A Survey on Efficient Training of Transformers
Abstract
Recent advances in Transformers have come with a huge requirement on computing resources, highlighting the importance of developing efficient training techniques to make Transformer training faster, at lower cost, and to higher accuracy by the efficient use of computation and memory resources. This survey provides the first systematic overview of the efficient training of Transformers, covering the recent progress in acceleration arithmetic and hardware, with a focus on the former. We analyze and compare methods that save computation and memory costs for intermediate tensors during training, together with techniques on hardware/algorithm co-design. We finally discuss challenges and promising areas for future research.
1 Introduction
Deep learning is a recent most profound approach which has revolutionised machine learning (ML) and artificial intelligence and is leading the fourth industrial revolution. At its core, the success of deep learning depends on the vast computational resources available and an extremely large amounts of labeled data. Despite the huge excitement generated by the recent developments, deep learning models, especially Transformers [87], have become formidably large and computationally intensive, resulting in two pressing challenges at the fundamental level.
The first issue concerns the intensive computation of training large Transformer-based models. A widely discussed energy study of deep learning models [82] estimates that training a Transformer base model with neural architecture search (NAS) [79] produces about 626,155 pounds of planet-warming carbon dioxide, equal to the lifetime emissions of five cars; as models grow bigger, their demand for computing is outpacing improvements in hardware efficiency. For example, GPT-3 [10] (the precursor to ChatGPT) was trained on half a trillion words and equips with 175 billion parameters. Notably, according to the technical overview of GPT-3111https://lambdalabs.com/blog/demystifying-gpt-3/, it would take 355 GPU-years and cost at least $4.6M for a single training run, estimated with theoretical 28 TFLOPS for V100 and lowest 3-year reserved cloud pricing. Therefore, the true groundbreaking success of deep learning, such as ChatGPT, is exclusively dominated by large and rich enterprises such as Google or Microsoft. It becomes extremely important to make deep learning tenable in computation and energy efficiency for Green AI [76], and democratize AI to wider communities with limited resources.
The second issue comes with the exponentially growing training memory proportional to the attention-based model size. For example, the largest language model in literature grows from 345M with BERT-large [48] in 2018, to hundreds of billions till now with models such as MT-NLG [78] equipped with 530B parameters. Therefore, these SOTA massive models call for memory efficient training techniques to reduce the memory footprint of storing intermediate tensors and data exchanges (communications) across accelerators, while ensuring high processing elements (PE) utilization.
In this survey, we review the generic techniques that boost computation and memory efficiency for training attention-based models, i.e., Transformers, as shown in Figure 1. We characterize them by the technical innovations and primary use case, summarize them and draw connections between them. We are primarily interested in arithmetic innovations that improve the training efficiency of Transformers and also briefly discuss hardware/algorithm codesign advances. We leave the review of hardware accelerator design, a broad class, as future work.
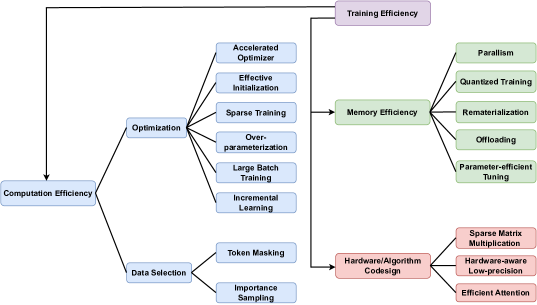
2 Computation Efficiency
2.1 Optimization
Optimizer. To achieve a faster convergence rate for gradient descent, a classic solution is to fuse the momentum technique, where each step is a combination of the steepest descent direction and the most recent iterate displacement, helping to accelerate gradient descent in the relevant direction and dampens oscillations. The seminal works include Nesterov’s accelerated gradient [67] for convex optimization and proximal gradient with momentum [55] towards non-convex problems, etc. To meet the demand of large-scale optimization of machine learning models, dominant optimizers are designed in a stochastic fashion. In particular, stochastic gradient descent (SGD) with momentum and the adaptive learning rate estimation method Adam [50] are widely used to train deep neural networks. Empirically, training Transformers with Adam outperforms the SGD counterpart, and [96] demystifies that a heavy-tailed distribution of the noise in stochastic gradients is the main cause of SGD’s poor performance and understands Adam through the lens of adaptive noise clipping. By default, AdamW [62], a variant of Adam which decouples the regularization and the weight decay, is the most widely used optimizer for Transformers. More recently, Google searches optimization algorithms and discovers a simple and effective optimizer called Lion [18]. Lion only keeps track of the momentum with the first-order gradient, and its update only considers the direction and has the same magnitude for each parameter, which is very different from the adaptive optimizers like AdamW. In practice, Lion in general converges faster, and is more memory-efficient and accurate than AdamW for training Transformers on various benchmarks. We refer readers to [60, 9] for more details about accelerated optimization methods in machine learning.
To improve the generalization of Transformers, Sharpness-aware minimization (SAM) [28] seeks to simultaneously minimize loss value and loss sharpness, based on the connection between the geometry of the loss landscape and generalization, i.e., a flatter minimum tends to improve generalization. The following work [17] applies SAM to Transformer, observing significant accuracy gains via smoothing the loss surface. However, SAM needs to solve a bi-level min-max optimization problem, which nearly doubles the training time. To accelerate optimization, [23] proposes stochastic weight perturbation to preserve the generalization capability and sharpness-sensitive subset selection strategies. More recently, [24] designs a near zero-cost proxy of the sharpness loss by replacing the sharpness estimation as the KL-divergence between the two consecutive update steps.
