LINe: Out-of-Distribution Detection by Leveraging Important Neurons
Abstract
It is important to quantify the uncertainty of input samples, especially in mission-critical domains such as autonomous driving and healthcare, where failure predictions on out-of-distribution (OOD) data are likely to cause big problems. OOD detection problem fundamentally begins in that the model cannot express what it is not aware of. Post-hoc OOD detection approaches are widely explored because they do not require an additional re-training process which might degrade the model’s performance and increase the training cost. In this study, from the perspective of neurons in the deep layer of the model representing high-level features, we introduce a new aspect for analyzing the difference in model outputs between in-distribution data and OOD data. We propose a novel method, Leveraging Important Neurons (LINe), for post-hoc Out of distribution detection. Shapley value-based pruning reduces the effects of noisy outputs by selecting only high-contribution neurons for predicting specific classes of input data and masking the rest. Activation clipping fixes all values above a certain threshold into the same value, allowing LINe to treat all the class-specific features equally and just consider the difference between the number of activated feature differences between in-distribution and OOD data. Comprehensive experiments verify the effectiveness of the proposed method by outperforming state-of-the-art post-hoc OOD detection methods on CIFAR-10, CIFAR-100, and ImageNet datasets. Code is available on https://github.com/LINe-OOD
1 Introduction
Recently, deep learning has made tremendous advances in various fields. This advancement has captivated numerous researchers, leading to many attempts to apply deep learning techniques to real-world applications. However, applying these state-of-the-art techniques to real-world applications is often limited for several reasons. One primary obstacle is the presence of unseen classes of samples during training. These samples, referred to as out-of-distribution (OOD) data, can compromise a model’s stability and, in some cases, severely impair its performance. The inherent characteristics of OOD samples can lead to potentially severe consequences in mission-critical domains, such as autonomous driving and medical applications. So, effectively handling these OOD samples is vital to avoid problems, such as car crashes and misdiagnosis.
For OOD detection, numerous techniques have been explored to analyze the distinction between in-distribution (ID) data and OOD data. There are several approaches to OOD detection, including confidence-based methods [29, 11, 7, 16, 19], density-based methods [27, 64, 1, 40, 42, 24, 63, 22, 51, 20, 38, 23], and distance-based methods[28, 47, 41, 49, 9, 59, 50, 18, 35]. The post-hoc method is one approach in OOD detection that offers significant advantages in real-world applications as it eliminates the need for a re-training process, which could potentially degrade the model’s performance and increase training costs [57].
Post-hoc OOD detection methods [32, 45, 46] employ outputs such as model logits or layer activations, which are typically used for prediction, to calculate OOD scores. These scores allow for the differentiation of ID and OOD data based on the disparities in their respective scores [57]. Enhancing the overall OOD score distribution difference between ID and OOD data is a critical aspect in improving the performance of post-hoc OOD detection methods. Recent studies [45, 46] have found that augmenting the overall difference is contingent upon the capacity to mitigate noisy signals. For example, ReAct [45] demonstrates that OOD data exhibit considerable values in the penultimate layer activation. By truncating these noisy activations, ReAct effectively improves OOD detection performance. Similarly, DICE [46] uncovers the presence of noisy signals that increase the variance of the OOD score distribution. By selectively employing the most salient weights, DICE enhances OOD detection performance while reducing the impact of noisy signals. Minimizing the influence of noisy model outputs is crucial for advancing post-hoc OOD detection performance. In this study, we reveal an additional factor that is also important in the context of OOD detection.
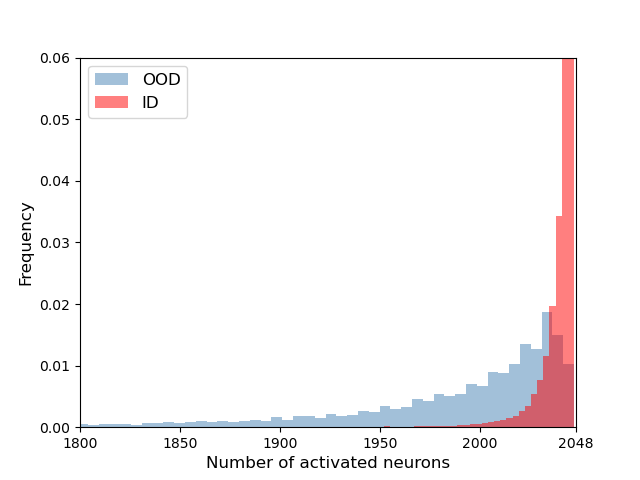
Figure 1 displays the histogram of the number of activated features in the penultimate layer. We define neurons with activation values greater than zero as activated neurons. As the figure demonstrates, a majority of neurons are activated when the model encounters ID samples. However, for OOD samples, fewer neurons are activated. To understand the primary cause of the observation in Figure 1, we investigate the model from the perspective of neuron-concept association [4, 5, 53, 21]. According to [4], neurons are trained to detect disentangled high-level features in the deep layers of convolutional neural networks (CNNs), and they can even learn new unlabeled abstract concepts from the data [53]. The number of neurons representing these high-level features increases in deeper layers and becomes the most significant amount in the penultimate layer [5]. Since the activation in the penultimate layer represents the presence of these high-level features [4], different input images activate high-level features in varying ways, such as magnitude and patterns. These distinct patterns of activation in the penultimate layer are ultimately used to predict the input image’s class. As each class possesses unique characteristics related to high-level concepts, the associated high-level features differ for each class. Consequently, each associated high-level feature can be categorized into one class-specific feature group. The disparity in associated high-level features in neurons results in a difference in penultimate layer activation between ID and OOD samples, which are predicted as the same class. Thus, taking into account the number of activated essential neurons can serve as a useful indicator for distinguishing ID and OOD samples.
In this paper, we present a novel post-hoc OOD detection method called Leveraging Important Neurons (LINe). LINe harnesses two crucial aspects: considering the number of activated important neurons and minimizing noisy activations to enhance OOD detection performance. To achieve this, we introduce two powerful techniques within LINe: 1) Shapley-based pruning and 2) activation clipping (AC).
Shapley value-based pruning is a method that mitigates the influence of noisy outputs by selecting activations essential for inferring input data classes. While several methods exist for identifying important activations, Sun et al. [46] use activation magnitude to determine their importance. However, this approach alone is insufficient for quantifying a neuron’s importance. Hence, we employ the Shapley value [44] to more accurately measure each neuron’s contribution. Applying the Shapley value concept [44] to neural networks allows us to quantify each neuron’s contribution to identifying a specific class. Moreover, neurons with high Shapley values are associated with critical input image features [21]. By leveraging the Shapley value [44], we can identify neurons that represent important high-level features for each class, which are essential for reducing noisy output.
