SeACo-Paraformer: A Non-Autoregressive ASR System with Flexible and Effective Hotword Customization Ability
Abstract
Hotword customization is one of the concerned issues remained in ASR field - it is of value to enable users of ASR systems to customize names of entities, persons and other phrases to obtain better experience. The past few years have seen effective modeling strategies for ASR contextualization developed, but they still exhibit space for improvement about training stability and the invisible activation process. In this paper we propose Semantic-Augmented Contextual-Paraformer (SeACo-Paraformer) a novel NAR based ASR system with flexible and effective hotword customization ability. It possesses the advantages of AED-based model’s accuracy, NAR model’s efficiency, and explicit customization capacity of superior performance. Through extensive experiments with 50,000 hours of industrial big data, our proposed model outperforms strong baselines in customization. Besides, we explore an efficient way to filter large-scale incoming hotwords for further improvement. The industrial models compared, source codes and two hotword test sets are all open source.
Index Terms— end-to-end ASR, non-autoregressive ASR, contextualized ASR, hotword customization
1 Introduction
End-to-end speech recognition has made significant progress in the past decade, with several classic and high-performance ASR backbone models including Transducer [1], listen-attend-and-spell (LAS) [2] and Transformer [3] receiving considerable attention and spawning numerous variants to address various issues in the field of ASR like streaming ASR [4, 5, 6], multi-lingual ASR [7, 8], and non-autoregressive ASR [9, 10], among others. In commercial ASR systems, especially those applied in vertical domains, enabling users to input personal names, place names, named entities and other words as hotwords to obtain personalized recognition results, in short supporting hotword customization, is a question of both academic and commercial value.
At the age of conventional ASR systems, as the acoustic model and language model focus on the phonetic and linguistic information separately, the personalized and biased information are introduced by adjusting the weights in weighted finite state transducer (WFST) decoder [11, 12]. For E2E ASR systems without WFST decoder, several works are explored to enable users to customize their own hotwords [13, 14, 15]. Contextual listen, attend and spell (CLAS) [13] is an E2E contextual ASR modeling method proposed by Golan Pundak et al. They first proposed to introduce a multi-headed attention (MHA) which is jointly trained with randomly sampled phrases in LAS model. Intuitively, the MHA is trained to capture the relationship between hotword embedding and decoder output in each step. leading the decoder to generate biased probabilities once matched. Such strategy is proved an efficient way for introducing bias information to ASR models without damaging the recognition performance, and then becomes a widely adopted contextual ASR solution.
Building upon the fundamental strategy of CLAS: random hotwords sampling and MHA, several extensions are explored to achieve hotword customization [14, 15, 16, 17, 18, 19]. These methods can be categorized as explicit and implicit ones. Huang et al. recently proposed contextual phrase prediction network (CPP Network) [15] which is similiar with CLAS (both implicit). An extra CTC [20] head is introduced for predicting hotwords. By jointly optimizing the CTC module, the encoder output is guided to obtain hotword information thus the ASR results are biased with given hotwords in inference stage. CPP network can be adopted in CTC, Transducer and Transformer models. Han et al. proposed Continuous integrate-and-fire (CIF) based collaborative decoding (ColDec) [14]. It is an explicit method based on CIF model to achieve hotword customization, predicting an external hotword probabilities which is synchronous with ASR prediction. In the training stage, MHA is conducted between CIF output and hotword embeddings. Each step of the MHA output carries hotword attended semantic information , then a feed-forward layer turns it to probabilities for computing cross-entropy (CE) loss with the hotword-position-aware target (e.g. ‘A B C D E F’ for ASR target, an ‘A B # # # #’ for bias target when ‘A B’ is sampled as a hotword and ‘#’ for no-bias label). The introduced modules actually work as a hotword detector to generate biased probabilities synchronous with ASR predictions. In the inference stage, ASR probabilities and biased probabilities are merged. In [19], the authors propose to filter the incoming hotword list with the attention weight which is proved to be an effective method for further improvement.
