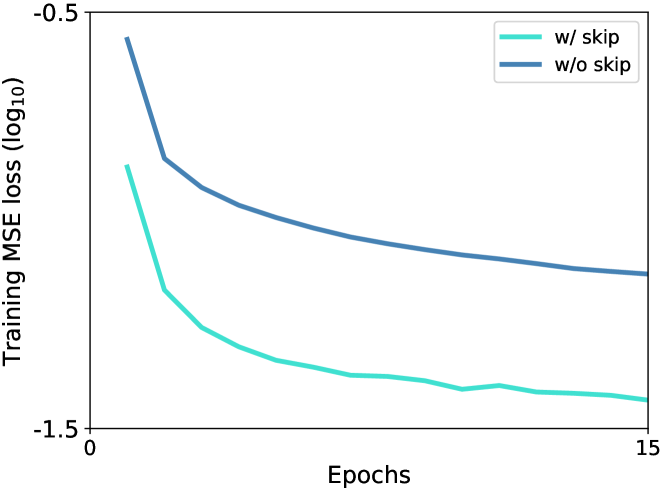
Impact of skip connections on pixel restoration. In Fig. 6, we present the mean square error (MSE) loss (cf. Eq. 4) curves during the training stage. We see that the MSE loss, with skip connections, decreases rapidly in the first 15 training epochs. In comparison, the proposed nsUNet (w/o skip) slows down the decreasing rate of MSE loss. These phenomena are consistent with the role of skip connections, which bridges the gap between low-level pixel details and high-level latent semantics. The existence of skip connections makes it easier to restore pixels by incorporating pixel-level details from low-level but high-resolution feature maps. However, nsUNet removes skip connections, avoiding shortcut solutions to context restoration. Although this design makes it harder to restore pixels (higher loss values in Fig. 6), it helps encode pixel-level information into high-level semantic representations. Such advantage can be verified by the performance gains in Table I, where removing skip connections brings over 1% improvement to chest pathology identification, brain tumor segmentation, and abdominal organ segmentation.
How to conduct siamese feature comparison for multiple feature scales? We illustrate two intuitive choices in Fig. 7. Besides the adopted pairwise comparison manner (Fig. 7a), another obvious choice is to compare siamese features following a crossed way (a similar strategy was used in [3]). As shown in Fig. 7b, the cross-scale comparison aggressively compares siamese features across all feature scales. The motivation behind is to introduce multi-scale latent representations by coupling features across different scales. Table II reports the experimental results of pairwise and cross-scale siamese feature comparison. We find that cross-scale feature comparison slightly deteriorates the performance of semi-supervised pathology identification by 0.6 percents. The underlying reason might be that the features in each scale maintains distinct characteristics, and neglecting these discrepancies can lead to degenerate feature representations.
Investigation of different modules in PCRLv2. In Table III, we study and report the impact of different modules on the whole tumor (WT) and enhancing tumor (ET) classes of BraTS. Note that in practice, most instances of WT are much larger than instances from ET, making ET instances harder to segment. Besides, we also present the transfer learning results on NIH ChestX-ray.
| Pairwise | Crossed [3] | Gain | |
| Mean AUROC | 76.6 | 76.0 | 0.6 |
| # | Res. | Comp. | S (3) | S (5) | MC | SC | WT (BraTS) | ET (BraTS) | NIH |
| 0 | ✓ | 74.2 | 64.9 | 78.2 | |||||
| 1 | ✓ | 76.4 | 63.8 | 78.5 | |||||
| 2 | ✓ | ✓ | 76.2 | 64.6 | 80.9 | ||||
| 3 | ✓ | ✓ | ✓ | 76.9 | 66.1 | 81.5 | |||
| 4 | ✓ | ✓ | ✓ | 77.2 | 66.8 | 82.0 | |||
| 5 | ✓ | ✓ | ✓ | ✓ | fail | fail | 82.5 | ||
| 6 | ✓ | ✓ | ✓ | ✓ | 77.7 | 67.2 | 82.7 |
First of all, we investigate the influence of pixel restoration (row 0) and feature comparison (row 1), respectively. We directly reconstruct the full resolution uncorrupted images for the pixel restoration task while siamese feature comparison is conducted on the last-layer output of the encoder. Comparing row 0 with row 1, we see that the context restoration task is more advantageous in segmentation of small tumor regions (i.e., ET) while the comparative SSL is more capable of dealing with large tumor regions (i.e., WT) and chest pathologies. Such comparison shows that semantic information preservation may be more helpful to the detection of large objects, while segmenting small objects requires the incorporation of pixel-level information. In row 2, we can already acquire noticeable performance gains by directly combining pixel restoration and feature comparison.