Activation clipping, a concept introduced in ReAct [45], is another powerful technique. Interpreting activation clipping in terms of class-specific features provides a new understanding of its role in considering the number of activated important neurons for OOD detection. Activation clipping adjusts values exceeding a certain threshold to the threshold value. This modification enables us to account for the differences in the number of activated features between in-distribution and OOD data by treating numerous class-specific features equally. By considering the variation in the number of activated class-specific features, we can effectively augment the overall OOD score difference between ID and OOD data, leading to enhanced performance.
Our key contributions are summarized as follows:
-
•
We propose a simple yet effective post-hoc OOD detection method, named LINe, which uses the Shapley value to rank the contribution of neurons and gives a new inspiration for leveraging selected important class-specific neurons.
-
•
We unveil the important factor for improving OOD scoring and show a new way of understanding the role of activation clipping for OOD detection. By applying activation clipping, we can fully consider the number of activated class-specific features and achieve higher OOD detection performance.
-
•
Comprehensive experiments have been conducted to verify the effectiveness of the proposed method on the CIFAR-10, CIFAR-100, and ImageNet-1K. Compared to the competitive post-hoc method DICE[46], LINe reduces the FPR95 by up to 14.05.
2 Background and Related Work
2.1 Neuron-Concept Association
Neuron-concept association methods are a field of study that tries to interpret the internal computation of CNN to a human-understandable concept [37, 8, 3, 14]. Several studies have shown that neurons of shallower layers tend to learn more simple and low-level concepts, such as curves and edges, while deeper layers learn more abstract and high-level concepts, such as arm and face[60, 61, 53]. The methods for quantifying the concept’s contribution are also introduced in [33, 12, 14]. Network Dissection[4, 5, 60] assigns each neuron to a concept to quantify its role. Bau et al. [6] investigate the effect of concept-specific neurons by observing the change of concept-related contents in generative models. Recently, Wang et al. [53] show that models can learn abstract concepts like mammal and carnivore, which is not in the label set of training data.
2.2 Shapley Value
Shapely value[44, 26, 48] is a concept from Game Theory, which evaluates each property’s individual and collaborative effects. Studies have been conducted using Shapley value in CNNs to measure each neuron’s contribution and interpret models’ behaviors [34, 2, 13, 48, 21]. Neuron Shapley[13] sorts the Shapley values to identify the most influential neurons from all hidden layers as image categories. Khazar et al. [21] show neurons that have high Shapley values have high correlations with important features of the input image. Previous studies have inspired us to select important class-specific neurons through the contribution scores calculated from the Shapley value. LINe can effectively eliminate the negative effects of noisy signals by leveraging the selected class-specific neurons.
2.3 Out-of-Distribution Detection
OOD detection aims to find inputs with different characteristics from the training data [57]. A lot of research efforts have been devoted to developing an effective method to distinguish OOD inputs from ID inputs. Confidence-based methods perform OOD detection by quantifying OOD scores based on different scoring functions [29, 11, 7, 16, 19]. Hendrycks et al. [16] used a maximum softmax probability (MSP) of the model as a baseline confidence-base OOD scoring function. ODIN[30] utilizes perturbation of inputs and temperature scaling on the softmax layer to increase the difference between ID and OOD. To enhance the effectiveness of confidence-based scores, recently, Liu et al. [32] introduced an energy-based score with the theoretical interpretation from a likelihood perspective, which is further adopted in [31, 54, 36] to distinguish ID and OOD samples. Distance-based approaches measure the distance between input sample and typical ID samples or centroids of them [28, 47, 41, 49, 9, 59, 50, 18, 35]. These approaches are based on simple evidence that OOD samples should have more distance than IDs. Similarly, density-based methods identify OOD samples based on the distribution of the training samples and use density (or likelihood) [27, 64, 1, 40, 42, 24, 63, 22, 51, 20, 38, 23].
But none of the aforementioned methods consider the number of activated features, which can be a good indicator to distinguish ID and OOD samples. The most similar study to our study is DICE[46]. DICE leverages sparsification to reduce the effect of noisy signals by selectively using salient weights from activation [46]. In this study, we effectively eliminate the outcomes of noisy signals by accurately selecting neurons leveraging the contribution of neurons calculated from Shapley value[44, 21]. In addition, our method performs OOD detection more effectively by considering the number of activated features. The neurons are known to be associated with the concepts, and the activation patterns of neurons in deep layers are different in ID and OOD. This gives a theoretical background for considering the number of activation in OOD detection. To the best of our knowledge, our work is the first study to leverage the neuron contribution based on Shapley value and consider the number of activated features for calculating OOD score.
3 Method
3.1 Method Overview
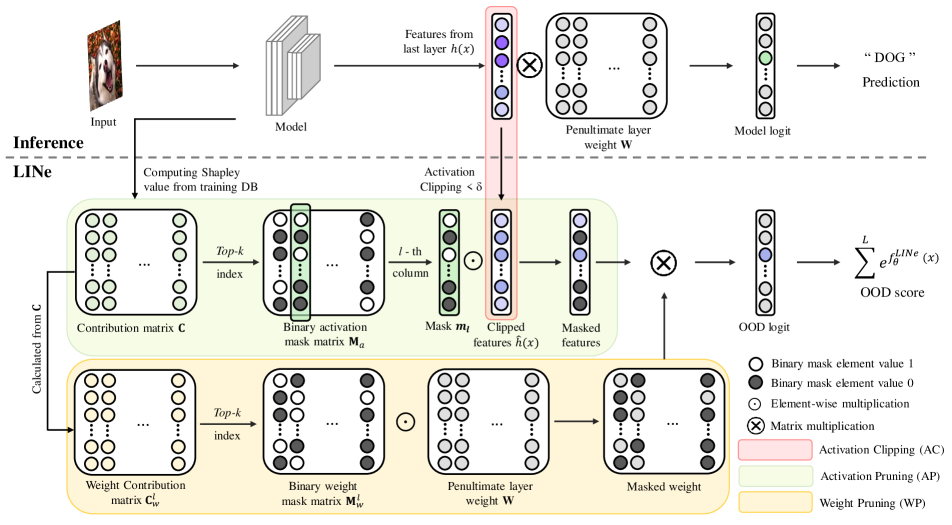
Our method mainly consists of two parts: Activation Clipping and Shapley-based pruning. Activation clipping is a method of clipping each neuron activation to a specific value when the activation value exceeds a particular threshold (). Through activation clipping, our method can consider the number of high-level features during calculating OOD scores, which are analyzed in terms of neuron-concept association. Next, Shapley-based pruning eliminates the negative effect of noisy signals by measuring neural contributions of neural networks using important neurons only. We can accurately measure the contribution of each neuron using Shapley value, which is a mathematically grounded method. Also, by applying Shapley value, we can obtain supporting evidence that neurons with large contributions represent critical features for recognizing input image[21]. This allows us to assemble all contributions for each class and select important class-specific neurons representing class-specific features. More details of activation clipping and Shapley-based pruning will be described in Subsection 3.2 and Subsection 3.3. In Subsection 3.4, we will explain the overall method.
