BiomedCLIP: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs
Abstract
Biomedical data is inherently multimodal, comprising physical measurements and natural language narratives. A generalist biomedical AI model needs to simultaneously process different modalities of data, including text and images. Therefore, training an effective generalist biomedical model requires high-quality multimodal data, such as parallel image-text pairs. Here, we present PMC-15M, a novel dataset that is two orders of magnitude larger than existing biomedical multimodal datasets such as MIMIC-CXR, and spans a diverse range of biomedical image types. PMC-15M contains 15 million biomedical image-text pairs collected from 4.4 million scientific articles. Based on PMC-15M, we have pretrained BiomedCLIP, a multimodal foundation model, with domain-specific adaptations tailored to biomedical vision-language processing. We conducted extensive experiments and ablation studies on standard biomedical imaging tasks from retrieval to classification to visual question-answering (VQA). BiomedCLIP achieved new state-of-the-art results in a wide range of standard datasets, substantially outperforming prior approaches. Intriguingly, by large-scale pretraining on diverse biomedical image types, BiomedCLIP even outperforms state-of-the-art radiology-specific models such as BioViL in radiology-specific tasks such as RSNA pneumonia detection. In summary, BiomedCLIP is a fully open-access foundation model that achieves state-of-the-art performance on various biomedical tasks, paving the way for transformative multimodal biomedical discovery and applications. We release our models at aka.ms/biomedclip to facilitate future research in multimodal biomedical AI.
Introduction
Biomedical data is inherently multimodal, comprising both physical measurements and natural-language narratives [1, 2]. However, only a fraction of such data is interpreted and made available in structured forms, as manual curation is costly and hard to scale. Multimodal learning can alleviate the curation bottleneck by leveraging self-supervision from cross-modal correspondence. It also helps uncover predictive signals that may remain latent in standalone modalities through multimodal fusion. As a result, biomedical vision-language foundation models [3, 4, 5, 6] have been developed to collectively model biomedical images (e.g., digital pathology and radiology images) and biomedical text (e.g., scientific papers and clinical notes). There are two key advantages of biomedical vision-language foundation models. First, by pretraining on large-scale data using self-supervised learning, these models excel in low-resource settings, where only a small amount of fine-tuning data is accessible, across a diverse range of downstream applications, thereby substantially decreasing the cost associated with data annotation. Second, by pretraining on high-quality parallel image-text data, these models can solve tasks that require a comprehensive understanding of both image and text data, such as image description generation and visual question-answering.
Since both advantages rely on high-quality biomedical image text data, obtaining such data is crucial to building an accurate and generalizable model. In contrast to the pretraining data used by general-domain vision-language models [7, 8, 9], the pretraining data used by existing biomedical vision-language models present three major limitations. First, many pretraining data are private data, resulting in the inaccessibility of many biomedical foundation models. Second, existing parallel image-text datasets in the biomedical domain are relatively small, ranging from 7k to 377k pairs (e.g., 377,110 pairs for MIMIC-CXR [10], 224,316 pairs for CheXpert [11], 7,562 pairs for ARCH [12], and 87,952 pairs for ROCO [13]). Finally, existing datasets are generally lacking in diversity and most of them focus on chest X-ray, thus limiting their generalizability to other biomedical image types. Prior studies in general domains have demonstrated the advantage of pretraining on diverse, expansive datasets [7], with increasing efforts on mining web images and captions [14, 15, 16, 17], yet biomedical image-text pairs are relatively scarce in such web resources and the quality varies.
In this paper, we develop PMC-15M, a large biomedical dataset with high-quality parallel image-text pairs extracted from scientific publications in PubMed Central (PMC)111https://www.ncbi.nlm.nih.gov/pmc/. Comprising 15 million biomedical image-text pairs, PMC-15M aims to address the three limitations in prior biomedical vision-language models. First, PMC-15M is a public dataset collected from scientific papers, which are devoid of privacy issues. Foundation models trained on PMC-15M are thus openly accessible. Second, PMC-15M is two orders of magnitude larger than prior large datasets such as MIMIC-CXR. Finally, PMC-15M covers essentially any category of interest to biomedical research, spanning thirty major biomedical image types, offering a diverse and representative dataset for biomedical research and clinical practice.
Based on PMC-15M, we have pretrained BiomedCLIP, a state-of-the-art biomedical vision-language foundation model that excels in a wide range of downstream applications such as cross-modal retrieval, zero-shot image classification, and medical visual question answering. BiomedCLIP outperformed the general-domain CLIP model [7] by a wide margin across the board, confirming the importance of exploring domain-specific models for biomedicine. By pretraining on much larger and more diverse data, BiomedCLIP also substantially outperformed prior state-of-the-art biomedical vision-language models such as PubMedCLIP and MedCLIP, especially in low-resource settings. Surprisingly, BiomedCLIP even outperformed radiology-specific state-of-the-art models such as BioViL [18] on radiology-specific tasks such as RSNA pneumonia detection [19], highlighting the potential of positive transfer in pretraining from diverse image categories. To facilitate future biomedical multimodal research, we will release our BiomedCLIP models and scripts to reproduce PMC-15M at aka.ms/biomedclip upon publication.
Results
Overview of dataset, model and benchmark
Dataset
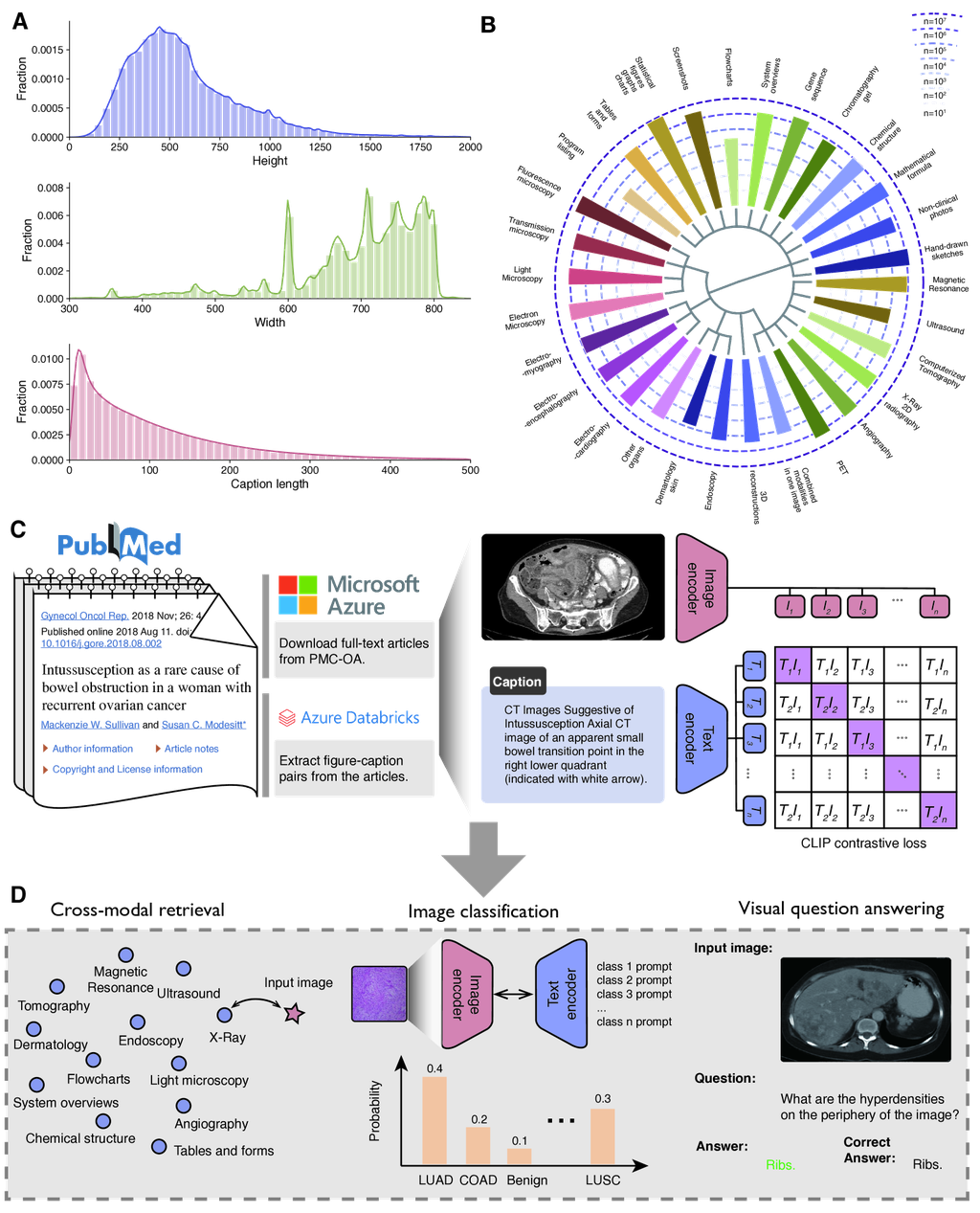
We have created PMC-15M, a large parallel image-text dataset from scientific papers collected from PubMed Central (PMC). See Fig. 1A, B. PMC is a comprehensive repository of biomedical research papers. We have previously used PubMed papers to pretrain state-of-the-art biomedical large language models (e.g., PubMedBERT [20], BioGPT [21]). Here, we propose to further leverage the abundant figure-caption pairs in PMC full-text articles for vision-language pretraining. PMC contains 4.4 million publicly available full-text articles (as of June 15, 2022). We downloaded and extracted compressed directories with complete article packages. Each article is represented as a package of XML, PDF, media, and supplementary materials. We extracted figure files and the matching captions, along with the PMID and the PMCID of the provenance articles. This yields a dataset with 15,282,336 image-caption pairs. We used Azure Databricks to process the data as it offered a scalable and reliable platform that is designed to handle large datasets and complex workflows in parallel using Apache Spark (Fig. 1C).