|
Labeling ratio |
Methodology |
Mean |
Atelectasis |
Cardiomegaly |
Effusion |
Infiltration |
Mass |
Nodule |
Pneumonia |
Pneumothorax |
Consolidation |
Edema |
Emphysema |
Fibrosis |
Pleural Thick. |
Hernia |
| 5% | TS | 61.8 | 58.8 | 72.0 | 68.8 | 51.5 | 63.8 | 49.2 | 57.4 | 67.4 | 61.5 | 71.0 | 62.7 | 58.1 | 60.0 | 63.1 |
| MG [49] | 66.4 | 63.4 | 74.1 | 72.9 | 53.5 | 67.2 | 54.3 | 59.9 | 71.3 | 66.5 | 77.0 | 65.8 | 64.5 | 62.8 | 76.2 | |
| TransVW [16] | 66.5 | 64.2 | 72.9 | 72.2 | 54.8 | 69.4 | 55.7 | 59.6 | 71.0 | 64.8 | 77.4 | 66.6 | 63.6 | 62.8 | 75.6 | |
| C2L [48] | 71.7 | 69.9 | 77.9 | 76.2 | 59.1 | 73.4 | 60.0 | 64.5 | 76.2 | 71.4 | 80.3 | 76.1 | 69.9 | 68.4 | 80.4 | |
| SimSiam [10] | 71.7 | 68.9 | 79.3 | 77.8 | 58.7 | 73.0 | 61.0 | 65.4 | 76.2 | 72.1 | 81.7 | 75.1 | 69.6 | 68.1 | 76.8 | |
| PCRLv1 [47] | 74.1 | 70.1 | 80.3 | 79.3 | 61.8 | 76.8 | 64.6 | 68.6 | 77.2 | 72.8 | 83.7 | 77.4 | 71.3 | 72.7 | 80.8 | |
| PCRLv2 | 76.6 | 75.7 | 81.0 | 80.3 | 64.0 | 76.8 | 68.7 | 70.7 | 83.2 | 77.5 | 87.8 | 79.2 | 72.5 | 73.2 | 81.8 | |
| 10% | TS | 68.1 | 65.8 | 77.6 | 74.4 | 57.1 | 69.4 | 54.8 | 63.0 | 72.9 | 68.3 | 78.8 | 68.2 | 64.3 | 66.4 | 72.5 |
| MG [49] | 70.0 | 67.1 | 78.1 | 76.1 | 57.2 | 72.8 | 57.5 | 63.3 | 75.5 | 70.9 | 79.5 | 68.8 | 67.4 | 68.0 | 77.6 | |
| TransVW [16] | 70.2 | 66.6 | 78.9 | 74.9 | 58.4 | 71.2 | 59.5 | 64.8 | 72.6 | 70.4 | 79.4 | 70.7 | 67.2 | 68.3 | 79.5 | |
| C2L [48] | 74.1 | 72.3 | 81.7 | 79.9 | 60.2 | 74.6 | 62.7 | 67.6 | 78.7 | 73.9 | 83.5 | 78.2 | 72.8 | 69.8 | 81.4 | |
| SimSiam [10] | 74.0 | 71.2 | 81.4 | 78.9 | 60.2 | 75.5 | 63.2 | 67.3 | 78.7 | 73.2 | 83.5 | 77.7 | 72.5 | 71.8 | 80.8 | |
| PCRLv1 [47] | 76.2 | 73.6 | 82.9 | 81.2 | 64.7 | 77.1 | 66.7 | 69.7 | 79.8 | 74.5 | 86.9 | 78.8 | 75.6 | 74.2 | 81.1 | |
| PCRLv2 | 78.2 | 77.2 | 84.3 | 84.4 | 67.4 | 77.5 | 68.9 | 71.6 | 84.4 | 77.8 | 89.0 | 79.3 | 76.1 | 74.0 | 82.4 | |
| 20% | TS | 71.5 | 68.9 | 80.7 | 77.5 | 60.2 | 73.6 | 58.7 | 66.2 | 76.1 | 71.7 | 82.9 | 72.2 | 69.0 | 68.7 | 74.7 |
| MG [49] | 73.9 | 71.9 | 83.0 | 80.0 | 62.3 | 75.2 | 62.2 | 67.5 | 79.0 | 73.3 | 83.6 | 73.4 | 71.0 | 70.6 | 81.4 | |
| TransVW [16] | 74.3 | 71.6 | 82.5 | 80.1 | 62.3 | 76.7 | 62.8 | 69.2 | 78.2 | 73.5 | 83.8 | 75.4 | 72.2 | 71.2 | 80.3 | |
| C2L [48] | 76.4 | 74.2 | 83.9 | 81.7 | 63.8 | 77.3 | 64.7 | 70.3 | 81.5 | 75.5 | 86.0 | 80.2 | 75.2 | 73.4 | 81.8 | |
| SimSiam [10] | 76.5 | 73.8 | 84.0 | 81.4 | 63.2 | 78.2 | 64.7 | 69.6 | 82.1 | 76.2 | 86.4 | 80.7 | 75.0 | 73.9 | 81.7 | |
| PCRLv1 [47] | 78.8 | 75.4 | 86.2 | 83.6 | 65.1 | 79.9 | 69.6 | 72.0 | 82.3 | 79.9 | 88.3 | 82.6 | 76.5 | 75.9 | 81.9 | |
| PCRLv2 | 79.9 | 78.1 | 87.2 | 85.9 | 68.2 | 80.5 | 69.9 | 72.5 | 85.3 | 80.4 | 89.2 | 83.1 | 77.5 | 77.0 | 83.5 | |
| 30% | TS | 73.4 | 70.6 | 81.9 | 79.1 | 61.6 | 75.5 | 60.7 | 68.8 | 78.3 | 72.7 | 84.3 | 74.1 | 70.3 | 70.9 | 78.9 |
| MG [49] | 76.1 | 74.3 | 84.4 | 82.1 | 63.6 | 78.3 | 64.4 | 69.6 | 81.2 | 75.8 | 85.6 | 75.9 | 73.6 | 73.6 | 82.8 | |
| TransVW [16] | 76.7 | 74.9 | 84.1 | 81.9 | 64.9 | 79.0 | 65.3 | 70.9 | 80.3 | 76.2 | 86.5 | 78.6 | 74.5 | 74.2 | 82.1 | |
| C2L [48] | 77.5 | 74.3 | 84.8 | 82.6 | 64.6 | 78.3 | 66.3 | 71.5 | 83.0 | 76.8 | 87.6 | 81.3 | 76.5 | 74.4 | 82.9 | |
| SimSiam [10] | 78.0 | 75.4 | 85.1 | 82.9 | 65.0 | 79.4 | 67.0 | 71.4 | 83.4 | 77.4 | 87.8 | 82.8 | 76.1 | 75.5 | 82.7 | |
| PCRLv1 [47] | 79.0 | 75.5 | 86.6 | 83.8 | 65.9 | 80.7 | 70.2 | 72.8 | 82.9 | 80.4 | 88.9 | 83.3 | 76.6 | 76.5 | 81.9 | |
| PCRLv2 | 81.1 | 78.4 | 87.6 | 86.6 | 69.6 | 82.8 | 72.0 | 74.0 | 86.2 | 81.0 | 89.9 | 84.4 | 79.5 | 79.0 | 84.6 | |