However, each of the aforementioned methods has its own respective shortcomings. The vanilla CLAS does not demonstrate consistent effectiveness - the label insertion strategy proposed in [13] is not applicable to all E2E systems. Additionally, implicit modeling make it hard to decouple the general ASR modeling and contextual modeling when the system encounters bad cases. Apparently, comparing to CLAS and its extensions, CIF ColDec has a more intuitive and controllable hotword predicting process and training for the external parameters is decoupled from ASR model. On the other hand, the ASR backbone it employs does not attain the high accuracy as attention-encoder-decoder (AED) models. Such factors motivate us to propose a novel hotword customization enabled ASR system: Semantic-Augmented Contextual Paraformer (SeACo-Paraformer). We adopt Paraformer [10] as our backbone model, which serves as a highly efficient NAR model while also maintaining the high accuracy of mainstream AED models. The parallel decoder inside Paraformer allow us to deploy a more complex customization modeling strategy based on CIF ColDec. To address the issue of performance decrease resulting from an expanding hotword list, we use attention score filtering (ASF) to filter the large scale incoming hotwords. We conduct a series of experiments over large scale industrial data to validate the performace of SeACo-Paraformer and ASF. The paper is structured as follows: Section 2 provides a brief introduction to the adopted CIF and Paraformer. Section 3 presents a detailed introduction to SeACo-Paraformer, including training, inference, and other techniques. Section 4 presents the experimental setup and results, while Section 5 analyzes the performance of the models. Finally, Section 6 concludes the paper.
2 PRELIMINARIES
2.1 Continuous Integrate-and-Fire
Continuous integrate-and-fire (CIF) is an alignment mechanism which utilizes the monotonic characteristic of ASR task to predict number of output tokens and obtain acoustic embedding with encoder output. CIF predicts weights for each frame and accumulates them from begin to end. Once the weights added up to 1.0, the encoder output of the former periods are integrated (weighted sum) to generate a step of acoustic embedding. Considering encoder output with predicted weights , The integrated acoustic embedding , . The sum of weights is - the token number of output sequence. The most important features of CIF is that the embedding it generates has the same length as the target sequence, which means it’s a entirely acoustic based representation but synchronous with predictions.
2.2 Paraformer
In this work, we adopt Paraformer [10], a novel NAR ASR model as our backbone. Paraformer stands for Parallel Transformer which contains a decoder receiving acoustic embedding or semantic embedding at the same time in training. Briefly, Paraformer achieves non-autoregressive decoding capacity by utilizing CIF [21] and two-pass training strategy as illustrated in Fig. 1 (lower dotted box). A CIF predictor is trained to predict the number of tokens and generate acoustic embedding for parallel decoder, which makes up Pass1 in training (w/o gradient). The steps in char embedding will be gradually replaced by as accuracy raises in Pass1 and the so called semantic embedding is generated according to the correctly recognized positions. Getting rid of the massive computation overhead introduced by auto-regressive decoding and beam-search, Paraformer gains more than 10x speedup with even lower error rate. More implementation details and experiment results can be found in [10, 22].
3 SeACo-Paraformer
3.1 Architecture and training
Taking the advantages and shortcomings of the previous works discussed in Section 1 into account, we propose a novel hotword customization system called Semantic-augmented Contextual-Paraformer (SeACo-Paraformer). Based on Paraformer which is a strong ASR backbone, 3 modules are introduced as illustrated in Fig 1. Intuitively, SeACo-Paraformer utilize the modeling characteristic of CIF predictor to conduct hotword prediction, while the CIF output and parallel decoder output are sent to bias decoder separately.
Formally, considering an speech feature and corresponding text , we retain the CIF output and parallel decoder hidden state (before output layer) in Paraformer inference:
| (1) | ||||
Then hotwords are randomly sampled out of batches of with batch size , denoted as . We use 4 hyper-parameter here to control the sampling process: for the ratio of batches to conduct sampling, the forward of the other batches will be conducted with a default hotword ; is similar with but in utterance level inside an active batch, the average number of hotwords sampled for active batch is (one for the default hotword); and for the minimum and maximum lengths of sampled hotwords.
