:
Iterative Refinement with Self-Feedback
Abstract
Like humans, large language models (LLMs) do not always generate the best output on their first try. Motivated by how humans refine their written text, we introduce , an approach for improving initial outputs from LLMs through iterative feedback and refinement. The main idea is to generate an initial output using an LLM; then, the same LLM provides feedback for its output and uses it to refine itself, iteratively. does not require any supervised training data, additional training, or reinforcement learning, and instead uses a single LLM as the generator, refiner and the feedback provider. We evaluate across 7 diverse tasks, ranging from dialog response generation to mathematical reasoning, using state-of-the-art (GPT-3.5 and GPT-4) LLMs. Across all evaluated tasks, outputs generated with are preferred by humans and automatic metrics over those generated with the same LLM using conventional one-step generation, improving by 20% absolute on average in task performance. Our work demonstrates that even state-of-the-art LLMs like GPT-4 can be further improved at test-time using our simple, standalone approach.111Code and data at https://selfrefine.info/.
1 Introduction
Although large language models (LLMs) can generate coherent outputs, they often fall short in addressing intricate requirements. This mostly includes tasks with multifaceted objectives, such as dialogue response generation, or tasks with hard-to-define goals, such as enhancing program readability. In these scenarios, modern LLMs may produce an intelligible initial output, yet may benefit from further iterative refinement—i.e., iteratively mapping a candidate output to an improved one—to ensure that the desired quality is achieved. Iterative refinement typically involves training a refinement model that relies on domain-specific data (e.g., Reid and Neubig (2022); Schick et al. (2022a); Welleck et al. (2022)). Other approaches that rely on external supervision or reward models require large training sets or expensive human annotations (Madaan et al., 2021; Ouyang et al., 2022), which may not always be feasible to obtain. These limitations underscore the need for an effective refinement approach that can be applied to various tasks without requiring extensive supervision.
Iterative self-refinement is a fundamental characteristic of human problem-solving (Simon, 1962; Flower and Hayes, 1981; Amabile, 1983). Iterative self-refinement is a process that involves creating an initial draft and subsequently refining it based on self-provided feedback. For example, when drafting an email to request a document from a colleague, an individual may initially write a direct request such as “Send me the data ASAP”. Upon reflection, however, the writer recognizes the potential impoliteness of the phrasing and revises it to “Hi Ashley, could you please send me the data at your earliest convenience?". When writing code, a programmer may implement an initial “quick and dirty” implementation, and then, upon reflection, refactor their code to a solution that is more efficient and readable. In this paper, we demonstrate that LLMs can provide iterative self-refinement without additional training, leading to higher-quality outputs on a wide range of tasks.
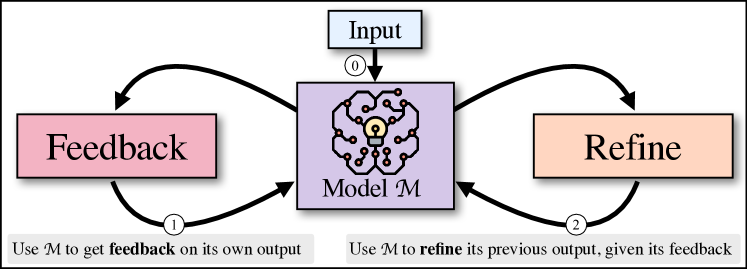
We present : an iterative self-refinement algorithm that alternates between two generative steps–feedback and refine. These steps work in tandem to generate high-quality outputs. Given an initial output generated by a model , we pass it back to the same model to get feedback. Then, the feedback is passed back to the same model to refine the previously-generated draft. This process is repeated either for a specified number of iterations or until determines that no further refinement is necessary. We use few-shot prompting (Brown et al., 2020) to guide to both generate feedback and incorporate the feedback into an improved draft. Figure 1 illustrates the high-level idea, that uses the same underlying language model to generate feedback and refine its outputs.
We evaluate on 7 generation tasks that span diverse domains, including natural language and source-code generation. We show that outperforms direct generation from strong LLMs like GPT-3.5 (text-davinci-003 and gpt-3.5-turbo; OpenAI, ; Ouyang et al., 2022) and GPT-4 (OpenAI, 2023) by 5-40% absolute improvement. In code-generation tasks, improves the initial generation by up to absolute 13% when applied to strong code models such as Codex (code-davinci-002; Chen et al., 2021). We release all of our code, which is easily extensible to other LLMs. In essence, our results show that even when an LLM cannot generate an optimal output on its first try, the LLM can often provide useful feedback and improve its own output accordingly. In turn, provides an effective way to obtain better outputs from a single model without any additional training, via iterative (self-)feedback and refinement.
2 Iterative Refinement with
Given an input sequence, generates an initial output, provides feedback on the output, and refines the output according to the feedback. iterates between feedback and refinement until a desired condition is met. relies on a suitable language model and three prompts (for initial generation, feedback, and refinement), and does not require training. is shown in Figure 1 and Algorithm 1. Next, we describe in more detail.
Initial generation
Given an input , prompt , and model , generates an initial output :
| (1) |
For example, in Figure 2(d), the model generates functionally correct code for the given input. Here, is a task-specific few-shot prompt (or instruction) for an initial generation, and denotes concatenation. The few-shot prompt contains input-output pairs for the task.222Few-shot prompting (also referred to as “in-context learning”) provides a model with a prompt consisting of in-context examples of the target task, each in the form of input-output pairs (Brown et al., 2020).
feedback
Next, uses the same model to provide feedback on its own output, given a task-specific prompt for generating feedback:
| (2) |
Intuitively, the feedback may address multiple aspects of the output. For example, in code optimization, the feedback might address the efficiency, readability, and overall quality of the code.
Here, the prompt provides examples of feedback in the form of input-output-feedback triples . We prompt the model to write feedback that is actionable and specific via . By ‘actionable’, we mean the feedback should contain a concrete action that would likely improve the output. By ‘specific’, we mean the feedback should identify concrete phrases in the output to change. For example, the feedback in Figure 2(e) is “This code is slow as it uses a for loop which is brute force. A better approach is to use the formula … (n(n+1))/2”. This feedback is actionable, since it suggests the action ‘use the formula…’. The feedback is specific since it mentions the ‘for loop’.
refine
Next, uses to refine its most recent output, given its own feedback:
| (3) |
For example, in Figure 2(f), given the initial output and the generated feedback, the model generates a re-implementation that is shorter and runs much faster than the initial implementation. The prompt provides examples of improving the output based on the feedback, in the form of input-output-feedback-refined quadruples .
Iterating alternates between feedback and refine steps until a stopping condition is met. The stopping condition either stops at a specified timestep , or extracts a stopping indicator (e.g. a scalar stop score) from the feedback. In practice, the model can be prompted to generate a stopping indicator in , and the condition is determined per-task.
To inform the model about the previous iterations, we retain the history of previous feedback and outputs by appending them to the prompt. Intuitively, this allows the model to learn from past mistakes and avoid repeating them. More precisely, Equation 3 is in fact instantiated as:
| (4) |
Finally, we use the last refinement as the output of .
Algorithm 1 summarizes , and Figure 2 shows an example of in the Dialogue Response Generation (Mehri and Eskenazi, 2020) and Code Optimization (Madaan et al., 2023) tasks. Appendix S provides examples of the , , prompts for various tasks. The key idea is that uses the same underlying LLM to generate, get feedback, and refine its outputs given its own feedback. It relies only on supervision present in the few-shot examples.
3 Evaluation
We evaluate on 7 diverse tasks: Dialogue Response Generation (Appendix M; Mehri and Eskenazi, 2020), Code Optimization (Appendix N; Madaan et al., 2023), Code Readability Improvement (Appendix L; Puri et al., 2021), Math Reasoning (Appendix O; Cobbe et al., 2021), Sentiment Reversal (Appendix P; Zhang et al., 2015), and we introduce two new tasks: Acronym Generation (Appendix Q) and Constrained Generation (a harder version of Lin et al. (2020) with 20-30 keyword constraints instead of 3-5; Appendix R)
Examples for all tasks and dataset statistics are provided in Table 4 (Appendix A).
3.1 Instantiating
We instantiate following the high-level description in Section 2. The feedback-refine iterations continue until the desired output quality or task-specific criterion is reached, up to a maximum of 4 iterations. To make our evaluation consistent across different models, we implemented both feedback and refine as few-shot prompts even with models that respond well to instructions, such as ChatGPT and GPT-4.
Base LLMs
Our main goal is to evaluate whether we can improve the performance of any strong base LLMs using . Therefore, we compare to the same base LLMs but without feedback-refine iterations. We used three main strong base LLM across all tasks: GPT-3.5 (text-davinci-003), ChatGPT (gpt-3.5-turbo), and GPT-4 (OpenAI, 2023). For code-based tasks, we also experimented with Codex (code-davinci-002). In all tasks, either GPT-3.5 or GPT-4 is the previous state-of-the-art.333A comparison with other few-shot and fine-tuned approaches is provided in Appendix F We used the same prompts from previous work when available (such as for Code Optimization and Math Reasoning); otherwise, we created prompts as detailed in Appendix S. We use greedy decoding with a temperature of 0.7 for all setups.
