Large Language Models are Versatile Decomposers: Decompose Evidence and Questions for Table-based Reasoning
Abstract
Table-based reasoning has shown remarkable progress in a wide range of table-based tasks. It is a challenging task, which requires reasoning over both free-form natural language (NL) questions and (semi-)structured tabular data. However, previous table-based reasoning solutions usually suffer from significant performance degradation on “huge” evidence (tables). In addition, most existing methods struggle to reason over complex questions since the essential information is scattered in different places. To alleviate the above challenges, we exploit large language models (LLMs) as decomposers for effective table-based reasoning, which (i) decompose huge evidence (a huge table) into sub-evidence (a small table) to mitigate the interference of useless information for table reasoning, and (ii) decompose a complex question into simpler sub-questions for text reasoning. First, we use a powerful LLM to decompose the evidence involved in the current question into the sub-evidence that retains the relevant information and excludes the remaining irrelevant information from the “huge” evidence. Second, we propose a novel “parsing-execution-filling” strategy to decompose a complex question into simper step-by-step sub-questions by generating intermediate SQL queries as a bridge to produce numerical and logical sub-questions with a powerful LLM. Finally, we leverage the decomposed sub-evidence and sub-questions to get the final answer with a few in-context prompting examples. Extensive experiments on three benchmark datasets (TabFact, WikiTableQuestion, and FetaQA) demonstrate that our method achieves significantly better results than competitive baselines for table-based reasoning. Notably, our method outperforms human performance for the first time on the TabFact dataset. In addition to impressive overall performance, our method also has the advantage of interpretability, where the returned results are to some extent tractable with the generated sub-evidence and sub-questions.
1 Introduction
Tabular data can be an important complement to textual data, which is informative and ubiquitous in our daily lives. Reasoning about tabular and textual information is a fundamental problem in natural language understanding (NLU) and information retrieval (IR) (Wang et al., 2021). It can benefit various downstream applications such as table-based fact verification (FV) (Chen et al., 2020; Aly et al., 2021; Gupta et al., 2020) and table-based question answering (QA) (Pasupat and Liang, 2015; Zhong et al., 2017; Nan et al., 2022; Cho et al., 2019). As shown in Figure 1, table-based reasoning is challenging since it involves sophisticated textual, numerical, and logical reasoning across both unstructured text and (semi-)structured tables. To address the above challenge, table-based reasoning is conventionally accomplished by synthesizing executable languages (e.g., SQL and SPARQL) to interact with tables (Date, 1989; Abdelaziz et al., 2017; Hui et al., 2021, 2022). However, these methods ignore the semantics of text chunks inside the table, struggling to effectively model web tables with unnormalized free-form text in table cells.
Recently, table-based pre-trained models(Herzig et al., 2020; Liu et al., 2021; Jiang et al., 2022; Gu et al., 2022; Cai et al., 2022) have proved to be powerful in enhancing reasoning skills on both textual and tabular data, which benefit from the rich knowledge learned from large-scale crawled or synthesized tabular and textual data. For example, TaPas (Herzig et al., 2020) enhanced the understanding of tubular data by recovering masked cell information in tables. Nevertheless, these models generally need to be fine-tuned on a significant amount of task-specific downstream datasets, struggling to achieve excellent performances when dealing with new datasets with unseen reasoning types. In addition, fine-tuning a pre-trained model on specific tasks generally destroys its in-context ability (Wang et al., 2022c). Instead of fine-tuning the pre-trained models, in-context learning in large language models (LLMs) (Brown et al., 2020; Wei et al., 2022; Kojima et al., 2022; Min et al., 2022) has recently gained noticeable attention to exploring the reasoning ability of LLMs, where several input–output exemplars are provided for prompting. For example, the chain of thought prompting (Wei et al., 2022) has been discovered to empower LLMs to perform complex reasoning by generating intermediate reasoning steps.
The prior studies (Wei et al., 2022; Kojima et al., 2022) revealed that LLMs could achieve impressive performance on many text reasoning tasks without task-specific model designs and training data. However, the capability of LLMs on table-based reasoning tasks is still under-explored. There are several technical challenges in leveraging LLMs for table-based reasoning with huge tables and complex questions. First, since a table could potentially contain a large number of rows and columns, directly encoding all table content via pre-trained models could be computationally intractable and interfere with huge irrelevant information. As pointed out in (Chen, 2022), the LLMs are unable to generalize to “huge” tables with 30+ rows due to the token limitation. Although previous studies have leveraged some approaches (Yin et al., 2020; Chen et al., 2020) such as text matching to retrieve sub-evidence, these approaches usually require a large amount of domain-specific data for training, as the sub-evidence retrieval process requires deep understanding and reasoning of questions and tables. Second, decomposing a complex question into simpler sub-questions can effectively facilitate multi-step reasoning of a large model (Huang et al., 2022; Dua et al., 2022; Chen et al., 2022). However, directly decomposing a complex question by leveraging chain-of-thought prompting (Wei et al., 2022) could easily fall into a hallucination dilemma (Ji et al., 2022), where the models may generate misleading sub-questions containing information that is inconsistent with the evidence. Chen et al. (Chen, 2022) showed that LLMs could sometimes make simple mistakes when performing symbolic operations. This will affect the process of subsequent reasoning, thus we need a more reliable table-based method for complex question decomposition
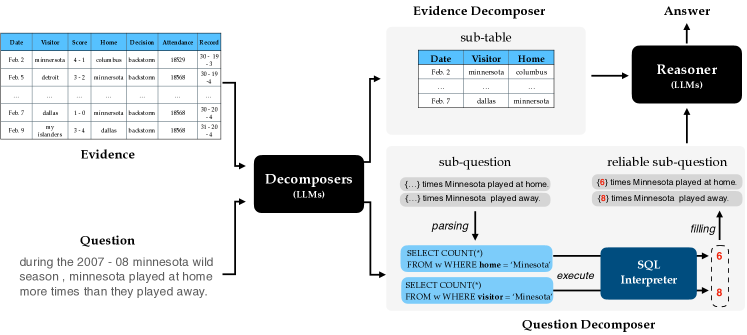
To mitigate the aforementioned challenges, in this paper, we explore in-context learning in LLMs to Decompose evidence And questions for effective Table-basEd Reasoning (Dater). First, we exploit a powerful LLM to decompose the (semi-)structured evidence (a huge table) involved in the current question into relevant sub-evidence (a small table). We implement sub-evidence extraction by predicting the indexes of the rows and columns with the help of a powerful LLM and a few prompts. In this way, we can retain the relevant evidence and exclude the remaining irrelevant evidence from interfering with the decision. In addition, our method has the advantage of interpretability, where the returned table-based results are tractable. Second, we propose a “parsing-execution-filling” strategy which explores the programming language SQL to decompose the complex unstructured natural language (NL) question into the logical and numerical computation. Concretely, we generate an abstract logic sub-question by masking the span of numerical values and then converting the abstract logic into SQL query language that is executed on the evidence for obtaining a reliable sub-question. Finally, we leverage the decomposed sub-evidence and sub-questions to get the final answer with the help of a few in-context prompting examples.