| 40% | TS | 75.4 | 72.6 | 83.6 | 81.5 | 62.9 | 77.3 | 63.3 | 70.1 | 80.3 | 74.9 | 85.5 | 76.4 | 72.5 | 73.0 | 81.8 |
| MG [49] | 77.3 | 75.4 | 86.0 | 83.3 | 65.1 | 79.0 | 65.1 | 70.8 | 82.1 | 77.0 | 87.3 | 76.7 | 74.8 | 74.9 | 83.5 | |
| TransVW [16] | 77.6 | 75.0 | 85.1 | 82.7 | 65.2 | 79.7 | 66.5 | 72.0 | 81.0 | 76.7 | 87.2 | 79.2 | 75.5 | 76.5 | 83.7 | |
| C2L [48] | 79.0 | 76.0 | 86.1 | 84.3 | 66.0 | 80.0 | 67.9 | 72.5 | 84.1 | 78.5 | 88.5 | 83.7 | 77.9 | 76.6 | 83.8 | |
| SimSiam [10] | 79.4 | 76.7 | 86.7 | 84.7 | 67.0 | 80.9 | 69.0 | 73.1 | 84.4 | 78.9 | 88.9 | 83.5 | 77.7 | 76.6 | 83.4 | |
| PCRLv1 [47] | 79.9 | 76.7 | 87.1 | 84.9 | 67.1 | 82.7 | 72.2 | 73.3 | 83.6 | 80.6 | 89.2 | 83.8 | 77.3 | 76.9 | 83.2 | |
| PCRLv2 | 81.5 | 78.7 | 87.8 | 87.0 | 69.8 | 83.2 | 72.5 | 74.7 | 86.3 | 81.2 | 90.2 | 84.9 | 80.0 | 79.4 | 85.0 |
| Methodology | Labeling ratio | |||
| 10% | 20% | 30% | 40% | |
| TS | 78.4 | 83.0 | 85.7 | 87.5 |
| MG [49] | 80.2 | 85.0 | 87.5 | 90.3 |
| TransVW [16] | 79.3 | 84.5 | 87.9 | 90.5 |
| Cube++ [35] | 81.4 | 85.2 | 87.9 | 90.0 |
| 3D-CPC [34] | 80.2 | 85.2 | 88.3 | 90.6 |
| PCRLv1 [47] | 84.4 | 87.5 | 89.8 | 92.2 |
| PCRLv2 | 85.5 | 88.3 | 90.3 | 93.1 |
Next, we show that multi-scale representations benefit both pixel restoration and feature comparison tasks. By conducting both tasks on 3 scales, we observe a 0.7-percent improvement on WT, a 1.5-percent gain on ET, and a 0.6-percent improvement on chest pathology classification. These results show that introducing multiple scales is more helpful to the segmentation of small regions. Moreover, by increasing the number of scales from 3 to 5, we can improve the accuracy of all three tasks consistently. Not surprisingly, ET benefits the most from the introduction of multiple scales, indicating the necessity of utilizing multi-scale representations in medical image segmentation.
|
Labeling ratio |
Methodology |
Mean |
Atelectasis |
Cardiomegaly |
Effusion |
Infiltration |
Mass |
Nodule |
Pneumonia |
Pneumothorax |
Consolidation |
Edema |
Emphysema |
Fibrosis |
Pleural Thick. |
Hernia |
| 10% | TS | 68.1 | 67.6 | 63.3 | 76.8 | 57.5 | 71.5 | 61.8 | 64.2 | 76.2 | 69.8 | 80.2 | 72.4 | 62.8 | 68.0 | 61.1 |
| IN [28] | 73.5 | 73.3 | 68.7 | 81.6 | 63.0 | 76.6 | 67.3 | 70.0 | 81.3 | 75.6 | 85.9 | 78.5 | 68.6 | 72.5 | 65.9 | |
| MG [49] | 70.1 | 69.9 | 65.6 | 79.2 | 59.4 | 72.9 | 64.3 | 67.0 | 77.9 | 72.0 | 82.3 | 75.8 | 65.9 | 69.6 | 59.4 | |
| TransVW [16] | 69.7 | 69.4 | 64.3 | 78.2 | 59.5 | 72.6 | 63.1 | 67.2 | 77.2 | 70.9 | 83.0 | 75.3 | 65.8 | 68.9 | 60.2 | |
| C2L [48] | 73.1 | 72.5 | 68.0 | 81.3 | 62.4 | 75.8 | 67.2 | 70.2 | 80.6 | 74.8 | 85.4 | 78.4 | 68.3 | 72.2 | 66.1 | |
| SimSiam [10] | 72.5 | 71.9 | 67.5 | 81.2 | 61.7 | 75.9 | 66.6 | 69.6 | 79.8 | 74.2 | 84.8 | 77.6 | 67.7 | 71.8 | 64.5 | |
| PCRLv1 [47] | 75.8 | 75.4 | 70.6 | 84.2 | 65.5 | 78.9 | 69.6 | 72.7 | 83.5 | 77.6 | 88.5 | 80.8 | 71.3 | 74.8 | 67.6 | |
| PCRLv2 | 77.2 | 76.8 | 72.0 | 85.6 | 66.8 | 80.2 | 71.0 | 74.0 | 84.8 | 78.9 | 89.8 | 82.2 | 72.6 | 76.2 | 69.7 | |
| 20% | TS | 71.4 | 71.8 | 73.1 | 78.4 | 59.6 | 72.5 | 64.5 | 66.6 | 77.7 | 71.7 | 82.0 | 75.5 | 69.8 | 68.9 | 68.2 |
| IN [14] | 76.2 | 75.9 | 78.3 | 82.9 | 64.2 | 77.8 | 68.8 | 70.7 | 83.0 | 76.4 | 87.2 | 80.0 | 75.3 | 73.9 | 73.1 | |
| MG [49] | 73.8 | 73.9 | 75.4 | 80.2 | 61.9 | 74.9 | 66.5 | 68.3 | 80.0 | 74.0 | 85.1 | 78.1 | 72.8 | 71.5 | 71.3 | |
| TransVW [16] | 73.8 | 73.0 | 75.5 | 80.1 | 62.3 | 75.6 | 66.7 | 68.6 | 80.2 | 74.0 | 85.2 | 77.5 | 72.9 | 71.5 | 69.4 | |
