A Survey on Self-supervised Learning: Algorithms, Applications, and Future Trends
Abstract
Deep supervised learning algorithms typically require a large volume of labeled data to achieve satisfactory performance. However, the process of collecting and labeling such data can be expensive and time-consuming. Self-supervised learning (SSL), a subset of unsupervised learning, aims to learn discriminative features from unlabeled data without relying on human-annotated labels. SSL has garnered significant attention recently, leading to the development of numerous related algorithms. However, there is a dearth of comprehensive studies that elucidate the connections and evolution of different SSL variants. This paper presents a review of diverse SSL methods, encompassing algorithmic aspects, application domains, three key trends, and open research questions. Firstly, we provide a detailed introduction to the motivations behind most SSL algorithms and compare their commonalities and differences. Secondly, we explore representative applications of SSL in domains such as image processing, computer vision, and natural language processing. Lastly, we discuss the three primary trends observed in SSL research and highlight the open questions that remain. A curated collection of valuable resources can be accessed at https://github.com/guijiejie/SSL.
Index Terms:
Self-supervised learning, Contrastive learning, Generative model, Representation learning, Transfer learning1 Introduction
Deep supervised learning algorithms have demonstrated impressive performance in various domains, including computer vision (CV) and natural language processing (NLP). To address this, models pre-trained on large-scale datasets like ImageNet [1] are commonly employed as a starting point and subsequently fine-tuned for specific downstream tasks (Table I). This practice is motivated by two primary reasons. Firstly, the parameters acquired from large-scale datasets offer a favorable initialization, enabling faster convergence of models trained on other tasks [2]. Secondly, a network trained on a large-scale dataset has already learned discriminative features, which can be easily transferred to downstream tasks and mitigate the overfitting issue arising from limited training data in such tasks [3, 4].
| Pre-training | Data | Pre-training Tasks | Downstream Tasks |
|---|---|---|---|
| Supervised | extensive labeled data | image categorization[5] | detection / segmentation / |
| pose estimation / depth estimation, etc | |||
| video action categorization[6] | action recognition / object tracking, etc | ||
| SSL | extensive unlabeled data | Image: rotation [7], jigsaw [8], etc | detection / segmentation / |
| pose estimation / depth estimation, etc | |||
| Video: the order of frames [9], playing direction [10], etc | action recognition / object tracking, etc | ||
| NLP: masked language modeling[11] | question answering / textual entailment recognition / | ||
| natural language inference, etc. |
Unfortunately, numerous real-world data mining and machine learning applications face a common challenge where an abundance of unlabeled training instances coexists with a limited number of labeled ones. The acquisition of labeled examples is frequently costly, arduous, or time-consuming due to the requirement of skilled human annotators with sufficient domain expertise [12, 13]. To illustrate, consider the analysis of web user profiles, where a substantial amount of data can be readily collected. However, the labeling of non-profitable or profitable users necessitates thorough scrutiny, judgment, and sometimes even time-intensive tracing tasks performed by experienced human assessors, resulting in significant expenses. Another instance pertains to the medical field, where unlabeled examples can be easily obtained through routine medical examinations. Nevertheless, assigning diagnoses individually to such a large number of cases places a substantial burden on medical experts. For example, in the case of breast cancer diagnosis, radiologists must label each focus in a vast collection of easily attainable, high-resolution mammograms. This process often proves to be highly inefficient and time-consuming. Additionally, supervised learning methods are susceptible to spurious correlations and generalization errors, and vulnerable to adversarial attacks.
To address the aforementioned limitations of supervised learning, various machine learning paradigms have been introduced, including active learning, semi-supervised learning, and self-supervised learning (SSL). This paper specifically emphasizes SSL. SSL algorithms aim to learn discriminative features from vast quantities of unlabeled instances without relying on human annotations. The overall framework of SSL is depicted in Fig. 1. In the self-supervised pre-training phase, a pre-defined pretext task is formulated for the deep learning algorithm to solve. Pseudo-labels for the pretext task are automatically generated based on specific attributes of the input data. Once the self-supervised pre-training process is completed, the acquired model can be transferred to downstream tasks.
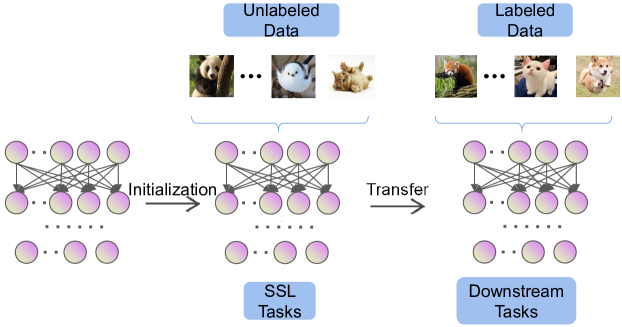
One notable advantage of SSL algorithms is their ability to leverage extensive unlabeled data since the generation of pseudo-labels does not necessitate human annotations. By utilizing these pseudo-labels during training, self-supervised algorithms have demonstrated promising outcomes, resulting in a reduced performance disparity compared to supervised algorithms in downstream tasks. Asano et al. [14] demonstrated that SSL can produce generalizable features that exhibit robust generalization even when applied to a single image.
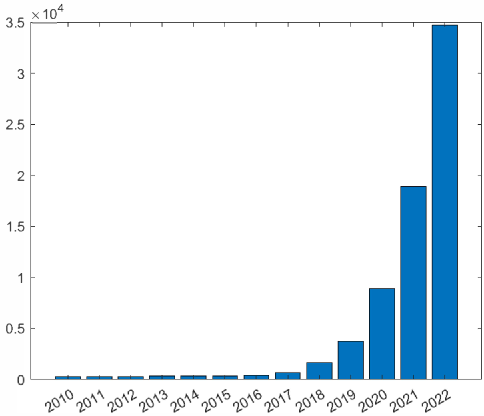
The advancement of SSL [15, 16, 17, 18, 19, 20, 21, 22, 23, 3, 4, 24] has exhibited rapid progress, capturing significant attention within the research community (Fig. 2), and is recognized as a crucial element for achieving human-level intelligence [25]. Google Scholar reports a substantial volume of SSL-related publications, with approximately 18,900 papers published in 2021 alone. This accounts for an average of 52 papers per day or more than two papers per hour (Fig. 2). To assist researchers in navigating this vast number of SSL papers and to consolidate the latest research findings, we aim to provide a timely and comprehensive survey on this subject.
Differences from previous work: Previous works have provided reviews on SSL that cater to specific applications such as recommender systems [26], graphs [27, 28], sequential transfer learning [29], videos [30], adversarial pre-training of self-supervised deep networks [31], and visual feature learning [32]. Besides, Liu et al. [4] primarily focused on papers published before 2020, lacking the latest advancements. Jaiswal et al. [33] centered their survey on contrastive learning (CL). Notably, recent breakthroughs in SSL research within the CV domain are of significant importance. Thus, this review predominantly encompasses recent SSL research derived from the CV community, particularly those influential and classic findings. The primary objectives of this review are to elucidate the concept of SSL, its categories and subcategories, its differentiation and relationship with other machine learning paradigms, as well as its theoretical foundations. We present an extensive and up-to-date review of the frontiers of visual SSL, dividing it into four key areas: context-based, CL, generative, and contrastive generative algorithms, aiming to outline prominent research trends for scholars.
2 Algorithms
This section begins by providing an introduction to SSL, followed by an explanation of the pretext tasks associated with SSL and their integration with other learning paradigms.
2.1 What is SSL?
The introduction of SSL is attributed to [34] (Fig. 3), who employed this architecture to learn in natural environments featuring diverse modalities. For instance, the sight of a cow and the sound of its characteristic “mooing” are frequently observed together. Therefore, although the cow image may not warrant a cow label, it is frequently associated with a “moo” instance. The crux lies in processing the cow image to derive a self-supervised label for the network, enabling it to process the corresponding “moo” sound, and vice versa.
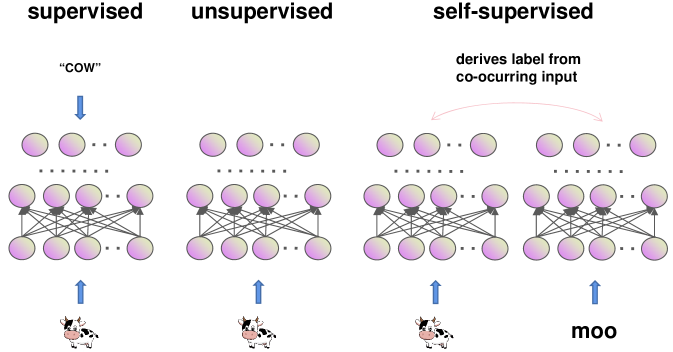
Subsequently, the machine learning community has advanced the concept of SSL, which falls within the realm of unsupervised learning. SSL involves generating output labels “intrinsically” from input data examples by revealing the relationships between data components or various views of the data. These output labels are derived directly from the data examples. According to this definition, an autoencoder (AE) can be perceived as a type of SSL algorithms, where the output labels correspond to the data itself. AEs have gained extensive usage across multiple domains, including dimensionality reduction and anomaly detection.
In the keynote talk at ICLR 2020, Yann LeCun elucidated the concept of SSL as an analogous process to completing missing information (reconstruction). He presented multiple variations as follows: 1) Predict any part of the input from any other part; 2) Predict the future from the past; 3) Predict the invisible from the visible; and 4) Predict any occluded, masked, or corrupted part from all available parts. In summary, a portion of the input is unknown in SSL, and the objective is to predict that particular segment.
Jing et al. [32] expanded the definition of SSL to encompass methods that operate without human-annotated labels. Consequently, any approach devoid of such labels can be categorized under SSL, effectively equating SSL with unsupervised learning. This categorization includes generative adversarial networks (GANs) [35], thereby positioning them within the realm of SSL.
Pretext tasks, also referred to as surrogate or proxy tasks, are a fundamental concept in the field of SSL. The term “pretext” denotes that the task being solved is not the primary objective but serves as a means to generate a robust pre-trained model. Prominent examples of pretext tasks include rotation prediction and instance discrimination, among others. Each pretext task necessitates the use of distinct loss functions to achieve its intended goal. Given the significance of pretext tasks in SSL, we proceed to introduce them in further detail.
2.2 Pretext tasks
This section provides a comprehensive overview of the pretext tasks employed in SSL. A prevalent approach in SSL involves devising pretext tasks for networks to solve, where the networks are trained by optimizing the objective functions associated with these tasks. Pretext tasks typically exhibit two key characteristics. Firstly, deep learning methods are employed to learn features that facilitate the resolution of pretext tasks. Secondly, supervised signals are derived from the data itself, a process known as self-supervision. Commonly employed techniques encompass four categories of pretext tasks: context-based methods, CL, generative algorithms, and contrastive generative methods. In our paper, generative algorithms primarily refer to masked image modeling (MIM) methods.
2.2.1 Context-based methods
Context-based methods rely on the inherent contextual relationships among the provided examples, encompassing aspects such as spatial structures and the preservation of both local and global consistency. We illustrate the concept of context-based pretext tasks using rotation as a simple example [36]. Subsequently, we progressively introduce additional tasks (Fig. 4).

Rotation: The approach of utilizing rotation involves training deep neural networks (DNNs) to learn image representations by recognizing the geometric transformations applied to the original image. In their work, Gidaris et al. [7] generated three rotated images (, , and rotations) for each original image (” rotation”). These images were classified into four classes corresponding to the rotation angles (, , , and ), serving as the output labels derived from the images themselves. Specifically, a set of discrete geometric transformations was employed, where represents the operator that applies a geometric transformation labeled as to the image , resulting in the transformed image .
To predict rotation, Gidaris et al. employed a deep convolutional neural network (CNN) denoted as , which tackled a four-class categorization task. The CNN takes an input image (where is unknown to ) and generates a probability distribution over potential geometric transformations, expressed as
| (1) |
Here, represents the predicted probability for the geometric transformation labeled as , while denotes the learnable parameters of .
In order to accurately classify the classes of natural images, a proficient CNN should possess the capability to do so. Therefore, when provided with a set of training instances , the self-supervised training objective of can be formulated as
| (2) |
Here, the loss function is defined as
| (3) |
In [37], the relative rotation angle was confined to the interval of . These rotations were discretized into bins of each, leading to a total of 20 classes (or bins).
Colorization: The concept of colorization was initially introduced in [38], and subsequent studies [39, 40, 41] demonstrated its effectiveness as a pretext task for SSL. Color prediction offers the advantageous feature of requiring freely available training data. In this context, a model can utilize the channel of any color image as input and utilize the corresponding color channels in the CIE color space as self-supervised signals. The objective is to predict the color channels given an input lightness channel , where and represent the height and width of the image, respectively. In this context, and denote the ground truth and predicted values, respectively. A commonly employed objective function aims to minimize the Frobenius norm between and , as expressed by
| (4) |
Besides, [38] utilized the multinomial cross-entropy loss instead of (4) to enhance robustness. Upon completing the training process, it becomes possible to predict the color channels for any grayscale image. Consequently, the channel and the color channels can be concatenated to restore the original grayscale image to a colorful representation.
Jigsaw: The jigsaw approach leverages jigsaw puzzles as surrogate tasks, operating under the assumption that a model accomplishes these tasks by comprehending the contextual information embedded within the examples. Specifically, images are fragmented into discrete patches, and their positions are randomly rearranged, with the objective of reconstructing the original order. In [42], the impact of scaling two self-supervised methods, namely jigsaw [8, 43] and colorization, was investigated along three dimensions: data size, model capacity, and problem complexity. The results indicated that transfer performance exhibits a log-linear growth pattern in relation to data size. Furthermore, representation quality was found to improve with higher-capacity models and increased problem complexity.
Others: The pretext task employed in [44, 45] involved a conditional motion propagation problem. To enforce a specific constraint on the feature representation process, Noroozi et al. [46] introduced an additional requirement where the sum of feature representations of all image patches should approximate the feature representation of the entire image. While many pretext tasks yield representations that exhibit covariance with image transformations, [47] argued for the importance of semantic representations being invariant to such transformations. In response, they proposed a pretext-invariant representation learning approach that enables the learning of invariant representations through pretext tasks.
2.2.2 Contrastive Learning
Numerous SSL methods based on CL have emerged, building upon the foundation of simple instance discrimination tasks [48, 49]. Notable examples include MoCo v1 [50], MoCo v2 [51], MoCo v3 [52], SimCLR v1 [53] and SimCLR v2 [54]. Pioneering algorithms, such as MoCo, have significantly enhanced the performance of self-supervised pre-training, reaching a level comparable to that of supervised learning, thus rendering SSL highly pertinent for large-scale applications. Early CL approaches were built upon the concept of utilizing negative examples. However, as CL has progressed, a range of methods have emerged that eliminate the need for negative examples. These methods embrace distinct ideas such as self-distillation and feature decorrelation, yet all adhere to the principle of maintaining positive example consistency. The following section outlines the various CL methods currently available (Fig. 5).