3.2 Metrics
We report three types of metrics:
-
Task specific metric: When available, we use automated metrics from prior work (Math Reasoning: % solve rate; Code Optimization: % programs optimized; Constrained Gen: coverage %)
-
Human-pref: In Dialogue Response Generation, Code Readability Improvement, Sentiment Reversal, and Acronym Generation, since no automated metrics are available, we perform a blind human A/B evaluation on a subset of the outputs to select the preferred output. Additional details are provided in Appendix C.
-
GPT-4-pref: In addition to human-pref, we use GPT-4 as a proxy for human preference following prior work (Fu et al., 2023; Chiang et al., 2023; Geng et al., 2023; Sun et al., 2023), and found high correlation (82% for Sentiment Reversal, 68% for Acronym Generation, and 71% for Dialogue Response Generation) with human-pref. For Code Readability Improvement, we prompt GPT-4 to calculate fraction of the variables that are appropriately named given the context (e.g., ). Additional details are provided in Appendix D.
| GPT-3.5 | ChatGPT | GPT-4 | ||||
|---|---|---|---|---|---|---|
| Task | Base | + | Base | + | Base | + |
| Sentiment Reversal | 8.8 | 30.4 (21.6) | 11.4 | 43.2 (31.8) | 3.8 | 36.2 (32.4) |
| Dialogue Response | 36.4 | 63.6 (27.2) | 40.1 | 59.9 (19.8) | 25.4 | 74.6 (49.2) |
| Code Optimization | 14.8 | 23.0 (8.2) | 23.9 | 27.5 (3.6) | 27.3 | 36.0 (8.7) |
| Code Readability | 37.4 | 51.3 (13.9) | 27.7 | 63.1 (35.4) | 27.4 | 56.2 (28.8) |
| Math Reasoning | 64.1 | 64.1 (0) | 74.8 | 75.0 (0.2) | 92.9 | 93.1 (0.2) |
| Acronym Generation | 41.6 | 56.4 (14.8) | 27.2 | 37.2 (10.0) | 30.4 | 56.0 (25.6) |
| Constrained Generation | 28.0 | 37.0 (9.0) | 44.0 | 67.0 (23.0) | 15.0 | 45.0 (30.0) |
3.3 Results
Table 1 shows our main results:
consistently improves over base models across all model sizes, and additionally outperforms the previous state-of-the-art across all tasks. For example, GPT-4+improves over the base GPT-4 by 8.7% (absolute) in Code Optimization, increasing optimization percentage from 27.3% to 36.0%. Confidence intervals are provided in Appendix J. For code-based tasks, we found similar trends when using Codex; those results are included in Appendix F.
One of the tasks in which we observe the highest gains compared to the base models is Constrained Generation, where the model is asked to generate a sentence containing up to 30 given concepts. We believe that this task benefits significantly from because there are more opportunities to miss some of the concepts on the first attempt, and thus allows the model to fix these mistakes subsequently. Further, this task has an extremely large number of reasonable outputs, and thus allows to better explore the space of possible outputs.
In preference-based tasks such as Dialogue Response Generation, Sentiment Reversal, and Acronym Generation, leads to especially high gains. For example in Dialogue Response Generation, GPT-4 preference score improve by 49.2% – from 25.4% to 74.6%. Similarly, we see remarkable improvements in the other preference-based tasks across all models.
The modest performance gains in Math Reasoning can be traced back to the inability to accurately identify whether there is any error. In math, errors can be nuanced and sometimes limited to a single line or incorrect operation. Besides, a consistent-looking reasoning chain can deceive LLMs to think that “everything looks good” (e.g., ChatGPT feedback for 94% instances is ’everything looks good’). In Section H.1, we show that the gains with on Math Reasoning are much bigger (5%+) if an external source can identify if the current math answer is incorrect.
Improvement is consistent across base LLMs sizes Generally, GPT-4+performs better than GPT-3.5+and ChatGPT+across all tasks, even in tasks where the initial base results of GPT-4 were lower than GPT-3.5 or ChatGPT. We thus believe that allows stronger models (such as GPT-4) to unlock their full potential, even in cases where this potential is not expressed in the standard, single-pass, output generation. Comparison to additional strong baselines is provided in Appendix F.
4 Analysis
The three main steps of are feedback, refine, and repeating them iteratively. In this section, we perform additional experiments to analyze the importance of each of these steps.
| Task | feedback | Generic feedback | No feedback |
|---|---|---|---|
| Code Optimization | 27.5 | 26.0 | 24.8 |
| Sentiment Reversal | 43.2 | 31.2 | 0 |
| Acronym Generation | 56.4 | 54.0 | 48.0 |
The impact of the feedback quality
Feedback quality plays a crucial role in . To quantify its impact, we compare , which utilizes specific, actionable feedback, with two ablations: one using generic feedback and another without feedback (the model may still iteratively refine its generations, but is not explicitly provided feedback to do so). For example, in the Code Optimization task: actionable feedback, such as Avoid repeated calculations in the for loop, pinpoints an issue and suggests a clear improvement. Generic feedback, like Improve the efficiency of the code, lacks this precision and direction. Table 2 shows feedback’s clear influence.
In Code Optimization, performance slightly dips from 27.5 (feedback) to 26.0 (generic feedback), and further to 24.8 (no feedback). This suggests that while generic feedback offers some guidance – specific, actionable feedback yields superior results.
This effect is more pronounced in tasks like Sentiment Transfer, where changing from our feedback to generic feedback leads to a significant performance drop (43.2 to 31.2), and the task fails without feedback. Similarly, in Acronym Generation, without actionable feedback, performance drops from 56.4 to 48.0, even with iterative refinements. These results highlight the importance of specific, actionable feedback in our approach. Even generic feedback provides some benefit, but the best results are achieved with targeted, constructive feedback.
| Task | ||||
|---|---|---|---|---|
| Code Opt. | 22.0 | 27.0 | 27.9 | 28.8 |
| Sentiment Rev. | 33.9 | 34.9 | 36.1 | 36.8 |
| Constrained Gen. | 29.0 | 40.3 | 46.7 | 49.7 |
How important are the multiple iterations of feedback-refine?
Figure 4 demonstrates that on average, the quality of the output improves as the number of iterations increases. For instance, in the Code Optimization task, the initial output () has a score of 22.0, which improves to 28.8 after three iterations (). Similarly, in the Sentiment Reversal task, the initial output has a score of 33.9, which increases to 36.8 after three iterations. This trend of improvement is also evident in Constrained Generation, where the score increases from 29.0 to 49.7 after three iterations. Figure 4 highlights the diminishing returns in the improvement as the number of iterations increases. Overall, having multiple feedback-refine iterations significantly enhances the quality of the output, although the marginal improvement naturally decreases with more iterations.
The performance may not always monotonically increase with iterations: in multi-aspect feedback tasks like Acronym Generation, where the output quality can vary during iteration with improvement in one aspect but decline in another aspect. To counter this, generates numerical scores for different quality aspects, leading to a balanced evaluation and appropriate output selection.
Can we just generate multiple outputs instead of refining?
Does improve because of the iterative refinement, or just because it generates more outputs? We compare with ChatGPT, when ChatGPT generates samples (but without feedback and refinement). Then, we compare the performance of against these initial outputs in a 1 vs. evaluation. In other words, we assess whether can outperform all initial outputs. The results of this experiment are illustrated in Figure 9 (Appendix H). Despite the increased difficulty of the 1 vs. setting, the outputs of are still preferred by humans over all initial outputs. This shows the importance of refinement according to feedback over the alternative of just generating multiple initial outputs.
Does work with weaker models?
The experiments in Section 3.3 were performed with some of the strongest available models; does work with smaller or weaker models as well? To investigate this, we instantiated with Vicuna-13B (Chiang et al., 2023), a less powerful base model. While Vicuna-13B is capable of generating initial outputs, it struggles significantly with the refinement process. Specifically, Vicuna-13B was not able to consistently generate the feedback in the required format. Furthermore, even when provided with Oracle or hard-coded feedback, it often failed to adhere to the prompts for refinement. Instead of refining its output, Vicuna-13B either repeated the same output or generated a hallucinated conversation, rendering the outputs less effective. We thus hypothesize that since Vicuna-13B was trained on conversations, it does not generalize as well as instruction-based models to test-time few-shot tasks. Example output and analysis is provided in Appendix G.
Qualitative Analysis
We conduct a qualitative analysis of the feedback generated by and its subsequent refinements. We manually analyze 70 samples in total (35 success cases and 35 failure cases) for Code Optimization (Madaan et al., 2023) and Math Reasoning (Cobbe et al., 2021). For both Math Reasoning and Code Optimization, we found that the feedback was predominantly actionable, with the majority identifying problematic aspects of the original generation and suggesting ways to rectify them.
When failed to improve the original generation, the majority of issues were due to erroneous feedback rather than faulty refinements. Specifically, 33% of unsuccessful cases were due to feedback inaccurately pinpointing the error’s location, while 61% were a result of feedback suggesting an inappropriate fix. Only 6% of failures were due to the refiner incorrectly implementing good feedback. These observations highlight the vital role of accurate feedback plays in .