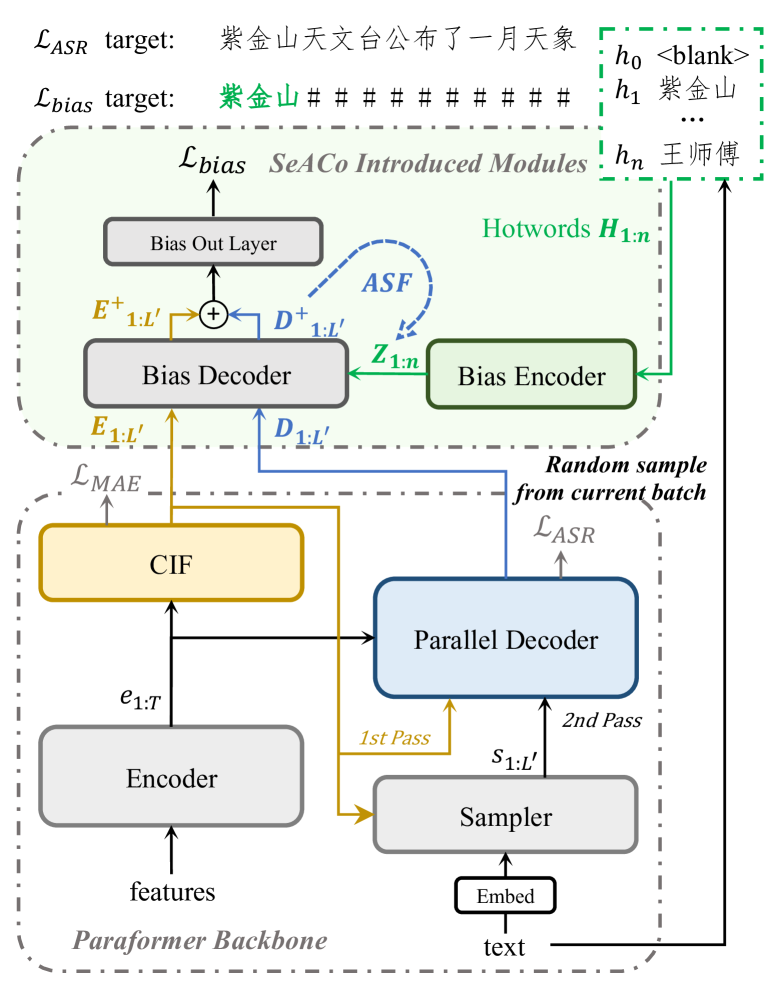
The character sequences in hotword list are then embedded with bias encoder which contains a embedding layer (parameter shared with ASR embedding) and an LSTM layer:
| (2) |
is unsqueezed and repeated on the 0th dimension for batch calculation. Then comes to the main part of SeACo-Paraformer. Inside bias decoder, the bias information of hotwords is introduced to acoustic embedding and decoder hidden state through the attention mechanism:
| (3) | ||||
Bias decoder is composed of several multi-headed attention and feed-forward layer. With biased acoustic embedding and biased decoder hidden state, the biased probabilities can be obtained with an output layer. Note that an additional token (counted as #, means no-bias) is appended to the ASR output vocabulary to mark non-hotword position outputs.
| (4) |
Given the biased probabilities , the bias-related parameters can be updated with the hotword-position-aware criterion in which labels in non-hotword positions are replaced by # (as shown as in Fig 1).
With a well-trained Paraformer model freezing, we enable contextualization of hotwords for an ASR system by introducing bias out layer, bias decoder and bias encoder, and training them with randomly sampled hotwords and their corresponding targets. Notably, the training of bias-related parameters is separate from the ASR training, thereby allowing for the use of specialized hotword data (e.g. low frequency language phrases) and training strategies without affecting the general ASR performance.
3.2 Inference and Auxiliary Technics
For -th step in SeACo-Paraformer inference with a given hotword list, we get the final merged probabilities for contextualized ASR as
| (5) |
When there is no hotword incoming or no hotword detected, SeACo-Paraformer uses only. is a tunable parameter to adjust the degree of trust bias decoder output.
In practical applications, as the number of incoming hotwords expands, the performance of hotword activation decreases accordingly - it becomes difficult for the cross-attention inside bias decoder to establish correct connection between ASR decoder output and large-sacle sparse hotword embedding . For enabling SeACo-Paraformer to conduct hotword customization with large scale hotword list, we propose attention score filtering (ASF) strategy. The bias decoder inference is conducted with full hotword list first to obtain the attention score matrix , where is the length of output tokens and is the number of hotwords. Then we sum up the scores of steps in and get the attention scores for each hotword. According to attention scores, we can pick the most active hotwords to conduct truly effective bias decoder inference. Comparing to the fine-grained contextual knowledge selection [19], our bias decoder is composed of multiple cross-attention layers and we found the score from the last layer most effective for filtering.
