RAMM: Retrieval-augmented Biomedical Visual Question Answering
with Multi-modal Pre-training
Abstract
Vision-and-language multi-modal pretraining and fine-tuning have shown great success in visual question answering (VQA). Compared to general domain VQA, the performance of biomedical VQA suffers from limited data. In this paper, we propose a retrieval-augmented pretrain-and-finetune paradigm named RAMM for biomedical VQA to overcome the data limitation issue. Specifically, we collect a new biomedical dataset named PMCPM which offers patient-based image-text pairs containing diverse patient situations from PubMed. Then, we pretrain the biomedical multi-modal model to learn visual and textual representation for image-text pairs and align these representations with image-text contrastive objective (ITC). Finally, we propose a retrieval-augmented method to better use the limited data. We propose to retrieve similar image-text pairs based on ITC from pretraining datasets and introduce a novel retrieval-attention module to fuse the representation of the image and the question with the retrieved images and texts. Experiments demonstrate that our retrieval-augmented pretrain-and-finetune paradigm obtains state-of-the-art performance on Med-VQA2019, Med-VQA2021, VQARAD, and SLAKE datasets. Further analysis shows that the proposed RAMM and PMCPM can enhance biomedical VQA performance compared with previous resources and methods. We will open-source our dataset, codes, and pretrained model.
1 Introduction
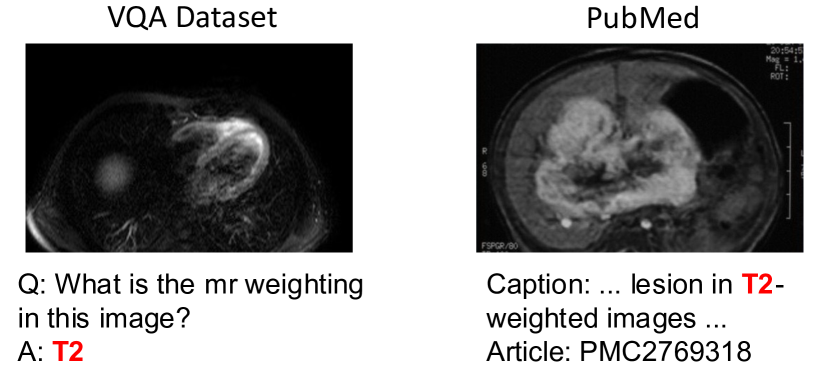
Biomedical visual question answering (VQA) aims to answer a biomedical-related question with a provided image. The images in the biomedical VQA are usually radiology images (e.g. CT, MRI, and X-Ray), and the questions usually involve modalities, body parts, planes, and abnormal parts in corresponding images. Answering these questions requires rich knowledge of clinical and medical imaging [17], which is challenging for automated approaches.
With the success of the general domain VQA [27, 10, 26], some works follow the pretrain-and-finetune paradigm to attempt domain-specific vision-and-language modeling for biomedical VQA [20, 4]. However, unlike the general domain that adequates labeled VQA pairs for fine-tuning, the biomedical domain still suffers from limited data in fine-tuning, which makes models vulnerable to overfitting and hampers the models’ ability to learn comprehensive domain knowledge for answering complicated questions.
In contrast to limited data in biomedical VQA datasets, biomedical literature contains abundant and high-quality image-text pairs. These texts usually describe the images in all aspects including modality, body part, plane, and abnormality which are the information in which biomedical VQA is interested. Figure 1 shows an example that the image-text pair from PubMed111https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2769318/ can benefit to answer the question in the VQA dataset. Based on this observation, we argue that retrieval is a feasible option for biomedical VQA. This procedure simulates how doctors solve complicated patient cases: doctors search for similar cases to the provided one and propose a solution based on previous experience. Therefore, we can retrieve similar image-text pairs from literature to help answer the question. To retrieve related image-text pairs from biomedical literature, there are three key questions to be answered: Where to retrieve? How to retrieve? and How to leverage the retrieved image-text pairs?
To this end, we propose a Retrieval-Augmented bioMedical Multi-modal pretrain-and-finetune paradigm (RAMM) for biomedical VQA. Firstly, there are existing biomedical image-text pairs including ROCO [36] and MIMIC-CXR [18] that can be used for retrieval. However, ROCO is limited by quantity and MIMIC-CXR only focuses on chest X-Ray. A massive, diverse, and high-quality dataset is required for better retrieval. Therefore, we propose PMC-Patients-Multi-modal (PMCPM), a patient-based image-text dataset filtered from PubMed Central, which is larger than ROCO and MIMIC-CXR with various modalities and conditions of images. Secondly, since questions are homogenous in biomedical VQA, we propose to use images for retrieving. We pretrain the biomedical multi-modal model with three tasks: masked language modeling, image-text contrastive learning, and image-text matching using the combination of our PMCPM dataset and previous widely-used ROCO and MIMIC-CXR datasets. As the image-text contrastive objective in the pretraining phase aims to align visual and textual representations in the same embedding space [37, 27], the image-text contrastive similarity can be used to retrieve similar pairs. Finally, taking the above datasets as resources, we propose to retrieve the related image-text pair to the given image. To leverage the retrieved pairs, we propose a retrieval-augmented fine-tuning method with a novel retrieval-attention module in the multi-modal encoder layer and apply the fused representation to predict the final answer.
We conduct experiments on four biomedical VQA datasets. Our RAMM achieves state-of-the-art results of 82.13, 39.20, 78.27, and 86.05 scores on VQA-Med 2019 [2], VQA-Med 2021 [16], VQARAD [22], and SLAKE (English Version) [30], respectively. We also conduct ablation studies to verify the effectiveness of our collected PMCPM dataset and the retrieval-augmented fine-tuning methods. Case studies show the retrieved image-text pairs benefit to answer the question.
