What does CLIP know about a red circle?
Visual pr![[Uncaptioned image]](circle.png) mpt engineering for VLMs
mpt engineering for VLMs
Abstract
Large-scale Vision-Language Models, such as CLIP, learn powerful image-text representations that have found numerous applications, from zero-shot classification to text-to-image generation. Despite that, their capabilities for solving novel discriminative tasks via prompting fall behind those of large language models, such as GPT-3. Here we explore the idea of visual prompt engineering for solving computer vision tasks beyond classification by editing in image space instead of text. In particular, we discover an emergent ability of CLIP, where, by simply drawing a red circle around an object, we can direct the model’s attention to that region, while also maintaining global information. We show the power of this simple approach by achieving state-of-the-art in zero-shot referring expressions comprehension and strong performance in keypoint localization tasks. Finally, we draw attention to some potential ethical concerns of large language-vision models.
1 Introduction
Large Language Models (LLMs) such as GPT-2/3 [7, 39] and ChatGPT [1] have demonstrated surprising emerging behaviours. For example, these models can perform language translation without being explicitly trained for it, in a zero-shot manner. This can be partially explained by the fact that occurrences of the desired behaviours, such as translating between two languages, naturally occur in their enormous training corpus, which is, essentially, the Internet.
Interesting emergent behaviours have been observed in large Vision-Language Models (VLMs) like CLIP [38] too. For example, CLIP can be used for zero-shot classification by checking the compatibility of a given image with prompts such as “an image of a ”, where is one of a set of class hypotheses to be tested.
Emergent behaviours are elicited by supplying suitably crafted inputs to the VLMs, often called prompts. As in the example above, researchers have mostly focused on engineering textual prompts, manipulating the textual input of the model. This approach is inspired by LLMs, where manipulating the textual modality is the only available option. However, VLMs are inherently multimodal and offer the possibility of manipulating both modalities, textual and visual. While the textual modality is the natural choice for expressing semantics, the visual modality can be better for expressing geometric properties such as location.

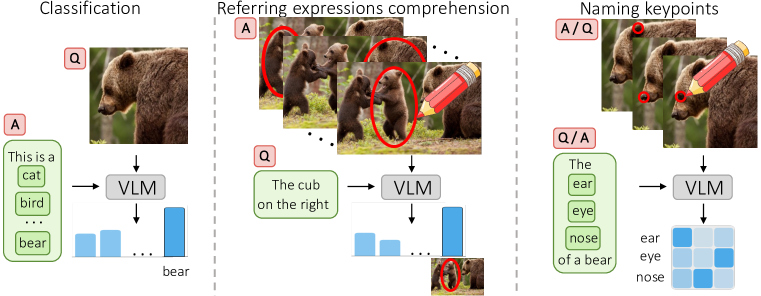
In this paper, we thus explore visual prompt engineering 111Note the difference between visual prompt tuning, a setting previously explored, where the prompts are task-specific learnable tokens, and visual prompt engineering, where we apply a fixed augmentation in pixel space.. We do so with two goals. The first goal is to contribute one more practical tool for extracting useful information from VLMs in a zero-shot manner. We demonstrate this by obtaining state-of-the-art zero-shot results in referring expressions comprehension by engineering visual prompts. The second goal is to characterise interesting and unexpected properties of the VLMs and their training data, including identifying some behaviours that can raise ethical concerns.
Perhaps the most surprising of our findings is the effectiveness of a particular type of visual prompting: drawing a plain red circle on top of the image (Fig. 1). We show that this simple intervention steers the VLM to analyse/talk about the image region contained in the circle. This behaviour can then be used for tasks such as naming a specific object or object part or detecting particular image regions based on a description. The latter, for instance, is achieved by marking each object proposal with a red circle and using the VLM to find the best match with respect to the provided referring expression, achieving strong results on multiple benchmarks in the unsupervised regime. Furthermore, we show that prompting with a circle also works for finer-grained localization, marking specific object parts or keypoints instead of just whole objects.
We further contrast marking an image with the alternative of cropping it, which, from sliding window classifiers to region neural networks, is the canonical approach to steer the focus of an image-level predictor to a particular image region. We show that, for VLMs at least, marking is significantly more effective than cropping, possibly because it does not lose contextual information like the latter.
Apart from the practical applications, our findings reveal unexpected and intriguing properties of VLMs. We show empirically, that marking with a red circle is optimal among a selection of possible markers (variants of the circle, boxes, arrows, etc.). Presumably, the VLMs understand red circles out of the box because these appear sufficiently frequently in the training corpus, i.e., the Internet. While we do not have access to the full training data of CLIP, we corroborate this intuition by seeking examples of such images in YFCC15M, a dataset of CC-BY images.
Our analysis shows that red circles are indeed present even in a (comparatively small) dataset of images like YFCC15M, but they are rare. It is a testament to the extraordinary capacity of VLMs that such a behaviour can be learned from such rare events, without an explicit focus on doing so. We test models of different sizes/capacities and show that only the larger models exhibit this behaviour reliably, which corresponds to our intuition.
Finally, we note that the ability of VLMs to learn even from rare events such “red circles” can acquire both desirable and undesirable behaviours. Red circles, in particular, can have a negative connotation in the training data as they are often used by news outlets to mark missing people or criminals and, evidently, the model learns from such examples. As a result, we show that drawing a red circle in an image increases the probability that the model would characterise a person as a criminal or as a missing person.
To summarise, we make the following main contributions: (1) We propose marking as a new form of visual prompt engineering that is effective in extracting useful emergent behaviours in VLMs like CLIP; (2) We use the latter to achieve state-of-the-art zero-shot referring expressions comprehension using a VLM; (3) We provide an analysis of why marking is effective for these models, and link that to the training data and large model capacity; (4) We show that visual prompt engineering can also elicit unwanted behaviours, such as triggering problematic biases in the VLMs, revealing potential ethical issues.
2 Related work
Emergent Behaviour from Large Scale Pretraining has mainly been observed in Large Language Models (LLMs). Most notably, GPT-2 [39], GPT-3 [7], and ChatGPT [1] have been shown to be capable of tasks such as zero-shot translation, question answering, arithmetic, as well as planning actions for embodied agents [18]. Fine-tuning LLMs can also lead to models that can generate code from docstrings [8] or solve math problems [13, 23]. Only a few emergent zero-shot behaviours have been reported for VLMs like CLIP, mainly for classification [38] and OCR [33]. Generative VLMs like FLAMINGO [3] and BLIP [24] excel in captioning and visual question-answering tasks, but also have no way of solving pixel-level computer vision tasks.
Prompting VLMs is most commonly performed by prepending a set of learnable tokens to the text input [16, 21, 65, 66], vision input [19, 46, 64], or both text and vision inputs [41, 60], in order to easily steer a frozen CLIP model to solve a desired task. [4] learn augmentations in pixel space, such as padding around the image, or changing a patch of the image, which are optimized with gradient descent on a downstream task. [5] cast image inpainting as a visual prompting task, using a generative model trained on figures from academic papers. Coloring regions of an image has been used for the VCR task [61], where a model is finetuned on annotated images [62]. Colorful Prompt Tuning (CPT) [57] color regions of an image and use a captioning model to predict which object in an image an expression refers to by predicting its color. Similarly to CPT, we augment the input image in pixel space and perform zero-shot inference. However, we annotate the image in a human-like manner and show that our method is more powerful and more flexible than CPT.