4 Experiments
4.1 Data Introduction
We conducted a series of experiments using large-scale internal industrial data - the random sampling based hotword modeling strategy requires sufficient diversity of data, otherwise it will easily overfit to limited semantic information. The total amount of training data we use is around 50,000 hours. For evaluating the performance of models in hotword customization as well as general ASR, we use test sets in different domains as shown in Table1. For all of the hotword test sets, we distinguish part of hotwords as R1-hotwords, which means that their recall rate counted in the recognition of the basic ASR model is lower than 40%. These hotwords exhibit a higher level of recall difficulty, thereby effectively showing the customization capability of the models. Test-General is a large collection of several general ASR test sets, covering various domains and scenarios. Test-Commercial, Test-Term and Test-Entity are three hotword test sets of different domain.
To demonstrate reproducible experiment results and model comparison, we construct and open source two data sets for testing hotword customization based on the open-source Aishell-1 dataset [23]. First we use part-of-speech tagging [24] to generate name entity list from transcription of Aishell-1 test and development sets. Then treating the name entities as hotwords, we use all of the R1-hotwords and a random part of the remaining ones to compose two hotword lists. Finally, Test-Aishell1-NE and Dev-Aishell1-NE are filtered out based on the hotword lists111Find the open source data sets, source codes, detailed experiment results and models at https://github.com/R1ckShi/SeACo-Paraformer.
| #utt | #hotword | #R1-hotword | |
|---|---|---|---|
| Test-Gerneral | 40603 | - | - |
| Test-Commercial | 2000 | 693 | 72 |
| Test-Term | 1639 | 969 | 258 |
| Test-Entity | 1308 | 231 | 54 |
| Test-Aishell1-NE | 808 | 400 | 226 |
| Dev-Aishell1-NE | 1334 | 600 | 371 |
4.2 Experimental Setup and Evaluation Metrics
We implement the models with FunASR222https://github.com/alibaba-damo-academy/FunASR. The Paraformer model, Paraformer-CLAS model and the proposed SeACo-Paraformer model are totally open source11footnotemark: 1 including source code, configuration files and models trained with industrial data. Paraformer base model is composed of 50-layers SAN-M [25] encoder and 16-layer NAR Transformer decoder, with 2048 hidden units. Comparing to the models discussed in [22], the Paraformer-CLAS presented in this paper has undergone an upgrade and is guaranteed to possess a strong and finely-tuned customization baseline. As for SeACo-Paraformer, the model is trained with ASR backbone freezing using the same 50,000 hours training data for 6 epochs. We set sampling ratio and to 0.75, and . The introduced modules have following architectures: bias encoder is a 2-layer LSTM with 512 hidden size, bias decoder is a 4-layer Transformer decoder with 1024 hidden units. Each training batch has 6,000 speech frames ( GPU).
![[Uncaptioned image]](x2.png)
Models are compared according to 3 metrics: character error rate (CER) over total test sets, recall rate/precision/F1 score (R/P/F) of the all hotwords in average and R/P/F of R1-hotwords in average. For more strict evaluation, we only consider a hotword to be successfully recalled when predicted entirety, so we exclude the calculation of error rates in hotword positions.
4.3 Results
Table 2 shows the experiment results over all test sets of the four models. Note that we use for Equation (5) in inference and for ASF. In the general test, Paraformer-CLAS demonstrated similar CER to the Paraformer-Base model. As the SeACo-Paraformer was trained with a frozen ASR backbone, the four models exhibited minimal differences in general ASR performance. In the internal hotword customization test, CLAS was shown to be an efficient method, with the average recall of R1-hotwords increasing from 12% to 51%. However, SeACo-Paraformer still outperformed CLAS with a recall rate of 60%. The addition of ASF results in a further enhancement, the recall rate increased to 65%. And SeACo-Paraformer achieved a 5% relative CER reduction compared to Paraformer-CLAS. We get similar results in open-source test sets while Paraformer-CLAS, SeACo-Paraformer and SeACo-Paraformer+ASF get 69%, 79% and 87% recall rates respectively. The proposed method achieves relative 30.2% CER reduction and 26.1% recall improvement comparing to Paraformer-CLAS.