| C2L [48] | 77.0 | 76.5 | 78.9 | 83.4 | 65.0 | 78.6 | 69.8 | 71.8 | 83.5 | 77.2 | 88.1 | 80.8 | 76.0 | 74.2 | 73.5 | |
| SimSiam [10] | 76.6 | 76.6 | 78.7 | 83.3 | 64.6 | 77.9 | 69.2 | 71.6 | 83.1 | 76.9 | 87.8 | 80.5 | 75.5 | 73.8 | 73.6 | |
| PCRLv1 [47] | 77.5 | 77.3 | 79.7 | 84.3 | 65.7 | 78.9 | 70.3 | 72.8 | 83.8 | 77.6 | 88.6 | 81.1 | 76.5 | 74.8 | 74.3 | |
| PCRLv2 | 79.4 | 79.0 | 81.3 | 85.9 | 67.3 | 80.8 | 72.1 | 74.0 | 86.0 | 79.4 | 90.3 | 83.1 | 78.4 | 76.7 | 76.6 | |
| 30% | TS | 73.5 | 71.7 | 79.7 | 79.9 | 60.5 | 76.5 | 68.4 | 66.8 | 79.2 | 72.8 | 83.4 | 76.9 | 71.4 | 70.5 | 71.3 |
| IN [14] | 78.5 | 77.2 | 84.6 | 84.3 | 66.2 | 80.8 | 73.0 | 72.3 | 84.0 | 78.0 | 88.5 | 82.0 | 76.8 | 75.3 | 76.0 | |
| MG [49] | 75.6 | 74.1 | 81.8 | 81.0 | 63.3 | 77.9 | 70.1 | 69.0 | 80.9 | 74.8 | 85.4 | 79.7 | 73.6 | 72.6 | 74.2 | |
| TransVW [16] | 75.7 | 74.8 | 81.4 | 81.0 | 63.6 | 77.7 | 69.9 | 69.8 | 80.9 | 75.4 | 86.0 | 79.3 | 73.9 | 72.3 | 73.8 | |
| C2L [48] | 78.6 | 77.1 | 84.5 | 84.5 | 66.1 | 81.1 | 73.0 | 72.5 | 84.0 | 78.1 | 88.3 | 82.1 | 76.8 | 75.5 | 76.8 | |
| SimSiam [10] | 78.3 | 77.0 | 84.4 | 84.1 | 65.7 | 80.7 | 72.7 | 72.2 | 83.9 | 77.9 | 88.1 | 82.1 | 76.6 | 75.2 | 75.6 | |
| PCRLv1 [47] | 79.9 | 78.5 | 85.8 | 85.6 | 67.4 | 82.3 | 74.2 | 73.8 | 85.5 | 79.4 | 89.7 | 83.5 | 78.1 | 76.7 | 78.1 | |
| PCRLv2 | 80.5 | 79.1 | 86.4 | 86.2 | 68.0 | 82.8 | 74.8 | 74.3 | 86.0 | 80.0 | 90.3 | 84.1 | 78.6 | 77.2 | 79.2 | |
| 40% | TS | 75.4 | 72.6 | 80.0 | 81.0 | 62.5 | 76.9 | 69.2 | 68.0 | 80.7 | 74.7 | 85.1 | 79.5 | 74.0 | 71.0 | 79.8 |
| IN [14] | 79.0 | 76.7 | 84.2 | 84.3 | 66.3 | 80.7 | 73.6 | 72.3 | 84.7 | 78.5 | 88.6 | 83.4 | 77.4 | 75.0 | 79.7 | |
| MG [49] | 76.5 | 74.1 | 81.3 | 81.7 | 63.9 | 77.9 | 71.1 | 70.1 | 82.5 | 76.1 | 85.6 | 80.6 | 74.5 | 73.1 | 77.9 | |
| TransVW [16] | 77.3 | 75.2 | 82.4 | 82.4 | 64.4 | 79.0 | 71.4 | 70.5 | 83.2 | 76.7 | 86.6 | 82.0 | 75.8 | 73.6 | 78.4 | |
| C2L [48] | 79.1 | 76.9 | 84.3 | 84.5 | 66.4 | 80.8 | 73.4 | 72.2 | 84.8 | 78.3 | 88.6 | 83.4 | 77.2 | 75.4 | 80.6 | |
| SimSiam [10] | 78.9 | 76.7 | 83.9 | 84.1 | 66.6 | 80.4 | 73.1 | 72.1 | 84.7 | 78.1 | 88.4 | 83.4 | 77.2 | 74.8 | 80.5 | |
| PCRLv1 [47] | 80.8 | 78.5 | 86.0 | 86.2 | 68.2 | 82.4 | 75.2 | 74.0 | 86.6 | 80.2 | 90.2 | 85.1 | 79.0 | 76.9 | 82.1 | |
| PCRLv2 | 81.5 | 79.2 | 86.6 | 86.9 | 68.9 | 83.0 | 75.8 | 74.6 | 87.2 | 80.8 | 90.9 | 85.8 | 79.7 | 77.6 | 83.4 | |
| 50% | TS | 77.5 | 75.2 | 82.0 | 82.0 | 64.5 | 79.6 | 71.8 | 71.3 | 82.9 | 75.8 | 86.6 | 80.9 | 76.1 | 75.5 | 80.3 |
| IN | 79.5 | 77.2 | 84.5 | 84.4 | 66.6 | 81.4 | 73.6 | 73.0 | 84.6 | 78.2 | 89.1 | 82.7 | 77.9 | 77.3 | 82.0 | |
| MG [49] | 77.6 | 75.0 | 82.8 | 82.8 | 64.8 | 79.5 | 71.8 | 71.6 | 82.3 | 75.7 | 86.7 | 81.5 | 76.2 | 75.7 | 79.5 | |
| TransVW [16] | 77.3 | 74.5 | 81.9 | 82.4 | 64.8 | 78.8 | 71.5 | 71.3 | 82.4 | 75.7 | 86.8 | 80.4 | 75.7 | 74.9 | 80.6 | |
| C2L [48] | 79.8 | 77.6 | 84.7 | 84.5 | 67.0 | 81.6 | 73.6 | 73.4 | 84.7 | 78.5 | 89.0 | 83.1 | 78.4 | 78.0 | 82.6 | |
| SimSiam [10] | 80.0 | 77.7 | 84.9 | 84.8 | 67.1 | 81.7 | 74.0 | 73.5 | 84.7 | 78.3 | 89.5 | 83.6 | 78.8 | 77.7 | 83.2 | |
| PCRLv1 [47] | 81.2 | 78.7 | 86.1 | 86.3 | 68.3 | 82.8 | 75.4 | 74.5 | 86.8 | 80.4 | 90.5 | 85.3 | 79.5 | 78.2 | 83.5 | |
| PCRLv2 | 82.5 | 80.0 | 87.4 | 87.3 | 69.6 | 84.1 | 76.4 | 76.1 | 87.4 | 81.0 | 91.8 | 85.9 | 81.0 | 80.4 | 86.1 | |
| 100% | TS | 80.9 | 77.7 | 86.1 | 85.1 | 67.7 | 84.2 | 73.3 | 73.9 | 84.9 | 78.7 | 89.4 | 85.4 | 79.4 | 78.5 | 87.6 |
