GenerateCT: Text-Conditional Generation of 3D Chest CT Volumes
Abstract
Text-conditional medical image generation has vital implications in radiology, like augmenting small real-world medical datasets, preserving data privacy, patient-specific data modeling, etc. However, this field lags behind text-to-natural image generation due to the significant distribution shift between the images and text descriptions. One approach is to fine-tune pre-trained vision language models (trained on 2D natural image-text pairs) for medical applications. However, this falls short in handling 3D medical images like CT and MRI, which are crucial for critical care.
In this paper, we introduce GenerateCT, a novel approach for generating CT volumes conditioned on free-form medical text prompts. GenerateCT includes a text encoder and three key components: a novel causal vision transformer for encoding CT volumes, a text-image transformer for aligning CT and text tokens, and a text-conditional super-resolution diffusion model. GenerateCT can produce realistic, high-resolution, and high-fidelity 3D chest CT volumes, validated by low FID and FVD scores. To explore GenerateCT’s clinical applications, we evaluated its utility in a multi-abnormality classification task. First, we established a baseline by training a multi-abnormality classifier on our real dataset. To further assess the model’s generalization to external datasets and its performance with unseen prompts in a zero-shot scenario, we employed an external dataset to train the classifier, setting an additional benchmark. We conducted two experiments in which we doubled the training datasets by synthesizing an equal number of volumes for each set using GenerateCT. The first experiment demonstrated an improvement in the AP score when training the classifier jointly on real and generated volumes. The second experiment showed a improvement when training on both real and generated volumes based on unseen prompts. Moreover, GenerateCT enables the scaling of synthetic training datasets to arbitrary sizes. As an example, we generated 100,000 CT volumes, fivefold the number in our real dataset, and trained the classifier exclusively on these synthetic volumes. Impressively, this classifier surpassed the performance of the one trained on all available real data by a margin of . Lastly, domain experts evaluated the generated volumes, confirming a high degree of alignment with the text prompt. Our code and pre-trained models are available at: https://github.com/ibrahimethemhamamci/GenerateCT.
![[Uncaptioned image]](x1.png)
1 Introduction
The generation of synthetic medical images holds significant promise for the medical field. It facilitates the large-scale adoption of machine learning, enhancing radiological workflows, accelerating medical research, and improving patient care. Additionally, it addresses key challenges in medical image analysis, such as data scarcity, the need for anonymization due to patient privacy concerns, imbalanced class distribution, and the need for trained clinicians [24].
In the field of natural image generation, generative modeling has experienced remarkable progress in recent years, especially in generating images from free-flowing text [10, 30, 31, 34, 45, 2, 7, 12, 16, 26]. Despite these advancements, the medical field has not yet fully capitalized on the potential of large-scale foundational models [22]. Of particular interest is the generation of 2D chest radiographs from radiology reports [5] using diffusion models, achievable by fine-tuning pre-trained open-source text-to-image models [31]. However, it is challenging to generalize this method to more spatially rich modalities critical for care, such as 3D computed tomography (CT) or magnetic resonance imaging. The primary reason is the exponential increase in computational requirements for 3D generative modeling [8]. Moreover, unlike 2D generation, there are no pre-trained 3D models available for fine-tuning [46]. Generating 2D slices also presents challenges due to the lack of spatial context. Moreover, there is a scarcity of 3D medical imaging data paired with radiology reports [25].
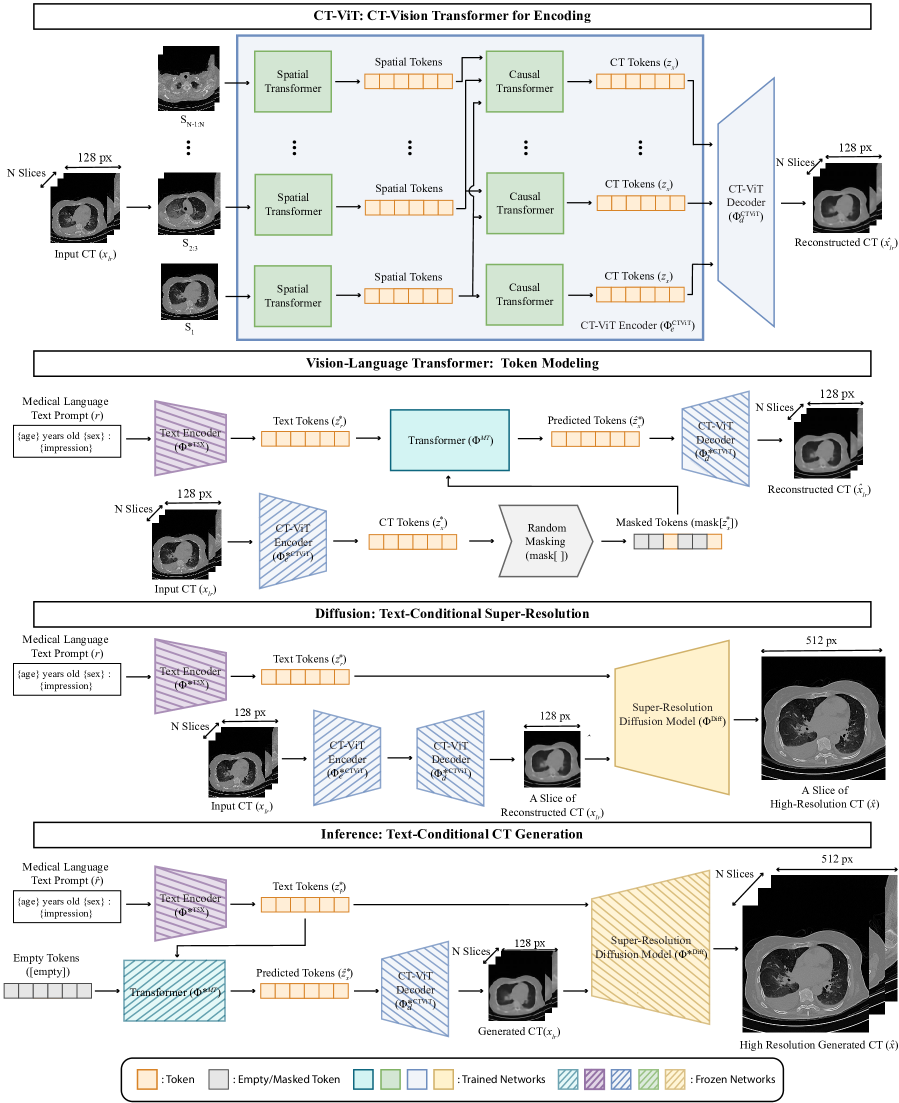
We propose GenerateCT, a novel text-to-image foundational model for the synthesis of high-resolution 3D CT volumes conditioned on the free-form text prompts (see Fig. 1). We conceptualize the synthesis of 3D CT volumes as a challenge of generating axial slices sequentially. It consists of three key components: The first is a causal vision transformer, CT-ViT, which encodes the CT volumes into tokens. CT-ViT is trained to reconstruct 2D axial slices autoregressively, which allows us to maintain high axial resolution and generate a variable number of axial slices, thus providing a variable axial field-of-view [1]. Second, a bidirectional text-image transformer aligns the CT tokens with the encoded tokens of the free-form radiology text. This alignment is facilitated using masked CT token prediction [6]. Third, we employ a cascaded diffusion model [16] to enhance the in-plane resolution of the generated low-resolution axial slices. This step is also text-conditioned, ensuring faithful resolution enhancement based on the input prompt [34].
Once trained, GenerateCT can produce realistic, high-fidelity 3D chest CT volumes from free-form text prompts. To our knowledge, this is the first approach to explore text-to-3D image generation, particularly in the medical domain. Our contributions can be summarized as follows:
-
•
We propose a novel text-to-CT generation framework and training regime capable of producing 3D chest CT volumes conditioned on medical language text prompts.
-
•
At the core of GenerateCT is CT-ViT, which enables autoregressive encoding and decoding of 3D CT volumes for flexible, arbitrary axial field-of-view handling.