3.2 Activation Clipping
For a pre-trained deep neural network parameterized by , encodes an input , where indicates dimension of input , and predicts a class distribution for different classes, i.e., . Feature vector from the penultimate layer of the network denotes , where stands for the dimension of penultimate layer output . Weight matrix weights the importance of each feature in and transfers to output as follows:
| (1) |
Activation clipping is applied to the feature vector in the penultimate layer. For each neuron that is activated above a certain threshold, AC limits the magnitude of the activation. As we discussed in Figure 1, the number of activated features in ID and OOD samples are different. By limiting the magnitude of the activation to the same value , we can treat every activated high-level feature equally, which allows us to consider the number of activated features in the OOD score. This increases the OOD score difference between ID and OOD samples, thereby improving performance.
For each activation in , penultimate layer feature can be denoted as . With a clipping threshold , the clipped activation can be described as . The clipped feature vector is then,
| (2) |
The model output after AC can be given as:
| (3) |
3.3 Shapley-based Pruning
Shapley-based pruning selectively uses a subset of important neuron activation and weights. To select these subsets, we calculate Shapley value[44] defined by an average of the effect of removing a single unit (e.g., marginal contribution) to all possible combinations of units. However, computing all the combinations of units is computationally expensive and practically infeasible for recent large neural networks. Therefore, we use the Taylor approximation to compute the Shapley value, which is introduced in [21]. For input , where denotes the sample of class from dataset , a contribution(i.e., Shapley value) of -th neuron in class , is calculated as
| (4) |
3.3.1 Activation Pruning
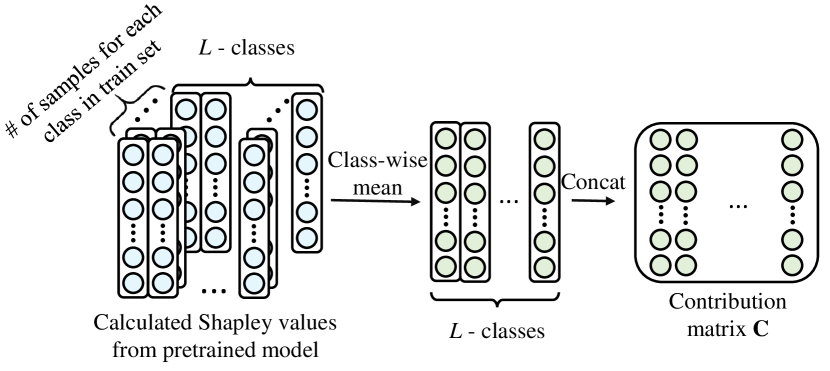
Activation pruning (AP) selectively uses the subset of important neuron activation. Through AP, We can effectively reduce the impact of noisy activation. From the contribution of each neuron , which is using obtained from all training data, contribution matrix is defined as the class-specific average of all contribution . An (,)-th entry of contribution matrix is defined as:
| (5) |
where denotes the number of training images in class .
We select top-k neurons for each class based on the k-largest elements from each column in and define an activation mask matrix , where we set 1 for the -largest elements from every column in , otherwise 0. The model output after AP with the predicted class is given as:
| (6) |
where indicates -th column of mask matrix and denotes the element-wise multiplication.
3.3.2 Weight Pruning
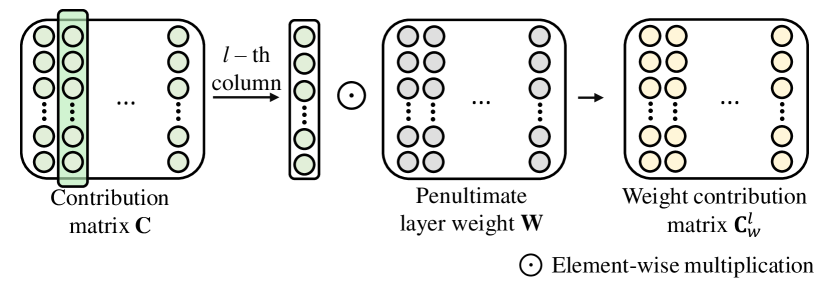
Weight pruning (WP) selectively uses the subset of important penultimate layer weights. Through WP, We can effectively reduce the impact of noisy signals due to the overparameterized model. The contribution of neurons is further used to refine the weight matrix as WP. For this purpose, we define a weight contribution matrix for the class as where indicates the -th column of contribution matrix . We select top-k weights for each class based on the -largest elements in and define a mask matrix for class as by setting 1 for the k-largest elements in , otherwise 0. The model output after WP with the predicted class is given as:
| (7) |
From the Shapley-based AP and WP, we can determine the neurons representing important high-level features for each class, which play a crucial role in reducing noisy output.
3.4 Leveraging Important Neurons (LINe)
As already described in the previous Subsection 3.2 and 3.3, there are two ideas to improve the performance of post-hoc OOD detection. One is considering the number of activated high-level features, and the other is reducing noisy signals from less important neurons. LINe achieves both ways to improve post-hoc OOD detection performance through the procedures described above. By adapting LINe to a model, we can effectively increase the overall difference in OOD scores between ID and OOD data. As a result, the model output under LINe with the predicted class is described as
| (8) |
Please note that there is no parameter change in the model itself and ID classification accuracy can be preserved.
4 Experiments
Comprehensive experiments have been conducted to evaluate our method. In section 4.1, we used the CIFAR[25] benchmark, which is one of the famous benchmarks in OOD studies[45, 32, 46]. In Section 4.2, experiments were conducted based on a large-scale dataset, ImageNet, with various OOD datasets. Section 4.3 analyzes why our method is effective through various ablation experiments.