We demonstrate the summary statistics of PMC-15M in Fig. 1A. We found that biomedical images are much larger than the standard image size () in general domains and biomedical image captions are much longer than the default max length (77) used by the standard CLIP method [7]. This necessitates the exploration of new model configurations for pretraining biomedical images and text. To probe the diversity and coverage of image classes in PMC-15M, we created PMC-Fine-Grained-46M by splitting each scientific figure into individual panel images (see Methods). We then used a curated taxonomy [22] with manually assigned image type keywords to estimate the frequency of each image type by assigning each image with the closest keywords in the learned embedding space from BiomedCLIP. The numbers likely overcount real class frequency but are close enough for a ball-park estimate. Fig. 1B shows the top 30 image types in PMC-Fine-Grained-46M. Images in PMC are extremely diverse, ranging from generic biomedical illustration (e.g., statistical figures, graphs, charts, tables and forms) to radiography (e.g., magnetic resonance, computerized tomography, and X-ray) to digital pathology and microscopy (e.g., light microscopy, and electron microscopy), among others. The large size and diversity raise our confidence that PMC-15M can be used to train a state-of-the-art foundation model for biomedical vision-language processing.
Modeling
BiomedCLIP is an advanced adaptation of the CLIP (Contrastive Language–Image Pretraining) model [7], specifically tailored for the biomedical domain. CLIP trains image and text encoders to embed image, text pairs in a shared space, optimizing for a high cosine similarity among positive pairs and a low similarity for negative pairs through the InfoNCE loss [23]. Unlike the original CLIP, which was trained from scratch on internet-sourced image-text pairs, BiomedCLIP adapts this approach to better suit the unique characteristics of biomedical images and texts. This adaptation involves employing a domain-specific language model, PubMedBERT [20], in place of general-domain GPT-2 [24] for the text encoder, and adjusting the tokenizer and context size to accommodate the typically longer biomedical literature. This contrasts with PubMedCLIP [25] and MedCLIP [26], where PubMedCLIP simply fine-tunes the original CLIP on a limited dataset from PubMed Central and MedCLIP incorporates medical knowledge into the learning process but still within the constraints of the original CLIP architecture. BiomedCLIP also introduces domain-specific adaptations to the image processing, utilizing larger Vision Transformer models [27] and higher image resolutions to better capture the detailed visual information necessary for biomedical understanding. Additionally, it implements a patch dropout strategy [28] to maintain pretraining efficiency while enhancing model performance. The tailored batch size optimization of BiomedCLIP further underscores its custom adaptation for the biomedical domain.
Benchmark
The overarching objective of pretraining is to improve performance across a broad spectrum of downstream applications. In general domains, comprehensive benchmarks like ELEVATER [29] have spurred rapid advances in vision-language pretraining by facilitating direct comparison among pretrained models. In contrast, prior work on biomedical vision-language pretraining tends to use different tasks and datasets for downstream evaluation, e.g., [30, 26, 25]. To facilitate evaluations of biomedical vision-language pretraining and expedite progress in biomedical vision-language processing, we compile a collection of eight standard vision-language datasets spanning key downstream tasks: image-to-text and text-to-image retrieval, image classification, and visual question answering (Fig. 1D). Table 1 provides an overview of the datasets used in downstream applications.