-
•
We conduct a thorough evaluation of our approach’s generative abilities using multiple image-quality metrics. We also assess the alignment with the input text by performing a multi-abnormality classification task in two settings: (a) data augmentation, with an increase of up to a factor of five, and (b) a zero-shot scenario, where no prompts from the training set are used for synthetic data generation.
-
•
To facilitate out-of-the-box chest CT generation, we make all trained models (and code) publicly available.
2 Related Works
Text-conditioned medical image generation.
Due to the increasing demand for high-fidelity medical data, medical image generation has emerged as an important research direction. Recent studies [5, 24] have explored the generation of 2D medical images based on medical language text prompts. These studies have successfully adapted pre-trained latent diffusion models [31], utilizing publicly available chest X-rays and corresponding radiology reports [19]. With GenerateCT, we expand this capability to include the text-conditioned generation of 3D medical images.
Text-conditioned video generation.
has seen significant advancements and is split into two primary research streams: diffusion-based [15, 4, 43, 38, 17] and transformer-based auto-regressive methods [37, 41, 18, 40]. Diffusion-based techniques, utilizing 3D U-Net architectures, typically generate shorter, low-resolution videos with a preset number of frames, but can enhance resolution and duration through cascaded diffusion models [15]. In contrast, transformer-based methods offer adaptability, handling variable frame numbers and producing longer videos, albeit at lower dimensions [42]. In this context, our method extends the concept of text-conditional video generation to 3D medical imaging, essentially treating CT volumes as a sequence of 2D images. GenerateCT combines a transformer-based [37] and a diffusion-based method [15], which enables the generation of high-resolution CT volumes with flexible and increased slice counts.
Datasets for text-conditioned medical image generation.
Training models to generate medical images from text requires paired imaging data with corresponding radiology reports. While publicly available 2D imaging datasets like MIMIC-CXR [19] exist, there is a scarcity of publicly accessible 3D medical imaging datasets with reports. Creating such datasets is challenging due to their larger size, the expertise required for annotating 3D images, and strict data-sharing restrictions. The limited availability of such datasets is evident, as even a study focusing on multi-abnormality detection in chest CT volumes [11] made only a small portion of their dataset publicly accessible. This highlights the urgent need for more publicly available 3D medical imaging data and the potential for text-conditioned 3D medical image data generation, which can drive further research in this field. To address this challenge, we have made our fully trained models publicly available. We hope that this will enable researchers to generate their own datasets using text prompts, virtually without restrictions.
3 Method
3.1 Dataset Preparation
Our dataset comprises 25,701 non-contrast 3D chest CT volumes with a resolution and varying axial slice counts ranging from 100 to 600. These volumes originate from 21,314 unique patients and have been reconstructed using multiple methods appropriate for different window settings [39]. This results in a total of 49,138 CT volumes, considering different reconstruction methods. We partitioned the volumes into a training set comprising 20,000 unique patients and a testing set comprising 1,314 unique patients, ensuring no patient overlap. Each CT volume is accompanied by metadata that includes the patient’s age, sex, and imaging specifics. Moreover, these volumes are paired with radiological reports that are categorized into separate sections: clinical information, technique, findings, and impression. The text prompts are formatted as {age} years old {sex}: {impression} using the impression section and metadata, as shown in Fig. 1. We convert the CT volumes into their respective Hounsfield Units (HU) using the slope and intercept values retrieved from the metadata. These values are clipped to the range , representing the practical lower and upper limits of the HU scale [9, 23]. The use of the dataset has been approved by the ethics committee.
3.2 GenerateCT: Text-Conditional CT Generation
GenerateCT, as shown in Fig. 2, consists of three primary components, each trained in distinct stages: (1) CT-ViT for CT volume encoding (Sec. 3.2.1), (2) a masked generative image-text transformer for text and image alignment (Sec. 3.2.2), and (3) text-conditional diffusion models for super-resolution (Sec. 3.2.3). It processes a 3D CT volume, , covering sagittal (), coronal (), and axial () dimensions, alongside a corresponding radiology text report, . GenerateCT is trained to create CT volumes from medical text prompts, with dimensions set to , , and in our experiments.
3.2.1 CT-ViT: CT-Vision Transformer for Encoding
We introduce CT-ViT to achieve compact latent representations of CT volumes. Inspired by video transformers like ViViT [1] and C-ViViT [37], CT-ViT extracts spatiotemporal tokens from the CT volume. These tokens are encoded through both all-to-all spatial attention and causal attention layers, resulting in encoded CT tokens. Subsequently, a decoder network operates on these tokens to recreate the input CT volume, forming an autoregressive encoder-decoder network. This design is advantageous for handling real-world CT volumes with variable cranio-caudal coverage.
The CT-ViT encoder network () accepts a low-resolution CT volume and outputs embedded CT tokens . The decoder network () uses these embedded CT tokens to reconstruct CT volumes () in the same space. Concisely:
The encoder network first extracts non-overlapping patches of pixels from the first slice, and patches from the remaining slices. Each patch is then linearly transformed into a -dimensional space, where is the latent space dimension, set to . For the first frame, the data is reshaped from to . Here, represents the batch size, the number of channels, and the height and width of the slices, and and the spatial patch sizes. A linear layer then transforms the final dimension to , resulting in a tensor with dimensions . The remaining slices undergo a similar reshaping and linear transformation, from to and finally to , with representing the temporal patch size and the number of temporal patches.
After combining the initial and subsequent frame embeddings, the resulting tensor is . This tensor is processed by two transformer networks in sequence. The spatial transformer operates on a reshaped tensor of , outputting a tensor of the same size. The causal transformer then processes this output, reshaped to , and produces an output maintaining these dimensions. This preserves both the spatial and latent dimensions after each transformer layer, ensuring volumetric information retention throughout the network’s processing stages.
The CT-ViT decoder mirrors the encoding process by transforming tokens back into their original voxel space, allowing for the reconstruction of CT volumes while preserving the axial dimensionality of the input. This capability enables the generation of CT volumes with varying numbers of slices. Additionally, the CT-ViT model incorporates a vector quantization technique to create a discrete latent space. This technique quantizes the encoder outputs into a set of entries from a learned codebook, as described in [36].
The model’s autoregressive training process combines multiple loss functions, including the L2 loss from ViT-VQGAN [44] to ensure reconstruction consistency, image perceptual loss [20] for perceptual similarity, and an adversarial loss in alignment with StyleGAN [21].
3.2.2 Vision-Language Transformer: Token Modeling
In GenerateCT’s second stage, we align CT and text spaces using masked visual token modeling [6]. This involves the previously trained CT-ViT encoder () and its produced CT tokens (), which are masked () and input into a bidirectional transformer (). The radiology report (), encoded with a T5X text encoder (), serves as a conditional input [29]. The transformer’s role is to predict these masked CT tokens based on the text embedding, incorporating cross-attention with the input CT tokens. These predicted CT tokens are then processed by the frozen CT-ViT decoder (), expected to reconstruct the input CT volume accurately. The forward pass in the text-CT alignment stage, utilizing masked token modeling with the trained CT-ViT, is represented as follows:
The training for this stage integrates reconstruction loss and token critic loss. Reconstruction loss assesses the model’s capability to predict masked video codebook IDs in sequences, using cross-entropy to quantify the difference between predicted and actual tokens. Additionally, the critic loss includes a component evaluating whether video codebook ID sequences are authentic or fabricated, employing binary cross-entropy to gauge the alignment between the predicted critics’ probabilities and the actual labels.
During inference, all CT tokens are masked and predicted by the bidirectional transformer, based on the text embeddings and the CT tokens previously predicted. These tokens are then reconstructed using the CT-ViT decoder.
3.2.3 Diffusion: Text-Conditional Super-Resolution
GenerateCT’s final stage employs a diffusion-based, text-conditional 2D super-resolution model () to enhance the resolution of initially produced low-resolution CT volumes. Using a cascaded diffusion approach [16], this process sequentially employs diffusion models that enhance image resolution by upsampling and introducing finer details. This method outperforms traditional U-Net diffusion models [27, 33] in terms of memory efficiency, achieved by incorporating a cross-attention layer with T5 embedded text tokens at the bottleneck stage, which replaces self-attention layers [3]. This layer conditions the diffusion on both the encoded text prompt and the initial low-resolution image. Optimal cascading steps have been identified through an ablation study (Tab. 2). Notably, using CT-ViT reconstructed volumes as input, instead of the original downsampled volumes, enhances performance, aligning with the principles of noisy conditioning [15]. The process is denoted as:
where represents the final full-resolution generated CT volume of size .