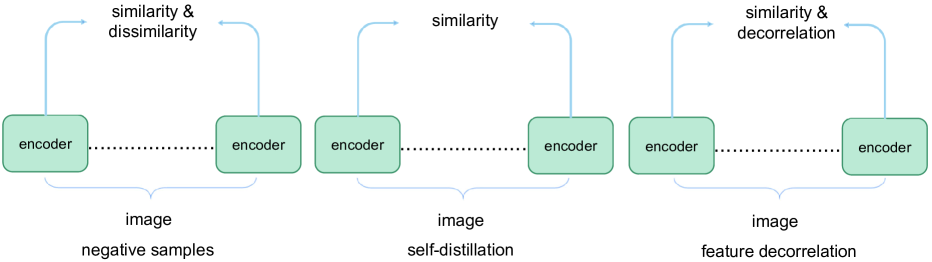
Negative example-based CL
Negative examples-based CL adheres to a pretext task known as instance discrimination, which involves generating distinct views of an instance. In negative examples-based CL, views originating from the same instance are treated as positive examples for an anchor sample, while views from different instances serve as negative examples. The underlying principle is to promote proximity between positive examples and maximize the separation between negative examples within the latent space. The definition of positive and negative examples varies depending on factors such as the modality being considered and specific requirements, including spatial and temporal consistency in video understanding or the co-occurrence of modalities in multi-modal learning scenarios. In the context of conventional 2D image CL, image augmentation techniques are utilized to generate diverse views from a single image.
MoCo: He et al. [50] framed CL as a dictionary look-up task. In this framework, a query and a set of encoded examples serve as the keys in a dictionary. Assuming a single key, denoted as in the dictionary, matches the query , a contrastive loss [55] function is employed. The value of this function is low when is similar to its positive key and dissimilar to all other negative keys. In the MoCo v1 [50] framework, the InfoNCE loss function [56], a form of contrastive loss, is utilized, i.e.,
| (5) |
where represents the temperature hyper-parameter. The summation is computed over one positive example and negative examples. InfoNCE is derived from noise contrastive estimation (NCE) [57], which is characterized by the following objective:
| (6) |
where exhibits similarity to the positive example and dissimilarity to the negative example .
MoCo v2 [51] builds upon the foundation established by MoCo v1 [50] and SimCLR v1 [53], incorporating an multilayer perceptron (MLP) projection head and more data augmentations.
SimCLR: SimCLR v1 [53] employs a mini-batch sampling strategy with instances, wherein a contrastive prediction task is formulated on pairs of augmented instances from the mini-batch, generating a total of 2 instances. Notably, SimCLR v1 does not explicitly select negative instances. Instead, for a given positive pair, the remaining 2 augmented instances in the mini-batch are treated as negatives. Let represent the cosine similarity between two instances and . The loss function of SimCLR v1 for a positive instance pair is defined as
| (7) |
where is an indicator function equal to 1 if , and denotes the temperature hyper-parameter. The overall loss is computed across all positive pairs, including both and , within the mini-batch.
In MoCo, the features generated by the momentum encoder are stored in a feature queue as negative examples. These negative examples do not undergo gradient updates during backpropagation. Conversely, SimCLR utilizes negative examples from the current mini-batch, and all of them are subjected to gradient updates during backpropagation. Both MoCo and SimCLR rely on data augmentation techniques, including cropping, resizing, and color distortion. Notably, SimCLR made a significant contribution by highlighting the crucial role of robust data augmentation in CL, a finding subsequently confirmed by MoCo v2. Additional augmentation methods have also been explored [58]. For instance, in [59], foreground saliency levels were estimated in images, and augmentations were created by selectively copying and pasting image foregrounds onto diverse backgrounds, such as grayscale images with random grayscale levels, texture images, and ImageNet images. Furthermore, views can be derived from various sources, including different modalities such as photos and sounds [60], as well as coherence among different image channels [61].
Minimizing the contrastive loss is known to effectively maximize a lower bound of the mutual information between the variables and [56]. Building upon this understanding, [62] proposes principles for designing diverse views based on information theory. These principles suggest that the views should aim to maximize and (, , and denoting the first view, the second view, and the label, respectively), representing the amount of information contained about the task label, while simultaneously minimizing , indicating the shared information between inputs encompassing both task-relevant and irrelevant details. Consequently, the optimal data augmentation method is contingent on the specific downstream task. In the context of dense prediction tasks, [63] introduces a novel approach for generating different views. This study reveals that commonly employed data augmentation methods, as utilized in SimCLR, are more suitable for classification tasks rather than dense prediction tasks such as object detection and semantic segmentation. Consequently, the design of data augmentation methods tailored to specific downstream tasks has emerged as a significant area of exploration.
Given the observed benefits of strong data augmentation in enhancing CL performance [53], there has been a growing interest in leveraging more robust augmentation techniques. However, it is worth noting that solely relying on strong data augmentation can actually lead to a decline in performance [62]. The distortions introduced by strong data augmentation can alter the image structure, resulting in a distribution that differs from that of weakly augmented images. This discrepancy poses optimization challenges. To address the overfitting issue arising from strong data augmentation, [64] proposes an alternative approach. Instead of employing a one-hot distribution, they suggest using the distribution generated by weak data augmentation as a mimic. This mitigates the negative impact of strong data augmentation by aligning the distribution of augmented examples with that of weakly augmented examples.
Self-distillation-based CL
Bootstrap Your Own Latent (BYOL) [65] is a prominent self-distillation algorithm designed specifically for self-supervised image representation learning, eliminating the need for negative pairs. This approach employs two identical DNNs, known as Siamese networks, with the same architecture but different weights. One serves as the online network, while the other is the target network. Similar to MoCo [50], BYOL enhances the target network through a gradual averaging of the online network. Siamese networks have emerged as prevalent architectures in contemporary self-supervised visual representation learning models, including SimCLR, BYOL, and SwAV [66]. These models aim to maximize the similarity between two augmented versions of a single image while incorporating specific conditions to mitigate the risk of collapsing solutions.
Simple Siamese (SimSiam) networks, introduced by [67], offers a straightforward approach to learning effective representations in SSL without the need for negative example pairs, large batches, or momentum encoders. Given a data point and two randomly augmented views and , an encoder and an MLP prediction head process these views. The resulting outputs are denoted as and . The objective of [67] is to minimize their negative cosine similarity:
| (8) |
Here, represents the -norm. Similar to [65], a symmetric loss [67] is defined as
| (9) |
This loss is defined based on the example , and the overall loss is the average of all examples. Notably, [67] employs a stop-gradient () operation by modifying Eq. (8) as . This implies that is treated as a constant. Similarly, Eq. (9) is revised as
| (10) |
Figure 6 illustrates the distinctions among SimCLR, BYOL, SwAV, and SimSiam. The categorization of BYOL and SimSiam as CL methods is a subject of debate due to their exclusion of negative examples. However, to be consistent with [68], this paper considers BYOL and SimSiam to belong to CL methods.
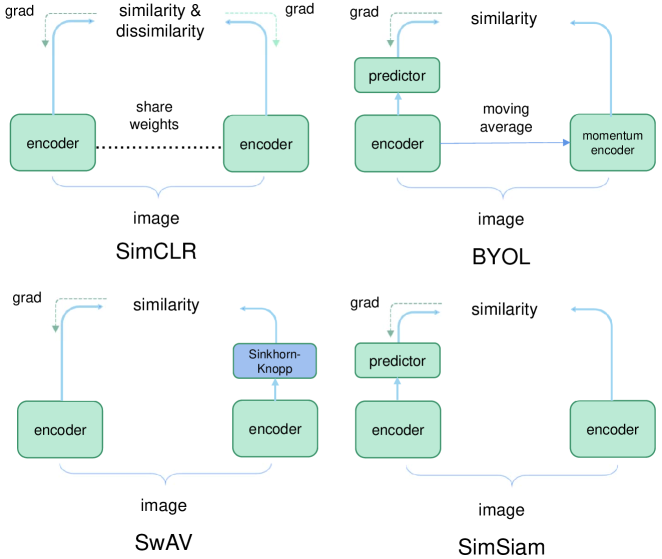
Feature decorrelation-based CL
The objective of feature decorrelation is to learn features that are decorrelated.
Barlow twins: Barlow twins [69] introduced a novel loss function that encourages the similarity of embedding vectors from distorted versions of an example while minimizing redundancy between their components. Similar to other SSL methods such as MoCo [50] and SimCLR [53], Barlow twins generate two views for each image in a batch sampled from a dataset, resulting in batches of embeddings and . The objective function of Barlow twins is defined as
| (11) |
Here, is a hyper-parameter, and represents the cross-correlation matrix computed between the outputs of two identical networks along the batch dimension:
| (12) |
In the above equation, represents the batch example index and denotes the vector dimension indices of the network outputs. The matrix has a square shape and its size is equal to the dimensionality of the network output.
Variance-Invariance-Covariance Regularization: Variance-invariance-covariance regularization (VICReg) [70] has been proposed for SSL, similar to Barlow twins [69]. While Barlow twins focus on a cross-correlation matrix, VICReg considers variance, invariance, and covariance simultaneously. Let , , and represent the dimensionality of the vectors in , the batch size, and the vector consisting of the values at dimension among all examples in , respectively. The variance regularization term in VICReg is defined as a hinge loss function applied to the standard deviation of the embeddings along the batch dimension:
| (13) |
Here, represents the regularized standard deviation, defined as
| (14) |
The constant determines the standard deviation and is set to 1 in the experiments, while is a small scalar used to prevent numerical instabilities. This criterion encourages the variance within the current batch to be equal to or greater than for every dimension, thereby preventing collapse scenarios where all data are mapped to the same vector.
The invariance criterion in VICReg, which captures the similarity between and , is defined as the mean-squared Euclidean distance between each pair of data without any normalization:
| (15) |
In addition, the covariance criterion in VICReg is defined as
| (16) |
where represents the covariance matrix of . The overall loss of VICReg is a weighted sum of the variance, invariance, and covariance:
| (19) |
where and are two hyper-parameters.
Analysis of CL
Despite the impressive results achieved by contrastive SSL, the underlying mechanisms responsible for its success remain somewhat obscure and not fully understood. Several studies have delved into this area [71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82]. Theoretical investigations by [72, 77, 80] have provided support for the value of feature representations generated through CL. Their findings demonstrate that these representations offer significant utility for downstream tasks.
Connection to principal component analysis: Tian [82] demonstrated that CL with loss functions like InfoNCE can be formulated as a max-min problem. The max function aims to maximize the contrast between feature representations, while the min function assigns weights to pairs of examples with similar representations. In the context of deep linear networks, Tian showed that the max function in representation learning is equivalent to principal component analysis (PCA), and most local minima correspond to global minima, thus recovering optimal PCA solutions. Experimental results revealed that this formulation, when extended to include new contrastive losses beyond InfoNCE, achieves comparable or even superior performance on datasets like STL-10 and CIFAR10. Furthermore, Tian extended his theoretical analysis to 2-layer rectified linear unit (ReLU) networks, emphasizing the substantial differences between linear and nonlinear scenarios and highlighting the essential role of data augmentation during the training process. It is noteworthy that PCA aims to maximize the inter-example distances within a low-dimensional subspace, making it a specific instance of instance discrimination.
Connection to spectral clustering: Chen et al. [79] established a connection between CL and spectral clustering, showing that the representations obtained from CL correspond to embeddings of a positive pair graph in spectral clustering. Specifically, the authors introduced a population augmentation graph, where nodes represent augmented data from the population distribution, and the presence of an edge between nodes is determined by whether they originate from the same original example. Their key assumption is that different classes exhibit only a limited number of connections, resulting in a sparser partition for such a graph. Empirical evidence has confirmed this characteristic, illustrating the data continuity within the same class [81].
Specifically, spectral decomposition is employed on the adjacency matrix to construct a matrix, where each row denotes the representation of an example. Through a linear transformation, they demonstrated that the corresponding feature extractor could be retrieved by minimizing an unconventional contrastive loss given as follows:
| (22) |
It is worth noting that in cases where the dimensionality of the representation surpasses the maximum count of disjoint subgraphs, the utilization of learned representations in linear classification is guaranteed to yield minimal error.
Connection to supervised learning: Recent research has highlighted the remarkable efficacy of self-supervised pre-training using CL for downstream tasks involving classification. However, its effectiveness may vary when applied to other task domains. Thus, there is a compelling need to investigate the potential of contrastive pre-training in augmenting supervised learning, particularly in terms of surpassing the accuracy achieved through traditional supervised learning.
Newell et al. [83] conducted a comprehensive investigation into the potential effects of pre-training on model performance. Their study explored three key hypotheses as follows. Firstly, whether pre-training consistently leads to performance improvements. Secondly, whether pre-training achieves higher accuracy when faced with limited labeled data, but eventually levels off at a performance comparable to the baseline when sufficient labeled data is available. Thirdly, whether pre-training converges to baseline performance before reaching its plateau in accuracy. To address these hypotheses, the authors conducted experiments on the synthetic COCO dataset with rendering, allowing for the availability of a large number of labels. The results revealed that self-supervised pre-training adheres to the assumption outlined in the third hypothesis. This suggests that SSL does not surpass supervised learning in terms of learning capability, but does perform effectively when dealing with limited labeled data.
Others
Besides the aforementioned works, several other approaches have employed CL. Among them, [52, 84] investigated the utilization of vision transformers (ViTs) as the backbone for contrastive SSL, employing multi-crop and cross-entropy losses [84]. Notably, [84] discovered that the resultant features exhibited exceptional performance as -nearest neighbors (-NN) classifiers and effectively encoded explicit information regarding the semantic segmentation of images. These desirable properties have also motivated specific downstream tasks [85]. In a different study, [86] adopted patches extracted from the same image as a positive pair, while patches from different images served as negative pairs. A mixing operation is further explored in RegionCL [87] to diversify the contrastive pairs. Yang et al. [88] integrated CL and MIM in the context of text recognition, utilizing a weighted objective function. Numerous CL-based methods are available in the literature [89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109]. It should be noted that CL is not restricted solely to SSL, as it can also be used in supervised learning [110].
2.2.3 Generative algorithms
For the category of generative algorithms, this study primarily focuses on MIM methods. MIM methods [111] (Fig. 7)—namely, bidirectional encoder representation from image transformers (BEiT) [112], masked AE (MAE) [68], context AE (CAE) [113], and a simple framework for MIM (SimMIM) [114]—have gained significant popularity and pose a considerable challenge to the prevailing dominance of CL. MIM leverages co-occurrence relationships among image patches as supervision signals.