Referring Expression Comprehension (REC) aims to localize a target object in an image that corresponds to a textual description. Most approaches to REC start with object proposals, for example, generated with Faster-RCNN [40], and learn to score them [17, 31, 30, 54, 48]. REC is sometimes considered together with referring expression generation — the task of generating a description of a given region. [31] use a comprehension model to guide a generator, whereas [9] jointly train a detector with a caption generator. Some works model the scene as a graph [30, 54, 48] or use language parsers and grammar-based methods [12, 29], leading to a more interpretable result. More recently, transformer architectures have been used [25, 22, 14, 55, 50]. [25, 22, 14, 55] perform text-modulated object detection, where a transformer decoder takes the referring expression as an input and predicts a bounding box. [50] train with a text-to-pixel contrastive loss, which allows for a text-driven segmentation or detection at test time.
Unsupervised Referring Expression Comprehension is a less explored area, only made possible with the introduction of large pre-trained models such as CLIP [38]. ReCLIP [44] crops object proposals and ranks them using CLIP before an ad-hoc postprocessing step to take into account relations such as left/right, smaller/bigger, etc. CPT [57] colors object proposal boxes and use a pre-trained captioning model [63] to auto-regressively predict which colored proposal corresponds to the query description. Pseudo-Q [20] generates descriptions for multiple objects in an image, which is used to train a REC network. However, this model is not fully unsupervised as the pseudo descriptions it uses are generated using a captioning model trained on COCO.
Visual Reasoning Using Large Pretrained Models has been an area of significant interest in the last few years. In addition to referring expression detection [44], CLIP [38] has been used for semantic segmentation [37, 27]. [37] use CLIP to assign text labels to object parts after doing part co-segmentation in the latent space of a GAN. [27] utilize CLIP for open-vocabulary segmentation by using a general-purpose mask proposal network and CLIP as a classifier. CLIP has also been used for unsupervised object proposal generation [42] and open-set detection [15]. Semantic segmentation also emerges from image only [34, 49] or image-text [53] self-supervision.
Bias of VLMs is an increasingly popular area of research, as downstream applications come with the risk of perpetuating biases and stereotypes existing in the training data. However, methods for assessing the bias of a VLM are still not well established. [2] measure the misclassification rate of CLIP of faces of people of different races with non-human and criminal categories, whereas [6, 11, 47] measure fairness in retrieval results. Here, we show a different kind of bias, where the addition of a red circle over a person can trigger a negative connotation.
3 Method
Our goal is to develop visual prompting in Vision-Language Models (VLMs). VLMs solve prediction tasks that involve jointly processing text and images. For example, models such as CLIP are trained to match text and image samples. The input to such a VLM is an image and text , where is an alphabet. The output is a score that expresses the degree of compatibility between the supplied image and text.
3.1 Prompt engineering
One of the most striking capabilities of VLMs is their ability to solve a variety of classification tasks with little to no further training at all, in a zero-shot manner. This is done by reducing the task of interest to that of evaluating the VLM on suitably-engineered image and text pairs.
For example, given an image-caption pair , consider the problem of localizing a named object keypoint in the image. We can cast this as a question-answer problem, where the question is the name of the object keypoint (e.g., “right ear”, “front left leg”, …) and the answer is one of a discrete set of image locations.
Because the VLM computes a compatibility score between an image and the text , it cannot be used to map the question to the answer directly. However, via prompt engineering, we can use the VLM to construct a compatibility score between question and answer, conditioned on the input image-text pair . This score is in general given by the expression
| (1) |
where and are versions of the input image and text, obtained by transforming the latter to reflect the question-answer pair .
The specific way Eq. 1 should be applied to a problem depends on the specific nature of the latter. For example, in the problem of localizing the named keypoints, it is natural to encode the name of the keypoint via the textual modality and its 2D location via the visual modality. For instance, in order to answer the question for a given input image with caption , we can engineer the textual prompt to encode a description of the named entity. Likewise, we can engineer the visual prompt in such a way as to ‘select’ the location in the image, using one of the methods discussed in Section 3.2. With this, we can answer the question by finding that maximizes the score which specializes Eq. 1.
In the following sections, we provide further details and apply these ideas to a few concrete tasks.
3.2 Visual prompting via marking
The usual way of encoding location information in a visual prompt is to crop the image around the desired location, meaning that is the image cropped around . This idea has been used extensively with VLMs, including to interpret referring expressions, where maximizing a score of the form seeks for the image crop that best matches the referring expression .
In this paper, we explore an alternative approach for visual prompting that uses the concept of marking the desired region in the image. Marking quite literally means overlaying to the image a circle, a box, or an arrow, which visually indicates the desired location .
While the idea of marking may sound strange, it is interesting for two reasons. First, differently from cropping, a marked image preserves almost all the information contained in the input image , including contextual information that crops lack. Second, we show that marking works well with VLMs, outperforming cropping-based prompt engineering in some prediction tasks.
While the simplest marking consisting of a red circle is particularly effective, in Section 4 we explore several different ways of generating markings. We refer the reader to that section for further details and examples.
3.3 Tasks
We study the idea of mark-based prompt engineering by considering several zero-shot prediction tasks, from simple tasks such as matching keypoints to their names to more complex ones such as referring expression comprehension.
Naming Keypoints.
The first and simplest task that we consider is matching the name of the keypoints of an object to their 2D locations in an image. The input is an image , a set of keypoint names , and a set of corresponding keypoint locations . The number of names and locations is the same () and the goal is to match the two. We express the latter as predicting the square permutation matrix that associates each name to its corresponding location (i.e., ).
In order to predict , we use Eq. 1 to define the cost of associating name to location as where is obtained either via cropping or marking and is just the name of the keypoints prefixed by the string “an image of”. For this problem, the role of questions and answers is symmetric and we decode the cost matrix into a permutation matrix via optimal transport:
| (2) |
where is a temperature parameter. This optimization problem is solved efficiently via the Sinkhorn-Knopp algorithm [43], which renormalizes matrix .
Keypoint Localization.
The second task is a more useful and difficult variant of the first. The goal is still to localize a named keypoint in an image, but this time the locations are a subset of a regular grid. These are further restricted to a salient image region extracted by using the unsupervised saliency method of [49] to avoid testing irrelevant locations in the background. The difference compared to naming keypoints is that this version of the problem does not assume prior knowledge of the possible locations of the keypoints. Given the name of a keypoint, its location is then obtained as where and are as defined previously.
| Method | Name-to-keypoint | Keypoint-to-name | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CUB | Spair71k | CUB | SPair71k | |||||||||||
| Random | 8.2 | 16.8 | 15.0 | 10.5 | 9.4 | 15.1 | 11.9 | 8.2 | 16.8 | 15.0 | 10.5 | 9.4 | 15.1 | 11.9 |
| Crop w/o SK | 15.8 | 28.5 | 28.5 | 28.5 | 20.1 | 26.1 | 29.7 | 18.7 | 22.4 | 19.1 | 24.0 | 14.9 | 27.3 | 25.1 |
| Crop w/ SK | 25.5 | 35.1 | 37.5 | 34.6 | 23.9 | 32.9 | 36.3 | 25.8 | 36.1 | 32.5 | 32.7 | 19.8 | 35.3 | 32.5 |
| Red Circle w/o SK | 46.5 | 54.8 | 53.1 | 51.6 | 40.1 | 47.4 | 45.2 | 29.5 | 26.8 | 24.9 | 36.9 | 18.8 | 31.8 | 28.9 |
| Red Circle w/ SK | 58.2 | 67.6 | 60.1 | 59.3 | 53.1 | 56.7 | 52.8 | 56.5 | 67.2 | 54.4 | 59.7 | 49.8 | 56.6 | 53.0 |
Referring Expression Comprehension.