We summarize our contributions as follows:
-
•
We collect PMCPM, a patient-based image-text dataset from PubMed which can be used for biomedical multi-modal pretraining and retrieving.
-
•
We propose RAMM, a retrieval-augmented multi-modal pretrain-and-finetune paradigm for biomedical VQA with a novel retrieval-attention module.
-
•
Experiments show that the proposed RAMM with additional PMCPM dataset outperforms previous VQA methods on VQA-Med 2019, VQA-Med 2021, VQARAD, and SLAKE datasets.
2 Related Work
Biomedical Multi-modal Pretraining
In the general domain, multi-modal pretraining models show effectiveness in various image-text-related downstream tasks [27, 10, 26, 41]. In the biomedical NLP community, previous research has shown that further continue training in the in-domain corpus can enhance the performance of pretrained language models [1, 23, 14, 45, 44]. Combining the above-mentioned two points, it is direct to consider pretraining a biomedical in-domain multi-modal model for biomedical VQA. Previous biomedical pretrained multi-modal models [11, 20, 34, 4, 5] mainly leverage ROCO [36] and MIMIC-CXR [18] as pretraining datasets. These models predict masked tokens [4, 5] or image patches [4] and conduct image-text alignment [11] as pretraining tasks. Compared with previous models, our RAMM is pretrained with our additional proposed PMCPM dataset which contains images from diverse conditions of patients. For pretraining tasks, our model adopts masked language modeling, image-text contrastive learning, and image-text matching. Image-text contrastive similarities are used for retrieving in RAMM.
Biomedical Visual Question Answering
VQA requires answering an image-related question. Different from general domain VQA [27, 10, 26], the training samples of biomedical VQA are much fewer. To overcome the data limitation in biomedical VQA, meta-learning is adapted for quick fitting to VQA questions [35, 9]. With the success of the pretrain-and-finetune paradigm, pretraining a multi-modal model with large-scale unsupervised datasets learns better visual and textual representations which mitigate the impact of data limitation and boosts biomedical VQA performances significantly [3, 11, 4]. In this paper, we also pretrain a biomedical multi-modal model RAMM with patient-based image-text pairs PMCPM. While fine-tuning VQA datasets, RAMM retrieves similar image-text pairs and tries to leverage useful information from these images and texts.
Retrieval Augmentation
has been applied successfully in NLP [24, 25, 15] and CV [32, 39] for knowledge-intensive tasks. In this paper, we decide to use retrieval augmentation to solve the knowledge-intensive and under-labeled biomedical VQA tasks. A retriever may be sparse like BM-25 [38, 24] or dense using pretrained encoders [15, 39]. For our task, the model pretrained by the image-text contrastive (ITC) task can be naturally used as a multi-modal retriever. Thus, we pretrain a biomedical multi-modal model by ITC for retrieval augmentation. We also propose a retrieval-attention module to fuse these retrieved samples. To the best of our knowledge, this is the first work to leverage retrieval augmentation in biomedical VQA.
3 Approach
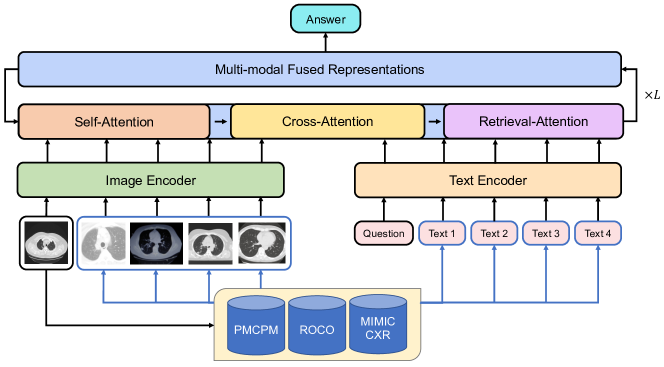
In this section, we first introduce how we build the PMCPM dataset. We then describe the model architecture and pretraining tasks. Finally, we introduce how RAMM retrieves image-text pairs from pretraining datasets, and how we combine retrieved samples during biomedical VQA fine-tuning. Our overall workflow is shown in Figure 2.