Initialization. A good initialization is essential to stabilize training, enable higher learning rate, accelerate convergence, and improve generalization. Thus, many works have been proposed for better initialization of Transformers. Specifically, Fixup [95] proposes to properly rescale a standard initialization to ensure proper gradient norm to avoid exploding or vanishing gradients, which can train very deep networks with over 10,000 layers without adding normalization layers. Based on the insight that the function computed by normalized residual blocks is close to the identity function (i.e., unit variance), the following works ReZero [5] and SkipInit [22] simply initialize each layer to perform the identity operation. Specifically, they add a learnable scaling multiplier on the output of each residual block:
| (1) |
where and are the input and the function at layer , where the function can be multi-head self-attention layers (MSA) and feed-forward networks (FFN), and is simply initialized to 0. Customized to Transformers, T-Fixup [40] analyzes that part of the optimization difficulty comes from the unstable early updates in the Adam optimizer as the variance of the second-order momentum is unbounded. Therefore, it follows Fixup to adopt rescaling schemes for the initialization of residual blocks. All the above-mentioned methods remove batch/layer normalization from all blocks and train without learning rate warmup. On training deep vision Transformers (ViT), [85] proposes channel-wise learnable scaling factors and empirically observe that re-introducing the warmup and layer normalization techniques can make training more stable.
Apart from the rescaling paradigm, some literature proposes to improve initialization from a new perspective by leveraging the relationship between self-attention and convolutional layers. [19] proves that a multi-head self-attention layer with heads and a relative positional encoding with dimension can be reparameterized to express any convolutional layer of filter size . The attention can be decomposed into a content term and a (relative) positional term, where the latter determines the center and width of attention of each head. Based on this property, ConViT [25] learns to control the locality by adding a soft gating parameter to balance the two terms, which has the effect of incorporating soft convolutional inductive biases into global self-attention.
Sparse training. The key idea of sparse training is to directly train sparse subnetworks instead of the full networks from scratch without sacrificing accuracy. The reliability was first demonstrated by the lottery ticket hypothesis (LTH) [29] that a dense, randomly initialized network contains subnetworks (winning tickets) which can be trained in isolation to match the accuracy of the original network. However, LTH requires identifying the winning tickets in an alternating train-prune-retrain manner, which makes the training extremely costly for large models and datasets, limiting the practical benefits. In light of this, follow-up works with higher training efficiency can be roughly categorized into three categories: (i) find sparse networks once at initialization by measuring the importance of connections on the loss, eliminating the need for the complex iterative optimization schedule [52, 88] ; (ii) identify the winning tickets in Transformers at a very early training stage via low-cost schemes and then merely train these early tickets until convergence [90, 16]; (iii) use an alternating pruning and growing schedule to dynamically update model sparsity patterns throughout training, suitable for general architectures [26, 14].
Overparameterization. Practical DNNs are heavily overparameterized, where the number of learnable parameters is much larger than the number of training samples. It is observed that overparameterization empirically improves both convergence and generalization, with theoretical guarantee though not sufficient. The early work [4] mathematically proves that increasing depth as overparameterization in linear neural networks can accelerate SGD convergence. [57] further explores two-layer non-linear neural networks and [3] proves that SGD can converge to global minima on the training objective of DNNs in polynomial time, assuming training samples are not duplicated, and the number of parameters is polynomial in the number of training samples and network depth. In terms of generalization, [2] theoretically proves that a sufficiently overparameterized (three-layer) neural network generalizes to the population risk and an intriguing property is that there exists an accurate network in the close neighborhood of any point on the SGD training trajectory with high probability over random initialization. Note that it has deep connections with LTH as it partially explains why LTH stands in sparse training as good small sub-networks with low risks are plentiful due to overparameterization. Applied to Transformers, [58] exploits the faster convergence and better generalization from the overparameterization theory to design an efficient training pipeline: training a very large model, then perform early stopping and heavily compress it, analogous to LTH.
Large batch training. Another prevailing way to accelerate training is to use a large batch size, delivering a reduced number of iterations per epoch and better computing resource utilization. From the statistical view, large batch training reduces the variance of the stochastic gradient estimates, so a reliable step size needs to be tuned for better convergence [9]. At the era of convolutional neural networks, [31] employs the linear scaling of the learning rate to train ResNet-50 on ImageNet with a batch size of 8,192 in 1 hour. More advanced step size estimation methods are then proposed. The widely used methods are LARS [92] for SGD and LAMB [93] for Adam, which propose to use layerwise adaptive learning rates for ResNet and Transformers respectively. The layerwise adaptation strategy can be formulated as
| (2) |
where , and are the learning rate, parameters and the momentum-based gradients of the -th layer at time step , is a scaling function. It equips with a normalization term that provides robustness to exploding gradients and plateaus, and the scaling term ensures that the norm of the update is of the same order as that of the parameter, promoting faster convergence. More recently, more powerful optimization methods customized to large batch training have been empirically shown to perform well. For example, [46] shows that averaging the weights of a certain number of latest checkpoints can facilitate faster training. DeepMind in [37] trains over 400 Transformer language models with varying scales of model size and # of training tokens, reaching to a practical hypothesis that the model size and the number of training tokens should be scaled equally for compute-optimal LLM training.