The main contributions of this paper are listed as follows:
-
•
We reduce “huge” evidence (a huge table) into “small” sub-evidence (a small table) by predicting the related indexes of rows and columns of the evidence with the help of a powerful LLM and a few prompting examples. Our evidence decomposition method makes the reasoners focus on the essential sub-evidence related to the given question.
-
•
We propose a novel “parsing-execution-filling” strategy to decompose a complex question into simper step-by-step sub-questions by generating an intermediate SQL as a bridge to produce numerical and logical sub-questions with the help of a powerful LLM and a few prompting examples. Our question decomposition method has proven to be effective in table-based reasoning without requiring a large amount of annotated training data.
-
•
We conduct extensive experiments on three benchmark datasets belonging to table-based fact verification and table-based question answering tasks. Experimental results demonstrate that our Dater method achieves significantly better results than competitive baselines for table-based reasoning. Particularly, Dater outperforms human performance for the first time on the TabFact dataset.
-
•
In addition to impressive overall performance, our Dater also has the advantage of interpretability, where the returned results are to some extent tractable with the generated sub-evidence and sub-questions.
2 Related Work
2.1 Table-based Reasoning
Table-based reasoning requires reasoning over both free-form natural language (NL) questions and (semi-)structured tables. Traditional methods produce executable languages (e.g., SQL and SPARQL) to access the tabular data (Date, 1989; Abdelaziz et al., 2017). However, these methods cannot capture the semantics of text chunks inside a table and fail to model web tables with free-form text in table cells. Recently, several table-based reasoning benchmarks, such as TabFact (Chen et al., 2020), WikiTableQuestion (Pasupat and Liang, 2015), and FetaQA (Nan et al., 2022), have been proposed to help learn different types of table-based tasks. The availability of large-scale training data has significantly enhanced the performance of table-based reasoning with the help of deep learning techniques (Neeraja et al., 2021; Aly et al., 2021).
In parallel, table pre-training has been proposed to encode both tables and texts, which further improves the performance of table-based reasoning. Inspired by the success of masked language modeling (MLM), TaPas (Herzig et al., 2020) enhanced the understanding of tubular data by recovering masked cell information in the table. TAPEX (Liu et al., 2021) utilized the BART model to imitate the SQL executor in the pre-training stage so that TAPEX can obtain better table reasoning capability. ReasTAP (Zhao et al., 2022) designed pre-training tasks based on the reasoning skills of table-based tasks, injecting reasoning skills via pre-training. TaBERT (Yin et al., 2020) proposed content snapshots to encode a subset of table content that was most relevant to the input utterance. PASTA (Gu et al., 2022) introduced a table-operations aware fact verification approach, which pre-trained LMs to be aware of common table-based operations with sentence-table cloze questions synthesized from WikiTables. Subsequently, (Chen, 2022; Cheng et al., 2022) explored the ability of LLMs for table-based tasks.
2.2 Large Language Models on Reasoning
Large language models (LLMs) have been shown to confer a range of reasoning abilities, such as arithmetic (Lewkowycz et al., 2022), commonsense (Liu et al., 2022) and symbolic reasoning (Zhou et al., 2022a), as the model parameters are scaled up (Brown et al., 2020). Notable, chain-of-thought (CoT) (Wei et al., 2022) leverages a series of intermediate reasoning steps, achieving better reasoning performance on complex tasks. Based on CoT, a number of advanced improvements have been proposed, including ensemble process (Wang et al., 2022b), iterative optimization (Zelikman et al., 2022), and example selection (Creswell et al., 2022). Notably, ZeroCoT (Kojima et al., 2022) improved reasoning performance by simply adding “Let’s think step by step” before each answer. Fu et al. (Fu et al., 2022) proposed complexity-based prompting can generate more reasoning steps for the chain, and achieve significantly better performance. Zhang et al. (Zhang et al., 2022) selected examples of in-context automatically by clustering, without the need for manual writing. Despite the remarkable performance of LLMs in textual reasoning, their reasoning capabilities on tabular tasks are still limited. The two most relevant works to this paper are (Cheng et al., 2022) and (Chen, 2022), but none of them focus on the ability of a powerful LLM to decompose the evidence (tables), and the reliability of the reasoning steps.
2.3 Question Decomposition
Question decomposition is essential to understand complex questions. Early work (Kalyanpur et al., 2012) utilized a suite of decomposition rules for question decomposition based on lexicon-syntactic features. The drawback of rule-based methods is that they need experts to manually design rules, making it difficult to extend the rules to new tasks or domains. In recent years, neural models (Talmor and Berant, 2018; Zhang et al., 2019) have been proposed to perform question decomposition in an end-to-end manner. Zhang et al. (Zhang et al., 2019) proposed a hierarchical semantic parsing method based on a sequence-to-sequence model, which combined a question decomposer and an information extractor. However, these supervised methods rely on a large amount of annotated training data which is labor-intensive to obtain. In parallel, unsupervised decomposition was proposed to produce sub-questions without strong supervision. For example, Perez et al. (Perez et al., 2020) automatically produced a noisy “pseudo-decomposition” for each complex question, which trained a decomposition model on the crawled data with unsupervised sequence-to-sequence learning. Different from previous decomposition methods, we explore LLMs as versatile decomposers, which decompose both huge evidence and complex questions for table-based reasoning with the help of a powerful LLM and a few prompting examples.