4.1 Evaluation on CIFAR Benchmarks
Implementation Details. In this experiment, we used 10,000 test images each from CIFAR-10[25] and CIFAR-100[25] as ID data, respectively. The model’s performance was evaluated using six commonly used OOD datasets as an OOD benchmark. The list of six OOD datasets is as follows: SVHN[39], Textures[10], iSUN[56], LSUN-Crop[58], LSUN-Resize[58], and Places365[62]. As the pre-trained models, we used DenseNet[17]. As in [46], the models are trained from CIFAR-10[25] and CIFAR-100[25] with 50,000 training images respectively. Following [46], the models were trained during 100 epochs with batch size 64, weight decay 0.0001, momentum 0.9, and start learning rate 0.1. The learning rate was decayed by a factor of 10 at epochs 50, 75, and 90. We used the entire training dataset to estimate the contribution matrix .
| Method | CIFAR-10 | CIFAR-100 | ||
|---|---|---|---|---|
| FPR95 | AUROC | FPR95 | AUROC | |
| MSP[16] | 48.73 | 92.46 | 80.13 | 74.36 |
| ODIN[30] | 24.57 | 93.71 | 58.14 | 84.49 |
| Mahalanobis[28] | 31.42 | 89.15 | 55.37 | 82.73 |
| Energy[32] | 26.55 | 94.57 | 68.45 | 81.19 |
| ReAct[45] | 26.45 | 94.95 | 62.27 | 84.47 |
| DICE[46] | 20.83 | 95.24 | 49.72 | 87.23 |
| DICE + ReAct | 16.48 | 96.64 | 49.57 | 85.08 |
| LINe (Ours) | 14.71 | 96.99 | 35.67 | 88.67 |
Comparison. For comparison, we adopted recent post-hoc OOD detection methods: MSP [16], ODIN[30], Mahalanobis distance[28], Energy [32], ReAct[45], and DICE[46].
For all methods, the performances were measured by OOD scores, derived from the same DenseNet model.
Experimental Results. Table 1 shows the comparisons between LINe and other post-hoc OOD detection methods on CIFAR-10 and CIFAR-100 benchmarks. As shown in the table, our method achieved state-of-the-art performances by outperforming all the other methods on both CIFAR-10 and CIFAR-100 datasets. In CIFAR-100, LINe reduced FPR 95 by 14.05 compared to the competitive method DICE[46]. In CIFAR-100, LINe achieved an FPR 95 of 14.05 which was lower than the FPR 95 of DICE[46] (49.72%) and DICE + ReAct (49.57%). DICE + ReAct is the method that is implemented by applying ReAct [45] on DICE [46]. DICE[46] removed the noisy signals by using the magnitude of activation and weight. LINe not only removed the noisy signals using class-specific neurons but also considered the number of activations of the high-level feature.
4.2 Evaluation on ImageNet
Implementation Details. In real-world applications, the model encounters high-resolution images with various scenes and features, and evaluation on a large-scale dataset can provide clues about model performance in a real-world application. Therefore, in this experiment, we evaluated LINe on a large-scale ImageNet dataset. Based on [19], a subset of the four datasets where all the overlapping categories with ImageNet-1k were eliminated was used as OOD datasets. The four OOD datasets are as follows: Textures[10], Places365[62], iNaturalist[52], and SUN[55]. We used a pre-trained ResNet-50 model[15], which is trained with ImageNet-1k. The entire training dataset was used to estimate the contribution matrix , and all images were resized to 224 224 at test time.
| Method | OOD Datasets | Average | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| iNaturalist | SUN | Places | Textures | |||||||
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| MSP[16] | 54.99 | 87.74 | 70.83 | 80.86 | 73.99 | 79.76 | 68.00 | 79.61 | 66.95 | 81.99 |
| ODIN[30] | 47.66 | 89.66 | 60.15 | 84.59 | 67.89 | 81.78 | 50.23 | 85.62 | 56.48 | 85.41 |
| Mahalanobis[28] | 97.00 | 52.65 | 98.50 | 42.41 | 98.40 | 41.79 | 55.80 | 85.01 | 87.43 | 55.47 |
| Energy[32] | 55.72 | 89.95 | 59.26 | 85.89 | 64.92 | 82.86 | 53.72 | 85.99 | 58.41 | 86.17 |
| ReAct[45] | 20.38 | 96.22 | 24.20 | 94.20 | 33.85 | 91.58 | 47.30 | 89.80 | 31.43 | 92.95 |
| DICE[46] | 25.63 | 94.49 | 35.15 | 90.83 | 46.49 | 87.48 | 31.72 | 90.30 | 34.75 | 90.77 |
| DICE + ReAct[46] | 18.64 | 96.24 | 25.45 | 93.94 | 36.86 | 90.67 | 28.07 | 92.74 | 27.25 | 93.40 |
| LINe (Ours) | 12.26 | 97.56 | 19.48 | 95.26 | 28.52 | 92.85 | 22.54 | 94.44 | 20.70 | 95.03 |
Experimental Results. In Table 2, we reported the performances of four OOD test datasets respectively. The average results from the four OOD test datasets were also reported. LINe outperformed all baselines including MSP[16], ODIN[30], Mahalanobis distance[28], Energy score[32], ReAct[45], DICE[46], and DICE + ReAct[46]. We compared LINe with Energy[32] first. LINe drastically reduced the FPR95 by 37.71, which shows the benefit of leveraging important neurons under the same OOD scoring function. Next, we compared LINe with ReAct[45]. LINe reduced the FPR95 by 10.73, which allows us to see the advantages of leveraging important neurons using Shapley value. LINe further outperformed recent DICE [46] and DICE + ReAct by 14.05% and 6.55%, respectively. Experimental results showed that the proposed method can be applied to real-world large dataset for OOD detection.
4.3 Ablation Study
In this section, we discuss the effectiveness of each part used in LINe and the detailed differences from other similar approaches. We also analyze the effect of hyperparameters.
4.3.1 Ablation Study of LINe on ImageNet
Table 3 shows an ablation study over various parts used in LINe. As shown in the table, each part of Shapley-based pruning (AP and WP) improved the performance. Comparing LINE w/o WP with Energy + AC allows us to see the advantages of reducing the noisy activation, which reduces FPR95 by 8.52. Next, we compared LINe w/o AP with Energy + AC, which also shows the benefits of reducing noisy weights. Compared to Energy + AC, LINe w/o AP reduced FPR95 by 12.21. Finally, we compared LINe w/o AP with DICE + ReAct[46] at Table 2, which allows us to see the benefit of leveraging class-wise contribution under similar circumstances. LINe w/o AP reduced the FPR95 by 4.06 from 27.25 to 23.19. DICE + ReAct[46] uses activations to select important weights, while LINe w/o AP selects important weights using class-wise contribution derived from the Shapley value[44].
| Method | AC | AP | WP | FPR95 | AUROC |
|---|---|---|---|---|---|
| Energy[32] | 58.41 | 86.17 | |||
| Energy + AC | ✓ | 35.40 | 91.86 | ||
| LINe w/o WP | ✓ | ✓ | 26.88 | 93.77 | |
| LINe w/o AP | ✓ | ✓ | 23.19 | 94.57 | |
| LINe (Ours) | ✓ | ✓ | ✓ | 20.70 | 95.03 |
4.3.2 Effect of Changing AC Threshold on ImageNet
In Section 3.2, we discussed the meaning of AC in terms of the neuron-concept association. AC allows us to consider the number of activated high-level features in the penultimate layer. In Table 4, we show various OOD detection performances of the model by changing threshold . Starting from clipping threshold = , the value of FPR95 is the highest in the table. As clipping threshold becomes smaller, the OOD detection performance is improved. But at clipping threshold 0.8, the OOD detection performance dropped. This is because, as the clipping threshold approaches 0, all the penultimate output values also approach zero. It is obvious that performance will drop when all the penultimate output values approach zero.