The training of the model employs a loss function designed to minimize the disparity between denoised and actual high-resolution images. This function incorporates a Mean Squared Error (MSE) component for pixel accuracy and integrates noise levels into the loss weighting, ensuring that noisy samples are properly accounted for. The overall loss is the mean of these noise-weighted MSE values, quantifying the denoised slices’ deviation from the actual slices.
3.2.4 Inference
After training GenerateCT, synthetic CT volume () generation from a novel radiological text prompt () is as follows:
where represents fully masked CT Token placeholders. This process involves encoding the prompt, predicting CT tokens with the masked transformer, and then decoding these tokens to create the synthetic CT volume.
4 Experiments
4.1 Implementation Details
The CT-ViT model was trained on 49,138 CT volumes (see Sec. 3.1). The transformer model training used the same CT volumes paired with corresponding text prompts (Fig. 2). The diffusion model used 9,876,738 CT slices, conditioned with text prompts from the matching CT volumes. Training parameters for each model are detailed in Tab. 1.
| CT-ViT | Transformer | Diffusion | |
| Optimizer | Adam | Adam | Adam |
| 1 | 0.9 | 0.9 | 0.9 |
| 2 | 0.99 | 0.99 | 0.99 |
| Learning Rate | 0.00003 | 0.00003 | 0.0005 |
| Batch Size | 32 | 4 | 10 |
| Scheduler | N/A | Cosine Annealing | N/A |
| Warmup Steps | N/A | 10,000 | N/A |
| Max Steps | N/A | 4,000,000 | N/A |
| GPUs Utilized | 8 | 8 | 8 |
| Train Duration | 1 week | 1 week | 1 week |
| Iterations | 100,000 | 500,000 | 275,000 |
4.2 Experimental Results
| Output Resolution of Each Submodel | Performance Metrics | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | S. Time (s) | Transformer | 1st SR | 2nd SR | 3rd SR | FVD | FVD | FID | CLIP |
| 1SCM | 23 | 512512 | N/A | N/A | N/A | 1886.8 | 9.5534 | 104.3 | 25.2 |
| 2SCM | 102 | 256256 | 512512 | N/A | N/A | 1661.4 | 8.9021 | 86.9 | 25.9 |
| 3SCM | 184 | 128128 | 256256 | 512512 | N/A | 1092.3 | 8.1745 | 55.8 | 27.1 |
| 4SCM | 244 | 6464 | 128128 | 256256 | 512512 | 1201.4 | 8.5869 | 71.3 | 26.6 |
Quantitative evaluation.
We evaluated the quality of the generated CT volumes using three metrics, see Tab. 2:
-
•
Fréchet Video Distance (FVD) quantifies the dissimilarity between generated and real CT volumes by extracting image features using the I3D model [35], which is well-suited for video datasets, denoted as . Recognizing its limitations for medical datasets, we also employed the 3D CT-Net model [11], trained on our training dataset for multi-abnormality classification (detailed in Sec. 4.2). This approach (denoted as ) allows for domain-relevant feature extraction and distance computation, providing a more appropriate comparison.
-
•
Fréchet Inception Distance (FID) assesses the quality of generated images, but at a slice-level using the InceptionV3 model [14]. It’s crucial to note that FID may not be fully suitable for our 3D generation as individual CT slices might not accurately reflect volume-level findings, potentially leading to misleading results.
-
•
CLIP Score measures the alignment between the text reports and the generated volumes [13]. This measurement is achieved by leveraging the pretrained CLIP model [28], a foundational text-image model trained to correlate visual and textual content. In our training dataset, which includes paired volumes and text, the image-text alignment achieved a CLIP score of , serving as a benchmark.
Ablation study.
GenerateCT’s cascaded architecture was evaluated across different stages, as shown in Tab. 2. We tested four -Stage Cascaded Models (SCM), which combine a transformer-based text conditional generation model with diffusion-based super-resolution steps to produce high-resolution CT volumes. The 1SCM model exclusively uses the transformer model, an adapted version of Phenaki [37], to directly generate the final resolution.
In performance metrics, consistently showed lower scores compared to , a result of CT-Net’s specific training on CT volumes. Both and , along with FID and CLIP scores, generally decreased as the number of super-resolution steps increased, with the 4SCM model being an exception due to its significantly low initial resolution. The 3SCM model, achieving a CLIP score of close to the baseline of , demonstrated an excellent alignment between the text and generated volumes. Therefore, the 3SCM model, outperforming others in all key metrics, was chosen for further GenerateCT experiments.

| First Radiologist (4 years of experience) | ||
| Task | Real Volumes | Synthetic Volumes |
| Reality Prediction | Real: 74 | Real: 41 |
| Synthetic: 26 | Synthetic: 59 | |
| Text Prompt | Matched: 82 | Matched: 66 |
| Mismatched: 18 | Mismatched: 34 | |
| Second Radiologist (11 years of experience) | ||
| Task | Real Volumes | Synthetic Volumes |
| Reality Prediction | Real: 71 | Real: 36 |
| Synthetic: 29 | Synthetic: 64 | |
| Text Prompt | Matched: 83 | Matched: 70 |
| Mismatched: 17 | Mismatched: 30 | |
Qualitative results.
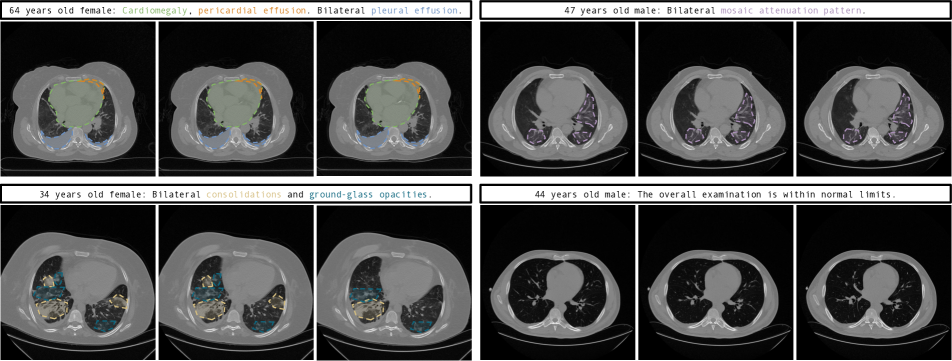
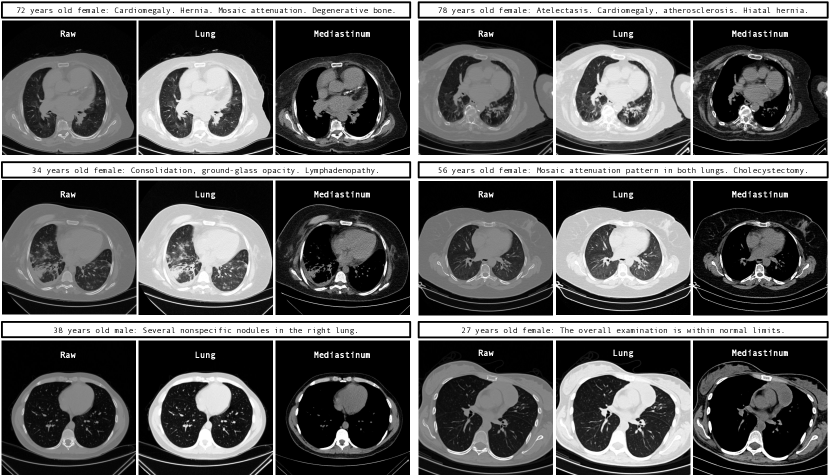
This section showcases CT volumes generated by GenerateCT in the raw HU range of , diverging from standard windowing to more authentically represent the data. Supplementary material offers varied windowing examples for comparison.