BiomedCLIP enables accurate cross-modal retrieval
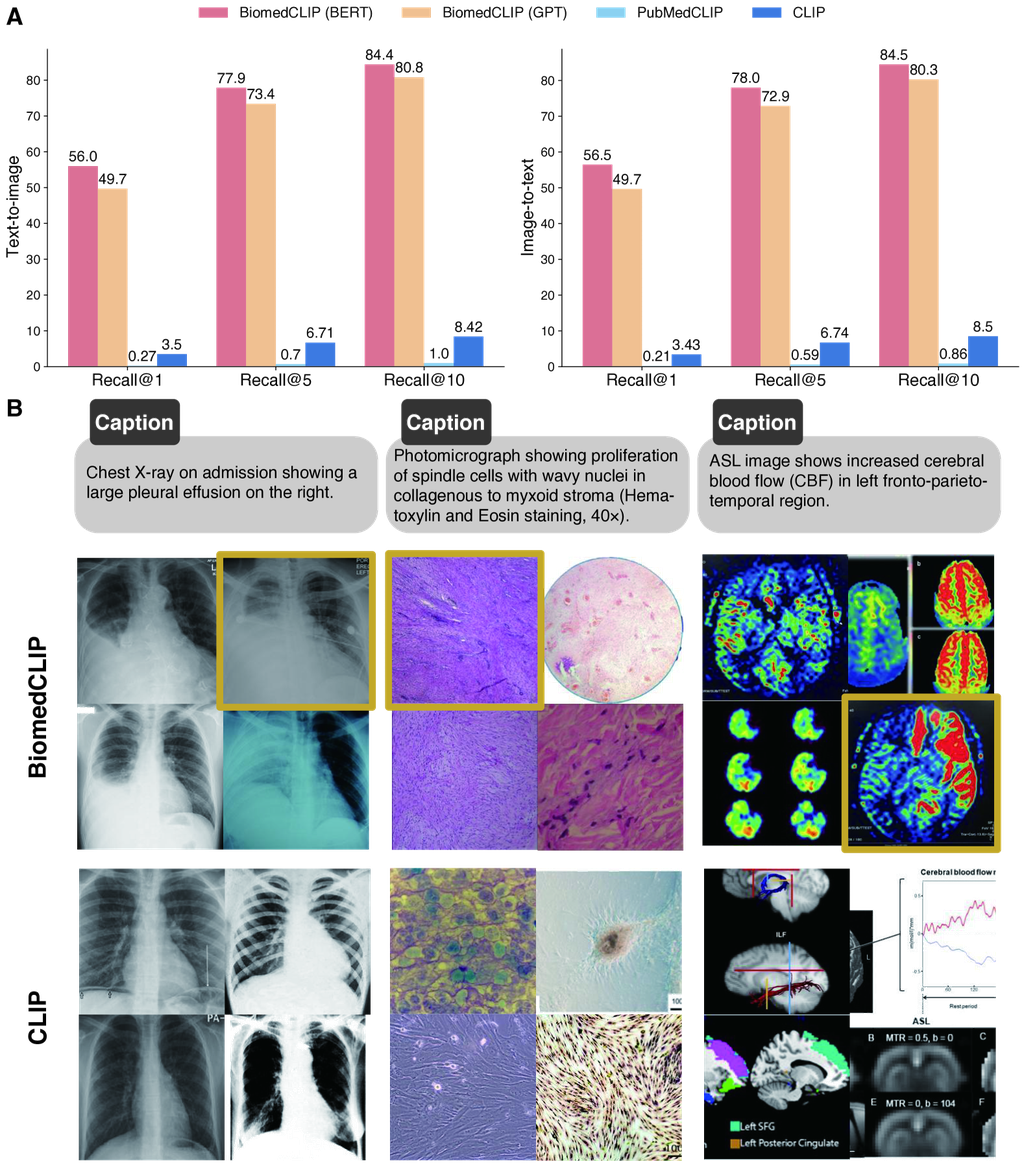
We first evaluate the task of cross-modal retrieval which aims to retrieve the corresponding image from the caption (text-to-image retrieval) or vice versa (image-to-text retrieval). The retrieval tasks mirror various image search and text generation in real-world applications and can be evaluated automatically in held-out image-text pairs. We use a held-out test set from PMC-15M comprising 725,739 PMC image-caption pairs. The results are summarized in Fig. 2A. We first notice that the general-domain CLIP model performs poorly in the biomedical domain, necessitating the development of a domain-specific vision language model. In contrast, BiomedCLIP attains remarkably high retrieval accuracy: out of over 700 thousand candidates, BiomedCLIP’s top-5 results contain the correct one over 77% of times, and its top-1 results are correct over 56% of times. To our surprise, PubMedCLIP [25] performs even worse than CLIP, despite biomedical adaptation. We attribute this to the training data that PubMedCLIP used. Despite being named after PubMed, PubMedCLIP only used a small set of radiology image-text pairs in the continual pretraining of CLIP, which accounts for a small fraction of images in the biomedical literature. Moreover, continual pretraining on a small dataset without extra care (e.g., augmenting with pretraining objective) may be prone to catastrophic forgetting [31]. In contrast, BiomedCLIP performs very well by pretraining on large-scale data from PMC-15M, further indicating the importance of utilizing a diverse and large dataset for domain-specific vision language models.
To understand how BiomedCLIP outperforms general-domain CLIP in biomedical cross-modal retrieval, we show three random examples in Fig. 2B. In each example, we show the top-4 image retrieval results given the text prompt, with the correct answer shown in a gold box. General CLIP can find images matching common keywords such as “chest X-ray”, but have trouble differentiating subtle semantics such as “pleural effusion”, “spindle shaped cells”, or even important biomedical image categories like “ASL” (Arterial Spin Labeling). By contrast, BiomedCLIP recognizes not only high-level categories but also details like “a large pleural effusion on the right”. For example, the images retrieved by BiomedCLIP in the first example are completely correct according to the caption, except the right-bottom one, which still looks quite similar to the others. In the second example, BiomedCLIP is able to find the correct answer and additional H&E images with spindle-shaped cells, as described in the prompt, unlike general CLIP. We attribute BiomedCLIP’s ability of capturing both coarse-grained and fine-grained semantics to our diverse and large pretraining dataset PMC-15M.
BiomedCLIP enables accurate biomedical image classification
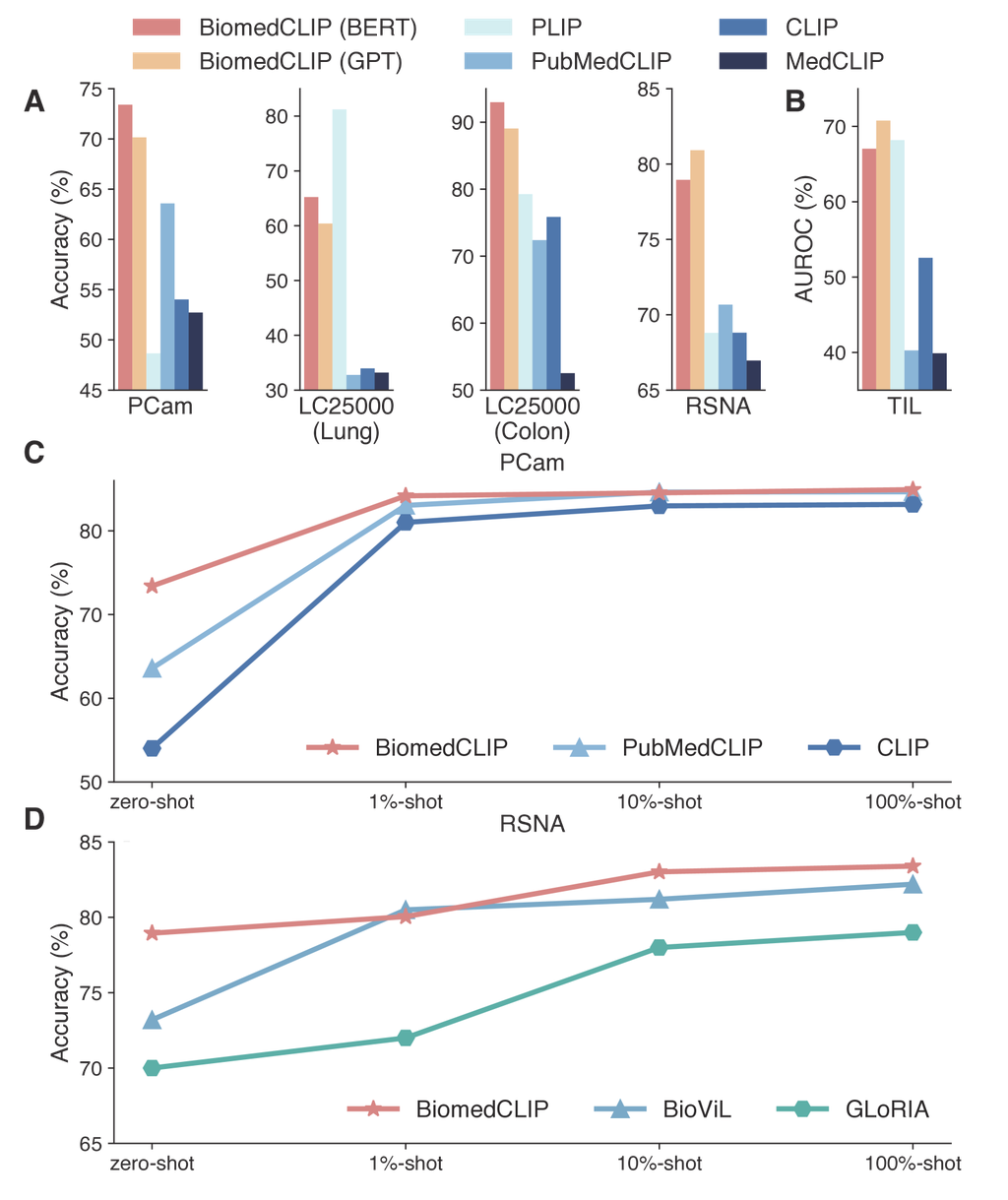
We next evaluate the performance of BiomedCLIP for biomedical image classification on five datasets (see Methods). We investigate the zero-shot performance on BiomedCLIP models, where a short text prompt describing the class is used to assist the classification (Supplementary Table 10). BiomedCLIP exhibits superior performance on zero-shot classification, attaining the highest overall accuracy (mean of the scores) across all the datasets (Fig. 3A,B). PubMedCLIP was continual pretrained using radiology data so it outperforms the general-domain CLIP on the RSNA benchmark but generally yields inferior performance on the digital pathology benchmarks such as LC25000 and TCGA-TIL. PLIP [6] was pretrained on digital pathology data from social media, so performs reasonably well on some of the pathology benchmarks, but yields much inferior performance on RSNA. Surprisingly, PLIP also performs rather poorly on the pathology benchmark PCam. We suspect that the pathology images in PCam (lymph nodes with metastatic tumors) might be under-represented in the social media data PLIP was pretrained on. In contrast, BiomedCLIP achieves good results on all datasets from diverse image sources, again indicating the importance of pretraining on a diverse and large-scale dataset for building a foundational vision-language model.