| Threshold () | FPR95 | AUROC |
|---|---|---|
| 41.18 | 88.44 | |
| 23.43 | 94.79 | |
| 20.70 | 95.03 | |
| 21.69 | 94.81 | |
| 26.96 | 93.99 | |
| 31.88 | 92.97 | |
| (no AC) | 44.88 | 89.14 |
4.3.3 Effect of Changing Pruning Percentile on ImageNet
In this section, we conducted ablation studies on pruning percentiles () variation on ImageNet datasets as ID data. In Table 5 we show effect of changing pruning percentile ( and ) on ImageNet. indicates pruning percentile for AP, indicates pruning percentile for WP. For a fixed WP percentile with extremely high value (e.g., = 90), the performance tends to increase when the AP percentile falls. Since LINe considers the number of activated features for detecting OOD samples, pruning most of the activations or weights has negatively impacted the performance. A lower pruning percentile is better to leverage differences in the number of activated features between ID and OOD samples. But to restrict the negative effect of noisy signals, we need some portions that can remove the noisy signals. As a result, the model performs the best when the pruning percentile is = 10 and = 10 on ImageNet.
| = 90 | = 70 | = 50 | = 30 | = 10 | |
|---|---|---|---|---|---|
| FPR95 | FPR95 | FPR95 | FPR95 | FPR95 | |
| = 90 | 27.56 | 24.79 | 24.74 | 24.55 | 24.54 |
| = 70 | 27.45 | 25.93 | 25.81 | 27.45 | 33.32 |
| = 50 | 33.69 | 27.78 | 26.28 | 25.90 | 27.45 |
| = 30 | 27.46 | 26.10 | 27.17 | 24.36 | 28.43 |
| = 10 | 27.64 | 26.75 | 27.75 | 25.41 | 20.70 |
4.3.4 Effect of Changing Pruning Percentile on CIFAR Benchmarks
In Table 6 and Table 7, we show effect of changing pruning percentile ( and ) on CIFAR Benchmarks. Both tables show similar tendencies. For all AP percentile , the performance tends to increase when the WP percentile increases. In Table 6, highest performance appeared at = 90 and = 90. On the other hand in Table 7, the highest performance appeared at = 90 and = 10. This result may seem to conflict with the result in Table 5, our observation in Table 8 can explain the cause of the difference.
| = 90 | = 70 | = 50 | = 30 | = 10 | |
|---|---|---|---|---|---|
| FPR95 | FPR95 | FPR95 | FPR95 | FPR95 | |
| = 90 | 14.72 | 15.00 | 15.00 | 15.00 | 14.99 |
| = 70 | 14.80 | 15.12 | 15.12 | 15.12 | 15.10 |
| = 50 | 14.80 | 15.12 | 15.11 | 15.11 | 15.10 |
| = 30 | 14.80 | 15.12 | 15.11 | 15.12 | 15.10 |
| = 10 | 14.80 | 15.13 | 15.13 | 15.12 | 15.73 |
| = 90 | = 70 | = 50 | = 30 | = 10 | |
|---|---|---|---|---|---|
| FPR95 | FPR95 | FPR95 | FPR95 | FPR95 | |
| = 90 | 38.75 | 37.81 | 37.81 | 37.75 | 35.67 |
| = 70 | 38.37 | 39.30 | 40.07 | 39.75 | 40.81 |
| = 50 | 38.37 | 39.19 | 40.54 | 40.27 | 42.14 |
| = 30 | 38.37 | 39.19 | 40.65 | 40.21 | 39.32 |
| = 10 | 38.40 | 39.31 | 40.76 | 40.91 | 38.17 |
4.3.5 Discussion
| Overlap | CIFAR-10 | CIFAR-100 | ImageNet |
|---|---|---|---|
| = 20 | 24.56 | 26.90 | 1.70 |
| = 30 | 23.39 | 0.58 | 0.15 |
In Table 8, we compared the percentage of class-specific neuron overlap in multiple classes on three data sets. For each dataset, we calculated the proportion of very important (top 10) neurons in more than of the class. These neurons activate in various classes which have semantically different features. Therefore, the higher proportion of these neurons can be seen as an overparameterized model with more numbers of generally activated neurons. These overparameterized models make OOD detection difficult by creating noisy signals, which can be reduced by leveraging AP and WP. To get optimal results from overparameterized models, we can lessen the effect of overparameterized weights with high WP percentile. Also, the effectiveness of considering the number of activated class-specific neurons can be maximized in the low AP percentile as a tendency shown in Table 7. But for a much more overparameterized model, which is shown in Table 6, we need to set high pruning percentile on both and .
The degree of an overparameterized model can be understood from Section 4.1. We used the same pre-trained model architecture for evaluating CIFAR-10 and CIFAR-100. Of the two models with the same structure, we can intuitively understand that a model trained using a relatively small dataset is more likely to be overparameterized, which can also be observed in Table 8. The proportion of very important (top 10) neurons in more than 30 of the class(i.e., = 30) on CIFAR-10 is the largest compared to other datasets. This observation shows that our pre-trained model used to evaluate CIFAR-10 is more overparameterized than other models we used.
5 Conclusion
In this paper, we propose a powerful OOD Detection method called LINe. LINe adopts a neural-concept association, which only uses important activations and weights selectively by measuring class-wise contribution from the Shapley value. Through LINe, we can effectively reduce the influence of the noise signal and make a difference in the overall OOD score between ID and OOD sample distribution. We conducted extensive experiments to demonstrate that LINe is superior to state-of-the-art OOD detection methods and effective on multiple datasets. From several theoretical studies and insights, we show how our method improves the performance of OOD detection. Our method is effective but has some limitations. It is fundamentally a trade-off relationship that pruning neurons to reduce the noisy output and considers the number of class-specific feature activations. Users have to examine the trade-off considering the degree of overparameterization of the model. We hope that as our study proposes an effective way to view OOD detection from a feature presentation perspective, attempts to understand the behavior of neural networks will be applied to multiple domains to discover other effective methods.
Acknowledgements
This work was supported in part by the Institute of Information and Communications Technology Planning and Evaluation (IITP) grant funded by the Korea Government (MSIT)(No. 2022-0-00078: Explainable Logical Reasoning for Medical Knowledge Generation, No. 2021-0-02068: Artificial Intelligence Innovation Hub, No. RS-2022-00155911: Artificial Intelligence Convergence Innovation Human Resources Development (Kyung Hee University)) and by the National Research Foundation of Korea (NRF) grant funded by the Korea government(MSIT) (No. 2021R1G1A1094990).
