From Global to Local:
Multi-scale Out-of-distribution Detection
Abstract
Out-of-distribution (OOD) detection aims to detect “unknown” data whose labels have not been seen during the in-distribution (ID) training process. Recent progress in representation learning gives rise to distance-based OOD detection that recognizes inputs as ID/OOD according to their relative distances to the training data of ID classes. Previous approaches calculate pairwise distances relying only on global image representations, which can be sub-optimal as the inevitable background clutter and intra-class variation may drive image-level representations from the same ID class far apart in a given representation space. In this work, we overcome this challenge by proposing Multi-scale OOD DEtection (MODE), a first framework leveraging both global visual information and local region details of images to maximally benefit OOD detection. Specifically, we first find that existing models pretrained by off-the-shelf cross-entropy or contrastive losses are incompetent to capture valuable local representations for MODE, due to the scale-discrepancy between the ID training and OOD detection processes. To mitigate this issue and encourage locally discriminative representations in ID training, we propose Attention-based Local PropAgation (), a trainable objective that exploits a cross-attention mechanism to align and highlight the local regions of the target objects for pairwise examples. During test-time OOD detection, a Cross-Scale Decision () function is further devised on the most discriminative multi-scale representations to distinguish ID/OOD data more faithfully. We demonstrate the effectiveness and flexibility of MODE on several benchmarks – on average, MODE outperforms the previous state-of-the-art by up to 19.24% in FPR, 2.77% in AUROC. Code is available at –https://github.com/JimZAI/MODE-OOD˝.
Index Terms:
Out-of-distribution detection, Outlier Detection, Anomaly Detection, Multi-scale Representations.I Introduction
“No machine is perfect”, modern machine learning (ML) systems are shown to produce overconfident and thus untrustworthy predictions for “unknown” out-of-distribution (OOD) inputs – whose labels have not been seen during the in-distribution (ID) training procedure [1, 2, 3]. This gives rise to a more general and realistic task of OOD detection recently, where the goal is to distinguish whether an incoming example is ID/OOD and allows the ML system to take precautions in deployment [4, 5, 6, 7]. For instance, in autonomous driving, a safety-critical application, the driving system must hand over the control to drivers when it detects OOD data, e.g., unusual objects, scenes.
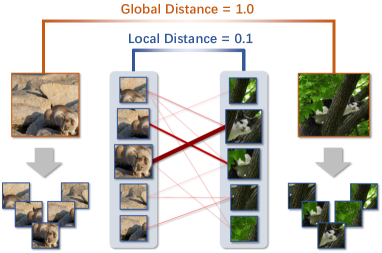
A plethora of OOD detection schemes have been proposed to mitigate the risk of OOD data, while classifying ID classes correctly. Many prior works safeguard against OOD examples relying on a softmax scoring mechanism, which is motivated by the simple observation that examples with lower softmax confidence scores are more likely to be OOD [5, 3]. Nevertheless, well-performed models can produce arbitrarily high softmax confidence for inputs far away from the training data [8, 9]. Recent progress in representation learning gives rise to distance-based OOD detection that represents image data in an appropriate representation space and uses a distance function to decide whether testing examples are ID/OOD according to their relative distances to the training data of ID classes [10, 11, 9]. Particularly, Sun et al. proposed KNN [9], a first work exploring the effectiveness of using a k-nearest neighbor search over global image representations (a.k.a. the penultimate layer representations) for OOD detection. In addition to establishing state-of-the-art performance on various OOD benchmarks and network structures, several compelling advantages of KNN-based OOD detection, such as i) easy-to-use, ii) model-agnostic, and iii) distribution assumption-free, make it enjoy good practicability and scalability.
Despite the encouraging advantages, we observe that the inevitable background clutter and intra-class variation may drive the global, image-level representations from the same ID class far apart in a given representation space, as illustrated in Fig. 1. Therefore, it becomes more difficult to effectively distinguish ID-OOD examples, relying only on the single-scale global representations. Furthermore, overwhelming empirical evidence reveals that exploring richer visual information from multi-scale representations is of great importance for understanding discriminative local regions, and semantic categories of the target objects [12, 13]. However, looking at the literature on OOD detection over the past years, the efficiency of exploiting discriminative local representations for achieving better ID-OOD separability has not received any attention so far, not to mention leveraging both global and local representations to maximally benefit OOD detection. This limitation begs the following question:
Can we take advantage of both global visual information and local region details from images to distinguish ID/OOD examples more effectively?
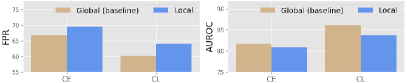
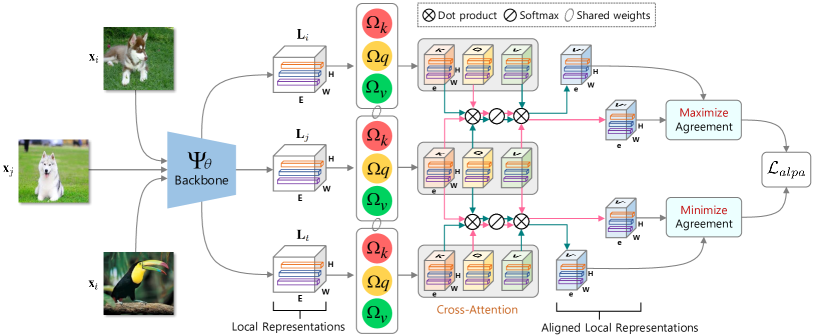
In this work, we answer the above question by proposing Multi-scale OOD DEtection (MODE), a first framework that leverages multi-scale (i.e., both global and local) representations for OOD detection. Specifically, as illustrated in Fig. 2, we first find that existing models pretrained by off-the-shelf cross-entropy (CE) or contrastive learning (CL) losses are incompetent to capture valuable local representations for MODE, due to the scale-discrepancy between the ID training and OOD detection procedures. To address this issue, we propose Attention-based Local PropAgation (), a trainable objective that encourages the mining of locally discriminative representations from images during ID training. As shown in Fig. 3, exploits contrastive representation learning to promote general-purpose visual information that captures richer and more flexible representations for recognizing ID/OOD data. Yet, instead of directly using global representations to maximize/minimize the agreement of pairwise examples, adopts a cross-attention mechanism to align and highlight the local regions of the target objects for each pair of examples, making the extracted local representations more discriminative. In test-time OOD detection, a Cross-Scale Decision () function is further devised for MODE, where the most discriminative multi-scale representations are explored to distinguish ID/OOD examples more faithfully, as shown in Fig. 4.
Flexibility and Strong Performance. The proposed MODE is orthogonal to the ID training procedure, as well as models pretrained with different fashions. More specifically, MODE can not only take as a plugin to regularize ID training losses, but also directly leverage it to finetune existing pre-trained models in an end-to-end manner. We demonstrate the effectiveness and flexibility of MODE on a broad spectrum of baseline methods applied to various network structures. Remarkably, our MODE establishes new state-of-the-art performance on several benchmarks, on average outperforming the previous best scheme KNN [9] by up to 19.24% in FPR, and 2.77% in AUROC (see Table I). What’s more, when MODE performs test-time OOD detection based only on 5% ID training data, it still exhibits superior performance than the strong competitor KNN (which relies on 100% ID training examples), outperforming KNN by 6.08% in FPR, 0.68% in AUROC (see Table V).
Contributions. To sum up, our contributions are fourfold.
-
•
We propose MODE, a first framework that takes advantage of multi-scale (i.e., both global and local) representations for OOD detection.
-
•
During ID training, we develop , an end-to-end, plug-and-play, and cross-attention based learning objective tailored for encouraging locally discriminative representations for MODE.
-
•
During test-time OOD detection, we devise , a simple, effective and multi-scale representations based ID-OOD decision function for MODE.
-
•
Comprehensive experimental results on several benchmark datasets demonstrate the effectiveness and flexibility of MODE. Remarkably, our MODE achieves significantly better performance than state-of-the-art methods.
II Related Work
In this section, we briefly review previous research closely related to our work, including out-of-distribution (OOD) detection, distance-based OOD detection, representation learning for OOD detection, and part-based visual correspondence.
Out-of-distribution Detection. Out-of-distribution (OOD) detection, a.k.a. outlier detection [14, 15], anomaly detection [16, 17] or novelty detection [18, 19], aims to recognize unknown inputs from the open world to prevent unpredictable risks. The vast majority of previous works are test-time approaches that rely on the output softmax confidence score of a pretrained model to safeguard against OOD inputs. The insight beneath this line of works is that incoming examples with lower output softmax confidence scores are more likely from OOD [5, 3]. Effective test-time scoring functions include OpenMax [20], MSP [1], LogitNorm [21], DICE [22], Energy [3], ODIN [5] and etc. In the recent work [23], a simple yet effective test-time approach named LINE is proposed. By leveraging important neurons for post-hoc OOD detection, LINE yields remarkable test-time OOD detection performance. While the results are impressive, it has been demonstrated that well-performed models can produce arbitrarily high softmax confidence for inputs far away from the training data [8]. Moreover, most of those test-time OOD methods often consider the development of effective OOD decision functions alone, our proposed MODE framework in this work considers training-time representation learning and test-time OOD detection, simultaneously.