We also evaluate few-shot and full-shot performance on PCam and RSNA by linear probing the models with 1%, 10%, and 100% of training data, respectively (Fig. 3C,D). Notably, by pretraining on diverse data across all biomedical image classes, BiomedCLIP even outperforms the state-of-the-art radiology-specific BioViL model [18] on the standard radiology benchmark RSNA. Furthermore, BiomedCLIP already outperforms fully supervised BioViL using only 10% of labeled data. As shown in (Fig. 1B), the radiology-related images used in BiomedCLIP pretraining are no more than MIMIC-CXR used in BioViL pretraining, and the image-text pairs are likely to be much noisier. This excludes the possibility that the superior performance of BiomedCLIP on RSNA stems from more radiology-specific pretraining. Instead, the overall pretraining on the large and diverse PMC-15M, including non-radiology image types, has helped pretrain a more robust image encoder, again indicating the superiority of using PMC-15M to develop a multimodal foundation model.
BiomedCLIP improves medical visual question answering
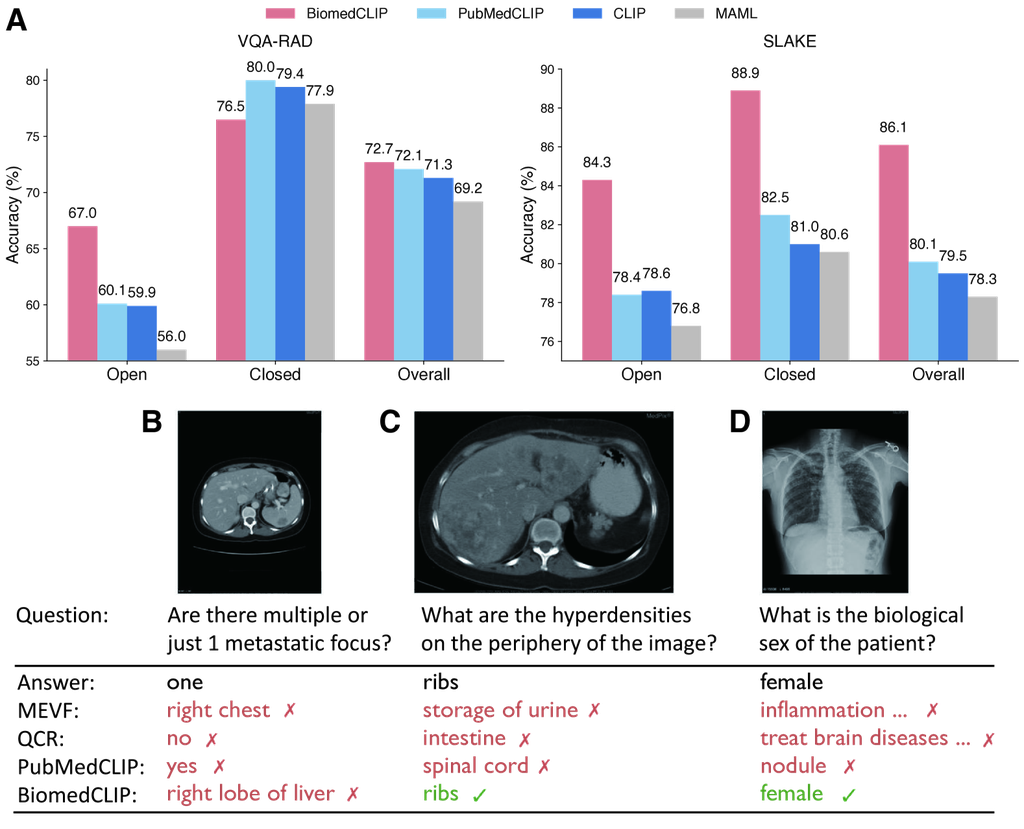
Finally, we evaluate BiomedCLIP on medical visual question answering (VQA). Following the standard approach in prior work, we formulate VQA as a classification task using the METER [32] framework (see Methods). We evaluate the models on two standard datasets: VQ-RAD and SLAKE (Fig. 4A). We report the overall accuracy as well as respective accuracies for open-ended questions and closed-ended questions. Again, BiomedCLIP exhibits superior performance compared to the radiology-specific state-of-the-art PubMedCLIP on both radiology benchmarks, with about one point and six points increases in overall accuracy respectively. BiomedCLIP’s gains are particularly pronounced for open-ended questions in VQA-RAD and for all question types in SLAKE.
To further examine the answers provided by BiomedCLIP, we evaluate BiomedCLIP on some of the most challenging examples highlighted in the PubMedCLIP paper [25], where all prior state-of-the-art models, including PubMedCLIP, failed to answer correctly (Fig. 4B-D). In the second example (Fig. 4C), prior models fail to return the right answer, whereas in the third example (Fig. 4D), their answers indicate that they even fail to understand what the question is about. BiomedCLIP nails both answers perfectly. In the first example, which is the most challenging one (Fig. 4B), MEVF misidentifies the body part as displayed in the image, whereas QCR and PubMedCLIP misinterpret the question as a binary one (yes/no). While BiomedCLIP didn’t get the correct answer either, it correctly identified the relevant organ as presented in the image. Since medical visual question answering requires both strong text understanding and image understanding ability, we attribute the superior results of BiomedCLIP to the large number of parallel image-caption pairs in PMC-15M.
Discussion
We present to our knowledge the largest study on biomedical vision-language pretraining using 15 million image-caption pairs extracted from PubMed Central full-text articles. Our pretraining data is at least two orders of magnitude larger than prior datasets, spanning an extremely diverse range of biomedical images. We conducted a systematic study on domain-specific adaptations for the biomedical domain and propose BiomedCLIP for biomedical vision-language processing. In extensive experiments on eight standard biomedical datasets, BiomedCLIP establishes new state of the art on standard applications such as cross-modal retrieval, image classification, and visual question answering. The promising results of our method indicate the effectiveness of BiomedCLIP on diverse biomedical image tasks and validate the advantage in conducting large-scale pretraining on extremely diverse data.