Comprehending a referring expression means detecting an object in an image that corresponds to a textual specification that explicitly refers to it (e.g., “fourth dog from the right”). Similarly to prior work [57, 44, 20], given an image , we approach this problem by extracting first a set of object proposals using the method from [58] and interpret those as the set of possible answers . The set of questions is instead a collection of referring expressions extracted from a given benchmark dataset. For each referring expression, the best matching proposal is then given by
| (3) |
The engineered prompts and are defined as in Section 3.3. In this case, we found it useful to subtract from the score the average with respect to all possible referring expressions . This weighs down hypotheses such as faces that are visually very salient and tend to respond very strongly to all questions .
4 Experiments
We study the properties of visual marking in VLMs by considering first the three tasks of Section 3.3: naming keypoints, localizing keypoints, and referring expression comprehension.
4.1 Naming Keypoints
Naming keypoints is a comparatively simple problem that has no direct application; however, it is simpler and faster to evaluate than the other tasks, so we use it to ablate various aspects of our method.
Data and implementation details.
For this task, we consider the CUB-200-2011 (CUB) [51] and SPair71k [35] datasets. The first contains named keypoint annotations for each image, whereas the second only annotates matching keypoints in pairs of images, but does not name them. We thus augment the latter, manually naming each keypoint instance in each animal image. We further crop the images from SPair71k with the provided bounding boxes. For the VLM, we use the ViT-L/14@336px backbone. Please see the sup. matt. for details.
Results.
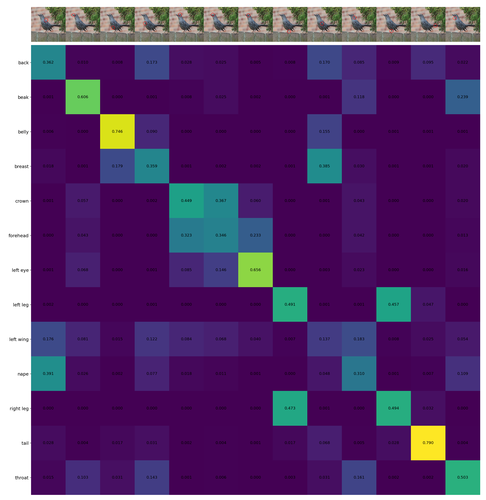
Recall that, in this task, the output of the predictor is a permutation matrix associating each keypoint location to a corresponding name. We report (i) the ratio of keypoint names that are mapped to the correct location and (ii) the ratio of keypoint locations that are mapped to the correct names. To the best of our knowledge, there are no prior works that associate keypoints with their names. We thus compare the result of this new task to (a) random choice and (b) a baseline where is obtained by cropping.
As seen in Table 1, prompting via visual marking (red circles) significantly outperforms the baselines, achieving almost twice the accuracy. Using the Sinkhorn-Knopp (SK) algorithm to normalize the matching score further boosts results, mainly improving results for points that are ambiguous and close to each other, e.g., mouth and nose.
What is the best visual marker?
We compare the use of (i) different shapes for highlighting a location: circle, rectangle, cross, arrow, (ii) different sizes, and (iii) different colors of the annotations, and show some examples in Fig. 4. We compare different shapes and colors in Table 2 and find that red circles perform best. Red is the best color despite the fact that it is a commonly occurring color in images, unlike colors like purple which can be found less often in nature and can thus be more distinctive, but lead to worse performance. We attribute this to the fact that this emergent capability of CLIP exists due to human-centric manipulations of its training data, and humans are likely to annotate using red circles, as shown next.
| Marker shape | Mean | Best |
|---|---|---|
| Circle | 33.5 4.5 | 46.5 |
| Arrow | 28.3 3.1 | 36.3 |
| Square | 24.1 3.6 | 36.3 |
| Cross | 21.5 6.3 | 34.5 |
| Circle color | Mean | Best |
|---|---|---|
| Red | 36.4 5.1 | 46.5 |
| Green | 34.3 4.2 | 43.3 |
| Purple | 34.0 3.7 | 41.9 |
| Blue | 32.7 3.9 | 41.1 |
| Yellow | 32.4 4.0 | 40.8 |

Are there visual markers in the training data?
To explore the hypothesis that CLIP can zero-shot classify annotations on images because of similar examples seen during training, we find images in YFCC15M that contain markers (YFCC15M is a subset of the CLIP training data). To this end, we train a binary classifier using an ensemble of a ViT-B/16 and RN50x16 CLIP vision encoders to classify images in YFCC15M that contain annotations. We then use this to filter a 6M subset of YFCC15M and take the top 10k images with the highest score. Finally, we manually examine the 10k images and find 70 images that have annotations drawn on top of them. We show 3 such images in Fig. 5. Hence, the training data contains examples of markers, but they are very rare (0.001%), suggesting that such behavior can only be learned from very large datasets by high-capacity models. This is further explored next.

How do different VLMs differ?
| Method | Backbone | Data | Params | Name-to-keypoint | Keypoint-to-name | ||
| CUB | Spair71k | CUB | SPair71k | ||||
| CLIP [38] | ViT-B/32 | 400M | 87M | 19.1 | 26.7 | 19.1 | 25.6 |
| CLIP [38] | ViT-B/16 | 400M | 86M | 22.2 | 34.0 | 22.1 | 33.6 |
| CLIP [38] | RN50x16 | 400M | 167M | 30.6 | 41.0 | 29.7 | 40.0 |
| CLIP [38] | ViT-L/14 | 400M | 304M | 47.9 | 54.3 | 48.0 | 51.2 |
| CLIP [38] | ViT-L/14 | 400M | 304M | 58.2 | 58.3 | 56.5 | 56.8 |
| OpenCLIP [10] | ViT-B/32 | 2B | 87M | 19.4 | 27.5 | 20.7 | 27.2 |
| OpenCLIP [10] | ViT-L/14 | 2B | 304M | 33.9 | 42.4 | 33.3 | 41.5 |
| OpenCLIP [10] | ViT-H/14 | 2B | 632M | 45.0 | 53.7 | 42.8 | 50.5 |
| OpenCLIP [10] | ViT-g/14 | 2B | 1.01B | 44.2 | 47.2 | 42.5 | 43.6 |
| OpenCLIP [10] | ViT-G/14 | 2B | 1.84B | 50.4 | 52.5 | 48.9 | 48.6 |
| SLIP [36] | ViT-S/16 | 15M | 22M | 13.0 | 17.8 | 12.0 | 16.7 |
| SLIP [36] | ViT-B/16 | 15M | 86M | 17.3 | 16.5 | 16.7 | 17.1 |
| SLIP [36] | ViT-L/16 | 15M | 303M | 24.6 | 26.3 | 24.1 | 25.0 |
| CLIP [36, 38] | ViT-S/16 | 15M | 22M | 11.4 | 16.5 | 12.4 | 15.8 |
| CLIP [36, 38] | ViT-B/16 | 15M | 86M | 14.0 | 18.4 | 14.8 | 17.8 |
| CLIP [36, 38] | ViT-L/16 | 15M | 303M | 15.0 | 20.5 | 15.8 | 20.4 |
| FILIP [26, 56] | ViT-B/32 | 15M | 90M | 8.9 | 15.6 | 8.7 | 15.6 |
| DeFILIP [26] | ViT-B/32 | 15M | 90M | 12.5 | 19.5 | 12.5 | 19.4 |
| CLIP [26, 38] | ViT-B/32 | 15M | 90M | 10.6 | 14.1 | 11.0 | 14.3 |
| DeCLIP [26] | ViT-B/32 | 15M | 90M | 15.8 | 19.9 | 15.8 | 18.7 |
| DeCLIP [26] | ViT-B/32 | 88M | 90M | 19.4 | 23.6 | 19.7 | 22.3 |
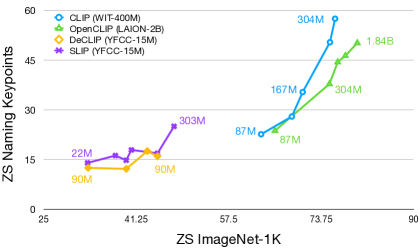
We compare a number of CLIP models in Fig. 6. In general, we observe that the performance of keypoint matching improves with (i) the size of the pretraining dataset and (ii) the size of the vision encoder. The former holds true for CLIP models trained on WIT-400M vs YFCC-15M (which is a subset of WIT-400M). However, using the LAION-2B dataset for pretraining leads to worse results. We suspect this result comes from differences in filtering when creating WIT-400M and LAION-2B, where in the latter, examples of annotations might have been discarded due to a stronger focus on aesthetic images for generative models. Similarly, we see big gains in performance as we increase the size of the vision encoder, and the gains do not seem to converge with the biggest available models. We emphasize on the dramatic increase in performance of the WIT-400M pretrained CLIP — the biggest models improve on the performance of the smallest by 250% on ZS keypoint matching, whereas the improvement on ZS ImageNet-1K classification is just 20%. We draw similarities between this task and tasks in the domain of NLP, such as zero-shot or one-shot arithmetic, where only the largest GPT models perform well [7]. We argue that in a similar fashion, the vision encoder needs sufficient capacity and data in order to show this emergent behavior.