3.1 PMCPM Dataset
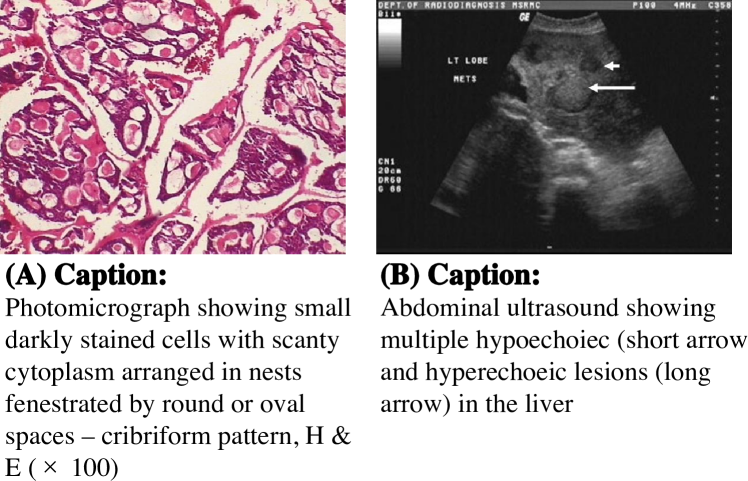
To obtain domain-specific image-text pairs of high quality and large scale, we first consider using the Open Access subset of PubMed Central (PMC OA)222https://www.ncbi.nlm.nih.gov/pmc/tools/openftlist/, a free biomedical literature archive of over M publications with both full-text (including figure captions) and figures in these articles publicly available through the official FTP service333https://www.ncbi.nlm.nih.gov/pmc/tools/ftp/. However, the figures in PMC OA full set can be quite noisy: apart from clinical images, many kinds of graphs appear in a research article, including flowcharts, histograms, and scatter plots, which provide little information for multi-modal pretraining. Pelka et al. [36] use neural networks trained on human annotated datasets to automatically filter compound, multi-pane, and non-radiology images, collecting a clean dataset with 81k image-text pairs. To further explore and utilize the figure resource in PMC, we instead resort to a “patient-based” collection pipeline inspired by Zhao et al. [47]. “Case Report” is a specific type of medical literature, generally describing the whole admission of a patient. Following Zhao et al. [47], we use regular expressions to identify sections containing patient notes, extract the corresponding texts, and apply various filters to remove noises, resulting in a collection of 167k patient notes with high-quality and diverse conditions. The figures accompanied by these patient notes are closely related to the patient’s clinical conditions and contain richer information than solely radiology images. We thus collect these figures with corresponding captions to build our PMCPM dataset. Figure 3 shows two examples of our PMCPM (PMCID: 509249) with the images and their corresponding captions. Figure 3A shows a photomicrograph describing the presence of adenoid cystic carcinoma with cribriform pattern and perineurial invasion. Figure 3B shows a radiology image that multiple metastatic lesions scatter in both lobes. The examples show that our patient-based collecting method can target clinical-related figures with more image modality and detailed text descriptions.
3.2 Model Architecture
Given an image-text pair , RAMM first obtains uni-modal features independently and then fuses them for multi-modal representations. Fused representations are used for VQA classification. RAMM consists of a text encoder, an image encoder, and a multi-modal encoder for fusing two different modal representations. The text is tokenized into subwords and transformed into hidden representations by the text encoder. The image is divided into patches and represented as by the image encoder. The multi-modal encoder is a co-attention style dual-stream transformer.
Multi-modal Fusion Layer
We apply co-attention style multi-modal fusion layers [10] upon text features and visual features with layer count . Specifically, co-attention fusion layers consist of dual-stream transformer layers where one stream corresponds to one modal. Each transformer layer is combined with a self-attention module and a cross-attention module444Feed-forward networks are omitted for notation brevity.. For layer , we denote text hidden representations as and image hidden representations as . The attention module in transformers is defined as:
| (1) |
Using this denotation, self-attention is defined as:
| (2) |
| (3) |
| (4) |
| (5) |
We reuse the notation of by replacing with and with , and cross-attention is defined as:
| (6) |
| (7) |
The fused representations of text and image are denoted as and .
3.3 Pretraining Tasks
To pretrain RAMM, we employ three pretraining tasks including Image-Text Contrastive learning (ITC) [27], Image-Text Matching (ITM) [27], and Masked Language Modeling (MLM) [8]. The pretraining objective function of RAMM is defined by the sum of these three tasks. ITC aligns uni-modal visual and textual representations and in the same embedding space, where and are two linear projections with normalization. ITM predicts whether one image and one text match each other based on fused representations and . MLM predicts masked token in text based on fused textual representations . Since ITC aims to align images and texts with cosine similarities, it becomes a natural choice to retrieve related images and texts.
3.4 Retrieval-augmented Fine-tuning
We use image-text contrastive similarity to retrieve related image-text pairs and fuse them with a retrieval-attention module in fine-tuning.
Retrieve related image text pairs
Let denotes the set of all image-text pairs, where is an index set. For image-question pair from VQA datasets, we retrieve augmented samples from based on uni-modal image representations . Here we do not use the representations from question to retrieve since questions in VQA datasets are homogeneous and non-informative. With different images, questions can be similar to What is the abnormality in this image? or Is there an abnormality in this image? For image-text pair with uni-modal representations and , we calculate the similarities between image using ITC similarity scores:
| (8) |
| (9) |
ITC optimizes while pretraining, and this leads and to be close. So we use the maximum of and to define the similarity between with :
| (10) |
We freeze the uni-modal encoders while calculating . The first reason is that ITC scores may change dramatically while fine-tuning. The second reason is representations from the pretraining dataset can be pre-computed, and similarity calculation can be conducted by Faiss [19] quickly.
We first calculate top- among and top- among using Faiss. contains image-text pairs. When training, we randomly select image-text pairs from . The probabilities of each image-text pair are rational to similarities . When inference, we select top- similar image-text pairs from based on . We denote retrieved image-text pairs as .
Retrieval fusion in multi-modal encoder
To fuse the knowledge of retrieved samples, we propose a retrieval-attention module in the multi-modal fusion layer. The retrieval-attention module is applied after the self-attention and cross-attention in each multi-modal fusion layer. Figures 4 shows the model architecture of retrieval-attention applied to text modality. Specifically, we use uni-modal encoders encode retrieved image-text pairs to . We denote the for symbol unification. For multi-modal fusion layer, inputs of text hidden representations are and image hidden representations are . By applying self-attention and cross-attention defined in Section 3.2, we obtain text representations and image representations . Retrieval-attention is applied to each modal independently. Takes text representations as an example, retrieval-attention uses the representations of as attention queries and representations of as attention keys and values. The outputs of retrieval attention are only added to original representations but not retrieved representations .
| (11) |
| (12) |
| (13) |
| (14) |
The retrieval-attention on image modality is calculated similarly.