As shown in Fig. 3, GenerateCT effectively translates specific text prompts into 3D chest CT volumes. The initial three volumes show distinct pathologies, marked with colored text and areas, consistent across slices, contrasting with a fourth volume of a healthy lung. These volumes display diversity in size, orientation, age, and sex, emphasizing the range of data producible from the text prompts.
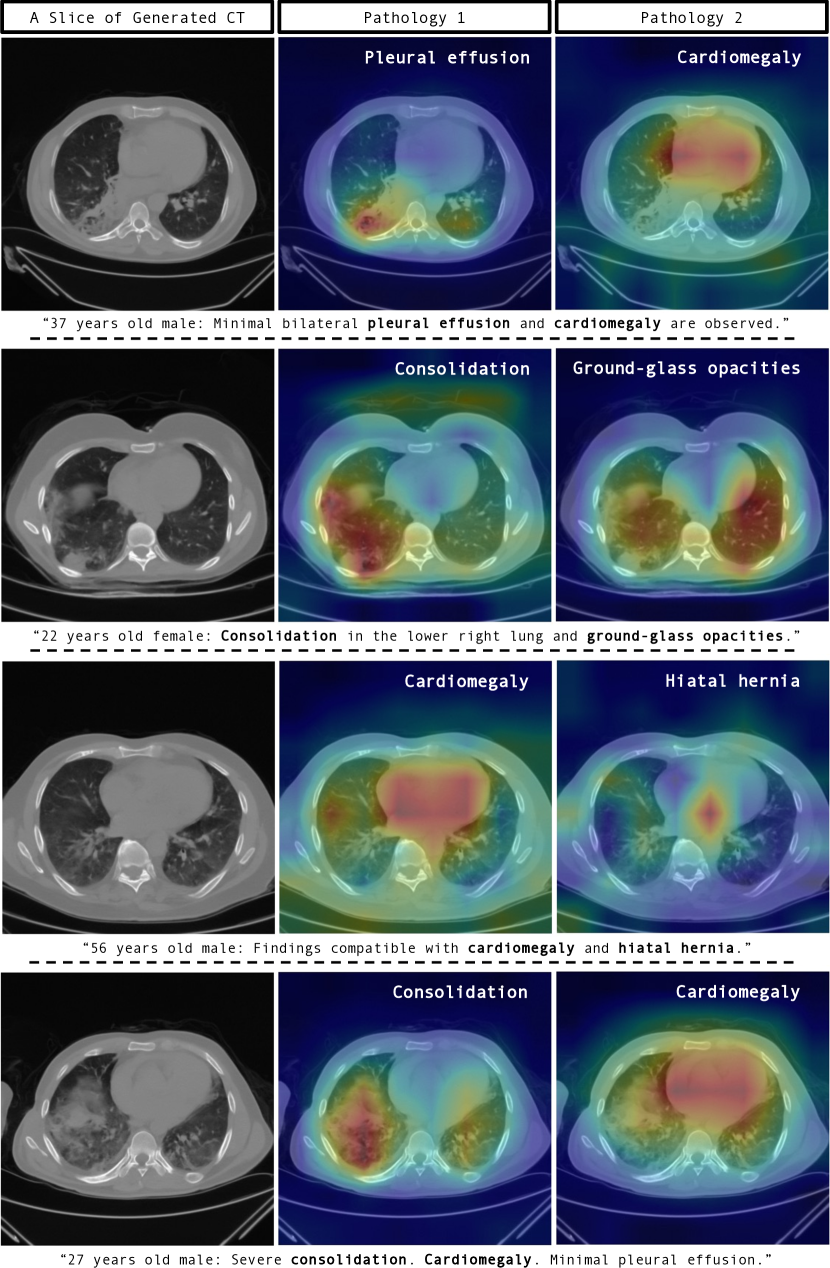
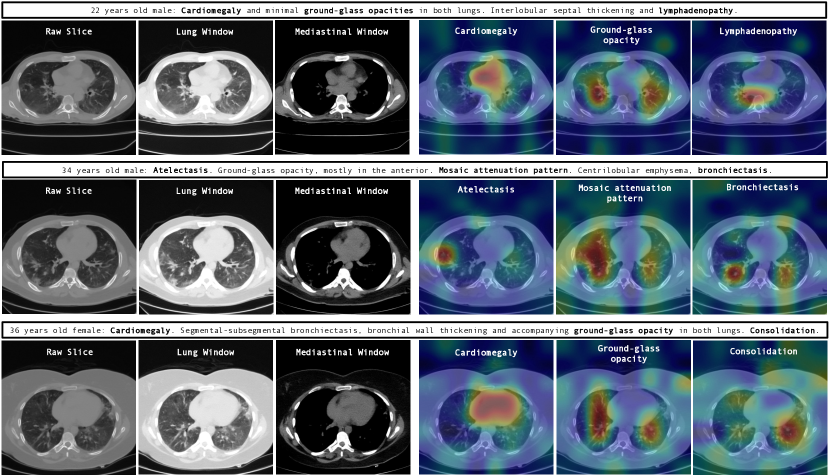
Fig. 4 further demonstrates GenerateCT’s ability to create comprehensive 3D images by including both sagittal and coronal slices, in addition to the axial ones. Fig. 5 showcases the model’s cross-attention between text and generated volumes, emphasizing regions corresponding to specific pathologies. This involves averaging attention outputs across heads and relevant tokens corresponding to each pathology in the input prompts, then upscaling the low-dimensional cross-attention outputs to high-resolution CT volume dimensions using an affine transformation. Such visualizations show GenerateCT’s precision in aligning text with the relevant regions, translating medical terms into spatially accurate and clinically significant image features, such as cardiomegaly around the heart, pleural effusion at the effusion site, and consolidation in the affected lung area.
Expert evaluation.
A blind study involving two radiologists evaluated 200 chest CT volumes, comprising an equal mix of 100 real and 100 synthetic, to assess the visual quality of the generated volumes and their alignment with text prompts. The radiologists were tasked to identify if each volume was real or synthetic and to verify the match between text prompts and volume findings (detailed in Tab. 3).
In the first task, despite knowing half of the volumes were synthetic, both radiologists had significant misclassification rates, highlighting GenerateCT’s capability to create highly indistinguishable synthetic volumes. The difference in false negative rates between real and synthetic volumes was statistically insignificant (, unpaired T-test), highlighting the synthesized volumes’ convincing realism.
In the second task, the radiologists found that a comparable number of synthetic volumes, such as , accurately matched the given text prompts, similar to the real volumes. This indicates a high level of alignment between the generated CT volumes and their corresponding text prompts.
Utilizing GenerateCT in data augmentation.
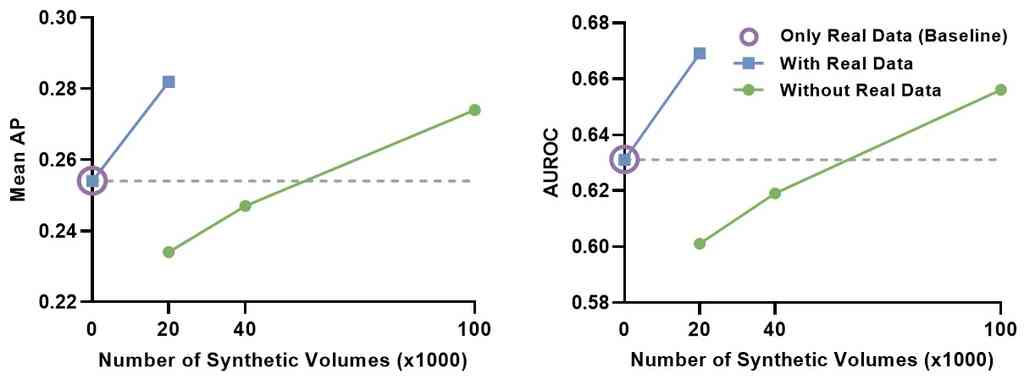
We assessed GenerateCT’s clinical application potential within a radiological framework. A multi-abnormality classification model was initially trained on 20,000 real chest CT volumes from our dataset, each representing a unique patient profile (see Sec. 3.1). This model, our baseline, achieved a mean average precision (AP) of and an area under the receiver operating characteristic curve (AUROC) of .