In successful cases, the refiner was guided by accurate and useful feedback to make precise fixes to the original generation in 61% of the cases. Interestingly, the refiner was capable of rectifying issues even when the feedback was partially incorrect, which was the situation in 33% of successful cases. This suggests resilience to sub-optimal feedback. Future research could focus on examining the refiner’s robustness to various types of feedback errors and exploring ways to enhance this resilience. In Figure 5, we illustrate how significantly improves program efficiency by transforming a brute force approach into a dynamic programming solution, as a result of insightful feedback. Additional analysis on other datasets such as Dialogue Response Generation is provided in Appendix H.
Going Beyond Benchmarks
While our evaluation focuses on benchmark tasks, is designed with broader applicability in mind. We explore this in a real-world use case of website generation, where the user provides a high-level goal and assists in iteratively developing the website. Starting from a rudimentary initial design, refines HTML, CSS, and JS to evolve the website in terms of both usability and aesthetics. This demonstrates the potential of in real-world, complex, and creative tasks. See Appendix I for examples and further discussion, including broader, societal impact of our work.
5 Related work
Leveraging human- and machine-generated natural language (NL) feedback for refining outputs has been effective for a variety of tasks, including summarization Scheurer et al. (2022), script generation Tandon et al. (2021), program synthesis Le et al. (2022a); Yasunaga and Liang (2020), and other tasks Bai et al. (2022a); Schick et al. (2022b); Saunders et al. (2022a); Bai et al. (2022b); Welleck et al. (2022). Refinement methods differ in the source and format of feedback, and the way that a refiner is obtained. Table 3 summarizes some related approaches; see Appendix B for an additional discussion.
Source of feedback.
Humans have been an effective source of feedback Tandon et al. (2021); Elgohary et al. (2021); Tandon et al. (2022); Bai et al. (2022a). Since human feedback is costly, several approaches use a scalar reward function as a surrogate of (or alternative to) human feedback (e.g., Bai et al. (2022a); Liu et al. (2022); Lu et al. (2022); Le et al. (2022a); Welleck et al. (2022)). Alternative sources such as compilers Yasunaga and Liang (2020) or Wikipedia edits Schick et al. (2022b) can provide domain-specific feedback. Recently, LLMs have been used to generate feedback for general domains Fu et al. (2023); Peng et al. (2023); Yang et al. (2022), However, ours is the only method that generates feedback using an LLM on its own output, for the purpose of refining with the same LLM.
| Supervision-free refiner | Supervision-free feedback | Multi-aspect feedback | Iterative | |
|---|---|---|---|---|
| Learned refiners: PEER Schick et al. (2022b), Self-critique Saunders et al. (2022b), CodeRL Le et al. (2022b), Self-correction Welleck et al. (2022). |
|
|
|
|
| Prompted refiners: Augmenter Peng et al. (2023), Re3 Yang et al. (2022), Reflexion Shinn et al. (2023). |
|
|
|
|
| (this work) |
|
|
|
|
Representation of feedback.
The form of feedback can be generally divided into natural language (NL) and non-NL feedback. Non-NL feedback can come in human-provided example pairs Dasgupta et al. (2019) or scalar rewards Liu et al. (2022); Le et al. (2022b). In this work, we use NL feedback, since this allows the model to easily provide self-feedback using the same LM that generated the output, while leveraging existing pretrained LLMs such as GPT-4.
Types of refiners.
Pairs of feedback and refinement have been used to learn supervised refiners Schick et al. (2022b); Du et al. (2022); Yasunaga and Liang (2020); Madaan et al. (2021). Since gathering supervised data is costly, some methods learn refiners using model generations Welleck et al. (2022); Peng et al. (2023). However, the refiners are trained for each new domain. Finally, Yang et al. (2022) use prompted feedback and refinement specifically tailored for story generation. In this work, we avoid training a separate refiner, and show that the same model can be used as both the refiner and the source of feedback across multiple domains.
Non-refinement reinforcement learning (RL) approaches.
Rather than having explicit refinement, an alternative way to incorporate feedback is by optimizing a scalar reward function, e.g. with reinforcement learning (e.g., Stiennon et al. (2020); Lu et al. (2022); Le et al. (2022a)). These methods differ from in that the model does not access feedback on an intermediate generation. Second, these RL methods require updating the model’s parameters, unlike .
6 Limitations and Discussion
The main limitation of our approach is that the base models need to have sufficient few-shot modeling or instruction-following abilities, in order to learn to provide feedback and to refine in an in-context fashion, without having to train supervised models and rely on supervised data.
Further, the experiments in this work were performed with language models that are not open-sourced, namely GPT-3.5, ChatGPT, GPT-4, and Codex. Existing literature (Ouyang et al., 2022) does not fully describe the details of these models, such as the pretraining corpus, model sizes, and model biases. Further, these models are not free to use, and using them for research requires some funding. Nonetheless, we release our code and model outputs to ensure the reproducibility of our work.
Another limitation of our work is that we exclusively experiment with datasets in English. In other languages, the current models may not provide the same benefits.
Finally, there is a possibility for bad actors to use prompting techniques to steer a model to generate more toxic or harmful text. Our approach does not explicitly guard against this.
7 Conclusion
We present : a novel approach that allows large language models to iteratively provide self-feedback and refine their own outputs. operates within a single LLM, requiring neither additional training data nor reinforcement learning. We demonstrate the simplicity and ease of use of across a wide variety of tasks. By showcasing the potential of in diverse tasks, our research contributes to the ongoing exploration and development of large language models, with the aim of reducing the cost of human creative processes in real-world settings. We hope that our iterative approach will help drive further research in this area. To this end, we make all our code, data and prompts anonymously available at https://selfrefine.info/.
References
- Amabile (1983) Teresa M. Amabile. 1983. A Theoretical Framework. In The Social Psychology of Creativity, pages 65–96. Springer New York, New York, NY.
- Bai et al. (2022a) Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. 2022a. Training a helpful and harmless assistant with reinforcement learning from human feedback. ArXiv:2204.05862.
- Bai et al. (2022b) Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. 2022b. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073.
- Berger et al. (2022) Emery D Berger, Sam Stern, and Juan Altmayer Pizzorno. 2022. Triangulating Python Performance Issues with SCALENE. ArXiv preprint, abs/2212.07597.
- Brown et al. (2001) Lawrence D Brown, T Tony Cai, and Anirban DasGupta. 2001. Interval estimation for a binomial proportion. Statistical science, 16(2):101–133.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901, Online. Curran Associates, Inc.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. 2021. Evaluating Large Language Models Trained on Code. arXiv preprint arXiv:2107.03374.
- Chiang et al. (2023) Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. 2023. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Dasgupta et al. (2019) Sanjoy Dasgupta, Daniel Hsu, Stefanos Poulis, and Xiaojin Zhu. 2019. Teaching a black-box learner. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 of Proceedings of Machine Learning Research, pages 1547–1555. PMLR.
- Du et al. (2022) Wanyu Du, Zae Myung Kim, Vipul Raheja, Dhruv Kumar, and Dongyeop Kang. 2022. Read, revise, repeat: A system demonstration for human-in-the-loop iterative text revision. In Proceedings of the First Workshop on Intelligent and Interactive Writing Assistants (In2Writing 2022), pages 96–108, Dublin, Ireland. Association for Computational Linguistics.
- Elgohary et al. (2021) Ahmed Elgohary, Christopher Meek, Matthew Richardson, Adam Fourney, Gonzalo Ramos, and Ahmed Hassan Awadallah. 2021. NL-EDIT: Correcting semantic parse errors through natural language interaction. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5599–5610, Online. Association for Computational Linguistics.
- Flower and Hayes (1981) Linda Flower and John R Hayes. 1981. A cognitive process theory of writing. College composition and communication, 32(4):365–387.
- Fu et al. (2023) Jinlan Fu, See-Kiong Ng, Zhengbao Jiang, and Pengfei Liu. 2023. Gptscore: Evaluate as you desire. arXiv preprint arXiv:2302.04166.
- Gao et al. (2022) Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2022. Pal: Program-aided language models. arXiv preprint arXiv:2211.10435.
- Geng et al. (2023) Xinyang Geng, Arnav Gudibande, Hao Liu, Eric Wallace, Pieter Abbeel, Sergey Levine, and Dawn Song. 2023. Koala: A dialogue model for academic research. Blog post.
- Le et al. (2022a) Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven C. H. Hoi. 2022a. CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning.
- Le et al. (2022b) Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven C. H. Hoi. 2022b. Coderl: Mastering code generation through pretrained models and deep reinforcement learning. ArXiv, abs/2207.01780.
- Li et al. (2018) Juncen Li, Robin Jia, He He, and Percy Liang. 2018. Delete, retrieve, generate: a simple approach to sentiment and style transfer. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1865–1874, New Orleans, Louisiana. Association for Computational Linguistics.
- Lin et al. (2020) Bill Yuchen Lin, Wangchunshu Zhou, Ming Shen, Pei Zhou, Chandra Bhagavatula, Yejin Choi, and Xiang Ren. 2020. CommonGen: A constrained text generation challenge for generative commonsense reasoning. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1823–1840, Online. Association for Computational Linguistics.
- Liu et al. (2022) Jiacheng Liu, Skyler Hallinan, Ximing Lu, Pengfei He, Sean Welleck, Hannaneh Hajishirzi, and Yejin Choi. 2022. Rainier: Reinforced knowledge introspector for commonsense question answering. In Conference on Empirical Methods in Natural Language Processing.
