Temporally-Adaptive Models
for Efficient Video Understanding
Abstract
Spatial convolutions111In this work, we use spatial convolutions and 2D convolutions interchangeably. are extensively used in numerous deep video models. It fundamentally assumes spatio-temporal invariance, i.e., using shared weights for every location in different frames. This work presents Temporally-Adaptive Convolutions (TAdaConv) for video understanding, which shows that adaptive weight calibration along the temporal dimension is an efficient way to facilitate modeling complex temporal dynamics in videos. Specifically, TAdaConv empowers spatial convolutions with temporal modeling abilities by calibrating the convolution weights for each frame according to its local and global temporal context. Compared to existing operations for temporal modeling, TAdaConv is more efficient as it operates over the convolution kernels instead of the features, whose dimension is an order of magnitude smaller than the spatial resolutions. Further, kernel calibration brings an increased model capacity. Based on this readily plug-in operation TAdaConv as well as its extension, i.e., TAdaConvV2, we construct TAdaBlocks to empower ConvNeXt and Vision Transformer to have strong temporal modeling capabilities. Empirical results show TAdaConvNeXtV2 and TAdaFormer perform competitively against state-of-the-art convolutional and Transformer-based models in various video understanding benchmarks. Our codes and models are released at: https://github.com/alibaba-mmai-research/TAdaConv.
Index Terms:
Dynamic Networks, Efficient Video Understanding, Action Recognition, Temporally-Adaptive Convolutions,Temporally-Adaptive Transformer
1 Introduction
Convolutions are an indispensable operation in modern deep vision models [1, 2, 3, 4], whose different variants have driven the state-of-the-art performances of convolutional neural networks (CNNs) in many visual tasks [5, 6, 7, 8, 9] and application scenarios [10, 11]. In the video paradigm, compared to the 3D convolutions [12], the combination of 2D spatial convolutions and 1D temporal convolutions is more widely preferred owing to its efficiency [13, 14]. Nevertheless, 1D temporal convolutions introduce non-negligible computation overhead on top of the spatial convolutions. Therefore, we seek to directly equip spatial convolutions with temporal modeling abilities.
One essential property of convolutions is the translation invariance [15, 16], resulting from its local connectivity and shared weights. However, recent works in dynamic filtering have shown that strictly shard weights for all pixels may be sub-optimal for modeling various spatial contents [17, 18].
Given the diverse nature of the temporal dynamics in videos, we hypothesize that temporal modeling could benefit from relaxed invariance along the temporal dimension. This means that convolution weights for different time steps are no longer strictly shared. Existing dynamic filter networks could achieve this but with two drawbacks. (i) it is difficult for most of them [17, 11] to leverage pre-trained weights, which is critical in video applications since training video models from scratch is highly resource demanding [19, 20] and prone to over-fitting on small datasets. (ii) for most dynamic filters, the weights are generated with respect to its spatial context [17, 21] or the global descriptor [22, 11], which is incapable of capturing the fine-grained temporal variations between frames.
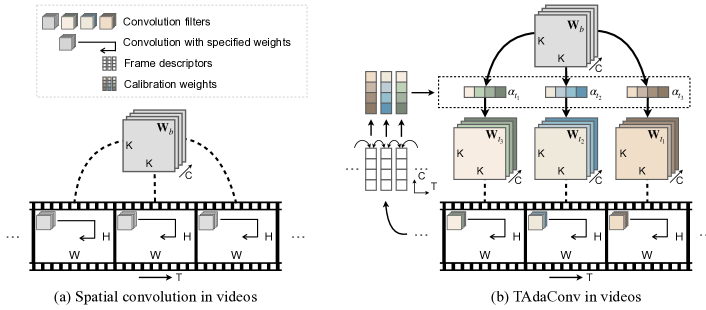
Motivated by this, we present Temporally-Adaptive Convolution (TAdaConv) for video understanding, where the convolution weights are no longer fixed across different frames. Specifically, the convolution kernel for the -th frame is factorized to the multiplication of the base weight and a calibration weight: , where the base weight is learnable and the calibration weight is adaptively generated from the input data in the base weight . For each frame, we generate the calibration weight based on the frame descriptors of its adjacent time steps as well as the global descriptor, which effectively encodes both local and global temporal dynamics in videos. The difference between TAdaConv and standard convolutions is visualized in Fig. 1.
The main advantages of this factorization are three-fold: (i) TAdaConv can be easily plugged into any existing models to enhance temporal modeling, and their pre-trained weights can still be exploited; (ii) the temporal modeling ability can be highly improved with the help of the temporally-adaptive weight; (iii) in comparison with temporal convolutions that often operate on the learned 2D feature maps, TAdaConv is more efficient by directly operating on the convolution kernels.
TAdaConv is proposed as a drop-in replacement for the convolutions in existing models. A preliminary version of this work [23] is published in ICLR 2022, where TAdaConv has demonstrated a strong capability of temporal modeling, introducing notable performance gains to both image-based models as well as existing video models. In this work, we follow the conceptual idea of TAdaConv and present improvements to the preliminary version on both structural designs as well as model and data scaling. In terms of structural designs, we optimize TAdaConv in the following aspects: (i) At the operation level, the calibration factor generation process of TAdaConv is optimized, where multi-head self-attention [24] is introduced for modeling the global information of the videos. (ii) At the block level, we construct stronger TAdaBlocks by introducing efficient temporal feature aggregation, which we use to construct our convolutional model TAdaConvNeXtV2 and transformer TAdaFormer. Our empirical results show a notable improvement brought by our modifications on both scene- and motion-centric benchmarks. Based on the TAdaConvNeXtV2 and TAdaFormer, we further scale up both the model and data scale, which lead to a competitive performance to existing state-of-the-art approaches.
2 Related Work
Convolutional models for video understanding. Early convolutional models obtain spatio-temporal representations by 3D convolutions [25, 12, 20, 26] or two-stream networks [27]. For efficiency, recent ones build upon 2D networks and design additional operations for temporal modeling [28, 29, 30, 13, 31, 32, 33, 34, 35], where the weights of the 2D convolutions are shared between different timestamps. Our preliminary version [23] find removing this constraint leads to stronger temporal modeling ability. In this work, we modernize the convolutional model according to ConvNeXt [36] and construct a stronger convolutional model for video understanding.
Vision Transformers for video understanding. With the great success of Transformers in natural language processing [24, 37, 38], Vision Transformers (ViT) [39] are showing strong performances in various vision tasks [40, 41, 42, 43, 44, 45, 46] including video understanding [47, 48, 49, 50, 51, 52, 53]. The capability of ViTs is further enhanced when it is pre-trained on a large corpus of image [54, 55], video [56, 57, 58] or multi-modal data [59, 60], or when the size of the model is increased [61, 62], or both [63, 64]. Since directly pre-training with video data is both resource- and time-consuming, an alternative is to exploit the models pre-trained on large-scale image data and empower the model thorough additional structures for temporal modeling, such as temporal [50] or 3D windowed self-attention [48], spatio-temporal adapters [65], etc. In our work, we exploit the vanilla Vision Transformer pre-trained on a large corpus of image-text data [59] and equip it with strong temporal modeling ability with our TAdaBlock.
Dynamic networks. Dynamic networks refer to networks with content-adaptive weights or modules, such as dynamic filters/convolutions [21, 11, 66, 17], dynamic activations [67, 68], and dynamic routing [69, 70], etc. They have demonstrated exceeding network capacity and performance compared to static ones in various tasks [71, 72, 73, 74] as well as in video understanding [31, 75, 76, 77]. Some recent spatially-adaptive convolutions [78, 79] show relaxing spatial invariance could help modeling diverse visual contents, and our preliminary version [23] shows video understanding can benefit from relaxing the temporal invariance. This work further exploits the idea and enhance the temporal modeling capability of TAdaConv by introducing multi-head self-attention for global temporal modeling.
3 Temporally-adaptive Convolutions
In this work, we seek to empower the spatial convolutions with temporal modeling abilities. Inspired by the calibration process of temporal convolutions (Sec. 3.1), TAdaConv dynamically calibrates the convolution weights for each frame (Sec. 3.2) according to its temporal context (Sec. 3.3).
3.1 Revisiting temporal convolutions
We first revisit the temporal convolution to show the underlying process and its relation to dynamic filters. We consider depth-wise temporal convolution for simplicity, which is more widely used due to its efficiency [31, 30]. Formally, for a 311 temporal convolution filter parameterized by and placed (ignoring normalizations) after the 2D convolution parameterized by , the output feature of the -th frame can be obtained by:
| (1) |
where the indicates the element-wise multiplication, denotes the convolution over the spatial dimension and denotes ReLU activation [80]. It can be rewritten as follows:
| (2) |
where and are spatio-temporal location adaptive convolution weights. is a dynamic tensor, with its value dependent on the result of the spatial convolutions (see Appendix for details). Hence, the temporal convolutions in the (2+1)D convolution essentially perform (i) weight calibration on the spatial convolutions and (ii) feature aggregation between adjacent frames. However, if the temporal modeling is achieved by coupling temporal convolutions to spatial convolutions, a non-negligible computation overhead is still introduced (see Table I).
3.2 Formulation of TAdaConv and TAdaConvV2
For efficiency, we set out to directly empower the spatial convolutions with temporal modeling abilities. Inspired by the recent finding that the relaxation of spatial invariance strengthens spatial modeling [17, 78], we hypothesize that temporally adaptive weights can also help temporal modeling. Therefore, the convolution weights in a TAdaConv layer are varied on a frame-by-frame basis. Since we observe that previous dynamic filters can hardly utilize the pretrained weights, we take inspiration from our observation in the temporal convolutions and factorize the weights for the -th frame into the multiplication of a base weight shared for all frames, and a calibration weight that are different for each time step:
| (3) |
3.3 Calibration weight generation.
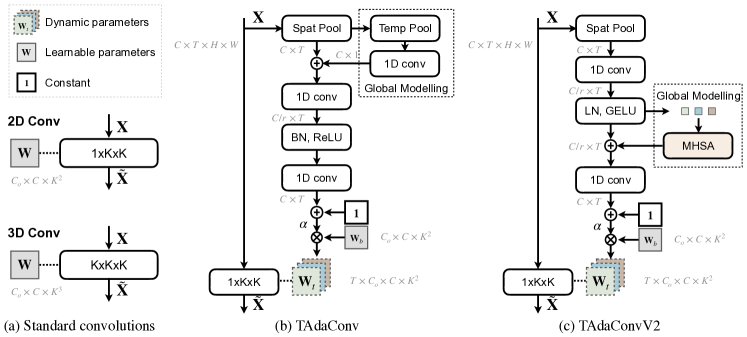
To allow for the TAdaConv to model temporal dynamics, it is crucial that the calibration weight for the -th frame takes into account not only the current frame, but more importantly, its temporal context, i.e., . Otherwise, TAdaConv would degenerate to a set of unrelated spatial convolutions with different weights applied on different frames. In practice, the calibration generation function can have various structural designs. In Fig. 2(b) and (c), we show two instantiations of the calibration generation function, which respectively correspond to TAdaConv and TAdaConvV2.
TAdaConv. In our design, we aim for efficiency and the ability to capture inter-frame temporal dynamics. For efficiency, we operate on the frame description vectors obtained by the global average pooling over the spatial dimension for each frame, i.e., . For temporal modeling, we apply two-layer 1D convolutions with a dimension reduction ratio of on the local temporal context :
| (4) |
where we use ReLU [80] and batch normalizations [81] for activation and normalization. denotes 1-D convolutions.
In order for a larger inter-frame field of view in complement to the local 1D convolution, we further incorporate global temporal information into the calibration weight generation process. For TAdaConv, we add a global descriptor to the weight generation process through a linear mapping function FC:
| (5) |
where denotes global average pooling over the temporal dimension on the frame descriptors . This is equivalent to global average pooling over all spatiotemporal dimensions on the original input . Hence, contains the global temporal context in the input videos.
TAdaConvV2. The instantiation of TAdaConvV2 is generally similar to TAdaConv, with two improvements. (i) We alter the combination of ReLU and batch normalizations to GELU and layer normalizations to conform to the structures in ConvNeXt models. (ii) For global temporal context modeling, we take advantage of the powerful global modeling capability of self-attention [24]. Specifically, the calibration weight generation function can be expressed as follows:
| (6) |
where MHSA denotes the multi-head self-attention [24]. Since the 1D convolution before MHSA essentially provides a dynamic positional embedding for the frame descriptors , we do not add additional positional embeddings before the MHSA operation.
| (2+1)D Conv | TAdaConv | |
| FLOPs | ||
| E.G. Op | 1.2331 (+0.308, 33) | 0.9268 (+0.002, 0.2) |
| E.G. Net | 37.94 (+4.94, 15) | 33.02 (+0.02, 0.06) |
| Params. | ||
| E.G. Op. | 49,152 (+12,288, 33) | 43,008 (+6,144, 17) |
| E.G. Net | 28.1M (+3.8M, 15.6) | 27.5M (+3.2M, 13.1) |
Initialization. The TAdaConv is designed to be readily inserted into existing models by simply replacing the 2D convolutions. For effective use of the pre-trained weights, TAdaConv is initialized to behave exactly the same as the standard convolution. This is achieved by zero-initializing the weight of the last convolution in and adding a constant vector to the formulation:
| (7) |
In this way, at initial state, , where we load with the pre-trained weights.