Our work is most relevant to biomedical multimodal representation learning. Most existing vision-language pretraining works focus on chest X-ray (CXR) with limited amounts of training data. ConVIRT [30] pioneers the use of naturally occurring medical image-text pairs for self-supervision and demonstrates the potential of contrastive learning in vision-language pretraining. Their image encoders benefit downstream CXR classification and retrieval tasks. Their text encoder inherits a general-domain vocabulary, which leads to frequent encounters with out-of-vocabulary words when processing medical text. While the word-piece tokenization mitigates this issue, common biomedical terms are often shattered into pieces, leading to suboptimal performance [20]. GLoRIA [33] uses the same general-domain vocabulary and extends ConVIRT by jointly learning multimodal global and local representations of medical images via contrasting attention weighted image regions with words in the paired reports. LoVT [34] proposes a similar pretraining approach that aligns local representations of image regions and report sentences. [35] learn multimodal representations by maximizing the mutual information between local features of medical images and text. PubMedCLIP [25] fine-tunes the original CLIP on 80 thousand radiology image-caption pairs from the ROCO dataset [13] collected from PubMed Central [36], which is a tiny subset compared to PMC-15M. [37] propose a transformer-based framework for mix-up image-text pretraining, which uses masked vision/language modeling for image-only or text-only data and uses binary cross entropy for paired image-text data. They demonstrate the benefits of adopting pretrained models in three CXR applications, i.e., classification, retrieval, and image regeneration. MedCLIP [26] similarly extends contrastive learning to cover image-only and text-only data. They additionally introduce medical knowledge to alleviate false negatives. MedAug [38] leverages patient metadata to select positive image pairs that go beyond augmentations of the same image. BioViL [18] improves contrastive learning in self-supervised vision-language processing with radiology-specific semantic modeling tailored to CXR images and reports. It achieves the state of the art in radiology natural language inference and a range of CXR benchmarks. [39] show self-supervised multimodal pretraining on CXR data consistently outperforms ImageNet-pretrained models for CXR interpretation.
In the future, we would like to explore further improvement on pretraining and fine-tuning, multimodal generation, as well as real-world applications such as image search, digital pathology, and multimodal fusion for precision health. While BiomedCLIP shows clear benefits of large-scale domain-specific pretraining for biomedical vision-language processing, there are several limitations in our current method: First, besides captions, in-line references (i.e., citances within the paper) can also be extracted and paired with the corresponding figures to create additional training signals. PMC-15M currently doesn’t include such data. Second, half of the images in PMC-15M are composite figures. Splitting such composite figures into sub-figures could enable more fine-grained modeling and potentially lead to better vision-language representations and grounding. PMC-Fine-Grained-46M is augmented with both in-line references and fine-grained image-text pairs. While our current us of PMC-Fine-Grained-46M is limited to tallying fine-grained image distribution, we plan to explore leveraging PMC-Fine-Grained-46M to enhance BiomedCLIP pretraining in future work. Third, due to computational constraints, the largest vision encoder we have explored is ViT-B, which is relatively small compared with ViT-L, ViT-H, and ViT-G. Similarly, we have been using a relatively low image resolution of 336. While this is more than sufficient for general-domain web images, biomedical images tend to have much higher resolution. E.g., more than 75% of images in PMC-15M have size larger than 336, as shown in Fig. 1. We plan to explore larger models and higher resolutions in future work. Finally, it would be interesting to apply our methodology to additional biomedical modalities other than images, where similar naturally co-occurring data abound, such as gene expression and sequence data along with textual descriptions.
Methods
Details of creating PMC-15M
PubMed Central Open Access Subset (PMC-OA) [40] contains 4.4 million publicly available full-text articles (as of June 15, 2022). We download PMC-OA from ncbi.nlm.nih.gov/pmc/tools/ftp/#indart and extract complete packages for articles that include XML, PDF, media, and supplementary materials. We use PubMed Parser [41] to parse the XML files and extract captions and the corresponding figure references, along with PMID and PMCID of the provenance articles. This processing results in JSON objects stored in JSONL format, where each line represents one article, for convenient post-processing. Articles without figure references, or with incorrectly formatted XML files with syntax errors or missing information errors are ignored. After this clean-up, we collect 15 million figure-caption pairs (PMC-15M) from over 3 million distinct articles.
Details of creating PMC-Fine-Grained-46M
PMC-Fine-Grained-46M is created using a novel data curation pipeline that extracts and refines image-text pairs from PMC-15M. The pipeline is designed to handle compound figures by breaking them down into sub-figures and captions, and it also incorporates in-line text references from articles as an additional data source for image-text pairs. The process begins with Data Ingestor, which downloads and processes article files. Then, Citance Extractor parses article text for figure references, and Caption Splitter uses regex and rules to separate figure captions into sub-captions with individual labels. Next, Citance Splitter assigns blocks of citances to each label, Optical Character Recognition (OCR) detects text in figures, and Label-To-Box Matcher matches labels with OCR-detected text. Finally, Figure Splitter segments compound images into panels (sub-figures), and Label-to-Panel Matcher assigns labels to the correct panels. The pipeline overcomes various challenges like inconsistent labeling styles, OCR errors, and the ambiguous positioning of labels relative to sub-figures. Advanced techniques and heuristics are employed, such as string matching for OCR text, layout analysis to correct OCR mistakes, and region-based heuristics to match labels with panels. Through this intricate process, the PMC-Fine-Grained-46M dataset, with 46 million image-text pairs, is carefully constructed to facilitate the development of vision-language representations in the biomedical domain.
Cross-modal retrieval
To evaluate the retrieval performance, we follow prior work [17] to precompute image and text embeddings and perform an approximate nearest neighbor search. Specifically, we use the pretrained vision encoder and text encoder from the CLIP models to precompute embeddings of figures and captions respectively. Given a figure embedding, we compute its cosine similarities with all captions in the test set and retrieve the most similar captions. Our evaluation metric measures if the original caption for the figure is within the retrieved captions, i.e., recall at top- or R@. Similarly, we evaluate Recall@ for text-to-image cross-modal retrieval.
We consider several CLIP models as baselines: OpenAI CLIP [7], which is pretrained on 400 million general-domain (image, text) pairs collected from the Internet; PubMedCLIP [42], which fine-tunes OpenAI CLIP on 80k radiology image-caption pairs. We also compare with a variant of our BiomedCLIP (i.e., BiomedCLIP ViT-B/16-224-GPT/77), which continues pretraining OpenAI CLIP on PMC-15M.
Biomedical image classification
We use the evaluation toolkit ELEVATER [29] to facilitate our experiments on image classification. ELEVATER is an easy-to-use toolkit that can efficiently adapt pretrained vision-language models and automatically tune hyper-parameters. It supports zero-shot, few-shot and full-shot evaluations, with linear probing and full model fine-tuning available for the latter two settings. It also contains twenty image classification datasets collected from various domains, including a biomedical one PatchCamelyon, which we use in our experiments. In addition, we evaluate on three standard biomedical imaging benchmarks LC25000, TCGA-TIL and RSNA.
An overview of the datasets can be found in Table 1. PatchCamelyon (PCam) [43] contains color images (9696px), which were taken from histophathology scans of lymph node sections. The images have been assigned a binary label indicating whether or not they contain metastatic tissue. LC25000 [44] contains histopathology images (768768px). These images were generated by augmentation from a collection of HIPAA-compliant, validated sources originally comprising 750 images of lung tissue (250 benign, 250 adenocarcinomas, and 250 squamous cell carcinomas) and 500 images of colon tissue (250 benign and 250 adenocarcinomas). The dataset is divided into five classes: lung benign tissue, lung adenocarcinoma, lung squamous cell carcinoma, colon adenocarcinoma, and colon benign tissue, with each class containing 5,000 images. TCGA-TIL [45, 46] contains image patches (500500px) that were partitioned from H&E whole-slide images from The Cancer Genome Atlas (TCGA) [47] lung adenocarcinoma (LUAD) cases (5.9% of the patches are labelled as LUAD). RSNA Pneumonia [19] contains about frontal-view chest radiographs collected from the National Institutes of Health’s public database of chest X-rays. It contains binary labels classifying pneumonia against normal cases.