Incremental learning. The high-level concept of incremental learning is relaxing the original challenging optimization problem into a sequence of easy-to-optimize sub-problems, where the solution of one sub-problem can serve as a good initialization to the subsequent one to circumvent the training difficulty, in analogy with annealing. Some works [30, 32] propose to accelerate BERT pretraining by progressively stacking layers, properly initializing a larger model from a smaller one. [97] goes in a reverse direction to train Transformers with stochastic depth via layer dropping, where it progressively increases dropping rate along both time dimension and depth dimension. Customized to ViT, AutoProg [54] proposes to automatically decide whether, where and how much should the model grow during progressive learning using neural architecture search. A key observation is that progressively increasing the resolution of the input images (reducing the patch size) can significantly accelerate ViT training, aligning with the widely known training dynamics that focus on low-frequency structure in the early stage and high-frequency semantics in the latter stage.
2.2 Data Selection
Apart from the model efficiency, data efficiency is also a crucial factor of efficient training.
Token masking. Token masking is a dominant approach in self-supervised pre-training tasks, such as masked language modeling (MLM) [48, 10] and masked image modeling (MIM) [6, 35]. The spirit of token masking is to randomly mask some input tokens and train the model to predict the missing content, e.g., vocabulary id or pixels, with the context information from the visible tokens. Since squeezing the sequence length reduces both the computational and memory complexity quadratically, skipping processing the masked tokens brings considerable training efficiency gain for MLM and MIM. For MLM, [80] proposes to jointly pre-train the encoder and decoder for language generation tasks while removing the masked tokens in the decoder to save memory and computation costs. For MIM, representative work [35] shows that in vision, removing the masked image patches before the encoder demonstrates stronger performance and 3 or more lower overall pre-training time and memory consumption than keeping the masked tokens. A similar phenomenon is also found in [56] that for language-image pre-training, randomly masking and removing the masked image patches shows 3.7 faster overall pre-training time than the original CLIP [72].
Importance sampling. Importance sampling over data, also known as data pruning, is theoretically guaranteed to accelerate stochastic gradient algorithms for supervised learning by prioritizing informative training examples, mainly benefiting from variance reduction. For DNNs, a principal way of estimating per-sample importance is to use gradient norm, and [47, 44] use different approximations to make calculating these norms tractable. [70] further speeds up the sampling process similar to the early-bird LTH, but in the data domain, that simple average gradient norms or error -norms over several weight initializations can be used to identify important examples at the very early stage in training. More recently, [81] shows an exciting analytic theory that the scaling of test error with dataset size can break beyond power scaling laws and be reduced to at least exponential scaling if equipped with a superior data pruning metric, and it employs a self-supervised metric using -means clustering. It demonstrates a promising direction towards more efficient neural scaling laws based on data importance sampling.
| Method | Class |
|---|---|
| Micikevicius et al. [64] | AMP |
| Chen et al. [15] | Rematerialization |
| Herrmann et al. [36] | Rematerialization |
| ZeRO-Offload [75] | Offloading |
| Beaumont et al. [7] | Offloading + Rematerization |
| ZeRO [73] | DP+MP+AMP |
| Megatron-LM [77] | DP+TP |
| GPipe [41] | DP+PP |
| torchgpipe [49] | PP+Rematerization |
| Megatron-LM∗[66] | DP+TP+PP+AMP |
| Wang et al. [89] | FP8 Training |
| Cambier et al. [11] | FP8 Training |
| Mesa [69] | 8-bit ACT |
| ACTNN [12], GACT [61] | 2-bit ACT |
| [53, 43, 38] | Addition-based PET |
| Bitfit [94], LoRA [39] | Reparameterization-based PET |
3 Memory Efficiency
Apart from the computation burden, the growing model size of large Transformer models, e.g., from BERT [48] 345M parameter model to GPT-3 of 1.75 trillion parameters, is a key bottleneck for training as they do not fit into the memory of a single device. We first analyze the memory consumption of the existing model training frameworks, which is occupied by 1) model states, including optimizer states (e.g., momentum and variance in Adam), gradients and parameters; and 2) activations (we ignore temporary buffers and idle fragmented memory as they are relatively small). We summarize the memory efficient training methods in Table 1. In the following, we discuss dominant solutions to optimize memory usage.
Parallelism. Training large DNNs with parallelism across devices is a common practice to meet the memory demands. There are basically two paradigms: Data Parallelism (DP) which distributes a minibatch of data across different devices and Model Parallelism (MP) which allocates subgraphs of a model across multiple workers. For DP, with the increase of available workers, the batch size is close to linear scaling. Large batch training discussed in Sec. 2 is developed for this case. However, it is obvious that DP has high communication/computation efficiency but poor memory efficiency - when model becomes large, the single device cannot store the model replica and the synchronized communications for gradients can hinder the scalability of DP. Therefore, DP itself is only suitable for training small to moderate models. To improve the scalability of DP, one solution for Transformer is parameter sharing [51], known as Albert, but it limits the representational power. More recently, ZeRO [73] incorporates uniform partitioning strategy with DP, where each data parallel process merely deals with one partition of model states, working in a mixed precision regime. To deal with very large DNNs, one always need to utilize model parallelism to allocate different layers across multiple accelerators in a “vertical” manner. Though MP has good memory efficiency, its communication and computation efficiency is low due to high volume data transfer cross devices and poor PE utilization. Luckily, there are two strategies to further boost MP efficiency in an orthogonal “horizontal” dimension, including Tensor Parallelism (TP) and Pipeline Parallelism (PP). TP partitions a tensor operation in a layer across workers for faster computation and more memory saving. Customized to Transformer-based models, Megatron-LM [77] slices both MSA and FFN across GPUs and requires only a few extra All-Reduce operations in the forward and backward pass, allowing them to train models up to 8.3 billion parameters using 512 GPUs. In terms of PP, it was originally proposed in GPipe [41], which splits the input mini-batch into multiple smaller micro-batches, enabling different accelerators (sequential layers are partitioned across accelerators) to work on different micro-batches simultaneously before applying a single synchronous gradient update for the entire mini-batch. However, it still suffers from pipeline bubbles (accelerator idle time) that reduce efficiency. In particular, PyTorch implements the torchgpipe [49], which performs micro-batch PP with checkpointing, allowing scaling to a large number of micro-batches to minimize the bubble overhead.