4.2 Localizing Keypoints
| Method | Mask | CUB | Spair71k | |||||
|---|---|---|---|---|---|---|---|---|
| Random | ✗ | 1.1 | 3.1 | 1.8 | 3.6 | 3.0 | 3.0 | 3.4 |
| Random | ✓ | 8.3 | 6.7 | 4.7 | 4.6 | 5.5 | 3.3 | 4.3 |
| Crop | ✗ | 16.9 | 25.5 | 27.3 | 22.6 | 16.1 | 20.0 | 22.7 |
| Crop | ✓ | 21.3 | 28.4 | 28.8 | 21.9 | 16.0 | 23.4 | 24.5 |
| Red Circle | ✗ | 32.3 | 50.7 | 52.7 | 55.9 | 38.3 | 42.4 | 38.0 |
| Red Circle | ✓ | 45.2 | 53.4 | 54.5 | 56.4 | 40.9 | 43.2 | 42.2 |
For this experiment, we use the same data and network architecture as for the previous one, but report the percentage of correct keypoints (PCK) as a metric, as the latter is widely used when evaluating semantic correspondences. Given a set of ground-truth points and predictions , PCK is given by:
Here, is a distance threshold given by , where is a ratio and is the bounding box size. For all datasets we use . Keypoint localization also utilizes an unsupervised saliency mask to ignore background locations.
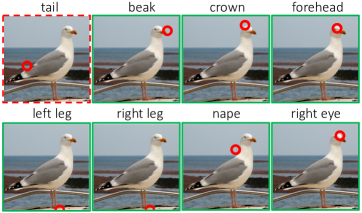
Similarly to the naming task, we compare keypoint localization to random guessing and the crop-based baseline. As shown in Table 4, using red circles significantly outperforms both; as expected, results are further improved by using saliency to further filter keypoint locations. We show qualitative results in Fig. 3.
4.3 Referring Expression Comprehension
| Method | ZS | RefCOCO | RefCOCO+ | RefCOCOg | |||||
| Val | TestA | TestB | Val | TestA | TestB | Val | Test | ||
| DTWREG [45] | ✗ | 39.2 | 41.1 | 37.7 | 39.2 | 40.1 | 38.1 | – | – |
| Pseudo-Q [20] | ✗ | 56.0 | 58.3 | 54.1 | 38.9 | 45.1 | 32.1 | 46.3 | 47.4 |
| CPT [57] | ✓ | 32.2 | 36.1 | 30.3 | 31.9 | 35.2 | 28.8 | 36.7 | 36.5 |
| ReCLIP [44] | ✓ | 42.0 | 43.5 | 39.0 | 47.4 | 50.1 | 43.9 | 57.8 | 57.2 |
| ReCLIP [44] | ✓ | 45.8 | 46.1 | 47.1 | 47.9 | 50.1 | 45.1 | 59.3 | 59.0 |
| Red Circle | ✓ | 49.8 | 58.6 | 39.9 | 55.3 | 63.9 | 45.4 | 59.4 | 58.9 |
Datasets and implementation details.
Referring expression comprehension is commonly evaluated on the RefCOCO [59], RefCOCO+ [59], and RefCOCOg [32] datasets, all of which consist of images from the MS-COCO dataset [28] together with expressions that refer to a unique object in the image, which are also annotated with a bounding box. RefCOCO+ only contains appearance-based expressions, whereas RefCOCO and RefCOCOg contain relation-based expressions (e.g., containing the words left/closer/bigger). The test sets of RefCOCO and RefCOCO+ are split in two, where “testA” and “testB” contain only people and non-people, respectively. We evaluate using the percentage of correct predictions, where a box is correctly predicted if its intersection-over-union with the ground-truth box is over 0.5.
For the referring expressions task, we use an ensemble RN50x16 and ViT-L/14@336 CLIP backbones. Following prior work [44, 57], we score the bounding box proposals of MAttNet [58].
Results.
| Model | Red Circle | FaceSynthetics | COCO | ||||
|---|---|---|---|---|---|---|---|
| Positive | Neutral | Criminal | Positive | Neutral | Criminal | ||
| ViT-L/14@336px | ✗ | 0.5% | 35.6% | 63.9% | 22.7% | 47.5% | 29.8% |
| ViT-L/14@336px | ✓ | 0.0% | 19.1% | 80.9% (+17.0%) | 1.6% | 505.% | 47.9 (+18.1%) |
| ViT-L/14 | ✗ | 1.3% | 40.8% | 57.9% | 25.0% | 46.5% | 28.6% |
| ViT-L/14 | ✓ | 0.0% | 32.5% | 67.5% (+9.6%) | 2.7% | 43.1% | 54.2 (+25.6%) |
| ViT-B/16 | ✗ | 0.7% | 49.1% | 50.2% | 19.4% | 56.7% | 23.9% |
| ViT-B/16 | ✓ | 0.0% | 37.1% | 62.9 (+12.7%) | 4.7% | 39.3% | 56.0 (+32.1%) |
| ViT-B/32 | ✗ | 0.0% | 85.2% | 14.8% | 15.3% | 61.8% | 22.9% |
| ViT-B/32 | ✓ | 0.0% | 70.5% | 29.5% (+14.7%) | 4.9% | 48.2% | 46.9 (+24.0%) |
| RN50x16 | ✗ | 0.7% | 46.4% | 52.9% | 26.5% | 30.5% | 43.0% |
| RN50x16 | ✓ | 0.1% | 52.2% | 47.7% (-5.2%) | 13.6% | 39.5% | 46.9 (+3.9%) |

Using a red circle, we achieve state-of-the-art on most referring expressions comprehension baselines in the zero-shot setting, as shown in Table 5. Interestingly, this even outperforms ReCLIP [44], which is based on scoring image crops, followed by post-processing with manually designed relations rules. A red circle also outperforms Pseudo-Q on most benchmarks, even though Pseudo-Q explicitly trains for this task.