Calibration dimension. The base weight can be calibrated in different dimensions. For standard convolutions, we instantiate the calibration on the dimension (), as the weight generation based on the input features yields a more precise estimation for the relation of the input channels than the output channels or spatial structures (empirical analysis in Table LABEL:tab:calibrationdim). For depthwise convolutions, since the convolution kernel does not have a dimension, the calibration is directly applied on the dimension of the convolution kernel.
Comparison with temporal convolutions. Table I compares the TAdaConv with R(2+1)D in parameters and FLOPs, which shows most of our additional computation overhead on top of the spatial convolution is an order of magnitude less than the temporal convolution.
| Temporal | Location | Pretrained | |
| Operations | modeling | adaptive | weights |
| CondConv [11] | ✗ | ✗ | ✗ |
| DynamicFilter [21] | ✗ | ✗ | ✗ |
| DDF [17] | ✗ | ✓ | ✗ |
| TAM [31] | ✓ | ✗ | ✗ |
| TAdaConv(V2) | ✓ | ✓ | ✓ |
Comparison with existing dynamic filters. Table II compares TAdaConv with existing dynamic filters. The main difference between different dynamic filtering approaches lies in the way that the dynamic weights are generated. Mixture-of-experts-based dynamic filters [11] generate content-dependent weights to dynamically aggregate learnable convolution weights. Other types of dynamic filters [21, 17, 31] generate dynamic weights entirely based on the input content. Our TAdaConv is different from existing dynamic filters in the following three aspects: (i) Compared to image-based dynamic filters [21, 17, 11], TAdaConv achieves temporal modeling by generating weights based on the local and global context. (ii) Compared to TANet [31] in the video paradigm, TAdaConv could model more complex temporal dynamics because of the temporally adaptive weights. (iii) Most existing dynamic filters are incapable of exploiting existing pre-trained weights, while TAdaConv could be initialized to generate dynamic weights that are identical to pre-trained ones. This reduces the training difficulty in video applications. More detailed comparisons of dynamic filters are included in Appendix.
4 TAdaBlocks
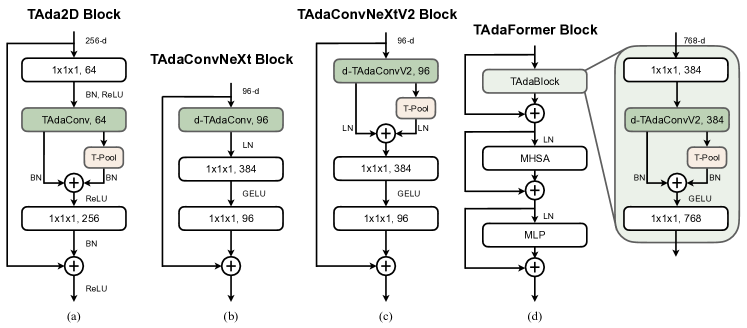
Based on TAdaConv and TAdaConvV2, we can construct a series of TAdaBlocks for various models, both convolutional and Transformer-based ones. In Fig. 3, we construct TAda2D block, TAdaConvNeXt(V2) block, and TAdaFormer block, respectively for ResNet [1], ConvNeXt [36] and ViT [39].
Apart from TAdaConv and TAdaConvV2, an important component of our TAdaBlocks is an efficient temporal feature aggregation scheme. This corresponds to the second essential step of temporal convolution. Formally, given the output of TAdaConv , the aggregated feature can be obtained as follows:
| (8) |
where represents the strided temporal pooling operation with a kernel size of . We use different normalization parameters for the features extracted by TAdaConv and aggregated by strided average pooling , as their distributions are essentially different.
During initialization, we load pre-trained weights (if any) to , and initialize the parameters of to zero. Coupled with the initialization of TAdaConv, the initial state of the TAdaBlocks is exactly the same as the base model, while the calibration and the aggregation notably increase the model capacity with training (See Appendix). In experiments, we refer to this structure as the shortcut (Sc.) branch and the separate BN (SepBN.) branch.
In our preliminary version [23], we explored the TAda2D block and TAdaConvNeXt block. Inspired by the improvements brought by the temporal feature aggregation, we present an improved version of the TAdaConvNeXt block in Fig. 3 (c), i.e., TAdaConvNeXtV2 block. To cater to the modernized convolutional block [36], the structure of the aggregation scheme in TAdaConvNeXtV2 block is modified accordingly, where the activation function is removed and the normalization is switched to LayerNorm [82].
For Transformer-based models, we construct a TAdaFormer block, as in Fig. 3 (d), where a ResNet-like convolutional block is inserted before each self-attention layer. Different from ResNet blocks, we use depth-wise TAdaConvV2 between two point-wise convolutions for efficiency. Inspired by the modernized convolutional block [36], some of the normalization and activation layers are removed, as in Fig. 3 (d). Temporal aggregation is similarly performed using the efficient feature aggregation scheme presented above. Empirically, we found batch normalizations work better in TAdaBlock for TAdaFormer.
5 Evaluations on video classification
Model. We construct different variants for TAda2D, TAdaConvNeXtV2, and TAdaFormer, following the structure of the respective base models ResNet [1], ConvNeXt [36], and Vision Transformer [39]. Our model variants are obtained by replacing the residual blocks or the transformer blocks in the original model with our TAdaBlocks. Additionally, for TAdaConvNeXtV2 and TAdaFormer, we follow recent works [48, 49] and use tubelet embedding stem. More details on the model structure is included in Appendix.
Datasets. For video classification, we use Kinetics-400 [83] (K400), Something-Something-V1 and V2 [84] (SSV1 and SSV2), Epic-Kitchens-100 [85] (EK100), and HACS [86]. Further, we employ UCF101 [87] and HMDB51 [88] for multi-modal zero-shot evaluations. K400 is a widely used action classification dataset with 400 categories covered by 300K videos. SSV1 and SSV2 include 108K and 220K videos with challenging spatio-temporal interactions in 174 classes. EK100 includes 90K segments labelled by 97 verb and 300 noun classes with actions defined by the combination of nouns and verbs. HACS contains 504K videos with a taxonomy of 200 action classes. The latter two datasets are used for evaluation on action localization as well.
In addition, we also construct a large-scale video classification dataset combining Kinetics-400 [83], Kinetics-600 [89], and Kinetics-700 [90] for pre-training our video models, following [91, 64]. This results in a dataset with around 660K videos over 710 action classes, which is referred to as K710 in the following sections.
| Temporally | SSV2 | SSV2 | |
| Calibration | Varying | Top-1 | Top-1* |
| None | ✗ | - | 32.0 |
| Learnable | ✗ | 34.3 | 32.6 |
| ✓ | 45.4 | 43.8 | |
| Dynamic | ✗ | 51.2 | 41.7 |
| ✓ | 53.8 | 49.8 | |
| TAda | ✓ | 59.2 | 47.8 |
| Cal. dim. | Top-1 | ||
| 3.16M | 0.016 | 63.8 | |
| 3.16M | 0.016 | 63.4 | |
| 4.10M | 0.024 | 63.7 | |
| 2.24M | 0.009 | 62.7 |
| TAda | |||||
| Base Model | Conv | #params. | GFLOPs | K400 | SSV2 |
| SlowOnly 88⋆ [19] | ✗ | 32.5M | 54.52 | 74.6 | 60.3 |
| ✓ | 35.6M | 54.53 | 75.9 (+1.3) | 63.3 (+3.0) | |
| SlowFast 416⋆ [19] | ✗ | 34.5M | 36.10 | 75.0 | 56.7 |
| ✓ | 37.7M | 36.11 | 76.5 (+1.5) | 59.8 (+3.1) | |
| SlowFast 88⋆ [19] | ✗ | 34.5M | 65.71 | 76.2 | 61.5 |
| ✓ | 37.7M | 65.73 | 77.4 (+1.2) | 63.9 (+2.4) | |
| R(2+1)D⋆ [13] | ✗ | 28.1M | 49.55 | 73.6 | 61.1 |
| ✓2d | 31.2M | 49.57 | 75.2 (+1.6) | 62.9 (+1.8) | |
| ✓(2+1)d | 34.4M | 49.58 | 75.4 (+1.8) | 63.8 (+2.7) | |
| R3D⋆ [13] | ✗ | 47.0M | 84.23 | 73.8 | 59.9 |
| ✓3d | 50.1M | 84.24 | 74.9 (+1.1) | 62.9 (+3.0) | |
| Notation indicates our own implementation. | |||||
| See Appendix for details on the model structure. | |||||
| Model | TAdaConv | K. | G. | Top-1 |
| TSN⋆ | - | - | - | 32.0 |
| Ours | Lin. | 1 | ✗ | 37.5 |
| Lin. | 3 | ✗ | 56.5 | |
| Non-Lin. | (1, 1) | ✗ | 36.8 | |
| Non-Lin. | (3, 1) | ✗ | 57.1 | |
| Non-Lin. | (1, 3) | ✗ | 57.3 | |
| Non-Lin. | (3, 3) | ✗ | 57.8 | |
| Lin. | 1 | ✓ | 53.4 | |
| Non-Lin. | (1, 1) | ✓ | 54.4 | |
| Non-Lin. | (3, 3) | ✓ | 59.2 |
| TAdaConv | FA. | Sc. | SepBN. | Top-1 | |
| ✗ | - | - | - | 32.0 | - |
| ✓ | - | - | - | 59.2 | +27.2 |
| ✗ | Avg. | ✗ | - | 47.9 | +15.9 |
| ✗ | Avg. | ✓ | ✗ | 49.0 | +17.0 |
| ✗ | Avg. | ✓ | ✓ | 57.0 | +25.0 |
| ✓ | Avg. | ✗ | - | 60.1 | +28.1 |
| ✓ | Avg. | ✓ | ✗ | 61.5 | +29.5 |
| ✓ | Avg. | ✓ | ✓ | 63.8 | +31.8 |
| ✓ | Max. | ✓ | ✓ | 63.5 | +31.5 |
| ✓ | Mix. | ✓ | ✓ | 63.7 | +31.7 |
Training. We train models initialized with ImageNet pre-training using AdamW [92] for 100/64/50 epochs on K400, SSV1/SSV2, and EK100, respectively. We adopt RandAugment [93] for data augmentation and stochastic depth [94] and label smoothing [95] for model regularization. We do not use Mixup [96] or Cutmix [97] for both models. Exponential Moving Average (EMA) [98] is used for reducing overfitting during traning. For TAdaFormer with CLIP pre-trained weights [59], we shorten the schedule to 30/24/24 epochs respectively. See Appendix for more details.
5.1 Verification of hypothesis
We start our experiments by verifying our hypothesis that relaxing the temporal invariance could lead to stronger temporal modeling capabilities of the video models. To this end, we choose several sources for the calibration weights and compare the action classification performance on SSV2, with and without the relaxation of temporal invariance. The results are shown in Table III(b). It can be observed that both learnable and dynamic calibration can bring a notable improvement to the baseline with no calibration (TSN [99]), with dynamic calibration performing stronger than learnable calibration. On top of the calibrated models, making the weights vary along the temporal dimension can further boost classification accuracy, which means the model shows a better capability of temporal modeling when the temporal variance is relaxed.
5.2 TAdaConv on existing video backbones
TAdaConv is designed as a plug-in substitution for the spatial convolutions in the video models. As in Table III(c), TAdaConv improves the classification performance with negligible computation overhead on a wide range of video models, including SlowFast [19], R3D [100] and R(2+1)D [13], by an average of 1.3% and 2.8% respectively on K400 and SSV2 at an extra computational cost of less than 0.02 GFlops. Further, not only can TAdaConv improve spatial convolutions, it also notably improve 3D and 1D convolutions. For fair comparison, all models are trained using the same training strategy. Further plug-in evaluations for action classification is presented in Appendix.
5.3 Ablative anslysis on TAdaConv
In this section, we thoroughly analyze our design choices and the effectiveness of TAdaConv and TAdaConvV2 in modeling temporal dynamics. We begin with TAdaConv, with SSV2 chosen as our main evaluation benchmark because of its more complex spatio-temporal relations.
Calibration weight initialization. In Table III(b), we show that our initialization strategy for the calibration weight generation plays a critical role in dynamic weight calibration. As in Table III(b), randomly initializing learnable weights slightly degrades the performance, while randomly initializing dynamic calibration weights (by randomly initializing the last layer of the weight generation function) notably degenerates the performance. It is likely that randomly initialized dynamic calibration weights perturb the pre-trained weights more severely than the learnable weights since it is dependent on the input. Further comparisons on the initialization are shown in the Appendix.