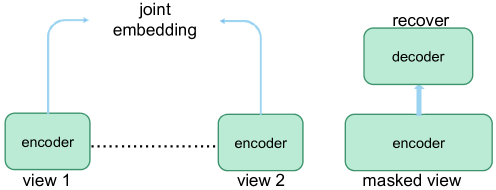
MIM represents a variant of the denoising AE (DAE) [16], emphasizing the importance of a robust representation that remains resilient to input noise. Notably, the bidirectional encoder representations from Transformers (BERT) [11] have emerged as a renowned variant of the DAE and achieved remarkable success in NLP. Researchers aspire to extend this success to CV by employing BERT-like pre-training strategies. However, it is crucial to acknowledge that BERT’s success in NLP can be attributed not only to its large-scale self-supervised pre-training but also to its scalable network architecture. A notable distinction between the NLP and CV communities is their use of different primary models, with transformers being prevalent in NLP and CNNs being widely adopted in CV.
The landscape changed significantly with the introduction of the original ViT [5], which marked a pivotal moment. Alexey Dosovitskiy et al. conducted pioneering research on applying MIM to CV, drawing inspiration from BERT’s masked image prediction paradigm. Their smaller ViT-B/16 model achieved 79.9% accuracy on ImageNet [1] through self-supervised pre-training, an impressive 2% improvement over training from scratch. However, it still fell short of the accuracy attained by supervised pre-training. Beyond ViTs, a separate early investigation adopted context encoders [115], employing a concept akin to MAE, i.e., image inpainting.
Despite their structural alignment, MAE did not find significant application in vision research until the emergence of BEiT. Prior to BEiT, there was another endeavor known as image generative pre-training (iGPT) [116], but it received limited attention due to its subpar accuracy and computational efficiency. In the footsteps of BERT’s success in NLP, BEiT introduced a tailored MIM task for visual pre-training, i.e., a tokenization approach which breaks down the input image into visual tokens, and then randomly masks a subset of the image patches. Similar to BERT, both masked and unmasked image tokens are fed into the ViT, aiming to recover the masked visual tokens based on the information from unmasked patches. To address the challenge of predicting raw pixels, the authors leveraged a discrete variational autoencoder (dVAE) [117] to create a predefined visual vocabulary. An interesting aspect is that the downstream task does not entail explicit [mask] labels, leading researchers to develop diverse algorithms to mitigate this issue. For instance, in the original BERT, methods like random words were used to alleviate inconsistencies between upstream and downstream tasks. In CV, both BEiT and SimMIM adopt paradigms akin to BERT, involving the inclusion of special [mask] tokens into the network.
In contrast to BEiT, MAE does not utilize special mask tokens and treats the task as a regression problem. It addresses the challenges of applying the DAE in CV from three key aspects: architecture, information density, and decoder design. MAE’s simplicity and effectiveness have established it as a crucial baseline within the MIM domain.
Here, we define
| (23) |
where denotes the encoder, denotes the decoder, represents the transformation applied to the input before it is fed into the network, and represents the transformation used to derive the target label. It is noteworthy that this representation is provided for the sake of clarity and ease of understanding rather than serving as a strict definition.
The primary distinction between BEiT and MAE lies in their choice of . While BEiT employs the token output from the pre-trained tokenizer as its target, MAE directly uses the original pixels as its target. BEiT adopts a two-stage approach, initially training a tokenizer to convert images into visual tokens, followed by BERT-style training. On the other hand, MAE is a one-stage end-to-end approach, incorporating a decoder to decode the encoder-derived representation into the original pixels. The two representative MIM approaches BEiT and MAE, showcase different architectural designs, with subsequent MIM methods often following one of these techniques. A central challenge in MIM lies in the selection of the target representation , which leads to the categorization of MIM methods, as presented in Table II.
| Low-Level Targets | High-Level Targets | Self-Distillation | Contrastive / Multi-modal Teacher | ||||||||
| Algorithm | ViT [5] | MAE [68] | SimMIM [114] | Maskfeat [118] | BEiT [112] | CAE [113] | PeCo [119] | data2vec [120] | SdAE [121] | MimCo [122] | BEiT v2 [123] |
| Target | Raw Pixel | HOG | VQ-VAE | VQ-GAN | self | MoCo v3 | CLIP | ||||

Following the introduction of BEiT and MAE, several variants have been proposed. iBOT [111] is an “online tokenizer” adaptation of BEiT, aiming to address the limitation of dVAE in capturing only low-level semantics within local details. The CAE introduces an alignment constraint to encourage masked patch representations (predicted by a “latent contextual regressor”) to lie in the encoded representation space. This decoupling of the representation learning task and pretext task enhances the model’s capacity for representation learning. Furthermore, MAE has been extended to other modalities beyond images [124, 125, 126].
MIM has demonstrated significant potential in pre-training vision transformers [127, 128, 129, 130]. Leveraging versatile ViT backbones, MIM acquires self-supervised visual representations by masking certain patches of the original image and subsequently recovering the masked information. However, in prior works, the random masking of image patches led to an underutilization of valuable semantic information essential for effective visual representation learning. Furthermore, the considerable size of the backbone resulted in extensive pre-training time for most previously developed methods. To address these issues, Liu et al. [131] introduced an attention-driven masking and throwing strategy, effectively tackling both aforementioned challenges.
2.2.4 Contrastive Generative Methods
As stated in [132], contrastive models tend to be data-hungry and vulnerable to overfitting issues, whereas generative models encounter data-filling challenges and exhibit inferior data scaling capabilities when compared to contrastive models. While contrastive models often focus on global views [84], overlooking internal structures within images, MIM primarily models local relationships. The divergent characteristics and challenges encountered in contrastive self-supervised learning and generative self-supervised learning have motivated researchers to explore the combination of these two kinds of approaches.
To elaborate further, let us compare the challenges faced by contrastive self-supervised methods and generative self-supervised methods. Generative self-supervised methods are characterized as data-filling approaches [133]. For a model of a certain size, when the dataset reaches a certain magnitude, further scaling of the data does not lead to significant performance gains in generative self-supervised methods. In contrast, recent studies have revealed the potential of data scaling to enhance the performance of CL [134]. As data increases, CL shows substantial performance improvements, demonstrating remarkable generalization without additional fine-tuning on downstream tasks. However, the scenario differs in low-data regimes. Contrastive models may find shortcuts with trivial representations that overfit the limited data [50], thus leading to inconsistent improvements in generalization performance for downstream tasks using pre-trained models with contrastive self-supervised methods [132]. On the other hand, generative methods are more adept at handling low-data scenarios and can even achieve notable performance improvements when data is extremely scarce, such as with only 10 images [135].
Several endeavors have sought to integrate both types of algorithms [136, 132]. In [136], GANs are employed for online data augmentation in CL. The study devises a contrastive module that learns view-invariant features for generation and introduces a view-invariant loss function to facilitate learning between original and generated views. On the other hand, [111] draws inspiration from both BEiT and DINO [84]. It modifies the tokenizer of BEiT to an online distilled teacher while integrating cross-view distillation from the DINO framework. As a result, iBOT [111] significantly enhances linear probing accuracy compared to the MIM method.
Despite attempts to combine both types of approaches, naive combinations may not always yield performance gains and can even perform worse than the generative model baseline, thereby exacerbating the issue of representation over-fitting [132]. The performance degradation could be attributed to the disparate properties of CL and generative methods. For instance, CL methods typically exhibit longer attention distances, whereas generative methods tend to favor local attention [137]. In light of this challenge, RECON [132] emerges as a solution by training generative modeling to guide CL, thereby leveraging the benefits of both paradigms.
2.2.5 Summary
As described above, numerous pretext tasks for SSL have been devised, with several significant milestone variants depicted in Fig. 8. Several other pretext tasks are available [138, 139], encompassing diverse approaches such as relative patch location [140], noise prediction [141], feature clustering [142, 143, 144], cross-channel prediction [145], and combining different cues [146]. Kolesnikov et al. [147] conducted a comprehensive investigation of previously proposed SSL pretext tasks, yielding significant insights. Besides, Krähenbühl et al. [148] proposed an alternative approach to pretext tasks and demonstrated the ease of obtaining data from video games.
It has been observed that context-based approaches exhibit limited applicability due to their inferior performance. In the realm of visual SSL, two dominant types of algorithms are CL and MIM. While visual CL may encounter overfitting issues, CL algorithms that incorporate multi-modality, exemplified by CLIP [2], have gained popularity.
2.3 Combinations with other learning paradigms
It is essential to acknowledge that the advancements in SSL did not occur in isolation; instead, they have been the result of continuous development over time. In this section, we provide a comprehensive list of relevant learning paradigms that, when combined with SSL, contribute to a clearer understanding of their collective impact.
2.3.1 GANs
GANs represent classical unsupervised learning methods and were among the most successful approaches in this domain before the surge of SSL techniques. The integration of GANs with SSL offers various avenues, with self-supervised GANs (SS-GAN) serving as one such example. The GANs’ objective function [35, 149] is given as
| (26) |
The SS-GAN [150] is defined by combining the objective functions of GANs with the concept of rotation [7]:
| (29) |
where represents the objective function of GANs as given in Eq. (26), and refers to a rotation selected from a set of possible rotations, similar to the concept presented in [7]. Here, denotes an image rotated by degrees, and corresponds to the discriminator’s predictive distribution over the angles of rotation for a given example . Notably, rotation [7] serves as a classical SSL method. The SS-GAN incorporates rotation invariance into the GANs’ generation process by integrating the rotation prediction task during training.
2.3.2 Semi-supervised learning
SSL and semi-supervised learning are contrasting paradigms that can be effectively combined. One notable example of this combination is self-supervised semi-supervised learning (S4L) [151]. In S4L, the objective function is given by
| (30) |
where represents the labeled training dataset, is the unlabeled training dataset, denotes the classification loss computed on all labeled examples, stands for the self-supervised loss (e.g., rotation task in Eq. (3)) utilizing both and , is a free parameter used for balancing the contributions of and , and represents the parameters of the learning model.
Incorporating SSL as an auxiliary task is a well-established approach in semi-supervised learning. Another classical method to leverage SSL within this context involves implementing SSL on unlabeled data, followed by fine-tuning the resultant model on labeled data, as demonstrated in the SimCLR framework.
To demonstrate the robustness of self-supervision against adversarial perturbations, Hendrycks et al. [152] proposed an overall loss function as a linear combination of supervised and self-supervised losses:
| (33) |
where represents an example, is the ground-truth label, denotes the model parameters, refers to the cross-entropy loss, and stands for projected gradient descent. The first and second terms in (33) correspond to the supervised learning loss and the SSL loss, respectively.
2.3.3 Multi-instance learning (MIL)
Miech et al. [13] introduced an extension of the InfoNCE loss (5) for MIL and termed it MIL-NCE:
| (34) |
where and represent a video clip and a narration, respectively. The functions and generate embeddings of and , respectively. For a specific example indexed by , denotes the set of positive video/narration pairs, while corresponds to the set of negative video/narration pairs.
2.3.4 Multi-view/multi-modal(ality) learning
Observation plays a vital role in infants’ acquisition of knowledge about the world. Notably, they can grasp the concept of apples through observational and comparative processes, which distinguishes their learning approach from traditional supervised algorithms that rely on extensive labeled apple data. This phenomenon was demonstrated by Orhan et al. [22], who gathered perceptual data from infants and employed an SSL algorithm to model how infants learn the concept of “apple”. Moreover, infants’ learning about the world extends to multi-view and multi-modal(ality) learning [2], encompassing various sensory inputs such as video and audio. Hence, SSL and multi-view/multi-modal(ality) learning converge naturally in infants’ learning mechanisms as they explore and comprehend the workings of the world.
Multiview CL
The objective function in standard multiview CL, as proposed by Tian et al. [62], is given by
| (35) |
where corresponds to Eq. (5). Additionally, it holds that , with and representing two views of the data point . Tian et al. [62] conducted a study to identify effective views for CL and introduced both unsupervised view learning and semi-supervised view learning. To split an image over its channels, the operation is represented as . Let denote , i.e., , where represents a flow-based model. For both unsupervised view learning and semi-supervised view learning, adversarial training was employed. Two encoders, and , were trained to maximize as stated in Eq. (35), while was trained to minimize . Formally, the objective function for unsupervised view learning can be expressed as
| (36) |
In the context of semi-supervised view learning, when several labeled examples are available, the objective function is formulated as
| (39) |
where represents the labels, and are classifiers, and denotes the cross-entropy loss. Further relevant works can be found in [62, 61, 153]. Table III summarizes different SSL losses.
| Category | Method | Loss | Equation | |
|---|---|---|---|---|
| Pretext | Context-Based | Rotation [7] | (3) | |
| CL | MoCo v1 [50] | (5) | ||
| SimCLR v1 [53] | (7) | |||
| SimSiam [67] | (10) | |||
| Barlow twins [69] | (11) | |||
| VICReg [70] | (19) | |||
| Combinations with Other Learning Paradigms | SS-GAN [150] | (29) | ||
| S4L [151] | (30) | |||
| SSL improving robustness [152] | (33) | |||
| unsupervised view learning [62] | (36) | |||
| semi-supervised view learning [62] | (39) | |||
Images and text
In the study conducted by Gomez et al. [154], the authors employed a topic modeling framework to project the text of an article into the topic probability space. This semantic-level representation was then utilized as the self-supervised signal for training CNN models on images. On a similar note, CLIP [2] leverages a CL-style pre-training task to predict the correspondence between captions and images. Benefiting from the CL paradigm, CLIP is capable of training models from scratch on an extensive dataset comprising 400 million image-text pairs collected from the internet. Consequently, CLIP’s advancements have significantly propelled multi-modal learning to the forefront of research attention.
Point clouds and other modalities
Several SSL methods have been proposed for joint learning of 3D point cloud features and 2D image features by leveraging cross-modality and cross-view correspondences through triplet and cross-entropy losses [155]. Additionally, there are efforts to jointly learn view-invariant and mode-invariant characteristics from diverse modalities, such as images, point clouds, and meshes, using heterogeneous networks for 3D data [156]. SSL has also been employed for point cloud datasets, with approaches including CL and clustering based on graph CNNs [157]. Furthermore, AEs have been used for point clouds in works like [158, 159, 125, 126], while capsule networks have been applied to point cloud data in [160].
2.3.5 Test time training
Sun et al. [161] introduced “test time training (TTT) with self-supervision” to enhance the performance of predictive models when the training and test data come from distinct distributions. TTT converts an individual unlabeled test example into an SSL problem, enabling model parameter updates before making predictions. Recently, Gandelsman et al. [162] combined TTT with MAE for improved performance. They argued that by treating TTT as a one-sample learning problem, optimizing a model for each test input could be addressed using the MAE as
| (40) |
| (41) |
Here, and refer to the encoder and decoder of MAE, and denotes the main task head, respectively.