4.4 Model biases and ethics
While drawing circles on images can extract useful behaviors from a VLM for a wide variety of legitimate image analysis tasks, it can also extract unwanted ones and must not be used for the analysis of sensitive data.
To demonstrate this fact, in Fig. 8 we take a random image from COCO that contains a male-looking and a female-looking individual and zero-shot classify the image, as well as the image with circles over each individual, into 4 categories: male, female, missing person, and suspected murderer. While this leads to a correct resolution of the apparent gender of the annotated person, the annotated images are more likely to be classified as containing a missing person or a murderer. While we cannot know for certain, we hypothesize that this is due to the presence in the CLIP model training data of missing person reports, police footage, or similar, where people have been marked.

We further quantify these biases following [2], using synthetic faces from FaceSynthetics [52] and person crops from COCO [28]. For FaceSyntetics, we take 1000 random synthetic faces, and for COCO, we crop all bounding boxes for the class person from the validation set that have an area of at least 10% of the total area of the image, which comes down to 1352 crops. Following [2], we measure zero-shot classification rates into criminal categories. We introduce a “positive” category (honest man/woman/person), “neutral” category (man/woman/person) and a “criminal” category (criminal/thief/suspicious person). Finally, we zero-shot classify the original images and the images with circles. In Table 6 we present classification rates into criminal categories. We see that for all ViT encoders, the rate at which people are classified as criminals is significantly higher. This is problematic as such existing biases can lead to harmful consequences. Note that there are various limitations in this analysis, including the usage of binary gender.
5 Conclusions
We have shown that visual prompt engineering via marking can extract useful behavior from VLMs such as CLIP in a zero-shot manner, achieving state-of-the-art zero-shot referring expression comprehension performance, and significantly outperforming traditional techniques like image cropping. Our analysis suggests that this behavior emerges because relevant samples of marking exist in the training data of the VLMs, but these samples are very rare. As a consequence, the behavior can only be learned by very large models trained on very large datasets. The analysis also shows that VLMs acquire undesirable behaviors too, where the mere addition of a red circle to an image increases the model’s belief that the image has a negative connotation.
Dataset Ethics.
We use the RefCOCO, RefCOCO+, MS-COCO, FaceSynthetics, YFCC15M, CUB, SPair71k in a manner compatible with their terms. Some of these images may contain personal data (faces). In Sections 4.1, 4.2 and 4.3 there is no extraction of biometric data. In Section 4.4 we use MS-COCO to demonstrate that such a method cannot reliably extract information about people due to the bias in the pre-trained CLIP model (there is no identification). The FaceSynthetics, used for the same purpose, is a dataset of synthetic faces, so it does not raise privacy concerns. For further details on ethics, data protection, and copyright please see https://www.robots.ox.ac.uk/~vedaldi/research/union/ethics.html.
Acknowledgements.
We thank Luke Melas-Kyriazi, Tim Franzmeyer, Rhydian Windsor and Bruno Korbar for proofreading A. Shtedritski is supported by EPSRC EP/S024050/1. A. Vedaldi and C. Rupprecht are supported by ERC-CoG UNION 101001212. C. Rupprecht is also partially supported by VisualAI EP/T028572/1.
References
- [1] Chatgpt. https://chat.openai.com/.
- [2] Sandhini Agarwal, Gretchen Krueger, Jack Clark, Alec Radford, Jong Wook Kim, and Miles Brundage. Evaluating clip: towards characterization of broader capabilities and downstream implications. arXiv preprint arXiv:2108.02818, 2021.
- [3] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. arXiv preprint arXiv:2204.14198, 2022.
- [4] Hyojin Bahng, Ali Jahanian, Swami Sankaranarayanan, and Phillip Isola. Visual prompting: Modifying pixel space to adapt pre-trained models. arXiv preprint arXiv:2203.17274, 2022.
- [5] Amir Bar, Yossi Gandelsman, Trevor Darrell, Amir Globerson, and Alexei A Efros. Visual prompting via image inpainting. arXiv preprint arXiv:2209.00647, 2022.
- [6] Hugo Berg, Siobhan Mackenzie Hall, Yash Bhalgat, Wonsuk Yang, Hannah Rose Kirk, Aleksandar Shtedritski, and Max Bain. A prompt array keeps the bias away: Debiasing vision-language models with adversarial learning. arXiv preprint arXiv:2203.11933, 2022.
- [7] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [8] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- [9] Yi-Wen Chen, Yi-Hsuan Tsai, Tiantian Wang, Yen-Yu Lin, and Ming-Hsuan Yang. Referring expression object segmentation with caption-aware consistency. arXiv preprint arXiv:1910.04748, 2019.
- [10] Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. arXiv preprint arXiv:2212.07143, 2022.
- [11] Ching-Yao Chuang, Varun Jampani, Yuanzhen Li, Antonio Torralba, and Stefanie Jegelka. Debiasing vision-language models via biased prompts. arXiv preprint arXiv:2302.00070, 2023.
- [12] Volkan Cirik, Taylor Berg-Kirkpatrick, and Louis-Philippe Morency. Using syntax to ground referring expressions in natural images. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018.
- [13] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- [14] Zi-Yi Dou, Aishwarya Kamath, Zhe Gan, Pengchuan Zhang, Jianfeng Wang, Linjie Li, Zicheng Liu, Ce Liu, Yann LeCun, Nanyun Peng, et al. Coarse-to-fine vision-language pre-training with fusion in the backbone. arXiv preprint arXiv:2206.07643, 2022.
- [15] Sepideh Esmaeilpour, Bing Liu, Eric Robertson, and Lei Shu. Zero-shot open set detection by extending clip. arXiv preprint arXiv:2109.02748, 2021.
- [16] Zixian Guo, Bowen Dong, Zhilong Ji, Jinfeng Bai, Yiwen Guo, and Wangmeng Zuo. Texts as images in prompt tuning for multi-label image recognition. arXiv preprint arXiv:2211.12739, 2022.
- [17] Ronghang Hu, Huazhe Xu, Marcus Rohrbach, Jiashi Feng, Kate Saenko, and Trevor Darrell. Natural language object retrieval. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4555–4564, 2016.
- [18] Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. In International Conference on Machine Learning, pages 9118–9147. PMLR, 2022.
- [19] Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Visual prompt tuning. arXiv preprint arXiv:2203.12119, 2022.
- [20] Haojun Jiang, Yuanze Lin, Dongchen Han, Shiji Song, and Gao Huang. Pseudo-q: Generating pseudo language queries for visual grounding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15513–15523, 2022.
- [21] Chen Ju, Tengda Han, Kunhao Zheng, Ya Zhang, and Weidi Xie. Prompting visual-language models for efficient video understanding. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXV, pages 105–124. Springer, 2022.
- [22] Aishwarya Kamath, Mannat Singh, Yann LeCun, Gabriel Synnaeve, Ishan Misra, and Nicolas Carion. Mdetr-modulated detection for end-to-end multi-modal understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1780–1790, 2021.
- [23] Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quantitative reasoning problems with language models. arXiv preprint arXiv:2206.14858, 2022.