- Lu et al. (2022) Ximing Lu, Sean Welleck, Liwei Jiang, Jack Hessel, Lianhui Qin, Peter West, Prithviraj Ammanabrolu, and Yejin Choi. 2022. Quark: Controllable text generation with reinforced unlearning. ArXiv, abs/2205.13636.
- Madaan et al. (2023) Aman Madaan, Alexander Shypula, Uri Alon, Milad Hashemi, Parthasarathy Ranganathan, Yiming Yang, Graham Neubig, and Amir Yazdanbakhsh. 2023. Learning performance-improving code edits. arXiv preprint arXiv:2302.07867.
- Madaan et al. (2021) Aman Madaan, Niket Tandon, Dheeraj Rajagopal, Peter Clark, Yiming Yang, and Eduard Hovy. 2021. Think about it! improving defeasible reasoning by first modeling the question scenario. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6291–6310, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Mehri and Eskenazi (2020) Shikib Mehri and Maxine Eskenazi. 2020. Unsupervised evaluation of interactive dialog with DialoGPT. In Proceedings of the 21th Annual Meeting of the Special Interest Group on Discourse and Dialogue, pages 225–235, 1st virtual meeting. Association for Computational Linguistics.
- Nijkamp et al. (2022) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. 2022. Codegen: An open large language model for code with multi-turn program synthesis. ArXiv preprint, abs/2203.13474.
- (27) OpenAI. Model index for researchers. https://platform.openai.com/docs/model-index-for-researchers. Accessed: May 14, 2023.
- OpenAI (2022) OpenAI. 2022. Model index for researchers. Blogpost.
- OpenAI (2023) OpenAI. 2023. Gpt-4 technical report.
- Ouyang et al. (2022) Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke E. Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Francis Christiano, Jan Leike, and Ryan J. Lowe. 2022. Training language models to follow instructions with human feedback. ArXiv:2203.02155.
- Peng et al. (2023) Baolin Peng, Michel Galley, Pengcheng He, Hao Cheng, Yujia Xie, Yu Hu, Qiuyuan Huang, Lars Liden, Zhou Yu, Weizhu Chen, and Jianfeng Gao. 2023. Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback.
- Prabhumoye et al. (2018) Shrimai Prabhumoye, Yulia Tsvetkov, Ruslan Salakhutdinov, and Alan W Black. 2018. Style transfer through back-translation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 866–876, Melbourne, Australia. Association for Computational Linguistics.
- Press et al. (2022) Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis. 2022. Measuring and narrowing the compositionality gap in language models. arXiv preprint arXiv:2210.03350.
- Puri et al. (2021) Ruchir Puri, David Kung, Geert Janssen, Wei Zhang, Giacomo Domeniconi, Vladmir Zolotov, Julian Dolby, Jie Chen, Mihir Choudhury, Lindsey Decker, Veronika Thost, Luca Buratti, Saurabh Pujar, Shyam Ramji, Ulrich Finkler, Susan Malaika, and Frederick Reiss. 2021. Codenet: A large-scale ai for code dataset for learning a diversity of coding tasks. arXiv preprint arXiv:2105.12655.
- Reid and Neubig (2022) Machel Reid and Graham Neubig. 2022. Learning to model editing processes. arXiv preprint arXiv:2205.12374.
- Saunders et al. (2022a) William Saunders, Catherine Yeh, Jeff Wu, Steven Bills, Long Ouyang, Jonathan Ward, and Jan Leike. 2022a. Self-critiquing models for assisting human evaluators.
- Saunders et al. (2022b) William Saunders, Catherine Yeh, Jeff Wu, Steven Bills, Long Ouyang, Jonathan Ward, and Jan Leike. 2022b. Self-critiquing models for assisting human evaluators. ArXiv:2206.05802.
- Scheurer et al. (2022) Jérémy Scheurer, Jon Ander Campos, Jun Shern Chan, Angelica Chen, Kyunghyun Cho, and Ethan Perez. 2022. Training language models with natural language feedback. ArXiv:2204.14146.
- Schick et al. (2022a) Timo Schick, Jane Dwivedi-Yu, Zhengbao Jiang, Fabio Petroni, Patrick Lewis, Gautier Izacard, Qingfei You, Christoforos Nalmpantis, Edouard Grave, and Sebastian Riedel. 2022a. Peer: A collaborative language model.
- Schick et al. (2022b) Timo Schick, Jane Dwivedi-Yu, Zhengbao Jiang, Fabio Petroni, Patrick Lewis, Gautier Izacard, Qingfei You, Christoforos Nalmpantis, Edouard Grave, and Sebastian Riedel. 2022b. Peer: A collaborative language model. ArXiv, abs/2208.11663.
- Shinn et al. (2023) Noah Shinn, Beck Labash, and Ashwin Gopinath. 2023. Reflexion: an autonomous agent with dynamic memory and self-reflection.
- Simon (1962) Herbert A. Simon. 1962. The architecture of complexity. Proceedings of the American Philosophical Society, 106(6):467–482.
- Stiennon et al. (2020) Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. 2020. Learning to summarize with human feedback. In Advances in Neural Information Processing Systems, volume 33, pages 3008–3021. Curran Associates, Inc.
- Sun et al. (2023) Zhiqing Sun, Yikang Shen, Qinhong Zhou, Hongxin Zhang, Zhenfang Chen, David Cox, Yiming Yang, and Chuang Gan. 2023. Principle-driven self-alignment of language models from scratch with minimal human supervision. arXiv preprint arXiv:2305.03047.
- Tandon et al. (2021) Niket Tandon, Aman Madaan, Peter Clark, Keisuke Sakaguchi, and Yiming Yang. 2021. Interscript: A dataset for interactive learning of scripts through error feedback. arXiv preprint arXiv:2112.07867.
- Tandon et al. (2022) Niket Tandon, Aman Madaan, Peter Clark, and Yiming Yang. 2022. Learning to repair: Repairing model output errors after deployment using a dynamic memory of feedback. In Findings of the Association for Computational Linguistics: NAACL 2022, pages 339–352.
- Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. 2022. Chain of Thought Prompting Elicits Reasoning in Large Language Models. arXiv preprint arXiv:2201.11903.
- Welleck et al. (2022) Sean Welleck, Ximing Lu, Peter West, Faeze Brahman, Tianxiao Shen, Daniel Khashabi, and Yejin Choi. 2022. Generating sequences by learning to self-correct. arXiv preprint arXiv:2211.00053.
- Yang et al. (2022) Kevin Yang, Nanyun Peng, Yuandong Tian, and Dan Klein. 2022. Re3: Generating longer stories with recursive reprompting and revision. In Conference on Empirical Methods in Natural Language Processing.
- Yasunaga and Liang (2020) Michihiro Yasunaga and Percy Liang. 2020. Graph-based, self-supervised program repair from diagnostic feedback. 37th Int. Conf. Mach. Learn. ICML 2020, PartF168147-14:10730–10739.
- Zhang et al. (2015) Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level convolutional networks for text classification. Advances in neural information processing systems, 28.
Appendix A Evaluation Tasks
Table 4 lists the tasks in our evaluation, and examples from each task.
| Task and Description | Sample one iteration of feedback-refine |
|---|---|
|
Sentiment Reversal
Rewrite reviews to reverse sentiment. Dataset: (Zhang et al., 2015) 1000 review passages |
: The food was fantastic…”
: The food was disappointing…” : Increase negative sentiment : The food was utterly terrible…” |
|
Dialogue Response Generation
Produce rich conversational responses. Dataset: Mehri and Eskenazi (2020) 372 conv. |
: What’s the best way to cook pasta?”
: The best way to cook pasta is to…” : Make response relevant, engaging, safe : Boil water, add salt, and cook pasta…” |
|
Code Optimization
Enhance Python code efficiency Dataset: (Madaan et al., 2023): 1000 programs |
: Nested loop for matrix product
: NumPy dot product function : Improve time complexity : Use NumPy’s optimized matmul function |
|
Code Readability Improvement
Refactor Python code for readability. Dataset: (Puri et al., 2021) 300 programs∗ |
: Unclear variable names, no comments
: Descriptive names, comments : Enhance variable naming; add comments : Clear variables, meaningful comments |
|
Math Reasoning
Solve math reasoning problems. Dataset: (Cobbe et al., 2021) 1319 questions |
: Olivia has $23, buys 5 bagels at $3 each”
: Solution in Python : Show step-by-step solution : Solution with detailed explanation |
|
Acronym Generation
Generate acronyms for a given title Dataset: (Appendix Q) 250 acronyms |
: Radio Detecting and Ranging”
: RDR : be context relevant; easy pronunciation : RADAR” |
|
Constrained Generation
Generate sentences with given keywords. Dataset: (Lin et al., 2020) 200 samples |
: beach, vacation, relaxation
: During our beach vacation… : Include keywords; maintain coherence : .. beach vacation was filled with relaxation |
Appendix B Broader Related Work
Compared to a concurrent work, Reflexion Shinn et al. (2023), our approach involves correction using feedback, whereas their setup involves finding the next best solution in planning using ReAct. While ReAct and Reflexion provide a free-form reflection on whether a step was executed correctly and potential improvements, our approach is more granular and structured, with multi-dimensional feedback and scores. This distinction allows our method to offer more precise and actionable feedback, making it suitable for a wider range of natural language generation tasks, including those that may not necessarily involve step-by-step planning such as open-ended dialogue generation.