Distance-based OOD Detection. The core concept of the distance-based OOD detection is to calculate a distance metric between the input examples and the training data. Testing examples are recognised as OOD (resp. ID) data if they are relatively far away from (resp. close to) training examples of ID classes. With the recent advances in representation learning, various kinds of distance-based OOD detection algorithms have been employed. Among those methods, the Mahalanobis distance-based methods possess remarkable performance [2, 24]. However, the success of those methods are established on a strong distributional assumption of the underlying representation space, which may not always held in reality. To address this limitation, Sun et al. proposed KNN [9], a first study exploring the effectiveness of using a k-nearest neighbor search over the penultimate layer representations for OOD detection. In contrast to the Mahalanobis distance-based methods, KNN [9] does not impose any distributional assumptions on the underlying representation space, which is more simple, flexible and effective. In [25], a novel representation learning framework coined CIDER is presented to exploit hyperspherical embeddings for distance-based OOD detection. Recently, utilizing large vision-language pre-trained models like CLIP [26] for multi-modal downstream tasks has achieved remarkable success. By matching visual features with textual class prototypes in the CLIP model, an effective test-time method coined MCM is proposed for distance-based OOD detection in [27]. Despite the encouraging advantages of distance-based OOD detection, we observe that the background clutter as well as the large intra-class variation may drive the image-level representations from the same ID class far apart in a given representation space. As a result, it becomes more difficult to correctly distinguish ID/OOD examples based only on the pairwise distances calculated from global image representations. Moreover, it has been widely demonstrated that a global average pooled image representation can destroy image structures and result in the compromise of a substantial amount of discriminative local representations of the target objects [28, 29]. In this work, for the first time, we exploit both global visual information and local region details from images to calculate the distance between each pair of examples for maximally benefiting distance-based OOD detection.
Representation Learning for OOD Detection. A good deal of methods have attempted to improve the compactness of intra-class examples during the ID training stage, so as to achieve better test-time OOD detection performance [11, 6, 30]. Contrastive representation learning [31, 32, 33, 34, 35, 36] that targets learning a discriminative representation space where positive samples are aligned while negative ones are dispersed, has been shown to improve OOD detection [10, 11, 37]. In particular, Tack et al. [11] proposed a scheme named Contrasting Shifted Instances (CSI) to learn a representation well-suited for novelty detection. In [10], authors present an effective outlier detector based on unlabeled ID data along with the self-supervised representation learning technique. Recent studies [38, 39] also revealed that improving the closed-set (i.e. ID) classification accuracy is the key to further boosting OOD detection performance. Another promising line of work improves ID training by conducting training-time regularization [3, 40, 41]. Most of those regularization approaches, however, require the availability of abundant simulating OOD data, which may not held in practice. Surprisingly, the obtained quantitive and qualitative results reveal that relying only on the ID training data, our devised loss function can shape the distributions of different classes to be more compact for benefiting both OOD detection and ID classification tasks.
Attention-based Local Feature Alignment. Local feature alignment [42, 43, 44] has emerged as a powerful paradigm enabling meaningful representations by matching local features of images (or image-text pairs), and has achieved great success in a wide spectrum of tasks, such as domain adaptation [45, 46], image-text matching [47, 48], few-shot learning [28, 49, 50]. Among those methods, the idea of utilizing cross-attention to enhance feature alignments has been extensively studied. Particularly, CDTrans [45] applies cross-attention and self-attention for source-target domain alignment to learn discriminative domain-invariant and domain-specific features simultaneously. SCAN [47] highlights the alignment of image regions and words in a sentence in cross-attention modules to learn modality-invariant features. FEAT [49] adapts the image features produced by deep convolution neural networks (CNNs) to the target few-shot task with a set-to-set function (i.e., Transformer [51]), yielding discriminative and informative features. Different from those works that leverage task-specific supervision to encourage the interaction between local features, the devised formulates the learning objective as a contrastive loss, where the cross-attention module takes the output dense features of CNNs as input to maximize (resp. minimize) the agreement of each pair of samples from the same ID class (resp. different ID classes). In addition, the goal of most of those works is to learn a shared feature space to align features from different domains [45] (or modalities[47]), while our ALPA aims to learn a discriminative feature space where a suitable threshold or compact decision boundary can be established to distinguish ID/OOD data accurately. To the best of our knowledge, this work is the first to use the idea of attention-based local feature alignment to promote locally discriminative representations in OOD detection.
Multi-scale Representation Learning. Multi-scale representations are of great importance to plenty of vision tasks such as classification [52, 53], retrieval [54, 55] and detection [12, 56], significantly boosting the performance achieved on single-scale (i.e., global) representations in those fields. Unlike most works in those fields that use multi-scale representations to recognize ID categories, in this work we for the first time leverage multi-scale representations to enable better ID-OOD separability in OOD detection, which is more challenging due to the following reasons. On the one hand, relying only on the training data of ID categories, the learned multi-scale representations may not be generalizable enough to recognize parts, objects, and their surrounding context of OOD data. On the other hand, the sample space of potential OOD data can be prohibitively large, even severely overlapped with the sample space of ID categories [40, 57], making it difficult to establish a decision boundary on the extracted multi-scale representations of ID categories and OOD data at test time.
III Methodology
In this section, we elaborate on our MODE framework. Before that, we introduce some important preliminaries.
III-A Preliminaries
When dealing with supervised multi-class classification, we typically denote , as the input, output space, respectively. Let be a distribution over , and be a neural network that takes input the examples drawn from to output a logit vector, which is then used to predict the label of an input example. Denote as the marginal distribution of for , which represents the distribution of in-distribution (ID) data. During test-time OOD detection, the environment can present a distribution over of OOD data, whose label space s.t. .
Out-of-distribution Detection. Essentially, OOD detection can be viewed as a binary classification task, where the goal is to reject the “unknown” inputs to prevent any potential risk. More specifically, to determine whether an example belongs to or not (i.e. ), the decision function can be made via a level set estimation:
| (1) |
where the input example x is classified as ID (resp. OOD) if its obtained score is higher (resp. lower) than the threshold . In practice, is typically selected so that a high fraction of ID data (e.g. 95%) is correctly classified.
KNN-based OOD Detection. Recent advances in representation learning give rise to distance-based OOD detection that represents image data in an appropriate representation space and leverages a distance function to decide whether testing examples are ID/OOD according to their relative distances to the seen examples of ID classes. In particular, Sun et al. proposed KNN [9] that established state-of-the-art performance using a -nearest neighbor (coined -NN in the following) search over global image representations for OOD detection.
Let be a feature backbone (parameterized by ) mapping the input x to a global average pooled representation . KNN-based OOD detection normalizes the global representation for distance calculation. Before testing an example , we first obtain the representation collection of ID training data, denoted as . During test-time OOD detection, we calculate the Euclidean distances w.r.t. representations . Denote the reordered ID data as , the decision function for KNN-based OOD detection takes the form of
| (2) |
where indicates the -th nearest neighbor. The threshold does not depend on OOD data, and can be selected when a large proportion of of ID data (e.g. 95%) is correctly classified in practice.
Contrastive Representation Learning. We take advantage of contrastive representation learning [58] to promote general-purpose visual information that captures richer and more flexible representations usable for recognizing ID/OOD data. Concretely, we first project the global representation of x, g, into a lower dimensional space with a projection head , i.e., . Let be the cosine similarity of every pair of images in the projected space. We sample a batch of pairs of images and labels from the training data of ID classes, and augment every image in the batch to obtain labeled data points. The loss function of supervised contrastive representation learning can therefore be expressed as
| (3) |
and we have
| (4) |
where is the indicator function, and is the number of the samples with the same label , is a scalar temperature parameter. The above learning objective introduces the label information to avoid pulling augmented views from the same class apart, enabling the mining of more discriminative and robust representations.
III-B Multi-scale OOD Detection (MODE)
Our goal in this work is to take advantage of multi-scale (i.e., both global and local) representations from images to distinguish ID/OOD examples more effectively. Particularly, local representations are the output feature maps before the final global average pooling layer of convolutional neural networks (CNNs). For an input image x, we denote the obtained -dimensional local representations as , and the global representation as , where denotes a feature backbone, and is an additional average pooling layer. The multi-scale representations for x thus can be expressed as .
Intuitively, we can directly borrow existing pretrained CNNs to generate multi-scale representations for MODE. Unfortunately, due to the scale-discrepancy between the ID training and OOD detection processes, models learned by off-the-shelf Cross-Entropy (CE) or Contrastive Learning (CL) losses are incompetent to capture discriminative local representations for recognizing OOD data, as demonstrated in Fig. 2. This observation is also consistent with abundant empirical evidence that an average pooled image representation can destroy image structures and lose a substantial amount of discriminative local representations of the target objects during training [59, 28, 60]. And once the model has been learned, those lost valuable local representations become difficult to recover. Hence, this challenge begs one important question:
Can we develop a model-agnostic approach to encourage locally discriminative representations in ID training, so as to overcome the scale-discrepancy issue and benefit MODE during testing?