References
- [1] Davide Abati, Angelo Porrello, Simone Calderara, and Rita Cucchiara. Latent space autoregression for novelty detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 481–490, 2019.
- [2] Marco Ancona, Cengiz Oztireli, and Markus Gross. Explaining deep neural networks with a polynomial time algorithm for shapley value approximation. In International Conference on Machine Learning, pages 272–281. PMLR, 2019.
- [3] Sarah Adel Bargal, Andrea Zunino, Vitali Petsiuk, Jianming Zhang, Kate Saenko, Vittorio Murino, and Stan Sclaroff. Guided zoom: Questioning network evidence for fine-grained classification. In British Machine Vision Conference (BMVC), 2019.
- [4] David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network dissection: Quantifying interpretability of deep visual representations. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6541–6549, 2017.
- [5] David Bau, Jun-Yan Zhu, Hendrik Strobelt, Agata Lapedriza, Bolei Zhou, and Antonio Torralba. Understanding the role of individual units in a deep neural network. Proceedings of the National Academy of Sciences, 117(48):30071–30078, 2020.
- [6] David Bau, Jun-Yan Zhu, Hendrik Strobelt, Bolei Zhou, Joshua B Tenenbaum, William T Freeman, and Antonio Torralba. Gan dissection: Visualizing and understanding generative adversarial networks. ICLR, 2019.
- [7] Abhijit Bendale and Terrance E Boult. Towards open set deep networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1563–1572, 2016.
- [8] Chaofan Chen, Oscar Li, Daniel Tao, Alina Barnett, Cynthia Rudin, and Jonathan K Su. This looks like that: deep learning for interpretable image recognition. Advances in neural information processing systems, 32, 2019.
- [9] Xingyu Chen, Xuguang Lan, Fuchun Sun, and Nanning Zheng. A boundary based out-of-distribution classifier for generalized zero-shot learning. In European Conference on Computer Vision, pages 572–588. Springer, 2020.
- [10] M. Cimpoi, S. Maji, I. Kokkinos, S. Mohamed, , and A. Vedaldi. Describing textures in the wild. In Proceedings of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2014.
- [11] Terrance DeVries and Graham W Taylor. Learning confidence for out-of-distribution detection in neural networks. arXiv preprint arXiv:1802.04865, 2018.
- [12] Amirata Ghorbani, James Wexler, James Y Zou, and Been Kim. Towards automatic concept-based explanations. Advances in Neural Information Processing Systems, 32, 2019.
- [13] Amirata Ghorbani and James Y Zou. Neuron shapley: Discovering the responsible neurons. Advances in Neural Information Processing Systems, 33:5922–5932, 2020.
- [14] Mara Graziani, Vincent Andrearczyk, and Henning Müller. Regression concept vectors for bidirectional explanations in histopathology. In Understanding and Interpreting Machine Learning in Medical Image Computing Applications, pages 124–132. Springer, 2018.
- [15] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. In Proceedings of the European conference on computer vision, pages 630–645. Springer, 2016.
- [16] Dan Hendrycks and Kevin Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural networks. Proceedings of International Conference on Learning Representations, 2017.
- [17] Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 4700–4708, 2017.
- [18] Haiwen Huang, Zhihan Li, Lulu Wang, Sishuo Chen, Bin Dong, and Xinyu Zhou. Feature space singularity for out-of-distribution detection. arXiv preprint arXiv:2011.14654, 2020.
- [19] Rui Huang and Yixuan Li. Towards scaling out-of-distribution detection for large semantic space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021.
- [20] Dihong Jiang, Sun Sun, and Yaoliang Yu. Revisiting flow generative models for out-of-distribution detection. In International Conference on Learning Representations, 2021.
- [21] Ashkan Khakzar, Soroosh Baselizadeh, Saurabh Khanduja, Christian Rupprecht, Seong Tae Kim, and Nassir Navab. Neural response interpretation through the lens of critical pathways. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13528–13538, 2021.
- [22] Durk P Kingma and Prafulla Dhariwal. Glow: Generative flow with invertible 1x1 convolutions. Advances in neural information processing systems, 31, 2018.
- [23] Polina Kirichenko, Pavel Izmailov, and Andrew G Wilson. Why normalizing flows fail to detect out-of-distribution data. Advances in neural information processing systems, 33:20578–20589, 2020.
- [24] Ivan Kobyzev, Simon JD Prince, and Marcus A Brubaker. Normalizing flows: An introduction and review of current methods. IEEE transactions on pattern analysis and machine intelligence, 43(11):3964–3979, 2020.
- [25] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- [26] Harold William Kuhn and Albert William Tucker. Contributions to the Theory of Games. Number 28. Princeton University Press, 1953.
- [27] Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. In Advances in Neural Information Processing Systems, pages 7167–7177, 2018.
- [28] Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. In Advances in Neural Information Processing Systems, pages 7167–7177, 2018.
- [29] Shiyu Liang, Yixuan Li, and Rayadurgam Srikant. Enhancing the reliability of out-of-distribution image detection in neural networks. In International conference on learning representations, 2018.
- [30] Shiyu Liang, Yixuan Li, and Rayadurgam Srikant. Enhancing the reliability of out-of-distribution image detection in neural networks. In Proceedings of International Conference on Learning Representations, 2018.
- [31] Ziqian Lin, Sreya Dutta Roy, and Yixuan Li. Mood: Multi-level out-of-distribution detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15313–15323, 2021.
- [32] Weitang Liu, Xiaoyun Wang, John Owens, and Yixuan Li. Energy-based out-of-distribution detection. Advances in Neural Information Processing Systems, 33:21464–21475, 2020.
- [33] Weizeng Lu, Xi Jia, Weicheng Xie, Linlin Shen, Yicong Zhou, and Jinming Duan. Geometry constrained weakly supervised object localization. In European Conference on Computer Vision, pages 481–496. Springer, 2020.
- [34] Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. Advances in neural information processing systems, 30, 2017.
- [35] Yifei Ming, Yiyou Sun, Ousmane Dia, and Yixuan Li. Cider: Exploiting hyperspherical embeddings for out-of-distribution detection. arXiv preprint arXiv:2203.04450, 2022.
- [36] Peyman Morteza and Yixuan Li. Provable guarantees for understanding out-of-distribution detection. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 8, 2022.
- [37] Jesse Mu and Jacob Andreas. Compositional explanations of neurons. Advances in Neural Information Processing Systems, 33:17153–17163, 2020.
- [38] Eric Nalisnick, Akihiro Matsukawa, Yee Whye Teh, Dilan Gorur, and Balaji Lakshminarayanan. Do deep generative models know what they don’t know? arXiv preprint arXiv:1810.09136, 2018.
- [39] Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y Ng. Reading digits in natural images with unsupervised feature learning. 2011.