3 Problem Formulation and Notations
Each instance in table-based reasoning consists of a table , a natural language question , and an answer . In particular, each table contains rows and columns, with representing the content in the -th cell. A question consists of tokens. In this paper, we focus on two table-based reasoning tasks, including table-based fact verification (FV) and table-based question answering (QA). For table-based FV, the final answer is a boolean value that determines the truth or falsity of the input statement. For table-based QA, the answer is a natural language sequence that answers the question described by the input statement.
4 Method
4.1 In-context Learning
Given a few examples with instructions about detailed specific tasks, Large Language Models (LLMs) can perform in-context learning without training, which learn from analogies. The powerful ability has been widely verified on nature language tasks, including text classification, semantic parsing, mathematical reasoning, etc. Inspired by the advances of LLMs, we aim to explore whether LLMs could tackle reasoning tasks on structured evidence (i.e., tabular data). Formally, the final answer can be obtained by predicting with evidence table and question . Here, is a small set of in-context prompts from manual writing, where each example . We provide the detailed in-context prompt as prompt 4.1.
![[Uncaptioned image]](x3.png)
![[Uncaptioned image]](x4.png)
Based on empirical observations, performing in-context learning directly by the above prompt 4.1 cannot achieve optimal performance. Table-based reasoning is a sophisticated and complex task that requires human-like thinking and a fine-grained understanding process. Recently, chain-of-thought (Wei et al., 2022) proposed a question decomposition method, which induces LLMs to perform step-by-step thinking, resulting in better reasoning. However, they did not break down the evidence, resulting in unsatisfactory performance. Specifically, dealing with the ponderous tables directly is usually inefficient and easily interfered with by huge irrelevant information. To this end, we introduce evidence and question decomposition to help large models perform fine-grained reasoning over both evidence (tables) and questions.
4.2 Evidence Decomposer
Humans process table-based reasoning tasks by observing sub-evidence related to the question at hand to complete their judgment. In this paper, we hope to use evidence decomposition to imitate this process. Although previous studies have leveraged some approaches (Yin et al., 2020; Chen et al., 2020) such as text matching to retrieve sub-evidence, empirical results suggest that these approaches are often imperfect and require a large amount of domain-specific data for training, as the sub-evidence retrieval process relies on strong commonsense as well as domain knowledge and requires a joint understanding and reasoning of questions and tables. To this end, we use a powerful LLM to break down the evidence (tables) involved in the current question, retaining the relevant evidence and excluding the remaining irrelevant evidence from interfering with the decision. Concretely, we implement sub-evidence extraction by predicting the indexes of the rows and columns with the help of a powerful LLM and a few prompts. Formally, in the in-context learning stage, the row index and column index of sub-evidence table can be obtained by predicting with complete evidence and corresponding question . is a small set of in-context examples, where each is the example instance . Some detailed prompts are illustrated as prompt 4.2.
4.3 Questions Decomposer
Decomposing complex questions into step-by-step sub-questions can effectively facilitate the reasoning process of a large model, which has been proven to be effective in numerical and commonsense reasoning (Huang et al., 2022; Dua et al., 2022; Chen et al., 2022). However, we observed that straightforwardly decomposing a complex question by leveraging a chain-of-thought process could easily fall into a hallucination dilemma, i.e., the LLM might not faithfully generate content consistent with the given evidence (tables), especially when numerical values were involved. This will affect the process of subsequent reasoning, thus we need a reliable method for the sub-question generation.
4.3.1 Reliable Sub-questions
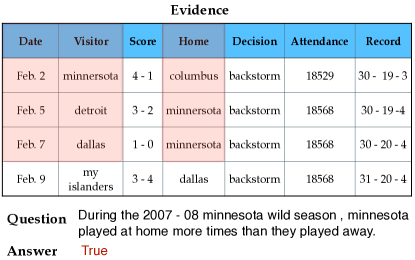
To effectively decompose a complex question into step-by-step sub-questions, we propose a “parsing-execution-filling” strategy to extend the vanilla chain-of-thought method by exploring the programming language SQL to divide logical steps and numerical computation. Specifically, we first generate an abstract logic sub-question, where we mask the span of numerical values by using cloze style and then convert the abstract logic into SQL queries, similar to text-to-SQL parsing (Qin et al., 2022; Wang et al., 2022a). Afterward, we execute the SQL language on the evidence to get the final result for back-filling, yielding a reliable sub-question. For example, as shown in the bottom of Figure 2, given a question “during the 2007 - 08 minnesota wild season, minnesota played at home more times than they played away.” , we first mask the spans involving numerical values in sub-questions in prompting examples, and the remaining part can be regarded as the logical question. Here, the logical sub-questions are “q1: {…} times minnesota played at home.” and “q2: {…} times minnesota played away.” Formally, a sub-question can be obtained by predicting with the complete evidence and complete question . is a small set of in-context prompting examples, where each is an example instance . The detailed prompt is as prompt 4.3.
![[Uncaptioned image]](x5.png)
![[Uncaptioned image]](x6.png)
The logical statement is then parsed into the SQL queries “SELECT COUNT(*) FROM w WHERE home = ’minnesota’” and “SELECT COUNT(*) FROM w WHERE visitor = ’minnesota’”, which are further executed on the evidence, yielding reliable spans “6” and “8” to be backfilled into the placeholder of sub-questions. In this way, we can obtain the reliable sub-questions “q1: {6} times minnesota played at home.” and “q2: {8} times minnesota played away.”.
Formally, the SQL query can be obtained by predicting with the help of complete evidence and sub-question . Here, is a small set of in-context examples, where each is an example instance . The detailed prompt is as prompt 4.4.
4.4 Jointly Reasoning
After performing the above evidence and question decomposition, the reasoner leverages both sub-evidence and reliable sub-questions to get a final answer by predicting , where is a small set of new in-context prompting examples. Here, each prompting example is denoted as . The detailed prompt as prompt 4.5.