| (15) |
| (16) |
| (17) |
| (18) |
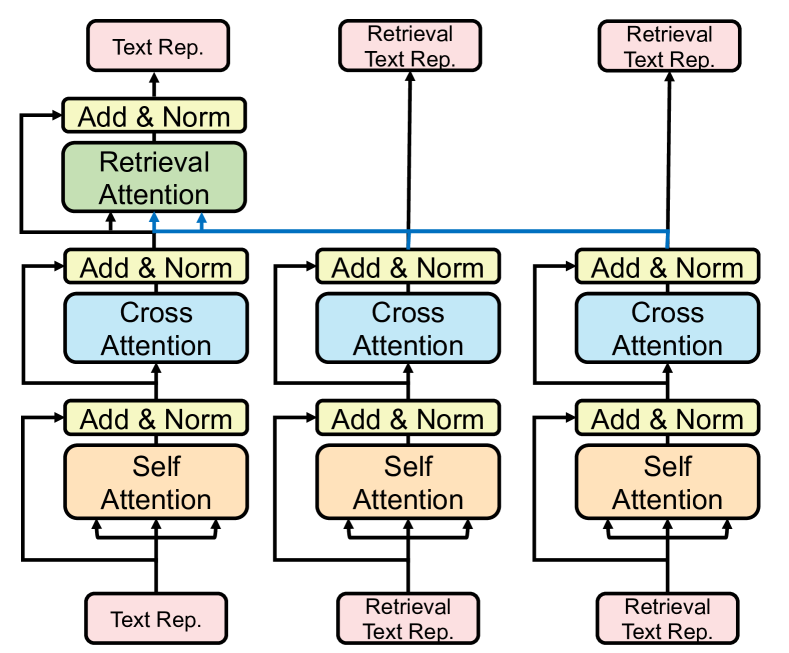
We perform retrieval-attention on original representations or to fuse additional information from or . We do not apply it to retrieved samples since we do not need to exchange information among them. We use the final layer of origin samples representations for VQA classification.
4 Experiments
4.1 Dataset
We conduct experiments on four biomedical VQA datasets as VQA-Med 2019 [2], VQA-Med 2021 [16], VQARAD [22], and SLAKE (English Version) [30]. To fairly compare with previous works, we follow the same data split with Chen et al. [4] for VQA-Med 2019, VQARAD, and SLAKE, as well as Gong et al. [13] for VQA-Med 2021. We use accuracy to measure model performance. Detailed statistics of these datasets are listed in Appendix A.
4.2 Baselines
We compare RAMM with non-pretrained methods [43, 42, 21, 13, 7] and pre-trained methods [3, 29, 46] in biomedical VQA. We introduce the following methods since they are more related to us:
PubmedCLIP [11] fine-tunes CLIP with ROCO to obtain the biomedical image and text representations.
MMBert [20] feeds CNN features of images with masked tokens to apply masked language model pretraining.
MTPT [12] proposes a multi-task pretraining with an image understanding task and a question-image compatibility task.
M3AE [4] pretrains a biomedical multi-modal model by reconstructing masked tokens and images.
4.3 Implementation Details
Pre-training Data
As introduced in Section 3.1, we collect 398k biomedical image-text pairs of publication quality and various types from PMC OA as PMCPM. Then, we combine the PMCPM with two widely-used biomedical pretrained datasets ROCO [36] and MIMIC-CXR [18] for model pre-training. Following the previous work, we only use their train splits as pretraining datasets and only use images in frontal view for MIMIC-CXR. The statistics of training data are shown in Table 1.
| Dataset | Count | Sources |
|---|---|---|
| ROCO | 70,306 | PubMed |
| MIMIC-CXR | 225,829 | BIDMC |
| PMCPM | 398,109 | Case Report |
Pre-training Setting
For the uni-modal encoders, we initialize the text encoder by PubmedBert [14] and the image encoder by Swin-Base [31]. For the multi-modal encoder, we apply a 6-layer Transformer [40] with hidden dimension and head count with random initialization. Images are transformed into resolutions with RandAugment [6]. We apply the momentum distillation [27] with the momentum parameter as 0.995. The model is trained for 30 epochs with a batch size of 512. We use AdamW [33] to optimize our models with a linear learning rate decay. For the detailed pretraining hyper-parameters, please refer to Appendix B.
Fine-tuning Setting
Following previous works, we regard biomedical VQA as a classification problem and optimize the model by the cross-entropy loss. For all datasets, we fine-tune our pretrained models with 100 epochs. We use frozen uni-modal encoders of RAMM to retrieve image-text pairs as mentioned in Section 3.4. We retrieve pairs for each instance from the combination of ROCO, MIMIC-CXR, and PMCPM. Images are transformed into resolutions while fine-tuning. In VQA-Med 2019, VQARAD, and SLAKE, we center crop images, while we use RandAugment [6] in VQA-Med 2021. Exponential moving average and R-Drop [28] are also used while fine-tuning. We list detailed hyper-parameters in Appendix C.