Attention-based Local Propagation (). Our solution to the above question is , a trainable loss function tailored for mining discriminative local representations during ID training. exploits contrastive representation learning to promote general-purpose visual information that captures richer and more flexible representations for recognizing ID/OOD data. However, instead of leveraging the global representations (, ) as in Eq. 3, we use the local representations (, ) to compute the similarity/dissimilarity of each pair of inputs (, ), as can be observed in Fig. 3.
Concretely, our adopts a cross-attention mechanism to align and highlight the local regions of the target objects for each pair of examples, so as to extract more discriminative local representations. Following the design of Transformers [61], the key , value and query are first generated for L using three independent linear maps: the key-head , the value-head , the query-head , respectively. Note that we set for simpler illustration. Let and be the local representations of two pairwise examples and respectively. Our goal is to calculate the aligned values of w.r.t. , denoted as . To this end, we first use the key and query to determine the attention weights , by which we can obtain :
| (5) |
In the same way, we can calculate by aligning the value of w.r.t. using the key and the query .
Therefore, for each pair values and , we can determine their two aligned formulations, i.e., and , by using the aforementioned cross-attention mechanism. We then conduct an normalization on each representation vector of all these values, . The similarity between and can thus be expressed as
| (6) |
Finally, similar to Eq. 3, we can define the loss function of our as follows:
| (7) |
where
| (8) |
Essentially, the objective in Eq. 7 breaks the boundaries of training examples from the same class, and makes use of their local representations collectively to provide richer and more flexible representations for every class. In addition, by leveraging a cross-attention mechanism to align and highlight the local representations of the target objects for each pair of examples, the adverse effects of background clutter and intra-class variation can be significantly alleviated. In this vein, the learned local representations are more transferable and capture more critical patterns outside the ID classes.
Remark ①: As A Plugin. In practice, the developed can be utilized as a plugin to encourage locally discriminative representations by i) regularizing the ID training procedure, coined -, or ii) directly finetuning models pretrained with different fashions, in an end-to-end manner, dubbed -. To sum up, the -enhanced, ID training objective can take the form of
| (9) |
where indicates the learning objective of the existing ID training (or representation learning) procedure, is a balance weight controlling the contribution of for -.
Remark ②: Key Differences Between ALPA and DenseCL. The work most closely related to ALPA is DenseCL [60], which implements contrastive representation learning by formulating a dense-feature-level contrastive loss based on different views of images. We highlight the key differences between and DenseCL as follows. On the one hand, DenseCL designs the loss function in an unsupervised learning setting, while our leverages label information to avoid pulling augmented views from the same class apart. On the other hand, DenseCL uses an identical convolution layer as a projection head to generate lower-dimensional dense feature vectors for individual examples, while our exploits a cross-attention mechanism to highlight the object regions of pairwise examples, making the learned representations more discriminative and robust. Nevertheless, DenseCL [60] does bring some inspiration to our method.
Remark ③: Time Complexity of . The time complexity of our is , where . Thus, we can i) reduce the batch size , ii) apply an extra average pooling step on (to reduce ), and iii) set a smaller dimensionality in attention heads to avoid excessive computational cost in practice.
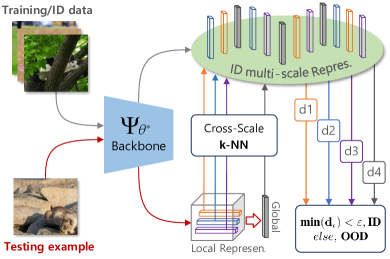
OOD Detection with Cross-scale Decision (). In the ID training procedure, we propose , an end-to-end, plug-and-play, and cross-attention based loss function for encouraging locally discriminative representations for MODE. To maximally benefit test-time OOD detection, we develop a Cross-Scale Decision () function to distinguish ID/OOD examples more faithfully, relying on the relative distances of the most discriminative multi-scale representations.
Mathematically, let be the -enhanced feature backbone. We first apply and to produce the multi-scale representations for the training data , denoted as , where . Similarly, denote the multi-scale representations of -th testing example as . For each , we search over to determine its distance to the k-th nearest neighbor in a normalized representation space (as in KNN [9]), denoted as . The decision function of for distinguish ID/OOD data takes the form of
| (10) |
where , and be the calculate the Euclidean distance between each representation in and its searched k-th nearest neighbor in . In like manner, the threshold can be selected when a large proportion of of ID data (e.g. 95%) is correctly classified.
| Method | SVHN | Places365 | LSUN | iSUN | Texture | Average | |||||||
| FPR | AUROC | FPR | AUROC | FPR | AUROC | FPR | AUROC | FPR | AUROC | FPR | AUROC | ||
| MSP[1]∗ | 59.66 | 91.25 | 62.46 | 88.64 | 51.93 | 92.73 | 54.57 | 92.12 | 66.45 | 88.50 | 59.01 | 90.65 | |
| Energy[3]∗ | 54.41 | 91.22 | 42.77 | 91.02 | 23.45 | 96.14 | 27.52 | 95.59 | 55.23 | 89.37 | 40.68 | 92.67 | |
| ODIN[5]∗ | 20.93 | 95.55 | 63.04 | 86.57 | 31.92 | 94.82 | 33.17 | 94.65 | 56.40 | 86.21 | 41.09 | 91.56 | |
| GODIN[4]∗ | 15.51 | 96.60 | 62.63 | 87.31 | 32.43 | 95.08 | 34.03 | 94.94 | 46.91 | 89.69 | 38.30 | 92.72 | |
| Mahalanobis[2]∗ | 9.24 | 97.80 | 83.50 | 69.56 | 4.76 | 98.85 | 6.02 | 98.63 | 23.21 | 92.91 | 25.35 | 91.55 | |
| KNN[9]∗ | 24.53 | 95.96 | 25.29 | 95.69 | 25.55 | 95.26 | 27.57 | 94.71 | 50.90 | 89.14 | 30.77 | 94.15 | |
| MODE-T (ours)∗ | 4.33 | 97.67 | 25.01 | 95.45 | 7.79 | 98.46 | 34.08 | 94.87 | 24.14 | 94.74 | 19.07 | 96.24 | |
| MODE-F (ours)∗ | 1.00 | 99.79 | 29.58 | 94.39 | 5.06 | 99.12 | 32.55 | 95.03 | 19.56 | 97.11 | 17.55 | 97.09 | |
| CE+SimCLR[62]† | 6.98 | 99.22 | 54.39 | 86.70 | 64.53 | 85.60 | 59.62 | 86.78 | 16.77 | 96.56 | 40.46 | 90.97 | |
| CSI[11]† | 37.38 | 94.69 | 38.31 | 93.04 | 10.63 | 97.93 | 10.36 | 98.01 | 28.85 | 94.87 | 25.11 | 95.71 | |
| SSD[10]† | 2.47 | 99.51 | 22.05 | 95.57 | 10.56 | 97.83 | 28.44 | 95.67 | 9.27 | 98.35 | 14.56 | 97.38 | |
| ProxyAnchor[63]† | 39.27 | 94.55 | 43.46 | 92.06 | 21.04 | 97.02 | 23.53 | 96.56 | 42.70 | 93.16 | 34.00 | 94.46 | |
| LINE[23]† | 5.46 | 98.37 | 23.98 | 94.71 | 4.49 | 98.43 | 22.11 | 96.72 | 9.12 | 97.86 | 13.03 | 97.21 | |
| CIDER[25]† | 2.89 | 99.72 | 23.88 | 94.09 | 5.45 | 99.01 | 20.61 | 96.64 | 12.33 | 96.85 | 12.95 | 97.26 | |
| KNN[9]† | 2.42 | 99.52 | 23.02 | 95.36 | 1.78 | 99.48 | 20.06 | 96.74 | 8.09 | 98.56 | 11.07 | 97.93 | |
| MODE-T (ours)† | 1.24 | 99.76 | 24.51 | 95.20 | 3.83 | 99.22 | 24.41 | 96.22 | 9.93 | 98.31 | 12.78 | 97.74 | |
| MODE-F (ours)† | 0.65 | 99.86 | 20.13 | 96.44 | 2.15 | 99.31 | 19.87 | 97.59 | 8.46 | 98.22 | 10.05 | 98.42 | |