Calibration weight generation function. Having established that the temporally adaptive dynamic calibration with appropriate initialization can be an ideal strategy for temporal modeling, we further ablate different ways for generating the calibration weight in Table LABEL:tab:calibrationweightgen. Linear weight generation function (Lin.) applies a single 1D convolution to generate the calibration weight, while non-linear one (Non-Lin.) uses two stacked 1D convolutions with batch normalizations and ReLU activation in between. When no temporal context is considered (K.=1 or (1,1)), TAdaConv can still improve the baseline but with a limited gap. Enlarging the kernel size to cover the temporal context (K.=3, (1,3), (3,1) or (3,3)) effectively yields a boost of over 20% on the accuracy, with K.=(3,3) having the strongest performance. This shows the importance of the local temporal context during calibration weight generation. Finally, for the scope of temporal context, introducing global context to frame descriptors performs similarly to only generating temporally adaptive calibration weights solely on the global context (in Table III(b)). The combination of the global and temporal context yields a better performance for both variants. In Appendix, we also show that this function in our TAdaConv yields a better calibration on the base weight than existing dynamic filters.
Feature aggregation. We ablate the aggregation scheme in TAda2D in Table III(e). The performance is similar for plain aggregation and aggregation with a shortcut (Sc.) branch , with Sc. being slightly better. Separating the batchnorm (Eq. 8) for the shortcut and the aggregation branch brings notable improvement. Strided max and mix (avg+max) pooling slightly underperform the average pooling variant. Overall, the combination of TAdaConv and our feature aggregation scheme has an advantage over the TSN baseline of 31.8%.
Calibration dimension. Multiple dimensions can be calibrated in the base weight. Table LABEL:tab:calibrationdim shows that calibrating the channel dimension more suitable than the spatial dimension, which means that the spatial structure of the original convolution kernel should be retained. Within channels, the calibration works better on than or both combined. This is probably because the calibration weight generated by the input feature can better adapt to itself.
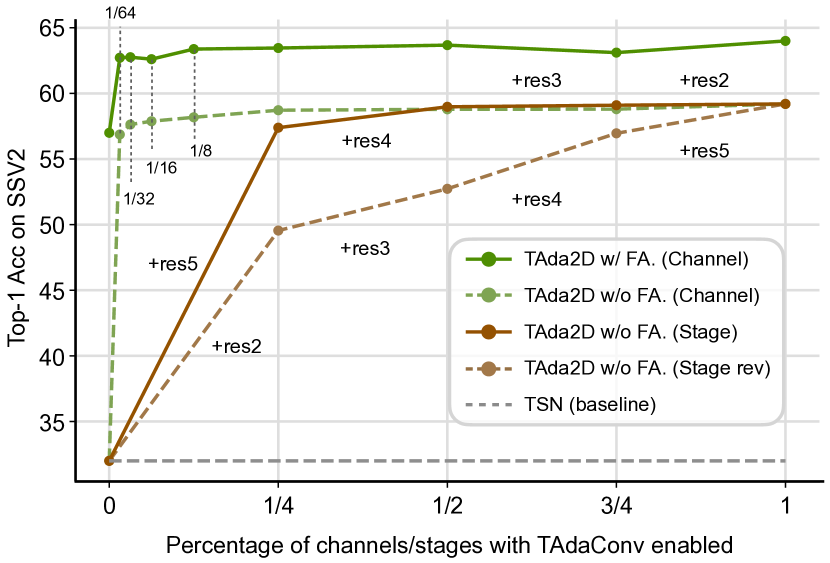
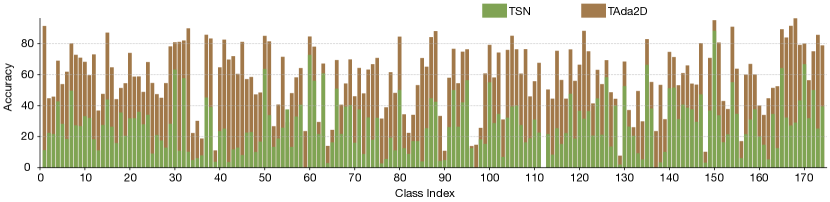
Different stages employing TAdaConv. Fig 4 shows the stage by stage replacement of the spatial convolutions with TAdaConv in a ResNet. A minimum improvement of 17.55% is observed when TAdaConv is used in Res2. Compared to early stages, later stages contribute more to the final performance, as later stages provide more accurate calibration because of its rich semantics. Overall, TAdaConv is used in all stages for the highest accuracy.
Different proportion of channels calibrated. Here, we calibrate only a proportion of channels using TAdaConv and leave the other channels uncalibrated. The results are shown in Fig. 4. We find TAdaConv can improve the baseline by a large margin even if only 1/64 channels are calibrated, with larger proportion yielding further larger improvements.
| Model | Variant | K400 | SSV2 |
| ResNet2D | Baseline | 70.4 | 32.0 |
| + TAdaConv | 73.9 | 59.2 | |
| TAda2D | + T-Pool | 76.7 | 64.0 |
| ConvNeXt | Baseline | 76.0 | 41.4 |
| + TAdaConv | 76.9 | 59.0 | |
| TAdaConvNeXt-T | + T-Down | 78.4 | 64.8 |
| + TAdaConvV2 | 78.9 | 66.0 | |
| + T-Pool | 79.3 | 66.8 | |
| TAdaConvNeXtV2-T | + Stronger Aug | 79.6 | 67.2 |
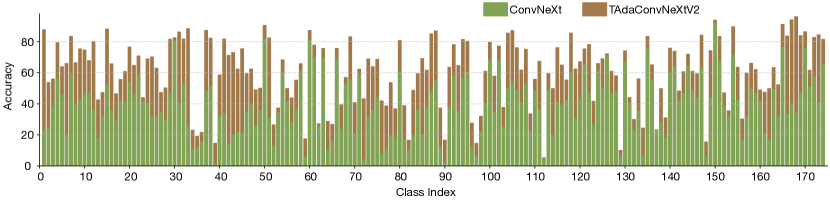
5.4 Modernizing and improving TAdaBlocks
We modernize our TAdaBlock following [36] and improve it with TAdaConvV2 and temporal aggregation in Table IV. We observe a 5.6% and 9.4% improvement in the classification accuracy on K400 and SSV2, respectively, when we switch the base model from ResNet [1] to ConvNeXt [36]. Substituting the depth-wise convolution for TAdaConv further brings a 0.9% and 17.6% improvement. Following [49, 48], we employ a tubelet embedding stem (T-Down) in our TAdaConvNeXt, instantiated as a 3D convolution with temporal downsampling and an increased number of frames to keep the overall computation unchanged.
On top of our TAdaConvNeXt model, we improve TAdaBlock by replacing TAdaConv with TAdaConvV2 and introducing the temporal aggregation scheme (T-Pool). The structural modification further leads to a performance gain of 0.9% and 2.0% on K400 and SSV2, respectively. Finally, with stronger augmentation (m7 to m9 for RandAugment [93]), we achieve an accuracy of 79.6% and 67.2% on the two benchmarks with our tiny model.
5.5 Ablative analysis on TAdaConvV2 and TAdaBlocks
TAdaConvV2 and T-Pool in TAdaBlocks. Table V presents the ablative analysis on the TAdaBlock in both TAdaFormer and TAdaConvNeXtV2, specifically with respect to TAdaConvV2 and the temporal aggregation strategy.
The baseline of TAdaFormer pretrained by CLIP [59] demonstrates a strong spatial modeling capability, achieving an impressive accuracy of 83.6% on K400. However, its ability to model complex dynamics is lacked. Introducing TAdaBlock with simple spatial convolution in between and no temporal aggregation brings negligible effect. On top of this, TAdaConvV2 notably improves the model in terms of temporal modeling, improving the performance on scene-related benchmark K400 by 0.9% while bringing a 20% performance gain on the temporal-related benchmark SSV2. On top of this, employing temporal aggregation (T-Pool) and tubelet embedding (Temp. Down.) further enhances the model’s ability to model complex temporal dynamics.
Compared to TAdaFormer, since TAdaConvNeXtV2 is pre-trained on ImageNet, the baseline performance is slightly lower. All three strategies bring notable improvements to both the scene- and temporal-centric benchmarks.
Pre-training. We explore different pre-trained weights as initialization for TAdaConvNeXt and TAdaFormer in Table VI. For TAdaConvNeXtV2, pre-training on K400 benefits SSV2 performance. For TAdaFormer, using pre-trained weights of CLIP [59] outperforms the ImageNet pre-trained ones on both K400 and SSV2. CLIP+K710 initialization further improve the CLIP pre-trained variant by 2.1% on K400, but the effect on SSV2 is less significant (0.1%). For the comparison against the state-of-the-art, we use ImageNet and CLIP as the default pre-training source respectively for TAdaConvNeXtV2 and TAdaFormer.
| TAdaBlock | Temp. | ||||
| Model | TAdaConvV2 | T-Pool | Down. | K400 | SSV2 |
| ViT-B/16 | N/A | N/A | ✗ | 83.6 | 48.1 |
| TAdaFormer-B/16 | ✗ | ✗ | ✗ | 83.6 | 48.2 |
| TAdaFormer-B/16 | ✓ | ✗ | ✗ | 84.5 | 68.6 |
| TAdaFormer-B/16 | ✓ | ✓ | ✗ | 84.5 | 69.2 |
| TAdaFormer-B/16 | ✓ | ✓ | ✓ | 84.5 | 70.4 |
| ConvNeXt-T | ✗ | ✗ | ✗ | 77.2 | 46.2 |
| TAdaConvNeXtV2-T | ✓ | ✗ | ✗ | 78.0 | 63.3 |
| TAdaConvNeXtV2-T | ✓ | ✓ | ✗ | 79.3 | 66.3 |
| TAdaConvNeXtV2-T | ✓ | ✓ | ✓ | 79.6 | 67.2 |
| Model | Pretrain | K400 | SSV2 |
| TAdaConvNeXtV2-T | IN1K | 79.6 | 65.2 |
| IN1K+K400 | - | 67.2 | |
| TAdaFormer-B/16 | IN1K | 76.3 | 63.9 |
| IN21K | 81.8 | 67.5 | |
| CLIP | 84.5 | 70.4 | |
| CLIP+K710 | 86.6 | 70.5 | |
| TimeSformer [50] | IN21K | 78.7 | 59.5 |
| UniFormerV2-B/16 [91] | IN21K | 81.6 | 67.5 |
| CLIP | 84.4 | 69.5 | |
| CLIP+K710 | 85.6 | - |
| Model | #frames | #param. | GFLOPsviews | Top-1 |
| Models without pretraining | ||||
| SlowFast 88 [19] | 8+32 | 34.5M | 66310 | 77.0 |
| MViTv2-B [101] | 32 | 51.2M | 22515 | 82.9 |
| ImageNet-1K pretrained models | ||||
| TSM [28] | 8 | 24.3M | 43310 | 74.1 |
| TAda2D [23] | 16 | 27.5M | 86310 | 77.4 |
| TAdaConvNeXt-T [23] | 32 | 38.6M | 9434 | 79.1 |
| TANet [31] | 16 | 25.6M | 24234 | 79.3 |
| TDN-R101 [29] | 8+16 | - | 258310 | 79.4 |
| X3D-XXL [20] | - | 20.3M | 194310 | 80.4 |
| Swin-T [48] | 32 | 28.2M | 8834 | 78.8 |
| Swin-S [48] | 32 | 49.8M | 16634 | 80.6 |
| Swin-B [48] | 32 | 88.1M | 28234 | 80.6 |
| MoViNet-A6 [102] | 120 | 31.4M | 38611 | 81.5 |
| TAdaConvNeXtV2-T | 16 | 45.9M | 4734 | 79.6 |
| TAdaConvNeXtV2-T | 32 | 45.9M | 9434 | 80.8 |
| TAdaConvNeXtV2-S | 16 | 82.2M | 9134 | 80.8 |
| TAdaConvNeXtV2-S | 32 | 82.2M | 18334 | 81.9 |