- [40] Stanislav Pidhorskyi, Ranya Almohsen, and Gianfranco Doretto. Generative probabilistic novelty detection with adversarial autoencoders. Advances in neural information processing systems, 31, 2018.
- [41] Jie Ren, Stanislav Fort, Jeremiah Liu, Abhijit Guha Roy, Shreyas Padhy, and Balaji Lakshminarayanan. A simple fix to mahalanobis distance for improving near-ood detection. arXiv preprint arXiv:2106.09022, 2021.
- [42] Mohammad Sabokrou, Mohammad Khalooei, Mahmood Fathy, and Ehsan Adeli. Adversarially learned one-class classifier for novelty detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3379–3388, 2018.
- [43] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4510–4520, 2018.
- [44] Lloyd S Shapley. A value for n-person games. Classics in game theory, 69, 1997.
- [45] Yiyou Sun, Chuan Guo, and Yixuan Li. React: Out-of-distribution detection with rectified activations. Advances in Neural Information Processing Systems, 34:144–157, 2021.
- [46] Yiyou Sun and Yixuan Li. Dice: Leveraging sparsification for out-of-distribution detection. In European Conference on Computer Vision, 2022.
- [47] Yiyou Sun, Yifei Ming, Xiaojin Zhu, and Yixuan Li. Out-of-distribution detection with deep nearest neighbors. arXiv preprint arXiv:2204.06507, 2022.
- [48] Mukund Sundararajan and Amir Najmi. The many shapley values for model explanation. In International conference on machine learning, pages 9269–9278. PMLR, 2020.
- [49] Engkarat Techapanurak, Masanori Suganuma, and Takayuki Okatani. Hyperparameter-free out-of-distribution detection using cosine similarity. In Proceedings of the Asian Conference on Computer Vision, 2020.
- [50] Joost Van Amersfoort, Lewis Smith, Yee Whye Teh, and Yarin Gal. Uncertainty estimation using a single deep deterministic neural network. In International conference on machine learning, pages 9690–9700. PMLR, 2020.
- [51] Aäron Van Den Oord, Nal Kalchbrenner, and Koray Kavukcuoglu. Pixel recurrent neural networks. In International conference on machine learning, pages 1747–1756. PMLR, 2016.
- [52] Grant Van Horn, Oisin Mac Aodha, Yang Song, Yin Cui, Chen Sun, Alex Shepard, Hartwig Adam, Pietro Perona, and Serge Belongie. The inaturalist species classification and detection dataset. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 8769–8778, 2018.
- [53] Andong Wang, Wei-Ning Lee, and Xiaojuan Qi. Hint: Hierarchical neuron concept explainer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10254–10264, 2022.
- [54] Haoran Wang, Weitang Liu, Alex Bocchieri, and Yixuan Li. Can multi-label classification networks know what they don’t know? Advances in Neural Information Processing Systems, 34:29074–29087, 2021.
- [55] Jianxiong Xiao, James Hays, Krista A. Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recognition from abbey to zoo. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 3485–3492. IEEE Computer Society, 2010.
- [56] Pingmei Xu, Krista A Ehinger, Yinda Zhang, Adam Finkelstein, Sanjeev R Kulkarni, and Jianxiong Xiao. Turkergaze: Crowdsourcing saliency with webcam based eye tracking. arXiv preprint arXiv:1504.06755, 2015.
- [57] Jingkang Yang, Kaiyang Zhou, Yixuan Li, and Ziwei Liu. Generalized out-of-distribution detection: A survey. arXiv preprint arXiv:2110.11334, 2021.
- [58] Fisher Yu, Ari Seff, Yinda Zhang, Shuran Song, Thomas Funkhouser, and Jianxiong Xiao. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv:1506.03365, 2015.
- [59] Alireza Zaeemzadeh, Niccolo Bisagno, Zeno Sambugaro, Nicola Conci, Nazanin Rahnavard, and Mubarak Shah. Out-of-distribution detection using union of 1-dimensional subspaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9452–9461, 2021.
- [60] Bolei Zhou, David Bau, Aude Oliva, and Antonio Torralba. Interpreting deep visual representations via network dissection. IEEE transactions on pattern analysis and machine intelligence, 41(9):2131–2145, 2018.
- [61] Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Object detectors emerge in deep scene cnns. arXiv preprint arXiv:1412.6856, 2014.
- [62] Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition. In IEEE Transactions on Pattern Analysis and Machine Intelligence, volume 40, pages 1452–1464. IEEE, 2017.
- [63] Ev Zisselman and Aviv Tamar. Deep residual flow for out of distribution detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13994–14003, 2020.
- [64] Bo Zong, Qi Song, Martin Renqiang Min, Wei Cheng, Cristian Lumezanu, Daeki Cho, and Haifeng Chen. Deep autoencoding gaussian mixture model for unsupervised anomaly detection. In International conference on learning representations, 2018.
Supplementary Material for LINe:
Out-of-Distribution Detection by Leveraging Important Neurons
Appendix A Detailed CIFAR Benchmark Results
Table 9 and Table 10 are detailed results of CIFAR-10 and CIFAR-100 benchmark experiments (detailed results for Table 1 in the main text). For both tables, all the results except DICE + ReAct and LINe are taken from Sun et al. [46]. We choose hyperparameters for DICE + ReAct as sparsity = 90 and ReAct threshold = 1.0, as in [46, 45].
Appendix B LINe on Other Models
In this section, we show LINe also works well with other models. In the main text, we show LINe with pre-trained DenseNet[17] and ResNet-50[15] on CIFAR and ImageNet datasets, respectively. In this section, we show LINe can be used for MobileNetV2 [43], which is pre-trained on the ImageNet-1k dataset from PyTorch. Experiment settings are the same in Section 4.2. We choose hyperparameters for LINe as pruning percentile and clipping threshold . As shown in Table 11, our method implemented on MobileNetV2 outperformed all the other methods.
Appendix C LINe with Other Shapley-value Approximation
We use the Taylor approximation in the main text to compute the Shapley value. To see the difference of changing approximation to compute the Shapley value, we use IntGrad approximation, which is also introduced in [21]. For input , where denotes the sample of class from dataset , a contribution(i.e., Shapley value) of -th neuron in class , is calculated as
| (9) |
Contribution matrix can be defined with contribution calculated by Equation 9. With this contribution matrix , we can apply LINe. Table 12 show the result of LINe with Taylor and IntGrad approximation. The results of both methods are the same. Calculated contributions from both methods are different, but the order of top-k neurons is still the same. However, the precomputing time of IntGrad is almost 11 times larger than the Taylor approximation, so it is better to choose Taylor as an approximation method.
