Mutual Information-Based Temporal Difference Learning for
Human Pose Estimation in Video
Abstract
Temporal modeling is crucial for multi-frame human pose estimation. Most existing methods directly employ optical flow or deformable convolution to predict full-spectrum motion fields, which might incur numerous irrelevant cues, such as a nearby person or background. Without further efforts to excavate meaningful motion priors, their results are suboptimal, especially in complicated spatio-temporal interactions. On the other hand, the temporal difference has the ability to encode representative motion information which can potentially be valuable for pose estimation but has not been fully exploited. In this paper, we present a novel multi-frame human pose estimation framework, which employs temporal differences across frames to model dynamic contexts and engages mutual information objectively to facilitate useful motion information disentanglement. To be specific, we design a multi-stage Temporal Difference Encoder that performs incremental cascaded learning conditioned on multi-stage feature difference sequences to derive informative motion representation. We further propose a Representation Disentanglement module from the mutual information perspective, which can grasp discriminative task-relevant motion signals by explicitly defining useful and noisy constituents of the raw motion features and minimizing their mutual information. These place us to rank No.1 in the Crowd Pose Estimation in Complex Events Challenge on benchmark dataset HiEve, and achieve state-of-the-art performance on three benchmarks PoseTrack2017, PoseTrack2018, and PoseTrack21.
1 Introduction
Human pose estimation has long been a nontrivial and fundamental problem in the computer vision community. The goal is to localize anatomical keypoints (e.g., nose, ankle, etc.) of human bodies from images or videos. Nowadays, as more and more videos are recorded endlessly, video-based human pose estimation has been extremely desired in enormous applications including live streaming, augmented reality, surveillance, and movement tracking [22, 42, 33].
An extensive body of literature focuses on estimating human poses in static images, ranging from earlier methods employing pictorial structure models [53, 49, 67, 41] to recent attempts leveraging deep convolutional neural networks [47, 54, 56, 33] or Vision Transformers [30, 63, 59]. Despite the impressive performance in still images, the extension of such methods to video-based human pose estimation still remains challenging due to the additional temporal dimension in videos [55, 32]. By nature, the video presents distinctive and valuable dynamic contexts (i.e., the temporal evolution in the visual content) [69]. Therefore, being able to effectively utilize the temporal dynamics (motion information) is fundamentally important for accurate pose estimation in videos [33].
One line of work [33, 52, 35] attempts to derive a unified spatial-temporal representation through implicit motion compensation. [52] presents a 3DHRNet which utilizes 3D convolutions to extract spatiotemporal features of a video tracklet to estimate pose sequences. [33] adopts deformable convolutions to align multi-frame features and aggregates aligned feature maps to predict human poses. On the other hand, [43, 38, 65] explicitly model motion contexts with optical flow. [43, 38] propose to compute dense optical flow between every two frames and leverage the flow features for refining pose heatmaps temporally across multiple frames.
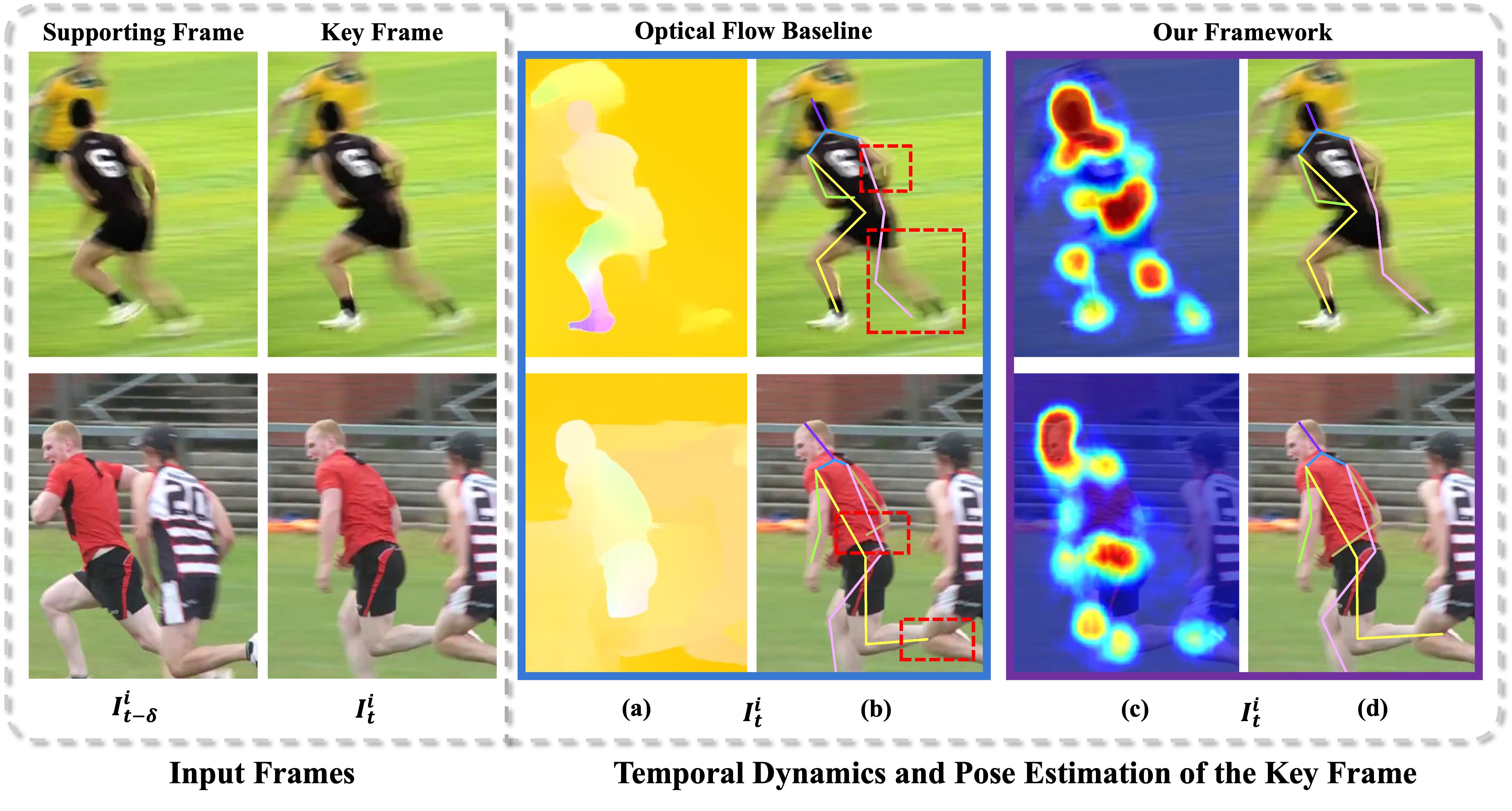
Upon studying the previous methods [32, 33, 38, 43], we empirically observe that the pose estimation performance is boosted with the implicit or explicit imposition of motion priors. However, the movement of any visual evidence is usually attended to in these paradigms, resulting in cluttered motion features that include numerous irrelevant information (e.g., nearby person, background), as illustrated in Fig. 1. Directly exploiting such vanilla motion features delivers inferior results, especially in complex scenarios of mutual occlusion and fast motion. More specifically, not all pixel movements are equally important in video-based human pose estimation [64]. For example, background variations and pixel changes caused by image quality degradation (e.g., blur and occlusion) are usually useless and distracting, whereas the salient pixel movements driven by human body motions play a more important role in understanding motion patterns [19]. Therefore, discovering meaningful motion dynamics is crucial to fully recovering human poses across a video. On the other hand, investigating temporal differences across video frames allows one to discover representative motion cues [50, 57, 23]. Although it has already shown success in various video-related tasks (action recognition [50], video super-resolution [22]), its application on video-based human pose estimation remains under-explored.