Comparison with Welleck et al. (2022)
The closest work to ours may be Self-Correction (Welleck et al., 2022); however, Self-Correction has several disadvantages compared to :
- 1.
-
2.
Self-Correction trains a separate refiner (or “corrector”) for each task. In contrast, uses instructions and few-shot prompting, and thus does not require training a separate refiner for each task.
-
3.
Empirically, we evaluated using the same base model of GPT-3 as Self-Correction, and with the same settings on the GSM8K benchmark. Self-Correction achieved 45.9% accuracy while (this work) achieved 55.7% (9.8).
Comparison with non-refinement reinforcement learning (RL) approaches.
Rather than having an explicit refinement module, an alternative way to incorporate feedback is by optimizing a scalar reward function, e.g. with reinforcement learning (e.g., Stiennon et al. (2020); Lu et al. (2022); Le et al. (2022a)). These methods differ from (and more generally, refinement-based approaches) in that the model cannot access feedback on an intermediate generation. Second, these reinforcement learning methods require updating the model’s parameters, unlike .
See Table 5 for an additional detailed comparison of related work.
Method
Primary Novelty
zero/few shot improvement
multi aspect critics
NL feedback with error localization
iterative framework
RLHF Stiennon et al. (2020)
optimize for human preference
![[Uncaptioned image]](x.png) trained on feedback
single (human)
trained on feedback
single (human)
![[Uncaptioned image]](check.png) (not self gen.)
Rainier RL Liu et al. (2022)
RL to generate knowledge
trained on end task
single(accuracy)
(knowl. only)
Quark RL Lu et al. (2022)
quantization to edit generations
trained on end task
single(scalar score)
(dense signal)
(train time iter.)
Code RL Le et al. (2022a)
actor critic RL for code improvement
trained on end task
single(unit tests)
(dense signal)
DrRepair Yasunaga and Liang (2020)
Compiler feedback to iteratively repair
trained semi sup.
single(compiler msg)
(not self gen.)
PEER Schick et al. (2022b)
doc. edit trained on wiki edits
trained on edits
single(accuracy)
(not self gen.)
Self critique Saunders et al. (2022a)
few shot critique generation
feedback training
single(human)
(self gen.)
Self-correct Welleck et al. (2022)
novel training of a corrector
trained on end task
single (task specific)
(limited setting)
(limited setting)
Const. AI Bai et al. (2022b)
train RL4F on automat (critique, revision) pair
critique training
(fixed set)
Self-ask Press et al. (2022)
ask followup ques when interim ans correct;final wrong
few shot
none
(none)
GPT3 score Fu et al. (2023)
GPT can score generations with instruction
few shot
single(single utility fn)
(none)
Augmenter Peng et al. (2023)
factuality feedback from external KBs
few shot
single(factuality)
(self gen.)
Re3 Yang et al. (2022)
ours: but one domain, trained critics
few shot
(trained critics)
(not self gen.)
fewshot iterative multi aspect NL fb
few shot
multiple(few shot critics)
(self gen.)
(not self gen.)
Rainier RL Liu et al. (2022)
RL to generate knowledge
trained on end task
single(accuracy)
(knowl. only)
Quark RL Lu et al. (2022)
quantization to edit generations
trained on end task
single(scalar score)
(dense signal)
(train time iter.)
Code RL Le et al. (2022a)
actor critic RL for code improvement
trained on end task
single(unit tests)
(dense signal)
DrRepair Yasunaga and Liang (2020)
Compiler feedback to iteratively repair
trained semi sup.
single(compiler msg)
(not self gen.)
PEER Schick et al. (2022b)
doc. edit trained on wiki edits
trained on edits
single(accuracy)
(not self gen.)
Self critique Saunders et al. (2022a)
few shot critique generation
feedback training
single(human)
(self gen.)
Self-correct Welleck et al. (2022)
novel training of a corrector
trained on end task
single (task specific)
(limited setting)
(limited setting)
Const. AI Bai et al. (2022b)
train RL4F on automat (critique, revision) pair
critique training
(fixed set)
Self-ask Press et al. (2022)
ask followup ques when interim ans correct;final wrong
few shot
none
(none)
GPT3 score Fu et al. (2023)
GPT can score generations with instruction
few shot
single(single utility fn)
(none)
Augmenter Peng et al. (2023)
factuality feedback from external KBs
few shot
single(factuality)
(self gen.)
Re3 Yang et al. (2022)
ours: but one domain, trained critics
few shot
(trained critics)
(not self gen.)
fewshot iterative multi aspect NL fb
few shot
multiple(few shot critics)
(self gen.)
, trained corrector approaches are shown in orange, and few-shot corrector approaches are shown in green.
Appendix C Human Evaluation
The A/B evaluation in our study was conducted by the authors, where a human judge was presented with an input, task instruction, and two candidate outputs generated by the baseline method and . The setup was blind, i.e., the judges did not know which outputs were generated by which method. The judge was then asked to select the output that is better aligned with the task instruction. For tasks that involve A/B evaluation, we calculate the relative improvement as the percentage increase in preference rate. The preference rate represents the proportion of times annotators selected the output produced by over the output from the baseline method. Table 6 shows the results.
| Task | (%) | Direct (%) | Either (%) |
|---|---|---|---|
| Sentiment Transfer | 75.00 | 21.43 | 3.57 |
| Acronym Generation | 44.59 | 12.16 | 43.24 |
| Response Generation | 47.58 | 19.66 | 32.76 |
Appendix D GPT-4 Evaluation
In light of the impressive achievements of GPT-4 in assessing and providing reasoning for complex tasks, we leverage its abilities for evaluation in . The approach involves presenting tasks to GPT-4 in a structured manner, promoting the model’s deliberation on the task and generating a rationale for its decision. This methodology is demonstrated in Figures 6, 7 and 8:
Appendix E Model Key
We use terminology here: https://platform.openai.com/docs/models/gpt-3-5
Appendix F Comparison of with State-of-the-art of Few-Shot Learning Models and Fine-Tuned Baselines
In this section, we present a comprehensive comparison of the performance of with other few-shot models and fine-tuned baselines across a range of tasks, including mathematical reasoning and programming tasks. Tables 8 and 7 display the performance of these models on the PIE dataset and GSM tasks, respectively. Our analysis demonstrates the effectiveness of different model architectures and training techniques in tackling complex problems.
| Method | Solve Rate | |
| Cobbe et al. (2021) | OpenAI 6B | 20.0 |
| Wei et al. (2022) | CoT w/ Codex | 65.6 |
| Gao et al. (2022) | PaL w/ Codex | 72.0 |
| PaL w/ GPT-3 | 52.0 | |
| PaL w/ GPT-3.5 | 56.8 | |
| PaL w/ ChatGPT | 74.2 | |
| PaL w/ GPT-4 | 93.3 | |
| Welleck et al. (2022) | Self-Correct w/ GPT-3 | 45.9 |
| Self-Correct (fine-tuned) | 24.3 | |
| This work | w/ GPT-3 | 55.7 |
| w/ GPT-3.5 | 62.4 | |
| w/ ChatGPT | 75.1 | |
| w/ GPT-4 | 94.5 | |
| Method | %Opt) | |
| Puri et al. (2021) | Human References | 38.2 |
| OpenAI Models: OpenAI (2022, 2023) | Codex | 13.1 |
| GPT-3.5 | 14.8 | |
| ChatGPT | 22.2 | |
| GPT-4 | 27.3 | |
| Nijkamp et al. (2022) | CodeGen-16B | 1.1 |
| Berger et al. (2022) | scalene | 1.4 |
| scalene (best@16) | 12.6 | |
| scalene (best@32) | 19.6 | |
| Madaan et al. (2023) | pie-2B | 4.4 |
| pie-2B (best@16) | 21.1 | |
| pie-2B (best@32) | 26.3 | |
| pie-16B | 4.4 | |
| pie-16B (best@16) | 22.4 | |
| pie-16B (best@32) | 26.6 | |
| pie-Few-shot (best@16) | 35.2 | |
| pie-Few-shot (best@32) | 38.3 | |
| This work | w/ GPT-3.5 | 23.0 |
| w/ ChatGPT | 26.7 | |
| w/ GPT-4 | 36.0 | |
Appendix G Evaluation of Vicuna-13b
We also experiment with Vicuna-13b (Chiang et al., 2023), a version of LLaMA-13b (Touvron et al., 2023) fine-tuned on conversations sourced from the web. Vicuna-13b was able to consistently follow the task initialization prompt. However, it struggled to follow the prompts intended for feedback and refinement. This often led to outputs that resembled assistant-like responses, a representative example of which can be found in Appendix G.
It’s important to note that we used the same prompts for Vicuna-13b as those used with other models in our study. However, the limited performance of Vicuna-13b suggests that this model may require more extensive prompt-engineering for optimal performance.
Mixed-refine: Improving Vicuna-13b with ChatGPT
While the focus of is improvement of the model without any external help, it may be possible to use a smaller model for the initialization, and then involving a bigger model for refinement. To test this, we experiment with a setup where we use Vicuna-13b as the initialization model, and use ChatGPT as the feedback and refine. The results on Math Reasoning show the promise of this approach: while Vicuna-13b was able to get only 24.18% on Math Reasoning, it was able to improve to 40.5% in this mixed-refinement setting.