In contrast to the classic paradigm, during training, the main task head utilizes features acquired from the MAE encoder rather than the original examples. Consequently, a singular example suffices for training during prediction. Moreover, this paper offers an intuitive rationale for the efficacy of TTT. Specifically, TTT achieves an improved bias-variance tradeoff under distribution shifts. A static model heavily depends on training data that may not accurately represent the new test distribution, leading to bias. On the other hand, training a new model from scratch for each test input, ignoring all training data, is undesirable. This approach results in an unbiased representation for each test input but exhibits high variance due to its singularity.
2.3.6 Summary
The evolution of SSL is characterized by its dynamic and interconnected nature. Analyzing the amalgamation of various methods allows for a clearer grasp of SSL’s developmental trajectory. An exemplar of this success is evident in CLIP, which effectively combines CL with multi-modal learning, leading to remarkable achievements. SSL has been extensively integrated with various machine learning tasks, showcasing its versatility and potential. It has been combined with clustering [66], semi-supervised learning [151], multi-task learning [163, 164, 165, 166], transfer learning [167, 168, 169], graph NNs [170, 171, 172, 173, 174, 153, 175], reinforcement learning [176, 177, 178], few-shot learning [179, 180], neural architecture search [181], robust learning [182, 183, 184, 152], and meta-learning [185, 186]. This diverse integration underscores the widespread applicability and impact of SSL in the machine learning domain.
3 Applications
SSL initially emerged in the context of vowel class recognition [187], and subsequently, it was extended to encompass object extraction tasks [188]. SSL has found widespread applications in diverse domains, including CV, NLP, medical image analysis, and remote sensing (RS).
3.1 CV
Sharma et al. [189] introduced a fully convolutional volumetric AE for unsupervised deep embeddings learning of object shapes. In addition, SSL has been extensively applied to various aspects of image processing and CV: image inpainting [115], human parsing [190, 191], scene deocclusion [192], semantic image segmentation [193, 194], monocular vision [195], person reidentification (re-ID) [196, 197, 198], visual odometry [199], scene flow estimation [200], knowledge distillation [201], optical flow prediction [202], vision-language navigation (VLN) [203], physiological signal estimation [204, 205], image denoising [206, 207], object detection [208, 209, 210], super-resolution [211, 212], voxel prediction from 2D images [213], ego-motion [214, 215], and mask prediction [216]. These applications highlight the broad impact and relevance of SSL in the realm of image processing and CV.
3.1.1 SSL models for videos
SSL has garnered widespread usage across various applications, including video representation learning [217, 218, 219] and video retrieval [220]. Wang et al. [221] employed a vast collection of unlabeled web videos to learn visual representations. The central concept revolves around utilizing visual tracking as a self-supervised signal. Consequently, two patches connected by a track are expected to possess similar visual representations, as they likely correspond to the same object or belong to the same object part. Srivastava et al. [222] proposed a composite self-supervised model by integrating two distinct models: a long short-term memory (LSTM) AE and an LSTM-based future prediction model. This composite model served the dual purpose of input reconstruction and future prediction.
Temporal information in videos
Various forms of temporal information in videos can be employed, encompassing frame order, video playback direction, video playback speed, and future prediction information [223, 224]. 1) The order of the frames. Several studies have explored the significance of frame order in videos. Misra et al. [9] introduced a method for learning visual representations from raw spatiotemporal signals and determining the correct temporal sequence of frames extracted from videos. Fernando et al. [225] proposed a novel self-supervised CNN pre-training approach called “odd-one-out learning,” where the objective is to identify the unrelated or odd element within a set of related elements. This odd element corresponds to a video subsequence with an incorrect temporal frame order, while the related elements maintain the correct temporal order. Lee et al. [226] employed temporally shuffled frames, presented in a non-chronological order, as inputs to train a CNN for predicting the correct order of the shuffled sequences, effectively using temporal coherence as a self-supervised signal. Building upon this work, Xu et al. [227] utilized temporally shuffled clips as inputs instead of individual frames, training 3D CNNs to sort these shuffled clips. 2) Video playback direction. Temporal direction analysis in videos, as studied by Wei et al. [10], involves discerning the arrow of time to determine if a video sequence progresses in the forward or backward direction. 3) Video playback speed. Video playback speed has been a subject of investigation in several studies. Benaim et al. [228] focused on predicting the speeds of moving objects in videos, determining whether they moved faster or slower than the normal speed. Yao et al. [229] leveraged playback rates and their corresponding video content as self-supervision signals for video representation learning. Additionally, Wang et al. [230] addressed the challenge of self-supervised video representation learning through the lens of video pace prediction.
Motions of objects in videos
Diba et al. [231] focused on SSL of motions in videos by employing dynamic motion filters to enhance motion representations, particularly for improving human action recognition. The concept of SSL with videos (CoCLR) [232] bears similarities to SimCLR [53].
Multi-modal(ality) data in videos
The auditory and visual components in a video are intrinsically interconnected. Leveraging this correlation, Korbar et al. [233] employed a self-supervised temporal synchronization approach to learn comprehensive and effective models for both video and audio analysis. Similarly, other methodologies [234, 60] are also founded on joint video and audio modalities while certain studies [235, 236, 237] incorporated both video and text modalities. Moreover, Alayrac et al. [238] explored a tri-modal approach involving vision, audio, and language in videos. On a different note, Sermanet et al. [239] proposed a self-supervised technique for learning representations and robotic behaviors from unlabeled videos captured from various viewpoints.
Spatial-temporal coherence of objects in videos
Wang et al. [240] introduced a self-supervised algorithm for learning visual correspondence in unlabeled videos by utilizing cycle consistency in time as a self-supervised signal. Extensions of this work have been explored by Li et al. [241] and Jabri et al. [242]. Lai et al. [243] presented a memory-augmented self-supervised method that enables generalizable and accurate pixel-level tracking. Zhang et al. [244] employed spatial-temporal consistency of depth maps to mitigate forgetting during the learning process. Zhao et al. [245] proposed a novel self-supervised algorithm named the “video cloze procedure (VCP),” which facilitates learning rich spatial-temporal representations for videos.
3.1.2 Universal sequential SSL models for image processing and CV
Contrastive predictive coding (CPC) [56] operates on the fundamental concept of acquiring informative representations through latent space predictions of future data using robust autoregressive models. While initially applied to sequential data like speech and text, CPC has also found applicability to images [246].
Drawing inspiration from the accomplishments of GPT [247, 248] in NLP, iGPT [116] investigates whether similar models can effectively learn representations for images. iGPT explores two training objectives, namely autoregressive prediction and a denoising objective, thereby sharing similarities with BERT [11]. In high-resolution scenarios, this approach [116] competes favorably with other self-supervised methods on ImageNet [1]. Similar to iGPT, ViT [5] also adopts a transformer architecture for vision tasks. By applying a pure transformer to sequences of image patches, ViT has demonstrated outstanding performance in image classification tasks. The transformer architecture has been further extended to various vision-related applications, as evidenced by [249, 68, 250, 112, 84, 52].
3.2 NLP
In the realm of NLP, pioneering works for performing SSL on word embeddings include the continuous bag-of-words model and the continuous skip-gram model [251]. SSL methods, notably BERT [11] and GPT, have found widespread application in NLP [252, 253, 254, 255, 256]. Moreover, SSL has been employed for other sequential data, including sound data [257].
3.3 Other fields
Within the medical field [258], the availability of labeled data is typically limited, while a vast amount of unlabeled data exists. This natural scenario makes SSL a compelling approach, which has been effectively employed for various tasks like medical image segmentation [259] and 3D medical image analysis [260]. Recently, SSL has also found applications in the remote sensing domain, benefiting from the abundance of large-scale unlabeled data that remains largely unexplored. For example, SeCo [261] leverages seasonal changes in RS images to construct positive pairs and perform CL. On the other hand, RVSA [262] introduces a novel rotated varied-size window attention mechanism that advances the plain vision transformer to serve as a fundamental model for various remote sensing tasks. Notably, it is pre-trained using the generative SSL method MAE [68] on the large-scale MillionAID dataset.
4 Performance comparison
Once a pre-trained model is obtained through SSL, the assessment of its performance becomes necessary. The conventional approach involves gauging the achieved performance on downstream tasks to ascertain the quality of the extracted features. However, this evaluation metric does not provide insights into what the network has specifically learned during self-supervised pre-training. To delve into the interpretability of self-supervised features, alternative evaluation metrics, such as network dissection [263], can be employed. Recently, a plethora of MIM methods have emerged, showcasing distinct focuses compared to previous approaches. In this section, we aim to present a clear demonstration of the performance exhibited by various methods. We summarize the classification and transfer learning efficacy of typical SSL methods on well-established datasets. It is important to note that SSL techniques can theoretically be applied to data with diverse modalities. However, for the sake of simplicity, we narrow our focus to SSL in the image domain. Within this domain, we compare the achieved performance across several downstream tasks, primarily encompassing image classification, object detection, and semantic segmentation.
4.1 Comprehensive comparison
In this section, we present the results obtained from diverse algorithms tested on respective datasets as summarized in Table IV. The experimental results are drawn either directly from the original papers or from other sources with annotations. When results are sourced from original papers, no specific indication is provided; however, for results from alternative works, the data source is indicated. In cases where a method replicated from another work achieves superior accuracy compared to the original paper, we consistently report the results with higher accuracy.
It is important to note that due to the aim of comparing a wide array of algorithms, the experimental setups are not strictly standardized. Nevertheless, we make efforts to align crucial hyper-parameters, while certain parameters such as the number of training epochs may not be completely aligned. The experimental results are uniformly obtained using the default backbone specified in the original papers, such as ResNet-50 or ViT-B. In instances where certain experimental results lack corresponding ResNet-50 or ViT-B implementations, we provide results based on other backbones, suitably marked with subscripts.
Setup. The pre-training process utilizes ImageNet-1k [1] as the primary dataset. Subsequently, following a standard procedure [50, 53] outlined in Table IV, a comparative analysis of these methods is conducted through linear classification of frozen features. This entails training a linear classifier, which consists of a fully connected layer followed by the softmax function, using features obtained from the pre-trained model. “Fine-tuning” denotes fine-tuning the entire model. The reported results indicate the top-1 classification accuracy obtained on the ImageNet validation set.
We also present our findings for the object detection and semantic segmentation tasks on widely recognized datasets, including PASCAL VOC [264], COCO [265], and ADE20k [266, 267]. The evaluation of object detection results on the PASCAL VOC dataset employs the default mean average precision (mAP), specifically . By default, the object detection task on PASCAL VOC employs VOC2007 for training. However, certain methods employ the combined 07+12 dataset instead of VOC2007 for training, and the results are annotated with a superscript “e”. As for the object detection and instance segmentation tasks on COCO, we adopt the bounding-box AP () and mask AP () metrics, in accordance with [50].
| Methods | Linear Probe | Fine-Tuning | VOC_det | VOC_seg | COCO_det | COCO_seg | ADE20K_seg | DB |
| Random: | [8] | - | [67] | [8] | [50] | [50] | - | - |
| R50 Sup | 76.5[66] | 76.5[66] | [67] | 74.4[65] | 40.6[50] | 36.8[50] | - | - |
| ViT-B Sup | 82.3[68] | 82.3[68] | - | - | 47.9[68] | 42.9[68] | 47.4[68] | - |
| Context-Based: | ||||||||
| Jigsaw[8] | [66] | [42] | - | - | - | 256 | ||
| Colorization[38] | [66] | [7] | - | - | - | - | ||
| Rotation[7] | - | - | - | 128 | ||||
| CL Based on Negative Examples: | ||||||||
| Examplar[138] | [48] | - | - | - | - | - | - | - |
| Instdisc[48] | - | - | - | - | - | 256 | ||
| MoCo v1[50] | - | - | - | 256 | ||||
| SimCLR[53] | [52] | - | [67] | - | [67] | [67] | - | 4096 |
| MoCo v2[51] | [67] | - | - | [70] | [70] | - | 256 | |
| MoCo v3[52] | 76.7 | 83.2 | - | - | 47.9[68] | 42.7[68] | 47.3[68] | 4096 |
| CL Based on Clustering: | ||||||||
| SwAV[66] | - | [70] | - | [70] | - | 4096 | ||
| CL Based on Self-distillation: | ||||||||
| BYOL[65] | - | [67] | [70] | [70] | - | 4096 | ||
| SimSiam[67] | - | [67] | - | - | 512 | |||
| DINO[84] | 78.2 | 83.6[111] | - | - | 46.8[113] | 41.5[113] | 44.1[112] | 1024 |
| CL Based on Feature Decorrelation: | ||||||||
| Barlow Twins[69] | - | [70] | - | - | 2048 | |||
| VICReg[70] | - | - | - | 2048 | ||||
| Masked Image Modeling (ViT-B by default): | ||||||||
| Context Encoder[115] | [7] | - | [7] | - | - | - | - | |
| BEiT v1[112] | 56.7[123] | 83.4[111] | - | - | 49.8[68] | 44.4[68] | 47.1[68] | 2000 |
| MAE[68] | 67.8 | 83.6 | - | - | 50.3 | 44.9 | 48.1 | 4096 |
| SimMIM[114] | 56.7 | 83.8 | - | - | [268] | - | [268] | 2048 |
| PeCo[119] | - | 84.5 | - | - | 43.9 | 39.8 | 46.7 | 2048 |
| iBOT[111] | 79.5 | 84.0 | - | - | 51.2 | 44.2 | 50.0 | 1024 |
| MimCo[122] | - | 83.9 | - | - | 44.9 | 40.7 | 48.91 | 2048 |
| CAE[113] | 70.4 | 83.9 | - | - | 50 | 44 | 50.2 | 2048 |
| data2vec[120] | - | 84.2 | - | - | - | - | - | 2048 |
| SdAE[121] | 64.9 | 84.1 | - | - | 48.9 | 43.0 | 48.6 | 768 |
| BEiT v2[123] | 80.1 | 85.5 | - | - | - | - | 53.1 | 2048 |
4.2 Summary
Firstly, the linear probe accuracy of the self-supervised algorithm based on CL consistently surpasses that of the other algorithms. This superiority can be attributed to the algorithm’s ability to generate well-structured latent spaces, wherein distinct categories are effectively separated, and similar categories are appropriately clustered.