We compare our method against four competing methods CLIP, MedCLIP, and PubMedCLIP. MedCLIP [26] extends the pretraining to include large unpaired images and texts through contrastive learning. It uses the pretrained BioClinicalBERT and Swin Transformer [48] as the backbone text encoder and visual encoder respectively, and fine-tunes on MIMIC-CXR and CheXpert datasets. PubMedCLIP [25] fine-tunes CLIP on the Radiology Objects in COntext (ROCO) dataset [13], which consists of 80K radiology image-text pairs drawn from PubMed articles. All the models are adapted into ELEVATER for evaluation.
Medical Visual Question Answering
We utilize the METER [32] framework to facilitate our experiments on visual question answering (VQA). It formulates the VQA task as a classification task. The core module of METER is a transformer-based co-attention multimodal fusion module that produces cross-modal representations over the image and text encodings, which are then fed to a classifier for predicting the final answer. We compare BiomedCLIP with general-domain CLIP, MAML (Model-Agnostic Meta-Learning) network pretrained only on visual data, and the state-of-the-art PubMedCLIP. All three models were fine-tuned for VQA tasks using the QCR (Question answering via Conditional Reasoning) framework [49] that alternatively uses a MLP-based attention networks with conditional reasoning as the fusion module. Results for MAML, CLIP and PubMedCLIP are collected from [25].
We evaluated our method and competing methods on VQA-RAD [50]. VQA-RAD consists of radiology images and question-answer pairs that were manually constructed by clinicians. Images in the test set are also present in training set but the question-answer pairs do not overlap. SLAKE (English only) [51] consists of radiology images and over question-answer pairs annotated by experienced physicians. It covers more human body parts than VQA-RAD and does not have common images between the training and test sets. See Supplementary Table 1 for details.
Data availability
We will provide scripts to reproduce PMC-15M and PMC-Fine-Grained-46M from PubMed Central Open-Access Data (PMC-OA), upon publication of this manuscript. These scripts will be made available at https://aka.ms/biomedclip. (Currently, this url is pointed to a preliminary model release at Hugging Face.)
Code availability
BiomedCLIP will be made fully available at https://aka.ms/biomedclip, including the model weights and relevant source code for pretraining, fine-tuning, and inference. We will also provide detailed methods and implementation steps to facilitate independent replication.
References
- [1] Moor, M. et al. Foundation models for generalist medical artificial intelligence. Nature 616, 259–265 (2023).
- [2] Tu, T. et al. Towards generalist biomedical ai. arXiv preprint arXiv:2307.14334 (2023).
- [3] Heiliger, L., Sekuboyina, A., Menze, B., Egger, J. & Kleesiek, J. Beyond medical imaging-a review of multimodal deep learning in radiology (2022).
- [4] Huang, S.-C., Pareek, A., Seyyedi, S., Banerjee, I. & Lungren, M. P. Fusion of medical imaging and electronic health records using deep learning: a systematic review and implementation guidelines. NPJ digital medicine 3, 1–9 (2020).
- [5] Ikezogwo, W. O. et al. Quilt-1m: One million image-text pairs for histopathology. arXiv preprint arXiv:2306.11207 (2023).
- [6] Huang, Z., Bianchi, F., Yuksekgonul, M., Montine, T. J. & Zou, J. A visual–language foundation model for pathology image analysis using medical twitter. Nature medicine 29, 2307–2316 (2023).
- [7] Radford, A. et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, 8748–8763 (PMLR, 2021).
- [8] Ramesh, A. et al. Zero-shot text-to-image generation. In International Conference on Machine Learning, 8821–8831 (PMLR, 2021).
- [9] Rombach, R., Blattmann, A., Lorenz, D., Esser, P. & Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10684–10695 (2022).
- [10] Johnson, A. E. et al. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports. Scientific data 6, 1–8 (2019).
- [11] Irvin, J. et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI conference on artificial intelligence, vol. 33, 590–597 (2019).
- [12] Gamper, J. & Rajpoot, N. Multiple instance captioning: Learning representations from histopathology textbooks and articles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 16549–16559 (2021).
- [13] Pelka, O., Koitka, S., Rückert, J., Nensa, F. & Friedrich, C. M. Radiology objects in context (roco): a multimodal image dataset. In Intravascular Imaging and Computer Assisted Stenting and Large-Scale Annotation of Biomedical Data and Expert Label Synthesis, 180–189 (Springer, 2018).
- [14] Sharma, P., Ding, N., Goodman, S. & Soricut, R. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2556–2565 (Association for Computational Linguistics, Melbourne, Australia, 2018). URL https://aclanthology.org/P18-1238.
- [15] Changpinyo, S., Sharma, P., Ding, N. & Soricut, R. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3558–3568 (2021).
- [16] Srinivasan, K., Raman, K., Chen, J., Bendersky, M. & Najork, M. Wit: Wikipedia-based image text dataset for multimodal multilingual machine learning. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2443–2449 (2021).
- [17] Schuhmann, C. et al. Laion-5b: An open large-scale dataset for training next generation image-text models. arXiv preprint arXiv:2210.08402 (2022).
- [18] Boecking, B. et al. Making the most of text semantics to improve biomedical vision–language processing. In European Conference on Computer Vision (ECCV), 1–21 (Springer, 2022).
- [19] Shih, G. et al. Augmenting the national institutes of health chest radiograph dataset with expert annotations of possible pneumonia. Radiology. Artificial intelligence 1 (2019).
- [20] Gu, Y. et al. Domain-specific language model pretraining for biomedical natural language processing. ACM Transactions on Computing for Healthcare (HEALTH) 3, 1–23 (2021).
- [21] Luo, R. et al. Biogpt: generative pre-trained transformer for biomedical text generation and mining. Briefings in Bioinformatics 23 (2022).
- [22] García Seco de Herrera, A., Müller, H. & Bromuri, S. Overview of the ImageCLEF 2015 medical classification task. In Working Notes of CLEF 2015 (Cross Language Evaluation Forum) (2015).
- [23] Oord, A. v. d., Li, Y. & Vinyals, O. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748 (2018).
- [24] Radford, A. et al. Language models are unsupervised multitask learners. OpenAI blog 1, 9 (2019).
- [25] Eslami, S., de Melo, G. & Meinel, C. Does clip benefit visual question answering in the medical domain as much as it does in the general domain? arXiv preprint arXiv:2112.13906 (2021).
- [26] Wang, Z., Wu, Z., Agarwal, D. & Sun, J. Medclip: Contrastive learning from unpaired medical images and text. arXiv preprint arXiv:2210.10163 (2022).
- [27] Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020).
- [28] Li, Y., Fan, H., Hu, R., Feichtenhofer, C. & He, K. Scaling language-image pre-training via masking. arXiv preprint arXiv:2212.00794 (2022).
- [29] Li, C. et al. Elevater: A benchmark and toolkit for evaluating language-augmented visual models. Neural Information Processing Systems (2022).
- [30] Zhang, Y., Jiang, H., Miura, Y., Manning, C. D. & Langlotz, C. P. Contrastive learning of medical visual representations from paired images and text. arXiv preprint arXiv:2010.00747 (2020).
- [31] McCloskey, M. & Cohen, N. J. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of learning and motivation, vol. 24, 109–165 (Elsevier, 1989).
- [32] Dou, Z.-Y. et al. An empirical study of training end-to-end vision-and-language transformers. In Conference on Computer Vision and Pattern Recognition (CVPR) (2022). URL https://arxiv.org/abs/2111.02387.
- [33] Huang, S.-C., Shen, L., Lungren, M. P. & Yeung, S. GLoRIA: A multimodal global-local representation learning framework for label-efficient medical image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 3942–3951 (2021).