In this paper, we present a novel framework, named Temporal Difference Learning based on Mutual Information (TDMI) for human pose estimation. Our TDMI consists of two key components: (i) A multi-stage Temporal Difference Encoder (TDE) is designed to model motion contexts conditioned on multi-stage feature differences among video frames. Specifically, we first compute the feature difference sequences across multiple stages by leveraging a temporal difference operator. Then, we perform incremental cascaded learning via intra- and inter-stage feature integration to derive the motion representation. (ii) We further introduce a Representation Disentanglement module (RDM) from the mutual information perspective, which distills the task-relevant motion features to enhance the frame representation for pose estimation. In particular, we first disentangle the useful and noisy constituents of the vanilla motion representation by activating corresponding feature channels. Then, we theoretically analyze the statistical dependencies between the useful and the noisy motion features and arrive at an information-theoretic loss. Minimizing this mutual information objective encourages the useful motion components to be more discriminative and task-relevant. Our approach achieves significant and consistent performance improvements over current state-of-the-art methods on four benchmark datasets. Extensive ablation studies are conducted to validate the efficacy of each component in the proposed method.
The main contributions of this work can be summarized as follows: (1) We propose a novel framework that leverages temporal differences to model dynamic contexts for video-based human pose estimation. (2) We present a disentangled representation learning strategy to grasp discriminative task-relevant motion signals via an information-theoretic objective. (3) We demonstrate that our approach achieves new state-of-the-art results on four benchmark datasets, PoseTrack2017, PoseTrack2018, PoseTrack21, and HiEve.
2 Related Work
Image-based human pose estimation. With the recent advances in deep learning architectures [16, 48] as well as the availability of large-scale datasets [21, 1, 11, 31], various deep learning methods [2, 10, 44, 56, 30, 63, 59] are proposed for image-based human pose estimation. These approaches broadly fall into two paradigms: bottom-up and top-down. Bottom-up approaches [7, 27, 28] detect individual body parts and associate them with an entire person. [28] proposes a composite framework that employs a Part Intensity Field to localize human body parts and uses a Part Association Field to associate the detected body parts with each other. Conversely, top-down approaches [56, 54, 44, 13, 30] detect bounding boxes of persons first and predict human poses within each bounding box region. [44] presents a high-resolution convolutional architecture that preserves high-resolution features in all stages, demonstrating superior performance for human pose estimation.
Video-based human pose estimation. Existing image-based methods could not generalize well to video streams since they inherently have difficulties in capturing temporal dynamics across frames. A direct approach would be to leverage optical flow to impose motion priors [43, 38]. These approaches typically compute dense optical flow among frames and leverage such motion cues to refine the predicted pose heatmaps. However, the optical flow estimation is computationally intensive and tends to be vulnerable when encountering severe image quality degradation. Another approach [33, 5, 32, 52] considers implicit motion compensation using deformable convolutions or 3DCNNs. [5, 32] propose to model multi-granularity joint movements based on heatmap residuals and perform pose resampling or pose warping through deformable convolutions. As the above cases generally consider motion details from all pixel locations, their resulting representations are suboptimal for accurate pose estimation.
Temporal difference modeling. Temporal difference operations, i.e., RGB Difference (image-level) [51, 69, 36, 50] and Feature Difference (feature-level) [34, 23, 29], are typically exploited for motion extraction, showing outstanding performance with high efficiency for many video-related tasks such as action recognition [50, 29] and video super-resolution [22]. [69, 36, 50] leverage RGB difference as an efficient alternative modality to optical flow to represent motions. [22] proposes to explicitly model temporal differences in both LR and HR space. However, the additional RGB difference branch usually replicates the feature-extraction backbone, which increases the model complexity. On the other hand, [34, 23, 29] employ a feature difference operation for network design which our work falls within this scope more closely. In contrast to previous methods that simply compute feature differences, we seek to disentangle discriminative task-relevant temporal difference representations for pose estimation.
3 Our Approach
Preliminaries. Our work follows the top-down paradigm, starting with an object detector to obtain the bounding boxes for individual persons in a video frame . Then, each bounding box is enlarged by to crop the same individual in a consecutive frame sequence with being a predefined temporal span. In this way, we attain the cropped video clip for person .
Problem formulation. Given a cropped video segment centered on the key frame , we are interested in estimating the pose in . Our goal is to better leverage frame sequences through principled temporal difference learning and useful information disentanglement, thereby addressing the common shortcoming of existing methods in failing to adequately mine motion dynamics.