| IN | 80.8 | 77.8 | 86.3 | 84.7 | 67.3 | 83.6 | 73.0 | 74.1 | 84.9 | 78.8 | 89.5 | 85.7 | 79.6 | 78.2 | 87.0 | |
| MG [49] | 80.8 | 77.8 | 86.3 | 84.7 | 67.3 | 83.6 | 73.0 | 74.1 | 84.9 | 78.8 | 89.5 | 85.7 | 79.6 | 78.2 | 87.0 | |
| TransVW [16] | 81.2 | 77.9 | 86.4 | 85.3 | 67.6 | 84.3 | 73.8 | 74.4 | 85.1 | 79.3 | 89.8 | 86.2 | 80.0 | 78.6 | 88.8 | |
| C2L [48] | 81.4 | 78.2 | 87.0 | 85.3 | 68.3 | 84.8 | 73.7 | 74.8 | 85.5 | 79.6 | 90.1 | 86.3 | 80.0 | 78.6 | 88.1 | |
| SimSiam [10] | 81.6 | 78.3 | 87.2 | 85.5 | 68.3 | 84.9 | 74.2 | 74.7 | 85.7 | 79.6 | 90.1 | 86.2 | 80.2 | 79.1 | 89.1 | |
| PCRLv1 [47] | 83.0 | 79.8 | 88.5 | 87.1 | 69.7 | 86.1 | 75.6 | 76.1 | 87.0 | 81.2 | 91.6 | 87.7 | 81.7 | 80.4 | 90.2 | |
| PCRLv2 | 84.0 | 80.7 | 89.3 | 87.9 | 70.5 | 87.0 | 76.4 | 77.0 | 87.9 | 82.0 | 92.5 | 88.6 | 82.6 | 81.3 | 91.6 |
Last but not the least, we investigate the significance of multi-crop (row 4) and sub-crop (row 5). We empirically found that directly applying multi-crop to 3D medical volumes leads to the failure of model training. The underlying reason might be that it is difficult for cropped global and local views to maintain clear spatial relations in the 3D space as in the 2D space. In contrast, sub-crop can provide consistent performance gains on both types of tumor regions by successfully preserving the spatial relations in latent representations. When applying sub-crop to 2D X-rays, we observe a marginal improvement over multi-crop. The underlying reason is that sub-crop is proposed to handle dispersed sampled views in a 3D space to guarantee the model captures local-global relations. However, in a 2D space, the sampled views usually (partly) overlap.
4.5 Semi-supervised chest pathology identification
Table IV presents the experimental results of applying semi-supervised learning on NIH ChestX-ray. Specifically, we use a specific amount of the training set (denoted as the labeling ratio in Table IV) as labeled data while the remaining training data is used for self-supervised pre-training.
From Table IV, we see that self-supervised pre-training can dramatically boost the performance compared to train from scratch (TS), which verify the necessity of conducting pre-training in medical imaging. Comparing MG with TransVW, they show similar performance in different labeling ratios. Such comparison is easy to explain as TransVW is built upon MG, and both are based on context restoration. TransVW performs slightly better than MG, as it incorporates an additional classification head to encode more semantics. Compared to context restoration based methods, comparative methodologies (C2L and SimSiam) display better overall and class-specific results, especially in small labeling ratios. The underlying reason might be that semantic information is more critical than pixel-level information in chest pathology detection. As for C2L and SimSiam, C2L performs better when the amount of labeled data is quite limited. However, SimSiam gradually produces better diagnosis results as the labeling ratio increases.
After incorporating the semantic, pixel-level, and scale information into a unified framework, PCRLv2 outperforms various SSL baselines in different labeling ratios significantly. It surpasses the previous conference version by clear margins, i.e., PCRLv1. Particularly, PCRLv2 seems to have more advantages in small labeling ratios. For instance, when the labeling ratio is 5%, PCRLv2 outperforms PCRLv1 by 2.5 percents on average, which verifies the significance of multi-scale latent representations.