- [24] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023.
- [25] Muchen Li and Leonid Sigal. Referring transformer: A one-step approach to multi-task visual grounding. Advances in Neural Information Processing Systems, 34:19652–19664, 2021.
- [26] Yangguang Li, Feng Liang, Lichen Zhao, Yufeng Cui, Wanli Ouyang, Jing Shao, Fengwei Yu, and Junjie Yan. Supervision exists everywhere: A data efficient contrastive language-image pre-training paradigm. arXiv preprint arXiv:2110.05208, 2021.
- [27] Feng Liang, Bichen Wu, Xiaoliang Dai, Kunpeng Li, Yinan Zhao, Hang Zhang, Peizhao Zhang, Peter Vajda, and Diana Marculescu. Open-vocabulary semantic segmentation with mask-adapted clip. arXiv preprint arXiv:2210.04150, 2022.
- [28] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014.
- [29] Daqing Liu, Hanwang Zhang, Feng Wu, and Zheng-Jun Zha. Learning to assemble neural module tree networks for visual grounding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4673–4682, 2019.
- [30] Yongfei Liu, Bo Wan, Xiaodan Zhu, and Xuming He. Learning cross-modal context graph for visual grounding. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 11645–11652, 2020.
- [31] Ruotian Luo and Gregory Shakhnarovich. Comprehension-guided referring expressions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7102–7111, 2017.
- [32] Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 11–20, 2016.
- [33] Joanna Materzyńska, Antonio Torralba, and David Bau. Disentangling visual and written concepts in clip. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16410–16419, 2022.
- [34] Luke Melas-Kyriazi, Christian Rupprecht, Iro Laina, and Andrea Vedaldi. Deep spectral methods: A surprisingly strong baseline for unsupervised semantic segmentation and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8364–8375, 2022.
- [35] Juhong Min, Jongmin Lee, Jean Ponce, and Minsu Cho. Spair-71k: A large-scale benchmark for semantic correspondence. arXiv preprint arXiv:1908.10543, 2019.
- [36] Norman Mu, Alexander Kirillov, David Wagner, and Saining Xie. Slip: Self-supervision meets language-image pre-training. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXVI, pages 529–544. Springer, 2022.
- [37] Daniil Pakhomov, Sanchit Hira, Narayani Wagle, Kemar E Green, and Nassir Navab. Segmentation in style: Unsupervised semantic image segmentation with stylegan and clip. arXiv preprint arXiv:2107.12518, 2021.
- [38] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR, 2021.
- [39] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- [40] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in neural information processing systems, 28, 2015.
- [41] Sheng Shen, Shijia Yang, Tianjun Zhang, Bohan Zhai, Joseph E Gonzalez, Kurt Keutzer, and Trevor Darrell. Multitask vision-language prompt tuning. arXiv preprint arXiv:2211.11720, 2022.
- [42] Hengcan Shi, Munawar Hayat, Yicheng Wu, and Jianfei Cai. Proposalclip: Unsupervised open-category object proposal generation via exploiting clip cues. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9611–9620, 2022.
- [43] Richard Sinkhorn and Paul Knopp. Concerning nonnegative matrices and doubly stochastic matrices. Pacific Journal of Mathematics, 21(2):343–348, 1967.
- [44] Sanjay Subramanian, Will Merrill, Trevor Darrell, Matt Gardner, Sameer Singh, and Anna Rohrbach. Reclip: A strong zero-shot baseline for referring expression comprehension. arXiv preprint arXiv:2204.05991, 2022.
- [45] Mingjie Sun, Jimin Xiao, Eng Gee Lim, Si Liu, and John Y Goulermas. Discriminative triad matching and reconstruction for weakly referring expression grounding. IEEE transactions on pattern analysis and machine intelligence, 43(11):4189–4195, 2021.
- [46] Cheng-Hao Tu, Zheda Mai, and Wei-Lun Chao. Visual query tuning: Towards effective usage of intermediate representations for parameter and memory efficient transfer learning. arXiv preprint arXiv:2212.03220, 2022.
- [47] Jialu Wang, Yang Liu, and Xin Eric Wang. Are gender-neutral queries really gender-neutral? mitigating gender bias in image search. arXiv preprint arXiv:2109.05433, 2021.
- [48] Peng Wang, Qi Wu, Jiewei Cao, Chunhua Shen, Lianli Gao, and Anton van den Hengel. Neighbourhood watch: Referring expression comprehension via language-guided graph attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1960–1968, 2019.
- [49] Yangtao Wang, Xi Shen, Yuan Yuan, Yuming Du, Maomao Li, Shell Xu Hu, James L Crowley, and Dominique Vaufreydaz. Tokencut: Segmenting objects in images and videos with self-supervised transformer and normalized cut. arXiv preprint arXiv:2209.00383, 2022.
- [50] Zhaoqing Wang, Yu Lu, Qiang Li, Xunqiang Tao, Yandong Guo, Mingming Gong, and Tongliang Liu. Cris: Clip-driven referring image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11686–11695, 2022.
- [51] Peter Welinder, Steve Branson, Takeshi Mita, Catherine Wah, Florian Schroff, Serge Belongie, and Pietro Perona. Caltech-ucsd birds 200. 2010.
- [52] Erroll Wood, Tadas Baltrušaitis, Charlie Hewitt, Sebastian Dziadzio, Matthew Johnson, Virginia Estellers, Thomas J. Cashman, and Jamie Shotton. Fake it till you make it: Face analysis in the wild using synthetic data alone, 2021.
- [53] Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, and Xiaolong Wang. Groupvit: Semantic segmentation emerges from text supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18134–18144, 2022.
- [54] Sibei Yang, Guanbin Li, and Yizhou Yu. Dynamic graph attention for referring expression comprehension. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4644–4653, 2019.
- [55] Zhengyuan Yang, Zhe Gan, Jianfeng Wang, Xiaowei Hu, Faisal Ahmed, Zicheng Liu, Yumao Lu, and Lijuan Wang. Crossing the format boundary of text and boxes: Towards unified vision-language modeling. arXiv preprint arXiv:2111.12085, 2021.
- [56] Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. Filip: fine-grained interactive language-image pre-training. arXiv preprint arXiv:2111.07783, 2021.
- [57] Yuan Yao, Ao Zhang, Zhengyan Zhang, Zhiyuan Liu, Tat-Seng Chua, and Maosong Sun. Cpt: Colorful prompt tuning for pre-trained vision-language models. arXiv preprint arXiv:2109.11797, 2021.
- [58] Licheng Yu, Zhe Lin, Xiaohui Shen, Jimei Yang, Xin Lu, Mohit Bansal, and Tamara L Berg. Mattnet: Modular attention network for referring expression comprehension. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1307–1315, 2018.
- [59] Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling context in referring expressions. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14, pages 69–85. Springer, 2016.
- [60] Yuhang Zang, Wei Li, Kaiyang Zhou, Chen Huang, and Chen Change Loy. Unified vision and language prompt learning. arXiv preprint arXiv:2210.07225, 2022.
- [61] Rowan Zellers, Yonatan Bisk, Ali Farhadi, and Yejin Choi. From recognition to cognition: Visual commonsense reasoning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6720–6731, 2019.
- [62] Rowan Zellers, Ximing Lu, Jack Hessel, Youngjae Yu, Jae Sung Park, Jize Cao, Ali Farhadi, and Yejin Choi. Merlot: Multimodal neural script knowledge models. Advances in Neural Information Processing Systems, 34:23634–23651, 2021.