Method overview. The overall pipeline of the proposed TDMI is outlined in Fig. 2. Our framework consists of two key components: a multi-stage Temporal Difference Encoder (TDE) (Sec. 3.1) and a Representation Disentanglement module (RDM) (Sec. 3.2). Specifically, we first extract visual features of the input sequence and feed them to TDE, which computes feature differences and performs information integration to obtain the motion feature . Then, RDM takes motion feature as input and excavates its useful constituents to yield . Finally, both the motion feature and the visual feature of the key frame are aggregated to produce the enhanced representation . is handed to a detection head which outputs the pose estimation . In the following, we explain the two key components in depth.
3.1 Multi-Stage Temporal Difference Encoder
As multi-stage feature integration enables the network to retain diverse semantic information from fine to coarse scale [24, 37, 64], we propose to simultaneously aggregate shallow feature differences (early stages) compressing detailed motion cues and deep feature differences (late stages) encoding global semantic movements to derive informative and fine-grained motion representations. A naive approach to fuse features in multiple stages is to feed them into a convolutional network [26, 9]. However, this simple fusion solution suffers from two drawbacks: (i) redundant features might be over-emphasized, and (ii) fine-grained cues of each stage cannot be fully reserved. Motivated by these observations and insights, we present a multi-stage temporal difference encoder (TDE) with an incremental cascaded learning architecture, addressing the above issues through two designs: a spatial modulation mechanism to adaptively focus on important information at each stage, and a progressive accumulation mechanism to preserve fine-grained contexts across all stages.
Specifically, given an image sequence , our proposed TDE first constructs multi-stage feature difference sequences and performs both intra- and inter-stage feature fusion to yield the encoded motion representation . For simplicity, we take in the following.
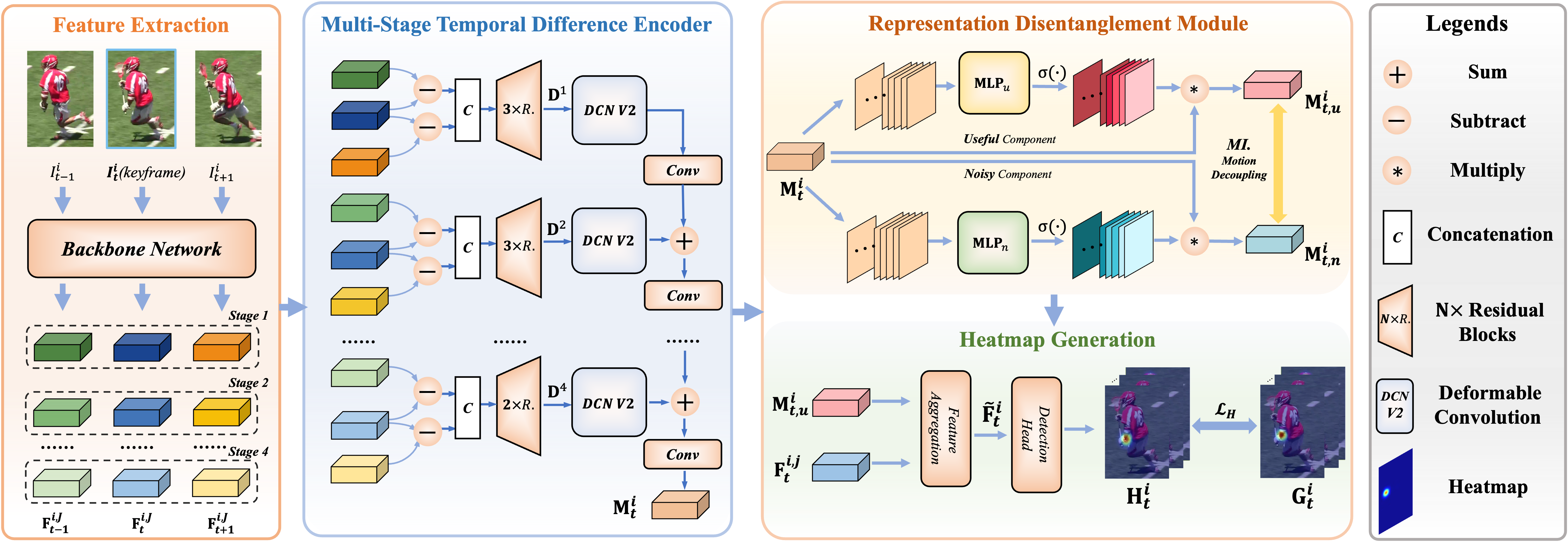
Feature difference sequences generation. We build TDE upon the HRNet-W48 [44] network, which includes four convolutional stages to extract feature maps of the input sequence . The superscript refers to network stages. Subsequently, we compute the consecutive feature difference sequences over four stages as follows:
| (1) |
Intra-stage feature fusion. Given the feature difference sequences , several residual blocks [16] are leveraged to separately aggregate the feature elements within each stage to generate stage-specific motion representations . This computation can be expressed as:
| (2) |
where is the concatenation operation and is the function of convolutional blocks. In practice, we employ residual blocks with kernel size to aggregate the features at corresponding stages, respectively.
Inter-stage feature fusion. After obtaining the motion features of each stage , we perform feature integration across stages to obtain the fused motion representation , via the proposed spatial modulation and progressive accumulation. (1) We first employ deformable convolutions (DCN V2 [70]) to adaptively modulate the spatial-wise responses of each stage feature. Specifically, given , we independently estimate the kernel sampling offsets and modulated scalars :
| (3) | ||||
The adaptively learned offsets reveal the pixel movement association fields while the modulated scalars reflect the magnitude of motion information in each pixel location. Then, we apply deformable convolutions which take the motion features , the kernel offsets , and the modulated scalars as input, and output the spatially calibrated motion features of each stage :
| (4) |
(2) As shown in Fig. 2, after the spatial modulation, TDE adds the motion feature in the previous stage to the modulated feature, followed by several convolutions. Such processing is executed progressively until all stages of features are converged to . The above computation is formulated as:
| (5) |
By selectively and comprehensively aggregating multi-stage features, our TDE is able to encode informative and fine-grained motion representation .