| Model | VQAMed2019 | VQARAD | SLAKE |
|---|---|---|---|
| No Pretraining | |||
| MFB [43] | - | 50.60 | 73.30 |
| SAN [42] | - | 54.30 | 76.00 |
| BAN [21] | - | 58.30 | 76.30 |
| With Pretraining | |||
| MEVF-BAN [3] | 77.86 | 66.10 | 78.60 |
| CPRD-BAN [29] | - | 67.80 | 81.10 |
| COND-RE [46] | - | 71.60 | - |
| PubmedCLIP [11] | - | 72.10 | 80.10 |
| MMBert [20] | 77.90 | 72.00 | - |
| MTPT [12] | - | 73.20 | - |
| M3AE [4] | 79.87 | 77.01 | 83.25 |
| RAMM | 82.13 | 78.27 | 86.05 |
| w/o retrieval | 80.27 | 76.72 | 85.58 |
| Model | VQA-Med 2021 |
|---|---|
| VilMedic * [7] | 37.80 |
| SYSU-HCP * [13] | 38.20 |
| RAMM | 39.20 |
4.4 Main Results
We compare our approach with baseline methods in four datasets. As shown in Table 2, methods with pretrained models outperform non-pretrained models by a large margin. Our proposed RAMM achieves 82.13, 78.27, and 86.05 on VQA-Med 2019, VQARAD, and SLAKE respectively, which exceeds the previous best result by 1.86, 1.26, and 2.80 respectively. Table 4 shows results on the VQA-Med 2021 dataset. Our RAMM achieves 39.20 in terms of accuracy, which even outperforms the state-of-the-art ensemble methods with 1.00 in the VQA-Med 2021 Challenge.
We also report the result of our RAMM without retrieving additional image-text pairs on the VQA-Med 2019, VQARAD, and SLAKE datasets. As shown in Table 2, it achieves 80.27, 76.72, and 85.58 on VQA-Med 2019, VQARAD, and SLAKE respectively. Without retrieval augmentation, RAMM still outperforms the previous state-of-the-art method M3AE on VQA-Med 2019 with 0.4 as well as SLAKE with 2.33 and performs on par on VQARAD (76.72 v.s. 77.01). This indicates that the pretraining with additional PMCPM dataset learns better visual and textual representations for biomedical VQA tasks. Compared with models without retrieval augmentation, we observe that our RAMM achieves consistent improvements of 1.90, 1.55, 0.47 on VQA-Med 2019, VQARAD, and SLAKE respectively, which demonstrates that our proposed retrieval augmentation can boost biomedical VQA performances.
| Pre-training | Retrieval | VQA Datasets | |||||
| PMCPM | ROCO+CXR | PMCPM | ROCO+CXR | VQAMed19 | VQARAD | SLAKE | |
| (a) | ✗ | ✗ | ✗ | ✗ | 77.60 | 74.06 | 81.43 |
| (b) | ✓ | ✗ | ✗ | ✗ | 78.40 | 74.94 | 83.60 |
| (c) | ✗ | ✓ | ✗ | ✗ | 79.73 | 75.17 | 82.94 |
| (d) | ✓ | ✓ | ✗ | ✗ | 80.27 | 76.72 | 85.58 |
| (e) | ✗ | ✓ | ✗ | ✓ | 80.00 | 76.72 | 85.20 |
| (f) | ✓ | ✓ | ✗ | ✓ | 81.07 | 77.16 | 85.67 |
| (g) | ✓ | ✓ | ✓ | ✓ | 82.13 | 78.27 | 86.05 |
| Task | VQAMed19 | VQARAD | SLAKE | |||
|---|---|---|---|---|---|---|
| Dataset | Retrieve% | Have Ans% | Retrieve% | Have Ans% | Retrieve% | Have Ans% |
| PMCPM + ROCO + MIMIC-CXR | 100.0% | 29.6% | 100.0% | 28.4% | 100.0% | 38.7% |
| PMCPM | 52.2% | 20.8% | 51.9% | 21.3% | 54.9% | 30.5% |
| ROCO + MIMIC-CXR | 47.8% | 21.1% | 48.1% | 20.0% | 45.1% | 26.9% |
4.5 Ablation Study
To further analyze the influence of the collected PMCPM dataset and the retrieval strategy, we conduct detailed ablation studies as shown in Table 4.
Firstly, we analyze the impact of using different data during the pre-training phase. ROCO and MIMIC-CXR are well-used biomedical multi-modal pre-training datasets. ROCO contains labeled radiology images in relatively small amounts. The amount of MIMIC-CXR is large, while it only contains chest X-Ray image-text pairs. The collection of PMCPM comes from the rich and diverse conditions of patients, and PMCPM is much larger than ROCO and MIMIC-CXR. With the numerous and diverse image-text pairs from PMCPM, the model has the potential to obtain better visual and textual representations. Comparing (a) and (b), we show the effectiveness of pretraining on our collected PMCPM dataset. Results from (b) and (c) show that the data of PMCPM and previous ROCO plus MIMIC-CXR can complement each other. ROCO plus MIMIC-CXR shows better results on VQA-Med-2019 and VQARAD datasets, while PMCPM is better on SLAKE dataset. By combining the two settings with three resources, setting (d) achieves the best performance with a large margin by only using either of them. The above results demonstrate that PMCPM can enhance the model pretraining in biomedical VQA tasks.
Secondly, the above datasets are also treated as retrieval resources in this work. Therefore, we also analyze the impact of using different data during the fine-tuning phase. Setting (e) only uses the previous ROCO and MIMIC-CXR datasets for retrieval. By comparing it with setting (c), we show that the proposed retrieval strategy is effective in the previously widely-used resource. Then, we further demonstrate the usefulness of our collected PMCPM data. Compared with settings (f) and (g), we observe that retrieving additional PMCPM data yields gains of 1.06, 1.11, and 0.38, respectively. In addition, results from setting (g) with (d) reflect the great improvement brought by our proposed retrieval method. The above ablation studies show that our collected PMCPM dataset and our proposed retrieval method can benefit both pretraining and retrieving in biomedical VQA tasks.