We then generated 20,000 synthetic volumes using text prompts and trained the classifier on this mixed dataset of real and synthetic data. The results showed an improvement in mean AP and a increase in mean AUROC compared to training on real data alone. Further experimentation involved expanding the synthetic dataset to 100,000 volumes using repeated prompts. Training exclusively on this synthetic data led to an increase in mean AP and a rise in mean AUROC compared to the real-data model.
The results, detailed in 6, demonstrate GenerateCT’s effectiveness in clinical settings. First, data augmentation even by a single factor significantly boosts performance, underscoring its potential for researchers who have real-world data and aim to enhance performance. Second, training on a larger, fully synthetic dataset after a fivefold increase yielded notably better scores compared to the real-data-only model, highlighting GenerateCT’s contribution to data privacy. This approach enables researchers to train and share generation models, like ours, facilitating the creation of synthetic data using text prompts, thus having even better performance without privacy or data-sharing concerns. Third, the increase in scores with repetitive prompt use for data generation indicates GenerateCT’s ability to generate variable data using the same prompts. Further details on the training process and specific accuracies for each abnormality type are provided in the supplementary material.
Utilizing GenerateCT in a zero-shot setting.
To evaluate GenerateCT’s ability to generalize to external datasets, we conducted an experiment using RadChestCT [11], consisting of 3,630 chest CT volumes with 83 different abnormalities and a mean abnormality label frequency of . We created a new dataset using text prompts not included in our GenerateCT training, matching RadChestCT’s training set in terms of volume count and abnormality distribution. The classifier [11] was trained on this synthetic dataset, the original RadChestCT dataset, and a combination of both.
The results were promising: the model trained on the synthetic data achieved close performance metrics to the model trained on real patient data, with mean APs of (real) versus (synthetic), and mean AUROCs of (real) versus (synthetic). Training on the combined dataset significantly increased the performance (mean AUROC , mean AP ). This demonstrates that GenerateCT’s key benefits extend to external datasets and its potential for clinical application even with unseen prompts. In the supplementary, we provide information on the training process and the specific accuracy for each abnormality.
5 Conclusion and Discussion
In this paper, we introduce GenerateCT, the first text-conditional 3D medical image generation framework, specifically for chest CT. Our experiments demonstrate its capability to generate realistic, high-quality chest CT volumes from text prompts, as well as its clinical applications in multi-abnormality classification. As a major step forward in this domain, we make GenerateCT fully open-source to lay a solid foundation for future research and development.
Limitations.
Despite its innovation, GenerateCT faces several challenges. The absence of benchmarks limits its full evaluation. We used a 2D super-resolution method for computational efficiency and handling varying slice counts, but this might reduce alignment accuracy with radiology reports, where a 3D method could be more precise. Although designed to handle 3D images of varying sizes in-depth, a detailed quantitative assessment of this feature is yet to be conducted. Our single-institution dataset might not be diverse enough, risking bias and limited applicability. Broadening training beyond impressions sections of radiology reports could enhance results. Finally, the substantial computational requirements of GenerateCT are a critical factor.
References
- Arnab et al. [2021] Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, and Cordelia Schmid. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6836–6846, 2021.
- Balaji et al. [2022] Yogesh Balaji, Seungjun Nah, Xun Huang, Arash Vahdat, Jiaming Song, Karsten Kreis, Miika Aittala, Timo Aila, Samuli Laine, Bryan Catanzaro, et al. ediffi: Text-to-image diffusion models with an ensemble of expert denoisers. arXiv preprint arXiv:2211.01324, 2022.
- Beltagy et al. [2020] Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020.
- Blattmann et al. [2023] Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. arXiv preprint arXiv:2304.08818, 2023.
- Chambon et al. [2022] Pierre Chambon, Christian Bluethgen, Jean-Benoit Delbrouck, Rogier Van der Sluijs, Małgorzata Połacin, Juan Manuel Zambrano Chaves, Tanishq Mathew Abraham, Shivanshu Purohit, Curtis P Langlotz, and Akshay Chaudhari. Roentgen: Vision-language foundation model for chest x-ray generation. arXiv preprint arXiv:2211.12737, 2022.
- Chang et al. [2022] Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. Maskgit: Masked generative image transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11315–11325, 2022.
- Chen et al. [2022] Wenhu Chen, Hexiang Hu, Chitwan Saharia, and William W Cohen. Re-imagen: Retrieval-augmented text-to-image generator. arXiv preprint arXiv:2209.14491, 2022.
- Clark et al. [2019] Aidan Clark, Jeff Donahue, and Karen Simonyan. Adversarial video generation on complex datasets. arXiv preprint arXiv:1907.06571, 2019.
- DenOtter and Schubert [2019] Tami D DenOtter and Johanna Schubert. Hounsfield unit, 2019.
- Ding et al. [2021] Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, et al. Cogview: Mastering text-to-image generation via transformers. Advances in Neural Information Processing Systems, 34:19822–19835, 2021.
- Draelos et al. [2021] Rachel Lea Draelos, David Dov, Maciej A Mazurowski, Joseph Y Lo, Ricardo Henao, Geoffrey D Rubin, and Lawrence Carin. Machine-learning-based multiple abnormality prediction with large-scale chest computed tomography volumes. Medical image analysis, 67:101857, 2021.
- Gu et al. [2022] Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, and Baining Guo. Vector quantized diffusion model for text-to-image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10696–10706, 2022.
- Hessel et al. [2021] Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. arXiv preprint arXiv:2104.08718, 2021.
- Heusel et al. [2017] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems, 30, 2017.
- Ho et al. [2022a] Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303, 2022a.
- Ho et al. [2022b] Jonathan Ho, Chitwan Saharia, William Chan, David J Fleet, Mohammad Norouzi, and Tim Salimans. Cascaded diffusion models for high fidelity image generation. J. Mach. Learn. Res., 23(47):1–33, 2022b.
- Ho et al. [2022c] Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. arXiv preprint arXiv:2204.03458, 2022c.
- Hong et al. [2022] Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers. arXiv preprint arXiv:2205.15868, 2022.
- Johnson et al. [2019] Alistair EW Johnson, Tom J Pollard, Seth J Berkowitz, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Roger G Mark, and Steven Horng. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports. Scientific data, 6(1):317, 2019.
- Johnson et al. [2016] Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14, pages 694–711. Springer, 2016.
- Karras et al. [2020] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8110–8119, 2020.
- Kebaili et al. [2023] Aghiles Kebaili, Jérôme Lapuyade-Lahorgue, and Su Ruan. Deep learning approaches for data augmentation in medical imaging: A review. Journal of Imaging, 9(4):81, 2023.
- Lamba et al. [2014] Ramit Lamba, John P McGahan, Michael T Corwin, Chin-Shang Li, Tien Tran, J Anthony Seibert, and John M Boone. Ct hounsfield numbers of soft tissues on unenhanced abdominal ct scans: variability between two different manufacturers’ mdct scanners. AJR. American journal of roentgenology, 203(5):1013, 2014.
- Lee et al. [2023] Hyungyung Lee, Wonjae Kim, Jin-Hwa Kim, Tackeun Kim, Jihang Kim, Leonard Sunwoo, and Edward Choi. Unified chest x-ray and radiology report generation model with multi-view chest x-rays. arXiv preprint arXiv:2302.12172, 2023.
- Linna and Kahn Jr [2022] Nathaniel Linna and Charles E Kahn Jr. Applications of natural language processing in radiology: A systematic review. International Journal of Medical Informatics, page 104779, 2022.
- Nichol et al. [2021] Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741, 2021.
- Nichol and Dhariwal [2021] Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In International Conference on Machine Learning, pages 8162–8171. PMLR, 2021.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Raffel et al. [2020] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
- Ramesh et al. [2022] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
- Rombach et al. [2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022.
- Ruder [2016] Sebastian Ruder. An overview of gradient descent optimization algorithms. arXiv preprint arXiv:1609.04747, 2016.