![[Uncaptioned image]](x7.png)
5 Experimental Setup
5.1 Datasets
We evaluate our proposed method Dater on three table-based reasoning datasets, including TabFact (Chen et al., 2020), WikiTableQuestion (Pasupat and Liang, 2015), and FetaQA (Nan et al., 2022). Given the request and cost constraints of the LLMs, we only evaluate our Dater on the test sets of these corpora, without fine-tuning it on the training sets. It is noteworthy that LLMs were trained primarily on the web-crawled and code data. Since the pre-training data of LLMs does not contain tabular data, there is no risk of test data leakage. The details of these three datasets are provided as follows.
-
•
TabFact is a table-based fact verification benchmark, which contains statements written by crowd workers based on Wikipedia tables. For example, a statement: “industrial and commercial panel has four more members than the cultural and educational panel.” is need to be judged whether it is “True” or “False” according to the given table. We report the accuracy on the test-small set containing 2,024 statements with 298 tables.
-
•
WikiTableQuestion contains complex questions annotated by crowd workers based on Wikipedia tables. The crowd workers are asked to write questions that involve several complex operations such as comparison, aggregation and arithmetic operations, which require compositional reasoning over a series of entries in the given table. We use the standard validation set and test set with 2,381 and 4,344 samples, respectively.
-
•
FetaQA contains free-form table questions that require deep reasoning and understanding. Most questions in FetaQA are based on information from discontinuous chunks in the table. We evaluate Dater on the test set containing 2,003 samples.
5.2 Evaluation Metrics
TabFact is used to evaluate table-based fact verification which aims to check if a statement is true based on tables. We adopt binary classification accuracy as the evaluation metric for the TabFact dataset. For WikiTableQuestion, we use denotation accuracy as our evaluation metric, which verifies whether the predicted answers equal the gold ones. Different from TabFact and WikiTableQuestion datasets that produce short phrase answers, the goal of FetaQA is to generate a complete long-form answer. Therefore, for FetaQA, we utilize BLEU (Papineni et al., 2002), ROUGE-1, ROUGE-2, ROUGE-L (Lin, 2004) as evaluation metrics.
5.3 Implementation Details
In the experiments, we employ GPT-3 Codex (code-davinci-002) as our large language model. For the final reasoning in-context learning step, we annotate 4, 2, and 6 prompting examples for TabFact, WikiTableQuestion, and FetaQA, respectively. To obtain consistent results, we use a self-consistence decoding strategy (Wang et al., 2022b).
| Model | Test |
| Fine-tuning based Methods | |
| Table-BERT | 68.1 |
| LogicFactChecker | 74.3 |
| SAT | 75.5 |
| TaPas | 83.9 |
| TAPEX | 85.9 |
| SaMoE | 86.7 |
| PASTA | 90.8 |
| w/ Dater | 93.0 ( 2.2) |
| Human | 92.1 |
| LLM based Methods | |
| Binder | 85.1 |
| Codex | 72.6 |
| w/ Dater | 85.6 ( 13.0) |
| Model | Dev | Test |
| Fine-tuning based Models | ||
| MAPO | 42.7 | 43.8 |
| MeRL | 43.2 | 44.1 |
| LatentAlignment | 43.7 | 44.5 |
| IterativeSearch | 43.1 | 44.7 |
| T5-3B | - | 49.3 |
| TaPas | 49.9 | 50.4 |
| TableFormer | 51.3 | 52.6 |
| TAPEX | 58.0 | 57.2 |
| ReasTAP | 58.3 | 58.6 |
| TaCube | 60.9 | 60.8 |
| OmniTab | 61.3 | 61.2 |
| w/ Dater | 62.5 ( 1.2) | 62.5 ( 1.3) |
| LLM based Methods | ||
| Binder | 62.6 | 61.9 |
| Codex | 49.3 | 47.6 |
| w/ Dater | 64.8( 15.5) | 65.9 ( 18.3) |
5.4 Baselines
We compare the proposed Dater with a range of strong baseline methods that can be divided into two categories: fine-tuning based methods that require training on task-specific data and LLM-based in-context learning methods that do not require fine-tuning.
Fine-tuning based Methods
For the fine-tuning based methods, we compare the following methods: Table-BERT (Chen et al., 2020) adopts rule-based method to linearize a table into a natural language (NL) sentence. The linearized table and statement are then directly encoded using a BERT model. LogicFactChecker (Zhong et al., 2020) employs a sequence-to-action semantic parser to generate a program, represented as a tree with multiple operations. A graph neural network is then utilized to encode statements, tables, and the generated programs. TaPas (Herzig et al., 2020) enhances the BERT architecture by incorporating the ability to encode tables as input. It is pre-trained on a joint dataset of text segments and tables collected from Wikipedia, allowing the model to better process tabular data and improving the overall performances on various downstream tasks. SAT (Zhang et al., 2020) improves the model’s ability to attend to the relevant information within a table by introducing a structure-aware mask matrix. In particular, it focuses on capturing low-level lexical information in the low layers and semantic information in the upper layers. TAPEX (Liu et al., 2021) is designed to make the BART model imitate the SQL executor, which allows the model to acquire better table comprehension ability. The corpus of pre-trained SQL query templates are extracted from the SQUALL dataset. SaMoE (Zhou et al., 2022c) introduces mixture-of-experts (MoE) (Masoudnia and Ebrahimpour, 2014) into the field of table-based fact verification, aiming to make different experts focus on different types of reasoning tasks. ReasTAP (Zhao et al., 2022) defines seven reasoning skills over semi-structured data, including in conjunction, temporal comparison, date difference, and so on. It infused tabular reasoning capability by pre-training the model on synthetic dataset. PASTA (Gu et al., 2022) designs six types of sentence–table cloze tasks that are pre-trained on a synthesized corpus of 1.2 million items from WikiTables. The “fine-tuning with select-then-rank” strategy is used to adapt the input length to the model, which allows the model to handle long input sequences effectively. TableFormer (Yang et al., 2022) proposes a method that is robust to perturbations in table rows and columns, thereby improving the model’s understanding of tables through the use of positional encoding. TaCube (Zhou et al., 2022b) is a pre-computation-based approach aiming to improve the ability of PLMs in numerical reasoning. This method pre-computes aggregation/arithmetic results for the table in advance, making them readily available for PLMs when tackling question answering. OmniTab (Jiang et al., 2022) proposes an omnivorous pre-training approach that consumes both natural and synthetic data to enhance models with abilities for both types of data.