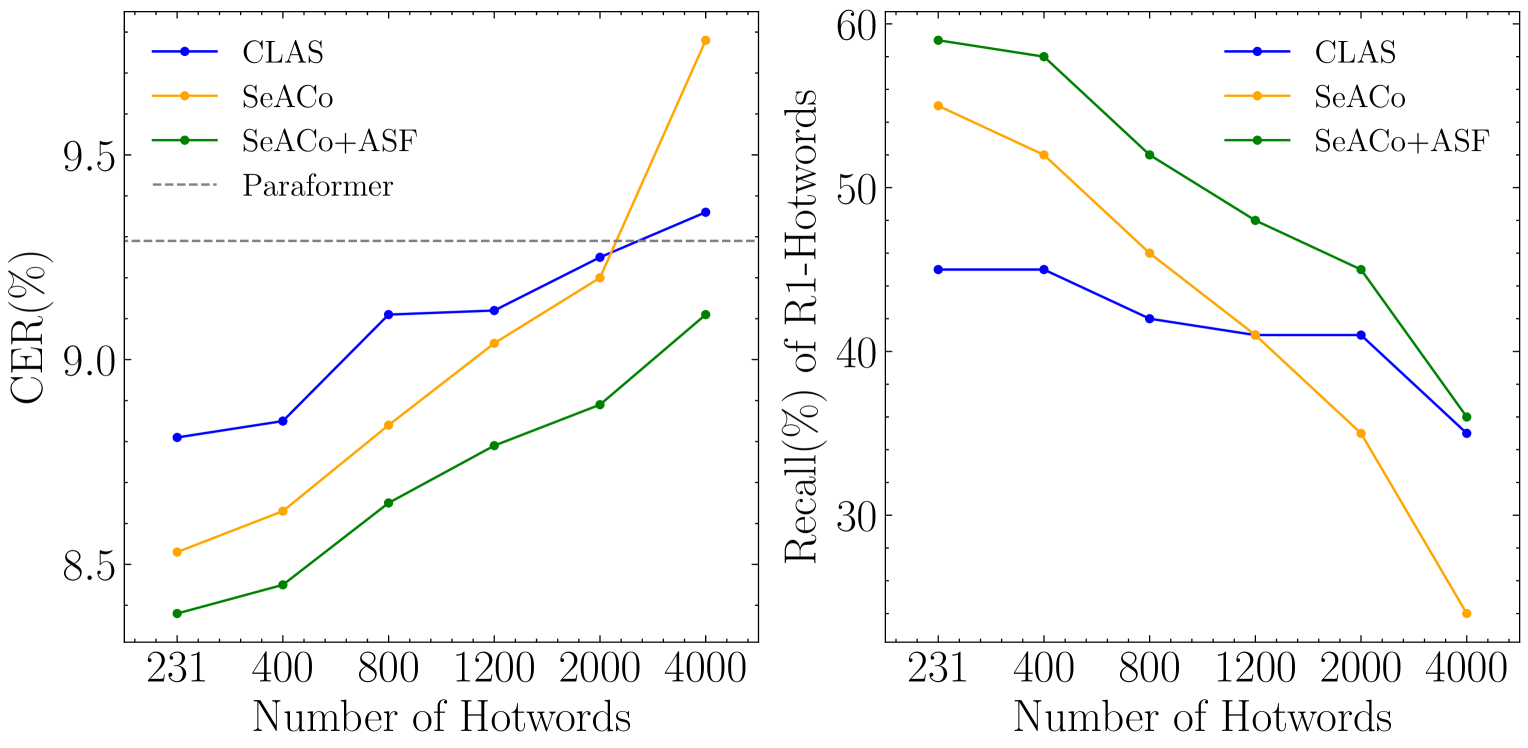
The experiment results of increasing hotword number are shown in Fig. 2. Test-Entity has 231 hotwords in total and we enlarge it with irrelevant hotwords to size of 400, 800, 1200, 2000 and 4,000. The curves in the figure indicate that the performance of all three models deteriorates as the hotword list expands. In terms of CER, only SeACo-Paraformer+ASF achieves a reduction in CER when the list expands to 4000 hotwords. From the perspective of recall rate, the SeACo-Paraformer model performs on par with with CLAS when the number of hotwords reaches 1200. However, by adopting ASF, the proposed model maintains its advantage over CLAS.