Appendix H Additional Analysis
H.1 Using Oracle Feedback
We experimented with Oracle Feedback following Welleck et al. (2022). This method uses correctness information to guide model refinement, only progressing to refine stage if the current answer is incorrect. This adjustment notably enhanced performance in the Math Reasoning task, with GPT-3 improving by 4.8% and GPT-4 by 0.7% Table 9. This indicates the potential of external signals to optimize model performance in particular tasks.
| GPT-3.5 | ChatGPT | GPT-4 | ||||
|---|---|---|---|---|---|---|
| Task | Base | + | Base | + | Base | + |
| Math Reasoning | 64.1 | 64.1 (0) | 74.8 | 75.0 (0.2) | 92.9 | 93.1 (0.2) |
| Math Reasoning (Oracle) | 64.06 | 68.9 (4.8) | 74.8 | 76.2 (1.4) | 92.9 | 93.8 (0.7) |
| Iteration | Acronym | Pronunciation | Pron. (5) | Spell. (5) | Rel. (5) | Pos. Con. (5) | Total (25) |
|---|---|---|---|---|---|---|---|
| 1 | USTACCSF | us-tacks-eff | 1 | 1 | 5 | 3 | 11 |
| 2 | TACC-SIM | tacks-sim | 4 | 4 | 5 | 3 | 17 |
| 3 | TACCSF | tacks-eff | 1 | 2 | 5 | 3 | 12 |
| 4 | TACC-SIMF | tack-simf | 4 | 4 | 5 | 3 | 17 |
Non-monotonic increase in output quality for acronym generation
For tasks with multi-aspect feedback like Acronym Generation, the output quality can fluctuate during the iterative process, improving on one aspect while losing out on another (Table 10). To address this, ’s feedback generates explicit numerical scores to capture the different aspects of output quality. This allows for a more balanced evaluation of outputs and the selection of the most appropriate one. The algorithm selects the best output based on the maximum score across all iterations, as described in Algorithm 1 (line 8). A similar selection is possible for other tasks like Math Reasoning and Sentiment Reversal, while we observe that output quality increases monotonically with iterations.
Feedback and Refinement Error Analysis for Response Generation
| Error Type | Occurrence | Feedback | Refinement |
|---|---|---|---|
| Incorrect feedback | 25% | Informative: The response provides some encouragement and reassurance, and additional information. 3/3 | Response: That’s hilarious! Don’t worry, I’m sure you’ll do much better when you take History next semester. Are you looking forward to it? |
| Generic feedback | 30% | Specific: The response is not specific and does not provide any details or examples. 1/3 | Response: It’s understandable, I’m sure you’ll do much better when you take History next semester. Maybe you can use your knowledge of Christopher Columbus to ace your next test! Are you looking forward to it? |
| Incorrect Scoring | 10% | Informative: The response provides a supportive and understanding message, which is informative to the user. 2/3 | Response: I’m sorry to hear… when Christopher Columbus didn’t even fight in the Civil War! I’m sure you’ll do much better…. Are you looking forward to it? |
| Error Type | Occurrence | Feedback | Refinement |
|---|---|---|---|
| Not-Robust | 10% | Specific: The response is specific and provides specific details or examples. 3/3 | Response: That’s pretty funny! It’s understandable that you didn’t do well on the test. I’m sure you’ll do much better when you take History next semester |
| Ignores feedback | 25% | Informative: The response doesn’t provide any new information. 1/3 | Response: That’s so kind and generous of you! I would love to hear more about the podcasts you enjoy. Do you have any favorites you can recommend? |
| Introduces new problem | 20% | Informative: 3/3 | Response: That would be a disaster! Luckily, my coworkers know better than to drink while they work. New Informative score: 2/3 |
| Robust to bad feedback | 60% | Informative: The response does not provide any information. 1/3 | Response: Wow, 25 people! That must have been an amazing experience. Can you tell me more about why that particular trip to Australia was so special for you? |
We perform a detailed error analysis of feedback and refinement process for Dialogue Response Generation, which we summarize in Tables Table 11 and Table 12.
Table 11 reports the occurrence of different types of errors in our sample, which includes Incorrect Feedback (25%), Generic Feedback (30%), and Incorrect Scoring (10%). We provide representative examples of the system’s responses and refinements for each error type. These errors highlight potential areas for improving our feedback handling mechanism, particularly in the interpretation and understanding of user inputs.
Table 12 breaks down errors found in the refinement stage of . Errors include: not being robust (10%), ignoring feedback (25%), and introducing a new problem (20%). We demonstrate how the model handles a variety of feedback types, how robust it is under different circumstances, and how often it inadvertently introduces new issues. 60% of the times, the model is robust to incorrect or generic feedback. These insights can guide us in enhancing the model’s refinement capabilities, especially in providing accurate and specific responses.
Appendix I Beyond Benchmarks
demonstrates its iterative feedback and refinement capabilities in the context of website layout generation. ChatGPT initially produces a rudimentary layout for a given topic, and then uses the feedback to suggest specific, actionable improvements, as demonstrated in Figures 10 and 12. These suggestions range from design changes such as color and font adjustments, to content enhancements and layout modifications. Figures 11 and 13 showcase the final layouts, post-feedback implementation, highlighting the potential and versatility of across different scenarios.
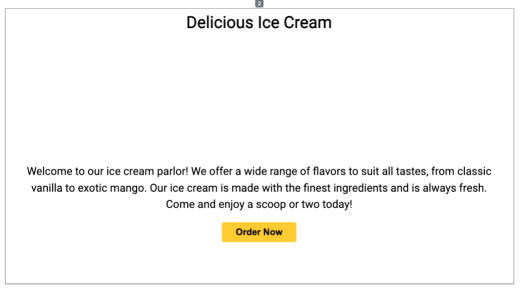
Ice Cream Generation
The feedback generated by feedback for ice cream generation:
-
Change the background color of the container to a light blue color (#6f2ff).
-
Change the font size of the heading to 48px.
-
Add a small icon before the "Welcome to our ice cream parlor!" text using the URL https://cdn-icons-png.flaticon.com/512/3622/3622340.png.
-
Add an additional paragraph after the existing text with the following text: "We also offer a variety of toppings and cones to complement your ice cream. Visit us today to try our latest flavors and indulge in a sweet treat!"
-
Increase the font size of the button text to 24px.
-
Update the button color to #9933.
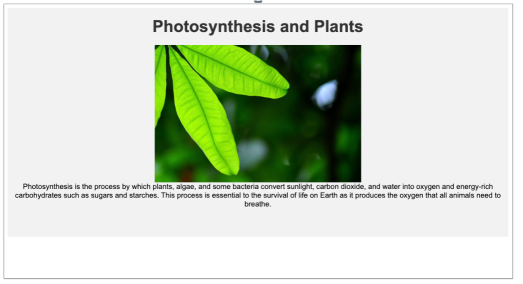
Photosynthesis
The feedback generated by feedback for photosynthesis:
-
Increase the font size of the text to 18px for better readability.
-
Add more information about the benefits of photosynthesis.
-
Remove the unnecessary margin-top from the header.
-
Add a ruler or divider below the header to separate it from the image.

Appendix J Statistical Confidence Intervals
| GPT-3.5 | ChatGPT | GPT-4 | ||||
|---|---|---|---|---|---|---|
| Task | Base | + | Base | + | Base | + |
| Sentiment Reversal | 8.8 2.05 | 30.4 3.61∗ | 11.4 2.34 | 43.2 3.98∗ | 3.8 1.28 | 36.2 3.82∗ |
| Dialogue Response | 36.4 6.14 | 63.6 6.62∗ | 40.1 6.33 | 59.9 6.67∗ | 25.4 5.36 | 74.6 6.22∗ |
| Code Optimization | 14.8 2.66 | 23.0 3.25∗ | 23.9 3.30 | 27.5 3.49 | 27.3 3.48 | 36.0 3.81∗ |
| Code Readability | 37.4 6.86 | 51.3 7.39 | 27.7 6.13 | 63.1 7.40∗ | 27.4 6.10 | 56.2 7.45∗ |
| Math Reasoning | 64.1 3.47 | 64.1 3.47 | 74.8 3.20 | 75.0 3.20 | 92.9 2.05 | 93.1 2.03 |
| Acronym Gen. | 41.6 7.72 | 56.4 8.15 | 27.2 6.60 | 37.2 7.46 | 30.4 6.92 | 56.0 8.15∗ |
| Constrained Gen. | 28.0 7.38 | 37.0 8.26 | 44.0 8.72 | 67.0 9.00∗ | 15.0 5.38 | 45.0 8.77∗ |
Table 13 shows results from Table 1 with Wilson confidence interval Brown et al. (2001) (at = 99% confidence interval) and statistical significance. Gains that are statistical significance based on these confidence intervals are marked with an asterisk. We find that nearly all of GPT-4 gains are statistically significant, ChatGPT gains are significant for 4 out of 7 datasets, and GPT-3.5 gains are significant for 3 out of 7 datasets.