LLM based Methods
For the LLM based methods with in-context learning, we compare the following methods: Codex (Chen et al., 2021) directly generates final answer by performing in-context learning as shown in Prompt 4.1. Binder (Cheng et al., 2022) generates programming language programs and extends the capability of the programming language to solve commonsense problems.
| Model | BLEU | ROUGE-1 | ROUGE-2 | ROUGE-L |
| Fine-tuning based Methods | ||||
| T5-small | 21.60 | 0.55 | 0.33 | 0.47 |
| T5-base | 28.14 | 0.61 | 0.39 | 0.51 |
| T5-large | 30.54 | 0.63 | 0.41 | 0.53 |
| LLM based Methods | ||||
| Codex | 27.96 | 0.62 | 0.40 | 0.52 |
| w/ Dater | 30.92 | 0.66 | 0.45 | 0.56 |
5.5 Main Results
We conduct extensive experiments on TabFact, WikiTableQuesion and FetaQA. The experimental results on TabFact are summarized in Table 2. From the results, we can observe that our Dater model achieves a substantial improvement over the compared methods. If we use LLM (Codex) as reasoner, our Dater achieves an accuracy of 85.6%, which is 13.0% higher than the result predicted by the Codex without evidence and questions decomposition stages. On the other hand, when we use the fine-tuned model as reasoner in Dater framework, i.e., injecting intermediate decomposition generated by Dater into PASTA, the accuracy increases by 2.2% (93.0% vs. 90.8%) over PASTA. It is noteworthy that Dater outperforms human performance for the first time on the TabFact dataset.
Table 2 provides the experimental results on the WikiTableQuestion dataset. Dater achieves a new state-of-the-art accuracy of 65.9% on the test set, surpassing the best baseline method (i.e., Binder) by 4.0%. When injecting intermediate decomposition generated by Dater into OmniTab, we can still achieve a gain of 1.3% on the test set. In addition, Dater has an absolute gain of 18.3% compared to the original Codex for table-based QA. The impressive improvement may be due to the fact that WikiTableQuestion has relatively large tables and complex questions, which can be effectively addressed by our table and question decomposition methods. Table 3 illustrates the experimental results on the FetaQA dataset. We can observe that our Dater method achieves better results than the compared methods T5 and Codex, further validating the effectiveness of Dater.
| Model | TabFact | WikiTableQuestion | FeTaQA | ||||
| All | Simple | Complex | All | Simple | Complex | BLEU | |
| Dater | 85.6 | 91.2 | 80.0 | 65.9 | 68.2 | 63.5 | 30.92 |
| w/o Evidence Decomposition | 81.8 ( 3.8) | 86.9 ( 4.3) | 76.8 ( 3.2) | 63.9 ( 2.0) | 65.5 ( 2.7) | 62.2 ( 1.3) | 28.46 ( 2.46) |
| w/o Question Decomposition | 81.9 ( 3.7) | 90.0 ( 1.2) | 74.1 ( 5.9) | 61.4 ( 4.5) | 63.6 ( 4.6) | 59.1 ( 4.4) | 30.73 ( 0.19) |
5.6 Ablation Study
To analyze the impact of two kinds of decomposition in Dater, we conduct an ablation study by discarding the evidence decomposition module (denoted as w/o Evidence Decomposition) and the question decomposition module (denoted as w/o Question Decomposition) on TabFact, WikiTableQuestion and FetaQA. The questions in the TabFact and WikiTableQuestion datasets can be further divided into two levels based on the difficulty of the questions: Simple and Complex, which can be used to better evaluate the model performance on different questions. Specifically, TabFact is divided based on officially provided question difficulty labels, while WikiTableQuestion is categorized by the length of the question. While FetaQA questions are more similar in length and difficult to distinguish, so we do not divide them. The ablation test results are reported in Table 4. It is no surprise that combining both evidence and question composition achieves the best performance in all the experimental settings. For FabFact, both evidence decomposition and question decomposition have large impacts on the performance of Dater. The accuracy of Dater without evidence/question decomposition decreases by 3.8%/3.7% on the All test set of FabFact. For WikiTableQuestion, question decomposition has a much larger impact than evidence decomposition on the performance of Dater. This is because WikiTableQuestion contains more complex questions that involve comparison, aggregation and arithmetic operations. This verifies the effectiveness of our question decomposition method in dealing with complex questions. For FetaQA, the questions are simpler and involve less numerical reasoning, thus the performance bottleneck is mainly in table content understanding. The performance of Dater drops significantly when discarding evidence decomposition. As FetaQA primarily focuses on the data-to-text generation, it is within our expectation that there is no significant gain from question decomposition.