| TAdaConvNeXtV2-B | 16 | 145.7M | 16234 | 81.4 |
| TAdaConvNeXtV2-B | 32 | 145.7M | 32434 | 82.3 |
| ImageNet-21K pretrained models | ||||
| X-ViT [103] | 16 | - | 28331 | 80.2 |
| TimeSformer [50] | 96 | 121.4M | 238031 | 80.7 |
| ViViT-L [49] | 16 | 310.8M | 144634 | 80.6 |
| MTV-B [104] | 32 | 310M | 93034 | 82.4 |
| Swin-B [48] | 32 | 88.1M | 28234 | 82.7 |
| Swin-L [48] | 32 | 197.0M | 60434 | 83.1 |
| MViT-v2-L [101] | 40 | 217.6M | 282835 | 86.1 |
| TAdaConvNeXtV2-S | 32 | 82.2M | 18334 | 82.9 |
| TAdaConvNeXtV2-B | 32 | 145.7M | 32434 | 83.7 |
| Model | #frames | #param. | GFLOPsviews | Top-1 |
| Other large-scale pretrained models | ||||
| MAE-ST [57] | 16 | 632M | 119337 | 85.1 |
| MAR [105] | 16 | 311M | 27635 | 85.3 |
| MaskFeat [106] | 40 | 218M | 379034 | 87.0 |
| CoVeR [107] (JFT-3B) | 16 | - | - | 87.2 |
| MTV-H(WTS) [104] | 32 | - | 613034 | 89.9 |
| VideoMAE V2-g [64] | 64 | - | 2671632 | 90.0 |
| CLIP pretrained models | ||||
| UniFormerV2-B/16 [91] | 8 | 115M | 15034 | 84.4 |
| ST-Adapter-B/16 [65] | 32 | 93M | 60731 | 82.0 |
| EVL ViT-B/16 [108] | 32 | 115M | 59231 | 84.2 |
| X-CLIP-B/16 [109] | 16 | - | 28734 | 84.7 |
| ViFi-CLIP [110] | 16 | 124.7M | 28143 | 83.9 |
| TAdaFormer-B/16 | 16 | 104.1M | 15334 | 84.5 |
| ST-Adapter-L/14 [65] | 32 | 347M | 274931 | 87.2 |
| EVL ViT-L/14 [108] | 32 | 363M | 269631 | 87.3 |
| X-CLIP-L/14 [109] | 8 | - | 65834 | 87.1 |
| TAdaFormer-L/14 | 16 | 364M | 70334 | 87.6 |
| CLIP+K710 post-pretrained models | ||||
| UniFormerV2-B/16 [91] | 8 | 115M | 15034 | 85.6 |
| TAdaConvNeXtV2-S | 32 | 82.2M | 18334 | 86.1 |
| TAdaConvNeXtV2-B | 32 | 145.7M | 32434 | 86.4 |
| TAdaFormer-B/16 | 16 | 104.1M | 15334 | 86.6 |
| UniFormerV2-L/14 [91] | 8 | 354M | 66734 | 88.8 |
| UniFormerV2-L/14 [91] | 16 | 354M | 133434 | 89.1 |
| UniFormerV2-L/14 [91] | 32 | 354M | 266734 | 89.5 |
| TAdaFormer-L/14 | 16 | 364M | 70334 | 88.9 |
| TAdaFormer-L/14 | 32 | 364M | 140634 | 89.5 |
| TAdaFormer-L/14 | 64 | 364M | 281234 | 89.9 |
| Model | #frames | GFLOPsviews | SSV1 | SSV2 |
| TSM [28] | 16 | 8632 | 47.2 | 63.4 |
| MoViNet-A3 [102] | 50 | 2411 | - | 64.1 |
| TANet [31] | 16 | 8632 | 47.6 | 64.6 |
| TEANet [111] | 16 | 8611 | 48.9 | - |
| TEANet [111] | 16 | 86310 | - | 65.1 |
| TAda2D [23] | 16 | 8632 | - | 65.6 |
| TAdaConvNeXt-T [23] | 32 | 9432 | - | 67.1 |
| TDN-R101 [29] | 8+16 | 25811 | 56.8 | 68.2 |
| TAdaConvNeXtV2-T | 16 | 4732 | 54.1 | 67.2 |
| TAdaConvNeXtV2-T | 32 | 9432 | 56.4 | 69.8 |
| TAdaConvNeXtV2-S | 16 | 9132 | 55.6 | 68.4 |
| TAdaConvNeXtV2-S | 32 | 18332 | 58.5 | 70.0 |
| TAdaConvNeXtV2-S† | 32 | 18332 | 59.7 | 70.6 |
| TAdaConvNeXtV2-B† | 32 | 32432 | 60.7 | 71.1 |
| ViViT-L/16x2 FE [49] | 32 | 90334 | - | 65.4 |
| X-ViT [103] | 16 | 28331 | - | 67.2 |
| MTV-B [104] | 32 | 93034 | - | 68.5 |
| Swin-B†[48] | 32 | 32131 | - | 69.6 |
| MViTv2-B [101] | 32 | 22531 | - | 70.5 |
| ST-Adapter-B/16⋆ [65] | 32 | 65131 | - | 69.5 |
| ST-Adapter-L/14⋆ [65] | 32 | 274931 | - | 72.3 |
| UniFormerV2-B/16⋆ [91] | 32 | 37032 | 59.5 | 71.0 |
| UniFormerV2-L/14⋆ [91] | 32 | 171632 | 62.9 | 73.1 |
| MViTv2-L [101] | 40 | 282831 | - | 73.3 |
| TAdaFormer-B/16⋆ | 16 | 18732 | 59.2 | 70.4 |
| TAdaFormer-B/16⋆ | 32 | 37432 | 61.2 | 71.3 |
| TAdaFormer-L/14⋆ | 16 | 85832 | 62.0 | 72.4 |
| TAdaFormer-L/14⋆ | 32 | 171632 | 63.7 | 73.6 |
| † indicates initialization with ImageNet21K+K400 pre-training. | ||||
| ⋆ indicates initialization with CLIP-400M pre-training. | ||||
5.6 Main results
| Model | Act. | Verb | Noun |
| TSN [99] | 33.2 | 60.2 | 46.0 |
| TRN [112] | 35.3 | 65.9 | 45.4 |
| TSM [28] | 38.3 | 67.9 | 49.0 |
| SlowFast [19] | 38.5 | 65.6 | 50.0 |
| TAda2D [23] | 41.6 | 65.1 | 52.4 |
| ir-CSN-152 [113] | 44.5 | 68.4 | 55.9 |
| MoViNet-A6 [102] | 47.7 | 72.2 | 57.3 |
| TAdaConvNeXtV2-T (IN1K) | 42.4 | 67.1 | 53.7 |
| TAdaConvNeXtV2-T (K710) | 47.4 | 70.4 | 58.6 |
| TAdaConvNeXtV2-S (K710) | 48.9 | 71.0 | 60.2 |
| ViViT-L/16x2 FE [49] | 44.0 | 66.4 | 56.8 |
| X-ViT [103] | 44.3 | 68.7 | 56.4 |
| ViViT-B/16x2 FE [113] | 47.0 | 67.2 | 59.0 |
| ST-Adapter-B/16 [65] | - | 67.6 | 55.0 |
| MeMViT [114] | 48.4 | 71.4 | 60.3 |
| MTV-B [104] | 48.6 | 68.0 | 63.1 |
| MTV-B(WTS) [104] | 50.5 | 69.9 | 63.9 |
| TAdaFormer-B/16 (K710) | 49.1 | 71.0 | 60.5 |
| TAdaFormer-L/14 (K710) | 51.8 | 71.7 | 64.1 |
| Model | HMDB-51 | UCF-101 |
| MTE [115] | 19.7 1.6 | 15.8 1.3 |
| ASR [116] | 21.8 0.9 | 24.4 1.0 |
| ER-ZSAR [117] | 35.3 4.6 | 51.8 2.9 |
| CLIP [59] | 40.8 0.3 | 63.2 0.2 |
| ActionCLIP [118] | 40.8 5.4 | 58.3 3.4 |
| X-CLIP-B/16 [109] | 44.6 5.2 | 72.0 2.3 |
| A5 [119] | 44.3 2.2 | 69.3 4.2 |
| ViFi-CLIP [110] | 51.3 0.6 | 76.8 0.7 |
| TAdaFormer-B/16 | 52.1 1.4 | 78.5 1.2 |
| TAdaFormer-L/14 | 57.2 0.7 | 81.1 0.9 |
| TAdaFormer-B/16 (K710) | 55.9 0.4 | 79.5 0.7 |
| TAdaFormer-L/14 (K710) | 59.7 0.5 | 83.0 0.7 |
| HACS | ||||||
| Model | @0.5 | @0.6 | @0.7 | @0.8 | @0.9 | Avg. |
| SSN [120] | 28.8 | - | - | - | - | 19.0 |
| G-TAD [121] | 41.1 | - | - | - | - | 27.5 |
| TadTR [51] | 47.1 | - | - | - | - | 32.1 |
| BMN [122]+ | ||||||
| TSN [23] | 43.6 | 37.7 | 31.9 | 24.6 | 15.0 | 28.6 |
| TAda2D [23] | 48.7 | 42.7 | 36.2 | 28.1 | 17.3 | 32.3 |
| TAdaFormer-L/14 | 51.3 | 44.8 | 38.0 | 30.0 | 18.6 | 34.1 |
| TAdaConvNeXt-S | 53.3 | 47.0 | 40.2 | 32.0 | 20.2 | 36.1 |
| Epic-Kitchens-100 | |||||||
| Model | Task | @0.1 | @0.2 | @0.3 | @0.4 | @0.5 | Avg. |
| BMN [122] +TSN | Verb | 15.98 | 15.01 | 14.09 | 12.25 | 10.01 | 13.47 |
| Noun | 15.11 | 14.15 | 12.78 | 10.94 | 8.89 | 12.37 | |
| Act. | 10.24 | 9.61 | 8.94 | 7.96 | 6.79 | 8.71 | |
| BMN [122] +TAda2D [23] | Verb | 19.70 | 18.49 | 17.41 | 15.50 | 12.78 | 16.78 |
| Noun | 20.54 | 19.32 | 17.94 | 15.77 | 13.39 | 17.39 | |
| Act. | 15.15 | 14.32 | 13.59 | 12.18 | 10.65 | 13.18 | |
| BMN [122] +TAdaFormer-L/14 | Verb | 20.87 | 20.09 | 18.99 | 16.42 | 13.81 | 18.03 |
| Noun | 27.75 | 26.28 | 24.51 | 21.86 | 17.97 | 23.67 | |
| Act. | 20.39 | 19.35 | 18.28 | 16.35 | 14.51 | 17.85 | |
| BMN [122] +TAdaConvNeXt-S | Verb | 17.81 | 16.94 | 16.05 | 14.25 | 11.89 | 15.39 |
| Noun | 21.90 | 20.92 | 19.33 | 17.22 | 14.68 | 18.81 | |
| Act. | 15.61 | 14.80 | 13.73 | 12.35 | 10.90 | 13.47 | |
| ActionFormer [123] +SlowFast | Verb | 26.58 | 25.42 | 24.15 | 22.29 | 19.09 | 23.51 |
| Noun | 25.21 | 24.11 | 22.66 | 20.47 | 16.97 | 21.88 | |
| Act. | 18.40 | 17.71 | 16.80 | 15.65 | 13.52 | 16.42 | |
| ActionFormer [124] +SlowFast&ViViT | Verb | 26.97 | 25.90 | 24.21 | 21.77 | 18.47 | 23.46 |
| Noun | 28.61 | 27.14 | 24.92 | 22.13 | 18.69 | 24.30 | |
| Act. | 23.90 | 22.98 | 21.37 | 19.57 | 16.94 | 20.95 | |
| ActionFormer +TAdaConvNeXt-S | Verb | 29.11 | 28.37 | 26.99 | 24.22 | 20.64 | 25.86 |
| Noun | 29.21 | 27.94 | 26.22 | 23.54 | 18.73 | 25.13 | |
| Act. | 20.78 | 19.75 | 18.56 | 17.07 | 14.54 | 18.14 | |
| ActionFormer +TAdaFormer-L/14 | Verb | 32.08 | 31.09 | 29.40 | 26.64 | 22.71 | 28.38 |
| Noun | 35.00 | 33.42 | 30.98 | 27.32 | 22.36 | 29.82 | |
| Act. | 24.92 | 23.68 | 22.33 | 20.61 | 18.29 | 21.97 | |
Kinetics-400. Table VII shows the results on Kinetics-400 without large-scale pre-training. TAdaConvNeXtV2 surpasses most existing approaches with a similar computation budget both when pre-trained on ImageNet-1K and ImageNet-21K. A highlight is observed where our TAdaConvNeXtV2-S with 32 frames outperforms Swin-B by 1.3 using only 57% of the computation.
Table VIII presents the comparison for models with large-scale pre-training. Compared to existing CLIP pre-trained models, TAdaFormer achieves competitive performance. When post-pre-trained on K710, TAdaFormer outperforms UniFormerV2 by a notable margin under similar computation budgets. We also observe better scalability of TAdaFormer when it is compared with TAdaConvNeXtV2.
Something-Something-V1 and V2. We show the performance comparison on temporal-related datasets, i.e., SSV1 and SSV2, in Table IX. TAdaConvNeXt and TAdaFormer achieve a favorable performance against existing convolutional and transformer-based models with identical or similar pre-training sources, respectively. Compared to the best convolutional model TDN-R101, TAdaConvNeXt-B outperforms it by 3.9 and 2.9 on SSV1 and SSV2. Compared to CLIP-pre-trained UniFormerV2-L/14, TAdaFormer-L/14 achieves an improvement of 0.8 and 0.5 on the two datasets.