4.6 Analysis and Discussion
4.6.1 Retrieval
Retrieval distribution
To understand how RAMM retrieve from different resources and how retrieved texts help our model for biomedical VQA tasks, we count the sources of retrieved samples and how many retrieved texts contain the answers. Statistics are listed in Table 5. There are 29.6%, 28.4%, and 38.7% of answers that can be found in retrieved texts in VQA-Med 2019, VQARAD, and SLAKE respectively, which are considerable amounts. These retrieved texts may help RAMM answer the questions directly. We observe that in these tasks, RAMM retrieves image-text pairs from PMCPM over half which shows that PMCPM is more related to biomedical VQA images than ROCO and MIMIC-CXR. The percentages of retrieved texts containing answers are nearly the same for PMCPM and out of PMCPM in VQA-Med 2019 and VQARAD. In SLAKE, PMCPM contributes more texts containing answers. To conclude, PMCPM is important during retrieval which supplies additional texts containing answers.
| # Retrieval | VQARAD | SLAKE |
|---|---|---|
| 0 | 76.72 | 85.58 |
| 1 | 77.38 | 86.33 |
| 2 | 78.05 | 86.33 |
| 4 | 78.27 | 86.05 |
| 8 | 76.50 | 84.54 |
| Model | VQARAD | SLAKE | ||
|---|---|---|---|---|
| Open | Closed | Open | Closed | |
| MEVF-BAN | 49.20 | 77.20 | 77.80 | 79.80 |
| CPRD-BAN | 52.50 | 77.90 | 79.50 | 83.40 |
| M3AE | 67.23 | 83.46 | 80.31 | 87.82 |
| RAMM | 67.60 | 85.29 | 82.48 | 91.59 |
Image-text pairs retrieval count
To explore how image-text pairs retrieval count influences biomedical VQA fine-tuning, we search the number of retrieved images among . Results for VQARAD and SLAKE are shown in Table 6. Compared with vanilla fine-tuning (i.e. retrieval count 0), retrieving image-text pairs can boost performances. We empirically find retrieving 2 or 4 image-text pairs work well. Furthermore, using 8 image-text pairs downgrades the model performance, which indicates that retrieving too many image-text pairs may introduce unrelated image-text pairs with noisy knowledge.
4.6.2 Question Type
In biomedical VQA, questions can be divided into closed-ended and open-ended questions. The answers to closed-ended questions are limited to multiple choices like Yes or No, while the answers to open-ended questions are not limited. Closed-ended questions are easier than open-ended questions due to the form. Table 7 lists comparisons among different methods on open-ended and closed-ended questions. RAMM performs better than M3AE on both closed-ended and open-ended questions. RAMM improves M3AE on closed-ended questions more than open-ended questions. The reason is that closed-ended questions are limited in answer choices, and are easier to be covered by retrieved texts.
4.6.3 Comparison with ROCO
ROCO and PMCPM are both subsets of PubMed. ROCO uses a trained neural network to filter radiology images, while PMCPM finds images by “Case Report” from PubMed. We calculate the involved article count in ROCO and PMCPM train split. ROCO uses 40,857 articles from PubMed, and PMCPM uses 127,455 articles from PubMed. There are 17,189 articles appeared in both datasets. Although ROCO and PMCPM filter image-text pairs using different methods, nearly half of the pairs in ROCO are also collected by PMCPM. Considering ROCO is a manually corrected dataset, it can reflect the quality of the larger dataset PMCPM from the side.
4.6.4 Case Study
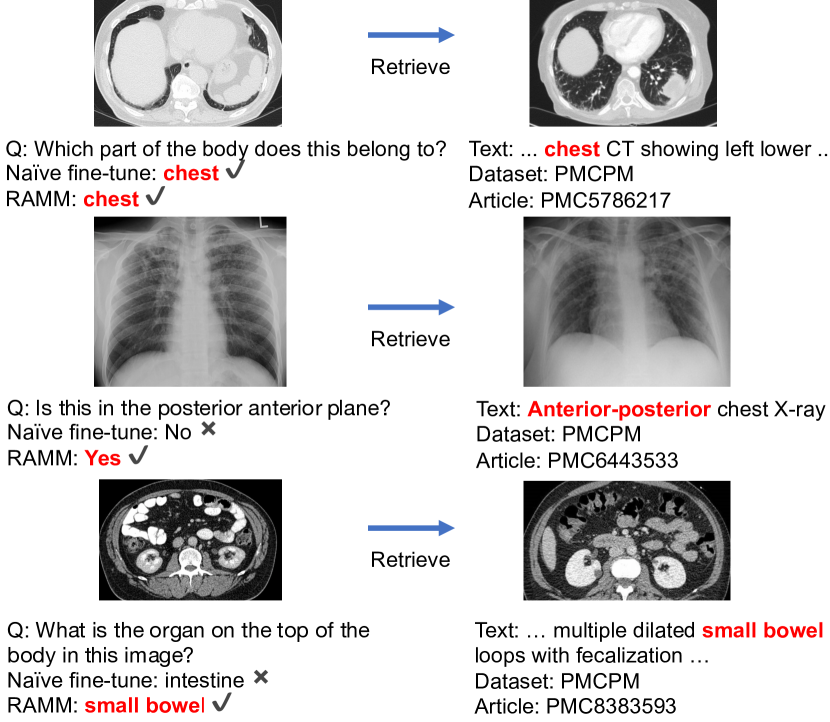
We show retrieved image-text pairs of RAMM in Figure 5. The retrieved samples are all from PMCPM. Retrieved images are in the same modalities and are the same organs as the original images. These cases show that the retrieved images contain useful information for answering questions. Although the answer (i.e. Yes/No) is not covered in retrieved text for the second example, the retrieved text is still useful for answering. The second and third examples further show that RAMM can answer correctly with retrieval augmentation while naive fine-tuning fails.