Appendix K New Tasks
Constrained Generation
We introduce “CommonGen-Hard," a more challenging extension of the CommonGen dataset Lin et al. (2020), designed to test state-of-the-art language models’ advanced commonsense reasoning, contextual understanding, and creative problem-solving. CommonGen-Hard requires models to generate coherent sentences incorporating 20-30 concepts, rather than only the 3-5 related concepts given in CommonGen. focuses on iterative creation with introspective feedback, making it suitable for evaluating the effectiveness of language models on the CommonGen-Hard task.
Acronym Generation
Acronym generation requires an iterative refinement process to create concise and memorable representations of complex terms or phrases, involving tradeoffs between length, ease of pronunciation, and relevance, and thus serves as a natural testbed for our approach. We source a dataset of 250 acronyms444https://github.com/krishnakt031990/Crawl-Wiki-For-Acronyms/blob/master/AcronymsFile.csv and manually prune it to remove offensive or uninformative acronyms.
Appendix L Code Readability
Orthogonal to the correctness, readability is another important quality of a piece of code: though not related to the execution results of the code, code readability may significantly affect the usability, upgradability, and ease of maintenance of an entire codebase. In this section, we consider the problem of improving the readability of code with . We let an LLM write natural language readability critiques for a piece of code; the generated critiques then guide another LLM to improve the code’s readability.
L.1 Method
Following the setup, we instantiate init, feedback, and refine. The init is a no-op — we directly start by critiquing the code with feedback and applying the changes with refine.
-
•
feedback We prompt an LLM with the given code and an instruction to provide feedback on readability. We give the LLM the freedom to freely choose the type of enhancements and express them in the form of free text.
-
•
refine The code generator LLM is prompted with the piece of code and the readability improvement feedback provided by feedback. In addition, we also supply an instruction to fix the code using the feedback. We take the generation from the code generator as the product of one iteration in the feedback loop.
Starting from an initial piece of code , we first critique, , and then edit the code, . This is recursively performed times, where and .
L.2 Experiments
Dataset
We use the CodeNet Puri et al. (2021) dataset of competitive programming.555https://github.com/IBM/Project_CodeNet For our purpose, these are hard-to-read multi-line code snippets. We consider a random subset of 300 examples and apply to them.
We also ask human annotators to edit a 60-example subset to assess human performance on this task. The human annotators are asked to read the code piece and improve its readability.
Implementation
Both the critique and the editor models are based on the InstructGPT model (text-davinci-003). We consider the temperature of both (greedy) and (sampling) for decoding Natural Language suggestion from the critique model. We always use a temperature (greedy) when decoding Programming Language from the code editor. Due to budget constraints, we run for iterations. The exact prompts we use can be found in Figures 25-26.
Evaluation Methods
We consider a few automatic heuristic-based evaluation metrics,
-
•
Meaningful Variable Names: In order to understand the flow of a program, having semantically meaningful variable names can offer much useful information. We compute the ratio of meaningful variables, the number of distinct variables with meaningful names to the total number of distinct variables. We automate the process of extracting distinct variables and the meaningful subset of variables using a few-shot prompted language model.
-
•
Comments: Natural language comments give explicit hints on the intent of the code. We compute the average number of comment pieces per code line.
-
•
Function Units: Long functions are hard to parse. Seasoned programmers will often refactor and modularize code into smaller functional units.
Result
For each automatic evaluation metric, the ratio of meaningful variable, of comment, and the number of function units, we compute for each iteration averaged across all test examples and plot for each iteration in 14(a), 14(b) and 14(c) respectively. The two curves each correspond to critique with temperature and . The iteration 0 number is measured from the original input code piece from CodeNet. We observe the average of all three metrics grows across iteration of feedback loops. A diverse generation of a higher temperature in the critique leads to more edits to improve the meaningfulness of variable names and to add comments. The greedy critique, on the other hand, provides more suggestions on refactoring the code for modularization. Figure 15 provides an example of code-readability improving over iterations.
In Table 14, we measure human performance on all three metrics and compare with last iteration output. At , produces more meaning variables, more function units and slightly more comments compared to the human annotators on average. At , produces less meaningful variables, less comments per line but even more function units.
| Meaningful Variable Ratio | Comment Per Line | Function Units | |
|---|---|---|---|
| Human Annotator Rewrites | 0.653 | 0.24 | 0.70 |
| (T = 0.0) | 0.628 | 0.12 | 1.41 |
| (T = 0.7) | 0.700 | 0.25 | 1.33 |
Example
Starting Code:
Code
Code
Appendix M Dialogue Response Generation
Open-domain dialogue response generation is a complex task that requires a system to generate human-like responses to a wide range of topics. Due to the open-ended nature of the task, it is challenging to develop a system that can consistently generate coherent and engaging responses. In this section, we use for automatically generated feedback and applying iterative refinement to improve the quality of the responses.
M.1 Modules
We follow the high-level description of the framework from Section 2, and instantiate our framework as follows.
Init
This is the first step in performing the task. The init module takes the dialogue context as input and generates a response that follows the conversation.
Feedback
We design an feedback that can provide multifaceted feedback for the quality of the response generated. Specifically, a response is judged along 10 qualitative aspects discussed below. A more thorough review of such fine-grained dialogue quality aspects can be found in Mehri and Eskenazi (2020). We use 6 in-context examples for feedback generation. In many cases, the feedback explicitly points out the reasons why a response scores low on some qualitative aspect. We show an example in Figure 16.
-
•
Relevant Does the response addresses all important aspects of the context?
-
•
Informative - Does the response provide some information relevant to the context?
-
•
Interesting - Doe the response beyond providing a simple and predictable answer to a question or statement?
-
•
Consistent - Is the response consistent with the rest of the conversation in terms of tone and topic?
-
•
Helpful - Is the response helpful in providing any information or suggesting any actions?
-
•
Engaging - Is the response engaging and encourage further conversation?
-
•
Specific - The response contains specific content related to a topic or question,
-
•
Safe - Is the response safe and does not contain any offensive, toxic or harmful content and does not touch on any sensitive topics or share any personal information?
-
•
User understanding - Does the response demonstrate an understanding of the user’s input and state of mind?
-
•
Fluent Is the response fluent and easy to understand?
Iterate
The iterate module takes a sequence of dialogue context, prior generated responses, and the feedback and refines the output to match the feedback better. An example of a context, response, feedback and a refined response is shown in Figure 16.
M.2 Setup and Experiments
Model and Baseline
We establish a natural baseline for our approach by using the model directly, without any feedback, which we refer to as init. Our implementation of employs a few-shot setup, where each module (init, feedback, iterate) is implemented as few-shot prompts, and we execute the self-improvement loop for a maximum iterations. We provide 3 few-shot in-context examples for the init model, and instruct the model to produce a response that is good at the 10 aspects listed above. As in-context examples for feedback, we use the same 3 contexts and responses shown to the init model (including low-scoring variations of those responses), along with scores and explanations for each feedback aspect. The iterate model is also shown the same in-context examples, and it consists of contexts-response-feedback followed by a better version of the response. For , we chose the response that gets the highest total score from the feedback model across all iterations excluding the initial response. We use text-davinci-003 for all the experiments.
| GPT-3.5 | ChatGPT | GPT4 | |
|---|---|---|---|
| wins | 36.0 | 48.0 | 54.0 |
| init wins | 23.0 | 18.0 | 16.0 |
| Both are equal | 41.0 | 50.0 | 30.0 |
Evaluation
We perform experiments on the FED dataset Mehri and Eskenazi (2020). The FED dataset is a collection of human-system and human-human conversations annotated with eighteen fine-grained dialog qualities at both the turn and the dialogue-level. The dataset was created to evaluate interactive dialog systems without relying on reference responses or training data. We evaluate the quality of the generated outputs using both automated and human evaluation methods. For automatic evaluation in Table1, we used zero-shot prompting with text-davinci-003 and evaluate on a test set of 342 instances. We show the model the responses generated by and the baseline init and ask the model to select the better response in terms of the 10 qualities. We report the win rate. However, we acknowledge that automated metrics may not provide an accurate assessment of text generation tasks and rely on human evaluation instead.
Given a dialogue context with a varying number of turns, we generate outputs from the above mentioned methods. For human evaluation, for 100 randomly selected test instances, we show annotators the 10 response quality aspects, responses from and init models and ask them to select the better response. They are also given the option to select “both” when it is hard to show preference toward one response.
Results
Automatic evaluation results are shown in Table1 and human evaluation results are are shown in Table 15. We experiment on 3 latest versions of GPT models. text-davinci-003 is capable of generating human-like responses of great quality for a wide range of dialogue contexts and hence GPT-3.5 is a strong baseline. Still, beats init by a wide margin on both automatic as well as human evaluation. Our manual analysis shows that outputs generated by are more engaging and interesting and generally more elaborate than the outputs generated by init.
Appendix N Code Optimization
Performance-Improving Code Edits or PIE (Madaan et al., 2023) focuses on enhancing the efficiency of functionally correct programs. The primary objective of PIE is to optimize a given program by implementing algorithmic modifications that lead to improved runtime performance.
Given an optimization generated by PIE, first generates a natural language feedback on possible improvements Figure 23. Then, the feedback is fed to refine Figure 24 for refinement.
| Setup | Iteration | % Optimized | Relative Speedup | Speedup |
|---|---|---|---|---|
| Direct | - | 9.7 | 62.29 | 3.09 |
| feedback | 1 | 10.1 | 62.15 | 3.03 |
| feedback | 2 | 10.4 | 61.79 | 3.01 |
| 1 | 15.3 | 59.64 | 2.90 | |
| 2 | 15.6 | 65.60 | 3.74 |
Appendix O Math Reasoning
We use the Grade School Math 8k (GSM-8k) dataset (Cobbe et al., 2021) for evaluating on math reasoning. In the context of grade school mathematics, aims to enable LLMs to iteratively refine their mathematical problem-solving outputs based on introspective feedback.