Epic-Kitchens-100. We compare the performance on ego-centric action recognition in Table X. Compared to existing convolutional models, our TAdaConvNeXtV2-S achieves a favourable performance. Notably, we observe a higher accuracy for TAdaConvNeXt models on noun recognition in ego-centric videos. Transformer-based models are generally stronger than convolutional ones on EK100, where our TAdaFormer achieves a competitive performance with existing Transformers for video understanding.
Zero-shot classification on UCF101 and HMDB51. To more comprehensively evaluate our TAdaFormer, we include the results on zero-shot classification in Table XI. Here, we initialize the model with CLIP pre-trained weights and train our TAdaFormer with the corresponding language model [59]. We observe a notable improvement of TAdaFormer-B/16 on both datasets compared to the fine-tuned CLIP ViFi-CLIP [110]. On top of this, we find scaling up the model and pre-training brings a further boost to the zero-shot performance.
6 Evaluations on action localization
Dataset, pipeline, and evaluation. Action localization is an essential task for understanding untrimmed videos, whose current pipeline makes it heavily dependent on the quality of the video representations. We evaluate our TAdaConvNeXtV2 and TAdaFormer on two large-scale action localization datasets, HACS [86] and Epic-Kitchens-100 [85]. The general pipeline follows [85, 125, 126], which uses Boundary Matching Network (BMN) [122] for generating action boundaries. For evaluation, we use the average mean Average Precision (average mAP) at IoU [0.5:0.05:0.95] for HACS and [0.1:0.1:0.5] for EK100, following the standard protocol. More details are included in the Appendix.
Main results. We present the results on the two datasets in Table XII and Table XIII. On HACS, we found BMN [122] using TAdaFormer and TAdaConvNeXt features yields a favourable performance compared to some recent methods. On Epic-Kitchens-100, we further employ ActionFormer [123] and found TAdaFormer stronger than the ensemble of ViViT and SlowFast. Overall, we found TAdaConvNeXt and TAdaFormer provide strong features for localzing actions in long videos.
7 Conclusions
Based on our preliminary work [23], this work presents TAdaConvV2 in replacement of the convolution operations in existing models for video understanding, and two strong video models, i.e., TAdaConvNeXtV2 and TAdaFormer. With large-scale pre-training and post-pre-training, our video models demonstrate competitive performances to the state-of-the-art approaches, both in the task of action recognition and localization. We hope our work can facilitate further research in video understanding.
Acknowledgments
This research is supported by the Agency for Science, Technology and Research (A*STAR) under its AME Programmatic Funding Scheme (Project #A18A2b0046), by the RIE2020 Industry Alignment Fund – Industry Collaboration Projects (IAF-ICP) Funding Initiative, as well as cash and in-kind contribution from the industry partner(s), and by Alibaba Group through Alibaba Research Intern Program.
References
- [1] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016, pp. 770–778.
- [2] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in CVPR, 2015, pp. 1–9.
- [3] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” NeurIPS, vol. 25, pp. 1097–1105, 2012.
- [4] Z. Dai, H. Liu, Q. V. Le, and M. Tan, “Coatnet: Marrying convolution and attention for all data sizes,” NeurIPS, vol. 34, pp. 3965–3977, 2021.
- [5] S. Xie, R. Girshick, P. Dollár, Z. Tu, and K. He, “Aggregated residual transformations for deep neural networks,” in CVPR, 2017, pp. 1492–1500.
- [6] J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, and Y. Wei, “Deformable convolutional networks,” in ICCV, 2017, pp. 764–773.
- [7] D. Zhou, X. Jin, Q. Hou, K. Wang, J. Yang, and J. Feng, “Neural epitome search for architecture-agnostic network compression,” arXiv preprint arXiv:1907.05642, 2019.
- [8] H. Zhang, C. Wu, Z. Zhang, Y. Zhu, H. Lin, Z. Zhang, Y. Sun, T. He, J. Mueller, R. Manmatha et al., “Resnest: Split-attention networks,” in CVPR, 2022, pp. 2736–2746.
- [9] Z. Tian, C. Shen, and H. Chen, “Conditional convolutions for instance segmentation,” in ECCV. Springer, 2020.
- [10] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,” arXiv preprint arXiv:1704.04861, 2017.
- [11] B. Yang, G. Bender, Q. V. Le, and J. Ngiam, “Condconv: Conditionally parameterized convolutions for efficient inference,” arXiv preprint arXiv:1904.04971, 2019.
- [12] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learning spatiotemporal features with 3d convolutional networks,” in ICCV, 2015, pp. 4489–4497.
- [13] D. Tran, H. Wang, L. Torresani, J. Ray, Y. LeCun, and M. Paluri, “A closer look at spatiotemporal convolutions for action recognition,” in CVPR, 2018, pp. 6450–6459.
- [14] Z. Qiu, T. Yao, and T. Mei, “Learning spatio-temporal representation with pseudo-3d residual networks,” in ICCV, 2017, pp. 5533–5541.
- [15] D. L. Ruderman and W. Bialek, “Statistics of natural images: Scaling in the woods,” Physical review letters, vol. 73, no. 6, p. 814, 1994.
- [16] E. P. Simoncelli and B. A. Olshausen, “Natural image statistics and neural representation,” Annual review of neuroscience, vol. 24, no. 1, pp. 1193–1216, 2001.
- [17] J. Zhou, V. Jampani, Z. Pi, Q. Liu, and M.-H. Yang, “Decoupled dynamic filter networks,” in CVPR, 2021, pp. 6647–6656.
- [18] J. Wu, D. Li, Y. Yang, C. Bajaj, and X. Ji, “Dynamic filtering with large sampling field for convnets,” in ECCV, 2018, pp. 185–200.
- [19] C. Feichtenhofer, H. Fan, J. Malik, and K. He, “Slowfast networks for video recognition,” in ICCV, 2019, pp. 6202–6211.
- [20] C. Feichtenhofer, “X3d: Expanding architectures for efficient video recognition,” in CVPR, 2020, pp. 203–213.
- [21] X. Jia, B. De Brabandere, T. Tuytelaars, and L. V. Gool, “Dynamic filter networks,” NeurIPS, vol. 29, pp. 667–675, 2016.
- [22] Y. Chen, X. Dai, M. Liu, D. Chen, L. Yuan, and Z. Liu, “Dynamic convolution: Attention over convolution kernels,” in CVPR, 2020, pp. 11 030–11 039.
- [23] Z. Huang, S. Zhang, L. Pan, Z. Qing, M. Tang, Z. Liu, and M. H. Ang Jr, “TAda! temporally-adaptive convolutions for video understanding,” in ICLR, 2022.
- [24] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” NeurIPS, vol. 30, 2017.
- [25] J. Carreira and A. Zisserman, “Quo vadis, action recognition? a new model and the kinetics dataset,” in CVPR, 2017, pp. 6299–6308.
- [26] D. Tran, H. Wang, L. Torresani, and M. Feiszli, “Video classification with channel-separated convolutional networks,” in ICCV, 2019, pp. 5552–5561.
- [27] K. Simonyan and A. Zisserman, “Two-stream convolutional networks for action recognition in videos,” arXiv preprint arXiv:1406.2199, 2014.
- [28] J. Lin, C. Gan, and S. Han, “Tsm: Temporal shift module for efficient video understanding,” in ICCV, 2019, pp. 7083–7093.
- [29] L. Wang, Z. Tong, B. Ji, and G. Wu, “Tdn: Temporal difference networks for efficient action recognition,” in CVPR, 2021, pp. 1895–1904.
- [30] B. Jiang, M. Wang, W. Gan, W. Wu, and J. Yan, “Stm: Spatiotemporal and motion encoding for action recognition,” in ICCV, 2019, pp. 2000–2009.
- [31] Z. Liu, L. Wang, W. Wu, C. Qian, and T. Lu, “Tam: Temporal adaptive module for video recognition,” ICCV, 2021.
- [32] H. Wang, D. Tran, L. Torresani, and M. Feiszli, “Video modeling with correlation networks,” in CVPR, 2020, pp. 352–361.
- [33] J. Wang, Z. Sun, Y. Qian, D. Gong, X. Sun, M. Lin, M. Pagnucco, and Y. Song, “Maximizing spatio-temporal entropy of deep 3d cnns for efficient video recognition,” in ICLR, 2023.
- [34] X. Li, Y. Wang, Z. Zhou, and Y. Qiao, “Smallbignet: Integrating core and contextual views for video classification,” in CVPR, 2020, pp. 1092–1101.
- [35] Y. Zhou, Z. Huang, X. Yang, M. Ang, and T. K. Ng, “Gcm: Efficient video recognition with glance and combine module,” Pattern Recognition, vol. 133, p. 108970, 2023.
- [36] Z. Liu, H. Mao, C.-Y. Wu, C. Feichtenhofer, T. Darrell, and S. Xie, “A convnet for the 2020s,” arXiv preprint arXiv:2201.03545, 2022.
- [37] J. D. M.-W. C. Kenton and L. K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” in Proceedings of NAACL-HLT, 2019, pp. 4171–4186.
- [38] A. Radford, K. Narasimhan, T. Salimans, I. Sutskever et al., “Improving language understanding by generative pre-training,” 2018.
- [39] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [40] H. Fan, B. Xiong, K. Mangalam, Y. Li, Z. Yan, J. Malik, and C. Feichtenhofer, “Multiscale vision transformers,” in ICCV, 2021, pp. 6824–6835.
- [41] T. Meinhardt, A. Kirillov, L. Leal-Taixe, and C. Feichtenhofer, “Trackformer: Multi-object tracking with transformers,” in CVPR, 2022, pp. 8844–8854.
- [42] Z. Cao, Z. Huang, L. Pan, S. Zhang, Z. Liu, and C. Fu, “Tctrack: Temporal contexts for aerial tracking,” in CVPR, 2022, pp. 14 798–14 808.
- [43] H. Bao, L. Dong, S. Piao, and F. Wei, “Beit: Bert pre-training of image transformers,” arXiv preprint arXiv:2106.08254, 2021.
- [44] C. Zhou, Z. Luo, Y. Luo, T. Liu, L. Pan, Z. Cai, H. Zhao, and S. Lu, “Pttr: Relational 3d point cloud object tracking with transformer,” in CVPR, 2022, pp. 8531–8540.
- [45] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical text-conditional image generation with clip latents,” arXiv preprint arXiv:2204.06125, 2022.
- [46] N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in ECCV. Springer, 2020, pp. 213–229.
- [47] X. Wang, R. Girshick, A. Gupta, and K. He, “Non-local neural networks,” in CVPR, 2018, pp. 7794–7803.
- [48] Z. Liu, J. Ning, Y. Cao, Y. Wei, Z. Zhang, S. Lin, and H. Hu, “Video swin transformer,” arXiv preprint arXiv:2106.13230, 2021.
- [49] A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lučić, and C. Schmid, “Vivit: A video vision transformer,” in ICCV, 2021, pp. 6836–6846.
- [50] G. Bertasius, H. Wang, and L. Torresani, “Is space-time attention all you need for video understanding,” arXiv preprint arXiv:2102.05095, vol. 2, no. 3, p. 4, 2021.
- [51] X. Liu, Q. Wang, Y. Hu, X. Tang, S. Zhang, S. Bai, and X. Bai, “End-to-end temporal action detection with transformer,” IEEE TIP, vol. 31, pp. 5427–5441, 2022.
- [52] G. Chen, Y.-D. Zheng, J. Wang, J. Xu, Y. Huang, J. Pan, Y. Wang, Y. Wang, Y. Qiao, T. Lu et al., “Videollm: Modeling video sequence with large language models,” arXiv preprint arXiv:2305.13292, 2023.
- [53] M. Patrick, D. Campbell, Y. Asano, I. Misra, F. Metze, C. Feichtenhofer, A. Vedaldi, and J. F. Henriques, “Keeping your eye on the ball: Trajectory attention in video transformers,” Advances in neural information processing systems, vol. 34, pp. 12 493–12 506, 2021.
- [54] X. Chen, S. Xie, and K. He, “An empirical study of training self-supervised vision transformers,” in ICCV, 2021, pp. 9640–9649.
- [55] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick, “Masked autoencoders are scalable vision learners,” in CVPR, 2022, pp. 16 000–16 009.
- [56] Z. Tong, Y. Song, J. Wang, and L. Wang, “Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training,” arXiv preprint arXiv:2203.12602, 2022.
- [57] C. Feichtenhofer, Y. Li, K. He et al., “Masked autoencoders as spatiotemporal learners,” NeurIPS, vol. 35, pp. 35 946–35 958, 2022.
- [58] Z. Qing, S. Zhang, Z. Huang, Y. Xu, X. Wang, C. Gao, R. Jin, and N. Sang, “Self-supervised learning from untrimmed videos via hierarchical consistency,” PAMI, 2023.
- [59] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in ICML. PMLR, 2021, pp. 8748–8763.
- [60] J. Yu, Z. Wang, V. Vasudevan, L. Yeung, M. Seyedhosseini, and Y. Wu, “Coca: Contrastive captioners are image-text foundation models,” arXiv preprint arXiv:2205.01917, 2022.