| Semantic Understanding | ||
| Question | on august 25 , remlinger (6 - 6) took the win against the rockies. | |
| Rule-based method | date, loss | ✗ |
| Dater | date, loss, score, opponent | ✓ |
| Ground Truth: | date, loss, score, opponent | |
| Commonsense Knowledge | ||
| Question | the top scorer (matias suarez) has 5 fewer goals than bart goor , who has 11 goals. | |
| Rule-based method | player, league | ✗ |
| Dater | player, total | ✓ |
| Ground Truth: | player, total | |
| Question | denver did not lose more than one game in a row during november. | |
| Rule-based method | date | ✗ |
| Dater | team, date, score | ✓ |
| Ground Truth | team, date, score |
| WikiTableQuestion | |
| Question 1 | what is the number of listings from barrington, farmington, and rochester combined? |
| Codex CoT | there are totally 1+1+1=3 listings from barrington, farmington, and rochester combined. |
| Codex Prediction | “3” ✗ |
| Dater Sub-question | the number of listings from barrington is {…}. the number of listings from farmington is {…}. the number of listings from rochester is {…}. |
| Dater Parsing | SELECT COUNT(*) FROM w WHERE city or town = ’barrington’ SELECT COUNT(*) FROM w WHERE city or town = ’farmington’ SELECT COUNT(*) FROM w WHERE city or town = ’rochester’ |
| Dater CoT | the number of listings from barrington is {1}. the number of listings from farmington is {1}. the number of listings from rochester is {3}. |
| Dater Prediction | “5” ✓ |
| Gold Answer | “5” |
| Question 2 | does the team have more 5th or 7th place finishes during the regular season? |
| Codex CoT | the team have 1 5th place finishes and 2 7th place finish during the regular season. |
| Codex Prediction | “7th” ✗ |
| Dater Sub-question | the team have {…} 5th place finishes during the regular season. the team have {…} 7th place finishes during the regular season. |
| Dater Parsing | SELECT COUNT(*) FROM w WHERE reg.season LIKE ’%5th%’ SELECT COUNT(*) FROM w WHERE reg.season LIKE ’%7th%’ |
| Dater CoT | the team have {3} 5th place finishes during the regular season. the team have {2} 7th place finishes during the regular season. |
| Dater Prediction | “5th” ✓ |
| Gold Answer | “5th” |
| TabFact | |
| Question 1 | pádraig harrington and graeme mcdowell are both fron northern ireland. |
| Codex CoT | pádraig harrington is fron northern ireland.graeme mcdowell is fron northern ireland. |
| Codex Prediction | True ✗ |
| Dater Sub-question | pádraig harrington is {…} fron northern ireland. graeme mcdowell is {…} fron northern ireland. |
| Dater Parsing | SELECT COUNT(*) FROM w WHERE player = ’pádraig harrington’ AND country = ’northern ireland’ SELECT COUNT(*) FROM w WHERE player = ’graeme mcdowell’ AND country = ’northern ireland’ |
| Dater CoT | pádraig harrington is {0} fron northern ireland. graeme mcdowell is {1} fron northern ireland. |
| Dater Prediction | False ✓ |
| Gold Answer | False |
| Question 2 | atlético ciudad played 28 matches with an average of less than 0.61 |
| Codex CoT | atlético ciudad played 28 matches. the average of atlético ciudad is 0.61. |
| Codex Predict | True ✗ |
| Dater Sub-question | atlético ciudad played {…} matches. atlético ciudad played {…} matches with an average of less than 0.61. |
| Dater Parsing | SELECT SUM(matches) FROM w WHERE team = ’atlético ciudad’ SELECT COUNT(*) FROM w WHERE team = ’atlético ciudad’ AND average < 0.61 |
| Dater CoT | atlético ciudad played {28} matches. atlético ciudad played {0} matches with an average of less than 0.61. |
| Dater Prediction | False ✓ |
| Gold Answer | False |
5.7 Case Study
Case Study for Evidence Decomposition
To better understand how evidence decomposition helps our model capture the relevant sub-evidence, we demonstrate three exemplary cases about sports selected from TabFact. Due to space limitations, we solely provide the table column selection results. From Table 5, we can observe that the rule-based method fails to precisely align the question and evidence since it cannot capture the deep semantic information of both the question and evidence. Taking the first case as an example, the rule-based method cannot link the phrase “against the rockies” and the column name “opponent”. In addition, the rule-based method often suffers from a lack of commonsense knowledge and cannot comprehend complex questions effectively. For example, as shown by the third case, the rule-based method fails to recognize “denver” as a team name and does not discover that the “score” column can be used to determine the results of the games. On the contrary, our Dater method can address the limitations of previous methods in evidence decomposition and accurately select the relevant columns from a table by eliciting rich semantic and commonsense knowledge from a powerful LLM.
Case Study for Question Decomposition
We use four exemplar cases selected from WikiTableQuestion and TabFact datasets to verify the effectiveness of our question decomposition qualitatively. Table 6 shows the “chain of thought” generated by Codex and our Dater method, where the first two cases are from WikiTableQuestion and the last two cases are from TabFact. From the cases, we can observe that Dater can decompose the complex question into simpler sub-questions that can be easily solved by leveraging a “parsing-execution-filling” strategy. In particular, Dater can generate high-quality SQL queries to retrieve correct information from the evidence. The retrieved information is essential to predict the final answer. In contrast, without question composition, Codex fails to understand and comprehend complex questions, therefore it just gets information from the given question. For example, Codex tends to generate a “chain of thought” (a series of intermediate reasoning steps) that is inconsistent with the evidence.
5.8 Analysis of Sub-evidence
As revealed by (Chen, 2022), the table-based reasoning models are unable to generalize to “huge” tables with 30+ rows, which is the major error source. To address this problem, evidence decomposition is proposed to obtain a sub-evidence by filtering the irrelevant information from the “huge” evidence. To illustrate the effectiveness of evidence decomposition in narrowing the scope of irrelevant evidence, in Figure 3, we report the average number of table cells before and after evidence decomposition on the three datasets. From the results, we can observe that the sub-evidence is about 3x smaller than the original evidence, while achieving better performance. In particular, for WikiTableQuestion, we can reduce the average number of table cells from 164 to 56, significantly relieving the burden of LLMs in dealing with “huge” tables. Similar trends can also be observed on TabFact and FetaQA datasets.
6 Conclusion
In this paper, we explored in-context learning in LLMs to decompose structured evidence and unstructured NL questions for effective table-based reasoning. First, we utilized a powerful LLM to decompose the evidence involved in the current question into a relevant sub-evidence. The sub-evidence extraction could identify the relevant sub-evidence and exclude the remaining irrelevant evidence by predicting the indexes of the rows and columns with the help of an LLM and a few prompts. Second, we introduced a “parsing-execution-filling” strategy, which explored the programming language SQL to decompose the complex question into logical and numerical computation. Finally, we leveraged the decomposed sub-evidence and sub-questions to obtain the final answer effectively with the help of a few in-context prompting examples. Experimental results on three benchmark datasets demonstrated that our Dater achieved significantly better results than previous competitive baselines (fine-tuning-based methods and LLM-based in-context learning methods) for table-based reasoning. Particularly, Dater outperforms human performance for the first time on the TabFact dataset. In addition to impressive overall performance, Dater also has the advantage of interpretability, where the returned results are to some extent tractable with the generated sub-evidence and sub-questions.
Our evidence decomposition method extracts indexes of the rows and columns as a whole via a powerful LLM without considering the “chain-of-thought” characteristic of the given question. In the future, we plan to learn the fine-grained alignment between tables and questions by performing step-by-step reasoning over tables.
References
- Abdelaziz et al. (2017) Ibrahim Abdelaziz, Razen Harbi, Zuhair Khayyat, and Panos Kalnis. 2017. A survey and experimental comparison of distributed sparql engines for very large rdf data. Proceedings of the VLDB Endowment, 10(13):2049–2060.