Appendix D Additional Theoretical Analysis
The outstanding performance of LINe is grounded on three different groups of papers in the related work section (Sec 2.1-2.3). In Network Dissection [4] and HINT [53], neurons in the deep layer (e.g., penultimate layer) represent a specific concept (e.g., window, mammal). Also, in Khazar et al. [21], neurons with high Shapely values have critical fragments of the encoded input information. We draw an insight from the above studies that a group of neurons in the penultimate layer with high Shapley values for a specific class has essential concepts for classifying that class. We call this group of neurons class-specific neurons. Therefore, we can select important class-specific neurons and mask less important neurons by ranking the contribution of neurons. The pruning parts in LINe (i.e., AP and WP) improve the performance by masking less important neurons which trigger noisy outputs. Since class-specific neurons are activated only for essential concepts for each class, OOD samples with different visual features (i.e., concept) cannot activate most of the class-specific neurons. This simple idea motivates AC by limiting the size of activation, which makes AC treat class-specific features equally and improves OOD detection performance.
| Method | OOD Datasets | Average | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SVHN | Textures | iSUN | LSUN | LSUN-Crop | Places365 | |||||||||
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| MSP[16] | 47.24 | 93.48 | 64.15 | 88.15 | 42.31 | 94.52 | 42.10 | 94.51 | 33.57 | 95.54 | 63.02 | 88.57 | 48.73 | 92.46 |
| ODIN[30] | 25.29 | 94.57 | 57.50 | 82.38 | 3.98 | 98.90 | 3.09 | 99.02 | 4.70 | 98.86 | 52.85 | 88.55 | 24.57 | 93.71 |
| Mahalanobis[28] | 6.42 | 98.31 | 21.51 | 92.15 | 9.78 | 97.25 | 9.14 | 97.09 | 56.55 | 86.96 | 85.14 | 63.15 | 31.42 | 89.15 |
| Energy[32] | 40.61 | 93.99 | 56.12 | 86.43 | 10.07 | 98.07 | 9.28 | 98.12 | 3.81 | 99.15 | 39.40 | 91.64 | 26.55 | 94.57 |
| ReAct[45] | 41.64 | 93.87 | 43.58 | 92.47 | 12.72 | 97.72 | 11.46 | 97.87 | 5.96 | 98.84 | 43.31 | 91.03 | 26.45 | 94.67 |
| DICE[46] | 25.99 | 95.90 | 41.90 | 88.18 | 4.36 | 99.14 | 3.91 | 99.20 | 0.26 | 99.92 | 48.59 | 89.13 | 20.83 | 95.24 |
| DICE + ReAct[46] | 12.49 | 97.61 | 25.83 | 94.56 | 5.27 | 99.02 | 3.95 | 99.14 | 0.43 | 99.89 | 50.94 | 89.63 | 16.48 | 96.64 |
| LINe (Ours) | 11.38 | 97.75 | 23.44 | 95.12 | 4.90 | 99.01 | 4.19 | 99.09 | 0.61 | 99.83 | 43.78 | 91.12 | 14.72 | 96.99 |
| Method | OOD Datasets | Average | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SVHN | Textures | iSUN | LSUN | LSUN-Crop | Places365 | |||||||||
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| MSP[16] | 81.70 | 75.40 | 84.79 | 71.48 | 85.99 | 70.17 | 85.24 | 69.18 | 60.49 | 85.60 | 82.55 | 74.31 | 80.13 | 74.36 |
| ODIN[30] | 41.35 | 92.65 | 82.34 | 71.48 | 67.05 | 83.84 | 65.22 | 84.22 | 10.54 | 97.93 | 82.32 | 76.84 | 58.14 | 84.49 |
| Mahalanobis[28] | 22.44 | 95.67 | 62.39 | 79.39 | 31.38 | 93.21 | 23.07 | 94.20 | 68.90 | 86.30 | 92.66 | 61.39 | 55.37 | 82.73 |
| Energy[32] | 87.46 | 81.85 | 84.15 | 71.03 | 74.54 | 78.95 | 70.65 | 80.14 | 14.72 | 97.43 | 79.20 | 77.72 | 68.45 | 81.19 |
| ReAct[45] | 83.81 | 81.41 | 77.78 | 78.95 | 65.27 | 86.55 | 60.08 | 87.88 | 25.55 | 94.92 | 82.65 | 74.04 | 62.27 | 84.47 |
| DICE[46] | 54.65 | 88.84 | 65.04 | 76.42 | 48.72 | 90.08 | 49.40 | 91.04 | 0.93 | 99.74 | 79.58 | 77.26 | 49.72 | 87.23 |
| DICE + ReAct[46] | 55.52 | 88.02 | 41.54 | 86.26 | 44.32 | 91.44 | 54.44 | 89.84 | 7.56 | 98.61 | 94.05 | 56.26 | 49.57 | 85.07 |
| LINe (Ours) | 31.10 | 91.90 | 39.29 | 87.84 | 24.07 | 94.85 | 25.32 | 94.63 | 5.72 | 98.87 | 88.50 | 63.93 | 35.67 | 88.67 |
| Method | OOD Datasets | Average | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| iNaturalist | SUN | Places | Textures | |||||||
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| MSP[16] | 64.29 | 85.32 | 77.02 | 77.10 | 79.23 | 76.27 | 73.51 | 77.30 | 73.51 | 79.00 |
| ODIN[30] | 55.39 | 87.62 | 54.07 | 85.88 | 57.36 | 84.71 | 49.96 | 85.03 | 54.20 | 85.81 |
| Mahalanobis[28] | 62.11 | 81.00 | 47.82 | 86.33 | 52.09 | 83.63 | 92.38 | 33.06 | 63.60 | 71.01 |
| Energy score[32] | 59.50 | 88.91 | 62.65 | 84.50 | 69.37 | 81.19 | 58.05 | 85.03 | 62.39 | 84.91 |
| ReAct [45] | 42.40 | 91.53 | 47.69 | 88.16 | 51.56 | 86.64 | 38.42 | 91.53 | 45.02 | 89.47 |
| DICE [46] | 43.09 | 90.83 | 38.69 | 90.46 | 53.11 | 85.81 | 32.80 | 91.30 | 41.92 | 89.60 |
| DICE + ReAct [46] | 32.30 | 93.57 | 31.22 | 92.86 | 46.78 | 88.02 | 16.28 | 96.25 | 31.64 | 92.68 |
| LINe (Ours) | 24.95 | 95.53 | 33.19 | 92.94 | 47.95 | 88.98 | 12.30 | 97.05 | 29.60 | 93.62 |
| Method | CIFAR-10 | CIFAR-100 | ImageNet | |||
|---|---|---|---|---|---|---|
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| Taylor | 14.71 | 96.99 | 35.67 | 88.67 | 20.70 | 95.03 |
| IntGrad | 14.71 | 96.99 | 35.67 | 88.67 | 20.70 | 95.03 |