3.2 Representation Disentanglement Module
Directly leveraging the encoded motion feature for subsequent pose estimation is prone to inevitable task-irrelevant pixel movements (e.g., background, occlusion). To alleviate this limitation, one can train a Vision Attention module end-to-end via a heatmap loss to further distill meaningful motion cues. While being straightforward, the learned features in this approach tend to be plain and undistinguished, which results in limited performance improvement (see Table 7). After manual examination of the extracted temporal dynamic features for pose estimation, it would be fruitful to investigate whether introducing supervision to the meaningful information distillation would facilitate the task.
Ideally, incorporating motion information annotations as feature constraints would simplify this problem. Unfortunately, such movement labels in videos are typically absent in most cases. In light of the above observations, we propose to approach this issue through a mutual information viewpoint. In specific, we explicitly define both useful composition and noisy composition of the vanilla motion feature , in which is used for subsequent task while serves as a contrastive landmark. By introducing mutual information supervision to reduce the statistical dependence between and , we can grasp discriminative task-relevant motion signals. Coupling these network objectives, the representation disentanglement module (RDM) is designed.
Representation factorization. Given the vanilla motion representation , we factorize it into useful motion component and noisy component by activating corresponding feature channels. Specifically, we first squeeze the global spatial information into a channel descriptor via a global average pooling (GAP) layer. Then, a Multilayer Perceptron (MLP) is used to capture channel-wise interactions followed by a sigmoid function to output an attention mask. This channel-wise attention matrix is finally exploited to rescale the input feature to output and , respectively. The above factorization process is formulated as:
| (6) | |||
The symbol denotes the sigmoid function and refers to the channel-wise multiplication. The network parameters of and are learned independently.
Heatmap generation. We integrate the useful motion feature and the visual feature of the key frame through several residual blocks to obtain the enhanced representation . is fed to a detection head to yield the estimated pose heatmaps . We implement the detection head using a convolutional layer.
Mutual information objective. Mutual information (MI) measures the amount of information one variable reveals about the other [33, 18]. Formally, the MI between two random variables and is defined as:
| (7) |
where is the joint probability distribution between and , while and are their marginals. Within this framework, our main objective for learning effective temporal differences is formulated as:
| (8) |
The term rigorously quantifies the amount of information shared between the useful motion feature and the noisy feature . Recall that is used for the subsequent pose estimation task. Intuitively, at the beginning of model training, both meaningful and noisy motion cues will be encoded into and simultaneously under the constraint of mutual information minimization. As the training progresses, the features encoded by and are gradually systematized into task-relevant motion information and irrelevant motion clues. Under this contrastive setting of , the useful motion feature would be more discriminative and beneficial for the pose estimation task, as shown in Fig. 1 (c).
Furthermore, two regularization functions are introduced to facilitate model optimization. (i) We propose to improve the capacity of the multi-stage temporal difference encoder (TDE) to perceive meaningful information:
| (9) |
where measures the useful motion information compressed in the vanilla motion feature . Maximizing this term encourages more abundant and effective motion cues to be encoded in our TDE.
(ii) We propose to mitigate the information dropping during the feature enhancement of :
| (10) |
where refers to the label, and terms and quantify the vanishing task-relevant information in and respectively when aggregating them into the enhanced feature . Minimizing these two regularization terms fosters the nondestructive propagation of information. Given the notorious difficulty of conditional MI calculations [17, 46], we adopt a simplified version as done in [33, 68]. We approximate the first term as:
3.3 Loss Functions
Overall, our loss function consists of two portions. (1) We employ the standard pose heatmap loss to supervise the final pose estimation:
| (14) |
where and denote the predicted and ground truth pose heatmaps, respectively. (2) We also leverage the proposed mutual information objective to supervise the learning of motion features. Our total loss is given by:
| (15) |
where is a hyper-parameter to balance the ratio of different loss terms.
4 Experiments
| Method | Head | Shoulder | Elbow | Wrist | Hip | Knee | Ankle | Mean |
|---|---|---|---|---|---|---|---|---|
| PoseTracker [14] | ||||||||
| PoseFlow [58] | ||||||||
| JointFlow [12] | - | - | - | - | - | - | - | |
| FastPose [66] | ||||||||
| TML++ [20] | - | - | - | - | - | - | - | |
| Simple (R-50) [56] | ||||||||
| Simple (R-152) [56] | ||||||||
| STEmbedding [25] | ||||||||
| HRNet [44] | ||||||||
| MDPN [15] | ||||||||
| CorrTrack [40] | ||||||||
| Dynamic-GNN [60] | ||||||||
| PoseWarper [5] | ||||||||
| DCPose [32] | ||||||||
| DetTrack [52] | ||||||||
| FAMI-Pose [33] | ||||||||
| TDMI (Ours) | ||||||||
| TDMI-ST (Ours) |
| Method | Head | Shoulder | Elbow | Wrist | Hip | Knee | Ankle | Mean |
|---|---|---|---|---|---|---|---|---|
| STAF [39] | - | - | - | - | - | |||
| AlphaPose [13] | ||||||||
| TML++ [20] | - | - | - | - | - | - | - | |
| MDPN [15] | ||||||||
| PGPT [3] | - | - | - | - | - | |||
| Dynamic-GNN [60] | ||||||||
| PoseWarper [5] | ||||||||
| PT-CPN++ [61] | ||||||||
| DCPose [32] | ||||||||
| DetTrack [52] | ||||||||
| FAMI-Pose [33] | ||||||||
| TDMI (Ours) | ||||||||
| TDMI-ST (Ours) |
| Method | Head | Shoulder | Elbow | Wrist | Hip | Knee | Ankle | Mean |
|---|---|---|---|---|---|---|---|---|
| Tracktor++ w. poses [4, 11] | - | - | - | - | - | - | - | |
| CorrTrack [40, 11] | - | - | - | - | - | - | - | |
| CorrTrack w. ReID [40, 11] | - | - | - | - | - | - | - | |
| Tracktor++ w. corr. [4, 11] | - | - | - | - | - | - | - | |
| DCPose [32] | ||||||||
| FAMI-Pose [33] | ||||||||
| TDMI (Ours) | ||||||||
| TDMI-ST (Ours) |
4.1 Experimental Settings
Datasets. PoseTrack is a large-scale benchmark dataset for video-based human pose estimation. Specifically, PoseTrack2017 contains video sequences for training and video sequences for validation (following the official protocol), with a total of pose annotations. PoseTrack2018 greatly increases the number of videos and includes for training and for validation (with pose annotations). Both datasets are annotated with keypoints, with an additional flag for joint visibility. PoseTrack21 further extends pose annotations of the PoseTrack2018 dataset, especially for particular small persons and persons in crowds, including pose annotations. The flag of joint visibility is re-defined in PoseTrack21 so that occlusion information can be utilized. HiEve [31] is a very challenging benchmark dataset for human-centric video analysis in various realistic crowded and complex events (e.g., earthquake, getting-off train, and bike collision), containing video clips where for training and for testing. This dataset possesses a substantially larger data scale and includes the currently largest number of pose annotations ().