Note that DP and MP are orthogonal and so one can use both simultaneously to train larger models with higher computation and memory capacity. For example, Megatron-LM∗ [66] and DeepSpeed [74] compose tensor, pipeline, and data parallelism to scale training to thousands of GPUs.
Quantized training. The standard routine for training neural networks adopts full-precision (i.e., FP32). In contrast, quantized training trains neural networks from scratch in reduced precision by compressing the activations/weights/gradients into low-bit values (e.g., FP16 or INT8). It has been shown in previous works that reduced precision training [98, 42] can accelerate neural network training with favorable performance. For Transformers, the most widely adopted approach is automatic mixed-precision (AMP) training [64]. Specifically, AMP stores a master copy of weights in full-precision for updates while the activations, gradients and weights are stored in FP16 for arithmetic. Compared to full-precision training, AMP is able to achieve faster training/inference speed and reduce memory consumption during network training. For example, based on a batch size of 64 and image resolution of , training a DeiT-B [84] on RTX3090 under AMP is 2 faster than full-precision training (305 vs. 124 images/s), as well as consuming 22% less peak GPU memory (7.9GB vs. 10.2GB). While it is commonly believed that at least 16-bits is necessary to train networks without impacting model accuracy [64, 21], the most recent support for FP8 training on NVIDIA H100 has shown promising results on Transformer training, where training DeiT-S and GPT [10] under FP8 can match those of 16-bit training. Apart from reduced precision training which simultaneously quantizes activations/weights/gradients, activation compressed training (ACT) [12] stores low-precision approximate copies of activations while computing the forward pass exactly, which helps to reduce the overall memory consumption during training. The saved activations are then dequantized to the original precision in the backward pass to calculate gradients. Recent work [69, 61] further propose to customize ACT to support memory-efficient Transformer training.
Rematerialization and offloading. Rematerialization, also known as checkpointing [15], is a widely used technique for space-time tradeoff that only stores a portion of activations/weights during the forward pass and recomputes the rest during the backward pass. [15] provides a simple periodic schedule which was implemented in PyTorch222https://pytorch.org/, but it is only optimal for homogeneous sequential networks. More advanced methods such as [36] implements optimal checkpointing for heterogeneous networks333https://gitlab.inria.fr/hiepacs/rotor. In terms of offloading, it is a technique to use external memory such as CPU memory as an extension of GPU memory to increase memory capacity during training, through communications between GPU and CPU. The model states as well as activations, can be offloaded to CPU, but the optimal choice needs to minimize communication cost (i.e., data movement) to/from GPU, reduce CPU computation and maximize GPU memory saving. A representative work is ZeRO-Offload [75], which offers optimal offloading strategy customized to mixed-precision training with Adam optimizer. It offloads all fp32 model states and the fp16 gradients on the CPU memory, and computes the fp32 parameter updates on CPU. The fp16 parameters are kept on GPU and the forward and backward computations are on GPU. For the best of both worlds, [7] proposes to jointly optimize activation offloading and rematerialization.
Parameter-efficient tuning. The public model zoo represented by HuggingFace, which contains rich pretrained models that are ready to be downloaded and executed, is contributing significantly to reductions in training costs. Efficient tuning these readily available models is becoming a prevailing way to drastically cut training costs. As a powerful alternative for the vanilla full fine-tuning, parameter-efficient tuning (PET) only updates a small number of additional parameters while freezing the pretrained model to significantly reduce the storage burden, which scales with dynamic deployment scenarios without the need to store a separate instance of model for each case. The general PET approaches can be categorized into addition-based methods and reparameterization-based methods. The former attaches additional trainable parameters to the pretrained model and only tune these parameters. For example, [53, 43] add trainable parameters to the input space, and [38] adds the adapter module twice to each Transformer block after the MSA and FFN. However, the extra parameters introduce additional computation and memory overhead during inference. To tackle this challenge, the latter proposes to tune parameters that are inherently in the model [94] or new parameters that can be reparameterized into the model [39], thereby yielding no sacrifice on the inference efficiency. Inspired by the observation that large language pretrained models have low intrinsic dimension [1], the representative work LoRA [39] approximates the update of self-attention weights into two low-rank matrices, which can be merged into the pretrained weights during inference. Notably, one of the most recognized efforts for democratizing LLM is Stanford Alpaca [83], which is fine-tuned from the open-sourced LLaMA models [86] using the 52K instruction-following data generated from ChatGPT. To fine-tune it cheaply and efficiently, its variant Alpaca-LoRA 444https://github.com/tloen/alpaca-lora further adopts the low-rank LoRA to enable instruct-tuning LLaMA on customer hardware, showing training can be done within hours on a single RTX 4090.