| (a) CIFAR-10 (ID) with ResNet-18 | |||||||||||||
| Method | SVHN | Places365 | LSUN | iSUN | Texture | Average | |||||||
| FPR | AUROC | FPR | AUROC | FPR | AUROC | FPR | AUROC | FPR | AUROC | FPR | AUROC | ||
| MSP[1]∗ | 78.89 | 79.80 | 84.38 | 74.21 | 83.47 | 75.28 | 84.61 | 74.51 | 86.51 | 72.53 | 83.12 | 75.27 | |
| ODIN[5]∗ | 70.16 | 84.88 | 82.16 | 75.19 | 76.36 | 80.10 | 79.54 | 79.16 | 85.28 | 75.23 | 78.70 | 79.11 | |
| Mahalanobis[2]∗ | 87.09 | 80.62 | 84.63 | 73.89 | 84.15 | 79.43 | 83.18 | 78.83 | 61.72 | 84.87 | 80.15 | 79.53 | |
| Energy[3]∗ | 66.91 | 85.25 | 81.41 | 76.37 | 59.77 | 86.69 | 66.52 | 84.49 | 79.01 | 79.96 | 70.72 | 82.55 | |
| GODIN[4]∗ | 74.64 | 84.03 | 89.13 | 68.96 | 93.33 | 67.22 | 94.25 | 65.26 | 86.52 | 69.39 | 87.57 | 70.97 | |
| LogitNorm[21]∗ | 59.60 | 80.74 | 80.25 | 78.58 | 91.07 | 82.99 | 84.19 | 80.77 | 86.64 | 75.60 | 78.35 | 81.74 | |
| KNN[9]∗ | 29.08 | 93.90 | 87.50 | 72.35 | 87.97 | 74.11 | 91.62 | 80.55 | 47.66 | 87.44 | 66.77 | 81.67 | |
| MODE-T (ours)∗ | 27.50 | 93.94 | 59.63 | 83.14 | 40.67 | 75.68 | 64.35 | 86.20 | 52.71 | 87.59 | 48.97 | 85.31 | |
| MODE-F (ours)∗ | 24.13 | 94.11 | 61.95 | 82.22 | 34.76 | 72.07 | 65.52 | 86.48 | 51.28 | 87.30 | 47.53 | 84.44 | |
| ProxyAnchor[63]† | 87.21 | 82.43 | 70.10 | 79.84 | 37.19 | 91.68 | 70.01 | 84.96 | 65.64 | 84.99 | 66.03 | 84.78 | |
| CE+SimCLR[62]† | 24.82 | 94.45 | 86.63 | 71.48 | 56.40 | 89.00 | 66.52 | 83.82 | 63.74 | 82.01 | 59.62 | 84.15 | |
| CSI[11]† | 44.53 | 92.65 | 79.08 | 76.27 | 75.58 | 83.78 | 76.62 | 84.98 | 61.61 | 86.47 | 67.48 | 84.83 | |
| SSD[10]† | 31.19 | 94.19 | 77.74 | 79.90 | 79.39 | 85.18 | 80.85 | 84.08 | 66.63 | 86.18 | 67.16 | 85.90 | |
| LINE[23]† | 30.45 | 92.21 | 79.54 | 77.67 | 50.70 | 89.01 | 67.84 | 83.64 | 54.60 | 89.37 | 56.62 | 86.38 | |
| CIDER[25]† | 23.09 | 95.16 | 79.63 | 73.43 | 16.16 | 96.33 | 71.68 | 82.98 | 43.87 | 90.42 | 46.89 | 87.67 | |
| KNN[9]† | 39.23 | 92.78 | 80.74 | 77.58 | 48.99 | 89.30 | 74.99 | 82.69 | 57.15 | 88.35 | 60.22 | 86.14 | |
| MODE-T (ours)† | 29.37 | 92.29 | 73.91 | 78.93 | 48.16 | 89.38 | 75.96 | 83.39 | 51.37 | 87.87 | 55.75 | 86.38 | |
| MODE-F (ours)† | 21.18 | 95.19 | 67.88 | 80.24 | 51.67 | 90.22 | 59.61 | 86.92 | 52.32 | 86.94 | 50.53 | 87.90 | |
| (b) CIFAR-100 (ID) with ResNet-34 | |||||||||||||
Remark ④: Strategies for Speeding Up . In practice, to avoid excessive time cost, we follow KNN [9] to i) store the multi-scale representations of all examples in a key-value map, and ii) use the library of [64] for speeding up the -NN search process. In concrete terms, we employ as the indexing scheme with Euclidean distance. Moreover, as illustrated in Fig. 5, we further reduce the number of extracted local representations for every image from to , by performing a neighbor aggregation step (i.e., a average pooling step) on every four nearest local representations at different positions. Quantitative analysis for the computational cost of our designed at inference is presented in Section IV-E.
Flexibility of our MODE Framework. Our proposed MODE framework is orthogonal to the ID training procedure, as well as models pretrained with different losses. In this work, we consider two versions of our MODE according to how promotes locally discriminative representations, i.e., MODE-T = - + , MODE-F = - + . In practice, we can flexibly decide whether to adopt MODE-T or MODE-F depending on the current training stage of the model, i.e., MODE-T if the model has not yet started training, MODE-F if the model is already pretrained.

IV Experiments.
In this section, we extensively test our proposed MODE on regularly used OOD benchmarks, feature backbones and evaluation metrics. In specific, we first scrutinize the effectiveness of our MODE on common benchmarks, then we move a step further to evaluate it on large-scale ImageNet benchmark. Ablation studies and visualization results are shown at the end.
Evaluation Metrics. We follow the widely-employed setup in the literature to use the following evaluation metrics: FPR (a.k.a. FPR95) [65]: The false positive rate of OOD examples when the true positive rate of ID examples reaches 95%. AUROC [1]: The area under the curve of the receiver operating characteristic. Note that both FPR and AUROC are utilized for testing the OOD detection performance, besides we don’t need to manually tune the threshold for FPR and AUROC at inference, as the two metrics can determine according to the classification results of testing ID samples. To investigate the ID training (or representation learning) performance we also introduce ID ACC: the classification accuracy of ID examples.
IV-A Evaluation on Common Benchmarks
Datasets. Following the common benchmarks in OOD detection, we adopt CIFAR-10 and CIFAR-100 as in-distribution (ID) datasets, and they are spilled normally for conducting ID training. In test-time OOD detection, Textures [66], SVHN [67], Places365 [68], LSUN-C [69] and iSUN [70] are used as OOD datasets for performance evaluation. Specifically, Places365 consists of 365 scene categories of images, SVHN and iSUN are datasets with colored street numbers and a large scale of natural scenes. Besides, Textures is made up of images in the wild from 47 terms, and LSUN contains millions of images from 10 scenes and 20 object categories.
| Method | iNaturalist | SUN | Places365 | Texture | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| FPR | AUROC | FPR | AUROC | FPR | AUROC | FPR | AUROC | FPR | AUROC | ||
| MSP[1]∗ | 54.99 | 87.74 | 70.83 | 80.86 | 73.99 | 79.76 | 68.00 | 79.61 | 66.95 | 81.99 | |
| ODIN[5]∗ | 47.66 | 89.66 | 60.15 | 84.59 | 67.89 | 81.78 | 50.23 | 85.62 | 56.48 | 85.41 | |
| Energy[3]∗ | 55.72 | 89.95 | 59.26 | 85.89 | 64.92 | 82.86 | 53.72 | 85.99 | 58.41 | 86.17 | |
| GODIN[4]∗ | 61.91 | 85.40 | 60.83 | 85.60 | 63.70 | 83.81 | 77.85 | 73.27 | 66.07 | 82.02 | |
| Mahalanobis[2]∗ | 97.00 | 52.65 | 98.50 | 42.41 | 98.40 | 41.79 | 55.80 | 85.01 | 87.43 | 55.47 | |
| SSD[10]† | 57.16 | 87.77 | 78.23 | 73.10 | 81.19 | 70.97 | 36.37 | 88.52 | 63.24 | 80.09 | |
| LINE[23]† | 32.31 | 92.51 | 43.37 | 90.50 | 60.73 | 84.81 | 30.24 | 91.97 | 41.66 | 89.95 | |
| KNN[9]† | 30.83 | 94.72 | 48.91 | 88.40 | 60.02 | 84.62 | 16.97 | 94.45 | 39.18 | 90.55 | |
| MODE-F (ours)† | 29.11 | 96.46 | 46.39 | 89.73 | 54.38 | 87.80 | 15.65 | 94.95 | 36.38 | 92.24 | |
Implementation Details. We follow the common practice to use ResNet-18 as the feature backbone for CIFAR-10, and ResNet-34 for CIFAR-100 in our experiments. We obtain the CE-trained and CL-trained models based on the open-source implementations of SupCE and SupCon in [58]111https://github.com/HobbitLong/SupContrast, respectively. We update the networks using stochastic gradient descent with momentum 0.9, and the weight decay is set to 0.0001. In particular, the balance weight in Eq. 9 is set to 1.0 for MODE-T (or -). The initial learning rate is set to 0.1 for MODE-F (or -). The dimensionality in attention heads takes the value of 80. The temperature in is 0.1. The -NN hyperparameter is 50. We found that the batch size has negligible effect on performance within a certain range, we therefore set to avoid excessive computational cost. We carefully adjust the critical hyperparamethers , , and in our ablation studies.