| Method | w_AP@avg | w_AP@50 | w_AP@75 | w_AP@90 | AP@avg | AP@50 | AP@75 | AP@90 |
|---|---|---|---|---|---|---|---|---|
| RSN18 [6] | ||||||||
| DHRN FT [44] | ||||||||
| ADAM+PRM [31] | ||||||||
| DH_IBA [62] | ||||||||
| TryNet [32] | ||||||||
| ccc [8] | ||||||||
| TDMI-ST (Ours) |
Evaluation metric. We employ the standard pose estimation metric namely average precision (AP) to evaluate our model. We first compute the AP for each joint and then obtain the final performance (mAP) by averaging all joints.
Implementation details. Our TDMI framework is implemented with PyTorch. For visual feature extraction, we leverage the HRNet-W48 [44] model that is pre-trained on the COCO dataset. We incorporate several data augmentation strategies as adopted in [44, 5, 56], including random rotation , random scale , truncation (half body), and flipping. The temporal span is set to , i.e., previous and future frames. We use the Adam optimizer with an initial learning rate of (decays to , , and at the , , and epochs, respectively). We train the model using TITAN RTX GPUs. The training process is terminated within epochs. To weight difference losses in Eq. 15, we empirically found that is the most effective. During the feature enhancement of , the final stage feature is adopted as the visual feature.

4.2 Comparison with State-of-the-art Approaches
Results on the PoseTrack2017 dataset. We first evaluate our method on the PoseTrack2017 dataset. A total of methods are compared and their performances on the validation set are reported in Table 1. Our TDMI model consistently outperforms existing state-of-the-art methods, reaching an mAP of . To fully leverage temporal clues, we extend the TDMI to TDMI-ST where we replace the keyframe visual feature with the spatiotemporal feature of the input sequence to yield the final representation . The proposed TDMI-ST further pushes forward the performance boundary and achieves an mAP of . Remarkably, our TDMI-ST improves mAP by points over the adopted backbone network HRNet-W48 [44]. Compared to the previous best-performed method FAMI-Pose [33], our TDMI-ST also delivers a mAP gain. The performance boost for challenging joints (i.e., wrist, ankle) is also encouraging: we obtain an mAP of () for wrists and an mAP of () for ankles. Such consistent and significant performance improvements suggest the importance of explicitly embracing meaningful motion information. Moreover, we display the visualized results for scenarios with complex spatio-temporal interactions (e.g., occlusion, blur) in Fig. 3, which attest to the robustness of the proposed method. Results on the PoseTrack2018 dataset. We further benchmark our model on the PoseTrack2018 dataset. Empirical comparisons on the validation set are tabulated in Table 2. As presented in this table, our basic model, TDMI, surpasses all other approaches and achieves an mAP of . Our TDMI-ST model, on the other hand, attains the new state-of-the-art results over all joints and obtains the final performance of mAP, with an mAP of , , and for the elbow, wrist, and ankle, respectively.
Results on the PoseTrack21 dataset. Table 3 reports the results of our method as well as other state-of-the-art methods on the PoseTrack21 dataset. Quantitive results of the first four baselines [4, 40, 11] are officially provided by the dataset [11]. We further reproduce several previous impressive approaches (i.e., DCPose [32] and FAMI-Pose [33]) according to their released implementations on GitHub, and evaluate their performances in this dataset. From Table 3, we observe that FAMI-Pose [33] achieves favorable pose estimation results with an mAP of . In contrast, our TDMI and TDMI-ST are able to obtain mAP and mAP, respectively. Another observation is that PoseTrack21 mainly increases the pose annotations of small persons and persons in crowds for PoseTrack2018. Interestingly, the proposed TDMI-ST attains a better performance on PoseTrack21 with respect to PoseTrack2018 ( mAP), which might be an evidence to show the effectiveness and robustness of our method especially for challenging scenes.
Results on the HiEve dataset. Furthermore, we evaluate our model on the largest HiEve benchmark dataset. The detailed results of the test set are tabulated in Table 4. We upload the prediction results of our model to the HiEve test server111http://humaninevents.org/oltp.html?title=3 to obtain results. Our TDMI-ST achieves top scoring weight-average AP (w_AP@avg) of on the HiEve leaderboard. Significantly, compared to ccc [8] that uses extra data to train the model, we still achieve performance improvements by w_AP and AP, respectively.
| Method | TDE | RDM | Mean |
|---|---|---|---|
| HRNet [44] | |||
| Op-Flow | |||
| (a) | ✓ | ||
| (b) | ✓ | ✓ |
| Method | Multi-stage | Spatial modulation | Progressive fusion | Mean |
| (a) | ||||
| (b) | ✓ | |||
| (c) | ✓ | ✓ | ||
| (d) | ✓ | ✓ | ✓ |
| Method | Factorization | MI objective | Mean |
|---|---|---|---|
| TDMI, w/o RDM | |||
| (a) | ✓ | ||
| (b) | ✓ | ✓ | |
| (c) | ✓ | ✓ |
Comparison of visual results. In addition to the quantitative analysis, we also qualitatively examine the capability of our approach in handling complex situations such as occlusion and blur. We depict in Fig. 4 the side-by-side comparisons of a) our TDMI against state-of-the-art methods b) HRNet [44] and c) FAMI-Pose [33]. It is observed that our approach consistently provides more accurate and robust pose detection for various challenging scenarios. HRNet is designed for static images and does not incorporate temporal dynamics, resulting in suboptimal results in degraded frames. In contrast, FAMI-Pose performs implicit motion compensation yet lacks effective information distillation. Through the principled design of TDE and RDM for temporal difference modeling and useful information disentanglement, our TDMI is more adept at handling challenging scenes such as occlusion and blur.