Open-source frameworks. There are several widely adopted prototypes for training large Transformer models at scale, in which Microsoft DeepSpeed555https://github.com/microsoft/DeepSpeed, HPC-AI Tech Colossal-AI666https://github.com/hpcaitech/ColossalAI and Nvidia Megatron-LM777https://github.com/NVIDIA/Megatron-LM are the pioneering ones. Specifically, DeepSpeed is implemented mainly based on [74] and ZeRO series works [73, 75], Colossal-AI is built upon [8], and Megatron-LM implements [66]. All of these support data and model parallelism in mixed precision, along with other general practices such as offloading and rematerialization. More libraries for efficient distributed training include but not limited to HuggingFace Transformers888https://github.com/huggingface/transformers, MosaicML Composer999https://github.com/mosaicml/composer, Baidu PaddlePaddle101010https://github.com/PaddlePaddle/Paddle, Bytedance Lightseq111111https://github.com/bytedance/lightseq, EleutherAI GPT-NeoX121212https://github.com/EleutherAI/gpt-neox, etc.
4 Hardware/Algorithm Co-design
Apart from computing and memory burden, designing efficient hardware accelerators enables faster training and inference for DNNs. Specifically, compared with central processing units (CPUs), graphics processing units (GPUs) are more powerful to perform matrix multiplication due to the high degree of parallelism. For applications that focus on specific computation tasks, application-specific integrated circuits (ASICs) have the advantage of low power consumption, and high training/inference speed. For example, a tensor processing unit (TPU) designed by Google delivered 3080 higher performance-per-watt than contemporary CPUs and GPUs [45]. However, ASICs are not easily reprogrammable or adaptable to a new task. In contrast, Field Programmable Gate Arrays (FPGAs) are designed to be reprogrammed to perform different functions as needed, and can also be used as a prototype for ASICs before finalizing the design. To further optimize the training efficiency of DNNs, especially Transformers, hardware-algorithm co-design takes the constraints and capabilities of the hardware into account when designing the algorithm, which will be introduced in the following subsections.
Sparse matrix multiplication. To reduce the computation overhead of Transformers, sparse general matrix multiplication (SpGEMM), which involves multiplying a sparse matrix with a dense matrix, takes advantage of the sparsity of the attention matrices to reduce the number of computations. There are several popular sparse matrix computation libraries, such as Intel Math Kernel Library131313https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl.html on CPU and cuSPARSE141414https://docs.nvidia.com/cuda/cusparse/, CUSP151515https://cusplibrary.github.io/ and 2:4 structured sparsity 161616https://developer.nvidia.com/blog/accelerating-inference-with-sparsity-using-ampere-and-tensorrt/[65] on GPU. However, due to the irregular sparsity, SpGEMM is often hardware unfriendly to general-purpose processors, such as CPUs and GPUs. To handle this, specialized hardware accelerators, such as FPGAs and ASICs, are required to handle the poor data locality issue. For example, OuterSPACE [68] transforms matrix multiplication into an outer product procedure and eliminates redundant memory accesses by decoupling multiplication from accumulation. To take full advantage of this reduction without introducing significant overheads, OuterSPACE builds a custom accelerator with reconfigurable memory hierarchy and achieves a mean speedup of 7.9 over the CPU running Intel Math Kernel Library and 14.0 against the GPU running CUSP. Furthermore, to alleviate the data movement bottleneck caused by high sparsity, ViTCoD [91] uses a learnable auto-encoder to compress the sparse attentions to a much more compact representation and designs encoder and decoder engines to boost the hardware utilization.
Hardware-aware low-precision. Lowering the precision of the computations reduces the amount of memory and computation, which can be implemented in hardware-friendly fixed-point or integer representations instead of floating-point ones. As a result, we can use lower precision multipliers, adders, and memory blocks, resulting in a significant improvement in power consumption and speedup. Moreover, low-precision arithmetic can be combined with other techniques, such as pruning and low-rank approximation, to achieve further acceleration. For example, Sanger [63] uses 4-bit queries and keys to compute the quantized prediction of sparse attention matrix. Then, the sparse attention masks are rearranged into structured blocks and handled by reconfigurable hardware. The following work DOTA [71] identifies unimportant connections in attention using low-rank transformation and low-precision computation. By incorporating token-level parallelism and out-of-order execution, DOTA achieves a 152.6 speedup over GPU.
Efficient attention. Apart from the sparse matrix multiplication and low-precision computation, several pioneering works focus on efficient and lightweight attention implementation in hardware [33, 34, 20]. Specifically, A3 [33] only selects those keys that are likely to have high similarity with the given queries to reduce the amount of computation in attention. ELSA [34] filters out irrelevant keys for a particular query based on the hashing similarity to save computation. With an efficient hardware accelerator, ELSA achieves a speedup of 58.1 as well as three orders of magnitude improvements in energy efficiency compared to an Nvidia V100 GPU equipped with 16GB memory. Notably, FlashAttention [20] proposes to exploit tiling to reduce the I/O communication between GPU high bandwidth memory (HBM) and on-chip SRAM, which is becoming a default fast and memory-efficient attention module for speedup.
5 Conclusion and Future Research
In this survey, we have reviewed several important factors that improve the training of Transformers: 1) appropriate initialization and optimization paradigms that can accelerate the convergence rate with fewer training iterations, resulting in lower computational costs; 2) higher data efficiency by sampling informative training samples towards more efficient neural scaling laws of test error with respect to dataset size; 3) memory-efficient techniques to meet the memory requirements for training large Transformers, which requires jointly optimizing PE utilization, memory and communication footprints across accelerators, using parallelism, low-precision arithmetic, checkpointing and offloading strategies, etc; 4) hardware and algorithm co-design to maximize the training scalability on hardware platforms.