Experimental Results. The experimental results are reported in Table I, where a broad spectrum of state-of-the-art OOD detection approaches are compared. Please visit [9] for more details of those approaches. In particular, we divide those approaches into two groups, depending on whether the pretrained model is learned by cross-entropy (CE) loss or contrastive learning (CL) loss. From the reported results in the table, we highlight the following observations. First, OOD detection performance is substantially improved with our proposed MODE. On average, with CE-trained (resp. CL-trained) models, our methods outperform the strong competitor KNN [9] by a maximum of 19.24% (resp. 9.69%) in terms of FPR, and 2.77% (resp. 1.76%) in terms of AUROC. Second, for the two versions of MODE, MODE-F (i.e. - + ) outperforms MODE-T (i.e. - + ) in the vast majority of cases, suggesting that our - does not raise the catastrophic forgetting problem – overwriting the previously learned knowledge of pretrained models. The OOD detection performance curves depicted in Fig. 7 further confirms this conclusion – MODE-F continually improves the OOD detection performance of the pretrained baseline models. Third, the performance improvement of our MODE upon CE-trained methods is significantly better than that on CL-trained methods. One possible reason is that our devised as a variant of CL loss is able to complement vanilla CE loss to mine general-purpose visual information that captures richer and more flexible representations for recognizing ID/OOD data. More qualitative results for this problem is systematically discussed in Section IV-F and demonstrated in Fig. 10. In a nutshell, the achieved results in Table I show that our MODE framework is agnostic to ID training losses, as well as models pretrained with different fashions.
IV-B Evaluation on Large-scale ImageNet Benchmark
Datasets. We move a step further to demonstrate the effectiveness and flexibility of our method by evaluating it on a large-scale OOD detection task using ImageNet [71] as ID dataset. Following the common setup in ImageNet-based OOD detection [72, 9], we evaluate on four OOD datasets that are specifically the subsets of Textures [66], Places365 [68], iNaturalist [73] and SUN [74], and without overlapping categories w.r.t. ImageNet.
Implementation Details. We use a ResNet-50 feature backbone for evaluation on the ID dataset ImageNet. Here, instead of meticulously training the backbone from scratch on ImageNet, we directly borrow the CL-trained ResNet-50 model from the public repository of KNN [9]222https://github.com/deeplearning-wisc/knn-ood for efficiency. Note that we only test our method on the CL-trained model, since the CE-trained model is not publicly available yet. During ID training, we iteratively finetune the pretrained model using our - for 300 epochs, where the batch size , and the initial learning rate with cosine scheduling. Other hyperparameters are set the same as in Section IV-A. In addition, following KNN [9], we sample a tiny ratio () of training data from ImageNet for nearest neighbor search during test-time OOD detection for our method and LINE [23].
Experimental Results. The achieved OOD detection performance for different approaches over the four OOD datasets are reported in Table II. From the table, we have the following findings. First, our method (MODE-F) significantly outperforms those strong competitors across the four OOD datasets, and establishes new state-of-the-art results. Second, it is worth noting that SSD [10] obtains inferior performance to both KNN [9] and our method. This is probably due to that the increased data complexity of large-scale benchmarks makes the class-conditional Gaussian assumption less viable for effective OOD detection. In contrast, KNN along with our method are distribution assumption-free therefore do not suffer from this limitation. Third, after finetuning the pretrained model (i.e. ResNet-50), our MODE-F (more concretely, the designed ) randomly samples a tiny ratio () of training data for nearest neighbor search as in KNN. In this case, our method still consistently outperforms other competitors across all OOD datasets, revealing that the -enhanced multi-scale representations are more informative and transferable.
IV-C Evaluation on Clean OOD Benchmarks
As revealed in [75], most of widely-used OOD datasets are noisy: the test OOD data is mixed with a large proportion (by up to 50% in some cases) of ID examples from ImageNet-1k. To further show the effectiveness of our proposed method, we also compare our method with the strong baseline KNN [9] on two clean OOD datasets: OpenImage-O [76], and NINCO [75]. The obtained results are reported in Table III, where the experimental setup is the same as in Section IV-B. From the results in the table, our method consistently outperforms the competitor KNN on the two datasets.
| Method | OpenImage-O | NINCO | |||
|---|---|---|---|---|---|
| FPR | AUROC | FPR | AUROC | ||
| KNN[9]† | 80.04 | 69.88 | 66.06 | 84.11 | |
| MODE-F (ours)† | 75.73 | 73.91 | 64.42 | 85.07 | |
| ID Training | ID ACC | + (Testing) | FPR | AUROC |
|---|---|---|---|---|
| CE | 73.23 | ✗ | 66.77 | 81.67 |
| ✔ | 66.52 | 81.63 | ||
| + - | 75.52 | ✗ | 52.31 | 83.94 |
| ✔ | 48.97 | 85.31 | ||
| + - | 75.04 | ✗ | 50.56 | 82.45 |
| ✔ | 47.53 | 84.44 | ||
| CL | 73.65 | ✗ | 60.22 | 86.14 |
| ✔ | 60.54 | 85.79 | ||
| + - | 74.26 | ✗ | 59.02 | 83.74 |
| ✔ | 55.75 | 86.38 | ||
| + - | 75.28 | ✗ | 54.31 | 85.89 |
| ✔ | 50.53 | 87.90 |

IV-D Ablation Studies
In this section, we first conduct ablative analysis to validate the effectiveness of designed components of our MODE in Table IV. Then, we analyze the effects of i) multi-scale representations, ii) balance weight , iii) learning rate , and iv) -NN hyperparameter to deeply investigate our MODE.
Effectiveness of the Designed Components of MODE. Here, we seek to answer the following two questions: ① Can our training-time encourage locally discriminative representations during ID training? ② Can our test-time further boost test-time OOD detection? To this end, we conduct experiments on the ResNet-34 feature backbone and use CIFAR-100 as the ID dataset. The average results w.r.t. ID ACC, FPR and AUROC on five common OOD benchmarks are reported in Table IV. We have the following observations. First, from the cells of “ID ACC”, it is obvious that both - and - improve the in-distribution classification performance, which indicates that the designed benefits the learning of discriminative representations from ID classes. This is in accordance with the historical evidence that local representations (i.e. dense features) inside images can provide richer and more flexible information about the target objects [28, 29, 60]. More qualitative results are presented in Fig. 11 and discussed in Section IV-F. Second, from the cells of “”, we can see that our significantly improves the test-time OOD detection results with multi-scale representations learned by both - and -, suggesting the efficacy of our function. Third, does not result in significant performance gains on single-scale image representations learned by off-the-shelf cross-entropy (CE) or contrastive learning (CL) losses, which proves the necessity of addressing the scale-discrepancy between ID training and OOD detection, and also confirms the effectiveness of our for tackling this problem. Fourth, from the cells of “FPR” and “AUROC”, it can be observed that each of - + and - + outperforms the baseline methods (i.e., vanilla CE/CL-trained models with KNN-based OOD detection [9]) by large margins, clearly demonstrating the effectiveness of the designed components (i.e. training-time and test-time ), as well as the flexibility of our proposed MODE framework.
| Method | Infer. Time (ms/img) | FPR | AUROC |
|---|---|---|---|
| KNN [9] | 0.14 | 60.22 | 86.14 |
| MODE-F () | 0.12 | 54.14 | 86.82 |
| MODE-F () | 0.25 | 53.18 | 87.15 |
| MODE-F () | 0.74 | 52.75 | 87.68 |
| MODE-F () | 1.51 | 50.53 | 87.90 |

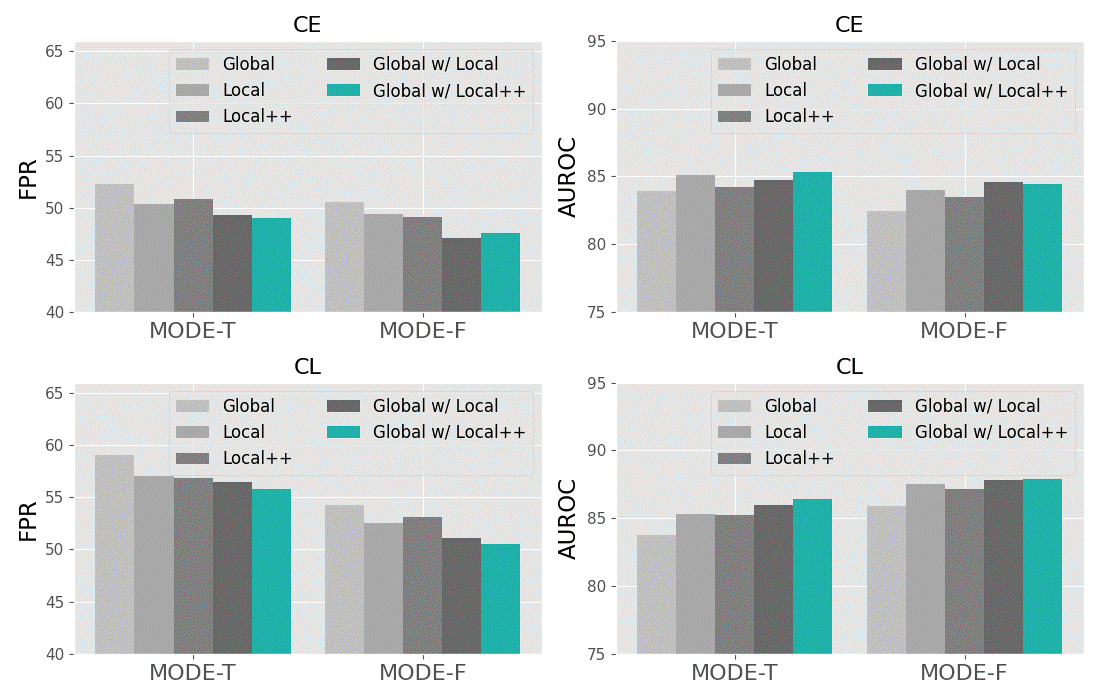
Effect of Multi-scale Representations. During test-time OOD detection, our designed function explores the most discriminative multi-scale (i.e., both global and local) representations to distinguish ID/OOD examples more faithfully. The extracted local representations of each input image x are concretely the output feature maps before the final global average pooling layer of convolutional networks (or feature backbones), denoted as . Therefore, an image can be mapped into local representations (or split image regions), with a corresponding region size . That means the larger the number of local representations, the smaller the size of a region. As aforementioned in Section III-B and depicted in Fig. 5, we can reduce the number of extracted local representations for every image from to (concretely, from to 5 in our experiments), by performing a neighbor aggregation procedure on every four nearest local representations at different positions, and obtain the neighbor aggregated local representations, called local++ representations. In Fig. 6, we investigate the effect of those multi-scale (i.e., global, local and local++) representations on the OOD detection performance of our MODE framework. We have several important observations from the figure. First, compared with the -enhanced global representations, the -enhanced local representations are more beneficial to improve OOD detection performance, which reveals the fact that our enables locally discriminative representations that captures richer and more flexible representations for recognizing ID/OOD data. Second, leveraging both global and local representations from images can further boost the results. This is in accordance with our intention that exploiting multi-scale representations from images help maximally benefit OOD detection. Third, the combination of global and local++ representations achieves the best performance in most cases. One possible reason is that when an image is divided into a larger number of (i.e. ) local representations, the size of every corresponding region becomes smaller, as a consequence, some of those split regions fail to capture the target objects. Therefore, for higher performance and computational efficiency, in our experiments the multi-scale representations for each image specifically include one global representation and five local++ representations.