- [61] X. Zhai, A. Kolesnikov, N. Houlsby, and L. Beyer, “Scaling vision transformers,” in CVPR, 2022, pp. 12 104–12 113.
- [62] M. Dehghani, J. Djolonga, B. Mustafa, P. Padlewski, J. Heek, J. Gilmer, A. Steiner, M. Caron, R. Geirhos, I. Alabdulmohsin et al., “Scaling vision transformers to 22 billion parameters,” arXiv preprint arXiv:2302.05442, 2023.
- [63] W. Wang, H. Bao, L. Dong, J. Bjorck, Z. Peng, Q. Liu, K. Aggarwal, O. K. Mohammed, S. Singhal, S. Som et al., “Image as a foreign language: Beit pretraining for all vision and vision-language tasks,” arXiv preprint arXiv:2208.10442, 2022.
- [64] L. Wang, B. Huang, Z. Zhao, Z. Tong, Y. He, Y. Wang, Y. Wang, and Y. Qiao, “Videomae v2: Scaling video masked autoencoders with dual masking,” arXiv preprint arXiv:2303.16727, 2023.
- [65] J. Pan, Z. Lin, X. Zhu, J. Shao, and H. Li, “St-adapter: Parameter-efficient image-to-video transfer learning for action recognition,” arXiv preprint arXiv:2206.13559, 2022.
- [66] Y. Li, Y. Chen, X. Dai, D. Chen, Y. Yu, L. Yuan, Z. Liu, M. Chen, N. Vasconcelos et al., “Revisiting dynamic convolution via matrix decomposition,” in ICLR, 2021.
- [67] Y. Li, Y. Chen, X. Dai, D. Chen, M. Liu, L. Yuan, Z. Liu, L. Zhang, and N. Vasconcelos, “Micronet: Towards image recognition with extremely low flops,” arXiv preprint arXiv:2011.12289, 2020.
- [68] Y. Chen, X. Dai, M. Liu, D. Chen, L. Yuan, and Z. Liu, “Dynamic relu,” in ECCV. Springer, 2020, pp. 351–367.
- [69] X. Wang, F. Yu, Z.-Y. Dou, T. Darrell, and J. E. Gonzalez, “Skipnet: Learning dynamic routing in convolutional networks,” in ECCV, 2018, pp. 409–424.
- [70] Y. Li, L. Song, Y. Chen, Z. Li, X. Zhang, X. Wang, and J. Sun, “Learning dynamic routing for semantic segmentation,” in CVPR, 2020, pp. 8553–8562.
- [71] Z. Ye, M. Xia, R. Yi, J. Zhang, Y.-K. Lai, X. Huang, G. Zhang, and Y.-j. Liu, “Audio-driven talking face video generation with dynamic convolution kernels,” IEEE Transactions on Multimedia, 2022.
- [72] Z.-H. Jiang, W. Yu, D. Zhou, Y. Chen, J. Feng, and S. Yan, “Convbert: Improving bert with span-based dynamic convolution,” NeurIPS, vol. 33, pp. 12 837–12 848, 2020.
- [73] Y.-S. Xu, S.-Y. R. Tseng, Y. Tseng, H.-K. Kuo, and Y.-M. Tsai, “Unified dynamic convolutional network for super-resolution with variational degradations,” in CVPR, 2020, pp. 12 496–12 505.
- [74] F. Wu, A. Fan, A. Baevski, Y. N. Dauphin, and M. Auli, “Pay less attention with lightweight and dynamic convolutions,” arXiv preprint arXiv:1901.10430, 2019.
- [75] Y. Meng, R. Panda, C.-C. Lin, P. Sattigeri, L. Karlinsky, K. Saenko, A. Oliva, and R. Feris, “Adafuse: Adaptive temporal fusion network for efficient action recognition,” in ICLR, 2021.
- [76] Z. Wu, C. Xiong, C.-Y. Ma, R. Socher, and L. S. Davis, “Adaframe: Adaptive frame selection for fast video recognition,” in CVPR, 2019, pp. 1278–1287.
- [77] Y. Meng, C.-C. Lin, R. Panda, P. Sattigeri, L. Karlinsky, A. Oliva, K. Saenko, and R. Feris, “Ar-net: Adaptive frame resolution for efficient action recognition,” in ECCV. Springer, 2020, pp. 86–104.
- [78] G. Elsayed, P. Ramachandran, J. Shlens, and S. Kornblith, “Revisiting spatial invariance with low-rank local connectivity,” in ICML. PMLR, 2020, pp. 2868–2879.
- [79] J. Chen, X. Wang, Z. Guo, X. Zhang, and J. Sun, “Dynamic region-aware convolution,” in CVPR, 2021, pp. 8064–8073.
- [80] V. Nair and G. E. Hinton, “Rectified linear units improve restricted boltzmann machines,” in Icml, 2010.
- [81] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in ICML. PMLR, 2015, pp. 448–456.
- [82] J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,” arXiv preprint arXiv:1607.06450, 2016.
- [83] W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijayanarasimhan, F. Viola, T. Green, T. Back, P. Natsev et al., “The kinetics human action video dataset,” arXiv preprint arXiv:1705.06950, 2017.
- [84] R. Goyal, S. E. Kahou, V. Michalski, J. Materzynska, S. Westphal, H. Kim, V. Haenel, I. Fruend, P. Yianilos, M. Mueller-Freitag et al., “The” something something” video database for learning and evaluating visual common sense.” in CVPR, vol. 1, 2017, p. 5.
- [85] D. Damen, H. Doughty, G. M. Farinella, A. Furnari, E. Kazakos, J. Ma, D. Moltisanti, J. Munro, T. Perrett, W. Price et al., “Rescaling egocentric vision,” arXiv preprint arXiv:2006.13256, 2020.
- [86] H. Zhao, A. Torralba, L. Torresani, and Z. Yan, “Hacs: Human action clips and segments dataset for recognition and temporal localization,” in ICCV, 2019, pp. 8668–8678.
- [87] K. Soomro, A. R. Zamir, and M. Shah, “Ucf101: A dataset of 101 human actions classes from videos in the wild,” arXiv preprint arXiv:1212.0402, 2012.
- [88] H. Kuehne, H. Jhuang, E. Garrote, T. Poggio, and T. Serre, “Hmdb: a large video database for human motion recognition,” in ICCV. IEEE, 2011, pp. 2556–2563.
- [89] J. Carreira, E. Noland, A. Banki-Horvath, C. Hillier, and A. Zisserman, “A short note about kinetics-600,” arXiv preprint arXiv:1808.01340, 2018.
- [90] J. Carreira, E. Noland, C. Hillier, and A. Zisserman, “A short note on the kinetics-700 human action dataset,” arXiv preprint arXiv:1907.06987, 2019.
- [91] K. Li, Y. Wang, Y. He, Y. Li, Y. Wang, L. Wang, and Y. Qiao, “Uniformerv2: Spatiotemporal learning by arming image vits with video uniformer,” arXiv preprint arXiv:2211.09552, 2022.
- [92] I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint arXiv:1711.05101, 2017.
- [93] E. D. Cubuk, B. Zoph, J. Shlens, and Q. V. Le, “Randaugment: Practical automated data augmentation with a reduced search space,” in CVPR Workshops, 2020, pp. 702–703.
- [94] G. Huang, Y. Sun, Z. Liu, D. Sedra, and K. Q. Weinberger, “Deep networks with stochastic depth,” in ECCV. Springer, 2016, pp. 646–661.
- [95] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” in CVPR, 2016, pp. 2818–2826.
- [96] H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz, “mixup: Beyond empirical risk minimization,” arXiv preprint arXiv:1710.09412, 2017.
- [97] S. Yun, D. Han, S. J. Oh, S. Chun, J. Choe, and Y. Yoo, “Cutmix: Regularization strategy to train strong classifiers with localizable features,” in ICCV, 2019, pp. 6023–6032.
- [98] B. T. Polyak and A. B. Juditsky, “Acceleration of stochastic approximation by averaging,” SIAM journal on control and optimization, vol. 30, no. 4, pp. 838–855, 1992.
- [99] L. Wang, Y. Xiong, Z. Wang, Y. Qiao, D. Lin, X. Tang, and L. Van Gool, “Temporal segment networks: Towards good practices for deep action recognition,” in ECCV. Springer, 2016, pp. 20–36.
- [100] K. Hara, H. Kataoka, and Y. Satoh, “Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet?” in CVPR, 2018, pp. 6546–6555.
- [101] Y. Li, C.-Y. Wu, H. Fan, K. Mangalam, B. Xiong, J. Malik, and C. Feichtenhofer, “Mvitv2: Improved multiscale vision transformers for classification and detection,” in CVPR, 2022, pp. 4804–4814.
- [102] D. Kondratyuk, L. Yuan, Y. Li, L. Zhang, M. Tan, M. Brown, and B. Gong, “Movinets: Mobile video networks for efficient video recognition,” in CVPR, 2021, pp. 16 020–16 030.
- [103] A. Bulat, J. M. Perez Rua, S. Sudhakaran, B. Martinez, and G. Tzimiropoulos, “Space-time mixing attention for video transformer,” NeurIPS, vol. 34, pp. 19 594–19 607, 2021.
- [104] S. Yan, X. Xiong, A. Arnab, Z. Lu, M. Zhang, C. Sun, and C. Schmid, “Multiview transformers for video recognition,” in CVPR, 2022, pp. 3333–3343.
- [105] Z. Qing, S. Zhang, Z. Huang, X. Wang, Y. Wang, Y. Lv, C. Gao, and N. Sang, “Mar: Masked autoencoders for efficient action recognition,” IEEE Transactions on Multimedia, 2023.
- [106] C. Wei, H. Fan, S. Xie, C.-Y. Wu, A. Yuille, and C. Feichtenhofer, “Masked feature prediction for self-supervised visual pre-training,” in CVPR, 2022, pp. 14 668–14 678.
- [107] B. Zhang, J. Yu, C. Fifty, W. Han, A. M. Dai, R. Pang, and F. Sha, “Co-training transformer with videos and images improves action recognition,” arXiv preprint arXiv:2112.07175, 2021.
- [108] Z. Lin, S. Geng, R. Zhang, P. Gao, G. de Melo, X. Wang, J. Dai, Y. Qiao, and H. Li, “Frozen clip models are efficient video learners,” in ECCV. Springer, 2022, pp. 388–404.
- [109] B. Ni, H. Peng, M. Chen, S. Zhang, G. Meng, J. Fu, S. Xiang, and H. Ling, “Expanding language-image pretrained models for general video recognition,” in ECCV. Springer, 2022, pp. 1–18.
- [110] H. Rasheed, M. U. Khattak, M. Maaz, S. Khan, and F. S. Khan, “Fine-tuned clip models are efficient video learners,” in CVPR, 2023, pp. 6545–6554.
- [111] Y. Li, B. Ji, X. Shi, J. Zhang, B. Kang, and L. Wang, “Tea: Temporal excitation and aggregation for action recognition,” in CVPR, 2020, pp. 909–918.
- [112] B. Zhou, A. Andonian, A. Oliva, and A. Torralba, “Temporal relational reasoning in videos,” in ECCV, 2018, pp. 803–818.
- [113] Z. Huang, Z. Qing, X. Wang, Y. Feng, S. Zhang, J. Jiang, Z. Xia, M. Tang, N. Sang, and M. H. Ang Jr, “Towards training stronger video vision transformers for epic-kitchens-100 action recognition,” arXiv preprint arXiv:2106.05058, 2021.
- [114] C.-Y. Wu, Y. Li, K. Mangalam, H. Fan, B. Xiong, J. Malik, and C. Feichtenhofer, “Memvit: Memory-augmented multiscale vision transformer for efficient long-term video recognition,” in CVPR, 2022, pp. 13 587–13 597.
- [115] X. Xu, T. M. Hospedales, and S. Gong, “Multi-task zero-shot action recognition with prioritised data augmentation,” in ECCV. Springer, 2016, pp. 343–359.
- [116] Q. Wang and K. Chen, “Alternative semantic representations for zero-shot human action recognition,” in Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2017, Skopje, Macedonia, September 18–22, 2017, Proceedings, Part I 10. Springer, 2017, pp. 87–102.
- [117] S. Chen and D. Huang, “Elaborative rehearsal for zero-shot action recognition,” in ICCV, 2021, pp. 13 638–13 647.
- [118] M. Wang, J. Xing, and Y. Liu, “Actionclip: A new paradigm for video action recognition,” arXiv preprint arXiv:2109.08472, 2021.
- [119] C. Ju, T. Han, K. Zheng, Y. Zhang, and W. Xie, “Prompting visual-language models for efficient video understanding,” in ECCV. Springer, 2022, pp. 105–124.
- [120] Y. Zhao, B. Zhang, Z. Wu, S. Yang, L. Zhou, S. Yan, L. Wang, Y. Xiong, D. Lin, Y. Qiao et al., “Cuhk & ethz & siat submission to activitynet challenge 2017,” arXiv preprint arXiv:1710.08011, vol. 8, no. 8, 2017.