- Saharia et al. [2022a] Chitwan Saharia, William Chan, Huiwen Chang, Chris Lee, Jonathan Ho, Tim Salimans, David Fleet, and Mohammad Norouzi. Palette: Image-to-image diffusion models. In ACM SIGGRAPH 2022 Conference Proceedings, pages 1–10, 2022a.
- Saharia et al. [2022b] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. Advances in Neural Information Processing Systems, 35:36479–36494, 2022b.
- Unterthiner et al. [2019] Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, and Sylvain Gelly. Fvd: A new metric for video generation, 2019.
- Van Den Oord et al. [2017] Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. Advances in neural information processing systems, 30, 2017.
- Villegas et al. [2022] Ruben Villegas, Mohammad Babaeizadeh, Pieter-Jan Kindermans, Hernan Moraldo, Han Zhang, Mohammad Taghi Saffar, Santiago Castro, Julius Kunze, and Dumitru Erhan. Phenaki: Variable length video generation from open domain textual description. arXiv preprint arXiv:2210.02399, 2022.
- Voleti et al. [2022] Vikram Voleti, Alexia Jolicoeur-Martineau, and Christopher Pal. Masked conditional video diffusion for prediction, generation, and interpolation. arXiv preprint arXiv:2205.09853, 2022.
- Willemink and Noël [2019] Martin J Willemink and Peter B Noël. The evolution of image reconstruction for ct—from filtered back projection to artificial intelligence. European radiology, 29:2185–2195, 2019.
- Wu et al. [2021] Chenfei Wu, Lun Huang, Qianxi Zhang, Binyang Li, Lei Ji, Fan Yang, Guillermo Sapiro, and Nan Duan. Godiva: Generating open-domain videos from natural descriptions. arXiv preprint arXiv:2104.14806, 2021.
- Wu et al. [2022] Chenfei Wu, Jian Liang, Lei Ji, Fan Yang, Yuejian Fang, Daxin Jiang, and Nan Duan. Nüwa: Visual synthesis pre-training for neural visual world creation. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XVI, pages 720–736. Springer, 2022.
- Yan et al. [2021] Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srinivas. Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:2104.10157, 2021.
- Yang et al. [2022] Ruihan Yang, Prakhar Srivastava, and Stephan Mandt. Diffusion probabilistic modeling for video generation. arXiv preprint arXiv:2203.09481, 2022.
- Yu et al. [2021] Jiahui Yu, Xin Li, Jing Yu Koh, Han Zhang, Ruoming Pang, James Qin, Alexander Ku, Yuanzhong Xu, Jason Baldridge, and Yonghui Wu. Vector-quantized image modeling with improved vqgan. arXiv preprint arXiv:2110.04627, 2021.
- Yu et al. [2022] Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, et al. Scaling autoregressive models for content-rich text-to-image generation. arXiv preprint arXiv:2206.10789, 2022.
- Zhang et al. [2023] Chenshuang Zhang, Chaoning Zhang, Mengchun Zhang, and In So Kweon. Text-to-image diffusion model in generative ai: A survey. arXiv preprint arXiv:2303.07909, 2023.
Supplementary Material
This supplementary document extends the results presented in the main paper, focusing on three key aspects:
-
•
We provide more examples with varied windowing for comparison, demonstrating how GenerateCT effectively generates 3D medical images from text descriptions.
-
•
We offer a detailed exploration of a practical clinical application of GenerateCT, specifically its use in data augmentation for multi-abnormality classification.
-
•
We also present a detailed exploration of another practical clinical application of GenerateCT, where we illustrate its ability to generalize to external datasets and its proficiency in generating CT volumes from unseen prompts.
1 Comprehensive Qualitative Results
This section showcases a broad spectrum of chest CT volumes generated by GenerateCT. In Fig. 1, we display the axial slices of the generated 3D CT volumes in both the raw Hounsfield Unit (HU) range of and through different windowing techniques to enhance alignment with clinical practice and to clearly show the generation details based on medical text descriptions. This underscores the accuracy of GenerateCT not only with respect to spatial details but also with respect to the dynamic range.
Additionally, Fig. 2 highlights GenerateCT’s effective cross-attention mechanism, which accurately maps specific pathologies mentioned in text prompts to the relevant areas of generated volumes across various window settings. These visualizations exhibit the model’s capability to precisely transform medical language into clinically relevant, spatially accurate image features, underscoring its ability to produce detailed and accurate 3D images from text prompts.
| 20k Real | 20k Real + 20k Synthetic | 20k Synthetic | 40k Synthetic | 100k Synthetic | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Abnormality | AUROC | AP | AUROC | AP | AUROC | AP | AUROC | AP | AUROC | AP | Test Set Ratio |
| Medical material | 0.650 | 0.143 | 0.702 | 0.156 | 0.594 | 0.109 | 0.623 | 0.141 | 0.656 | 0.149 | 0.082 |
| Arterial wall calcification | 0.648 | 0.434 | 0.605 | 0.452 | 0.714 | 0.445 | 0.705 | 0.415 | 0.715 | 0.405 | 0.292 |
| Cardiomegaly | 0.804 | 0.310 | 0.745 | 0.352 | 0.590 | 0.142 | 0.593 | 0.154 | 0.599 | 0.184 | 0102 |
| Pericardial effusion | 0.667 | 0.044 | 0.685 | 0.056 | 0.642 | 0.079 | 0.690 | 0.094 | 0.662 | 0.152 | 0.026 |
| Coronary artery wall calcification | 0.649 | 0.384 | 0.691 | 0.452 | 0.794 | 0.428 | 0.790 | 0.493 | 0.825 | 0.493 | 0.246 |
| Hiatal hernia | 0.544 | 0.159 | 0.542 | 0.152 | 0.638 | 0.298 | 0.652 | 0.325 | 0.685 | 0.345 | 0.140 |
| Lymphadenopathy | 0.616 | 0.345 | 0.679 | 0.399 | 0.591 | 0.301 | 0.612 | 0.351 | 0.642 | 0.345 | 0.245 |
| Emphysema | 0.522 | 0.202 | 0.621 | 0.254 | 0.512 | 0.235 | 0.542 | 0.254 | 0.582 | 0.288 | 0.193 |
| Atelectasis | 0.609 | 0.314 | 0.585 | 0.352 | 0.595 | 0.284 | 0.550 | 0.276 | 0.625 | 0.297 | 0.231 |
| Lung nodule | 0.560 | 0.483 | 0.621 | 0.456 | 0.523 | 0.415 | 0.562 | 0.420 | 0.685 | 0.452 | 0.449 |
| Lung opacity | 0.603 | 0.477 | 0.785 | 0.490 | 0.549 | 0.485 | 0.542 | 0.506 | 0.598 | 0.545 | 0.395 |
| Pulmonary fibrotic sequela | 0.531 | 0.256 | 0.638 | 0.258 | 0.558 | 0.241 | 0.592 | 0.240 | 0.624 | 0.245 | 0.241 |
| Pleural effusion | 0.777 | 0.323 | 0.815 | 0.365 | 0.632 | 0.198 | 0.678 | 0.205 | 0.725 | 0.286 | 0.125 |
| Mosaic attenuation pattern | 0.739 | 0.152 | 0.712 | 0.195 | 0.594 | 0.097 | 0.612 | 0.087 | 0.661 | 0.125 | 0.056 |
| Peribronchial thickening | 0.513 | 0.073 | 0.503 | 0.152 | 0.551 | 0.084 | 0.580 | 0.099 | 0.604 | 0.158 | 0.069 |
| Consolidation | 0.655 | 0.235 | 0.693 | 0.264 | 0.592 | 0.154 | 0.599 | 0.168 | 0.6355 | 0.185 | 0.146 |
| Bronchiectasis | 0.573 | 0.111 | 0.658 | 0.132 | 0.535 | 0.098 | 0.582 | 0.095 | 0.598 | 0.098 | 0.093 |