| Test -C | Test -T | Test-E | Avg. | |
|---|---|---|---|---|
| Seaco-Paraformer | 3.16/67 | 4.51/59 | 8.53/55 | 5.40/60 |
| A1: merge first | 3.28/65 | 4.72/61 | 8.67/53 | 5.56/60 |
| A2: only | 3.86/64 | 5.29/62 | 8.66/58 | 5.94/61 |
| A3: only | 3.25/63 | 4.59/50 | 8.60/51 | 5.49/55 |
Table 3 shows the results of ablation study over calculation of bias decoder. Focus on Equation (3), there are several ways to introduce bias information before bias output layer, merging and before MHA rather thar after also makes sense (A1). Besides, it’s essential to conduct ablation experiment for using or only (A2 and A3). The result indicates that using CIF output alone to calculate hotword loss leads to higher recall but worse in CER, which means that predicting hotword with acoustic embedding only is not a stable method and decoder output is indispensable. On the other hand, conducting MHA with and twice and separately is better than merging them first.
5 Analysis
The attention in bias decoder plays the most critical role in hotword customization, in this section we go deep into the attention score matrix. Figure 3 reveals how the bias decoder establishes the connection between hotwords and semantic information (attention score matrix of the last layer in bias decoder), but the phenomenon contradicts our initial hypothesis. In this case SeACo-Paraformer predicts two hotwords correctly. Two yellow dotted boxes depict the attention pattern upon successful matches, revealing that semantic information selectively attends to non-blank phrases solely when relevant hotwords initiate and conclude (indicated by yellow arrows). This phenomenon occurs in almost all utterances and is not an isolated case. Besides, we found the attention scores of at each step imply the probability of hotwords to appear, which is different from [14]. The cumulative scores across all steps for each hotword reflect its likelihood of occurrence, which constitutes the fundamental concept of ASF.

6 Conclusion
In this paper we propose a flexible and effective hotword customization model based on NAR ASR backbone called SeACo-Paraformer. A series of experiments with industrial data proved that the proposed model outperforms CLAS which is a classic hotword customization solution, and the ASF strategy for inference is proved an effective method to improve ASR accuracy and hotwords recall rate. Besides, we make further analysis over the performance with increasing number of hotwords, ablation study of bias decoder calculation and the attention score matrix. In the future, we will focus on large-scale incoming hotword list and different bias encoder structure.
References
- [1] Alex Graves, Abdel-rahman Mohamed, and Geoffrey Hinton, “Speech recognition with deep recurrent neural networks,” in 2013 IEEE international conference on acoustics, speech and signal processing. IEEE, 2013, pp. 6645–6649.
- [2] William Chan, Navdeep Jaitly, Quoc Le, and Oriol Vinyals, “Listen, attend and spell: A neural network for large vocabulary conversational speech recognition,” in 2016 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2016, pp. 4960–4964.
- [3] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [4] Kanishka Rao, Haşim Sak, and Rohit Prabhavalkar, “Exploring architectures, data and units for streaming end-to-end speech recognition with rnn-transducer,” in 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2017, pp. 193–199.
- [5] Niko Moritz, Takaaki Hori, and Jonathan Le, “Streaming automatic speech recognition with the transformer model,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6074–6078.
- [6] Zhifu Gao, Shiliang Zhang, Ming Lei, and Ian McLoughlin, “Universal asr: Unifying streaming and non-streaming asr using a single encoder-decoder model,” arXiv preprint arXiv:2010.14099, 2020.
- [7] Shiyu Zhou, Shuang Xu, and Bo Xu, “Multilingual end-to-end speech recognition with a single transformer on low-resource languages,” arXiv preprint arXiv:1806.05059, 2018.
- [8] Shigeki Karita, Nanxin Chen, Tomoki Hayashi, Takaaki Hori, Hirofumi Inaguma, Ziyan Jiang, Masao Someki, Nelson Enrique Yalta Soplin, Ryuichi Yamamoto, Xiaofei Wang, et al., “A comparative study on transformer vs rnn in speech applications,” in 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2019, pp. 449–456.
- [9] Fan Yu, Haoneng Luo, Pengcheng Guo, Yuhao Liang, Zhuoyuan Yao, Lei Xie, Yingying Gao, Leijing Hou, and Shilei Zhang, “Boundary and context aware training for cif-based non-autoregressive end-to-end asr,” in 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2021, pp. 328–334.