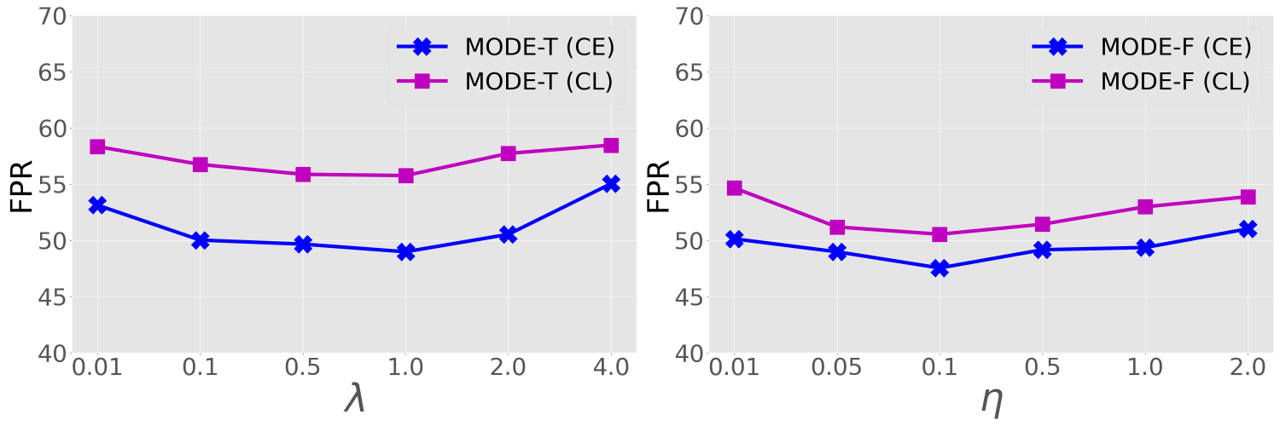
Effect of the Balance Weight for MODE-T. During ID training, MODE-T (i.e. - + ) employs - to encourage discriminative local representations by regularizing existing ID training loss functions with the devised , i.e., in Eq. 9, where the hyperparameter is adopted to balance the contribution of our . In this part, we carefully tune by setting it to the values of {0.001, 0.1, 0.5, 1.0, 2.0, 4.0}, and report the average testing results on five common OOD datasets in Fig. 8 (left). As can be observed, our MODE-T is not sensitive to the change of within a certain range (from 0.1 to 2.0). It’s worth noting that when takes the value of 1.0 our MODE-T establishes the best OOD detection performance with both CE-trained and CL-trained baseline models. We thus set for MODE-T in our experiments.
Effect of the Learning Rate for MODE-F. The most important hyperparameter of our MODE-F (i.e., - + ) is the initial learning rate for finetuning pretrained models learned by different losses, using the developed -. To investigate the effect of on the performance MODE-F, we carefully tune by setting it to different values of {0.001, 0.05, 0.1, 0.5, 1.0, 2.0}. We report the average results on five common OOD datasets in Fig. 8 (right). As seen, our MODE-F achieves remarkable and stable performance when takes the values within a certain range (from 0.05 to 0.5). In particular, when our MODE-F achieves the best results with both CE-trained and CL-trained baselines, we therefore set for MODE-F in our experiments.
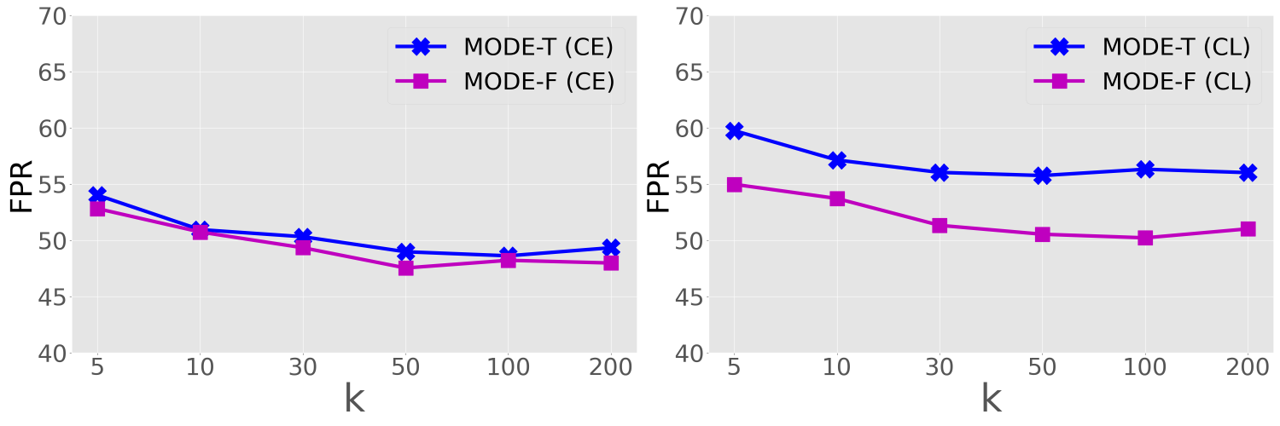
Effect of the -NN Hyperparameter . Both KNN [9] and our MODE (, more concretely) need to adjust the -NN hyperparameter . In Fig. 9, we analyze the effect of on the OOD detection performance of our MODE. Specifically, we carefully tune by setting it to the values of {5, 10, 30, 50, 100, 200}, and report the average results on five common OOD datasets. As can be observed from the figure, the OOD detection performance gradually improves with the increase of before reaches 50. This trend is also consistent with the ablation results of in KNN [9] under the same setting. Additionally, we also observe that the OOD detection results of both MODE-T and MODE-F remain similar when takes the values of 50, 100 and 200. Hence, in our experiments, we set as in KNN [9].
IV-E Computational Cost
It is important to study the computational cost of our proposed MODE for practical purposes. In this part, we quantitatively investigate the test-time OOD detection computational cost of our MODE (concretely, brought by the test-time ), according to the per-image inference time (in milliseconds). In particular, we randomly sample training data from each class of the ID dataset (i.e., CIFAR-100 with 50,000 training examples) for -nearest neighbor search on testing OOD data. We report the per-image inference time of MODE-F (while the results of MODE-T have similar trends) at different values of in Table V, where we conduct the experiment on an NVIDIA GeForce RTX 3090. It should be noted that when takes the values of {5, 10, 50, 100}, we set the -NN hyperparameter to {10, 20, 30, 50} for our MODE-F, respectively. We highlight four important observations in the table. First, when , the per-image inference time of our method is 1.51 milliseconds, a result that may be acceptable in many real-world (offline or online) applications. Second, as expected, the inference time cost of our method gradually decreases as decreases. Third, the plunge in does not severely degrade the OOD detection performance of our method. Fourth, when spending a comparable time consumption as the state-of-the-art KNN [9], our method still outperforms KNN by a large margin (i.e., 6.08% in FPR). All the above results suggest that our proposed MODE enjoys good practicability and scalability.
IV-F Visualization Analysis
So far, we have quantitatively demonstrated the effectiveness and flexibility of our developed MODE framework for OOD detection. In this part, we present some visualization results to qualitatively investigate our MODE.