Following Gao et al. (2022), we write solutions to the reasoning problems in Python. Consider the following example from the paper, where an error in the code demonstrates a lack of understanding of the problem:
By using , we can identify the error in the code and refine the solution through an iterative process of introspection and feedback:
is thus instantiated naturally: the generator generates an initial solution, and feedback scans the solution to spot errors on which to provide feedback. The feedback is supplied to refine to create a new solution. Following Welleck et al. (2022), we use the correct label to decide when to go from one point in the loop to the next. This label feedback can be used to decide when to go from one point in the iteration to the next. We show results using in Figure 17.
Appendix P Sentiment Reversal
We consider the task of long-form text style transfer, where given a passage (a few sentences) and an associated sentiment (positive or negative), the task is to re-write the passage to flip its sentiment (positive to negative or vice-versa). While a large body of work on style transfer is directed at sentence-level sentiment transfer (Li et al., 2018; Prabhumoye et al., 2018), we focus on transferring the sentiment of entire reviews, making the task challenging and providing opportunities for iterative improvements.
Instantiating for sentiment reversal
We instantiate for this task following the high-level description of the framework shared in Section 2. Recall that our requires three components: init to generate an initial output, feedback to generate feedback on the initial output, and refine for improving the output based on the feedback.
is implemented in a complete few-shot setup, where each module (init, feedback, iterate) is implemented as few-shot prompts. We execute the self-improvement loop for a maximum of iterations. The iterations continue until the target sentiment is reached.
P.1 Details
Evaluation
Given an input and a desired sentiment level, we generate outputs and the baselines. Then, we measure the % of times output from each setup was preferred to better align with the desired sentiment level (see Section 2 for more details).
We also experiment with standard text-classification metric. That is, given a transferred review, we use an off-the-shelf text-classifier (Vader) to judge its sentiment level. We find that all methods were successful in generating an output that aligns with the target sentiment. For instance, when the target sentiment was positive, both GPT-3.5 with text-davinci-003 and generates sentences that have a positive sentiment (100% classification accuracy). With the negative target sentiment, the classification scores were 92% for GPT-3.5 and 93.6% for .
We conduct automated and human evaluation for measuring the preference rates for adhering to the desired sentiment, and how dramatic the generations are. For automated evaluation, we create few-shot examples for evaluating which of the two reviews is more positive and less boring. We use a separate prompt for each task. The examples are depicted in Figure 36 for initialization, Figure 37 for feedback generation, and Figure 38 for refinement. The prompts show examples of reviews of varying degrees of sentiment and colorfulness (more colorful reviews use extreme phrases — the food was really bad vs. I wouldn’t eat it if they pay me.). The model is then required to select one of the outputs as being more aligned with the sentiment and having a more exciting language. We report the preference rates: the % of times a variant was preferred by the model over the outputs generated by .
Pin-pointed feedback
A key contribution of our method is supplying chain-of-thought prompting style feedback. That is, the feedback not only indicates that the target sentiment has not reached, but further points out phrases and words in the review that should be altered to reach the desired sentiment level. We experiment with an ablation of our setup where the feedback module simply says “something is wrong.” In such cases, for sentiment evaluation, the output from were preferred 73% of the time (down from 85% with informative feedback). For dramatic response evaluation, we found that the preference rate went down drastically to 58.92%, from 80.09%. These results clearly indicate the importance of pin-pointed feedback.
Evaluation
We evaluate the task using GPT-4. Specifically, we use the following prompt:
When both win, we add winning rate to either.
Appendix Q Acronym Generation
Good acronyms provide a concise and memorable way to communicate complex ideas, making them easier to understand and remember, ultimately leading to more efficient and effective communication. Like in email writing, acronym generation also requires an iterative refinement process to achieve a concise and memorable representation of a complex term or phrase. Acronyms often involve tradeoffs between length, ease of pronunciation, and relevance to the original term or phrase. Thus, acronym generation is a natural method testbed for our approach.
We source the dataset for this task from https://github.com/krishnakt031990/Crawl-Wiki-For-Acronyms/blob/master/AcronymsFile.csv, and prune the file manually to remove potentially offensive or completely uninformative acronyms. This exercise generated a list of 250 acronyms. The complete list is given in our code repository.
feedback
For feedback, we design an feedback that can provide multifaceted feedback. Specifically, each acronym is judged along five dimensions:
-
•
Ease of pronunciation: How easy or difficult is it to pronounce the acronym? Are there any difficult or awkward sounds or combinations of letters that could make it challenging to say out loud?
-
•
Ease of spelling: How easy or difficult is it to spell the acronym? Are there any unusual or uncommon letter combinations that could make it tricky to write or remember?
-
•
Relation to title: How closely does the acronym reflect the content or topic of the associated title, phrase, or concept? Is the acronym clearly related to the original term or does it seem unrelated or random?
-
•
Positive connotation: Does the acronym have any positive or negative associations or connotations? Does it sound upbeat, neutral, or negative in tone or meaning?
-
•
Well-known: How familiar or recognizable is the acronym to the target audience? Is it a common or widely-used term, or is it obscure or unfamiliar?
Some of these criteria are difficult to quantify, and are a matter of human preference. As with other modules, we leverage the superior instruction following capabilities of modern LLMs to instead provide a few demonstrations of each task. Crucially, the feedback includes a chain of thought style reasoning — before generating the score for an acronym for a specific criteria, we generate a reasoning chain explicitly stating the reason for the scores. We use human evaluation to judge the final quality of the acronyms. An example of generated acronyms and associated feedback is given in Table 18.
Criteria output from GPT3: STSLWN output from : Seq2Seq Ease of pronunciation Pronounced as ess-tee-ess-ell-double-you-enn which is very difficult. Pronounced as seq-two-seq which is easy. Ease of spelling Very difficult to spell. Easy to spell. Relation to title No relation to the title. Mentions sequence which is somewhat related to the title. Positive connotation Meaningless acronym. Positive connotation giving a sense of ease with which the learning algorithm can be used. Well-known Not a well-known acronym. Close to the word sequence which is a well-known word. Total score 5/25 20/25
Appendix R Constrained Generation
In this work, we introduce a more challenging variant of the CommonGen task, dubbed “CommonGen-Hard,” designed to push the boundaries of state-of-the-art language models. CommonGen-Hard requires models to generate coherent and grammatically correct sentences incorporating 20-30 concepts, as opposed to the original task which presents a set of 3-5 related concepts. This significant increase in the number of concepts tests the model’s ability to perform advanced commonsense reasoning, contextual understanding, and creative problem-solving, as it must generate meaningful sentences that encompass a broader range of ideas. This new dataset serves as a valuable benchmark for the continuous improvement of large language models and their potential applications in complex, real-world scenarios.
The increased complexity of the CommonGen-Hard task makes it an ideal testbed for evaluating the effectiveness of our proposed framework, , which focuses on iterative creation with introspective feedback. Given that initial outputs from language models may not always meet the desired level of quality, coherence, or sensibility, applying enables the models to provide multi-dimensional feedback on their own generated output and subsequently refine it based on the introspective feedback provided. Through iterative creation and self-reflection, the framework empowers language models to progressively enhance the quality of their output, closely mimicking the human creative process and demonstrating its ability to improve generated text on complex and demanding natural language generation tasks like CommonGen-Hard (Figure 18).
Appendix S Prompts
Recall that the Base LLM requires a generation prompt with input-output pairs , the feedback module requires a feedback prompt with input-output-feedback triples , and the refinement module (refine) requires a refinement prompt with input-output-feedback-refined quadruples .
-
•
Sentiment Reversal We create positive and negative variants of a single review from the training set and manually write a description for converting the negative variant to positive and vice versa. For each variant, the authors generate a response and create a feedback based on the conversion description.
-
•
Dialogue Response Generation We sample six examples as for the few-shot prompt for the Base LLM. For each output , the authors create a response, evaluate it based on a rubric to generate , and produce an improved version .
-
•
Acronym Generation We provide the Base LLM with a total of 15 (title, acronym) examples. Then, for one title () we generate an acronym () using ChatGPT. The authors then score the acronyms based on a 5-point rubric to create the corresponding , and write improved versions of the acronym to create . 3 such examples are used for refine and feedback.
-
•
Code Optimization We use the slow () and fast () versions of programs released by Madaan et al. (2023) for Base LLM. We use their provided explanations (Madaan et al., 2023) for feedback and refine.
-
•
Math Reasoning The prompts for the Base LLM are sourced from PaL (Gao et al., 2022) as . We select two examples from the training set on which Codex fails when prompted with PaL-styled prompts, and manually write the correct solution () and reasoning () for refine and feedback.
-
•
Constrained Generation We provide ten examples to the Base LLM as . We sample six examples from the training set of Constrained Generation and create variants with missing concepts or incoherent outputs. The missing concepts and the reason for incoherence form .
-
•
TODO: Add relevant information for the remaining task.