| Interlobular septal thickening | 0.699 | 0.132 | 0.768 | 0.141 | 0.614 | 0.121 | 0.645 | 0.124 | 0.691 | 0.185 | 0.070 |
| Mean | 0.631 | 0.254 | 0.669 | 0.282 | 0.601 | 0.234 | 0.619 | 0.247 | 0.656 | 0.274 | 0.179 |
| Real Data | Synthetic Data | Composite Data | |||||
|---|---|---|---|---|---|---|---|
| Abnormality | AUROC | AP | AUROC | AP | AUROC | AP | Test Set |
| Air trapping | 0.561 | 0.044 | 0.621 | 0.050 | 0.633 | 0.051 | 0.031 |
| Airspace disease | 0.605 | 0.258 | 0.571 | 0.210 | 0.607 | 0.233 | 0.171 |
| Aneurysm | 0.577 | 0.015 | 0.493 | 0.012 | 0.587 | 0.020 | 0.011 |
| Arthritis | 0.515 | 0.284 | 0.510 | 0.298 | 0.505 | 0.282 | 0.279 |
| Aspiration | 0.616 | 0.091 | 0.518 | 0.051 | 0.624 | 0.092 | 0.049 |
| Atelectasis | 0.575 | 0.349 | 0.579 | 0.356 | 0.596 | 0.408 | 0.290 |
| Atherosclerosis | 0.550 | 0.314 | 0.473 | 0.281 | 0.525 | 0.297 | 0.294 |
| Bandlike or linear | 0.461 | 0.156 | 0.511 | 0.191 | 0.483 | 0.166 | 0.177 |
| Breast implant | 0.387 | 0.016 | 0.325 | 0.012 | 0.550 | 0.066 | 0.017 |
| Breast surgery | 0.499 | 0.030 | 0.504 | 0.026 | 0.484 | 0.037 | 0.023 |
| Bronchial thickening | 0.556 | 0.080 | 0.474 | 0.074 | 0.566 | 0.086 | 0.070 |
| Bronchiectasis | 0.704 | 0.313 | 0.543 | 0.179 | 0.666 | 0.234 | 0.154 |
| Bronchiolectasis | 0.739 | 0.068 | 0.475 | 0.021 | 0.683 | 0.044 | 0.021 |
| Bronchiolitis | 0.443 | 0.024 | 0.492 | 0.025 | 0.509 | 0.026 | 0.025 |
| Bronchitis | 0.533 | 0.010 | 0.567 | 0.023 | 0.570 | 0.011 | 0.008 |
| CABG | 0.754 | 0.118 | 0.504 | 0.068 | 0.764 | 0.115 | 0.041 |
| Calcification | 0.426 | 0.669 | 0.501 | 0.727 | 0.428 | 0.676 | 0.721 |
| Cancer | 0.593 | 0.614 | 0.523 | 0.575 | 0.618 | 0.636 | 0.563 |
| Cardiomegaly | 0.752 | 0.238 | 0.622 | 0.142 | 0.798 | 0.314 | 0.094 |
| Catheter or port | 0.660 | 0.218 | 0.591 | 0.120 | 0.681 | 0.266 | 0.084 |
| Cavitation | 0.604 | 0.056 | 0.493 | 0.058 | 0.589 | 0.056 | 0.040 |
| Chest tube | 0.864 | 0.123 | 0.640 | 0.037 | 0.881 | 0.173 | 0.018 |
| Clip | 0.488 | 0.098 | 0.532 | 0.117 | 0.491 | 0.106 | 0.092 |
| Congestion | 0.885 | 0.042 | 0.701 | 0.015 | 0.951 | 0.266 | 0.005 |
| Consolidation | 0.690 | 0.286 | 0.565 | 0.193 | 0.680 | 0.256 | 0.139 |
| Coronary artery disease | 0.567 | 0.608 | 0.500 | 0.568 | 0.582 | 0.607 | 0.566 |
| Cyst | 0.497 | 0.169 | 0.469 | 0.156 | 0.488 | 0.162 | 0.167 |
| Debris | 0.697 | 0.081 | 0.572 | 0.048 | 0.697 | 0.111 | 0.038 |
| Deformity | 0.580 | 0.062 | 0.475 | 0.051 | 0.551 | 0.057 | 0.052 |
| Density | 0.536 | 0.106 | 0.499 | 0.095 | 0.538 | 0.116 | 0.092 |
| Dilation or ectasia | 0.571 | 0.063 | 0.458 | 0.051 | 0.589 | 0.066 | 0.046 |
| Distention | 0.592 | 0.020 | 0.653 | 0.056 | 0.641 | 0.019 | 0.011 |
| Emphysema | 0.623 | 0.329 | 0.421 | 0.230 | 0.614 | 0.352 | 0.275 |
| Fibrosis | 0.792 | 0.332 | 0.574 | 0.152 | 0.775 | 0.259 | 0.118 |
| Fracture | 0.601 | 0.094 | 0.536 | 0.075 | 0.588 | 0.097 | 0.070 |
| GI tube | 0.900 | 0.192 | 0.710 | 0.067 | 0.910 | 0.269 | 0.018 |
| Granuloma | 0.448 | 0.071 | 0.411 | 0.066 | 0.450 | 0.071 | 0.080 |
| Groundglass | 0.594 | 0.415 | 0.524 | 0.341 | 0.589 | 0.422 | 0.325 |
| Hardware | 0.447 | 0.022 | 0.513 | 0.028 | 0.416 | 0.021 | 0.026 |
| Heart failure | 0.878 | 0.056 | 0.585 | 0.013 | 0.951 | 0.199 | 0.009 |
| Heart valve replacement | 0.745 | 0.043 | 0.721 | 0.059 | 0.858 | 0.165 | 0.014 |
| Hemothorax | 0.889 | 0.125 | 0.721 | 0.011 | 0.833 | 0.032 | 0.005 |
| Hernia | 0.523 | 0.120 | 0.488 | 0.126 | 0.548 | 0.126 | 0.115 |
| Honeycombing | 0.903 | 0.258 | 0.566 | 0.045 | 0.846 | 0.105 | 0.032 |
| Infection | 0.539 | 0.355 | 0.448 | 0.301 | 0.538 | 0.354 | 0.317 |
| Infiltrate | 0.413 | 0.015 | 0.438 | 0.021 | 0.352 | 0.014 | 0.018 |
| Inflammation | 0.529 | 0.087 | 0.429 | 0.076 | 0.521 | 0.086 | 0.082 |
| Interstitial lung disease | 0.739 | 0.362 | 0.565 | 0.196 | 0.742 | 0.304 | 0.152 |
| Lesion | 0.467 | 0.234 | 0.487 | 0.246 | 0.482 | 0.235 | 0.251 |
| Lucency | 0.574 | 0.028 | 0.567 | 0.028 | 0.556 | 0.041 | 0.018 |
| Lung resection | 0.519 | 0.222 | 0.516 | 0.236 | 0.545 | 0.242 | 0.229 |
| Lymphadenopathy | 0.682 | 0.260 | 0.580 | 0.191 | 0.686 | 0.272 | 0.151 |
| Mass | 0.498 | 0.123 | 0.541 | 0.149 | 0.505 | 0.128 | 0.128 |
| Mucous plugging | 0.519 | 0.028 | 0.413 | 0.027 | 0.480 | 0.027 | 0.028 |
| Nodule | 0.649 | 0.858 | 0.600 | 0.855 | 0.682 | 0.873 | 0.800 |
| Nodule >1cm | 0.515 | 0.136 | 0.544 | 0.158 | 0.499 | 0.121 | 0.128 |
| Opacity | 0.369 | 0.456 | 0.539 | 0.571 | 0.634 | 0.667 | 0.543 |
| Pacemaker/defibrillator | 0.778 | 0.128 | 0.563 | 0.079 | 0.857 | 0.261 | 0.049 |
| Pericardial effusion | 0.626 | 0.207 | 0.544 | 0.167 | 0.629 | 0.236 | 0.143 |
| Pericardial thickening | 0.501 | 0.024 | 0.551 | 0.076 | 0.538 | 0.026 | 0.025 |
| Plaque | 0.608 | 0.034 | 0.408 | 0.023 | 0.566 | 0.031 | 0.024 |
| Pleural effusion | 0.770 | 0.424 | 0.656 | 0.308 | 0.792 | 0.507 | 0.199 |
| Pleural thickening | 0.583 | 0.120 | 0.573 | 0.125 | 0.549 | 0.118 | 0.100 |
| Pneumonia | 0.629 | 0.079 | 0.569 | 0.067 | 0.664 | 0.096 | 0.050 |
| Pneumonitis | 0.677 | 0.070 | 0.578 | 0.034 | 0.689 | 0.052 | 0.027 |
| Pneumothorax | 0.780 | 0.196 | 0.576 | 0.030 | 0.815 | 0.193 | 0.024 |
| Postsurgical | 0.554 | 0.525 | 0.517 | 0.503 | 0.537 | 0.521 | 0.485 |
| Pulmonary edema | 0.816 | 0.144 | 0.638 | 0.081 | 0.852 | 0.217 | 0.034 |
| Reticulation | 0.747 | 0.211 | 0.559 | 0.121 | 0.710 | 0.165 | 0.090 |
| Scarring | 0.448 | 0.193 | 0.462 | 0.219 | 0.531 | 0.247 | 0.227 |
| Scattered calcifications | 0.519 | 0.187 | 0.506 | 0.190 | 0.491 | 0.187 | 0.183 |
| Scattered nodules | 0.497 | 0.216 | 0.463 | 0.211 | 0.494 | 0.225 | 0.223 |
| Secretion | 0.587 | 0.019 | 0.530 | 0.019 | 0.599 | 0.021 | 0.014 |
| Septal thickening | 0.793 | 0.176 | 0.612 | 0.105 | 0.794 | 0.195 | 0.060 |
| Soft tissue | 0.475 | 0.166 | 0.558 | 0.206 | 0.466 | 0.160 | 0.171 |
| Staple | 0.501 | 0.032 | 0.536 | 0.040 | 0.462 | 0.033 | 0.031 |
| Stent | 0.580 | 0.040 | 0.550 | 0.064 | 0.554 | 0.037 | 0.032 |
| Sternotomy | 0.743 | 0.186 | 0.536 | 0.086 | 0.779 | 0.241 | 0.068 |
| Suture | 0.507 | 0.028 | 0.534 | 0.022 | 0.466 | 0.022 | 0.020 |
| Tracheal tube | 0.937 | 0.234 | 0.710 | 0.033 | 0.931 | 0.232 | 0.013 |
| Transplant | 0.701 | 0.174 | 0.574 | 0.099 | 0.713 | 0.178 | 0.074 |
| Tree in bud | 0.573 | 0.064 | 0.399 | 0.020 | 0.591 | 0.035 | 0.023 |
| Tuberculosis | 0.534 | 0.005 | 0.366 | 0.003 | 0.467 | 0.006 | 0.003 |
| Mean | 0.613 | 0.177 | 0.536 | 0.146 | 0.623 | 0.190 | 0.129 |
2 Utilizing GenerateCT in Data Augmentation