| Methodology | 10% | 20% | 30% | 40% | 100% | |||||||||||||||
| Mean | WT | TC | ET | Mean | WT | TC | ET | Mean | WT | TC | ET | Mean | WT | TC | ET | Mean | WT | TC | ET | |
| TS | 66.6 | 71.2 | 66.7 | 62.1 | 72.7 | 78.5 | 74.3 | 65.5 | 76.7 | 81.8 | 77.9 | 70.6 | 77.1 | 82.3 | 78.3 | 70.9 | 81.5 | 86.8 | 82.8 | 75.1 |
| MG [49] | 69.6 | 72.4 | 71.4 | 65.1 | 75.5 | 80.4 | 77.3 | 68.9 | 79.6 | 84.2 | 80.6 | 74.1 | 80.4 | 85.3 | 82.0 | 74.0 | 82.4 | 87.1 | 83.6 | 76.6 |
| TransVW [16] | 70.3 | 74.6 | 71.7 | 64.6 | 75.6 | 79.9 | 75.4 | 71.5 | 79.1 | 83.8 | 79.9 | 73.6 | 80.8 | 85.8 | 82.1 | 74.5 | 82.3 | 87.1 | 83.3 | 76.5 |
| Cube++ [35] | 69.0 | 74.5 | 70.6 | 61.9 | 74.9 | 80.7 | 75.9 | 68.1 | 79.3 | 84.0 | 79.4 | 74.5 | 79.7 | 84.5 | 80.0 | 74.6 | 82.2 | 87.2 | 82.4 | 77.0 |
| 3D-CPC [34] | 70.1 | 76.7 | 70.5 | 63.1 | 75.9 | 81.6 | 75.6 | 70.5 | 79.4 | 84.6 | 79.9 | 73.7 | 81.2 | 86.5 | 81.8 | 75.3 | 82.9 | 88.0 | 83.3 | 77.4 |
| PCRLv1 [47] | 71.6 | 76.9 | 73.1 | 65.2 | 77.6 | 81.4 | 79.1 | 72.7 | 81.1 | 84.9 | 82.2 | 76.6 | 83.3 | 87.5 | 84.6 | 78.2 | 85.0 | 89.0 | 86.2 | 80.2 |
| PCRLv2 | 73.0 | 77.7 | 74.3 | 67.2 | 78.8 | 83.2 | 79.4 | 74.0 | 82.1 | 85.1 | 82.7 | 78.7 | 84.1 | 87.9 | 84.5 | 80.1 | 85.6 | 89.4 | 85.9 | 81.7 |
| Methodology | Labeling ratio | ||||
| 10% | 20% | 30% | 40% | 100% | |
| TS | 71.1 | 77.2 | 84.1 | 87.3 | 90.7 |
| MG [49] | 73.3 | 79.5 | 84.3 | 87.9 | 91.3 |
| TransVW [16] | 73.8 | 79.3 | 85.5 | 88.2 | 91.4 |
| Cube++ [35] | 74.2 | 79.3 | 84.5 | 88.2 | 91.8 |
| 3D-CPC [34] | 74.8 | 80.2 | 85.6 | 88.9 | 91.9 |
| PCRLv1 [47] | 77.3 | 83.5 | 87.8 | 90.1 | 93.7 |
| PCRLv2 | 79.0 | 86.5 | 89.3 | 90.9 | 94.5 |
4.6 Semi-supervised pulmonary nodule detection
In Table V, we report the experimental results of semi-supervised pulmonary nodule detection. Interestingly, we observe narrowed performance gaps between TS and SSL baselines than those reported in Table IV. One possible explanation is that the task of detecting pulmonary nodules is less sensitive to the amount of labeled data. Among all SSL baselines, Cube++ gives better performance when utilizing small amounts of labeled data, while 3D-CPC is more advantageous in large labeling ratios. In addition, we see TransVW quickly catching up with MG and Cube++ as the labeling ratio increases.
PCRLv1 outperforms previous SSL approaches in different labeling ratios by large margins. After incorporating multi-scale latent representations, PCRLv2 consistently surpasses PCRLv1 in a range of labeling ratios. When the baseline SSL methods show similar performance as the labeling ratio increases, PCRLv2 can still provide impressive improvements over PCRLv1 and previous SSL approaches.
4.7 Transfer learning on chest pathology identification
In Table VI, we validate the transferable ability of visual representations provided by different pre-training methodologies. Specifically, we compare PCRLv2 against train from scratch, ImageNet-based pre-training (IN), different SSL baselines, and PCRLv1.
Comparing MG/TransVW with IN, we see context restoration based SSL maintains the limited transferable ability. This phenomenon becomes more apparent when the target domain has quite limited annotations. The underlying reason is that semantic information plays a crucial role in transfer learning. In contrast, the significant performance gains brought by C2L and SimSiam again verify the effectiveness of comparative SSL. C2L and SimSiam still cannot outperform IN by significant margins, especially when considering that IN is more advantageous when the labeling ratio is 10%.
After integrating the benefits of context restoration based and comparative SSL, PCRLv1 is already capable of outperforming previous SSL methodologies by observable margins. Furthermore, by exploiting multi-scale semantic and pixel-level information, PCRLv2 achieves consistent improvements over PCRLv1 in overall and class-specific results in different labeling ratios.
4.8 Transfer learning on brain tumor segmentation
We report the experimental results of applying transfer learning to brain tumor segmentation in Table VII, where we use LUNA dataset for self-supervised pre-training and fine-tune the pre-trained model with different amounts of labeled data.
Somewhat surprisingly, we find 3D-CPC does not outperform context restoration based SSL (MG, TransVW, and Cube++) as obviously as those in Tables IV, V, and VII. This comparison is consistent with our intuition: pixel-level information matters a lot in medical image segmentation. Again, PCRLv1 and PCRLv2 outperform previous SSL methodologies in all three classes by large margins. Compared to PCRLv1, PCRLv2 is more advantageous in segmenting the enhancing tumor (ET) regions, which are often smaller than WT and TC, and thus harder to segment. The performance gains on ET again verify the effectiveness of multi-scale latent representations, which advances the segmentation of small objects.
4.9 Transfer learning on liver segmentation
In Table VIII, we present the results of liver segmentation. There exist three observable phenomena. First, we see that all SSL approaches provide substantial performance gains over train from scratch. Second, we find the comparative methodology, i.e., 3D-CPC, achieves comparable segmentation performance to traditional context restoration based SSL. This phenomenon verifies the necessity of utilizing pixel-level information in medical image segmentation (similar results also appear in Table VII). Last but not the least, PCRLv2 consistently outperforms PCRLv1 in all labeling ratios, which again validates the effectiveness of introducing multiple scales into SSL.