Visualization with tSNE [77]. In Fig. 10, we present the tSNE visualization of the vanilla CE-trained and our -enhanced global representations (extracted from the penultimate layer of the feature backbone ResNet-18) of the ID dataset CIFAR-10 and the OOD data LSUN (OOD) – the results of vanilla CL-trained representations have similar trends. As can be observed from the figure, compared with the vanilla CE-trained global representations, the global representations learned by each of our - or - exhibit better ID-OOD separability. We also see that although the baseline improves the compactness of each ID class, there is a significant overlap between these ID classes and the OOD data. Generally speaking, in combination with the quantitative ID classification and OOD detection results in Table IV, it is apparent that our designed not merely encourage locally discriminative representations during ID training, but also drive the extracted image representations of different ID/OOD classes to be more compact for benefiting both OOD detection as well as multi-class classification tasks.
Visualization of -Nearest Neighbors. In Fig. 11, we further demonstrate the effectiveness of our MODE by qualitatively comparing its searched -nearest neighbors with that of KNN [9] on testing examples. In this experiment, leveraging the {“Lemon” vs. “Orange”} task for visualization analysis is inspired by the fact that hard OOD detection tasks composed with near ID-OOD classes/examples are the major challenge for existing machine learning systems, as revealed in [39, 78]. In this task, when we treat “Lemon” as ID data, “Orange” becomes OOD, and vice versa. As can be observed from the figure, our method successfully identifies the most discriminative multi-scale representations corresponding to the target objects (or object regions) in the vast majority of cases. What is noteworthy is that local representations/regions play a key role in successfully recognizing those hard examples with cluttered backgrounds. Moreover, when , totally 6 and 2 OOD examples are wrongly detected as ID data for KNN [9] and our method, respectively. All in all, benefiting from highlighting richer and more transferable representations during ID training (by ), and taking advantage of the most discriminative multi-scale representations for test-time OOD detection (by ), our proposed MODE shows remarkable performance on distinguishing ID/OOD data.
V Conclusion
For the first time, this work proposes MODE to leverage multi-scale representations inside images for OOD detection. Concretely, we first observe that due to the scale-discrepancy between the ID training and OOD detection processes, existing models pretrained by off-the-shelf cross-entropy or contrastive losses are unable to capture usable local representations for MODE. To address this issue, we propose , which enables locally discriminative representations by aligning and highlighting the local object regions of pairwise examples during ID training. During test-time OOD detection, we devise a function on the most discriminative multi-scale representations to distinguish ID/OOD examples more faithfully. Our MODE framework is orthogonal to ID training losses and models pretrained with different fashions. Extensive experimental results demonstrate the effectiveness and flexibility of our MODE on a wide range of baseline methods applied to various network structures. We hope this work can bring new inspiration to OOD detection as well as other related fields. To facilitate future research, we have made our code publicly available at: –https://github.com/JimZAI/MODE-OOD˝.
References
- [1] D. Hendrycks and K. Gimpel, “A baseline for detecting misclassified and out-of-distribution examples in neural networks,” ICLR, 2017.
- [2] K. Lee, K. Lee, H. Lee, and J. Shin, “A simple unified framework for detecting out-of-distribution samples and adversarial attacks,” NeurIPS, vol. 31, 2018.
- [3] W. Liu, X. Wang, J. Owens, and Y. Li, “Energy-based out-of-distribution detection,” NeurIPS, vol. 33, pp. 21 464–21 475, 2020.
- [4] Y.-C. Hsu, Y. Shen, H. Jin, and Z. Kira, “Generalized odin: Detecting out-of-distribution image without learning from out-of-distribution data,” in CVPR, 2020, pp. 10 951–10 960.
- [5] S. Liang, Y. Li, and R. Srikant, “Enhancing the reliability of out-of-distribution image detection in neural networks,” ICLR, 2018.
- [6] H. Bai, R. Sun, L. Hong, F. Zhou, N. Ye, H.-J. Ye, S.-H. G. Chan, and Z. Li, “Decaug: Out-of-distribution generalization via decomposed feature representation and semantic augmentation,” in AAAI, vol. 35, no. 8, 2021, pp. 6705–6713.
- [7] M. Salehi, H. Mirzaei, D. Hendrycks, Y. Li, M. H. Rohban, and M. Sabokrou, “A unified survey on anomaly, novelty, open-set, and out of-distribution detection: Solutions and future challenges,” Transactions of Machine Learning Research.
- [8] A. Nguyen, J. Yosinski, and J. Clune, “Deep neural networks are easily fooled: High confidence predictions for unrecognizable images,” in CVPR, 2015, pp. 427–436.
- [9] Y. Sun, Y. Ming, X. Zhu, and Y. Li, “Out-of-distribution detection with deep nearest neighbors,” in ICML, 2022, pp. 20 827–20 840.
- [10] V. Sehwag, M. Chiang, and P. Mittal, “Ssd: A unified framework for self-supervised outlier detection,” in ICLR, 2021.
- [11] J. Tack, S. Mo, J. Jeong, and J. Shin, “Csi: Novelty detection via contrastive learning on distributionally shifted instances,” NeurIPS, vol. 33, pp. 11 839–11 852, 2020.
- [12] S.-H. Gao, M.-M. Cheng, K. Zhao, X.-Y. Zhang, M.-H. Yang, and P. Torr, “Res2net: A new multi-scale backbone architecture,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 2, pp. 652–662, 2019.
- [13] A. Jain and G. Healey, “A multiscale representation including opponent color features for texture recognition,” IEEE Transactions on Image Processing, vol. 7, no. 1, pp. 124–128, 1998.
- [14] W. Lu, Y. Cheng, C. Xiao, S. Chang, S. Huang, B. Liang, and T. Huang, “Unsupervised sequential outlier detection with deep architectures,” IEEE Transactions on Image Processing, vol. 26, no. 9, pp. 4321–4330, 2017.
- [15] H. Zhao, H. Liu, Z. Ding, and Y. Fu, “Consensus regularized multi-view outlier detection,” IEEE Transactions on Image Processing, vol. 27, no. 1, pp. 236–248, 2017.
- [16] P. Wu and J. Liu, “Learning causal temporal relation and feature discrimination for anomaly detection,” IEEE Transactions on Image Processing, vol. 30, pp. 3513–3527, 2021.
- [17] M. Sabokrou, M. Fayyaz, M. Fathy, and R. Klette, “Deep-cascade: Cascading 3d deep neural networks for fast anomaly detection and localization in crowded scenes,” IEEE Transactions on Image Processing, vol. 26, no. 4, pp. 1992–2004, 2017.
- [18] S.-Y. Lo, P. Oza, and V. M. Patel, “Adversarially robust one-class novelty detection,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 4, pp. 4167–4179, 2023.
- [19] W. Hu, T. Hu, Y. Wei, J. Lou, and S. Wang, “Global plus local jointly regularized support vector data description for novelty detection,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–13, 2021.
- [20] A. Bendale and T. Boult, “Towards open world recognition,” in CVPR, 2015, pp. 1893–1902.
- [21] H. Wei, R. Xie, H. Cheng, L. Feng, B. An, and Y. Li, “Mitigating neural network overconfidence with logit normalization,” in ICML, 2022, pp. 23 631–23 644.
- [22] Y. Sun and Y. Li, “Dice: Leveraging sparsification for out-of-distribution detection,” in ECCV, 2022.
- [23] Y. H. Ahn, G.-M. Park, and S. T. Kim, “Line: Out-of-distribution detection by leveraging important neurons,” in CVPR, 2023, pp. 19 852–19 862.
- [24] J. Ren, S. Fort, J. Liu, A. G. Roy, S. Padhy, and B. Lakshminarayanan, “A simple fix to mahalanobis distance for improving near-ood detection,” arXiv preprint arXiv:2106.09022, 2021.
- [25] Y. Ming, Y. Sun, O. Dia, and Y. Li, “How to exploit hyperspherical embeddings for out-of-distribution detection?” ICLR, 2023.
- [26] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in ICML, 2021, pp. 8748–8763.
- [27] Y. Ming, Z. Cai, J. Gu, Y. Sun, W. Li, and Y. Li, “Delving into out-of-distribution detection with vision-language representations,” NeurIPS, vol. 35, pp. 35 087–35 102, 2022.
- [28] W. Li, L. Wang, J. Xu, J. Huo, Y. Gao, and J. Luo, “Revisiting local descriptor based image-to-class measure for few-shot learning,” in CVPR, 2019, pp. 7260–7268.
- [29] C. Zhang, Y. Cai, G. Lin, and C. Shen, “Deepemd: Few-shot image classification with differentiable earth mover’s distance and structured classifiers,” in CVPR, 2020, pp. 12 203–12 213.
- [30] J. Nandy, W. Hsu, and M. L. Lee, “Towards maximizing the representation gap between in-domain & out-of-distribution examples,” NeurIPS, vol. 33, pp. 9239–9250, 2020.
- [31] E. Cole, X. Yang, K. Wilber, O. Mac Aodha, and S. Belongie, “When does contrastive visual representation learning work?” in CVPR, 2022, pp. 14 755–14 764.