- [63] Pengchuan Zhang, Xiujun Li, Xiaowei Hu, Jianwei Yang, Lei Zhang, Lijuan Wang, Yejin Choi, and Jianfeng Gao. Vinvl: Revisiting visual representations in vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5579–5588, 2021.
- [64] Sheng Zhang, Salman Khan, Zhiqiang Shen, Muzammal Naseer, Guangyi Chen, and Fahad Khan. Promptcal: Contrastive affinity learning via auxiliary prompts for generalized novel category discovery. arXiv preprint arXiv:2212.05590, 2022.
- [65] Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Conditional prompt learning for vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16816–16825, 2022.
- [66] Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models. International Journal of Computer Vision, 130(9):2337–2348, 2022.
Appendix
| Method | Backbone | RefCOCO | RefCOCO+ | RefCOCOg | |||||
|---|---|---|---|---|---|---|---|---|---|
| Val | TestA | TestB | Val | TestA | TestB | Val | Test | ||
| ReCLIP | RN5016 | 37.61 | 38.32 | 37.19 | 44.12 | 46.02 | 41.81 | 55.94 | 54.36 |
| ViT-B/32 | 40.69 | 43.98 | 37.55 | 45.00 | 48.15 | 41.65 | 55.25 | 54.35 | |
| ViT-B/16 | 38.23 | 40.53 | 37.00 | 41.53 | 42.91 | 41.32 | 55.19 | 55.16 | |
| ViT-L/14 | 34.40 | 33.52 | 34.35 | 37.86 | 37.53 | 37.70 | 53.82 | 52.25 | |
| ViT-L/14@336px | 35.90 | 37.72 | 35.66 | 40.06 | 42.49 | 39.07 | 54.25 | 53.92 | |
| RN5016,ViT-B/32 | 41.96 | 43.52 | 39.00 | 47.44 | 50.11 | 43.93 | 57.76 | 57.15 | |
| RN5016,ViT-B/1 | 39.94 | 41.61 | 38.71 | 45.06 | 47.17 | 43.63 | 57.93 | 56.85 | |
| RN5016,ViT-L/14 | 37.98 | 38.08 | 37.51 | 42.87 | 44.57 | 41.66 | 56.78 | 56.02 | |
| RN5016,ViT-L/14@336px | 38.79 | 39.49 | 37.82 | 44.27 | 46.44 | 42.46 | 57.86 | 56.28 | |
| ViT-B/32,ViT-B/16 | 41.34 | 44.25 | 38.55 | 45.20 | 48.01 | 43.36 | 57.37 | 56.52 | |
| ViT-B/32,ViT-L/14 | 39.68 | 41.65 | 37.84 | 43.74 | 46.25 | 41.17 | 56.74 | 56.07 | |
| ViT-B/32,ViT-L/14@336px | 40.82 | 43.47 | 39.22 | 45.41 | 48.52 | 42.83 | 58.09 | 56.94 | |
| ViT-B/16,ViT-L/14 | 37.69 | 38.29 | 37.53 | 40.87 | 42.07 | 40.93 | 56.35 | 55.76 | |
| ViT-B/16,ViT-L/14@336px | 39.18 | 41.01 | 38.35 | 42.81 | 44.32 | 42.07 | 57.82 | 56.21 | |
| ViT-L/14,ViT-L/14@336px | 35.47 | 36.26 | 35.70 | 39.52 | 40.69 | 38.70 | 54.51 | 54.04 | |
| Red Circle | RN5016 | 45.52 | 52.99 | 38.59 | 49.98 | 57.55 | 42.11 | 53.94 | 54.35 |
| ViT-B/32 | 38.72 | 45.09 | 33.52 | 42.85 | 49.46 | 36.53 | 45.81 | 45.57 | |
| ViT-B/16 | 45.30 | 52.70 | 36.51 | 49.39 | 57.67 | 40.60 | 53.72 | 53.26 | |
| ViT-L/14 | 46.71 | 55.03 | 39.24 | 52.07 | 58.63 | 42.83 | 57.00 | 56.40 | |
| ViT-L/14@336 | 48.27 | 56.44 | 39.71 | 53.59 | 59.99 | 43.28 | 59.95 | 58.51 | |
| RN5016, ViT-B/32 | 45.62 | 54.04 | 37.13 | 50.73 | 60.46 | 41.69 | 54.00 | 53.84 | |
| RN5016, ViT-B/16 | 49.98 | 57.15 | 38.04 | 52.98 | 61.95 | 42.99 | 56.01 | 55.78 | |
| RN5016, ViT-L/14 | 48.50 | 58.03 | 39.76 | 54.56 | 63.17 | 44.41 | 58.17 | 57.76 | |
| RN5016, ViT-L/14@336 | 49.84 | 58.57 | 39.96 | 55.28 | 63.92 | 45.35 | 59.40 | 58.93 | |
| ViT-B/32,ViT-B/16 | 44.62 | 53.03 | 35.90 | 49.13 | 58.96 | 40.21 | 52.23 | 51.61 | |
| ViT-B/32,ViT-L/14 | 47.19 | 56.27 | 38.14 | 52.75 | 62.07 | 42.69 | 56.66 | 55.54 | |
| ViT-B/32,ViT-L/14@336px | 48.59 | 58.05 | 38.69 | 54.61 | 63.45 | 43.28 | 57.80 | 57.48 | |
| ViT-B/16,ViT-L/14 | 48.18 | 57.49 | 39.33 | 53.66 | 62.38 | 43.36 | 57.56 | 57.45 | |
| ViT-B/16,ViT-L/14@336px | 49.86 | 58.41 | 39.92 | 55.35 | 62.43 | 44.34 | 59.05 | 58.82 | |
| ViT-L/14,ViT-L/14@336px | 48.82 | 57.03 | 40.35 | 53.62 | 60.65 | 44.04 | 59.03 | 58.27 | |
In this supplementary material, we provide more details about the datasets we use, implementation details and ablations, as well as further qualitative and quantitative evaluations.
6 Datasets
As noted in the main paper, we contribute additional annotations to the Spair71k dataset for some of our experiments. We start from their keypoint annotations, which have no keypoint name annotations in the original dataset. We then manually name all keypoints of the animal classes in Spair71k, as shown in Table 8. We purposefully leave out some point annotations:
-
•
All animals have a left and right nostril annotated — we take the right one in all classes and annotate it as nose, and leave the left nostril out.
-
•
All tails have point annotations at the start of the tail (attached to the body) and end of the tail. Because of the lack of words to precisely describe both points, we take the point not attached to the body and annotate it as tail, and leave the other one out.
-
•
All ears have point annotations at the start of the ear (attached to the head), and at the pointy end. Because of the lack of words to precisely describe both points, we take the point not attached to the head and annotate it as ear, and leave the other one out.
-
•
Birds have annotations for (i) foot, (ii) ankle, (iii) knee, which are often ambiguous and very close together. We only keep the foot annotation.
Note we explicitly define different names for keypoints that can be ambiguous, e.g. eyes, ears, legs, etc. This ensures the role of questions and answers in Section 3.3 is satisfied.
7 Discovered annotations
Out of the discovered annotations in YFCC-15M, 44% contain red circles. Overall, 73% of the annotations were circles, and the rest were rectangles. 65% of all annotations were red, 10% yellow, 7% blue, 7% white, and the rest were black, green, and purple.