4.10 Visual analysis
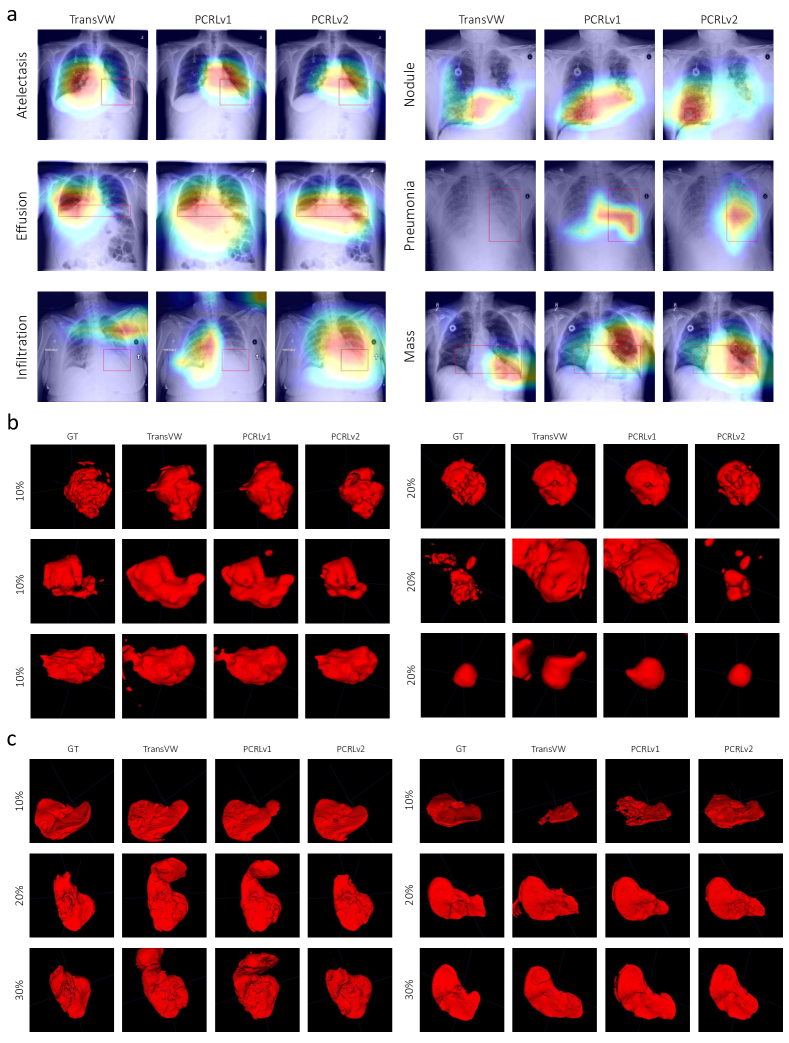
In Fig. 8, we visually analyze the experimental results of transfer learning with limited annotations on chest pathology identification (10%), brain tumor segmentation (10% and 20%), and liver segmentation (10%, 20%, and 30%). Here, we compare PCRLv2 against generic SSL methodologies. Considering TransVW was developed on top of MG, we exclude MG and compare PCRLv2 against PCRLv1 and TransVW.
Fig. 8a presents the visual interpretation of chest pathology diagnoses using CAM [45] on six different pathologies. We find that TransVW fails to capture the correct location of lesions on atelectasis, infiltration, nodule, and pneumonia. In comparison, PCRLv1 can generate more interpretable diagnosis results but still yields inconsistent predictions on infiltration and nodule. By integrating multi-scale latent representations, PCRLv2 can capture the small lesion areas on infiltration and nodule, resulting in centralized yet accurate diagnosis results.
In Fig. 8b and Fig. 8c, we visualize the segmentation results of the enhancing tumor (ET) on BraTS and liver on LiTS. Compared to TransVW and PCRLv1, PCRLv2 reduces the false positive predictions and contains richer fine-grained details. We believe such superiority of PCRLv2 can be attributed to the integration of multi-scale pixel-level and semantic information.
We also provide some failure examples in Fig. 9. One common characteristic of these detection results is that they include high-confidence predictions outside the lung area. However, in daily clinical practice, such anomalies should not be located outside the lung area. Similar phenomena have been reported in [13], where the authors summarized them as “shortcuts” that are common in learning systems based on neural networks. To mitigate this problem in self-supervised learning, we can add commonsense knowledge to pre-trained models. Besides, it is also necessary to develop more powerful machine learning tools for model interpretation in various downstream tasks.
5 Conclusion
We present a unified visual information preservation framework for self-supervised learning in medical imaging. This framework aims to encode the pixel-level, semantic, and scale information into latent representations simultaneously. To achieve this goal, we conduct multi-scale pixel restoration and feature comparison on the feature pyramid, which non-skip U-Net supports. The proposed PCRLv2 outperforms previous self-supervised pre-training approaches by large margins and yields consistent improvements over its conference version (PCRLv1) on four well-established datasets in both quantitative and qualitative validation. We will continue to explore how to optimally integrate different types of information into SSL in the future.
References
- [1] Samuel G Armato III, Geoffrey McLennan, Luc Bidaut, Michael F McNitt-Gray, Charles R Meyer, Anthony P Reeves, Binsheng Zhao, Denise R Aberle, Claudia I Henschke, Eric A Hoffman, et al. The lung image database consortium (lidc) and image database resource initiative (idri): a completed reference database of lung nodules on ct scans. Medical Physics, 38(2):915–931, 2011.
- [2] Shekoofeh Azizi, Basil Mustafa, Fiona Ryan, Zachary Beaver, Jan Freyberg, Jonathan Deaton, Aaron Loh, Alan Karthikesalingam, Simon Kornblith, Ting Chen, et al. Big self-supervised models advance medical image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3478–3488, 2021.
- [3] Philip Bachman, R Devon Hjelm, and William Buchwalter. Learning representations by maximizing mutual information across views. Advances in neural information processing systems, 32, 2019.
- [4] Patrick Bilic, Patrick Ferdinand Christ, Eugene Vorontsov, Grzegorz Chlebus, Hao Chen, Qi Dou, Chi-Wing Fu, Xiao Han, Pheng-Ann Heng, Jürgen Hesser, et al. The liver tumor segmentation benchmark (lits). arXiv preprint arXiv:1901.04056, 2019.
- [5] Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments. Advances in Neural Information Processing Systems, 33:9912–9924, 2020.
- [6] Krishna Chaitanya, Ertunc Erdil, Neerav Karani, and Ender Konukoglu. Contrastive learning of global and local features for medical image segmentation with limited annotations. Advances in Neural Information Processing Systems, 33:12546–12558, 2020.
- [7] Liang Chen, Paul Bentley, Kensaku Mori, Kazunari Misawa, Michitaka Fujiwara, and Daniel Rueckert. Self-supervised learning for medical image analysis using image context restoration. Medical Image Analysis, 58:101539, 2019.
- [8] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International Conference on Machine Learning, pages 1597–1607. PMLR, 2020.
- [9] Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297, 2020.
- [10] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15750–15758, 2021.
- [11] Özgün Çiçek, Ahmed Abdulkadir, Soeren S Lienkamp, Thomas Brox, and Olaf Ronneberger. 3d u-net: learning dense volumetric segmentation from sparse annotation. In International Conference on Medical Image Computing and Computer-assisted Intervention, pages 424–432. Springer, 2016.
- [12] Navneet Dalal and Bill Triggs. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, volume 1, pages 886–893, 2005.
- [13] Alex J DeGrave, Joseph D Janizek, and Su-In Lee. Ai for radiographic covid-19 detection selects shortcuts over signal. Nature Machine Intelligence, 3(7):610–619, 2021.