- Aly et al. (2021) Rami Aly, Zhijiang Guo, Michael Schlichtkrull, James Thorne, Andreas Vlachos, Christos Christodoulopoulos, Oana Cocarascu, and Arpit Mittal. 2021. Feverous: Fact extraction and verification over unstructured and structured information. ArXiv preprint, abs/2106.05707.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
- Cai et al. (2022) Zefeng Cai, Xiangyu Li, Binyuan Hui, Min Yang, Bowen Li, Binhua Li, Zhen Cao, Weijie Li, Fei Huang, Luo Si, and Yongbin Li. 2022. Star: Sql guided pre-training for context-dependent text-to-sql parsing. In EMNLP.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. ArXiv preprint, abs/2107.03374.
- Chen (2022) Wenhu Chen. 2022. Large language models are few (1)-shot table reasoners. ArXiv preprint, abs/2210.06710.
- Chen et al. (2022) Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W Cohen. 2022. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. ArXiv preprint, abs/2211.12588.
- Chen et al. (2020) Wenhu Chen, Hongmin Wang, Jianshu Chen, Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou Zhou, and William Yang Wang. 2020. Tabfact: A large-scale dataset for table-based fact verification. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net.
- Cheng et al. (2022) Zhoujun Cheng, Tianbao Xie, Peng Shi, Chengzu Li, Rahul Nadkarni, Yushi Hu, Caiming Xiong, Dragomir Radev, Mari Ostendorf, Luke Zettlemoyer, et al. 2022. Binding language models in symbolic languages. ArXiv preprint, abs/2210.02875.
- Cho et al. (2019) Minseok Cho, Gyeongbok Lee, and Seung-won Hwang. 2019. Explanatory and actionable debugging for machine learning: A tableqa demonstration. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2019, Paris, France, July 21-25, 2019, pages 1333–1336. ACM.
- Creswell et al. (2022) Antonia Creswell, Murray Shanahan, and Irina Higgins. 2022. Selection-inference: Exploiting large language models for interpretable logical reasoning. ArXiv preprint, abs/2205.09712.
- Date (1989) Chris J Date. 1989. A Guide to the SQL Standard. Addison-Wesley Longman Publishing Co., Inc.
- Dua et al. (2022) Dheeru Dua, Shivanshu Gupta, Sameer Singh, and Matt Gardner. 2022. Successive prompting for decomposing complex questions. ArXiv preprint, abs/2212.04092.
- Fu et al. (2022) Yao Fu, Hao Peng, Ashish Sabharwal, Peter Clark, and Tushar Khot. 2022. Complexity-based prompting for multi-step reasoning. ArXiv preprint, abs/2210.00720.
- Gu et al. (2022) Zihui Gu, Ju Fan, Nan Tang, Preslav Nakov, Xiaoman Zhao, and Xiaoyong Du. 2022. Pasta: Table-operations aware fact verification via sentence-table cloze pre-training. ArXiv preprint, abs/2211.02816.
- Gupta et al. (2020) Vivek Gupta, Maitrey Mehta, Pegah Nokhiz, and Vivek Srikumar. 2020. INFOTABS: Inference on tables as semi-structured data. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2309–2324, Online. Association for Computational Linguistics.
- Herzig et al. (2020) Jonathan Herzig, Pawel Krzysztof Nowak, Thomas Müller, Francesco Piccinno, and Julian Eisenschlos. 2020. TaPas: Weakly supervised table parsing via pre-training. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4320–4333, Online. Association for Computational Linguistics.
- Huang et al. (2022) Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. 2022. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. In International Conference on Machine Learning, pages 9118–9147. PMLR.
- Hui et al. (2021) Binyuan Hui, Ruiying Geng, Qiyu Ren, Binhua Li, Yongbin Li, Jian Sun, Fei Huang, Luo Si, Pengfei Zhu, and Xiaodan Zhu. 2021. Dynamic hybrid relation exploration network for cross-domain context-dependent semantic parsing. In AAAI Conference on Artificial Intelligence.
- Hui et al. (2022) Binyuan Hui, Ruiying Geng, Lihan Wang, Bowen Qin, Yanyang Li, Bowen Li, Jian Sun, and Yongbin Li. 2022. S2SQL: Injecting syntax to question-schema interaction graph encoder for text-to-SQL parsers. In Findings of the Association for Computational Linguistics: ACL 2022, pages 1254–1262, Dublin, Ireland. Association for Computational Linguistics.
- Ji et al. (2022) Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Andrea Madotto, and Pascale Fung. 2022. Survey of hallucination in natural language generation. ACM Computing Surveys.
- Jiang et al. (2022) Zhengbao Jiang, Yi Mao, Pengcheng He, Graham Neubig, and Weizhu Chen. 2022. OmniTab: Pretraining with natural and synthetic data for few-shot table-based question answering. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 932–942, Seattle, United States. Association for Computational Linguistics.
- Kalyanpur et al. (2012) Aditya Kalyanpur, Siddharth Patwardhan, BK Boguraev, Adam Lally, and Jennifer Chu-Carroll. 2012. Fact-based question decomposition in deepqa. IBM Journal of Research and Development, 56:13–1.
- Kojima et al. (2022) Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. ArXiv preprint, abs/2205.11916.
- Lewkowycz et al. (2022) Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. 2022. Solving quantitative reasoning problems with language models. ArXiv preprint, abs/2206.14858.
- Lin (2004) Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
- Liu et al. (2022) Jiacheng Liu, Skyler Hallinan, Ximing Lu, Pengfei He, Sean Welleck, Hannaneh Hajishirzi, and Yejin Choi. 2022. Rainier: Reinforced knowledge introspector for commonsense question answering. ArXiv preprint, abs/2210.03078.
- Liu et al. (2021) Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, and Jian-Guang Lou. 2021. Tapex: Table pre-training via learning a neural sql executor. ArXiv preprint, abs/2107.07653.
- Masoudnia and Ebrahimpour (2014) Saeed Masoudnia and Reza Ebrahimpour. 2014. Mixture of experts: a literature survey. The Artificial Intelligence Review, 42(2):275.