We finally highlight several promising directions based on the reviewed progress: (i) joint training and deployment efficiency optimization. In reality, we usually need to deploy models to diverse tasks and platforms with different resource constraints. Therefore, it is highly desirable to develop new methods for efficiently training an elastic supertnet that supports many diverse architectural configurations following single-shot NAS [13] or mixture of experts [27], for multiple tasks and budget requirements; (ii) on-device training [59] on the edge with limited resources (e.g., low battery and memory capacity), to avoid frequently transmitting data which results in privacy and latency issues; (iii) combine efficient approximation techniques such as token/model pruning, low-rank factorization, lightweight architecture design, dynamic neural networks and etc, to reduce the model size and computational cost in the complimentary sense; (iv) a standard benchmark to evaluate and compare the efficient training methods. Having such a benchmark would fasten the adoption of these methods and lead to actual costs reduction down the line.
References
- [1] A. Aghajanyan, S. Gupta, and L. Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In ACL, 2021.
- [2] Z. Allen-Zhu, Y. Li, and Y. Liang. Learning and generalization in overparameterized neural networks, going beyond two layers. In NeurIPS, 2019.
- [3] Z. Allen-Zhu, Y. Li, and Z. Song. A convergence theory for deep learning via over-parameterization. In ICML, 2019.
- [4] S. Arora, N. Cohen, and E. Hazan. On the optimization of deep networks: Implicit acceleration by overparameterization. In ICML, 2018.
- [5] T. Bachlechner, B. P. Majumder, H. Mao, G. Cottrell, and J. McAuley. Rezero is all you need: Fast convergence at large depth. In UAI, 2021.
- [6] H. Bao, L. Dong, and F. Wei. Beit: Bert pre-training of image transformers. In ICLR, 2022.
- [7] O. Beaumont, L. Eyraud-Dubois, and A. Shilova. Efficient combination of rematerialization and offloading for training dnns. In NeurIPS, 2021.
- [8] Z. Bian, H. Liu, B. Wang, H. Huang, Y. Li, C. Wang, F. Cui, and Y. You. Colossal-ai: A unified deep learning system for large-scale parallel training. arXiv preprint arXiv:2110.14883, 2021.
- [9] L. Bottou, F. E. Curtis, and J. Nocedal. Optimization methods for large-scale machine learning. SIAM Review, 2018.
- [10] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. In NeurIPS, 2020.
- [11] L. Cambier, A. Bhiwandiwalla, T. Gong, M. Nekuii, O. H. Elibol, and H. Tang. Shifted and squeezed 8-bit floating point format for low-precision training of deep neural networks. In ICLR, 2020.
- [12] J. Chen, L. Zheng, Z. Yao, et al. Actnn: Reducing training memory footprint via 2-bit activation compressed training. In ICML, 2021.
- [13] M. Chen, H. Peng, J. Fu, and H. Ling. Autoformer: Searching transformers for visual recognition. In ICCV, 2021.
- [14] T. Chen, Y. Cheng, Z. Gan, L. Yuan, L. Zhang, and Z. Wang. Chasing sparsity in vision transformers: An end-to-end exploration. In NeurIPS, 2021.
- [15] T. Chen, B. Xu, C. Zhang, and C. Guestrin. Training deep nets with sublinear memory cost. arXiv preprint arXiv:1604.06174, 2016.
- [16] X. Chen, Y. Cheng, S. Wang, Z. Gan, Z. Wang, and J. Liu. Earlybert: Efficient bert training via early-bird lottery tickets. In ACL, 2021.
- [17] X. Chen, C.-J. Hsieh, and B. Gong. When vision transformers outperform resnets without pre-training or strong data augmentations. In ICLR, 2022.
- [18] X. Chen, C. Liang, D. Huang, E. Real, K. Wang, Y. Liu, H. Pham, X. Dong, T. Luong, C.-J. Hsieh, et al. Symbolic discovery of optimization algorithms. arXiv preprint arXiv:2302.06675, 2023.
- [19] J.-B. Cordonnier, A. Loukas, and M. Jaggi. On the relationship between self-attention and convolutional layers. In ICLR, 2020.
- [20] T. Dao, D. Y. Fu, S. Ermon, A. Rudra, and C. Ré. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. In NeurIPS, 2022.
- [21] D. Das, N. Mellempudi, D. Mudigere, D. D. Kalamkar, et al. Mixed precision training of convolutional neural networks using integer operations. In ICLR, 2018.
- [22] S. De and S. Smith. Batch normalization biases residual blocks towards the identity function in deep networks. In NeurIPS, 2020.
- [23] J. Du, H. Yan, J. Feng, J. T. Zhou, L. Zhen, et al. Efficient sharpness-aware minimization for improved training of neural networks. In ICLR, 2022.
- [24] J. Du, D. Zhou, J. Feng, V. Y. Tan, and J. T. Zhou. Sharpness-aware training for free. In NeurIPS, 2022.
- [25] S. d’Ascoli, H. Touvron, M. L. Leavitt, A. S. Morcos, G. Biroli, and L. Sagun. Convit: Improving vision transformers with soft convolutional inductive biases. In ICML, 2021.
- [26] U. Evci, T. Gale, J. Menick, P. S. Castro, and E. Elsen. Rigging the lottery: Making all tickets winners. In ICML, 2020.
- [27] W. Fedus, B. Zoph, and N. Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. JMLR, 2022.
- [28] P. Foret, A. Kleiner, H. Mobahi, and B. Neyshabur. Sharpness-aware minimization for efficiently improving generalization. In ICLR, 2021.