Secondly, it is observed that pre-trained models using MIM can be fine-tuned to achieve superior performance in most cases. Conversely, pre-trained models based on CL lack this property. One primary reason for this discrepancy lies in the increased susceptibility of CL-based models to overfitting [269, 64, 270]. This observation also extends to the fine-tuning of pre-trained models for downstream tasks. MIM-based approaches consistently exhibit substantial performance enhancements in downstream tasks, while CL-based methods offer comparatively limited assistance.
Thirdly, CL-based methods tend to employ resource-intensive techniques like momentum encoders, memory queues, and multi-crop, significantly increasing the demands on computing, storage, and communication resources. In contrast, MIM-based methods have a more efficient resource utilization, possibly attributed to the absence of example interactions. This advantageous property allows MIM-based algorithms to easily scale up models and data, efficiently leveraging modern GPUs for high parallel computing.
5 Conclusions, Future Trends, and Open Questions
In summary, this comprehensive review offers essential insights into contemporary SSL research, providing newcomers with an overall picture of the field. The paper presents a thorough survey of SSL from three main perspectives: algorithms, applications, and future trends. We focus on mainstream visual SSL algorithms, classifying them into four major types: context-based methods, generative methods, contrastive methods, and contrastive generative methods. Furthermore, we investigate the correlation between SSL and other learning paradigms while comparing early SSL algorithms with current mainstream ones. Lastly, we will delve into future trends and open problems as outlined below.
Main trends: Firstly, while practical developments in SSL have progressed significantly, its theoretical analysis lags behind. For instance, investigations into why BYOL and SimSiam [67] do not collapse [271] have been conducted, but the fundamental reason remains elusive. Further theoretical explorations are necessary to unravel this mystery and potentially uncover more effective solutions. Moreover, recent research has shown that MIM-based methods can attain comparable or even superior performance when compared to traditional CL-based methods. This also urgently calls for a theoretical explanation.
Secondly, a crucial question arises concerning the automatic design of an optimal pretext task to enhance the performance of a fixed downstream task. Various methods have been proposed to address this challenge, including the pixel-to-propagation consistency method [63] and dense contrastive learning [272]. However, this problem remains insufficiently resolved, and further theoretical investigations are warranted in this direction.
Thirdly, there is a pressing need for a unified SSL paradigm that encompasses multiple modalities. MIM has demonstrated remarkable progress in vision tasks, akin to the success of masked language model in NLP, suggesting the possibility of unifying learning paradigms. Additionally, the ViT architecture bridges the gap between visual and verbal modalities, enabling the construction of a unified transformer model for both CV and NLP tasks. Recent endeavors [273, 120] have sought to unify SSL models, yielding impressive results in downstream tasks and showing broad applicability. Nevertheless, NLP has advanced further in leveraging SSL models, prompting the CV community to draw inspiration from NLP approaches to effectively harness the potential of pre-trained models.
Open problems: Firstly, can SSL harness the advantages of almost limitless data? Considering the abundance of unlabeled data, can SSL consistently benefit from additional unlabeled data, and can the theoretical inflection point be determined?
Secondly, it is pertinent to explore the interconnection between SSL and multi-modality learning, as both methodologies share resemblances with the cognitive processes observed in infants. Consequently, a critical inquiry arises: how can these two approaches be synergistically integrated to forge a robust and comprehensive learning model?
Thirdly, determining the most optimal or recommended SSL algorithm poses a challenge as there is no universally applicable solution. The ideal selection of an algorithm should align with the specific problem structure, yet practical situations often complicate this process. Consequently, the development of a checklist to aid users in identifying the most suitable method under particular circumstances warrants investigation and should be pursued as a promising avenue for future research.
Fourthly, the assumption that unlabeled data invariably leads to improved outcomes warrants scrutiny. Our hypothesis challenges this notion, especially concerning semi-supervised learning methods, as the no free lunch theorem comes into play. Performance degradation can arise when model assumptions fail to align effectively with the underlying problem structure. For instance, if a model assumes a substantial separation between decision boundaries and regions of high data density, it may perform poorly when faced with data originating from heavily overlapping Cauchy distributions, as the decision boundary would traverse through dense areas. However, preemptively identifying such mismatches remains intricate and an unresolved matter. Consequently, this topic merits further research to shed light on the matter.
References
- [1] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 248–255, 2009.
- [2] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al., “Learning transferable visual models from natural language supervision,” in Int. Conf. Mach. Learn., pp. 8748–8763, 2021.
- [3] L. Ericsson, H. Gouk, and T. M. Hospedales, “How well do self-supervised models transfer?,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 5414–5423, 2021.
- [4] X. Liu, F. Zhang, Z. Hou, L. Mian, Z. Wang, J. Zhang, and J. Tang, “Self-supervised learning: Generative or contrastive,” IEEE T. Knowl. Data Eng., 2022.
- [5] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” in Int. Conf. Learn. Represent., 2021.
- [6] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learning spatiotemporal features with 3d convolutional networks,” in IEEE Int. Conf. Comput. Vis., pp. 4489–4497, 2015.
- [7] S. Gidaris, P. Singh, and N. Komodakis, “Unsupervised representation learning by predicting image rotations,” in Int. Conf. Learn. Represent., pp. 1–14, 2018.
- [8] M. Noroozi and P. Favaro, “Unsupervised learning of visual representations by solving jigsaw puzzles,” in Eur. Conf. Comput. Vis., pp. 69–84, 2016.
- [9] I. Misra, C. L. Zitnick, and M. Hebert, “Shuffle and learn: unsupervised learning using temporal order verification,” in Eur. Conf. Comput. Vis., pp. 527–544, 2016.
- [10] D. Wei, J. J. Lim, A. Zisserman, and W. T. Freeman, “Learning and using the arrow of time,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 8052–8060, 2018.
- [11] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [12] X. Zeng, Y. Pan, M. Wang, J. Zhang, and Y. Liu, “Realistic face reenactment via self-supervised disentangling of identity and pose,” in AAAI Conf.Artif. Intell., pp. 12154–12163, 2020.
- [13] A. Miech, J.-B. Alayrac, L. Smaira, I. Laptev, J. Sivic, and A. Zisserman, “End-to-end learning of visual representations from uncurated instructional videos,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 9879–9889, 2020.
- [14] Y. M. Asano, C. Rupprecht, and A. Vedaldi, “A critical analysis of self-supervision, or what we can learn from a single image,” in Int. Conf. Learn. Represent., 2020.
- [15] G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” Science, vol. 313, no. 5786, pp. 504–507, 2006.
- [16] P. Vincent, H. Larochelle, Y. Bengio, and P.-A. Manzagol, “Extracting and composing robust features with denoising autoencoders,” in Int. Conf. Mach. Learn., pp. 1096–1103, 2008.
- [17] L. Pinto and A. Gupta, “Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours,” in IEEE Int. Conf. Robot. Autom., pp. 3406–3413, 2016.
- [18] Y. Li, M. Paluri, J. M. Rehg, and P. Dollár, “Unsupervised learning of edges,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 1619–1627, 2016.
- [19] D. Li, W.-C. Hung, J.-B. Huang, S. Wang, N. Ahuja, and M.-H. Yang, “Unsupervised visual representation learning by graph-based consistent constraints,” in Eur. Conf. Comput. Vis., pp. 678–694, 2016.
- [20] H. Lee, S. J. Hwang, and J. Shin, “Rethinking data augmentation: Self-supervision and self-distillation,” arXiv preprint arXiv:1910.05872, 2019.
- [21] B. Zoph, G. Ghiasi, T.-Y. Lin, Y. Cui, H. Liu, E. D. Cubuk, and Q. Le, “Rethinking pre-training and self-training,” in Neural Inf. Process. Syst., pp. 1–13, 2020.
- [22] A. E. Orhan, V. V. Gupta, and B. M. Lake, “Self-supervised learning through the eyes of a child,” in Neural Inf. Process. Syst., pp. 9960–9971, 2020.
- [23] J. Mitrovic, B. McWilliams, J. Walker, L. Buesing, and C. Blundell, “Representation learning via invariant causal mechanisms,” in Int. Conf. Learn. Represent., pp. 1–19, 2021.
- [24] T. Hua, W. Wang, Z. Xue, S. Ren, Y. Wang, and H. Zhao, “On feature decorrelation in self-supervised learning,” in IEEE Int. Conf. Comput. Vis., pp. 9598–9608, 2021.
- [25] VentureBeat, “Yann LeCun, Yoshua Bengio: Self-supervised learning is key to human-level intelligence.” https://cacm.acm.org/news/244720-yann-lecun-yoshua-bengio-self-supervised-learning-is-key-to-human-level-intelligence/fulltext.
- [26] J. Yu, H. Yin, X. Xia, T. Chen, J. Li, and Z. Huang, “Self-supervised learning for recommender systems: A survey,” arXiv preprint arXiv:2203.15876, 2022.
- [27] Y. Liu, M. Jin, S. Pan, C. Zhou, Y. Zheng, F. Xia, and P. Yu, “Graph self-supervised learning: A survey,” IEEE T. Knowl. Data Eng., 2022.
- [28] L. Wu, H. Lin, C. Tan, Z. Gao, and S. Z. Li, “Self-supervised learning on graphs: Contrastive, generative, or predictive,” IEEE T. Knowl. Data Eng., 2022.
- [29] H. H. Mao, “A survey on self-supervised pre-training for sequential transfer learning in neural networks,” arXiv preprint arXiv:2007.00800, 2020.
- [30] M. C. Schiappa, Y. S. Rawat, and M. Shah, “Self-supervised learning for videos: A survey,” arXiv preprint arXiv:2207.00419, 2022.
- [31] G.-J. Qi and M. Shah, “Adversarial pretraining of self-supervised deep networks: Past, present and future,” arXiv preprint arXiv:2210.13463, 2022.
- [32] L. Jing and Y. Tian, “Self-supervised visual feature learning with deep neural networks: A survey,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 43, no. 11, pp. 4037–4058, 2021.
- [33] A. Jaiswal, A. R. Babu, M. Z. Zadeh, D. Banerjee, and F. Makedon, “A survey on contrastive self-supervised learning,” Technologies, vol. 9, no. 1, pp. 1–22, 2020.
- [34] V. R. de Sa, “Learning classification with unlabeled data,” in Neural Inf. Process. Syst., pp. 112–119, 1994.
- [35] J. Gui, Z. Sun, Y. Wen, D. Tao, and J. Ye, “A review on generative adversarial networks: Algorithms, theory, and applications,” IEEE T. Knowl. Data Eng., 2022.
- [36] T. Nathan Mundhenk, D. Ho, and B. Y. Chen, “Improvements to context based self-supervised learning,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 9339–9348, 2018.
- [37] P. Agrawal, J. Carreira, and J. Malik, “Learning to see by moving,” in IEEE Int. Conf. Comput. Vis., pp. 37–45, 2015.
- [38] R. Zhang, P. Isola, and A. A. Efros, “Colorful image colorization,” in Eur. Conf. Comput. Vis., pp. 649–666, 2016.
- [39] G. Larsson, M. Maire, and G. Shakhnarovich, “Learning representations for automatic colorization,” in Eur. Conf. Comput. Vis., pp. 577–593, 2016.
- [40] R. Zhang, J.-Y. Zhu, P. Isola, X. Geng, A. S. Lin, T. Yu, and A. A. Efros, “Real-time user-guided image colorization with learned deep priors,” arXiv preprint arXiv:1705.02999, 2017.
- [41] G. Larsson, M. Maire, and G. Shakhnarovich, “Colorization as a proxy task for visual understanding,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 6874–6883, 2017.
- [42] P. Goyal, D. Mahajan, A. Gupta, and I. Misra, “Scaling and benchmarking self-supervised visual representation learning,” in IEEE Int. Conf. Comput. Vis., pp. 6391–6400, 2019.
- [43] U. Ahsan, R. Madhok, and I. Essa, “Video jigsaw: Unsupervised learning of spatiotemporal context for video action recognition,” in Proc. Winter Conf. Appl. Comput. Vis., pp. 179–189, 2019.
- [44] X. Zhan, X. Pan, Z. Liu, D. Lin, and C. C. Loy, “Self-supervised learning via conditional motion propagation,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 1881–1889, 2019.
- [45] K. Wang, L. Lin, C. Jiang, C. Qian, and P. Wei, “3d human pose machines with self-supervised learning,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 42, no. 5, pp. 1069–1082, 2019.
- [46] M. Noroozi, H. Pirsiavash, and P. Favaro, “Representation learning by learning to count,” in IEEE Int. Conf. Comput. Vis., pp. 5898–5906, 2017.
- [47] I. Misra and L. v. d. Maaten, “Self-supervised learning of pretext-invariant representations,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 6707–6717, 2020.
- [48] Z. Wu, Y. Xiong, S. X. Yu, and D. Lin, “Unsupervised feature learning via non-parametric instance discrimination,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 3733–3742, 2018.
- [49] N. Zhao, Z. Wu, R. W. Lau, and S. Lin, “What makes instance discrimination good for transfer learning?,” in Int. Conf. Learn. Represent., pp. 1–11, 2021.
- [50] K. He, H. Fan, Y. Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 9729–9738, 2020.
- [51] X. Chen, H. Fan, R. Girshick, and K. He, “Improved baselines with momentum contrastive learning,” arXiv preprint arXiv:2003.04297, 2020.
- [52] X. Chen, S. Xie, and K. He, “An empirical study of training self-supervised visual transformers,” in IEEE Int. Conf. Comput. Vis., pp. 9640–9649, 2021.
- [53] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” in Int. Conf. Mach. Learn., pp. 1597–1607, 2020.
- [54] T. Chen, S. Kornblith, K. Swersky, M. Norouzi, and G. Hinton, “Big self-supervised models are strong semi-supervised learners,” in Neural Inf. Process. Syst., pp. 1–13, 2020.
- [55] R. Hadsell, S. Chopra, and Y. LeCun, “Dimensionality reduction by learning an invariant mapping,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 1735–1742, 2006.
- [56] A. v. d. Oord, Y. Li, and O. Vinyals, “Representation learning with contrastive predictive coding,” arXiv preprint arXiv:1807.03748, 2019.
- [57] M. Gutmann and A. Hyvärinen, “Noise-contrastive estimation: A new estimation principle for unnormalized statistical models,” in Int. Conf. Artif. Intell. Statist., pp. 297–304, 2010.
- [58] M. Zheng, S. You, F. Wang, C. Qian, C. Zhang, X. Wang, and C. Xu, “Ressl: Relational self-supervised learning with weak augmentation,” arXiv preprint arXiv:2107.09282, 2021.
- [59] N. Zhao, Z. Wu, R. W. Lau, and S. Lin, “Distilling localization for self-supervised representation learning,” in AAAI Conf.Artif. Intell., pp. 10990–10998, 2021.
- [60] R. Arandjelovic and A. Zisserman, “Objects that sound,” in Eur. Conf. Comput. Vis., pp. 435–451, 2018.