- [10] Zhifu Gao, Shiliang Zhang, Ian McLoughlin, and Zhijie Yan, “Paraformer: Fast and accurate parallel transformer for non-autoregressive end-to-end speech recognition,” INTERSPEECH, 2022.
- [11] Petar Aleksic, Cyril Allauzen, David Elson, Aleksandar Kracun, Diego Melendo Casado, and Pedro J Moreno, “Improved recognition of contact names in voice commands,” in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2015, pp. 5172–5175.
- [12] Keith Hall, Eunjoon Cho, Cyril Allauzen, Francoise Beaufays, Noah Coccaro, Kaisuke Nakajima, Michael Riley, Brian Roark, David Rybach, and Linda Zhang, “Composition-based on-the-fly rescoring for salient n-gram biasing,” 2015.
- [13] Golan Pundak, Tara N Sainath, Rohit Prabhavalkar, Anjuli Kannan, and Ding Zhao, “Deep context: end-to-end contextual speech recognition,” in 2018 IEEE spoken language technology workshop (SLT). IEEE, 2018, pp. 418–425.
- [14] Minglun Han, Linhao Dong, Shiyu Zhou, and Bo Xu, “Cif-based collaborative decoding for end-to-end contextual speech recognition,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 6528–6532.
- [15] Kaixun Huang, Ao Zhang, Zhanheng Yang, Pengcheng Guo, Bingshen Mu, Tianyi Xu, and Lei Xie, “Contextualized end-to-end speech recognition with contextual phrase prediction network,” arXiv preprint arXiv:2305.12493, 2023.
- [16] Ke Hu, Antoine Bruguier, Tara N Sainath, Rohit Prabhavalkar, and Golan Pundak, “Phoneme-based contextualization for cross-lingual speech recognition in end-to-end models,” arXiv preprint arXiv:1906.09292, 2019.
- [17] Mahaveer Jain, Gil Keren, Jay Mahadeokar, Geoffrey Zweig, Florian Metze, and Yatharth Saraf, “Contextual rnn-t for open domain asr,” arXiv preprint arXiv:2006.03411, 2020.
- [18] Kanthashree Mysore Sathyendra, Thejaswi Muniyappa, Feng-Ju Chang, Jing Liu, Jinru Su, Grant P Strimel, Athanasios Mouchtaris, and Siegfried Kunzmann, “Contextual adapters for personalized speech recognition in neural transducers,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 8537–8541.
- [19] Minglun Han, Linhao Dong, Zhenlin Liang, Meng Cai, Shiyu Zhou, Zejun Ma, and Bo Xu, “Improving end-to-end contextual speech recognition with fine-grained contextual knowledge selection,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 8532–8536.
- [20] Alex Graves, Santiago Fernández, Faustino Gomez, and Jürgen Schmidhuber, “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks,” in Proceedings of the 23rd international conference on Machine learning, 2006, pp. 369–376.
- [21] Linhao Dong and Bo Xu, “Cif: Continuous integrate-and-fire for end-to-end speech recognition,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6079–6083.
- [22] Zhifu Gao, Zerui Li, Jiaming Wang, Haoneng Luo, Xian Shi, Mengzhe Chen, Yabin Li, Lingyun Zuo, Zhihao Du, Zhangyu Xiao, et al., “Funasr: A fundamental end-to-end speech recognition toolkit,” arXiv preprint arXiv:2305.11013, 2023.
- [23] Hui Bu, Jiayu Du, Xingyu Na, Bengu Wu, and Hao Zheng, “Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline,” in 2017 20th conference of the oriental chapter of the international coordinating committee on speech databases and speech I/O systems and assessment (O-COCOSDA). IEEE, 2017, pp. 1–5.
- [24] Zhenyu Jiao, Shuqi Sun, and Ke Sun, “Chinese lexical analysis with deep bi-gru-crf network,” arXiv preprint arXiv:1807.01882, 2018.
- [25] Zhifu Gao, Shiliang Zhang, Ming Lei, and Ian McLoughlin, “San-m: Memory equipped self-attention for end-to-end speech recognition,” arXiv preprint arXiv:2006.01713, 2020.