In this section, we take a closer look at a practical clinical application of GenerateCT. Through a case study, we demonstrate the training of a multi-abnormality classification model with synthetic chest CT volumes generated from medical text prompts. This detailed examination underscores the substantial potential of GenerateCT in data augmentation, particularly in scenarios where obtaining real patient data is limited or challenging. Furthermore, we highlight GenerateCT’s contribution to data privacy. Our approach enables researchers to train and share models similar to ours, promoting the creation of synthetic data through text prompts, thereby enhancing performance without compromising privacy or data-sharing concerns. Additionally, we show that GenerateCT can reliably generate diverse data, even when using the same prompts repeatedly.
2.1 Experimental Setup
Our initial step involved training a multi-abnormality classification model on all of our available training data comprising 20,000 unique patient profiles with 18 different abnormality labels, using real chest CT volumes. This baseline model achieved a mean average precision (AP) of and a mean area under the receiver operating characteristic curve (AUROC) of . To illustrate GenerateCT’s effectiveness in scenarios with available real patient data, we augmented the training dataset by creating an equal number of synthetic volumes with GenerateCT, effectively doubling it. Furthermore, to demonstrate GenerateCT’s efficacy in situations lacking real patient data and its capacity to generate large numbers of synthetic volumes, we produced 100,000 CT volumes, fivefold the number in our original dataset, through the repetitive use of the same prompts and trained the classifier solely on this synthetic data.
Our experiment utilized the CT-Net model [11], with its default parameters for classifying 18 distinct abnormalities. The Stochastic Gradient Descent optimizer [32] was employed with a learning rate of 0.001 and a weight decay of 0.0000001. All training sessions spanned 15 epochs with a batch size of 12, conducted on three A6000 48G GPUs. For consistency, all volumes were resized to , and HU values were calibrated to a range of , focusing on heart and lung abnormalities [9].
2.2 Experimental Results
Tab. 1 details the model’s performance in various training scenarios, highlighting AUROC and AP metrics across 18 abnormalities. We observed an improvement in mean AP and a increase in mean AUROC when training on both real and an equal number of synthetic volumes, compared to using only real data. Expanding the synthetic dataset to 100,000 volumes and training exclusively on this data resulted in an rise in mean AP and a increase in mean AUROC compared to the model trained on all the real data available to us. Validation was performed on the same real patient dataset across all training scenarios.
These results demonstrate GenerateCT’s effectiveness in clinical settings. Data augmentation, even just doubling the dataset size, significantly enhances performance, proving beneficial for researchers with access to real-world data. Moreover, training with a larger, entirely synthetic dataset produced superior results over the real-data-only model, underscoring GenerateCT’s role in ensuring data privacy. This approach facilitates the training and sharing of models like ours, allowing the generation of synthetic data using text prompts, thus enhancing performance while avoiding privacy or data-sharing concerns. Furthermore, the consistent improvement in performance metrics, even with repetitive use of the same prompts, illustrates GenerateCT’s ability to produce varied data from identical inputs.
In conclusion, the results in Tab. 1 establish GenerateCT as a valuable asset in data augmentation. Our experimental findings underscore GenerateCT’s capability to generate detailed and realistic 3D chest CT volumes that accurately align with diverse text prompts. These outcomes mark a significant advancement in medical imaging, suggesting that GenerateCT can be a powerful tool in enhancing diagnostic and treatment planning processes. Moreover, the potential of GenerateCT to simulate realistic, high-resolution medical images based on textual descriptions opens new avenues for future research and applications in healthcare.
3 Utilizing GenerateCT in a Zero-Shot Setting
In this section, we delve into GenerateCT’s application in a zero-shot scenario, assessing the model’s generalization to external datasets and its performance with unseen prompts. As an external dataset, we utilized RadChestCT [11], containing 3,630 chest CT volumes with 83 different abnormalities and a mean abnormality label frequency of .
3.1 Experimental Setup
Initially, we trained the classifier on RadChestCT to set a baseline. This dataset included 2,286 CT volumes for training and 1,344 for validation, each associated with abnormality labels for 83 unique abnormalities. We then generated a new dataset, replicating the volume count and abnormality distribution of the real patient data’s training set, resulting in 2,286 synthetic CT volumes. The generation process followed a predefined structure for medical language text prompts, {age} years old {sex}: {impression}, where {impression} reflected the abnormality labels. These text prompts, notably novel in terms of their abnormality distribution, were not included in our original GenerateCT training. Since age and sex parameters were absent in RadChestCT, they were randomly assigned. The classifier was trained on both this synthetic dataset and a combination of synthetic and real data. The same preprocessing and model parameters as in Sec. 2 were applied to ensure consistency.
3.2 Experimental Results
Tab. 2 displays the performance of each training for all 83 abnormalities, noting comparable results between models trained on synthetic and real data: a mean AP of and AUROC of for synthetic, against AP and AUROC for real data. This similarity is significant, given that both scenarios used the same real patient dataset for validation, originating from a different institutional setup than that used for GenerateCT training. Training jointly with synthetic and real patient data showed a modest increase in both mean AUROC () and mean AP (), underscoring the value of synthetic data in model training.
The results in Tab. 2 establish GenerateCT as a valuable tool for data generation from unseen prompts. Our experimental results highlight GenerateCT’s ability to create detailed and realistic 3D chest CT volumes that correspond accurately to diverse text prompts not used during training. This demonstrates the extension of GenerateCT’s key benefits, mentioned in Sec. 2, to external datasets and its potential for clinical application with unseen prompts.