- [61] Y. Tian, D. Krishnan, and P. Isola, “Contrastive multiview coding,” in Eur. Conf. Comput. Vis., pp. 776–794, 2020.
- [62] Y. Tian, C. Sun, B. Poole, D. Krishnan, C. Schmid, and P. Isola, “What makes for good views for contrastive learning,” in Neural Inf. Process. Syst., pp. 1–13, 2020.
- [63] Z. Xie, Y. Lin, Z. Zhang, Y. Cao, S. Lin, and H. Hu, “Propagate yourself: Exploring pixel-level consistency for unsupervised visual representation learning,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 16684–16693, 2021.
- [64] X. Wang and G.-J. Qi, “Contrastive learning with stronger augmentations,” IEEE Trans. Pattern Anal. Mach. Intell., pp. 1–12, 2022.
- [65] J.-B. Grill, F. Strub, F. Altché, C. Tallec, P. H. Richemond, E. Buchatskaya, C. Doersch, B. A. Pires, Z. D. Guo, M. G. Azar, et al., “Bootstrap your own latent: A new approach to self-supervised learning,” in Neural Inf. Process. Syst., pp. 1–14, 2020.
- [66] M. Caron, I. Misra, J. Mairal, P. Goyal, P. Bojanowski, and A. Joulin, “Unsupervised learning of visual features by contrasting cluster assignments,” in Neural Inf. Process. Syst., 2020.
- [67] X. Chen and K. He, “Exploring simple siamese representation learning,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 15750–15758, 2021.
- [68] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick, “Masked autoencoders are scalable vision learners,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 16000–16009, 2022.
- [69] J. Zbontar, L. Jing, I. Misra, Y. LeCun, and S. Deny, “Barlow twins: Self-supervised learning via redundancy reduction,” in Int. Conf. Mach. Learn., 2021.
- [70] A. Bardes, J. Ponce, and Y. LeCun, “Vicreg: Variance-invariance-covariance regularization for self-supervised learning,” in Int. Conf. Learn. Represent., pp. 1–12, 2022.
- [71] M. Tschannen, J. Djolonga, P. K. Rubenstein, S. Gelly, and M. Lucic, “On mutual information maximization for representation learning,” in Int. Conf. Learn. Represent., pp. 1–12, 2020.
- [72] N. Saunshi, O. Plevrakis, S. Arora, M. Khodak, and H. Khandeparkar, “A theoretical analysis of contrastive unsupervised representation learning,” in Int. Conf. Mach. Learn., pp. 5628–5637, 2019.
- [73] Y. Yang and Z. Xu, “Rethinking the value of labels for improving class-imbalanced learning,” in Neural Inf. Process. Syst., 2020.
- [74] Y.-H. H. Tsai, Y. Wu, R. Salakhutdinov, and L.-P. Morency, “Self-supervised learning from a multi-view perspective,” arXiv preprint arXiv:2006.05576, 2020.
- [75] T. Wang and P. Isola, “Understanding contrastive representation learning through alignment and uniformity on the hypersphere,” in Int. Conf. Mach. Learn., pp. 9929–9939, 2020.
- [76] C.-Y. Chuang, J. Robinson, L. Yen-Chen, A. Torralba, and S. Jegelka, “Debiased contrastive learning,” in Int. Conf. Learn. Represent., 2020.
- [77] J. D. Lee, Q. Lei, N. Saunshi, and J. Zhuo, “Predicting what you already know helps: Provable self-supervised learning,” arXiv preprint arXiv:2008.01064, 2020.
- [78] S. Chen, G. Niu, C. Gong, J. Li, J. Yang, and M. Sugiyama, “Large-margin contrastive learning with distance polarization regularizer,” in Int. Conf. Mach. Learn., pp. 1673–1683, 2021.
- [79] J. Z. HaoChen, C. Wei, A. Gaidon, and T. Ma, “Provable guarantees for self-supervised deep learning with spectral contrastive loss,” in Neural Inf. Process. Syst., pp. 5000–5011, 2021.
- [80] C. Tosh, A. Krishnamurthy, and D. Hsu, “Contrastive learning, multi-view redundancy, and linear models,” in Algorithmic Learning Theory, pp. 1179–1206, 2021.
- [81] C. Wei, K. Shen, Y. Chen, and T. Ma, “Theoretical analysis of self-training with deep networks on unlabeled data,” in Int. Conf. Learn. Represent., pp. 1–15, 2021.
- [82] Y. Tian, “Deep contrastive learning is provably (almost) principal component analysis,” arXiv preprint arXiv:2201.12680, 2022.
- [83] A. Newell and J. Deng, “How useful is self-supervised pretraining for visual tasks?,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 7345–7354, 2020.
- [84] M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” in IEEE Int. Conf. Comput. Vis., pp. 9650–9660, 2021.
- [85] Y. Wang, X. Shen, S. X. Hu, Y. Yuan, J. L. Crowley, and D. Vaufreydaz, “Self-supervised transformers for unsupervised object discovery using normalized cut,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 14543–14553, 2022.
- [86] E. Hoffer, I. Hubara, and N. Ailon, “Deep unsupervised learning through spatial contrasting,” arXiv preprint arXiv:1610.00243, 2016.
- [87] Y. Xu, Q. Zhang, J. Zhang, and D. Tao, “Regioncl: exploring contrastive region pairs for self-supervised representation learning,” in European Conference on Computer Vision, pp. 477–494, Springer, 2022.
- [88] M. Yang, M. Liao, P. Lu, J. Wang, S. Zhu, H. Luo, Q. Tian, and X. Bai, “Reading and writing: Discriminative and generative modeling for self-supervised text recognition,” arXiv preprint arXiv:2207.00193, 2022.
- [89] H. Wu, Y. Qu, S. Lin, J. Zhou, R. Qiao, Z. Zhang, Y. Xie, and L. Ma, “Contrastive learning for compact single image dehazing,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 10551–10560, 2021.
- [90] R. Zhu, B. Zhao, J. Liu, Z. Sun, and C. W. Chen, “Improving contrastive learning by visualizing feature transformation,” in IEEE Int. Conf. Comput. Vis., pp. 10306–10315, 2021.
- [91] M. Yang, Y. Li, Z. Huang, Z. Liu, P. Hu, and X. Peng, “Partially view-aligned representation learning with noise-robust contrastive loss,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 1134–1143, 2021.
- [92] L. Xiong, C. Xiong, Y. Li, K.-F. Tang, J. Liu, P. Bennett, J. Ahmed, and A. Overwijk, “Approximate nearest neighbor negative contrastive learning for dense text retrieval,” in Int. Conf. Learn. Represent., pp. 1–12, 2021.
- [93] J. Li, P. Zhou, C. Xiong, and S. C. Hoi, “Prototypical contrastive learning of unsupervised representations,” in Int. Conf. Learn. Represent., pp. 1–12, 2021.
- [94] K. Kotar, G. Ilharco, L. Schmidt, K. Ehsani, and R. Mottaghi, “Contrasting contrastive self-supervised representation learning pipelines,” in IEEE Int. Conf. Comput. Vis., pp. 9949–9959, 2021.
- [95] S. Liu, H. Fan, S. Qian, Y. Chen, W. Ding, and Z. Wang, “Hit: Hierarchical transformer with momentum contrast for video-text retrieval,” in IEEE Int. Conf. Comput. Vis., pp. 11915–11925, 2021.
- [96] A. Islam, C.-F. Chen, R. Panda, L. Karlinsky, R. Radke, and R. Feris, “A broad study on the transferability of visual representations with contrastive learning,” in IEEE Int. Conf. Comput. Vis., pp. 8845–8855, 2021.
- [97] J. Li, C. Xiong, and S. C. Hoi, “Learning from noisy data with robust representation learning,” in IEEE Int. Conf. Comput. Vis., pp. 9485–9494, 2021.
- [98] H. Cha, J. Lee, and J. Shin, “Co2l: Contrastive continual learning,” in IEEE Int. Conf. Comput. Vis., pp. 9516–9525, 2021.
- [99] O. J. Hénaff, S. Koppula, J.-B. Alayrac, A. v. d. Oord, O. Vinyals, and J. Carreira, “Efficient visual pretraining with contrastive detection,” in IEEE Int. Conf. Comput. Vis., pp. 10086–10096, 2021.
- [100] D. Dwibedi, Y. Aytar, J. Tompson, P. Sermanet, and A. Zisserman, “With a little help from my friends: Nearest-neighbor contrastive learning of visual representations,” in IEEE Int. Conf. Comput. Vis., pp. 9588–9597, 2021.
- [101] J. Cui, Z. Zhong, S. Liu, B. Yu, and J. Jia, “Parametric contrastive learning,” in IEEE Int. Conf. Comput. Vis., pp. 715–724, 2021.
- [102] A. Shah, S. Sra, R. Chellappa, and A. Cherian, “Max-margin contrastive learning,” in AAAI Conf.Artif. Intell., 2022.
- [103] L. Jing, P. Vincent, Y. LeCun, and Y. Tian, “Understanding dimensional collapse in contrastive self-supervised learning,” in Int. Conf. Learn. Represent., pp. 1–11, 2022.
- [104] J. Zhang, X. Xu, F. Shen, Y. Yao, J. Shao, and X. Zhu, “Video representation learning with graph contrastive augmentation,” in ACM Int. Conf. Multimedia, pp. 3043–3051, 2021.
- [105] S. Lal, M. Prabhudesai, I. Mediratta, A. W. Harley, and K. Fragkiadaki, “Coconets: Continuous contrastive 3d scene representations,” in IEEE Conf. Comput. Vis. Pattern Recognit., 2021.
- [106] Q. Hu, X. Wang, W. Hu, and G.-J. Qi, “Adco: Adversarial contrast for efficient learning of unsupervised representations from self-trained negative adversaries,” in IEEE Conf. Comput. Vis. Pattern Recognit., 2021.
- [107] Y. Kalantidis, M. B. Sariyildiz, N. Pion, P. Weinzaepfel, and D. Larlus, “Hard negative mixing for contrastive learning,” in Neural Inf. Process. Syst., pp. 1–12, 2020.
- [108] G. Bukchin, E. Schwartz, K. Saenko, O. Shahar, R. Feris, R. Giryes, and L. Karlinsky, “Fine-grained angular contrastive learning with coarse labels,” in IEEE Conf. Comput. Vis. Pattern Recognit., 2021.
- [109] S. Purushwalkam and A. Gupta, “Demystifying contrastive self-supervised learning: Invariances, augmentations and dataset biases,” in Neural Inf. Process. Syst., pp. 1–12, 2020.
- [110] P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y. Tian, P. Isola, A. Maschinot, C. Liu, and D. Krishnan, “Supervised contrastive learning,” in Neural Inf. Process. Syst., pp. 18661–18673, 2020.
- [111] J. Zhou, C. Wei, H. Wang, W. Shen, C. Xie, A. Yuille, and T. Kong, “ibot: Image bert pre-training with online tokenizer,” in Int. Conf. Learn. Represent., pp. 1–12, 2022.
- [112] H. Bao, L. Dong, S. Piao, and F. Wei, “Beit: Bert pre-training of image transformers,” in Int. Conf. Learn. Represent., pp. 1–13, 2022.
- [113] X. Chen, M. Ding, X. Wang, Y. Xin, S. Mo, Y. Wang, S. Han, P. Luo, G. Zeng, and J. Wang, “Context autoencoder for self-supervised representation learning,” arXiv preprint arXiv:2202.03026, 2022.
- [114] Z. Xie, Z. Zhang, Y. Cao, Y. Lin, J. Bao, Z. Yao, Q. Dai, and H. Hu, “Simmim: A simple framework for masked image modeling,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 9653–9663, 2022.
- [115] D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, and A. A. Efros, “Context encoders: Feature learning by inpainting,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 2536–2544, 2016.
- [116] M. Chen, A. Radford, R. Child, J. Wu, H. Jun, P. Dhariwal, D. Luan, and I. Sutskever, “Generative pretraining from pixels,” in Int. Conf. Mach. Learn., pp. 1691–1703, 2020.
- [117] A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever, “Zero-shot text-to-image generation,” in Int. Conf. Mach. Learn., pp. 8821–8831, 2021.
- [118] C. Wei, H. Fan, S. Xie, C.-Y. Wu, A. Yuille, and C. Feichtenhofer, “Masked feature prediction for self-supervised visual pre-training,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 14668–14678, 2022.
- [119] X. Dong, J. Bao, T. Zhang, D. Chen, W. Zhang, L. Yuan, D. Chen, F. Wen, and N. Yu, “Peco: Perceptual codebook for bert pre-training of vision transformers,” arXiv preprint arXiv:2111.12710, 2021.
- [120] A. Baevski, W.-N. Hsu, Q. Xu, A. Babu, J. Gu, and M. Auli, “Data2vec: A general framework for self-supervised learning in speech, vision and language,” arXiv preprint arXiv:2202.03555, 2022.
- [121] Y. Chen, Y. Liu, D. Jiang, X. Zhang, W. Dai, H. Xiong, and Q. Tian, “Sdae: Self-distillated masked autoencoder,” in Eur. Conf. Comput. Vis., pp. 108–124, 2022.
- [122] Q. Zhou, C. Yu, H. Luo, Z. Wang, and H. Li, “Mimco: Masked image modeling pre-training with contrastive teacher,” in ACM Int. Conf. Multimedia, pp. 4487–4495, 2022.
- [123] Z. Peng, L. Dong, H. Bao, Q. Ye, and F. Wei, “Beit v2: Masked image modeling with vector-quantized visual tokenizers,” arXiv preprint arXiv:2208.06366, 2022.
- [124] C. Feichtenhofer, H. Fan, Y. Li, and K. He, “Masked autoencoders as spatiotemporal learners,” arXiv preprint arXiv:2205.09113, 2022.
- [125] Y. Liang, S. Zhao, B. Yu, J. Zhang, and F. He, “Meshmae: Masked autoencoders for 3d mesh data analysis,” in Eur. Conf. Comput. Vis., pp. 37–54, 2022.
- [126] Y. Pang, W. Wang, F. E. Tay, W. Liu, Y. Tian, and L. Yuan, “Masked autoencoders for point cloud self-supervised learning,” in Eur. Conf. Comput. Vis., pp. 604–621, 2022.
- [127] Z. Liu, H. Hu, Y. Lin, Z. Yao, Z. Xie, Y. Wei, J. Ning, Y. Cao, Z. Zhang, L. Dong, et al., “Swin transformer v2: Scaling up capacity and resolution,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 12009–12019, 2022.
- [128] Q. Zhang, Y. Xu, J. Zhang, and D. Tao, “Vitaev2: Vision transformer advanced by exploring inductive bias for image recognition and beyond,” Int. J. Comput. Vis., pp. 1–22, 2023.