- [121] M. Xu, C. Zhao, D. S. Rojas, A. Thabet, and B. Ghanem, “G-tad: Sub-graph localization for temporal action detection,” in CVPR, 2020, pp. 10 156–10 165.
- [122] T. Lin, X. Liu, X. Li, E. Ding, and S. Wen, “Bmn: Boundary-matching network for temporal action proposal generation,” in ICCV, 2019, pp. 3889–3898.
- [123] C.-L. Zhang, J. Wu, and Y. Li, “Actionformer: Localizing moments of actions with transformers,” in ECCV. Springer, 2022, pp. 492–510.
- [124] C. Zhang, L. Sui, A. Majeedi, V. R. Gajjala, and Y. Li, “Detecting egocentric actions with actionformer,” https://epic-kitchens.github.io/Reports/EPIC-KITCHENS-Challenges-2022-Report.pdf.
- [125] Z. Qing, Z. Huang, X. Wang, Y. Feng, S. Zhang, J. Jiang, M. Tang, C. Gao, M. H. Ang Jr, and N. Sang, “A stronger baseline for ego-centric action detection,” arXiv preprint arXiv:2106.06942, 2021.
- [126] Z. Qing, X. Wang, Z. Huang, Y. Feng, S. Zhang, M. Tang, C. Gao, N. Sang et al., “Exploring stronger feature for temporal action localization,” arXiv preprint arXiv:2106.13014, 2021.
- [127] G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. R. Salakhutdinov, “Improving neural networks by preventing co-adaptation of feature detectors,” arXiv preprint arXiv:1207.0580, 2012.
- [128] Y. Li, B. Ji, X. Shi, J. Zhang, B. Kang, and L. Wang, “Tea: Temporal excitation and aggregation for action recognition,” in CVPR, 2020, pp. 909–918.
- [129] Z. Qing, H. Su, W. Gan, D. Wang, W. Wu, X. Wang, Y. Qiao, J. Yan, C. Gao, and N. Sang, “Temporal context aggregation network for temporal action proposal refinement,” in CVPR, 2021, pp. 485–494.
Appendix A Overview
In the appendix, we provide detailed analysis on the temporal convolutions (Appendix B), further implementation details (Appendix C) on the action classification and localization, model structures that we used for evaluation (Appendix D), per-category improvement analysis on Something-Something-V2 (Appendix E), further plug-in evaluations on Epic-Kitchens classification (Appendix G) plug-in evaluations on the temporal action localization task (Appendix H), the visualization of the training procedure of TSN and TAda2D (Appendix I), as well as detailed comparisons between TAdaConv and existing dynamic filters (Appendix J).
Appendix B Detailed analysis on temporal convolutions
Here, we provide a detailed analysis to showcase the underlying process of temporal modeling by temporal convolutions. As in Sec. 3.1, we use depth-wise temporal convolutions for simplicity and its wide application. We first analyze the case where temporal convolutions are directly placed after spatial convolutions without non-linear activation in between, before activation functions are inserted in the second part of our analysis.
Without activation. We first consider a simple case with no non-linear activation functions between the temporal convolution and the spatial convolution. Given a 311 depth-wise temporal convolution parameterized by , where , a spatial convolution parameterized by , the output feature of the -th frame can be obtained by:
| (9) |
where denotes element-wise multiplication with broadcasting, and denotes convolution over the spatial dimension. In this case, could be grouped with the spatial convolution weight and the combination of temporal and spatial convolution can be rewritten as:
| (10) |
where , and . This equation shares the same form with the Eq. 2 in the manuscript. In this case, the combination of temporal convolution with spatial convolution can be certainly viewed as the temporal convolution simply performs calibration on spatial convolutions before aggregation, with different weights assigned to different time steps for the calibration.
With activation. Next, we consider a case where activation is in between the temporal convolution and spatial convolution. The output feature are now obtained by:
| (11) |
Next, we show that this can be still rewritten in the form of Eq. 2. Here, we consider the case where ReLU [80] is used as the activation function, denoted as :
| (12) |
Hence, the term can be easily expressed as:
| (13) |
where is a binary map sharing the same shape as , indicating whether the corresponding element in is greater than 0 or not. That is:
| (14) |
where are the location index in the tensor. Hence, with activation, temporal convolution can be expressed as:
| (15) |
In this case, we can set , , and , where indicate the spatial location index. In this case, each filter for a specific time step is composed of filters and Eq. 1 can be rewritten as Eq. 2. Interestingly, it can be observed that with ReLU activation function, the convolution weights are different for all spatio-temporal locations, since the binary map depends on the results of the spatial convolutions.
Appendix C Further implementation details
Here, we further describe the implementation details for the action classification and action localization experiments. For fair comparisons, we keep all the training strategies the same for our baseline, the plug-in evaluations as well as our own models.
| training config | K710 | K400 (K710) | K400 (ImageNet) | SSV1/SSV2 | EK100 |
| optimizer | AdamW [92] | ||||
| learning rate schedule | cosine decay | ||||
| weight decay | 0.02 | ||||
| optimizer momentum | |||||
| dropout [127] | 0.5 | ||||
| clip grading | None | ||||
| base learning rate | 5e-4 | ||||
| batch size | 512 | ||||
| training epochs | 100 | 30 | 100 | 64 | 50 |
| warmup epochs | 8 | 4 | 8 | 2.5 | 5 |
| randaugment [93] | (9, 0.5) | ||||
| label smoothing [95] | 0.0 | 0.1 | |||
| stochastic depth | 0.2 (T) | 0.2 (T) | 0.2 (T) | 0.3 (T) | 0.3 (T) |
| 0.4 (S) | 0.4 (S) | 0.4 (S) | 0.5 (S) | 0.5 (S) | |
| 0.6 (B) | 0.6 (B) | 0.6 (B) | 0.6 (B) | - | |
C.1 Action classification with TAdaConvNeXtV2
We evaluate our approach on action classification using four large-scale benchmarks. We list the training configurations for TAdaConvNeXtV2 and TAdaFormer on action classification benchmarks in Table A1 and Table A2, respectively.
| training config | K710 | K400 (K710) | K400 (CLIP) | SSV1/SSV2 | EK100 | |||||
| optimizer | AdamW [92] | |||||||||
| learning rate schedule | cosine decay | |||||||||
| weight decay | 0.05 | |||||||||
| optimizer momentum | ||||||||||
| dropout [127] | 0.5 | |||||||||
| clip grading | None | |||||||||
| EMA [98] | 0.9996 | |||||||||
| Base | Large | Base | Large | Base | Large | Base | Large | Base | Large | |
| base learning rate | 1e-4 | 5e-5 | 1e-5 | 5e-6 | 5e-5 | 2e-5 | 5e-4 | 2.5e-4 | 2.5e-4 | 1e-4 |
| batch size | 512 | 256 | 256 | 128 | 256 | 128 | 256 | 128 | 128 | 64 |
| training epochs | 30 | 24 | 15 | 10 | 30 | 24 | 24 | 24 | 24 | 15 |
| warmup epochs | 5 | 5 | 2.5 | 2 | 5 | 5 | 5 | 5 | 5 | 2.5 |
| layer-wise lr decay [43] | 0.7 | 0.8 | 0.7 | 0.8 | 0.7 | 0.85 | 0.7 | 0.85 | 0.7 | 0.85 |
| randaugment [93] | (9, 0.5) | (9, 0.5) | (9, 0.5) | (9, 0.5) | (9, 0.5) | |||||
| label smoothing [95] | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | |||||
| stochastic depth | - | - | - | - | 0.2 | - | ||||
C.2 Action Localization
We evaluate our model on the action localization task using two large-scale datasets. The overall pipeline for our action localization evaluation is divided into finetuning the classification models, obtaining action proposals, and classifying the proposals.
Finetuning. On Epic-Kitchens, we simply use the evaluated action classification model. On HACS, following [126], we initialize the model with Kinetics-400 pre-trained weights and train the model with adamW [92] for 30 epochs (8 warmups) using 32 GPUs. The mini-batch size is 16 videos per GPU. The base learning rate is set to 0.0002, with cosine learning rate decay as in Kinetics. In our case, only the segments with action labels are used for training.
Proposal generation. For the action proposals, a boundary matching network (BMN) [122] is trained over the extracted features on the two datasets. On Epic-Kitchens, we extract features with the videos uniformly decoded at 60 FPS. For each clip, we use 8 frames with an interval of 8 to be consistent with finetuning, which means a feature roughly covers a video clip of one seconds. The interval between each clip for feature extraction is 8 frames (i.e., 0.133 sec) as well. The shorter side of the video is resized to 224 and we feed the whole spatial region into the backbone to retain as much information as possible. Following [125], we generate proposals using BMN based on sliding windows. The predictions on the overlapped region of different sliding windows are simply averaged. On HACS, the videos are decoded at 30 FPS, and extend the interval between clips to be 16 (i.e., 0.533 sec) because the actions in HACS last much longer than in Epic-Kitchens. The shorter side is resized to 128 for efficient processing. For the settings in generating proposals, we mainly follow [126], except that the temporal resolution is resized to 100 in our case instead of 200.
Classification. On Epic-Kitchens, we classify the proposals with the fine-tuned model using 6 clips. Spatially, to comply with the feature extraction process, we resize the shorter side to 224 and feed the whole spatial region to the model for classification. On HACS, considering the property of the dataset that only one action category can exist in a video, we obtain the video level classification results by classifying the video level features, following [126].
Action localization with ActionFormer. We follow all the settings in [124, 123] for action localization experiments with ActionFormer.
Evaluation. For evaluation, we follow the standard evaluation protocol used in the respective datasets, i.e., the average mean Average Precision (average mAP) at IoU threshold [0.5:0.05:0.95] for HACS [86] and [0.1:0.1:0.5] for Epic-Kitchens-100 [85].
Appendix D Model structures
| Stage | R3D | R(2+1)D | R2D | output sizes |
| Sampling | interval 8, 1 | interval 8, 1 | interval 8, 1 | 8224224 |
| conv1 | 37, 64 | 17, 64 | 17, 64 | 8112112 |
| stride 1, 2 | stride 1, 2 | stride 1, 2 | ||
| res2 | 3 | 3 | 3 | 85656 |
| res3 | 4 | 4 | 4 | 82828 |
| res4 | 6 | 6 | 6 | 81414 |
| res5 | 3 | 3 | 3 | 877 |
| global average pool, fc | 111 | |||
The detailed model structures for R2D, R(2+1)D and R3D is specified in Table A3. We highlight the convolutions that are replaced by TAdaConv by default or optionally. For all of our models, a small modification is made in that we remove the max pooling layer after the first convolution and set the spatial stride of the second stage to be 2, following [32]. Temporal resolution is kept unchanged following recent works [19, 128, 30]. Our R3D is obtained by simply expanding the R2D baseline in the temporal dimension by a factor of three. We initialize with weights reduced by 3 times, which means the original weight is evenly distributed in adjacent time steps. We construct the R(2+1)D by adding a temporal convolution operation after the spatial convolution. The temporal convolution can also be optionally replaced by TAdaConv, as shown in both the manuscript and Table A5. For its initialization, the temporal convolution weights are randomly initialized, while the others are initialized with the pre-trained weights on ImageNet. For SlowFast models, we keep all the model structures identical to the original work [19].