4.3 Ablation Study
We perform ablation studies focused on examining the contribution of each component in our TDMI framework, including the multi-stage Temporal Difference Encoder (TDE) and the Representation Disentanglement module (RDM). We also investigate the effectiveness of various micro designs within each component. All experiments are conducted on the PoseTrack2017 validation set.

Study on components of TDMI. We empirically evaluate the efficacy of each component in the proposed TDMI and report quantitative results in Table 7. Op-Flow is a baseline where we employ optical flows predicted by the RAFT [45] as motion representations. (a) For the first setting, we introduce TDE to the HRNet-W48 [44] baseline for capturing motion contexts. Remarkably, the motion clues encoded by the TDE already improve over the baseline by a large margin of mAP. This demonstrates the effectiveness of our TDE in introducing motion information to facilitate video-based human pose estimation. On the other hand, our TDE also delivers a performance gain of mAP over the baseline Op-Flow. This highlights the great potential of temporal differences in representing motions as compared to complex optical flow. (b) For the next setting, we further incorporate the RDM to discover meaningful motions. The results in mAP increase to by . This significant performance improvement on top of the well-established TDE corroborates the importance of excavating meaningful temporal dynamics in guiding accurate pose estimation.
Study on multi-stage Temporal Difference Encoder. We modify the TDE with various designs to investigate their influences on the final performance. As reported in Table 7, four experiments are conducted: (a) fusing only the features of the final stage , (b) directly aggregating multi-stage features via simple concatenation and convolution, (c) progressively integrating multi-stage features, and (d) our complete TDE with spatial modulation and progressive fusion. From this table, we observe that multi-stage feature fusion indeed outperforms using only single-stage features, yet the simple fusion scheme (b) yields a slight performance improvement ( mAP). By progressively aggregating multi-stage features (c), detailed information at each stage is preserved which provides an mAP gain of points. Our complete TDE (d) further incorporates a spatial modulation mechanism to adaptively select important information of each stage, achieving the best performance.
Study on Representation Disentanglement module. In addition, we examine the effects of RDM under different settings and present the results in Table 7. We first conduct a simple baseline (a) in which the MI objective is removed. This method partially distills the useful motion information and marginally improves the mAP by (). We then incorporate the MI objective, which corresponds to our full RDM (b). The noticeable performance enhancement of mAP provides empirical evidence that our proposed MI objective is effective as additional supervision to facilitate the learning of discriminative task-relevant motion clues. We also attempt to perform the feature factorization by splitting channels (c) and the mAP drops , which suggests that the channel splitting scheme might be inapplicable to our TDMI framework.
5 Conclusion and Future Works
In this paper, we investigate the video-based human pose estimation task from the perspective of effectively exploiting dynamic contexts through temporal difference learning and useful information disentanglement. We present a multi-stage Temporal Difference Encoder (TDE) to capture motion clues conditioned on explicit feature difference representation. Theoretically, we further build a Representation Disentanglement module (RDM) on top of mutual information to grasp task-relevant information. Extensive experiments demonstrate that the proposed method outperforms state-of-the-art approaches on four benchmark datasets, including PoseTrack2017, PoseTrack2018, PoseTrack21, and HiEve. Future works include applications to other video-related tasks such as 3D human pose estimation and action recognition. The temporal difference features can also be integrated into existing pose-tracking pipelines to assess the similarity of human motions for data association.
6 Acknowledgements
This work is supported in part by the National Natural Science Foundation of China under grant No. 62203184. This work is also supported in part by the MSIT, Korea, under the ITRC program (IITP-2022-2020-0-01789) and the High-Potential Individuals Global Training Program (RS-2022-00155054) supervised by the IITP.
References
- [1] Mykhaylo Andriluka, Umar Iqbal, Eldar Insafutdinov, Leonid Pishchulin, Anton Milan, Juergen Gall, and Bernt Schiele. Posetrack: A benchmark for human pose estimation and tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
- [2] Bruno Artacho and Andreas Savakis. Unipose: Unified human pose estimation in single images and videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7035–7044, 2020.
- [3] Qian Bao, Wu Liu, Yuhao Cheng, Boyan Zhou, and Tao Mei. Pose-guided tracking-by-detection: Robust multi-person pose tracking. IEEE Transactions on Multimedia, 23:161–175, 2020.
- [4] Philipp Bergmann, Tim Meinhardt, and Laura Leal-Taixe. Tracking without bells and whistles. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 941–951, 2019.
- [5] Gedas Bertasius, Christoph Feichtenhofer, Du Tran, Jianbo Shi, and Lorenzo Torresani. Learning temporal pose estimation from sparsely-labeled videos. In Advances in Neural Information Processing Systems, pages 3027–3038, 2019.
- [6] Yuanhao Cai, Zhicheng Wang, Zhengxiong Luo, Binyi Yin, Angang Du, Haoqian Wang, Xinyu Zhou, Erjin Zhou, Xiangyu Zhang, and Jian Sun. Learning delicate local representations for multi-person pose estimation. arXiv preprint arXiv:2003.04030, 2020.
- [7] Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
- [8] Shuning Chang, Li Yuan, Xuecheng Nie, Ziyuan Huang, Yichen Zhou, Yupeng Chen, Jiashi Feng, and Shuicheng Yan. Towards accurate human pose estimation in videos of crowded scenes. In Proceedings of the 28th ACM International Conference on Multimedia, pages 4630–4634, 2020.
- [9] Yilun Chen, Zhicheng Wang, Yuxiang Peng, Zhiqiang Zhang, Gang Yu, and Jian Sun. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7103–7112, 2018.