- [29] J. Frankle and M. Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks. In ICLR, 2019.
- [30] L. Gong, D. He, Z. Li, T. Qin, L. Wang, and T. Liu. Efficient training of bert by progressively stacking. In ICML, 2019.
- [31] P. Goyal, P. Dollár, R. Girshick, P. Noordhuis, L. Wesolowski, et al. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677, 2017.
- [32] X. Gu, L. Liu, H. Yu, J. Li, C. Chen, and J. Han. On the transformer growth for progressive bert training. In NAACL, 2021.
- [33] T. J. Ham, S. J. Jung, S. Kim, Y. H. Oh, Y. Park, et al. A^ 3: Accelerating attention mechanisms in neural networks with approximation. In HPCA, 2020.
- [34] T. J. Ham, Y. Lee, S. H. Seo, S. Kim, H. Choi, et al. Elsa: Hardware-software co-design for efficient, lightweight self-attention mechanism in neural networks. In ISCA, 2021.
- [35] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick. Masked autoencoders are scalable vision learners. In CVPR, 2022.
- [36] J. Herrmann, O. Beaumont, L. Eyraud-Dubois, J. Hermann, A. Joly, and A. Shilova. Optimal checkpointing for heterogeneous chains: how to train deep neural networks with limited memory. arXiv preprint arXiv:1911.13214, 2019.
- [37] J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. d. L. Casas, L. A. Hendricks, J. Welbl, A. Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
- [38] N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, et al. Parameter-efficient transfer learning for nlp. In ICML, 2019.
- [39] E. J. Hu, yelong shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. Lora: Low-rank adaptation of large language models. In ICLR, 2022.
- [40] X. S. Huang, F. Perez, J. Ba, and M. Volkovs. Improving transformer optimization through better initialization. In ICML, 2020.
- [41] Y. Huang, Y. Cheng, A. Bapna, O. Firat, D. Chen, M. Chen, H. Lee, J. Ngiam, Q. V. Le, Y. Wu, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism. In NeurIPS, 2019.
- [42] I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y. Bengio. Quantized neural networks: Training neural networks with low precision weights and activations. JMLR, 2017.
- [43] M. Jia, L. Tang, B.-C. Chen, C. Cardie, S. Belongie, B. Hariharan, and S.-N. Lim. Visual prompt tuning. In ECCV, 2022.
- [44] T. B. Johnson and C. Guestrin. Training deep models faster with robust, approximate importance sampling. In NeurIPS, 2018.
- [45] N. P. Jouppi, C. Young, N. Patil, D. Patterson, et al. In-datacenter performance analysis of a tensor processing unit. In ISCA, 2017.
- [46] J. Kaddour. Stop wasting my time! saving days of imagenet and bert training with latest weight averaging. In NeurIPS workshop, 2022.
- [47] A. Katharopoulos and F. Fleuret. Not all samples are created equal: Deep learning with importance sampling. In ICML, 2018.
- [48] J. D. M.-W. C. Kenton and L. K. Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In NAACL-HLT, 2019.
- [49] C. Kim, H. Lee, M. Jeong, W. Baek, B. Yoon, et al. torchgpipe: On-the-fly pipeline parallelism for training giant models. arXiv preprint arXiv:2004.09910, 2020.
- [50] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. In ICLR, 2015.
- [51] Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Soricut. Albert: A lite bert for self-supervised learning of language representations. In ICLR, 2020.
- [52] N. Lee, T. Ajanthan, and P. Torr. Snip: Single-shot network pruning based on connection sensitivity. In ICLR, 2019.
- [53] B. Lester, R. Al-Rfou, and N. Constant. The power of scale for parameter-efficient prompt tuning. In EMNLP, 2021.
- [54] C. Li, B. Zhuang, G. Wang, X. Liang, X. Chang, and Y. Yang. Automated progressive learning for efficient training of vision transformers. In CVPR, 2022.
- [55] Q. Li, Y. Zhou, Y. Liang, and P. K. Varshney. Convergence analysis of proximal gradient with momentum for nonconvex optimization. In ICLR, 2017.
- [56] Y. Li, H. Fan, R. Hu, C. Feichtenhofer, and K. He. Scaling language-image pre-training via masking. arXiv preprint arXiv:2212.00794, 2022.
- [57] Y. Li and Y. Liang. Learning overparameterized neural networks via stochastic gradient descent on structured data. In NeurIPS, 2018.
- [58] Z. Li, E. Wallace, S. Shen, K. Lin, et al. Train big, then compress: Rethinking model size for efficient training and inference of transformers. In ICML, 2020.
- [59] J. Lin, W.-M. Chen, Y. Lin, C. Gan, S. Han, et al. Mcunet: Tiny deep learning on iot devices. In NeurIPS, 2020.
- [60] Z. Lin, H. Li, and C. Fang. Accelerated optimization for machine learning. Nature Singapore: Springer, 2020.
- [61] X. Liu, L. Zheng, D. Wang, Y. Cen, W. Chen, X. Han, J. Chen, et al. GACT: activation compressed training for generic network architectures. In ICML, 2022.
- [62] I. Loshchilov and F. Hutter. Decoupled weight decay regularization. In ICLR, 2019.
- [63] L. Lu, Y. Jin, H. Bi, Z. Luo, P. Li, T. Wang, and Y. Liang. Sanger: A co-design framework for enabling sparse attention using reconfigurable architecture. In MICRO, 2021.