- [129] Y. Li, H. Mao, R. Girshick, and K. He, “Exploring plain vision transformer backbones for object detection,” in Eur. Conf. Comput. Vis., pp. 280–296, 2022.
- [130] Y. Xu, J. Zhang, Q. Zhang, and D. Tao, “Vitpose: Simple vision transformer baselines for human pose estimation,” in Neural Inf. Process. Syst., pp. 38571–38584, 2022.
- [131] Z. Liu, J. Gui, and H. Luo, “Good helper is around you: Attention-driven masked image modeling,” in AAAI Conf.Artif. Intell., pp. 1799–1807, 2023.
- [132] Z. Qi, R. Dong, G. Fan, Z. Ge, X. Zhang, K. Ma, and L. Yi, “Contrast with reconstruct: Contrastive 3d representation learning guided by generative pretraining,” arXiv preprint arXiv:2302.02318, 2023.
- [133] Z. Xie, Z. Zhang, Y. Cao, Y. Lin, Y. Wei, Q. Dai, and H. Hu, “On data scaling in masked image modeling,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 10365–10374, 2023.
- [134] M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec, V. Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, et al., “Dinov2: Learning robust visual features without supervision,” arXiv preprint arXiv:2304.07193, 2023.
- [135] X. Kong and X. Zhang, “Understanding masked image modeling via learning occlusion invariant feature,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 6241–6251, 2023.
- [136] H. Chen, Y. Wang, B. Lagadec, A. Dantcheva, and F. Bremond, “Joint generative and contrastive learning for unsupervised person re-identification,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 2004–2013, 2021.
- [137] Z. Xie, Z. Geng, J. Hu, Z. Zhang, H. Hu, and Y. Cao, “Revealing the dark secrets of masked image modeling,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 14475–14485, 2023.
- [138] A. Dosovitskiy, J. T. Springenberg, M. Riedmiller, and T. Brox, “Discriminative unsupervised feature learning with convolutional neural networks,” in Neural Inf. Process. Syst., pp. 766–774, 2014.
- [139] A. Dosovitskiy, P. Fischer, J. T. Springenberg, M. Riedmiller, and T. Brox, “Discriminative unsupervised feature learning with exemplar convolutional neural networks,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 38, no. 9, pp. 1734–1747, 2015.
- [140] C. Doersch, A. Gupta, and A. A. Efros, “Unsupervised visual representation learning by context prediction,” in IEEE Int. Conf. Comput. Vis., pp. 1422–1430, 2015.
- [141] P. Bojanowski and A. Joulin, “Unsupervised learning by predicting noise,” in Int. Conf. Mach. Learn., 2017.
- [142] J. Xie, R. Girshick, and A. Farhadi, “Unsupervised deep embedding for clustering analysis,” in Int. Conf. Mach. Learn., pp. 478–487, 2016.
- [143] J. Yang, D. Parikh, and D. Batra, “Joint unsupervised learning of deep representations and image clusters,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 5147–5156, 2016.
- [144] M. Caron, P. Bojanowski, A. Joulin, and M. Douze, “Deep clustering for unsupervised learning of visual features,” in Eur. Conf. Comput. Vis., pp. 132–149, 2018.
- [145] R. Zhang, P. Isola, and A. A. Efros, “Split-brain autoencoders: Unsupervised learning by cross-channel prediction,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 1058–1067, 2017.
- [146] X. Wang, K. He, and A. Gupta, “Transitive invariance for self-supervised visual representation learning,” in IEEE Int. Conf. Comput. Vis., pp. 1329–1338, 2017.
- [147] A. Kolesnikov, X. Zhai, and L. Beyer, “Revisiting self-supervised visual representation learning,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 1920–1929, 2019.
- [148] P. Krähenbühl, “Free supervision from video games,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 2955–2964, 2018.
- [149] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Neural Inf. Process. Syst., pp. 2672–2680, 2014.
- [150] T. Chen, X. Zhai, M. Ritter, M. Lucic, and N. Houlsby, “Self-supervised gans via auxiliary rotation loss,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 12154–12163, 2019.
- [151] X. Zhai, A. Oliver, A. Kolesnikov, and L. Beyer, “S4l: Self-supervised semi-supervised learning,” in IEEE Int. Conf. Comput. Vis., pp. 1476–1485, 2019.
- [152] D. Hendrycks, M. Mazeika, S. Kadavath, and D. Song, “Using self-supervised learning can improve model robustness and uncertainty,” in Neural Inf. Process. Syst., pp. 15663–15674, 2019.
- [153] K. Hassani and A. H. Khasahmadi, “Contrastive multi-view representation learning on graphs,” in Int. Conf. Mach. Learn., 2020.
- [154] L. Gomez, Y. Patel, M. Rusiñol, D. Karatzas, and C. Jawahar, “Self-supervised learning of visual features through embedding images into text topic spaces,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 4230–4239, 2017.
- [155] L. Jing, Y. Chen, L. Zhang, M. He, and Y. Tian, “Self-supervised feature learning by cross-modality and cross-view correspondences,” arXiv preprint arXiv:2004.05749, 2020.
- [156] L. Jing, Y. Chen, L. Zhang, M. He, and Y. Tian, “Self-supervised modal and view invariant feature learning,” arXiv preprint arXiv:2005.14169, 2020.
- [157] L. Zhang and Z. Zhu, “Unsupervised feature learning for point cloud understanding by contrasting and clustering using graph convolutional neural networks,” in International Conference on 3D Vision, pp. 395–404, 2019.
- [158] Y. Yang, C. Feng, Y. Shen, and D. Tian, “Foldingnet: Point cloud auto-encoder via deep grid deformation,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 206–215, 2018.
- [159] M. Gadelha, R. Wang, and S. Maji, “Multiresolution tree networks for 3d point cloud processing,” in Eur. Conf. Comput. Vis., pp. 103–118, 2018.
- [160] Y. Zhao, T. Birdal, H. Deng, and F. Tombari, “3d point capsule networks,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 1009–1018, 2019.
- [161] Y. Sun, X. Wang, Z. Liu, J. Miller, A. A. Efros, and M. Hardt, “Test-time training with self-supervision for generalization under distribution shifts,” in Int. Conf. Mach. Learn., 2020.
- [162] Y. Gandelsman, Y. Sun, X. Chen, and A. A. Efros, “Test-time training with masked autoencoders,” arXiv preprint arXiv:2209.07522, 2022.
- [163] J. J. Sun, A. Kennedy, E. Zhan, D. J. Anderson, Y. Yue, and P. Perona, “Task programming: Learning data efficient behavior representations,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 2876–2885, 2021.
- [164] Z. Ren and Y. Jae Lee, “Cross-domain self-supervised multi-task feature learning using synthetic imagery,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 762–771, 2018.
- [165] K. Hassani and M. Haley, “Unsupervised multi-task feature learning on point clouds,” in IEEE Int. Conf. Comput. Vis., pp. 8160–8171, 2019.
- [166] A. Piergiovanni, A. Angelova, and M. S. Ryoo, “Evolving losses for unsupervised video representation learning,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 133–142, 2020.
- [167] K. Saito, D. Kim, S. Sclaroff, and K. Saenko, “Universal domain adaptation through self supervision,” in Neural Inf. Process. Syst., pp. 1–11, 2020.
- [168] Y. Sun, E. Tzeng, T. Darrell, and A. A. Efros, “Unsupervised domain adaptation through self-supervision,” arXiv preprint arXiv:1909.11825, 2019.
- [169] M. Noroozi, A. Vinjimoor, P. Favaro, and H. Pirsiavash, “Boosting self-supervised learning via knowledge transfer,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 9359–9367, 2018.
- [170] W. Hu, B. Liu, J. Gomes, M. Zitnik, P. Liang, V. Pande, and J. Leskovec, “Strategies for pre-training graph neural networks,” arXiv preprint arXiv:1905.12265, 2019.
- [171] Y. You, T. Chen, Z. Wang, and Y. Shen, “When does self-supervision help graph convolutional networks?,” arXiv preprint arXiv:2006.09136, 2020.
- [172] J. Qiu, Q. Chen, Y. Dong, J. Zhang, H. Yang, M. Ding, K. Wang, and J. Tang, “Gcc: Graph contrastive coding for graph neural network pre-training,” in ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1150–1160, 2020.
- [173] Z. Hu, Y. Dong, K. Wang, K.-W. Chang, and Y. Sun, “Gpt-gnn: Generative pre-training of graph neural networks,” in ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1857–1867, 2020.
- [174] Y. Rong, Y. Bian, T. Xu, W. Xie, Y. Wei, W. Huang, and J. Huang, “Self-supervised graph transformer on large-scale molecular data,” in Neural Inf. Process. Syst., 2020.
- [175] Y. Zhu, Y. Xu, F. Yu, Q. Liu, S. Wu, and L. Wang, “Deep graph contrastive representation learning,” arXiv preprint arXiv:2006.04131, 2020.
- [176] U. Buchler, B. Brattoli, and B. Ommer, “Improving spatiotemporal self-supervision by deep reinforcement learning,” in Eur. Conf. Comput. Vis., pp. 770–786, 2018.
- [177] D. Guo, B. A. Pires, B. Piot, J.-b. Grill, F. Altché, R. Munos, and M. G. Azar, “Bootstrap latent-predictive representations for multitask reinforcement learning,” arXiv preprint arXiv:2004.14646, 2020.
- [178] N. Hansen, Y. Sun, P. Abbeel, A. A. Efros, L. Pinto, and X. Wang, “Self-supervised policy adaptation during deployment,” arXiv preprint arXiv:2007.04309, 2020.
- [179] S. Gidaris, A. Bursuc, N. Komodakis, P. Pérez, and M. Cord, “Boosting few-shot visual learning with self-supervision,” in IEEE Int. Conf. Comput. Vis., pp. 8059–8068, 2019.
- [180] J.-C. Su, S. Maji, and B. Hariharan, “Boosting supervision with self-supervision for few-shot learning,” arXiv preprint arXiv:1906.07079, 2019.
- [181] C. Li, T. Tang, G. Wang, J. Peng, B. Wang, X. Liang, and X. Chang, “Bossnas: Exploring hybrid cnn-transformers with block-wisely self-supervised neural architecture search,” in IEEE Int. Conf. Comput. Vis., 2021.
- [182] L. Fan, S. Liu, P.-Y. Chen, G. Zhang, and C. Gan, “When does contrastive learning preserve adversarial robustness from pretraining to finetuning?,” in Neural Inf. Process. Syst., 2021.
- [183] M. Kim, J. Tack, and S. J. Hwang, “Adversarial self-supervised contrastive learning,” in Neural Inf. Process. Syst., pp. 1–12, 2020.
- [184] T. Chen, S. Liu, S. Chang, Y. Cheng, L. Amini, and Z. Wang, “Adversarial robustness: From self-supervised pre-training to fine-tuning,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 699–708, 2020.
- [185] Y. Lin, X. Guo, and Y. Lu, “Self-supervised video representation learning with meta-contrastive network,” in IEEE Int. Conf. Comput. Vis., pp. 8239–8249, 2021.
- [186] Y. An, H. Xue, X. Zhao, and L. Zhang, “Conditional self-supervised learning for few-shot classification,” in Int. Joint Conf. Artif. Intell., pp. 2140–2146, 2021.
- [187] S. Pal, A. Datta, and D. D. Majumder, “Computer recognition of vowel sounds using a self-supervised learning algorithm,” Journal of the Anatomical Society of India, pp. 117–123, 1978.
- [188] A. Ghosh, N. R. Pal, and S. K. Pal, “Self-organization for object extraction using a multilayer neural network and fuzziness mearsures,” IEEE Transactions on Fuzzy Systems, pp. 54–68, 1993.
- [189] A. Sharma, O. Grau, and M. Fritz, “Vconv-dae: Deep volumetric shape learning without object labels,” in Eur. Conf. Comput. Vis., pp. 236–250, 2016.
- [190] K. Gong, X. Liang, D. Zhang, X. Shen, and L. Lin, “Look into person: Self-supervised structure-sensitive learning and a new benchmark for human parsing,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 932–940, 2017.
- [191] X. Liang, K. Gong, X. Shen, and L. Lin, “Look into person: Joint body parsing & pose estimation network and a new benchmark,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 41, no. 4, pp. 871–885, 2018.
- [192] X. Zhan, X. Pan, B. Dai, Z. Liu, D. Lin, and C. C. Loy, “Self-supervised scene de-occlusion,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 3784–3792, 2020.
- [193] D. Pathak, R. Girshick, P. Dollár, T. Darrell, and B. Hariharan, “Learning features by watching objects move,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 2701–2710, 2017.
- [194] Y. Wang, J. Zhang, M. Kan, S. Shan, and X. Chen, “Self-supervised equivariant attention mechanism for weakly supervised semantic segmentation,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 12275–12284, 2020.
- [195] Z. Chen, X. Ye, L. Du, W. Yang, L. Huang, X. Tan, Z. Shi, F. Shen, and E. Ding, “Aggnet for self-supervised monocular depth estimation: Go an aggressive step furthe,” in ACM Int. Conf. Multimedia, pp. 1526–1534, 2021.
- [196] H. Chen, B. Lagadec, and F. Bremond, “Ice: Inter-instance contrastive encoding for unsupervised person re-identification,” in IEEE Int. Conf. Comput. Vis., pp. 14960–14969, 2021.
- [197] T. Isobe, D. Li, L. Tian, W. Chen, Y. Shan, and S. Wang, “Towards discriminative representation learning for unsupervised person re-identification,” in IEEE Int. Conf. Comput. Vis., pp. 8526–8536, 2021.
- [198] Z. Wang, J. Zhang, L. Zheng, Y. Liu, Y. Sun, Y. Li, and S. Wang, “Cycas: Self-supervised cycle association for learning re-identifiable descriptions,” in Eur. Conf. Comput. Vis., 2020.
- [199] S. Li, X. Wang, Y. Cao, F. Xue, Z. Yan, and H. Zha, “Self-supervised deep visual odometry with online adaptation,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 6339–6348, 2020.
- [200] W. Wu, Z. Y. Wang, Z. Li, W. Liu, and L. Fuxin, “Pointpwc-net: Cost volume on point clouds for (self-) supervised scene flow estimation,” in Eur. Conf. Comput. Vis., 2020.
- [201] G. Xu, Z. Liu, X. Li, and C. C. Loy, “Knowledge distillation meets self-supervision,” arXiv preprint arXiv:2006.07114, 2020.
- [202] J. Walker, A. Gupta, and M. Hebert, “Dense optical flow prediction from a static image,” in IEEE Int. Conf. Comput. Vis., pp. 2443–2451, 2015.