- [10] Bowen Cheng, Bin Xiao, Jingdong Wang, Honghui Shi, Thomas S Huang, and Lei Zhang. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5386–5395, 2020.
- [11] Andreas Doering, Di Chen, Shanshan Zhang, Bernt Schiele, and Juergen Gall. Posetrack21: A dataset for person search, multi-object tracking and multi-person pose tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20963–20972, 2022.
- [12] Andreas Doering, Umar Iqbal, and Juergen Gall. Joint flow: Temporal flow fields for multi person tracking. arXiv preprint arXiv:1805.04596, 2018.
- [13] Hao-Shu Fang, Shuqin Xie, Yu-Wing Tai, and Cewu Lu. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, pages 2334–2343, 2017.
- [14] Rohit Girdhar, Georgia Gkioxari, Lorenzo Torresani, Manohar Paluri, and Du Tran. Detect-and-track: Efficient pose estimation in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 350–359, 2018.
- [15] Hengkai Guo, Tang Tang, Guozhong Luo, Riwei Chen, Yongchen Lu, and Linfu Wen. Multi-domain pose network for multi-person pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), pages 0–0, 2018.
- [16] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [17] R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Bachman, Adam Trischler, and Yoshua Bengio. Learning deep representations by mutual information estimation and maximization. In International Conference on Learning Representations, 2018.
- [18] Xuege Hou, Yali Li, and Shengjin Wang. Disentangled representation for age-invariant face recognition: A mutual information minimization perspective. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3692–3701, 2021.
- [19] Ziyuan Huang, Shiwei Zhang, Jianwen Jiang, Mingqian Tang, Rong Jin, and Marcelo H Ang. Self-supervised motion learning from static images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1276–1285, 2021.
- [20] Jihye Hwang, Jieun Lee, Sungheon Park, and Nojun Kwak. Pose estimator and tracker using temporal flow maps for limbs. In 2019 International Joint Conference on Neural Networks (IJCNN), pages 1–8. IEEE, 2019.
- [21] Umar Iqbal, Anton Milan, and Juergen Gall. Posetrack: Joint multi-person pose estimation and tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
- [22] Takashi Isobe, Xu Jia, Xin Tao, Changlin Li, Ruihuang Li, Yongjie Shi, Jing Mu, Huchuan Lu, and Yu-Wing Tai. Look back and forth: Video super-resolution with explicit temporal difference modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17411–17420, 2022.
- [23] Boyuan Jiang, MengMeng Wang, Weihao Gan, Wei Wu, and Junjie Yan. Stm: Spatiotemporal and motion encoding for action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2000–2009, 2019.
- [24] Chenru Jiang, Kaizhu Huang, Shufei Zhang, Xinheng Wang, and Jimin Xiao. Pay attention selectively and comprehensively: Pyramid gating network for human pose estimation without pre-training. In Proceedings of the 28th ACM International Conference on Multimedia, pages 2364–2371, 2020.
- [25] Sheng Jin, Wentao Liu, Wanli Ouyang, and Chen Qian. Multi-person articulated tracking with spatial and temporal embeddings. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5664–5673, 2019.
- [26] Lipeng Ke, Ming-Ching Chang, Honggang Qi, and Siwei Lyu. Multi-scale structure-aware network for human pose estimation. In Proceedings of the european conference on computer vision (ECCV), pages 713–728, 2018.
- [27] Muhammed Kocabas, Salih Karagoz, and Emre Akbas. Multiposenet: Fast multi-person pose estimation using pose residual network. In Proceedings of the European conference on computer vision (ECCV), pages 417–433, 2018.
- [28] Sven Kreiss, Lorenzo Bertoni, and Alexandre Alahi. Pifpaf: Composite fields for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 11977–11986, 2019.
- [29] Yan Li, Bin Ji, Xintian Shi, Jianguo Zhang, Bin Kang, and Limin Wang. Tea: Temporal excitation and aggregation for action recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 909–918, 2020.
- [30] Yanjie Li, Shoukui Zhang, Zhicheng Wang, Sen Yang, Wankou Yang, Shu-Tao Xia, and Erjin Zhou. Tokenpose: Learning keypoint tokens for human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11313–11322, 2021.
- [31] Weiyao Lin, Huabin Liu, Shizhan Liu, Yuxi Li, Rui Qian, Tao Wang, Ning Xu, Hongkai Xiong, Guo-Jun Qi, and Nicu Sebe. Human in events: A large-scale benchmark for human-centric video analysis in complex events. arXiv preprint arXiv:2005.04490, 2020.
- [32] Zhenguang Liu, Haoming Chen, Runyang Feng, Shuang Wu, Shouling Ji, Bailin Yang, and Xun Wang. Deep dual consecutive network for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 525–534, 2021.
- [33] Zhenguang Liu, Runyang Feng, Haoming Chen, Shuang Wu, Yixing Gao, Yunjun Gao, and Xiang Wang. Temporal feature alignment and mutual information maximization for video-based human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11006–11016, 2022.
- [34] Zhaoyang Liu, Donghao Luo, Yabiao Wang, Limin Wang, Ying Tai, Chengjie Wang, Jilin Li, Feiyue Huang, and Tong Lu. Teinet: Towards an efficient architecture for video recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 11669–11676, 2020.
- [35] Yue Luo, Jimmy Ren, Zhouxia Wang, Wenxiu Sun, Jinshan Pan, Jianbo Liu, Jiahao Pang, and Liang Lin. Lstm pose machines. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5207–5215, 2018.
- [36] Joe Yue-Hei Ng and Larry S Davis. Temporal difference networks for video action recognition. In 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1587–1596. IEEE, 2018.
- [37] Yanwei Pang, Yazhao Li, Jianbing Shen, and Ling Shao. Towards bridging semantic gap to improve semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4230–4239, 2019.
- [38] Tomas Pfister, James Charles, and Andrew Zisserman. Flowing convnets for human pose estimation in videos. In Proceedings of the IEEE International Conference on Computer Vision, pages 1913–1921, 2015.