- [64] P. Micikevicius, S. Narang, J. Alben, G. F. Diamos, E. Elsen, et al. Mixed precision training. In ICLR, 2018.
- [65] A. Mishra, J. A. Latorre, J. Pool, D. Stosic, D. Stosic, et al. Accelerating sparse deep neural networks. arXiv preprint arXiv:2104.08378, 2021.
- [66] D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, et al. Efficient large-scale language model training on gpu clusters using megatron-lm. In SC, 2021.
- [67] Y. Nesterov. A method for unconstrained convex minimization problem with the rate of convergence o (1/k^ 2). In Doklady ANSSSR, volume 269, pages 543–547, 1983.
- [68] S. Pal, J. Beaumont, D.-H. Park, A. Amarnath, S. Feng, et al. Outerspace: An outer product based sparse matrix multiplication accelerator. In HPCA, 2018.
- [69] Z. Pan, P. Chen, H. He, J. Liu, J. Cai, and B. Zhuang. Mesa: A memory-saving training framework for transformers. arXiv preprint arXiv:2111.11124, 2021.
- [70] M. Paul, S. Ganguli, and G. K. Dziugaite. Deep learning on a data diet: Finding important examples early in training. In NeurIPS, 2021.
- [71] Z. Qu, L. Liu, F. Tu, Z. Chen, Y. Ding, and Y. Xie. Dota: detect and omit weak attentions for scalable transformer acceleration. In ASPLOS, 2022.
- [72] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, et al. Learning transferable visual models from natural language supervision. In ICML, 2021.
- [73] S. Rajbhandari, J. Rasley, O. Ruwase, and Y. He. Zero: Memory optimizations toward training trillion parameter models. In SC, 2020.
- [74] J. Rasley, S. Rajbhandari, O. Ruwase, and Y. He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In KDD, 2020.
- [75] J. Ren, S. Rajbhandari, R. Y. Aminabadi, O. Ruwase, S. Yang, M. Zhang, et al. Zero-offload: Democratizing billion-scale model training. In USENIX ATC, 2021.
- [76] R. Schwartz, J. Dodge, N. A. Smith, and O. Etzioni. Green ai. Communications of the ACM, 2020.
- [77] M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053, 2019.
- [78] S. Smith, M. Patwary, B. Norick, et al. Using deepspeed and megatron to train megatron-turing nlg 530b, a large-scale generative language model. arXiv preprint arXiv:2201.11990, 2022.
- [79] D. So, Q. Le, and C. Liang. The evolved transformer. In ICML, pages 5877–5886, 2019.
- [80] K. Song, X. Tan, T. Qin, J. Lu, and T.-Y. Liu. Mass: Masked sequence to sequence pre-training for language generation. In ICML, 2019.
- [81] B. Sorscher, R. Geirhos, S. Shekhar, S. Ganguli, and A. S. Morcos. Beyond neural scaling laws: beating power law scaling via data pruning. In NeurIPS, 2022.
- [82] E. Strubell, A. Ganesh, and A. McCallum. Energy and policy considerations for deep learning in nlp. In ACM, 2019.
- [83] R. Taori, I. Gulrajani, T. Zhang, Y. Dubois, X. Li, C. Guestrin, P. Liang, and T. B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
- [84] H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. Jégou. Training data-efficient image transformers & distillation through attention. In ICML, 2021.
- [85] H. Touvron, M. Cord, A. Sablayrolles, G. Synnaeve, and H. Jégou. Going deeper with image transformers. In ICCV, 2021.
- [86] H. Touvron, T. Lavril, G. Izacard, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [87] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. In NeurIPS, 2017.
- [88] C. Wang, G. Zhang, and R. Grosse. Picking winning tickets before training by preserving gradient flow. In ICLR, 2020.
- [89] N. Wang, J. Choi, D. Brand, C.-Y. Chen, and K. Gopalakrishnan. Training deep neural networks with 8-bit floating point numbers. In NeurIPS, 2018.
- [90] H. You, C. Li, P. Xu, Y. Fu, Y. Wang, X. Chen, R. G. Baraniuk, et al. Drawing early-bird tickets: Towards more efficient training of deep networks. In ICLR, 2020.
- [91] H. You, Z. Sun, H. Shi, Z. Yu, Y. Zhao, Y. Zhang, C. Li, B. Li, and Y. Lin. Vitcod: Vision transformer acceleration via dedicated algorithm and accelerator co-design. In HPCA, 2023.
- [92] Y. You, I. Gitman, and B. Ginsburg. Large batch training of convolutional networks. arXiv preprint arXiv:1708.03888, 2017.
- [93] Y. You, J. Li, S. Reddi, J. Hseu, S. Kumar, S. Bhojanapalli, X. Song, J. Demmel, K. Keutzer, and C.-J. Hsieh. Large batch optimization for deep learning: Training bert in 76 minutes. In ICLR, 2019.
- [94] E. B. Zaken, Y. Goldberg, and S. Ravfogel. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. In ACL, 2022.
- [95] H. Zhang, Y. N. Dauphin, and T. Ma. Fixup initialization: Residual learning without normalization. In ICLR, 2019.
- [96] J. Zhang, S. P. Karimireddy, A. Veit, S. Kim, et al. Why adam beats sgd for attention models. In OpenReview, 2019.
- [97] M. Zhang and Y. He. Accelerating training of transformer-based language models with progressive layer dropping. In NeurIPS, 2020.
- [98] S. Zhou, Y. Wu, Z. Ni, X. Zhou, H. Wen, and Y. Zou. Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv preprint arXiv:1606.06160, 2016.