- [32] J. Zhang, J. Song, L. Gao, Y. Liu, and H. T. Shen, “Progressive meta-learning with curriculum,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 9, pp. 5916–5930, 2022.
- [33] J. Zhang, J. Song, L. Gao, and H. Shen, “Free-lunch for cross-domain few-shot learning: Style-aware episodic training with robust contrastive learning,” in ACM MM, 2022, pp. 2586–2594.
- [34] Y. Fu, Y. Fu, J. Chen, and Y.-G. Jiang, “Generalized meta-fdmixup: Cross-domain few-shot learning guided by labeled target data,” IEEE Transactions on Image Processing, vol. 31, pp. 7078–7090, 2022.
- [35] Y. Mo, Y. Chen, Y. Lei, L. Peng, X. Shi, C. Yuan, and X. Zhu, “Multiplex graph representation learning via dual correlation reduction,” IEEE Transactions on Knowledge and Data Engineering, pp. 1–14, 2023.
- [36] P. Zeng, H. Zhang, L. Gao, J. Song, and H. T. Shen, “Video question answering with prior knowledge and object-sensitive learning,” IEEE Transactions on Image Processing, vol. 31, pp. 5936–5948, 2022.
- [37] Y. Zhou, P. Liu, and X. Qiu, “Knn-contrastive learning for out-of-domain intent classification,” in ACL, 2022, pp. 5129–5141.
- [38] S. Vaze, K. Han, A. Vedaldi, and A. Zisserman, “Open-set recognition: a good closed-set classifier is all you need?” ICLR, 2022.
- [39] S. Fort, J. Ren, and B. Lakshminarayanan, “Exploring the limits of out-of-distribution detection,” NeurIPS, vol. 34, pp. 7068–7081, 2021.
- [40] Y. Ming, Y. Fan, and Y. Li, “Poem: Out-of-distribution detection with posterior sampling,” in ICML, 2022, pp. 15 650–15 665.
- [41] X. Du, Z. Wang, M. Cai, and S. Li, “Towards unknown-aware learning with virtual outlier synthesis,” ICLR, 2022.
- [42] O. Halimi, O. Litany, E. Rodola, A. M. Bronstein, and R. Kimmel, “Unsupervised learning of dense shape correspondence,” in CVPR, 2019, pp. 4370–4379.
- [43] S. Kim, D. Min, B. Ham, S. Jeon, S. Lin, and K. Sohn, “Fcss: Fully convolutional self-similarity for dense semantic correspondence,” in CVPR, 2017, pp. 6560–6569.
- [44] Y. Lifchitz, Y. Avrithis, S. Picard, and A. Bursuc, “Dense classification and implanting for few-shot learning,” in CVPR, 2019, pp. 9258–9267.
- [45] T. Xu, W. Chen, P. Wang, F. Wang, H. Li, and R. Jin, “Cdtrans: Cross-domain transformer for unsupervised domain adaptation,” ICLR, 2021.
- [46] Y. Zuo, H. Yao, and C. Xu, “Attention-based multi-source domain adaptation,” IEEE Transactions on Image Processing, vol. 30, pp. 3793–3803, 2021.
- [47] K.-H. Lee, X. Chen, G. Hua, H. Hu, and X. He, “Stacked cross attention for image-text matching,” in ECCV, 2018, pp. 201–216.
- [48] K. Zhang, Z. Mao, Q. Wang, and Y. Zhang, “Negative-aware attention framework for image-text matching,” in CVPR, 2022, pp. 15 661–15 670.
- [49] H.-J. Ye, H. Hu, D.-C. Zhan, and F. Sha, “Few-shot learning via embedding adaptation with set-to-set functions,” in CVPR, 2020, pp. 8808–8817.
- [50] J. Zhang, L. Gao, X. Luo, H. Shen, and J. Song, “Deta: Denoised task adaptation for few-shot learning,” arXiv preprint arXiv:2303.06315, 2023.
- [51] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” ICLR, 2020.
- [52] C.-F. R. Chen, Q. Fan, and R. Panda, “Crossvit: Cross-attention multi-scale vision transformer for image classification,” in CVPR, 2021, pp. 357–366.
- [53] L. Jiao, J. Gao, X. Liu, F. Liu, S. Yang, and B. Hou, “Multi-scale representation learning for image classification: A survey,” IEEE Transactions on Artificial Intelligence, 2021.
- [54] Y. Gao, Z. Kuang, G. Li, P. Luo, Y. Chen, L. Lin, and W. Zhang, “Fashion retrieval via graph reasoning networks on a similarity pyramid,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [55] J. Bai, B. Gong, Y. Zhao, F. Lei, C. Yan, and Y. Gao, “Multi-scale representation learning on hypergraph for 3d shape retrieval and recognition,” IEEE Transactions on Image Processing, vol. 30, pp. 5327–5338, 2021.
- [56] Y. Gao, Z. Kuang, G. Li, W. Zhang, and L. Lin, “Hierarchical reasoning network for human-object interaction detection,” IEEE Transactions on Image Processing, vol. 30, pp. 8306–8317, 2021.
- [57] X. Du, Z. Wang, M. Cai, and Y. Li, “Vos: Learning what you don’t know by virtual outlier synthesis,” in ICML, 2022.
- [58] P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y. Tian, P. Isola, A. Maschinot, C. Liu, and D. Krishnan, “Supervised contrastive learning,” NeurIPS, vol. 33, pp. 18 661–18 673, 2020.
- [59] O. Boiman, E. Shechtman, and M. Irani, “In defense of nearest-neighbor based image classification,” in CVPR. IEEE, 2008, pp. 1–8.
- [60] X. Wang, R. Zhang, C. Shen, T. Kong, and L. Li, “Dense contrastive learning for self-supervised visual pre-training,” in CVPR, 2021, pp. 3024–3033.
- [61] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” NeurIPS, vol. 30, 2017.
- [62] J. Winkens, R. Bunel, A. G. Roy, R. Stanforth, V. Natarajan, J. R. Ledsam, P. MacWilliams, P. Kohli, A. Karthikesalingam, S. Kohl et al., “Contrastive training for improved out-of-distribution detection,” EMNLP, 2021.
- [63] S. Kim, D. Kim, M. Cho, and S. Kwak, “Proxy anchor loss for deep metric learning,” in CVPR, 2020, pp. 3238–3247.
- [64] J. Johnson, M. Douze, and H. Jégou, “Billion-scale similarity search with gpus,” IEEE Transactions on Big Data, vol. 7, no. 3, pp. 535–547, 2019.
- [65] D. Macêdo, T. I. Ren, C. Zanchettin, A. L. Oliveira, and T. Ludermir, “Entropic out-of-distribution detection: Seamless detection of unknown examples,” IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 6, pp. 2350–2364, 2021.
- [66] M. Cimpoi, S. Maji, I. Kokkinos, S. Mohamed, and A. Vedaldi, “Describing textures in the wild,” in CVPR, 2014, pp. 3606–3613.
- [67] Y. Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, and A. Y. Ng, “Reading digits in natural images with unsupervised feature learning,” 2011.
- [68] B. Zhou, A. Lapedriza, A. Khosla, A. Oliva, and A. Torralba, “Places: A 10 million image database for scene recognition,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 6, pp. 1452–1464, 2017.
- [69] F. Yu, A. Seff, Y. Zhang, S. Song, T. Funkhouser, and J. Xiao, “Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop,” arXiv preprint arXiv:1506.03365, 2015.
- [70] P. Xu, K. A. Ehinger, Y. Zhang, A. Finkelstein, S. R. Kulkarni, and J. Xiao, “Turkergaze: Crowdsourcing saliency with webcam based eye tracking,” arXiv preprint arXiv:1504.06755, 2015.
- [71] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in CVPR. IEEE, 2009, pp. 248–255.
- [72] R. Huang and Y. Li, “Mos: Towards scaling out-of-distribution detection for large semantic space,” in CVPR, 2021, pp. 8710–8719.
- [73] G. Van Horn, O. Mac Aodha, Y. Song, Y. Cui, C. Sun, A. Shepard, H. Adam, P. Perona, and S. Belongie, “The inaturalist species classification and detection dataset,” in CVPR, 2018, pp. 8769–8778.
- [74] J. Xiao, J. Hays, K. A. Ehinger, A. Oliva, and A. Torralba, “Sun database: Large-scale scene recognition from abbey to zoo,” in CVPR. IEEE, 2010, pp. 3485–3492.
- [75] J. Bitterwolf, M. Müller, and M. Hein, “In or out? fixing imagenet out-of-distribution detection evaluation,” ICML, 2022.
- [76] H. Wang, Z. Li, L. Feng, and W. Zhang, “Vim: Out-of-distribution with virtual-logit matching,” in CVPR, 2022, pp. 4921–4930.
- [77] L. Van der Maaten and G. Hinton, “Visualizing data using t-sne.” Journal of machine learning research, vol. 9, no. 11, 2008.
- [78] C. S. Sastry and S. Oore, “Detecting out-of-distribution examples with gram matrices,” in ICML. PMLR, 2020, pp. 8491–8501.