- [39] Yaadhav Raaj, Haroon Idrees, Gines Hidalgo, and Yaser Sheikh. Efficient online multi-person 2d pose tracking with recurrent spatio-temporal affinity fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4620–4628, 2019.
- [40] Umer Rafi, Andreas Doering, Bastian Leibe, and Juergen Gall. Self-supervised keypoint correspondences for multi-person pose estimation and tracking in videos. In European Conference on Computer Vision, pages 36–52. Springer, 2020.
- [41] Benjamin Sapp, Alexander Toshev, and Ben Taskar. Cascaded models for articulated pose estimation. In European conference on computer vision, pages 406–420. Springer, 2010.
- [42] Luca Schmidtke, Athanasios Vlontzos, Simon Ellershaw, Anna Lukens, Tomoki Arichi, and Bernhard Kainz. Unsupervised human pose estimation through transforming shape templates. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2484–2494, 2021.
- [43] Jie Song, Limin Wang, Luc Van Gool, and Otmar Hilliges. Thin-slicing network: A deep structured model for pose estimation in videos. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4220–4229, 2017.
- [44] Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5693–5703, 2019.
- [45] Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. In European conference on computer vision, pages 402–419. Springer, 2020.
- [46] Xudong Tian, Zhizhong Zhang, Shaohui Lin, Yanyun Qu, Yuan Xie, and Lizhuang Ma. Farewell to mutual information: Variational distillation for cross-modal person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1522–1531, 2021.
- [47] Alexander Toshev and Christian Szegedy. Deeppose: Human pose estimation via deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2014.
- [48] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008, 2017.
- [49] Fang Wang and Yi Li. Beyond physical connections: Tree models in human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 596–603, 2013.
- [50] Limin Wang, Zhan Tong, Bin Ji, and Gangshan Wu. Tdn: Temporal difference networks for efficient action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1895–1904, 2021.
- [51] Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal segment networks: Towards good practices for deep action recognition. In European conference on computer vision, pages 20–36. Springer, 2016.
- [52] Manchen Wang, Joseph Tighe, and Davide Modolo. Combining detection and tracking for human pose estimation in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11088–11096, 2020.
- [53] Yang Wang and Greg Mori. Multiple tree models for occlusion and spatial constraints in human pose estimation. In European Conference on Computer Vision, pages 710–724. Springer, 2008.
- [54] Shih-En Wei, Varun Ramakrishna, Takeo Kanade, and Yaser Sheikh. Convolutional pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
- [55] Jiamin Wu, Tianzhu Zhang, Zhe Zhang, Feng Wu, and Yongdong Zhang. Motion-modulated temporal fragment alignment network for few-shot action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9151–9160, 2022.
- [56] Bin Xiao, Haiping Wu, and Yichen Wei. Simple baselines for human pose estimation and tracking. In Proceedings of the European conference on computer vision (ECCV), pages 466–481, 2018.
- [57] Junfei Xiao, Longlong Jing, Lin Zhang, Ju He, Qi She, Zongwei Zhou, Alan Yuille, and Yingwei Li. Learning from temporal gradient for semi-supervised action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3252–3262, 2022.
- [58] Yuliang Xiu, Jiefeng Li, Haoyu Wang, Yinghong Fang, and Cewu Lu. Pose flow: Efficient online pose tracking. arXiv preprint arXiv:1802.00977, 2018.
- [59] Sen Yang, Zhibin Quan, Mu Nie, and Wankou Yang. Transpose: Keypoint localization via transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11802–11812, 2021.
- [60] Yiding Yang, Zhou Ren, Haoxiang Li, Chunluan Zhou, Xinchao Wang, and Gang Hua. Learning dynamics via graph neural networks for human pose estimation and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8074–8084, 2021.
- [61] Dongdong Yu, Kai Su, Jia Sun, and Changhu Wang. Multi-person pose estimation for pose tracking with enhanced cascaded pyramid network. In Proceedings of the European Conference on Computer Vision (ECCV), pages 0–0, 2018.
- [62] Lei Yuan, Shu Zhang, Feng Fubiao, Naike Wei, and Huadong Pan. Combined distillation pose. In Proceedings of the 28th ACM International Conference on Multimedia, pages 4635–4639, 2020.
- [63] Yuhui Yuan, Rao Fu, Lang Huang, Weihong Lin, Chao Zhang, Xilin Chen, and Jingdong Wang. Hrformer: High-resolution vision transformer for dense predict. Advances in Neural Information Processing Systems, 34:7281–7293, 2021.
- [64] Wang Zeng, Sheng Jin, Wentao Liu, Chen Qian, Ping Luo, Wanli Ouyang, and Xiaogang Wang. Not all tokens are equal: Human-centric visual analysis via token clustering transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11101–11111, 2022.
- [65] Dingwen Zhang, Guangyu Guo, Dong Huang, and Junwei Han. Poseflow: A deep motion representation for understanding human behaviors in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6762–6770, 2018.
- [66] Jiabin Zhang, Zheng Zhu, Wei Zou, Peng Li, Yanwei Li, Hu Su, and Guan Huang. Fastpose: Towards real-time pose estimation and tracking via scale-normalized multi-task networks. arXiv preprint arXiv:1908.05593, 2019.
- [67] Xiaoqin Zhang, Changcheng Li, Xiaofeng Tong, Weiming Hu, Steve Maybank, and Yimin Zhang. Efficient human pose estimation via parsing a tree structure based human model. In 2009 IEEE 12th International Conference on Computer Vision, pages 1349–1356. IEEE, 2009.
- [68] Long Zhao, Yuxiao Wang, Jiaping Zhao, Liangzhe Yuan, Jennifer J Sun, Florian Schroff, Hartwig Adam, Xi Peng, Dimitris Metaxas, and Ting Liu. Learning view-disentangled human pose representation by contrastive cross-view mutual information maximization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12793–12802, 2021.
- [69] Yue Zhao, Yuanjun Xiong, and Dahua Lin. Recognize actions by disentangling components of dynamics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6566–6575, 2018.
- [70] Xizhou Zhu, Han Hu, Stephen Lin, and Jifeng Dai. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9308–9316, 2019.