For TAdaConvNeXt, we keep most of the model architectures as in ConvNeXt [36], except that we use a tubelet embedding similar to [49], with a size of 344 and stride of 244. Center initialization is used as in [49]. Based on this, we simply replace the depth-wise convolutions with TAdaConv to construct TAdaConvNeXt. For TAdaConvNeXtV2, we additionally substitute TAdaConv for TAdaConvV2 and introduce the temporal aggregation scheme.
| Kernel size | Top-1 |
| 1 | 37.5 |
| 3 | 56.5 |
| 5 | 57.3 |
| 7 | 56.5 |
| K2=1 | K2=3 | K2=5 | K2=7 | |
| K1=1 | 36.8 | 57.1 | 57.8 | 57.9 |
| K1=3 | 57.3 | 57.8 | 57.9 | 58.0 |
| K1=5 | 57.6 | 57.9 | 58.2 | 57.9 |
| K1=7 | 57.4 | 57.6 | 58.0 | 57.6 |
| Ratio | Top-1 |
| 1 | 57.79 |
| 2 | 57.83 |
| 4 | 57.78 |
| 8 | 57.66 |
| Top-1 | Top-5 | ||||||||
| Model | Frames | GFLOPs | Params. | Act. | Verb | Noun | Act. | Verb | Noun |
| SlowFast 416 | 4+32 | 36.10 | 34.5M | 38.17 | 63.54 | 48.79 | 58.68 | 89.75 | 73.37 |
| SlowFast 416 + TAdaConv | 4+32 | 36.11 | 37.7M | 39.14 | 64.50 | 49.59 | 59.21 | 89.67 | 73.88 |
| SlowFast 88 | 8+32 | 65.71 | 34.5M | 40.08 | 65.05 | 50.72 | 60.10 | 90.04 | 74.26 |
| SlowFast 88 + TAdaConv | 8+32 | 65.73 | 37.7M | 41.35 | 66.36 | 52.32 | 61.68 | 90.59 | 75.89 |
| R(2+1)D | 8 | 49.55 | 28.1M | 37.45 | 62.92 | 48.27 | 58.02 | 89.75 | 73.60 |
| R(2+1)D + TAdaConv | 8 | 49.57 | 31.3M | 39.72 | 64.48 | 50.26 | 60.22 | 90.01 | 75.06 |
| R(2+1)D + TAdaConv | 8 | 49.58 | 34.4M | 40.10 | 64.77 | 50.28 | 60.45 | 89.99 | 75.55 |
| R3D | 8 | 84.23 | 47.0M | 36.67 | 61.92 | 47.87 | 57.47 | 89.02 | 73.05 |
| R3D + TAdaConv | 8 | 84.24 | 50.1M | 39.30 | 64.03 | 49.94 | 59.67 | 89.84 | 74.56 |
| HACS | Epic-Kitchen-100 | ||||||||||||
| Model | @0.5 | @0.6 | @0.7 | @0.8 | @0.9 | Avg. | Task | @0.1 | @0.2 | @0.3 | @0.4 | @0.5 | Avg. |
| S.F. 88 | 50.0 | 44.1 | 37.7 | 29.6 | 18.4 | 33.7 | Verb | 19.93 | 18.92 | 17.90 | 16.08 | 13.24 | 17.21 |
| Noun | 17.93 | 16.83 | 15.53 | 13.68 | 11.41 | 15.07 | |||||||
| Act. | 14.00 | 13.19 | 12.37 | 11.18 | 9.52 | 12.04 | |||||||
| S.F. 88 + TAdaConv | 51.7 | 45.7 | 39.3 | 31.0 | 19.5 | 35.1 | Verb | 19.96 | 18.71 | 17.65 | 15.41 | 13.35 | 17.01 |
| Noun | 20.17 | 18.90 | 17.58 | 15.83 | 13.18 | 17.13 | |||||||
| Act. | 14.90 | 14.12 | 13.32 | 12.07 | 10.57 | 13.00 | |||||||
Appendix E Per-category improvement analysis on SSV2
This section provides a per-category improvement analysis on the Something-Something-V2 dataset in Fig.A1 and Fig. A2. In terms of overall performance, our TAda2D achieves an improvement of 31.7% over the baseline TSN, while TAdaConvNeXtV2 improves over ConvNeXt by 25.4%. Our per-category analysis shows a mean improvement of 30.35% and 21.36% over all the classes, respectively for TAda2D and TAdaConvNeXtV2. Since both TSN and ConvNeXt have no temporal modeling capabilities, and our approach introduce similar modifications to the base model, the difference pattern in the per-category accuracy is similar. Hence, we take TAda2D as an example for analysis. The largest improvement is observed in class 0 (78.5%, Approaching something with your camera), 32 (78.4%, Moving away from something with your camera), 30 (74.3%, Lifting up one end of something without letting it drop down), 44 (66.2%, Moving something towards the camera) and 41 (66.1%, Moving something away from the camera). Most of these categories contain large movements across the whole video, whose improvement benefits from temporal reasoning over the global spatial context. For class 30, most of its actions last a long time (as it needs to be determined whether the end of something is let down or not). The improvements over the baseline mostly benefit from the global temporal context that is included in the weight generation process.
Appendix F Further ablation studies
Here we provide further ablation studies on the kernel size in the calibration weight generation. As shown in Table LABEL:tab:ablationstudieskernelsizelin and Table LABEL:tab:ablationstudieskernelsizenonlin, kernel size does not affect the classification much, as long as the temporal context is considered. Further, Table LABEL:tab:ablationstudiesreductionratio shows the sensitivity analysis on the reduction ratio, which demonstrate the robustness of our approach against different set of hyper-parameters.
Appendix G Further plug-in evaluation for TAdaConv on classification
In complement to the manuscript, we further show in Table A5 the plug-in evaluation on the action classification task on the Epic-Kitchens-100 dataset. As in the plug-in evaluation on Kinetics and Something-Something-V2, we compare performances with and without TAdaConv over three baseline models, SlowFast [19], R(2+1)D [13] and R3D [100] respectively representing three kinds of temporal modeling techniques. The results are in line with our observation in the plug-in evaluation in the manuscript. Over all three kinds of temporal modelling strategies, adding TAdaConv further improves the recognition accuracy of the model.
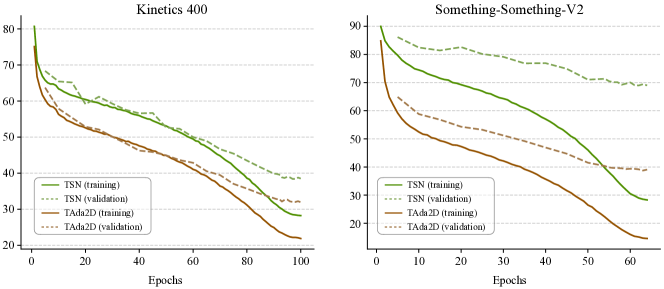
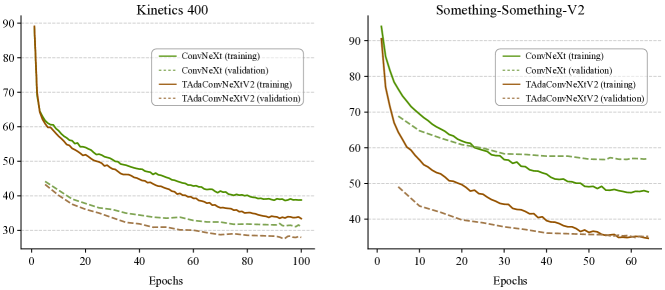
Appendix H Plug-in evaluation for TAdaConv on Action Localization
Here, we show the plug-in evaluation on the temporal action localization task. Specifically, we use SlowFast as our baseline, as it is shown to be superior in the localization performance in [129] compared to many early backbones. The result is presented in Table A6. With TAdaConv, the average mAP on HACS is improved by 1.4%, and the average mAP on Epic-Kitchens-100 action localization is improved by 1.0%.
Appendix I Comparison of training procedure
we compare the training procedure of TSN and TAda2D on Kinetics-400 and Something-Something-V2 in Fig. A3, and that of ConvNeXt and TAdaConvNeXtV2 in Fig. A4. Although TAda2D and TAdaConvNeXtV2 are initialized to be identical to TSN and ConvNeXt, both TAda2D and TAdaConvNeXtV2 demonstrates a stronger performance on both training and validation sets.
| Temporal | Location | Pretrained | ||
| Operations | Weights | Modelling | Adaptive | weights |
| CondConv | Mixture of experts | ✗ | ✗ | ✗ |
| DynamicFilter | Completely generated | ✗ | ✗ | ✗ |
| DDF | Completely generated | ✗ | ✓ | ✗ |
| TAM | Completely generated | ✓ | ✗ | ✗ |
| TAdaConv | Calibrated from a base weight | ✓ | ✓ | ✓ |
| Calibration Generation | Our Init. | Temp. Varying | Generation source | Top-1 |
| DynamicFilter | ✗ | ✗ | 41.7 | |
| DDF-like | ✗ | ✓ | 49.8 | |
| TAM (global branch) | ✗ | ✗ | 39.7 | |
| TAM (local*+global branch) | ✗ | ✓ | 41.3 | |
| DynamicFilter | ✓ | ✗ | 51.2 (+9.5) | |
| DDF-like | ✓ | ✓ | 53.8 (+4.0) | |
| TAM (global branch) | ✓ | ✗ | 52.9 (+13.2) | |
| TAM (local*+global branch) | ✓ | ✓ | 54.3 (+13.0) | |
| TAdaConv w/o global info | ✓ | ✓ | 57.9 | |
| TAdaConv | ✓ | ✓ | both | 59.2 |
| and |
Appendix J Comparison with existing dynamic filters
In this section, we compare our TAdaConv with previous dynamic filters in two perspectives, respectively the difference in the methodology and in the performance.
J.1 Comparison in terms of methodology
We compare TAdaConv with several representative dynamic filtering approaches in image and in videos, respectively CondConv [11], DynamicFilter [21], DDF [17] and TAM [31].
The first difference in terms of methodology lies in the source of weights, where previous approaches obtain weights by mixture of experts or generation completely dependent on the input. Mixture of experts denotes , where is a scalar obtained by a function , i.e., . Completely generated means the weights are only dependent on the input, i.e., , where generates complete kernel for the convolution. In comparison, the weights in TAdaConv are obtained by calibration, i.e,, , where is a vector calibration weight and where generates the calibration vector for the convolutions. Hence, this fundamental difference in how to obtain the convolution weights makes the previous approaches difficult to exploit pre-trained weights, while TAdaConv can easily load pre-trained weights in . This ability is essential for video models to speed up the convergence.
The second difference lies in the ability to perform temporal modelling. The ability to perform temporal modelling does not only mean the ability to generate weights according to the whole sequence in dynamic filters for videos, but it also requires the model to generate different weights for the same set of frames with different orders. For example, weights generated by the global descriptor obtained by global average pooling over the whole video does not have the temporal modelling ability, since they can not generate different weights if the order of the frames in the input sequence are reversed or randomized. Hence, most image based approaches based on global descriptor vectors (such as CondConv and DynamicFilter) or based on adjacent spatial contents (DDF) can not achieve temporal modelling. TAM generates convolution weights for temporal convolutions based on temporally local descriptors obtained by the global average pooling over the spatial dimension , which yields different weights if the sequence changes. Hence, in this sense, TAM has the temporal modelling abilities. In contrast, TAdaConv exploits both temporally local and global descriptors to utilize not only local but also global temporal contexts. Details on the source of the weight generation process is also shown in Table A8.
The third difference lies in whether the weights generated are shared for different locations. For CondConv, DynamicFilter and TAM, their generated weights are shared for all locations, while for DDF, the weights are varied according to spatial locations. In comparison, TAdaConv generates temporally adaptive weights.
J.2 Comparison in the performance level
Since TAdaConv is fundamentally different from previous approaches in the generation of calibration weights, it is difficult to directly compare the performance on video modelling, especially for those that are not designed for video modelling. However, since the calibration weight in TAdaConv is completely generated, i.e., , we can use other dynamic filters to generate the calibration weights for TAdaConv. Since MoE-based approaches such as CondConv were essentially designed for applications with less memory constraint but high computation requirements, it is not suitable for video applications since it would be too memory-heavy for video models. Hence, we apply approaches that generate complete kernel weights to generate calibration weights and compare them with TAdaConv. The performance is listed in Table A8.
It is worth noting that these approaches originally generate weights that are randomly initialized. However, as is shown in the manuscript, our initialization strategy for the calibration weights are essential for yielding reasonable results, we further apply our initialization on these existing approaches to see whether their generation function is better than the one in TAdaConv. In the following paragraphs, we provide details for applying representative previous dynamic filters in TAdaConv to generate the calibration weight.
For DynamicFilter [21], the calibration weight is generated using an MLP over the global descriptor that is obtained by performing global average pooling over the whole input , i.e., . In this case, the calibration weights are shared between different time steps.
For DDF [17], we only use the channel branch since it is shown in the manuscript that it is better to leave the spatial structure unchanged for the base kernel. Similarly, the weights in DDF are also generated by applying an MLP over the global descriptor, i.e., . The difference between DDF and DynamicFilter is that for different time step, DDF generates a different calibration weight.
The original structure of TAM [31] only generates kernel weights with its global branch and uses the local branch to generate attention maps over different time steps. In our experiments, we modify the TAM a little bit and further make the local branch generate kernel calibration weights as well. Hence, for the only-global version of TAM, the calibration weights are calculated as follows: , where denotes global average pooling over the spatial dimension and denotes the global branch in TAM. In this case, calibration weights are shared for all temporal locations. For local+global version of TAM, the calibration weight are calculated by combining the results of the local and the global branch , i.e., , where denotes element-wise multiplication with broadcasting. This means in this case, the calibration weights are temporally adaptive. Note that this is our modified version of TAM. The original TAM droes not have temporally adaptive convolution weights.
The results in Table A8 show that (a) without our initialization strategy, previous approaches that generate random weights at initialization are not suitable for generating the calibration weights in TAdaConv; (b) our initialization strategy can conveniently change this and make previous approaches yield reasonable performance when they are used for generating calibration weights; and (c) the calibration weight generation function in TAdaConv, which combines the local and global context, outperform all previous approaches for calibration.
Further, when we compare TAdaConv without global information with TAM (local*+global branch), it can be seen that although both approach generates temporally varying weights from the frame descriptors with shape , our TAdaConv achieves a notably higer performance. Adding the global information enables TAdaConv to achieve a more notable lead in the comparison with previous dynamic filters.