5 Conclusion
In this paper, we present a retrieval-augmented pretrain-and-finetune paradigm RAMM for biomedical VQA which includes a high-quality image-text pairs PMCPM, a pretrained multi-modal model, and a novel retrieval-augmented attention module for fine-tuning. RAMM uses ITC to retrieve related image-text pairs and fuse retrieved information with retrieval-attention. Experiments have shown that our approach outperforms state-of-the-art methods in various biomedical VQA datasets. Ablation studies show the effectiveness of proposed RAMM and PMCPM for pretraining and retrieving.
References
- [1] Iz Beltagy, Kyle Lo, and Arman Cohan. SciBERT: A pretrained language model for scientific text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3615–3620, Hong Kong, China, Nov. 2019. Association for Computational Linguistics.
- [2] Asma Ben Abacha, Sadid A Hasan, Vivek V Datla, Dina Demner-Fushman, and Henning Müller. Vqa-med: Overview of the medical visual question answering task at imageclef 2019. In Proceedings of CLEF (Conference and Labs of the Evaluation Forum) 2019 Working Notes. 9-12 September 2019, 2019.
- [3] D. Nguyen Binh, Do Thanh-Toan, X. Nguyen Binh, Do Tuong, Tjiputra Erman, and D. Tran Quang. Overcoming data limitation in medical visual question answering. In MICCAI, 2019.
- [4] Zhihong Chen, Yuhao Du, Jinpeng Hu, Yang Liu, Guanbin Li, Xiang Wan, and Tsung-Hui Chang. Multi-modal masked autoencoders for medical vision-and-language pre-training. In International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2022.
- [5] Zhihong Chen, Guanbin Li, and Xiang Wan. Align, reason and learn: Enhancing medical vision-and-language pre-training with knowledge. In Proceedings of the 30th ACM International Conference on Multimedia, pages 5152–5161, 2022.
- [6] Ekin Dogus Cubuk, Barret Zoph, Jon Shlens, and Quoc Le. Randaugment: Practical automated data augmentation with a reduced search space. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 18613–18624. Curran Associates, Inc., 2020.
- [7] Jean-benoit Delbrouck, Khaled Saab, Maya Varma, Sabri Eyuboglu, Pierre Chambon, Jared Dunnmon, Juan Zambrano, Akshay Chaudhari, and Curtis Langlotz. ViLMedic: a framework for research at the intersection of vision and language in medical AI. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 23–34, Dublin, Ireland, May 2022. Association for Computational Linguistics.
- [8] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics.
- [9] Tuong Do, Binh X. Nguyen, Erman Tjiputra, Minh Tran, Quang D. Tran, and Anh Nguyen. Multiple meta-model quantifying for medical visual question answering. In MICCAI, 2021.
- [10] Zi-Yi Dou, Yichong Xu, Zhe Gan, Jianfeng Wang, Shuohang Wang, Lijuan Wang, Chenguang Zhu, Pengchuan Zhang, Lu Yuan, Nanyun Peng, Zicheng Liu, and Michael Zeng. An empirical study of training end-to-end vision-and-language transformers. In Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
- [11] Sedigheh Eslami, Gerard de Melo, and Christoph Meinel. Does CLIP benefit visual question answering in the medical domain as much as it does in the general domain? arXiv e-prints, Dec. 2021.
- [12] Haifan Gong, Guanqi Chen, Sishuo Liu, Yizhou Yu, and Guanbin Li. Cross-modal self-attention with multi-task pre-training for medical visual question answering. In ICMR ’21: International Conference on Multimedia Retrieval, Taipei, Taiwan, August 21-24, 2021, pages 456–460. ACM, 2021.
- [13] Haifan Gong, Ricong Huang, Guanqi Chen, and Guanbin Li. Sysu-hcp at vqa-med 2021: A data-centric model with efficient training methodology for medical visual question answering. In CLEF 2021 – Conference and Labs of the Evaluation Forum, September 21–24, 2021, Bucharest, Romania, CEUR Workshop Proceedings, 2021.
- [14] Yuxian Gu, Robert Tinn, Hao Cheng, Michael R. Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, and Hoifung Poon. Domain-specific language model pretraining for biomedical natural language processing. ACM Transactions on Computing for Healthcare (HEALTH), 3:1 – 23, 2022.
- [15] Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. Retrieval augmented language model pre-training. In International Conference on Machine Learning, pages 3929–3938. PMLR, 2020.
- [16] Bogdan Ionescu, Henning Müller, Renaud Péteri, Asma Ben Abacha, Mourad Sarrouti, Dina Demner-Fushman, Sadid A Hasan, Serge Kozlovski, Vitali Liauchuk, Yashin Dicente Cid, et al. Overview of the imageclef 2021: Multimedia retrieval in medical, nature, internet and social media applications. In International Conference of the Cross-Language Evaluation Forum for European Languages, pages 345–370. Springer, 2021.
- [17] Qiao Jin, Zheng Yuan, Guangzhi Xiong, Qianlan Yu, Huaiyuan Ying, Chuanqi Tan, Mosha Chen, Songfang Huang, Xiaozhong Liu, and Sheng Yu. Biomedical question answering: A survey of approaches and challenges. ACM Comput. Surv., 55(2), jan 2022.
- [18] Alistair E. W. Johnson, Tom J. Pollard, Seth J. Berkowitz, Nathaniel R. Greenbaum, Matthew P. Lungren, Chih ying Deng, Roger G. Mark, and Steven Horng. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports. Scientific Data, 6, 2019.
- [19] Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with GPUs. IEEE Transactions on Big Data, 7(3):535–547, 2019.