- [14] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009.
- [15] Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning. Advances in Neural Information Processing Systems, 33:21271–21284, 2020.
- [16] Fatemeh Haghighi, Mohammad Reza Hosseinzadeh Taher, Zongwei Zhou, Michael B Gotway, and Jianming Liang. Transferable visual words: Exploiting the semantics of anatomical patterns for self-supervised learning. IEEE Transactions on Medical Imaging, 40(10):2857–2868, 2021.
- [17] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9729–9738, 2020.
- [18] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016.
- [19] Olivier Henaff. Data-efficient image recognition with contrastive predictive coding. In International Conference on Machine Learning, pages 4182–4192. PMLR, 2020.
- [20] R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Bachman, Adam Trischler, and Yoshua Bengio. Learning deep representations by mutual information estimation and maximization. In International Conference on Learning Representations, 2018.
- [21] Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, et al. CheXpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pages 590–597, 2019.
- [22] Fabian Isensee, Paul F Jaeger, Simon AA Kohl, Jens Petersen, and Klaus H Maier-Hein. nnu-net: a self-configuring method for deep learning-based biomedical image segmentation. Nature Methods, 18(2):203–211, 2021.
- [23] Gustav Larsson, Michael Maire, and Gregory Shakhnarovich. Learning representations for automatic colorization. In European Conference on Computer Vision, pages 577–593. Springer, 2016.
- [24] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2117–2125, 2017.
- [25] Fengze Liu, Ke Yan, Adam P Harrison, Dazhou Guo, Le Lu, Alan L Yuille, Lingyun Huang, Guotong Xie, Jing Xiao, Xianghua Ye, et al. SAME: Deformable image registration based on self-supervised anatomical embeddings. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 87–97. Springer, 2021.
- [26] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3431–3440, 2015.
- [27] David G Lowe. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 60(2):91–110, 2004.
- [28] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- [29] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A Efros. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2536–2544, 2016.
- [30] Fernando Pérez-García, Rachel Sparks, and Sebastien Ourselin. Torchio: a python library for efficient loading, preprocessing, augmentation and patch-based sampling of medical images in deep learning. Computer Methods and Programs in Biomedicine, 208:106236, 2021.
- [31] Bart M Haar Romeny. Front-end vision and multi-scale image analysis: multi-scale computer vision theory and applications, written in mathematica, volume 27. Springer Science & Business Media, 2008.
- [32] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015.
- [33] Arnaud Arindra Adiyoso Setio, Alberto Traverso, Thomas De Bel, Moira SN Berens, Cas Van Den Bogaard, Piergiorgio Cerello, Hao Chen, Qi Dou, Maria Evelina Fantacci, Bram Geurts, et al. Validation, comparison, and combination of algorithms for automatic detection of pulmonary nodules in computed tomography images: the luna16 challenge. Medical Image Analysis, 42:1–13, 2017.
- [34] Aiham Taleb, Winfried Loetzsch, Noel Danz, Julius Severin, Thomas Gaertner, Benjamin Bergner, and Christoph Lippert. 3D self-supervised methods for medical imaging. Advances in Neural Information Processing Systems, 33:18158–18172, 2020.
- [35] Xing Tao, Yuexiang Li, Wenhui Zhou, Kai Ma, and Yefeng Zheng. Revisiting rubik’s cube: self-supervised learning with volume-wise transformation for 3d medical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 238–248. Springer, 2020.
- [36] Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive multiview coding. In European Conference on Computer Vision, pages 776–794. Springer, 2020.
- [37] Yen Nhi Truong Vu, Richard Wang, Niranjan Balachandar, Can Liu, Andrew Y Ng, and Pranav Rajpurkar. Medaug: Contrastive learning leveraging patient metadata improves representations for chest x-ray interpretation. In Machine Learning for Healthcare Conference, pages 755–769. PMLR, 2021.
- [38] Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mohammadhadi Bagheri, and Ronald M Summers. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2097–2106, 2017.
- [39] Songfan Yang and Deva Ramanan. Multi-scale recognition with dag-cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1215–1223, 2015.
- [40] Chenyu You, Ruihan Zhao, Lawrence Staib, and James S Duncan. Momentum contrastive voxel-wise representation learning for semi-supervised volumetric medical image segmentation. arXiv preprint arXiv:2105.07059, 2021.
- [41] Chenyu You, Yuan Zhou, Ruihan Zhao, Lawrence Staib, and James S Duncan. Simcvd: Simple contrastive voxel-wise representation distillation for semi-supervised medical image segmentation. IEEE Transactions on Medical Imaging, 2022.
- [42] Jure Zbontar, Li Jing, Ishan Misra, Yann LeCun, and Stéphane Deny. Barlow twins: Self-supervised learning via redundancy reduction. In International Conference on Machine Learning, pages 12310–12320. PMLR, 2021.
- [43] Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. Mixup: Beyond empirical risk minimization. International Conference on Learning Representations, 2017.
- [44] Richard Zhang, Phillip Isola, and Alexei A Efros. Split-brain autoencoders: Unsupervised learning by cross-channel prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1058–1067, 2017.
- [45] Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Learning deep features for discriminative localization. In IEEE Conference on Computer Vision and Pattern Recognition, pages 2921–2929, 2016.
- [46] Hong-Yu Zhou, Hualuo Liu, Shilei Cao, Dong Wei, Chixiang Lu, Yizhou Yu, Kai Ma, and Yefeng Zheng. Generalized organ segmentation by imitating one-shot reasoning using anatomical correlation. In International Conference on Information Processing in Medical Imaging, pages 452–464. Springer, 2021.
- [47] Hong-Yu Zhou, Chixiang Lu, Sibei Yang, Xiaoguang Han, and Yizhou Yu. Preservational learning improves self-supervised medical image models by reconstructing diverse contexts. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3499–3509, 2021.
- [48] Hong-Yu Zhou, Shuang Yu, Cheng Bian, Yifan Hu, Kai Ma, and Yefeng Zheng. Comparing to learn: Surpassing imagenet pretraining on radiographs by comparing image representations. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 398–407. Springer, 2020.
- [49] Zongwei Zhou, Vatsal Sodha, Jiaxuan Pang, Michael B Gotway, and Jianming Liang. Models genesis. Medical Image Analysis, 67:101840, 2021.