- [34] Müller, P., Kaissis, G., Zou, C. & Rueckert, D. Joint learning of localized representations from medical images and reports. In European Conference on Computer Vision, 685–701 (Springer, 2022).
- [35] Liao, R. et al. Multimodal representation learning via maximization of local mutual information. In International Conference on Medical Image Computing and Computer-Assisted Intervention, 273–283 (Springer, 2021).
- [36] Roberts, R. J. Pubmed central: The genbank of the published literature (2001).
- [37] Wang, X., Xu, Z., Tam, L., Yang, D. & Xu, D. Self-supervised image-text pre-training with mixed data in chest x-rays. arXiv preprint arXiv:2103.16022 (2021).
- [38] Vu, Y. N. T. et al. Medaug: Contrastive learning leveraging patient metadata improves representations for chest x-ray interpretation. In Jung, K., Yeung, S., Sendak, M., Sjoding, M. & Ranganath, R. (eds.) Proceedings of the 6th Machine Learning for Healthcare Conference, vol. 149 of Proceedings of Machine Learning Research, 755–769 (PMLR, 2021). URL https://proceedings.mlr.press/v149/vu21a.html.
- [39] Iyer, N. S. et al. Self-supervised pretraining enables high-performance chest x-ray interpretation across clinical distributions. medRxiv (2022). URL https://www.medrxiv.org/content/early/2022/11/25/2022.11.19.22282519. https://www.medrxiv.org/content/early/2022/11/25/2022.11.19.22282519.full.pdf.
- [40] Pmc open access subset. [Internet] (2003). URL https://www.ncbi.nlm.nih.gov/pmc/tools/openftlist/.
- [41] Achakulvisut, T., Acuna, D. & Kording, K. Pubmed parser: A python parser for pubmed open-access xml subset and medline xml dataset xml dataset. Journal of Open Source Software 5, 1979 (2020). URL https://doi.org/10.21105/joss.01979.
- [42] Eslami, S., de Melo, G. & Meinel, C. Does CLIP benefit visual question answering in the medical domain as much as it does in the general domain? arXiv e-prints (2021). 2112.13906.
- [43] Veeling, B. S., Linmans, J., Winkens, J., Cohen, T. & Welling, M. Rotation equivariant CNNs for digital pathology (2018). 1806.03962.
- [44] Borkowski, A. A. et al. Lung and colon cancer histopathological image dataset (lc25000). arXiv preprint arXiv:1912.12142 (2019).
- [45] Saltz, J., Gupta, R., Hou, L. et al. Tumor-infiltrating lymphocytes maps from tcga h&e whole slide pathology images. Cancer Imaging Arch (2018).
- [46] Saltz, J. et al. Spatial organization and molecular correlation of tumor-infiltrating lymphocytes using deep learning on pathology images. Cell reports 23, 181–193 (2018).
- [47] Clark, K. et al. The cancer imaging archive (tcia): maintaining and operating a public information repository. Journal of digital imaging 26, 1045–1057 (2013).
- [48] Liu, Z. et al. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2021).
- [49] Zhan, L.-M., Liu, B., Fan, L., Chen, J. & Wu, X.-M. Medical visual question answering via conditional reasoning. In Proceedings of the 28th ACM International Conference on Multimedia, 2345–2354 (2020).
- [50] Lau, J. J., Gayen, S., Ben Abacha, A. & Demner-Fushman, D. A dataset of clinically generated visual questions and answers about radiology images. Scientific data 5, 1–10 (2018).
- [51] Liu, B. et al. Slake: A semantically-labeled knowledge-enhanced dataset for medical visual question answering. In 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), 1650–1654 (IEEE, 2021).
- [52] He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778 (2016).
- [53] Vaswani, A. et al. Attention is all you need. Advances in neural information processing systems 30 (2017).
- [54] Sennrich, R., Haddow, B. & Birch, A. Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1715–1725 (Association for Computational Linguistics, Berlin, Germany, 2016). URL https://aclanthology.org/P16-1162.
- [55] Kudo, T. & Richardson, J. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 66–71 (Association for Computational Linguistics, Brussels, Belgium, 2018). URL https://aclanthology.org/D18-2012.
- [56] Cherti, M. et al. Reproducible scaling laws for contrastive language-image learning. arXiv preprint arXiv:2212.07143 (2022).
- [57] Loshchilov, I. & Hutter, F. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017).
- [58] Ilharco, G. et al. Openclip (2021). URL https://doi.org/10.5281/zenodo.5143773.
- [59] Li, S. et al. Pytorch distributed: Experiences on accelerating data parallel training. arXiv preprint arXiv:2006.15704 (2020).
- [60] Paszke, A. et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems 32 (2019).
| Task | Dataset | Metric | Description | Data size | ||
| Train | Dev | Test | ||||
|
Cross-Modal Retrieval |
PMC-15M |
Recall@k |
Given textual description (caption), retrieve the corresponding image, or vice versa. (Image size: see Fig. 1A) |
13.9M | 13.6k | 726k |
|
PCam |
Accuracy |
Binary classification on whether a histopathology image of lymph node contains metastatic tumor tissue. (Image size: 9696) |
262,144 | 32,769 | 32,769 | |
|
LC25000 (Lung) |
Accuracy |
Ternary classification (benign, adenocarcinoma, squamous cell carcinoma) on histopathology images of lung tissue. (Image size: 768768) |
- | - | 15,000 | |
|
Image Classification |
LC25000 (Colon) |
Accuracy |
Binary classification (benign, adenocarcinoma) on histopathology images of colon tissue. (Image size: 768768) |
- | - | 10,000 |
|
TCGA-TIL |
AUROC |
Binary classification on whether lung H&E whole-slide image patches show adenocarcinoma. (Image size: 512512) |
- | - | 2,480 | |
|
RSNA |
Accuracy |
Binary classification on whether chest X-rays show pneumonia. (Image size: 500500) |
18,678 | 4,003 | 9,069 | |
|
VQA |
VQA-RAD |
Accuracy |
Answer clinician questions about radiology images. |
3,064 | - | 451 |
|
SLAKE |
Accuracy |
Answer clinician questions about radiology images (X-rays, and single slices of CTs and MRIs). |
9,849 | 2,109 | 2,070 | |
Supplementary Note
Details of BiomedCLIP architecture and ablation studies
Review of CLIP
We first give a brief review of the CLIP pretraining approach [7]. Given a batch of (image, text) pairs, CLIP learns a multimodal embedding space by jointly training an image encoder and a text encoder to maximize the cosine similarity between the image and text embeddings of the pairs in the batch while minimizing the cosine similarity of the embeddings of the other non-pairs. Concretely, CLIP minimizes the InfoNCE loss [23], i.e., a symmetric cross entropy loss over these similarity scores:
| (1) |
where is a learnable temperature parameter, directly optimized during training as a log-parameterized multiplicative scalar; and are embeddings for the -th image and text, produced by a linear projection layer on top of the image encoder and text encoder. Rather than initializing with pretrained weights, CLIP trains the image encoder and text encoder from scratch. For the image encoder, CLIP considers two different architectures, ResNet-50 [52] and Vision Transformer [ViT; 27]. The text encoder is effectively GPT-2 [24] based on transformer [53].
Adapting CLIP to BiomedCLIP
Biomedical text and images are drastically different from the web data used in CLIP pretraining. We find that the standard CLIP settings are suboptimal for biomedical vision-language pretraining. We thus conducted a systematic study of potential adaptations and identified a series of domain-specific adaptations for the biomedical domain. We used the optimization loss and cross-modal retrieval results on the validation set to guide our initial exploration and conducted detailed ablation studies.