8 Additional implementation details
8.1 Referring Expressions Detection.
Backbone
We base the evaluation of our method on ReCLIP [44], where an ensemble of two CLIP backbones is used — RN50x16 and ViT-B/32. We evaluated ReCLIP for all combinations of CLIP backbones in Table 7 and found that, on average, this is the highest-performing one. Similarly, for our method, we choose the ensemble of two backbones that lead to the highest performance — RN50x16 and ViT-L/14@336. Full comparison between the backbones can be found in Table 7.
Annotations
We experiment with different marker shapes, sizes, and colours, and present the results in Table 10. We find that, on average, a thin red circle leads to the best performance. We use an ensemble of the red circle annotation and two additional augmentations — blurring and gray-scaling the outside of the circle, for a total of three images per annotation, as shown. These augmentations were inspired by examples in YFCC15M we discovered that were annotated like that. We found that adding augmentations improves overall results. However, we did not explore including augmentations beyond these. We ablate these choices in Table 9.
Additional details
We augment the text queries by prepending “This is”. When subtracting the average with respect to other referring expressions, we use randomly sampled expressions.
8.2 Keypoint tasks
Backbone
We evaluate different backbones in Table 3 in the main paper and find that ViT-L/14@336 performs best.
Annotations
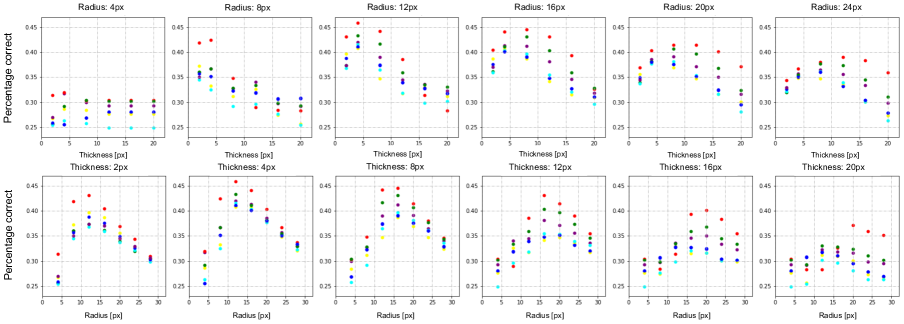
We show examples of the markers we use in Fig. 4 in the main paper . We compare a large range of sizes and colors, as shown in Table 2 in the main paper. We find that a circle is the best marker, and drawing a cross over the point of interest is the worst. The best-performing marker out of all is a red circle, which is the one we end up using. In Fig. 10 we show a more detailed comparison of different colors, diameters, and thicknesses when using a circle annotation. We see that a thin red circle is the best-performing marker. We show what that circle looks like on an image in Fig. 11.
Given this, we draw red circles over the images, with radius and thickness , where H is the shorter side of the image. For the backbone we use, where the input size has px, this becomes px and px.
Additional details
For the keypoint localization task, we set , for a total of query locations before applying the pseudo mask. The templates we use are “This is the {part} of a bird” for CUB and “This image shows the {part} of the {animal}” for SPair71k. We use a temperature parameter .
9 Qualitative evaluations
We present qualitative evaluations on naming keypoints in Figs. 14 and 15, keypoint localization in Figs. 11 and 12 and referring expressions comprehension in Fig. 13.
| Part No | Bird | Cat | Cow | Dog | Horse | Sheep |
|---|---|---|---|---|---|---|
| 0 | crown | — | — | — | — | — |
| 1 | right wing | — | — | — | — | — |
| 2 | left wing | right ear | right ear | right ear | right ear | right ear |
| 3 | beak | left ear | left ear | left ear | left ear | left ear |
| 4 | — | right eye | right eye | right eye | right eye | right eye |
| 5 | — | left eye | left eye | left eye | left eye | left eye |
| 6 | forehead | nose | nose | nose | nose | nose |
| 7 | right eye | — | — | forehead | — | — |
| 8 | left eye | mouth | mouth | mouth | mouth | mouth |
| 9 | nape | front right paw | front right hoof | front right paw | forehead | front right hoof |
| 10 | right foot | front left paw | front left hoof | front left paw | front right hoof | front left hoof |
| 11 | left foot | hind right paw | hind right hoof | hind right paw | front left hoof | hind left hoof |
| 12 | — | hind left paw | hind left hoof | hind left paw | hind right hoof | hind right hoof |
| 13 | tail | tail | tail | tail | hind left hoof | tail |
| 14 | — | — | — | — | tail | — |
| 15 | — | — | front right knee | neck | — | front right knee |
| 16 | — | — | front left knee | — | front right knee | front left knee |
| 17 | — | — | hind right knee | — | front left knee | hind right knee |
| 18 | — | — | hind left knee | — | hind right knee | hind left knee |
| 19 | — | — | right horn | — | hind left knee | right horn |
| 20 | — | — | left horn | — | — | — |

| Component | RefCOCO | RefCOCO+ | RefCOCOg | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Red Circle | Subtract | Ensemble | Val | TestA | TestB | Val | TestA | TestB | Val | Test |
| ✓ | ✗ | ✗ | 42.01 | 48.58 | 36.90 | 47.55 | 53.56 | 41.05 | 50.84 | 51.47 |
| ✓ | ✓ | ✗ | 43.67 | 50.20 | 38.59 | 48.98 | 54.70 | 43.06 | 54.29 | 52.98 |
| ✓ | ✓ | ✓ | 49.84 | 58.57 | 39.96 | 55.28 | 63.92 | 45.35 | 59.40 | 58.93 |
| Annotation Type | RefCOCO | RefCOCO+ | RefCOCOg | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Shape | Color | Size | Val | TestA | TestB | Val | TestA | TestB | Val | Test |
| Circle | Red | 1 | 38.7 | 45.1 | 34.0 | 44.4 | 50.0 | 39.1 | 48.1 | 50.0 |
| Circle | Red | 2 | 32.2 | 35.9 | 29.1 | 37.6 | 40.9 | 33.5 | 45.3 | 46.4 |
| Circle | Red | 4 | 37.4 | 43.6 | 31.5 | 43.3 | 47.8 | 37.3 | 43.7 | 48.0 |
| Circle | Red | 8 | 36.3 | 42.6 | 31.3 | 42.1 | 47.3 | 36.3 | 45.2 | 45.4 |
| Rectangle | Red | 1 | 35.1 | 38.3 | 33.5 | 39.2 | 41.4 | 37.3 | 44.3 | 43.4 |
| Rectangle | Red | 2 | 35.1 | 38.3 | 33.2 | 39.1 | 41.8 | 37.3 | 44.8 | 44.1 |
| Rectangle | Red | 4 | 34.1 | 37.8 | 32.3 | 39.0 | 41.3 | 36.5 | 43.7 | 44.1 |
| Rectangle | Red | 8 | 33.7 | 37.6 | 32.7 | 37.9 | 40.3 | 34.9 | 41.1 | 40.1 |
| Circle | Green | 1 | 39.3 | 45.4 | 34.8 | 43.8 | 49.9 | 38.1 | 47.2 | 47.4 |
| Circle | Purple | 1 | 38.9 | 44.8 | 34.0 | 44.5 | 49.4 | 39.2 | 49.5 | 49.2 |
| Circle | Blue | 1 | 37.7 | 44.9 | 33.5 | 43.4 | 49.1 | 37.3 | 48.2 | 48.3 |
| Circle | Yellow | 1 | 38.5 | 44.1 | 34.6 | 43.7 | 49.0 | 38.9 | 48.6 | 48.1 |