- Min et al. (2022) Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2022. Rethinking the role of demonstrations: What makes in-context learning work? ArXiv preprint, abs/2202.12837.
- Nan et al. (2022) Linyong Nan, Chiachun Hsieh, Ziming Mao, Xi Victoria Lin, Neha Verma, Rui Zhang, Wojciech Kryściński, Hailey Schoelkopf, Riley Kong, Xiangru Tang, Mutethia Mutuma, Ben Rosand, Isabel Trindade, Renusree Bandaru, Jacob Cunningham, Caiming Xiong, Dragomir Radev, and Dragomir Radev. 2022. FeTaQA: Free-form table question answering. Transactions of the Association for Computational Linguistics, 10:35–49.
- Neeraja et al. (2021) J. Neeraja, Vivek Gupta, and Vivek Srikumar. 2021. Incorporating external knowledge to enhance tabular reasoning. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2799–2809, Online. Association for Computational Linguistics.
- Papineni et al. (2002) Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA. Association for Computational Linguistics.
- Pasupat and Liang (2015) Panupong Pasupat and Percy Liang. 2015. Compositional semantic parsing on semi-structured tables. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1470–1480, Beijing, China. Association for Computational Linguistics.
- Perez et al. (2020) Ethan Perez, Patrick Lewis, Wen-tau Yih, Kyunghyun Cho, and Douwe Kiela. 2020. Unsupervised question decomposition for question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8864–8880, Online. Association for Computational Linguistics.
- Qin et al. (2022) Bowen Qin, Binyuan Hui, Lihan Wang, Min Yang, Jinyang Li, Binhua Li, Ruiying Geng, Rongyu Cao, Jian Sun, Luo Si, Fei Huang, and Yongbin Li. 2022. A survey on text-to-sql parsing: Concepts, methods, and future directions. ArXiv, abs/2208.13629.
- Talmor and Berant (2018) Alon Talmor and Jonathan Berant. 2018. The web as a knowledge-base for answering complex questions. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 641–651, New Orleans, Louisiana. Association for Computational Linguistics.
- Wang et al. (2021) Fei Wang, Kexuan Sun, Muhao Chen, Jay Pujara, and Pedro Szekely. 2021. Retrieving complex tables with multi-granular graph representation learning. ArXiv preprint, abs/2105.01736.
- Wang et al. (2022a) Lihan Wang, Bowen Qin, Binyuan Hui, Bowen Li, Min Yang, Bailin Wang, Binhua Li, Fei Huang, Luo Si, and Yongbin Li. 2022a. Proton: Probing schema linking information from pre-trained language models for text-to-sql parsing. Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining.
- Wang et al. (2022b) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022b. Self-consistency improves chain of thought reasoning in language models.
- Wang et al. (2022c) Yihan Wang, Si Si, Daliang Li, Michal Lukasik, Felix Yu, Cho-Jui Hsieh, Inderjit S Dhillon, and Sanjiv Kumar. 2022c. Preserving in-context learning ability in large language model fine-tuning. ArXiv preprint, abs/2211.00635.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. ArXiv preprint, abs/2201.11903.
- Yang et al. (2022) Jingfeng Yang, Aditya Gupta, Shyam Upadhyay, Luheng He, Rahul Goel, and Shachi Paul. 2022. TableFormer: Robust transformer modeling for table-text encoding. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 528–537, Dublin, Ireland. Association for Computational Linguistics.
- Yin et al. (2020) Pengcheng Yin, Graham Neubig, Wen-tau Yih, and Sebastian Riedel. 2020. TaBERT: Pretraining for joint understanding of textual and tabular data. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8413–8426, Online. Association for Computational Linguistics.
- Zelikman et al. (2022) Eric Zelikman, Yuhuai Wu, and Noah D Goodman. 2022. Star: Bootstrapping reasoning with reasoning. ArXiv preprint, abs/2203.14465.
- Zhang et al. (2019) Haoyu Zhang, Jingjing Cai, Jianjun Xu, and Ji Wang. 2019. Complex question decomposition for semantic parsing. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4477–4486, Florence, Italy. Association for Computational Linguistics.
- Zhang et al. (2020) Hongzhi Zhang, Yingyao Wang, Sirui Wang, Xuezhi Cao, Fuzheng Zhang, and Zhongyuan Wang. 2020. Table fact verification with structure-aware transformer. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1624–1629, Online. Association for Computational Linguistics.
- Zhang et al. (2022) Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. 2022. Automatic chain of thought prompting in large language models. ArXiv preprint, abs/2210.03493.
- Zhao et al. (2022) Yilun Zhao, Linyong Nan, Zhenting Qi, Rui Zhang, and Dragomir Radev. 2022. Reastap: Injecting table reasoning skills during pre-training via synthetic reasoning examples. ArXiv preprint, abs/2210.12374.
- Zhong et al. (2017) Victor Zhong, Caiming Xiong, and Richard Socher. 2017. Seq2sql: Generating structured queries from natural language using reinforcement learning. CoRR, abs/1709.00103.
- Zhong et al. (2020) Wanjun Zhong, Duyu Tang, Zhangyin Feng, Nan Duan, Ming Zhou, Ming Gong, Linjun Shou, Daxin Jiang, Jiahai Wang, and Jian Yin. 2020. LogicalFactChecker: Leveraging logical operations for fact checking with graph module network. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6053–6065, Online. Association for Computational Linguistics.
- Zhou et al. (2022a) Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Olivier Bousquet, Quoc Le, and Ed Chi. 2022a. Least-to-most prompting enables complex reasoning in large language models. ArXiv preprint, abs/2205.10625.
- Zhou et al. (2022b) Fan Zhou, Mengkang Hu, Haoyu Dong, Zhoujun Cheng, Shi Han, and Dongmei Zhang. 2022b. Tacube: Pre-computing data cubes for answering numerical-reasoning questions over tabular data. ArXiv preprint, abs/2205.12682.
- Zhou et al. (2022c) Yuxuan Zhou, Xien Liu, Kaiyin Zhou, and Ji Wu. 2022c. Table-based fact verification with self-adaptive mixture of experts. In Findings of the Association for Computational Linguistics: ACL 2022, pages 139–149, Dublin, Ireland. Association for Computational Linguistics.