- [203] F. Zhu, Y. Zhu, X. Chang, and X. Liang, “Vision-language navigation with self-supervised auxiliary reasoning tasks,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 10012–10022, 2020.
- [204] X. Niu, S. Shan, H. Han, and X. Chen, “Rhythmnet: End-to-end heart rate estimation from face via spatial-temporal representation,” IEEE Trans. Image Process., vol. 29, pp. 2409–2423, 2020.
- [205] X. Niu, Z. Yu, H. Han, X. Li, S. Shan, and G. Zhao, “Video-based remote physiological measurement via cross-verified feature disentangling,” in Eur. Conf. Comput. Vis., 2020.
- [206] Y. Xie, Z. Wang, and S. Ji, “Noise2same: Optimizing a self-supervised bound for image denoising,” in Neural Inf. Process. Syst., 2020.
- [207] T. Huang, S. Li, X. Jia, H. Lu, and J. Liu, “Neighbor2neighbor: Self-supervised denoising from single noisy images,” in IEEE Conf. Comput. Vis. Pattern Recognit., 2021.
- [208] C. Yang, Z. Wu, B. Zhou, and S. Lin, “Instance localization for self-supervised detection pretraining,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 3987–3996, 2021.
- [209] I. Croitoru, S.-V. Bogolin, and M. Leordeanu, “Unsupervised learning from video to detect foreground objects in single images,” in IEEE Int. Conf. Comput. Vis., pp. 4335–4343, 2017.
- [210] E. Xie, J. Ding, W. Wang, X. Zhan, H. Xu, Z. Li, and P. Luo, “Detco: Unsupervised contrastive learning for object detection,” arXiv preprint arXiv:2102.04803, 2021.
- [211] G. Wu, J. Jiang, X. Liu, and J. Ma, “A practical contrastive learning framework for single image super-resolution,” arXiv preprint arXiv:2111.13924, 2021.
- [212] S. Menon, A. Damian, S. Hu, N. Ravi, and C. Rudin, “Pulse: Self-supervised photo upsampling via latent space exploration of generative models,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 2437–2445, 2020.
- [213] R. Girdhar, D. F. Fouhey, M. Rodriguez, and A. Gupta, “Learning a predictable and generative vector representation for objects,” in Eur. Conf. Comput. Vis., pp. 484–499, 2016.
- [214] D. Jayaraman and K. Grauman, “Learning image representations tied to ego-motion,” in IEEE Int. Conf. Comput. Vis., pp. 1413–1421, 2015.
- [215] Z. Yin and J. Shi, “Geonet: Unsupervised learning of dense depth, optical flow and camera pose,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 1983–1992, 2018.
- [216] Y. Zhao, G. Wang, C. Luo, W. Zeng, and Z.-J. Zha, “Self-supervised visual representations learning by contrastive mask prediction,” in IEEE Int. Conf. Comput. Vis., 2021.
- [217] L. Huang, Y. Liu, B. Wang, P. Pan, Y. Xu, and R. Jin, “Self-supervised video representation learning by context and motion decoupling,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 13886–13895, 2021.
- [218] K. Hu, J. Shao, Y. Liu, B. Raj, M. Savvides, and Z. Shen, “Contrast and order representations for video self-supervised learning,” in IEEE Int. Conf. Comput. Vis., pp. 7939–7949, 2021.
- [219] M. Tschannen, J. Djolonga, M. Ritter, A. Mahendran, N. Houlsby, S. Gelly, and M. Lucic, “Self-supervised learning of video-induced visual invariances,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 13806–13815, 2020.
- [220] X. He, Y. Pan, M. Tang, Y. Lv, and Y. Peng, “Learn from unlabeled videos for near-duplicate video retrieval,” in International Conference on Research on Development in Information Retrieval, pp. 1–10, 2022.
- [221] X. Wang and A. Gupta, “Unsupervised learning of visual representations using videos,” in IEEE Int. Conf. Comput. Vis., pp. 2794–2802, 2015.
- [222] N. Srivastava, E. Mansimov, and R. Salakhudinov, “Unsupervised learning of video representations using lstms,” in Int. Conf. Mach. Learn., pp. 843–852, 2015.
- [223] T. Han, W. Xie, and A. Zisserman, “Video representation learning by dense predictive coding,” in ICCV Workshops, 2019.
- [224] T. Han, W. Xie, and A. Zisserman, “Memory-augmented dense predictive coding for video representation learning,” in Eur. Conf. Comput. Vis., 2020.
- [225] B. Fernando, H. Bilen, E. Gavves, and S. Gould, “Self-supervised video representation learning with odd-one-out networks,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 3636–3645, 2017.
- [226] H.-Y. Lee, J.-B. Huang, M. Singh, and M.-H. Yang, “Unsupervised representation learning by sorting sequences,” in IEEE Int. Conf. Comput. Vis., pp. 667–676, 2017.
- [227] D. Xu, J. Xiao, Z. Zhao, J. Shao, D. Xie, and Y. Zhuang, “Self-supervised spatiotemporal learning via video clip order prediction,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 10334–10343, 2019.
- [228] S. Benaim, A. Ephrat, O. Lang, I. Mosseri, W. T. Freeman, M. Rubinstein, M. Irani, and T. Dekel, “Speednet: Learning the speediness in videos,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 9922–9931, 2020.
- [229] Y. Yao, C. Liu, D. Luo, Y. Zhou, and Q. Ye, “Video playback rate perception for self-supervised spatio-temporal representation learning,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 6548–6557, 2020.
- [230] J. Wang, J. Jiao, and Y.-H. Liu, “Self-supervised video representation learning by pace prediction,” in Eur. Conf. Comput. Vis., 2020.
- [231] A. Diba, V. Sharma, L. V. Gool, and R. Stiefelhagen, “Dynamonet: Dynamic action and motion network,” in IEEE Int. Conf. Comput. Vis., pp. 6192–6201, 2019.
- [232] T. Han, W. Xie, and A. Zisserman, “Self-supervised co-training for video representation learning,” in Neural Inf. Process. Syst., pp. 1–12, 2020.
- [233] B. Korbar, D. Tran, and L. Torresani, “Cooperative learning of audio and video models from self-supervised synchronization,” in Neural Inf. Process. Syst., pp. 7763–7774, 2018.
- [234] R. Arandjelovic and A. Zisserman, “Look, listen and learn,” in IEEE Int. Conf. Comput. Vis., pp. 609–617, 2017.
- [235] C. Sun, A. Myers, C. Vondrick, K. Murphy, and C. Schmid, “Videobert: A joint model for video and language representation learning,” in IEEE Int. Conf. Comput. Vis., pp. 7464–7473, 2019.
- [236] A. Nagrani, C. Sun, D. Ross, R. Sukthankar, C. Schmid, and A. Zisserman, “Speech2action: Cross-modal supervision for action recognition,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 10317–10326, 2020.
- [237] J. C. Stroud, D. A. Ross, C. Sun, J. Deng, R. Sukthankar, and C. Schmid, “Learning video representations from textual web supervision,” arXiv preprint arXiv:2007.14937, 2020.
- [238] J.-B. Alayrac, A. Recasens, R. Schneider, R. Arandjelović, J. Ramapuram, J. De Fauw, L. Smaira, S. Dieleman, and A. Zisserman, “Self-supervised multimodal versatile networks,” arXiv preprint arXiv:2006.16228, 2020.
- [239] P. Sermanet, C. Lynch, Y. Chebotar, J. Hsu, E. Jang, S. Schaal, and S. Levine, “Time-contrastive networks: Self-supervised learning from video,” in IEEE Int. Conf. Robot. Autom., pp. 1134–1141, 2018.
- [240] X. Wang, A. Jabri, and A. A. Efros, “Learning correspondence from the cycle-consistency of time,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 2566–2576, 2019.
- [241] X. Li, S. Liu, S. De Mello, X. Wang, J. Kautz, and M.-H. Yang, “Joint-task self-supervised learning for temporal correspondence,” in Neural Inf. Process. Syst., pp. 318–328, 2019.
- [242] A. Jabri, A. Owens, and A. A. Efros, “Space-time correspondence as a contrastive random walk,” in Neural Inf. Process. Syst., pp. 19545–19560, 2020.
- [243] Z. Lai, E. Lu, and W. Xie, “Mast: A memory-augmented self-supervised tracker,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 6479–6488, 2020.
- [244] Z. Zhang, S. Lathuiliere, E. Ricci, N. Sebe, Y. Yan, and J. Yang, “Online depth learning against forgetting in monocular videos,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 4494–4503, 2020.
- [245] D. Luo, C. Liu, Y. Zhou, D. Yang, C. Ma, Q. Ye, and W. Wang, “Video cloze procedure for self-supervised spatio-temporal learning,” in AAAI Conf.Artif. Intell., pp. 11701–11708, 2020.
- [246] O. J. Hénaff, A. Srinivas, J. De Fauw, A. Razavi, C. Doersch, S. Eslami, and A. v. d. Oord, “Data-efficient image recognition with contrastive predictive coding,” in Int. Conf. Mach. Learn., 2020.
- [247] A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding by generative pre-training,” 2018.
- [248] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al., “Language models are few-shot learners,” arXiv preprint arXiv:2005.14165, 2020.
- [249] C. Li, J. Yang, P. Zhang, M. Gao, B. Xiao, X. Dai, L. Yuan, and J. Gao, “Efficient self-supervised vision transformers for representation learning,” arXiv preprint arXiv:2106.09785, 2021.
- [250] Z. Li, Z. Chen, F. Yang, W. Li, Y. Zhu, C. Zhao, R. Deng, L. Wu, R. Zhao, M. Tang, and J. Wang, “Mst: Masked self-supervised transformer for visual representation,” in Neural Inf. Process. Syst., pp. 1–12, 2021.
- [251] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” in Neural Inf. Process. Syst., pp. 3111–3119, 2013.
- [252] L. Kong, C. d. M. d’Autume, W. Ling, L. Yu, Z. Dai, and D. Yogatama, “A mutual information maximization perspective of language representation learning,” arXiv preprint arXiv:1910.08350, 2019.
- [253] J. Wu, X. Wang, and W. Y. Wang, “Self-supervised dialogue learning,” arXiv preprint arXiv:1907.00448, 2019.
- [254] K. Clark, M.-T. Luong, Q. V. Le, and C. D. Manning, “Electra: Pre-training text encoders as discriminators rather than generators,” in Int. Conf. Learn. Represent., 2020.
- [255] X. Qiu, T. Sun, Y. Xu, Y. Shao, N. Dai, and X. Huang, “Pre-trained models for natural language processing: A survey,” arXiv preprint arXiv:2003.08271, 2020.
- [256] H. Wang, X. Wang, W. Xiong, M. Yu, X. Guo, S. Chang, and W. Y. Wang, “Self-supervised learning for contextualized extractive summarization,” in Annual Meeting of the Association for Computational Linguistics, pp. 2221–2227, 2019.
- [257] Y. Aytar, C. Vondrick, and A. Torralba, “Soundnet: Learning sound representations from unlabeled video,” in Neural Inf. Process. Syst., pp. 892–900, 2016.
- [258] H.-Y. Zhou, C. Lu, S. Yang, X. Han, and Y. Yu, “Preservational learning improves self-supervised medical image models by reconstructing diverse contexts,” in IEEE Int. Conf. Comput. Vis., pp. 3499–3509, 2021.
- [259] K. Chaitanya, E. Erdil, N. Karani, and E. Konukoglu, “Contrastive learning of global and local features for medical image segmentation with limited annotations,” in Neural Inf. Process. Syst., 2020.
- [260] J. Zhu, Y. Li, Y. Hu, K. Ma, S. K. Zhou, and Y. Zheng, “Rubik’s cube+: A self-supervised feature learning framework for 3d medical image analysis,” Medical Image Analysis, p. 101746, 2020.
- [261] O. Manas, A. Lacoste, X. Giró-i Nieto, D. Vazquez, and P. Rodriguez, “Seasonal contrast: Unsupervised pre-training from uncurated remote sensing data,” in IEEE Int. Conf. Comput. Vis., pp. 9414–9423, 2021.
- [262] D. Wang, Q. Zhang, Y. Xu, J. Zhang, B. Du, D. Tao, and L. Zhang, “Advancing plain vision transformer toward remote sensing foundation model,” IEEE Trans. Geoscience and Remote Sensing, vol. 61, pp. 1–15, 2022.
- [263] D. Bau, B. Zhou, A. Khosla, A. Oliva, and A. Torralba, “Network dissection: Quantifying interpretability of deep visual representations,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 6541–6549, 2017.
- [264] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes (voc) challenge,” Int. J. Comput. Vis., vol. 88, pp. 303–338, 2010.
- [265] T.-Y. Lin, M. Maire, S. Belongie, L. Bourdev, R. Girshick, J. Hays, P. Perona, D. Ramanan, C. L. Zitnick, and P. Dollár, “Microsoft coco: Common objects in context,” 2015.
- [266] B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, and A. Torralba, “Scene parsing through ade20k dataset,” in IEEE Conf. Comput. Vis. Pattern Recognit., 2017.
- [267] B. Zhou, H. Zhao, X. Puig, T. Xiao, S. Fidler, A. Barriuso, and A. Torralba, “Semantic understanding of scenes through the ade20k dataset,” Int. J. Comput. Vis., vol. 127, no. 3, pp. 302–321, 2019.
- [268] J. Liu, X. Huang, Y. Liu, and H. Li, “Mixmim: Mixed and masked image modeling for efficient visual representation learning,” arXiv preprint arXiv:2205.13137, 2022.
- [269] J. Robinson, L. Sun, K. Yu, K. Batmanghelich, S. Jegelka, and S. Sra, “Can contrastive learning avoid shortcut solutions?,” in Neural Inf. Process. Syst., pp. 4974–4986, 2021.
- [270] Y. Wei, H. Hu, Z. Xie, Z. Zhang, Y. Cao, J. Bao, D. Chen, and B. Guo, “Contrastive learning rivals masked image modeling in fine-tuning via feature distillation,” arXiv preprint arXiv:2205.14141, 2022.
- [271] Y. Tian, X. Chen, and S. Ganguli, “Understanding self-supervised learning dynamics without contrastive pairs,” in Int. Conf. Mach. Learn., pp. 10268–10278, 2021.
- [272] X. Wang, R. Zhang, C. Shen, T. Kong, and L. Li, “Dense contrastive learning for self-supervised visual pre-training,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 3024–3033, 2021.
- [273] W. Wang, H. Bao, L. Dong, J. Bjorck, Z. Peng, Q. Liu, K. Aggarwal, O. K. Mohammed, S. Singhal, S. Som, et al., “Image as a foreign language: Beit pretraining for all vision and vision-language tasks,” arXiv preprint arXiv:2208.10442, 2022.