- [20] Yash Khare, Viraj Bagal, Minesh Mathew, Adithi Devi, U Deva Priyakumar, and CV Jawahar. Mmbert: multimodal bert pretraining for improved medical vqa. In 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), pages 1033–1036. IEEE, 2021.
- [21] Jin-Hwa Kim, Jaehyun Jun, and Byoung-Tak Zhang. Bilinear Attention Networks. In Advances in Neural Information Processing Systems 31, pages 1571–1581, 2018.
- [22] Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. A dataset of clinically generated visual questions and answers about radiology images. Scientific data, 5(1):1–10, 2018.
- [23] Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240, 2020.
- [24] Kenton Lee, Ming-Wei Chang, and Kristina Toutanova. Latent retrieval for weakly supervised open domain question answering. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 6086–6096, Florence, Italy, July 2019. Association for Computational Linguistics.
- [25] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- [26] Chenliang Li, Haiyang Xu, Junfeng Tian, Wei Wang, Ming Yan, Bin Bi, Jiabo Ye, Hehong Chen, Guohai Xu, Zheng Cao, et al. mplug: Effective and efficient vision-language learning by cross-modal skip-connections. arXiv preprint arXiv:2205.12005, 2022.
- [27] Junnan Li, Ramprasaath R. Selvaraju, Akhilesh Deepak Gotmare, Shafiq Joty, Caiming Xiong, and Steven Hoi. Align before fuse: Vision and language representation learning with momentum distillation. In NeurIPS, 2021.
- [28] Xiaobo Liang, Lijun Wu, Juntao Li, Yue Wang, Qi Meng, Tao Qin, Wei Chen, Min Zhang, and Tie-Yan Liu. R-drop: Regularized dropout for neural networks. In NeurIPS, 2021.
- [29] Bo Liu, Li-Ming Zhan, and Xiao-Ming Wu. Contrastive pre-training and representation distillation for medical visual question answering based on radiology images. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 210–220. Springer, 2021.
- [30] Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiao-Ming Wu. Slake: a semantically-labeled knowledge-enhanced dataset for medical visual question answering. In 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), pages 1650–1654. IEEE, 2021.
- [31] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10012–10022, 2021.
- [32] Alexander Long, Wei Yin, Thalaiyasingam Ajanthan, Vu Nguyen, Pulak Purkait, Ravi Garg, Alan Blair, Chunhua Shen, and Anton van den Hengel. Retrieval augmented classification for long-tail visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6959–6969, 2022.
- [33] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019, 2019.
- [34] Jong Hak Moon, Hyungyung Lee, Woncheol Shin, Young-Hak Kim, and Edward Choi. Multi-modal understanding and generation for medical images and text via vision-language pre-training. IEEE Journal of Biomedical and Health Informatics, 2022.
- [35] Binh D Nguyen, Thanh-Toan Do, Binh X Nguyen, Tuong Do, Erman Tjiputra, and Quang D Tran. Overcoming data limitation in medical visual question answering. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 522–530. Springer, 2019.
- [36] Obioma Pelka, Sven Koitka, Johannes Rückert, Felix Nensa, and Christoph M Friedrich. Radiology objects in context (roco): a multimodal image dataset. In Intravascular Imaging and Computer Assisted Stenting and Large-Scale Annotation of Biomedical Data and Expert Label Synthesis, pages 180–189. Springer, 2018.
- [37] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR, 2021.
- [38] Stephen E. Robertson and Hugo Zaragoza. The probabilistic relevance framework: Bm25 and beyond. Found. Trends Inf. Retr., 3:333–389, 2009.
- [39] Sara Sarto, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. Retrieval-augmented transformer for image captioning. In International Conference on Content-based Multimedia Indexing, pages 1–7, 2022.
- [40] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [41] Wenhui Wang, Hangbo Bao, Li Dong, Johan Bjorck, Zhiliang Peng, Qiang Liu, Kriti Aggarwal, Owais Khan Mohammed, Saksham Singhal, Subhojit Som, et al. Image as a foreign language: Beit pretraining for all vision and vision-language tasks. arXiv preprint arXiv:2208.10442, 2022.
- [42] Zichao Yang, Xiaodong He, Jianfeng Gao, Li Deng, and Alex Smola. Stacked attention networks for image question answering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 21–29, 2016.
- [43] Zhou Yu, Jun Yu, Jianping Fan, and Dacheng Tao. Multi-modal factorized bilinear pooling with co-attention learning for visual question answering. IEEE International Conference on Computer Vision (ICCV), pages 1839–1848, 2017.
- [44] Hongyi Yuan, Zheng Yuan, Ruyi Gan, Jiaxing Zhang, Yutao Xie, and Sheng Yu. BioBART: Pretraining and evaluation of a biomedical generative language model. In Proceedings of the 21st Workshop on Biomedical Language Processing, pages 97–109, Dublin, Ireland, May 2022. Association for Computational Linguistics.
- [45] Zheng Yuan, Yijia Liu, Chuanqi Tan, Songfang Huang, and Fei Huang. Improving biomedical pretrained language models with knowledge. In Proceedings of the 20th Workshop on Biomedical Language Processing, pages 180–190, Online, June 2021. Association for Computational Linguistics.
- [46] Li-Ming Zhan, Bo Liu, Lu Fan, Jiaxin Chen, and Xiao-Ming Wu. Medical visual question answering via conditional reasoning. In Proceedings of the 28th ACM International Conference on Multimedia, pages 2345–2354, 2020.
- [47] Zhengyun Zhao, Qiao Jin, and Sheng Yu. Pmc-patients: A large-scale dataset of patient notes and relations extracted from case reports in pubmed central. arXiv preprint arXiv:2202.13876, 2022.