On the text side, we replace a blank-slate GPT-2 with a pretrained language model more suited for biomedicine. Specifically, we initialize with PubMedBERT, which shows substantial gains from domain-specific pretraining [20]. Correspondingly, for the tokenizer, we replace Byte-Pair Encoding [BPE; 54] with WordPiece [55], which uses unigram-based likelihood rather than shattering all words to characters and greedily forming larger tokens based on frequency. The original CLIP uses a context of 77 tokens, but biomedical text is typically longer, as shown in Fig. 1A. We thus increase the context size to 256, which covers 90% of PMC captions. Supplementary Table 1 shows that both modifications bring substantial improvements over the original CLIP model on the validation set.
| img2txt (%) | txt2img (%) | ||||
| text encoder | vocab | context length | loss () | R@1() | R@1() |
| GPT | 50k general domain | 77 | 0.6626 | 64.53 | 63.56 |
| PubMedBERT | 30k domain specific | 77 | 0.5776 | 69.03 | 67.41 |
| PubMedBERT | 30k domain specific | 256 | 0.4807 | 73.50 | 72.26 |
On the image side, we first evaluated Vision Transformer (ViT) across different scales, ranging from ViT-Small, ViT-Medium, to ViT-Base. The suffix “/16” in the ViT model names refers to the patch size of 1616 pixels i.e., the input images are divided into patches of this size, and fed through the transformer blocks. As shown in Supplementary Table 2, we found that larger ViT results in better performance, confirming the importance of model scalability on our new dataset PMC-15M. We used the largest one (ViT-B/16) in all subsequent experiments.
| img2txt (%) | txt2img (%) | ||||
| vision encoder | trainable params | hidden dim | loss () | R@1() | R@1() |
| ViT-S/16 | 22M | 384 | 0.5342 | 69.45 | 68.02 |
| ViT-M/16 | 39M | 512 | 0.5063 | 71.85 | 70.22 |
| ViT-B/16 | 86M | 768 | 0.4807 | 73.50 | 72.26 |
| img2txt (%) | txt2img (%) | |||
| vision encoder | initialization | loss () | R@1() | R@1() |
| ViT-B/16 | random initialization | 0.3814 | 83.15 | 81.75 |
| ViT-B/16 | pretrained on ImageNet | 0.3819 | 82.90 | 81.86 |
Next, we compared two different ways to initialize the vision encoder. Supplementary Table 3 shows that the vision encoder pretrained on ImageNet [27] does not have advantages over random initialization. However, in our downstream tasks, ImageNet-pretrained weights offer more stable performance. Therefore, we chose to initialize ViT-B/16 with ImageNet-pretrained weights. Lastly, biomedical image understanding often requires fine-grained visual features [30]. In Supplementary Table 4, we compared two choices of input image resolution: 224224 and 384384. By increasing image resolution, we observe significant gains in validation results. But this also leads to a doubling of pretraining time. In addition, increased image resolution does not consistently enhance performance in downstream tasks. As Table Supplementary Table 5 shows, BiomedCLIP exhibits inferior performance in zero-shot classification across all five datasets when using larger image size of 384 compared to 224. This discrepancy is particularly notable in PCam, where the raw image resolution (9696) is considerably smaller than the model’s input image size. Upsampling images here may introduce noise, potentially contributing to the observed decrease in performance. Consequently, we opt for an image size of 224 in the subsequent experiments.
| img2txt (%) | txt2img (%) | |||
| image size | training time | loss () | R@1() | R@1() |
| 224px | 1.00x | 0.3819 | 82.90 | 81.86 |
| 384px | 1.92x | 0.3406 | 84.63 | 83.56 |
| LC25000 | LC25000 | TCGA- | ||||
| image size | PCam | (Lung) | (Colon) | TIL | RSNA | mean |
| 224px | 73.41 | 65.23 | 92.98 | 67.04 | 78.95 | 75.52 |
| 384px | 67.15 | 61.80 | 87.42 | 57.00 | 78.49 | 70.37 |
| image-to-text retrieval (%) | text-to-image retrieval (%) | |
| batch size | R@1() | R@1() |
| 2k | 79.69 | 78.43 |
| 4k | 82.90 | 81.86 |
| img2txt (%) | txt2img (%) | |
| batch size | R@1() | R@1() |
| 4k 4k | 83.98 | 82.71 |
| 4k 64k | 87.32 | 86.66 |
Finally, we investigated the impact of batch size. In Supplementary Table 6, we show larger batch size generally has better validation performance. In Supplementary Table 7, we studied increasing the batch size up to 64k to match the choices of [7, 56]. While there was a further increase in validation performance, we found that the gain did not translate to the downstream evaluation after reaching the batch size of 4k (Supplementary Table 6). The potential explanation for this could be that an extremely large batch size requires more training data and longer epochs. CLIP [7] uses 400M image-text pairs, while PMC-15M has 15M pairs. We chose the 4k batch size to train our BiomedCLIP.
Putting it all together
We pretrained a series of BiomedCLIP models on PMC-15M using the optimal batch schedule above and compared them with general-domain CLIP models [7]. As Supplementary Table 8 shows, large-scale pretraining or continual pretraining on PMC-15M is always helpful, and the best validation performance are generally attained using the biomedical pretrained language model (PubMedBERT), a larger vision transformer, and a higher image resolution. All hyperparameters are summarized in Supplementary Table 9.
| img2txt (%) | txt2img (%) | |||
| model | config | data | R@1() | R@1() |
| OpenAI CLIP | ResNet-50-224-GPT/77 | WIT-400M | 10.31 | 10.38 |
| OpenAI CLIP | ViT-B/16-224-GPT/77 | WIT-400M | 11.82 | 11.65 |
| BiomedCLIP | ResNet-50-224-GPT/77 | WIT-400M PMC-15M | 81.17 | 80.17 |
| BiomedCLIP | ViT-B/16-224-GPT/77 | WIT-400M PMC-15M | 81.57 | 80.89 |
| BiomedCLIP | ViT-B/16-224-BERT/256 | ImageNet/PubMed PMC-15M | 82.90 | 81.86 |
| Hyperparameters | Value |
| optimizer | AdamW [57] |
| peak learning rate | 5.0e-4 |
| weight decay | 0.2 |
| optimizer momentum | , = 0.9, 0.98 |
| eps | 1.0e-6 |
| learning rate schedule | cosine decay |
| epochs | 32 |
| warmup (in steps) | 2000 |
| random seed | 0 |
| image mean | (0.48145466, 0.4578275, 0.40821073) |
| image std | (0.26862954, 0.26130258, 0.27577711) |
| augmentation | RandomResizedCrop |
| validation frequency | every epoch |
Implementation
Our implementation is based on OpenCLIP [58], an open source software adapted for large-scale distributed training with contrastive image-text supervision. The pretraining experiments were conducted with up to 16 NVIDIA A100 GPUs or 16 NVIDIA V100 GPUs, via PyTorch DDP [59, 60]. To reduce memory consumption, we enable gradient checkpointing and automatic mixed precision (AMP) with datatype of bfloat16 (whenever supported by the hardware). In addition, we use a sharding contrastive loss [56], which achieves identical gradients to InfoNCE [23] and reduces memory usage by eliminating redundant computations and only computing the similarities of locally relevant features on each GPU.
| BiomedCLIP | ||
| dataset | classes | templates |
| PCam | normal lymph node | this is an image of {}; |
| lymph node metastasis | {} presented in image | |
| LC25000 (Lung) | lung adenocarcinomas | this is an image of {}; |
| normal lung tissue | {} presented in image | |
| lung squamous cell carcinomas | ||
| LC25000 (Colon) | colon adenocarcinomas | a photo of {}; |
| normal colonic tissue | {} presented in image | |
| TCGA-TIL | none | a photo of {}; |
| tumor infiltrating lymphocytes | {} presented in image | |
| RSNA | normal lung | a photo of {}; |
| pneumonia | {} presented in image | |